

Abstract
Background
Although numerous epidemiologic studies now use models of intraurban exposure, there has been little systematic evaluation of the performance of different models.
Objectives
In this present article we proposed a modeling framework for assessing exposure model performance and the role of spatial autocorrelation in the estimation of health effects.
Methods
We obtained data from an exposure measurement substudy of subjects from the Southern California Children’s Health Study. We examined how the addition of spatial correlations to a previously described unified exposure and health outcome modeling framework affects estimates of exposure–response relationships using the substudy data. The methods proposed build upon the previous work, which developed measurement–error techniques to estimate long-term nitrogen dioxide exposure and its effect on lung function in children. In this present article, we further develop these methods by introducing between- and within-community spatial autocorrelation error terms to evaluate effects of air pollution on forced vital capacity. The analytical methods developed are set in a Bayesian framework where multistage models are fitted jointly, properly incorporating parameter estimation uncertainty at all levels of the modeling process.
Results
Results suggest that the inclusion of residual spatial error terms improves the prediction of adverse health effects. These findings also demonstrate how residual spatial error may be used as a diagnostic for comparing exposure model performance.
Keywords: air pollution, Bayesian analysis, lung function, measurement error, spatial exposure models
Leading researchers have identified the development of models for assessing air pollution exposure within cities as a priority for future research (Brauer et al. 2003; Brunekreef and Holgate 2002; National Research Council 2002). In the present article we compare and evaluate four spatial models for assigning air pollution exposure at the within-community or intraurban scale. We assess how each model predicts exposure and affects health risks in the context of the Southern California Children’s Health Study (CHS; Peters et al. 1999a, 1999b). The CHS study assessed childhood lung function in 12 communities selected to represent a range of exposures. Effects of a correlated group of pollutants, including particulate exposure and nitrogen dioxide were associated with deficits in forced vital capacity (FVC, a measurement of lung volume) and forced expiratory volume in 1 sec (FEV1, a measurement of flow rate) (Gauderman et al. 2004, 2007; Molitor et al. 2006; Peters et al. 1999b). The data allow us to examine the effect of incorporating spatial residual errors into the modeling framework of Molitor et al. (2006), potentially explaining a spatial structure not accounted for by the exposure predictors. Therefore, the data serve as a foundation on which to test different exposure models with and without spatially distributed errors and to examine the role of exposure measurement error in air pollution studies.
Interest in assessing exposure at the intraurban scale has grown for a variety of reasons, including early evidence of the large adverse health effects that may emerge from this scale of analysis. For example, Hoek et al. (2002) reported a near doubling of cardiopulmonary mortality [relative risk = 1.95; 95% confidence interval (CI), 1.09–3.52] for Dutch subjects living near major roads in a cohort of 5,000 people, after control of many confounding variables. Although these findings may be robust, the basic exposure models used in these analyses may misclassify exposure because they treat the continuous air pollution field as a discrete entity, that is, either within or outside a specified distance from a road (Jerrett et al. 2005a, 2005b). Thus, questions remain about the validity of results from health effects studies that use exposure surrogates such as road buffers.
Other factors have heightened interest in assessing the relation between air pollution and adverse health effects at the intraurban scale. Empirical exposure studies have shown that for some pollutants associated with traffic, such as NO2 and ultrafine particles, variation within cities may exceed variations among central monitoring locations in different cities. Earlier studies from the United Kingdom indicate 2- to 3-fold differences in NO2 within distances of ≤ 50 m of a major road (Hewitt 1991), whereas U.S. studies suggest ultrafine particle concentrations are higher than background until about 300 m from highways during daytime hours (Zhu et al. 2002). The preliminary evidence of large health effects at the intraurban scale and the empirical findings that air pollution exposure varies more within than between communities imply that the most meaningful exposure gradient for research on the adverse health effects of air pollution may occur at the intraurban scale.
Assessing pollution distributions at the intraurban scale has proved challenging because of the lack of routinely collected data, but a new class of models (Jerrett et al. 2005a) that uses geographic information systems (GIS) to integrate existing information now shows promise. These models combine available data on monitoring concentrations, land use, meteorology, time–activity patterns, and emissions. Calibrated exposure models based on this information can identify variation in air pollution concentrations within small areas. Resulting pollution surfaces can then be overlaid on georeferenced study data to assign exposure to individuals at their place of residence, work, or some combination of these microenvironments.
There is little doubt that air pollution levels are spatially autocorrelated within cities, and it is also possible that residual health outcomes would be autocorrelated, either because of imperfect estimates of air pollution levels or because of other unmeasured risk factors not represented in the prediction. This implies that standard regression methods for exposure assessment that assume independence are not valid and would be expected to yield biased variance of parameter estimates and inefficient significance tests. Furthermore, one would expect that methods that exploit these spatial correlations should lead to better prediction of individual exposures by “borrowing strength” from measurements at neighboring locations and improving the imputation of exposures for individuals for whom no measurements are available. To date, few models have exploited spatial dependence to refine estimates of air pollution exposure within cities or the associated prediction of health outcomes.
