

Abstract
Visual Working Memory (VWM) was explored separately for features and for their binding. Features were better recognized when the probes retained the same binding as in the original display, but changing the locations had little effect overall. However, there were strong interactions of location with binding and with matching or new feature, suggesting that, when the objects are attended, features and locations are spontaneously integrated in VWM. Despite this, when the locations are changed, features can also be accessed with little decrement, perhaps from separate feature maps. Bindings, on the other hand, are more vulnerable to location changes, suggesting that locations play a central role in the early maintenance and retrieval of bound objects as well as in their initial encoding, at least when verbal coding is prevented. The results qualify past claims about the separation of locations and objects in VWM.
We live in a world of objects and events and this is the world with which we must interact, not a world of separate features and locations. However, there is evidence that, on the way to forming the representations that reach awareness and that control our behavior, we do separately analyze features and locations in specialized feature maps (Treisman and Gelade, 1980). Thus we are faced with the problem of binding these components to form integrated objects, and of maintaining the bound representations in visual working memory (VWM) over short intervals of time while we make decisions about what action to take. Feature integration theory (FIT) proposed that focused attention is directed to one filled location at a time to bind the features it contains. The temporary episodic representations formed in this way (we called them ‘object files’; (Kahneman, Treisman, and Gibbs, 1992)) are addressed by their spatio-temporal coordinates and maintain the identity and perceptual continuity of objects in dynamic displays as they move around and change. It seems plausible that these representations are also the perceptual elements that are stored as object tokens in VWM (Irwin and Andrews, 1996).
Independent evidence that bound objects are stored in VWM comes from experiments by Luck and Vogel (1997). They showed 1-12 colored squares, followed after 900 ms by either the identical display or the same display with one feature changed. They found accurate recognition memory for up to four colors. Using bars that varied in size, orientation, color, and the presence or absence of gaps, they found the same four-object limit, despite a fourfold increase in the number of features. They concluded that VWM holds up to 4 bound objects with at least 4 features each, a claim for which Irwin and Andrews (1996) had also previously found evidence in a series of experiments on trans-saccadic memory.
Earlier findings, however, raise some questions about the idea that bound objects are the only units encoded in VWM. Treisman (1977) showed that, at least under time pressure, memory for features is much more accurate than memory for conjunctions. Participants made more than 30% errors in a successive same-different judgment task when both features matched but the binding was changed. This far exceeded the error rate when new features were introduced. Stefurak and Boynton (1986) tested memory for color-shape conjunctions across longer intervals of 3 and 15 seconds and found that recognition was at chance for the bindings when verbal labeling was prevented, although the features were quite well recognized. These results suggest that features may be retained in an unbound form as well as in bound object representations.
Wheeler and Treisman (2002) used the Luck and Vogel paradigm to compare memory for separate features and memory for their bindings, using as foils in the feature tests a new color, location, or shape, and in the binding tests a new pairing of previously presented features. Change detection was significantly worse for changes of binding than for new features when we presented a whole display at test, whether all the items were potential targets or whether we post-cued a single target item. However when we tested with single item probes, memory was as good for the bindings as for the features. This implies that the bindings were encoded and stored just as well as the features, but that they were more vulnerable to interference from the whole display probes. We suggested that VWM can draw information both from separate feature stores, each with its own independent capacity, and from integrated object files, but that forming and maintaining the latter requires additional attentional resources. When a whole display is used to probe recognition for the bindings, each probe object must be selectively attended, drawing attention away from items stored in VWM. When a single probe is presented, its features can be bound by default and attention remains with the memorized items. Up to four integrated object files can be retained, so long as attention to them is maintained. We attributed the better performance with feature changes than with binding changes to additional memory traces of unbound features.
Another type of information that can also be retained in VWM is the set of spatial locations occupied by the presented objects. How are these stored? Are they integrated with the objects, or held in a separate specialized store? This question has been tackled using a variety of different kinds of evidence. Initially the main tests devised by Baddeley and his colleagues were based on selective interference in dual task paradigms. If memory could be selectively disrupted for one kind of material by one kind of activity and for another by a different kind of activity, the two were likely to be separate (see for example Baddeley, 1992; Logie and Marchetti, 1991; Hecker and Mapperson, 1997; Magnussen, 2000; Zimmer, Speiser, and Seidler, 2003; Tresch, Sinnamon, & Seaman, 1993). More recently neuroscientists using PET, fMRI, or ERPs, have looked for selective activation in different brain areas for different kinds of material (e.g. Smith, Jonides, Koeppe, Awh, Schmacher, and Minoshima, 1995; Courtney, Ungerleider, Keil, and Haxby, 1996; Postle and d'Esposito, 1999; Haxby, Petit, Ungerleider, and Courtney, 2000; Munk, Linden, Muckli, Lanfermann, Zanella, Singer and Goebel, 2002). Evidence can also be sought in the selective deficits of patients with localized lesions (e.g. Hanley, Young, and Person, 1991; Nunn, Polkey and Morris, 1998; Carlesimo, Perri, Turriziani, Tomaiuolo, and Caltagirone, 2001) or in the localized effects of TMS (e.g. Mottaghy, Gangitano, Sparing, Krause, and Pascual-Leone, 2002).
Although there is certainly evidence supporting the existence of separate storage for locations and for objects, this is not a universal conclusion. For example Postle and D'Esposito found the two intermixed in frontal areas; Rizzuto Mamelak, Sutherling, Fineman, & Andersen (2005) found that the ventral prefrontal area, which was assumed to be specialized in object working memory (Wilson et al, 1993), is also active in spatial working memory; Prabhakaran, Narayanan Zhao, and Gabrieli, 2000, found frontal areas that specialized in coding integrated representations, and Haxby et al. emphasize that the segregation is “a matter of the degree of participation of different regions, not the discrete parcellation of different functions to different modules.” Single unit activity in monkeys also suggests an initial separation of object and spatial storage, but a reintegration of the two in frontal cortex where “over half of the PF neurons with delay activity showed both what and where tuning” (Rao, Rainer, and Miller, 1997).
A final source of evidence on the organization of VWM comes from the observation of interference with recognition of one aspect of a stimulus by irrelevant variation in another. The rationale is that if recognition is disrupted by task-irrelevant changes, we can infer that the memory trace has integrated them with the relevant features. Changes in the physical stimuli can only affect performance if they are also present in the memory representation that mediates the response. The first display is no longer present when the comparison is made to the probe, so the nature of the encoding is critical. The present experiments explore this method. It was previously used by Jiang, Olson and Chun (2000) and by Woodman, Vogel, and Luck (2005) to compare memory for colors when the locations or the orientations of the objects changed and when they remained the same. Jiang et al found some decrement when the locations changed, while Woodman et al found none. Woodman et al. explained the discrepancy with the suggestion that Jiang et al's participants were cued to the relevant item with a spatial location, and therefore were encouraged to encode the conjunctions. Woodman et al. collected further evidence for the separation of objects and locations in VWM. Presenting the colors sequentially in the same single location did not impair memory. They found no effects of either spatial shifts or scrambling, although memory for color was impaired when the orientations changed, showing that the method was sensitive enough to reveal interference when integration had occurred. Finally they found better memory for three colors and three locations than for six colors or six locations, whereas there was no such benefit to dividing the items between colors and orientations. They suggest that features are bound in VWM, but that their locations are separately stored. “Representations in visual working memory are not tightly bound to either absolute or relative spatial locations.”
The general consensus, then, although not unanimous, seems to be that spatial and object information are held in distinct stores. None of the experiments so far distinguished the effect of location changes on memory for the features from memory for their bindings, although some tested both at once (e.g. Munk et al., 2002). It seemed worth investigating further how tightly bound locations are in VWM to features on the one hand and to objects on the other. Because locations seem to be crucial in establishing the bindings in the first place, and because we have evidence that object files are addressed by their locations, our prediction was that location should be more important to visual working memory for bound objects than to memory for features. However, it is, of course, possible that locations are used in binding features only during perception, and that once established the object representations become independent of location.
