

Abstract
Bioinformatics is yielding extensive, and in some cases complete, genetic and biochemical information about individual cell types and cellular processes, providing the composition of living cells and the molecular structure of its components. These components together perform integrated cellular functions that now need to be analyzed. In particular, the functional definition of biochemical pathways and their role in the context of the whole cell is lacking. In this study, we show how the mass balance constraints that govern the function of biochemical reaction networks lead to the translation of this problem into the realm of linear algebra. The functional capabilities of biochemical reaction networks, and thus the choices that cells can make, are reflected in the null space of their stoichiometric matrix. The null space is spanned by a finite number of basis vectors. We present an algorithm for the synthesis of a set of basis vectors for spanning the null space of the stoichiometric matrix, in which these basis vectors represent the underlying biochemical pathways that are fundamental to the corresponding biochemical reaction network. In other words, all possible flux distributions achievable by a defined set of biochemical reactions are represented by a linear combination of these basis pathways. These basis pathways thus represent the underlying pathway structure of the defined biochemical reaction network. This development is significant from a fundamental and conceptual standpoint because it yields a holistic definition of biochemical pathways in contrast to definitions that have arisen from the historical development of our knowledge about biochemical processes. Additionally, this new conceptual framework will be important in defining, characterizing, and studying biochemical pathways from the rapidly growing information on cellular function.
Keywords: null space, stoichiometric matrix, bioinformatics, metabolic pathways, genome annotation
Biology is going through a period of fundamental change. The entire genome sequence for an increasing number of organisms is becoming available. Currently, the full DNA sequence for 14 unicellular organisms are at hand, and it is expected that the full DNA sequences will become available for well known multicellular organisms within a few years (1). The identification of ORFs and their assignments are proceeding at a rapid pace, and 50 to 80% of the ORFs have been assigned in the fully sequenced microbial genomes (2). Once complete, these efforts will result in a complete “spare part catalogue” of the components found in a multitude of living cells.
Given the long history of metabolic research, the assignment of metabolic genes to ORFs has been particularly successful. About 91% of the known metabolic enzymes found in Escherichia coli K-12 had ORF assignments in the initial publication of its DNA sequence (3). Furthermore, a large fraction of the ORFs assigned in the first sequenced and annotated genomes shows that metabolic genes make up a large fraction of the genes found in the microbial genotype (4). In addition, metabolism has general features that are found in most organisms. Comparison of seven sequenced genomes from five major phylogenic lineages has lead to the definition of 720 clusters of orthologous groups of genes based on patterns of sequence similarities (5). These clusters have been grouped into 15 functional groups, nine of which are metabolic in nature. With all of this genomic information now present, there is a demand for creative approaches to deal with these data sets (6, 7). What is now needed is a systemic definition of the underlying metabolic pathways that allow for the analysis of the overall function of individual metabolic genotypes.
Flux-balance analysis can be used to analyze, interpret, and predict the capabilities and function of metabolic genotypes (8). This analysis method is based on mass balances on all the metabolites found in a given metabolic system (9–11). The analysis relies solely on the stoichiometry of the metabolic reactions present and a handful of strain-specific parameters. This analysis method has been shown to be able to predict quantitatively the behavior of E. coli under a variety of growth conditions (12, 13).
The metabolic capabilities of the defined metabolic genotype correspond to the null space of the stoichiometric matrix. Particular solutions found within this space represent expressed metabolic phenotypes (10). The null space can be spanned with a set of basis vectors (14, 15), a combination of which can represent all the metabolic phenotypes found within the metabolic genotype. Here, we show how these basis vectors, originating from the fundamentals of linear algebra, are related to metabolic pathways intrinsic to stoichiometric matrices. Thus, all the metabolic phenotypes can be represented by a combination of these systemically defined metabolic pathways. This development not only redefines the notion of a metabolic pathway but also forms a fundamental basis for the development of analysis methods in microbial genomics.
