

Abstract
Objective. We examined whether the influence of neighborhood-level socioeconomic status (SES) on mortality differed by individual-level SES.
Methods. We used a population-based, mortality follow-up study of 4476 women and 3721 men, who were predominately non-HIspanic White and aged 25–74 years at baseline, from 82 neighborhoods in 4 California cities. Participants were surveyed between 1979 and 1990, and were followed until December 31, 2002 (1148 deaths; mean follow-up time 17.4 years). Neighborhood SES was defined by 5 census variables and was divided into 3 levels. Individual SES was defined by a composite of educational level and household income and was divided into tertiles.
Results. Death rates among women of low SES were highest in high-SES neighborhoods (1907/100000 person-years), lower in moderate-SES neighborhoods (1323), and lowest in low-SES neighborhoods (1128). Similar to women, rates among men of low SES were 1928, 1646, and 1590 in high-, moderate-, and low-SES neighborhoods, respectively. Differences were not explained by individual-level baseline risk factors.
Conclusion. The disparities in mortality by neighborhood of residence among women and men of low SES demonstrate that they do not benefit from the higher quality of resources and knowledge generally associated with neighborhoods that have higher SES.
An established body of contextual studies in the United States has demonstrated that neighborhood indicators of socioeconomic status (SES) predict individual mortality.1–9 Most studies show significant, but modest neighborhood effects after they account for individual SES and other factors. These studies have focused on the main effect of neighborhood SES on mortality. However, several studies in the United States and elsewhere have examined the cross-level interaction between individual and neighborhood SES on mortality,6,8,10,11 which provides the opportunity to explore whether neighborhood effects are different for women and men of low and high SES. For example, adults of low SES in high-SES neighborhoods might experience a lower risk of dying than adults of low SES in low-SES neighborhoods, because they benefit from the collective resources in their neighborhoods.6,12–15 Alternatively, adults of low SES in high-SES neighborhoods might experience a higher risk of dying because of relative deprivation, low relative social standing, or both.16–18
Our study adds to previous work by using a population-based sample, extended mortality follow-up (mean 17.4 years), comprehensive survey and medical data, and geocoded data about neighborhood goods and services. Two study questions were examined: (1) does neighborhood SES exert a different effect on risk of dying for women and men of high, moderate, and low SES, and (2) are any differences explained by individual baseline sociodemographic characteristics, health behaviors, risk factors, health status, causes of death, and proximity to goods and services near participants’ homes.
METHODS
Design and Sample
Data are from the Stanford Heart Disease Prevention Program, a cardiovascular disease intervention study.19–21 Participants were drawn from 2 treatment (Monterey, Salinas) and 2 control (Modesto, San Luis Obispo) cities in Northern California with populations that ranged from 35 000 to 145 000 residents in 1980.
Our analysis included adults, aged 25–74 years, who were English- or Spanish-speaking and who participated in 1 of 5 separate cross-sectional surveys that were conducted from 1979 to 1990. For each survey, the sampling unit was the household. All dwellings were enumerated and households were randomly selected from directories that contained a list of dwellings. To avoid the possibility of clustering of risk factors by household, 1 woman, 1 man, or 1 of each was randomly selected from each household, and results were stratified by gender. Sample sizes by survey were 1603 in survey 1 (1979–1980), 1652 in survey 2 (1981–1982), 1763 in survey 3 (1983–1984), 1682 in survey 4 (1985–1986), and 1719 in survey 5 (1989–1990). Because few or no significant changes in risk factors21,22 and morbidity or mortality23 were found between treatment and control cities, all cities were combined.
Nurses and laboratory technicians collected survey and medical data at centers in the 4 cities. Response rates for the 5 surveys were 65%, 69%, 65%, 56%, and 61%, respectively. All participants were able to attend a 2-hour clinic visit at baseline that included a physical activity assessment using a stationary bicycle. A questionnaire was completed for eligible individuals who declined to participate in the study (75% response). There were no significant differences between respondents and nonrespondents for age, gender, or body mass index (P ≥ .20), and only slight differences by educational level (mean years of education 13 vs 12 for respondents vs nonrespondents).21
Death Certificate Match
California death records were used to determine which participants had died through December 31, 2002, and to ascertain the underlying cause of death. Registration of deaths is almost 100% complete in California. To determine who had died, we used a multistep matching algorithm, based on parts and combinations of names, dates of birth, street addresses, and social security numbers, that evaluated data errors and name changes.20
Neighborhood Definition
To characterize neighborhoods by census data, we decided a priori to use census-defined boundaries based on census tracts, block groups, or both; both of which have been used as proxies for geographically based neighborhoods.7,24,25 Before deciding on the final boundaries we (1) made site visits to each city to obtain archival neighborhood maps from 1980 to 1990 and to solicit advice from city planners about how each city defined its neighborhoods during the time of the surveys, and (2) compared census tracts and block group boundaries from the 1980 and 1990 census. Most of the single census tract or block group boundaries corresponded well with neighborhoods defined on city maps. When there was a difference, we used either a combination of block groups (N = 16 in 1980, N = 9 in 1990) or of census tracts (N = 3 in 1990) to represent neighborhood boundaries. There were only 7 neighborhoods (out of 82) for which boundaries did not match exactly in 1980 and 1990 (5 in Monterey and 2 in San Luis Obispo). In each case, we matched boundaries as closely as possible by using a combination of census tract or block group boundaries. We defined a final sample of 82 neighborhoods was defined; the same boundaries were used for all 5 surveys.
Although data were clustered by neighborhood, the intraclass correlation was very low (.007), which indicated that one person’s mortality was unlikely to affect another person’s mortality in the same neighborhood. The intraclass correlation was computed according to the formula provided for a multilevel logistic model.26
Address Geocoding
Participants’ addresses were geocoded to identify in which of the 82 neighborhoods they lived. To test the accuracy of the geocodes,27 we used the federal government geocoding Web site as the standard,28 and found that more than 95% of a random sample of 173 addresses geocoded to the same 1990 census tract as the geocoding service that we used. Participants who reported an address that was not within one of the cities (N = 84/1.0%) and participants whose addresses were not able to be geocoded (N = 138/1.6%) were excluded, which resulted in a final analytic sample size of 8197 participants. There was an average of 21 and a median of 17 participants per neighborhood, calculated separately by survey.
