

Abstract
The majority of computationally specified models of recognition memory have been based on a single-process interpretation, claiming that familiarity is the only influence on recognition. There is increasing evidence that recognition is, in fact, based on two processes: recollection and familiarity. This article reviews the current state of the evidence for dual-process models, including the usefulness of the remember/know paradigm, and interprets the relevant results in terms of the source of activation confusion (SAC) model of memory. We argue that the evidence from each of the areas we discuss, when combined, presents a strong case that inclusion of a recollection process is necessary. Given this conclusion, we also argue that the dual-process claim that the recollection process is always available is, in fact, more parsimonious than the single-process claim that the recollection process is used only in certain paradigms. The value of a well-specified process model such as the SAC model is discussed with regard to other types of dual-process models.
The two dominant approaches to explaining human recognition memory are the single-process theories (e.g., Dunn, 2004; McClelland & Chappell, 1998; Shiffrin & Steyvers, 1997), which evolved from global matching models (Gillund & Shiffrin, 1984; Hintzman, 1988; Murdock, 1982), and the dual-process theories (e.g., Jacoby, 1991; Joordens & Hockley, 2000; Mandler, 1980; Reder et al., 2000; Yonelinas, 1994).1 Dual-process theories assume that recognition involves both recollection (retrieval of episodic information) and familiarity processes, whereas single-process theories claim that there is no need to assume anything more than a familiarity- or strength-based model. Some theorists have recently modified their single-process positions to accommodate use of recollection in certain classes of recognition paradigms (e.g., plurality reversal; Malmberg, Holden, & Shiffrin, 2004).
Yonelinas (2002) has reviewed examples of dual-process models of recognition, assuming from the outset that single-process models are incorrect. Others have made similar arguments (Reder et al., 2000; Rotello, Macmillan, & Reeder, 2004) but, like Yonelinas (2002), have not focused on the challenges for single-process models across a wide range of effects. Those who adhere to the dual-process view of recognition often believe that the debate is closed, that there is no doubt that recognition must be considered a dual process. On the other hand, those who adhere to the single-process view (e.g., Malmberg, Zeelenberg, & Shiffrin, 2004) consider that the parsimony of a single-process account makes it undesirable to consider more complicated theories, unless it is absolutely necessary. Indeed, a recent article by Dunn (2004) suggests that the single-process signal detection theory approach to understanding remember/know data makes the postulation of a dual-process account unnecessary. It is our view that the parsimony advantage of single-process models may no longer hold, given the extant data. Therefore, we will proceed with an analysis of the ability of single-process models to account for the key effects that distinguish between single- and dual-process models. In addition, we will argue that parsimony is best served by advancing a single explanation for recognition memory results in general, rather than assuming that recollection is involved to a certain extent in processes such as associative recognition, but not at all in item recognition. This issue is timely, because many theorists now accept that recollection is important for these “special” types of recognition tasks, although still arguing that participants do not use recollection-based information in item recognition (e.g., Malmberg, Holden, & Shiffrin, 2004).
Thus, the goal of this article is to review and critique single-process models and, by extension, the arguments against dual-process models. In light of Yonelinas's (2002) prior review of dual-process theories other than the source of activation confusion (SAC) model (Reder et al., 2000) and his discussion of where those models agree and disagree, we will spend little time reviewing the history of dual-process theories. Instead, we will review empirical evidence from the primary areas of research that distinguish between single- and dual-process accounts of recognition.2 As a solution to the limitations of extant single-process models, we will elucidate how the SAC model provides a mechanistic, dual-process account of recognition memory.
The SAC model is a computationally implemented model of memory that posits both a recollection and a familiarity process to account for recognition memory phenomena. In addition to fitting a broad range of recognition memory phenomena, it has been used to model other memory phenomena (e.g., feeling-of-knowing data) without making additional assumptions about memory representations or processes. We will argue that it is at least as parsimonious as the well-specified single-process models, given that its explanations provide an arguably simpler account of the range of current empirical findings in recognition. We also believe that it is the most well-specified dual-process model at this time. That is, the SAC model specifies the mechanisms behind encoding, storage, and retrieval, using mathematical predictions, as well as descriptions of how those mathematics map onto processes. Therefore, we will undertake to show how the SAC model deals with current challenges to single-process theories, as well as what the current challenges are for the SAC model and how they might be addressed.
An important part of the debate between single- and dual-process models is the value and diagnosticity of the phenomenological judgments of recollection, usually measured in terms of the remember/know paradigm developed by Tulving (1985) and recently called into question by Dunn (2004). We will begin with a discussion of the remember/know paradigm as support for a dual-process characterization of recognition.
Remember/Know Data
The remember/know paradigm (Tulving, 1985) asks participants to report their state of awareness associated with each old recognition response. When participants can recall specific details about the experience of studying an item, they are to respond remember. When participants are unable to recall specific details about the encoding event but an item seems familiar enough that they believe that they studied it, they are to respond know. Remember responses are thought to correspond to the recollection process, and know responses are thought to correspond to the familiarity process, in the absence of recollection.
Gardiner and Richardson-Klavehn (2000) have comprehensively reviewed the studies in which remember/know procedures have been used and have demonstrated dissociations between the two responses. A number of variables have been shown to increase remember responses without affecting know responses (e.g., Gardiner, 1988; Gardiner & Java, 1990, 1991; Gregg & Gardiner, 1991; Rajaram, 1998). For example, deep processing increases remember responses without affecting know responses (Gardiner, 1988). Other variables, such as maintenance rehearsal, increase know responses without affecting remember responses (e.g., Dewhurst & Hitch, 1999; Gardiner, Gawlik, & Richardson-Klavehn, 1994; Rajaram, 1993). There are also manipulations that cause both types of responses to increase (Gardiner, Kaminska, Dixon, & Java, 1996).
Some researchers have argued that remember/know responses do not index recollection and familiarity but, rather, are indicators of confidence (W. Donaldson, 1996; Dunn, 2004). Dunn analyzed a number of claims that oppose the idea that remember/know responses can be explained as confidence-based responses. He argued for a signal-detection–based model in which two criteria are placed on a single axis of familiarity in order to make remember/know judgments. Dunn claimed that none of the previously made arguments against this type of model actually disprove the signal detection theory account of remember/know responses. One of the most convincing arguments that remember/know responses necessitate the use of multiple sources of information is a dissociation between the two types of responses. That is, if manipulating some variables can produce changes for remember or know responses separately from one another, the argument can be made that different types of information are used to make each type of response (see Gardiner & Richardson-Klavehn, 2000). Dunn modeled these effects by fitting the remember and know criteria and d′ estimate separately for each experimental condition. That is, when modeling the effects of Gardiner and Java (1990), he modeled each within-list condition separately, so that the estimates of the remember and know criteria were different for words on the list and nonwords on the list. The same technique was used to model data from conditions in which words presented once were compared with words presented four times on the same list (Gardiner et al., 1996).
Fitting each condition's criteria separately is problematic because of the convincing evidence found by Stretch and Wixted (1998; see also Morrell, Gaitan, & Wixted, 2002). Their study showed that participants are extremely reluctant to use different criteria to make judgments about items with a single presentation versus five presentations, even when those items are conspicuously presented in different colors so as to allow the participants to differentiate them on the test list. If participants do not shift their criterion within list even under these very encouraging circumstances, it is unlikely that they will do so under the types of conditions used by Gardiner and colleagues. Similarly, Morrell et al. used a within-list strength manipulation and did not find a difference in false alarms with strength (supporting the claim that the participants did not shift their criterion). Dunn's (2004) model as it is currently proposed could not fit Gardiner et al.'s (1996) data accurately without supposing a criterion shift. It is possible that allowing the means and variances of the lure distributions to vary in the model would produce effects similar to criterion shifts; however, this has not been demonstrated.
It should also be noted that a signal detection interpretation of remember/know responses does not necessarily doom the idea of a dual process. Wixted and Stretch (2004) reinterpreted the signal detection model and proposed that the strength dimension could be a combination of recollection- and familiarity-based recognition. The dissociations between remember and know responses are less difficult for this type of model to account for, because it allows for the possibility that the contribution of remember and know responses could change independently of one another.
Although we disagree with Dunn's (2004) claim that the remember/know paradigm can be explained by a single-process, additional criticisms of the remember/know paradigm should be considered. When remember/know findings are assessed, it is important to keep in mind the possibility that demand characteristics may play a role and that the responses are based on phenomenology.3 For example, some might claim that the reporting of phenomenological experience without the type of verification that is required in source memory experiments leads to uncertainty about what participants are reporting. This argument is key to the single-process perspective that remember/know responses are actually indexing differences in confidence, rather than two qualitatively different recognition processes (W. Donaldson, 1996; Hirshman & Master, 1997). There is some evidence to the contrary, such as the fact that comparisons between source judgments and remember/know responses show high similarity (W. Donaldson, MacKenzie, & Underhill, 1996).
Another concern is that by virtue of using the remember/know paradigm, the likelihood of participants' producing recollection-based responses is inflated. That is, asking for remember responses creates a demand characteristic and may induce participants to use recollection more than they would if old/new responses alone were required. However, when remember/know judgments are compared with process dissociation procedures and estimates from receiver-operating characteristic (ROC) analyses, similar proportions of recollection-based and familiarity-based responding are found (Yonelinas, 2002, Appendix). Also, even if the likelihood of a recollection response is artificially inflated in remember/know experiments, findings such as dissociations between remember and know responses still provide evidence that a second process is available. The crux of the argument for two processes is the fact that remember and know responses show qualitatively different patterns of behavior in experiments, not simply that participants make remember responses when asked to do so.
Finally, it is important to note that remember and know responses are not independent of one another. There is often a negative correlation between remember and know responses, so that as remember responses increase, know responses decrease. Although this is not always the case, it is common, due to the nature of the responses.4 When a person makes a remember response, that judgment precludes a know response, so that a large number of remembers will likely lead to a smaller number of knows, particularly as the responses approach ceiling. Even though a person cannot respond both remember and know for the same item, it would be rare for a person to be able to recollect an item without also having temporarily increased the item's base familiarity. This redundancy between remember and know responses must be kept in mind when analyzing experiments in which this paradigm has been used. When remember responses increase, an associated decrease in know responses may simply be an artifact of the procedure. Yonelinas and Jacoby (1995) developed a mathematical correction to allow estimation of the probability that an item is familiar even though know responses underestimate this probability. When this procedure is used, the problem of dependence between the two responses may be eliminated.5 The SAC model does not predict that remember/know responses are independent. Rather, the principles of the SAC model instantiate the redundancy in recollection and familiarity in such a way that decreasing remember responses will often increase know responses.
We think that remember/know responses provide useful information about recognition. We do not think that the caveat for interpreting remember/know results, as described above, is reason to ignore the remember/know literature and the extensive information that it provides, but we do think that remember/know data should not be the only evidence against single-process models. In the present review, we will attempt to use evidence from both simple old/new effects and remember/know data to support our claims.
