

Abstract
The use of conceptual knowledge collections or structures within the biomedical domain is pervasive, spanning a variety of applications including controlled terminologies, semantic networks, ontologies, and database schemas. A number of theoretical constructs and practical methods or techniques support the development and evaluation of conceptual knowledge collections. This review will provide an overview of the current state of knowledge concerning conceptual knowledge acquisition, drawing from multiple contributing academic disciplines such as biomedicine, computer science, cognitive science, education, linguistics, semiotics, and psychology. In addition, multiple taxonomic approaches to the description and selection of conceptual knowledge acquisition and evaluation techniques will be proposed in order to partially address the apparent fragmentation of the current literature concerning this domain.
Introduction
Conceptual knowledge can be defined as a combination of atomic units of information and meaningful relationships between those units [1]. Examples of such knowledge collections can include terminologies, ontologies, and databases. Although biomedical informatics articles frequently report on the design and evaluation of systems that use conceptual knowledge collections [2-11], few articles report methods for the population of such structures. Such methods fall within the domain of Knowledge Acquisition (KA): the process of identifying, eliciting, and verifying or validating domain-specific knowledge [12]. Sources of domain-specific knowledge can include experts, literature, and databases. The goal of this review is to provide an overview of Conceptual Knowledge Acquisition (CKA) as it applies to biomedicine. At this time, so many articles been published on various aspects of CKA that a comprehensive review is far beyond the scope of any individual paper. Rather, the more modest goal is to provide a synthetic overview that addresses: 1) theoretical foundations of CKA, 2) methods for the acquisition of conceptual knowledge and 3) methods for verification and validation of the acquired knowledge. New taxonomies for both the acquisition and of the verification and validation will be presented as a component of the discussion.
CKA is a complex, expansive, rambling and heterogeneous topic that has been tackled by a number of different fields of research, including education, computer science, semiotics, linguistics, cognitive science and psychology. Synthesizing CKA across these various disciplines is challenging because of variability in approaches to CKA by the various disciplines. Additional layers of complexity are introduced by different terminologies and different definitions used by the various disciplines. To promote a fuller understanding of later discussions presented, a conceptual framework regarding this heterogeneity is presented relative to the following topics:
A brief discussion of CKA within the broader context of Knowledge Engineering (KE)
A more precise definition of CKA, drawing on the various definitions that have been proposed.
A meta-review of previous reviews of sub-components of CKA.
Background
Knowledge Acquisition in the context of Knowledge Engineering
The theories and methods that underlie KA are part of a larger domain known as knowledge engineering (KE). The KE process (Figure 1) incorporates multiple steps:
Figure 1. Key components of the KE process.
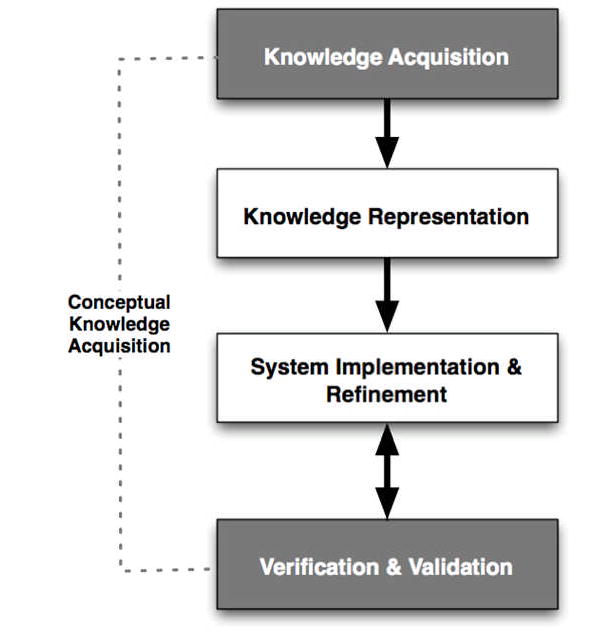
Components that are involved in the conceptual KA sub-process of KE are shaded. (Adapted from Liou, “Knowledge Acquisition: Issues, Techniques, and Methodology”, 1990)
Acquisition of knowledge (KA)
Representation of that knowledge (KR) in a computable form
Implementation or refinement of knowledge-based agents or applications using the knowledge collection generated in the preceding steps
Verification and validation of the output of those knowledge-based agents or applications utilizing one or more reference standards as the basis of comparison.
The reference standards described in step four can include expert performance measures, which are defined as requirements acquired before designing the knowledge-based system, or requirements that were realized upon implementation of the knowledge-based system. In this context, verification is the process of ensuring that the knowledge-based system meets the initial requirements of the potential end-user community. In comparison, validation is the process of ensuring that the knowledge-based system meets the realized requirements of the end-user community once a knowledge-based system has been implemented [13].
Within the overall KE process, KA can be defined as the sub-process involving the extraction of knowledge from existent sources (e.g., experts, literature, databases, other sources) with the purpose of representing that knowledge in a computable format [12, 14-18]. This definition also includes the verification or validation of knowledge-based systems that use the resultant knowledge collections [12]. Viewing KA within the broader KE context has two important implications. First, within the biomedical informatics domain, KA usually refers to the process of eliciting knowledge specifically for use in knowledge bases that are integral to expert systems or intelligent agents (e.g., clinical decision support systems). However, a review of the literature concerned with KA beyond this domain shows a broad variety of application areas for KA, including construction of shared database models, ontologies and human-computer interaction models [14, 19-23]. Therefore, Payne and Starren [24] argue that the definition of KA within the biomedical informatics domain should be expanded commensurately. Second, verification and validation methods are often applied to knowledge-based systems only during the final stage of the KE process. However, such techniques are most effective when employed iteratively throughout the entire KE process. As such, they also become integral components of the KA process.
A More Precise Definition
Synthesizing CKA across domains is complicated by a cross disciplinary heterogeneity in definitions with lack of standardization. For example, the cognitive science literature describes two types of knowledge—procedural and declarative. Declarative knowledge is largely synonymous with conceptual knowledge as defined earlier, but differs in that the cognitive science literature describes such knowledge as consisting solely of “facts” without any explicit reference to the relationships that may exist between those “facts” [25]. Procedural knowledge is a process-oriented understanding of a given problem domain.
The education literature takes a more nuanced view. Conceptual knowledge is defined as a combination of atomic units of information and the meaningful relationships between those units. The education literature also describes two other types of knowledge, labeled as procedural and strategic. Reflecting the cognitive science definition, procedural knowledge is defined as a process-oriented understanding of a given problem domain [1, 26-28]. However, the education literature adds strategic knowledge, which is used to operationalize conceptual knowledge into procedural knowledge [1] (Figure 2). These definitions are derived from empirical research on learning and problem-solving in complex scientific and quantitative domains such as mathematics and engineering [27, 28].
Figure 2. Spectrum of knowledge types.
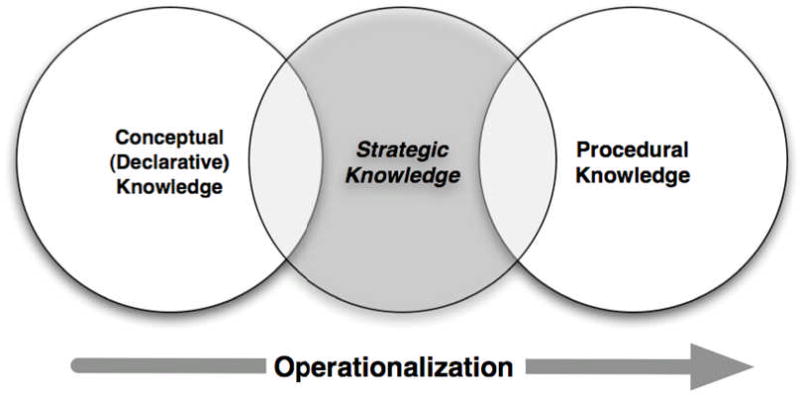
(Adapted from McCormick, “Conceptual and Procedural Knowledge”, 1997)
This three-part definition provides several advantages. [1]. Specifically, these definitions:
Directly address the implicit and explicit relationships (which are in and of themselves forms of knowledge) that exist between elements of conceptual knowledge,
Define conceptual knowledge as being dynamic, rather than a static set of facts
Postulate that conceptual knowledge has a direct relationship to procedural knowledge via the process of operationalization afforded by strategic knowledge.
Given these potential advantages, the definitions found in the education literature will be used for the remainder of this review to frame the discussion of KA. The selection of this specific definition is critical since it positions our discussion of CKA theories and methods within the specific context of the elicitation of both units of knowledge and relationships between those units.
The value of this definition can be seen in the context of a decision support system. In biomedicine, conceptual knowledge collections rarely exist in isolation. Instead, they usually occur within structures that contain multiple types of knowledge. For example, a knowledge-base used in a modern clinical decision support system might include: (1) a knowledge collection containing potential findings, diagnoses, and the relationships between them (conceptual knowledge), (2) a knowledge collection containing guidelines or algorithms used to logically traverse the previous knowledge structure (procedural knowledge), and (3) a knowledge structure containing application logic used to apply or operationalize the preceding knowledge collections (strategic knowledge). Realization of a functional decision support system becomes possible only when these three types of knowledge are combined. [29].
For the remainder of this review, the frameworks and methodologies associated with the domains of psychology and cognitive science will be discussed collectively. Differentiation between these two fields is often found within the biomedical informatics literature based upon variations in the frameworks and methodologies. However, within the context of KA, such a separation would add potential redundancy in this review without yielding any practical advantage because the majority of cognitive science frameworks in this domain are direct derivatives of pre-existing psychological theory.
Finally, when discussing KA, it can be argued that significant literature can be found in the computer science literature, specifically those concerning artificial intelligence. This is true for discussions focused on procedural knowledge, including those used in a large number of intelligent agents and decision support systems [30-33]. However, artificial intelligence literature is extremely sparse with respect to KA methods intended to elicit conceptual knowledge. For example, a general literature search was performed using 1) the ACM Digital Library, and 2) a focused literature search targeting the journal Artificial Intelligence in Medicine using the search term “conceptual knowledge acquisition”, applied to the title and/or abstract. Manual review of article abstracts yielded no articles which met inclusion criteria for this literature review, which are detailed later in this review.
Meta-review of Reviews
Although the lack of an over-arching review motivated this work, several published reviews have addressed key sub-components of the overall KA process previously. For example, Liou described a basic taxonomy of KA techniques composed of three major categories: basic, group and supplementary techniques [12]. This taxonomy will be further examined later in this review. Similarly, Menzies and van Harmelen proposed a framework of six essential theories of contemporary KE. These methodologies all result in knowledge structures that incorporate one or more forms of knowledge representation, such as procedures, axioms, single general purpose inference engines (e.g., persistent, stored procedures) and ontologies [34]. Gaines and Shaw provided a more targeted review, describing KA tools and methods based on personal construct theory, which represents a theoretical framework used in the psychology literature to describe how individuals make sense of their surrounding environment via categorization processes [17]. Finally, Hereth et al. reviewed KE methods specifically focusing on representational levels that may be used to formalize knowledge collections in a computable format [35].
While not specifically focusing upon KA, some reports in the biomedical informatics literature described application of conceptual knowledge collections for the design or operation of information systems. Examples include:
Evans’ medical-concept representation language [36]
Campbell’s logical foundation for the representation of clinical data, and reports describing use of the National Library of Medicine’s (NLM) Unified Medical Language System (UMLS) as the basis for a biomedical conceptual knowledge structure [6, 37]
Cimino’s work concerning the generation of biomedical knowledge from concept-oriented, controlled terminologies [38].
