

Abstract
In tonal languages such as Mandarin Chinese, a lexical tone carries semantic information and is preferentially processed in the left brain hemisphere of native speakers as revealed by the functional MRI or positron emission tomography studies, which likely measure the temporally aggregated neural events including those at an attentive stage of auditory processing. Here, we demonstrate that early auditory processing of a lexical tone at a preattentive stage is actually lateralized to the right hemisphere. We frequently presented to native Mandarin Chinese speakers a meaningful auditory word with a consonant-vowel structure and infrequently varied either its lexical tone or initial consonant using an odd-ball paradigm to create a contrast resulting in a change in word meaning. The lexical tone contrast evoked a stronger preattentive response, as revealed by whole-head electric recordings of the mismatch negativity, in the right hemisphere than in the left hemisphere, whereas the consonant contrast produced an opposite pattern. Given the distinct acoustic features between a lexical tone and a consonant, this opposite lateralization pattern suggests the dependence of hemisphere dominance mainly on acoustic cues before speech input is mapped into a semantic representation in the processing stream.
Keywords: hemispheric specialization, mismatch negativity, preattentive auditory processing
The two hemispheres of the human brain are functionally specialized (1–4) for efficient processing of diverse information with the complex neural structures confined in a limited skull space. The left hemisphere has been thought since the 19th century to be dominant in speech perception (5, 6), but what cues are used by the brain to determine this labor division is still an issue of debate (7–9). The functional hypothesis claims that the cues are the linguistic function of auditory inputs: sounds carrying semantic information are preferentially processed in the left hemisphere (10, 11). Alternatively, the acoustic hypothesis claims that the cues are the acoustic structures of auditory inputs: spectrally variant sounds are preferentially processed in the right hemisphere, whereas temporally variant sounds such as nontonal speech are processed in the left (12, 13). The two hypotheses are competing, and neither can account for a full range of experimental data (14–16).
Two types of auditory stimuli, which have an equal linguistic function but one is spectrally variant and the other is temporally variant, can be designed for a robust test of the two hypotheses. A lexical tone and a consonant in Mandarin Chinese, a tonal language, are ideal materials for such stimuli. The meaning of a Chinese word cannot be defined solely by consonants and vowels without a lexical tone, which is a varying pattern of voice pitch in vowels (17). For example, syllable /bai/ can be accented in four lexical tones to represent four completely different auditory words that mean “split,” “white,” “swing,” or “defeat,” respectively (Table 1). With the exception of the first tone, also known as the flat tone, the lexical tones in Chinese feature slow changes in frequency with time (spectrally variant) (Fig. 1A) in contrast to the consonants, which feature rapid temporal variations (temporally variant) (Fig. 1B). A lexical tone and a consonant in Chinese language thus have an equal linguistic function in defining word meaning but are distinct in acoustic features. The functional hypothesis would predict left hemisphere dominance for processing both lexical tones and consonants based on their equal linguistic functions regardless of their acoustic features. However, the acoustic hypothesis would predict right hemisphere dominance for processing lexical tones and left hemisphere dominance for processing consonants based on their distinct acoustic features regardless of their linguistic functions.
Table 1.
Auditory words used for stimuli
| Syllable and lexical tone | bai1 | bai2 | bai3 | bai4 | sai1 | dai1 | tai1 |
| Chinese character |  |
 |
 |
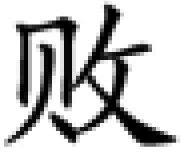 |
 |
 |
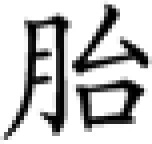 |
| Meaning | split | white | swing | defeat | plug | silly | tire |
The syllable is expressed in Pinyin Roman phonemic transcription system. The numeric suffix represents the lexical tone of the syllable.
Fig. 1.
