

Abstract
This study examined whether ventral frontostriatal regions differentially code expected and unexpected reward outcomes. We parametrically manipulated the probability of reward and examined the neural response to reward and nonreward for each probability condition in the ventral striatum and the orbitofrontal cortex (OFC). By late trials of the experiment, subjects showed slower behavioral responses for the condition with the lowest probability of reward, relative to the condition with the highest probability of reward. At the neural level, both the nucleus accumbens (NAcc) and OFC showed greater activation to rewarded relative to nonrewarded trials, but the accumbens appeared to be most sensitive to violations in expected reward outcomes. These data suggest distinct roles for frontostriatal circuitry in reward prediction and in responding to violations in expectations.
Introduction
Forming accurate predictions and detecting violations in expectations about upcoming rewarding events is an essential component of goal-directed behavior. Nonhuman primate and human imaging studies suggest that dopamine-rich frontostriatal regions are involved in forming predictions about future reward outcomes and optimizing behavior accordingly. The neural mechanisms of reward-related prediction error - a representation of the discrepancy between the actual and expected reward (Schultz et al, 1997) - have been studied in nonhuman primates in terms of expected and unexpected rewards and/or omissions of reward (Hollerman et al, 1998, Leon and Shadlen, 1999; Tremblay and Schultz, 1999). The current study used a simple spatial delay match-to-sample task, similar to one used previously with nonhuman primates (Fiorillo et al, 2003), which manipulated the probability of reward outcome, to examine neural responses to expected and unexpected rewards.
Converging evidence implicates the dopamine system as being critical to prediction and reward processing (Olds and Milner, 1954; Montague et al, 2004, Schultz, 2002 for review). Nonhuman primate studies have shown that dopamine neurons respond to unexpected primary rewards and eventually to the stimuli that predict those rewards (Mirencowicz & Schultz, 1994, Tobler et al, 2005). Dopamine neurons in the ventral tegmental area (VTA) of the monkey will fire in response to a primary reward that is unpredicted (or predicted with a low probability) more than to a reward that is fully predicted (Fiorillo et al, 2003;Tobler et al, 2005). Conversely, the activity of the same neurons is suppressed when an expected reward is not delivered relative to an expected omission of reward (Fiorillo et al, 2003; Tobler et al, 2005). Thus, dopamine neurons code for prediction error by representing the discrepancy between the actual and predicted outcome (Schultz et al, 1997; Tobler et al, 2005), such that unexpected presentation of reward results in increased activity and unexpected omissions of reward results in decreased activity.
Changes in dopamine firing in response to changes in reward outcome is paralleled by alterations in behavior. Nonhuman primate studies have found that a monkey will increase its anticipatory licking as a function of the probability with which a conditioned stimulus is associated with subsequent unconditioned stimulus (juice delivery). As such, stimuli representing a high probability of subsequent juice delivery elicit more anticipatory licking (Fiorillo et al., 2003).
Reciprocal anatomical connections exist between regions associated with goal-directed behavior (e.g. prefrontal cortex) and those associated with more automatic appetitive behaviors (e.g. ventral striatum) where predictions might be computed (Shultz et al., 1997; Haber et al., 2003). These regions are heavily innervated with dopamine through projections from midbrain dopamine neurons and these connections may form a functional neuroanatomical circuit that supports optimization of behavior in favoring actions that result in the greatest gains.
Recently, human functional magnetic resonance imaging (fMRI) studies have implicated two regions of this circuit, the nucleus accumbens and orbitofrontal cortex, in the representation of prediction error. For instance, unpredictable sequences of juice and water delivery have been shown to elicit increased activity in the NAcc relative to predictable delivery (Berns et al, 2001). Prediction error based on temporal (McClure et al, 2003) and stimulus (O’Doherty et al, 2003 O’Doherty et al, 2004) violations also activate the ventral striatum.
The role of the OFC in reward prediction has been less clear. While some studies have reported sensitivity of the OFC under conditions of prediction error (Berns et al., 2001; O’Doherty et al., 2003; Ramnini et al., 2004; Dreher et al., 2005) others have not (McClure et al., 2003; O’Doherty et al., 2004; Delgado et al., 2005). Studies with less emphasis on prediction error show greater OFC activation to favorable relative to unfavorable outcomes (O’Doherty et al, 2001; Elliott et al, 2003; Galvan et al, 2005) in studies of reward value (Gottfried et al, 2003), and valence (Cox et al, 2005; O’Doherty, 2000 O’Doherty, 2003 O’Doherty, 2004). Recently, Kringelbach and Rolls (2004) integrated the neuroimaging and neuropsychological literature to account for varied functions of the orbitofrontal cortex. They suggest a medial-lateral distinction and an anterior-posterior distinction. The medial and lateral orbitofrontal cortex monitor reward value and evaluation of punishers, respectively (e.g. O’Doherty et al, 2001 ; Rolls et al, 2003). The anterior orbitofrontal cortex is thought to be involved more in the representation of abstract reinforcers (O’Doherty et al, 2001) over simpler ones related to taste (e.g. De Araujo et al, 2003) and pain (e.g. Craig et al, 2000).