Translating Biochemical Networks into the Realm of Linear Algebra
The interconnectivity of metabolites within a network of biochemical reactions is given by reaction equations defining the stoichiometric conversion of substrates into products for every reaction. Enzymatic reactions as well as the transport of metabolites across system boundaries constitute various fluxes, which serve to dissipate and generate metabolites. In following the law of conservation of mass, material balances describing the activity of a particular reactant through each reaction can be written in the form of homogeneous linear equations, that in matrix notation is:
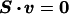 |
1 |
The stoichiometric matrix S is an m × n matrix where m corresponds to the number of metabolites and n is the number of reactions or fluxes taking place within the network. The Smn element of the stoichiometric matrix corresponds to the stoichiometric coefficient of the reactant m in the reaction denoted by n, and vn is the flux through this metabolic reaction. The vector v then refers to the relative activity of each flux and is 1 × n (contained in ℝn). Through the matrix S, the biochemical system is cast into a mathematical context, permitting the application of the methods of linear algebra. The stoichiometric matrix remains constant at all times because only the values comprising v change to reflect different flux distribution patterns. Furthermore, the metabolic genotype of an organism directly leads to the definition of S (8).
We are seeking to define the architecture of the network represented by S in functional biochemical terms. Namely, we are interested in the inherent structure and connectivity of the metabolites within a metabolic network. Mathematically, this question is concerned with the vector space containing all of the possible solutions of the system of linear equations represented by Eq. 1. This vector space is termed the null space of the matrix S, represented as NulS. Fundamentally, we are interested in determining the characteristics of this space and interpreting it from an overall metabolic perspective.
The dimension of the null space (the nullity of S) depends on the number of free variables in the original set of linear equations, which is referred to as the rank of S, given by the relation termed the Rank Theorem:
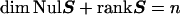 |
2 |
The null space contains all of the solutions and hence vectors (v) that satisfy Eq. 1. The characteristics of the solution vector v is of great interest because it describes the relative distribution of fluxes throughout the entire metabolic system. A particular solution of interest to Eq. 1 can be determined either through the use of linear programming, given a suitable objective function (10), or by reducing the number of unknown fluxes to allow the system to be exactly determined (16–18). The first approach is akin to selecting a point within the null space that optimizes an objective (such as cellular growth), whereas the second is an attempt to reduce the dimensions of the null space to the zero subspace (a point). Both of these approaches aim to find a single point or solution contained within the null space. However, to address more general issues, such as metabolic capacity and regulation in regards to the entire network, a thorough analysis of the entire null space is in order.
To explicitly define the null space, it is necessary to generate a set of vectors that can be used to span the vector space (i.e., a spanning set). The most “efficient” way to span a vector space is through the use of a minimum number of linearly independent vectors that together form a basis. The minimum number of vectors necessary to form a basis is equal to the dimensions of the vector space (dim NulS). As in any problem involving vector spaces in any dimension, the key is to select a basis that clearly describes all of the points contained within the space in a meaningful way.‡ With this in mind, we will attempt to develop a rational approach for the selection of basis vectors, so as to span the null space in a manner that is theoretically and biochemically meaningful.
System Descriptions and Conventions
For any given biochemical reaction network, there are reactions involving the interconversion of chemical species along with transport processes, which serve to replenish or drain the relative amounts of certain metabolites. A system boundary can be drawn around all of the chemical reactions occurring within a system. These reactions and their relative activity will be referred to as internal fluxes whose relative activity is indicated by v1–vi where i is the number of internal fluxes. Only those fluxes corresponding to the transport of a metabolite are permitted to cross the system boundary. These fluxes constitute sources and sinks on the system and will be referred to as exchange fluxes denoted as b1–bj where j is the total number of exchange fluxes. All of the exchange fluxes are defined as positive if the activity is draining a metabolite or leaving the system.
An example of a chemical reaction scheme is illustrated in Fig. 1A. The system contains five metabolites (A–E) undergoing the reactions indicated by each line with arrows indicating the direction of the reaction. Note that the reversible reaction occurring between metabolite B and D is represented as two opposing reactions. All of the metabolites, with the exception of B, contain either a source or a sink thus creating four exchange fluxes. The biochemical reaction network in Fig. 1A is then converted to conform to the conventions described above and is represented in Fig. 1B where all internal fluxes and exchange fluxes are labeled along with the system boundaries.
