

Abstract
Upper and lower bounds on cell counts in cross-classifications of nonnegative counts play important roles in a number of practical problems, including statistical disclosure limitation, computer tomography, mass transportation, cell suppression, and data swapping. Some features of the Fréchet bounds are well known, intuitive, and regularly used by those working on disclosure limitation methods, especially those for two-dimensional tables. We previously have described a series of results relating these bounds to theory on loglinear models for cross-classified counts. This paper provides the actual theory and proofs for the special case of decomposable loglinear models and their related independence graphs. It also includes an extension linked to the structure of reducible graphs and a discussion of the relevance of other results linked to nongraphical loglinear models.
Keywords: Fréchet bounds, loglinear models, reducible graphs, disclosure limitation
1. Introduction
Upper and lower bounds on cell counts in cross-classifications of positive counts given certain marginal totals play important roles in a number of the disclosure limitation procedures, e.g., see the various papers in the 1998 special issue of The Journal of Official Statistics (1). In that context, if a cell count is small and the upper bound is “close” to the lower bound, the intruder knows with certainty that there is only a small number of individuals possessing the characteristics corresponding to the cell and this may pose an undo risk of disclosure of the identity of these individuals. Similarly, such bounds also arise in a variety of other contexts including mass transportation problems (2), computer tomography (3), ecological inference in the social sciences (4), causal inference in imperfect experiments (5), and are the focus of the probabilistic literature on copulas (6). Much of the work on this problem has been focused on bounds in the case when the marginal totals are nonoverlapping.
The class of bounds we describe is a generalization of bounds usually attributed to Fréchet (7), whose original presentation was in terms of cumulative distribution functions (c.d.f.) for a random vector (D1, D2, … , Dm) in Rm:
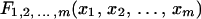 |
1 |
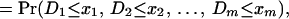 |
which are essentially equivalent to contingency tables when the underlying variables are categorical. For example, suppose we have a two-dimensional table of counts, {nij} adding up to the total n++ = n. If we normalize each entry by dividing by n and then create a table of partial sums, by cumulating the proportions from the first row and first column to the present ones, we have a set of values of the form [1]. Thus, Fréchet bound results for distribution functions correspond to bounds for the cell counts where the values {xi} in [1] represent “cut-points” between categories for the ith categorical variable. Bonferroni (8) and Hoeffding (9) independently developed related results on bounds.
We are interested in the following generalization of the Bonferroni–Fréchet–Hoeffding bounds. Consider a k-dimensional contingency table nK arranged as a linear list of m counts. The random variable assigned to the ith cell will be denoted Yi. Let 𝒮 be a system of nonempty subsets of {1, 2, … , m}, such that ∪S∈𝒮 S = {1, 2, … , m}. The Fréchet class ℱ(𝒮) (6) is the class of m-variate distributions with fixed marginals {FS : S ∈ 𝒮}, where FS is the joint c.d.f. of random variables {Yi : i ∈ 𝒮}. Because the indices of the margins being fixed might be overlapping, we have to impose a consistency constraint, namely
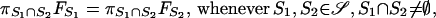 |
where πS means integrating out the variables that do not appear in S. Following Rüschendorf (10), for a measurable function φ: Rm → R, we define M(φ) = sup {∫ φdF : F ∈ ℱ (𝒮)} and m(φ) = inf {∫ φdF : F ∈ ℱ (𝒮)}. Our goal is to determine M(φ) and m(φ) in the particular case when φ is the identity function on the set R × … × (− ∞,yi] × … × R. This is equivalent to determining sharp upper and lower bounds for the ith cell in the cross-classification nK, given the marginals {nS : S ∈ 𝒮}.
Fienberg (11) noted that there is an intimate link between bounds for non-negative cell entries in a cross-classification subject to marginal constraints, and maximum likelihood estimates for the same cell entries under the loglinear model whose minimal sufficient statistics are the margins. This link seems especially clear in the special case of cross-classifications of non-negative counts and loglinear models for their expectations that are decomposable, i.e., for tables where estimated expected values can be explicitly written as a function of the marginal totals (e.g., see refs. 12–14). Such models are a special subclass of the graphical loglinear models (e.g., see refs. 14 and 15), and these models are representable in terms of graphs that display conditional independence relationships. We present the results here in terms of graphs and explain how they apply to the more general situation. In the next section, we introduce some basic notation for the corresponding theory of decomposable graphs. Then, in Section 3, we give results on Fréchet bounds when the margins correspond to those that characterize decomposable loglinear models. Sections 4 and 5 extend the approach to reducible graphs and provide some explicit examples. In the final section, we present some conjectures on how these bound results can be extended to cases corresponding to bounds for cross-classifications that are not quite representable in graphical form but that utilize our results for reducible graphs.
2. Basic Graph Theory Results
In this section, we begin with some basic definitions and notations for graphs and then define decomposable graphs and present some results that characterize them.
2.1. Graph Terminology.
A graph is a pair 𝒢 = (V, E), where V is a finite set of vertices and E ⊆ V × V is a set of edges linking the vertices. Our interest is in undirected graphs, for which (u, v) ∈ E implies (v, u) ∈ E. For any vertex set A ⊆ V, we define the edge set associated with it as
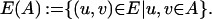 |
Let 𝒢(A) = (A, E(A)) denote the subgraph of 𝒢 induced by A. The section graph 𝒢\A := 𝒢(V\A) is the subgraph of 𝒢 obtained by removing a set of vertices A ⊂ V from the graph. Two vertices u, v ∈ V are adjacent (neighbors) if (u, v) ∈ E. A set of vertices of 𝒢 is independent if no two of its elements are adjacent. The boundary bd(A) of a subset of vertices A ⊂ V is the set of vertices in V\A adjacent to at least one vertex in A:
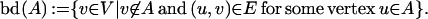 |
The closure of A ⊂ V is cl(A) = A ∪ bd(A). An induced subgraph 𝒢(A) is complete if the vertices in A are pairwise adjacent in 𝒢. We also say that A is complete in 𝒢. A complete vertex set A in 𝒢 that is maximal is a clique.