These ventral frontostriatal regions have recently (Knutson et al, 2005) been associated with the representation of expected value (the product of expected probability and magnitude of outcome) during anticipation of reward outcome. Given the elegant, but complex, design that included 18 cues representing numerous combinations of magnitude, probability and/or valence, a lack of statistical power precluded the authors from examining brain activation related to incentive outcomes. In the present study, we used three distinct cues, each of which was associated with 33%, 66% or 100% reward for correct trials. The emphasis of this study was on reward outcome rather than reward anticipation, in order to examine sensitivity at the neural level to violations in reward expectations, rather than to anticipation of reward prior to the outcome. This analysis is critical in understanding predictability of rewards because of the changes in dopamine firing that occur at reward outcome when violations of predicted expectations occur (Fiorillo et al, 2003).The a priori predictions about the accumbens and the OFC response to expected and unexpected monetary reward were based on prior imaging work implicating these regions in reward processing (Knutson et al, 2001; 2005; O’Doherty et al, 2001; Galvan et al, 2005). We used a simple spatial delayed match to sample paradigm similar to that used by Fiorillo et al (2003) in electrophysiological studies of dopamine neurons in nonhuman primates. We hypothesized that activity in the ventral striatum, in particular the NAcc, would increase when an unexpected reward was delivered and would decrease when an expected reward was not delivered. Behavior was expected to parallel these changes with faster mean reaction times to cues predicting reward most often, but slower reaction times to the cue predicting reward least often. Furthermore, we hypothesized that the OFC would be sensitive to reward outcome (reward or not), but that the accumbens would be most sensitive to changes in reward predictions. These hypotheses were based on reports from previous imaging studies (Galvan et al 2005, in press) and nonhuman primate work showing greater striatal involvement in reward probability parameters, relative to the reward-locked activity of the OFC (Schultz, et al, 2000) and on the fixed rather than varying amount of reward across the probability conditions.
Methods
Participants
Twelve right-handed healthy adults (7 female), ages 19–27 (mean age 24 years), were included in the fMRI experiment. Subjects had no history of neurological or psychiatric illness and all subjects were consented to the Institutional Review Board approved study prior to participation.
Experimental Task
Participants were tested using a modified version of a delayed response two-choice task described previously (Galvan et al, 2005) in an event-related fMRI study (Figure 1). In this task, three cues were each associated with a distinct probability (33%, 66% and 100%) of obtaining a fixed amount of reward. Subjects were instructed to press either their index or middle finger to indicate the side on which a cue appeared when prompted, and to respond as quickly as possible without making mistakes. One of three pirate cartoon images was presented in random order on either the left or right side of a centered fixation for 1000 msec (see Figure 1). After a 2000 msec delay, subjects were presented with a response prompt of two treasure chests on both sides of the fixation (2000 msec) and instructed to press a button with their right index finger if the pirate was on the left side of the fixation or their right middle finger if the pirate was on the right side of the fixation. After another 2000 msec delay, either reward feedback (cartoon coins) or an empty treasure chest was presented in the center of the screen (1000 msec) based on the reward probability of that trial type. There was a 12 sec intertrial interval (ITI) before the start of the next trial.
Figure 1. Task Design.
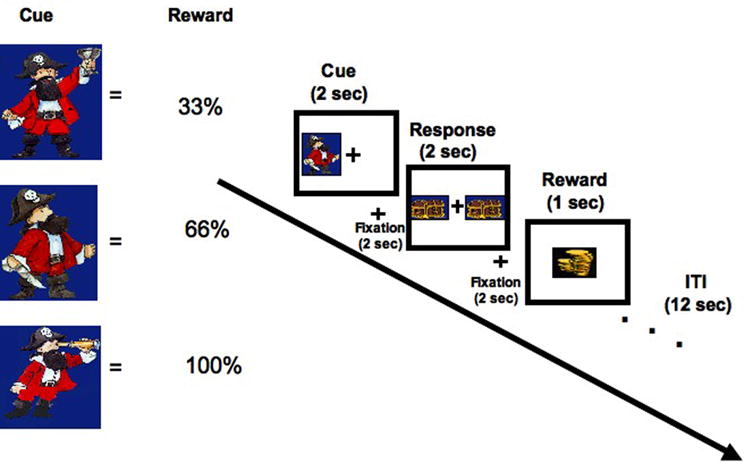
One of three cues (each associated with a distinct probability (33%, 66% and 100%) of obtaining a fixed amount of reward) appeared on the left or right side of a fixation for 1 s. After a 2 s delay, a response prompt appeared for 2 s and subjects were instructed to press with pointer finger if the cue had been on the left and with their middle finger if the cue had been on the right. After another 2 s delay, either reward feedback (cartoon coins) or an empty treasure chest were presented in the center of the screen (1000 msec) based on the reward probability of the trial type. There was a 12 sec intertrial interval (ITI) before the start of the next trial. Total trial length was 20 s.
There were three reward probability conditions: a 33%, 66% and 100% reward probability. In the 33% condition, subjects were rewarded on 33% of the trials and no reward (an empty treasure chest) occurred on the other 66% of the trials in that condition. In the 66% condition, subjects were rewarded on 66% of trials and no reward occurred for the other 33% of trials. In the 100% condition, subjects were rewarded for all correct trials.
Subjects were guaranteed $50 for participation in the study and were told they could earn up to $25 more, depending on performance (as indexed by reaction time and accuracy) on the task. Stimuli were presented with the integrated functional imaging system (IFIS) (PST, Pittsburgh) using a LCD video display in the bore of the MR scanner and a fiber optic response collection device.
The experiment consisted of five runs of 18 trials (6 each of the 33%, 66% and 100% probability of reward trial types), which lasted 6 min and 8 s each. Each run had 6 trials of each reward probability presented in random order. At the end of each run, subjects were updated on how much money they had earned during that run. Prior to beginning the experiment, subjects received detailed instructions that included familiarization with the stimuli employed and performed a practice run to ensure task comprehension. They were told that a relationship existed between the cues and monetary outcomes, but the exact nature of that relationship was not revealed.
Image Acquisition
Imaging was performed using a 3T General Electric MRI scanner using a quadrature head coil. Functional scans were acquired using a spiral in and out sequence (Glover & Thomason, 2004). The parameters included a TR=2000, TE=30, 64 X 64 matrix, 29 5-mm coronal slices, 3.125 X 3.125-mm in-plane resolution, flip 90°) for 184 repetitions, including four discarded acquisitions at the beginning of each run. Anatomical T1 weighted in-plane scans were collected (TR=500, TE=min, 256 X 256, FOV=200 mm, 5-mm slice thickness) in the same locations as the functional images in addition to a 3-D data set of high resolution SPGR images (TR=25, TE=5, 1.5 mm slice thickness, 124 slices).
