

Abstract
Auditory stream segregation was measured in cochlear implant (CI) listeners using a subjective “Yes-No” task in which listeners indicated whether a sequence of stimuli was perceived as two separate streams or not. Stimuli were brief, 50-ms pulse trains A and B, presented in an A-B-A-A-B-A…sequence, with 50 ms in between consecutive stimuli. All stimuli were carefully loudness-balanced prior to the experiments. The cochlear electrode location of A was fixed, while the location of B was varied systematically. Measures of electrode discrimination and subjective perceptual difference were also included for comparison. There was strong intersubject variation in the pattern of results. One of the participants participated in a second series of experiments, the results of which indicated that he was able to perceptually segregate stimuli that were different in cochlear electrode location, as well as stimuli that were different in temporal envelope. Although preliminary, these results suggest that it is possible for some cochlear implant listeners to perceptually segregate stimuli based on differences in cochlear location as well as temporal envelope.
1. INTRODUCTION
Auditory scene analysis refers to the perceptual process by which a complex auditory scene is analyzed into its different constituent sound sources. One example of this process is observed in “auditory streaming”, in which two concurrent or interleaved sequences of tones are heard as two perceptually separate streams of sounds. These two streams can be attended to individually, one forming the “background” and the other the “foreground” depending on the attentional emphasis (van Noorden, 1975; Bregman, 1990; Carlyon, 2004). Normal-hearing listeners can segregate sounds based on differences in spectrum, complex pitch, and temporal envelope (Vliegen and Oxenham, 1999; Grimault et al., 2000; Grimault et al., 2001; Grimault et al., 2002; Roberts et al., 2002; Moore and Gockel, 2002). Grimault et al. (2001) found that hearing-impaired listeners could stream tonal complexes on the basis of differences in fundamental frequency, as long as the harmonics were resolved. Compared to psychophysical discrimination or detection tasks, streaming seems to involve fairly high-level processes in the brain (i.e., processes requiring more than simple comparisons of individual stimuli in a sequence): there is evidence that it takes time to build (a few seconds) and is somewhat dependent upon attention (Cusack et al., 2004; Carlyon, 2004). Recent work with auditory event-related potentials suggests that the actual process of segregation of the sounds may not require attention, but the process of building up the streaming percept does (Snyder et al., 2006).
It is known that cochlear implant (CI) listeners have particular difficulty in understanding speech in the presence of background noise or competing speech. Work by Mackersie (2003) suggests that measures of stream segregation by hearing-impaired listeners are related to their ability to perceptually separate competing, concurrent sentences spoken by talkers of different genders. It is of considerable interest, therefore, to discover whether CI listeners are capable of stream segregation. Recent work by Hong and Turner (2006) suggests that some CI listeners are able to perceptually segregate sequences of acoustic tones when listening through their speech processors. In addition, they found moderate, but significant, correlations between measures of perceptual segregation and the ability to hear speech in background noise or in competing babble. As Hong and Turner’s experiments were conducted using acoustic stimuli presented to the listener’s speech processor, the results are informative about CI users’ performance in the real world. However, the large individual variation in CI users’ speech processing strategies and processor parameters, makes stimulus control difficult in such experiments: hence, the results do not provide sufficient insight into fundamental mechanisms. Despite the potential limitations, Hong and Turner’s work clearly showed a connection between streaming and the ability to understand speech in competing noise.
Preliminary experiments in our laboratory with three CI listeners attending to sequences of loudness-balanced pulse trains showed evidence for build-up of streaming, as well as the expected dependence of streaming on inter-stimulus interval (Chatterjee and Galvin, 2002). One of the three subjects was musically trained, and had no difficulty with any of the streaming tasks in the study. The other two listeners had no musical training, but one of them reported a “normal” streaming percept (including spontaneous perceptual switching of individual streams between background and foreground, duplex percepts of perceptually fusion and segregation, build-up of streaming with duration of the sequence, etc.). Listeners were able to stream stimuli based on differences between their cochlear location or temporal envelope.
Here, we report on a study of subjective stream segregation compared against a discrimination measure in five CI listeners. Our preliminary studies indicated that, as in normal hearing listeners, CI listeners are able to use loudness differences between stimuli to perceptually segregate sequences of stimuli. Therefore, all stimuli were presented through a research interface and were carefully loudness-balanced. The listeners were required to indicate whether a sequence of stimuli appeared to separate into two perceptual streams in a Yes-No task. The sequences consisted of two pulse trains, A and B, which were different in cochlear location. The duration of the sequences was varied in order to measure build-up of streaming. Only one of the five listeners showed build-up of streaming with the sequence durations used in these experiments. This listener had also participated in the earlier experiments described above. Further experiments with this listener showed similar effects when the stimuli were identical in cochlear electrode location but different in temporal envelope.
