

Abstract
Motor control requires the generation of a precise temporal sequence of control signals sent to the skeletal musculature. We describe an experiment that, for good performance, requires human subjects to plan movements taking into account uncertainty in their movement duration and the increase in that uncertainty with increasing movement duration. We do this by rewarding movements performed within a specified time window, and penalizing slower movements in some conditions and faster movements in others. Our results indicate that subjects compensated for their natural duration-dependent temporal uncertainty as well as an overall increase in temporal uncertainty that was imposed experimentally. Their compensation for temporal uncertainty, both the natural duration-dependent and imposed overall components, was nearly optimal in the sense of maximizing expected gain in the task. The motor system is able to model its temporal uncertainty and compensate for that uncertainty so as to optimize the consequences of movement.
Author Summary
Many recent models of motor planning are based on the idea that the CNS plans movements to minimize “costs” intrinsic to motor performance. A minimum variance model would predict that the motor system plans movements that minimize motor error (as measured by the variance in movement) subject to the constraint that the movement be completed within a specified time limit. A complementary model would predict that the motor system minimizes movement time subject to the constraint that movement variance not exceed a certain fixed threshold. But neither of these models is adequate to predict performance in everyday tasks that include external costs imposed by the environment where good performance requires that the motor system select a tradeoff between speed and accuracy. In driving to the airport to catch a plane, for example, there are very real costs associated with driving too fast and also with being just a bit too late. But the “optimal” tradeoff depends on road conditions and also on how important it is to catch the plane. We examine motor performance in analogous experimental tasks where we impose arbitrary monetary costs on movements that are “late” or “early” and show that humans systematically trade off risk and reward so as to maximize their expected monetary gain.
Introduction
In the execution of any movement, there is always timing uncertainty. This uncertainty has two major consequences. First, it limits performance on any task for which there are costs associated with temporal imprecision. Second, it has implications for how the motor system should plan movements when the costs of temporal imprecision are asymmetric. In hurrying to catch a subway train, for example, the cost of arriving early is usually small compared to the cost of arriving late and missing the train. An optimal movement planner must take into account temporal reward asymmetries in forming movement plans.
The complexity of movement planning under risk is further increased because temporal uncertainty in the motor system changes constantly. Two major sources of variation in temporal uncertainty occur over different time courses and have different properties: One is a uniform, global shift in temporal uncertainty possibly due to aging, fatigue, injury or disease [1]–[9]. The second is a linear increase in the standard deviation of movement duration with increases in mean movement duration [10].
Here we use a model of optimal temporal movement planning to investigate the control of movement duration in the face of these two types of temporal uncertainty while human subjects attempted to touch a computer screen within a specified temporal window. We introduced asymmetries in the penalties imposed for early vs. late movement timing (Figure 1A), while at the same time increasing subjects' temporal uncertainty by adding Gaussian noise with 25 ms standard deviation (see Methods). As in all models of motor planning and motor control based on decision theory, we are concerned with the interplay of three elements: possible decisions (here planned movement time, τ), uncertainty in the mapping of motor decisions to motor outcomes (represented by the family of probability distributions p[t|τ]), and the costs/benefits resulting from those motor outcomes, G(t). The mathematical models considered here are part of a growing literature on Bayesian decision models of motor phenomena, such as models of motor adaptation [11]–[13] and motor planning/control e.g., [14]–[21], including the use of prior information in spatial [16],[18] and temporal [17] motor planning, the use of asymmetric cost functions in spatial motor planning [14]–[15],[19] and when selecting a speed-accuracy tradeoff [20]–[21]. The neural computation of decision variables such as those considered here and in previous work has also begun to be investigated [22]–[25].
Figure 1. Reward/Penalty Configurations and Expected Gain.

(A) Four reward/penalty configurations. The horizontal axis represents time (ms) and the color of each interval specified the reward the subject received if the reach time fell within that interval. Intervals that incurred penalties (−36 points) were coded red (also striped in the figure), those that earned reward (+12 points), green (also cross-hatched). The choice of times t 1,…,t 4 that defined the reward and penalty regions was defined based on each subject's movement duration variance (for a target duration of 650 ms) to equate task difficulty. (B) Expected gain calculation. Upper Panel: The Gaussian distribution of actual movement durations t for four choices of planned movement durations τ. The vertical dashed lines mark four possible planned movement durations. Standard deviations σ(τ) increase linearly with planned duration. Middle Panel: The gain G(t) associated with each actual movement duration t. Lower Panel: Expected gain EG(t) as a function of planned movement duration τ. Expected gain is determined by the probability that the actual movement duration falls into the reward or penalty regions. The maximum expected gain (MEG) and the corresponding planned movement duration τopt are indicated. (C) Schematic diagram showing the geometric relationship between the start position of the reach and the circular arc along which spatial reach targets were drawn. Reach distance was always 430 mm, regardless of the position of the target along the arc.
Figure 1B illustrates the computations needed to maximize expected gain with temporally asymmetric penalties. When discussing movement duration, we must distinguish between the planned arrival time, denoted τ, and the actual arrival time, t. When movements are executed, the actual arrival time will be unpredictably earlier or later than τ. In Figure 1B we show four possible choices of τ and outline the calculation of expected gain for each. Note that the optimal planned arrival time need not fall within the temporal reward window.
Human performance will be optimal if the CNS learns its linear temporal uncertainty function,
| (1) |
as it relates to planned movement time (τ), and uses this information (ασ and βσ) to plan reach times that maximize expected gain. Human performance in our task could be sub-optimal in several ways, each depending on the type of information the CNS maintains about Equation 1. We consider 5 such sub-optimal models, denoted M 1, …, M 5. In the first three of these, subjects fail to take account of ασ, βσ, or both when planning reaches. In model M 1, subjects fail to compensate for the experimentally imposed static increase in temporal uncertainty due to the added Gaussian noise (SD = 25 ms); in M 2 subjects fail to compensate for the linear increase in temporal uncertainty with increasing reach duration; and in M3 subjects fail in both respects (for details, see Methods: Data Analysis and Model Comparison). Models M 4 and M 5 were analogous to models M 2 and M 3, respectively, but assumed the offset or slope were unknown and hence not fixed to match the training data or added 25 ms timing uncertainty. We compare subjects' performance to each of these sub-optimal movement strategies, and to the optimal strategy (M 0) that results in maximum expected gain.