Neighborhood-Level Socioeconomic Status
To characterize neighborhood-level SES, we conducted an index based on a principal components analysis with 11 SES-related variables from the 1980 US census. We identified the following 5 variables that had the highest coefficients on the first component and explained 72% of the total variance: percentage aged 25 years and older with less than a high-school education, median annual family income, percentage blue collar workers, percentage unemployed, and median housing value. Correlations among the 5 variables ranged from 0.50 to 0.85. When constructing the index, 1980 census data were used for the first survey (1979–1980) and 1990 census data were used for the fifth survey (1989–1990). For the remaining surveys, the index was estimated using linear interpolation. Each of the 5 variables were standardized separately by city and survey and summed with equal weights for each of the 82 neighborhoods in each survey. Because previous research suggests that neighborhood effects are nonlinear,25,29,30 the index was then divided into 3 groups: low SES (bottom 25%), moderate SES (middle 50%), and high SES (top 25%), which were calculated separately by city and survey.
Individual-Level Measures
Individual-level measures included all-cause mortality (death from any cause); specific causes of death (according to codes in International Classification of Diseases, Ninth Revision31); time to death (number of years from baseline survey to death or censoring [December 31, 2002]); demographic factors (gender, age, race/ethnicity, marital status, years lived in the community); and socioeconomic status. A composite SES index was created and conceptualized as a relative standing measure within each city and over time. The index was based on the mean of individual education (< 12 years, 12 years, 13–15 years, ≥ 16 years) and annual household income (expressed as a percentage of the federal poverty level specific to family size: 0–200%, 201–400%, 401–600%, ≥ 601%). For each individual, the education and income categories were averaged to create an SES index that was used to classify individuals into 3 approximately equal groups (tertiles), calculated separately by city, survey, and gender. The Spearman correlation between education and income was 0.33. Additional individual-level measures included health behaviors and risk factors (obesity,32 smoking,33 hypertension,34 hypercholesterolemia, physical inactivity, alcohol intake,35 anger, trouble sleeping, and cardiovascular disease knowledge21); health status (illness and hospitalized days); and proximity to neighborhood goods and services derived from the number of health care-related resources, basic amenities, and other stores and restaurants within a 0.5-mile buffer zone of a participant’s home on the basis of 7235 items, geocoded from historical telephone books, data from Parks and Recreation Departments, and the California Department of Education, specific to each survey year.
Analytic Approach
Age-standardized death rates per 100 000 person-years were calculated for the follow-up period by dividing the number of deaths by the number of person-years of follow-up. Direct age standardization, using 10-year age strata, was used with the full sample as the standard population. Age-adjusted, and age-and risk factor–adjusted hazards ratios were calculated with the PHREG procedure in SAS version 9.1.3 (SAS Institute Inc., Cary, NC), using people of high SES in high-SES neighborhoods as the referent category. The baseline risk factors used in the age- and risk factor–adjusted rates were obesity, smoking, hypertension, hypercholesterolemia, physical inactivity, and alcohol intake. Death rates and hazard ratios were calculated for women and men separately and were stratified by individual and neighborhood SES, with 95% confidence intervals.36
Survival curves, stratified by individual SES and neighborhood SES, were estimated with time to death or censoring at December 31, 2002,37 adjusting for age as a continuous variable using the SAS PHREG procedure.38 A Cox proportional hazards model was used to test for differences between survival curves. This is the standard model for analyzing survival curves,39 and previous neighborhood studies have used similar approaches.4,7,24,25 The Cox model included age as a continuous variable, centered at mean age,40,41 individual SES and neighborhood SES (both coded −0.5, 0, +0.5 on an ordinal scale), and an interaction term between individual SES and neighborhood SES. Separate models were estimated for women and men. The model was repeated, and 6 baseline risk factors were added in as covariates (obesity, smoking, hypertension, hypercholesterolemia, physical inactivity, and alcohol intake) to test whether these individual risk factors explained differences in survival.
RESULTS
There were 4476 women and 3721 men in the sample. Approximately 83% were non-Hispanic Whites, 11% were Hispanic, and 6% were of other racial/ethnic backgrounds. Sixty-nine percent were married and 78% had lived in their community 5 years or longer. Women and men from all education and income levels were adequately represented. By the end of follow-up, there were 575 deaths among women and 573 deaths among men.
Each of the 5 census variables in the neighborhood SES index showed substantial variability across neighborhood SES; high-SES neighborhoods had the most advantageous characteristics. For example, in 1980, the mean percentages of study subjects who had a high-school education or more in high-SES and low-SES neighborhoods were 83% and 48%, respectively; mean annual family income was $24,000 and $14,000, respectively. A similar pattern was evident for each of the variables in 1980 and 1990 and in each of the 4 cities.
Death rates for women and men who had moderate and high individual SES showed no clear pattern by neighborhood SES but overall were substantially lower than those for women and men of low SES (Table 1 ▶). By contrast, death rates among women who had low SES were highest in neighborhoods of high SES (1907 per 100 000 person-years), lower in neighborhoods of moderate SES (1323), and lowest in neighborhoods of low SES (1128). Similar to those among women, death rates among men who had low SES were 1928, 1646, and 1590, respectively, in neighborhoods of high, moderate, and low SES. The 95% confidence intervals indicate that the higher death rates for women and men who had low SES in neighborhoods of high SES were significantly different from all other groups. This effect was evident in each of the 4 cities and when restricted to non-Hispanic Whites (sample sizes were too small to examine Hispanic respondents separately).