We now will move on to discussing challenges for single-process models of recognition in terms of the areas of research in which it is difficult for single-process models to explain the findings. In each of these areas, we will present an SAC model fit to the relevant data. The following description of the SAC model will provide a background for understanding these model fits.
The SAC Model
Throughout this review, we will base the claims of the SAC model on the details described below. The SAC model has also been described in previously published articles (Cary & Reder, 2003; Park, Reder, & Dickison, 2005; Reder et al., 2000; Schunn, Reder, Nhouyvanisvong, Richards, & Stroffolino, 1997). Whenever further details or model complexities are necessary to explain a set of results, these will be noted in the description of the specific implementation. Otherwise, all model simulations in this article are based on the parameter values in Table 1, which are standard to the SAC model and which, except for threshold values, generally have not changed in our previous SAC modeling efforts.
Table 1.
Values of the Constant Parameters for SAC Models of Qualitative Data Patterns (Exceptions Noted in Text)
| Parameter | Function | Value |
|---|---|---|
| cN | Power law growth constant for base-level activation | 25 |
| dN | Power law decay constant for base-level activation | .175 |
| cL | Power law growth constant for link strength | 25 |
| dL | Power law decay constant for link strength | .12 |
| ρ | Exponential decay constant for current activation | .8 |
| ti | Time parameter | 100 |
| σe | Study event node decision standard deviation | 40 |
| σw | Study concept node standard deviation | 20 |
| Te | Study event node decision threshold | 40 |
| Tw | Study concept node decision threshold | 60 |
| Current boost | Input current activation for a node being currently perceived | 40 |
| Preexperimental frequency (based on Kučera & Francis) | ||
| High frequency | 142.0 | |
| Medium frequency | 43.0 | |
| Low frequency | 1.6 | |
| Frequency exponent | Converts Kučera & Francis frequency to baseline activation | .4 |
| Fan exponent | Converts Kučera & Francis frequency to preexisting fan | .7 |
The SAC model predicts the percentage of recollection-based and familiarity-based responses that will be produced under the conditions of a recognition task. The per- centage of recollection and familiarity responses can be combined to predict old/new responses. These predicted response percentages are based on the current activation values of memory traces within the model. The relationships among information stored in memory are represented in a localist node structure, shown in Figure 1.
Figure 1.

Schematic representation of how information is stored in memory according to the SAC model.
At the start of each trial, the concept nodes (also called word nodes in past articles) already exist in memory. These nodes represent the conceptual information we have stored from previous experience with the item. The (general) experimental context node exists after the first study trial and represents those characteristics of the environment that the participant experiences during the experiment, such as the lighting, the equipment in the room, and the participant's mood during the task. A specific context node also may be created during a study trial to capture a novel element of context that differs from the general experimental context. This might include the presentation of a word in a unique font, a sound occurring outside the room, or the participant's response to the stimulus. These three types of information—the concept node, the specific context node, and the experimental context node—are bound together by an episode node, which represents the experience of studying the word in the experiment.
When a probe word is presented at test, its concept node is activated, along with the experimental context node. The contextual features of the word at test will also be activated. If the word is presented in the same specific context as that linked to the episode node during study, the specific context will be a relevant source of activation that can spread to the episode node. The activations from the concept and context nodes may intersect at the same episode node (depending on whether the probe is a target item or a foil or whether the same specific context is reinstated). Activation of episode nodes and concept nodes produces recollection- and familiarity-based judgments, respectively. That is, recollection responses are based on the activation of the episode node, where activation accrues due to spread from associated concept nodes, specific context nodes, and experimental context nodes. Familiarity responses are based on the activation of the concept node and sometimes, spuriously, of the specific context node.
The initial strength of each concept node is based on the participant's history of exposure to that word, which is estimated on the basis of word frequency. This baseline activation (B) of a node both increases and decays slowly, according to a power function6:
| (1) |
in which Bw is the base-level activation of the node (set to zero for episode nodes), cN and dN are constants (dN represents the decay of activation of the node), and ti is the time since the ith presentation. This is different from current activation (A), which is higher than the base-level activation whenever the item occurs in the environment or receives activation from its connections. Current activation decays according to an exponential function, moving back toward the baseline within a short period of time:
| (2) |
After each trial, current activation decreases by the proportion ρ times the node's current distance from base-level activation. The variable ρ is a stable parameter with a value of .8.
Activation spreads from each node in the structure that is activated by the environment (including concept nodes, specific context nodes, and experimental context nodes) to other connected nodes. The activation spreads according to the number and relative strength of the links connected to the node, so that more links result in less activation spread along each individual link. For example, a concept node may be connected to many episode nodes, which bind the concept to the various situations in which that concept has been studied. The amount of activation that any node r receives is calculated according to the following equation:
| (3) |
in which ΔAr is the change in activation of the receiving node, As is the activation of each source node (s), Ss,r is the strength of the link between nodes s and r, and Σ Ss,I is the sum of the strengths of all links emanating from node s. The total spread of activation is limited to node s's current activation.
The links between nodes also vary in strength, on the basis of the frequency with which two pieces of information have been associated. The strengthening and weakening of these links occurs according to a power function
| (4) |
In this equation, Ss,r is the strength of the link from node s to node r, ti is the time since the ith association between the two nodes, and cL and dL are constants for the links (dL represents the decay of link strength).
Once the activation of each node and its subsequent spread of activation to other nodes have been calculated, we can determine the probability of making a remember or a know response. The probability of a remember response is calculated by assuming a normal distribution of activation with fixed variance and a threshold for responding remember. The probability is computed by the following formula:
| (5) |
in which AE is the activation of the episode node, TE is the participant's threshold for the episode node, and σE is the standard deviation of the episode node's activation distribution. N[x] is the area under the standard normal curve to the left of x for a normal curve with a mean of zero and standard deviation of one. The probability of a know response is calculated as
| (6) |
In other words, the probability of a know response is the probability of not responding remember multiplied by the probability that the concept node or the specific context node will be above threshold.7 P(Kw) represents the likelihood of a know response due to activation of the concept node.
The model is implemented by calculating the strength of the episode nodes, concept nodes, and context nodes at test. The episode, concept, and specific context nodes may have different strengths for different conditions of the experiment. The activation of the episode node is based on the sum of the activation that is sent to it from the experimental context, specific context, and concept nodes, as well as on its baseline activation from its creation at study. The spread of activation from the concept and context nodes is modulated by the number and strength of links from each node, so that the sum of activation spreading from a node is equal to its total activation. On the basis of the activation of the word and episode nodes in each condition, the probability that a node will pass threshold is calculated using the standard normal distribution. The probability of an episode node's passing threshold is equivalent to the probability of a remember response. The probability of a concept node's surpassing threshold is equivalent to the probability of a know response.
Several assumptions of the SAC model should be noted. Remember and know judgments are assumed to be partially redundant; however, this partial redundancy is unidirectional. The proportion of remember responses affects know responses, but not the converse, because participants are instructed to respond remember if any recollected information is available, even when the item is familiar. Also, the model is simplistic in that it ignores details of the components of concept nodes, such as se- mantic and lexical features, and the components of the experimental context node. We do not claim that these representations are, in fact, simple but, rather, that the details of the representations will not affect our simulations (except in the case of plurality recognition, in which added complexity is necessary, which will be discussed later in the article).
When Is Recollection Used?
The SAC model incorporates information that informs both the familiarity and the recollection processes. Episodic information is bound to conceptual information at the episode node. This binding allows one to make recognition judgments on the basis of explicit recollection of episodic details whenever the episode node is sufficiently strong. When the node binding the episodic details to the conceptual information is not sufficiently strong, one will rely on the less accurate process of familiarity. Familiarity is based on the concept node, which can sometimes be strengthened by an experience other than the episodic instance that one is attempting to retrieve.
This model emphasizes the recollection process as the more accurate of the two available processes; however, the familiarity process is frequently also used when the encoding of the episode is not sufficient (this would include both amnesic patients on most trials and healthy participants on some trials) or when some other aspect of the task creates interference. Cases in which recollection is less likely to be used are those in which episodic encoding is made more difficult (by increasing working memory demands) or those in which demands at retrieval require faster performance (such as in response deadline tasks). When these types of demands are instituted, familiarity may become the primary process, although recollection would still be an available process. Thus, we would argue that participants will attempt to use the recollection process whenever sufficient time and resources are available and that they will be successful at using the process whenever the binding between episodic and conceptual information is sufficiently strong.
Single-process models originally differed from this model in that they proposed that recognition memory could be explained as resulting from the familiarity process alone. This type of model gave an accurate account of many effects in the literature and was seen as more parsimonious than an account that proposes two processes to make the same predictions. However, in this article, several findings in the recognition memory literature will be analyzed that have required that single-process models add additional assumptions/complexity and, in some cases, posit the use of a recall-like process in order to account for the data. As will be seen in the following sections, newer single-process models sometimes take the position that recollection is used in some types of recognition tasks, but not in simple single-item recognition.
We will begin our discussion by examining the findings related to the mirror effect and comparing the single-process and the dual-process accounts of these results. Then we will proceed through each of the other areas of research, including the accounts of single-process models and simulations of the SAC model, where appropriate.
Word Frequency Mirror Effect
The mirror effect (Glanzer & Adams, 1985) is the finding that recognition memory hit rates and false alarm rates tend to be affected in opposite directions as a function of word frequency. It is given this name because the patterns of hit rates and false alarm rates mirror one another. That is, low-frequency words are recognized more accurately than high-frequency words, in terms of recognizing both old items as old and new items as new. Low-frequency words produce more hits and fewer false alarms than do high-frequency words. Although mirror effects based on other manipulations have been demonstrated, the primary type of mirror effect is caused by word frequency manipulations (Gorman, 1961; Glanzer & Bowles, 1976; Greene & Thapar, 1994; Hintzman, Caulton, & Curran, 1994; Hockley, 1994).
Most current models of recognition memory account for the occurrence of the word frequency mirror effect. Single-process models—REM (Shiffrin & Steyvers, 1997) and the McClelland and Chappell (1998) model explain the mirror effect as being due to a single factor. REM and the McClelland and Chappell models were developed simultaneously and independently but take a similar approach. Both propose that memory consists of patterns, with each value in a pattern representing a feature of a particular piece of information. A pattern of values is stored when a word is studied in a list, but this pattern can be incomplete and can include errors. In REM, when a test probe is presented, it is matched in parallel with the episodic representation of each word that was on the study list. REM assumes that high-frequency words have more common features than do low-frequency words. This means that high-frequency words will more likely match both target and lure items. However, the likelihood that high-frequency words will match is also higher, and this cancels any matching advantage for the more common features of high-frequency words for target items. For lure items, the likelihood ratio does not compensate for the matching advantage, and the proportion of false alarms is greater for high-frequency words (see Shiffrin & Steyvers, 1997, p. 153). Therefore, the model predicts both the hit rate and the false alarm rate portions of the mirror effect.
