

Abstract
Previous investigations of adult age differences in visual search suggest that an age-related decline may exist in attentional processes dependent on the observer's knowledge of task-relevant features (top–down processing). The present experiments were conducted to examine age-related changes in top–down attentional guidance during a highly efficient form of search, singleton detection. In Experiment 1 reaction times to detect targets were lower when target features were constant (feature condition) than when target features were allowed to vary between trials (mixed condition), and this reaction time benefit was similar for younger and older adults. Experiments 2 and 3 investigated possible interactions between top–down and bottom–up (stimulus-driven) processes. Experiment 2 demonstrated that search times for both age groups could be improved when targets varied on an additional feature from distractors (double-feature condition) but only when top–down control was available (feature search). In Experiment 3, the availability of top–down guidance enabled both younger and older adults to override the distracting effects of a noninformative spatial location cue. These findings indicate that top–down attentional control mechanisms interact with bottom–up processes to guide search for targets, and that in the context of singleton detection these mechanisms of top–down control are preserved for older adults.
A considerable debate has existed for some time as to how and when target features in a display are identified by the observer (Logan, 2004; Quinlan, 2003; Wolfe, 1998, 2003). Different configurations of target and nontarget (distractor) features lead to markedly different levels of performance. When the target is a singleton whose features are unique and separable from those of the distractors (e.g., a red target among green distractors), reaction time (RT) tends to be independent of the number of distractors (or to even decrease at larger display sizes), expressed as a zero or negative RT × Display Size slope. If, however, a target is a conjunction of distractor features (e.g., a red vertical target among red horizontal and green vertical distractors), RT tends to increase monotonically as a function of increasing display size, yielding a positive RT slope. These different patterns of the RT × Display Size function represent a continuum of search efficiency, anchored by the two extremes of a highly efficient search (zero or negative RT slope) and a more difficult search (positive RT slope). This continuum of search difficulty, in turn, depends on the degree of featural similarity among the display items, with higher levels of search efficiency resulting from low target–distractor similarity, high similarity among distractors, or both (Duncan & Humphreys, 1989).
A common component of current models of visual search is a central or master map of activation, which represents the summation of signals from the constellation of features in the display (Found & Müller, 1996; Müller, Heller, & Ziegler, 1995; Treisman, 1988; Wolfe, 1994). Observers base their target detection response on the relative saliency, in terms of the degree of activation, of the features in this map. Activation is enhanced not only by stimulus-driven or bottom–up processes, such as featural similarity, but also by top–down processes such as the observer's general knowledge of task goals and specific information about target probabilities (Yantis, 1998). To use an everyday example, in trying to find one's car in a parking lot, one could simply walk down every aisle of the lot until the particular combination of colour, size, and shape in a given car activated a correct identification, in a bottom–up manner. Alternatively, the search process is made considerably easier by top–down processes such as remembering that one's car was parked in the far northwest corner of the lot.
Top–down attentional guidance is of obvious importance in conjunction search tasks, in which knowledge of the set of features distinguishing the target from the distractors is a necessary component of target identification. Top–down guidance can also be valuable, however, in highly efficient search tasks involving the detection of a featural singleton. Bravo and Nakayama (1992) demonstrated this principle with a two-choice discrimination task (left/right orientation of a shape), in which the target shape was always a colour singleton. When the particular colour of the singleton was not predictable (i.e., either a red target among green distractors or vice versa), discrimination RT decreased with increasing display size, suggesting a bottom–up search process in which mutual suppression of similar target features (Duncan & Humphreys, 1989; Kastner & Ungerleider, 2000) occurred at the larger display sizes. When, in contrast, the singleton and distractor colours remained constant across trials, RT was lower and relatively constant across display size, suggesting a significant top–down contribution from the observer's knowledge of the target and distractor colours.
Wolfe, Butcher, Lee, and Hyle (2003) obtained similar results in a singleton detection paradigm (i.e., yes/no response regarding target presence), in which the singleton target features were either blocked (consistent across trials) or mixed (varied across trials). Wolfe et al. proposed that top–down attentional guidance sets weights in the activation map of display features, in a manner that optimizes the signal to noise ratio. Variation in the target and distractor features across trials decreases the signal to noise ratio, thus increasing RT, even though the search remains efficient in terms of a zero slope for the RT × Display Size function. In this model, the top–down weighting of specific features is implemented by both an explicit mechanism defined by the observer's intentions and an implicit mechanism based on the repetition priming of features across trials (Maljkovic & Nakayama, 1994). Müller and colleagues have developed a similar account, although they emphasize the weighting of target dimensions, rather than individual features, in the activation map (Found & Müller, 1996; Krummenacher, Müller, & Heller, 2001, 2002; Müller, Heller, & Ziegler, 1995).
Adult age differences in visual search and top–down control
Evidence from a large body of research has confirmed what is frequently observed outside the laboratory: In tasks that rely heavily on visual search and discrimination, older adults are typically slower and less accurate than younger adults (Madden & Whiting, 2004; McDowd & Shaw, 2000; Schneider & Pichora-Fuller, 2000). Whether these age differences represent attention specifically, rather than a decline in sensory processing and/or generalized slowing of information processing, is a matter of debate. There is, in addition, considerable evidence that older adults are comparable to younger adults in the ability to improve search performance when a stimulus dimension defines task-relevant information. This age constancy in attentional guidance has been most clearly evident when the task provides observers with advance information regarding the spatial location or other characteristics of the target (Madden & Plude, 1993).
Whether some bottom–up processes may be insulated from age-related decline, or whether there is any change associated specifically with top–down attentional guidance, is less clear. Manipulating target motion coherence of distractors in a visual search task, Folk and Lincourt (1996) found that older adults were less successful than younger adults at top–down inhibition of distractors, a finding later supported by Watson and Maylor (2002). Research using nonin-formative onset singletons as a means of capturing attention (or an eye movement) suggests that under some conditions older adults are more vulnerable than younger adults to attentional capture, perhaps as result of a decline in the ability to inhibit the irrelevant singleton (Colcombe et al., 2003; Kramer, Hahn, Irwin, & Theeuwes, 2000; Pratt & Bellomo, 1999). In some forms of conjunction search, however, top–down knowledge of either the proportion of features shared by targets and distractors (Humphrey & Kramer, 1997) or the homogeneity of distractors (Madden, Pierce, & Allen, 1996) leads to comparable levels of improvement in search for younger and older adults, implying some preservation of top–down control. In these latter studies, the specification of top–down processing is difficult because featural similarity (and thus bottom–up processing) varies across task conditions. However, a preservation of top–down attentional control during conjunction search has also been reported when the features of individual displays are equated across task conditions (Madden, Whiting, Cabeza, & Huettel, 2004).
The present experiments
Previous investigations of age differences in top–down attentional guidance have addressed this issue primarily in the context of difficult task conditions (e.g., moving distractors) or inefficient search performance as evidenced by positive display size slopes. The goal of the present experiments was to determine whether age differences in top–down attentional control would be evident in a very efficient form of search, singleton detection. Our general design was a singleton search task, similar to that of Wolfe et al. (2003), in which the target differed from a set of homogeneous distractors on at least one feature. As noted previously, younger adults' performance in this type of search task typically yields RT × Display Size slopes that are either zero or negative, implying a rapid detection process, and there is a further decline in mean RT with the addition of top–down control.
As in the Wolfe et al. (2003) research, participants in the present experiments responded regarding the presence or absence of a line bar that could differ in colour, size, or orientation from a set of homogeneous distractors. In each of three experiments, the amount of top–down information available during search was defined in terms of whether the target and distractor features either remained constant within trial blocks, thus encouraging top–down guidance (feature condition), or varied across trials within a block (mixed condition), thus allowing bottom–up processes to predominate.
Within this general framework, we explored age differences in relation to several issues: First, is top–down attentional guidance limited to the activation of target features? Wolfe et al. (2003) reported several findings suggesting that top–down guidance affects the activation of target features at a relatively early stage of perceptual identification. Wolfe et al., however, did not analyse RT for target-absent trials in detail. Because the activation of target features on these latter trials is minimal (limited to the activation of target-similar distractors), the presence of top–down effects on target-absent trials would indicate some influence of top–down control on the decision and response selection processes following target identification (Chun & Wolfe, 1996; Cohen & Magen, 1999). Second, how do bottom–up and top–down mechanisms interact in search performance? Featural similarity effects, for example, can be influenced by top–down control (Hodsoll & Humphreys, 2001; Krummenacher et al., 2001), and this interaction between top–down and bottom–up effects may vary in relation to age, even if top–down guidance in isolation is relatively preserved. Third, how do top–down and bottom–up mechanisms interact in preventing attentional capture? Previous research with younger adults suggests that top–down attentional guidance can reduce attentional capture by an irrelevant singleton (Peterson & Kramer, 2001). In exploring this latter issue we investigated whether older adults could successfully use top–down guidance to reduce an attentional capture effect (Colcombe et al., 2003; Kramer et al., 2000; Pratt & Bellomo, 1999).