TABLE 1—
Death Rates and Hazard Ratios (With 95% Confidence Intervals [CIs]) From Cross-Tabulation of Neighborhood and Individual Socioeconomic Status (SES) for Women and Men Aged 25–74 Years: Stanford Heart Disease Prevention Program, 1979–1990
| Age-Standardized Death Rates per 100 000 Person Years (95% CI) | Age-Adjusted Hazard Ratios (95% CI) | Age- and Risk Factor–Adjusted Hazard Ratiosa (95% CI) | |||||||
| Individual SESb | High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES | High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES | High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES |
| Women | |||||||||
| Low (n=1015) | 1907 (1773, 2040) | 1323 (1282, 1363) | 1128 (1073, 1183) | 1.70 (1.20, 2.41) | 1.56 (1.15, 2.11) | 1.42 (1.01, 2.00) | 1.64 (1.14, 2.21) | 1.40 (1.01, 1.94) | 1.35 (0.94, 1.95) |
| Moderate (n=1817) | 896 (863, 929) | 684 (666, 702) | 846 (777, 916) | 1.39 (0.99, 1.94) | 1.22 (0.88, 1.68) | 1.45 (0.92, 2.27) | 1.46 (1.06, 2.13) | 1.15 (0.82, 1.61) | 1.39 (0.85, 2.28) |
| High (n=1644) | 687 (665, 708) | 438 (418, 459) | 894 (797, 991) | 1.00c | 1.01 (0.70, 1.47) | 1.49 (0.84, 2.66) | 1.00c | 1.01 (0.68, 1.51) | 1.50 (0.834, 2.69) |
| Men | |||||||||
| Low (n=1173) | 1928 (1829, 2028) | 1646 (1610, 1683) | 1590 (1505, 1674) | 1.74 (1.24, 2.44) | 1.64 (1.22, 2.19) | 1.38 (0.97, 1.96) | 1.77 (1.22, 2.54) | 1.65 (1.20, 2.38) | 1.40 (0.96, 2.03) |
| Moderate (n=1471) | 562 (524, 599) | 717 (690, 744) | 720 (631, 809) | 1.51 (1.08, 2.11) | 1.41 (1.03, 1.92) | 1.40 (0.85, 2.31) | 1.55 (1.09, 2.19) | 1.43 (1.03, 1.99) | 1.48 (0.88, 2.48) |
| High (n=1077) | 696 (665, 727) | 562 (524, 599) | 724 (579, 869) | 1.00c | 1.03 (0.73,1.46) | 1.06 (0.57,1.95) | 1.00c | 1.10 (0.77, 1.58) | 1.12 (0.60, 2.08) |
Note. Neighborhood SES was based on 5 US census variables, standardized and averaged to form an index and divided into low (bottom 25%), moderate (middle 50%), and high (top 25%) categories, calculated separately by city and survey.
aAdjusted for 6 baseline risk factors: obesity, smoking, hypertension, hypercholesterolemia, physical inactivity, and alcohol intake.
bComposite index based on mean of individual education (4 levels) and annual household income (expressed as a percentage of the federal poverty level according to family size) and divided into approximate tertiles, calculated separately by city, survey, and gender.
cReference category.
Age-adjusted hazard ratios followed a similar pattern. The risk of death, as indicated by the hazard ratios for women and men of low SES in neighborhoods with high SES, was 70% and 74% higher, respectively, than the risk of death for women and men of high SES in neighborhoods with high SES (Table 1 ▶). There was little change in the hazard ratios after adjustment for age and the 6 baseline risk factors.
The survival curves that examined at what time point mortality differences were first apparent showed that all women and men who had low SES fared poorly as the curves began to separate (Figure 1 ▶). In particular, between 10 and 15 years of follow-up, the curves for women and men of low SES in neighborhoods of high SES separated disproportionately. The probability of dying at 10–15 years follow-up (conditional on survival to 10 years) was 11.6% for women of low SES in high-SES neighborhoods, compared with 6.7% and 2.8% for women of low SES in moderate- and low-SES neighborhoods, respectively. For men of low SES, the probability of dying was 10.4%, 7.7%, and 6.5% in high-, moderate-, and low-SES neighborhoods, respectively (data not shown). The cross-level interaction term from the Cox model was significant for both women and men (P<.04 for women and<.001 for men), which indicates that the patterns across neighborhoods differed by individual SES. The results of the cross-level interaction were primarily because the survival curve for individuals who had low SES in high SES neighborhoods was different from the survival curves of all other individual SES and neighborhood SES categories. The interaction term remained significant for both women and men (P <.04 for women and <.01 for men) when the Cox model was repeated and the 6 individual-level baseline risk factors were added in. It was also significant when repeated for non-Hispanic Whites only (P<.03 for women and<.01 for men).
FIGURE 1—
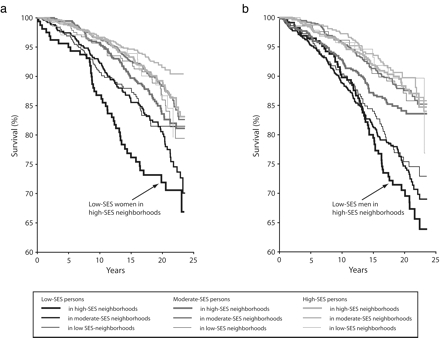
Age-adjusted survival curves, by individual-level and neighborhood-level SES for women (a) and men (b).
At baseline, individuals who had low SES in high-SES neighborhoods had significantly higher levels of education, higher median household income (men only), lower prevalence of obesity (women only), and higher levels of cardiovascular disease knowledge, although they also had higher mean age and higher prevalence of hypertension (men only) than did individuals who had low SES in low-SES neighborhoods (P <.05) (Table 2 ▶). There were no significant differences in health status or causes of death. Consistent with past literature, individuals who had low SES tended to have higher risk factors than did individuals who had high SES, regardless of the neighborhood in which they lived. An ancillary survival analysis, conducted using a subsample of 4446 women and 3680 men who had almost identical age distributions across the 9 individual and neighborhood SES groups, found the same pattern of results, which demonstrates that the differences in age at baseline across subgroups did not explain the results.