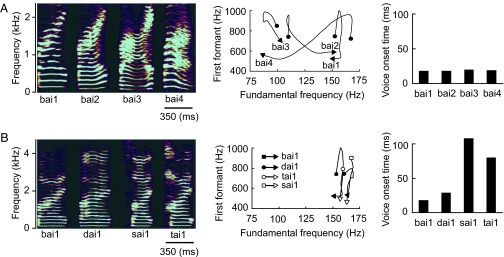
The lexical tone and consonant used for auditory odd-ball stimuli were acoustically distinct. (A) Spectrograms of syllable /bai / pronounced in four lexical tones (bai1, bai2, bai3, and bai4) illustrate that the lexical tones are featured by the varying frequency with time (Left). Note that only when the syllable is pronounced in first tone, or flat tone (bai1), the frequency remains relatively constant with time. The varying frequency of the lexical tones with time is more clearly demonstrated by the trajectories of fundamental frequency and first formant (Center). The lexical tones have minimal effects on the voice onset time (Right). (B) Spectrograms of syllables bai, sai, dai, and tai pronounced in a flat tone (bai1, dai1, sai1, and tai1) illustrate that the syllables have relatively unchanged frequencies with time (Left). The fundamental frequency is particularly time-invarying as demonstrated by the trajectories of fundamental frequency and first formant (Center). The consonants are featured by the temporal variation as reflected by the voice onset time (Right).
When nonspeech sounds are used as the stimulus, the lateralization patterns as revealed with functional MRI (fMRI) or positron emission tomography (PET) are well predicted by the acoustic hypothesis (12, 18). Arguing against this hypothesis are data from the fMRI or PET experiments that use lexical tones as the stimulus to demonstrate that additional areas of the left hemisphere will be activated in native tonal language speakers versus English speakers (19–21), suggesting the dependence of hemisphere lateralization based on linguistic functions and language experience rather than on acoustic features. Because fMRI or PET measures hemodynamic responses with a temporal resolution ranging from seconds to tens of seconds (22, 23), the observation from these neuroimaging studies, which require subjects to execute a discrimination task, likely represents the temporally aggregated brain activities including those at an attentive stage of auditory processing. However, the hemisphere lateralization for an auditory response to speech sound can occur as early as 144 ms after the onset of stimulus (24). Thus, there is a possibility that the auditory response to lexical tones at such an early stage was actually lateralized to the right hemisphere on the basis of their acoustic features but confounded with the response components at a later stage of processing and not explicitly revealed in the previous fMRI or PET studies. In the present study, we attempted to identify which hypothesis prevails in early auditory processing by using whole-head electric recordings of the mismatch negativity (MMN) from native Mandarin Chinese speakers under a passive auditory odd-ball paradigm (25). The recorded MMN response occurred ≈200 ms after the onset of stimulus and reflected the brain's automatic processing at a preattentive stage (26). Our results suggest the dependence of hemisphere dominance mainly on acoustic cues, rather than on linguistic cues, in early lexical processing.
Results
The auditory stimuli were the lexical tone contrast and the consonant contrast (Fig. 1 and Table 2). To evoke MMN with the lexical tone contrast, we frequently presented to one group of subjects syllable /bai/ pronounced in one tone, which was a meaningful auditory word, as the standard stimulus and infrequently presented the same syllable accented in a different tone as the deviant stimulus. The standard and deviant stimuli differed mainly in the fundamental frequency (Fig. 1A Center) but kept constant voice onset time (Fig. 1A Right). The deviation of the lexical tone created a contrast and caused a change in word meaning. The MMN responses under this stimulus sequence reflected the detection of changes arising from deviations in the spectral features of the lexical tones. To evoke MMN with the consonant contrast, we frequently presented to a second group of subjects a syllable consisting of an initial consonant and vowel /ai/ pronounced in first tone, or flat tone, which was a meaningful auditory word, as the standard stimulus and infrequently replaced the initial consonant with a different one as the deviant stimulus. The standard and deviant stimuli had a relatively time-invarying fundamental frequency (Fig. 1A Center) but different voice onset time (Fig. 1B Right). The deviation of the initial consonant created a contrast and caused a change in word meaning. The MMN responses under this stimulus sequence reflected the detection of changes arising from deviations in the temporal features of the consonants.
Table 2.