However, the literature concerning KA found in the biomedical informatics domain rarely describes reproducible approaches for populating such knowledge collections. A notable exception are a collection of reports concerning computer-facilitated collaboration methodologies that have been employed in the context of constructing shared biomedical ontologies such as SNOMED-CT [36, 37, 39, 40].
Table 1 contains a selected bibliography that provides an overview of the KA literature and literature sources that will be examined in greater detail in this review.
Table 1.
Selected bibliography of theoretical and practical frameworks contributing to the current state of knowledge concerning KA
| Topic Area | Author(s) | Year | Title | Source Domain |
|---|---|---|---|---|
| Definition of knowledge types | McCormick | 1997 | Conceptual and Procedural Knowledge (1) | Education |
| Patel, Arocha et al. | 2001 | A primer on aspects of cognition for medical informatics (56) | Cognitive Science | |
| Zhang | 2002 | Representations of health concepts: a cognitive perspective (49) | Biomedical | |
| Knowledge Engineering (KE) frameworks | Liou | 1990 | Knowledge acquisition: issues, techniques, and methodology (12) | Computer Science |
| Menzies and Harmelen | 1999 | Evaluating knowledge engineering techniques (34) | Computer Science | |
| Computational representation of knowledge | Newell and Simon | 1981 |
Computer science as empirical nquiry: symbols and search
In Mind Design (45) |
Computer Science |
| Compton and Jansen | 1990 | A philosophical basis for knowledge acquisition (15) | Psychology | |
| Hereth, Stumme et al. | 2000 | Conceptual Knowledge Discovery and Data Analysis (35) | Computer Science | |
| Knowledge acquisition (KA) frameworks | Brachman and McGuinness | 1988 | Knowledge representation, connectionism and conceptual retrieval (14) | Computer Science |
| Gaines and Shaw | 1989 | Social and Cognitive Processes in Knowledge Acquisition (16) | Cognitive Science | |
| Compton and Jansen | 1990 | A philosophical basis for knowledge acquisition (15) | Psychology | |
| Liou | 1990 | Knowledge acquisition: issues, techniques, and methodology (12) | Computer Science | |
| Psychological basis for conceptual knowledge acquisition | Kelly | 1955 | The psychology of personal constructs (47) | Psychology |
| Cognitive basis for conceptual knowledge acquisition | Liou | 1990 | Knowledge acquisition: issues, techniques, and methodology (12) | Computer Science |
| McCormick | 1997 | Conceptual and Procedural Knowledge (1) | Education | |
| Zhang | 2002 | Representations of health concepts: a cognitive perspective (49) | Biomedical | |
| Semiotic basis for conceptual knowledge acquisition | Campbell, Oliver et al. | 1998 | Representing thoughts, words, and things in the UMLS (6) | Biomedical |
| Conceptual knowledge acquisition (KA) methods | Liou | 1990 | Knowledge acquisition: issues, techniques, and methodology (12) | Computer Science |
| Knowledge collection verification and validation methods | Preece | 2001 | Evaluating Verification and Validation Methods in Knowledge Engineering (13) | Computer Science |
Review Methodology and Results
The following review of the state of knowledge concerning KE, and in particular CKA, was undertaken to address three specific goals:
To define and differentiate conceptual knowledge from other types of knowledge,
To enumerate major theoretical bases for the elicitation and symbolic representation of conceptual knowledge, and
To develop an extensible framework for a taxonomy of conceptual KA methods and techniques
To achieve these goals, a simple literature review was performed, of work published in the domains of biomedicine, computer science, cognitive science, education, linguistics, semiotics, and psychology. Bibliographic databases queried included PubMED [41], ACM Portal [42], PsycArticles [43], and ERIC [44]. Search terms used varied with the source being queried. Search strategies included a process of iterative, heuristic refinement to focus search results on either theoretical or methodological work reporting on knowledge acquisition, representation, and verification or validation. A summary of the search terms and numbers of articles retrieved for inclusion in this review is provided in Table 2.
Table 2.
Summary of literature review results. Those articles found using the search terms in bold face were selected for more detailed review and potential inclusion in this review.
| Search Term | Pubmed | ACM | PsycArticles | ERIC | ||||
|---|---|---|---|---|---|---|---|---|
| n | % of total | n | % of total | n | % of total | n | % of total | |
| Procedural Knowledge | 458 | 5.4 | 36 | 0.7 | 3 | 5.4 | 35 | 7 |
| Conceptual Knowledge | 2005 | 23.7 | 21 | 0.4 | 28 | 50 | 112 | 22.4 |
| Knowledge Acquisition | 2509 | 29.7 | 773 | 15.4 | 12 | 21.4 | 228 | 45.7 |
| Knowledge Representation | 1696 | 20.1 | 1718 | 34.2 | 10 | 17.9 | 72 | 14.4 |
| Procedural Knowledge AND Acquisition | 42 | 0.5 | 73 | 1.5 | 0 | 0 | 5 | 1 |
| Procedural Knowledge AND Representation | 19 | 0.2 | 219 | 4.4 | 0 | 0 | 0 | 0 |
| Conceptual Knowledge AND Acquisition | 60 | 0.7 | 342 | 6.8 | 1 | 1.8 | 10 | 2 |
| Conceptual Knowledge AND Representation | 142 | 1.7 | 740 | 14.7 | 2 | 3.6 | 2 | 0.4 |
| Knowledge Sharing | 1304 | 15.4 | 201 | 4 | 0 | 0 | 34 | 6.8 |
| Knowledge Representation AND Evaluation | 208 | 2.5 | 898 | 17.9 | 0 | 0 | 0 | 0.2 |
| TOTAL | 8443 | 100 | 5021 | 100 | 56 | 100 | 499 | 100 |
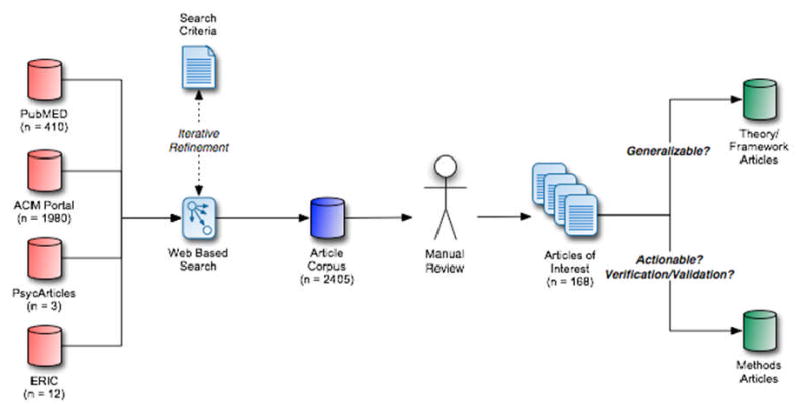
After selecting combinations of search terms (indicated in bold in Table 2) that yielded results most relevant to the goals of this review, the search strategy generated an initial corpus of 2405 articles. Manual review of abstracts yielded 168 articles of potential interest (6.9% of the initial corpus) that were then subjected to a more comprehensive review. Selection for further inclusion or reference in this manuscript was based on one of two criteria:
Articles reporting upon methodological approaches to KE or KA, those that included both an actionable description of the methodology as well as a discussion of either qualitative or quantitative verification or validation metrics or techniques were selected.
Articles whose specific focus did not include methodological approaches to KE or KA, but that presented generalizable theoretical foundations or framework models were also selected.
A summary of the literature review methodology employed is presented in Figure 4.
Figure 4. Overview of methodology employed for literature review process. Labels in italics indicate article selection criteria subject to iterative refinement.
Review of the Literature
An overview of the current state of knowledge concerning theoretical and methodological approached to CKA will be described relative to the following topics:
The contribution of different research domains to CKA.
The theoretical and practical foundations for CKA, including computational, psychological and cognitive science, semiotic, and linguistic theories
A novel taxonomy of CKA methods, and discussion of individual methods.
A novel taxonomy of methods to verify or validate conceptual knowledge collections, and discussion of individual methods.
Contributions of Various Disciplines to KA
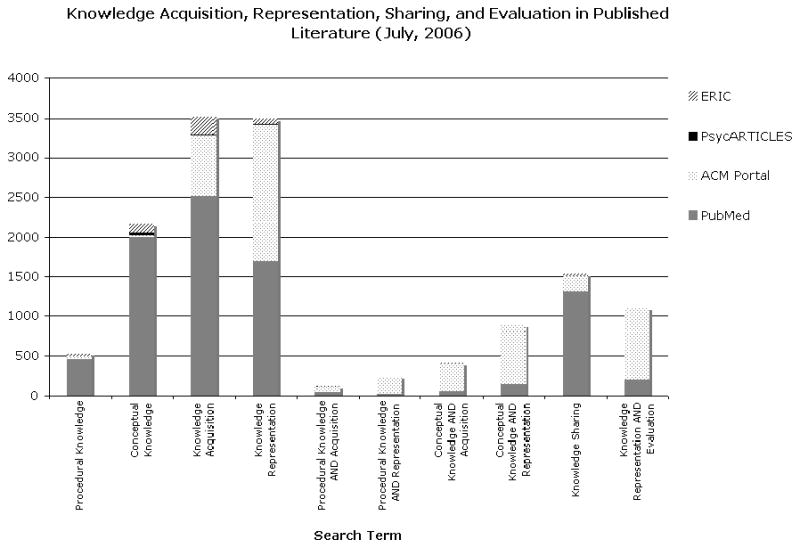
The theories and methods that support KA are drawn from several academic and practical disciplines. Beyond the literature already presented concerning the overall KE process, a number of academic domains have also addressed various sub-problems associated with KA. Specifically, the disciplines of biomedicine, computer science, cognitive science, education, linguistics, semiotics and psychology have each contributed to an understanding of the KA process. Accessing this literature is complicated by differences in the nomenclature used to describe KE. A simple literature search (conducted in July 2006) involving heuristically derived phrases intended to retrieve articles related to KE domain serves to illustrate the contributions from several different fields of study and the terms favored by the different domains (Figure 3).
Figure 3. Literature search results for phrases intended to retrieve articles pertinent to the KE domain, drawn from biomedical (PubMed), computer science (ACM), psychology and cognitive science (PsycARTICLES), and education (ERIC) literature databases.
Theoretical and Practical Foundations
The theories that support the ability to acquire, represent, and verify or validate conceptual knowledge come from multiple domains. In the following sections, several of those domains will be discussed, including; Computer science; psychology and cognitive science; Semiotics; and Linguistics. Each domain has approached CKA with a distinct set of assumption and goals. Whereas each approach has strengths and weaknesses, each contributes to the overall understanding of the CKA process.
Computer Science Foundations of Knowledge Acquisition
A critical theory that supports the ability to acquire and represent knowledge in a computable format is the physical symbol hypothesis. First proposed by Newell and Simon in 1981 [45], and expanded by Compton and Jansen in 1989 [15], the physical symbol hypothesis postulates that knowledge consists of both symbols of reality, and relationships between those symbols. The hypothesis further argues that intelligence is defined by the ability to appropriately and logically manipulate both symbols and relationships. A critical component of this the theory is the definition of what constitutes a “physical symbol system”, which Newell and Simon describe as:
“…a set of entities, called symbols, which are physical patterns that can occur as components of another type of entity called an expression (or symbol structure). Thus, a symbol structure is composed of a number of instances (or tokens) of symbols related in some physical way (such as one token being next to another). At any instant of time the system will contain a collection of these symbol structures.” [46]
This preceding definition bears similarity with of the definition of conceptual knowledge presented previously. Thus, computational representation of conceptual knowledge collections should be well supported by computational theory. However, due to the paucity of reproducible methods for eliciting such symbol systems, elicitation of the symbols and relationships that constitute a “physical symbol system”, or conceptual knowledge collection, remains a significant impediment to the widespread use of conceptual knowledge-based systems.