The McClelland and Chappell (1998) model also proposes that a pattern of features is stored at study but that this pattern is initially noisy. As the item becomes more familiar, the features become more similar to the actual features of the item. This model also involves calculation of a likelihood estimate, which increases when an item's familiarity increases. In addition, the likelihood estimate that a lure has been seen on the list decreases as familiarity with the items on the list increases. This principle is called differentiation and explains why variables that increase hits also decrease false alarms. The McClelland and Chappell model explains the word frequency mirror effect by proposing that representations of low-frequency words are less variable than representations of high-frequency words, on the assumption that high-frequency words have more definitions than do low-frequency words and, therefore, have more common semantic features. Therefore, the parameter that controls the noise in the representation is set to a higher value for high-frequency words.
In summary, REM says that low-frequency targets are more likely to produce hits, due to the likelihood ratio, whereas high-frequency foils are more likely to match the episodic trace of a target, due to having more common letter features. McClelland and Chappell (1998) claimed that there is greater variance in the representations of high-frequency words, as compared with low-frequency words, due to the greater number of common semantic features. It was originally thought that these models would predict that both hits and false alarms will show the same effects for any manipulation. They must provide an additional explanation for those situations in which only the hit rate or the false alarm rate portion of the effect occurs.
Malmberg, Zeelenberg, and Shiffrin (2004) showed that in situations in which episodic encoding is noisy at study, the hit rate portion of the mirror effect will not be expected to occur, whereas the false alarm rate portion will still occur, because the false alarms to high-frequency words are due to chance matches of lures to targets. Decreasing the probability of correctly storing a feature does not affect the false alarm rate but decreases the hit rate. It is important to note that if storage were reduced in REM, rather than being made noisier, the false alarm rate would be expected to decrease, due to the fact that less information about targets is available for a chance match with lure items. Therefore, the model would not be able to account for concordant data patterns in cases in which storage is simply reduced (Malmberg, Zeelenberg, & Shiffrin, 2004). The noisy encoding account was developed for REM, but the McClelland and Chappell (1998) model previously included the assumption that initial item storage is noisy, rather than incomplete. Therefore, it is likely that when storage is noisy, both models can account for concordant patterns of hits and false alarms. Generally speaking, dual-process models, those accounts that propose that the hit rate and false alarm rate differences are caused by separate processes, can naturally account for situations in which only one of the two effects occurs by claiming that there is a reduction in use of one of the two processes.
Studies that have demonstrated exceptions to the mirror effect typically have shown that the hit advantage for the more memorable stimulus class is eliminated but that the false alarm advantage remains. In order for single-process models such as REM to explain these results, they must assume one of two explanations. The first is that storage of information is noisier in these conditions than in standard conditions of recognition tasks. The second is that high-frequency words are studied to a greater degree under the experiment's conditions than are low-frequency words. Cases in which the word frequency mirror effect has not been found are those in which Alzheimer's patients (Balota, Burgess, Cortese, & Adams, 2002) and amnesiacs (Huppert & Piercy, 1978) have been tested. These patients show a concordant pattern, so that high-frequency words produce both more hits and more false alarms than do low-frequency words. Also, when the drug midazolam, which induces temporary amnesia, has been administered to participants, they have shown a similar concordant pattern (Hirshman, Fisher, Henthorn, Arndt, & Passannante, 2002).
Hirshman and Arndt (1997) demonstrated that the mirror effects resulting from the manipulation of word frequency did not occur when participants were asked to rate stimulus items' concreteness at study. Specifically, although the false alarm effects typically associated with word frequency occurred, the hit rate differences across conditions either were not significant or showed a pattern similar to that of the false alarm rates. However, when imagery instructions, a lexical decision task, or a frequency-rating task was used, the hit rate advantage for the mirror effect did occur (Hirshman & Arndt, 1997; Joordens & Hockley, 2000; Rao & Proctor, 1984). Similarly, Hoshino's (1991) experiments showed that only certain encoding tasks produce the mirror effect. Although using mid-range frequency, rather than low-frequency, words can reduce the mirror effect, Hoshino demonstrated that a lexical decision task, rather than either acoustic judgments or concreteness ratings, still produced the mirror effect. Other research has demonstrated that the hit rate portion of the word frequency effect occurs only under encoding conditions that have either no task requirement or an unusual letter judgment task (Criss & Shiffrin, 2004). However, given that these findings occurred with a within-list manipulation of multiple encoding tasks, the difficulty of task switching may have played some role.
Once again, single-process models would need to assume either that storage is noisier when a task such as acoustic judgments or concreteness ratings is used at study or that high-frequency words are studied more than low-frequency words with these tasks. It is not obvious that shallower tasks would provide noisier storage. Indeed, a priori, one might have assumed that semantic encoding, such as in imagery or lexical decision tasks, would be noisier/more variable than superficial encodings. It is also not clear that concreteness and acoustic tasks would lead to differential encoding of high-frequency and low-frequency items.
Another departure from the typical mirror effect that is not explained by assuming noisier storage or differential encoding at study involves a word frequency manipulation within a reversed-plurality lure recognition task (Arndt & Reder, 2002).8 In this type of task, participants are shown both singular and plural words at study. At test, the participants are asked to distinguish between words shown in a plurality that is identical to their form at study, which are to be called old, and those that are shown in a plurality that is the reverse of their form at study, which are to be called new. Arndt and Reder found that the false alarm portion of the word frequency mirror effect did not occur for plurality recognition. That is, low-frequency words received more hits than did high-frequency words, but high-frequency reversed-plurality lures did not receive more false alarms than did those of a low frequency. Single-process models may have difficulty accounting for these data without assuming that a second process is involved in the discrimination of reversed-plurality lures. However, some single-process modelers have claimed that this type of task requires the use of a recollection process in REM, and thus they may explain these results in that way (Malmberg, Holden, & Shiffrin, 2004).
These exceptions to the mirror effect fit with the hypothesis that the hit portion of the mirror effect is caused by a recollection process, whereas the false alarm portion of the mirror effect is caused by a familiarity process. All of the manipulations that result in attenuation of the hit rate portion of the mirror effect can be described as affecting either episodic encoding or the ability to use a recollection process in recognition. That is, tasks such as concreteness ratings and acoustic judgments require participants to focus on specific characteristics of the words, whereas lexical decision tasks and encoding with no task requirements allow attention to be focused on the semantic characteristics of a word and may improve recollection. Thus, as was concluded by Joordens and Hockley (2000), those manipulations that decrease recollection reduce the hit rate differences of the mirror effect, whereas the false alarm differences remain.
A dual-process account of the word frequency mirror effect is supported by other empirical results, in addition to the exceptions to the mirror effect. Rugg, Cox, Doyle, and Wells (1995) used a source judgment task, so that when words were labeled old at test, the participant was required to report the context in which the word had been seen at study. This type of task is thought to use recollection-based processing (e.g., Quamme, Frederick, Kroll, Yonelinas, & Dobbins, 2002). The authors found that low-frequency words were more likely to be correctly judged old and be assigned to the correct study context than were high-frequency words. This indicates that the participants could more easily recollect the specific context for low-frequency items and, thus, were more able to use recollection processing for low-frequency words. Similar results were found by Reder and colleagues (Reder et al., 2000, Experiment 3). This is consistent with a dual-process account that claims that the increased hit rate for low-frequency words is based on better recollection.
Additional evidence supporting this view comes from experiments that induced temporary anterograde amnesia, using the drug midazolam (Hirshman et al., 2002). They examined the word frequency mirror effect when half of the participants had induced amnesia. It is often proposed that patients with Alzheimer's disease and other forms of anterograde amnesia have damage to the recollection capability in memory but that their familiarity capabilities remain intact (e.g., Balota & Ferraro, 1996). The typical word frequency mirror effect was seen when the participants were injected with saline; however, the participants under the influence of midazolam produced a concordant pattern, so that there were more hits and false alarms to high-frequency words than to low-frequency words. It is thought that midazolam affects people's ability to recollect information from study but does not impair familiarity processes (Hirshman et al., 2002). In fact, midazolam produced large decrements on remember responses but had little effect on know responses (although the dependence between remember and know responses would tend to predict that know responses will increase with decreasing remember responses). The participants given saline produced more remember hits to low-frequency than to high-frequency words but, when under the influence of midazolam, had an equal number of remember hits to low- and high-frequency words. The pattern for know hits, which showed more hits for high frequency than for low frequency, remained the same for both groups of participants. Know false alarms were greater for high-frequency than for low-frequency words in both conditions as well. All of these findings provide supporting evidence for the dual-process account that the hit portion of the mirror effect is driven by recollection-based responses and the false alarm portion is driven by familiarity-based responses.
The specific SAC account of the word frequency mirror effect was proposed in Reder et al. (2000), and details can be found in that article. The empirical results from that article support the idea that the hit portion of the mirror effect was driven by recollection, whereas the false alarm portion was due to familiarity. The SAC model was shown to successfully fit the data. For the purposes of this article, we need to show that the SAC model can account for findings that both portions of the mirror effect do not always occur. The SAC model can naturally explain these findings, because the model includes two separate processes to produce the hit and the false alarm portions of the mirror effect. Joordens and Hockley (2000) have provided a similar account, based on their data showing that reducing participants' ability to recollect eliminated the hit rate portion of the mirror effect.
SAC model of the word frequency mirror effect
Using the SAC framework, we developed a model of the word frequency mirror effect. The model is based on the representation shown in Figure 2. More activation spreads from the low-frequency concept node to its connected episode nodes because there are fewer episode nodes associated with a low-frequency word. The base-level activation of a high-frequency word is higher than that of a low-frequency word. The results of the simulation can be seen in Figure 3. The specific context is the same for all words and thus, for simplicity, was not included in the model. The qualitative pattern is that of the mirror effect, in which low-frequency words produce more hits and fewer false alarms than do high-frequency words. The hit portion of the effect is due to recollection-based responses, whereas the false alarm portion of the effect is due to familiarity-based responses. Because the model predicts more recollection-based responses for low-frequency than for high-frequency words, it also predicts better source memory for low-frequency words, as was found by Rugg and colleagues (Rugg et al., 1995). The predictions of both more recollection-based responses and better source memory for low-frequency words are due to the fact that low-frequency words have fewer connections (sometimes called lower fan) from the concept node to competing contexts, allowing more activation to spread to the relevant associated episode node.
Figure 2.

Schematic representation of high- and low-frequency words in memory according to the SAC model.
Figure 3.
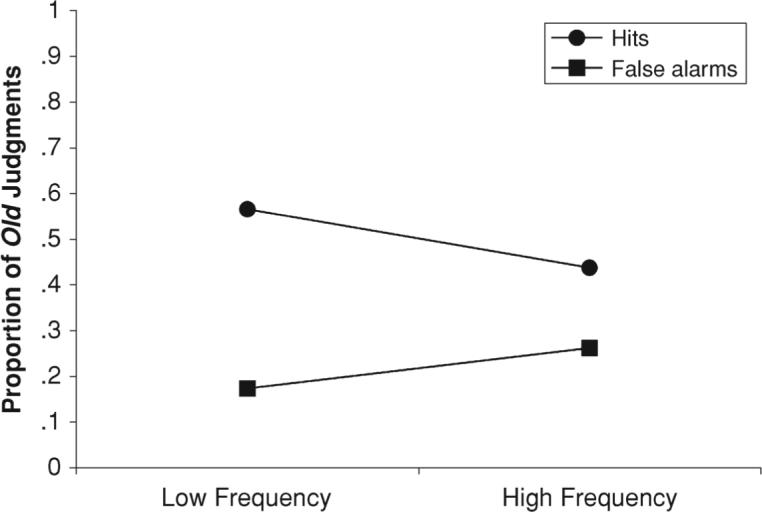
SAC simulation of the word frequency mirror effect with normal participants: Mean proportion of hits and false alarms as a function of word frequency.
