

Abstract
This paper presents national estimates of the population likely to identify with more than one race in the 2000 census as a result of a new federal policy allowing multiple racial identification. A large number of race-based public policies—including affirmative action and the redistricting provisions of the Voting Rights Act—may be affected by the shift of some 8–18 million people out of traditional single-race statistical groups. The declines in single-race populations resulting from the new classification procedure are likely to be greater in magnitude than the net undercount in the U.S. census at the center of the controversy over using census sampling. Based on ancestry data in the 1990 census and experimental survey results from the 1995 Current Population Survey, we estimate that 3.1–6.6% of the U.S. population is likely to mark multiple races. Our results are substantially higher than those suggested by previous research and have implications for the coding, reporting, and use of multiple response racial data by government and researchers. The change in racial classification may pose new conundrums for the implementation of race-based public policies, which have faced increasing criticism in recent years.
Keywords: racial classification, government statistics, U.S. census
A minor change in wording in the 2000 census may have major implications for population statistics in the United States. Instead of limiting respondents to a single race, the new census instructions will allow respondents to mark “one or more” races (1). The decision to allow multiple racial identification represents a sea change in the U.S. system of racial statistics, which has until now relied on a set of mutually exclusive, single-race categories. Counts of the population by race are used for enforcing a broad set of race-based public policies, including the redistricting provisions of the Voting Rights Act, equal opportunity laws, and affirmative action (2). The treatment of multiple-race responses is likely to be a challenge for race-based policies in the United States, many of which already face a rising tide of public and political criticism.†
The new method of racial classification will have impacts on both population counts and on the treatment of individuals. If those marking more than one race differ from those who mark single races, then this reclassification could also affect estimates of group characteristics such as health status, income, and educational attainment. At an individual level, multiple responses will create a series of conundrums for race-based policies. To give just two examples: Does someone who used to identify as “White” and now marks “White” and “American Indian” now qualify for a minority small business loan? Does someone who formerly marked “Black” but now marks “White” and “Black” no longer qualify? The indeterminacy of race is not new for people with mixed heritage, but whereas the old system put the burden of choosing a single race on individuals, the new system will put this burden on the government, institutions, and users of racial data.
This paper presents new national estimates of the size and characteristics of the population likely to mark more than one race. Based on ancestry data from the 1990 census and experimental results from the 1995 Current Population survey, we create two sets of independent estimates that place the count of the multiple-race population between 8 and 18 million people. To put this into perspective, the controversy over census adjustment in the 1990 census involved a net undercount of only about 4 million persons. Our estimates of the multiple-race population are higher than previous estimates based on the introduction of a separate “multiracial” category into the census question, which ranged from 1 to 1.5% of the U.S. population, about 3 million people (4, 5, 7). Based on the results presented here, we expect the population counts of single-race groups to decline by 3–6% for Whites, 3–7% for Blacks, 15–25% for American Indians, and 4–9% for Asians and Pacific Islanders.
The change in racial statistics is part of a new federal statistical policy on race that will go beyond the 2000 census to affect all federal statistics, including those dealing with health, economics, and program participation. Furthermore, federal statistical policy has a strong “trickle-down” effect and is usually imitated by state and local governments as well as most private and public research. Researchers in medicine, public health, and the economic and social sciences will be affected. The results given in this paper thus have implications for all research and program administration that collects or analyzes data on race.
Despite the fielding of experimental surveys during the four-year review of the policy on racial and ethnic statistics, the “mark one or more” option remains virtually untested. The multiple response option emerged relatively late into consideration, and most research focused on the introduction of a separate “multiracial” category (3, 4). The only survey that did include a “mark one or more” format was the 1996 Race and Ethnicity Targeted Test (RAETT) (5). To ensure large sample sizes, the RAETT sampled only census tracts with very high proportions of particular racial or ethnic groups. As a consequence the survey was not able to produce results that would be “generalizable to the national population” (5). In fact, other research shows that people living in racially segregated census tracts have lower intermarriage rates than the national population (6). Furthermore, respondents living in homogeneous areas who are of mixed ancestry may be less likely to identify multiple races than those living in more diverse settings.