Psychological and Cognitive Basis for Knowledge Acquisition
Expertise transfer forms the accepted psychological basis for KA. Expertise transfer hypothetically assumes that humans transfer their expertise to computational systems so that those systems are able to replicate expert human performance (Figure 5). An example of the expertise transfer theory is provided by Kelly’s Personal Construct Theory (PCT). This theory defines humans as “anticipatory systems”, where individuals create templates, or constructs that allow them to recognize situations or patterns in the “information world” surrounding them. These templates are then used to anticipate the outcome of a potential action given knowledge of similar previous experiences [47]. Kelly views all people as “personal scientists” who make sense of the world around them through the use of a hypothetico-deductive reasoning system.
Figure 5. Overview of psychology-based theoretical model of expert knowledge transfer.
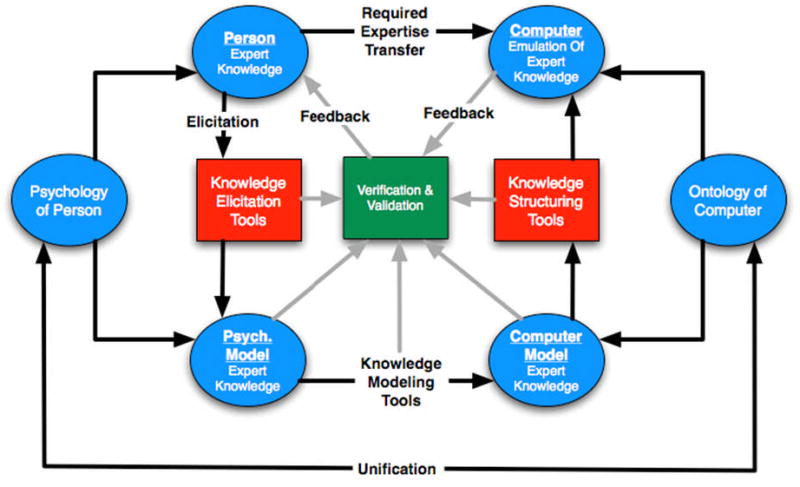
Implicit in this model is the ultimate unification of the psychology of the person (expert knowledge source) and the ontology (conceptual knowledge collection) of the computer. (Adapted from Gaines and Shaw, “Knowledge Acquisition Tools Based On Personal Construct Psychology”, 1993)
It has been argued within the KE literature that the constructs used by experts can be used as the basis for designing or populating conceptual knowledge collections [17]. The details of PCT help to explain how experts create and use such constructs. Specifically, Kelly’s fundamental postulate states: “a person’s processes are psychologically channelized by the way in which he anticipated events.” This is complemented by the theory’s first corollary:
“Man looks at his world through transparent templates which he creates and then attempts to fit over the realities of which the world is composed… Constructs are used for predictions of things to come… The construct is a basis for making a distinction… not a class of objects, or an abstraction of a class, but a dichotomous reference axis.”
Kelly builds on these concepts in his Dichotomy Corollary, stating that “a person’s construction system is composed of a finite number of dichotomous constructs.” Finally, the parallel nature of personal constructs and conceptual knowledge is illustrated in Kelly’s Organization Corollary, which states, “each person characteristically evolves, for his convenience of anticipating events, a construction system embracing ordinal relationships between constructs” [17, 47].
Thus, personal constructs essentially represent templates applied to the creation of knowledge classification schemas used in reasoning. If such constructs are elicited from experts, atomic units of information can be defined, and the Organization Corollary can be applied to generate networks of ordinal relationships between those units. Collectively, these arguments serve to satisfy and reinforce the earlier definition of conceptual knowledge, and provide insight into the expert knowledge structures that can be targeted when eliciting conceptual knowledge.
A number of cognitive science theories have also been applied to inform KA methods. Though usually very similar to the preceding psychological theories, cognitive science theories specifically describe KA within a broader context where humans are anticipatory systems who engage in frequent transfers of expertise. The cognitive science literature identifies expertise transfer pathways as an existent medium for the elicitation of knowledge from domain experts. This conceptual model of expertise transfer is often illustrated using the Hawkins model for expert-client knowledge transfer [48] (Figure 6).
Figure 6. Hawkins model of expert-client knowledge transfer.
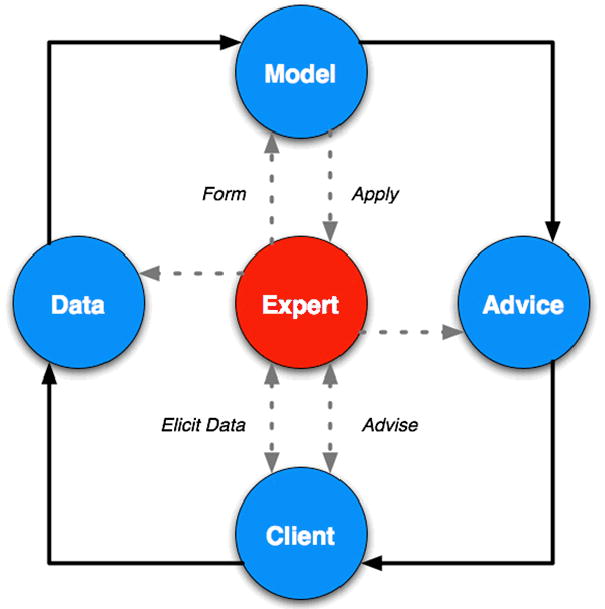
In this model, the client elicits advice and data from the expert, which are in turn formulated and applied by the expert via a pre-existing knowledge model. (Adapted from Gaines, “Social and Cognitive Processes in Knowledge Acquisition”, 1989)
At a higher level, cognitive science theories focus upon the differentiation among knowledge types. Cognitive scientists make a primary differentiation between procedural knowledge and declarative knowledge [1]. While cognitive science theory does not necessarily link declarative and procedural knowledge, an implicit relationship is provided by defining procedural knowledge as consisting of three orders, or levels. For each level, the complexity of declarative knowledge involved in problem solving increases commensurately with the complexity of procedural knowledge being used [1, 18, 49].
A key difference between the theories provided by the cognitive science and psychology domains is that the cognitive science literature emphasizes the importance of placing KA studies within appropriate context in order to account for the distributed nature of human cognition [16, 50-56]. In contrast, the psychology literature does not frame KA studies in this context.
Semiotic Basis for Knowledge Acquisition
Semiotic theory has been cited as a theoretical basis for KA in limited instances. Semiotics can be broadly defined as “the study of signs, both individually and grouped in sign systems, and includes the study of how meaning is transmitted and understood” [57]. As a discipline, much of its initial theoretical basis is derived from the domain of linguistics, and thus, has been traditionally focused on written language. However, the scope of contemporary semiotics literature has expanded to incorporate the analysis of meaning in visual presentation systems, knowledge representation models and multiple communication mediums. The basic premise of the semiotic theory of “meaning” is frequently presented in a schematic format using the Ogden-Richards semiotic triad, as shown in Figure 7 [6].
Figure 7. Ogden-Richards semiotic triad, illustrating the relationships between the three major semiotic-derived types of “meaning”.
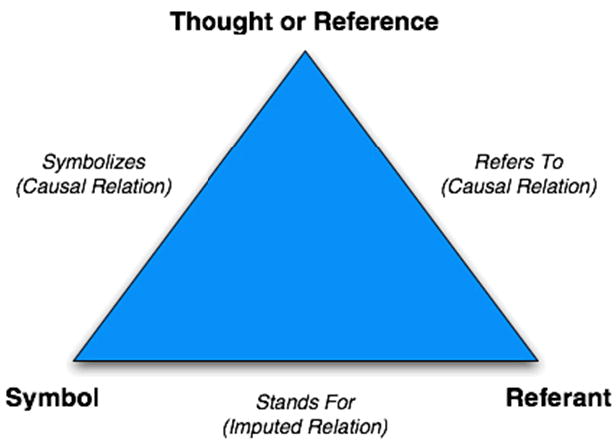
The semiotic triad hypothesizes three representational formats for knowledge. Specifically, these are:
Symbol: representational artifact of a unit of knowledge (e.g., text or icons).
Referent: actual unit of knowledge.
Thought or Reference: unit of knowledge as actually understood by the individual or system utilizing or acting upon that knowledge.
Further, existence of three primary relationships is hypothesized, thus linking the three preceding representational formats:
“Stands-for” imputed relation: relationship between the symbolic representation of the knowledge and the actual unit of knowledge
“Refers-to” causal relation: relationship between the actual unit of knowledge, and the unit of knowledge as understood by the individual or system utilizing or acting upon that knowledge
“Symbolizes” causal relation: relationship between the unit of knowledge as understood by the individual or system utilizing or acting upon that knowledge, and the symbolic representation of the knowledge
The strength of these relationships is usually evaluated using heuristic methods or criteria [6].
Despite the mention of semiotic theory as a basis for KA in some literature, there are three potential shortcomings to application of current semiotic theory within this domain. Specifically these include:
There is a lack of empirically validated research that explicitly demonstrates the efficacy of measuring the relationships described by the Ogden-Richards semiotic triads as a means of evaluating knowledge collections.
Given the earlier definition of conceptual knowledge as a dynamic entity, surrogate metrics would be necessary to measure the strengths of the relationships that may exist between the three representational formats for knowledge defined by semiotic theory. This reliance on surrogate metrics is a result of the inability to directly measure what a designer or end-user is actually “thinking”. As a result, determination of the strengths of semiotic relationships would only be representative of a “snap-shot” of the dynamic knowledge under study.
The relationship between a referent as defined by the Ogden-Richards semiotic triad and a unit of conceptual knowledge previously defined in the context of CKA is not necessarily one of equivalence. Instead, such a relationship is complicated by differences in the semantics of conceptual knowledge. Therefore, use of the referent construct as a basis for evaluating conceptual knowledge may lead to erroneous conclusions [6].
Linguistic Basis for Knowledge Acquisition
The preceding theories have focused almost exclusively on knowledge that may be elicited from domain experts. In contrast, domain knowledge can also be extracted through the analysis of existing sources, such as collections of narrative text or databases. Sub-language analysis is a commonly-described approach to the elicitation of conceptual knowledge from collections of text (e.g., narrative notes, published literature, etc.). The theoretical basis for sublanguage analysis, known as sub-language theory was first described by Zellig Harris in his work concerning the nature of language usage within highly specialized domains [58]. Zellig Harris’s sub-language theory assumes that language usage in such highly specialized domains is characterized by regular and reproducible structural features and grammars [58, 59]. At an application level, these features and grammars can be discovered through the application of manual or automated pattern recognition processes to large corpora of language for a specific domain. Once such patterns have been discovered, templates may be created that describe instances in which concepts and relationships between those concepts are defined. These templates can then be utilized to extract knowledge from sources of language, such as text [60]. The process of applying sub-language analysis to existing knowledge sources has been empirically validated in numerous areas, including the biomedical domain [59, 60]. Within the biomedical domain, sub-language analysis techniques have been extended beyond conventional textual language to also include sub-languages that consist of graphical symbols [61].