EXPERIMENT 1
In this experiment we varied the amount of top–down control available during singleton detection. In each of three search conditions, the target differed from the distractors in a single feature (i.e., colour, size, or orientation). During the feature condition, the target's features remained constant across all trials within a block, and observers were explicitly instructed of target features (e.g., “target will always be a red line”). In the opposing search condition—mixed—targets could differ in colour, size, or orientation from distractors, thus minimizing the amount of top–down information available to guide search.1 An intermediate condition was also included in which observers were told the dimension of the target (e.g., “target will always be a different colour”), though the specific feature value was allowed to vary between trials within a block, thus creating a degree of uncertainty about the target's specific feature value.
If older adults are as capable of benefiting from top–down guidance as are younger adults, as has been demonstrated for conjunction search (Humphrey & Kramer, 1997; Madden et al., 1996, 2004), then the decrease in search RT in the feature and dimension conditions, relative to the mixed condition, should be at least as great for older adults as for younger adults. An age-related decline in top–down guidance (Folk & Lincourt, 1996; Watson & Maylor, 2002), in contrast, would be evident as a less pronounced difference in RT across the search conditions. In this experiment we also examined the top–down effects on target-absent trials as well as on target-present trials, to assess potential top–down guidance beyond the level of target activation.
Method
Participants
A total of 24 younger adults between 18 and 28 years of age (M = 21.5 years) and 24 older adults between 60 and 81 years of age (M = 66.8 years) participated in Experiment 1. Testing was conducted at the Duke University Medical Center (Durham, NC), Radford University (Radford, VA), and the University of Akron (Akron, OH). The older participants were healthy, community-dwelling individuals who possessed at least a high-school education. The younger participants were university students and staff. Within each age group, 12 participants (6 women) were tested at Duke, and 6 participants (3 women) were tested at each of the Radford and Akron sites.
Participants completed a vocabulary measure (Salthouse, 1993) and a computer administered digit-symbol substitution test (Salthouse, 1992). Corrected visual acuity was at least 20/40 for each participant, and all participants were screened for normal colour vision using Dvorine or Ishihara colour plates. Participant characteristics (e.g., education, acuity, and psychometric performance) are presented in Table 1. Analyses of these data indicated that there were no Age Group × Testing Site interactions in the psychometric data, and thus the data were averaged across the three testing sites.
TABLE 1.
Participant characteristics
|
M |
SD |
||||
|---|---|---|---|---|---|
| Expt | Variable | Younger | Older | Younger | Older |
| 1 | Agec | 21.9 | 67.2a | 3.2 | 5.3 |
| Educationc | 14.2 | 15.6a | 1.8 | 2.4 | |
| Vocabularyd | 12.0 | 13.6 | 5.0 | 6.1 | |
| Acuityb | 17.7 | 19.8 | 2.9 | 4.5 | |
| Digit symbol RTe | 1,319.0 | 1,950.0a | 180.8 | 400.0 | |
| Digit symbol accuracyf | 96.3 | 94.9 | 2.6 | 3.8 | |
| 2 & 3 | Agec | 19.6 | 68.4a | 1.7 | 5.0 |
| Educationc | 13.6 | 16.3a | 1.8 | 2.5 | |
| Vocabularyd | 63.5 | 63.8 | 3.0 | 4.5 | |
| Acuityb | 16.7 | 23.5a | 4.3 | 11.0 | |
| Digit symbol RTe | 1,355.0 | 2,034.0a | 249.1 | 354.1 | |
| Digit symbol accuracyf | 98.0 | 97.4 | 1.8 | 2.0 | |
Note: RT=reaction time. n=24 per age group.
Age group comparison reliable at p <.05.
Denominator of the Snellen fraction for corrected near vision.
In years.
No. correct; max.=20.
In ms.
%correct.
Apparatus and stimuli
The experimental task was created and run using E-Prime© software. At each testing site, stimuli were presented using either a Pentium II or Pentium III processor microcomputer and CRT monitor (either 17- or 20-in.). On each trial, participants viewed a display of 4, 8, or 16 lines constructed from three stimulus dimensions (colour, size, orientation), each with two feature values: big or small, red or green, and horizontal or vertical. Participants responded manually to indicate their yes/no decision regarding whether a target line differing in colour, size, or orientation was present among the nontarget (distractor) lines. This was a feature search task in which the distractors were homogeneous, and the target (present on half of the trials) was a singleton that differed from all of the distractors in a single feature value—colour, size, or orientation (see Figure 1). Participants viewed the targets on the computer monitor at a distance of approximately 60 cm, under slightly lower than normal room illumination. Display items were presented against a black background. The red lines (RGB 255, 0, 0) and green lines (RGB 0, 164, 0) were matched for luminance. Big lines were 1.8° × 0.57°, and small lines were 1.34°× 0.19° as viewed at a distance of 60 cm. Participants responded using the “Z” and “/” keys on the computer keyboard, resting the index finger of each hand on the two response buttons during testing. The assignment of yes/no responses to the two keys was counterbalanced across participants.
Figure 1.
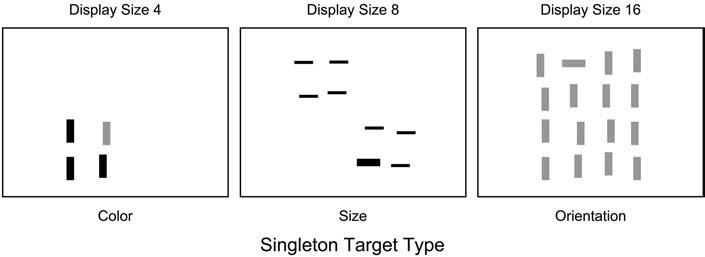
Display configurations for display size and singleton types in Experiment 1.
In constructing the displays, the 16 possible locations were arranged in a 4 × 4 cell grid spanning approximately 13.5° × 13.5°. For display sizes of four items, all four lines were presented in one of the four-cell quadrants of the grid (see Figure 1). In display sizes of eight, four lines were presented in one quadrant, and the other four lines were presented in the diagonally opposite quadrant. For display sizes of 16, the lines were divided equally among the four quadrants. This design maintained a comparable density of the items across the display sizes, thus minimizing changes in lateral interference effects as a function of display size. Within each quadrant, the position of each of the four lines was jittered randomly up to 0.56° both horizontally and vertically from the centre of its cell.
Design
Each participant performed a total of 1,080 search trials. Two 1,080 display sets (each of an opposing colour) were created and balanced across participants so that singleton target type would not be confounded with colour. Three search conditions (feature, dimension, and mixed) each contained 360 trials. Within each colour set, there were four possible singleton targets (see Table 2) that were all used in each of the three search conditions. What varied across the task conditions was the feature distinguishing the target from the distractors (which defines the type of singleton target in the display) and the predictability of a particular type of target (which defines top–down attentional control). The task conditions were distributed across 17 blocks of trials, each of which contained an equal number of trials for each combination of the three display sizes and two response types (yes/no). These trials were ordered randomly within trial blocks, with the constraint that the same response type did not occur on more than five consecutive trials. On the target-present (yes response) trials, each type of singleton target (colour, size, orientation) appeared in each of the 16 display cell locations equally often within each search condition.
TABLE 2.
Target-distractor pairs during feature search for each singleton type by colour set and block in Experiment 1
|
Singleton type |
||||
|---|---|---|---|---|
| Colour set | Block | Colour | Size | Orientation |
| A | 1 | BRV–BGV, SRH–SGH | BRV–SRV, BGH–SGH | BRV–BRH, SGV–SGH |
| 2 | SGV–SRV, BGH–BRH | SRH–BRH, SGV–BGV | BGH–BGV, SRH–SRV | |
| B | 1 | BGV–BRV, SGH–SRH | SGH–BGH, SRV–BRV | SGH–SGV, BRH–BRV |
| 2 | SRV–SGV, BRH–BGH | BRH–SRH, BGV–SGV | BGV–BGH, SRV–SRH | |
Note: B=big, S=small, V=vertical, H=horizontal, R=red, G=green. For each pair of three letters, the first set of three letters represents the target, and the second set of three letters represents the distractors, with the singleton feature presented in bold (e.g., BRV–BGV represents a big, red, vertical target among big, green, vertical distractors). Data are presented for target-present trials only. Within each trial block, the displays on target-absent trials would be represented by the second set of three letters of each pair.