Results
Training
During training trials, subjects attempted to produce reaches with an experimenter-specified temporal duration; no rewards or penalties were imposed. In Figure 2A, we plot the mean movement duration as a function of the target duration for subject HT. The points lie near the identity line, indicating that the subject could accurately produce a wide range of movement times on command. Figure 2B shows the temporal uncertainty function (the standard deviation of arrival times as a function of target duration, with and without the added noise) measured during training for the same subject. As expected, unperturbed standard deviations (dot-dashed line, open symbols) increase linearly across this range. Estimated Weber-noise parameters (ασ) for all subjects' temporal uncertainty functions, and verification of the stationarity of those functions (across the training trials and the subsequent main experiment), are provided in Figure 3. Note that fitted functions obtained from training data (lines) and the standard deviations measured during main-experiment reaches (filled diamonds) were well-matched, consistent with the idea that subject performance did not change during the experimental reaches.
Figure 2. Data from the Training Trials for One Subject (HT).

(A) Mean observed time versus experimenter-specified target time with a line of slope = 1, intercept = 0 superimposed. (B) Temporal uncertainty σ(τ) is plotted as a function of planned movement duration τ for both noise-added (filled symbols, dashed line) and unperturbed (open symbols, fitted dash-dotted line) data. The estimated uncertainty σ 650 for a movement of planned duration 650 ms was used to equate the difficulty of the task across subjects. Subjects' fitted slopes (unperturbed) are provided in Figure 3.
Figure 3. Temporal Uncertainty Functions by Subject.

(A) Fitted slope values ασ±1 SE for temporal uncertainty functions calculated from training data. The corresponding intercepts (βσ) were −25, −19, −26, −31 and −10 ms, respectively. (B–F) Temporal uncertainty functions calculated from unperturbed training data (solid lines; the dotted lines represent±1 SE) with temporal uncertainty measured during each of the four experimental conditions (diamonds) overlaid.
Main Experiment
Each of the models makes predictions of reach durations that are based on the aspects of the temporal uncertainty function it incorporates. Because the optimal model (M 0) incorporates both components of the temporal uncertainty function, it can take account of the temporal noise actually experienced by each subject when planning reaches, in turn allowing it to predict optimal movement times. Three of the sub-optimal models (M 1–M 3) each specify only a portion of the actual temporal noise experienced by subjects. Because these models cannot account for the full temporal uncertainty function, their predicted ‘best’ movement times are sub-optimal. For each subject and model, we derived predictions of the mean duration in each of the four conditions that would maximize expected gain in the task given that temporal uncertainty function (see Methods: Model Predictions; Figure 4 illustrates these calculations for an example subject). These predictions allow us to compare observed performance in the task to the theoretical performance of subjects who maximize expected gain under the constraints imposed by each of the four models. In addition to these four models, we considered two sub-optimal models that did not have fixed parameters (M 4 and M 5). In models of this type, the model likelihood (see Method: Data Analysis and Model Comparison) is calculated by integrating over the possible values of the unknown parameters (e.g., overall noise level).
Figure 4. Expected Gain as a Function of Planned Movement Duration for One Subject (HT).

The expected gain EG(τ) for each possible planned movement duration is shown as a solid line. MEG points are marked as circles and observed mean durations are marked as diamonds. The four panels A–D correspond to the four conditions in Figure 1A. Reward and penalty regions are coded as in Figure 1A.
The results of a Bayesian comparison of the performance of the four models (see Methods: Data Analysis and Model Comparison) favored the optimal model M 0 over the sub-optimal models; yielding 11.5 dB in favor of M 0, but −60.5 dB, −11.5 dB and −41.4 dB of evidence for M 1, M 2 and M 3, respectively. Models M 4 and M 5 are less constrained, resulting in evidence below −100 dB. Negative evidence is evidence against a model relative to the other possible models. In our previous work [26] we have used 3 dB evidence, corresponding to odds of nearly 2∶1, as a minimal guideline for inferring an advantage for a model over its competitors. The 11.5 dB evidence for M 0 is strong, corresponding to nearly 15∶1 odds in favor of the optimal model over the set of alternatives.
To assess inter-subject variability, we recomputed the evidence values for 5 subgroups of subjects, with each subgroup consisting of all subjects but one. The change in evidence that occurred as we left each subject out is a measure of how much the conclusions we draw are based on one subject alone. While the evidence decreases somewhat when each subject is removed (and it should since we are basing our conclusion on fewer data), it always favored M 0, and always by at least 7.5 dB, consistent with the conclusions based on all subjects taken together. We note, in particular, that removing the non-naive subject who was an author (TEH) still resulted in evidence of 9 dB in favor of M 0.
In addition, we plotted, for all subjects and conditions, the mean observed movement duration as a function of the duration predicted by each of the four models (Figure 5 plots the deviations of the actual from the predicted movement times). In such a plot, consistency of the data with the model corresponds to the data falling along the identity line. We computed linear regressions of observed mean duration as a function of predicted mean duration for each of the four models. Only M 0 had a best-fit slope and intercept whose confidence intervals contained those of the identity line (Table 1), corroborating the result of the Bayesian model comparison. We conclude that the evidence favoring M 0 over any of the competing models is overwhelming, implying that subjects compensated for their increased uncertainty at longer durations and also for the 25 ms added uncertainty imposed experimentally.