Conceptual Knowledge Acquisition Methods: Taxonomy and Description
The conduct of KA studies is complex and resource-intensive. As a result, it is critical to select appropriate KA methods at the outset of such projects. A key issue to consider when planning a KA study is the source of the knowledge to be elicited. Knowledge sources take many forms, including narrative text, databases and domain experts. Domain experts are the most common, yet simultaneously problematic, source of knowledge. First and foremost, the use of domain experts presupposes that the selected individuals: (1) have sufficient domain knowledge, (2) have an interest in participating in the KA process, (3) are adequately representative of the “typical” domain expert, and (4) will introduce minimal bias to the study during participation. This combination of attributes is not always easily attained. Further complicating the use of domain experts in KA studies is the frequent necessity to collect knowledge from several individuals. Multiple experts are often needed to mitigate the problems associated with using a single expert, potentially including individual bias, limitations associated with a single expert’s line of reasoning in the given domain, and incomplete domain expertise [12]. Potentially any of these problems could adversely impact knowledge collection rendering it either incomplete or problematic in content. Another benefit of employing multiple experts is that the quality of consensus knowledge generated through group synergies is generally greater than the sum of the contributing individual knowledge [8, 12, 16, 39, 62, 63]. Multi-expert methods however also have limitations including difficulties associated with merging the knowledge of multiple experts [63]. Furthermore, such a knowledge collection may represent an acquiescence to a single expert’s opinion, rather than true group consensus [12]. Despite these concerns, the potential benefits of using multiple experts in a KA study generally outweigh potential risks [64]. Therefore, with a few exceptions, the following discussion will focus on multi-expert methods.
A Novel Taxonomy of CKA Methods
In the 15 years following the publication Liou’s initial taxonomy of KA techniques [12], numerous additional classes of KA methods have been reported that do not fit neatly into Liou’s three groups (basic, group and supplementary). Therefore, in an effort to provide an extensible framework under which modern KA techniques can be organized, an alternative taxonomy was designed. In the taxonomy, KA techniques are grouped into the following three categories (Figure 8):
Figure 8. Organizing taxonomy of KA techniques, composed of three primary categories: knowledge unit elicitation, knowledge relationship elicitation and combined elicitation, which includes techniques that incorporate aspects of both of the preceding categories.
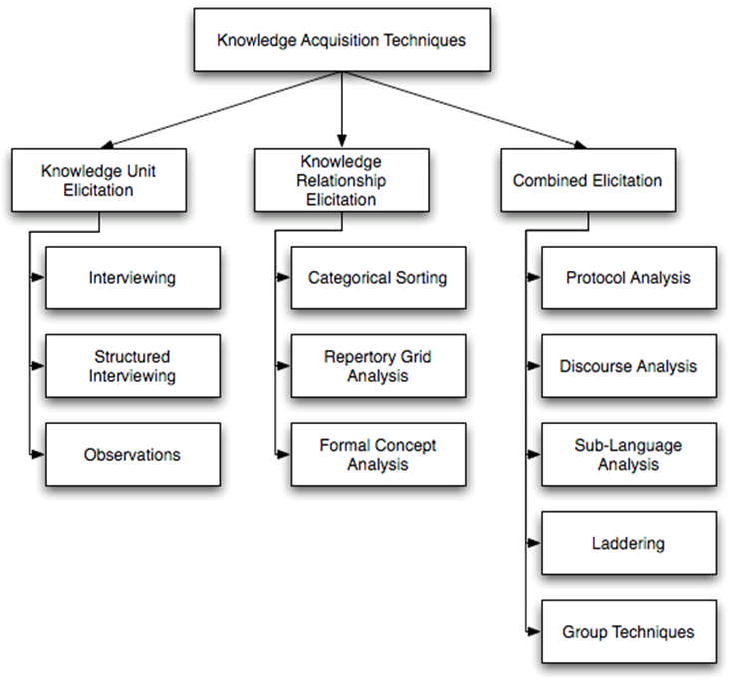
Knowledge unit elicitation: techniques for the elicitation of atomic units of information or knowledge
Knowledge relationship elicitation: techniques for the elicitation of relationships between atomic units of information or knowledge
Combined elicitation: techniques that elicit both atomic units of information or knowledge, and the relationships that exist between them
The resulting taxonomy provided for generalized categories of KA techniques that subsume other specialized approaches to KA. This taxonomic restructuring provides a sufficiently extensible framework to accommodate inclusion of future KA techniques. Furthermore, by specifically associating techniques with the type of knowledge to be elicited, the selection of appropriate techniques is facilitated.
Informal and Structured Interviewing
Interviews conducted either individually or in groups can provide investigators with insights into the knowledge used by domain experts. Furthermore, interviews can be performed either informally (e.g., conversational exchange between the interviewer and subjects) or formally (e.g., structured using a pre-defined series of questions). The advantages of utilizing such interviewing techniques include: 1) their requirement for a minimal level of resources, 2) they can be performed in a relatively short time frame, and 3) their potential to yield a significant amount of qualitative knowledge. However, interviewing techniques often result in minimal amounts of quantitative data, which can limit subsequent analysis. In addition, they rely on the ability of subjects to adequately articulate their domain knowledge, which can be especially difficult if interviews are conducted out of context. Another possible limitation of interviewing techniques is the potential introduction of bias via the framing or presentation of questions or topics of interest to researchers [18, 48, 62, 65]. More detailed descriptions of interviewing techniques are provided in the methodological reviews provided by Boy [62], Morgan [63], and Wood [65].
Observations
Ethnographic evaluations or observational studies are usually conducted in context, with minimal researcher involvement in the workflow or situation under consideration. These observational methods generally focus on the evaluation of expert performance, and the implicit knowledge used by those experts. Examples of observational studies have been described in many domains, ranging from air traffic control systems to complex healthcare workflows [66, 67]. Primary benefits of such observational methods include that their design minimize potential bias (e.g., Hawthorne effect [68]), while simultaneously allowing for the collection of information in context. The qualitative data generated by observational studies is often characterized as being “rich” or “concrete” [69]. The disadvantages of observational studies are similar to those of interviews, and include a lack of quantitative data. Further, when required, the process of coding observational transcripts for the sake of extracting quantitative data is extremely labor-intensive. Additional detail concerning specific observational and ethnographic field study methods can be found in the reviews provided by John [67] and Rahat [69].
Categorical Sorting
A number of categorical, or card sorting techniques have been developed, including Q-sorts, hierarchical sorts, all-in-one sorts and repeated single criterion sorts [70]. All of these techniques involve one or more subjects sorting of a group of artifacts (e.g., text, pictures, physical objects, etc.) according to criteria either generated by the sorter or provided by the researcher. In the case of Q-sorts, the artifacts are placed into groups that define their degree of relatedness to an investigator-defined attribute. In contrast, hierarchical sorts are less restrictive. They involve sorting artifacts into initial groups based on either investigator- or sorter-defined attributes or number of groups, followed by the sorting of those groups into additional hierarchical groupings until all of the initial groups have been combined. All-in-one sorts involve the creation of an arbitrary number of groups by each sorter based on sorter-selected attributes. Finally, repeated single criterion sorts involve the repetition of Q-sorts or hierarchical sorts, using a single attribute to define the sort groups. The objective is to determine the reproducibility and stability of the groups created by the sorters. In all of these cases, sorters may be asked to assign names to the groups they create.
When multiple experts participate in any of the preceding card sorting studies, the individual results can either be quantified using simple agreement statistics [71], or aggregated using hypothesis-discovery tools, such as hierarchical clustering [72]. Categorical sorting methods are ideally suited for the discovery of relationships between atomic units of information or knowledge. In contrast, such methods are less effective for determining the atomic units of information or knowledge. However, when sorters are asked to provide names for their groups, this data may help to define domain-specific units of knowledge or information. Further details concerning the conduct and analysis of categorical sorting studies can be found in the review provided by Rugg and McGeorge [70].
Repertory Grid Analysis
Repertory grid analysis is a method based on the Personal Construct Theory (PCT) introduced previously. PCT argues that humans make sense of the ”information world” through the creation and use of categories [47]. Repertory grid analysis involves the construction of a non-symmetric matrix, where each row represents a construct which corresponds to a distinction of interest, and each column represents an element (e.g., unit of information or knowledge) under consideration (Figure 9). A construct may be thought of as the classification criteria used by individuals to make sense of the “information world.” Such distinctions serve as the operationalization of the personal constructs [47]. During the conduct of repertory grid analysis, subjects score the degree of the relationship between each distinction and element using a provided scale, which is usually numeric. Once such grids have been populated with data, a number of statistical measures can be applied to judge inter-observer agreement and reliability, and construct a summary grid [17]. One advantage of repertory grid analysis is that the resulting matrices are amenable to traditional statistical analyses. However, the disadvantage of this technique is the possibility that participants may not understand the distinctions provided by the investigator. In this scenario, subjects may not be able to accurately complete the matrix, and may require training from investigators, which introduces significant bias. Greater detail on the techniques used to conduct repertory grid studies can be found in the review provided by Gaines et al. [17].
Figure 9. Example of a basic repertory grid eliciting relationships between treatment options (elements) and various decision-making metrics (constructs).
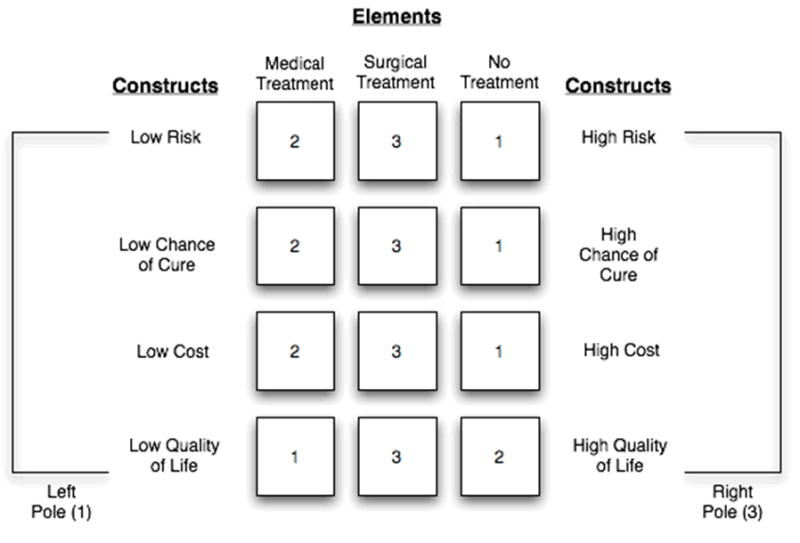
For each element in the grid, the expert completing the grid provides a numeric score using a prescribed scale (defined by a left and right pole) for each distinction, indicating the strength of relatedness between the given element-distinction pair. In many instances, the description of the distinction being used in each row of the matrix is stated differently in the left and right poles, providing a frame of reference for the prescribed scoring scale.
Formal Concept Analysis
Formal concept analysis (FCA) has often been applied to the tasks of developing and merging ontologies [73, 74]. FCA focuses on the discovery of “natural clusters” of entities and entity-attribute pairings [73], where attributes are similar to the distinctions used in repertory grids. Much like categorical sorting, FCA is almost exclusively used for eliciting the relationships between units of information or knowledge. The conduct of FCA studies involves two phases: (1) elicitation of “formal contexts” from subjects, and (2) visualization and exploration of resulting “concept lattices”. During the first phase, subjects populate a simple relational table, where the rows consist of the entities of interest, and the columns contain attributes that may be associated with those entities. Subjects populate the table by indicating with a binary variable whether there is a relationship between the entities and attributes. A “formal context” is considered “closed” when all possible relationships have been enumerated. In the second phase, the “formal context” is visualized as a “concept lattice”, where the relationships between entities and attributes are displayed as a graph. Additional relationships can then been inferred based on the transitive nature of this graph [75]. In those cases where FCA studies involve multiple subjects, the “concept lattice” may be further defined through the assignment of weights to the edges between vertices that indicate the strength of agreement for each relation, as a function of multi-expert agreement [74]. The “concept lattices” used in FCA are in many ways analogous to Sowa’s Conceptual Graphs [76], which are comprised of both concepts and labeled relationships. The use of Conceptual Graphs has been described in the context of KR [76-78], as well as a number of biomedical KE instances [6, 37, 38, 79].