TABLE 2—
Baseline Characteristics and Causes of Death for Women and Men, by Individual and Neighborhood Socioeconomic Status (SES)
| Low Individual SES | Moderate Individual SES | High Individual SES | |||||||
| High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES | High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES | High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES | |
| Women | |||||||||
| Number of participants | 159 | 502 | 354 | 542 | 997 | 278 | 753 | 755 | 136 |
| Number of deaths | 44 | 100 | 59 | 78 | 108 | 35 | 80 | 55 | 16 |
| Sociodemographic characteristics | |||||||||
| Mean age, y ± SD | 52.0 ± 16.1 | 47.8 ± 14.8 | 47.2 ± 15.0 | 46.7 ± 14.2 | 43.9 ± 13.8 | 42.8 ± 15.5 | 46.3 ± 12.9 | 42.9 ± 12.8 | 42.0 ± 15.1 |
| Education ≥ high school, % | 49.7 | 32.7 | 25.1 | 94.8 | 94.7 | 94.6 | 100.0 | 100.0 | 100.0 |
| Median annual household income, $ | 13600 | 13400 | 10500 | 26100 | 24100 | 20700 | 42600 | 39000 | 33600 |
| Health behaviors and risk factors | |||||||||
| Obese (body mass index ≥ 30), %a | 23.1 | 25.8 | 35.1 | 11.2 | 16.4 | 15.0 | 11.0 | 11.9 | 11.2 |
| Current cigarette smoker, %b | 24.7 | 28.1 | 31.8 | 25.6 | 28.1 | 20.5 | 16.1 | 20.7 | 14.0 |
| Hypertensive (≥ 140/90 mmHg or using medication), %c | 39.5 | 33.7 | 30.0 | 23.9 | 23.6 | 21.0 | 26.7 | 21.1 | 23.5 |
| Hypercholesterolemia (≥ 240 mg/dL), %d | 26.0 | 19.6 | 20.0 | 19.7 | 15.6 | 13.4 | 13.4 | 13.0 | 9.2 |
| Physically inactive, %e | 34.2 | 32.9 | 36.2 | 27.7 | 30.4 | 28.1 | 27.6 | 29.3 | 25.0 |
| More than moderate alcohol intake, %f | 13.5 | 8.0 | 7.1 | 16.0 | 13.4 | 11.4 | 20.5 | 16.6 | 15.7 |
| Anger, mean times per week ± SDg | 4.5 ± 9.2 | 5.2 ± 10.8 | 5.5 ± 10.0 | 4.6 ± 6.2 | 5.3 ± 9.9 | 4.2 ± 4.6 | 4.5 ± 7.5 | 5.1 ± 9.0 | 4.0 ± 5.4 |
| Trouble sleeping, %h | 27.8 | 27.2 | 31.8 | 17.6 | 18.1 | 19.0 | 14.6 | 11.2 | 15.9 |
| High CVD knowledge score, %i | 51.7 | 45.6 | 34.3 | 76.0 | 74.2 | 69.1 | 87.7 | 86.9 | 86.4 |
| Health status | |||||||||
| Illness past year, mean days per y ± SD | 24.3 ± 72.3 | 21.0 ± 64.5 | 14.6 ± 41.2 | 9.9 ± 33.8 | 10.1 ± 32.9 | 14.4 ± 44.1 | 8.8 ± 36.3 | 6.0 ± 16.7 | 5.5 ± 12.7 |
| Hospitalized past year, mean days per y ± SD | 1.6 ± 8.0 | 0.9 ± 3.4 | 1.8 ± 8.9 | 0.5 ± 2.6 | 0.6 ± 2.5 | 1.0 ± 7.8 | 0.7 ± 2.7 | 0.5 ± 2.4 | 0.5 ± 3.4 |
| Causes of death, % | |||||||||
| Cancerj | 29.5 | 16.0 | 30.5 | 30.8 | 30.6 | 17.1 | 36.3 | 47.3 | 43.8 |
| CVDk | 31.8 | 49.0 | 44.1 | 32.1 | 35.2 | 48.6 | 28.8 | 29.1 | 37.5 |
| COPDl | 4.5 | 5.0 | 8.5 | 9.0 | 5.6 | 11.4 | 5.0 | 5.5 | 6.3 |
| Diabetes mellitusm | 6.8 | 3.0 | 3.4 | 2.6 | 1.8 | 0.0 | 2.5 | 0.0 | 0.0 |
| All other causes | 27.3 | 27.0 | 13.6 | 25.6 | 26.8 | 22.9 | 27.5 | 18.2 | 12.5 |
| Men | |||||||||
| Number of participants | 225 | 657 | 291 | 519 | 745 | 207 | 515 | 469 | 93 |
| Number of deaths | 64 | 157 | 64 | 76 | 84 | 23 | 54 | 42 | 9 |
| Sociodemographic characteristics | |||||||||
| Mean age, y ± SD | 50.0 ± 15.7 | 45.9 ± 15.3 | 44.6 ± 15.8 | 44.2 ± 13.8 | 42.1 ± 12.9 | 39.0 ± 14.0 | 46.2 ± 12.4 | 44.1 ± 12.5 | 42.8 ± 14.2 |
| Education ≥ high school, % | 72.4 | 61.4 | 41.2 | 97.5 | 97.7 | 97.1 | 100.0 | 100.0 | 100.0 |
| Median annual household income, $ | $18300 | $17700 | $15200 | $27600 | $26100 | $22200 | $46900 | $42600 | $38600 |
| Health behaviors and risk factors | |||||||||
| Obese (body mass index ≥ 30), %a | 17.0 | 14.6 | 19.8 | 13.8 | 16.1 | 12.1 | 12.9 | 13.3 | 9.8 |
| Current cigarette smoker, %b | 32.0 | 36.1 | 32.3 | 20.8 | 27.0 | 22.7 | 16.0 | 20.9 | 15.2 |
| Hypertensive (≥ 140/90 mmHg or using medication), %c | 44.1 | 34.1 | 30.9 | 36.0 | 30.4 | 23.8 | 32.5 | 27.4 | 26.1 |
| Hypercholesterolemia (≥ 240 mg/dL), %d | 19.4 | 17.2 | 14.7 | 14.3 | 15.9 | 9.0 | 15.4 | 19.0 | 16.3 |
| Physically inactive, %e | 22.1 | 23.2 | 23.2 | 19.4 | 20.1 | 17.9 | 23.2 | 24.9 | 13.3 |
| More than moderate alcohol intake, %f | 17.9 | 17.6 | 16.2 | 15.2 | 18.6 | 18.0 | 21.8 | 18.3 | 22.0 |
| Anger, mean times per week ± SDg | 3.8 ± 6.4 | 4.5 ± 7.8 | 5.4 ± 13.0 | 4.7 ± 7.8 | 4.7 ± 7.9 | 5.2 ± 11.0 | 4.4 ± 7.6 | 4.1 ± 5.0 | 4.7 ± 9.0 |
| Trouble sleeping, %h | 18.3 | 18.1 | 16.8 | 10.1 | 9.6 | 10.2 | 6.5 | 8.6 | 9.9 |
| High CVD knowledge score, %i | 51.4 | 48.1 | 39.8 | 73.6 | 72.7 | 75.4 | 87.1 | 83.7 | 78.0 |