2. METHODS
2.1 Stimuli and loudness-balancing
All stimuli were presented through a custom-built research interface (House Ear Institute Nucleus Research Interface: Shannon et al., 1990; Robert, 2002). In this device, there are 22 intracochlear electrodes that are always stimulated in bipolar mode (i.e., active and return electrodes are both intracochlear). Electrode numbering starts at the base (i.e., lower numbers correspond to higher frequency regions according to normal tonotopic representation). Stimuli were 50-ms trains of 200 μs/phase biphasic pulses presented at 500 pulses/second. Two experiments were conducted. In both experiments, two such 50-ms bursts (A and B) were presented in alternating sequences of varying duration. The inter-burst interval was always 50 ms. The reference burst is referred to as A, and the comparison burst as B. The sequence consisted of repeated presentations of A_B_A (the number of stimuli varied with the sequence duration). Note that the duration between the A_B_A triplets was identical to the duration between consecutive bursts. This temporal arrangement was selected as it produced strong perceptual segregation when the authors listened to similar acoustic sequences of tones. When A and B are close together in pitch, the sequence sounds like an up-down melodic pattern: as their frequencies become more disparate, streaming becomes stronger and two perceptually distinct patterns emerge, one with the rhythm A-A---A-A---A-A… and the other with the rhythm B-----B-----B-----.
In Experiment 1, stimulus A was fixed in cochlear electrode location (the centrally located electrode pair (10, 13)) and presented at a comfortable listening level for all listeners except for S1, who had apical electrodes inactivated: in her case, A was presented to electrode pair (8, 10). Stimulus B was presented to different electrode pairs along the array (always using the same stimulation mode as for A) and always loudness-balanced to A. For stimulus A presented to electrode pair (10, 13), stimulus B was presented to one of the following electrode pairs: (2, 5), (4, 7), (6, 9), (7, 10), (8, 11), (9, 12), (10, 13), (11, 14), (12, 15), (13, 16), (14, 17), (16, 19) and (18, 21). For listener S1, stimulus B was presented to one of the following electrode pairs: (2, 4), (4, 6), (6, 8), (7, 9), (8, 10), (9, 11), (10, 12) and (12, 14). The selection of electrode locations for stimulus B ensured that the measure of selectivity incorporated the maximum spatial resolution allowed by the device in the immediate neighborhood of stimulus A. The stimulation mode that would yield the narrowest electrical field (greatest spatial resolution) possible without resulting in an excessively shallow loudness growth function (Chatterjee, 1999), was selected for each participant.
Loudness balancing was achieved using a double-staircase, two-alternative forced choice, 2-down, 1-up (descending track) or 2-up, 1-down (ascending track) adaptive method (Jesteadt, 1980; Zeng and Turner, 1991). In this procedure, the listener indicates which of two presented stimuli sounds louder. Randomly, one of the two intervals contains the reference stimulus and the other contains the experimental stimulus (i.e., the stimulus being balanced to the reference). The current level of the experimental stimulus is adaptively varied during the run. Each run consists of two interleaved tracks: in the descending track, the experimental stimulus starts out at a level estimated to be louder than the reference, while in the other, the experimental stimulus starts out at a level estimated to be softer than the reference. When the descending track converges, the experimental stimulus is judged louder than the reference 70.7% of the time. When the ascending track converges, the experimental stimulus is judged louder than the reference 29.3% of the time. The mean of the two final levels is calculated as the loudness balanced level. In the specific procedure used in these experiments, a track was considered complete after a minimum of 10 reversals, or a maximum of 12 reversals, was achieved. The initial (first four reversals) and final step sizes were 1 and 0.5 dB respectively. The first four reversal points were discarded, and the final 6 to 8 reversals were used to compute the mean amplitude for the track.
Only one listener (S5) participated in Experiment 2. In this experiment, the stimuli A and B were presented to the same electrode pair: stimulus A was sinusoidally amplitude-modulated at a fixed rate (100 Hz) and B was modulated at varying rates. The modulation depths of A and B were identical and fixed at either 20% or 40%; both depths were very salient for the listener, whose modulation detection thresholds at these modulation rates and this current level fell between 0.3% and 2%. The 100-Hz modulated signal in each case was loudness-balanced to an unmodulated pulse train at a comfortable listening level. This loudness-balanced level was used for all the other modulated signals. The loudness did not change across the different modulation rates: the listener confirmed this when the stimuli were presented to him in succession. In experiment 2, for all loudness-balancing measures, the mean of three repetitions of the double-staircase procedure was taken as the final loudness-balanced current level. Particular care was taken in this case because cochlear implant listeners tend to be more sensitive to loudness differences between stimuli on the same electrode pair (same sound quality).
The duration of the A-B-A-A-B-A… pattern was a parameter of interest. In Experiment 1, the durations were 1.2 s., 1.8 s., 2.7 s., and 3.9 s. Only S5 was able to complete the entire set with all four durations. In Experiment 2, the durations were 0.9 s., 1.8 s., 2.7 s., and 3.9 s. When the duration of the sequence varied, the interstimulus duration remained constant at 50 ms: thus, the total number of stimuli within the sequence varied with the sequence duration.