Recent literature has described the use of FCA in multi-dimensional “formal contexts” (i.e., instances where relational structures between conceptual entities cannot be expressed as a single, many-valued “formal context”). One approach to the utilization of multi-dimensional “formal contexts” is the agreement context model proposed by Cole and Becker [74], which uses logic-based decomposition to partition and aggregate n-ary relations. This algorithmic approach has been implemented in a freely available application named “Tupleware” [80]. Additionally, “formal contexts” may be defined from existing data sources, such as databases. These “formal contexts” are discovered using data mining techniques that incorporate FCA algorithms, such as the open-source TOSCANA or CHIANTI tools. Such algorithmic FCA methods are representative examples of a sub-domain known as Conceptual Knowledge Discovery and Data Analysis (CKDD) [35].
The primary advantage of all FCA techniques is their ability to extrapolate significant relational detail from relatively sparse data sources. When FCA is performed using automated methods, large-scale KA studies are feasible. However, FCA techniques are limited to the discovery of relationships between conceptual entities, rather than the entities themselves. Therefore, other KA techniques must often be applied prior to FCA to determine a corpus of entities and attributes. Additional details concerning FCA techniques can be found in the reviews provided by Cimiano et al. [73], Hereth et al. [35], and Priss [75].
Protocol and Discourse Analysis
The techniques of protocol and discourse analysis are very closely related. Both techniques elicit knowledge from individuals while they are engaged in problem-solving or reasoning tasks. Such analyses may be performed to determine a unit of information or knowledge, and relationships between units used by individuals performing tasks in the domain under study. These techniques are based on theories from the psychology and cognitive science [56, 81]. During protocol analysis studies, subjects are requested to “think out loud” (i.e., vocalize internal reasoning and thought processes) while performing a task. Their vocalizations and actions are recorded for later analysis. The recordings are then codified at varying levels of granularity to allow for thematic or statistical analysis [81, 82].
Similarly, discourse analysis is a technique by which an individual’s intended meaning within a body of text or some other form of narrative discourse (e.g., transcripts of a “think out loud” protocol analysis study) is ascertained by atomizing that text or narrative into discrete units of thought. These “thought units” are then subject to analyses of both the context in which they appear, and the quantification and description of the relationships between those units [83, 84]. The advantage of protocol and discourse analyses is that they are usually situated in context [50, 51, 55, 56]. Specific methodological approaches to the conduct of protocol and discourse analysis studies can be found in the reviews provided by Alvarez [83] and Polson et al. [82].
Sub-Language Analysis
Sub-language analysis is a technique for discovering units of information or knowledge, and the relationships between them within existing knowledge sources, including published literature or corpora of narrative text. The process of sub-language analysis is based on the sub-language theory initially proposed by Zellig Harris [58]. Sub-language theory argues that language in highly specialized domains can be characterized by reoccurring structures and grammars. The process by which concepts and relationships are discovered using sub-language analysis involves two stages. In the first stage, large corpora of domain-specific text are analyzed either manually or using automated pattern recognition techniques, in an attempt to define a number of critical characteristics, including:
Semantic categorization of terms used within the sub-language
Co-occurrence patterns or constraints, and periphrastic patterns present within the sublanguage
Context-specific omissions of information within the sub-language
Intermingling of sub-language and general language patterns
Usage of terminologies and controlled vocabularies (i.e., limited, reoccurring vocabularies) within the sub-language (Friedman et al [59])
Once these characteristics have been defined, templates or sets of rules may be established. In the second phase, the resulting templates or rules are applied to narrative text in order to discover units of information or knowledge, and their relationships. This is usually enabled by a natural language processing engine or other similar intelligent agent [85-89]. A potential shortcoming of sub-language analysis-based methods includes a potential for an extremely labor- and resource-intensive initial discovery of critical characteristics within a domain-specific sub-language.
Laddering
Laddering techniques involve the creation of tree structures that hierarchically organize domain-specific units of information or knowledge. Laddering is another example of a technique that can be used to determine both units of information or knowledge and the relationships between those units. In conventional laddering techniques, a researcher and subject collaboratively create and refine a tree structure that defines hierarchical relationships and units of information or knowledge [90]. Laddering has also been applied in the context of structuring relationships between domain-specific processes (e.g., procedural knowledge). Therefore, laddering may also be suitable for discovering strategic knowledge in the form of relationships between conceptual and procedural knowledge. One advantage of laddering techniques is the ability to formally structure knowledge in a manner that lends itself to the creation of ontological or taxonomic knowledge collections. Limitations of laddering techniques include the inability to compare or combine results from multiple subjects. Additional information concerning the conduct of laddering studies can be found in the review provided by Corbdridge et al. [90].
Group Techniques
Several group techniques for multi-subject KA studies have been reported, including brainstorming, nominal group studies, Delphi studies, consensus decision-making and computer-aided group sessions. All of these techniques focus on the elicitation of consensus-based knowledge. Whereas consensus-based knowledge is arguably superior to the knowledge elicited from a single expert [12], conducting multi-subject KA studies can be difficult due to the need to recruit appropriate experts and logistical challenges involved in assembling the experts. Further, in multi-subject KA studies, it is possible for a forceful or coercive minority of experts or a single expert to exert disproportionate influence on the contents of a knowledge collection [12, 16, 63, 64]. In the case of computer-aided group sessions, additional flexibility and potential rigor is provided by allowing for the dynamic development and refinement of knowledge collections [17, 65]. Additional detail concerning group techniques is available in reviews provided by Gaines [17], Liou [12], Morgan [63], Roth [91], and Wood [65].
Verification and Validation
The verification and validation of conceptual knowledge collections is ideally applied throughout the entire KE spectrum. Therefore, an understanding of the types of verification and validation techniques that may be used during the course of KA studies is fundamentally important. To reiterate earlier definitions, verification is the evaluation of whether a knowledge-based system meets the requirements of end-users established prior to design and implementation, and validation is the evaluation of whether that system meets the realized (i.e., “real-world”) requirements of the end-users after design and implementation. The difference between these techniques is that during verification, results are compared to initial design requirements, whereas during validation the results are compared to the requirements for the system that are realized after its implementation. Notably, there is a close parallel in these definitions to the concepts of internal and external validity. In this parallel, verification would address the internal validity of the knowledge collection, while validation would address the external validity of the knowledge collection.
Verification and Validation Criteria
Examples of verification and validation criteria include the degree of interrelatedness of the relationships within a knowledge collection, axiomatic consistency of the knowledge collection, and multiple-source or expert agreement. The degree of interrelatedness of the relationships within a knowledge collection is a measure of its “quality”, as defined by the degree to which possible relationships between entities are enumerated or otherwise defined within the collection. The axiomatic consistency of the knowledge collection is a measure of its logical consistency, as defined by the concordance of axioms that are derived from the knowledge collection. These two criteria will be discussed in greater detail in the context of the following discussions of specific verification and validation techniques.
Multiple-source or expert agreement is the “quality” of the knowledge sources used to populate knowledge collections, as measured by the type and degree of agreement between sources (e.g., such as experts) and is a critical criterion when verifying or validating a knowledge collection. Unfortunately, there is not a single approach for measuring multiple-source, or expert agreement. Instead, metrics must be chosen based upon variables such as data type, and the number and types of knowledge sources. Most importantly, such analyses must be formulated in a manner consistent with the relative importance of four different types of agreement: consensus, correspondence, conflict and contrast. Definitions of each of these types of agreement are provided in Figure 10. A detailed discussion of the techniques that may be applied to measure agreement can be found in the reviews provided by Hripcsak et al. [92, 93].
Figure 10. Differentiation of types of agreement in multi-expert KA studies.

In this model, the use of the “same” nomenclature or distinctions refers to the sources or experts using semantically similar or compatible means of describing or classifying concepts in a domain. Similarly, the use of “different” nomenclature or distinctions refers to the sources or experts using semantically dissimilar or incompatible means of describing or classifying concepts in a domain. (Adapted from Gaines and Shaw, “Knowledge Acquisition Tools based on Personal Construct Psychology”, 1993)
Taxonomy of Verification and Validation Methods
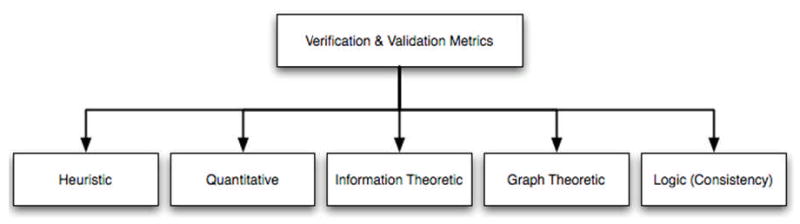
A review of the literature regarding verification and validation techniques determined that no single organizing taxonomy of such methods exists. Therefore, in order to structure the remainder of this discussion, the following general taxonomy of verification and validation techniques was designed (Figure 11). While not explicitly included as a category within this taxonomy, a number of “hybrid” techniques are described, which incorporate approaches from two or more of the included categories. The taxonomy consists of the following methodological categories: heuristic, quantitative, information theoretic, graph theoretic and logical. Brief descriptions of the techniques included in each category follow.
Figure 11. Proposed taxonomy of verification and validation metrics for conceptual knowledge collections.
Heuristic Methods
The most common approach to verifying or validating knowledge collections is the use of heuristic evaluation metrics, which may address any of the previously discussed criteria of interest. The advantages of this approach are the ability to incorporate domain-specific knowledge or conventions, and its simplicity (i.e., knowledge engineers or experts manually review the knowledge collection to determine if the contents are consistent with the heuristics). However, since they are difficult to automate, these heuristic techniques are limited in their tractability when applied to large knowledge collections. Furthermore, heuristically comparing “quality” across multiple knowledge collections is difficult, as a result of the relative and qualitative nature of the evaluation. Specific heuristic criteria for verifying or validating knowledge collections represented as an ontology have been proposed by Gruber [94]:
Clarity
Coherence
Extendibility
Minimal encoding bias
Minimal deviation from ontological commitment, where ontological commitment refers to the situation were all observable actions of a knowledge-based system utilizing the given ontology are consistent with the relationships and definitions contained within that ontology.
In a similar body of work found in the business and information science literature, Demming and colleagues have defined a body of heuristic criteria and methods for assessing the “quality” of knowledge collections, such as databases. Broadly, these heuristics are concerned with assessing: (1) data quality, (2) the usability of systems that operate based upon knowledge collection contents, and (3) the accountability of the contents of a knowledge collection [95, 96]. Examples of specific questions that may be generated via this approach include [96]:
Do the contents of a database correspond to “actual” values that would be considered “accurate” in real-world settings?
What is the threshold for accuracy of a record in a database (e.g., how many fields must contain “accurate” values for the entire record to be considered accurate)?
What level of statistical assurance (e.g., what is the probability of a database containing “accurate” contents) is required to meet end-user and legal/regulatory requirements?
Notably, these types of “quality” heuristics have been applied in numerous commercial and governmental settings, including ISO standards compliance [97], budgetary auditing [98], military logistics [99], and criminal justice [100]. Similar types of heuristic evaluation criteria for knowledge collections have been reported upon by Campbell [79], Cimino [101], Humphreys [10, 102], and Wood and Roth [65].
