

Abstract
Multidimensional liquid-based separation is required for fractionation and mapping of complex protein mixtures from cells. A method that has been used as the first dimension in such separations is chromatofocusing, which is a based on generating a pH gradient on an anion exchange column. The use of pH in the first dimension is essential where pH is a fundamental property of proteins and can provide information on post-translationally modified forms of a protein. In this work, a micro-chromatofocusing technique is introduced which can separate microgram levels of proteins from cell lysates for further analysis by LC-MS/MS. It is shown that this method can analyze 10 µg of sample and detect nearly 700–800 proteins from ovarian cancer cell line lysates.
Keywords: micro separation, capillary column, micro-chromatofocusing, pH gradient, protein separation
1. Introduction
An important issue in current proteomic analysis is the ability to work with small amounts of samples. This becomes particularly important in situations where only a limited amount of sample may be available such as tissue or fluid samples extracted from aspirates[1], laser capture micro-dissection[2], tumor micro-environment experiments[3] or stem cell research[4]. In these cases, there may be <100,000 cells available or fluids in the amount of 50µl or less. This number may correspond to only several micrograms of total protein where if there are a thousand proteins present, then on average there may only be tens of femtomoles of each protein available. It thus becomes critical to find methods capable of separating and analyzing such small amounts of sample with the ability to identify the presence of large numbers of proteins.
A number of methods have been developed to fractionate the protein content of a cell on a micro-proteomic scale [5,6,7,8]. These methods may use an approach based upon fractionation of intact proteins [6,9] or alternatively fractionation of the protein content of a cell following total digestion of the proteins into peptides [5,10,11,12]. Both of the approaches have been used in previous work for analysis of small amounts of sample. An advantage of the intact protein method is that it may allow isolation of the original protein for further analysis by protein molecular weight measurement or antibody analysis. The presence of the intact protein information may also ultimately provide information on posttranslational modifications [13].
Ion exchange chromatography (IEC) is a widely used process that separates inorganic ions and proteins based on charge-charge interaction [14,15,16]. Protein separation by IEC can be performed using two methods, the salt-gradient method, and the pH- gradient method. Compared with the salt-gradient method, the pH-gradient method has the ability to produce protein separation with a high degree of fractionation based upon an on-column pH-based separation. Despite the capabilities of the pH-gradient method, IEC has been limited because of the difficulty producing linear pH gradients. Several improvements have been made in this area where, for example, Sluyterman and co-workers [17,18] generated linear-pH gradients with no buffer mixture externally in a process called chromatofocusing (CF). During CF, a quasi linear-pH gradient was produced using simple buffer solutions where proteins elute down the column creating focused bands. Most CF has been conducted using a weak anion exchanger. In other work, Frey and coworkers [19,20] have developed an advanced theory for CF using simple buffer solutions. Also, Shan and Anderson [21,22] have generated pH-gradient IEC with amine buffer solutions.
CF has been exploited in proteomics and used as the first dimension in multi-dimensional separation because of its ability to obtain pI information, a fundamental property of proteins. This information is important for identification of proteins and ultimately, posttranslational modifications. For example, Lubman and coworkers [23, 24, 25] studied various cancers, e.g. breast, ovary, and pancreatic using chromatofocusing, for separation followed by mass spectrometry, and showed a difference of protein expression and post-translational modifications with a mass map based on protein pI and molecular weight of proteins. In this work, they used an analytical scale column requiring several hundred micrograms to several milligrams for separation. Alternatively, a method has been developed using a micro-chromatofocusing (micro-CF) procedure with a weak anion exchanger packed in a capillary column. This method is a scaled down version of the CF separation currently used in the Beckman PF2D instrument. However, instead of milligram amounts of starting material 2–30µg of material can be fractionated based upon pH. The intact protein can be collected according to pH value and further analyzed by a second dimension. In this work, we demonstrate digestion of the eluted fraction of intact proteins from micro-CF followed by nano-RPLC-MS/MS. This micro-proteomic procedure is demonstrated for analysis of 700–800 proteins from only 10 µg of two ovarian cell lines (MDAH 2774 and TOV 112D).