Figure 5. Residuals.

Residual differences between mean movement duration and model predictions under the assumptions of each of the four models (M 0–M 3). Data from HT, as described in Figure 4, are plotted as diamonds.
Table 1. Linear Fits of tobs to topt and 95% Confidence Bounds.
| Model | αt | βt |
| M0 | 0.94, [0.85:1.03] | 41 ms, [−20:101] |
| M1 | 1.34, [1.18:1.49] | −223 ms, [−325: −124] |
| M2 | 0.89, [0.81:0.97] | 71 ms, [17:123] |
| M3 | 1.2, [1.05:1.35] | −143 ms, [−243: −46] |
Confidence intervals in bold span the relevant parameter value of an identity line.
To investigate how the suboptimal models fail, we present differences between observed average temporal endpoints and model predictions for each of the four models (Figure 5). For each of the sub-optimal models, we describe how the pattern would appear if data were fit with that model.
Model M 1 compensates for increased temporal uncertainty with increased movement duration but fails to compensate for the σ = 25 ms temporal noise added experimentally. Subjects conforming to this model will have temporal aim points closer to the center of the target region than they should be since they are based on an erroneously small estimate of temporal uncertainty. That is, compared with the optimal model (M 0), model M 1 predicts longer durations for predictions of durations shorter than the target duration (650 ms), and shorter durations for predictions longer than the target duration. Thus, we predict the left-hand cloud of residuals to move down and right and the right-hand cloud to move up and left, which is precisely what happened (upper-right panel, Figure 5).
Subjects employing model M 2 (lower-left panel, Figure 5) would fail to take duration-dependent noise into account, but compensate for the s = 25 ms temporal noise added experimentally. Such subjects overestimate noise for short durations and underestimate it for long durations. Intuitively, the residuals should move up and left. This is true of most data points, but not all. The intuitive pattern is occasionally broken due to the complex, nonlinear calculation of expected gain (Figure 1B) and the switch from the veridical uncertainty function (M 0) to an incorrect, flat function (M 2). As expected, the predictions of M 3 combine the shifts of the other two suboptimal models.
In summary, based on the comparison of the optimal and three suboptimal models, we conclude that subjects delayed or advanced their temporal endpoints in accordance with the calculated optimal times defined by M 0. The Bayesian model comparison employed is novel and correct for comparison of non-nested models (see Method: Data Analysis and Model Comparison). We also carried out a set of statistical tests based on linear regression of actual versus predicted times. The conclusions based on these regressions tests are identical to those just reported: we reject models M 1, M 2 and M 3 but not M 0 (Table 1).
The gains earned by subjects potentially provide an additional dimension for testing the models. We have compared actual gains to expected gains predicted by each of the models. However, the gain functions are flat relative to the sampling variability of observed points earned, so that this analysis does not serve to differentiate the models.
Learning
To investigate the possibility that subjects used a hill-climbing strategy during the main experiment, instead of maximizing expected gain by taking account of their own temporal uncertainty function and experimentally imposed gain function, we performed a hill-climbing simulation using each subject's temporal uncertainty function. In the simulation, intended duration was moved away from the penalty region by 3Δt ms after each penalty and towards the center of the target region by Δt ms for each miss of the target that occurred on the opposite side from the penalty (corresponding to the 3∶1 ratio of penalty to reward). The value of Δt was initially set to be relatively large. With each change of direction of step, Δt was reduced by 25% to a minimum step size of 1.5 ms. While this simulation approximately reproduced the final average reach times observed experimentally, it does not provide a good model of subject performance. First, there were significant autocorrelations of reach durations beyond lag zero in the simulation data but not in the experimental data. Second, a learning algorithm would be expected to produce substantially higher σ values during test than those observed during training. This is what we found with our hill-climbing simulation. Using subjects' training σ values to produce the simulated data, the simulation produced 17 out of 20 main-experiment σ values that were above the training values, whereas our subjects' main-experiment σ values (Figure 3) were entirely consistent with temporal uncertainty functions measured during training.
Discussion
Movement Planning as Gain Maximization
To move accurately, an organism's motor system must generate an intricate series of precisely timed neural commands. The exact nature of these commands is not known. Whatever the format of the command signals [27]–[32], movement controlled by any physical controller-actuator system, including biological motor systems, will always exhibit some motor uncertainty. Nevertheless, it is possible to plan movements that will maximize expected gain in the face of that uncertainty. To do so, an organism must be capable of assessing both the probabilities of possible movement outcomes and their consequences.
One of the most thoroughly studied cases in which humans integrate the probabilities of possible movement outcomes and their consequences is the tradeoff between movement speed and spatial accuracy [20]–[21], [33]–[34]. However, in our experiment we were concerned with temporal accuracy, and faster movements are typically more temporally accurate (the opposite of the spatial speed-accuracy tradeoff). By imposing costs for early/late arrivals, we were able to determine whether the motor system is capable of picking movement times that maximize expected gain, taking into account temporal uncertainty.
We conclude that, in the timing task we examined, the motor system estimates and compensates almost perfectly for its own temporal uncertainty and correctly anticipates how that uncertainty interacts with the asymmetric reward structure of the environment. This outcome is plausible given the close neurophysiological links between motor timing and the assessment of probabilities and consequences [22]–[25], [35]–[37].
We note however that it has been argued that a representation of time plays no role in one of the most basic forms of motor learning: motor adaptation [38]. The current study provides evidence that the motor system is capable of using a representation of time in at least some circumstances where the consequences of the movement are unambiguously linked to the timing of the movement, and in addition that it does so optimally.