Our studies also explore some further questions. Under what conditions do we store bound objects and when do we also, or only, store their features? How flexible are the strategies used in encoding visual information? Can features and locations be separately stored when required, or is binding automatic when attention is directed to an object? FIT (Treisman and Gelade, 1980) claimed that attention is necessary for accurate binding; however it does not follow that it is sufficient - i.e. that attention makes binding unavoidable. Evidence of interference when the bindings are changed would suggest that binding is automatic for attended objects, even when only the separate features are relevant to the task.
In all our experiments, we presented three colored shapes, followed by either three (Whole Display) or one (Single Probe) colored shapes. In Experiments 1 and 2, participants were asked to decide whether the features in the probe exactly matched those in the preceding display, ignoring any changes in binding or in location. The features in the probe display either exactly matched those in the previous display or differed from them in one feature (either color or shape). For example a red T would become a blue T or a red O (where blue or O were not present in the previous display). In Experiments 3, 4, and 5 the task was to decide whether the bindings were the same as in the previous display, again regardless of any location changes. In these binding tests, the probe display always contained the same features as the original display, and either the bindings also matched or one feature (shape or color) was exchanged between two of the objects, so that the bindings were changed. For example a red T and green X would become a green T and a red X.
EXPERIMENT 1. Visual Working Memory for Features
In the first two experiments, we explicitly tested memory only for features, - shapes and colors, - but we looked for indirect evidence that bindings and locations are also stored. Luck and Vogel (1997) claimed that VWM contains only bound objects. Wheeler and Treisman (2002) suggested instead that VWM stores both separate features and integrated objects, with attentional resources required to produce and maintain the binding. The new question was whether there is any voluntary control over what is stored. When only the features are relevant to the task, can they be stored without forming integrated object files that are bound to their locations, or is binding automatic when attention is directed to the items in the display? The distinction between attention and intention is often blurred, since both are contrasted with 'automaticity. In the present experiments, we ensured that participants would attend to the stimuli by explicitly testing memory for their features, but the locations and bindings were supposedly irrelevant, making any memory for these properties unintentional. If features are bound in working memory only when this is necessary to the task, there should be no effect of changing locations and/or bindings between presentation and test when only the features are relevant. On the other hand if irrelevant features are integrated automatically with the relevant ones, the changes might facilitate “Different” trials and interfere with “Same” trials relative to the baseline case with no irrelevant changes (as in Luck and Vogel (1997) and most other VWM experiments). But because they are orthogonal to the task, they also introduce uncertainty about the objects, which may cancel any facilitation on “Different” trials.
If binding is automatic when the objects are attended, we can further ask exactly what is bound? Are feature-feature bindings retained only indirectly, through links to shared locations? If so, they should be lost when the locations are changed, making any switch of binding irrelevant. But if the features, once selected through their shared location, are bound directly to each other, the resulting object files might become independent of location. If so, a change of bindings might interfere with feature memory even when the locations are new. Finally the features might be bound both to their locations and to each other, resulting in interference in feature recognition both from changed locations and from changed bindings.
Participants were asked to remember only the features in displays of three bound items, and were tested with displays that either preserved the original locations or used new locations, and that either preserved the feature-feature bindings or switched those. We tested both colored shapes and colored letters (with separate groups of 8 participants each). Color often contributes to the identification of objects, but is normally irrelevant for symbols, so we thought that binding might be more automatic for shapes than for letters.
Method
Participants
16 Princeton undergraduates (3 males) participated in the 1-hr study for class credit. Eight were tested with letters and 8 with shapes. All were naïve to the experimental paradigm and reported normal or corrected to normal visual acuity and color vision.
Stimuli
Stimuli were presented on a light gray background on the 15″ screen of a Power Macintosh G3 computer, using MatLab with the psychophysics toolbox (Brainard, 1997; Pelli, 1997). The viewing distance was 60 cm. There were six possible values on each dimension. The colors were red, blue, yellow, green, brown, and violet, chosen to maximize discriminability. The shapes were a circle, (with diameter subtending 1°40′); a square, (1°30′); an equilateral triangle, (1°60′ × 1°40′); a heart, (1°55′); a star, (1°45′ × 1°50′); a cross, (1°40′). The letters were ‘S’, ‘X’, ‘T’, ‘C’, ‘Q’, and ‘Z’, in Arial Black Bold font, size 60, subtending 1°20′. On each trial, three shapes (or three letters) were presented in randomly chosen locations in a 3×3 invisible grid subtending 16°8′ by 12°7′. Colors and shapes (letters) were never repeated within a display, either in the initial presentation or at test. Figure 1 shows an example of a trial sequence.
Figure 1.
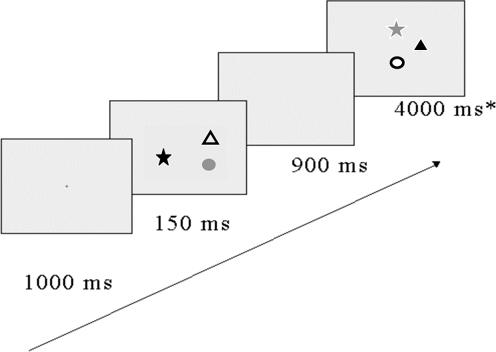
Schematic description of a Match trial in the Whole Display condition with colored shape stimuli tested in new locations with changed bindings.
Design and Procedure
Two otherwise identical experiments were run on different participants, one using colored shapes and one using colored letters. Three variables were manipulated within each experiment:
Match or New-Feature. On Match trials all the probe features were also present in the original display. On New-Feature trials one randomly chosen color or shape (letter) was replaced by a new color or shape (letter). Color and shape (letter) were tested equally often.
Location: The probe display occupied either the same three locations as the original display (Old locations) or three previously empty locations in the same grid (New locations). The location factor was blocked, and the order was counterbalanced between participants.
Binding: In 50% of trials within each location condition, the test display kept the same binding of colors and shapes (letters), while in the remaining 50%, the binding changed for all three items. Trials of each type were randomly mixed within blocks. When the locations were the same, half of the changed binding trials changed the locations of the colors, and half changed the locations of the shapes (letters).
Each participant did 32 trials in each combination of binding and location match or mismatch. On each trial the sequence of events was as follows: A small black cross was presented at center screen for 1000 ms, then an initial display of three items flashed for 150 ms, then a 900 ms blank interval, and finally a probe display which remained present until a response was made, or for 4000 ms, whichever came first (Figure 1). Participants indicated by a key-press whether there was a new feature in the probe display or whether the display contained all the original features. In the New Locations condition, they were told that the test items would appear in new locations. They were also told that in all the trials the features might be recombined, but that neither the bindings nor the locations were relevant to their task. If a new color or shape (letter) appeared, the correct response was “Different”. Otherwise they should answer “Same”. The ratio of Match to New-Feature trials was 1:1, and this was balanced across all levels of the other two factors. Participants were instructed to aim for accuracy, and received a tone as feedback if they made an error. Articulatory suppression was used to prevent verbal labeling of the stimuli: Participants repeated the word, “Coca Cola” throughout each trial. At the beginning of the experiment, they practiced 16 trials of each block type and were given a chance to ask questions. At the conclusion, they were given an opportunity to comment and ask questions and then were debriefed.
Results and Discussion
Figure 2 shows the mean recognition accuracy in each condition. Letters gave much better performance than Shapes (80% correct compared to 66%; F(1,14) = 15.73, p <.005). They may have been more discriminable or more familiar. However the effects of the other variables were very similar for both shapes and letters. There was a significant main effect of changing the binding (Mean = 6%, F(1,14) = 20.27, p < .001), suggesting that features are bound even when the task does not require it. Surprisingly, there was no overall effect of changing locations (0%). One might infer that location is not stored or not retrieved in VWM for features, but this would clearly be wrong, since there was a strong interaction between Location and Binding (F (1.14) = 17.87, p< .001). Repeating the locations made participants better on Same Binding trials but worse on Different Binding trials. Mean accuracy did not differ between Match and New-Feature trials, suggesting no overall response bias. However, there were highly significant interactions of Match/New-Feature with Binding (F(1.14) = 24.67, p< .001), with Location (F(1.14) = 10.78, p< .01) and a significant three-way interaction with Binding and Location (F(1,14) = 31.75, p< .001; see Figure 3). The interaction results from a bias to say “Same” except on trials with different bindings in old locations. The default seems to be to assume no change unless there were feature-location mismatches between the original display and the probe. Finally Match trials showed an interesting asymmetry of interference between binding changes and location changes: Changed bindings in the old locations were much more likely to evoke false positive change detections than changed locations with the same binding (35% difference in accuracy compared to 8%).