Let u, v ∈ V. A path (or chain) from u to v is a sequence u = v0, … , vn = v of distinct vertices such that (vi−1, vi) ∈ E for all i = 1, 2, … , n. The path is a cycle if the end points are allowed to be the same, u = v. If there is a path from u to v we say that u and v are connected. The sets A, B ⊂ V are disconnected if u and v are not connected for all u ∈ A, v ∈ B. The connected component of a vertex u ∈ V is the set of all vertices connected with u. A graph is connected if all the pairs of vertices are connected.
The set C ⊂ V is an uv-separator if all paths from u to v intersect C. The set C ⊂ V separates A from B if it is an uv-separator for every u ∈ A, v ∈ B. C is a separator (cut-set) of 𝒢 if two vertices in the same connected component of 𝒢 are in two distinct connected components of 𝒢\C or, equivalently, if 𝒢\C is disconnected. In addition, C is a minimal separator of 𝒢 if C is a separator and no proper subset of C separates the graph. Unless otherwise stated, the separators we work with will be complete.
Consider a connected graph 𝒢 = (V, E) having a clique separator C, and let V1, … , Vs be the vertex sets of the connected components of 𝒢\C. The subgraphs 𝒢(V1 ∪ C), … , 𝒢(Vs ∪ C) are the leaves of 𝒢 produced by C. A graph is bipartite if its set of vertices can be partitioned into two disjoint subsets V1 and V2 such that every edge of the graph connects between a vertex of V1 and a vertex of V2, i.e. V1 and V2 are independent sets. A tree is a connected graph with no cycles. It has n vertices and n − 1 edges. In a tree, there is a unique path between any two vertices.
2.2. Decomposable Graphs.
Decomposable graphs possess the special property that allows us to “decompose” them into components or subgraphs and work directly with these components. They also allow us to make use of divide-and-conquer techniques to solve any type of problem associated with such a graphical structure. The idea is to decompose the graph 𝒢 in two possibly overlapping subgraphs 𝒢′ and 𝒢" so that no structural information of the graph is lost when transforming 𝒢 into 𝒢′ and 𝒢". Furthermore, by “correctly” decomposing 𝒢′ and 𝒢", and so on, one ends up with a set of subgraphs of 𝒢 that allow for no further decompositions. A set of subgraphs of 𝒢 generated in this way is called a derived system of 𝒢, while its elements are called atoms (16). If one does not lose any information along the way in the decomposition, then one can solve problems for each atom and then put together the component solutions to solve a combined problem for the initial graph 𝒢. But first we need to define what we mean by “correct” decomposition.
Definition 1: The partition (A1, A2, A3) of V is said to form a decomposition of 𝒢 if A2 is a minimal separator of A1 and A3.
In this case (A1, A2, A3) decomposes 𝒢 into the components 𝒢(A1 ∪ A2) and 𝒢(A2 ∪ A3). The decomposition is proper if A1 and A3 are not empty. If A2 is empty, A1 and A3 form two nonoverlapping connected components.
Throughout the remainder of this section, we will assume that the graphs we work with are connected. No loss of generality is incurred because all the results can be applied to a disconnected graph by applying them successively to each connected component. We follow closely Blair and Barry (17) and Lauritzen (18).
Definition 2: The graph 𝒢 is decomposable if it is complete or if there exists a proper decomposition (A1, A2, A3) into decomposable graphs 𝒢(A1 ∪ A2) and 𝒢(A2 ∪ A3).
Because we require a proper decomposition of the graph at every step, the components 𝒢(A1 ∪ A2) and 𝒢(A2 ∪ A3) have fewer vertices than the original graph 𝒢, hence the procedure will stop after a finite number of steps. The smallest nondecomposable graph is a cycle with four vertices.
Definition 3: A vertex v ∈ V is simplicial in 𝒢 = (V, E) if bd(v) is a clique.
If v ∈ V is simplicial in 𝒢 and 𝒢 is not complete, ({v}, bd(v), V\cl(v)) is a proper decomposition of 𝒢. Simplicial vertices have very nice and useful properties:
Lemma 1. (i) A vertex is simplicial if and only if it belongs to precisely one clique. (ii) Any decomposable graph has at least one simplicial vertex.
The importance of simplicial vertices in describing the structure of decomposable graphs will soon become apparent. Assume that the graph 𝒢 has n vertices. An ordering of 𝒢 is a bijection from the vertex set V to a set of labels {1, 2, … , n}. Let v1, v2, … , vn be an ordering of the vertex set V. The monotone adjacency set of vi is given by:
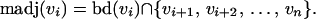 |
2 |
There is a special class of orderings of 𝒢 that plays a central role in the characterization of decomposable graphs.
Definition 4: The ordering v1, v2, … , vn is a perfect elimination ordering (PEO) if vi is simplicial in the graph 𝒢 ({vi, vi+1, … , vn}) for every i = 1, 2, … , n.
Any decomposable graph is characterized by the possession of a PEO, as the next result shows.
Theorem 1. A graph 𝒢 is decomposable if and only if 𝒢 has a perfect elimination ordering.
The maximum cardinality search algorithm (MCS) is a linear-time procedure for generating a perfect elimination ordering. It starts with an arbitrary vertex v ∈ V for which it sets v = vn. The next vertex will be labeled n − 1 and will be one of the unlabeled vertices with the maximum number of labeled neighbors. The ordering v1, v2, … , vn generated by continuing in this way will always be a PEO if the input graph is decomposable.
Let 𝒞(𝒢) = {C1, C2, … , Cp} be the set of cliques of a decomposable graph 𝒢 and v1, v2, … , vn be a PEO obtained by applying the MCS algorithm. We will refer to viq as the representative vertex of Cq whenever Cq = {viq} ∪ madj(viq). The following result shows how MCS can efficiently generate the cliques in 𝒞(𝒢) by identifying their representative vertices.
Theorem 2. [Blair and Barry (17).] Let v1, v2, … , vn be a PEO obtained by applying the MCS algorithm to a connected decomposable graph 𝒢. Then 𝒞(𝒢) contains precisely the following sets: {v1} ∪ madj(v1) and {vi+1} ∪ madj(vi+1), 1 ≤ i ≤ n − 1, for which | madj(vi)| ≤ | madj(vi+1)|.
Because MCS labels the vertices of 𝒢 in decreasing order, the cliques also will be generated in a decreasing order with respect to the labels of their representative vertices. More explicitly, assume that vi1, vi2, … , vip are the representative vertices of the cliques C1, C2, … , Cp, respectively, where i1 > i2 > … > ip. The MCS algorithm finds the cliques in 𝒞(𝒢) in the order C1, C2, … , Cp. We need to introduce one additional class of sets.