Timing as an Element of Movement Optimization
Several models of spatio-temporal movement control are based on optimizing an internal cost function that either includes or predicts movement timing. One such model of trajectory formation, the minimum variance model [39], assumes that the CNS selects a spatio-temporal reach trajectory by optimizing a cost function based on the movement's endpoint variance. In particular, the minimum variance model selects “…the temporal profile of the neural command … so as to minimize the final positional variance for a specified movement duration…” [39], p. 782. More recently the minimum-time model of trajectory formation has been proposed [40] based on the assumption that, subject to a constraint on movement accuracy, the CNS attempts to minimize movement duration. In both models, the speed-accuracy tradeoff is modeled by scaling the spatial variance of the reach with the amplitude of the motor control signal; that is, they assume signal-dependent spatial motor noise.
In the absence of signal-dependent noise, both models would predict a ‘bang-bang’ control scheme, where the control signal takes first a maximum positive and then maximum negative value producing alternating maximum forward and reverse accelerations leading to maximum movement speed and hence minimum duration. However, bang-bang control predicts trajectories that are inconsistent with typical motor behavior. By modeling spatial noise as signal-dependent, it is possible to predict a range of important behavioral results with both the minimum-variance and minimum-time models, such as the smooth variation in spatial and temporal reach profiles e.g., [41]–[42], Fitts' law [33], and the spatio-temporal details of saccadic trajectories [43].
Unlike these previous studies, here the emphasis is on accuracy of movement duration. This results in a reverse speed-accuracy tradeoff; slower movements have lower temporal accuracy (even though they have higher spatial accuracy). We show that, in a task where spatial uncertainty (and therefore signal-dependent spatial noise) plays essentially no role, reach durations are selected to nearly maximize expected gain in the presence of duration-dependent temporal uncertainty.
Duration-dependent temporal uncertainty constitutes a constraint on the temporal aspects of movement planning that is similar in many respects to the planning constraint imposed by signal-dependent spatial noise. Simultaneously minimizing temporal and spatial noise provides a method of solving the underconstrained problem of trajectory selection. Although several previous studies have proposed multiply-constrained models of movement planning [44]–[45] and the duration-dependence of temporal uncertainty is well known e.g.,[10]; [46]–[47], we provide the first demonstration of the CNS making use of its own temporal uncertainty in movement planning. While selecting the movement trajectory that minimizes spatial and/or temporal noise is a possible method of movement planning, the optimal movement planner carefully separates the constraints imposed on spatial and temporal accuracy (duration-dependent temporal noise and signal-dependent spatial noise) with the costs of spatial and temporal errors, which we discuss next.
Cost Functions in Models of Movement Planning
In both the minimum-time and minimum-variance models [39]–[40], a trajectory is selected so as to optimize an internal cost for spatial variance or movement duration (respectively) in the presence of signal-dependent spatial noise. The cost is internal in the sense that it does not make reference to any externally imposed costs on movement errors, such as monetary rewards and penalties that may be imposed due to one's spatial precision or movement duration. There have been a large number of models of movement based on the optimization of internal cost functions that identify movement cost with an invariant kinematic or dynamic variable (time [48], spatial precision [39], torque-change [49]–[50], jerk [51], etc.). However, there are pitfalls inherent in identifying movement cost with an aspect of the movement itself, despite the current movement goals. For example, the minimum-variance model always chooses a movement with the best possible spatial precision, even when that level of precision is unnecessary for the task. Similarly, the minimum-time model always chooses the shortest duration movement that satisfies the constraint on spatial precision even when, as in some conditions of the current study, an external temporal cost function rewards longer-duration movements.
Recent models of optimal movement planning e.g., [14],[18],[26],[44] approach the problem somewhat differently. In these models, which have previously been used to predict spatial movement endpoints [14],[18] and movement trajectories [44], the difference between a constraint on movement planning and a cost incurred from movement error must be recognized. While duration-dependent temporal noise, signal-dependent spatial noise, energy consumption, biomechanics, etc. constitute constraints on movement planning and control, they are not properly costs. A cost essentially imposes a weighting on the available constraints, and is task dependent. By experimentally imposing costs [14]–[15], [18]–[21],[26] on spatial or temporal inaccuracy, it is possible to predict flexible movement strategies that incorporate task-relevant constraints (e.g., duration-dependent temporal uncertainty) while effectively ignoring (down-weighting) constraints that are not as important to the task at hand (signal-dependent spatial uncertainty). In the present study, we manipulated the temporal cost function by imposing penalties on too-short reach durations in some conditions, and too-long durations in other conditions, and determined whether subjects responded appropriately to these different cost functions.
We have modeled movement planning as minimizing an external gain function in the presence of task-relevant internal temporal noise. By identifying the to-be-minimized cost with the movement goal we have separated fixed kinematic/dynamic variables from the purpose of the movement. This allows us to predict flexible movement plans that may minimize spatial or temporal uncertainty, but only when that is relevant to the task at hand. A deeper understanding of movement planning and execution will result from models that similarly separate cost functions from fixed sets of kinematic/dynamic variables while simultaneously taking account of task-relevant spatial and/or temporal uncertainty.
Materials and Methods
Subjects were instructed to reach to a computer screen. Prior to each reach, a timer bar was presented on-screen, indicating the timing of the rewarded and penalized temporal windows, along with a circular spatial target. To earn rewards, subjects had to touch within the circular target area within a specified temporal window (“temporal target”). All spatial targets (12 mm radius) were presented along a circular arc 430 mm from the start position (Figure 1C). The timer bar was used to indicate the reward structure of each trial (described below), and also to signal to the subject the movement duration achieved following completion of each reach. All measurements (spatial and temporal) were made with an Optotrak 3020, sampling at 200 Hz. Reach initiation was defined as the moment when the fingertip moved (at least) 2 mm toward the computer monitor, and reach termination as the time when the fingertip arrived within 3 mm of the monitor and the forward fingertip velocity fell below 3 mm/s. Subjects were seated facing the center of the (upright) computer monitor.