The performance of amnesic patients on a word frequency memory task can be modeled in the SAC framework, using the same procedure as that for normal subjects' word frequency mirror effect. This is an example of one of the ways in which the hit portion of the word frequency mirror effect may be attenuated, whereas the false alarm portion remains. The model is identical to the model described above, except that, since amnesiacs are thought to have impaired recollection with relatively spared familiarity, the probability of a remember response is multiplied by the probability of creating an episode node in the study phase. SAC models of normal performance assume that the probability of creating an episode node is 1. The SAC model of amnesiac performance shown in Figure 4 is based on a probability of creating an episode node of .3. This change affects low-frequency words more than high-frequency words because the model predicts that low-frequency hits are more often based on recollection than on familiarity. The probability of a hit for a high-frequency word is reduced by approximately 6%, whereas that probability is reduced by approximately 20% for low-frequency words.
Figure 4.

SAC simulation of the word frequency mirror effect with amnesiac participants: Mean proportion of hits and false alarms as a function of word frequency.
Summary of the mirror effect
The findings of a mirror effect for word frequency manipulations in recogni- tion memory are a regularity within the field. However, there are also situations in which this regularity does not occur. Single-process models may claim that, in these cases, storage of information at study is typically noisy (Malmberg, Zeelenberg, & Shiffrin, 2004) or that high-frequency words are more strongly encoded than low-frequency words. These explanations would need to explain the data from amnesiacs, participants under the influence of midazolam, and shallow encoding tasks. More research is required to support these accounts; however, they are not ruled out by the current data. Also, single-process models must account for the mirror effect with reversed-plurality lures, in which the hit rate portion of the mirror effect remains but the false alarms to high- and low-frequency words are equal, by assuming that a recollection process is involved in plurality recognition. Thus, the single-process account of the described data sets requires two separate mechanisms. All of the data described thus far can be explained by dual-process models as originally proposed, so that the hit rate portion of the mirror effect is due to a recollection process, whereas the false alarm portion is due to a familiarity process. The SAC model provides a mechanism for this assumption, so that high-frequency words have a higher base familiarity but more associations and, thus, fewer recollection-based hits are produced but more familiarity-based false alarms, when compared with low-frequency words.
Time Course of Recognition
Studies of the time course of recognition have consistently demonstrated that familiarity information is available earlier in processing than is recollection. In many of these studies, the response lag procedure has been used, which requires participants to respond at one of a range of lags that is randomly determined for each trial. Under these conditions, participants are able to accurately complete tasks for which familiarity is informative, such as single-item recognition, earlier than they are able to accurately complete tasks that require recollection, such as source judgments (e.g., Hintzman & Caulton, 1997; Hintzman, Caulton, & Levitin, 1998; McElree, Dolan, & Jacoby, 1999). Similarly, it has been shown that as the response lags increase, the likelihood of making a false alarm to a similar item first increases and then decreases (e.g., Dosher, 1984; Dosher & Rosedale, 1991). Also, Rotello and Heit (2000) showed that false alarms to repaired items in an associative memory task were greater at short lags—presumably, the result of familiarity-based responses—and decreased at long lags.
Most of these data can be accounted for by a single-process model that proposes an earlier perceptual-processing stage to recognition, in which sensory information is processed before access to memory representations is available (Brockdorff & Lamberts, 2000). However, this model would have difficulty accounting for the results of Dosher and Rosedale (1991), described above, in which the false alarm rate to semantically related lures first increased and then decreased as more time was given to make a recognition decision. The studies described above have led to the conclusion that familiarity is a faster process than recollection, since familiarity should lead to acceptance of similar lures and inaccurate completion of associative tasks. The more accurate recollective information is available later in processing. This dissociation between the availability of two types of information in recognition indicates that there is a process involved in recognition besides familiarity.
Using the response lag procedure, Boldini and colleagues also recently found a dissociation between modality match and levels-of-processing manipulations (Boldini, Russo, & Avons, 2004). They found that matching modality provided an advantage when responses were required at a short response signal delay, whereas deep processing provided an advantage only when long response signal delays were given. The authors assumed that modality has an effect on familiarity, whereas deep processing has an effect on recollection. Thus, they concluded that the dissociation provides evidence for a dual-process model of recognition. In fact, the data were fit with a two-process model that provided a better fit than did a familiarity-based model.
Other studies have shown that response deadline procedures disrupt the hit rate portion of the mirror effect, but not the false alarm portion (Balota et al., 2002; Joordens & Hockley, 2000). When participants are forced to respond more quickly than normal (either 500 or 800 msec), there is no difference in hit rate for low-frequency and high-frequency words. However, high-frequency words still produce more false alarms than do low-frequency words. The claim that response deadline procedures force participants to respond by using the faster familiarity process, whereas longer response times allow use of recollection, means that these data fit nicely with the SAC explanation of the mirror effect. Under conditions in which familiarity is the primary process, the hit rate portion of the mirror effect will not occur.
In addition to the evidence for separate processes from the response lag procedure with old/new responses, the remember/know paradigm provides supporting evidence by demonstrating that remember responses occur more quickly than know responses (Dewhurst & Conway, 1994; Trott, Friedman, Ritter, Fabiani, & Snodgrass, 1999). This may seem contradictory to the response lag findings; however, dual-process modelers have provided some explanations. Yonelinas (2002) has argued that this outcome is an artifact of the remember/know instructions that state that a know response should be made only when there is no contextual information available about the memory. Thus, participants must assess recollection before they can determine that a know response is appropriate. Mandler and Boeck's (1974) data support this claim that fast remembers are an artifact of the remember/know procedure. They conducted an experiment in which neither the remember/know paradigm nor the response lag procedure was used. They showed that the number of categories used for an organization task during study (a manipulation that is thought to affect recollection) affects responses made at long reaction times and not responses made at shorter reaction times. This indicates that slower responses may be based on recollection, whereas faster responses are based on familiarity.
SAC explanation of time course data
The finding that reaction times in recognition data show a dissociation between the types of judgments that can be made at short lags (from stimulus presentation until response), as compared with those that can be made at long lags, is consistent with the SAC perspective. It has been proposed that familiarity information is available prior to recollection information. The SAC model naturally predicts this effect, on the basis of the fact that the model first calculates activation at individual concept nodes and then calculates activation at episode nodes on the basis of how the concept node activation spreads. Thus, the activation of the concept node, which corresponds to familiarity, is available before the activation of the episode node.
SAC also assumes that when the remember/know paradigm is used, participants will search their memory in an attempt to recollect, before deciding to use familiarity. That is, participants will determine whether the episode node surpasses threshold before they assess the activation of the concept node. This is because remember/know instructions ask participants to make a remember response when any recollected information is available and to make a know response only when no recollected information is available but the item is familiar. Thus, even though familiarity information is available prior to information about recollection, participants will check the results of the recollection process before making a response.
Summary of time course data
Studies of the time course of recognition have shown that different types of judgments can be made at different points in time following presentation of a test probe. Familiarity-based judgments can be made earlier than recollection-based judgments. Particularly difficult for single-process models is the finding that false alarms to similar lures initially increase with more processing but then decrease as lags become even longer. This rules out the explanation that more information is constantly becoming available during processing time, since recognition actually becomes less accurate before it improves. The SAC model explains these results as being due to the increasing contribution of familiarity-based processes at short lags, followed by the use of recollection-based processes as time increases. However, when the remember/know procedure is used, participants will actually use recollection-based processing before familiarity-based processing.
Fan Effect Data
The fan effect is the finding that increasing the number of associations (increasing the fan) to a concept increases the time to retrieve a particular association (e.g., Anderson, 1974) and decreases the ability to recollect an associated item (e.g., Reder, Donavos, & Erickson, 2002; Reder et al., 2000). The classic study in this paradigm involves presenting a series of sentences to participants, with some of the concepts in the sentences contained in several sentences. When the participants are later asked to recognize the sentences that they had seen previously, they are slower to recognize those sentences that contained concepts that had been presented in multiple sentences. This finding may be explained by single-process models such as REM (Shiffrin & Steyvers, 1997) and the McClelland and Chappell (1998) model as a type of associative effect, where recollection may be involved.
More recent work has involved the presentation of single words in a variety of fonts, with some of the fonts being presented with many words (high-fan font) and others seen with only one word (low-fan font). At test, for words that are re-presented in the same font, the participants are less accurate at recognizing words shown in a high-fan font than words shown in a low-fan font, with this difference manifested in fewer remember responses (Reder et al., 2002). In addition, the participants are more likely to false alarm to lure words that are presented in a high-fan font than to those presented in a low-fan font (Diana et al., 2004). Therefore, the fan of associated contextual features creates a mirror effect for recognition accuracy. The font fan mirror effect may be explained by models such as REM and the McClelland and Chappell (1998) model as a sort of list length effect, where the list of words associated with a high-fan context is longer than that associated with a low-fan context. This account would be sufficient, provided that it could show both the hit rate advantage for words associated with low-fan fonts and the false alarm disadvantage for words associated with high-fan fonts.
SAC model of the font fan mirror effect
The SAC model can easily explain fan effects on the assumption that activation is spread from a node to other nodes according to the number and strength of its links. Increasing the number of contexts with which a concept is associated, as in the original fan experiments, increases the number of links emanating from that concept. Therefore, less activation spreads to any one episode node, which represents the binding of the concept to a particular context. Thus, fewer recollection-based responses are made. This is similar to the representation shown in Figure 2, in which high-fan words have more associations and, therefore, spread less activation to any one associated episode node.
The SAC model can easily explain fan effects because it proposes that perceptual information is linked to the episode node in the same way as conceptual information. The font of a word is represented by the specific context node, which is separate from the semantic information. The nodes are bound by an episode node. In order to make a recollection, a sufficient amount of activation must spread to the episode node to push it over threshold. A high-fan font spreads less activation from its specific context node to any one of its episode nodes, due to its larger number of competing links, than does a low-fan font. The simulation in Figure 5 uses the parameters given in Table 1 and the assumptions described above to produce the font fan mirror effect. This pattern is qualitatively similar to that found by Diana et al. (2004).
Figure 5.

SAC simulation of the font fan mirror effect: Mean proportion of hits and false alarms as a function of the fan of the associated font.
As was stated in note 3, the reinstatement of a previously studied specific context with a lure item provides participants with a source of spurious familiarity for making know responses to lures. The model instantiates this by using Equation 6. In this equation, the probability of a know response is limited by remember responses, which have precedence. Both sources of familiarity, the concept node and the specific context node, affect the probability of a know response, but their activations are not cumulative. The activation for one of the two nodes must exceed threshold in order for a know response to occur. The calculation of know responses from the specific context node is important in font fan experiments because the specific context nodes that represent high-fan fonts are more strongly activated than those representing low-fan fonts. Thus, there are more know responses to words presented in high-fan fonts than to those presented in low-fan fonts.