The feature condition contained six blocks of 60 trials, two blocks for each of the three target types (colour, size, and orientation). Participants were informed of the individual feature that would identify the singleton target (e.g., red) at the beginning of each of these trial blocks, and this particular feature remained constant throughout the block (see Table 2). Within each block there were 10 trials for each combination of display size and response type, yielding 20 target-present trials (across the two blocks) for each response type within each of the target types (colour, size, and orientation). Within each feature condition block, the irrelevant features varied across trials (e.g., the orientation and size of lines—when the relevant dimension was colour). However, within a display, the features of all of the distractors were identical, and thus the target differed from the distractors on only one feature.
In the dimension condition, participants were informed at the beginning of each trial block that the target would differ from the distractors along a particular dimension, but the specific feature value distinguishing the target varied across trials (e.g., in the colour dimension trial blocks, the target feature varied randomly between red and green across trials). As in the feature condition, the irrelevant features varied across trials. There were six trial blocks in this condition. For each target type (colour, size, and orientation), participants performed one block of 48 trials and one block of 72 trials. (Counterbalancing required the number of trials in each block to be a multiple of 24.) This design yielded 20 trials for each combination of response type and display size, per target type.
In the mixed condition, participants were informed at the beginning of each trial block that the target could differ from the distractors on colour, size, or orientation. Participants performed five blocks of 72 trials, yielding 20 target-present trials per display size for each target type and 60 target-absent trials per display size. (In the mixed condition, target type is undefined on target-absent trials.) As in the other search conditions, the distractors within each display in the mixed condition were homogeneous (though varying across trials), and the target differed from the distractors on only one feature. Unlike the other conditions, however, the mixed condition did not enable participants to predict the type of singleton that would occur in an upcoming display.
Procedure
Each block of trials began with an instruction screen that contained information about the characteristics of the target within that block, as described in the previous section (Design). Participants pressed a button to start the first trial. Participants performed a practice block of 36 trials of the mixed search condition before testing began; this practice block was repeated if necessary. The 17 trial blocks used to comprise the feature, dimension, and mixed conditions were counterbalanced across participants with respect to presentation order.
Displays remained on the screen until the participant's key-press response for the target present/absent (yes/no) decision, up to a maximum of 5 s. Reaction times were measured from display onset. After a correct response, the next trial immediately appeared on the screen. After an incorrect response, the computer displayed the word “Error” on the screen for 1.5 s and sounded a tone, before continuing to the next trial.
Results and discussion
Error rate
For all three experiments, error rates were low for both age groups, and t tests revealed no age differences in error rate in any of the three experiments (see Table 3). We recorded failures to respond separately from errors, and response failures did not exceed 0.2% of the trials for either age group in any experiment.
TABLE 3.
Proportional error rates by age group and experiment
|
Misses |
False alarms |
|||||||
|---|---|---|---|---|---|---|---|---|
|
Younger |
Older |
Younger |
Older |
|||||
| Experiment | M | SD | M | SD | M | SD | M | SD |
| 1 | .025 | .014 | .028 | .019 | .020 | .018 | .018 | .013 |
| 2 | .030 | .025 | .017 | .012 | .010 | .011 | .013 | .011 |
| 3 | .023 | .022 | .012 | .009 | .015 | .013 | .014 | .020 |
Note: Using a Bonferroni corrected alpha level of .025 for each experiment, no age differences in either misses or false alarms were observed for any of the three experiments.
Target-present RT
The dependent variable in the RT analyses was each participant's median RT in each task condition. Because the differences among the singleton types were undefined for target-absent trials in the mixed condition, we analysed target-present trials and target-absent trials separately. Thus, for the target-present trials in Experiment 1, the resulting design was an Age Group (younger, older) × Search Condition (feature, dimension, mixed) × Singleton Type (colour, size, orientation) × Display Size (4, 8, 16) factorial design. With the exception of age group, all variables were manipulated within subjects.
Figure 2 displays the means of the median RTs for correct responses on target-present trials. We analysed these data with a split-plot analysis of variance (ANOVA), averaging across the two blocks of the same singleton type (e.g., red and green) within each search condition. All of the main effects were significant: Reaction time decreased across the mixed, dimension, and feature conditions, F(2, 92) = 140.7, p < .001. Further, singleton type also affected RT, F(2, 92) = 85.62, p < .001, with RT decreasing across the size, orientation, and colour singletons. Reaction time also decreased with increasing display size, F(2, 92) = 30.19, p < .001. Finally, older adults exhibited RTs that were 169 ms higher than those of younger adults, F(1, 46) = 33.9, p < .001; no interaction involving age group, however, was significant.
Figure 2.

Mean reaction time (± SE) on target-present trials as a function of display size, singleton type, and age group in Experiment 1.
The significant Display Size × Singleton Type interaction, F(4, 184) × 12.73, p < .001, occurred as the result of a decrease in RT as a function of increasing display size for colour and orientation singletons, both Fs(2, 94) > 33.2, p < .001, but not for size singletons. The negative display size effect represents the degree of suppression among distractor features, a bottom–up process (Bravo & Nakayama, 1992; Duncan & Humphreys, 1989; Kastner & Ungerleider, 2000). The present variation in the negative display size effect suggests that suppression among distractor features is more effective for colour and orientation than for size.
The Search Condition × Singleton Type interaction, F(4, 184) = 4.61, p = .001, represents changes in top–down effects across the singleton target features. Bonferroni comparisons revealed that for both colour and orientation singletons, responses were significantly faster during the dimension condition than during the mixed condition, and were in addition faster during the feature condition than during the dimension condition, all t(92)s > 2.40, p < .05. For size singletons, however, although responses were significantly faster in the feature condition than in either the dimension or the mixed condition, t(92)s > 2.40, p < .05, these last two conditions did not differ significantly. That is, both feature-guided and dimension-guided forms of top–down control were effective for colour and orientation singletons, whereas only feature-guided top–down control was effective for size singletons.
The above pattern was modified by a Search Condition × Singleton Type × Display Size interaction, F(8, 368) = 4.10, p < .001. This effect occurred because there was one exception to the RT benefit provided by both feature and dimension conditions, relative to the mixed condition, for colour and orientation singletons. This exception was colour singletons in four-item displays; there was a substantial benefit for the feature condition relative to the mixed condition, t(94) > 2.44, p < .05, but the advantage in the dimension condition was not significant.
Target-absent RT
Given that the variable of singleton target type is undefined for target-absent trials in the mixed condition, median target-absent RTs were collapsed across singleton type. Overall, target absent RTs were only 16 ms slower than target present RTs. As with previous analyses, older adults' RT (823 ms) was slower than that of the younger adults' (630 ms), F(1, 46) = 35.67, p < .001, and display size effects were slightly negative (22-ms difference between 4- and 16-item displays), F(2, 92) = 27.61, p < .001. Furthermore, an effect of search condition, F(2, 92) = 90.52, p < .001, reflects reliable increases in target-absent RT from the feature (664 ms) to the dimension condition (732 ms), and from the latter condition to the mixed condition (784 ms), all t(92)s > 2.44, p < .05. A Search Condition × Display Size interaction revealed relatively greater effects of top–down processing for larger display sizes, F(4, 92) = 5.53, p < .001.
In summary, the effects of search condition in Experiment 1 indicate that colour, size, and orientation were able to effectively support top–down attentional guidance in a highly efficient form of search, singleton detection. That is, as target features became increasingly predictable (i.e., from mixed, to dimension, to feature conditions), responses became reliably faster, as was reported by Wolfe et al. (2003) for target-present trials. In addition, Experiment 1 demonstrated that the top–down effect was present for target-absent trials as well as for target-present trials, which suggests that the top–down attentional guidance influences the decision and response selection processes involved in terminating search (Chun & Wolfe, 1996; Cohen & Magen, 1999), as well as target identification.
The general benefit of top–down guidance was present for all singleton target types, though colour and orientation singletons showed top–down benefits even in the dimension condition, whereas size singletons did not. These results demonstrate that top–down search processes are moderated, in part, by the visual characteristics of the stimulus. That is, top–down and bottom–up attentional processes are not entirely independent but instead interact (Hodsoll & Humphreys, 2001; Krummenacher et al., 2001).
Despite the fact that older adults' responses were generally slower than those of younger adults, the two age groups were similar in the bottom–up processing expressed by the negative display size slopes (i.e., distractor suppression) on both the target-present and the target-absent trials. More critically, younger and older adults did not differ in their ability to engage top–down processing capabilities to facilitate target detection. This result is consistent with the age-related preservation of top–down attentional guidance that has been observed in conjunction search tasks (Humphrey & Kramer, 1997; Madden et al., 1996, 2004). In contrast, Folk and Lincourt (1996) and Watson and Maylor (2002) did report an age-related decline in top–down control in the presence of moving distractors, which may reflect age differences in motion perception specifically. In fact, both Watson and Maylor, and Kramer and Atchley (2000) found that top–down inhibition of distractors, in a visual marking paradigm, was comparable for younger and older adults when the distractors were stationary.