| Health status | |||||||||
| Illness past year, mean days per y ± SD | 9.4 ± 40.4 | 15.9 ± 54.5 | 17.4 ± 54.4 | 7.3 ± 31.2 | 8.7 ± 33.9 | 4.7 ± 14.7 | 6.2 ± 31.2 | 4.4 ± 21.4 | 2.2 ± 4.9 |
| Hospitalized past year, mean days per y ± SD | 0.6 ± 3.1 | 1.5 ± 7.7 | 1.6 ± 9.1 | 0.7 ± 3.8 | 0.8 ± 4.0 | 0.4 ± 2.4 | 0.6 ± 3.2 | 0.4 ± 2.8 | 0.3 ± 1.5 |
| Causes of death, % | |||||||||
| Cancer j | 23.4 | 20.4 | 25.0 | 19.7 | 31.0 | 30.4 | 31.5 | 21.4 | 0.0 |
| CVDk | 53.1 | 43.3 | 45.3 | 40.8 | 36.9 | 39.1 | 51.9 | 35.7 | 88.9 |
| COPDl | 6.3 | 8.9 | 3.1 | 7.9 | 6.0 | 4.4 | 3.7 | 0.0 | 0.0 |
| Diabetes mellitusm | 3.1 | 1.3 | 1.6 | 0.0 | 1.2 | 4.4 | 0.0 | 0.0 | 0.0 |
| All other causes | 14.1 | 26.1 | 25.0 | 31.6 | 25.0 | 21.7 | 13.0 | 42.9 | 11.1 |
aClinical measurement, standard definition.32
bEver smoked on daily basis, and smoked ≥ 1 cigarette in the past 48 hours; confirmed by expired air carbon monoxide and plasma thiocyanate.33
cBlood pressure calculated as the mean of second and third measurements, using a semiautomatic recorder.34
dDerived from total serum cholesterol from nonfasting venous samples.
eCurrent activity compared with others of the same gender and age: 7-point scale, with scores 1–3 being considered inactive.
f> 7 drinks/week (women) and > 14 drinks/week (men), standard definition.35
g Times per week felt angry or frustrated.
h6 categories, ≥ 2–3 times/week considered trouble sleeping.
iIndex of 17 questions, scores ≥ 6 considered high knowledge.21
jCancer: ICD-9 codes 140–208.31
kCardiovascular disease: ICD-9 codes 410–411 for coronary heart disease, ICD-9 codes 430–438 for stroke.31
lChronic obstructive pulmonary disease: ICD-9 codes 490–496.31
mDiabetes mellitus: ICD-9 code 250.31
The analysis of geocoded goods and services showed that individuals who had low SES in high-SES neighborhoods had significantly more resources for health care (e.g., primary care physicians and health care clinics) near their homes than did their counterparts in low-SES neighborhoods (Table 3 ▶). There were no clear patterns for other basic goods and services. For example, individuals of low SES in high-SES neighborhoods had slightly fewer basic amenities near their homes (e.g., grocery stores, banks) but individuals of low SES in low-SES neighborhoods had substantially more stores near their homes that were often considered detrimental to health (e.g., convenience stores, alcohol outlets).
TABLE 3—
Number of Neighborhood Goods and Services in Close Proximity to Participant’s Home, by Individual and Neighborhood SES
| Women of Low SES | Men of Low SES | |||||||
| High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES | Pa | High Neighborhood SES | Moderate Neighborhood SES | Low Neighborhood SES | Pa | |
| Health care–related resources, ± SD | ||||||||
| Primary care physicians | 4.5 ± 11.3 | 1.7 ± 4.4 | 2.5 ± 6.4 | <.01 | 5.5 ± 12.3 | 1.9 ± 4.9 | 3.1 ± 7.0 | <.01 |
| Health care clinics | 0.2 ± 0.8 | 0.1 ± 0.4 | 0.0 ± 0.2 | <.01 | 0.3 ± 0.9 | 0.1 ± 0.4 | 0.0 ± 0.2 | <.01 |
| Pharmacies | 0.7 ± 1.0 | 0.8 ± 1.1 | 0.7 ± 1.1 | .19 | 0.8 ± 1.1 | 0.8 ± 1.0 | 0.8 ± 1.1 | .86 |
| Basic amenities, ± SD | ||||||||
| Grocery stores | 0.3 ± 0.6 | 0.7 ± 1.1 | 0.5 ± 0.7 | <.01 | 0.3 ± 0.6 | 0.7 ± 1.0 | 0.5 ± 0.6 | <.01 |
| Parks/gyms | 1.5 ± 1.4 | 1.5 ± 1.2 | 1.7 ± 1.8 | .20 | 1.6 ± 1.3 | 1.5 ± 1.2 | 1.9 ± 2.0 | <.01 |
| Schools | 1.9 ± 1.4 | 1.9 ± 1.6 | 2.0 ± 1.6 | .68 | 2.0 ± 1.5 | 2.0 ± 1.6 | 2.1 ± 1.7 | .37 |
| Day care centers | 0.4 ± 0.6 | 0.4 ± 0.8 | 0.3 ± 0.5 | <.01 | 0.4 ± 0.6 | 0.5 ± 0.8 | 0.4 ± 0.7 | .12 |
| Banks | 0.8 ± 1.8 | 1.1 ± 1.9 | 1.4 ± 2.7 | <.01 | 1.0 ± 2.1 | 1.2 ± 2.2 | 1.6 ± 2.7 | <.01 |
| Other stores and restaurants, ± SD | ||||||||
| Fast food restaurants | 0.3 ± 0.7 | 0.6 ± 1.0 | 0.2 ± 0.5 | <.01 | 0.4 ± 0.8 | 0.7 ± 1.1 | 0.2 ± 0.6 | <.01 |
| Convenience stores | 0.8 ± .2 | 1.8 ± 1.8 | 2.4 ± 2.3 | <.01 | 1.0 ± 1.3 | 1.8 ± 1.8 | 2.4 ± 2.3 | <.01 |
| Alcohol outlets | 1.4 ± 3.1 | 2.8 ± 5.3 | 3.1 ± 4.6 | <.01 | 1.9 ± 3.6 | 3.6 ± 6.2 | 3.8 ± 5.4 | <.01 |
Note. Numbers of neighborhood goods and services were based on counts within a 0.5-mile radius of a participant’s home.
aFor comparison across neighborhood SES, by analysis of variance.
