

Abstract
Inference on the association between a primary endpoint and features of longitudinal profiles of a continuous response is of central interest in medical and public health research. Joint models that represent the association through shared dependence of the primary and longitudinal data on random effects are increasingly popular; however, existing inferential methods may be inefficient or sensitive to assumptions on the random effects distribution. We consider a semiparametric joint model that makes only mild assumptions on this distribution and develop likelihood-based inference on the association and distribution, which offers improved performance relative to existing methods that is insensitive to the true random effects distribution. Moreover, the estimated distribution can reveal interesting population features, as we demonstrate for a study of the association between longitudinal hormone levels and bone status in peri-menopausal women.
Keywords: Conditional score, Generalized linear model, Mixed effects model, Pseudo-likelihood, Seminonparametric density
1 Introduction
Joint models that represent the association between a primary endpoint and features of longitudinal profiles of a related continuous response by shared dependence on underlying random effects have enjoyed increasing popularity when the focus of inference is on the strength and nature of the association. The primary endpoint may be a censored time-to-event (e.g. Henderson et al., 2000; Tsiatis and Davidian, 2004) or a single binary response, count, or other continuous measure. In the latter case, on which we focus, the joint model involves a linear mixed effects model (e.g. Laird and Ware, 1982), whose random effects characterize the salient features of the subject-specific longitudinal response profiles, linked to a generalized linear model (McCullagh and Nelder, 1989) for the primary endpoint, in which the random effects appear as covariates. Inference on the coefficients of these covariates addresses explicitly the association of interest.
A number of authors have proposed methods for implementation of this model. Wang et al. 2000 showed that replacing the random effects by subject-specific ordinary least squares estimators leads to biased estimation of primary model parameters. Wang et al. also proposed regression calibration (Carroll et al., 1995), which in this context involves replacing the random effects by estimated best linear unbiased predictors from a fit of the mixed effects model to the longitudinal profiles, assuming the random effects are normally distributed. Because this method does not entirely eliminate bias when the primary mean model is nonlinear, e.g. as for a binary endpoint, they also proposed a “refined” regression (RR) calibration technique for binary endpoint, which reduces or eliminates the bias but is still predicated on normality of the random effects. Concern over robustness of inference to departures from normality led Li et al. 2004 to a study of this issue, which showed that these methods can be alarmingly biased, inspiring these authors to extend methods of Stefanski and Carroll (1987) for generalized linear measurement error models to this setting. Li et al. 2004 derived so-called sufficiency score (SS) and conditional score (CS) methods, in which dependence on the random effects is removed by conditioning arguments, yielding estimators that are consistent regardless of the their distribution; see also Wang and Huang (2001). Li et al. demonstrated that SS and CS estimators are unbiased, yield valid inferences under departures from random effects normality, and are competitive to methods such as RR on basis of efficiency when normality does hold.
Because the SS and CS estimators “condition away” dependence on the random effects, they are valid under any true random effects distribution, including discrete or “unusual” distributions that are unlikely models for underlying features of profiles of continuous responses. Thus, although these methods enjoy robustness to nonnormality, the price is possible inefficiency relative to approaches that restrict to “plausible” distributional assumptions. Moreover, as the conditioning eliminates the random effects, these methods do not facilitate inference on the nature of the true random effects distribution, which may yield insight into inter-subject heterogeneity.
In this paper, we consider a semiparametric joint model in which the random effects distribution is left unspecified, as for SS and CS methods, but is assumed to lie in a broad class whose members have “smooth” densities that render them likely candidates to represent variation in subject-specific random effects for continuous longitudinal responses. The approach assumes that the linear mixed effects model for the longitudinal response is that of Zhang and Davidian (2001), in which the random effects density is assumed to lie in a class whose elements may be represented by the so-called “seminonparametric” (SNP) density estimator proposed by Gallant and Nychka (1987). Similar to Song et al. 2002 for a time-to-event endpoint, we develop likelihood-based inference for the primary model parameters and the random effects density.
In Section 2, we introduce data from the Study of Women’s Health Across the Nation (SWAN, Sowers et al., 2003), in which interest focuses on the association between characteristics of longitudinal hormone level profiles and a measure of bone mineral density in peri-menopausal women. In Section 3, the semiparametric joint model is described. We derive a full-likelihood-based implementation via the expectation-maximization (EM) algorithm in Section 4. When the primary endpoint is nonnormal, the EM involves computationally-expensive numerical integration; accordingly, in Section 5, we develop a less burdensome pseudo-likelihood approach. We apply both methods to the SWAN data in Section 6, and demonstrate performance in Section 7 via extensive simulations across a range of conditions.
2 The Study of Women Across the Nation
Low bone mineral density (BMD) is considered to be a key risk factor for osteoporosis, which afflicts 20% of US women over the age of 50 (Sowers et al., 2003), and an understanding of the relationship between monthly patterns of reproductive hormone levels and bone mineral density is thought to hold promise for identifying women for whom intervention to preserve bone mass may be indicated. The Study of Women’s Health Across the Nation (SWAN), a multi-ethnic cohort study enrolling over 3300 women undergoing transition to menopause examining physical, biological, psychological and social changes, offers a rich resource for studying this issue. In a SWAN substudy, the Daily Hormone Study (Santoro et al., 2004), total hip BMD (g/cm2) was measured for each participant at a clinical visit, and longitudinal urine samples were collected over an adjacent menstrual cycle and assayed for levels of several reproductive hormones. In addition, a number of subject characteristics, including body mass index (BMI, kg/m2), age (years), and ethnicity (Black, White, Chinese, Japanese), were recorded for each woman.
We focus on progesterone (pregnanediol glucuronide, PDG, μg/mg creatinine), a hormone implicated in fertility, available for 624 women in the substudy. Because women experience different cycle lengths, it is conventional to standardize to a 28-day reference (e.g. Zhang et al., 1998); Figure 1 shows longitudinal log PDG plotted against standardized days for 4 women. As noted by Li et al. 2004, profiles are fairly constant up to 14 days, then exhibit an apparent approximately symmetric rise and fall for the remainder of the cycle. Letting Wij denote log PDG for woman i on standardized day tij, Li et al. 2004 represented the profile for woman i as
Figure 1.