In the present article we build on epidemiologic, land use, air pollution, and emission data to produce estimates of long-term NO2 exposure for 11 CHS communities. These estimates will be integrated within a Bayesian statistical framework to assess a) the marginal benefit of moving from less to more refined exposure models, b) the specific contribution of spatial terms to reducing exposure error, and c) the role of uncertainty in health effects analysis.
Materials and Methods
We obtained data used in this study from the Southern California CHS, a study of over 5,000 children enrolled from schools in communities selected to represent the range and mix of regional ambient air pollution (Peters et al. 1999b). We obtained resident-level pollution data from a study conducted in 2000 (Gauderman et al. 2005), in which out-door NO2 concentrations were measured at 233 homes of CHS children selected from 11 of the 12 communities (Figure 1; the mountain community of Lake Arrowhead was excluded because the home addresses could not be accurately geocoded). Subjects were selected randomly from within two strata defined by the distributions of local traffic counts within each community. Two-week average measurements of NO2 concentrations were taken in 2000 at each home, one in summer and one in winter. Subjects’ home and school addresses were geocoded for exposure assignment and specification of the spatial correlation structure, as described below. The predicted average NO2 exposure from the California line source dispersion (CALINE4) model (Benson 1989) and distance from the residence to the nearest freeway were also selected as standard exposure models. Details of the sampling and measurement protocols can be found in Gauderman et al. (2005) and of the specification of the exposure prediction variables in Molitor et al. (2006).
Figure 1.

Location map of communities in CHS study. All communities are located in Southern California (see inset)
The household pollution data that we analyzed are from a study conducted in 2000, in which outdoor NO2 concentrations were measured at 233 homes of CHS children during one 2-week period in the summer and one 2-week period in the winter. Subjects were approximately 10 years of age at enrollment and between 14–17 years of age when the NO2 measurements were taken. Here, we focus on the relationship between exposure to NO2 and FVC, a standard spirometric measure of lung volume (Gauderman et al. 2004), which allowed for direct comparison with previous analyses (Molitor et al. 2006). Previous studies have linked local traffic and regional air pollutants to this outcome (Ackermann-Liebrich et al. 1997; Gauderman et al. 2007). Lung testing maneuvers were performed using a standardized protocol based on American Thoracic Society recommendations, modified for children (Peters et al. 1999a).
In the present article we extend the approaches used by Gauderman et al. (2005) and Molitor et al. (2006) by including extra spatial residual terms. This addition is potentially beneficial because subjects living in the same town might exhibit geographic cluster effects of NO2 exposure or some other unmeasured covariate. We tested this cluster effect by including the spatial variance component in the model similar to Borgoni and Billari (2003). To extract the unobserved spatial error, the spatial patterns of subjects were specified through the use of explicit spatial connectivity matrices for subjects in different towns and those within the same town. The formulation of the spatial models is explained below.
Model
Similar to recent studies (Chaix et al. 2006), NO2 serves as a proxy to local traffic pollution exposure in our model. In our previous study (Molitor et al. 2006), the unified Bayesian framework for the multilevel analysis improved the estimates of the effect of NO2 exposure on lung function in children with incomplete outcome measures by fitting the multilevel models as a unit. In this present article, we extend this framework to include spatial autoregressive error terms, and we compare the estimates of NO2 exposure obtained from these models that include the spatial error terms with models that specify only independent errors. First, we define the following notations for the subject i in town c in season j: a) Yci denotes measurements of lung function (FVC); b) Zcij denotes observed subject-level outdoor NO2 exposure measurements; c) Xci denotes the “true” unobserved annual outdoor household-level NO2 exposure level; d) Pcj denotes season-specific central-site exposure; e) Wci denotes a vector of household-level NO2 exposure predictors, including distance to the nearest major road, categorized as distance to the nearest freeway based on the road buffer (> 300 m; 150–300 m; 75–150 m; < 75 m), traffic density within 150 m of subjects’ locations, and predicted NO2 concentration from the CALINE4 model; f ) Vci is a vector of personal covariates that affect the lung function, specifically including age, sex, race/ethnicity, height, body mass index (BMI), cohort enrollment group, height, exercise, smoking behavior, asthma, and respiratory illness at the time of lung function measurements; g) Ac and Bc are the community-specific intercepts in the lung function and exposure models, respectively; h) sy,ci and sX,ci are in turn the within-community spatial errors for the lung function and the long-term NO2 exposure. All NO2 levels, both observed and unobserved, are on the log scale. This analytical framework consists of the following three-level hierarchical models, lung function (level 1), exposure (level 2), and measurement (level 3) models, respectively:
 |
 |
 |
where Xc. and Pc. are community-specific averages of Xci and Pcj. The community-specific intercepts Ac and Bc were further modeled as:
 |
and
 |
where SY,c and SX,c are between-community spatial errors for Equations 4 and 5, respectively. In addition, the terms eY,ci , eX,ci, eZ,ci , EAc, and EBc are assumed to be normally distributed random errors with zero means and variances σY 2, σX 2, σZ 2, σh2, and σk 2, respectively. All the spatial error terms, sY,ci , sX,ci , SY,c, and SX,c , were based on a conditional autoregressive (CAR) model. A directed acyclic graph (DAG) for the overall model is illustrated in Figure 2. Note that observed quantities are denoted as squares and unobserved quantities are denoted as circles.