EXPERIMENT 2
Although in Experiment 1 each target singleton differed from the distractors on a single feature, the target features varied in their susceptibility to top–down control, which suggests that top–down and bottom–up processes interact to determine search efficiency. Such effects, however, were similar for younger and older adults. In Experiment 2 we investigated this interaction further. Specifically, we were interested in whether RT changes associated with the degree of target–distractor similarity (a bottom–up process) would vary as a function of top–down control, and whether this interaction varied further in relation to age. We again manipulated the amount of top–down control available by employing both feature- and mixed-search conditions (dimension search was not used). As in Experiment 1, we used size and orientation target types (colour was not manipulated) and homogeneous distractors (see Table 4).2 We included an additional type of singleton, which differed from the distractors in both size and orientation (e.g., a big vertical target among small horizontal distractors), and participants were aware of this fact. Thus, the difference between the double- and single-feature trials in the mixed condition (which allowed target features to vary) reflects the influence of bottom–up processing (decreasing target–distractor similarity) in the absence of top–down control. Similarly, this single- versus double-feature difference in the feature condition represents the additional contribution of bottom–up processing when top–down control is available.
TABLE 4.
Target-distractor pairs during feature and mixed search for each target type by colour set and block in Experiment 2
| Colour set | Block | Search | Target-distractor pairs | ||
|---|---|---|---|---|---|
| A | Mixed | BV–SH, SH–BV, BV–BH, SH–SV, BH–SH, SV–BV | |||
| B | Mixed | BH–SV, SV–BH, BV–BH, SH–SV, BH–SH, SV–BV | |||
| Double | Orientation | Size | |||
| A | 1 | Feature | BV–SH | BV–BH | BV–SV |
| 2 | Feature | SH–BV | SH–SV | SH–BH | |
| B | 1 | Feature | BH–SV | BH–BV | BH–SH |
| 2 | Feature | SV–BH | SV–SH | SV–BV | |
Note: Letter pairs represent display features, as described in the legend to Table 2. In this experiment the colour of all display items was alternated randomly between red and green across trials. For mixed search each colour set block was repeated five times.
Using similar manipulations, Krummenacher et al. (2001) and Wolfe et al. (2003) have found an RT advantage for younger adults when targets differed from distractors on two features as opposed to one, indicating a bottom–up effect of target–distractor similarity. These previous investigations differ, however, with regard to the influence of top–down control on this similarity effect. In the Krummenacher et al. study, the advantage for two features (colour and orientation), relative to one, was present for mean RT in both mixed and feature conditions. Only in the feature condition, however, was there additional evidence, from RT distribution analyses (tests of violations of the race model inequality; Miller, 1982), of a particular interaction between top–down and bottom–up effects: The parallel-coactive processing of the colour and orientation dimensions was evident only in the presence of top–down control, when the target feature was blocked. In the Wolfe et al. investigation, in contrast, the double-feature RT advantage was evident only during a mixed condition and not during a feature condition, which suggests that top–down control may be sufficient to preclude further improvement from bottom–up processing.
In view of the age-related decline in efficiency of visual processing at the sensory level (Schneider & Pichora-Fuller, 2000), we predicted that additional support from bottom–up attentional processes, expressed as the RT benefit for double-feature targets relative to single-feature targets, may differentially benefit older adults, especially in the mixed condition where bottom–up processes predominate. If, in addition, older adults are less efficient than younger adults in modifying bottom–up processing by means of top–down control, then the variation in the effect of target–distractor similarity, across feature and mixed search conditions, should be relatively less pronounced for older adults.
Method
Participants
A total of 24 younger adults between 18 and 24 years of age (M = 19.6 years) and 24 older adults between 62 and 78 years of age (M = 68.4 years) participated in Experiment 2. None of these individuals had participated in Experiment 1, and there were 12 women in each age group. All of these participants were recruited at the Duke University Medical Center, using the same screening criteria as used in Experiment 1, and participants completed the same psychometric measures as those in Experiment 1 (Table 1).
Apparatus and stimuli
All of the testing was conducted with a Pentium 4 processor microcomputer using a 19-in. flat-panel LCD monitor positioned at a viewing distance of 60 cm. The same software as that used to control stimulus presentation in Experiment 1 was also used in Experiment 2. The size and RGB values of the display items were the same as those in Experiment 1. The CIE values of display items on this monitor were measured with the OptiCAL 3.7 system (http://www.colorvision.com). The CIE values were x = 0.640, y = 0.345, for the red items, and x = .282, y = 0.602, for the green items. Luminance of red and green display items was 37.0 cd/m2 and 31.2 cd/m2, respectively, against a black background.
Design and procedure
The two search conditions, feature and mixed, each comprised 360 trials (see Table 4 for possible singleton target types). The feature condition contained six blocks of 60 trials, with two blocks for each single-feature target (size, orientation) and two blocks for the double-feature target (size plus orientation). The order in which these six blocks were performed across the testing session was counterbalanced using a Latin square design with one of five mixed blocks occurring between each feature block. In each feature condition block, there were 10 single-feature singletons for each display size, yielding a total of 20 trials per response type across both feature condition blocks for size, orientation, and double-feature targets.
The mixed condition contained five blocks of 72 trials, comprising 36 trials per response type. The target-present trials in each block contained (per display size) four targets for each singleton target type (double, size, and orientation) totaling 20 target-present trials for each singleton target type across the five blocks. Each of the mixed blocks also contained 12 target-absent trials per display size. As with the previous experiment, we counterbalanced two colour sets of target–distractor features across participants (see Table 4 for target–distractor pairs).
As in Experiment 1, participants viewed instructions regarding the singleton target at the beginning of each trial block, the displays remained on the screen until the yes/no response, and we counterbalanced response hand assignment across participants within each age group. In the double-feature blocks the instructions specified both features of the target (e.g., “target will always be a big, vertical line”), whereas the single-feature and mixed-condition instructions were identical to those in Experiment 1.
Results and discussion
Target-present RT
As in Experiment 1, we analysed the two response types in separate factorial ANOVAs including age group as a between-subjects variable. On the target-present trials, the within-subjects variables were search condition (feature, mixed), singleton type (size, orientation, double), and display size (4, 8, 16). The means of participants' median RT, for correct responses on target-present trials, are presented in Figure 3.
Figure 3.

Mean reaction time (± SE) on target-present trials as a function of display size, singleton type, and age group in Experiment 2.
As with the previous experiment, the main effect of age group, F(1, 46) = 36.1, p < .001, was the result of responses for older adults that were 236 ms slower than those for younger adults, but no interaction involving age group was significant. The main effect of search condition, F(1, 46) = 182.6, p < .001, represented the decrease in RT for the feature condition relative to the mixed condition. The singleton type effect, F(1, 92) = 19.6, p < .001, was significant because mean RT (averaged over search condition) was higher for orientation singletons (804 ms) than for both the size (775 ms) and double-feature (759 ms) singletons. The main effect of display size was also significant, F(1, 92) = 10.0, p < .001, because mean RTs were higher for 8-item displays (796 ms) than for 4-item (767 ms) or 16-item (774 ms) displays, replicating the negative display size effect observed in Experiment 1.
The Search Condition × Singleton Type interaction, F(2, 92) = 11.9, p < .001, demonstrated an important difference between the two search conditions. During the mixed condition, even though there was an effect of target type, representing faster responses to size targets (836 ms) than to orientation targets (889 ms), t(94) > 2.44, p < .05, mean RT for double-feature targets (820 ms) was slightly, but not significantly, lower than that associated with the most discriminable single-feature target (size). During the feature condition, in contrast, mean RT was comparable for size targets (708 ms) and orientation targets (703 ms). Responses to the double-feature targets (678 ms), in the feature condition, were significantly lower than those to both types of single-feature target, t(94) > 2.44, p < .05.
Target-absent RT
Again, target-absent responses were on average 15 ms slower than target-present responses. Effects were similar to the target-present data, with RT increasing between younger (670 ms) and older adults (919 ms), F(1, 46) = 28.19, p < .001. Averaged across search condition, there was a 12-ms increase from 4- to 16-item displays, F(1, 46) = 15.06, p < .001. Responses were faster in the feature (720 ms) than in the mixed condition (869 ms), F(1, 46) = 91.87, p < .001. (Singleton type is, of course, undefined on the target-absent trials.) The only interaction was a Search Condition × Display Size effect, F(2, 92) × 13.40, p < .001, which occurred because the positive display size effect was more pronounced in the mixed condition than in the feature condition.
The results of Experiment 2 were in many respects similar to those of Experiment 1. Again, the benefits of top-down processing in the feature condition relative to the mixed condition were present for all three singleton target types (size, orientation, and size plus orientation), and these benefits were comparable for younger and older adults. One difference between the experiments is that the negative display size effect, representing the bottom–up suppression of distractor features at larger display sizes, was present only for target-present trials in Experiment 2, but had been evident for both target-present and target-absent trials in Experiment 1. This pattern may have occurred because target-absent RT receives a relatively greater influence from top–down decision and response selection processes (Chun & Wolfe, 1996), thus reducing the bottom–up effect of distractor suppression.