In the absence of a national survey testing the actual “mark one or more” format, we turn to two large, nationally representative surveys that gathered multiple-race identities in ways that differ somewhat from the planned 2000 census question but still allow estimation of the population likely to mark multiple races. First, we analyze the results of the 1990 census. Responses to the census ancestry item, which allowed multiple responses (in an open format), can, in combination with responses to the traditional single-format census race question, be used to estimate the multiple-race population. As a second source of data, we analyze one of the panels from the Current Population Survey (CPS) May 1995 Supplement on Race and Ethnicity. The CPS has been previously analyzed (4), but in a different manner than here. We estimate the number of multiple-race respondents based on follow-up questions that gave single-race respondents the chance to list additional races to “better describe” themselves. In addition to obtaining counts, the sources we use also allow us to examine the socioeconomic characteristics of the multiple-race population and to order multiple responses by an approximate measure of the strength of identification.
Framework
Distinguishing between mixed and unmixed racial ancestry can only be meaningful if consideration is limited to relatively recent times. Scientists have long abandoned the search for rigid biological distinctions between races (8, 9). Current research on human origins concerns itself not with the question of whether common origins exist—this is taken for granted—but, rather, with when our most recent common ancestors lived and when subpopulations branched off from this common ancestor. The concept of the four single-race groups used in the United States (American Indian, Asian and Pacific Islander, Black, and White) usually relies on the view that these populations were somehow unmixed and therefore definable at the time of their arrival in North America. Only from such a perspective is it possible to distinguish between those whose ancestors are entirely within a single racial population and those whose ancestors come from more than one of these populations.
With the above caveat in mind, it is useful to distinguish between three different concentric definitions of the multiple-race population: (i) by genealogy, (ii) by awareness, and (iii) by identification. A genealogical definition includes everyone with mixed ancestry, even at a remove of many generations. A definition taking into account awareness limits this genealogically defined population to those who know of their mixed ancestry. An identification-based definition further limits itself to those who actively identify, for example on surveys, with more than one racial group. When we refer to the population that will mark more than one race in the 2000 census, we are referring to this last definition.
The logical relation of these populations is shown in Fig. 1. We see that each subsequent definition is a subset of the previous one (i.e., C ⊂ B ⊂ A). This figure also shows that the children of interracial unions form only a subset of the aware multiple-race population (B). We do this to highlight that not all multiple-race people have parents who identify with distinct races and that not all of the children of interracial unions will necessarily identify with both races.
Figure 1.

The logical relations of the various definitions of the multiple-race population in the United States according to various criteria. The population C identifying more than one race on surveys and the census will be only a subset of those with mixed racial ancestry, whether this is defined by genealogy A or by awareness B. Only the populations N and C will be enumerated in the 2000 census and other federal statistics. The population C marking more than one race differs from the population that would mark a separate “multiracial” category (the right-most dashed-line ellipse), the option rejected in the revised federal statistical standard. It also differs from the population made up of the children of interracial unions (the left-most dashed ellipse).
The proportion of the population identifying with multiple races can be expressed in terms of the following identity:
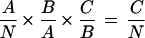 |
where N is the national population, and A, B, and C are the counts of the populations identified in Fig. 1. This decomposition illustrates that the proportion of the national population enumerated with multiple racial identities is a product of the demographic history of a country (represented by A/N), the degree of awareness about racial ancestry (B/A), and the strength of multiple-race identification (C/B). All of these factors are subject to change over time, whether through changing demography, changes in the population's awareness of its ancestry, or social changes that affect the appeal of identifying with more than one race.