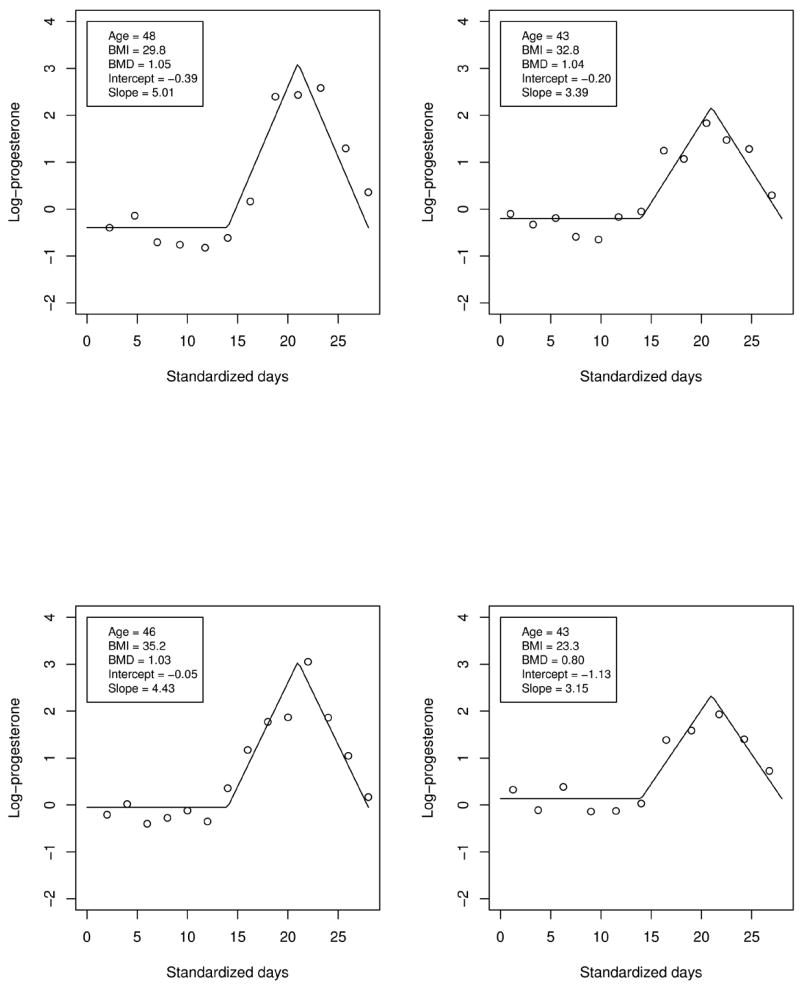
Natural logarithm of PDG levels (μg/mg creatinine) for four randomly selected women with individual ordinary least squares fits of the piecewise linear model (1) superimposed.
| (1) |
where i = 1, …, n(= 624), j = 1, …, mi, u+ = u if u > 0 and 0 otherwise, X1i is the woman-specific constant log PDG up to day 14, X2i is the “slope” of the symmetric rise (days 14–21) and fall (days 21–28) observed in Figure 1, and Uij is a deviation representing within-woman variation and measurement error. The subset of the data we consider includes available every-other-day PDG measurements for each woman; mi ranges from 8 to 25. In (1), X1i and X2i summarize for woman i the prominent features of the profiles: the first-cycle-half log PDG level and the second-cycle-half steepness of log PDG rise and fall, respectively.
Osteopenia, a precursor condition to osteoporosis, is characterized by low BMD (at or below the 33rd percentile). Letting Yi = 1 denote absence of osteopenia for woman i, to characterize the association between presence/absence of osteopenia and the longitudinal pattern of log PDG, summarized by Xi = (X1i, X2i)T, a natural framework is the logistic regression model
| (2) |
where Ci is a vector of additional covariates (e.g. BMI, age, ethnicity) whose effects are to be taken into account. Model (2) represents the relationship between features of log PDG profiles and the primary endpoint osteopenia through shared dependence on Xi, and inference on β0 and β1 addresses formally this association and that between osteopenia and other subject attributes. As we discuss in the next section, (1) and (2) together define a joint model.
3 Semiparametric Joint Model
Generalizing the situation for SWAN in Section 2, suppose that for each subject i = 1, …, n, longitudinal measurements (W1i, …, Wimi)T at times t1i, …, timi follow the linear mixed model
| (3) |
where Di is a full-rank (mi × q) design matrix; Xi is a (q × 1) random effect representing unobserved subject-specific features of the longitudinal profiles; and Ui = (Ui1, …, Uimi)T are within-subject deviations, independent of Xi, independently and identically distributed as for (l × l) identity matrix Il. Let Yi denote the primary endpoint and Ci (p × 1) be a vector of covariates for subject i. To relate the primary endpoint to features of the longitudinal profiles and covariates, assume the generalized linear model in canonical form given by the conditional density of Yi given Xi and Ci (we suppress conditioning on Ci throughout)
| (4) |
Where Ci has first element 1 when an intercept is included; are regression parameters; ρ is a dispersion parameter; and a(·), b(·), and c(·, ·) are known functions. Conditional on Xi, we take Yi and Wi to be independent, the surrogacy assumption (e.g., Carroll et al., 1995).
The standard assumption for the distribution of the random effects is normality; however, this may characterize poorly heterogeneity in features of subject-specific profiles. Accordingly, supposing that random effects for a continuous response would themselves be continuous, Zhang and Davidian (2001) proposed replacing this assumption for the linear mixed model by the broader assumption that the random effects have density in a class of “smooth” differentiable densities studied by Gallant and Nychka (1987) that includes normal, multimodal, skewed, and heavy- or thin-tailed but not “unusual” densities. Densities in the class may be approximated by truncated series expansion referred to as “seminonparametric” (SNP), where the degree of truncation dictates the flexibility of the representation. Thus, following these authors, let
| (5) |
where μ is a q-dimensional vector of parameters, R is a (q × q) lower-triangular matrix, and the random vector Zi (q × 1) has density that may be approximated by the SNP density
| (6) |
Here, PK (z) is a Kth order polynomial with coefficients aλ chosen so that (6) is a density, ϕ(·) is the density, λ = (λ1, …, λq) is a vector of non-negative integers, and zλ is the monomial of order . E.g., in the case q = 2 of interest in SWAN, z = (z1, z2)T, PK (z) = a00 + a10z1 + a01z2 when K = 1 and when K = 2. Zhang and Davidian (2001) showed that ∫ hK (z)dz = 1 holds if the collection a of the aλ satisfies aTAa = cTc = 1 for a certain known positive definite matrix A depending on q and K, which may be imposed by a radial transformation. E.g. with q = 2, a is of dimension d = (K + 1)(K + 2)/2, and take c1 = sin(φ1), c2 = cos(φ1) sin(φ2), …, cd−1 = cos(φ1) cos(φ2) … cos(φd−2) sin(φd−1), cd = cos(φ1) cos(φ2) … cos(φd−1), where −π/2 < φl ≤ π/2 for l = 1, …, d − 1; when K = 2, a = (a00, a10, a01, a20, a11, a02)T and d = 6. Parameterization of (6) in terms of φ = (φ1, …, φd−1)T thus ensures it is a density, and it follows that when K = 0, (6) reduces to the density. The choice of K is discussed in Section 4.