Figure 2.

Accuracy in feature recognition for colored shapes and colored letters as a function of preserved or changed binding and locations.
Figure 3.

Accuracy on colored shapes on match and on new feature trials, from Experiment 1 (with Whole Display probes)
We defer discussion until after describing Experiment 2.
EXPERIMENT 2. Feature memory with Single Probe versus Whole Display probes
Wheeler and Treisman (2002) found that when the whole display was presented at test, memory was worse for the bindings than for the features themselves, but when a single probe was used the two were equal. What should we predict when the bindings are irrelevant? Since bindings were better remembered with a single probe in the earlier study, we might expect more interference with feature memory from a changed binding when the single probe is presented. On the other hand, more items change their binding in the Whole display test, which might increase the total conflict.
Method
The displays and procedure were the same as in the shape condition of Experiment 1, except that at test a single probe item was presented, either in the same location or in a new previously empty location. Again, the location factor was blocked and Match versus New-Feature trials were randomly mixed, as were Same and Different binding in the Match trials. On New-Feature trials in the Single Probe condition, the binding can neither match nor differ from the original because only one of the original features is present. Nine new Princeton undergraduate volunteers (2 males) participated in the 1-hr study for class credit.
Results
We analyzed the data from Experiment 2, testing Single Probe recognition on 9 participants, together with the Whole Display data from Experiment 1 with the 8 participants who were tested on shapes rather than letters. In the first ANOVA and in Figure 4, we collapsed across same and different binding, since these cannot be distinguished in the New feature trials of the Single Probe condition.
Figure 4.

Accuracy in feature recognition for shapes and colors with Single probes or Whole Display probes.
Performance was better when tested with the Single Probe (75%) than with the Whole Display (66%; F(1,15) = 5.65, p<.05). The Single Probe condition has two possible advantages, both of which could play a part: One is the fact that only one item must be checked, reducing the decision load relative to the Whole Display. Wheeler and Treisman (2002) ruled out this account in their experiments by presenting the Whole Display but cueing just one item at test. The cue did not improve performance relative to the Whole Display condition (78% versus 82%) although it narrowed down the relevant items to a single one. The other potential advantage with the Single Probe is that interference from multiple items in the probe is eliminated.
Again there was no main effect of changing the locations and no interaction of location with probe type. Location did interact with Match versus New feature (F(1,15) = 10.82, p<.005), with the New locations actually giving 4% better performance than the Old locations when the features matched the original display. This probably results from the decrement when the features and locations are the same but the binding is changed.
In order to see the effects of changed versus preserved binding, we also did an ANOVA on both experiments on the Match trials only, since changes of binding were impossible in the New feature trials. Here the effects pf probe type were not significant, suggesting that the main decrement with the Whole Display takes the form of change blindness rather than false change detections. The Match trials showed a highly significant effect of binding (81% for same binding versus 67% for different binding; F(1,15) = 28.92, p=.0001), a significant interaction of binding with probe type, with a decrement of 21% for Whole display probes and 7% with the Single probe (F(1,15) = 7.00, p<.05), of binding with location (F(1.15) = 8.69, =.01), and a three-way interaction of binding with location and with probe type (F(1,15) = 12.37, p<.005).
Discussion
The results of Experiments 1 and 2 throw some light on the nature of representations in VWM. We argued that if the features from a single object are stored in an integrated format, participants should be more efficient in responding to test items that preserve the original binding than to test items that re-pair features from separate objects. Moreover, if memory for binding is mediated through links to locations, there should be differences between probes in the old locations and in new ones. On the other hand, if features can be stored separately, there should be no differences.
The main findings can be summarized as follows:
Memory for features showed clear effects of the original binding, even though this was irrelevant to the task. When the locations were new, or when the probe was a single item, changing the binding had a smaller but still significant effect. This effect was not present on Letter trials, suggesting weaker feature-feature bindings with letters than with shapes. We can draw two conclusions: First it seems that feature-feature bindings are mediated at least in part through location-feature bindings. But second, there seems in addition to be some automatic binding of feature to feature that survives the loss or reduction of location information. The findings suggest that features are bound automatically when the object is attended. No intentional effort is required, and there may be little voluntary control.
Retrieval of features was as efficient overall when the locations were changed between encoding and test as when they were preserved. However, we should not conclude that the memory traces are independent of location. There were strong interactions of location with binding and with Match versus New displays. The old locations had a clear advantage both on Match trials when the binding also matched and on Change trials when the binding also differed. When the binding was changed but the features matched, the new locations actually gave better recognition, presumably because in the old location the change of binding was mistaken for a change of feature. The results suggest that when a previously filled location is reactivated, retrieval of its previous contents (if they survive) is automatic. Within each location, participants compare the present to the past features. If either color or shape is new, they tend to respond “Different”, even if the feature in question had been present in another location in the initial display. Thus feature-location bindings seem to be automatically encoded.
The location interactions mostly disappeared with Single Probes, suggesting that the locations were represented as spatial patterns, i.e. as relative rather than absolute locations. The effect of binding changes was also reduced on Single probe match trials, most likely as a result of the loss of relative location information, although, as with the Whole Display probes, there was still some decrement when the features were re-bound, even without the support of the feature-location bindings.
EXPERIMENT 3. Memory for binding: Effects of location and delay
How do the effects of preserved versus new locations in the probe differ when we test memory for the bindings rather than for the features? We used the same stimuli as in the earlier experiment and again we tested both with Whole Display probes and with Single probes, to see the effects of relative and of absolute locations. Each display again contained 3 colored shapes drawn from sets of 6 colors and 6 shapes. In the present experiment, the features always matched between the initial display and the probe. The task was to decide whether the bindings also matched. In change trials with Whole Display probes, two of the three stimuli in the initial display exchanged either their shapes or their colors, thus changing the binding of two of the colored shapes, leaving the third unchanged. With Single probes, a shape and a color from the original display were recombined. The probes were presented either in the old locations (keeping the location of the color on half the binding change trials and of the shape on the other half), or in new locations, previously unoccupied.
We were interested also in possible changes over time in the representation stored in VWM. If location is initially important to the binding process, it might become less so as the delay between the initial presentation and the recognition probe increased, allowing the consolidation of feature-feature bindings. We therefore tested two groups of participants, one with a brief interval (100 ms) between initial display and probe, and one with a longer delay (900 ms). Since we did not want to introduce differential interference from verbal articulation in one case and not in the other, neither group used articulatory suppression. (The effects of articulatory suppression are tested in the same conditions in Experiment 4.)
Method
Stimuli
The stimuli were drawn from the same shapes and colors as in the previous experiments. On each trial, three items (all differing in color and shape) were presented in randomly chosen locations in a 3×3 invisible grid subtending 16°8′ by 12°7′. The probe displays either matched the originals or exchanged the binding of two features from the original display. The probes were either presented in the same locations as the originals or in new, previously unfilled locations (see Figure 5).
Figure 5.

Schematic description of design of Experiment 3
Design and Procedure
Four factors were varied in this experiment, the first three within participants and the last between participants:
Matching or Changed-Binding. On Match trials the probe items were identical to the original items. On Changed-Binding trials, the same features were present in the probe as in the original display, but with Whole Display probes, two bindings were changed by exchanging the shapes between two objects on half the trials and the colors on the other half of the trials. With Single Probes, the probe had the shape of one of the original items and the color of another. When the location was an Old one, the probe was presented in the location of the matching shape on half the trials and in the location of the matching color on the other half. Again there were an equal number of trials of each type and they were randomly mixed within blocks.