2.2 Procedures
a. Streaming
Listeners were presented with varying durations of the A-B-A-A-B-A-A-B-A… sequence. When the sequence ended, they responded to the question “Did you hear two separate streams?” by pressing a “Yes” or “No” button on the computer screen. In Experiment 1, each sequence was presented 20 – 120 times, depending upon the individual participant’s availability. On average, listeners S1, S2, S3, S4 and S5 heard 3.85, 2.03, 2.05, 2.95, and 5.15 repetitions of the 20 trials of each condition, respectively. We note here that no learning or training effects were observed with increasing number of repetitions. All presentations were randomized within blocks of 20 trials. In Experiment 2 (in which only listener S5 participated), each sequence was presented 100 times. The sequences were randomized within blocks, and presented in blocks of 10 trials. In the case of the shortest sequence in Experiment 2 (900 ms), the number of presentations was truncated at 60 when it was observed that the listener responded “No” 100% of the time.
Prior to data collection, the concept of streaming was explained to each listener with the help of visual aids. They were instructed to respond “Yes” only when they heard out the “A-A---A-A---A-A…” and/or the “B-----B-----B…” sequences individually, as if one were in the foreground and the other in the background. Listeners were informed that sometimes, they might hear the A-B-A sequence as integrated in the beginning of a sequence, and that it might (or might not) separate out perceptually toward the end of the sequence. They were also specifically instructed that if they heard an up-down pitch sequence (A-B-A) throughout the duration of the sequence, they should consider the sequence to be a single stream. For each A, there was one condition in which B was identical to A: listeners were informed of this, and generally judged such sequences to be a single stream.
b. Discrimination measure
Listeners were presented with only one triplet of the sequence (A-B-A) and asked whether the sound was changing within the sequence. They were asked to listen for any changes in the sound quality of the middle sound, and were told that the change could be in pitch or timbre or other tonal quality. They responded by pressing a “Yes’ or “No” button on the computer screen. The percentage of time the listener responded “Yes” to a particular sequence was recorded. A minimum of 20 presentations was completed for each comparison. This was repeated for each combination of stimulus A and stimulus B used in these experiments, including the conditions in which A and B were identical. Stimuli were randomized within blocks. Listeners had little difficulty performing this task.
c. Measure of Perceptual Difference
Listeners were presented with stimuli A and B and asked to rate the perceptual magnitude of the difference between them on a scale of 0 to 100. For each rating, the stimuli were presented with a 200-ms interstimulus interval, and each pair was presented 5 times, with 400 ms in-between presentations. This process was repeated 1 – 4 times for each condition, as time permitted, and the mean of the ratings taken as the final rating: the number of runs is indicated in each panel of Fig 1.
Fig 1.
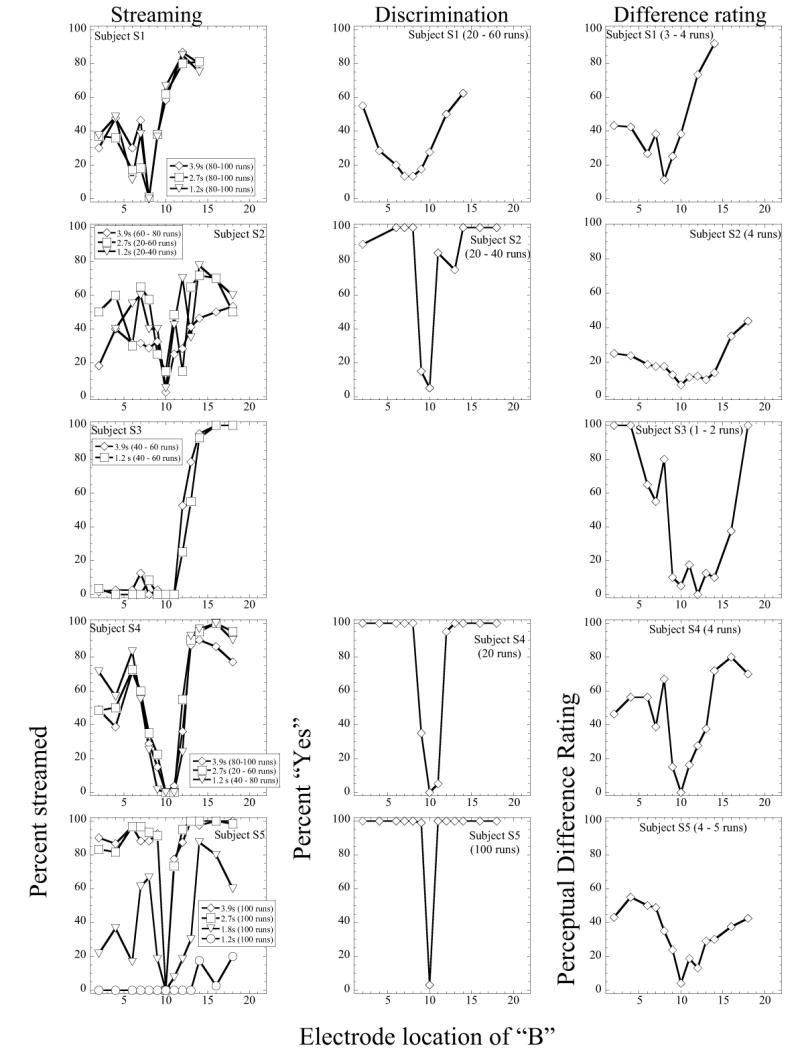
Results obtained with five listeners in Experiment 1. The left-hand column shows results obtained with streaming (the parameter is sequence duration). The middle column shows results obtained in the single-pattern discrimination measure. The right-hand column shows results obtained in the perceptual difference rating measure. The electrode pair for stimulus A was (10, 13) for each listener, with the exception of listener S1, for whom A was presented to (8, 10). The downward-pointing arrow indicates the location of A. The legend indicates the number of runs completed in each case.