Image Analysis
The Brainvoyager QX (Brain Innovations, Maastricht, The Netherlands) software package was used to perform a random effects analysis of the imaging data. Before analysis, the following preprocessing procedures were performed on the raw images: 3D motion correction to detect and correct for small head movements by spatial alignment of all volumes to the first volume by rigid body transformation, slice scan time correction (using sinc interpolation), linear trend removal, high-pass temporal filtering to remove non-linear drifts of 3 or fewer cycles per time course, and spatial data smoothing using a Gaussian kernel with a 4mm FWHM. Estimated rotation and translation movements never exceeded 2mm for subjects included in this analysis.
Functional data were co-registered to the anatomical volume by alignment of corresponding points and manual adjustments to obtain optimal fit by visual inspection and were then transformed into Talairach space. During Talairach transformation, functional voxels were interpolated to a resolution of 1 mm3 for alignment purposes, but the statistical thresholds were based on the original acquisition voxel size. The nucleus accumbens and orbital frontal cortex were defined by a whole-brain voxelwise GLM with reward as the primary predictor (see below) and then localized by Talairach coordinates in conjunction with reference to the Duvernoy brain atlas (Talairach & Tournoux, 1988; Duvernoy, 1991).
Statistical analyses of the imaging data were conducted on the whole brain using a general linear model (GLM) comprised of 60 (5 runs X 12 subjects) z-normalized functional runs. The primary predictor was reward (reward versus nonreward trials) across all reward probabilities at reward outcome. The predictor was obtained by convolution of an ideal boxcar response (assuming a value 1 for the volume of task presentation and a volume of 0 for remaining time points) with a linear model of the hemodynamic response (Boynton et al, 1996) and used to build the design matrix of each time course in the experiment. Only correct trials were included and separate predictors were created for error trials. Post hoc contrast analyses on the regions of interest were then performed based on t-tests on the beta weights of predictors. Monte Carlo simulations were run using the AlphaSim program within AFNI (Cox, 1996) to determine appropriate thresholds to achieve a corrected alpha level of p<0.05 based on search volumes of approximately 25,400 mm3 and 450 mm3 for the orbital frontal cortex and nucleus accumbens, respectively. Percent changes in the MR signal relative to baseline (interval immediately preceding the 20 sec trial) in the nucleus accumbens and orbital frontal cortex were calculated using event-related averaging over significantly active voxels obtained from the contrast analyses.
The whole brain GLM was based on 50 reward trials per subject (n=12) for a total of 600 trials and 30 nonreward trials per subject (n=12) for a total of 360 nonreward trials across the entire experiment. Subsequent contrasts on the reward probability conditions consisted of different numbers of reward and no reward trials. For the 100% reward probability condition there were 6 reward trials per run (5) per subject (12) for a total of 360 reward trials and no nonreward trials. For the 66% reward probability condition there were 4 reward trials per run (5) per subject (12) for a total of 240 reward trials and 120 nonreward trials. For the 33% reward probability condition, there were 2 reward trials per run (5) per subject (12) for a total of 120 reward trials and 240 nonreward trials.
Results
Behavioral Data
The effects of reward probability and time on task were tested with a 3 (33%, 66%, 100%) x 5 (runs 1–5) repeated measures analysis of variance (ANOVA) for the dependent variables of mean reaction time (RT) and mean accuracy.
There were no main effects or interactions of probability of reward (F[2,22]=.12, p<.85) time on task (F[4,44]=2.02, p<.14) or reward probability X time on task (F[8, 88]=1.02, p<.41) for mean accuracy. This was to be expected as participants’ accuracy reached near ceiling levels for all probabilities of the experiment (33% condition=97.2%; 66% condition=97.5%; 100% condition=97.7%).
There was a significant interaction between probability of reward and time on task (F[8,88] = 3.5, p < .01) on mean RT, but no main effects of time on task (F[4,44] = .611, p < 0.59) or probability of reward (F[2,22]= 2.84, p < 0.08). Post-hoc t tests of the significant interaction showed that there was a significant difference between the 33% and 100% reward probability conditions during late trials of the experiment (run 5) (t(11)=3.712, p<.003), with faster mean RT for the 100% reward probability condition (mean =498.30, sd=206.23) relative to the 33% condition (mean=583.74, sd=270.23).
The difference in mean reaction time between the 100% and 33% conditions increased two-fold from early to late trials (see Figure 2a). To further show learning, we introduced a reversal, switching the probabilities of reward for the 33% and 100% conditions at the end of the experiment. A 2 (probability) X 2 (reversal and non-reversal) ANOVA for late trials showed a significant interaction (F (1,11)=18.97, p=0.001), with a decrease in RT to the condition that was the 33% probability in the non-reversal (mean=583.74, sd=270.24) and 100% in the reversal (mean=519.89,sd=180.46) (Figure 2b).
Figure 2. Behavioral results (RT).