Figure 1.

(A) Chemical reaction scheme consisting of five metabolites and 11 fluxes. (B) Conversion of the reaction scheme using conventions described within the text. A system boundary is drawn with internal fluxes (v1–v7) and external fluxes (b1–b4) labeled.
Starting from a series of material balances around each metabolite a stoichiometric matrix S can be generated for the above reaction scheme which mathematically represents all 11 fluxes and the metabolites involved in each flux (Fig. 2). In this example, the stoichiometric matrix is of dimension 5 × 11, here structured so that the first seven columns represent the internal fluxes and the remaining four constitute the exchange fluxes. In constructing the stoichiometric matrix in this way, the vector v is composed first of entries v1–v7 followed by b1–b4. With the structure and connectivity of the network now translated into mathematical form, we can begin to develop our approach to spanning the null space.
Figure 2.

Representation of reaction balance equations in matrix notation. From the five balance equations, a 5 × 11 stoichiometric matrix is generated.
Spanning the Null Space
Beginning with Eq. 2, we determined the dimensions of the null space. In the example given, the rank of S is five and thus the dimension of the null space is six. Therefore, to explicitly define the null space of this system, we need a set of six basis vectors ℬ = {b1–b6} in ℝ11 that span NulS. A set of basis vectors can be determined by expressing the general solution to Eq. 1 in parametric form, as a linear combination of the free variables in the balance equations (15). The vectors indicating the weights of the free variables then become a set of basis vectors that span the null space. Using this procedure a set of six basis vectors are constructed (Fig. 3). The basis vectors of ℬ are all linearly independent and theoretically feasible as they satisfy Eq. 1. However, what do these vectors tell us from a biochemical viewpoint?
Figure 3.

Transformation of the theoretically feasible basis ℬ (spanning the null space of S) to a set of basis vectors 𝒫 (also spanning the null space of S), which are both theoretically and biochemically feasible. Note that all internal fluxes (above the dashed line) are positive in the basis 𝒫.
The first seven entries of each vector correspond to the internal fluxes (vi) whereas the last four indicate the activity of the exchange fluxes (bj). Through inspection of each of the components of the basis vectors, we see that each vector traces out a theoretical pathway through the system in which the components of each vector describe the relative flux distributions of each of the reactions in the pathway. Notice that, in two of the vectors (b4 and b5), there are negative values representing the activity of certain internal fluxes. These vectors represent pathways that are biochemically impossible and thus are of little use in interpreting the system’s biochemical structure and associated physiology. A biochemically meaningful basis is needed.
Spanning the Null Space with Biochemical Pathways
Because all of the vectors in the basis ℬ are linearly independent, these vectors can be used to create a different set of six basis vectors, which also form a spanning set of the null space. To guide the construction of these basis vectors, we impose two constraints on both the internal and exchange fluxes:
1. We constrain all internal fluxes to be positive;
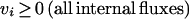 |
3 |
creating a new spanning set which is both theoretically and biochemically feasible. This requirement is critical to ensure that the basis vectors exhibit biochemical relevance to the analysis of the reaction network.
2. We selectively impose further restrictions on the values of the exchange fluxes,
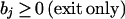 |
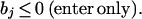 |
4 |
Therefore, the value of the exchange fluxes indicates whether or not a particular metabolite is being transported into the system or being siphoned off for other purposes in each pathway. If a reactant is known to enter the system and does not exit, then we may wish to impose the constraint that the value for that particular flux must be negative.
Under these constraints, the basis ℬ is transformed into a new basis 𝒫 defined by the equations relating the two different bases shown in Fig. 3. The basis 𝒫 will be composed of six linearly independent vectors because it is a linear combination of the vectors of basis ℬ.