2.3 Participants
Seven listeners were originally recruited to participate in the experiments. Owing to time constraints, two of them were not able to complete the minimum required set of tasks and tasks/data for them are not included in this report. Relevant information about the remaining five listeners is provided in Table I. All were post-lingually deaf adult users of the Nucleus-22 or Nucleus-24 device. Both devices consist of 22 intra-cochlear electrodes: the N-24 has 2 extra-cochlear ground contacts and can be stimulated in monopolar mode. However, for the purposes of this experiment, all stimuli were presented in bipolar mode for all listeners.
Table I. Relevant participant information.
Vowel tests were performed using materials from the Hillenbrand et al. (1995) vowel set (12 vowels, 5 male and 5 female speakers). Consonant tests were performed using materials from the Shannon et al. (1999) consonant set (20 consonants, 5 male and 5 female speakers).
| Listener | Age | Gender | Years of implant experience | Device | Vowels (% correct) | Consonsants (% correct) |
|---|---|---|---|---|---|---|
| S1 | 76 | F | 11 | N-22 | 38.3 | 52 |
| S2 | 63 | M | 10 | N-22 | 63 | 69 |
| S3 | 57 | F | 13 | N-24 | 59.6 | 63 |
| S4 | 53 | M | 10 | N-22 | 68.3 | 79.5 |
| S5 | 47 | M | 12 | N-22 | 85 | 80 |
3. RESULTS
3.1 Experiment 1: streaming stimuli presented to different electrode locations
The five rows of Figure 1 show initial results obtained with the five listeners in Experiment 1. The left-hand panels show results obtained in the streaming experiment. In this case, stimulus A was presented to electrode pair (10, 13) [with the exception of Listener S1, in whose case stimulus A was presented to electrode pair (8, 10)] and stimulus B was varied in location. The figures show the percentage of times the sequence was reported being heard as two streams, as a function of the electrode location of stimulus B. The parameter in each case is the duration of the sequence. Results obtained with the discrimination measure are shown in the middle column. Owing to time constraints, we were unable to obtain this measure in listener S3. The perceptual difference ratings were obtained in all listeners. These are shown in the right-hand panels.
The results shown in the middle and right-hand panels indicate that all five listeners were able to discriminate between electrode A and the remaining electrodes. Listeners S2, S4 and S5 showed fairly sharp tuning and excellent performance in the electrode discrimination measure. Listener S1 did not perform as well in this measure: the tuning curve was broader and performance did not exceed 60% correct. The perceptual difference rating, although a rough measure, suggests that the listeners found the stimuli A and B to be different in most instances. Listener S2 did not rate the differences as very high, although his electrode discrimination was very good. This is also true for listener S5.
The results obtained in the streaming experiment (left-hand panels) show that listeners responded “Yes” in the task in most cases. There was some intersubject variation in the pattern of results. Thus, while S1, S2, S4 and S5 gave increasing proportions of “Yes” responses when B was moved away from A in either the apical or basal direction, listener S3 showed an asymmetric response, with almost no reported streaming on the basal side of A. Additionally, while listeners S1 – S4 showed no evidence of build-up of streaming from the 1.2 – 3.9s long stimuli, listener S5 showed an obvious build-up effect. Based on his own subjective reports, this listener appeared to experience the streaming percept in the “normal” manner. This listener had also participated in the previous study (Chatterjee and Galvin, 2002). Listener S3 presents an interesting case: she was able to discriminate between these electrodes well: however, she appeared not to stream the basal electrodes from electrode A. This would suggest that she was not simply using pitch differences as the primary cue in this task. Listener S4, who showed no build-up in these experiments, had also participated in the previous study by Chatterjee and Galvin (2002). In that study, this listener had shown build-up of streaming using similar durations of the sequence. However, in the present study, build-up was absent. It is possible that his previous experience with similar stimuli played a role in these results.
While the presence of build-up in S5 indicates that he was indeed streaming, the absence of build-up in the remaining listeners does not necessarily mean that streaming did not occur: for instance, despite the instructions, the listeners may have based their judgment on the pitch/quality differences between stimuli instead of attending to whether streaming was occurring or not. On the other hand, it is also possible that when the stimuli were highly discriminable, streaming always occurred, even at the shortest durations, for these listeners. Note that the rapid repetition rate of the stimuli was selected because it elicits strong streaming percepts.