The start position of the reach was on the tabletop, in front of the upright computer screen. Fingertip position was controlled at the start of each reach, and constrained to be within 1 mm of the start position. The start position was 350 mm in front of the center of the monitor's bottom edge (Figure 1C). Target locations were selected from a circular arc on the screen. The arc was centered on the projection of the start position to the bottom edge of the screen (Figure 1C). All points on this arc were equidistant from the start position. Reaches were made in a dimly lit room (the majority of the light coming from the CRT), and subjects could see their hands. No feedback was presented on the screen showing the fingertip landing point, although an auditory beep indicated that the target had been touched.
Subjects were not told that Gaussian noise with σ = 25 ms was added to all measured temporal endpoints. This added noise, in combination with subjects' natural duration-dependent variations in temporal uncertainty, allowed us to determine whether subjects were sensitive to changes in the two sources of variation in temporal uncertainty described above. The noise-added temporal endpoint was displayed after each reach, shown as a thin line intersecting the timer bar at the appropriate position.
Each subject completed two sessions, a training session and the main experiment. Both sessions were completed within the same hour on a single day.
Training
Subjects were first given a training session in which temporal targets (width: 3 ms, no adjacent penalty region) were presented at six target durations (565, 595, 625, 655, 685 and 715 ms; 8 repetitions each, in separate blocks, followed by 50 repetitions each, in separate blocks) spanning the range of temporal aim points observed during pilot work. Although this window was too narrow for subjects to reliably hit, subjects were not scored during training, and were told simply to time their reaches as closely to each target time as possible. This session allowed us to estimate the standard deviation of each subject's movement durations for a set of precisely known target durations, and also allowed subjects to learn their own (noise-added) temporal uncertainties in the task. Standard deviations at each target time (Figures 2B and 3) were measured from the final 40 repetitions to avoid possible initial practice effects.
Main Experiment
Immediately following training, subjects were given a temporal target centered at 650 ms, with a half-width of 0.6σ 650, where σ 650 was the estimated SD of movement duration for a mean duration of 650 ms. In this way, we equated the difficulty of the task across subjects based on their training performance.
Subjects were paid a bonus for touching the spatial target within the temporal target window (Figure 1A, green, cross-hatched bars), and penalized for touching the spatial target within a temporal penalty window (Figure 1A, red, striped bars) or for failing to touch the spatial target. Four blocked conditions were employed (Figure 1A), two early temporal penalty conditions and two late penalty conditions (64 trials each). The two early temporal penalty regions began at 0 ms and ended either 0.6σ 650 or 1.35σ 650 ms prior to 650 ms. The two late temporal penalty regions began either 0.6σ 650 or 1.35σ 650 ms following 650 ms, and were open-ended.
The outcome of each trial was signaled by distinct auditory tones notifying the subject that a reward was earned or a penalty assessed. The possible reward earned on any trial was $0.12 and the penalty was −$0.36 (or −$0.60 for missed spatial targets). Note that the ratio of penalty to bonus magnitudes was 3∶1. Trials in which the spatial target was not touched were re-run (fewer than 1% of all trials) to equate the number of touched-target trials in each condition. The untouched-target trials were not analyzed.
Subjects
Subjects were four students at New York University who were not aware of the purpose of the experiment and one author (TEH). All subjects gave informed consent before the experiment. The experimental protocol had been approved by the Institutional Review Board at New York University.
Model Predictions
As described in the Introduction, decision theoretic models of motor behavior are concerned with the interplay of three elements: movement strategy, uncertainty, and the gain or loss from possible movement outcomes. The interplay of these three elements is represented graphically in Figure 1B for the optimal model, M 0. Calculation of the temporal endpoints predicted by each of the models to be considered required that the expected gain, in terms of average bonus earned per reach, be computed based on the constraints supplied by the hypothetical system. For example, the optimal neuromotor controller would make use of information concerning both Weber-like increases in temporal uncertainty with increasing reach time, and the experimentally increased overall temporal uncertainty.
A given motor strategy or plan, s, determines the critical states of the system. Although motor plans are complex sequences of control signals in time, the only consequence of the choice of motor plan in our task is to select an expected temporal endpoint, τ s. The expected gain from s is then given by (Figure 1B):
| (2) |
where G(t) describes the gain or loss associated with a particular temporal endpoint (Figure 1A and Figure 1B, middle panel). The term p(t | τs) describes the probability density of temporal endpoints expected from any chosen movement strategy s. Note that these are planned durations, not reaction times, and hence we have no a priori expectation that these distributions will be skewed. We model the duration distribution as a Gaussian with mean arrival time τs and a standard deviation σ(τs)
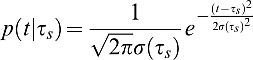 |
(3) |
(QQ plots of these distributions confirm that the Gaussian distribution models the data well). The temporal uncertainty function, σ(τs) is able to capture the well-known Weber-like scaling of temporal standard deviation with mean arrival time τs (Figure 1B, top panel). We used values estimated from each subject's training data to compute individual σ(τs) functions for models M 0–M 3.
In Figure 1B (bottom panel), for the rightmost choice of τ, the probability of arrival in the penalty zone is nearly as high as that of arrival in the reward zone. This choice of τ is likely to lead to nearly as many penalties as rewards. Given that the penalty/reward ratio was 3∶1, expected gain is negative for this choice of τ. The distribution associated with the leftmost choice of τ is primarily in the uncolored time zone where the subject earns nothing. This choice of τ is likely to lead to rare rewards and extremely rare penalties, resulting in only a small total reward across many trials. Interestingly, a third choice of τ, centered on the temporal reward region, earns even less than the previous choice of τ because of a combination of its proximity to the temporal penalty, the magnitude of temporal movement noise, and the ratio of the reward to penalty magnitudes.