The transformation defined results in basis vectors that represent biochemical pathways. For the example system, the new basis is illustrated in Fig. 4. Each basis vector is depicted as a pathway, and the directions of the exchange fluxes are indicated. By virtue of the way that the system was constructed, the overall reaction balance equation for the pathways is given by the values of the exchange fluxes with negative values indicating substrates and positive values indicating products in stoichiometric ratios indicated by their respective values.
Figure 4.

Fundamental pathways traced out by each of the six linearly independent basis vectors in 𝒫. Exchange flux activity that enters the system (i.e., negative) is indicated by the gray filled arrows, whereas activity that exits the system (i.e., positive) is indicated by the black filled arrows. Active internal fluxes are indicated by the black arrows.
Note that by the unique representation theorem of coordinate systems, any vector (v) in NulS can be written as a unique combination of these six basis vectors, thus providing a one-to-one mapping of points in the null space. Therefore, any flux distribution can be viewed as a linear combination of the pathways traced by the basis vectors in 𝒫. If the basis vectors represent particular metabolic functions, any experimentally determined or computed solution can be represented as a linear combination of such metabolic functions. Any changes from this solution can then directly be related to the underlying systemic metabolic functions. These basis vectors thus represent a metabolically meaningful pathway structure of the biochemical reaction network under consideration. In the following application, we span the null space for a network of reactions involved in human erythrocyte metabolism demonstrating this approach for the analysis of biochemical networks.
Application to Integrated Metabolic Functions: The Human Red Blood Cell
The mature red blood cell emerges from the bone marrow enucleated and stripped of a large portion of the metabolic machinery available to most cells. These cells are incapable of protein or lipid synthesis and oxidative phosphorylation, as well as tricarboxcylic acid cycling (20). The focus of the red blood cell is on gas transport and exchange. Beyond this function, the cell requires energy to maintain the plasticity of its membrane, prevent the accumulation of methemoglobin, protect its hemoglobin from oxidative denaturation, synthesize glutathione, acylate CoA, and replenish its adenine nucleotide pool using salvage pathways. The metabolic resources used in these functions are found in the high energy phosphate of ATP, or as a reducing compound in the form of reduced glutathione and the pyridine cofactors, NADH, and NADPH. Glucose is the primary carbon source used to derive the energy necessary to synthesize the energy carriers mentioned above. Through anaerobic glycolysis via the Embden–Meyerhof pathway, the red cell generates ATP. In addition, this common pathway also can produce NADH, used in methemoglobin reduction, and 2,3-bisphosphoglycerate (2,3-DPG) used for oxyhemoglobin modulation. Additionally, the red cell contains the necessary pathways for oxidative glycolysis through the pentose phosphate pathway. This pathway mainly is used to produce NADPH used in the reduction of glutathione to ultimately provide protection against oxidative damage to the cell.
Pathway Analysis of the Null Space
We will now analyze this reaction network following the approach outlined above to define systemically the metabolic pathways of the red cell and to provide an interpretation of the metabolic machinery of the human erythrocyte. The reaction network analyzed is shown in Fig. 5. These are the Embden–Meyerhof pathway of anaerobic glycolysis, which includes the Rapoport–Luebering shunt (production of 2,3-DPG), and the pentose phosphate shunt. Following the definitions given above, this system of three interacting pathways consists of 37 internal fluxes and 14 exchange fluxes. Of the 37 internal fluxes, 32 can be paired together as 16 reversible reactions. All of the enzymes represented in the system and the fluxes for which they are responsible are listed in Table 1. The exchange fluxes consist of those for glucose, pyruvate, and lactate, which are all transported across the cell membrane, 2,3-DPG and ribose 5-phosphate, which are then used for other metabolic activities within the cell such as oxyhemoglobin modulation and adenosine metabolism, respectively. The remaining nine exchange fluxes correspond to those for ADP, ATP, NAD+, NADH, NADP+, NADPH, CO2, H+, and Pi. There are 29 metabolites involved in the reaction network listed in Table 2. They are classified as internal or exchange metabolite corresponding to the presence of an exchange flux for a particular metabolite. Note that ADP, NAD+, NADP+, H+, and Pi could be removed from the system with no effect on the dimensions of the null space, but for completeness, we have left them in the system in this example.