Old or New Location: In Whole Display trials, the test display occupied either the same three locations as the original display or three previously empty locations in the same grid. In Single Probe trials, the single probe occupied either the same location as in the original display or a new location that had previously been unfilled. On Changed binding old location trials, the location was the one that matched in shape on half the trials and in color on the other half of the trials. The location factor was blocked, and the order counterbalanced between participants.
Whole Display or Single Probe. With Whole Display probes there were three colored shapes in the probe as well as in the initial display. With Single Probes, there was only one item in the probe display. There were an equal number of trials of each type and they were randomly mixed within blocks. Figure 5 shows examples of each combination of same and different location and same and different binding for the Whole Display condition.
Delay of 900 ms or 100 ms: One group of 13 participants (5 men) was tested with a delay of 900 ms between the initial display and the probe, and another group of 13 participants (5 men) was tested with a delay of 100 ms.
Each participant did 32 trials in each combination of binding, location, and probe type. On each trial the sequence of events was as follows: A small black cross was presented at center screen for 1000 ms, then a blank screen for 900 ms, then an initial display of three items flashed for 150 ms, then a 900 ms blank interval for the long delay group and a 100 ms blank interval for the short delay group, and finally a test display which remained present until a response was made, or for 4000 ms, whichever came first. Participants were told that the same features would be present in the original display and in the probe. They were to indicate by a key-press whether there was a change of binding in the probe display or whether the shapes and colors were paired as in the original display. In the New Locations condition, they were told that the test items would appear in new locations, but that this was not relevant to their task. They were to respond solely to the bindings of color and shape. The ratio of Match to Changed-Binding trials was 1:1, and this was balanced across all levels of the other two factors. No articulatory suppression was used, since with 100 ms delay, there was no time for it, and we did not wish delay to be confounded with possible articulatory interference. Participants were instructed to aim for accuracy, and received a tone as feedback if they made an error. At the beginning of the experiment, they practiced 16 trials of each block type and were given a chance to ask questions. At the conclusion, they were given an opportunity to comment and ask questions and then were debriefed.
Results and Discussion
The mean accuracy in each condition is shown in Figure 6. An ANOVA showed a significant effect of location (F(1.24) = 52.34, p<.0001), with better performance in the old locations (83.9 vs 75.3%). There was also a significant interaction of probe type and location (F(1,24)= 82.28, p<.0001), showing that the location difference was much reduced in the Single Probe trials (3% difference compared to 14%). Neither delay nor probe type nor their interaction had significant effects, but the three-way interaction between delay, location and probe type was highly significant (F(1,24) = 14.80, p<.001). Relative locations are available only in the Whole Display conditions and these seem to be mediating the effects of location. At the short delay, changing the locations in the Whole Display probes led to a drop of 18%, while at the long delay the drop was only 9%. The result suggests that the object files are initially closely dependent on location and that the direct link between the features is gradually consolidated over the first second of delay, reducing without eliminating the dependence on location.
Figure 6.

Accuracy in recognition of binding in VWM as a function of delay and of old or new locations
Although at the shortest delay there was some apparent motion with the Single probe New location displays, it does not seem to have had much effect on performance. The results are almost identical to those at 900 ms. With the Whole display probes, the apparent motion was not present or was very much weaker, probably because the three new locations were randomly related to the three original locations, so that the three items could not be seen to move coherently. It is unlikely therefore that apparent motion is responsible for the large effect of location at the shortest delay.
Finally, in the present experiment, Match versus Changed-Binding gave highly significant effects (F(1,24) = 40.27, p<.0001) with an overall bias of 84% to 75% to say “Match”. There was also a shift in this bias across the different probe types: the Single Probe favored the response “Change” by 3% and the Whole Display probes favored the response “Match” by 14%, giving a significant interaction between probe type and response (F(1,24) = 73.44, p<.0001). The default assumptions seem to be that the Whole Display probes are the same as the originals and that the Single Probes are changed. Thus there were strong biases in opposite directions, favoring change blindness with the Whole Display, and match blindness with the Single Probe. Participants were particularly likely to miss the change of binding in the new locations of the Whole Displays.
The results support a number of conclusions: First, locations are clearly more important in memory for binding than they are in memory for features, where they had no main effect on recognition. With feature memory, even when the binding was unchanged, probes in the old locations were only about 3% better recognized than those in new locations, whereas with memory for binding, the drop due to new locations with Whole Display probes averaged 9% at the 900 ms delay. The greater importance of location in memory for binding is consistent with the claim from FIT that spatial attention is involved in binding features and establishing object files.
Secondly, the effect of location is considerably stronger immediately after presentation than after 900 ms, as though the bindings initially depend heavily on location and become less dependent with time. The bindings may start as feature-location bindings, while the feature-feature bindings take time to consolidate, reducing the dependence on location as time passes and the object file becomes more firmly established. Thirdly, the location effects are almost entirely restricted to the Whole Display probes, implying that the locations are coded as a spatial pattern of relative rather than absolute locations.
EXPERIMENT 4: Interference with memory for binding
In this experiment, we ran some variations on Experiment 3 to look at different kinds of interference that might reveal more about the nature of the VWM representations. The method was identical to that in Experiment 3 except that in Experiment 4a, participants were required to use articulatory suppression (they repeated the word “Coca-cola” over and over throughout each trial). In Experiment 4b, they saw a single word presented between the initial display and the probe. They were told to read the word to themselves, but no other task was required. The goal was to see whether simply attending to another visual stimulus with different properties and semantic characteristics would disrupt the memory for binding. Two groups of twelve participants (6 men in Experiment 4a and 4 men in Experiment 4b), ran in each of these two additional experiments.
Figure 7 shows the results, together with the control condition from the 900 ms delay in Experiment 3. The pattern is very similar across the three experiments with just a slight and non-significant reduction in recognition memory with articulatory suppression and with word interference. We ran separate between-group ANOVAS, pairing the 900 ms baseline condition from Experiment 3 with each of the two experimental variations - articulatory suppression, and intervening word. Table 2 shows the significance levels in these ANOVAs.
Figure 7.

Accuracy in recognition of binding with articulatory suppression and with intervening visual presentation of a word
Table 2.
ANOVAs on effects of articulatory suppression and word interference (both relative to 900 ms delay with no articulation).
| Articulation | Word interference | |
|---|---|---|
| Experiment (Baseline vs. Interference) | N.S. (p=.075). N.S. | |
| Location (Old versus New) | 35.38*** | 30.89*** |
| Probe type (Single vs.Whole Display) | N.S. | N.S. |
| Location × Probe type | 34.17*** | 11.64*** |
| Match (versus Changed binding) | 35.39*** | 23.33*** |
| Match × Probe type | 170.33*** | 163.24*** |
| Match × Probe type × Experiment | 6.67* | NS |
| Match × Probe type × Location | 32.53*** | 18.86*** |
| Match × Probe type × Location × Experiment NS | 6.95* | |
There were no significant main effects of Experiment, (although the impairment due to articulatory suppression approached significance, suggesting some minimal benefit from verbal coding). Either participants do not attempt to store verbal labels or they are not particularly helpful in this recognition memory task. Performance in Experiment 4b was not impaired by the presentation of an extraneous word during the delay period. VWM clearly differs from iconic memory. The material has been encoded into a format which is no longer vulnerable to intervening visual events, at least when they are different enough in category (word versus colored shapes).
Old versus New locations had a highly significant effect in both ANOVAs. As in Experiment 3, performance dropped significantly when the probe items were presented in new locations rather than reappearing in the original locations. Again this is a clear contrast with the findings with feature memory in Experiment 1, suggesting that location plays an important role specifically in the retention as well as in the encoding of binding. Location change also interacted strongly with probe type, with large effects on Whole Display trials and little effect with the Single Probes, probably because the pattern of relative locations is preserved only with Whole Display probes.