Block design of odd-ball paradigm
| Lexical tone contrast | ||||||
| Standard | bai1 | bai1 | bai1 | bai2 | bai2 | bai3 |
| Deviant | bai2 | bai3 | bai4 | bai3 | bai4 | bai4 |
| Consonant contrast | ||||||
| Standard | bai1 | sai1 | sai1 | |||
| Deviant | dai1 | dai1 | tai1 | |||
The standard stimuli occur in 90% of trials, and the deviant stimuli occur in 10% of trials.
We have found that MMN in response to the lexical tone contrast was stronger in magnitude when recorded on the right side of the scalp than when recorded on the left side. In contrast, MMN in response to the consonant contrast demonstrated an opposite pattern: it was stronger in magnitude when recorded on the left side of the scalp than when on the right. The upper panel of Fig. 2A shows the grand average traces of MMN in response to the lexical tone contrast recorded with three electrodes on the left side of the scalp (F3, Fc3, C3) and three electrodes on the right side of the scalp (F4, Fc4, C4). These MMN traces recorded on the right side were larger in magnitude than those recorded on the left side. The lower panel of Fig. 2A shows the scalp topographic maps constructed with the grand average MMN from whole-head recordings in response to the lexical tone contrast. The MMN maps were obviously lateralized in strength to the right side of the scalp. Fig. 2B shows the grand average traces of MMN recorded with the three pairs of electrodes (Upper) and the scalp topographic maps of the grand average MMN with whole-head recordings (Lower) in response to the consonant contrast. The MMN traces recorded on the left side of the scalp (F3, Fc3, C3) were larger in magnitude than the traces recorded on the right side (F4, Fc4, C4), and the MMN topographic maps were obviously lateralized in strength to the left side of the scalp.
Fig. 2.

MMN responses recorded on the left and right sides of the scalp. (A) Grand average traces of MMN evoked by the lexical tone contrast and recorded from three pairs of electrodes on the left (solid blue lines) and right (dashed red lines) sides of the scalp (Upper) (n = 11). Gray bars indicate the time window in which MMN amplitude was calculated. Scalp topographic maps constructed from grand average MMN evoked by the lexical tone contrast are shown in lower panel. (B) Grand average traces recorded from three pairs of electrodes (Upper) and grand average scalp topographic maps (Lower) of MMN evoked by the consonant contrast (n = 11). Gray bars indicate the time window in which MMN amplitude was calculated. (C) Average amplitudes of MMN recorded from three pairs of electrodes on the left and right sides of the scalp. MMN was significantly larger in amplitude on the right side of the scalp than on the left in response to the lexical tone contrast (P < 0.01) but larger in amplitude on the left side of the scalp than on the right in response to the consonant contrast (P < 0.05). Vertical bars represent one standard error.
The analysis of the MMN amplitudes calculated with recordings from three pairs of electrodes on the left (F3, Fc3, C3) and right (F4, Fc4, C4) sides of the scalp for individual subjects (Fig. 2C) demonstrates that the opposite pattern of hemisphere lateralization for the MMN responses to the lexical tone contrast and to the consonant contrast is statistically significant. ANOVA with hemisphere (left vs. right, within groups) as one factor and with stimulus condition (lexical tone contrast vs. consonant contrast, between groups) as the other factor indicates a significant interaction between the two factors (P < 0.05). A one-way ANOVA with hemisphere (left vs. right, repeated measures) as the factor was further performed for each stimulus condition (lexical tone contrast and consonant contrast), and the results indicate that the MMN response was significantly lateralized to the right side of the scalp for the lexical tone contrast (P < 0.01) and significantly lateralized to the left side of the scalp for the consonant contrast (P < 0.05).