Figure 5.

Metabolic reaction network analyzed from the human erythrocyte containing 29 metabolites and the related 51 fluxes (37 internal and 14 exchange fluxes). Not shown in the figure is the involvment of ATP, ADP, NAD, NADH, NADP, NADPH, CO2, H+, and Pi in associated reactions.
Table 1.
Names and abbreviations of the 21 enzymes included in the red cell reaction network
| Flux | Abbreviation | Enzyme |
|---|---|---|
| v1 | hk | Hexokinase |
| v2, v3 | pgi | Phosphoglucoisomerase |
| v4, v5 | pfk | Phosphofructokinase |
| v6, v7 | ald | Aldolase |
| v8, v9 | tpi | Triose phosphate isomerase |
| v10, v11 | gapdh | Glyceraldehyde phosphate dehydrogenase |
| v12, v13 | pgk | Phosphoglycerate kinase |
| v14 | dpgm | Diphosphoglyceromutase |
| v15 | dpgp | Diphosphoglycerate phosphatase |
| v16, v17 | pgm | Phosphoglyceromutase |
| v18, v19 | en | Enolase |
| v20 | pk | Pyruvate kinase |
| v21, v22 | ldh | Lactate dehydrogenase |
| v23 | g6pdh | Glucose-6-phosphate dehydrogenase |
| v24, v25 | pgl | 6-Phosphoglyconolactonase |
| v26, v27 | pgdh | 6-Phosphoglyconate dehydrogenase |
| v28, v29 | rpi | Ribose-5-phosphate isomerase |
| v30, v31 | xpi | Xylulose-5-phosphate epimerase |
| v32, v33 | tkI | Transketolase |
| v34, v35 | ta | Transaldolase |
| v36, v37 | tkII | Transketolase |
The presence of two fluxes related to an enzyme indicates the potential for reversible reactions.
Table 2.
Names and abbreviations of the 29 metabolites included in the reaction network
| Internal | Exchange | Abbreviation | Metabolite |
|---|---|---|---|
| x | GLU | Glucose | |
| x | G6P | Glucose 6-phosphate | |
| x | F6P | Fructose 6-phosphate | |
| x | FDP | Fructose 1,6-bisphosphate | |
| x | GA3P | Glyceraldehyde 3-phosphate | |
| x | DHAP | Dihydroxyacetone phosphate | |
| x | 13DPG | 1,3-Diphosphoglycerate | |
| x | 23DPG | 2,3-Diphosphoglycerate | |
| x | 3PG | 3-Phosphoglycerate | |
| x | 2PG | 2-Phosphoglycerate | |
| x | PEP | Phosphoenolpyruvate | |
| x | PYR | Pyruvate | |
| x | LAC | Lactate | |
| x | D6PGL | 6-Phosphogluconolactone | |
| x | D6PGC | 6-Phosphogluconate | |
| x | RL5P | Ribulose 5-phosphate | |
| x | X5P | Xylulose 5-phosphate | |
| x | R5P | Ribose 5-Phosphate | |
| x | S7P | Sedoheptulose 7-phosphate | |
| x | E4P | Erythose 4-phosphate | |
| x | CO2 | Carbon dioxide | |
| x | Pi | Inorganic phosphate | |
| x | ADP | Adenosine 5′-diphosphate | |
| x | ATP | Adenosine 5′-triphosphate | |
| x | NAD | Nicotinamide adenine dinucleotide | |
| x | NADH | Nicotinamide adenine dinucleotide (R) | |
| x | NADP | Nicotinamide adenine dinucleotide phosphate | |
| x | NADPH | Nicotinamide adenine dinucleotide phosphate (R) | |
| x | H+ | Hydrogen ion |
Metabolites are classified as internal or exchange compounds based on the presence/absence of an exchange flux for the given metabolite.