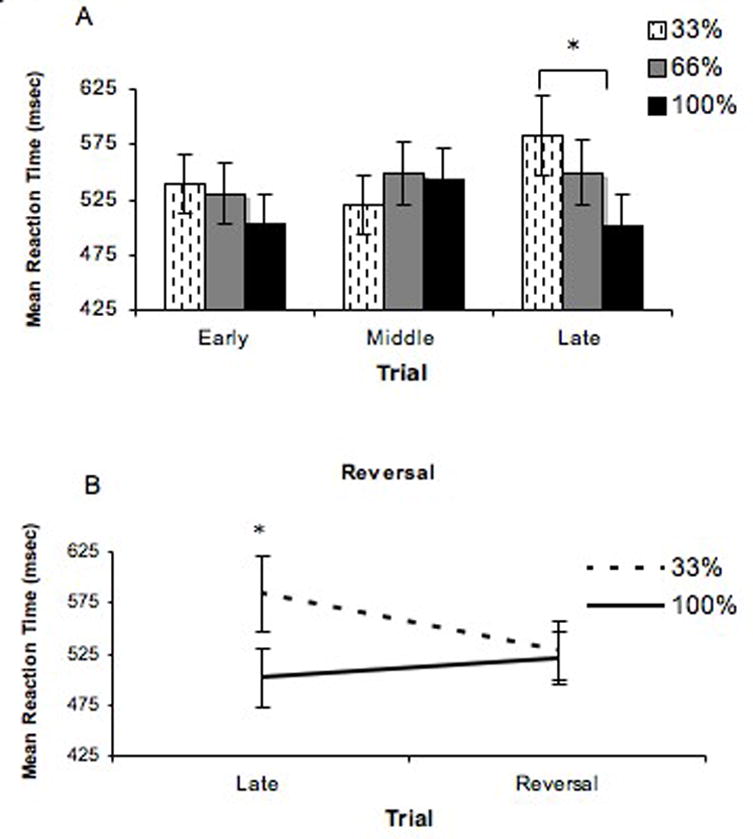
a) There was a significant interaction of reward probability and time on task on mean reaction time. By late trials, subjects were faster when responding to cues associated with the 100% reward probability condition (mean =498.30, sd=206.23) relative to the 33% condition (mean=583.74, sd=270.23). The difference in mean reaction time between the 100% and 33% conditions increased two-fold from early to late trials. b) In a reversal condition at the end of the experiment, the probabilities of reward for the 33% and 100% conditions and showed a decrease in RT to the condition that was the 33% probability in the non-reversal (mean=583.74, sd=270.24) and 100% in the reversal (mean=519.89,sd=180.46).
Imaging Results
A GLM for correct trials using reward probability as the primary predictor was modeled at the point in which the subject received feedback of reward or not (i.e. outcome). This analysis identified the regions of the NAcc (x=9, y=6, z=−1 and x=−9, y=9, z=−1) and OFC (x=28, y=39, z =−6) (see Figure 3a,b). Post-hoc t-tests between the beta weights of the rewarded versus nonrewarded trials showed greater activation in both of these regions to reward (NAcc: t(11)=3.48, p<0.01; OFC x=28, y=39, z =−6, t(11)=3.30, p<0.02)1.
Figure 3.
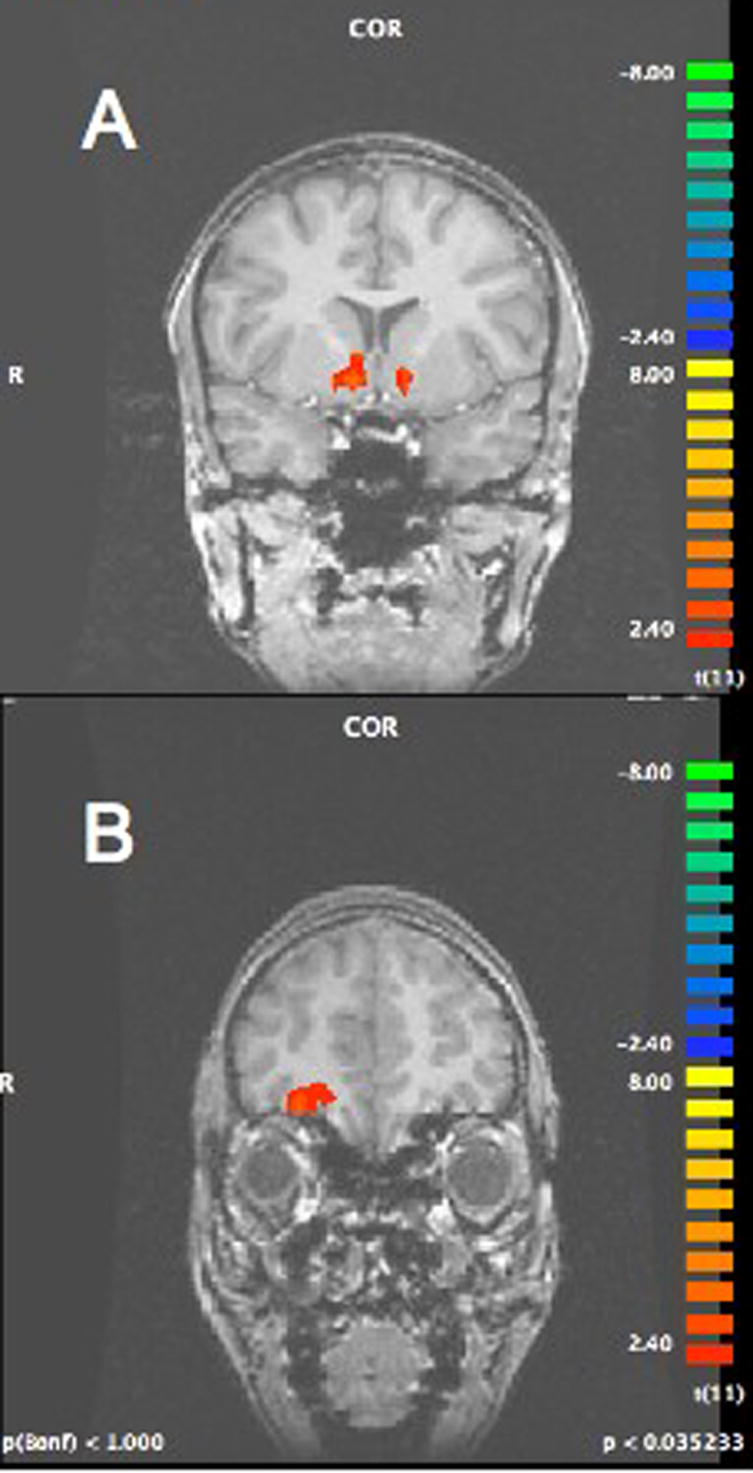
Greater activation to rewarded versus nonrewarded outcomes in the a) nucleus accumbens (x=9,y=6,z=−1; x=−9, y=9, z=−1) and b) orbital frontal cortex (x=28,y=39, z=−6).