Definition 5: Let V1, … , Vk be a sequence of subsets of the vertex set of a graph 𝒢 = (V, E). Let Hj = V1 ∪ … ∪ Vj, Sj = Hj−1 ∩ Vj, and Rj = Vj\Hj−1. The sequence is said to be perfect if (i) for all j > 1, there is an i < j such that Sj ⊆ Vi, and (ii) the sets Sj are complete for all j.
The first condition in Definition 5 is known as the running intersection property. The sets Sj are called the separators of the sequence.
Theorem 3. [Lauritzen (14).] Let V1, … , Vk be a perfect sequence of sets that contains all cliques of a graph 𝒢. Then for every j, Sj separates Hj−1\Sj from Rj in 𝒢(Hj) and hence (Hj−1\Sj, Sj, Rj) decomposes 𝒢(Hj).
A total ordering C1, C2, … , Cp of the cliques in 𝒞(𝒢) generated by the MCS algorithm will always have the running intersection property (17). Because C1, C2, … , Cp are complete in 𝒢, the vertex sets Sj = (C1 ∪ … ∪Cj−1) ∩ Cj will also be complete, and consequently C1, C2, … , Cp is a perfect sequence of sets. By recursively applying Theorem 3, we obtain that 𝒞(𝒢) is a derived system of 𝒢, whereas Sj (j = 2, … , p) is the corresponding sequence of separators [c.f. the recursive result described by Rüschendorf (10)]. We note that, although a clique can appear only once in 𝒞(𝒢), a separator can appear more than once in 𝒞(𝒢). Therefore, 𝒮(𝒢) is not really a set, but a “multiset” of separators (17).
3. Generalized Fréchet Bounds for Decomposable Loglinear Models
Let X = (X1, X2, … , Xk) be a vector of discrete random variables. Denote K = {1, 2, … , k} the index set associated with X1, X2, … , Xk. The random variable Xj can take the values xj ∈ {1, 2, … , Ij}, for j = 1, 2, … , k. Let JK = I1 × I2 × … × Ik and x = (x1, x2, … , xk) ∈ JK.
Consider the k-way contingency table nK := {nK(x)}x∈JK. We let a = {i1, i2, … , ip} denote an arbitrary subset of K, and we define Xa as the ordered tuple Xa = (Xi; i ∈ a). Similarly, we denote Ja = Ji1 × Ji2 × … × Jip. The marginal table of counts na := {na(xa)}xa∈Ja corresponding to Xa is given by
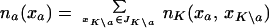 |
We write nab instead of na∪b, where a, b ⊆ K. The grand total of the complete table is n∅.
Assume we are given m possibly overlapping marginal tables nC1, nC2, … , nCp such that C1 ∪ C2 ∪ … ∪ Cp = K. Moreover, C1, C2, … , Cp are the cliques of a decomposable graph 𝒢 = (K, E). Let S2, … , Sp be the separators associated with (Cj)j. Every Sj is included in some clique Ci, hence the marginals nS2, … , nSp will also be fixed.
The class of Fréchet bounds we present is linked with the theory of decomposable loglinear models. We think of every vertex i ∈ K of 𝒢 as being associated with a variable Xi. The structural information embedded in 𝒢 might be interpreted in the following way: If S separates A1 and A2 in 𝒢, then XA1 is conditionally independent of XA2 given XS. The loglinear model with minimal sufficient statistics C1, C2, … , Cp will be decomposable because its independence graph 𝒢 is decomposable, and consequently the maximum likelihood estimates (MLEs) will exist and can be expressed in a closed form (14, 15). We develop explicit formulas for the tightest upper and lower bounds for the cell counts in the cross-classification nK provided that the marginals nC1, nC2, … , nCp are known by employing a similar machinery to the one used for developing formulas for MLEs for a decomposable loglinear model. This machinery provides us with the tools we need for extending the usual Fréchet bounds to more complicated graphical structures.
We begin with a slightly more general statement of the original Fréchet bound result (2, 11).
Theorem 4. (Fréchet). (i) Let a1, a2 ⊆ K such that (a1\a2, a1 ∩ a2, a2\a1) is a proper decomposition of the graph 𝒢 (a1 ∪ a2). Then the following inequality holds:
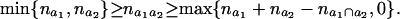 |
3 |
(ii) The above inequality provides sharp bounds for the cells in the contingency table na1∪a2 given the marginals na1 and na2.
If two vertex sets are in two distinct connected components, they are separated by the empty set. It is not hard to see that Theorem 4 implies the following result.
Corollary 1. (i) If a1 and a2 are two disjoint subsets of K, we have
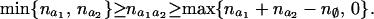 |
(ii) The above inequality provides sharp bounds for the cells in the contingency table na1∪a2 given the marginals na1 and na2.
This immediately generalizes to a graph with any number of connected components.
Theorem 5. (i) Let {a1,
a2, … , am} denote the set
of connected components of the graph
𝒢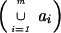 .
Then the following is true:
.
Then the following is true:
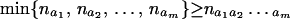 |
4 |
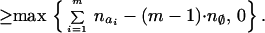 |
(ii) The above inequality provides sharp bounds for the
cells in the contingency table
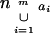 given the marginals na1,
na2, … , nam.
given the marginals na1,
na2, … , nam.
We are now ready to explore the situation when the minimal sufficient statistics of a decomposable loglinear model define a connected graph.
Theorem 6. Suppose 𝒢 = (K, E) is connected and decomposable. Let 𝒞(𝒢) = {C1, C2, … , Cp} the set of cliques of 𝒢 ordered in a perfect sequence and 𝒮(𝒢) = {S2, … , Sp} the corresponding set of separators. Then
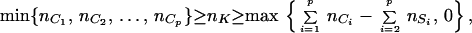 |
5 |
and these are sharp bounds for the cells in the contingency table nK given the marginals nC1, … , nCp.
Proof: By induction. If 𝒢 decomposes in p = 2 cliques, then Eq. 5 is a direct consequence of Theorem 4. Suppose we know that Eq. 5 holds for any connected decomposable graph with p − 1 cliques. We want to prove Eq. 5 for a graph with p cliques.