Quantitative Methods
Quantitative methods of evaluating knowledge collections are best suited for measuring both multi-source agreement and the degree of interrelatedness of the collection. Such measures can include simple statistics such as the precision, accuracy and chance-corrected agreement of the multiple sources used during knowledge elicitation [63, 93, 102-104]. Using frequency-based measures (e.g., measuring the frequency with which a given entity is related to other entities within the knowledge collection) in addition to simple statistics can permit assessment of the degree of interrelatedness of a knowledge collection [14].
Information Theoretic Methods
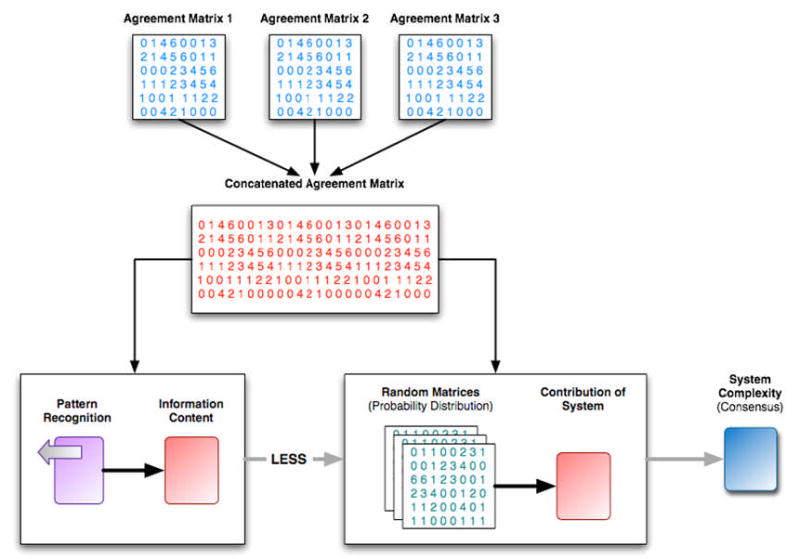
Information theoretic methods are most commonly applied to measure multi-source agreement in knowledge collections. The use of information theory to evaluate the agreement between multiple sources is based on the argument that if such agreement exists, it will be manifested as repetitive patterns within the resulting knowledge collection (e.g., repeating classification or categorization schemes for the units of knowledge within the collection). To utilize this approach to verification and validation, relationships between units of knowledge in the collection must be represented as a numerical matrix. In such matrices, each cell contains a numerical indication of the strength of the relationship between the two units of knowledge identified by the corresponding row and column indices. Given such a matrix, repeating patterns can be quantified relative to their effect on information content or complexity. Matrix complexity is determined by calculating the number of repeating patterns within the matrix less the contribution of the overall environment within which the matrix is constructed. The probability of each repeating pattern detected in the actual matrix occurring randomly or as a result of the environmental contribution can be computed by generating multiple random matrices. As matrix complexity decreases, the degree of multi-source agreement increases [104]. This type of evaluation is summarized in Figure 12, and further detail can be found in the work reported on by Kudikyala et al. [104].
Figure 12. Overview of information theoretic evaluation method for determining the degree of multi-source or expert agreement within a knowledge collection or system.
Graph Theoretic Methods
Graph theoretic methods are based on the ability to represent knowledge collections as graph constructs, where individual units of information or knowledge are represented as nodes, and the relationships between these units as arcs. Such graph representation of knowledge collections has been described in a number of areas, including ontologies [21, 94], taxonomies [19, 105], controlled terminologies [38] and semantic networks [105, 106]. Given a graphic representation, the degree of interrelatedness of a knowledge collection can be assessed using a group of graph-theoretic techniques known as class cohesion measures. Such metrics are used to assess the degree of cohesion, a property representative of connectivity within a graph. Specific class cohesion measurement algorithms include the Lack of Cohesion of Methods (LCOM), Configurational-Bias Monte Carlo (CBMC), Improved Configurational-Bias Monte Carlo (ICBMC) and Geometrical Design Rule Checking (DRC) algorithms [107]. All of these algorithms use some combination of the number of, and distance between, interrelated vertices within the graph as the basis for determining cohesion. More cohesive graphs generally possess more interrelated vertices with relatively short edges between them. However universal consensus regarding a precise definition of what constitutes “cohesion” in a graph has not been attained. Consequently, class cohesion algorithms tend to utilize different measures for cohesion. The applicability of these metrics varies with the specific evaluation context. The selection of an appropriate cohesion measure is therefore highly dependent on the specific nature of the knowledge collection being evaluated. Further details concerning the theoretical basis and application of graph theory-based cohesion measures can be found in the review provided by Zhou et al. [107].
Logical Methods
The application of logic-based verification and validation techniques for conceptual knowledge collections focuses on the detection of axiomatic consistency. These techniques require the extraction of logical axioms from the knowledge collection. Once axioms have been extracted, they are applied within the targeted domain in order to evaluate their consistency and performance. In addition, logical methods can be utilized to examine axioms and assess the existence of unnecessary or redundant relationships within the knowledge collection. One of the most common approaches to implementing this type of evaluation is the representation of the knowledge collection within the Protegé knowledge editor [108]. Once the knowledge collection has been represented in Protégé, logical axioms can be extracted and evaluated using the Protegé Axiom Language (PAL) extension [40]. An example of this method can be found in the formal evaluation of the logical consistency of the Gene Ontology (GO) [3] reported by Yeh et al. [40].
Hybrid Methods
Hybrid methods for verifying or validating knowledge collections involve the use of techniques belonging to two or more of the classes shown in the preceding taxonomy (Figure 11). An example of such a hybrid method is the novel computational simulation approach to validating the results of multi-expert categorical sorting studies as proposed by Payne and Starren [24]. This approach measures multi-source agreement using a combination of quantitative and graph theoretic methods. Another example of a hybrid technique includes the use of hypothesis discovery methods, such as hierarchical clustering [72] to determine the degree of interrelatedness of a knowledge collection. Such hypothesis discovery methods combine statistical, heuristic and graph theoretic techniques.
Selecting Verification and Validation Metrics
The importance of applying appropriate verification and validation techniques during KA studies cannot be overstated. Based on the preceding review of the current literature regarding verification and validation techniques, the following three-axis verification and validation ontology was designed (Figure 13). Three primary axes are represented in the proposed ontology,: 1) evaluation type, 2) criteria of interest to be evaluated and 3) methods that may be used to measure the selected criteria of interest. By traversing the ontology from Axis 1 to Axis 3, it is possible to define: (1) a verification and validation scenario that incorporates an evaluation type, (2) the criteria of interest to be measured during that evaluation, and (3) the appropriate method by which to accomplish such an evaluation. For example, when validating a knowledge-based system using multi- source agreement as the criteria of interest and a focus upon the agreement sub-type of nomenclature usage by those sources, both heuristic and quantitative methods are applicable techniques. The intent of defining this ontology is to provide a generalizable and extensible model for determining the appropriate selection of verification and validation techniques, which is critical for ensuring the quality and performance of the knowledge-based system that uses such knowledge collections.
Figure 13. Verification and validation ontology, composed of three axes.
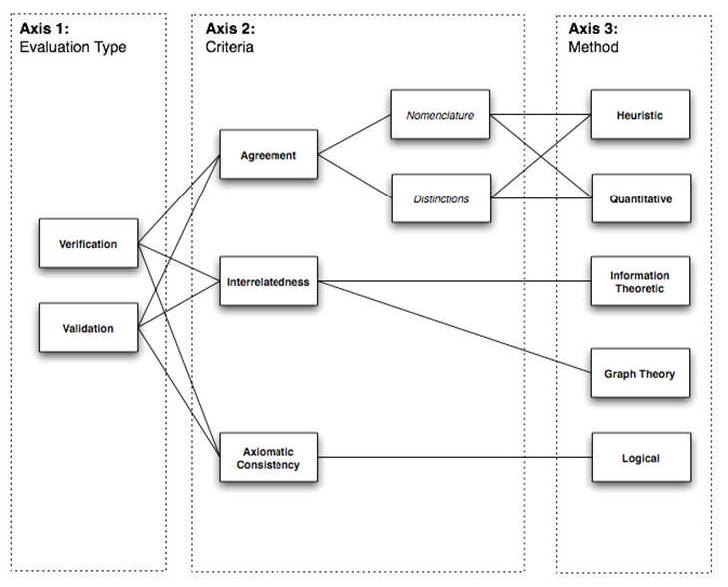
Axis 1 defines the type of evaluation being performed (e.g., verification or validation). Axis 2 defines both major criteria of interest to be evaluated, as well as any applicable sub-types. Axis 3 defines the methods that may be applied to measure the criteria of interest. The connections between members of each axis indicate the applicable verification and validation scenarios that combine an evaluation type, criteria and method.
Discussion
The importance of conceptual knowledge and the methods used to acquire, represent, and verify or validate such knowledge collection is critical within the biomedical domain. Such knowledge collections are broadly pervasive within biomedicine, with applications including clinical decision support systems, complex data mining and information retrieval. The ability of informaticians to translate domain knowledge into computational forms amenable to generalization or inference, and effectively and efficiently develop, maintain, and disseminate knowledge-based systems is dependent on the ability to reliably collect conceptual knowledge. The preceding review has attempted to provide a high-level overview of the theoretical underpinnings of CKA, with particular emphasis on the methods that may be used to acquire and subsequently verify or validate conceptual knowledge collections. In addition, an extensible framework for a uniform taxonomic description of conceptual KA methods and techniques was proposed, with the objective of providing a more standardized description of such knowledge and definition as a framework for future discussions or reports on this topic. Use of a defined framework is central to the ability to regularly and equitably compare the underlying knowledge structures and resulting performance of knowledge-based systems. Development of this taxonomic approach was prompted authors’ recognition of the widespread irregularity and fragmentation of related literature across multiple fields of study while reviewing the current state of knowledge concerning conceptual KA. Further, an ontological approach to describing and selecting verification and validation methods intended to enable the evaluation of conceptual knowledge collections in a uniform and reproducible manner was also presented in this review.
Limitations
As noted at the outset, the goal of this review was not to provide a comprehensive review of all literature concerning CKA, but rather, a representative review of the critical theoretical bases and methodological approaches to KA that have been applied to the biomedical domain. Given the context of this goal, and aforementioned recognition of fragmentation of the available literature, it is probable that some contributions to the domain may have been omitted from the review. Furthermore, the literature concerning information theoretic and graph theoretic approaches to the verification and validation is so voluminous that comprehensive evaluation is beyond the scope of this review. Finally, issues concerning the computational tractability of the various approaches described in this manuscript, while important, were also beyond the scope of our review. This may be particularly true of the information theoretic methods described above. For this reason, the authors caution practitioners of conceptual KA to carefully consider computational tractability issues when selecting such metrics.
Future Directions
Given the current state of knowledge CKA, the following high priority areas of further research regarding the acquisition and verification or validation of conceptual knowledge collections are proposed:
The computational tractability of semi-automated or automated CKA and verification or validation techniques, as applied to knowledge collection or sources of varying size or complexity: studies of such phenomena would be highly informative to practitioners endeavoring to select optimal techniques or methods in corresponding situations (e.g., selecting the appropriate methods given a knowledge source or collection of a particular size)
Development of a unified theory of CKA based upon the various existing theories: given the obvious similarities exhibited in the current contributing theoretical constructs (e.g., biomedicine, computer science, cognitive science, education, linguistics, semiotics, and psychology) development of such a theory appears feasible. Such a unified theory may provide greater insight and understanding of the role such theoretical bases play in selecting and applying appropriate CKA methods.