There were two possible outcomes (reward or no reward) for the two intermittent reward schedules (33% and 66% probability) and only one outcome for the continuous reward schedule (100% reward probability), which was used as a comparison condition. Whereas there was a main effect of reward (reward versus no reward trials) in the OFC described above, OFC activity did not vary as a function of reward probability in the current study [F(2,10)=0.84, p=0.46). In contrast, the NAcc showed distinct changes in activity to outcome as a function of the reward probability manipulation [F(2,10)=9.32, p<0.005]. Specifically, NAcc activity increased to reward outcomes, when the reward was unexpected (33% reward probability condition) relative to expected (100% baseline condition) [t(11)=2.54, p<.03 see Figure 4a]. Second, there was diminished NAcc activity to no reward, when a reward was expected and not received (66% reward probability condition) relative to reward that was not expected or received (33% reward probability condition; t(59)=2.08, p<.04; see Figure 4b). Note that there were no significant differences in activation between the 33% and 66% reward probability conditions [t(11)=.510, p=.62] or between the 66% and 100% rewarded probability conditions [t(11)=1.20, p=.26] in rewarded outcomes. MR signal as a function of reward outcome and probability are shown in Figure 4.
Figure 4.
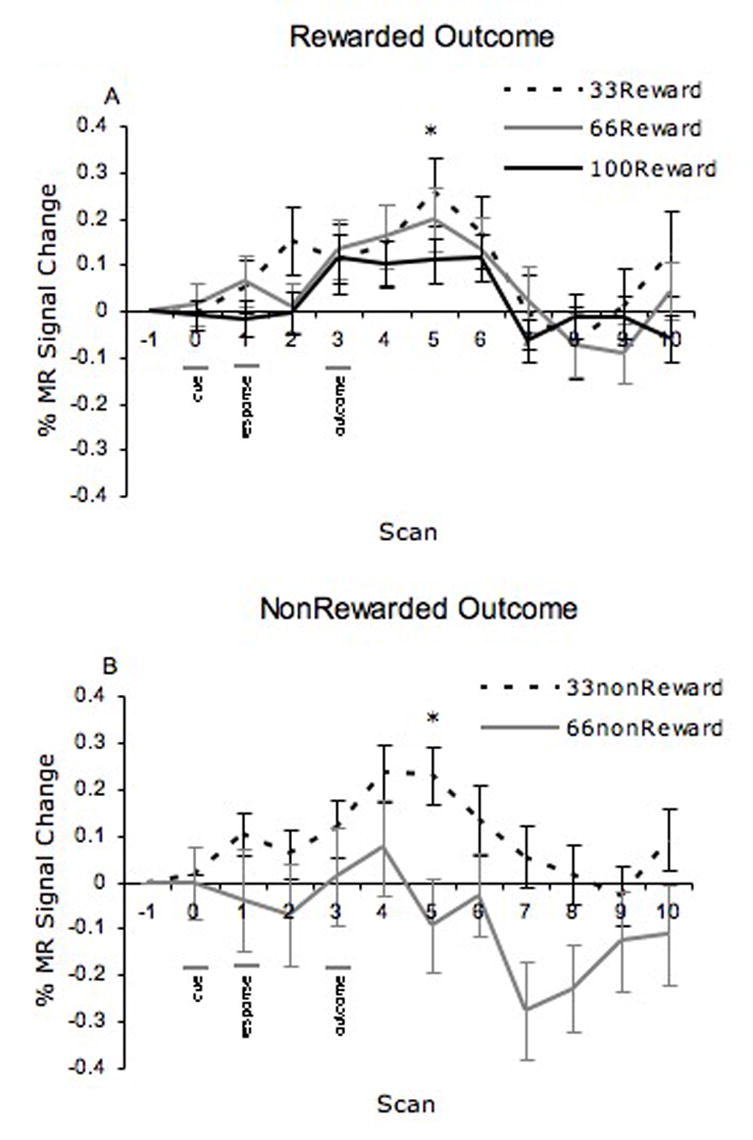
Percent MR signal changes as a function of reward outcome and probability in the nucleus accumbens to a) rewarded and b) nonrewarded outcomes.
Discussion
This study examined the effects of violations in expected reward outcomes on behavior and neural activity in the accumbens and orbital frontal cortex (OFC), shown previously to be involved in anticipation of reward outcomes (McClure et al 2004; Knutson et al, 2005). We showed that both the nucleus accumbens and OFC were recruited during rewarded trials relative to nonrewarded trials, but only the nucleus accumbens showed sensitivity to violations in predicted reward outcome in this study. Greater sensitivity of the accumbens to reward value (e.g., magnitude) relative to the OFC has been shown in previous work (Galvan et al 2005), and together these findings suggest this region may be involved in the computation of both magnitude and probability of reward. The lack of sensitivity in the OFC to these manipulations may reflect a more absolute representation of reward or ambiguity in outcome (Hsu et al., 2005). Alternatively, as the MR signal was more variable in this region, these effects may have been weakened in the current study.