At this point, we cannot easily explain the inter-subject variability seen in the pattern of results. We note here that in terms of speech recognition, S5 is the best performer of the group with his device: however, it is not clear how this would explain the results obtained in the present experiments. The remainder of the Results section will focus on further experiments conducted with listener S5.
The three panels in Figure 2 show the complete set of results obtained in Experiment 1 with listener S5. As in the left-hand panels of Figure 1, plots are in the form of percent streaming plotted as a function of the electrode location of B. The location of A (shown by the downward-facing arrow) was apical (16,19), middle (10, 13), or basal (4, 7) in the cochlea. The parameter was the duration of the entire sequence. The open circles plot results obtained in the discrimination experiment, in which the A-B-A sequence was presented as a single triplet. Recall that all stimuli were loudness-balanced to the reference A, which was presented at a comfortable listening level. It is apparent that for this listener, the two longest sequences (2.7 and 3.9 seconds) resulted in relatively strong streaming. As the duration of the sequence was decreased to 1.2 seconds, percent streaming decreased to nearly zero. The variability of responses also increased somewhat when the sequence duration was shortened. For the longer sequences, streaming appeared to be limited only by the ability to discriminate the electrodes.
Fig. 2.
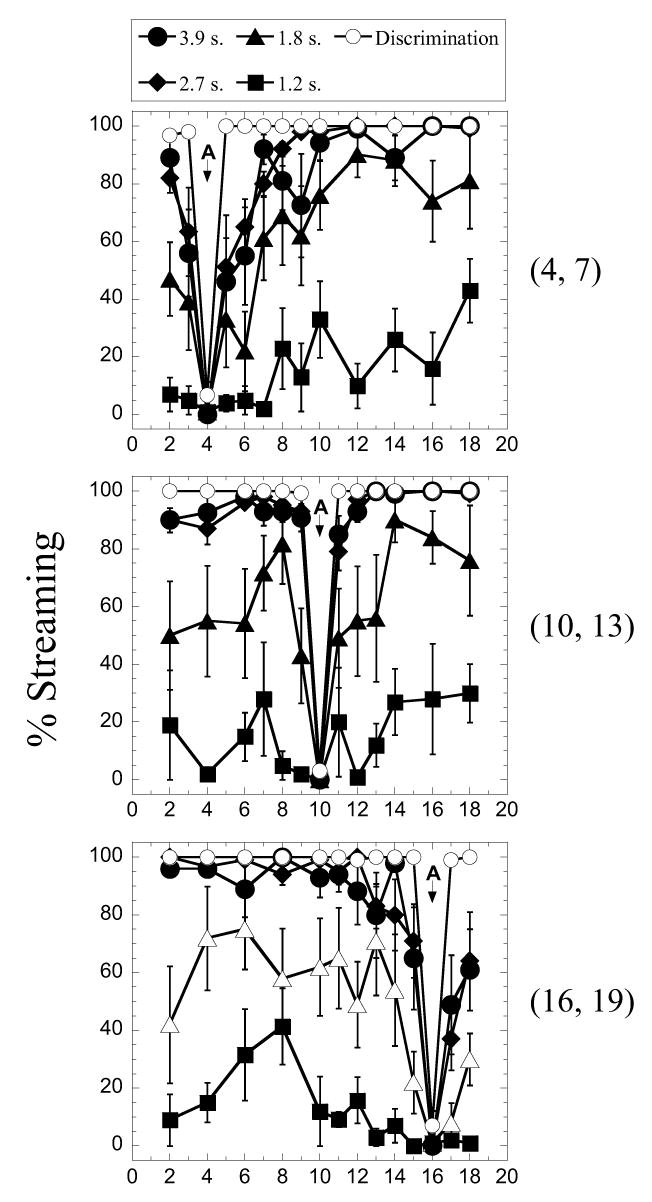
Percent “Yes” reported by S5 plotted as a function of the electrode location of stimulus B (see text for details). Each panel shows results obtained with a different reference location of stimulus A (downward-pointing arrow and legend to the right). Within each panel, the parameter is the pattern duration. The condition labeled “Discrimination” corresponds to the presentation of a single sequence of A_B_A (see text for details). Error bars show +/− one standard error.
3.2 Experiment 2: streaming stimuli that are temporally different
Figures 3A and 3B show results obtained in Experiment 2 with the listener S5. Recall that n this case, A and B stimulated the same electrode pair and therefore the same cochlear location, but had different temporal envelopes: A was sinusoidally modulated at 100 Hz, while B was modulated at varying rates. The modulation depths of the stimuli were either 20% (results in Fig. 3a) or 40% (results in Fig. 3b). As in Fig. 1, the parameter is the duration of the sequence. The results show increasing likelihood of streaming as the modulation rate of B departs from the modulation rate of A. These “modulation tuned” functions appear to become steeper as the modulation depth increases.
Fig. 3.