Again there was an overall bias to respond “Same” rather than “Different” (80 versus 73%), and also a highly significant two-way interaction between Probe type and Match vs. Changed binding. The mean correct responses were 90% “Match” and 63% “Changed” for the Whole Display, but the bias was reversed to 71% “Match” and 83% “Changed” for Single Probes. Finally the three-way interactions between Probe type, Location, and Match versus Changed binding were also highly significant. These three-way interactions reflect the very poor performance in detecting the change of binding in a New location with Whole Display probes.
EXPERIMENT 5: The effects of longer delays on VWM for binding
We had two goals in this experiment: First to see what happens to the role of location in memory for binding at somewhat longer delays, and secondly to see whether the previous results reflected specific strategies that might be absent when the participants could no longer predict either the delay interval or the probe locations. In the present experiment we randomly mixed within blocks both the locations and the delays rather than testing them separately. It seemed possible that participants might encode the display differently when they knew whether it would be probed immediately or only after a delay, and whether the probe items would appear in the same locations or in different locations.
Method
Apparatus and stimuli
These were the same as in Experiment 3.
Procedure
The procedure was the same as for the Whole Display condition in Experiment 3 with the following exceptions. Two additional delays between the initial display and the probe, 3 sec and 6 sec, were added to the 100 ms and 900 ms delays tested before, and the four delays were presented randomly mixed within blocks. The old and new location trials were also randomly mixed within blocks rather than separated as they had been in the earlier experiments. Participants repeated the word “coca-cola” throughout each trial in order to prevent verbal coding of the displays.
Results
An ANOVA on Experiment 5 again showed a significant overall benefit in memory for binding when tested in Old rather than in New locations (F(1,14)= 38.70, p<.001). There was no overall effect of delay (F(3,14) = 2.27, p= .094), suggesting that VWM for binding retains its strength for at least a few seconds after the stimuli have disappeared, provided that there is no additional interference. However, a more detailed analysis shows marked changes in the nature of the memory trace over those first few seconds (see Figure 8). There was a significant interaction of location with delay (F(3,42) = 9.61, p<.001), reflecting the fact that items in Old locations were much better recognized than items in New ones at the very short intervals but that this advantage dropped smoothly across delay from 0.1 to 6 sec (see Figure 8). Memory for items in New locations steadily increased over time up to 3 sec, then began to drop in parallel with memory for items in the Old locations. After three seconds have passed, recognition of the bindings is almost as good when they are seen in a new location as in the original one. Before that, there is substantial benefit from a matching location and also substantial interference when the probes appear in new locations. The results suggest that immediately after presentation, location is an integral part of the representation of the objects, and/or is actively used in the retrieval process, but as time passes the binding between the features within objects is consolidated and need no longer be mediated primarily through their shared location.
Figure 8.
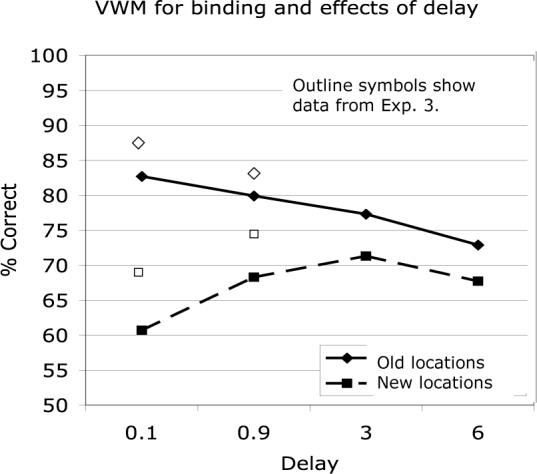
Effects of longer delays on VWM for binding in Experiment 5
There is a significant bias to say “Same” binding overall, in other words to miss the changes in binding (F(1,14) = 63.60, p<.001), suggesting a propensity to form illusory conjunctions in memory to match those that have just been seen. There is also a significant interaction of response bias with delay (F(3,42) = 12.35, p<.001), shown in Figure 9. The bias peaks around 0.9 seconds and has disappeared at 6 sec. There is no three-way interaction with location. As the original binding between the features is consolidated over time, the propensity to form illusory conjunctions may also be reduced.
Figure 9.
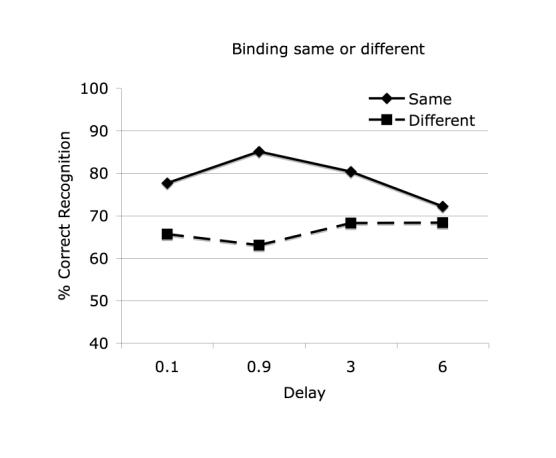
Response biases across delays in Experiment 5
The present participants were less accurate overall than those in Experiment 3. The drop in performance may be explained by the increased uncertainty about where the probe would appear and how soon, and also by the fact that there was articulatory suppression throughout the trials in Experiment 5 but not in Experiment 3. However the pattern of performance on old and new location trials at the two short delays was strikingly similar across the experiments, suggesting that these effects are inherent to VWM for binding and are not induced by different strategies adapted to the particular conditions being tested.
General Discussion
Our research was directed at two related questions: (1) What is the relation between memory for locations and memory for their contents, - both features, and bound objects? (2) Is binding automatic when attention is directed to each item in a display, or do we have the option of storing only the separate features? Data from Wheeler and Treisman (2002) suggested that VWM can hold both separate features, perhaps in the form of traces activated in separate feature maps during perceptual processing, and bound objects when attentional resources are available. This raises the question whether we have strategic control of the format used in VWM?
Location
One of the striking findings was the greater dependence of recognition on location when we tested the bindings than when we tested memory for the features. In explicitly retrieving bound objects, the original locations provide strong support. If locations and objects were stored independently, it is hard to see how we could get these strong dependencies. At the least there must be strong connections facilitating retrieval of the object through its location and perhaps of the location through the object. Evidence consistent with the idea that object retrieval can be facilitated by location information comes from a study of memory for objects in natural scenes by Hollingworth & Henderson (2002). They showed that fixating the location in which an object had appeared facilitated its retrieval.
Features too are clearly stored and retrieved preferentially through their locations, as shown by the strong interactions of location with binding and with Match versus New Feature. However, when tested in new locations they can be accessed independently of their original locations without loss of accuracy. Retrieval from VWM may be initially and naturally at the object level, where features have been bound to their locations and to each other, but if this route is ruled out because the locations are new, unbound features can still be retrieved, perhaps from separate feature modules, by matching to those in the probe. These conclusions are consistent with those drawn by Wheeler and Treisman (2002).
Another finding is that the locations in our tests of VWM seem to be defined as relative locations in a spatial configuration rather than as absolute locations, either in the real world or on the retina. Evidence for this comes from the fact that with Single Probes, where no pattern of spatial relations was available, location matches had no effect on feature memory and little effect on memory for binding. A similar conclusion was reached by Jiang, Olson, and Chun (2000), who found that changes in spatial configuration disrupted VSTM for color or shape even though the configuration was irrelevant to the task. It is possible that absolute locations can also be stored when they are relevant to the task, but we find little evidence that they contribute to memory when they are not explicitly needed.
Binding
Features are also better retrieved when probed in their original conjunctions rather than in new ones. A new binding presented in a location that contained one of the re-bound features was very often interpreted as a new feature, giving only 51% correct recognition on Match trials. A critical question is whether the changed bindings also damage recognition when probed in new locations. The fact that they do (participants were 8% worse on changed bindings than same bindings in New locations) implies that features are bound to each other as well as to their locations. Thus it seems that features are automatically bound in memory, even when this is not required and even when it actually interferes with feature recognition. Binding is not optional; it occurs as a direct consequence of attending to an object and storing it for later recognition. This is a new finding to add to the model proposed by Wheeler and Treisman (2002).