The best of the four choices shown is therefore the τ located at the left edge of the rewarded temporal region. Of the four shown, it makes the best compromise between the width of the probability distribution for t and its distance from the centers of the reward and penalty regions, given the widths of those regions and the ratio of gains to losses. Of course, there are infinitely many possible choices of τ. The lower panel shows the expected gain as a function of τ, with the maximum expected gain (MEG) point indicated with a circle at the peak of the expected gain function. If observers select this value τopt, they maximize their expected gain.
We computed τopt for each of the four penalty conditions and each subject based on an estimated temporal uncertainty function σ(τs) that was specific to each subject. In all cases the optimal (maximum expected gain) value of τs was shifted away from the penalty region.
Data Analysis and Model Comparison
The optimal Bayesian model (M 0) makes full use of the temporal uncertainty function σ(τs) from each subject's training session. The five sub-optimal models use less information. M 1 uses the σ(τs) calculated from each subject's training data without the experimentally added σ = 25 ms noise. M 2 uses each subject's constant σ for all τs that includes the overall added σ = 25 ms noise; it uses the square root of the average of perturbed variances about the target durations measured during training. M 3 uses the subject's constant σ without the experimentally added noise. M 4 and M 5 use a constant offset and constant offset and slope, respectively, but assume that the values of these parameters are unknown. Of course, some subjects are more accurate than others but this is explicitly taken account of in our analysis. Each model's predictions are defined in terms of performance relative to an individual's temporal uncertainty function. Subjects who are inherently poorer timers are being compared to a standard (defined by each model) that is tailored to (defined in terms of) the limits of that subject's abilities. So while there are in fact individual differences between subjects, these were removed in the design and analysis of the experiment. Because we equated subjects in this way we could analyze group data.
The predicted movement strategy, s, is therefore a function of the type(s) of temporal uncertainty information incorporated by each model Mm, the reward structure defined by the j
th experimental condition (j = 1 to 4), and the temporal uncertainties measured during training for the k
th subject (k = 1 to 5). Let 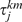 denote the value of τ predicted by model Mm based on an estimate of timing uncertainty calculated from the assumptions of each model. For convenience, we denote the temporal uncertainty for an attempt to produce a movement duration of
denote the value of τ predicted by model Mm based on an estimate of timing uncertainty calculated from the assumptions of each model. For convenience, we denote the temporal uncertainty for an attempt to produce a movement duration of 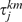 (using the full temporal uncertainty function based on the training trials),
(using the full temporal uncertainty function based on the training trials), 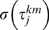 , as
, as 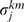 .
.
The models we considered are not all nested and consequently we chose a method of model comparison for non-nested models [52]–[54] that we describe next. Let 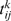 denote the i
th arrival time (of the 64 trials per condition) in condition j for the k
th subject. The likelihood of model Mm is given by:
denote the i
th arrival time (of the 64 trials per condition) in condition j for the k
th subject. The likelihood of model Mm is given by:
| (4) |
where
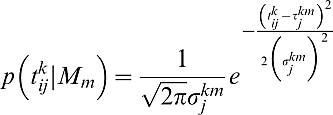 . .
|
(5) |
Note however that for M4 and M5, the model likelihood must be calculated by integrating over the unknown parameters: the constant offset, 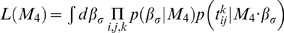 , and constant offset and slope,
, and constant offset and slope, 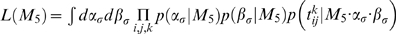 , of the temporal uncertainty function, respectively, where the prior probability distributions over the parameters are taken to be bounded Jeffreys (uninformative) priors [55].
, of the temporal uncertainty function, respectively, where the prior probability distributions over the parameters are taken to be bounded Jeffreys (uninformative) priors [55].
Let π(Mm) denote the prior probability of the m th model. Then the posterior probability of the m th model given the data is
| (6) |
and
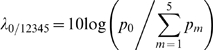 |
(7) |
is a comparison of the posterior probability of the optimal model M 0 to the combined posterior probabilities of sub-optimal models: it is a measure of evidence [53] favoring the optimal model (the factor of 10 allows us to express evidence in decibels, denoted dB). A similar evidence measure can be computed for each of the sub-optimal models using the odds ratio of the probability of each sub-optimal model to the combined probability for the remaining five models (four sub-optimal and one optimal). We set the prior probabilities of the six models to be equal and computed these evidence measures.
Footnotes
The authors have declared that no competing interests exist.