Summary of the fan effect
The font fan mirror effect is easily accounted for within the SAC model, which assumes that increasing the number of associations to a node, such as a high-fan font, decreases the amount of activation that will spread from that node to an episode, thus making recollection more difficult to achieve. Single-process models may account for this effect, using the same explanation as a list length effect, where the list of items associated with each high-fan font is longer than that associated with each low-fan font.
Associative Recognition and Plurality Recognition
There are two sets of effects that are widely believed, even by some single-process theorists, to include some type of recollection component. We will give a brief summary of these effects, in order to show how the SAC model accounts for data from these paradigms.
Associative recognition
In associative recognition tasks, participants study pairs of words and are tested on intact pairs, as well as on rearranged pairs, both members of which were previously studied with different words. The participants are required to respond old to intact pairs and new to rearranged pairs. The familiarity of the elements of both types of pairs at test should be approximately equal, because all the words have been studied previously. Therefore, discrimination between intact and rearranged pairs is thought to require the retrieval of the binding between the two component words or retrieval of a representation that chunks the two component words, if it was created at study. However, it is important to demonstrate through experimental techniques that recollection is actually used by participants.
If associative recognition relies primarily on recollection, with familiarity being ineffective, the time course of recognition should reflect this. As was discussed earlier, familiarity-based judgments can be made earlier than recollection-based judgments. Gronlund and Ratcliff (1989) used a response lag procedure, in which participants were required to respond immediately upon presentation of a cue, which was presented varying amounts of time after the probe item. They found that old and new single words could be successfully discriminated after 350 msec, whereas intact and rearranged pairs of words could not be discriminated until after 570 msec. In other words, associative tasks can be successfully completed only later than single-item recognition tasks, which can be completed on the basis of familiarity. Rotello and Heit (2000) also demonstrated that discrimination between intact and rearranged pairs increases as retrieval duration increases.
Associative recognition resulted in more remember responses and fewer know responses than did item recognition (Hockley & Consoli, 1999). In addition, the remember responses were highly accurate, whereas the know responses were at chance. This indicates that familiarity may not be an effective process in associative recognition. ERP studies have shown that brain activity during associative recognition produces the components that have previously been linked to recollection (D. I. Donaldson & Rugg, 1998, 1999).
Given the evidence from remember/know, ERP, and time course studies, it seems evident that a recollection process is involved in associative recognition. Single-process models would need to include a recollection process in order to explain the data from these studies. Here, we will illustrate how the SAC model's recollection process accounts for associative recognition performance.
SAC model of associative recognition
In the SAC model, pairs of words in an associative recognition task are represented as separate concept nodes that are linked together by an episode node. Distinguishing old pairs from rearranged pairs at test requires the participant to retrieve the episode node that represents that the two words were seen together at study. Each concept node corresponding to a studied word spreads activation to the linked episode node. If the two presented words were studied together, their activation will converge on the same episode node. When a pair is rearranged, the two concept nodes send activation to different episode nodes. If one of these two episode nodes is retrieved (having sufficient activation to get over threshold), the participant may be able to recall the original pairing of the word and reject the rearranged pair on that basis (this is often called recall to reject). If an episode node is not retrieved, the participant may generate a know response on the basis of the familiarity of the two words in the rearranged pairs. Note that it is more difficult to retrieve either of the episode nodes from rearranged pairs, because less activation will accrue at the individual episode nodes. This is because there is only one source of activation, as opposed to two when an intact pair is presented.
The simulation results presented in Figure 6 were achieved using the parameter values in Table 1, except for the episode and concept node thresholds. For this paradigm, it was necessary to double the ordinary thresholds for recognition, because each trial involved the presentation of two words and, thus, twice the activation was available. We think it is reasonable to assume that participants would adjust their thresholds to maintain responding at an appropriate level. If the thresholds are left at 40 and 60 for the episode and concept nodes, the model produces hit and false alarm rates of approximately 95% each. With the thresholds adjusted for the increase in activation in the system, the pattern closely resembles that of a typical associative memory experiment (e.g., Hockley & Consoli, 1999).
Figure 6.

SAC simulation of associative memory performance: Mean proportion of hits and false alarms, as remember and know judgments, to intact/old pairs and rearranged pairs.
One additional issue that has been explored in the associative recognition literature is whether item recognition and associative recognition are based on fundamentally different types of information (e.g., Clark & Shiffrin, 1992; Criss & Shiffrin, 2005; Hockley & Cristi, 1996). The effects in this literature fit nicely with the SAC account of associative recognition, because this account claims that associative recognition is based on an episode node that represents the binding of two words into a single representation, whereas item recognition can be based on either an episodic binding or the activation of a single concept node. In this way, the SAC model can account for findings that the encoding and retrieval of associative information are fundamentally different from those for item information.
Reversed-plurality lures
Plurality recognition is a simple item recognition task in which the lure items comprise new words, as well as studied words in reversed-plurality form (Hintzman & Curran, 1994). For instance, if frogs was studied, frog might be a lure item. The familiarity of reversed-plurality lures should be very similar to the familiarity of the study item, thus requiring recollection of the study event to determine the exact form of the word that was seen previously. This assumption is supported by the finding that there are more know responses to similar foils than to target items in a reversed-plurality task (Park et al., 2005).9 Also, ERP evidence shows that the FN400, which reflects brain activity that is thought to be a correlate of familiarity-based processing, does not distinguish between old items and reversed-plurality items, indicating that familiarity is the same for both types of items (Curran, 2000; Curran & Cleary, 2003).
A recent exploration of the reversed-plurality lure recognition task led some single-process theorists to conclude that a recollection process was required to account for the data, using the REM model (Malmberg, Holden, & Shiffrin, 2004). The authors found that when similar foils are used, the dual-process model provides a better fit to the data. We will now present a simulation of plurality recognition data, using the SAC model that demonstrates one way in which recollection can be used to discriminate between old items and similar lures.
SAC model of plurality recognition
Similar to associative recognition, successful discrimination of old words from reversed-plurality lures in the SAC model requires participants to retrieve the episode node that binds a conceptual representation of the word presented with a node representing whether or not the word was in its plural form. We treat this plurality node much like a specific context node in a font-matching experiment (see Park et al., 2005; Reder et al., 2002). An assumption of the SAC model's representation is that a concept represents the features that are associated with it. Not all features of a concept need to be activated for the concept to pass threshold and be recognized. Plurality is a feature that may not typically be encoded during study, unless the participant has some reason to think that it is important. When attention is called to the importance of plurality at study, participants will try to encode plurality information as an elaboration. We assume that plurality information is not likely to be encoded when participants are not aware that it will be varied at test, because the plurality of a word is not highly salient in this type of task (Park et al., 2005).
It is important to note that the plural and singular nodes would be connected to a large number (half of the study items) of episode nodes and, thus, would spread only a small fraction of their activation to any given episode node from the study phase of the experiment. Therefore, the plurality node contributes little additional activation to facilitate the retrieving of the episode node (for other types of context that are more experiment unique, a larger contribution would be expected) but will be consciously available when the participant is able to retrieve the episode node and spread activation from the episode node back to the plurality node. A schematic representation of the relationships between the nodes in this type of task is illustrated in Figure 7. The link between the plurality node and the episode node is dashed, in order to indicate that this link is not always formed during study.
Figure 7.

Schematic representation of memory traces following the study phase of a reversed-plurality lure experiment.
The instantiation of this in the SAC model (Figure 8A) was accomplished by including a parameter to represent the probability that a link forms between the plurality information and the episode node. For the purposes of this simulation, the probability of forming a link from the plurality node to the episode node was allowed to vary, in order to find the best fit value with regard to Arndt and Reder's (2002) data. The resulting probability was .5. Therefore, the activation from the plurality node contributed only 50% of the time and recall to reject could be used only when the plurality link was formed. The probability of an old response to a similar foil was based on the following equation:
| (7) |
so that false alarms to similar foils resulted from the likelihood of a remember response, minus the probability of a recollection given that a link existed to the plurality node and, thus, recall to reject could occur, plus the probability of a familiarity-based know response when a remember response did not occur. Using this technique, the pattern of data closely matches what would be expected for midrange word frequency on the basis of Arndt and Reder's data. We can also model the word frequency data from Arndt and Reder using the same technique. This simulation is shown in Figure 8B. In the word frequency manipulation, the probability of forming a link from the episode node to the plurality information was set at .5, on the basis of the parameter value used in the previous model. All additional parameter values were the same as those reported in Table 1. Also, this account fits with Park et al.'s (2005) findings that participants sometimes make erroneous remember responses to similar lures. This would occur when the participants can retrieve the episodic information but plurality information was not linked to episodic information.
Figure 8.
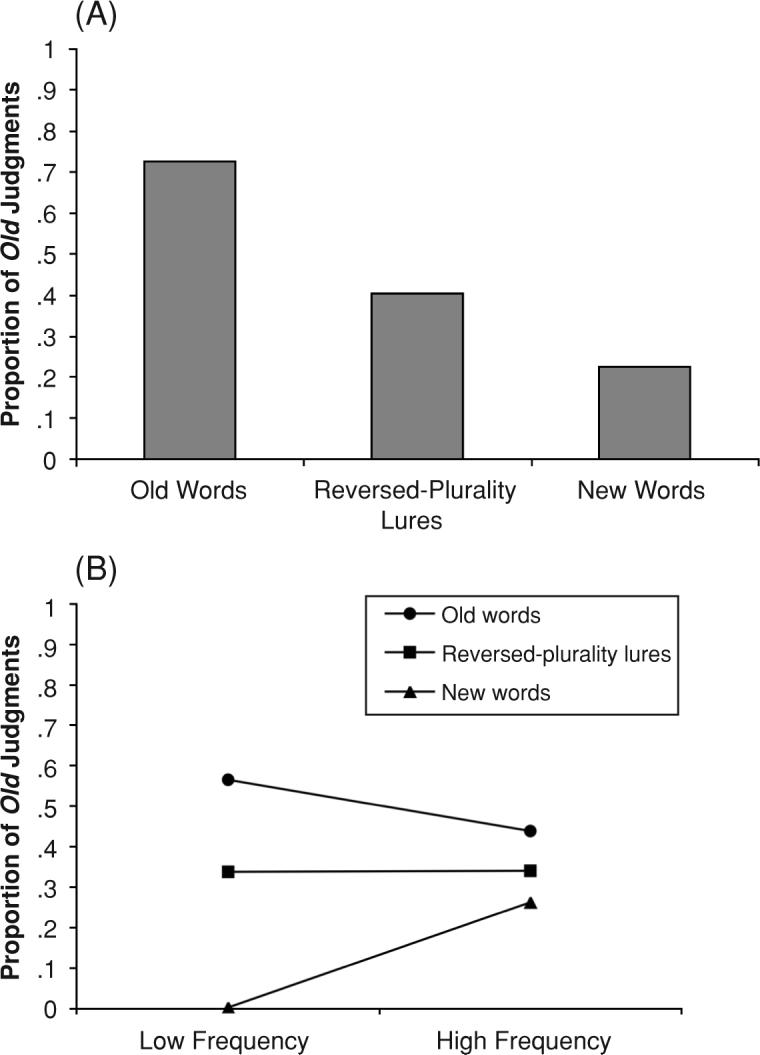
SAC simulation of performance on a recognition test using reversed-plurality lures: Mean proportion of hits and false alarms for old words, reversed-plurality lures, and new words. (A) Fit to interpolated mid-range word frequency data. (B) Fit to low-frequency and high-frequency word data.