Theorem 3 tells us that (Hp−1\Sp, Sp, Rp) is a decomposition of the graph 𝒢(Hp) = 𝒢. By using Theorem 4, we obtain
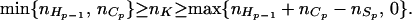 |
6 |
The cliques of 𝒢(Hp−1) are C1, C2, … , Cp−1, and this is a perfect sequence in 𝒢(Hp−1). From the induction assumption that we made, we have
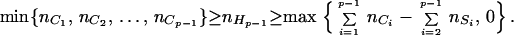 |
7 |
By combining Eqs. 6 and 7, we obtain the desired Eq. 5. Again, because the bounds in Eq. 6 are the tightest possible for the counts in table nK, and the same is true for the bounds in Eq. 7 for the cell counts in table nHp−1, we conclude that the bounds in Eq. 5 are also the tightest bounds for the counts in table nK.
Buzzigoli and Giusti (18) proposed an algorithm, which they call the shuttle algorithm, that alternates iteratively between upper and lower bounds, and that when applied to decomposable structures appears to indirectly exploit the structure implicit in Theorem 6. But it does not achieve the sharp bounds in as computationally efficient fashion as we can by using the formula directly.
At this point we succeeded in developing formulas for the sharpest bounds when the sets of indices defining the known marginals define a connected decomposable graph. However, the connectivity assumption is not by any means essential. We can extend the definition of decomposable graphs to include disconnected graphs with all their connected components decomposable. By employing the maximum cardinality search algorithm sequentially for every connected component, we can determine the set of cliques of such a disconnected decomposable graph as the union of the sets of cliques associated with the connected components. The corresponding set of separators can be obtained in the same way.
The next result provides an explicit formula for the generalized Fréchet bounds associated with an arbitrary decomposable graphical structure. We emphasize that the generalized Fréchet bounds are sharp bounds given the information that we assumed we have.
Theorem 7. (i) Let 𝒢 = (K, E) be a decomposable graph. Then the following inequality is true:
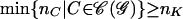 |
8 |
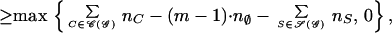 |
where 𝒞(𝒢) is the set of cliques of 𝒢, 𝒮(𝒢) is the set of separators associated with 𝒞(𝒢), and m is the number of connected components of the graph 𝒢. (ii) The above inequality provides sharp bounds for the cells in the contingency table nK given the marginals {nC|C ∈ 𝒞(𝒢)}.
Proof: We apply Lemma 6 for each connected component of 𝒢, then Theorem 5 to combine the resulting inequalities. All the bounds for the marginal tables involved are tight, hence the bounds in Eq. 8 will also be tight.
4. Reducible Graphs
By exploiting decomposability in an appropriate manner, we have been able to find sharp bounds for cell counts when some special sets of marginals characterizing decomposable loglinear models are given. It is natural to ask ourselves whether we could develop similar results for reducible graphs, as described in refs. 16 and 19.
Definition 6: A graph 𝒢 is reducible if 𝒢 admits a proper decomposition, otherwise 𝒢 is a prime graph.
Any complete graph is prime, whereas any disconnected graph is reducible. By definition, the atoms contained in a derived system of a graph are all prime. Given that every reducible graph 𝒢 might have several derived systems (16), we would like to be able to isolate one of them that could fully characterize the input graph 𝒢.
Definition 7: A subgraph 𝒢(A) is a maximal prime (mp-) subgraph of 𝒢, if 𝒢(A) is prime and 𝒢(B) is reducible for all B with A ⊂ B ⊆ V.
The set of mp-subgraphs of 𝒢 is contained in every derived system of 𝒢. Moreover, the set of mp-subgraphs of 𝒢 is always a derived system of 𝒢 (19), and consequently it is the unique minimal derived system. If 𝒢 is decomposable, the mp-subgraphs of 𝒢 are complete, hence the unique minimal derived system of a decomposable graph contains only its cliques (19).
Section 2 describes a procedure for finding the mp-subgraphs of a decomposable graph. The order in which the MCS algorithm identifies the mp-subgraphs along with the set of separators are needed to reconstruct the original graph from its minimal derived system. We would like to devise a similar decomposition algorithm for the more general case when the input graph is reducible, not necessarily decomposable.
It is easy to see that any decomposable graph is reducible, but the converse is not true, as we will prove next. Gavril (20) introduced the family of clique separable graphs in the following recursive manner.
Definition 8: 𝒢 = (V, E) is a clique-separable graph if (i) 𝒢 is a Type 1 or Type 2 graph, or (ii) 𝒢 has a separator C, and the leaves of 𝒢 produced by C are clique-separable graphs.
A graph 𝒢 is a Type 1 graph if its vertex set can be partitioned in two subsets V1, V2, such that |V1| ≥ 3, 𝒢(V1) is a connected bipartite graph, V2 is complete, and every vertex of V1 is adjacent to every vertex of V2. In addition, 𝒢 = (V, E) is a Type 2 graph if there exists a partition V1, … , Vk of V, such that V1, … , Vk are independent sets in 𝒢, and every vertex of Vi is adjacent to every vertex of Vj, for i ≠ j.
By definition, any decomposable graph is also clique-separable, and any clique-separable graph is reducible. However, Type 2 graphs are clique-separable but obviously they are not necessarily decomposable, hence the class of reducible graphs is much richer than the class of decomposable graphs.
Tarjan (16) has proposed an O(nm)-time method for decomposing a reducible graph with n vertices and m edges. The downside of Tarjan's algorithm is that it generates an arbitrary derived system of prime graphs. Leimer (19) has adapted this algorithm so that the input graph is decomposed exactly into its mp-subgraphs. A reducible graph 𝒢 might have several separators that would induce a proper decomposition of 𝒢. If we could select the “right” separator at every step of the decomposition procedure, then we would manage to avoid including nonmaximal prime subgraphs in the final derived system.
Definition 9: [Leimer (19).] Let (A1, A2, A3) be a decomposition of 𝒢 into the subgraphs 𝒢′ = 𝒢(A1 ∪ A2) and 𝒢" = 𝒢(A2 ∪ A3). If the mp-subgraphs of 𝒢′ and 𝒢" are pairwise different and if they are all mp-subgraphs of 𝒢, then (A1, A2, A3) is called a P-decomposition and A2 is called a P-separator.