Letting r = vech(R), the non-zero elements of R, for given K, characterizes the proposed joint model. Inference on θ thus addresses not only the association, through β, but also yields an explicit estimate of the density through (μ, r, φ).
4 Full-likelihood Inference
With Y = (Y1, …, Yn)T, , the observed-data loglikelihood for θ is
| (7) |
for fixed K, where we now emphasize dependence of PK on θ, f (Yi, Wi; θ) is the density of (Yi, Wi), and f (Yi, Wi|Zi; θ) is the conditional density of (Yi, Wi) given Zi.
When Yi is normally distributed given Xi (and Ci), (4) implies . Here, f (Yi; Wi|Zi; θ)ϕ(Zi) can be viewed as the joint density of (Yi; Wi; Zi) when Zi is assumed to be . Letting g(Yi, Wi; θ) denote the density of (Yi, Wi) and g(Zi|Yi, Wi; θ) denote the conditional density of Zi given (Yi, Wi) when Zi is standard normal, f (Yi, Wi|Zi; θ)ϕ(Zi) = g(Yi, Wi; θ)g(Zi|Yi, Wi; θ) and hence
where EZi|YiWiθ (·) represents expectation with respect to the conditional distribution of (normal) Zi given (Yi, Wi). It is straightforward to show that g(Yi, Wi; θ) is the normal density with mean and covariance matrix
and that g(Zi|Yi, Wi; θ) is the normal density with mean and covariance matrix
Hence the observed-data loglikelihood (7) becomes
| (8) |
where the first term is the usual loglikelihood for the normal model for (Yi, Wi) with mean ηi and covariance matrix Ωi, i = 1, …, n, which has a closed form; and the second term involves moments of a random vector and also has a closed form that may be calculated using the series representation of the moment generating function of a normal random variable similar to Zhang and Davidian (2001). Thus, for normal Yi, (8) has a closed-form expression and so may be maximized in θ using standard optimization software.
When Yi is not normal, (7) does not have a closed-form representation. In principle, (7) may be maximized in θ by carrying out the required numerical integrations, but this can lead to computational instability. Accordingly, we derive an EM algorithm. Treating the random effects as missing data, the complete-data (Y, W, X) likelihood for θ is
| (9) |
for fixed K, where f (Yi|Xi; β, ρ) is as in (4), is the density as in (3), and is the representation of the density of Xi. The maximum likelihood estimator θ̂ is obtained by iterating between an E-step and an M-step to convergence. Let θ̂(l) denote the estimate at the lth iteration. In the E-step, compute Q(θ|θ̂(l)) = E{log Lc(θ; Y, W, X)|Y, W ; θ̂(l)}, i.e. the conditional expectation of the logarithm of (9) given the observed data and current parameter estimates. In the M-step, maximize Q(θ|θ̂(l)) with respect to θ to obtain the update θ̂(l+1).
At the (l + 1)th iteration, it may be shown that
The updates ( ) maximize
They may also be obtained by a one-step Newton-Raphson approximation similar to Wulfsohn and Tsiatis (1997). Letting γ = (βT, ρ)T, the updates are, , where Sγ̂l) and Iγ̂(l) are the score vector and information matrix for γ at the lth iteration, respectively; e.g. for the logistic primary endpoint model as in (2), γ = β and
where . As PK depends on θ only through φ, in (9), the parameters (μ, r, φ) in the SNP density representation are separated from the others, so that iterative updates (μ(l+1), r(l+1), φ(l+1)) are obtained by maximizing
which may be carried out using a standard optimizer.
These expressions all involve integrals of the form E{s(X i)|Yi, Wi; θ̂(l)} = ∫ s(x)f(x|Yi, Wi; θ̂(l))dx, where s(Xi) is a function of Xi and f (Xi|Yi, Wi; θ) is the conditional density of Xi given the observed data (Yi, Wi). These integrals must be computed numerically, facilitated by noting
where , which has an explicit expression. Our implementation uses Gauss-Hermite quadrature.
To obtain the starting value θ̂(0) for given K, we use the estimates of from the conditional score method of Li et al. 2004, which is fast and straightforward to implement and yields consistent estimators regardless of the true random effects distribution. For the starting values for the parameters in the SNP density representation, we fit (3) via the approach of Zhang and Davidian (2001) for the chosen K, and use the resulting estimates of (μ, r, φ).
Standard errors for the final estimator θ̂ for given K may be derived from the inverse of the observed information, i.e. the second derivative matrix of (7) evaluated at θ̂, which may be carried out using numerical integration (e.g. Gauss-Hermite quadrature) or Monte Carlo approximation as in Chen et al. 2002; we use the former in the analyses of subsequent sections.
The preceding development is for fixed K. In practice, the analyst may take K > 0 fixed to allow for departures from normality. Alternatively, it is standard to choose K via objective information criteria, fitting the model for different K and selecting the K that minimizes a penalized version of the maximized observed-data loglikelihood; i.e. −ℓ(θ̂; Y, W)/N + C(N)(p/N), where is the total number of observations; p = dim(θ); and C(N ) is a penalty factor equal to 1 for Akaike’s Information Criterion (AIC), log(log N) for the Hannan-Quinn Criterion (HQ), and (log N)/2 for the Schwarz Information Criterion (BIC). Practically, the analyst may increase K from 0 until Kmax when an information criterion no longer decreases; often Kmax up to 2 suffices in practice for representing complicated shapes, as demonstrated in Sections 6 and 7. Zhang and Davidian (2001) discussed the relative merits of these criteria, noting that HQ tends to offer a compromise between AIC and BIC.
Based on the final chosen K, inference on individuals is possible via the empirical Bayes approach of Davidian and Gallant (1993), where “estimates” X̂i of subject-specific random effects Xi are obtained as posterior modes; i.e. X̂i = arg maxXi f(Xi|Yi, Wi; θ̂).