Figure 2.

Directed acyclic graph (DAG) for entire model.
Spatial error structure and Bayesian estimation procedures
The spatial error terms sY,ci and sX,ci are assumed to follow a spatial distribution defined by the CAR model (Besag et al. 1991). If we let S_i denote the vector of spatial residual errors, excluding the subject i, the CAR model specifies that,
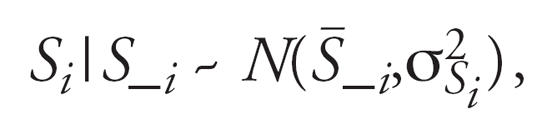 |
where
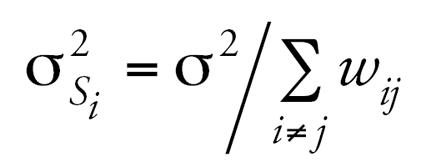 |
and
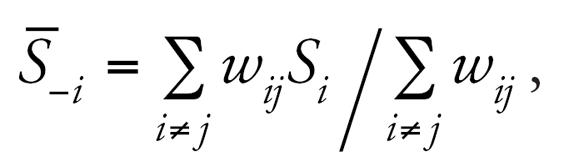 |
based on a weight matrix, WN× N = [wij]N× N, specified to determine the amount of spatial similarity between all pairs of individuals, i,j. A first approximation for this weight matrix is to set wij = 1 if areas i and j are “adjacent” to one another and zero otherwise. This is the kind of similarity matrix used to define all within-community spatial error terms, namely, sY,ci and sX,ci. To construct these adjacency-based similarity matrices, ArcGIS 9.0/ArcMap 9.1 software packages (ESRI, Redlands, CA) were used to produce the Thiessen polygons for each subject where each polygon contains exactly one individual. Thiessen (sometimes called “Voronoi’) polygons are defined by a set of “center” points where each polygon is defined as the set of all points that are closer to a particular center than any other center. Using these polygons, adjacency-based weight matrices were constructed.
Thiessen polygons were used as a first approximation of possible spatial autocorrelation in health and environmental data. Because there is little prior evidence available on the likely spatial associations among subjects, the first-order connectivity matrix based on nearest neighbor proximity is used. This is a common approach in studies when little is known about the spatial processes that generate similarity of attributes by proximity (Odland 1988). The model is capable of adjustments for more informed spatial matrices when prior information is available, such as likely walking distances for the children.
The between-community spatial residual error terms SY,c and SX,c were assumed to follow a CAR model with elements of the weight matrix specified as the inverse of driving distance between two communities. Because the subjects in this study were living in separate, disjoint communities all within a relatively small area within Southern California (an area of about 500 km at its maximum distance), most subjects would travel from one community to another via automobile. Therefore, community-level spatial correlation is reasonably well estimated by the driving distance between the communities. These driving distances were obtained by taking the average distances to drive in both directions for each pair of communities. Each one-way driving distance was obtained from the online mapping site Mapquest (2006). This community-level residual error leads to robust estimates of spatial errors (Borgoni et al. 2003).
The main structure of the Bayesian estimation procedures was described previously (Molitor et al. 2006). Briefly, the Markov chain Monte Carlo (MCMC) method Gibbs sampling was used to estimate the parameters of our model using the WinBUGS software package (version 1.4.1; Spiegelhalter et al. 2003). The Bayesian models were run for 20,000 burn-in iterations followed by 100,000 iterations that were stored for computing posterior distributions of parameters of interest. (This program is available upon request from the first author of this article.) Diffuse priors were used on all parameters. The regression parameters were assigned N(0, τN) priors, where τN denotes precision with τN = 10−4. All standard deviation parameters were given flat uniform priors, U(0,τU) with τU = 10. Throughout the analyses, all measures of NO2, both estimated and observed, distance to nearest freeway, and the predicted NO2 based on CALINE4, as well as the outcome, Yci, were measured on a log scale. The log transformation of the lung function outcome helps satisfy the normality assumptions of the model as was established in previous analysis of CHS data (e.g., Gauderman 2004). The additional log transformation of the exposure variables allows parameter estimates to be interpreted as rates of change based on the concept of elasticity. The coefficient in front of a particular covariate is interpreted as the percent change in the response Y, corresponding to a 1% change in the value of the covariate X, assuming everything else in the model is held constant, which is established in the econometric regression literature (Gujarati 1995).