The primary manipulation in the present experiment was the inclusion of a double-feature singleton target (size plus orientation). We were interested in whether the additional bottom–up information provided by double-feature target would be differentially effective depending on the availability of top–down control. The most intriguing finding involving this manipulation was the presence of the Search Condition × Singleton Target type interaction for target-present trials, which did not interact with age group. In the feature condition, responses to double-feature targets were significantly faster than to both single-feature targets, whereas in the mixed condition there was a nonsignificant RT advantage for the double-feature targets. This result indicates that, for both age groups, the availability of top– down control in the feature condition facilitated the use of additional bottom-up information.
Using a similar manipulation of target–distractor similarity in singleton detection, Wolfe et al. (2003) reported the opposite effect, with double-feature targets showing an RT advantage only in the mixed conditions, whereas Krummenacher et al. (2001) observed faster RTs for double-feature targets than for single-feature targets, in both feature and mixed conditions. Krummenacher et al. also demonstrated, through RT distribution analyses, that the parallel-coactive processing of colour and orientation was evident only in a blocked condition that allowed top–down control. Krummenacher et al. proposed that their results support a dimension-weighting model of search, in which the bottom-up saliency of relevant dimensions is weighted by a top–down mechanism at a detection stage prior to object identification (Found & Müller, 1996; Krummenacher et al., 2002; Müller et al., 1995). Although the RT advantage for double-feature targets was significant only in the feature condition of Experiment 2, our results are generally consistent with the type of interactive effect reported by Krummenacher et al. The feature condition may have allowed the participants in Experiment 2 to alter a top–down template in preparation for the size plus orientation targets. Additional research with a sufficient number of trials to permit RT distribution analyses would be helpful in testing this type of dimension-weighting account.
EXPERIMENT 3
Experiment 2 revealed that top–down and bottom–up processes interacted during a visual search task, resulting in the facilitation of target detection. The goal of Experiment 3 was to examine whether the interaction of these two search processes might also influence the degree to which a noninformative spatial cue was effective in capturing attention. There is a precedent demonstrating that top–down processing has an effect on attentional capture. In a previous study of younger adults, Peterson and Kramer (2001) found that onset distractors were less effective at increasing search RTs when the configuration of the display was one that had been repeated across trials (presumably allowing top–down guidance), relative to during new configuration displays. This result suggests that top–down processes may reduce attentional capture, perhaps by allowing an inhibitory set (cf. Theeuwes, 1992; Theeuwes & Burger, 1998). Pratt and Bellomo (1999) have shown older adults to be more susceptible (relative to younger adults) to attentional capture by onset cues even though the cue is nonpredictive of the target's location, which may be related to the ability to maintain the appropriate level of top–down inhibition (Kramer et al., 2000).
In Experiment 3 we included a noninformative spatial cue indicating target location. As in the previous experiments, we compared feature and mixed blocks as a measure of top–down control. Each trial in this experiment, however, also included the appearance of a spatial cue 150 ms before display onset (see Figure 4), which on some trials indicated a single display location (i.e., an exogenous cue). There were three types of cue trial. On validly cued trials, the cue was presented in the same location as that of the singleton target, whereas on invalid trials a distractor location was cued. On neutral trials a large grey outline box appeared around what would be the entire display. Display size was constant at four items, and cue validity was 25% on target-present trials. The cue was thus noninformative, in that it did not predict the location of the singleton target at a greater than chance level, and participants were instructed to ignore the cue. Any changes in target detection RT associated with the cue should consequently reflect attentional capture: relatively automatic attentional shifts associated with the onset of an exogenous cue. Our question was whether this automatic shift of attention interacts with top–down control.
Figure 4.

Display presentation sequence in Experiment 3. ITI = intertrial interval.
In Experiment 2 we found that providing additional information that facilitated the distinction between targets and distractors (double-feature singletons) resulted in more efficient search, but only when top–down processing was engaged (i.e., during feature search). In Experiment 3, however, the bottom–up information (the cue) was more frequently unhelpful to target detection (i.e., invalid) than helpful, and thus the best strategy would be to avoid attending to the cue. Thus, participants should be more successful at ignoring the cue when top–down control is available (feature blocks) than when bottom–up processing predominates (mixed blocks). If ageing decreases the ability to avoid attentional capture (Kramer et al., 2000; Pratt & Bellomo, 1999), then this interaction between top–down and bottom–up processing should be more clearly evident for younger adults than for older adults.
Method
Participants, apparatus, and stimuli
The same individuals who participated in Experiment 2 also participated in Experiment 3. The microcomputer and software used in Experiment 2 were also used in Experiment 3, and participants completed both experiments in a single testing session. The task was search for either a colour or orientation singleton line, among homogeneous distractor lines. Two changes were introduced in Experiment 3. First, as noted previously, a valid, invalid, or neutral cue regarding singleton location was presented 150 ms before display onset. Second, both display size (four items) and the size of the lines (1.8° × 0.38° at a distance of 60 cm) remained constant across all trials. Further, each display of four lines was centred on the screen (see Figure 4) as opposed to being presented in one of four quadrants as in the previous two experiments (see Figure 1).
Design
The order in which participants completed Experiment 2 and Experiment 3 was counterbalanced across participants within each age group. Participants in Experiment 3 performed 960 trials, divided equally between the two search conditions, feature and mixed. As in the previous experiments, age group was a between-subjects variable. On the target-present trials (50% of trials), the within-subjects variables were search condition (feature, mixed), cue type (valid, invalid, neutral), and singleton type (colour, orientation), which were varied orthogonally. The target singleton feature either was repeated across all trials in a block (feature condition) or varied from trial to trial (mixed condition) as in the previous experiments.
The feature condition consisted of eight blocks of 60 trials, comprising four blocks for each singleton target type (colour and orientation). Table 5 displays the target–distractor pairings for each block. Within each block there were 30 trials per response type. For the 30 target-present trials, 5 of the trials were validly cued (with each display location being cued at least once), 15 were invalidly cued (with each location being cued at least three times), and 10 were neutral trials. The occurrence of the different types of cued trial was random within the block. The mixed condition contained 10 blocks of 48 trials each (24 per response type), with the type of singleton feature varying across trials between the four types of target–distractor pairs listed in Table 5. These blocks also maintained the 25% cue validity for target-present trials. The 24 target-present trials in each block contained 4 validly cued trials (1 per display location), 12 invalidly cued trials (3 per display location), and 8 neutral trials. The singleton features were also counterbalanced within blocks (though not independently of cue type). Thus, across the 10 blocks in the mixed condition, there was the same representation of target features as in the feature condition, for each of the colour and orientation singletons, on the target-present trials. Similarly, for the target-absent trials, across the 10 mixed blocks there was a total of 80 invalidly cued and 40 neutral trials per singleton dimension. Two types of mixed blocks were created, each using two display types from the colour and orientation features (see Table 5). The order in which the eight colour and orientation feature condition blocks were presented followed an “ABBA” design with mixed blocks positioned in between each feature block. Two slightly different order variations were used as a counterbalancing measure across participants.
TABLE 5.
Target-distractor pairs during feature and mixed search for each target type by block in Experiment 3
| Block | Search | Target-distractor pairs | |
|---|---|---|---|
| 1 | Mixed | RV–RH, GH–GV, RH–GH, GV–RV | |
| 2 | Mixed | GV–GH, RH–RV, GH–RH, RV–GV | |
| Colour | Orientation | ||
| 1 | Feature | RV–GV | RV–RH |
| 2 | Feature | RH–GH | RH–RV |
| 3 | Feature | GV–RV | GV–GH |
| 4 | Feature | GH–RH | GH–GV |
Note: Letter pairs represent display features, as described in the legend to Table 2. Each mixed block was repeated five times.
Procedure
Practice trials and instructions for the mixed and feature blocks were similar to those in the previous experiments. Further, participants were explicitly instructed that the spatial cue only predicted the target position at chance levels and that they should try to ignore the cue as best they could. All trials began with a 500-ms blank screen. The spatial cue was then presented for 100 ms, followed by a 50-ms blank screen, after which the search display was presented. The search display was terminated by the participant's response, up to a maximum of 5 s. Auditory and visual feedback were given when an error was made, as in the previous experiments.