DISCUSSION
We examined the interaction between individual and neighborhood SES on risk of mortality among a predominately non-Hispanic White study population, and found excess mortality among adults who had low SES and lived in high-SES neighborhoods. This finding suggests that these individuals do not benefit from the higher quality of resources and knowledge generally associated with higher SES neighborhoods. Although the specific mechanisms that underlay the excess mortality are unknown, we consider 2 plausible explanations that are consistent with a relative deprivation model or a relative standing model. These may act alone or in combination. First, adults of low SES in high-SES neighborhoods may experience relative deprivation because they have less disposable income for essential goods and services (e.g., food, health care, medications, and transportation) because of factors such as higher housing costs. Higher costs in high-SES neighborhoods might also create a need for adults of low SES to work longer hours and therefore have less time to maintain or adopt healthy behaviors. Furthermore, adults of low SES in high-SES neighborhoods may live farther from essential goods and services or be more removed from social services and other resources (e.g., free community clinics, subsidized food and housing) than are adults who have low SES in low-SES neighborhoods. This may be particularly problematic if they also have limited access to transportation. We found little support for this from our analysis of geocoded goods and services. Adults of low SES in high-SES neighborhoods had more primary care physicians and health care clinics near their homes, as well as fewer grocery stores and banks, and fewer convenience stores and alcohol outlets (the latter 2 have been linked with negative health outcomes).42,43 Although proximity assures neither access nor quality, and goods and services may be used outside of neighborhoods, our data suggest that proximity to essential goods and services do not explain our findings.
A second explanation for the excess mortality among adults of low SES in high-SES neighborhoods may be their low relative standing in their communities. It has long been suggested that the discrepancy between an individual’s social position relative to others in his or her community may influence risk of death.16,44–46 Low social position may also be associated with fewer resources to cope with stressful life events, lack of social support, and low sense of control, which may result in real or perceived social isolation, discrimination, or other psychosocial stressors.18,44–50 This explanation is consistent with the finding that a range of psychosocial factors may affect health, either indirectly by influencing health behaviors, or directly by influencing neuroendocrine or immune functioning.50
It is important to note that there may be unrecognized benefits that adults of low SES gain from living in higher SES neighborhoods. It is possible, for example, that adults, despite having higher mortality, may benefit from a higher quality of life in other unmeasured ways or that their children may benefit from amenities in such neighborhoods, such as safer and higher quality schools.51,52
Previous Studies
Several studies have examined the cross-level interaction between individual and neighborhood SES on mortality.6,8,10,11 Two of these studies were conducted in the United States and 2 were done in Canada. One study showed no significant cross-level effects8 and the other 3 studies showed results in the same direction as ours.6,10,11 Yen and Kaplan6 used data from Alameda County, California, and found that low-income adults in neighborhoods that had the highest SES had a significantly higher risk of death than did low-income adults who lived in neighborhoods with the lowest SES (odds ratios of 5.51 vs 1.98; no confidence intervals were reported). This association persisted after they adjusted for a wide range of individual sociodemographic factors and risk behaviors. In 2 recent studies from Canada, Veugelers et al.10 and Roos et al.11 used data from Nova Scotia and Manitoba and found that low-income adults in advantaged neighborhoods had a significantly higher mortality risk than did low-income adults in disadvantaged neighborhoods. Their findings were consistent for both provinces but the results were significant only in Manitoba where the sample size was 4 times the sample in Nova Scotia.
Strengths and Limitations
The strengths of our study include the use of a population-based sample, extended mortality follow-up of 17 years, careful assessment of geographic neighborhood boundaries, virtually complete addresses for geocoding, validation of geocodes, assessment of neighborhood goods and services, and survey data that were comprehensive, consistent over time, and highly complete.21 The unusually high rate of geocoding (97%–99%) was achieved for all survey years because addresses were enumerated in person and verified by study center nurses so that medical results could be sent to participants.
Our study also has limitations. Our death match was based on California death records that miss residents who die outside of California. We assessed the completeness of our California death match by conducting a death match that used both California and national death records for the first survey (1979–1980, n = 1603 people). There were few differences: the California death match identified 260 deaths and the national death search identified 18 additional deaths but missed 13 deaths. The 18 California deaths identified by the national match but missed by the California match were fairly evenly distributed among the 9 individual and neighborhood SES groups (< 2 deaths missed in all groups, except 6 deaths missed among individuals who had moderate SES in moderate SES neighborhoods). We also obtained California hospital discharge records of participants from the last survey (1989–1990, n = 1719 people with 627 hospitalizations). We repeated the survival curves for the same 9 individual and neighborhood SES groups and found an almost identical pattern for hospitalizations as for mortality.53 There were also higher proportions of Hispanic participants who had low SES in low-SES neighborhoods (42% for women, 38% for men) compared with the other 8 individual and neighborhood SES groups (2%–28%). Deaths may have been missed in this group because of reverse migration, matching errors, or other reasons, which could result in an underestimate of the death rate for women or men in that category. We do not believe this is the case, however, given that we found similar results when we restricted the analyses to White, non-Hispanic participants.
Another potential limitation is that factors associated with self-selection into certain neighborhoods could account for the results and lead to erroneous conclusions of neighborhood effects. Our neighborhoods were based on geographically defined census tract, block group boundaries, or both, and considerable debate exists as to whether such boundaries represent neighborhoods as defined by their residents.54,55 Finally, we did not measure the length of time people were exposed to their neighborhood environments and whether they lived in the same type of neighborhood over time (e.g., at time of death or censoring). Although 78% of participants reported living in “their community” 5 or more years, this does not guarantee that they lived in their census-defined neighborhoods, or in similar neighborhoods, after the survey.
Implications
Our findings demonstrate how important it is for health professionals and policymakers to understand people within the context of their neighborhoods. The high mortality that we observed among adults of low SES who live in high-SES neighborhoods suggests that they may encounter factors that hinder health or compromise medical treatment, factors that may be different from those that affect adults of low SES who live in low-SES neighborhoods. Our findings also highlight how important it is for neighborhoods to share collective resources and knowledge to support all residents. Public health strategies need to continue to focus on adults who have the lowest SES in neighborhoods of greatest deprivation in order to reduce health inequalities; however, our findings also show the need to focus attention on people of low SES who live in more advantaged neighborhoods who represent a potentially “hidden” population at high risk of death.