From a definitional standpoint, the count of the multiple-race population also depends on the definition of single-race categories. As part of the revision of the directive on racial statistics, the former “Asian and Pacific Islander” category has been divided into two separate categories. Such changes in category definitions affect the sizes of all of the variously defined multiple-race populations A, B, and C. If in the future the concept of multiple race included Hispanic responses, there could be a great increase in the number of multiple respondents.
Most of the factors that contribute to the size of the multiple-race population are not subject to measurement using survey research. In the end, we can only measure C and N, since we do not know the racial genealogy of the American population, nor can we ask about awareness in a way that does not involve at least some filter on the part of respondents of choosing to identify their multiple ancestry in a survey. Still, some estimates do exist for the size of the genealogically mixed population in the United States. It has been suggested that the proportion of population identifying as Black with some degree of White ancestry is as least three-quarters and perhaps closer to 90% (10, 11). The proportion of American Indians with multiple-race heritage is so high that no federally recognized tribes have blood quantum levels for membership greater than one-half (12). We cite these examples to illustrate that the ratio C/A of those who actively identify with multiple races to those who potentially could identify as such is probably quite small.
A final consideration in terms of measuring the multiple-race population is the effect of questionnaire design. About 0.5% of respondents in the 1990 census and in recent national surveys mark at least two races despite instructions to “mark only one” race (7). In the year 2000, the number of multiple respondents may depend in large part on what proportion of the population actually reads and notices the instructions reading, “Mark one or more.” An additional uncertainty is whether media attention will make the public broadly aware of the multiple-race option even before census forms are delivered. After publication of the 2000 census results, awareness of the multiple-race option will probably increase.
Data and Methods
We use two data sources to estimate the number of respondents who are likely to mark more than one race in the 2000 census. First, the 1990 census provides an indication of multiple-race respondents because it includes both a single-response race question and an open, write-in question on ancestry (http://www.ipums.umn.edu) (13). The ancestry question included explicit instructions that “persons who have more than one origin and cannot identify with a single ancestry group may report two ancestry groups (for example, German-Irish)” (14). Using an algorithm developed by the Bureau of Labor Statistics, we map the roughly 500 detailed ancestry codes to the major racial groups: American Indian and Alaskan Native; Asian and Pacific Islander; Black; White; and Other. For example, we code Irish ancestry as “White,” Japanese ancestry as “Asian and Pacific Islander,” and Nigerian ancestry as “Black.” We code the single-race response to the race question as r1, the assigned race of the first ancestry as r2, and the assigned race of the second ancestry as r3. If the responses to any two of these three racial designations (r1, r2, r3) corresponded to distinct single-race groups, we coded the individual as identifying multiple races. About 90% of census respondents gave at least one ancestry, and 30% gave at least two. Our algorithm tries to err on the conservative side by not counting “other” responses to the race question or ancestry responses that are mapped to “other” as indicating distinct single races. To further reduce the risk of making “false positive” (15) identifications of the multiple-race population, we changed the Bureau of Labor Statistics ancestry-to-race algorithm so that those who wrote in “American” as their ancestry were coded as listing an “other” race. The original Bureau of Labor Statistics algorithm coded these responses as “White.”
The second data source we use is Panel 2 of the Current Population Survey May 1995 supplement on Race and Ethnicity (http://www.bls.census.gov/cps/racethn/sdata.htm), which was fielded as part of the federal research effort accompanying the revision of standards for racial and ethnic statistics. We compare responses to the CPS “control card” single-response race question administered several months before the supplement to a modified race question and follow-up items in the supplement. The modified race question in the supplement included a separate “multiracial” category in addition to the standard single-race categories. Two types of follow-up questions were then asked. First, respondents who identified “multiracial” were asked to identify component single races. Second, respondents who identified with a single-race group (instead of the “multiracial” category) in the supplement's first race question were asked to list additional races if they would choose more than one group to “better describe” themselves. We defined multiple-race respondents both as (i) those who chose “multiracial” and then listed at least two distinct races in follow-up questions and (ii) those who chose a single-race and then listed at least one additional single race to “better describe” themselves.