Material balances on all 29 metabolites were performed to create a stoichiometric matrix (29 × 51) representing the connectivity of the network. The dimension of the null space of the matrix was then determined to be 22. Using mathematica 3.0 (Wolfram Research Inc., Champaign, IL), a set of basis vectors that spanned the null space was generated. These vectors constituted a theoretically feasible basis; however, there were numerous vectors that contained negative values for the internal fluxes. Therefore, a new set of basis vectors was constructed from the original set by using strict linear combinations of the previous set in accordance with Eqs. 3 and 4. Glucose only was allowed to enter the system whereas the exchange fluxes for pyruvate, lactate, 2,3-DPG, and ribose 5-phosphate were constrained to be positive because they could only leave the system. All of the other exchange fluxes remained unconstrained. Then, 22 linearly independent basis vectors that spanned the null space were constructed that indicated the relative activity of each flux in the pathways.
Sixteen of the 22 basis vectors were constructed to represent the cycling of reversible reactions that have no net effect on the input/output of the system as indicated by the absence in activity of any exchange fluxes. The remaining six vectors constitute true biochemical pathways through the system. The balance equations for these fundamental pathways traced by the basis vectors are shown in Table 3. The first pathway p1 refers to the catabolism of glucose through the Embden–Meyerhof pathway continuing to the formation and removal of lactate. This pathway is the primary route for the formation of ATP. The second pathway p2 also follows the Embden–Meyerhof pathway but uses the Rapoport–Luebering shunt in the ultimate formation and removal of pyruvate. This route can be used for the sole production of the reducing power of NADH. The third independent pathway p3 is similar to p1 except that the route ends in the removal of pyruvate as opposed to lactate. This route then results in the net production of ATP and NADH in equimolar amounts. Note that if lactate were dumped by the cell in p2, there would have been no net gain of energy in any form. In addition, this pathway can be constructed from a linear combination of p1, p2, and p3, whereby making it dependent on those vectors and subsequently excluding it from the spanning set of basis vectors. The fourth pathway p4 is the route used for the production of 2,3-DPG, which follows straight down the Embden–Meyerhof pathway taking the first arm of the Rapoport–Luebering shunt. Notice that when 2 moles of 2,3-DPG and NADH are formed for every mole of glucose, there is an expense of 2 moles of ATP. The fifth pathway p5 results in the first use of the pentose phosphate shunt for the production of 1 mole of ribose 5-phosphate and 2 moles of NADPH per mole of glucose. The final pathway p6 represents the classic use of the pentose phosphate shunt for the oxidation of glucose ultimately to generate 12 moles of NADPH for every mole of glucose by cycling carbon compounds through the shunt.
Table 3.
Net reaction balance equations and functional attributes of basis pathways used to span the null space of the red blood cell stoichiometric matrix
| Basis pathway | Net reaction equation | Primary functional attribute |
|---|---|---|
| p1 | glucose + 2 Pi + 2 ADP → 2 lactate + 2 ATP | ATP energy production for metabolic energy |
| p2 | glucose + 2 NAD+ → 2 pyruvate + 2 NADH + 2 H+ | NADH energy production for methemoglobin reduction |
| p3 | glucose + 2 Pi + 2 ADP + 2 NAD+ → 2 pyruvate + 2 ATP +2 NADH + 2 H+ | ATP production for metabolic energy and NADH production for methemoglobin reduction |
| p4 | glucose + 2 ATP + 2 NAD+ → 2 23DPG + 2 Pi + 2 ADP +2 NADH + 2 H+ | 2,3-DPG production for oxyhemoglobin modulation |
| p5 | glucose + ATP + 2 NADP+ → R5P + CO2 + ADP + 2 NADPH + 2 H+ | Ribose 5-phosphate production for adenosine salvaging |
| p6 | glucose + 12 NADP+ → 6 CO2 + 12 NADPH + 12 H+ | NADPH energy production for glutathione reduction and subsequent antioxidant activity |
| p7–p22 | (no net reaction) | (none) |
In viewing the metabolic machinery as a factory for energy, redox, and precursor production, we can use these basis vectors to guide our interpretation of this metabolic system. The demands clearly are to produce various metabolic resources in different ratios based on dynamic needs of the cell, while the cell is continuously supplied with glucose from the plasma to be used as its “raw material.” Focusing attention on the activity of the exchange fluxes, we see that the cell essentially has six independent routes through which it can channel glucose with each one addressing specific needs of the cell. The remaining pathways, representing reversible reactions have no net effect on the performance of the system, which for our purposes serves to narrow down our consideration of the null space to six dimensions. There are pathways designed strictly for energy production with the release of certain by-products (i.e., pyruvate and lactate). There are then pathways that generate metabolites (i.e., 2, 3-DPG and ribose 5-phosphate) to be fed into other reaction schemes in the cell. These pathways may cost energy to operate and thus can be balanced by other pathways. As an example, the operation of p4 producing 2,3-DPG at the expense of ATP can be compensated by the operation of p1 to solely produce ATP.