Results and discussion
Target-present RT
The means of participants' median RT, for correct responses on target-present trials, are presented in Figure 5. As with the previous two experiments, there were reliable effects of age group, F(1, 46) = 59.16, p < .001 and search condition, F(1, 46) = 259.76, p < .001, representing a 181-ms age-related slowing and 133-ms top–down control effects (i.e., faster responses in the feature condition than in the mixed condition). Several significant effects involving the singleton type variable were also obtained. The singleton type main effect reflected faster responses to colour targets than to orientation targets, F(1, 46) = 120.18, p < .001. The Search Condition × Singleton Type interaction, F(1, 46) = 26.91, p < .001, occurred because although the top–down effect (i.e., RT advantage for the feature condition relative to the mixed condition) was significant for both types of singleton target, the effect was greater in magnitude for colour singletons than for orientation singletons.
Figure 5.

Mean reaction time (+ SE) on target-present trials as a function of cue type, age group, and singleton type in Experiment 3.
An Age Group × Singleton Type interaction, F(1, 46) = 4.13, p < .05, indicated that age differences in RT were more pronounced during the orientation trials than during the colour trials, but were significant for both types of singleton. To determine whether the Age Group × Singleton Type interaction was a generalized age-related slowing effect, we created Brinley plots of younger and older adults' mean RT for each cell mean in the ANOVA design (see Figure 6). We then used the resulting slope and intercept from the linear regression of the target-present task condition means (r2 = .98) to transform younger adults' RTs (Madden, Pierce, & Allen, 1992). Following this transformation, the age interaction was no longer significant, indicating an effect attributable to generalized slowing.
Figure 6.

Brinley plot of task condition mean RTs for each experiment. Data for target-present trials and target-absent trials are presented separately.
The remaining effects all involved cue type, in which RTs were generally lower in response to neutral cues than to both valid and invalid cues, F(2, 92) = 9.17, p < .001. The Singleton Type × Cue Type interaction, F(2, 92) = 10.46, p < .001, occurred because the cueing effects were present only for orientation targets, and this effect was modified further by the three-way interaction of Search Condition × Singleton Type × Cue Type, F(2, 92) = 7.43, p = .001. Although the cueing effect for orientation targets was significant for both search conditions, F(2, 94) > 4.0, p < .05, in each case, the differences among the RT means were more pronounced in the mixed condition than in the feature condition.
An Age Group × Cue Type interaction, F(2, 92) = 4.20, p < .05, occurred because the cueing effect was significant for older adults, F(2, 23) = 8.98, p < .001, but not for younger adults. This latter interaction was further modulated by an Age Group × Singleton Type × Cue Type interaction, F(2, 92) = 4.42, p < .05, that limited the Age × Cue Type effect to the orientation singletons, F(2, 92) = 7.03, p = .001 (see Figure 5). Tests of simple effects revealed that, for orientation targets, the cueing effect was significant within each age group, F(2, 46) > 5.0, p < .01, but the pattern of cueing effects varied with age. For the older adults, RTs for both valid and invalid cues were higher than those for neutral cues, both ts(23) > 2.48, p < .05, whereas for younger adults, RT in response to invalid cues was higher than that for both neutral and valid cues, both ts(23) > 2.48, p < .05, and these latter two conditions did not differ. Further, these age interactions remained significant, with F(2, 92) > 3.39, p < .05, in each case, after the younger adults' RTs were transformed by the Brinley plot function (r2 = .98), to account for linear slowing effects.
Target-absent RT
Overall RTs were the same as those for target-present trials (less than 1 ms difference). Replicating the two previous experiments, responses were faster for younger (549 ms) than for older adults (741 ms), F(1, 46) = 56.5, p < .001, faster during the feature condition (587 ms) than during the mixed (703 ms) condition, F(1, 46) = 281.8, p < .001, and slower for invalidly cued trials (653 ms) than for neutral trials (637 ms), F(1, 46) = 31.3, p < .001. (Note that there are only two possible types of cue for the target-absent data.)
A Search Condition × Cue Type interaction, F(1, 46) = 7.29, p < .01, indicated that although the cueing effect was significant in both search conditions, Fs(1, 47) > 15.0, p < .001, the cueing effect was larger in magnitude during the mixed condition than during the feature condition. An Age Group × Search Condition effect, F(1, 46) = 6.32, p < .05, showed that whereas both younger and older adults responded most rapidly during the feature condition, F(1, 23) > 98.0, p < .001, the effect was larger in magnitude for older adults than for younger adults. When, however, the younger adults' data were transformed by the Brinley plot function for the target-absent mean RTs (r2 = .99), the Age Group × Search Condition interaction was no longer significant.
The results of Experiment 3 support the previous two experiments demonstrating that both younger and older adults are capable of efficiently using top–down processing to guide visual search to the target, in terms of the decrease in RT in the feature condition relative to the mixed condition. Unlike in Experiments 1 and 2, however, an additional task goal was to minimize attentional capture from an irrelevant spatial cue. The effects of spatial cueing on RTs were limited primarily to displays in which targets differed in orientation from distractors, which probably reflects the fact that orientation discrimination is a more spatially dependent process than colour discrimination. Consistent with previous findings with younger adults (Peterson & Kramer, 2001; Theeuwes & Burger, 1998), the Search Condition × Singleton Type × Cue Type interaction for the target-present trials indicated that this cueing effect was more pronounced in the mixed condition than in the feature condition, confirming our prediction of an ability of top–down control to override attentional capture. The target-absent trials also exhibited greater attentional capture in the mixed condition than in the feature condition. Both Experiments 2 and 3 demonstrate that, for both younger and older adults, top–down and bottom–up processes have an interactive role in aiding target detection even when search is highly efficient.
Averaged across the search conditions, the presence of spatial cues overall had a greater impact on RT for older adults than for younger adults. In particular, for orientation targets, both valid and invalid cues disrupted older adults' search performance relative to the neutral cue condition. For the younger adults, in contrast, only the invalid cues led to a significant increase in RT. This Age Group × Singleton Type × Cue Type interaction in addition survived the transformation controlling for a generalized slowing effect. These results are consistent with findings by Pratt and Bellomo (1999) and Kramer et al. (2000) indicating that under some conditions older adults are more vulnerable to attentional capture than are younger adults. This form of attentional capture is involuntary in that participants are not capable of ignoring the cue even though they know that it is noninformative, but the age difference is independent of the top–down versus bottom–up dimension defined by the difference between the mixed and feature conditions. It would be important to determine whether other forms of top–down control would be able to eliminate entirely the age-related increase in attentional capture expressed in the cueing effects.
GENERAL DISCUSSION
Top–down guidance in singleton detection
The primary purpose of these three experiments was to assess younger and older adults' ability to use top–down attentional guidance during highly efficient forms of visual search. We were also interested in potential top–down effects beyond the level of target activation, the potential interaction between top–down and bottom–up attentional mechanisms, and the ability of top–down control to reduce attentional capture. To these ends, we used a singleton detection paradigm (Wolfe et al., 2003) in which a target differed from a set of homogeneous distractors on one feature (colour, size, or orientation). We manipulated the amount of top–down control available during search by varying the consistency of target and distractor features across trials within a block. In this design, the featural composition of individual displays is comparable across conditions, and decreases in RT for the feature conditions (when target and distractor features remain constant) relative to the mixed conditions (when the features vary unpredictably) thus demonstrate the ability of top–down, a priori knowledge to successfully guide attention during search.
Our data are largely consistent with the recent findings of Wolfe et al. (2003), who demonstrated that singleton detection in both the mixed and feature conditions is very efficient, with flat (if not negative) display size slopes. As in the Wolfe et al. experiments, we found in Experiment 1 that top–down knowledge regarding individual target features (e.g., red, small, or horizontal) is capable of leading to further improvement in singleton detection. Our Experiment 1 data also replicate those of Wolfe et al. in demonstrating that attentional guidance does not require a specific feature value and can be effective at a relatively abstract level of feature dimension, such as colour or orientation, although guidance by size was less reliable at this higher level.
The present findings extend those of Wolfe et al. by documenting top–down effects on target-absent trials. Wolfe et al. focused primarily on the process of target detection and did not include detailed analyses of target-absent data. In all three experiments we obtained an RT advantage for feature conditions, relative to mixed conditions, on target-absent trials as well as on target-present trials. Krummenacher et al. (2001) also reported a significant top–down (feature vs. mixed) effect on target-absent trials in singleton detection. Top–down attentional guidance during singleton detection is thus not limited to target identification processes but also includes the decision and selection processes involved in terminating search when a target is not located (Chun & Wolfe, 1996). This type of result does not necessarily imply that the top–down effect is entirely a response-level effect (cf. Cohen & Magen, 1999), but rather that the attentional guidance influences stages beyond the activation of target features, most likely the setting of a response deadline.
Though it is convenient to conceptualize top–down and bottom–up processes as operating in isolation, the present results agree with other data highlighting the interactive nature of these different attentional processes. The frequently observed fact, confirmed by Experiment 1, that some features are more effective than others, as a basis for top–down control, is a simple illustration of the interactive relation between top–down and bottom–up processing. Hodsoll and Humphreys (2001) reported a more elegant exploration of this issue, in which they demonstrated that top–down guidance for a size singleton is more effective when the target is linearly separable from the distractors (e.g., a small circle target among medium and large circle distractors), relative to when the target is not linearly separable (e.g., a medium target among small and large distractors).