Acknowledgments
This study was funded as part of the National Institute of Environmental Health Sciences Initiative, in collaboration with 6 other National Institutes of Health (National Heart, Lung, and Blood Institute grant RO1 HL67731).
We thank Ying-Chih Chuang, Craig Pollack, Soowon Kim, May Wang, and Lauren Cochran for their comments on an earlier draft; David Rogosa for biostatistical assistance; and Alana Koehler for assistance with manuscript preparation.
Human Participant Protection
All research was approved by the administrative panels on human subjects in medical research at Stanford University School of Medicine and conforms to the principles of the Declaration of Helsinki.
Peer Reviewed
Contributors M. Winkleby conceptualized the study, acquired and interpreted the data, wrote much of the article, and completed the revisions. C. Cubbin helped conceptualize the study, assisted with the data analysis, helped interpret the data, wrote parts of the article, and contributed to the revisions. D. Ahn analyzed the data and reviewed drafts of the article and revisions.
References
- 1.Haan M, Kaplan GA, Camacho T. Poverty and health: prospective evidence from the Alameda County Study. Am J Epidemiol. 1987;125:989–998. [DOI] [PubMed] [Google Scholar]
- 2.Anderson RT, Sorlie P, Backlund E, Johnson N, Kaplan GA. Mortality effects of community socioeconomic status. Epidemiology. 1996;8:42–47. [DOI] [PubMed] [Google Scholar]
- 3.Waitzman NJ, Smith KR. Phantom of the area: poverty-area residence and mortality in the United States. Am J Public Health. 1998;88:973–976. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.LeClere FB, Rogers RG, Peters KD. Ethnicity and mortality in the United States: individual and community correlates. Social Forces. 1997;76:169–198. [Google Scholar]
- 5.Steenland K, Henley J, Calle E, Thun M. Individual- and area-level socioeconomic status variables as predictors of mortality in a cohort of 179 383 persons. Am J Epidemiol. 2004;159:1047–1056. [DOI] [PubMed] [Google Scholar]
- 6.Yen IH, Kaplan GA. Neighborhood social environment and risk of death: multilevel evidence from the Alameda County Study. Am J Epidemiol. 1999;149: 898–907. [DOI] [PubMed] [Google Scholar]
- 7.Winkleby MA, Cubbin C. Influence of individual and neighbourhood socioeconomic status on mortality among Black, Mexican-American, and White women and men in the United States. J Epidemiol Commun Health. 2003;57:444–452. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Borrell LN, Diez Roux AV, Rose K, Catellier D, Clark BL. Neighbourhood characteristics and mortality in the Atherosclerosis Risk in Communities Study. Int J Epidemiol. 2004;33:398–407. [DOI] [PubMed] [Google Scholar]
- 9.Lochner K, Pamuk E, Makuc D, Kennedy BP, Kawachi I. State-level income inequality and individual mortality risk: a prospective, multilevel study. Am J Public Health. 2001;91:385–391. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Veugelers PJ, Yip AM, Kephart G. Proximate and contextual socioeconomic determinants of mortality: multilevel approaches in a setting with universal health care coverage. Am J Epidemiol. 2001;154:725–732. [DOI] [PubMed] [Google Scholar]
- 11.Roos LL, Magoon J, Gupta S, Chateau D, Veugelers PJ. Socioeconomic determinants of mortality in two Canadian provinces: multilevel modelling and neighborhood context. Soc Sci Med. 2004;59:1435–1447. [DOI] [PubMed] [Google Scholar]
- 12.Macintyre S, Ellaway A, Cummins S. Place effects on health: how can we conceptualise, operationalise and measure them? Soc Sci Med. 2002;55:125–139. [DOI] [PubMed] [Google Scholar]
- 13.Sampson RJ, Raudenbush SW, Earls F. Neighborhoods and violent crime: a multilevel study of collective efficacy. Science. 1997;277:918–924. [DOI] [PubMed] [Google Scholar]
- 14.Stafford M, Marmot M. Neighbourhood deprivation and health: does it affect us all equally? Int J Epidemiol. 2003;32:357–366. [DOI] [PubMed] [Google Scholar]
- 15.Troutt DD. The thin red line: how the poor still pay more. San Francisco, CA: West Coast Regional Office, Consumers Union of the United States; 1993.
- 16.Åberg Yngwe M, Fritzell J, Lundberg O, Diderichsen F, Burström B. Exploring relative deprivation: is social comparison a mechanism in the relation between income and health? Soc Sci Med. 2003;57:1463–1473. [DOI] [PubMed] [Google Scholar]
- 17.Wilkinson RG. National mortality rates: the impact of inequality? Am J Public Health. 1992;82: 1082–1084. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Jencks C, Mayer SE. The social consequences of growing up in a poor neighborhood. In: Lynn LE, Jr., McGeary MGH, eds. Inner-City Poverty in the United States. Washington, DC: National Academy Press; 1990:111–186.
- 19.Farquhar JW, Fortmann SP, Maccoby N, et al. The Stanford Five-City Project: design and methods. Am J Epidemiol. 1985;122:323–334. [DOI] [PubMed] [Google Scholar]
- 20.Fortmann SP, Haskell WL, Williams PT, Varady AN, Hulley SB, Farquhar JW. Community surveillance of cardiovascular diseases in the Stanford Five-City Project: methods and initial experience. Am J Epidemiol. 1986;123:656–669. [DOI] [PubMed] [Google Scholar]
- 21.Farquhar JW, Fortmann SP, Flora JA, et al. Effects of communitywide education on cardiovascular disease risk factors: the Stanford Five-City Project. JAMA. 1990;264:359–365. [PubMed] [Google Scholar]
- 22.Winkleby MA, Feldman HA, Murray DM. Joint analysis of three US community intervention trials for reduction of cardiovascular disease risk. J Clin Epidemiol. 1997;50:645–658. [DOI] [PubMed] [Google Scholar]
- 23.Fortmann SP, Varady AN. Effects of a community-wide health education program on cardiovascular disease morbidity and mortality: the Stanford Five-City Project. Am J Epidemiol. 2000;152:316–323. [DOI] [PubMed] [Google Scholar]
- 24.Diez Roux AV, Merkin SS, Arnett D, et al. Neighborhood of residence and incidence of coronary heart disease. N Engl J Med. 2001;345:99–106. [DOI] [PubMed] [Google Scholar]
- 25.Cubbin C, Hadden WC, Winkleby MA. Neighborhood context and cardiovascular disease risk factors: the contribution of material deprivation. Ethnicity Dis. 2001;11:687–700. [PubMed] [Google Scholar]
- 26.Snijders TAB, Bosker RJ. Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling. Thousand Oaks, CA: Sage Publications; 1999.