Note that for changes in location and/or in binding to affect performance even when they are irrelevant to the task, they must be mediated by changes in the perceptual and/or memory representations, not simply by objective differences in similarity between the original displays and the probes. Thus they provide evidence that (1) when only the features are relevant, they are nevertheless at least to some degree bound to each other and to their locations, and (2) that when the bindings are relevant, locations play an important role in their early retention and retrieval.
Verbal coding
There was little decrement for the group who were required to repeat the word “coca-cola” during the presentation, delay, and response. If articulatory suppression is assumed to remove or reduce the possibility of verbal coding, we can conclude that participants do not rely on verbal coding with these brief displays of colored shapes. The interaction between Articulation, Probe type, and Same versus Different binding suggests that if there is any interference from articulation it is primarily with the detection of a match in the Single probe condition.
Visual interference
The presentation of an extraneous visual pattern (the word) in the same general area as the display had no effect on recognition of color-shape bindings. Thus pulling visual attention to an irrelevant intervening stimulus is not sufficient to disrupt visual memory for binding. It is possible, of course, that more similar visual stimuli or a more attention-demanding task would interfere. Our data are consistent with those of Woodman, Vogel, & Luck (2001) (testing feature memory rather than binding). They asked whether an intervening search task interfered with VWM. The estimated memory capacity was 3.2 items with memory alone and 2.7 with search added. Using the same type of items (Landolt Cs) in memory and in search did not increase the interference, ruling out a similarity-based account. Finally in another experiment, the search stimuli were shown but participants could ignore them. Again memory dropped from 3.3 to 2.6 items. Thus the requirement to search had no additional effect beyond some small, shared visual disruption. On the other hand if one of the search stimuli had to be remembered as well as the colored squares, memory was considerably impaired. Woodman et al. conclude that “objects can be attended at a perceptual level without automatically being entered into working memory.”
Overall, the absence of effect of these two manipulations suggests that the characteristics of visual memory that we have probed in this paradigm are fairly robust. Working memory is much more affected by the factors that we varied within experiments, - the new or old locations and the nature of the probe.
Delay
Memory for binding, although limited, seems neither to decay very fast nor to improve much across brief intervals after presentation. It is possible, of course that if we had tested longer delays, we would have seen more decrements. The main change over time in the first few seconds after presentation is seen in the effect of location. There is a marked improvement in performance in New locations, accompanied by a decrease in performance in the Old locations. Apparently, the traces become less location-specific over the first few seconds of delay, dropping to an asymptotic advantage for Old locations of only 6% after 3 seconds (Figure 8). There was also a marked bias to say “Same” (or to rely on feature matches and to miss changes of binding) at the shorter delays. This disappears by 6 sec. delay.
How does our framework relate to earlier theories of visual short-term memory, such as those proposed by Phillips (1974) and by Irwin (1992). Phillips suggested that short-term visual memory goes through two stages – an initial brief, high capacity, topographic, sensory store, subject to masking, and a more limited but longer-lasting schematic memory that survives for a few seconds. Irwin (following Coltheart, 1980) distinguished three stages: precategorical visible persistence and nonvisible information persistence, both of which contribute to traditional measures of iconic memory, and post-categorical visual short-term memory. Visible persistence depends on exposure duration whereas information persistence does not, but information persistence shares with visible persistence properties like its high capacity for detailed form and structure information, and it remains maskable, whereas VWM is more abstract and is limited to about five items. Where would our studies fit in relation to these hypothesized stores? At 100 ms delay visible persistence has ended since the stimulus itself lasted 150 ms and visible persistence is measured from stimulus onset rather than offset (Di Lollo, 1980). Could performance at our 100 ms delay be using informational persistence? Informational persistence lasts about 150 to 300 ms after stimulus offset (Irwin &Yeomans, 1986; Phillips, 1974; Yeomans & Irwin, 1985). However, there is no evidence that masking by the probe display played any role in our Old location conditions, although informational persistence, like sensory persistence, should be subject to visual masking: Accuracy was, if anything, better at 100 ms delay than at 900 ms. and better in the old locations than in the new. Nevertheless, the dependence on location fits better with the sensory than with the schematic store.
An alternative account that seems more consistent with our data emphasizes the distinction between different types of information: the separate features and locations on the one hand, and the object files on the other, all of which may coexist and contribute to performance at early intervals after presentation. Features and locations are registered automatically in separate maps and their traces may last for brief durations after the stimulus is removed. Meanwhile, object files are formed as attention scans the display to integrate their features. These are initially tied to locations as attention is focused on them. As time passes there is a gradual consolidation in which the object features are bound more firmly to each other and become less dependent on their locations. We see the change from early to late object files as more of a continuum than a dichotomous translation. In the early stages, together with the persisting traces of features and locations, they may function most like the sensory and informational persistence described by Irwin and others. In the later stages, attended object files become gradually abstracted from sensory details and from their locations and are consolidated into the more lasting representations attributed to VWM.
Whole display versus Single probe
We hoped that the comparison of Whole display with Single probe cues for retrieval might throw light on the retrieval process in VWM. Would the reinstatement of the complete context make the matching process easier, or would it add to the decision load? In the Wheeler and Treisman experiments (2002), memory for binding was better with a Single Probe than with the Whole Display, whereas memory for features showed no effect of probe type. We proposed that when three items are presented in the probe and the bindings have to be checked, attention must be focused on each item in turn to ensure accurate binding. This pulls attention away from the stored items and leads to some loss of binding in memory. When the probe is a single item, there is less need for attention, since its features can be bound by default. When only the separate features are tested, differential demands on attention are less important.
In the present experiments, we see the reverse pattern (see Figure 10): Memory for features was better with the Single Probes, whereas memory for bindings was, if anything, worse with the Single Probe than with the Whole Display, averaging 75% with the Single Probes and 79% with the Whole Display. Does this inconsistency cast doubt on the Wheeler and Treisman model? We think not. The discrepancy can be explained by some important differences of method in the two experiments. Firstly, in the present feature memory experiments, we were not directly interested in the relative difficulty of recognizing changes of features versus binding, so we changed only one feature on New feature trials, whereas Wheeler and Treisman changed two features on Whole Display New feature trials, in order to match the load across features and bindings. This made their feature recognition tests much easier than the present ones. Secondly our feature recognition tests were also disrupted by changes of binding, which never occurred in the feature memory tests of Wheeler and Treisman. Again this would damage the Whole display tests more than the Single probes, since more items differed on changed binding trials.
Figure 10.
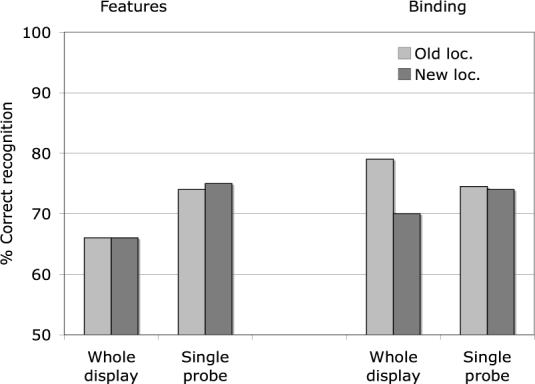
Comparison of Whole display and Single probe in tests of memory for features and memory for binding
Finally, in both the binding and the feature tests, the relation between the locations in the original display and in the probes was different in the present experiments from those in Wheeler and Treisman. In the Whole Display trials of their color-shape experiment, Wheeler and Treisman (2002) reused the same locations but exchanged items between those locations, whereas in Single probe trials, the probe was always presented at the center of the display in a location that was previously empty. Thus the interference on their Whole display trials could have come partly from overwriting the previous memory traces, whereas the Single probe would not interfere with any location-specific traces. In the current experiments, we used new locations in half the trials and old locations with the original allocation of items on the other half (apart from the change in binding on New Binding trials). Thus the present participants could benefit on Old location trials from the preserved location-feature bindings, giving performance that was actually better on Whole Display than on Single probe trials. If we look only at trials with new locations, we replicate the Wheeler and Treisman finding of better performance with the single probe (78% versus 72%), consistent with the attention overload hypothesis that we suggested in the earlier paper.