Discussion
Because genomics is leading to the complete definition of genotypes of an increasing number of organisms, the definition and conceptualization of biochemical pathways in the context of a whole cell has emerged as an important issue (21). An approach to the study of biochemical reaction systems and their capabilities and performance has been introduced, combining the laws of material conservation in biochemical reactions with the methods of linear algebra. A biochemical system is first balanced and then translated into mathematical representation as a stoichiometric matrix. The null space of the matrix is then spanned in a manner that is theoretically and biochemically feasible providing an explicit description of the null space. By incorporating biochemical knowledge to guide the construction of these basis vectors, we arrive at independent biochemical pathways, which operate within the defined metabolic system. The structure of the null space, the space that contains all possible metabolic phenotypes, is now given in terms of systemically defined pathways.
Treating the structure of metabolic reaction networks in the framework of pathways operating through the system affords many advantages and potential implications for additional conceptual developments. With the ability to decompose a metabolic reaction network into independently operating pathways or modalities, it is possible to gain insight into the regulatory logic implemented by the cell using a new pathway-oriented perspective (22). In addition, the use of such a pathway-oriented approach will undoubtedly assist in attempts to make sense of all of the metabolic components revealed through genomics. By using this approach to pathway definition, organisms can be studied based on the existence of fundamental metabolic pathways, which trace their ability to synthesize required precursors and cofactors.
As is the case in any coordinate translation, there are many sets of bases that can be used to span the null space of a stoichiometric matrix; thus, the selection of bases is nonunique. The development of a useful basis depends on the removal and addition of biochemical and regulatory constraints, as well as the application of interest and how one may wish to interpret the pathways and fluxes operating within a network. In developing an algorithm to perform this critical basis transformation, the challenge is to incorporate biochemical intuition as the guiding force in the selection of a basis with biochemical importance as opposed to relying purely on the machinery of linear algebra. Algorithm construction is currently underway for the automation of this procedure for the general case.
Traditionally biochemical pathways have been defined in the context of their historical discovery, such as glycolysis, the pentose phosphate pathway, and the citric acid cycle. Through the approach developed here, we move away from the traditional definitions of biochemical pathways to a new classification of pathways—classification based on systemic function as opposed to historical discovery. Defining the functional metabolic pathways in an organism will undoubtedly impact our views of metabolism, from its capabilities to its regulation and even perhaps its evolution. Taken together, the conceptual development and analysis presented represents a step toward the establishment of fundamental concepts on which we can build as we move beyond bioinformatics. Functional analysis and representation of genomes and their characteristics represent one of the most interesting challenges that now faces bioengineering and other quantitative disciplines focused on analysis of fundamental biological phenomena.
Acknowledgments
We thank the Whitaker Foundation and their support through graduate fellowships in biomedical engineering.
ABBREVIATION
- 2
3-DPG, 2,3-bisphosphoglycerate
Footnotes
Whereas large dimensional spaces (more than three dimensions) become abstract, recall that in three dimension we commonly use the x, y, and z coordinate system as our basis; yet, for certain problems, this system becomes an inefficient set of basis vectors, and therefore, we transform the basis. Examples of this transformation would include simple basis rotations and more complex transformations such as spherical or cylindrical bases (e.g., see ref. 19) for solutions of various transport phenomena problems. In each case, the basis vectors all span the entire three dimensional space.