A large number of respondents chose “Something else” as one of the races listed in follow-up questions in the CPS. We used two systems of classification to reflect the uncertainty about how such individuals would respond to the 2000 census question. A larger multiple-race population is obtained by counting “Something else” responses as reflecting a distinct racial category from that already stated. We call this the “CPS High” estimate.‡ A more conservative set of estimates was obtained by counting as “multiple race” only those “Something else” respondents who gave other indications that they were referring to a second distinct race. These indications came from either the original control-card race question or from a separate ancestry question (recoding ancestry to race).
We estimated the number and proportion of multiple-race respondents by using unweighted counts from our analysis of the census and CPS. Estimates of the sampling error, unless otherwise indicated, were made assuming independent multinomial sampling. The standard errors for our estimates are considerably smaller than those in previous research because we do not compare question formats across independently drawn samples. Instead, we take advantage of the fact that the same populations were administered different question formats in a manner similar to repeated trial experimental design (16).
Characteristics of the multiple-race population were also estimated from both data sources. Respondents' primary single race was determined by answers to the single-response race questions, the census race question and the CPS control card race question. We interpret primary race as indicating the preferred single-race identity of multiple-race individuals when faced with the historical system of mutually exclusive single-race categories. Primary race was also used to estimate the single-race groups from which multiple-race respondents would be drawn. Household income was used as a measure of socioeconomic well-being. We rely on household rather than individual income to minimize any systematic age differences between the populations. The multiple-race population tends to be somewhat younger, because of the increase in interracial unions in recent decades (17).
Results
Table 1 summarizes our estimates of the multiple-race population from the CPS and 1990 census. It also provides, for contrast, the estimates of the targeted population from the RAETT (5). It should be kept in mind that for the RAETT the row labels refer to the race of the targeted population and not necessarily to the race of the actual respondents. The size of the entire multiple-race population is 3.1% according to our low CPS estimate, 3.7% according to our 1990 census-based estimate, and 6.6% according to our high CPS estimate. The census-based and CPS-based estimates are consistent with each other, with the census-based estimate between the “high” and “low” CPS estimates. All of our estimates are higher than the 1–1.5% estimates given by previous researchers (3, 5, 7).
Table 1.
Percent of traditional single-race populations expected to mark more than race, by source of estimate, with associated standard errors in parentheses
| CPS (high) | CPS (low) | 1990 Census | RAETT | |
|---|---|---|---|---|
| White | 6.0 (0.1) | 2.6 (0.1) | 3.7 (0.0) | 1.4 (0.4) |
| Black | 6.8 (0.4) | 4.8 (0.4) | 2.5 (0.0) | 1.8 (0.6) |
| American Indian | 20.1 (2.3) | 14.3 (2.0) | 20.3 (0.3) | 4.2 (0.7) |
| Asian and Pacific Islander | 8.2 (0.9) | 4.4 (0.7) | 5.1 (0.1) | 10.0 (1.0) |
| “Other” | 20.0 (1.5) | 5.4 (0.8) | 0.6 (0.0) | |
| All races | 6.6 (0.1) | 3.1 (0.1) | 3.7 (0.0) |
Estimates for the RAETT refer to race of targeted sample and not necessarily to the race of respondents. No national estimate for all races is available for the RAETT. Standard errors less than 0.05% are rounded to 0.0.
The multiple response option will have differential effects on existing single-race populations. Most strongly affected will be the American Indian population, who may see their numbers shrink by about 14–20%. The Black and Asian-and-Pacific-Islander populations may see declines ranging from about 5–8%. It appears that the White population will be least affected, but could still shrink by 3–6%.
The finding that all single-race groups will be affected by allowing multiple responses is in sharp contrast with previous research, which found statistically significant declines for Alaskan Native and Asian-and-Pacific-Islander targeted samples but not for White, Black, or American Indian populations (5). This earlier research differed from ours not only in that it focused on racially segregated populations, but also because estimates were less precise (and therefore less likely to find statistically significant differences) as a result of comparing independently drawn rather than repeatedly tested samples.