Our findings suggest that the comparison between these two probe types is complicated by a number of different factors: Whole display probes load attention and decision processes more than Single probes and they may overwrite the earlier memory traces if new items appear in the old locations. On the other hand, they may help retrieval by reinstating the complete context including the relative locations if these are preserved in the probes.
Bias
In looking at the relative frequencies of responses of “Same” and of “Different”, we made an interesting observation. The overall bias was to respond “Same” with the Whole Display and “Different” with the Single Probe, particularly with probes in the Old locations. Thus task differences seem to induce different strategies for performing the tasks: With the Whole Display probes, most items from the initial display match items in the probe, so it makes sense to look for a change, and to have “no change” as a default assumption. On the other hand in the Single Probe condition, most of the initial display items do not match the single probe, so it makes more sense to look for a match. Note that these overall biases cannot explain differences in performance within the two probe types. In the Old locations, people are better not only on Match trials but also on Changed binding trials where the response should be “Different”, and in New locations, they are better, not only on Changed binding trials but also on Match trials where the response should be “Same”.
Capacity
Our three-item displays were correctly recognized on about 80% of trials. Using the formula devised by Pashler (1988) for estimating the capacity of VWM, (capacity k = (S × (H-F))/(1-F), where S items are presented, H is the Hit rate, and F is the false alarm rate), the capacity in our experiments averaged only about 2 objects. This is substantially less than the estimate of 3 to 4 objects reported in a feature memory experiment by Luck and Vogel (1997). The estimate given by Luck & Vogel may be higher in part because they tested displays with more than three items presented, giving more scope for higher recognition scores, and also in part because they tested feature memory without changing the binding.
However, the change of bias with the different probe types described in the previous paragraph raises a question about this measure of capacity. We assumed in making the calculations that detecting a change counts as a hit. But a hit could instead be the correct detection of a match between probe and memory set. The estimates change with the assumption selected. For example with the Single Probes in new locations, the estimates are 2.35 if participants are looking for a change of binding and 2.02 if they are looking for a match. If we follow the response biases and infer change blindness in Whole Display probes and match blindness with Single Probes, we should take responses of “Different” as hits with the Whole Display probes and responses of “Same” as hits with the Single Probes. The capacity would then be 1.57 for the Whole Display and 2.02 for the Single Probe, making the Whole Display condition a little worse than the Single Probe. If we reverse these assumptions, the Whole Display estimate would be 2.45 and the Single Probe estimate would be 2.35 or slightly worse than the Whole Display. The former assumptions seem more plausible here, but in general we would argue that the ambiguity needs to be resolved in each experiment before VWM capacity can be estimated.
Conclusions
The view of VWM that emerges from these experiments is of a representation that is still close to the perceptual encoding. Attended objects are automatically bound to their locations within a spatial configuration (not to absolute locations), and their features are integrated with each other. There is in addition some memory for unbound features, perhaps for items that did not receive attention in the brief presentations we used, or for items that lost their binding during the memory delay. The locations become less salient, or the objects become detached from their locations, over the first seconds after presentation, but at 900ms delay they still play a substantial role in feature retrieval and they are still critical in retrieving the bindings. The implications are consistent with the FIT view that features are initially registered preattentively in separate feature maps, while at the same time the filled locations activate areas in a map of locations. If focused attention is directed to each filled location, it binds the features to their locations and to each other perceptually, forming object files that are, at least initially, addressed by their current location. Once the object files have been set up and the features bound, they may be identified, verbally labeled, and stored independently of their locations, but the initial representations integrate the locations with the features in bound object tokens. These form the main content of VWM.
Finally, how do we reconcile this framework for our experiments with the behavioral and neural evidence that objects and locations occupy separate stores? Our experiments directly tested only memory for “what?”, providing indirect evidence about memory for “where?”. Experiments 3 to 5 cast doubt on the possibility of storing bound objects without their locations, at least in the initial phases of memory encoding. However, the inference need not be symmetrical. We suggest that, if the task requires it, the pattern of filled locations may be stored without the features or objects that occupy them, which in this context would act simply as place markers.
Table 1.
Mean accuracy in Shape memory with Whole Display and Single Probe test
| Single probe (Experiment 2) | ||||
|---|---|---|---|---|
| Match | New | Mean | ||
| Same binding | Different binding | |||
| Same location | 78 | 72 | 73 | 74 |
| Different location | 82 | 74 | 71 | 75 |
| Mean | 80 | 73 | 72 | |
| Whole display (Experiment 1) | ||||
| Same location | 86 | 51 | 63 | 66 |
| Different location | 78 | 70 | 58 | 66 |
| Mean | 82 | 60 | 61 | |
Acknowledgements
The research was supported by grants from the NIH Conte Center # P50 MH62196, from the Israeli Binational Science Foundation, # 1000274, and from NIH grant 2004 2RO1 MH 058383-04A1 Visual coding and the deployment of attention.
References
- BADDELEY A. Is working memory working? The Fifteenth Bartlett Lecture. Quarterly Journal of Experimental Psychology. 1992;44:1–32. [Google Scholar]
- BRAINARD DH. The psychophysics toolbox. Spatial Vision. 1997;10:433–436. [PubMed] [Google Scholar]
- CARLESIMO G, PERRI R, TURRIZIANI P, TOMAIUOLO F, CALTAGIRONE C. Remembering what but not where: independence of spatial and visual working memory in the human brain. Cortex. 2001;37:519–534. doi: 10.1016/s0010-9452(08)70591-4. [DOI] [PubMed] [Google Scholar]
- CARLESIMO GA, OSCAR-BERMAN M. Memory deficits in Alzheimer's patients: A comprehensive review. Neuropsychology Review. 1992;3:119–169. doi: 10.1007/BF01108841. [DOI] [PubMed] [Google Scholar]
- COLTHEART M. “Iconic memory and visible persistence.”. Perception and Psychophysics. 1980;27:183–228. doi: 10.3758/bf03204258. [DOI] [PubMed] [Google Scholar]
- COURTNEY SM, UNGERLEIDER L, KEIL K, HAXBY J. Object and spatial visual working memory activate separate neural systems in human cortex. Cerebral Cortex. 1996;6:39–49. doi: 10.1093/cercor/6.1.39. [DOI] [PubMed] [Google Scholar]
- DI LOLLO V. Temporal integration in visual memory. Journal of Experimental Psychology: General. 1980;109:75–97. doi: 10.1037/0096-3445.109.1.75. [DOI] [PubMed] [Google Scholar]