Further development and extension of the taxonomic approaches provided in this manuscript, as well as a meta-analysis of current knowledge sources concerning CKA: Given the previously introduced problems of fragmentation within the literature concerning CKA, and the lack of uniform descriptors for such work, these ventures would be extremely informative in addressing or identifying deficiencies in the current state of knowledge concerning this topic.
Conclusion
The value of conceptual knowledge collections and of the methods and theories applied to acquire and verify or validate such knowledge collection has been demonstrated in multiple studies spanning a broad variety of application domains. This review has attempted to provide practitioners of CKA within the biomedical domain with a broad overview of the theories, techniques, and methods used to address this complex task. In doing so, it is hoped that a greater interest will be elicited within the biomedical informatics community concerning the further development and evaluation of rigorous or systematic approaches to CKA. Such interest would have the desirable outcome of reversing the current lack of ongoing research concerning what is arguably a fundamental discipline within the field of informatics, and which may otherwise be passed over in favor of advancing procedural knowledge engineering and systems.
Acknowledgments
This work was supported in part by NLM training grant N01-LM07079.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.McCormick R. Conceptual and Procedural Knowledge. International Journal of Technology and Design Education. 1997;7:141–159. [Google Scholar]
- 2.Achour SL, et al. A UMLS-based knowledge acquisition tool for rule-based clinical decision support system development. J Am Med Inform Assoc. 2001;8(4):351–60. doi: 10.1136/jamia.2001.0080351. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Ashburner M, et al. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet. 2000;25(1):25–9. doi: 10.1038/75556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Bakken S, et al. Evaluation of the clinical LOINC (Logical Observation Identifiers, Names, and Codes) semantic structure as a terminology model for standardized assessment measures. J Am Med Inform Assoc. 2000;7(6):529–38. doi: 10.1136/jamia.2000.0070529. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Bell DS, Pattison-Gordon E, Greenes RA. Experiments in concept modeling for radiographic image reports. J Am Med Inform Assoc. 1994;1(3):249–62. doi: 10.1136/jamia.1994.95236156. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Campbell KE, et al. Representing thoughts, words, and things in the UMLS. J Am Med Inform Assoc. 1998;5(5):421–31. doi: 10.1136/jamia.1998.0050421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Cimino JJ, et al. Knowledge-based approaches to the maintenance of a large controlled medical terminology. J Am Med Inform Assoc. 1994;1(1):35–50. doi: 10.1136/jamia.1994.95236135. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Coenen A, et al. Collaborative efforts for representing nursing concepts in computer-based systems: international perspectives. J Am Med Inform Assoc. 2001;8(3):202–11. doi: 10.1136/jamia.2001.0080202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Dolin RH, et al. Kaiser Permanente’s Convergent Medical Terminology. Medinfo. 2004;11(Pt 1):346–50. [PubMed] [Google Scholar]
- 10.Humphreys BL, et al. Planned NLM/AHCPR large-scale vocabulary test: using UMLS technology to determine the extent to which controlled vocabularies cover terminology needed for health care and public health. J Am Med Inform Assoc. 1996;3(4):281–7. doi: 10.1136/jamia.1996.96413136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Peleg M, et al. The InterMed approach to sharable computer-interpretable guidelines: a review. J Am Med Inform Assoc. 2004;11(1):1–10. doi: 10.1197/jamia.M1399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Liou YI. Proceedings of the 1990 ACM SIGBDP conference on Trends and directions in expert systems. Orlando, Florida, United States: ACM Press; 1990. Knowledge acquisition: issues, techniques, and methodology; pp. 212–236. [Google Scholar]
- 13.Preece A. Evaluating Verification and Validation Methods in Knowledge Engineering. Micro-Level Knowledge Management. 2001:123–145. [Google Scholar]
- 14.Brachman RJ, McGuinness DL. Proceedings of the 11th annual international ACM SIGIR conference on Research and development in information retrieval. ACM Press; Grenoble, France: 1988. Knowledge representation, connectionism and conceptual retrieval. [Google Scholar]
- 15.Compton P, Jansen R. A philosophical basis for knowledge acquisition. Knowledge Acquisition. 1990;2(3):241–257. [Google Scholar]
- 16.Gaines BR. Social and Cognitive Processes in Knowledge Acquisition. Knowledge Acquisition. 1989 [cited 2005 8/23/2005]; Available from: http://www.repgrid.com/reports/PSYCH/SocioCog/
- 17.Gaines BR, Shaw MLG. Knowledge Acquisition Tools based on Personal Construct Psychology. 1993 [cited 2005 8/23/2005]; Available from: http://www.repgrid.com/reports/KBS/KER/
- 18.Liou YI. Knowledge acquisition: issues, techniques, and methodology. ACM Press; New York, United States: 1990. [Google Scholar]
- 19.Alan LR, et al. Proceedings of the international conference on Knowledge capture. ACM Press; Victoria, British Columbia, Canada: 2001. Untangling taxonomies and relationships: personal and practical problems in loosely coupled development of large ontologies. [Google Scholar]
- 20.Canas AJ, Leake DB, Wilson DC. Proceedings of the AAAI-99 Workshop on Exploring Synergies of Knowledge Management and Case-Based Reasoning. Menlo Park: AAAI Press; 1999. Managing, mapping, and manipulating conceptual knowledge. [Google Scholar]
- 21.Ian N, Adam P. Proceedings of the international conference on Formal Ontology in Information Systems. Vol. 2001. ACM Press; Ogunquit, Maine, USA: 2001. Towards a standard upper ontology. [Google Scholar]
- 22.Joachim H, et al. Conceptual Knowledge Discovery and Data Analysis. Proceedings of the Linguistic on Conceptual Structures: Logical Linguistic, and Computational Issues; 2000; Springer-Verlag. pp. 421–437. [Google Scholar]
- 23.Tayar N. CIKM ’93: Proceedings of the second international conference on Information and knowledge management. Washington, D.C., United States: ACM Press; 1993. A model for developing large shared knowledge bases. [Google Scholar]
- 24.Payne PR, Starren JB. Quantifying visual similarity in clinical iconic graphics. J Am Med Inform Assoc. 2005;12(3):338–45. doi: 10.1197/jamia.M1628. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Barsalow LW, et al. Grounding conceptual knowledge in modaltiy-specific systems. TRENDS in Cognitive Sciences. 2003;7(2):84–91. doi: 10.1016/s1364-6613(02)00029-3. [DOI] [PubMed] [Google Scholar]
- 26.Glaser R. Education and Thinking: The Role of Knowledge. American Psychologist. 1984;39(2):93–104. [Google Scholar]
- 27.Hiebert J. Procedural and Conceptual Knowledge: The Case of Mathematics. London: Lawrence Erlbaum Associates; 1986. [Google Scholar]
- 28.Scribner S. Knowledge at Work. Anthropology & Education Quarterly. 1985;16(3):199–206. [Google Scholar]
- 29.Borlawsky T, et al. Partitioning knowledge bases between advanced notification and clinical decision support systems. AMIA Annu Symp Proc. 2005:901. [PMC free article] [PubMed] [Google Scholar]
- 30.Cook L. Knowledge Acquisition Tools for Expert Systems. In: Boose JH, Gaines BR, editors. Knowledge Acquisition for Knowledge Based Systems. ACM Press; New York: 1990. [Google Scholar]
- 31.Hoffman RR. A survey of methods for eliciting the knowledge of experts. ACM SIGART Bulletin. 1989;(108):19–27. [Google Scholar]
- 32.Lavrac N, Mozetic I. Methods for knowledge acquisition and refinement in second generation expert systems. ACM SIGART Bulletin. 1989;(108):63–69. [Google Scholar]
- 33.Rook FW, Croghan JW. Proceedings of the 1st international conference on Industrial and engineering applications of artificial intelligence and expert systems. Vol. 2. ACM Press: Tullahoma, Tennessee, United States; 1988. Knowledge acquisition for AI system requirements analysis: a systems engineering methodology. [Google Scholar]
- 34.Menzies T, Harmelen Fv. Evaluating knowledge engineering techniques. Int J Hum-Comput Stud. 1999;51(4):715–727. [Google Scholar]
- 35.Hereth J, et al. Conceptual Knowledge Discovery and Data Analysis. Proceedings of the Linguistic on Conceptual Structures: Logical Linguistic, and Computational Issues; 2000; Springer-Verlag. pp. 421–437. [Google Scholar]
- 36.Evans DA, et al. Toward a medical-concept representation language. The Canon Group. J Am Med Inform Assoc. 1994;1(3):207–17. doi: 10.1136/jamia.1994.95236153. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Campbell KE, Oliver DE, Shortliffe EH. The Unified Medical Language System: toward a collaborative approach for solving terminologic problems. J Am Med Inform Assoc. 1998;5(1):12–6. doi: 10.1136/jamia.1998.0050012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Cimino JJ. From data to knowledge through concept-oriented terminologies: experience with the Medical Entities Dictionary. J Am Med Inform Assoc. 2000;7(3):288–97. doi: 10.1136/jamia.2000.0070288. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Friedman C, et al. The Canon Group’s effort: working toward a merged model. J Am Med Inform Assoc. 1995;2(1):4–18. doi: 10.1136/jamia.1995.95202547. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Yeh I, et al. Knowledge acquisition, consistency checking and concurrency control for Gene Ontology (GO) Bioinformatics. 2003;19(2):241–8. doi: 10.1093/bioinformatics/19.2.241. [DOI] [PubMed] [Google Scholar]
- 41.PubMed. 2005 [cited; Available from: www.pubmed.org.
- 42.ACM Portal. 2005 [cited; Available from: http://portal.acm.org/portal.cfm.