The opposite pattern of hemisphere lateralization for the MMN responses to the lexical tone contrast and to the consonant contrast was also revealed by the dipole solutions (mirror dipoles). The average dipole locations resolved with MMN recorded from individual subjects indicate that the neural generators of MMN in response to the lexical tone contrast and to the consonant contrast were bilaterally located near the primary auditory cortex (Fig. 3A). The average dipole strengths were also obtained from individual subjects for each hemisphere and for each stimulation condition, which showed an opposite pattern of hemisphere lateralization for the lexical tone contrast and for the consonant contrast (Fig. 3B). To test whether this opposite pattern of hemisphere lateralization is statistically significant, a two-way ANOVA with hemisphere (left vs. right, within groups) as one factor and with stimulus condition (lexical tone contrast vs. consonant contrast, between groups) as the other factor was performed, and the results indicate a significant interaction between the two factors (P < 0.01). A paired Student t test was further performed for each stimulus condition (lexical tone contrast and consonant contrast), and the results indicate that the dipole was significantly stronger in strength in the right hemisphere than in the left for the lexical tone contrast (n = 11, P < 0.01) but stronger in strength in the left hemisphere than in the right for the consonant contrast (n = 11, P < 0.01).
Fig. 3.

Dipole solutions. (A) An axial view of average dipole locations resolved with MMN recorded from individual subjects in response to the lexical tone contrast (Left) and to the consonant contrast (Right). Dipole locations are indicated with respect to the Talairach coordinate system. (B) Average dipole strengths obtained from dipole solutions for individual subjects. The dipole was significantly stronger in strength in the right hemisphere than in the left for the lexical tone contrast (n = 11, P < 0.01) (Left) but stronger in strength in the left hemisphere than in the right for the consonant contrast (n = 11, P < 0.01) (Right). Vertical bars represent one standard error.
Discussion
Our results demonstrate that the preattentive auditory processing of a lexical tone, which defines word meaning as a consonant does, is actually lateralized to the right hemisphere in opposite to left hemisphere lateralization for the processing of a consonant. The observed lateralization to the right hemisphere for lexical tone processing is not likely due to a presumably more difficult task for perceiving lexical tones than consonants because the auditory processing of lexical tones in native speakers would otherwise have been lateralized to the right hemisphere in the previous fMRI or PET studies (19–21) as well. Given the equal linguistic function of and the distinct acoustic features between a lexical tone and a consonant (Fig. 1), this opposite pattern of hemisphere lateralization observed in the present study suggests the dependence of hemisphere dominance mainly on acoustic cues in early lexical processing. As far as low-level auditory perception is concerned, the results are consistent with the acoustic hypothesis, which claims that the labor division of the two hemispheres is closely tied to the physical nature of sounds (13).
The present study used electric recordings of MMN under a passive odd-ball paradigm with a temporal resolution in order of milliseconds to reveal that the hemisphere asymmetry for preattentive auditory processing of a lexical tone and a consonant occurs as early as ≈200 ms after onset of the stimulus (Fig. 2). The evoked brain activities at such an early stage may not be explicitly revealed by the hemodynamic techniques such as fMRI or PET with a temporal resolution in the order of seconds (22, 23). Therefore, the activation of neural circuits in the inferior frontal areas of the left hemisphere in native tonal language speakers by lexical tones observed in the previous fMRI or PET studies (19–21), which demand that subjects perform a discrimination task, may occur downstream from the preattentive auditory processing. In fact, some investigators have already speculated that there possibly exists acoustically specialized processing at a low level and functionally specialized processing at a high level (13, 19, 21). Our present study provides strong and direct evidence for their speculation. To reconcile the results from the present study and the previous fMRI or PET studies (19–21), we propose a two-stage model in which speech is initially processed as a general acoustic signal, rather than a function-specific signal, at a preattentive stage and then mapped into a semantic representation with activation of neural circuits lateralized to the left hemisphere at an attentive stage. The model states that hemisphere dominance for speech processing depends on the acoustic structure at the first stage as a need for solving a computational problem posed by precise extraction of temporal and spectral information (13) but depends on the linguistic function at the second stage as a need for integrating information within the language network of the left hemisphere. According to this model, the acoustic hypothesis and the functional hypothesis are not mutually exclusive but simply work at different temporal stages of auditory processing.
Our study reveals a possible acoustic basis for language-dependent recruitment of the two hemispheres for speech processing at an early stage. Much semantic information in a tonal language is encoded by lexical tones. In fact, every syllable in the speech stream of a Mandarin Chinese speaker is accented in one of four lexical tones for encoding the word meaning. For a tonal language speaker, the right hemisphere may be more actively recruited at an early stage of auditory processing than for a nontonal language speaker when they are in their respective native language environments.