Model comparisons
Several different models were fit to the data to examine the effects of including various amounts of spatial information into exposure model (Equation 2). The “base” model did not include any traffic-level exposure variables. In other words, Wci was removed from the exposure model (Equation 2), resulting in a new exposure model in which a random town-level intercept term is the only nonresidual term used to predict long-term NO2. Subsequent models were formed by including combinations of relevant traffic-related parameters; namely, models were formed by including/excluding various combinations of covariates in the term Wci. All these models were fit with and without the presence of spatial error terms in order to examine the usefulness of various traffic-related covariates in explaining the extent to which the relationship of interest (lung function and NO2) varied spatially.
For each model, we calculated the deviance information criterion (DIC) (Spiegelhalter et al. 2002), which can be viewed as a Bayesian analogue of the Akaike Information Criterion (AIC; Akaike 1973). This measure of model fit can be easily computed in WinBugs (Spiegelhalter et al. 2003), and it provides another way of comparing different modeling approaches.
Results
Table 1 shows the results of the integrated Bayesian model without the spatial autoregressive terms included; the bottom part shows results obtained with the spatial error terms. Comparison with previous results without spatial error allows for explicit testing of the contribution that spatial error makes to refining exposure–response relationships. Table 1 also gives DIC values computed using different models, with smaller values indicating a better model fit. Smaller DIC values were associated with models that resulted in tighter posterior credible intervals for the parameters of interest.
Table 1.
NO2 effects on lung function.
| Model | Estimate (% change) | 95% credible interval | Width of 95% CI | Total DIC (small is better) |
|---|---|---|---|---|
| Without spatial errors | ||||
| Base | −0.159 | −0.374 to 0.017 | 0.390 | −308.560 |
| Base + dist | −0.152 | −0.312 to −0.005 | 0.308 | −331.160 |
| Base + dist.buffer | −0.163 | −0.348 to 0.002 | 0.350 | −311.526 |
| Base + addt150m | −0.163 | −0.360 to 0.005 | 0.365 | −311.046 |
| Base + caline | −0.135 | −0.273 to −0.004 | 0.269 | −349.570 |
| With spatial errors | ||||
| Base | −0.131 | −0.249 to −0.015 | 0.234 | −368.481 |
| Base + dist | −0.131 | −0.238 to −0.023 | 0.215 | −408.516 |
| Base + dist.buffer | −0.122 | −0.238 to −0.005 | 0.233 | −365.369 |
| Base + addt150m | −0.135 | −0.252 to −0.020 | 0.233 | −370.630 |
| Base + caline | −0.129 | −0.236 to −0.023 | 0.213 | −418.446 |
dist, distance to nearest freeway. Base = NO2 exposure level was estimated without any predictors of exposure level (level 2 in Equation 2). Base + dist = NO2 exposure level was estimated by distance to a freeway in exposure level (level 2 in Equation 2). Base + dist.buffer = NO2 exposure level was estimated by the categorized distance to a freeway in exposure level (level 2 in Equation 2). Base + addt150m = NO2 exposure level was estimated by the traffic counts within 150 m in exposure level (level 2 in Equation 2). Base + CALINE = NO2 exposure level was estimated by predicted NO2 level based on CALINE model.
All models show a negative association between lung function and long-term exposure to NO2, meaning that higher air pollution exposure is associated with decreased lung function as measured by FVC. Models may be interpreted as log–log elasticities, such that a value of −0.14 means that for every 10% increase in long-term NO2 exposure, there is a decrease of 1.4% in lung function. The posterior 95% credibility intervals for the effect of NO2 on lung function are consistently narrower in models that use spatial residual terms compared with models without spatial errors included. The point estimates are also consistently smaller in the spatial models. Figure 3 graphically displays the increase in parameter estimate precision obtained when spatial information is included in the modeling process. As expected, estimates from the base model, namely, the model with no traffic related covariates, were changed the most by the inclusion of spatial information in estimating the residual errors. Table 1 also shows that the model with the narrowest credible interval for the effect of air pollution on lung function is the model that includes spatial errors and the CALINE4 dispersion model estimates. In contrast to the base model, the CALINE4 model includes the most exposure information, and as expected, this model is least affected by inclusion of the spatial error term. Figures 4 and 5 display the variances of the individual-level spatial and independent residuals for each community for the exposure and lung function models, respectively. Figures 6 and 7 show the corresponding variances of the community-level spatial and independent residual error terms. The within-community variances of the individual-level spatial residual terms are computed at each iteration of the Gibbs sampler to be
Figure 3.

Spatial versus nonspatial effects across models. Abbreviations: w, with; w/o, without.
Figure 4.

Variances of the individual-level spatial and independent residual terms for each California community in the exposure model Equation 2 for different choices of exposure predictors. (See text for definition of the variances plotted.) Numbers in parentheses indicate sample size.
Figure 5.

Variances of the individual-level spatial and independent residual terms for each community in the lung function model Equation 1 for different choices of exposure predictors. (See text for definition of the variances plotted.)