- HANLEY J, YOUNG A, PERSON N. Impairment of the visuo-spatial sketchpad. Quarterly Journal of Experimental Psychpology. 1991;43A:101–125. doi: 10.1080/14640749108401001. [DOI] [PubMed] [Google Scholar]
- HAXBY J, PETIT L, UNGERLEIDER L, COURTNEY S. Distinguishing the Functional Roles of Multiple Regions in Distributed Neural Systems for Visual Working Memory. Neuroimage. 2000;11:98–110. doi: 10.1006/nimg.1999.0527. [DOI] [PubMed] [Google Scholar]
- HECKER R, MAPPERSON B. Dissociation of visual and spatial processing in working memory. Neuropsychologia. 1997;35:599–603. doi: 10.1016/s0028-3932(96)00106-6. [DOI] [PubMed] [Google Scholar]
- HOLLINGWORTH A, HENDERSON JM. Accurate visual memory for previously attended objects in natural scenes. Journal of Experimental Psychology: Human Perception and Performance. 2002;28:113–136. [Google Scholar]
- IRWIN D. Visual memory within and across fixations. In: Rayner K, editor. Eye movements and visual cognition: Scene perception and reading. Springer-Verlag; New York: 1992. pp. 146–165. [Google Scholar]
- IRWIN DE, ANDREWS RV. Integration and accumulation of information across saccadic eye movements. In: McClelland J, Inui T, editors. Attention and Performance XVI: Information integration in perception and communication. MIT Press; Cambridge, MA: 1996. pp. 125–155. [Google Scholar]
- IRWIN DE, YEOMANS JM. Sensory registration and informational persistence. Journal of Experimental Psychology: Human Perception and Performance. 1986;12:343–360. doi: 10.1037//0096-1523.12.3.343. [DOI] [PubMed] [Google Scholar]
- JIANG Y, OLSON IR, CHUN MM. Organization of visual short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2000;26:683–702. doi: 10.1037//0278-7393.26.3.683. [DOI] [PubMed] [Google Scholar]
- KAHNEMAN D, TREISMAN A, GIBBS B. The reviewing of object files: Object-specific integration of information. Cognitive Psychology. 1992;24:175–219. doi: 10.1016/0010-0285(92)90007-o. [DOI] [PubMed] [Google Scholar]
- LOGIE RH, MARCHETTI C. Visuo-spatial working memory: Visual, spatial, or central executive? In: Logie RH, Denis M, editors. Mental images in human cognition. Elsevier; 1991. [Google Scholar]
- LUCK SJ, VOGEL EK. The capacity of visual working memory for features and conjunctions. Nature. 1997;390:279–281. doi: 10.1038/36846. [DOI] [PubMed] [Google Scholar]
- MAGNUSSEN S. Low level memory processes in vision. Trends in Neuroscience. 2000;23:247–251. doi: 10.1016/s0166-2236(00)01569-1. [DOI] [PubMed] [Google Scholar]
- MOTTAGHY FM, GANGITANO M, SPARING R, KRAUSE B, PASCUAL-LEONE A. Segregation of areas related to visual working memory in the prefrontal cortex revealed by rTMS. Cerebral Cortex. 2002;12:369–375. doi: 10.1093/cercor/12.4.369. [DOI] [PubMed] [Google Scholar]
- MUNK M, LINDEN D, MUCKLI L, LANFERMANN H, ZANELLA F, SINGER W, GOEBEL R. Distributed cortical systems in visual short-term memory revealed by event-related functional magnetic resonance imaging. Cerebral Cortex. 2002;12:866–876. doi: 10.1093/cercor/12.8.866. [DOI] [PubMed] [Google Scholar]
- NUNN J, POLKEY C, MORRIS R. Selective spatial memory impairment after right unilateral temporal lobectomy. Neuropsychologia. 1998;25:726–737. doi: 10.1016/s0028-3932(98)00030-x. [DOI] [PubMed] [Google Scholar]
- PASHLER H. Familiarity and visual change detection. Perception and Psychophysics. 1988;44:369–378. doi: 10.3758/bf03210419. [DOI] [PubMed] [Google Scholar]
- PELLI DG. The video toolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision. 1997;10:437–442. [PubMed] [Google Scholar]
- PHILLIPS WA. On the distinction between sensory storage and short-term visual memory. Perception and Psychophysics. 1974;16:283–290. [Google Scholar]
- POSTLE B, D'ESPOSITO M. “What”—Then—“Where” in Visual Working Memory: An Event-Related fMRI Study. Journal of Cognitive Neuroscience. 1999;11:585–597. doi: 10.1162/089892999563652. [DOI] [PubMed] [Google Scholar]
- POSTLE B, STERN C, ROSEN B, CORKIN S. An fMRI Investigation of Cortical Contributions to spatial and nonspatial visual working memory. Neuroimage. 2000;11:409–423. doi: 10.1006/nimg.2000.0570. [DOI] [PubMed] [Google Scholar]
- PRABHAKARAN V, NARAYANAN K, ZHAO Z, GABRIELI JD. Integration of diverse information in working memory within the frontal lobes. Nature Neuroscience. 2000;3:85–90. doi: 10.1038/71156. [DOI] [PubMed] [Google Scholar]
- RAO SC, RAINER G, MILLER EK. Integration of What and Where in the primate prefrontal cortex. Science. 1997;276:821–824. doi: 10.1126/science.276.5313.821. [DOI] [PubMed] [Google Scholar]
- RIZZUTO DS, MAMELAK AN, SUTHERLING WW, FINEMAN I, ANDERSEN RA. Spatial selectivity in human ventrolateral prefrontal cortex. Nature Neuroscience. 2005;8:415–417. doi: 10.1038/nn1424. [DOI] [PubMed] [Google Scholar]
- SMITH EE, JONIDES J, KOEPPE RA, AWH E, SCHUMACHER EH, MINOSHIMA S. Spatial versus object working memory: PET investigations. Journal of Cognitive Neuroscience. 1995;7:337–356. doi: 10.1162/jocn.1995.7.3.337. [DOI] [PubMed] [Google Scholar]
- STEFURAK DL, BOYNTON RM. Independence of memory for categorically different colors and shapes. Perception and Psychophysics. 1986;39:164–174. doi: 10.3758/bf03212487. [DOI] [PubMed] [Google Scholar]
- TREISMAN A. Focused attention in the perception and retrieval of multidimensional stimuli. Perception & Psychophysics. 1977;22:1–11. [Google Scholar]
- TREISMAN A, GELADE G. A feature integration theory of attention. Cognitive Psychology. 1980;12:97–136. doi: 10.1016/0010-0285(80)90005-5. [DOI] [PubMed] [Google Scholar]
- TRESCH MC, SINNAMON HM, SEAMON JG. Double dissociation of spatial and object visual memory: Evidence from selective interference in intact human subjects. Neuropsychologia. 1993;31:211–219. doi: 10.1016/0028-3932(93)90085-e. [DOI] [PubMed] [Google Scholar]
- VOGEL EK, WOODMAN GF, LUCK SJ. The time course of consolidation in visual working memory. doi: 10.1037/0096-1523.32.6.1436. personal communication. [DOI] [PubMed] [Google Scholar]
- VUONTELA V, RAMA P, RANINEN A, ARONEN H, CARLSON SD. Selective interference reveals dissociation between memory for location and color. Neuroreport. 1999;10:2235–2240. doi: 10.1097/00001756-199908020-00002. [DOI] [PubMed] [Google Scholar]
- WHEELER ME, TREISMAN AM. Binding in short-term visual memory. Journal of Experimental Psychology: General. 2002;131:48–64. doi: 10.1037//0096-3445.131.1.48. [DOI] [PubMed] [Google Scholar]
- WILSON FA, O SCALAIDHE SP, GOLDMAN-RAKIC PS. Dissociation of object and spatial processing domains in primate prefrontal cortex. Science. 1993;260:1955–1958. doi: 10.1126/science.8316836. [DOI] [PubMed] [Google Scholar]
- WOODMAN G, LUCK S. Visual search is slowed when visuospatial working memory is occupied. Psychonomic Bulletin & Review. 2004;11:269–274. doi: 10.3758/bf03196569. [DOI] [PubMed] [Google Scholar]
- WOODMAN GF, VOGEL EK, LUCK SJ. Visual search remains efficient when visual working memory is full. Psychological Science. 2001;12:219–224. doi: 10.1111/1467-9280.00339. [DOI] [PubMed] [Google Scholar]
- WOODMAN G, VOGEL E, LUCK SJ. Independent visual working memory stores for object identity and location. 2005 in press. [Google Scholar]
- YEOMANS JM, IRWIN DE. Stimulus duration and partial report performance. Perception & Psychophysics. 1985;37:163–169. doi: 10.3758/bf03202852. [DOI] [PubMed] [Google Scholar]
- ZIMMER H, SPEISER H, SEIDLER B. Spatio-temporal working-memory and short-term object location tasks use different memory mechanisms. Acta Psychologica. 2003;114:41–65. doi: 10.1016/s0001-6918(03)00049-0. [DOI] [PubMed] [Google Scholar]