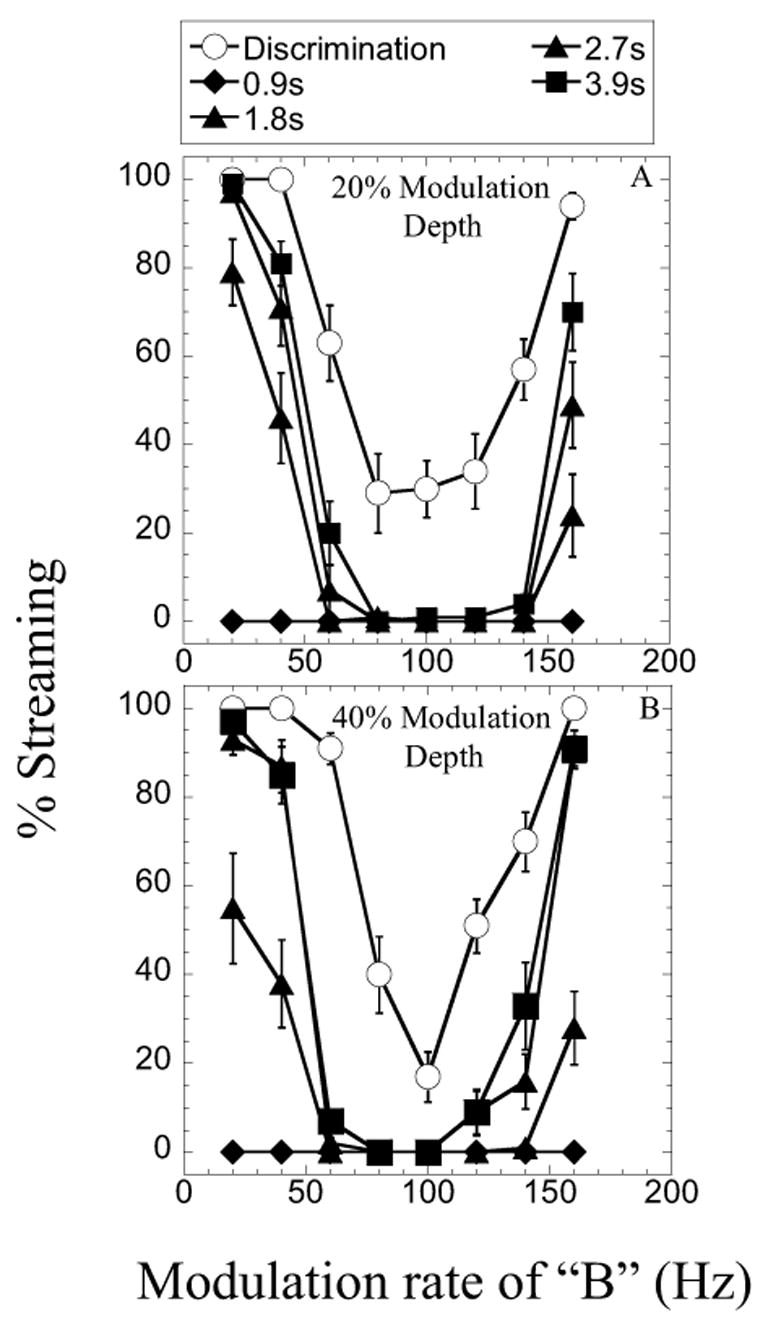
Percent “Yes” reported by S5 plotted as a function of the modulation rate of stimulus B (see text for details). The two panels correspond to the two modulation depths used in this study. Within each panel, the parameter is the pattern duration. Both A and B were presented to the same electrode pair. Error bars show +/− one standard error.
In this experiment, the measure of discrimination using the single-pattern presentation resulted in greater bias than observed when A and B were varied in cochlear location: the listener was more inclined to respond “Yes” when the three stimuli in the single pattern A-B-A were modulated at the same rate. It is possible that this stems from an overall smaller range of perceptual difference between the modulated signals.
4. DISCUSSION
These results indicate that it is possible for the electrically stimulated auditory system to perceptually segregate stimuli based on differences in either cochlear place or temporal envelope. As the experiments in the present study were conducted with a research interface, the frequency analysis of the speech processor was bypassed entirely. Therefore, changing the modulation rate in Experiment 2 should have resulted in only temporal differences between the neural responses evoked by the stimuli A and B respectively. Other investigators have shown that normal hearing and hearing impaired listeners can perceptually segregate stimuli on the basis of difference in temporal cues (Vliegen and Oxenham, 1999; Grimault et al., 2002). This capability may have specific significance for the development of future speech processing strategies for cochlear implant listeners or hearing-impaired listeners, who have limited access to the temporal fine structure of natural acoustic stimuli. Stimuli that might not be separable on the basis of spectral differences may be processed to carry temporal/envelope cues that would perceptually separate them from competing sounds. McKay and Carlyon (1999) have shown that in cochlear implants, the envelope contributes a pitch-related perceptual dimension that is independent of the perceptual dimension of the carrier pulse train. In future speech processor designs, such additional dimensions may be exploited to the listeners’ advantage.