NIH EY08266
References
- 1.Billaut F, Basset FA, Falgairette G. Muscle coordination changes during intermittent cycling sprints. Neurosci Lett. 2005;380:265–269. doi: 10.1016/j.neulet.2005.01.048. [DOI] [PubMed] [Google Scholar]
- 2.Churchyard AJ, Morris ME, Georgiou N, Chiu E, Cooper R, et al. Gait dysfunction in Huntington's disease: Parkinsonism and a disorder of timing. Adv Neurol. 2001;87:375–385. [PubMed] [Google Scholar]
- 3.Corcos DM, Jiang HY, Wilding J, Gottlieb GL. Fatigue induced changes in phasic muscle activation patterns for fast elbow flexion movements. Exp Brain Res. 2002;142:1–12. doi: 10.1007/s00221-001-0904-9. [DOI] [PubMed] [Google Scholar]
- 4.Gribble PL, Ostry DJ. Compensation for Interaction Torques During Single- and Multijoint Limb Movement. J Neurophysiol. 1999;82:2310–2326. doi: 10.1152/jn.1999.82.5.2310. [DOI] [PubMed] [Google Scholar]
- 5.Howard RM, Shea CH, Herbert WG. The effects of fatigue on the control of a coincident timing response. J Gen Psychol. 1982;106:263–271. [PubMed] [Google Scholar]
- 6.Pope PA, Praamstra P, Wing AM. Force and time control in the production of rhythmic movement sequences in Parkinson's disease. Eur J Neurosci. 2006;23:1643–1650. doi: 10.1111/j.1460-9568.2006.04677.x. [DOI] [PubMed] [Google Scholar]
- 7.Sainburg RL, Poizner H, Ghez C. Loss of proprioception produces deficits in interjoint coordination. J Neurophysiol. 1993;70:2136–2147. doi: 10.1152/jn.1993.70.5.2136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Schwarz M, Fellows SJ, Schaffrath C, Noth J. Deficits in sensorimotor control during precise hand movements in Huntington's disease. Clin Neurophysiol. 2001;112:95–106. doi: 10.1016/s1388-2457(00)00497-1. [DOI] [PubMed] [Google Scholar]
- 9.Wadsworth DJ, Bullock-Saxton JE. Recruitment patterns of the scapular rotator muscles in freestyle swimmers with subacromial impingement. Int J Sports Med. 1997;18:618–624. doi: 10.1055/s-2007-972692. [DOI] [PubMed] [Google Scholar]
- 10.Rakitin BC, Gibbon J, Penney TB, Malapani C, Hinton SC, et al. Scalar expectancy theory and peak-interval timing in humans. J Exp Psychol Anim Behav Process. 1998;24:15–33. doi: 10.1037//0097-7403.24.1.15. [DOI] [PubMed] [Google Scholar]
- 11.Korenberg AT, Ghahramani Z. A Bayesian view of motor adaptation. Curr Psychol Cogn. 2002;21:537–564. [Google Scholar]
- 12.Körding KP, Tenenbaum JB, Shadmehr R. Multiple timescales and uncertainty in motor adaptation. Adv Neural Inf Process Syst. 2006;19 [Google Scholar]
- 13.Körding KP, Tenenbaum JB, Shadmehr R. The dynamics of memory as a consequence of optimal adaptation to a changing body. Nat Neurosci. 2007;10:779–786. doi: 10.1038/nn1901. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Trommershäuser J, Maloney LT, Landy MS. Statistical decision theory and trade-offs in the control of motor response. Spat Vis. 2003;16:255–275. doi: 10.1163/156856803322467527. [DOI] [PubMed] [Google Scholar]
- 15.Trommershäuser J, Maloney LT, Landy MS. Statistical decision theory and the selection of rapid, goal-directed movements. J Opt Soc Am A Opt Image Sci Vis. 2003;20:1419–1433. doi: 10.1364/josaa.20.001419. [DOI] [PubMed] [Google Scholar]
- 16.Körding KP, Wolpert DM. Bayesian integration in sensorimotor learning. Nature. 2004;427:244–247. doi: 10.1038/nature02169. [DOI] [PubMed] [Google Scholar]
- 17.Miyazaki M, Nozaki D, Nakajima Y. Testing Bayesian Models of Human Coincidence Timing. J Neurophysiol. 2005;94:395–399. doi: 10.1152/jn.01168.2004. [DOI] [PubMed] [Google Scholar]
- 18.Tassinari H, Hudson TE, Landy M. Combining Priors and Noisy Visual Cues in a Rapid Pointing Task. J Neurosci. 2006;26:10154–10163. doi: 10.1523/JNEUROSCI.2779-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Maloney LT, Trommershäuser J, Landy MS. Questions without words: A comparison between decision making under risk and movement planning under risk. In: Gray W, editor. Integrated models of cognitive cystems. New York, NY: Oxford University Press; 2007. pp. 297–315. [Google Scholar]
- 20.Battaglia PW, Schrater PR. Humans Trade Off Viewing Time and Movement Duration to Improve Visuomotor Accuracy in a Fast Reaching Task. J Neurosci. 2007;27:6984–6994. doi: 10.1523/JNEUROSCI.1309-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Dean M, Wu S-W, Maloney LT. Trading off speed and accuracy in rapid, goal-directed movements. J Vis. 2007;7:1–12. doi: 10.1167/7.5.10. [DOI] [PubMed] [Google Scholar]
- 22.Leon MI, Shadlen MN. Representation of Time by Neurons in the Posterior Parietal Cortex of the Macaque. Neuron. 2003;38:317–327. doi: 10.1016/s0896-6273(03)00185-5. [DOI] [PubMed] [Google Scholar]
- 23.Wallis JD. Orbitofrontal cortex and its contribution to decision-making. Ann Rev Neurosci. 2007;30:31–56. doi: 10.1146/annurev.neuro.30.051606.094334. [DOI] [PubMed] [Google Scholar]
- 24.Gold JI, Shadlen MN. The neural basis of decision making. Ann Rev Neurosci. 2007;30:535–574. doi: 10.1146/annurev.neuro.29.051605.113038. [DOI] [PubMed] [Google Scholar]
- 25.Knutson B, Bossaerts P. Neural Antecedents of Financial Decisions. J Neurosci. 2007;27:8174–8177. doi: 10.1523/JNEUROSCI.1564-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Hudson TE, Maloney LT, Landy MS. Movement Planning With Probabilistic Target Information. J Neurophys. 2007;98:3034–3046. doi: 10.1152/jn.00858.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Gribble PL, Scott SH. Overlap of internal models in motor cortex for mechanical loads during reaching. Nature. 2002;417:938–941. doi: 10.1038/nature00834. [DOI] [PubMed] [Google Scholar]