5 Pseudo-likelihood Inference
For nonnormal Yi, the EM algorithm in Section 4 can be computationally burdensome. We thus consider an alternative approach to inference on θ under the semiparametric joint model that exploits the fact that may be estimated based on W and the mixed model (3) only. We propose a two-step scheme: (i) estimate by fitting the mixed model (3) to the data W via the approach of Zhang and Davidian (2001), selecting K by inspection of a suitable information criterion; and (ii) estimate the remaining parameters (β, ρ) characterizing (4) via an approach similar to that of Carroll et al. 1984, maximizing in (β, ρ) holding fixed at the estimates from (i), where f (Yi|Wi; θ) is the conditional density of Yi given Wi. We may regard (ii) as a “pseudo-likelihood" approach, where the “nuisance parameters” are held fixed at previous estimates.
We thus derive the form of f(Yi|Wi; θ). It is easy to see that
where f(Yi|Zi; θ) and f (Wi|Zi; θ) are the density of (4) and the normal density of Wi given Xi, respectively, with Xi replaced by μ + RZi; and f(Wi; θ) is the marginal density of the longitudinal data. Note that f(Wi|Zi; θ)ϕ(Zi) can be viewed as the joint density of Wi and Zi when . Let f* (Zi|Wi; θ) and f* (Wi; θ) denote the conditional density of Zi given Wi and the marginal density of Wi when , respectively. Then f (Wi|Zi; θ)ϕ(Zi) = f* (Zi|Wi; θ) f* (Wi; θ) and in fact
| (10) |
where EZi|Wi (·) is the conditional expectation of Zi given Wi with Zi normal. Hence,
| (11) |
It is straight forward to show that f* (Zi|Wi; θ) is the normal density with mean and covariance .
Thus, to implement step (ii), we represent the log-pseudo-likelihood pℓ(θ, Y, W) in terms of (11). Note that f* (Zi|Wi; θ) and depend only on . Thus, in step (ii), these are fixed for each i when evaluated at from step (i).
We demonstrate for binary Yi, so that f(Yi|Wi; θ) = {pr(Yi = 1|Wi; θ)}Y<sub>i</sub> {1 − pr(Yi = 1|Wi; θ)}1−Yi. For logistic regression as in (2), for , adopting the probit-to-logistic approximation Φ(u) ≈ H(cu), where Φ(·) is the standard normal cumulative distribution function and , (11) gives
| (12) |
This integral is evaluable in a closed form; e.g. when K = 1 and q = 2, (12) becomes
| (13) |
where δ00i = a00 + (a10,a01)ζi; akl, kl = 00, 01, 10, are the coefficients in PK ; and denotes the (k, l)th element of . Thus, pℓ (θ, Y, W) may be expressed in terms of (13) and depends on β only through αi and (γ1i, γ2i) (ρ = 1 here). When K = 0, i.e. random effects, for any q, , and it is straightforward to show that the resulting estimator is the RR estimator of Wang et al. (2000, sec. 4.2), which admits a simple closed form expression for pr(Yi = 1|Wi; θ). Of course, these results apply to a probit model by eliminating the constant c. See Li (2004) for logistic-probit formulæ for other K and q.
For the logistic-probit case, then, step (ii) may be carried out using a standard optimization routine or via software performing iteratively reweighted least squares (IRWLS) such as SAS proc nlin (SAS Institute, 2003). For K = 0, IRWLS is straightforward. For K = 1, due to the complexity of (13), these may be sensitive to starting values. In our implementation, we set a grid about the conditional score estimates and use as the starting value for IRWLS the grid point yielding the largest value of the log-pseudo-likelihood. For K > 1, the form of (12) becomes very complicated, which can lead to numerical instability. We have found that choosing between K = 0 and 1 only provides sufficient flexibility to achieve efficiency of estimation close to that of the full likelihood approach with K up to 2; see Section 7. To choose objectively between K = 0 and 1, AIC, HQ, and BIC may be applied, treating the log-pseudo-likelihood as a loglikelihood. For the final estimate of β under the chosen K, we investigated different methods for obtaining standard errors. Ideally, this should take account of estimation of the “nuisance parameters” , which may be accomplished by, e.g. the strategy outlined in Section A.3.6 of Carroll et al. 1995. We have found that basing standard errors on the inverse of the estimated Fisher information matrix for the pseudo-likelihood, treating pℓ (θ, Y, W) as a log-likelihood for β and ignoring estimation of the nuisance parameters (regarding them as fixed), leads to estimates of uncertainty that do not differ appreciably from those that do take the nuisance parameter estimation into account. This approach is also numerically more stable. Evidently, are sufficiently approximately “orthogonal" to β to justify this simpler method in practice, and it is used in Sections 6 and 7.
For general nonlinear primary endpoint models, the integral for f(Yi|Wi; θ) may not be tractable and requires numerical evaluation. However, both for this situation and the binary case, the pseudo-likelihood approach reduces computing time considerably over the full likelihood method; e.g. for a data set with 500 subjects and mi = 5, full likelihood for the logistic model implemented via EM in SAS, including fitting for each of K = 0, 1, 2, evaluation and comparison of information criteria, and calculation of standard errors, takes roughly 1.5 hours on a 2.80GHz Windows PC, whereas pseudo-likelihood, including evaluating starting values, fitting via IRWLS for K = 0, 1 and identifying K, and calculation of standard errors is 6–7 times faster.
6 Application to SWAN
Consider the joint model given in (1) and (2); here, for woman i, let CBMI,i denote body mass index (BMI, kg/m2); Cage,i denote age (years); CB,i, CW,i and CC,i denote ethnicity indicator variables = 1 as woman i is Black, White, or Chinese, respectively, so CB,i = CW,i = CC,i = 0 indicates woman i is Japanese; and Ci = (1, CBMI,i, Cage,i, CB,i, CW,i, CC,i)T. Thus, we have β0 = (β0, β0,BMI, β0,age, β0,B, β0,W, β0,C)T and β1 = (β11, β12)T.
We fitted this model using the full likelihood (FL) method implemented by EM for K = 0, 1, 2, 3, 4 and by the pseudo-likelihood (PL) method using IRWLS for K = 0, 1. Table 1 shows the results. For FL, we used eight-point Gauss-Hermite quadrature to calculate all integrals; increasing the number of abscissæ beyond eight did not improve performance. All information criteria prefer K = 2 (i.e., Kmax = 2) for FL and K = 1 for PL, indicating evidence that the distribution of Xi is nonnormal. Estimates obtained using FL for K = 1, 3, 4 are very similar to those for FL (K = 2) as in Table 1. Figure 2 shows various views of the estimated density based on the FL fit with K = 2, which suggest a departure from normality; the estimate for PL (K = 1) is virtually identical. As illustrated in Figure 2, the estimated marginal densities for FL with K = 1, 2, 3, 4 are alike.