The standard errors attached to the estimates in Table 1 measure only the uncertainty introduced by random sampling. Recoding and sample frame bias are two other potential sources of uncertainty. In the case of our estimates, the recoding uncertainty is much greater than the sampling error, as can be seen by comparing the CPS high and low estimates. However, the national sample frame of the CPS and the census do not introduce additional bias. In the case of the RAETT results, there is no recoding error since the “mark one or more” format was used directly as part of the survey instrument. However, the bias introduced by the targeted sample frame is potentially large.
Taking advantage of the multiplicity of questions on race in both the CPS and census data sets, it is possible to order the primary and secondary identities of multiple-race respondents. This will not be possible using data gathered under the “mark one or more” format planned for the 2000 census, since no follow-up questions will elicit the strength of identification. Table 2 provides estimates of the joint primary-secondary race distribution of the multiple-race population obtained from the CPS “high” classification and the census data. The table also provides estimates from two additional surveys, the 1993 round of the Panel Study of Income Dynamics (http://www.umich.edu/∼psid/) and the National Health Interview Survey (J. Kuo, personal communication), which did not explicitly allow multiple responses but did code multiple responses if they were given. We see in Table 2 that all four sources show a consistent pattern: the vast majority—from 64 to 82%—of the multiple-race population list White as their primary race. The most common secondary race is American Indian. According to the CPS estimates, almost two-thirds of multiple-race respondents list White as their first race and American Indian as their second. In the census, the numbers are even higher, with almost three-quarters of the multiple-race respondents being of this type. The prevalence of American Indian as a second ancestry is consistent with the growth in American Indian race and ancestry responses in the 1970, 1980, and 1990 censuses, which has far outstripped rates of natural increase (19). By contrast, Black-White and White-Black combinations form a small portion of the multiple-race population. Although people of mixed Black and White heritage have been among the most vocal advocates of abandoning the mutually exclusive single-race system of racial classification, they constitute only about one-tenth of the population likely to be enumerated as multiple-race in the 2000 census. It appears that the multiple-race population will consist mostly of people who currently identify with the White majority and not with historically disadvantaged Black, American Indian, and Asian populations.
Table 2.
Primary and secondary races of the multiple-race population in several national surveys (in %)
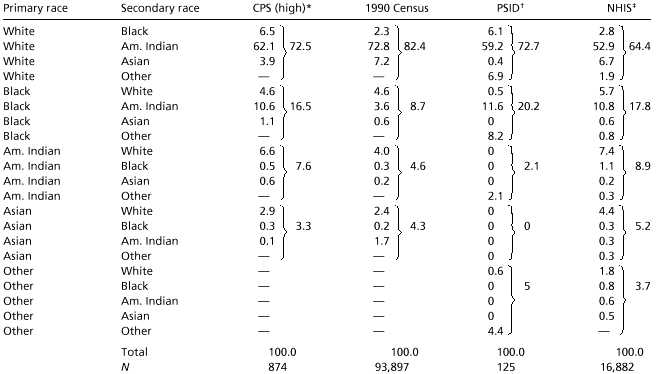 |
Cells with a dash were not counted as possible primary-secondary source combinations in this survey. Small sample size in the PSID and CPS make estimates subject to potentially large sampling errors. Standard errors can be approximated by  , where p = percentage/100. “Am. Indian” category includes American Indians and Native Alaskans. “Asian” category includes Asians and Pacific Islanders.
, where p = percentage/100. “Am. Indian” category includes American Indians and Native Alaskans. “Asian” category includes Asians and Pacific Islanders.
*According to “high” estimate (see text).
† Panel Study of Income Dynamics. Primary and secondary races determined by first and second mentioned races. Order of presentation in the survey may have affected order of responses and their coding.
‡National Health Interview Survey. Preliminary unpublished estimates, subject to revision.