Figure 6.

Variances of the community-level spatial and independent residual terms in the exposure model Equation 5 for different choices of exposure predictors. (See text for definition of the variances plotted.)
Figure 7.

Variances of the community-level spatial and independent residual terms in the lung function model Equation 4 for different choices of exposure predictors. (See text for definition of the variances plotted.)
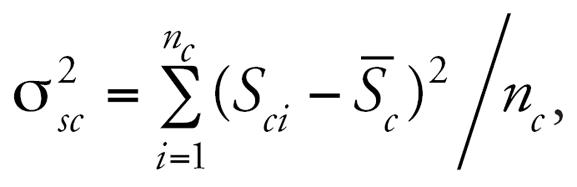 |
and these are then averaged across Gibbs samples; the variances of the independent errors are computed similarly with eci replacing Sci . The variances of the community-level spatial and independent error terms across all subjects are defined to be the average across Gibbs samples of the within-community variances, namely,
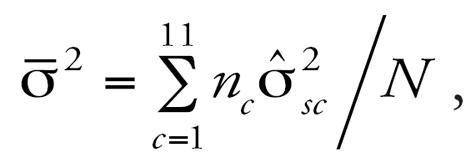 |
where
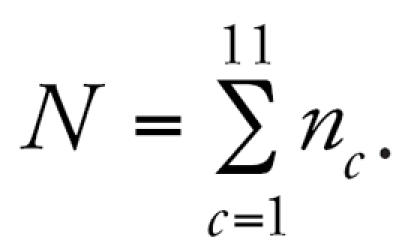 |
Posterior distributions are obtained for each of these community-specific parameters, and from these posterior means, each
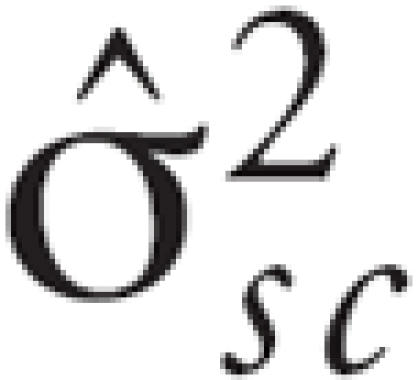 |
is obtained. It is evident from these figures that the spatial error terms were of much greater value in estimating long-term NO2 exposure than in modeling lung function. We have not reported results from the between-community spatial variances because these were very small.
Figure 8 graphically compares average modeled estimates of long-term NO2 with observed seasonal and central-site averages. Although this figure displays only posterior averages of modeled exposure, the MCMC framework fully incorporates the uncertainty in these modeled estimates in the estimation of all model parameters.
Figure 8.

Comparison of different levels of NO2.
Discussion and Conclusion
Recent interest in health effects of air pollution requires a better understanding of which exposure models should be used in epidemiologic investigations. Our results are consistent with previous work in the entire CHS cohort demonstrating associations between lung function and NO2 measurements made at community central site monitors and between lung function and local variation in traffic exposure (Gauderman et al. 2007). A few European studies have examined associations of childhood lung function and local variation within communities of exposure indicators to traffic-related pollutants, with inconsistent results (Brunekreef et al. 1997; Janssen et al. 2003; Sugiri et al. 2006; Wjst et al. 1993).
The results presented in this article extend previous methodologic work (Molitor et al. 2006) by improving exposure assessment through the consideration of spatial correlation in air quality. In this previous work, we reported that multilevel Bayesian models without spatial errors performed better than simpler, one-level frequentist-based approaches (Molitor et al. 2006). The models with spatial error structures that have been proposed here represent a further improvement in modeling these data, as demonstrated in Table 1.
Our analysis reveals a range of point estimates and credible intervals, depending on which predictors were considered and whether spatial error terms are included. In the base model with only central site data, we obtained the widest credible intervals and large point estimates (in absolute value). Comparing the results in Table 1 without spatial errors for the base model and the model with the smallest credibility interval, the CALINE4 model, the point estimate is nearly 18% greater (in absolute value) for the base model and the credible interval is more than 45% wider for the base model when compared with that obtained from the CALINE4 model. A similar comparison between the CALINE4 model and the distance model shows a point estimate increase (in absolute value) of about 13% and a credible interval width increase of more than 14%. In both cases, exclusion of the more refined exposure information appears to inflate both the point estimate (in absolute value) and the uncertainty of that estimate. This situation differs from a standard regression setting, where one may compare the ability of a single covariate to predict an observed outcome with a model consisting of several covariates used to predict the same observed outcome. Here, observed covariate information such as traffic-related covariates and observed seasonal NO2 levels are not directly used to predict levels of lung function. Rather, these observed quantities are combined to estimate an unobserved latent variable, namely, long-term NO2 exposure, and this unobserved NO2 exposure is then used to predict the observed outcome—lung function. In this setting, with the data available, models with informative covariates and informative spatial error terms provide slightly smaller estimates of the effect of long-term NO2 on lung function, with tighter confidence levels. The estimates of health effects in this sample are sensitive to the exposure models used for analysis. Models with less robust information, such as the distance metric, tend to inflate both point estimates and statistical uncertainty, at least in the latent variable setup used with the current data. Further research with simulations and other health data sets is needed before drawing definitive conclusions about the best exposure metrics.