Moreover, a decomposition (A1, A2, A3) is a P-decomposition if and only if 𝒢(A2) is not an mp-subgraph of any of the graphs 𝒢(A1 ∪ A2) and 𝒢(A2 ∪ A3) (19). If a graph has a decomposition, then it also has a P-decomposition. Therefore it is possible to decompose a reducible graph by means of P-separators, and in this case we are guaranteed to obtain the minimal derived system of maximal prime subgraphs.
Assume that we somehow managed to order the vertex sets of the mp-subgraphs 𝒢(V1), … , 𝒢(Vk) of a graph 𝒢 in a perfect sequence. By using the same notations as before, we have the following result.
Theorem 8. [Leimer (19).] (Hk−1\Sk, Sk, Rk) is a P-decomposition of 𝒢 into 𝒢′ = 𝒢(Hk−1) and the prime graph 𝒢" = 𝒢(Vk). 𝒢(V1), … , 𝒢(Vk−1) are the mp-subgraphs of 𝒢′ and V1, … , Vk−1 is a perfect sequence of sets in 𝒢′.
Theorem 8 can be applied recursively to generate a derived system of 𝒢. Because the decompositions performed along the way are P-decompositions, the minimal derived system of 𝒢 will be generated.
We are interested in the existence of a perfect sequence of the mp-subgraphs of a graph only for proving the correctness of our results. The ordering of the mp-subgraphs is not relevant when computing the generalized Fréchet bounds, and consequently, in an actual implementation of our algorithms, we would only have to obtain the set 𝒱(𝒢) of mp-subgraphs along with the corresponding sequence 𝒮(𝒢) of separators.
Leimer (19) has suggested an alternative approach that would allow us accomplish this task by taking advantage of the MCS algorithm we previously presented. The first step would be to transform a connected reducible graph 𝒢 = (V, E) in a closely related decomposable graph by adding extra edges in E. We would like to keep the number of edges added to a minimum, so that a minimal decomposable graph is derived.
Definition 10: [Tarjan (16).] Let π be an ordering of the vertex set of a graph 𝒢 = (V, E). The fill-in Fπ caused by the ordering π is the set of edges:
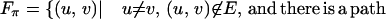 |
9 |
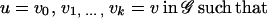 |
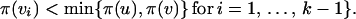 |
The graph 𝒢π = (V, E ∪ Fπ) is called the minimal fill-in graph if there does not exist a numbering π′ of 𝒢 with Fπ′ ⊂ Fπ. It can be shown that the fill-in graph 𝒢π is decomposable for any numbering π of 𝒢. Algorithms for generating a minimal fill-in graph can be found in Ohtsuki and Cheung (21).
The second step consists of applying the maximum cardinality search algorithm to the minimal fill-in graph 𝒢π associated with the input graph 𝒢. However, we will not employ the “original” maximum cardinality search algorithm. We will make use instead of an expanded version (17) that can find the set 𝒞(𝒢π) = {C1, C2, … , Cr} of cliques of 𝒢π along with the associated system 𝒮(𝒢π) = {S2, … , Sr} of separators by constructing a tree 𝒯π = (𝒞(𝒢π), ℰτπ). We assume that the sequence C1, C2, … , Cr is perfect. For every clique Cj, j > 1, we choose a “parent” clique Ci, i < j such that Sj ⊂ Ci, and include the edge (Cj, Ci) in ℰτπ. Because the parent of a clique might not be unique, more than one tree could be constructed on 𝒞(𝒢π). Moreover, C1 cannot have a parent and will be called the root of the tree. This is certainly not a restriction because every clique can be C1 in some perfect sequence. The tree 𝒯π generated by the MCS algorithm has the additional property that S ⊂ V is a minimal vertex separator of 𝒢π if and only if S = Cj ∩ Ci for some edge (Cj, Ci) ∈ ℰτπ. Consequently, the set of separators associated with 𝒞(𝒢π) will be given by 𝒮(𝒢π) = {Ci ∩ Cj : (Ci, Cj) ∈ ℰτπ}. Then S ∈ 𝒮(𝒢π) will also be a minimal separator in 𝒢 if S is complete in 𝒢.
The last step of the algorithm is presented below in pseudo-code. With every clique C ∈ 𝒞(𝒢π), we associate a vertex set Δ(C). Initially we set Δ(C) ← C for all C ∈ 𝒞(𝒢π). A clique C is terminal in 𝒯π if C is not the parent of any other clique, i.e., if there is no such C′ with (C′, C) ∈ ℰτπ.
• 𝒱(𝒢) ← ∅; 𝒮(𝒢) ← ∅;
• while ℰτπ ≠ ∅ do
- 1.
Identify a terminal clique Cj;
- 2.
𝒞(𝒢π) ← 𝒞(𝒢π)\{Cj};
- 3.
ℰτπ ← ℰτπ\{(Cj, Ci)};
- 4.
if Cj ∩ Ci is complete in 𝒢 then
𝒱(𝒢) ← 𝒱(𝒢) ∪ {Δ(Cj)};
𝒮(𝒢) ← 𝒮(𝒢) ∪ {Cj ∩ Ci};
else
Δ(Ci) ← Δ(Ci) ∪ Δ(Cj);
end while
• 𝒱(𝒢) ← 𝒱(𝒢) ∪ {Δ(C1)}.
This algorithm provides a computational approach for identifying the maximal prime subgraphs 𝒱(𝒢) of an arbitrary connected reducible graph 𝒢, along with its associated system 𝒮(𝒢) of separators. We utilize it in the following section.
5. Generalized Fréchet Bounds for Reducible Loglinear Models
In Section 3, we showed that we can explicitly determine the tightest bounds for the cells in a table of counts nK given a set of marginals when that set of marginals define a decomposable graph 𝒢 = (K, E). When the graph associated with some set of marginals is not decomposable, we have no choice but to employ iterative methods such as the simplex algorithm. Generally speaking, linear programming methods are computationally expensive and might yield results that are very difficult to interpret, so they should be used with care. The natural question to ask is whether we could reduce the computational effort needed to determine the tightest bounds by employing the same strategy used for decomposable graphs, i.e., decompositions of graphs by means of complete separators.