- 27.Krieger N, Waterman P, Lemieux K, Zierler S, Hogan JW. On the wrong side of the tracts? Evaluating the accuracy of geocoding in public health research. Am J Public Health. 2001;91:1114–1116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Federal Financial Institutions Examination Council. FFIEC geocoding system. Available at: http://www.ffiec.gov/geocode/default.htm. Accessed May 17, 2005.
- 29.Granovetter M. Threshold models of collective behavior. Am J Sociol. 1978;83:1420–1443. [Google Scholar]
- 30.Crane J. The epidemic theory of ghettos and neighborhood effects on dropping out and teenage childbearing. Am J Sociol. 1991;96:1226–1259. [Google Scholar]
- 31.International Classification of Diseases, Ninth Revision. Geneva, Switzerland: World Health Organization; 1980.
- 32.National Heart, Lung, and Blood Institute. Clinical Guidelines on the Identification, Evaluation, and Treatment of Overweight and Obesity in Adults: The Evidence Report. Bethesda, MD: National Institutes of Health; 1998. Report 98–4083.
- 33.Fortmann SP, Rogers T, Haskell WL, Solomon DS, Vranizan K, Farquhar JW. Indirect measures of cigarette use: expired air carbon monoxide vs plasma thiocyanate. Prev Med. 1984;13:127–134. [DOI] [PubMed] [Google Scholar]
- 34.Fortmann SP, Marcuson R, Bitter PH, Haskell WL. A comparison of the Sphygmetrics SR-2 automatic blood pressure recorder to the mercury sphygmomanometer in population studies. Am J Epidemiol. 1981;114:836–844. [DOI] [PubMed] [Google Scholar]
- 35.US Department of Health and Human Services. 10th Special Report to the US Congress on Alcohol and Health. Bethesda, MD: National Institute on Alcohol Abuse and Alcoholism, National Institutes of Health; 2000. Report REP023.
- 36.Ury HK, Wiggins AD. Another shortcut method for calculating the confidence interval of a Poisson variable (or of a standardized mortality ratio). Am J Epidemiol. 1985;122:197–198. [DOI] [PubMed] [Google Scholar]
- 37.Kaplan EL, Meier P. Nonparametric estimation from incomplete observations. J Am Stat Assoc. 1958; 53:457–481. [Google Scholar]
- 38.Thakkar B, Hur K, Henderson WG, Oprian C. A method to generate Kaplan–Meier and adjusted survival curves using SAS. Available at: http://www2.sas.com/proceedings/sugi23/Stats/p226.pdf. Accessed October 4, 2005.
- 39.Cox DR. Regression models and life tables. J Royal Stat Soc Series B. 1972;34:187–202. [Google Scholar]
- 40.Kraemer HC, Blasey CM. Centring in regression analyses: a strategy to prevent errors in statistical inference. Int J Methods Psychiatr Res. 2004;13:141–151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Aiken LS, West SG. Multiple Regression: Testing and Interpreting Interactions. Newbury Park, CA: Sage Publications; 1991.
- 42.Pollack CE, Cubbin C, Ahn D, Winkleby M. Neighbourhood deprivation and alcohol consumption: does the availability of alcohol play a role? Int J Epidemiol. 2005;34:772–780. [DOI] [PubMed] [Google Scholar]
- 43.Chuang YC, Cubbin C, Ahn D, Winkleby MA. Effects of neighborhood socioeconomic status and convenience store concentration on individual-level smoking. J Epidemiol Community Health. 2005;59:568–573. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Elstad JI. The psycho-social perspective on social inequities in health. Sociol Health Illness. 1998;20: 598–618. [Google Scholar]
- 45.Pearce N, Davey Smith G. Is social capital the key to inequalities in health? Am J Public Health. 2003;93: 122–129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Wilkinson R. Commentary: liberty, fraternity, equality. Int J Epidemiol. 2002;31:538–543. [DOI] [PubMed] [Google Scholar]
- 47.Boyce WT, Chesterman EA, Winkleby MA. Psychosocial predictors of maternal and infant health among adolescent mothers. Am J Dis Child. 1991;145: 267–273. [DOI] [PubMed] [Google Scholar]
- 48.Williams DR, Yu Y, Jackson JS, Anderson NB. Racial differences in physical and mental health: socioeconomic status, stress, and discrimination. J Health Psych. 1997;2:335–351. [DOI] [PubMed] [Google Scholar]
- 49.Kawachi I, Kennedy BP, Lochner K, Prothrow-Stith D. Social capital, income inequality, and mortality. Am J Public Health. 1997;87:1491–1498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.McEwen BS. Protective and damaging effects of stress mediators. N Engl J Med. 1998;338:171–179. [DOI] [PubMed] [Google Scholar]
- 51.Ludwig J, Duncan GJ, Hirschfield P. Urban poverty and juvenile crime: evidence from a randomized housing-mobility experiment. Q J Economics. 2001;116: 655–679. [Google Scholar]
- 52.Leventhal T, Brooks-Gunn J. Moving to opportunity: an experimental study of neighborhood effects on mental health. Am J Public Health. 2003;93: 1576–1582. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Taylor CB, Ahn D, Winkleby MA. High rates of being hospitalized among low SES adults in high SES neighborhoods. Am J Prev Med. 2006;31:127–134. [DOI] [PubMed] [Google Scholar]
- 54.Tienda M. Poor people and poor places: deciphering neighborhood effects on poverty outcomes. In: Huber J, ed. Macro-Micro Linkages in Sociology. New-bury Park, CA: Sage Publications; 1991:244–262.
- 55.Sampson RJ, Morenoff JD, Gannon-Rowley T. Assessing neighborhood effects: social processes and new directions in research. Annu Rev Sociol. 2002;28: 443–478. [Google Scholar]