Comparison of Figure 6 with Figure 7 illustrates how the exposure and health models differ. Health models tend to have lower variance overall, and for the most part they are dominated by nonspatial residual error. Exposure models, in contrast, are dominated by spatial error, and they have higher variances overall. This is not surprising, given that it is likely that spatial heterogeneity of genetic and other factors such as diet may contribute to lung function, whereas NO2 pollution is caused by near-source traffic emissions or consistent transport from neighboring communities.
In the health-plus-exposure models, there is heterogeneity in the residual variance between the communities. For example, in the health model, the communities of Lancaster, Atascadero, and Upland have the largest unexplained variance. These communities are in different locations some hundreds of kilometers apart. Thus there is no obvious underlying similarity or spatial pattern in how community location and characteristics influence the residual variation in lung function.
In contrast, the exposure models perform much better in the inland areas of the Los Angeles Basin with respect to the magnitude of residual errors displayed in Figure 4. With the exception of Long Beach (a coastal community), most of the predictions in the Basin appear superior to those outside the Basin. Atascadero is poorly predicted by the model as are Lompoc, Santa Maria, and Alpine, all outside the basin. This may be because of the relatively lower levels of NO2 in these locations and the associated lower range of exposure.
Regarding spatial errors, one could use a Bayesian geostatistical kriging model of the form described in Diggle et al. (1998) as opposed to the CAR model used in the present article. The Bayesian kriging model assumes that spatial errors are modeled using a multivariate Gaussian distribution with covariance matrix expressed as a parametric function of the distance between pairs of points. This model is useful if one is primarily interested in making predictions of exposure on the spatial surface. For example, one may be interested in predicting levels of NO2 exposure at homes not measured in the pilot study. To facilitate the prediction of exposure, this model assumes stationarity, in that the amount of spatial correlation between two points is simply a function of the Euclidian distance between the points. Because we are primarily interested in assessing the effect of exposure on lung function and not in spatial prediction, and because assumptions of stationarity would questionable in our context, we have decided against using this model here.
Through examination of DIC, spatial autocorrelation in the outcome and exposure, and the subsequent impacts on point estimates and credible intervals, we have developed a framework for assessing spatial exposure model performance. In most cases, we were able to improve the certainty of our health effects estimates with information on residual spatial autocorrelation, but these improvements were, as expected, more pronounced in models that contained less informative exposure information. Exposure models with small (good) DIC had relatively less improvement from additional spatial information. This finding suggests a more general approach for assessing model performance where the point estimates and confidence intervals are more robust to inclusion of additional information, probably because of less bias in the initial estimates from nonindependence in the observations, particularly from excluded exposure information. As noted below, the generalizability of these findings is limited by the sample size used, but this will be partly addressed in future research.
There are limitations to this study that merit attention in future research. We have exposure information from only two 2-week periods in different seasons measured at the home. Although there are more field measurements than in most similar large epidemiologic investigations, it is possible that our estimates are not an accurate depiction of long-term exposure because of temporal variation in exposure. However, the measurement model (Equation 3) is not written in the way classic measurement error models are generally written, where observed measures of exposure are assumed to deviate around true unobserved exposure values with zero-error residuals. Instead, we have incorporated an extra term that calibrates local measurements for temporal variation as assessed by the central site measurements.
Furthermore, the relatively small sample size, although drawn from a larger cohort, may not be representative of the general population or of the exposure experienced by the entire cohort. Other analyses suggested few significant differences between this sample and the larger cohort (Gauderman et al. 2005), but caution must be exercised in comparing these results to those of the full cohort (i.e., Gauderman et al. 2007).
We have collected subsequent information from over 1,000 locations in a related study over three seasons that will allow us to address the weaknesses described previously. Also, our unified modeling framework will allow us to combine information from the entire cohort, as individual-level exposures that may not exist in the larger cohort study but are present in the pilot study can be imputed in a way that fully utilizes all available covariate information. Because of the small sample within each community in the pilot study analyzed for this article, we were unable to evaluate other predictors of exposure based on other land uses (Jerrett et al. 2005a), a method that has been used in a few health studies (Brauer et al. 2002) and has performed as well or better than dispersion models like CALINE4 when predicting exposures at unmeasured locations (Briggs et al. 2000). We will address this limitation as well in future studies with the larger samples of measured exposures.