Table 1.
Parameter estimates and p-values for the SWAN data analysis via the conditional score, full-likelihood, and pseudo-likelihood methods. CS, conditional score; FL, full-likelihood, where K = 2 corresponds to the value preferred by information criteria; PL, pseudo-likelihood, where K = 1 corresponds to the value preferred by information criteria; SE, estimated standard error. The values of the model selection criteria (AIC, HQ, BIC) are given for the likelihood methods; smaller values are preferred.
| CS | FL (K = 2) | PL (K = 1) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Est. | SE | p-value | Est. | SE | p-value | Est. | SE | p-value | |
| β0 | −7.32 | 2.25 | 0.00 | −7.22 | 2.17 | 0.00 | −7.21 | 2.17 | 0.00 |
| β0,BMI | 0.29 | 0.04 | 0.00 | 0.29 | 0.03 | 0.00 | 0.29 | 0.04 | 0.00 |
| β0,age | 0.02 | 0.04 | 0.70 | 0.01 | 0.04 | 0.74 | 0.01 | 0.04 | 0.74 |
| β0,B | 0.55 | 0.39 | 0.16 | 0.54 | 0.39 | 0.17 | 0.54 | 0.39 | 0.17 |
| β0,W | −0.20 | 0.28 | 0.46 | −0.22 | 0.26 | 0.40 | −0.22 | 0.27 | 0.41 |
| β0,C | −0.68 | 0.25 | 0.01 | −0.68 | 0.26 | 0.01 | −0.68 | 0.26 | 0.01 |
| β11 | 0.15 | 0.22 | 0.50 | 0.15 | 0.22 | 0.50 | 0.15 | 0.22 | 0.49 |
| β12 | 1.29 | 0.81 | 0.11 | 1.29 | 0.76 | 0.09 | 1.27 | 0.76 | 0.09 |
| 0.33 | 0.012 | 0.10 | 0.33 | 0.005 | 0.00 | 0.33 | 0.005 | 0.00 | |
| Full-likelihood | Pseudo-likelihood | ||||||||
| AIC | HQ | BIC | AIC | HQ | BIC | ||||
| K = 0 | 1.007 | 1.009 | 1.012 | 1.019 | 1.020 | 1.022 | |||
| K = 1 | 0.996 | 0.998 | 1.002 | 1.008 | 1.009 | 1.011 | |||
| K = 2 | 0.994 | 0.997 | 1.002 | ||||||
| K = 3 | 0.994 | 0.997 | 1.003 | ||||||
| K = 4 | 0.994 | 0.997 | 1.004 | ||||||
Figure 2.

Fit to the SWAN data using the full-likelihood approach. (a) Estimated density of Xi for K = 2. (b) Contour plot of the density in (a) with empirical Bayes estimates superimposed (Contours are 10, 25, 50, 75, 90, and 95%). (c) and (d) Corresponding estimated marginal densities for K = 0 (dotted line), K = 1 (dashed line), K = 2 (solid line), K = 3 (long-dashed line), and K = 4 (dot-dashed line) superimposed on histograms of empirical Bayes estimates of the intercept and slope from the K = 2 fit, respectively.
For comparison, Table 1 shows the fit using the CS method of Li et al. 2004. The fits do not differ appreciably across methods. Standard errors for the likelihood methods tend to be smaller than those for CS, suggesting a slight gain in efficiency (borne out in the simulations of Section 7). The results suggest that, controlling for baseline characteristics, absence of osteopenia may be associated with the post-14-day rise and fall of log PDG represented by X2i; a strong association with BMI is also evident. The consistency of inferences across the methods in Table 1, as well as for other methods, including regression calibration, RR, and SS, reported by Li et al. 2004, is likely due to the fact that intra-woman variation in log PDG was not great and most women had relatively rich longitudinal information, as discussed by these authors.
The estimated density of Xi, available from the likelihood approaches, offers additional insights not possible with other methods. The estimate in Figure 2(a) shows two apparent “subpopulations" of women in the “slope" dimension. Figure 2(b) depicts the empirical Bayes estimates X̂2i, calculated as at the end of Section 4, which further highlight the apparent bi-modality of the implied marginal density for X2i; 21% of the n = 624 women had X̂2i < 0.2. It is natural to ask whether membership in a possible subpopulation of women with a higher rate of rise and fall of post-14-day log PDG is systematically associated with known subject characteristics. Figure 3 plots the X̂2i against the covariates and suggests that steeper rise and fall of log PDG may be associated with lower BMI and younger age. More generally, it is possible that an important explanatory characteristic implicated in hormonal patterns may not have been measured. These observations can aid in interpretation of results and suggest issues for future investigation.
Figure 3.

Empirical Bayes estimates of slope (X2i) from the K = 2 fit by full likelihood plotted against observed covariates for the SWAN data. (a) Body mass index. (b) Age. (c) Ethnicity.
7 Simulation Studies
7.1 Simulation Based on SWAN
For each of 200 Monte Carlo data sets, we generated data for n = 624 women based on (1) and (2) and the FL (K = 2) SWAN results. For woman i, we generated Xi from a bivariate 79-21 bimodal mixture of normals with characteristics similar to the estimated density for SWAN; e.g. E(X1i) = −0.48, E(X2i) = 0.30, var(X1i) = 0.29, var(X2i) = 0.02, cov(X1i, X2i) = 0.02. We then generated log PDG measurements Wij, j = 1, …, mi, according to (1) with , where, for simplicity, mi = 5 with the tij equal to the first and last time points and three approximately equally-spaced time points in between for woman i in the actual data. Finally, we generated Yi according to (2) with β0 = (β0, β0,BMI, β0,age, β0,B, β0,W, β0,C)T = (−7.22, 0.29, 0.01, 0.54, −0.22, −0.68)T, β1 = (β11, β12)T = (0.15, 1.27), where the covariates Ci = (1, CBMI,i, Cage,i, CB,i, CW,i, CC,i)T were the same as those for woman i in the SWAN data.