Materials and Methods
Subjects
Twenty-two native speakers of Mandarin Chinese (23–25 years old, right-handed, musically untrained, 13 males and 9 females) with normal hearing participated in the study. An informed written consent was obtained from each subject.
Stimulus.
MMN was elicited with the lexical tone contrast and the consonant contrast. The lexical tone contrast was created by a sequence of /bai/ frequently pronounced in one lexical tone, which was a meaningful auditory word, as the standard stimulus and infrequently pronounced in a different lexical tone as the deviant stimulus. The consonant contrast was created by a sequence of syllables consisting of an initial consonant and vowel /ai/ pronounced in a flat tone, which was a meaningful auditory word, as the standard stimulus with the initial consonant infrequently replaced by a different consonant as the deviant stimulus (Table 2). The syllable materials were originally pronounced by an adult male speaker (Sinica Corpus, Institute of Linguistics, Chinese Academy of Social Sciences, Beijing, China) and modified with Praat software (Institute of Phonetic Sciences, University of Amsterdam, The Netherlands; available from www.praat.org) to create the fundamental frequency contour for four Chinese lexical tones. The stimulus duration was normalized to 350 ms, including a 5-ms linear rise and fall time. The acoustic properties of the stimulus were analyzed with CoolEdit Pro-1.2 (Syntrillium Software Corporation, Phoenix, AZ) and Praat software.
Procedure.
MMN was evoked with the lexical tone contrast from one group of subjects (n = 11) and with the consonant contrast from the other group of subjects (n = 11) by using a passive auditory odd-ball paradigm (27). The subject was instructed to ignore the auditory stimulus and watch a silent cartoon movie during the course of experiment. The stimuli were presented diotically at 60 dB above each subject's threshold through headphones (TDH-39; Telephonics, Farmingdale, NY) in a soundproof room with a stimulus onset asynchrony of 900 ms and in a pseudorandom fashion. The standard stimuli occurred in 90% of the trials, and the deviant stimuli occurred in 10% of the trials. At least two standard stimuli were presented between two adjacent deviant stimuli. Six odd-ball blocks were constructed for the lexical tone contrast, and three blocks were constructed for the consonant contrast (Table 2). Each block consisted of 1,080 trials.
Whole-Head Electric Recordings.
A ESI-128 system (Neuroscan, Sterling, VA) was used to record MMN with a cap carrying 32 Ag/AgCl electrodes placed at standard locations of the scalp following the extended international 10-20 system (established by the American Electroencephalographic Society). In addition, electrical activities were recorded from both mastoids. The reference electrode was placed at the tip of the nose, and the ground electrode was placed at FPz. The electroocular activity was recorded from two bipolar channels to adjust the recorded signals. Skin impedances were kept <5 kΩ. Alternating current signals (0.5–100 Hz) were continuously recorded by using SynAmps amplifiers (Neuroscan) and sampled at 500 Hz. The electrode positions of each subject were read into computer by an electrode positioning system (3DspaceDX; Neuroscan) and were used for source localization analysis.
Data Analysis.
The data from the whole-head recordings were off-line band-pass filtered (1–30 Hz) with a finite impulse response filter. The trial-based epochs with fluctuation in amplitude >100 mV were considered artifacts and rejected. The event-related potentials evoked by standard stimuli and by deviant stimuli were calculated by averaging individual trials from each subject within a time window of 600 ms, including a 100-ms prestimulus baseline. MMN was then derived by subtracting the event-related potentials evoked by the standard stimuli from those evoked by the deviant stimuli (25, 27). For the purpose of statistical analysis, locations F3, Fc3, and C3 on the left side of the scalp and F4, Fc4, and C4 on the right side of the scalp were taken as the regions of interest. The MMN amplitudes in these regions were calculated (Fig. 2C) by averaging the responses within a time window ranging from 20 ms before the peak of MMN recorded from electrode Fz to 20 ms after that peak (as indicated by gray bars in Fig. 2 A and B).