To indicate the relative socioeconomic status of multiple-race respondents and the multiple-race population considered as a whole, we report the median household income of the populations obtained from the census and CPS in Table 3. We see from the CPS data that the $27,500/year median household income of the entire multiple-race population is half-way between that of single-race Whites and Asians ($37,500/year) on the one hand and single-race Blacks and American Indians ($17,500/year) on the other. The intermediate status of the multiple-race population hides important variation within the multiple-race population, in which median household income ranges from $17,500 for respondents whose primary race is Black to $45,000 for those whose primary race is Asian or Pacific Islander. The variation of income by primary race within the multiple-race population is not substantially less than that by race within the single-race population. It appears that primary racial identity, not whether one has single or multiple heritages, drives income differences.
Table 3.
Median annual household income by race of the single-race population and the multiple-race population (in thousands of dollars)
| 1995 CPS | 1990 Census | |
|---|---|---|
| Single-race populations | ||
| White | 37.5 | 34.9 |
| Black | 17.5 | 21.3 |
| American Indian | 17.5 | 20.0 |
| Asian and Pacific Islander | 37.5 | 40.0 |
| Multiple-race population, by primary race | ||
| White | 27.5 | 28.5 |
| Black | 17.5 | 22.7 |
| American Indian | 22.5 | 26.4 |
| Asian and Pacific Islander | 45.0 | 41.7 |
| All multiple races | 27.5 | 28.4 |
CPS income is reported as the midpoints of income categories. The CPS income refers to household income; the 1990 Census data refers to family income, a slightly narrower definition. Census income has been rounded to the nearest hundred dollars.
A systematic difference that does appear between single- and multiple-race populations is that people who list Black, Asian, and American Indian as a primary race tend to have slightly higher incomes if they list additional races. The reverse is true for those listing White as their primary race. One possible explanation is that the family backgrounds of multiple-race respondents might be wealthier than single-race respondents, particularly since most multiple-race respondents report some White ancestry, and Whites have enjoyed a historical economic advantage. A second possible explanation is that the tendency to identify multiple races might itself increase with household income. Selective reporting might mean that the multiple-race population defined by surveys (population C) is more affluent than the multiple-race population defined by ancestry (A) or even by awareness (B). A third possibility is that being multiracial may itself have consequences for income, due perhaps to differences in discrimination.
Discussion
The new multiple-response format for racial statistics provides a new set of options for Americans filling out census forms and other data collection instruments. The decision by individuals about whether to identify with more than one race is a personal one, making any estimates concerning the size of the more-than-one-race population inherently uncertain. Many people may be aware of their mixed heritage, but how many will choose it? It appears that the factor that will most affect the counts of the multiple-race population is not how the children of interracial unions will identify, but rather how those with more distant, often American Indian, ancestry choose to identify themselves. In the 1990 census, 2.9% of the national population identified American Indian ancestry while at the same time choosing a race other than American Indian. If all of these people mark two races in the year 2000, then the multiple-race population will be at least this high, even before any other racial combinations are counted.
The 1990 U.S. census and the May 1995 Current Population Survey allow estimates of the multiple-race population likely to be enumerated by the 2000 census. We found that 3.1–6.6% of the national population actively identifies with more than one racial group. While neither source included question formats identical to the planned census question, the estimates derived from these sources may prove better predictions of the 2000 census results than those previously made from samples that were not representative of the national population (5) or from tests of a separate “multiracial” category (3, 4). In particular, the multiple response option may prove much more attractive than a separate “multiracial” category, because instructions to mark “one or more” categories involve a supplementation rather than replacement of previously identified single-race identities.
Unlike previous research, we find that multiple-race identification could indeed reduce the counts of all single-race populations. If multiple responses are counted separately from single-race responses, we estimate that single race counts will decline by about 3–6% for Whites, 3–7% for Blacks, 15–25% for American Indians, and 4–9% for Asians and Pacific Islanders. The width of these estimates is due to uncertainty in the coding of certain multiple responses and will depend in part on how the Census Bureau and others decide to code multiple responses, one of which is “Other race.” Such declines are larger in magnitude than the net census undercount from the 1990 census, which is estimated at about 4.4 million people, or less than 2% of the national population.