2. Experimental
2.1. Chemicals and Materials
Urea, Thiourea, bis-tris, acetonitrile, n-Octyl-D-glucopyranoside, DTT and formic acid were purchased from Sigma-Aldrich. PMSF was purchased from Bio-Rad. Polybuffer 74 was obtained from Amersham Biosciences (Pittsburgh, PA). The packing material (AX-300) for micro - CF column was obtained from Eprogen, Inc. (Darien, IL). The fused-silica capillary with 200um i.d./360um o.d. was purchased from Polymicro Technologies, LLC. (Phoenix, AZ).
2.2. Micro-Chromatofocusing
The column used in this experiment was a fused silica capillary column (200um × 200mm), packed with anion exchange packing materials (AX-300) (Eprogen, Inc., Darien, IL), using a packing bomb built in house at a pressure of 2000psi for 2–3h. The experiments were performed using an ultra-pure II capillary pump with high-pressure mixer (Micro-Tech Scientific, Vista, CA). Two buffer solutions, a starting buffer (SB) and an elution buffer (EB), were used to generate a pH gradient on the CF column. The SB solution was composed of 6M urea and 25mM Bis-tris. The upper limit pH of the SB solution was set at pH 7.8. The EB solution was prepared with 6M urea and polybuffer74, while the lower limit of the EB was set at pH 3.8–4.0. The pH for both buffer solutions was established by addition of a saturated solution of iminodiacetic acid. The CF column was pre-equilibrated with the SB solution. 5–20µg of sample was injected into the micro-CF column and the mobile phase was then switched to the EB solution to initiate the pH gradient. The pH gradient in the column was monitored by an on-line post column detector flow-through pH electrode (Microelectrodes, Inc., Bedford, NH). The flow rate was 5ul/min, with fractions collected in 0.2 pH units. The pH fraction above 7.5 and the elution by salt wash solution (1M NaCl) were collected separately for further analysis. Each sample of the MDAH and TOV cell lines was run by micro-CF three times for reproducibility.
2.2 Analytical Chromatofocusing
Chromatofocusing (CF) was performed on a Beckman System Gold model 127s binary HPLC pump with high-pressure mixer (Fullerton, CA, USA), using a HPCF 1D column (2.1 × 250 mm) (Eprogen, Inc., Darien, IL). Two buffer solutions (a start buffer (SB) and an elution buffer (EB)) were utilized for the generation of a pH gradient on the CF column. The SB solution was composed of 6M urea and 25mM Bis-Tris (pH 7.8). The EB solution was composed of 6M urea and 10% polybuffer74 (pH 3.8–4.0). Both buffer solutions were brought to pH by addition of a saturated solution of iminodiacetic acid. The CF column was pre-equilibrated with SB, after which the mobile phase was switched to the EB solution for pH gradient initiation. The pH gradient was monitored on-line with a post detector pH flow cell (Lazar Research Laboratories, Inc., Los Angeles, CA). The UV absorbance of the eluent was monitored on-line at 280nm. The flow rate was 0.2ml/min, with fractions collected in 0.2 pH units. Each fraction was stored at −80°C.
2.3 Trypsin Digestion
The NPS RP-HPLC sample fractions were lyophilized by vacuum centrifugation to remove remaining solvent in the sample tubes. The remaining Trifluoroacetic acid (TFA) was neutralized by adding 10% (v/v) NH4HCO3 into the samples. 10% (v/v) DTT and 0.01µg of TPCK-treated trypsin (Promega, Madison, WI) were added. The samples were vortexed and then incubated at 37°C for approximately 18h. The tryptic digestion was terminated by addition of 2.5 % (v/v) of TFA.