References
- 1.Koonin E V. Genome Res. 1997;7:418–421. doi: 10.1101/gr.7.5.418. [DOI] [PubMed] [Google Scholar]
- 2.Pennisi E. Science. 1997;277:1432–1434. doi: 10.1126/science.277.5331.1432. [DOI] [PubMed] [Google Scholar]
- 3.Blattner F R, Plunkett G, III, Bloch C A, Perna N T, Burland V, Riley M, Collado-Vides J, Glasner J D, Rode C K, Mayhew G F, et al. Science. 1997;277:1453–1474. doi: 10.1126/science.277.5331.1453. [DOI] [PubMed] [Google Scholar]
- 4.Ouzounis C, Casari G. Trends Biotechnol. 1996;14:280–285. doi: 10.1016/0167-7799(96)10043-3. [DOI] [PubMed] [Google Scholar]
- 5.Tatusov R L, Koonin E V, Lipman D J. Science. 1997;278:631–637. doi: 10.1126/science.278.5338.631. [DOI] [PubMed] [Google Scholar]
- 6.Fields S. Nat Genet. 1997;15:325–327. doi: 10.1038/ng0497-325. [DOI] [PubMed] [Google Scholar]
- 7.Metting F B, Romine M F. Trends Microbiol. 1997;5:91–92. doi: 10.1016/s0966-842x(97)01003-2. [DOI] [PubMed] [Google Scholar]
- 8.Palsson B O. Integrating Engineering and Biology: A Revolution in the Making. Washington, DC: Natl. Acad. Press; 1998. , in press. [Google Scholar]
- 9.Edwards J S, Schilling C H, Ramarkrishna R, Palsson B O. In: Metabolic Engineering. Lee S Y, Papousakis E T, editors. New York: Springer; 1998. , in press. [Google Scholar]
- 10.Varma A, Palsson B O. Bio/Technology. 1994;12:994–998. [Google Scholar]
- 11.Bonarius H P J, Schmid G, Tramper J. Trends Biotechnol. 1997;15:308–314. [Google Scholar]
- 12.Varma A, Palsson B O. Appl Environ Microbiol. 1994;60:3724–3731. doi: 10.1128/aem.60.10.3724-3731.1994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Varma A, Palsson B O. Biotechnol Bioeng. 1994;43:275–285. doi: 10.1002/bit.260430403. [DOI] [PubMed] [Google Scholar]
- 14.Strang G. Linear Algebra and Its Applications. Orlando, FL: Harcourt Brace; 1988. [Google Scholar]
- 15.Lay D C. Linear Algebra and Its Applications. Reading, MA: Addison–Wesley; 1997. [Google Scholar]
- 16.Papoutsakis E, Meyer C. Biotechnol Bioeng. 1985;27:50–66. doi: 10.1002/bit.260270108. [DOI] [PubMed] [Google Scholar]
- 17.Pons A, Dussap C, Pequignot C, Gros J. Biotechnol Bioeng. 1996;51:177–189. doi: 10.1002/(SICI)1097-0290(19960720)51:2<177::AID-BIT7>3.0.CO;2-G. [DOI] [PubMed] [Google Scholar]
- 18.Henriksen C M, Christensen L H, Nielsen J, Villadsen J. J Biotechnol. 1996;45:149–164. doi: 10.1016/0168-1656(95)00164-6. [DOI] [PubMed] [Google Scholar]
- 19.Bird R B, Stewart W E, Lightfoot E N. Transport Phenomena. New York: Wiley; 1960. [Google Scholar]
- 20.Paglia D E. In: Hematology: Basic Principles and Practice. Hoffman R, Benz E J, Shattil S J, Furie B, Cohen H J, editors. New York: Churchill Livingstone; 1991. pp. 269–273. [Google Scholar]
- 21.Ash C. Trends Microbiol. 1997;5:135–139. doi: 10.1016/S0966-842X(97)01031-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Stephanopoulos G, Simpson T W. Chem Eng Sci. 1997;52:2607–2627. [Google Scholar]