In electrophysiological studies in animals, dopamine neurons in the midbrain (which project to the nucleus accumbens) have been shown to have little to no response to predicted reward outcomes (probability=1.0), but show phasic firing when reward is delivered with less than 100% probability, even after extensive training (Fiorillo et al, 2003). In the current study, we showed greater accumbens activity to reward when the reward was unexpected (33% condition) relative to when it was expected (100% condition) consistent with these findings. Further, electrophysiological studies of dopamine neurons in animals (e.g., Fiorillo et al, 2003) have shown that for trials on which reward was predicted, but did not occur, neuronal activity decreased. The current study showed a similar pattern in the accumbens, with a decrease in activity in this region in the non-rewarded trials for the 66% reward probability condition relative to the 33% condition.2
Dopamine neurons have been implicated in learning in two ways. First, they encode contingencies between stimuli (or response) and outcomes through prediction errors signals that detect violations in expectations (Schultz et al, 1997; Mirencowicz and Schultz, 1998; Fiorillo et al, 2003). Thus the prediction error seems to provide a teaching signal that corresponds to the learning principles initially described by Rescorla and Wagner (1972). Second, they serve to alter behavioral responses (Schultz et al, 1997; McClure et al, 2004) such that actions are biased toward the cues that are most predictive. In the current study we show that by late trials of the experiment, the most optimal performance is for the condition with the highest probability of reward (100% reward probability) and least optimal for the lowest probability condition (33% reward probability). This behavioral finding is consistent with previous probability work showing least optimal performance with the lowest probability of reward outcome, suggesting that reward contingencies were learned over time (Delgado et al, 2005). To further show learning, we introduced a reversal, switching the probabilities of reward for the 33% and 100% conditions at the end of the experiment. This manipulation resulted in attenuation of differences between these conditions further corroborating learning effects.
A major goal of reward-related studies is to determine how rewards influence and bias behavior (e.g. Robbins and Everitt, 1996; Schultz, 2004) in addition to characterizing the underlying neural processing. Numerous factors contribute to how quickly and robustly rewards influence behavior, including schedules of reinforcement (Skinner, 1958), reward value (Galvan et al, 2005), and reward predictability (Fiorillo et al, 2003; Delgado et al, 2005). Expected value, which is the product of the magnitude and probability of a reward (Pascal, ca 1600s), influences behavioral choices (von Frisch, 1967; Montague et al, 1995; Montague and Berns, 2002). Using a very similar task in which only the outcome (magnitude instead of probability) differed from the current study, we showed that the nucleus accumbens was sensitive to discrete reward values (Galvan et al, 2005). Taken together with the evidence presented here and elsewhere (Tobler et al, 2005), we suggest that the ventral striatum likely contributes to the computation of expected reward value given its sensitivity to both reward probability and magnitude.
The role of the orbital frontal cortex in reward prediction is consistent with functional subdivisions of this region by Kringelbach and Rolls (2004). They suggest that more anterior and medial portions of OFC are sensitive to abstract reward manipulations. The OFC activation in this study was observed in this general location. Electrophysiological studies implicate the OFC in coding subjective value of a reward stimulus (for review, O’Doherty, 2004). For instance, OFC neurons fire to a particular taste when an animal is hungry, but decrease their firing rate once the animal is satiated and the reward value of the food has diminished (Critchley and Rolls, 1996). As such, others have suggested the OFC is most sensitive to relative rewards (Tremblay and Schultz, 1999) and reward preference (Schultz et al, 2000). Neuroimaging studies have shown an analogous pattern in humans with a variety of stimuli, including taste (O’Doherty et al, 2001; Kringelbach et al, 2003), olfaction (Anderson et al, 2003; Rolls et al, 2003), and money (Elliott et al, 2003; Galvan et al, 2005), with each activation varying in the location of activity from anterior to posterior and from medial to lateral OFC. The OFC has been implicated in anticipation of reward (O’Doherty et al 2002), but only insofar as the predictive value of the response is linked to the specific value of the associated reward, rather than in the probability of that reward occurring (O’Doherty, 2004 ). In the current study, we did not see sensitivity to violations in reward prediction in the OFC. Knutson and colleagues (2005) have reported correlations between probability estimates and brain activation in anticipation of reward in the mesial prefrontal cortex (Knutson et al 2005), but not specifically in the orbital frontal cortex. In contrast, Ramnani et al (2004 ) reported OFC sensitivity to positive prediction error in medial orbital frontal cortex using a passive viewing task and Dreher et al. (2005) reported OFC error prediction in a task that manipulated both the probability and magnitude of predictive cues, but these contingencies were learned prior to scanning. It is therefore still tenable that OFC can compute predicted rewards, but perhaps these calculations are cruder (i.e. summed over a range of probabilities) or slower to form relative to the precise calculations that appear to occur in the NAcc. Alternatively, this region may be more sensitive at detecting stimuli of uncertain and/or ambiguous value, as proposed by Hsu et al (2005), than at detecting violations in reward prediction. Hsu et al (2005) show that the level of ambiguity in choices (uncertain choices made because of missing information) correlates positively with activation in the OFC. Finally, the greater variability in MR signal in this region may have diminished our ability to detect these effects as well.
The fundamental question of the current study was how the accumbens and OFC differentially code predicted reward outcomes relative to unpredicted outcomes (i.e. violations in expectations). We parametrically manipulated the probability of reward and examined the neural response to reward and nonreward trials for each probability reward condition. Our data are consistent with previous human imaging and nonhuman electrophysiological studies (Fiorillo et al, 2003; Schultz, 2002) and suggest that the accumbens and OFC are sensitive to reward outcome (reward or not). However, activity in these regions, especially the accumbens, appears to be modulated by predictions about the likelihood of reward outcomes that are formed with learning over time. This dynamic pattern of activation might represent modifications in dopamine activity within or projecting to these regions as information about predicted reward is learned and updated.