- 28.Kawato M. Internal models for motor control and trajectory planning. Curr Opin Neurobiol. 1999;9:718–727. doi: 10.1016/s0959-4388(99)00028-8. [DOI] [PubMed] [Google Scholar]
- 29.Shidara M, Kawato K, Gomi H, Kawato M. Inverse-dynamics model eye movement control by Purkinje cells in the cerebellum. Nature. 1993;365:50–52. doi: 10.1038/365050a0. [DOI] [PubMed] [Google Scholar]
- 30.Wolpert DM, Ghahramani Z. Computational principles of movement neuroscience. Nat Neurosci. 2000;3(suppl):1212–1217. doi: 10.1038/81497. [DOI] [PubMed] [Google Scholar]
- 31.Feldman AG. Once more on the equilibrium-point hypothesis (lambda model) for motor control. J Mot Behav. 1986;18:17–54. doi: 10.1080/00222895.1986.10735369. [DOI] [PubMed] [Google Scholar]
- 32.Feldman AG, Latash M. Testing hypotheses and the advancement of science: recent attempts to falsify the equilibrium point. Exp Brain Res. 2005;161:91–103. doi: 10.1007/s00221-004-2049-0. [DOI] [PubMed] [Google Scholar]
- 33.Fitts PM. The Information Capacity of the Human Motor System in Controlling the Amplitude of Movement. J Exp Psychol. 1954;47:381–391. [PubMed] [Google Scholar]
- 34.Meyer DE, Abrams RA, Kornblum S, Wright CE, Smith JE. Optimality in human motor performance: Ideal control of rapid aimed movements. Psychol Rev. 1988;95:340–370. doi: 10.1037/0033-295x.95.3.340. [DOI] [PubMed] [Google Scholar]
- 35.Daw ND, Courville AC, Touretzky DS. Representation and timing in theories of the dopamine system. Neural Comput. 2006;18:1637–1677. doi: 10.1162/neco.2006.18.7.1637. [DOI] [PubMed] [Google Scholar]
- 36.Elliott R, Newman JL, Longe OA, Deakin JFW. Differential Response Patterns in the Striatum and Orbitofrontal Cortex to Financial Reward in Humans: A Parametric Functional Magnetic Resonance Imaging Study. J Neurosci. 2003;23:303–307. doi: 10.1523/JNEUROSCI.23-01-00303.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.McCoy AN, Platt ML. Expectations and outcomes: decision-making in the primate brain. J Comp Physiol A. 2005;191:201–211. doi: 10.1007/s00359-004-0565-9. [DOI] [PubMed] [Google Scholar]
- 38.Conditt MA, Mussa-Ivaldi FA. Central representation of time during motor learning. Proc Natl Acad Sci USA. 1999;96:11625–11630. doi: 10.1073/pnas.96.20.11625. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Harris CM, Wolpert DM. Signal-dependent noise determines motor planning. Nature. 1998;394:780–784. doi: 10.1038/29528. [DOI] [PubMed] [Google Scholar]
- 40.Tanaka H, Krakauer JW, Qian N. An Optimization Principle for Determining Movement Duration. J Neurophysiol. 2006;95:3875–3886. doi: 10.1152/jn.00751.2005. [DOI] [PubMed] [Google Scholar]
- 41.Lackner JR, DiZio P. Rapid adaptation to Coriolis force perturbations of arm trajectory. J Neurophysiol. 1994;72:299–313. doi: 10.1152/jn.1994.72.1.299. [DOI] [PubMed] [Google Scholar]
- 42.Shadmehr R, Mussa-Ivaldi FA. Adaptive representation of dynamics during learning of a motor task. J Neurosci. 1994;14:3208–3224. doi: 10.1523/JNEUROSCI.14-05-03208.1994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Pelisson D, Prablanc C. Kinematics of centrifugal and centripetal saccadic eye movements in man. Vis Res. 1988;28:87–94. [PubMed] [Google Scholar]
- 44.Liu D, Todorov E. Evidence for the Flexible Sensorimotor Strategies Predicted by Optimal Feedback Control. J Neurosci. 2007;27:9354–9368. doi: 10.1523/JNEUROSCI.1110-06.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Biess A, Liebermann DG, Flash T. A Computational Model for Redundant Human Three-Dimensional Pointing Movements: Integration of Independent Spatial and Temporal Motor Plans Simplifies Movement Dynamics. J Neurosci. 2007;27:13045–13064. doi: 10.1523/JNEUROSCI.4334-06.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Drew MR, Zupan B, Cooke A, Couvillon PA, Balsam PD. Temporal control of conditioned responding in goldfish. J Exp Psychol Anim Behav Process. 2005;31:31–39. doi: 10.1037/0097-7403.31.1.31. [DOI] [PubMed] [Google Scholar]
- 47.Gallistel CR, King A, McDonald R. Sources of variability and systematic error in mouse timing behavior. J Exp Psychol Anim Behav Process. 2004;30:3–16. doi: 10.1037/0097-7403.30.1.3. [DOI] [PubMed] [Google Scholar]
- 48.Fitzhugh R. A model of optimal voluntary muscular control. J Math Biol. 1977;4:203–236. doi: 10.1007/BF00280973. [DOI] [PubMed] [Google Scholar]
- 49.Uno Y, Kawato M, Suzuki R. Formation and control of optimal trajectory in human multijoint arm movement. Biol Cybern. 1989;61:89–101. doi: 10.1007/BF00204593. [DOI] [PubMed] [Google Scholar]
- 50.Kawato M, Maeda Y, Uno Y, Suzuki R. Trajectory formation of arm movement by cascade neural network model based on minimum torque-change. Biol Cybern. 1990;62:275–288. doi: 10.1007/BF00201442. [DOI] [PubMed] [Google Scholar]
- 51.Hogan N. An organizing principle for a class of voluntary movements. J Neurosci. 1984;4:2745–2754. doi: 10.1523/JNEUROSCI.04-11-02745.1984. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Berger JO. Statistical Decision Theory and Bayesian Analysis. New York, USA: Springer-Verlag; 2002. p. 648. [Google Scholar]
- 53.Jaynes ET. Probability theory: The logic of science. Cambridge, UK: Cambridge University Press; 2003. p. 727. [Google Scholar]
- 54.Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian Data Analysis. Boca Raton, USA: Chapman & Hall Press; 2004. p. 702. [Google Scholar]
- 55.Jeffreys H. Proc R Soc Lond A Math Phys Sci. 1946;186:453–461. doi: 10.1098/rspa.1946.0056. [DOI] [PubMed] [Google Scholar]