To be more specific, assume we want to determine the bounds for a contingency table nK given the marginals nC1, nC2, … , nCp. In addition, C1, C2, … , Cp are the cliques of the graph 𝒢 = (K, E). 𝒢 is assumed to be reducible, not necessarily decomposable. Let V1, V2, … , Vq be the maximal prime subgraphs of 𝒢 ordered in a perfect sequence, and let S2, S3, … , Sq be the sequence of separators associated with V1, V2, … , Vq. Suppose we could compute tight bounds for the marginals nV1, nV2, … , nVq given nC1, nC2, … , nCp, i.e., we know nV1U, nV2U, … , nVqU and nV1L, nV2L, … , nVqL such that
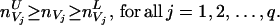 |
10 |
Because Sj is complete in 𝒢, there will exist an i ∈ {1, 2, … , p} such that Sj ⊆ Ci. Hence nSj is a marginal table of nCi. Therefore, once we fixed nC1, nC2, … , nCp, the marginals nS2, … , nSq will also be fixed. With the notations introduced above, we develop explicit formulas for sharp bounds for the cells counts in table nK.
Theorem 9. Suppose 𝒢 = (K, E) is connected and reducible. The tightest bounds for the cell counts in the contingency table nK given the marginals nC1, nC2, … , nCp are given by
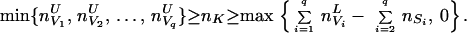 |
11 |
Proof: Because V1, V2, … , Vq is a derived system of 𝒢, we could think about the subgraphs 𝒢(V1), … , 𝒢(Vq) as being the cliques of a connected decomposable graph 𝒢′. Moreover, S2, … , Sq will be the system of separators associated with V1, V2, … , Vq in 𝒢′. By employing Theorem 6, we obtain
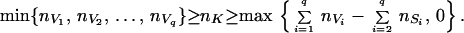 |
12 |
Then Eq. 11 follows immediately from Eqs. 12 and 10. The bounds for the marginal tables involved are all sharp, hence the bounds in Eq. 11 will also be tight.
Once again, we will point out the link with maximum likelihood estimation in loglinear models. We define a reducible loglinear model as one for which the corresponding minimal sufficient statistics are margins that characterize the maximal prime subgraphs of a reducible graph. Assuming that one has calculated maximum likelihood estimates for the loglinear models determined by the independence graphs 𝒢(V1),𝒢(V2), … ,𝒢(Vq), then one can easily derive explicit formulae for the maximum likelihood estimates in the reducible loglinear model with independence graph 𝒢. By employing results of Lauritzen (14), we find that
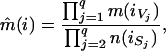 |
13 |
(c.f. the special cases given in ref. 12).
We continue the analogy with the decomposable case we previously discussed by considering a reducible disconnected graph. We know how to find the maximal prime subgraphs (along with the corresponding sequence of separators) successively for every connected component. The set of mp-subgraphs for the complete graph is defined as the union of the sets of mp-subgraphs of every connected component. The set of separators can be determined in a similar way. We are now ready for the main result of the paper. However, we are going to postpone presenting it for the moment.
5.1. Example.
To clarify the concepts and the results presented so far, we use an example similar to the one proposed by Tarjan (16). The graph 𝒢 in Fig. 1 has 11 vertices and 17 edges represented by continuous lines. We want to determine the mp-subgraphs of 𝒢. The edge {3, 9} is a separator for {1, 3, 4, 5, 6, 7, 8, 9, 11} and {2, 3, 9, 10}. The latter is a four-cycle, hence cannot be further decomposed, and because it is not a complete, 𝒢 cannot be decomposable. Similarly, {4, 7} separates {1, 3, 4, 7, 8, 9, 11} and {4, 5, 6, 7}. Again, the latter is a four-cycle, hence it is a prime subgraph. Now the clique {1, 3, 4, 11} is separated from {3, 4, 7, 8, 9, 11} by the triangle {3, 4, 11}. The subgraph 𝒢({3, 4, 7, 8, 9, 11}) does not have a separator, therefore we have finished decomposing 𝒢. The set of mp-subgraphs is 𝒱(𝒢) = {{2, 3, 9, 10}, {4, 5, 6, 7}, {1, 3, 4, 11}, {3, 4, 7, 8, 9, 11}}, whereas the sequence of separators is 𝒮(𝒢) = {{3, 9}, {4, 7}, {3, 4, 11}}.
Figure 1.

A graph and its minimal fill-in set of edges.
Next we illustrate how to obtain 𝒱(𝒢) and 𝒮(𝒢) by using the decomposition algorithm from Section 4. The minimal fill-in graph 𝒢π is obtained by adding six new edges to 𝒢. These edges are represented with dotted lines in Fig. 1. The cliques of 𝒢π are C1 = {1, 3, 4, 11}, C2 = {3, 4, 7, 11}, C3 = {3, 7, 8, 11}, C4 = {4, 6, 7}, C5 = {4, 5, 6}, C6 = {3, 8, 9}, C7 = {3, 9, 10}, and C8 = {2, 3, 10}. The tree 𝒯π constructed by the MCS algorithm on 𝒞(𝒢π) = {C1, C2, … , C8} has edges
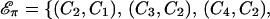 |
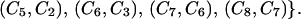 |
We proceed to the last step of the algorithm. The clique C5 is terminal, but C5 ∩ C4 = {4, 6} is not complete in 𝒢, hence we set Δ(C4) = {4, 5, 6, 7}. After eliminating C5 from the clique tree, C4 becomes terminal. Because S1 = C4 ∩ C2 = {4, 7} is complete in 𝒢, we identified the first mp-subgraph V1 = Δ(C4) and its associated separator S1. We eliminate C4 from 𝒯π, and the algorithm proceeds in a similar manner.
The set 𝒞(𝒢) of cliques is essentially the set of edges of 𝒢 from which we take out {1, 3}, {1, 4}, {1, 11}, {4, 11}, {3, 4}, {3, 11}, and then add {1, 3, 4, 11}. Assume we want to determine upper and lower bounds for a cross-classification nK with 11 dimensions. Given the marginal tables {nC : C ∈ 𝒞(𝒢)}, it is possible to compute sharp bounds for the marginal tables corresponding to the mp-subgraph of 𝒢. Because the separators in 𝒮(𝒢) are subsets of some cliques, they will define marginals of some tables in {nC : C ∈ 𝒞(𝒢)}, hence it is possible to make use of Theorem 9 to calculate sharp bounds for the cell counts in table nK.