- 43.PsycArticles. 2005 [cited; Available from: http://www.apa.org/psycarticles/
- 44.ERIC. 2005 [cited; Available from: http://www.eric.ed.gov/
- 45.Newell A, Simon HA. Computer science as empirical inquiry: symbols and search. In: Haugeland J, editor. Mind Design. MIT Press/Bradfor Books; Cambridge: 1981. pp. 35–66. [Google Scholar]
- 46.Newell A, Simon HA. Computer Science as Empirical Inquiry: Symbols and Search. ACM Annual Conference; 1975; Minneapolis. [Google Scholar]
- 47.Kelly GA. The psychology of personal constructs. 1. 1218 Vol. 2. New York: Norton; 1955. [Google Scholar]
- 48.Hawkins D. An analysis of expert thinking. Int J Man-Mach Stud. 1983;18:1–47. [Google Scholar]
- 49.Zhang J. Representations of health concepts: a cognitive perspective. J Biomed Inform. 2002;35(1):17–24. doi: 10.1016/s1532-0464(02)00003-5. [DOI] [PubMed] [Google Scholar]
- 50.Horsky J, et al. A framework for analyzing the cognitive complexity of computer-assisted clinical ordering. J Biomed Inform. 2003;36(12):4–22. doi: 10.1016/s1532-0464(03)00062-5. [DOI] [PubMed] [Google Scholar]
- 51.Horsky J, Kaufman DR, Patel VL. The cognitive complexity of a provider order entry interface. AMIA Annu Symp Proc. 2003:294–8. [PMC free article] [PubMed] [Google Scholar]
- 52.Horsky J, Kaufman DR, Patel VL. Computer-based drug ordering: evaluation of interaction with a decision-support system. Medinfo. 2004;11(Pt 2):1063–7. [PubMed] [Google Scholar]
- 53.Horsky J, Kuperman GJ, Patel VL. Comprehensive analysis of a medication dosing error related to CPOE. J Am Med Inform Assoc. 2005;12(4):377–82. doi: 10.1197/jamia.M1740. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Horsky J, Zhang J, Patel VL. To err is not entirely human: complex technology and user cognition. J Biomed Inform. 2005;38(4):264–6. doi: 10.1016/j.jbi.2005.05.002. [DOI] [PubMed] [Google Scholar]
- 55.Patel VL, et al. Methods of cognitive analysis to support the design and evaluation of biomedical systems: the case of clinical practice guidelines. J Biomed Inform. 2001;34(1):52–66. doi: 10.1006/jbin.2001.1002. [DOI] [PubMed] [Google Scholar]
- 56.Patel VL, Arocha JF, Kaufman DR. A primer on aspects of cognition for medical informatics. J Am Med Inform Assoc. 2001;8(4):324–43. doi: 10.1136/jamia.2001.0080324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Chandler D. Semiotics: The Basics. 1. New York: Routledge; 2003. [Google Scholar]
- 58.Harris Z. On a theory of Language. The Journal of Philosophy. 1976;73(10):253–276. [Google Scholar]
- 59.Friedman C, Kra P, Rzhetsky A. Two biomedical sublanguages: a description based on the theories of Zellig Harris. J Biomed Inform. 2002;35(4):222–35. doi: 10.1016/s1532-0464(03)00012-1. [DOI] [PubMed] [Google Scholar]
- 60.Grishman R, Kittredge R. Analyzing language in restricted domains: sublangauge description and processing. Hillsdale, Nj: Lawrence Erlbaum; 1986. [Google Scholar]
- 61.Starren J. Department of Medical Informatics. Columbia University; New York: 1997. From Multimodal Sublanguages to Medical Data Presentations. [Google Scholar]
- 62.Boy GA. The group elicitation method for participatory design and usability testing. interactions. 1997;4(2):27–33. [Google Scholar]
- 63.Morgan MS, Benjamin Martz Wm., Jr . Proceedings of the Proceedings of the 37th Annual Hawaii International Conference on System Sciences (HICSS’04) - Track 1. Vol. 1. IEEE Computer Society; 2004. Group Consensus: Do We Know It When We See It? [Google Scholar]
- 64.Agostini A, et al. GROUP ’03: Proceedings of the 2003 international ACM SIGGROUP conference on Supporting group work. Sanibel Island, Florida, USA: ACM Press; 2003. Stimulating knowledge discovery and sharing. [Google Scholar]
- 65.Wood WC, Roth RM. SIGBDP ’90: Proceedings of the 1990 ACM SIGBDP conference on Trends and directions in expert systems. Orlando, Florida, United States: ACM Press; 1990. A workshop approach to acquiring knowledge from single and multiple experts. [Google Scholar]
- 66.Adria HL, William AS, Stephen DK. Proceedings of the 2003 conference on Designing for user experiences. San Francisco, California: ACM Press; 2003. GMS: preserving multiple expert voices in scientific knowledge management; pp. 1–4. [Google Scholar]
- 67.John H, et al. The role of ethnography in interactive systems design. interactions. 1995;2(2):56–65. [Google Scholar]
- 68.Wickstrom G, Bendix T. The “Hawthorne effect”--what did the original Hawthorne studies actually show? Scand J Work Environ Health. 2000;26(4):363–7. [PubMed] [Google Scholar]
- 69.Rahat I, Richard G, Anne J. Proceedings of the 23rd annual international conference on Design of communication: documenting & designing for pervasive information. Coventry, United Kingdom: ACM Press; 2005. A general approach to ethnographic analysis for systems design; pp. 34–40. [Google Scholar]
- 70.Rugg G, McGeorge P. The sorting techniques: a tutorial paper on card sorts, picture sorts and item sorts. Expert Systems. 1997;14(2):80–93. [Google Scholar]
- 71.Stockburger DW. Introductory Statistics: Concepts, Models, and Applications. 1998 [Web site] 2/19/1998 [cited 2003; 1:[Available from: http://www.psychstat.smsu.edu/sbk00.htm.
- 72.Everitt B, Landau S, Leese M. Cluster analysis. 4. viii. New York: Oxford University Press; 2001. p. 237. [Google Scholar]
- 73.Cimiano P, et al. Conceptual Knowledge Processing with Formal Concept Analysis and Ontologies. Lecture Notes in Computer Science. 2004:189. [Google Scholar]
- 74.Cole R, Becker P. Agreement Contexts in Formal Concept Analysis. Lecture Notes in Computer Science. 2004:172. [Google Scholar]
- 75.Priss U. Formal Concept Analysis in Information Science. In: Blaise C, editor. Annual Review of Information Science and Technology. Information Today, Inc.; Medford, NJ: 2006. [Google Scholar]
- 76.Sowa JF. Proceedings of the 1980 workshop on Data abstraction, databases and conceptual modeling. Pingree Park, Colorado, United States: ACM Press; 1980. A conceptual schema for Knowledge-based systems; pp. 193–195. [Google Scholar]
- 77.Salomons OW, van Houten FJAM, Kals HJJ. Proceedings of the third ACM symposium on Solid modeling and applications. ACM Press: Salt Lake City, Utah, United States; 1995. Conceptual graphs in constraint based re-design. [Google Scholar]
- 78.Yang G, Oh J. Proceedings of the 1993 ACM/SIGAPP symposium on Applied computing: states of the art and practice. ACM Press; Indianapolis, Indiana, United States: 1993. Knowledge acquisition and retrieval based on conceptual graphs. [Google Scholar]
- 79.Campbell JR, et al. Phase II evaluation of clinical coding schemes: completeness, taxonomy, mapping, definitions, and clarity. CPRI Work Group on Codes and Structures. J Am Med Inform Assoc. 1997;4(3):238–51. doi: 10.1136/jamia.1997.0040238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.TOCKIT. Tupleware. Technische Universitaet Darmstadt and University of Queensland; 2006. [Google Scholar]
- 81.Polson PG. Interfacing thought: cognitive aspects of human-computer interaction. MIT Press; 1987. A quantitative theory of human-computer interaction; pp. 184–235. [Google Scholar]
- 82.Polson PG, et al. Cognitive walkthroughs: a method for theory-based evaluation of user interfaces. Int J Man-Mach Stud. 1992;36(5):741–773. [Google Scholar]
- 83.Alvarez R. Proceedings of the 35th Annual Hawaii International Conference on System Sciences (HICSS’02)-Volume 8. Vol. 8. IEEE Computer Society; 2002. Discourse Analysis of Requirements and Knowledge Elicitation Interviews; p. 255. [Google Scholar]
- 84.Davidson JE. Topics in Discourse Analysis. University of British Columbia; 1977. [Google Scholar]
- 85.Friedman C, et al. A general natural-language text processor for clinical radiology. J Am Med Inform Assoc. 1994;1(2):161–74. doi: 10.1136/jamia.1994.95236146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Friedman C, Hripcsak G. Evaluating natural language processors in the clinical domain. Methods Inf Med. 1998;37(45):334–44. [PubMed] [Google Scholar]
- 87.Friedman C, Hripcsak G. Natural language processing and its future in medicine. Acad Med. 1999;74(8):890–5. doi: 10.1097/00001888-199908000-00012. [DOI] [PubMed] [Google Scholar]
- 88.Friedman C, Hripcsak G, Shablinsky I. An evaluation of natural language processing methodologies. Proc AMIA Symp. 1998:855–9. [PMC free article] [PubMed] [Google Scholar]
- 89.Hripcsak G, et al. Unlocking clinical data from narrative reports: a study of natural language processing. Ann Intern Med. 1995;122(9):681–8. doi: 10.7326/0003-4819-122-9-199505010-00007. [DOI] [PubMed] [Google Scholar]
- 90.Corbridge C, et al. Laddering: technique and tool use in knowledge acquisition. Knowledge Acquisition. 1994;6:315–341. [Google Scholar]
- 91.Roth RM, Wood WC. SIGBDP ’90: Proceedings of the 1990 ACM SIGBDP conference on Trends and directions in expert systems. Orlando, Florida, United States: ACM Press; 1990. A Delphi approach to acquiring knowledge from single and multiple experts. [Google Scholar]
- 92.Hripcsak G, Heitjan DF. Measuring agreement in medical informatics reliability studies. J Biomed Inform. 2002;35(2):99–110. doi: 10.1016/s1532-0464(02)00500-2. [DOI] [PubMed] [Google Scholar]
- 93.Hripcsak G, Wilcox A. Reference standards, judges, and comparison subjects: roles for experts in evaluating system performance. J Am Med Inform Assoc. 2002;9(1):1–15. doi: 10.1136/jamia.2002.0090001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Gruber TR. Toward Principles for the Design of Ontologies Used for Knowledge Sharing. In: Guarino N, Poli R, editors. Formal Ontology in Conceptual Analysis and Knowledge Representation. Kluwer Academic Publishers; 1993. [Google Scholar]
- 95.Demming WE. Out of the crisis. Cambridge, MA: MIT-CAES; 1966. [Google Scholar]
- 96.Walton M. The Demming management method. New York: The Putnam Publishing Group; 1986. [Google Scholar]
- 97.Robinson RE. Annual Conference - Society for Technical Communication. Society for Technical Communication; Washington, D.C: 1995. Tackling the ISO 9000 Documentation Monster. [Google Scholar]
- 98.Pivka M, Mulej M. Requisitely Holistic ISO 9000 Audt Leads to Continuous Innovation/Improvement. Cybernetics and Systems. 2004;35(4):363–378. [Google Scholar]
- 99.Delano K. Identifying Factros that Contribute to Program Success. Acquisition Review Quarterly. 1998 Winter;:35–50. [Google Scholar]
- 100.Gottfredson DM. Prediction and Classification in Criminal Justice Decision Making. Crime and Justice. 1987;9(1):1–20. [Google Scholar]
- 101.Cimino JJ. Desiderata for controlled medical vocabularies in the twenty-first century. Methods Inf Med. 1998;37(45):394–403. [PMC free article] [PubMed] [Google Scholar]
- 102.Humphreys BL, McCray AT, Cheh ML. Evaluating the coverage of controlled health data terminologies: report on the results of the NLM/AHCPR large scale vocabulary test. J Am Med Inform Assoc. 1997;4(6):484–500. doi: 10.1136/jamia.1997.0040484. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Hripcsak G, Rothschild AS. Agreement, the f-measure, and reliability in information retrieval. J Am Med Inform Assoc. 2005;12(3):296–8. doi: 10.1197/jamia.M1733. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Kudikyala UK, Allen EB, Vaughn RB. Measuring Consensus during Verification and Validation of Requirements. Proceedings of the tenth IEEE International Software Metrics Symposium (METRICS 2004); 2004; Chicago, Illinois. [Google Scholar]
- 105.Burgun A, Bodenreider O. Proceedings of the international conference on Formal Ontology in Information Systems. Vol. 2001. Ogunquit, Maine, USA: ACM Press; 2001. Aspects of the taxonomic relation in the biomedical domain; pp. 222–233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.Griffith RL. Three principles of representation for semantic networks. ACM Trans Database Syst. 1982;7(3):417–442. [Google Scholar]
- 107.Zhou Y, Lu J, Xu HB. A comparative study of graph theory-based class cohesion measures. SIGSOFT Softw Eng Notes. 2004;29(2):13–13. [Google Scholar]
- 108.Noy NF, et al. Protege-2000: an open-source ontology-development and knowledge-acquisition environment. AMIA Annu Symp Proc. 2003:953. [PMC free article] [PubMed] [Google Scholar]