Here we sought to examine how different models of intraurban air pollution exposure classify and predict FVC in an integrated Bayesian modeling framework. Building on the CHS (Gauderman et al. 2004, 2007) and related methodologic developments (Molitor et al. 2006), we assessed three intraurban predictors (i.e., distance to a freeway, traffic density, and CALINE4 dispersion models) in a Bayesian measurement error framework. Traffic density and distance buffer are commonly used in epidemiologic studies (Jerrett et al. 2005b), and CALINE has been used in a few studies (e.g., Gauderman et al. 2005, 2007; McConnell et al. 2006). The novelty to our method is the inclusion of between- and within-community spatial autocorrelation terms and the systematic testing of different exposure models. Results obtained through the Bayesian framework suggest that the inclusion of residual spatial terms can reduce uncertainty in the prediction of exposures and associated health effects. The findings also imply that more informative exposure models appear to reduce uncertainty in health effects estimation.
Footnotes
We thank B. Beckerman for his geographic information systems expertise.
Funding was provided by Southern California Environmental Health Sciences Center funded by National Institute of Environmental Health Sciences (NIEHS) grant 5P30 ES07048. Additionally we acknowledge funding from U.S. Environmental Protection Agency grant RD83186101; NIEHS grants 5P01 ES11627, 5P01 ES09581; the Health Effects Institute; the Hastings Foundation; Health Canada; and the Canadian Institutes of Health Research.
References
- Ackermann-Liebrich U, Leuenberger P, Schwartz J, Schindler C, Monn C, Bolognini G, et al. Lung function and long term exposure to air pollutants in Switzerland. Study on Air Pollution and Lung Diseases in Adults (SAPALDIA) Team. Am J Respir Crit Care Med. 1997;155(1):122–129. doi: 10.1164/ajrccm.155.1.9001300. [DOI] [PubMed] [Google Scholar]
- Akaike H. Information theory and an extension of the maximum likelihood principle. In: Petrov BN, Cs′aki F, editors. Proceedings of the Second International Symposium on Information Theory. Budapest: Akad′emiai Kiado; 1973. pp. 267–281. [Google Scholar]
- Benson P. CALINE4—a Dispersion Model for Predicting Air Pollution Concentration near Roadways. Sacramento, CA: Office of Transportation Laboratory, California Department of Transportation.; 1984. [Google Scholar]
- Besag J, York J, Mollie A. Bayesian image restoration, with two applications in spatial statistics. Ann Inst Stat Math. 1991;43(1):1–59. [Google Scholar]
- Borgoni R, Billari FC. Bayesian spatial analysis of demographic survey data. Demographic Res. 2003;8(3):61–92. [Google Scholar]
- Brauer M, Hoek G, Van Vliet P, Meliefste K, Fischer P, Gehring U, et al. Estimating long-term average particulate air pollution concentrations: application of traffic indicators and geographic information systems. Epidemiology. 2003;14:228–239. doi: 10.1097/01.EDE.0000041910.49046.9B. [DOI] [PubMed] [Google Scholar]
- Brauer M, Hoek G, Van Vliet P, Meliefste K, Fischer P, Wijga A, et al. Air pollution from traffic and the development of respiratory infections and asthmatic and allergic symptoms in children. Am J Respir Crit Care Med. 2002;166(8):1092–1098. doi: 10.1164/rccm.200108-007OC. [DOI] [PubMed] [Google Scholar]
- Briggs DJ, de Hoogh C, Gulliver J, Wills J, Elliott P, Kingham S, et al. A regression-based method for mapping traffic-related air pollution: application and testing in four contrasting urban environments. Sci Total Environ. 2000;253(1–3):151–167. doi: 10.1016/s0048-9697(00)00429-0. [DOI] [PubMed] [Google Scholar]
- Brunekreef B, Holgate S. Air pollution and health. Lancet. 2002;360(9341):1233–1242. doi: 10.1016/S0140-6736(02)11274-8. [DOI] [PubMed] [Google Scholar]
- Brunekreef B, Janssen NA, de Hartog J, Harssema H, Knape M, van Vliet P. Air pollution from truck traffic and lung function in children living near motorways. Epidemiology. 1997;8(3):298–303. doi: 10.1097/00001648-199705000-00012. [DOI] [PubMed] [Google Scholar]
- Chaix B, Gustafsson S, Jerrett M, Kristersson H, Lithman T, Boalt Å, et al. Children’s exposure to nitrogen dioxide in Sweden: investigating environmental injustice in an egalitarian country. J Epidemiol Community Health. 2006;60(3):234–241. doi: 10.1136/jech.2005.038190. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diggle PJ, Tawn JA, Moyeed RA. Model-based geostatistics. Appl Stat. 1998;47(3):299–350. [Google Scholar]