Several other findings from the present experiment are relevant to the issue of the interaction of top–down and bottom–up effects. In particular, Experiment 2 indicated that top–down guidance amplified the RT advantage for double-feature targets relative to single-feature targets. To explore this particular finding further it would be useful to increase the number of trials sufficiently to permit analyses of the RT distribution, which would in turn be informative regarding how target dimensions are weighted in the master map of activations (Found & Müller, 1996; Krummenacher et al., 2001, 2002; Müller et al., 1995). The negative slope of the RT × Display Size function in Experiments 1 and 2 is evidence for a specific bottom–up process, the mutual suppression among homogeneous distractors (Duncan & Humphreys, 1989; Kastner & Ungerleider, 2000). This suppression was evident for target-present trials in both Experiments 1 and 2 but only for target-absent trials in Experiment 1, suggesting that additional decision processes associated with search termination (in the absence of target activation) may either obscure or eliminate the bottom–up suppression. Finally, Experiment 3 exhibited another interaction between top–down and bottom–up processing. For orientation targets, noninformative spatial cues led to greater RT costs (attentional capture) during mixed conditions than during feature conditions. These findings confirm that top–down attention can reduce the effects of attentional capture (Peterson & Kramer, 2001; Theeuwes & Burger, 1998).
Effects of age on top–down guidance
In all three of our experiments we found that the RT benefit of top–down processing during the feature condition relative to the mixed condition was similar for both age groups, on both target-present trials and target-absent trials. Thus, in this context of highly efficient search, we find no evidence of an age-related impairment in top–down attentional control, either for target detection or for the decision processes associated with terminating search. In Experiment 1 we found that the ability to use specific target features (colour, size, and orientation) as a basis for top–down attentional control was similar for younger and older adults. The use of a more abstract level of representation for top–down control (the dimension condition in Experiment 1) was also similar for the two age groups. Increasing the amount of bottom–up information via increased target salience (Experiment 2) led to additional improvement in target detection, when top–down processes predominated (feature condition), and this RT benefit was present for both younger and older adults. Though older adults were more vulnerable to attentional capture from a noninformative spatial cue (Experiment 3), this age difference was independent of the reduction in attentional capture associated with the feature condition relative to the mixed condition.
The age constancy in top–down attentional control for this highly efficient (singleton detection) task is consistent with the age-related preservation of top-down effects reported by Humphrey and Kramer (1997) and Madden et al. (1996, 2004) for a less efficient (conjunction search) task. In contrast, both Folk and Lincourt (1996) and Watson and Maylor (2002) concluded that their results were indicative of an age-related decline in top–down attention. One characteristic of both the latter two studies was the use of displays containing moving targets and distractors. It may consequently be some aspect of motion perception that is differentially difficult for older adults (Kramer & Atchley, 2000; Watson & Maylor, 2002). Interestingly, recent evidence has shown fairly robust age-related deficits in priming for motion stimuli (Jiang, Luo, & Parasuraman, 2002) suggesting that top–down control in older adults may be more sensitive to motion-related features than to colour, size, and orientation (but cf. Kramer, Martin-Emerson, Larish, & Andersen, 1996).
As noted in the Introduction, top–down attentional guidance comprises both an explicit component representing the observer's expectations and an implicit component representing the accumulation of priming effects from repeated targets and distractors (Maljkovic & Nakayama, 1994; Wolfe et al., 2003). The present experiments were concerned primarily with explicit top–down control and were not designed to address the priming issue. Post hoc analyses of priming effects across pairs of adjacent trials in Experiment 1 did not reveal a substantial effect of repetition priming.3 In other contexts, changes in choice RT associated with repetition priming appear to be largely similar for younger and older adults (Howard & Howard, 1992; Schmitter-Edgecombe & Nissley, 2002). Whether the specific form of implicit top–down control supporting singleton detection varies with age is unknown, but it appears that, at minimum, there is a considerable degree of preservation of top–down attentional guidance during later adulthood. Given that incoming “featural” signals experience decay with age for virtually all of the senses (Madden & Whiting, 2004; Schneider & Pichora-Fuller, 2000), any mechanism that could compensate for such declines would presumably be of considerable benefit in maintaining cognitive performance. The flexibility of knowledge-driven (top–down) processes thus may aide bottom–up processes that rely exclusively on a declining and less flexible sensory system.
Our conclusion that top–down attentional guidance is preserved for older adults is to some extent dependent on the absence of an effect (an age group difference), even though we demonstrated the presence of significant differences between the feature and mixed conditions within each age group. We acknowledge that age differences in top–down control during visual search may exist but were not detected due to lack of statistical power. To investigate this possibility, we conducted post hoc power analyses to calculate the number of participants required to detect the Age × Search condition interaction in Experiment 1, which represented the test of age differences in the use of top–down control during search. The calculated effect size f (Cohen, 1988) of our Age × Search Condition effect was 0.03, indicating a very small effect. Given our alpha level of .05 and numerator df = 2, over 1,000 participants in each age group would be necessary to detect this interaction with a power of 0.80. The lack of age effects in this study thus appear to be more the result of very small effects rather than small sample sizes.
In conclusion, across three experiments we consistently found evidence for an age-related preservation of top–down guidance during visual search. Specifically, when top–down control was made available, both younger and older adults showed similar reductions in RT relative to conditions in which search was driven instead by bottom–up processes (Experiment 1). Furthermore, increasing bottom–up saliency between targets and distractors (Experiment 2) further reduced RTs for both age groups when top–down control was engaged. Similarly, including an irrelevant onset cue that induced involuntary attentional capture (Experiment 3), did result in larger capture effects during mixed conditions (relative to feature conditions) for orientation targets. Although older adults were more vulnerable overall to this attentional capture effect, the top–down reduction in the capture effect in the feature condition did not vary with age. The results not only demonstrate a form of top–down attentional control that is preserved with age, they also underscore that top–down and bottom–up search processes operate interactively rather than independently. Singleton detection is a highly efficient form of search, however, and in further research it will be important to determine whether increasing particular types of task demands lead to age-related changes in top–down attentional guidance.
Footnotes
We refer to these conditions as feature, dimension, and mixed to characterize the different types of information available for attentional guidance. It is important to note that all three task conditions are a form of feature search, in which the target differs from the distractors on a single feature.
Colour was not relevant in this task. To maintain similarity to the size and orientation singletons in Experiment 1, all of the items in each display were the same colour, either red or green, and display colour was alternated randomly across trials within each trial block.
Details of these analyses are available from the corresponding author.
This research was supported by grants R37 AG02163 and T32 000029 from the National Institute on Aging. We are grateful to Susanne M. Harris, Sara Moore, Niko Harlan, and Leslie Crandell Dawes for technical assistance. Barbara Bucur and Julia Spaniol provided helpful comments on a draft of this article.