Summary of associative and plurality recognition
We conclude that both associative and reversed-plurality lure recognition involve recollection processes. Recent single-process models (McClelland & Chappell, 1998; Shiffrin & Steyvers, 1997) cannot account for the findings of associative and plurality recognition without positing the use of a recollection process, in addition to the standard mechanisms of the familiarity-based model. Dual-process models can easily account for the data described in this section with the use of a recollection process that is assumed to be an inherent property of recognition memory.
Summary of Evidence for Dual-Process Models
The body of data on the mirror effect requires that single-process models must claim that storage is noisier when the mirror effect does not occur. The two separate processes proposed in dual-process models explain the mirror effect, because the hit and false alarm effects are products of different processes. Associative and plurality recognition must use some recollection to be accurate, and direct tests of the involvement of recollection have supported this conclusion. Finally, reaction time data show that recollection and familiarity have different time courses, not all of which are consistent with the single-process view.
In addition to these effects, dual-process theory can account for a number of effects that discriminate less clearly between single- and dual-process models. Research in which various cognitive neuroscience methodologies have been used supports the proposal of two processes in recognition (reviewed by Rugg & Yonelinas, 2003). The SAC model can also account for the list length effect (Cary & Reder, 2003) and the small recollection list strength effect (Diana & Reder, in press; Norman, 2002). It also naturally accounts for fan effect data. The ability of dual-process theories, and the SAC model in particular, to account for the relevant evidence in recognition memory research argues strongly that this account accurately represents the processes that occur during recognition.
The Issue of Parsimony
A classic argument against dual-process models has been one of parsimony. If two models explain the same range of data equally well, the simpler model should be preferred. Of course, if the more complicated model is required to explain the range of data, we must prefer that model. The important point is that parsimony is only an “all things being equal” factor, and we think that the data presented here demonstrate an inequality in favor of dual-process theory. Even if one allows the assumption that the two explanations are equally effective in explaining the data, we contend that the explanation that recollection is used in recognition is, in fact, more parsimonious.
The evidence that recollection is involved in associative and plurality recognition has been strong for some time. This has led some theorists to argue that, although it is likely that recollection can be used in recognition, it is not, in fact, used under normal recognition conditions (Finnigan, Humphreys, Dennis, & Geffen, 2002; Malmberg, Zeelenberg, & Shiffrin, 2002). In fact, it was recently shown that a recollection process must be added to REM in order to account for discrimination of reversed-plurality lures. The authors concluded that “recognition performance will be increasingly influenced by the outcome of a recall-like process to the extent that targets and foils are similar and the features that distinguish them are known” (Malmberg, Holden, & Shiffrin, 2004, p. 330). The argument that recollection is used only under special conditions is difficult to differentiate from our claim that recollection is an integral process in recognition. How can we determine what the standard conditions are for recognition? It seems likely that if a recollection process is available and, in fact, more accurate for use in some tasks, participants are likely to use this process even when the similarity of the lures does not strictly require it. If the possibility for recollection exists, complete theories of recognition must explain it and must explain why it would not be used in some tasks, although it provides accurate information in other tasks.
The dual-process approach to the recollection process says that recollection is always an available process. Responses will be based on this process whenever one is able to retrieve contextual information that has been bound to the relevant episodic information. The claim that recollection is used only during associative recognition or item recognition that includes reversed-plurality lures is more complex than the claim that the process is always available. This is particularly true in the absence of a principled explanation for why recollection would not be used during simple recognition tasks.
A second point arguing for greater simplicity in dual-process models as currently implemented is that single-process models now include some assumptions that complicate the models beyond a single familiarity dimension. Dual-process models are able to explain the relevant effects primarily by virtue of including a second process in recognition, whereas single-process models must posit mechanisms in addition to familiarity. For example, in order to explain the pattern of word frequency mirror effects in which the effect occurs in certain situations and not in others, an assumption has been added to REM that storage must be noisier in conditions in which the hit rate portion of the mirror effect does not occur, although the false alarm portion remains. This seems like a difficult assumption to test empirically, but until such empirical evidence exists, this claim could be seen as a hindrance to the parsimony of REM. The increasing complexity being added to single-process models in order to account for the data in the literature, in the form of both further assumptions and selective use of the recollection process, leads us to conclude that the parsimony advantage does not necessarily belong to single-process theories.
Challenges to the SAC Model
There are two issues in the current recognition memory literature that provide challenges to the SAC model: ROC curves and remember false alarms. ROC curves demonstrate the relationship between hits and false alarms at a variety of levels of participant confidence. When the probabilities of hits and false alarms are transformed into z-coordinates, a z-ROC curve is produced. Predictions for the shape of the ROC curve can be derived from a model's proposals regarding participants' decision processes. Most single-process models that assume that recognition decisions are made by placing decision criteria along a continuous axis predict a linear z-ROC. Recent models predict that the slope of the z-ROC will be less than 1.0 (e.g., McClelland & Chappell, 1998; Shiffrin & Steyvers, 1997). Yonelinas's (1994) dual-process model states that recognition is based on a continuous familiarity process, as well as on a high-threshold recollection process. This type of model predicts an approximately linear z-ROC curve, with a concavity at the lower end that reflects the contribution of recollection.
The ROC data are moderately challenging for the SAC model, which uses a continuous activation function for both recollection and familiarity. Judgments are then made according to thresholds for each process. As has been described by Arndt and Reder (2002), a dual-threshold model predicts a linear ROC curve. Current attempts to use the SAC model to model ROC data involve fitting each confidence category, using successively more lenient thresholds for both episode and concept nodes. These fits reveal a deficiency in fitting the highest threshold conditions. This deficiency may be corrected to some degree by the addition of remember false alarms to the SAC model, as will be described in the following paragraphs. The shape of ROC curves are currently best fit by the unequal-variance signal detection model (Heathcote, 2003), although Yonelinas's (1994) model also provides a good fit by describing familiarity as a continuous process and recollection as a discrete process. Wixted and Stretch (2004) have shown that the unequal-variance signal detection model is compatible with a dual-process model when recollection and familiarity are combined to form the single dimension on which the detection model is based.
A second issue that the SAC model must deal with is the increasing evidence that remember false alarms occur and are important in understanding the remember/know paradigm. The SAC model already predicts that know hits and false alarms will be correlated, because both responses are made on the basis of the activation of the concept node. A class of words that are more familiar will produce both more know hits and more know false alarms. However, recent research has shown that remember false alarms are correlated with remember hits and are both more confident and faster than know false alarms (Wixted & Stretch, 2004). Previous SAC models have assumed that remember false alarms are due to noise, such as responding errors, but it is becoming increasingly clear that the number of remember false alarms is higher than would be expected from noise. Also, given the confidence rating and reaction time evidence that remember false alarms are different from other false alarms, there must be something else causing these responses.
We have therefore altered our position on remember false alarms to say that these responses are due to false recollections. In order to achieve a recollection, the SAC model requires that activation accrue at an episode node from other nodes, such as the concept node and the experimental context node. In the case of a remember false alarm, activation would not be spreading from a concept node to an episode node, because the word presented on the screen was not presented at study and would not be connected to an episode node. However, activation could spread from features of the test probe that match features of the studied items and intersect with the experimental context node at an incorrect episode node (i.e., an episode node connected to one of the concepts from the studied words). This would be particularly likely to occur in experiments in which context is manipulated to be highly familiar in some conditions, such as font manipulations. For example, if a word presented in a highly familiar font were a lure, enough activation could spread from that font node to episode nodes associated with other target items. There would also be experimental context activation spreading to all of the episode nodes associated with the experiment. A remember false alarm would require us to assume that contextual activation was strong enough to activate the episode node binding contextual information with a target word. Presumably, the participants would then respond on the basis of the activation of the episode node, without confirming that the information about context that they were retrieving was actually associated with the lure word. Therefore, the remember false alarms are related to the degree of familiarity of contextual features of the lure word, as well as the likelihood that the participants will attempt to confirm that the retrieval is based on the word presented on the screen.
This account would explain Wixted and Stretch's (2004) finding that remember false alarms are both more confident and faster than know false alarms. First, because participants believe that they have made a recollection (albeit spurious), they will respond quickly, rather than proceeding to assess familiarity. This fits with the fact that remember hits are typically faster than know hits. Also, remember false alarms would be based on the spreading of a similar amount of activation to an incorrect episode node as would be spread to a correct episode node for a remember hit. We can also now explain why Wixted and Stretch found a correlation between know false alarms and remember false alarms. Know false alarms can be based on spurious activation of specific context nodes that are not related to the word being presented on the test trial. This is the same source of information as the one that can cause remember false alarms. Although we are developing an account of remember false alarms, the specifics of the implementation are still under development. Thus, remember false alarms remain a challenge for the SAC model, pending further evidence.
Interestingly, the SAC model does instantiate a combination of familiarity information and recollection information responses, as Wixted and Stretch (2004) suggested may occur. This occurs in the SAC model in the sense that the familiarity of a concept is represented as activation of that concept and the activation of the concept node is what spreads to activate the associated episode node and produces a recollection response (modulated by the strength of the link and the fan of the concept node). That is, the more familiar a concept, the more likely that the associated episode node (if created) will be retrievable and that a recollection response will occur.
The primary difference between the SAC model and other recent dual-process models of recognition memory is that the SAC model is a process model, whereas others (Rotello et al., 2004; Wixted & Stretch, 2004; Yonelinas, 1994) are largely mathematical. That is, the SAC model attempts to postulate mechanisms behind effects in recognition, rather than providing specifically a mathematical analysis of those effects. Although we find mathematical models useful, we think that a description of process provides valuable information for understanding behavior and leads to more predictions, so that the model can be tested. However, it is important to note that these other models provide insight into how a dual-process model can address the two challenges described above. In particular, Wixted and Stretch's model proposes that the single dimension along which signal detection occurs could be based on a combination of the recognition evidence from recollection and familiarity assessments. Therefore, recognition would be less a result of two processes than the analysis of two sources of evidence. This account can easily explain Wixted and Stretch's recent findings regarding remember false alarms. Rotello and colleagues (Rotello et al., 2004) have proposed the STREAK model of recognition that accounts for ROC findings and, due to its signal detection properties, would likely have no trouble explaining the remember false alarm findings. Finally, Yonelinas's (1994) model also accounts nicely for ROC effects.