- Gauderman WJ, Avol E, Gilliland F, Vora H, Thomas D, Berhane K, et al. The effect of air pollution on lung development from 10 to 18 years of age. N Engl J Med. 2004;351(11):1057–1067. doi: 10.1056/NEJMoa040610. [DOI] [PubMed] [Google Scholar]
- Gauderman WJ, Avol E, Lurmann F, Kuenzli N, Gilliland F, Peters J, et al. Childhood asthma and exposure to traffic and nitrogen dioxide. Epidemiology. 2005;16(6):737–743. doi: 10.1097/01.ede.0000181308.51440.75. [DOI] [PubMed] [Google Scholar]
- Gauderman WJ, Vora H, McConnell R, Berhane K, Gilliland F, Thomas D, et al. Effect of exposure to traffic on lung development from 10 to 18 years of age: a cohort study. Lancet. 2007;369(9561):571–577. doi: 10.1016/S0140-6736(07)60037-3. [DOI] [PubMed] [Google Scholar]
- Gujarati D. Basic Econometrics. New York: McGraw-Hill; 1995. [Google Scholar]
- Hewitt CN. Spatial variations in nitrogen dioxide concentrations in an urban area. Atmos Environ. 1991;25(3):429–434. [Google Scholar]
- Hoek G, Brunekreef B, Goldbohm S, Fischer P, van den Brant P. Association between mortality and indicators of traffic-related air pollution in the Netherlands: a cohort study. Lancet. 2002;360(9341):1203–1209. doi: 10.1016/S0140-6736(02)11280-3. [DOI] [PubMed] [Google Scholar]
- Janssen NA, Brunekreef B, van Vliet P, Aarts F, Meliefste K, Harssema H, et al. The relationship between air pollution from heavy traffic and allergic sensitization, bronchial hyperresponsiveness, and respiratory symptoms in Dutch schoolchildren. Environ Health Perspect. 2003;111:1512–1518. doi: 10.1289/ehp.6243. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jerrett M, Burnett RT, Ma R, Pope CA, III, Krewski D, Newbold KB, et al. Spatial analysis of air pollution and mortality in Los Angeles. Epidemiology. 2005a;16(6):727–736. doi: 10.1097/01.ede.0000181630.15826.7d. [DOI] [PubMed] [Google Scholar]
- Jerrett M, Finkelstein M. Geographies of risk in studies linking chronic air pollution exposure to health outcomes. J Toxicol Environ Health. 2005b;68(13–14):1207–1242. doi: 10.1080/15287390590936085. [DOI] [PubMed] [Google Scholar]
- Mapquest. Homepage. 2006. [[accessed 21 July 2006]]. Available: http://www.mapquest.com.
- McConnell R, Berhane K, Yao L, Jerrett M, Lurmann F, Gilliland F, et al. Traffic, susceptibility, and childhood asthma. Environ Health Perspect. 2006;114:766–772. doi: 10.1289/ehp.8594. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Molitor J, Molitor NT, Jerrett M, McConnell R, Gauderman J, Berhane K, et al. Bayesian modeling of air pollution health effects with missing exposure data. Am J Epidemiol. 2006;164(1):69–76. doi: 10.1093/aje/kwj150. [DOI] [PubMed] [Google Scholar]
- National Research Council. Estimating the Public Health Benefits of Proposed Air Pollution Regulations. Washington, DC: National Academies Press; 2002. [PubMed] [Google Scholar]
- Odland J. Spatial Autocorrelation. Beverly Hills, CA: Sage; 1988. [Google Scholar]
- Peters JM, Avol E, Gauderman J, Linn WS, Navidi W, London SJ, et al. A study of twelve Southern California communities with differing levels and types of air pollution. II. Effects on pulmonary function. Am J Respir Crit Care Med. 1999a;159(3):768–775. doi: 10.1164/ajrccm.159.3.9804144. [DOI] [PubMed] [Google Scholar]
- Peters JM, Avol E, Navidi W, London SJ, Gauderman WJ, Lurmann F, et al. A study of twelve Southern California communities with differing levels and types of air pollution. I. Prevalence of respiratory morbidity. Am J Respir Crit Care Med. 1999b;159(3):760–767. doi: 10.1164/ajrccm.159.3.9804143. [DOI] [PubMed] [Google Scholar]
- Spiegelhalter DJ, Best NG, Carlin BP, van der Linde A. Bayesian measures of model complexity and fit. J Roy Statist Soc B. 2002;64(4):583–640. [Google Scholar]
- Spiegelhalter D, Thomas A, Best N. WinBUGS, Version 1.4 User Manual. Cambridge, MA: MRC Biostatistics Unit; 2003. [Google Scholar]
- Sugiri D, Ranft U, Schikowski T, Kramer U. The influence of large-scale airborne particle decline and traffic-related exposure on children’s lung function. Environ Health Perspect. 2006;114:282–288. doi: 10.1289/ehp.8180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wjst M, Reitmeir P, Dold S, Wulff A, Nicolai T, von Loeffelholz-Colberg EF, et al. Road traffic and adverse effects on respiratory health in children. BMJ. 1993;307(6904):596–600. doi: 10.1136/bmj.307.6904.596. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu Y, Hinds W, Kim S, Shen S, Sioutas C. Study on ultra-fine particules near a major highway with heavy-duty diesel traffic. Atmos Environ. 2002;36(27):4323–4335. [Google Scholar]