Our quantitative conclusions are limited to the extent that our sources are indeed comparable to the “mark one or more” format to be used in the 2000 census race question. It may be that Americans will be more reluctant to report additional “races” on the census form than they were to either report additional “ancestry” on previous census forms or to list additional races in an interviewer-based survey such as the CPS. The similarity of results obtained from these two sources does, however, add confidence to our results. Still, it is clear that precise estimates of the effect of changing the question format will require the fielding of surveys that use the actual “mark one or more” format. Such surveys were, unfortunately, not undertaken as part of the research effort accompanying the revision of the directive on race and ethnicity. We recommend that future surveys include the ability to match responses to the new format with previous responses to the former single-race format. Such a method will provide estimates of the effect of question change with much smaller sampling errors than the independent panel format previously used. As a final consideration, we note that the effect of any publicity or public discussion on awareness of the multiple-race format is left out of pilot tests and will have to await the 2000 census itself.
Does the multiple-race population form a meaningful category, one that should be used for race-based policies like affirmative action, redistricting, and other civil rights enforcement? Perhaps most remarkable about the population marking multiple races is its diversity. Depending on the combination of racial backgrounds, the multiple-race population includes those from the most historically disadvantaged groups (e.g., those with a mix of American Indian and Black ancestry) and those from the wealthiest segments of society (e.g., the offspring of recent White and Asian unions). As a whole, the socioeconomic situation of the multiple-race population is fairly close to the national average. Membership in a multiple-race category is not, in and of itself, terribly predictive. However, knowledge of a particular combination of racial backgrounds appears to be quite predictive. Because multiple-race Americans, as a group, differ little in their socioeconomic characteristics from the general population, it may prove tempting to exclude this population from the protections given to disadvantaged groups. Such an approach would, however, clearly exclude a number of people from protections to which they had a right under the old system of classification.
The diversity of the more-than-one-race population poses some serious problems for any method of classification and for the treatment of this population under existing civil rights legislation. The option of counting anyone with any non-white ancestry as a minority may lead to controversy over whether those who were previously counted as White should now be included in counts of the minority population and be entitled to policies aimed at the non-white population, a sensitive issue given the current climate against race-based public policies. On the other hand, multiracial people as a group might be considered exempt from programs that seek to benefit traditional, single-race minorities, but this would bring to life fears already expressed by minority groups regarding the reduction of their constituency base. In any case, the government will have to be careful to avoid accusations of reinventing a modern “one-drop rule” or of counting whole people as fractions in a manner similar to the original wording of the U.S. constitution (20). The Voting Rights Act makes racial classification unavoidably political; classification decisions which affect where district lines are drawn may be subject to accusations of a new form of gerrymandering.
For researchers in the health and social sciences, the change in racial statistics also creates the need for decisions and rules when using multiple-race data. Like government agencies, they also face the complications of discontinuity in time series information. Our results suggest that the addition of the multiple-race option will indeed affect the counts of single-race groups and may also affect estimates of group characteristics.
Taken together, the issues raised by multiple-race reporting may fuel criticism not only of race-based policies but also of the rationale for the collection of racial statistics in the first place. The growing presence of mixed-race Americans, and of immigrants who do not find an obvious place for themselves in U.S. racial categories, will continue to raise questions about what is meant by “race” and why we are trying to measure it.
Acknowledgments
This research was supported by the Russell Sage Foundation, Grant 97-98-06.
Abbreviations
- RAETT
Race and Ethnicity Targeted Test
- CPS
Current Population Survey
Footnotes
The Office of Management and Budget has begun to issue guidelines regarding the classification and tabulation of multiple race responses. See OMB Bulletin No. 00-02 (http://www.whitehouse.gov/omb/bulletins/b00-02.html) for guidance issued while this paper was under review.