Conclusions
We have presented evidence from a number of areas to support the argument that a recollection process is involved in recognition memory. We claim that models of recognition memory must include a recollection process, in addition to familiarity, in order to explain the range of findings in recognition memory. This claim is not based on any single piece of evidence that was presented here but, rather, on the body of evidence that converges to compel a dual-process explanation.
We do not claim that any dual-process model currently exists that can completely account for the range of data on its own, although the SAC model does account for many effects in the literature. Instead, we argue that dual-process models as a class provide better explanations of the range of recognition results. Recollection exists, is used in many situations, and must be included in comprehensive models of recognition. However, dual-process theories can benefit from the example of single-process theories. Single-process models were initially extremely successful at accounting for data and were widely popular in the literature because they are often well specified. A formal model can be more easily interpreted and make clearer predictions than can a verbal or nonprocess model. Dual-process theorists should follow the lead of single-process theorists in order to more efficiently test ideas. The SAC model is one example of a model that has been implemented formally and, thus, can be easily tested and applied to a range of experimental results.
Finally, because we contend that recollection is a process available for use in recognition tasks of all types and that participants will rely on it for recognition that is more accurate than that from familiarity processes, we think that future research in recognition would benefit from analyzing how recollection contributes and how this affects behavior. In this way, we can learn in more detail how recollection and familiarity information interact in recognition and what this means for memory in general.
Acknowledgments
This work was supported by Grant 2-R01-MH52808 from the National Institute of Mental Health. R.A.D. was supported by an NSF graduate fellowship and NIMH Training Grant 5 T32 MH019983. Partial support was provided by the Center for the Neural Basis of Cognition at Carnegie Mellon University and the University of Pittsburgh. We thank Michael Erickson, Amy Criss, and Phil Pavlik for comments on the manuscript. We also thank Doug Nelson, John Wixted, and Steve Joordens for their thoughtful reviews.
Footnotes
There are other approaches that are single-process ones but do not really fall into either of the categories being compared here. A notable instance is the ACT–R theory of Anderson (e.g., Anderson, Bothell, Lebiere, & Matessa, 1998). In that cognitive architecture, all recognition is assumed to be retrieval, whereas the single process discussed here is familiarity.
We will restrict our discussion to recent single-process theories that are sufficiently well specified and provide accounts across a wide range of phenomena. (For example, we will not discuss classic global matching models, because it is generally accepted that they do not provide a sufficient account of the mirror effect.)
Thanks to Doug Nelson for drawing these concerns to our attention.
There are certainly other relationships between remember and know responses that can be found, such as a decrease in know responses with no change in remember responses (Gregg & Gardiner, 1994) or an increase in both remember and know responses (Gardiner et al., 1996).
Other discussions of how to handle the question of independence in dual-process models are found in Joordens and Merikle (1993) and Jones (1987).
The SAC equations were adapted from ACT–R (Anderson & Lebiere, 1998) but are not identical in form or assumptions.
The effect of the activation from the specific context node on the probability of making a know response is important when the specific context can be varied between study and test (see Diana, Peterson, & Reder, 2004, for more details).
See the Associative Recognition and Plurality Recognition section for more data from this paradigm.
Target items receive more remember responses. The finding of more know responses to similar foils than to targets, instead of comparable numbers, may indicate that some familiar target items are recollected, thus reducing the number of know responses.
Contributor Information
JASON ARNDT, Middlebury College, Middlebury, Vermont.
HEEKYEONG PARK, University of California, Irvine, California.
REFERENCES
- Anderson JR. Retrieval of propositional information from long-term memory. Cognitive Psychology. 1974;6:451–474. [Google Scholar]
- Anderson JR, Bothell D, Lebiere C, Matessa M. An integrated theory of list memory. Journal of Memory & Language. 1998;38:341–380. [Google Scholar]
- Anderson JR, Lebiere C. The atomic components of thought. Erlbaum; Mahwah, NJ: 1998. [Google Scholar]
- Arndt J, Reder LM. Word frequency and receiver-operating characteristic curves in recognition memory: Evidence for a dual-process interpretation. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2002;28:830–842. doi: 10.1037//0278-7393.28.5.830. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Balota DA, Burgess GC, Cortese MJ, Adams DR. The word-frequency mirror effect in young, old, and early-stage Alzheimer's disease: Evidence for two processes in episodic recognition performance. Journal of Memory & Language. 2002;46:199–226. [Google Scholar]
- Balota DA, Ferraro FR. Lexical, sublexical, and implicit memory processes in healthy young and healthy older adults and in individuals with dementia of the Alzheimer type. Neuropsychology. 1996;10:82–95. [Google Scholar]
- Boldini A, Russo R, Avons SE. One process is not enough! A speed–accuracy tradeoff study of recognition memory. Psychonomic Bulletin & Review. 2004;11:353–361. doi: 10.3758/bf03196582. [DOI] [PubMed] [Google Scholar]
- Brockdorff N, Lamberts K. A feature-sampling account of the time course of old–new recognition judgments. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2000;26:77–102. doi: 10.1037//0278-7393.26.1.77. [DOI] [PubMed] [Google Scholar]
- Cary M, Reder LM. A dual-process account of the list-length and strength-based mirror effects in recognition. Journal of Memory & Language. 2003;49:231–248. [Google Scholar]
- Clark SE, Shiffrin RM. Cuing effects and associative information in recognition memory. Memory & Cognition. 1992;20:580–598. doi: 10.3758/bf03199590. [DOI] [PubMed] [Google Scholar]
- Criss AH, Shiffrin RM. Interactions between study task, study time, and the low-frequency hit rate advantage in recognition memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2004;30:778–786. doi: 10.1037/0278-7393.30.4.778. [DOI] [PubMed] [Google Scholar]
- Criss AH, Shiffrin RM. List discrimination in associative recognition and implications for representation. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2005;31:1199–1212. doi: 10.1037/0278-7393.31.6.1199. [DOI] [PubMed] [Google Scholar]
- Curran T. Brain potentials of recollection and familiarity. Memory & Cognition. 2000;28:923–938. doi: 10.3758/bf03209340. [DOI] [PubMed] [Google Scholar]
- Curran T, Cleary AM. Using ERPs to dissociate recollection from familiarity in picture recognition. Cognitive Brain Research. 2003;15:191–205. doi: 10.1016/s0926-6410(02)00192-1. [DOI] [PubMed] [Google Scholar]
- Dewhurst SA, Conway MA. Pictures, images, and recollective experience. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1994;20:1088–1098. doi: 10.1037//0278-7393.20.5.1088. [DOI] [PubMed] [Google Scholar]
- Dewhurst SA, Hitch GJ. Cognitive operations and recollective experience in recognition memory. Memory. 1999;7:129–146. doi: 10.1080/741944067. [DOI] [PubMed] [Google Scholar]
- Diana RA, Peterson MJ, Reder LM. The role of spurious feature familiarity in recognition memory. Psychonomic Bulletin & Review. 2004;11:150–156. doi: 10.3758/bf03206475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diana RD, Reder LM. The list strength effect: A contextual competition account. Memory & Cognition. 7:1289–1302. doi: 10.3758/bf03193229. (in press) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donaldson DI, Rugg MD. Recognition memory for new associations: Electrophysiological evidence for the role of recollection. Neuropsychologia. 1998;36:377–395. doi: 10.1016/s0028-3932(97)00143-7. [DOI] [PubMed] [Google Scholar]
- Donaldson DI, Rugg MD. Event-related potential studies of associative recognition and recall: Electrophysiological evidence for context dependent retrieval processes. Cognitive Brain Research. 1999;8:1–16. doi: 10.1016/s0926-6410(98)00051-2. [DOI] [PubMed] [Google Scholar]
- Donaldson W. The role of decision processes in remembering and knowing. Memory & Cognition. 1996;24:523–533. doi: 10.3758/bf03200940. [DOI] [PubMed] [Google Scholar]
- Donaldson W, MacKenzie TM, Underhill CF. A comparison of recollective memory and source monitoring. Psychonomic Bulletin & Review. 1996;3:486–490. doi: 10.3758/BF03214551. [DOI] [PubMed] [Google Scholar]
- Dosher BA. Degree of learning and retrieval speed: Study time and multiple exposures. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1984;10:541–574. [Google Scholar]
- Dosher BA, Rosedale G. Judgments of semantic and episodic relatedness: Common time-course and failure of segregation. Journal of Memory & Language. 1991;30:125–160. [Google Scholar]
- Dunn JC. Remember–know: A matter of confidence. Psychological Review. 2004;111:524–542. doi: 10.1037/0033-295X.111.2.524. [DOI] [PubMed] [Google Scholar]
- Finnigan S, Humphreys MS, Dennis S, Geffen G. ERP “old/new” effects: Memory strength and decisional factor(s). Neuropsychologia. 2002;40:2288–2304. doi: 10.1016/s0028-3932(02)00113-6. [DOI] [PubMed] [Google Scholar]
- Gardiner JM. Functional aspects of recollective experience. Memory & Cognition. 1988;16:309–313. doi: 10.3758/bf03197041. [DOI] [PubMed] [Google Scholar]
- Gardiner JM, Gawlik B, Richardson-Klavehn A. Maintenance rehearsal affects knowing, not remembering; elaborative rehearsal affects remembering, not knowing. Psychonomic Bulletin & Review. 1994;1:107–110. doi: 10.3758/BF03200764. [DOI] [PubMed] [Google Scholar]
- Gardiner JM, Java RI. Recollective experience in word and nonword recognition. Memory & Cognition. 1990;18:23–30. doi: 10.3758/bf03202642. [DOI] [PubMed] [Google Scholar]
- Gardiner JM, Java RI. Forgetting in recognition memory with and without recollective experience. Memory & Cognition. 1991;19:617–623. doi: 10.3758/bf03197157. [DOI] [PubMed] [Google Scholar]
- Gardiner JM, Kaminska Z, Dixon M, Java RI. Repetition of previously novel melodies sometimes increases both remember and know responses in recognition memory. Psychonomic Bulletin & Review. 1996;3:366–371. doi: 10.3758/BF03210762. [DOI] [PubMed] [Google Scholar]
- Gardiner JM, Richardson-Klavehn A. Remembering and knowing. In: Tulving E, Craik FIM, editors. The Oxford handbook of memory. Oxford University Press; Oxford: 2000. pp. 229–244. [Google Scholar]
- Gillund G, Shiffrin RM. A retrieval model for both recognition and recall. Psychological Review. 1984;91:1–67. [PubMed] [Google Scholar]
- Glanzer M, Adams JK. The mirror effect in recognition memory. Memory & Cognition. 1985;13:8–20. doi: 10.3758/bf03198438. [DOI] [PubMed] [Google Scholar]