A dipole analysis was performed for each subject with Curry software (Neuroscan) to localize the neural sources of the MMN responses to the lexical tone contrast and to the consonant contrast. To enable source localization with accuracy close to that achieved with models based on the individual magnetic resonance imaging, a realistically shaped volume conductor was constructed and scaled to each subject's real head size by adjusting the size of the Curry-Warped brain (averaged brain image from >100 subjects) to individual's head shape. The dipole analysis was conducted by using a rotating dipole model (mirror dipoles). Seed points were set for all of the subjects in the same location in the bilateral superior temporal gyri (28–30). The maximal distance from the seed points was 30 mm, and the minimal distance between two dipoles was 90 mm. Dipole localization was first performed within a time window from 150 to 250 ms after the stimulus onset. Then, the time point with the best explanation of variance was chosen to repeat dipole localization for each subject at this time point. The dipole locations and the dipole strengths obtained from each subject were finally grand-averaged across all of the subjects within the group.
Acknowledgments
We thank the Instrument Center for Biological Research at the University of Science and Technology of China and Yong-Sheng Bai for technical support. We also thank Abby Copeland and Henry Michalewski for their helpful comments on the manuscript. This work was supported by the National Natural Science Foundation of China (Grants 30228021, 30270380, and 30470560), the National Basic Research Program of China (Grants 2006CB500803 and 2006CB500705), and the CAS Knowledge Innovation Project (Grant KSCX1-YW-R-36).
Abbreviations
- fMRI
functional MRI
- MMN
mismatch negativity
- PET
positron emission tomography.
Footnotes
The authors declare no conflict of interest.
This article is a PNAS direct submission.
References
- 1.Geschwind N, Galaburda AM. Arch Neurol. 1985;42:428–459. doi: 10.1001/archneur.1985.04060050026008. [DOI] [PubMed] [Google Scholar]
- 2.Kimura D. Sci Am. 1973;228:70–78. doi: 10.1038/scientificamerican0373-70. [DOI] [PubMed] [Google Scholar]
- 3.Penfield W. Z Neurol. 1972;201:297–309. doi: 10.1007/BF00316235. [DOI] [PubMed] [Google Scholar]
- 4.Wada JA, Clarke R, Hamm A. Arch Neurol. 1975;32:239–246. doi: 10.1001/archneur.1975.00490460055007. [DOI] [PubMed] [Google Scholar]
- 5.Broca P. Bull Soc Anat. 1861;36:330–357. [Google Scholar]
- 6.Wernicke C. Der aphasische Symptomencomplex: Enie psychologische Studie auf anatomischer basis. Germany: Kohn und Weigert, Breslau; 1874. [Google Scholar]
- 7.Shtyrov Y, Pihko E, Pulvermuller F. Neuroimage. 2005;27:37–47. doi: 10.1016/j.neuroimage.2005.02.003. [DOI] [PubMed] [Google Scholar]
- 8.Tervaniemi M, Hugdahl K. Brain Res Brain Res Rev. 2003;43:231–246. doi: 10.1016/j.brainresrev.2003.08.004. [DOI] [PubMed] [Google Scholar]
- 9.Wong PC. Brain Res Bull. 2002;59:83–95. doi: 10.1016/s0361-9230(02)00860-2. [DOI] [PubMed] [Google Scholar]