5.2. Bounds for Reducible Loglinear Models.
The foregoing example indicates that Theorem 9 is applicable in a more general setting than the one we previously suggested. Determining bounds for cell counts in a cross-classification given the marginals defined by the set of cliques is equivalent to the problem of calculating the MLEs of a graphical loglinear model. The minimal sufficient statistics of a graphical log-linear model define a graph, and the cliques of this graph are exactly the minimal sufficient statistics. If the minimal sufficient statistics are not cliques in the associated graph, the model is not graphical.
For example, suppose we have a table nK corresponding to the graph in Fig. 1. Now assume we don't have access to the marginal n[1,3,4,11], but instead we do know n[1,3], n[1,4], n[1,11] and also n[3,4,11]. These marginals no longer correspond to the cliques of a graph. Yet it is still possible to compute sharp bounds for the marginals determined by the mp-subgraphs of 𝒢, and then to combine these bounds using Theorem 9 to obtain tight bounds for the complete table nK.
To be more explicit, suppose we are provided with a set of marginals
nD1, nD2, … ,
nDr that define a graph 𝒢 = (K, E).
We have K =
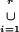 Di and E = {(u, v) : {u, v} ⊂
Dj, for some j = 1, … , r}.
The mp-subgraphs of 𝒢 are 𝒱(𝒢) = {V1,
V2, … , Vq}, whereas the
corresponding sequence of separators is 𝒮(𝒢) =
{S2, … , Sq}. We emphasize that
(Dj)j do not have to be the set of
cliques of 𝒢 and that 𝒢 is not necessarily connected. However, we
need to impose one additional constraint, namely for every
Si, there is a j ∈ {1, 2, … ,
r} such that Si ⊂ Dj. This
implies that the marginals nS2, … ,
nSq will be fixed once
nD1, nD2, … ,
nDr are fixed. With these notations, we announce
a more general version of Theorem 9.
Di and E = {(u, v) : {u, v} ⊂
Dj, for some j = 1, … , r}.
The mp-subgraphs of 𝒢 are 𝒱(𝒢) = {V1,
V2, … , Vq}, whereas the
corresponding sequence of separators is 𝒮(𝒢) =
{S2, … , Sq}. We emphasize that
(Dj)j do not have to be the set of
cliques of 𝒢 and that 𝒢 is not necessarily connected. However, we
need to impose one additional constraint, namely for every
Si, there is a j ∈ {1, 2, … ,
r} such that Si ⊂ Dj. This
implies that the marginals nS2, … ,
nSq will be fixed once
nD1, nD2, … ,
nDr are fixed. With these notations, we announce
a more general version of Theorem 9.
Theorem 10. Let 𝒢 = (K, E) be a reducible graph. Then the following inequality is true:
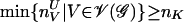 |
14 |
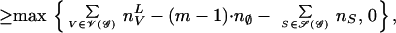 |
where 𝒱(𝒢) is the set of maximal prime subgraphs of 𝒢, 𝒮(𝒢) is the set of separators associated with 𝒱(𝒢), and m is the number of connected components of the graph 𝒢. In addition, {nVU|V ∈ 𝒱(𝒢)} and {nVL|V ∈ 𝒱(𝒢)} are the tightest upper and lower bounds for the marginal tables {nV|V ∈ 𝒱(𝒢)}, respectively.
Proof: Because 𝒱(𝒢) is a derived system of the graph 𝒢, we can think about the subgraphs {𝒢(V)|V ∈ 𝒱(𝒢)} as being the derived system of cliques of a graph 𝒢′. In this case 𝒮(𝒢) will be the set of separators associated with 𝒱(𝒢) in 𝒢′, hence Eq. 14 follows immediately from Eq. 8.
6. Conclusions
The results described in this paper are part of a programmatic effort to understand and operationalize the computation of upper and lower bounds for non-negative entries in cross-classifications subject to a set of marginal constraints. From research on mass transportation and other versions of this problem, we know that the computational problem is typically characterized as being NP-complete, and thus we cannot expect to find a simple approach that will deal effectively with the bound calculation problem, especially in high dimensions. Thus, instead of attempting to utilize a general computational approach such as linear programming or the simplex algorithm (22) or network methods (23, 24), we have opted to exploit the structure of the underlying probability structures based on statistical and mathematical theory.
In particular, we have worked with the graphical representation of probability distributions subject to conditional independence relationships and utilized existing results on decomposable graphs to derive explicit bounds for cell entries when the given marginals correspond to the maximal cliques of a decomposable graph. Our approach was motivated by the more specialized results for decomposable loglinear models for tables of counts where the minimal sufficient statistics are marginals and the expected cell values are explicit functions of them.
We also have extended the bound results from the decomposable to the reducible case, and this allows us to exploit other results and computational approaches for bounds applied to subtables corresponding to the reducible components that are not cliques. The results of Section 5 focus on the cases where tables still have a graphical representation representing conditional independence relationships. But there are many other probability structures where we would like to be able to calculate bounds but are not graphical in this sense. For example, a k-dimensional probability distribution given all (k − 1)-dimensional marginals is not graphical, but we are still able to exploit statistical theory to compute upper and lower bounds in this case. Fienberg (11) outlines an approach for doing this in the k = 3 case, and Dobra and Fienberg (25) provide detailed algorithms for k > 3. Suppose that one wants to compute bounds for a cross-classification that has a structure similar to that in the reducible case, except that we replace a d-dimensional nonclique by a d-dimensional probability distribution given all (d − 1)-dimensional marginals. Then we can combine the bounds computed for this nongraphical distribution using the reducible representation of Section 5.
Cox (26) raised a very interesting question, namely, whether one can actually construct a feasible table with a prescribed set of possibly overlapping margins. The solution to the feasibility problem is straightforward if the marginal tables constitute the maximal cliques of a decomposable graph. In this case, the explicit formulas for calculating the MLEs of the associated loglinear model provide us with a feasible table. In addition, if the set of margins are the minimal sufficient statistics of a reducible loglinear model, Eq. 13 tells us how to construct a feasible table given a consistent set of marginals associated with the maximal prime subgraphs of the induced independence graph. Therefore, the results substantially reduce the computational effort needed to solve the feasibility problem by reducing it to a number of smaller and hopefully easier-to-solve problems.