- Glanzer M, Bowles N. Analysis of the word-frequency effect in recognition memory. Journal of Experimental Psychology: Human Learning & Memory. 1976;2:21–31. [Google Scholar]
- Gorman AM. Recognition memory for nouns as a function of abstractness and frequency. Journal of Experimental Psychology. 1961;61:23–29. doi: 10.1037/h0040561. [DOI] [PubMed] [Google Scholar]
- Greene RL, Thapar A. Mirror effect in frequency discrimination. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1994;20:946–952. doi: 10.1037//0278-7393.20.4.946. [DOI] [PubMed] [Google Scholar]
- Gregg VH, Gardiner JM. Components of conscious awareness in a long-term modality effect. British Journal of Psychology. 1991;82:153–162. [Google Scholar]
- Gregg VH, Gardiner JH. Recognition memory and awareness: A large effect of study–test modalities on “know” responses following a highly perceptual orienting task. European Journal of Cognitive Psychology. 1994;6:131–147. [Google Scholar]
- Gronlund SD, Ratcliff R. Time course of item and associative information: Implications for global memory models. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1989;15:846–858. doi: 10.1037//0278-7393.15.5.846. [DOI] [PubMed] [Google Scholar]
- Heathcote A. Item recognition memory and the receiver operating characteristic. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2003;29:1210–1230. doi: 10.1037/0278-7393.29.6.1210. [DOI] [PubMed] [Google Scholar]
- Hintzman DL. Judgments of frequency and recognition memory in a multiple-trace memory model. Psychological Review. 1988;95:528–551. [Google Scholar]
- Hintzman DL, Caulton DA. Recognition memory and modality judgments: A comparison of retrieval dynamics. Journal of Memory & Language. 1997;37:1–23. [Google Scholar]
- Hintzman DL, Caulton DA, Curran T. Retrieval constraints and the mirror effect. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1994;20:275–289. [Google Scholar]
- Hintzman DL, Caulton DA, Levitin DJ. Retrieval dynamics in recognition and list discrimination: Further evidence of separate processes of familiarity and recall. Memory & Cognition. 1998;26:449–462. doi: 10.3758/bf03201155. [DOI] [PubMed] [Google Scholar]
- Hintzman DL, Curran T. Retrieval dynamics of recognition and frequency judgments: Evidence for separate processes of familiarity and recall. Journal of Memory & Language. 1994;33:1–18. [Google Scholar]
- Hirshman E, Arndt J. Discriminating alternative conceptions of false recognition: The cases of word concreteness and word frequency. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1997;23:1306–1323. [Google Scholar]
- Hirshman E, Fisher J, Henthorn T, Arndt J, Passannante A. Midazolam amnesia and dual-process models of the word-frequency mirror effect. Journal of Memory & Language. 2002;47:499–516. [Google Scholar]
- Hirshman E, Master S. Modeling the conscious correlates of recognition memory: Reflections on the remember–know paradigm. Memory & Cognition. 1997;25:345–351. doi: 10.3758/bf03211290. [DOI] [PubMed] [Google Scholar]
- Hockley WE. Reflections of the mirror effect for item and associative recognition. Memory & Cognition. 1994;22:713–722. doi: 10.3758/bf03209256. [DOI] [PubMed] [Google Scholar]
- Hockley WE, Consoli A. Familiarity and recollection in item and associative recognition. Memory & Cognition. 1999;27:657–664. doi: 10.3758/bf03211559. [DOI] [PubMed] [Google Scholar]
- Hockley WE, Cristi C. Tests of the separate retrieval of item and associative information using a frequency-judgment task. Memory & Cognition. 1996;24:796–811. doi: 10.3758/bf03201103. [DOI] [PubMed] [Google Scholar]
- Hoshino Y. A bias in favor of the positive response to high-frequency words in recognition memory. Memory & Cognition. 1991;19:607–616. doi: 10.3758/bf03197156. [DOI] [PubMed] [Google Scholar]
- Huppert FA, Piercy M. The role of trace strength in recency and frequency judgements by amnesic and control subjects. Quarterly Journal of Experimental Psychology. 1978;30:347–354. doi: 10.1080/14640747808400681. [DOI] [PubMed] [Google Scholar]
- Jacoby LL. A process dissociation framework: Separating automatic from intentional uses of memory. Journal of Memory & Language. 1991;30:513–541. [Google Scholar]
- Jones GV. Independence and exclusivity among psychological processes: Implications for the structure of recall. Psychological Review. 1987;94:229–235. [Google Scholar]
- Joordens S, Hockley WE. Recollection and familiarity through the looking glass: When old does not mirror new. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2000;26:1534–1555. doi: 10.1037//0278-7393.26.6.1534. [DOI] [PubMed] [Google Scholar]
- Joordens S, Merikle PM. Independence or redundancy? Two models of conscious and unconscious influences. Journal of Experimental Psychology: General. 1993;122:462–467. [Google Scholar]
- Kučera H, Francis WN. Computational analysis of present-day American English. Brown University Press; Providence, RI: 1967. [Google Scholar]
- Malmberg KJ, Holden JE, Shiffrin RM. Modeling the effects of repetitions, similarity, and normative word frequency on old–new recognition and judgments of frequency. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2004;30:319–331. doi: 10.1037/0278-7393.30.2.319. [DOI] [PubMed] [Google Scholar]
- Malmberg KJ, Zeelenberg R, Shiffrin RM. Turning up the noise or turning down the volume? On the nature of the impairment of episodic recognition memory by midazolam. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2004;30:540–549. doi: 10.1037/0278-7393.30.2.540. [DOI] [PubMed] [Google Scholar]
- Mandler G. Recognizing: The judgment of previous occurrence. Psychological Review. 1980;87:252–271. [Google Scholar]
- Mandler G, Boeck WJ. Retrieval processes in recognition. Memory & Cognition. 1974;2:613–615. doi: 10.3758/BF03198129. [DOI] [PubMed] [Google Scholar]
- McClelland JL, Chappell M. Familiarity breeds differentiation: A subjective-likelihood approach to the effects of experience in recognition memory. Psychological Review. 1998;105:724–760. doi: 10.1037/0033-295x.105.4.734-760. [DOI] [PubMed] [Google Scholar]
- McElree B, Dolan PO, Jacoby LL. Isolating the contributions of familiarity and source information to item recognition: A time course analysis. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1999;25:563–582. doi: 10.1037//0278-7393.25.3.563. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morrell HER, Gaitan S, Wixted JT. On the nature of the decision axis in signal-detection-based models of recognition memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2002;28:1095–1110. [PubMed] [Google Scholar]
- Murdock BB. A theory for the storage and retrieval of item and associative information. Psychological Review. 1982;89:609–626. doi: 10.1037/0033-295x.100.2.183. [DOI] [PubMed] [Google Scholar]
- Norman KA. Differential effects of list strength on recollection and familiarity. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2002;28:1083–1094. doi: 10.1037//0278-7393.28.6.1083. [DOI] [PubMed] [Google Scholar]
- Park H, Reder LM, Dickison D. The effects of word frequency and similarity on recognition judgments: The role of recollection. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2005;31:568–578. doi: 10.1037/0278-7393.31.3.568. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Quamme JR, Frederick C, Kroll NEA, Yonelinas AP, Dobbins IG. Recognition memory for source and occurrence: The importance of recollection. Memory & Cognition. 2002;30:893–907. doi: 10.3758/bf03195775. [DOI] [PubMed] [Google Scholar]
- Rajaram S. Remembering and knowing: Two means of access to the personal past. Memory & Cognition. 1993;21:89–102. doi: 10.3758/bf03211168. [DOI] [PubMed] [Google Scholar]
- Rajaram S. The effects of conceptual salience and perceptual distinctiveness on conscious recollection. Psychonomic Bulletin & Review. 1998;5:71–78. [Google Scholar]
- Rao KV, Proctor RW. Study-phase processing and the word frequency effect in recognition memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1984;10:386–394. [Google Scholar]
- Reder LM, Donavos DK, Erickson MA. Perceptual match effects in direct tests of memory: The role of contextual fan. Memory & Cognition. 2002;30:312–323. doi: 10.3758/bf03195292. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reder LM, Nhouyvanisvong A, Schunn CD, Ayers MS, Angstadt P, Hiraki K. A mechanistic account of the mirror effect for word frequency: A computational model of remember–know judgments in a continuous recognition paradigm. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2000;26:294–320. doi: 10.1037//0278-7393.26.2.294. [DOI] [PubMed] [Google Scholar]
- Rotello CM, Heit E. Associative recognition: A case of recall-to-reject processing. Memory & Cognition. 2000;28:907–922. doi: 10.3758/bf03209339. [DOI] [PubMed] [Google Scholar]
- Rotello CM, Macmillan NA, Reeder JA. Sum–difference theory of remembering and knowing: A two-dimensional signal detection model. Psychological Review. 2004;111:588–616. doi: 10.1037/0033-295X.111.3.588. [DOI] [PubMed] [Google Scholar]
- Rugg MD, Cox CJC, Doyle MC, Wells TC. Event-related potentials and the recollection of low and high frequency words. Neuropsychologia. 1995;33:471–484. doi: 10.1016/0028-3932(94)00132-9. [DOI] [PubMed] [Google Scholar]
- Rugg MD, Yonelinas AP. Human recognition memory: A cognitive neuroscience perspective. Trends in Cognitive Sciences. 2003;7:313–319. doi: 10.1016/s1364-6613(03)00131-1. [DOI] [PubMed] [Google Scholar]
- Schunn CD, Reder LM, Nhouyvanisvong A, Richards DR, Stroffolino PJ. To calculate or not to calculate: A source activation confusion model of problem familiarity's role in strategy selection. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1997;23:3–29. [Google Scholar]
- Shiffrin RM, Steyvers M. A model for recognition memory: REM—retrieving effectively from memory. Psychonomic Bulletin & Review. 1997;4:145–166. doi: 10.3758/BF03209391. [DOI] [PubMed] [Google Scholar]
- Stretch V, Wixted JT. On the difference between strength-based and frequency-based mirror effects in recognition memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1998;24:1379–1396. doi: 10.1037//0278-7393.24.6.1379. [DOI] [PubMed] [Google Scholar]
- Trott CT, Friedman D, Ritter W, Fabiani M, Snodgrass JG. Episodic priming and memory for temporal source: Event-related potentials reveal age-related differences in prefrontal functioning. Psychology & Aging. 1999;14:390–413. doi: 10.1037//0882-7974.14.3.390. [DOI] [PubMed] [Google Scholar]
- Tulving E. Memory and consciousness. Canadian Psychology. 1985;26:1–12. [Google Scholar]
- Wixted JT, Stretch V. In defense of the signal detection interpretation of remember/know judgments. Psychonomic Bulletin & Review. 2004;11:616–641. doi: 10.3758/bf03196616. [DOI] [PubMed] [Google Scholar]
- Yonelinas AP. Receiver-operating characteristics in recognition memory: Evidence for a dual-process model. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1994;20:1341–1354. doi: 10.1037//0278-7393.20.6.1341. [DOI] [PubMed] [Google Scholar]
- Yonelinas AP. The nature of recollection and familiarity: A review of 30 years of research. Journal of Memory & Language. 2002;46:441–517. [Google Scholar]
- Yonelinas AP, Jacoby LL. The relation between remembering and knowing as bases for recognition: Effects of size congruency. Journal of Memory & Language. 1995;34:622–643. [Google Scholar]