For each data set, we fit the joint model several ways. In Table 2, we report results for CS, FL with normal random effects (K = 0) and with K chosen from K = 0, 1, 2 using the HQ criterion, and PL with K chosen from K = 0, 1 via HQ. 95% Wald confidence intervals were constructed using ±1.96 times estimated standard errors, where those for CS were found as in Li et al. (2004) and those for FL and PL were calculated as in Sections 4 and 5. For FL, HQ selected K = 0, 1, and 2 4%, 42%, and 54% of the time, respectively; for PL, HQ selected K = 0 6% and K = 1 94% of the time. The CS estimators and FL and PL estimators with K chosen adaptively via HQ for each component of β exhibit negligible bias and coverage probabilities that achieve the nominal level. However, the FL (K = 0) estimators for β11 and β12 show a hint of bias, suggesting that incorrectly assuming normal random effects may degrade performance. On the basis of Monte Carlo MSE, the likelihood estimators with K chosen adaptively show slight efficiency gains over CS. Overall, the results are consistent with those for the actual data, suggesting that the advantage of the proposed methods over CS is modest in this setting.
Table 2.
Simulation results for SWAN design. True parameter values are in parentheses. CS, conditional score; FL, full-likelihood, where K = 0 corresponds to normal random effects, and HQ denotes the estimates preferred by HQ; PL, pseudo-likelihood. Mean, Monte Carlo average; RB, relative bias (%); MSE, mean square error; CP, Monte Carlo coverage probability of 95% Wald confidence interval.
| CS | FL (K = 0) | FL (HQ) | PL (HQ) | |||||
|---|---|---|---|---|---|---|---|---|
| Mean RB | MSE CP | Mean RB | MSE CP | Mean RB | MSE CP | Mean RB | MSE CP | |
| β0 (−7.22) | −7.38 | 4.735 | −7.41 | 4.135 | −7.30 | 4.045 | −7.39 | 4.271 |
| 2.24 | 0.96 | 2.61 | 0.95 | 1.15 | 0.95 | 2.31 | 0.96 | |
| β0,BMI (0.29) | 0.30 | 0.001 | 0.30 | 0.001 | 0.29 | 0.001 | 0.30 | 0.001 |
| 2.73 | 0.95 | 2.36 | 0.96 | 1.00 | 0.96 | 2.52 | 0.94 | |
| β0,age (0.01) | 0.01 | 0.002 | 0.01 | 0.002 | 0.01 | 0.002 | 0.01 | 0.002 |
| 4.81 | 0.96 | −5.97 | 0.96 | −2.97 | 0.95 | 5.27 | 0.95 | |
| β0,B (0.54) | 0.52 | 0.150 | 0.55 | 0.151 | 0.55 | 0.149 | 0.53 | 0.149 |
| −3.57 | 0.96 | 2.13 | 0.95 | 1.84 | 0.95 | −2.68 | 0.96 | |
| β0,W (−0.22) | −0.23 | 0.072 | −0.23 | 0.072 | −0.23 | 0.063 | −0.23 | 0.067 |
| 2.89 | 0.96 | 5.68 | 0.95 | 2.04 | 0.95 | 3.19 | 0.96 | |
| β0,C (−0.68) | −0.68 | 0.073 | −0.69 | 0.073 | −0.68 | 0.072 | −0.68 | 0.072 |
| −0.34 | 0.94 | 1.49 | 0.94 | 0.60 | 0.94 | −1.05 | 0.94 | |
| β11 (0.15) | 0.15 | 0.061 | 0.15 | 0.058 | 0.15 | 0.058 | 0.15 | 0.058 |
| 2.51 | 0.94 | 7.93 | 0.97 | 2.52 | 0.96 | 3.41 | 0.94 | |
| β12 (1.27) | 1.27 | 0.553 | 1.17 | 0.560 | 1.27 | 0.543 | 1.27 | 0.550 |
| −1.99 | 0.97 | −10.23 | 0.93 | −2.59 | 0.96 | −2.49 | 0.96 | |
7.2 Simulations Under Generic Scenarios
To examine performance of the proposed methods more generally, we carried out simulations under several true random effects distributions for binary Yi using the same scenarios as in Section 5 of Li et al. (2004). For each of 200 Monte Carlo data sets, we generated Xi, i = 1, …, n = 500, from a bivariate distribution with E(X1i) = E(X2i) = 0.5, var(X1i) = 1.0, var(X2i) = 0.64, cov(X1i, X2i) = −0.2, β0 = −2.5, and then generated longitudinal data according to the mixed model with , where tij was generated from for j = 1, …, 5 and Wij could be arbitrarily missing with probability 0.05, so that mi ≥ 5. We then generated Yi according to with Xi = (X1i, X2i) and β1 = (β11, β12)T, where β0 = −2.5, and β1 = (3.0, 2.0)T.
Four true distributions for Xi were considered, scaled to have the moments given above: (a) bivariate normal; (b) a bimodal 70–30 mixture of normals; (c) a bivariate skew-normal (Azzalini and Dalla Valle, 1996), with coefficients of skewness (−0.10, 0.85) for (X1i, X2i), a mildly skewed distribution; and (d) a bivariate t with 5 degrees of freedom, a density with heavy tails. For each data set under each of (a)–(d), the model was fit by the methods used in Section 7.1, with standard errors and confidence intervals constructed as in that section. Li et al. (2004) have demonstrated that the naive approach replacing Xi by individual least squares estimates and the RC estimator can exhibit appreciable biases under nonnormal random effects and that the SS and CS estimators perform similarly; hence, we do not report results for these methods.
Table 3 summarizes performance under each random effects distribution (a)–(d). For CS and FL and PL with K chosen based on HQ, bias is negligible, estimated standard errors are close to the Monte Carlo values, and coverage is close to nominal. Notably, the likelihood methods offer gains in efficiency of up to 38% over CS, demonstrating the potential for considerable improvement in precision over existing procedures. Moreover, the simpler PL method either equals the performance of FL or only suffers mild efficiency loss while still showing impressive gains over CS, suggesting that this computationally cheaper method may be appealing for practical use.
Table 3.