- 10.Liberman AM, Whalen DH. Trends Cogn Sci. 2000;4:187–196. doi: 10.1016/s1364-6613(00)01471-6. [DOI] [PubMed] [Google Scholar]
- 11.Whalen DH, Liberman AM. Science. 1987;237:169–171. doi: 10.1126/science.3603014. [DOI] [PubMed] [Google Scholar]
- 12.Zatorre RJ, Belin P. Cereb Cortex. 2001;11:946–953. doi: 10.1093/cercor/11.10.946. [DOI] [PubMed] [Google Scholar]
- 13.Zatorre RJ, Belin P, Penhune VB. Trends Cogn Sci. 2002;6:37–46. doi: 10.1016/s1364-6613(00)01816-7. [DOI] [PubMed] [Google Scholar]
- 14.Shankweiler D, Studdert-Kennedy M. Brain Lang. 1975;2:212–225. doi: 10.1016/s0093-934x(75)80065-4. [DOI] [PubMed] [Google Scholar]
- 15.Shankweiler D, Studdert-Kennedy M. Q J Exp Psychol. 1967;19:59–63. doi: 10.1080/14640746708400069. [DOI] [PubMed] [Google Scholar]
- 16.Shtyrov Y, Kujala T, Palva S, Ilmoniemi RJ, Naatanen R. Neuroimage. 2000;12:657–663. doi: 10.1006/nimg.2000.0646. [DOI] [PubMed] [Google Scholar]
- 17.Howie J. Acoustical Studies of Mandarin Vowels and Tones. New York: Cambridge Univ Press; 1976. [Google Scholar]
- 18.Schonwiesner M, Rubsamen R, von Cramon DY. Eur J Neurosci. 2005;22:1521–1528. doi: 10.1111/j.1460-9568.2005.04315.x. [DOI] [PubMed] [Google Scholar]
- 19.Gandour J, Wong D, Lowe M, Dzemidzic M, Satthamnuwong N, Tong Y, Li X. J Cogn Neurosci. 2002;14:1076–1087. doi: 10.1162/089892902320474526. [DOI] [PubMed] [Google Scholar]
- 20.Klein D, Zatorre RJ, Milner B, Zhao V. Neuroimage. 2001;13:646–653. doi: 10.1006/nimg.2000.0738. [DOI] [PubMed] [Google Scholar]
- 21.Wong PC, Parsons LM, Martinez M, Diehl RL. J Neurosci. 2004;24:9153–9160. doi: 10.1523/JNEUROSCI.2225-04.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Amaro E, Jr, Barker GJ. Brain Cogn. 2006;60:220–232. doi: 10.1016/j.bandc.2005.11.009. [DOI] [PubMed] [Google Scholar]
- 23.Kim SG, Richter W, Ugurbil K. Magn Reson Med. 1997;37:631–636. doi: 10.1002/mrm.1910370427. [DOI] [PubMed] [Google Scholar]
- 24.Alho K, Connolly JF, Cheour M, Lehtokoski A, Huotilainen M, Virtanen J, Aulanko R, Ilmoniemi RJ. Neurosci Lett. 1998;258:9–12. doi: 10.1016/s0304-3940(98)00836-2. [DOI] [PubMed] [Google Scholar]
- 25.Picton TW, Alain C, Otten L, Ritter W, Achim A. Audiol Neurootol. 2000;5:111–139. doi: 10.1159/000013875. [DOI] [PubMed] [Google Scholar]
- 26.Naatanen R, Gaillard AW, Mantysalo S. Acta Psychol (Amsterdam) 1978;42:313–329. doi: 10.1016/0001-6918(78)90006-9. [DOI] [PubMed] [Google Scholar]
- 27.Naatanen R, Pakarinen S, Rinne T, Takegata R. Clin Neurophysiol. 2004;115:140–144. doi: 10.1016/j.clinph.2003.04.001. [DOI] [PubMed] [Google Scholar]
- 28.Giard MH, Lavikainen J, Reinikainen K, Perrin F, Bertrand O, Pernier J, Naatanen R. J Cogn Neurosci. 1995;7:133–143. doi: 10.1162/jocn.1995.7.2.133. [DOI] [PubMed] [Google Scholar]
- 29.Huotilainen M, Winkler I, Alho K, Escera C, Virtanen J, Ilmoniemi RJ, Jaaskelainen IP, Pekkonen E, Naatanen R. Electroencephalogr Clin Neurophysiol. 1998;108:370–379. doi: 10.1016/s0168-5597(98)00017-3. [DOI] [PubMed] [Google Scholar]
- 30.Knosche TR, Lattner S, Maess B, Schauer M, Friederici AD. Neuroimage. 2002;17:1493–1503. doi: 10.1006/nimg.2002.1262. [DOI] [PubMed] [Google Scholar]