It is not clear from the present results whether listeners S1-S4 were attending to, or perceiving, streaming. These listeners may have been largely attending to differences in pitch, rather than streaming, while performing the task. We note that the listeners were repeatedly reminded of the requirements of the task, and the visual aids were available to them as a reference during the experiment. It is, however, possible that the instructions were not clear enough: if listeners did not know what to listen for, they might have resorted to using the pitch difference as a primary cue. Additionally, we cannot rule out aging as a factor in this experiment: listener S5, who had no difficulty with the task, was the youngest in the group at 47 yrs of age, and the oldest was 76 yrs old: however, Stainsby et al. (2004) found that elderly hearing-impaired listeners show normal auditory streaming. Finally, we note that listener S5 is by far the best performer in the group in both electrode discrimination and speech recognition tasks: it is not clear, however, whether this would directly explain the difference between his pattern of results from those of the remaining listeners.
More objective methods (such as those used by Hong and Turner, 2006, Micheyl et al., 2004, Roberts et al., 2002 or Divenyi et al., 1997) are likely to be more informative in such studies. In addition to the Yes-No task, Chatterjee and Galvin (2002) used a rhythm-matching task. Stimuli were similar to those used in the present experiments: the listeners were given a preview of one of the two rhythms in the sequence (A-A---A-A---A-A… or B-----B-----B…) and asked whether they could hear the previewed rhythm in the actual sequence A-A-B-A-A-B… The A and B stimuli in the preview were different (in electrode position and sometimes in temporal envelope) from the A and B stimuli in the actual listening task. Results obtained with this method were consistent with those obtained with subjective methods. It is possible that a rhythm-matching task of this sort would provide a more objective measure of streaming.
Finally, we note that while experiments investigating stream segregation of relatively simple stimuli such as the ones in the present study are informative about potential processing mechanisms, they may not apply directly to hearing sounds in everyday life. When the stimuli are acoustically more complex, factors such as degraded frequency resolution and the subsequent poorer processing of fundamental frequency information, are likely to limit cochlear implant users’ ability to group and to separate sound sources from one another.
Thus, although several studies (Vliegen and Oxenham, 1999; Grimault et al., 2000; Grimault et al, 2001; Roberts et al., 2002) have shown that normal-hearing listeners are able to stream stimuli based on temporal differences, this capability may not help in separating speech sounds from competing backgrounds in more challenging listening environments. For instance, recent work by Gaudrain et al. (2006) suggests that listeners have difficulty perceptually segregating vowels when listening to spectrally degraded stimuli. This suggests that a strong pitch cue is important in perceptual segregation. The importance of the fundamental frequency is further supported by the work of Qin and Oxenham (2005) indicating that the ability to identify concurrent vowels requires salient, spectral fundamental frequency (F0) cues. Taken together, these studies indicate that listening in noise will remain a significant challenge for cochlear implant listeners until an improved method to deliver F0 cues can be devised.
Acknowledgments
We thank the listeners who participated in these experiments. Mark E. Robert provided software support. Cochlear Corporation is thanked for their help with obtaining the calibration information for each listener’s device. We gratefully acknowledge the comments of Christophe Micheyl and Brian Moore on an earlier version of this manuscript. This work was supported by NIDCD R01 DC04786.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Bregman A. Auditory Scene Analysis. MIT Press; Cambridge, MA: 1990. [Google Scholar]
- Carlyon RP. How the brain separates sounds. Trends in Cognitive Sciences. 2004;8:1364–1366. doi: 10.1016/j.tics.2004.08.008. [DOI] [PubMed] [Google Scholar]
- Cusack R, Decks J, Aikman G, Carlyon RP. Effects of location, frequency region, and time course of selective attention on auditory scene analysis. J Exp Psychol Hum Percept Perform. 2004;30:643–656. doi: 10.1037/0096-1523.30.4.643. [DOI] [PubMed] [Google Scholar]
- Chatterjee M. Effects of stimulation mode on threshold and loudness growth in multielectrode cochlear implants. J Acoust Soc Am. 1999;105:850–860. doi: 10.1121/1.426274. [DOI] [PubMed] [Google Scholar]