Simulation results for generic random effect distributions for pr(Yi = 1|Xi) = [1 + exp{−(β0 + β11X1i + β12X2i)}]−1, with true values β0 = −2.5, β1 = (β11, β12)T = (3.0, 2.0)T, , n = 500. Estimators: CS, conditional score; FL, full-likelihood, PL, pseudo-likelihood, where K = 0 corresponds to normal random effects, and HQ indicates preferred by HQ when choosing K among K = 0, 1, 2 for FL and K = 0, 1 for PL. RB, relative bias (%); SD, Monte Carlo standard deviation; SE, average of estimated standard errors; CP, Monte Carlo coverage probability of 95% Wald confidence interval; RE, relative efficiency with respect to CS, i.e., Monte Carlo mean square errors for CS divided by that for the indicated estimator.
| Method | RB (%) | SD | SE | CP | RE | RB (%) | SD | SE | CP | RE | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) Xi Normal | (b) Xi Bimodal mixture | ||||||||||
| β0 | CS | 1.0 | 0.38 | 0.40 | 0.96 | 1.00 | 2.2 | 0.46 | 0.47 | 0.95 | 1.00 |
| FL (K = 0) | 0.5 | 0.35 | 0.36 | 0.96 | 1.16 | 22.8 | 0.65 | 0.56 | 0.98 | 0.29 | |
| FL (HQ) | 0.5 | 0.35 | 0.36 | 0.96 | 1.16 | 1.7 | 0.41 | 0.43 | 0.96 | 1.24 | |
| PL (HQ) | −0.3 | 0.35 | 0.36 | 0.96 | 1.15 | −1.0 | 0.42 | 0.43 | 0.95 | 1.18 | |
| β11 | CS | 2.0 | 0.43 | 0.48 | 0.94 | 1.00 | 2.8 | 0.38 | 0.40 | 0.96 | 1.00 |
| FL (K = 0) | 0.9 | 0.39 | 0.42 | 0.94 | 1.25 | 32.3 | 0.74 | 0.58 | 0.73 | 0.10 | |
| FL (HQ) | 0.9 | 0.39 | 0.42 | 0.94 | 1.25 | 3.8 | 0.37 | 0.36 | 0.95 | 1.02 | |
| PL (HQ) | 0.1 | 0.39 | 0.42 | 0.95 | 1.25 | 2.4 | 0.38 | 0.36 | 0.96 | 1.02 | |
| β12 | CS | 1.7 | 0.30 | 0.31 | 0.95 | 1.00 | 1.5 | 0.32 | 0.34 | 0.96 | 1.00 |
| FL (K = 0) | 1.0 | 0.28 | 0.29 | 0.97 | 1.22 | 17.1 | 0.42 | 0.39 | 0.96 | 0.35 | |
| FL (HQ) | 1.0 | 0.28 | 0.29 | 0.97 | 1.22 | 1.8 | 0.31 | 0.33 | 0.96 | 1.04 | |
| PL (HQ) | 0.1 | 0.28 | 0.29 | 0.96 | 1.20 | −2.8 | 0.31 | 0.31 | 0.93 | 1.04 | |
| (c) Xi Skewed | (d) Xi Bivariate t5 | ||||||||||
| β0 | CS | 3.4 | 0.37 | 0.42 | 0.98 | 1.00 | 2.1 | 0.40 | 0.44 | 0.97 | 1.00 |
| FL (K = 0) | 2.4 | 0.35 | 0.37 | 0.98 | 1.19 | −6.5 | 0.31 | 0.34 | 0.93 | 1.26 | |
| FL (HQ) | 0.2 | 0.34 | 0.35 | 0.96 | 1.27 | −4.0 | 0.35 | 0.35 | 0.94 | 1.18 | |
| PL (HQ) | −1.9 | 0.35 | 0.32 | 0.94 | 1.19 | −4.2 | 0.35 | 0.31 | 0.93 | 1.16 | |
| β11 | CS | 4.4 | 0.43 | 0.50 | 0.96 | 1.00 | 3.4 | 0.47 | 0.54 | 0.95 | 1.00 |
| FL (K = 0) | 3.3 | 0.40 | 0.43 | 0.94 | 1.15 | −8.3 | 0.36 | 0.38 | 0.87 | 1.21 | |
| FL (HQ) | 0.5 | 0.38 | 0.40 | 0.95 | 1.38 | −4.7 | 0.41 | 0.41 | 0.94 | 1.21 | |
| PL (HQ) | −2.0 | 0.39 | 0.34 | 0.94 | 1.27 | −5.9 | 0.39 | 0.37 | 0.93 | 1.20 | |
| β12 | CS | 2.4 | 0.32 | 0.32 | 0.95 | 1.00 | 2.8 | 0.30 | 0.34 | 0.97 | 1.00 |
| FL (K = 0) | 2.0 | 0.30 | 0.29 | 0.95 | 1.15 | −4.5 | 0.25 | 0.28 | 0.94 | 1.32 | |
| FL (HQ) | 0.0 | 0.29 | 0.28 | 0.94 | 1.19 | −3.5 | 0.27 | 0.29 | 0.94 | 1.18 | |
| PL (HQ) | −1.2 | 0.30 | 0.26 | 0.94 | 1.16 | −3.9 | 0.27 | 0.26 | 0.93 | 1.15 | |
The advantage of estimating the random effects distribution is illustrated Figure 4 for the bimodal normal mixture scenario (b) and FL. The estimated densities with K chosen via all information criteria track the true very well; the pattern is similar for those using PL (not shown). Only a few of the 200 individual marginal estimates exhibit “overfitting” with a spurious extra mode. In practice, Zhang and Davidian (2001) and others recommend examining the fitted density and choosing K by subjectively combining the information from the information criterion with the visual evidence, using a smaller K than objectively indicated if the estimate is “bumpier” than expected. In the simulations, the information criteria reliably detected departures from normality: under (a) for both FL and PL, HQ chose K = 0 in 99.5% of the 200 data sets; under (b), FL-HQ chose K = 0, 1, 2 0%, 26.5%, and 73.5% of the time and PL-HQ chose K = 1 for all 200 data sets; under (c), FL-HQ chose K = 0, 1, 2 5.5%, 32.5%, and 62.0% of the time and PL-HQ chose K = 0, 1 27.0% and 73.0% of the time; and under (d), FL-HQ chose K = 0, 1, 2 9.0%, 27.0%, and 64.0% of the time and PL-HQ chose K = 0, 1 39.0% and 61.0% of the time.
Figure 4.

Estimated densities for the bimodal random effects simulation using the full-likelihood approach. (a) True density of Xi. (b) Monte Carlo average of estimated densities of Xi preferred by HQ. (c) and (d) True marginal densities (solid line), and Monte Carlo average of estimated marginal densities preferred by AIC (long-dashed line), HQ (dashed line) and BIC (dotted line). (e) and (f) Estimated marginal densities preferred by HQ for 200 data sets.
For FL with K = 0, so assuming normal random effects, Table 3 shows that this incorrect assumption can lead to significant biases for some true random effects distributions; bias is severe under the bimodal scenario (b), and there is a suggestion of mild bias in estimation of β11 for the heavy-tailed situation (d). This is in contrast to reports of apparent surprising robustness to the random effects assumption for likelihood methods for joint models where the primary endpoint is a censored time-to-event following a proportional hazards model (e.g. Song et al., 2002, sec. 6). Evidently, such a robustness property does not hold here. We carried out a further simulation for the bimodal random effects with different intra-subject correlation (e.g., cov(X1i, X2i) = −0.1 ~ −0.3) and found that the bias of FL (K = 0) became more severe for larger magnitude of the intra-subject correlation, while the proposed FL and PL with K chosen adaptively (which model the correlation using the multivariate SNP density) and the CS (which “conditions away” the entire random effects) demonstrated expected good performance.