REFERENCES
- Bravo MJ, Nakayama K. The role of attention in different visual search tasks. Perception & Psychophysics. 1992;51:465–472. doi: 10.3758/bf03211642. [DOI] [PubMed] [Google Scholar]
- Chun MM, Wolfe JM. Just say no: How are visual searches terminated when there is no target present? Cognitive Psychology. 1996;30:39–78. doi: 10.1006/cogp.1996.0002. [DOI] [PubMed] [Google Scholar]
- Cohen A, Magen H. Intra- and cross-dimensional visual search for single-feature targets. Perception & Psychophysics. 1999;61:291–307. doi: 10.3758/bf03206889. [DOI] [PubMed] [Google Scholar]
- Cohen J. Statistical power analyses for the behavioral sciences. 2nd ed. Lawrence Erlbaum Associates, Inc.; Hillsdale, NJ: 1988. [Google Scholar]
- Colcombe AM, Kramer AF, Irwin DE, Peterson MS, Colcombe S, Hahn S. Age-related effects of attentional and oculomotor capture by onsets and color singletons as a function of experience. Acta Psychologica. 2003;113:205–225. doi: 10.1016/s0001-6918(03)00019-2. [DOI] [PubMed] [Google Scholar]
- Duncan J, Humphreys GW. Visual search and stimulus similarity. Psychological Review. 1989;96:433–458. doi: 10.1037/0033-295x.96.3.433. [DOI] [PubMed] [Google Scholar]
- Folk CL, Lincourt AE. The effects of age on guided conjunction search. Experimental Aging Research. 1996;22:99–118. doi: 10.1080/03610739608254000. [DOI] [PubMed] [Google Scholar]
- Found AP, Müller HJ. Searching for unknown feature targets on more than one dimension: Investigating a “dimension-weighting” account. Perception & Psychophysics. 1996;58:88–101. doi: 10.3758/bf03205479. [DOI] [PubMed] [Google Scholar]
- Hodsoll J, Humphreys GW. Driving attention with the top down: The relative contribution of target templates to the linear separability effect in the size dimension. Perception & Psychophysics. 2001;63:918–926. doi: 10.3758/bf03194447. [DOI] [PubMed] [Google Scholar]
- Howard DV, Howard JH. Adult age differences in the rate of learning serial patterns: Evidence from direct and indirect tests. Psychology and Aging. 1992;7:2–241. doi: 10.1037//0882-7974.7.2.232. [DOI] [PubMed] [Google Scholar]
- Humphrey DG, Kramer AF. Age differences in visual search for feature, conjunction, and triple-conjunction targets. Psychology and Aging. 1997;12:704–717. doi: 10.1037//0882-7974.12.4.704. [DOI] [PubMed] [Google Scholar]
- Jiang Y, Luo Y-J, Parasuraman R. Priming of two-dimensional visual motion is reduced in older adults. Neuropsychology. 2002;16:140–145. doi: 10.1037//0894-4105.16.2.140. [DOI] [PubMed] [Google Scholar]
- Kastner S, Ungerleider LG. Mechanisms of visual attention in the human cortex. Annual Review of Neuroscience. 2000;23:315–341. doi: 10.1146/annurev.neuro.23.1.315. [DOI] [PubMed] [Google Scholar]
- Kramer AF, Atchley P. Age-related effects in the marking of old objects in visual search. Psychology and Aging. 2000;15:286–296. doi: 10.1037//0882-7974.15.2.286. [DOI] [PubMed] [Google Scholar]
- Kramer AF, Hahn S, Irwin DE, Theeuwes J. Age differences in the control of looking behavior: Do you know where your eyes have been? Psychological Science. 2000;11:210–217. doi: 10.1111/1467-9280.00243. [DOI] [PubMed] [Google Scholar]
- Kramer AF, Martin-Emerson R, Larish JF, Andersen GJ. Aging and filtering by movement in visual search. Journal of Gerontology: Psychological Sciences. 1996;51B:P201–P216. doi: 10.1093/geronb/51b.4.p201. [DOI] [PubMed] [Google Scholar]
- Krummenacher J, Müller HJ, Heller D. Visual search for dimensionally redundant pop-out targets: Evidence for parallel-coactive processing of dimensions. Perception & Psychophysics. 2001;63:901–917. doi: 10.3758/bf03194446. [DOI] [PubMed] [Google Scholar]
- Krummenacher J, Müller HJ, Heller D. Visual search for dimensionally redundant pop-out targets: Parallel-coactive processing of dimensions is location specific. Journal of Experimental Psychology: Human Perception and Performance. 2002;28:1303–1322. [PubMed] [Google Scholar]
- Logan GD. Cumulative progress in formal theories of attention. Annual Review of Psychology. 2004;55:207–234. doi: 10.1146/annurev.psych.55.090902.141415. [DOI] [PubMed] [Google Scholar]
- Madden DJ, Pierce TW, Allen PA. Adult age differences in attentional allocation during memory search. Psychology and Aging. 1992;7:594–601. doi: 10.1037//0882-7974.7.4.594. [DOI] [PubMed] [Google Scholar]
- Madden DJ, Pierce TW, Allen PA. Adult age differences in the use of distractor homogeneity during visual search. Psychology and Aging. 1996;11:454–474. doi: 10.1037//0882-7974.11.3.454. [DOI] [PubMed] [Google Scholar]
- Madden DJ, Plude DJ. Selective preservation of selective attention. In: Cerella J, Rybash J, Hoyer W, Commons ML, editors. Adult information processing: Limits on loss. Academic Press; San Diego: 1993. pp. 273–300. [Google Scholar]
- Madden DJ, Whiting WL. Age-related changes in visual attention. In: Costa PT, Siegler IC, editors. Recent advances in psychology and aging. Elsevier; Amsterdam: 2004. pp. 41–88. [Google Scholar]
- Madden DJ, Whiting WL, Cabeza R, Huettel SA. Age-related preservation of top-down attentional guidance during visual search. Psychology and Aging. 2004;19:304–309. doi: 10.1037/0882-7974.19.2.304. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maljkovic V, Nakayama K. Priming of pop-out: I. Role of features. Memory & Cognition. 1994;22:657–672. doi: 10.3758/bf03209251. [DOI] [PubMed] [Google Scholar]
- McDowd JM, Shaw RJ. Attention and aging: A functional perspective. In: Craik FIM, Salthouse TA, editors. Handbook of aging and cognition. 2nd ed. Lawrence Erlbaum Associates, Inc.; Mahwah, NJ: 2000. pp. 221–292. [Google Scholar]
- Miller J. Divided attention: Evidence for coactivation with redundant signals. Cognitive Psychology. 1982;14:247–279. doi: 10.1016/0010-0285(82)90010-x. [DOI] [PubMed] [Google Scholar]
- Müller HJ, Heller D, Ziegler J. Visual search for singleton feature targets within and across feature dimensions. Perception & Psychophysics. 1995;57:1–17. doi: 10.3758/bf03211845. [DOI] [PubMed] [Google Scholar]
- Peterson MS, Kramer AF. Contextual cueing reduces interference from task-irrelevant onset dis-tractors. Visual Cognition. 2001;8:843–859. [Google Scholar]
- Pratt J, Bellomo CN. Attentional capture in younger and older adults. Aging, Neuropsychology, and Cognition. 1999;6:19–31. [Google Scholar]
- Quinlan PT. Visual feature integration theory: Past, present, and future. Psychological Bulletin. 2003;129:643–673. doi: 10.1037/0033-2909.129.5.643. [DOI] [PubMed] [Google Scholar]
- Salthouse TA. What do adult age differences in the digit symbol substitution test reflect? Journal of Gerontology: Psychological Sciences. 1992;47:P121–P128. doi: 10.1093/geronj/47.3.p121. [DOI] [PubMed] [Google Scholar]
- Salthouse TA. Speed and knowledge as determinants of adult age differences in verbal tasks. Journal of Gerontology: Psychological Sciences. 1993;48:P29–36. doi: 10.1093/geronj/48.1.p29. [DOI] [PubMed] [Google Scholar]
- Schmitter-Edgecombe M, Nissley HM. Effects of aging on implicit covariation learning. Aging, Neuropsychology, and Cognition. 2002;9:61–75. [Google Scholar]
- Schneider BA, Pichora-Fuller MK. Implication of perceptual deterioration for cognitive aging research. In: Craik FIM, Salthouse TA, editors. The handbook of aging and cognition. 2nd ed. Lawrence Erlbaum Associates, Inc.; Mahwah, NJ: 2000. pp. 155–219. [Google Scholar]
- Theeuwes J. Perceptual selectivity for color and form. Perception & Psychophysics. 1992;51:599–606. doi: 10.3758/bf03211656. [DOI] [PubMed] [Google Scholar]
- Theeuwes J, Burger R. Attentional control during visual search: The effect of irrelevant singletons. Journal of Experimental Psychology: Human Perception and Performance. 1998;24:1342–1353. doi: 10.1037//0096-1523.24.5.1342. [DOI] [PubMed] [Google Scholar]
- Treisman A. Features and objects: The fourteenth Bartlett memorial lecture. Quarterly Journal of Experimental Psychology. 1988;40A:201–237. doi: 10.1080/02724988843000104. [DOI] [PubMed] [Google Scholar]
- Watson DG, Maylor EA. Aging and visual marking: Selective deficits for moving stimuli. Psychology and Aging. 2002;17:321–339. [PubMed] [Google Scholar]
- Wolfe JM. Guided search 2.0: A revised model of visual search. Psychonomic Bulletin & Review. 1994;1:202–238. doi: 10.3758/BF03200774. [DOI] [PubMed] [Google Scholar]
- Wolfe JM. Visual search. In: Pashler HA, editor. Attention. Psychology Press; Hove, UK: 1998. pp. 13–73. [Google Scholar]
- Wolfe JM. Moving towards solutions to some enduring controversies in visual search. Trends in Cognitive Sciences. 2003;7:70–76. doi: 10.1016/s1364-6613(02)00024-4. [DOI] [PubMed] [Google Scholar]
- Wolfe JM, Butcher SJ, Lee C, Hyle M. Changing your mind: On the contributions of top-down and bottom-up guidance in visual search for feature singletons. Journal of Experimental Psychology: Human Perception and Performance. 2003;29:483–502. doi: 10.1037/0096-1523.29.2.483. [DOI] [PubMed] [Google Scholar]
- Yantis S. Control of visual attention. In: Pashler HA, editor. Attention. Psychology Press; Hove, UK: 1998. pp. 223–256. [Google Scholar]