Footnotes
The NAcc [t(11)=3.2, p<0.04] and OFC [t(11)=3.5, p<0.02] showed increased activity in anticipation of reward for the intermittent but not the continuous reward condition
Omission of reward outcome in the 33% condition resulted in a slight increase in NAcc activity rather than a decreased one, similar to that observed by Knutson et al., 2001. One possible interpretation of this result is that subjects were intrinsicially motivated or rewarded if they predicted that no reward would come for that trial, and none did. Alternatively, since reward outcome for these trials were the fewest in number across the experiment, the activity may reflect continued learning for this condition.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Anderson A, Christoff K, Stappen I, Panitz D, Ghahremani D, Glover G, Gabrieli JD, Sobel N. Dissociated neural representations of intensity and valence in human olfaction. Nature Neuroscience. 2003;6:196–202. doi: 10.1038/nn1001. [DOI] [PubMed] [Google Scholar]
- Berns GS, McClure SM, Pagnoni G, Montague PR. Predictability modulates human brain response to reward. Journal of Neuroscience. 2001;21:2793–2798. doi: 10.1523/JNEUROSCI.21-08-02793.2001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boynton GM, Engel SA, Glover GH, Heeger DJ. Linear systems analysis of functional magnetic resonance imaging in human V1. Journal of Neuroscience. 1996;16:4207–4221. doi: 10.1523/JNEUROSCI.16-13-04207.1996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox RW. AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computations in Biomedical Research. 1996;29:162–173. doi: 10.1006/cbmr.1996.0014. [DOI] [PubMed] [Google Scholar]
- Cox SM, Andrade A, Johnsrude IS. Learning to like: A role for human orbitofrontal cortex in conditioned reward. Journal of Neuroscience. 2005;25:2733–2740. doi: 10.1523/JNEUROSCI.3360-04.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Craig AD, Chen K, Bandy D, Reiman EM. Thermosensory activation of insular cortex. Nature Neuroscience. 2000;3:184–190. doi: 10.1038/72131. [DOI] [PubMed] [Google Scholar]
- Critchley HD, Rolls ET. Hunger and satiety modify the responses of olfactory and visual neurons in the primate orbitofrontal cortex. Journal of Neurophysiology. 1996;75:1673–1686. doi: 10.1152/jn.1996.75.4.1673. [DOI] [PubMed] [Google Scholar]
- De Araujo IET, Kringelbach ML, Rolls ET, McGlone F. Human cortical responses to water in the mouth, and the effects of thirst. Journal of Neurophysiology. 2003;90:1865–1876. doi: 10.1152/jn.00297.2003. [DOI] [PubMed] [Google Scholar]
- Delgado MR, Miller M, Inati S, Phelps EA. An fMRI study of reward-related probability learning. Neuroimage. 2005;24:862–873. doi: 10.1016/j.neuroimage.2004.10.002. [DOI] [PubMed] [Google Scholar]
- Dreher J-C, Kohn P, Berman KF. Neural coding of distinct statistical properties of reward information in humans. Cerebral Cortex. 2005 doi: 10.1093/cercor/bhj004. Epub ahead of print. [DOI] [PubMed] [Google Scholar]
- Elliott R, Newman JL, Longe OA, Deakin JFW. Differential response patterns in the striatum and orbitofrontal cortex to financial reward in humans: a parametric functional magnetic resonance imaging study. Journal of Neuroscience. 2003;23:303–307. doi: 10.1523/JNEUROSCI.23-01-00303.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fiorillo CD, Tobler PN, Schultz W. Discrete coding of reward probability and uncertainty by dopamine neurons. Science. 2003;299:1898–1902. doi: 10.1126/science.1077349. [DOI] [PubMed] [Google Scholar]
- Galvan A, Hare TA, Davidson M, Spicer J, Glover G, Casey BJ. The role of ventral frontostriatal circuitry in reward-based learning in humans. The Journal of Neuroscience. 2005;25:8650–8656. doi: 10.1523/JNEUROSCI.2431-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Galvan A, Hare TA, Parra C, Penn J, Voss H, Glover G, Casey BJ. Earlier development of the accumbens relative to the orbitofrontal cortex may underlie risk-taking behaviors in adolescents. The Journal of Neuroscience. 2006;26:6885–6892. doi: 10.1523/JNEUROSCI.1062-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gottfried JA, O'Doherty J, Dolan RJ. Encoding predictive reward value in human amygdala and orbitofrontal cortex. Science. 2003;301:1104–1107. doi: 10.1126/science.1087919. [DOI] [PubMed] [Google Scholar]
- Haber SN. The primate basal ganglia: parallel and integrative networks. Journal of Chemical Neuroanatomy. 2003;26:317–330. doi: 10.1016/j.jchemneu.2003.10.003. [DOI] [PubMed] [Google Scholar]
- Hollerman J, Schultz W. Dopamine neurons report an error in the temporal prediction of reward during learning. Nature Neuroscience. 1998;1:304–309. doi: 10.1038/1124. [DOI] [PubMed] [Google Scholar]
- Hsu M, Bhatt M, Adolphs R, Tranel D, Camerer CF. Neural systems responding to degrees of uncertainty in human decision-making. Science. 2005;310:1680–1683. doi: 10.1126/science.1115327. [DOI] [PubMed] [Google Scholar]
- Knutson B, Adams CM, Fong GW, Hommer D. Anticipation of increasing monetary reward selectively recruits nucleus accumbens. Journal of Neuroscience. 2001;21:1–5. doi: 10.1523/JNEUROSCI.21-16-j0002.2001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Knutson B, Taylor J, Kaufman M, Peterson R, Glover G. Distrbuted neural representation of expected value. The Journal of Neuroscience. 2005;25:4806–4812. doi: 10.1523/JNEUROSCI.0642-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kringelbach ML, O'Doherty J, Rolls ET, Andrews C. Activation of the human orbitofrontal cortex to a liquid food stimulus is correlated with its subjective pleasantness. Cerebral Cortex. 2003;13:1064–1071. doi: 10.1093/cercor/13.10.1064. [DOI] [PubMed] [Google Scholar]