These results represent only a small part of those needed to allow the computation of upper and lower bounds for high-dimensional cross-classifications of the sort that arise in disclosure limitation and other practical problems.
Acknowledgments
Preparation of this paper was supported in part by the U.S. Bureau of the Census and the National Science Foundation under Grant EIA-9876619 to the National Institute of Statistical Sciences.
Abbreviations
- c.d.f.
cumulative distribution function
- PEO
perfect elimination ordering
- MCS
maximum cardinality search
- MLE
maximum likelihood estimate
- mp-
maximal prime
Appendix
We give below a proof of Theorem 4.
Proof: Let a1 = {1, … , p} and a2 = {q, … , m} where 1 ≤ q ≤ p ≤ m. Let ni10 … im0 be an arbitrary cell in the table na1∪a2. To avoid confusion, the marginals na1, na2, na1∩a2 will be denoted by A1, A2, A12, respectively. The following equalities should hold:
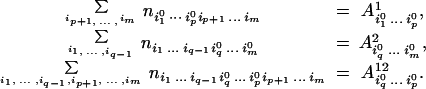 |
Consider the sums:
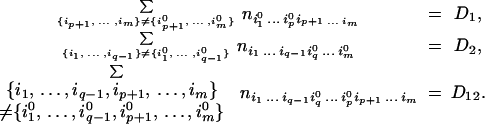 |
With these notations, we have
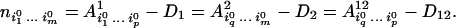 |
15 |
We can write D12 = D1 + D2 + D3, where
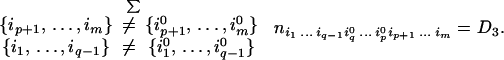 |
It follows that
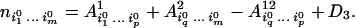 |
16 |
Clearly D1, D2, D3 ≥ 0. From Eqs. 15 and 16, we deduce
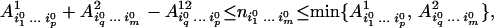 |
which concludes the proof.
Footnotes
This contribution is part of the special series of Inaugural Articles by members of the National Academy of Sciences elected on April 27, 1999.
References
- 1.Various authors (1998) J. Off. Stat. 14, Special Issue 4.
- 2.Rachev S T, Rüschendorf L. Mass Transportation Problems. 1 and 2. New York: Springer; 1998. [Google Scholar]
- 3.Gutmann S, Kemperman J H B, Reeds J A, Shepp L A. Ann Probabil. 1991;19:1781–1797. [Google Scholar]
- 4.King G. A Solution to the Ecological Inference Problem. Princeton: Princeton Univ. Press; 1997. [Google Scholar]
- 5.Balke A, Pearl J. J Am Stat Assoc. 1997;92:1172–1176. [Google Scholar]
- 6.Joe H. Multivariate Models and Dependence Concepts. New York: Chapman & Hall; 1997. [Google Scholar]
- 7.Fréchet M. Les Probabilitiés, Associées a un Système d'Événments Compatibles et Dépendants. P. Paris: Hermann & Cie; 1940. remiere Partie. [Google Scholar]
- 8.Bonferroni C E. Teoria Statistica delle Classi e Calcolo delle Probabilitá. Vol. 8. Florence, Italy: Publicazioni del R. Instituto Superiore di Scienze Economiche e Commerciali di Firenze; 1936. pp. 1–62. [Google Scholar]
- 9.Hoeffding W. Scale-Invariant Correlation Theory. Vol. 5. Berlin: Schriften des Mathematischen Instituts und des Instituts für Angewandte Mathematik der Universität Berlin; 1940. pp. 181–233. [Google Scholar]
- 10.Rüschendorf L. Stochastic Orders and Decision Under Risk. Vol. 19. Institute of Mathematical Statistics Lecture Notes—Monograph Series; 1991. pp. 285–310. [Google Scholar]
- 11.Fienberg S E. Statistical Data Protection, Proceedings of the Conference (Lisbon, 25 to 27 March 1998) Luxembourg: Eurostat; 1999. pp. 115–129. [Google Scholar]
- 12.Bishop Y M M, Fienberg S E, Holland P W. Discrete Multivariate Analysis: Theory and Practice. Cambridge, MA: MIT Press; 1975. [Google Scholar]
- 13.Haberman S J. The Analysis of Frequency Data. Chicago: Univ. of Chicago Press; 1974. [Google Scholar]
- 14.Lauritzen S L. Graphical Models. Oxford: Clarendon; 1996. [Google Scholar]
- 15.Whittaker J. Graphical Models in Applied Multivariate Statistics. New York: Wiley; 1990. [Google Scholar]
- 16.Tarjan R E. Discrete Math. 1985;55:221–232. [Google Scholar]
- 17.Blair J R S, Barry P. Graph Theory and Sparse Matrix Computation. Vol. 56. New York: Springer; 1993. pp. 1–30. [Google Scholar]
- 18.Buzzigoli L, Giusti A. Statistical Data Protection, Proceedings of the Conference (Lisbon, 25 to 27 March 1998) Luxembourg: Eurostat; 1999. pp. 131–147. [Google Scholar]
- 19.Leimer H G. Discrete Math. 1993;113:99–123. [Google Scholar]
- 20.Gavril F. Discrete Math. 1977;19:159–165. [Google Scholar]
- 21.Ohtsuki T, Cheung L K, Fujisawa T. J Math Anal Appl. 1976;54:622–633. [Google Scholar]
- 22.Roehrig S F, Padman R, Duncan G T, Krishnan R. Statistical Data Protection, Proceedings of the Conference (Lisbon, 25 to 27 March 1998) Luxembourg: Eurostat; 1999. pp. 149–162. [Google Scholar]
- 23.Cox L H. J Am Stat Assoc. 1980;75:377–385. [Google Scholar]
- 24.Cox L H. J Am Stat Assoc. 1995;90:1453–1462. [Google Scholar]
- 25.Dobra A, Fienberg S E. Computing Bounds for Entries in k-dimensional Cross-Classifications Given All (k − 1)-Dimensional Marginals. Carnegie Mellon University, New York: Department of Statistics Technical Report; 2000. [Google Scholar]
- 26.Cox L H. Statistical Data Protection, Proceedings of the Conference (Lisbon, 25 to 27 March 1998) Luxembourg: Eurostat; 1999. pp. 163–176. [Google Scholar]