Article published online before print: Proc. Natl. Acad. Sci. USA, 10.1073/pnas.100086897.
Article and publication date are at www.pnas.org/cgi/doi/10.1073/pnas.100086897
It corresponds to the PRSARAC5 variable constructed by the Bureau of Labor Statistics and the Census Bureau in the publicly available data set.
References
- 1.Office of Management and Budget. Federal Register. 1997;62:58782–58790. [Google Scholar]
- 2.Edmonston B, Goldstein J R, Lott J T. Spotlight on Heterogeneity: The Federal Standards for Racial and Ethnic Classification. Washington, DC: Natl. Acad. Press; 1996. [Google Scholar]
- 3.Bureau of the Census. Findings on Questions on Race and Hispanic Origin Tested in the 1996 National Content Survey, Population Division Working Paper No. 16. Washington, DC: U.S. Bureau of the Census; 1996. [Google Scholar]
- 4.Tucker C, McKay R, Kojetin B, Harrison R, de la Puente M, Stinson L, Robinson E. Testing Methods of Collecting Racial and Ethnic Information: Results of the Current Population Survey Supplement on Race and Ethnicity. Washington, DC: U.S. Bureau of Labor Statistics; 1996. [Google Scholar]
- 5.Bureau of the Census. Results of the 1996 Race and Ethnic Targeted Test, Population Division Working Paper No. 18. Washington, DC: U.S. Bureau of the Census; 1997. [Google Scholar]
- 6.Blau P M, Blum T C, Schwartz J E. Am Sociol Rev. 1982;47:45–62. [Google Scholar]
- 7.Office of Management and Budget. Federal Register. 1997;62:36873–36946. [Google Scholar]
- 8.Montagu A. The Concept of Race. New York: Free Press; 1964. [Google Scholar]
- 9.Cavalli-Sforza L L, Menozzi P, Piazza A. The History and Geography of Human Genes. Princeton, NJ: Princeton Univ. Press; 1996. [Google Scholar]
- 10.Reed T E. Science. 1969;165:762–768. doi: 10.1126/science.165.3895.762. [DOI] [PubMed] [Google Scholar]
- 11.Davis F J. Who is Black? One Nation's Definition. University Park, PA: Pennsylvania State Univ. Press; 1991. [Google Scholar]
- 12.Snipp C M. American Indians: The First of this Land. New York: Russell Sage; 1989. [Google Scholar]
- 13.Ruggles S, Sobek M. Integrated Public Use Microdata Series: Version 2.0. University of Minnesota, Minneapolis: Historical Census Projects; 1997. [Google Scholar]
- 14.Bureau of the Census. 1990 Census of Population, Supplementary Reports, Detailed Ancestry Groups for States, 1990 CP-S-1-2. Washington, DC: U.S. Government Printing Office; 1992. [Google Scholar]
- 15.McKay R B. Statistics Canada Symposium 96, Nonsampling Errors, November 1996. Ottawa: Statistics Canada; 1996. pp. 107–118. [Google Scholar]
- 16.Agresti A. Categorical Data Analysis. New York: Wiley; 1990. [Google Scholar]
- 17.Bureau of the Census. Marital Status and Living Arrangements; March 1997 PPL-90. Washington, DC: U.S. Bureau of the Census; 1998. [Google Scholar]
- 18.Holmes S A. The New York Times June 14, 1998, A32. 1998. [Google Scholar]
- 19.Eschbach K, Supple K, Snipp C M. Demography. 1998;35:35–43. [PubMed] [Google Scholar]
- 20.Waters M C Subcommittee on Government Management Information and Technology of the Committee on Government Reform and Oversight, editors. Federal Measures of Race and Ethnicity and the Implications for the 2000 Census. 105-57. Washington, DC: U.S. Government Printing Office; 1997. pp. 442–460. [Google Scholar]