- Chatterjee M, Galvin JJ. Auditory streaming in cochlear implant listeners. J Acoust Soc Am. 2002;111:2429. [Google Scholar]
- Divenyi PL, Carré R, Algazi AP. Auditory segregation of vowel-like sounds with static and dynamic spectral properties. In: Ellis DPW, editor. IEEE Mohonk Mountain Workshop on Applications of Signal Processing to Audio and Acoustics. New Paltz, N.Y: IEEE; 1997. pp. 14.1.1–4. [Google Scholar]
- Gaudrain E, Grimault N, Healy EW, Bera JC. Segregation of vowel sequences having spectral cues reduced using a noise-band vocoder. J Acoust Soc Am. 2006;119:3238. [Google Scholar]
- Grimault N, Bacon SP, Micheyl C. Auditory stream segregation on the basis of amplitude modulation rate. JAcoust Soc Am. 2002;111:1340–1348. doi: 10.1121/1.1452740. [DOI] [PubMed] [Google Scholar]
- Grimault N, Micheyl C, Carlyon RP, Arthaud P, Collet L. Perceptual auditory stream segregation of sequences of complex sounds in subjects with normal and impaired hearing. Br J Audiol. 2001;35:173–182. doi: 10.1080/00305364.2001.11745235. [DOI] [PubMed] [Google Scholar]
- Grimault N, Micheyl C, Carlyon RP, Arthaud P, Collet L. Influence of peripheral resolvability on the perceptual segregation of harmonic complex tones differing in fundamental frequency. J Acoust Soc Am. 2000;108:263–271. doi: 10.1121/1.429462. [DOI] [PubMed] [Google Scholar]
- Hillenbrand J, Getty L, Clark M, Wheeler K. Acoustic characteristics of American English vowels. J Acoust Soc Am. 1995;97:3099–3111. doi: 10.1121/1.411872. [DOI] [PubMed] [Google Scholar]
- Hong RS, Turner CW. Pure-tone auditory stream segregation and speech perception in noise in cochlear implant recipients. J Acoust Soc Am. 2006;120:360–374. doi: 10.1121/1.2204450. [DOI] [PubMed] [Google Scholar]
- Jesteadt W. An adaptive procedure for subjective judgments. Percept Psychophys. 1980;28:85–88. doi: 10.3758/bf03204321. [DOI] [PubMed] [Google Scholar]
- Mackersie CL. Talker separation and sequential stream segregation in listeners with hearing loss: patterns associated with talker gender. J Speech Lang Hear Res. 2003;46:912–918. doi: 10.1044/1092-4388(2003/071). [DOI] [PubMed] [Google Scholar]
- McKay CM, Carlyon RP. Dual temporal pitch percepts from acoustic and electric amplitude-modulated pulse trains. J Acoust Soc Am. 1999;105:347–357. doi: 10.1121/1.424553. [DOI] [PubMed] [Google Scholar]
- Micheyl C, Carlyon RP, Cusack R, Moore BCJ. Performance measures of auditory organization. In: Pressnitzer D, de Cheveigné A, McAdams S, Collet L, editors. Auditory signal processing: physiology, psychoacoustics, and models. New York: Springer; 2003. 2005. [Google Scholar]
- Moore BCJ, Gockel H. Factors influencing sequential stream segregation. Acta Acustica-Acustica. 2002;88:320–332. [Google Scholar]
- Qin MK, Oxenham AJ. Effects of envelope-vocoder processing on F0 discrimination and concurrent-vowel identification. Ear Hear. 2005;26:451–460. doi: 10.1097/01.aud.0000179689.79868.06. [DOI] [PubMed] [Google Scholar]
- Robert ME. House Ear Institute Nucleus Research Interface User’s Guide. House Ear Institute; Los Angeles: 2002. [Google Scholar]
- Roberts B, Glasberg BR, Moore BC. Primitive stream segregation of tone sequences without differences in fundamental frequency or passband. J Acoust Soc Am. 2002;112:2074–2085. doi: 10.1121/1.1508784. [DOI] [PubMed] [Google Scholar]
- Shannon RV, Jensvold A, Padilla M, Robert M, Wang X. Consonant recordings for speech testing. J Acoust Soc Am ARLO. 1999;106:L71–L74. doi: 10.1121/1.428150. [DOI] [PubMed] [Google Scholar]
- Shannon RV, Adams DD, Ferrel RL, Palumbo RL, Grandgenett M. A computer interface for psychophysical and speech research with the Nucleus cochlear implant. J Acoust Soc Am. 1990;87:905–907. doi: 10.1121/1.398902. [DOI] [PubMed] [Google Scholar]
- Snyder JS, Alain C, Picton TW. Effects of attention on neuroelectric correlates of auditory stream segregation. J Cogn Neurosci. 2006;18:1–13. doi: 10.1162/089892906775250021. [DOI] [PubMed] [Google Scholar]
- Stainsby TH, Moore BCJ, Glasberg BR. Auditory streaming based on temporal structure in hearing-impaired listeners. Hear Res. 2004;192:119–130. doi: 10.1016/j.heares.2004.02.003. [DOI] [PubMed] [Google Scholar]
- Van Noorden LPAS. Doctoral dissertation. Eindhoven University of Technology; 1975. Temporal coherence in the perception of tone sequences. [Google Scholar]
- Vliegen J, Oxenham A. Sequential stream segregation in the absence of spectral cues. J Acoust Soc Am. 1999;105:339–346. doi: 10.1121/1.424503. [DOI] [PubMed] [Google Scholar]
- Zeng FG, Turner CW. Binaural loudness matches in unilaterally hearing impaired listeners. Q J Psychol A. 1991;43:565–583. doi: 10.1080/14640749108400987. [DOI] [PubMed] [Google Scholar]