- Kringelbach ML, Rolls ET. The functional neuroanatomy of the human orbitofrontal cortex: evidence from neuroimaging and neuropsychology. Progress in Neurobiology. 2004;72:341–372. doi: 10.1016/j.pneurobio.2004.03.006. [DOI] [PubMed] [Google Scholar]
- Leon MI, Shadlen MN. Effect of expected reward magnitude on the response of neurons in the dorsolateral prefrontal cortex of the macaque. Neuron. 1999;24:415–425. doi: 10.1016/s0896-6273(00)80854-5. [DOI] [PubMed] [Google Scholar]
- McClure SM, Berns GS, Montague PR. Temporal prediction errors in a passive learning task activate human striatum. Neuron. 2003;38:339–346. doi: 10.1016/s0896-6273(03)00154-5. [DOI] [PubMed] [Google Scholar]
- McClure SM, Laibson DI, Loewenstein G, Cohen JD. Separate neural systems value immediate and delayed monetary rewards. Science. 2004;306:503–507. doi: 10.1126/science.1100907. [DOI] [PubMed] [Google Scholar]
- Mirenowicz J, Schultz W. Importance of unpredictability for reward responses in primate dopamine neurons. Journal of Neurophysiology. 1994;72:1024–1027. doi: 10.1152/jn.1994.72.2.1024. [DOI] [PubMed] [Google Scholar]
- Montague PR, Berns GS. Neural economics and the biological substrates of valuation. Neuron. 2002;36:265–284. doi: 10.1016/s0896-6273(02)00974-1. [DOI] [PubMed] [Google Scholar]
- Montague PR, Hyman SE, Cohen JD. Computational roles for dopamine in behavioral control. Nature. 2004;431:379–387. doi: 10.1038/nature03015. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP. Reward representations and reward-related learning in the human brain: insights from neuroimaging. Current Opinion in Neurobiology. 2004;14:769–776. doi: 10.1016/j.conb.2004.10.016. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Dayan P, Friston K, Critchley H, Dolan RJ. Temporal differences models and reward-related learning in the human brain. Neuron. 2003;38:329–337. doi: 10.1016/s0896-6273(03)00169-7. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Deichmann R, Critchley HD, Dolan RJ. Neural responses during anticipation of a primary taste reward. Neuron. 2002;33:815–826. doi: 10.1016/s0896-6273(02)00603-7. [DOI] [PubMed] [Google Scholar]
- O'Doherty J, Kringelbach M, Rolls ET, Hornak J, Andrews C. Abstract reward and punishment representations in the human orbitofrontal cortex. Nature Neuroscience. 2001;4:95–102. doi: 10.1038/82959. [DOI] [PubMed] [Google Scholar]
- O'Doherty J, Rolls ET, Francis S, Bowtell R, McGlone F, Kobal G, Renner B, Ahne G. Sensory-specific satiety-related olfactory activation of the human orbitofrontal cortex. Neuroreport. 2000;11:893–897. doi: 10.1097/00001756-200003200-00046. [DOI] [PubMed] [Google Scholar]
- Olds J, Milner P. Positive reinforcement produced by electrical stimulation of septal area and other regions of rat brain. Journal of Comparative Physiology and Psychology. 1954;47:419–427. doi: 10.1037/h0058775. [DOI] [PubMed] [Google Scholar]
- Ramnani N, Elliott R, Athwal B, Passingham R. Prediction error for free monetary reward in the human prefrontal cortex. NeuroImage. 2004;23:777–786. doi: 10.1016/j.neuroimage.2004.07.028. [DOI] [PubMed] [Google Scholar]
- Rescorla R, Wagner A. In: Classical Conditioning 2: Current Research and Theory. Black A, Prokasy W, editors. Appleton Century-Crofts; New York: 1972. pp. 64–69. [Google Scholar]
- Robbins TW, Everitt BJ. Neurobehavioral mechanisms of reward and motivation. Current Opinions in Neurobiology. 1996;6:228–235. doi: 10.1016/s0959-4388(96)80077-8. [DOI] [PubMed] [Google Scholar]
- Rolls E, Kringelbach M, DeAraujo I. Different representations of pleasant and unpleasant odours in the human brain. European Journal of Neuroscience. 2003;18:695–703. doi: 10.1046/j.1460-9568.2003.02779.x. [DOI] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Schultz W, Tremblay L, Hollerman JR. Reward processing in primate orbitofrontal cortex and basal ganglia. Cereb Cortex. 2000;10:272–284. doi: 10.1093/cercor/10.3.272. [DOI] [PubMed] [Google Scholar]
- Schultz W. Getting formal with dopamine and reward. Neuron. 2002;36:241–263. doi: 10.1016/s0896-6273(02)00967-4. [DOI] [PubMed] [Google Scholar]
- Schultz W. Neural coding of basic reward terms of animal learning theory, game theory, microeconomics and behavioral ecology. Current Opinion in Neurobiology. 2004;14:139–147. doi: 10.1016/j.conb.2004.03.017. [DOI] [PubMed] [Google Scholar]
- Skinner BF. Diagramming schedules of reinforcement. Journal of Experimental Analysis of Behavior. 1958;1:103–107. doi: 10.1901/jeab.1958.1-67. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sutton RS, Barto AG. Reinforcement Learning: An Introduction. MIT Press; Cambridge, MA: 1998. [Google Scholar]
- Schultz W, Tremblay L, Hollerman J. Reward processing in primate orbitofrontal cortex and basal ganglia. Cerebral Cortex. 2000;10:272–284. doi: 10.1093/cercor/10.3.272. [DOI] [PubMed] [Google Scholar]
- Talairach J, Tournoux P. Co-planar stereotaxic atlas of the human brain. Thieme; New York: 1988. [Google Scholar]
- Tobler PN, Fiorillo CD, Schultz W. Adaptive coding of reward value by dopamine neurons. Science. 2005;307:1642–1645. doi: 10.1126/science.1105370. [DOI] [PubMed] [Google Scholar]
- Tremblay L, Schultz W. Relative reward preference in primate orbitofrontal cortex. Nature. 1999;398:704–708. doi: 10.1038/19525. [DOI] [PubMed] [Google Scholar]
- von Frisch K. The Dance Language and Orientation of Bees. Harvard University Press; Cambridge, Massachusetts: 1967. [Google Scholar]