8 Discussion
We have proposed full-likelihood and pseudo-likelihood approaches for inference in a joint model for a primary endpoint and continuous longitudinal response. The joint model we consider may be viewed as semiparametric in that the distribution of random effects in the mixed model for the longitudinal data is not specified parametrically but is assumed only to belong to a class of distributions with “smooth” densities. The approaches yield not only estimates of parameters in the primary endpoint model representing associations between the endpoint and underlying features of the longitudinal trajectories and other subject characteristics, but also provide an estimate for the random effects density. This density estimate offers the analyst additional insight on the population that may suggest further hypotheses and issues for future investigation.
The new methods offer impressive efficiency gains over existing ones proposed by Li et al. (2004) that also do not require a parametric assumption on the random effects. These gains come at the expense of an increase in computational complexity. The full likelihood approach, implemented by an EM algorithm, can entail significant computational intensity; however, the simpler pseudo-likelihood approach can achieve almost equal performance, and we recommend it for practical use when computational burden is an issue.
Robustness to assumptions on the random effects distribution in these and related joint models deserves systematic study. We are currently developing a framework for assessing robustness; this work will be reported elsewhere.
Acknowledgments
This work was supported by NIH grants R01-CA085848 and R37-AI31789. The authors are grateful to MaryFran Sowers for providing the SWAN data.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Azzalini A, Dalla Valle A. The multivariate skew-normal distribution. Biometrika. 1996;83:715–726. [Google Scholar]
- 2.Carroll RJ, Ruppert D, Stefanski LA. Measurement Error in Nonlinear Models. London: Chapman and Hall; 1995. [Google Scholar]
- 3.Carroll RJ, Spiegelman C, Lan KK, Bailey KT, Abbott RD. On-errors-invariables for binary regression models. Biometrika. 1984;71:19–26. [Google Scholar]
- 4.Chen J, Zhang D, Davidian M. Generalized linear mixed models with flexible distributions of random effects for longitudinal data. Biostatistics. 2002;3:347–360. [Google Scholar]
- 5.Davidian M, Gallant AR. The nonlinear mixed effects model with a smooth random effects density. Biometrika. 1993;80:475–488. [Google Scholar]
- 6.Gallant AR, Nychka DW. Seminonparametric maximum likelihood estimation. Econometrica. 1987;55:363–390. [Google Scholar]
- 7.Henderson R, Diggle P, Dobson A. Joint modeling of longitudinal measurements and event time data. Biostatistics. 2000;4:465–480. doi: 10.1093/biostatistics/1.4.465. [DOI] [PubMed] [Google Scholar]
- 8.Laird NM, Ware JH. Random effects models for longitudinal data. Biometrics. 1982;38:963–974. [PubMed] [Google Scholar]
- 9.Li E, Zhang D, Davidian M. Conditional estimation for generalized linear models when covariates are subject-specific parameters in a mixed model for longitudinal measurements. Biometrics. 2004;60:1–7. doi: 10.1111/j.0006-341X.2004.00170.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.McCullagh P, Nelder JA. Generalized Linear Models. 2. London: Chapman and Hall; 1989. [Google Scholar]
- 11.Santoro N, Lasley B, McDonnell D, Allsworth J, Crawford S, Gold EB, Finkelstein JS, Greendale GA, Kelsey J, Korenman S, Luborsky JL, Matthews K, Midgley R, Powell L, Sabatine J, Schocken M, Sowers MF, Weiss G. Body size and ethnicity are associate with menstrual cycle alternations in the early menopausal transition: The Study of Women’s Health Across the Nation (SWAN) Daily Hormone Study. Journal of Clinical Endocrincology and Metabolism. 2004;89:2622–2631. doi: 10.1210/jc.2003-031578. [DOI] [PubMed] [Google Scholar]
- 12.SAS Institute Inc. SAS OnlineDoc, Version 9.1. Cary, NC: SAS Institute Inc; 2003. [Google Scholar]
- 13.Song X, Davidian M, Tsiatis AA. A semiparametric likelihood approach to joint modeling of longitudinal and time-to-event data. Biometrics. 2002;58:742–753. doi: 10.1111/j.0006-341x.2002.00742.x. [DOI] [PubMed] [Google Scholar]
- 14.Sowers MR, Finkelstein J, Ettinger B, Bondarenko I, Neer R, Cauley J, Sherman S, Greendale G. The association of endogenous hormone concentrations and bone mineral density measures in pre- and peri-menopausal women of four ethnic groups: SWAN. Osteoporosis International. 2003;14:44–52. doi: 10.1007/s00198-002-1307-x. [DOI] [PubMed] [Google Scholar]
- 15.Stefanski LA, Carroll RJ. Conditional scores and optimal scores for generalized linear measurement-error models. Biometrika. 1987;74:703–716. [Google Scholar]
- 16.Tsiatis AA, Davidian M. Joint modeling of longitudinal and time-to-event data: An overview. Statistica Sinica. 2004;14:809–834. [Google Scholar]
- 17.Wang CY, Huang Y. Functional methods for logistic regression on random-effect-coefficients for longitudinal measurements. Statistics and Probability Letters. 2001;53:347–356. [Google Scholar]
- 18.Wang CY, Wang N, Wang S. Regression analysis when covariates are regression parameters of a random effects model for observed longitudinal measurements. Biometrics. 2000;56:487–495. doi: 10.1111/j.0006-341x.2000.00487.x. [DOI] [PubMed] [Google Scholar]
- 19.Wulfsohn MS, Tsiatis AA. A joint model for survival and longitudinal data measured with error. Biometrics. 1997;53:330–339. [PubMed] [Google Scholar]
- 20.Zhang D, Davidian M. Linear mixed models with flexible distributions of random effects for longitudinal data. Biometrics. 2001;57:795–802. doi: 10.1111/j.0006-341x.2001.00795.x. [DOI] [PubMed] [Google Scholar]
- 21.Zhang D, Lin X, Raz J, Sowers MF. Semiparametric stochastic mixed models for longitudinal data. Journal of the American Statistical Association. 1998;93:710–719. [Google Scholar]