2.4 Protein Identification and quantification
The digested peptide mixture was analyzed by nano-flow reverse-phase LC/MS/MS using the LTQ mass spectrometer with a nano-spray ESI ion source (Thermo, San Jose, CA). The samples were separated using a (0.1 × 150mm) capillary reverse phase column (MichromBioresources, Auburn, CA) with a flow rate of 5ul/min. An acetonitrile:water gradient method was used, starting with 5% acetonitrile which was ramped to 60% in 25min and to 90% in another 5min. Both solvent A (water) and B(ACN) contained 0.1% formic acid. The electrospray voltage was 2.6V, with a capillary temperature of 200°C and a capillary voltage of 4kV. The normalized collision energy was set at 35% for MS/MS. The MS/MS spectra obtained were analyzed using the Sequest feature of Bioworks 3.1 SR1. Peptide ions were assigned with the Xcorr values to consider >3.5 for +3, >2.5 for +2, and >1.7 for +1 ions and ΔCn of 0.1 or higher. To further validate data obtained from Sequest, Protein prophet/peptide prophet software [26] modified in house were used to provide a confidence level in identification of 95%. In order to quantify proteins, DTA select program has been used as described previously [27]. The DTA program is a form of spectral counting where the program reads individual spectra from the Sequest output files and evaluates the result using a filter set by the user. This then is followed by generating a dtaselect.html file and text file containing information on identified proteins and the corresponding spectral counts.
2.5 Description of MDAH and TOV
Two ovarian endometrioid cancer cell lines (MDAH 2774, TOV 112D) were obtained from the American Type Culture Collection. The cell lines were cultured as described previously [28]. Cultured cells were removed by scrapping with a cell scraper (Costar, Cambridge, MA) and washed three times with PBS solution. Then, cells were lysed with lysis buffer solution composed of 6M urea (Sigma), 2M thiourea (Sigma), 1% n-Octyl-D-glucopyranoside(Sigma), 2mM DTT(Sigma), and 2.5mM PMSF(Bio-Rad). The lysed solution containing cells were centrifuged at 35,000rpm at 4°C for 1h and the supernatant was stored at −80°C for further use.
3. Results and Discussion
3.1 Micro CF column
Chromatofocusing is an on-column, non-gel fractionation technique that has been used as the first dimension in multi-dimensional separations based on the pI values of proteins in complex mixtures. The dimension of the column used for chromatofocusing(CF) on an analytical scale in our previous work[25] has been 2.1mm(i.d.) × 250mm, while the dimension of the column for micro-CF is 200µm (i.d.) × 200mm. These two columns, which differ in volume by a factor of 100, result in several experimental differences since columns size affects both the amount of protein loaded onto the column and the composition of the elution buffer (EB) solution. The amount of protein loaded onto the column for multidimensional separation is an important factor in proteomic research where it will determine the number of proteins detected, especially those at lower abundance. The amount of protein required for analytical scale CF is ~ 5mg, whereas in micro-CF the total protein loading can be reduced to typically 5–20µg of sample. Indeed, the protein loading in these micro-CF experiments can be as little as 2µg of total protein.
Another difference between CF and micro-CF is the time required to generate a pH gradient. In the analytical scale CF used in prior work, the EB solution contained a 10% polybuffer solution, which generates a 40–70 min pH gradient. However, in micro-CF separation, a 10% polybuffer solution generates a pH gradient separation for only a limited time before reaching a lower pH. This rapid pH gradient was insufficient to generate adequate protein separation based on pI or to collect sufficient volume of the fractionated samples for further experiments. To generate a longer elution time, a 2% polybuffer solution was used in micro-CF for the pH gradient. Highly repeatable pH gradients (pH 7.6-3.8) were obtained for micro-CF using the EB solution as shown for 10µg of sample injected on-column in Figure 1. Compared to the gradient change of analytical CF involving a 10% polybuffer solution, the 2% polybuffer system yielded a pH gradient that was twice as long in our experiments.
Figure 1.
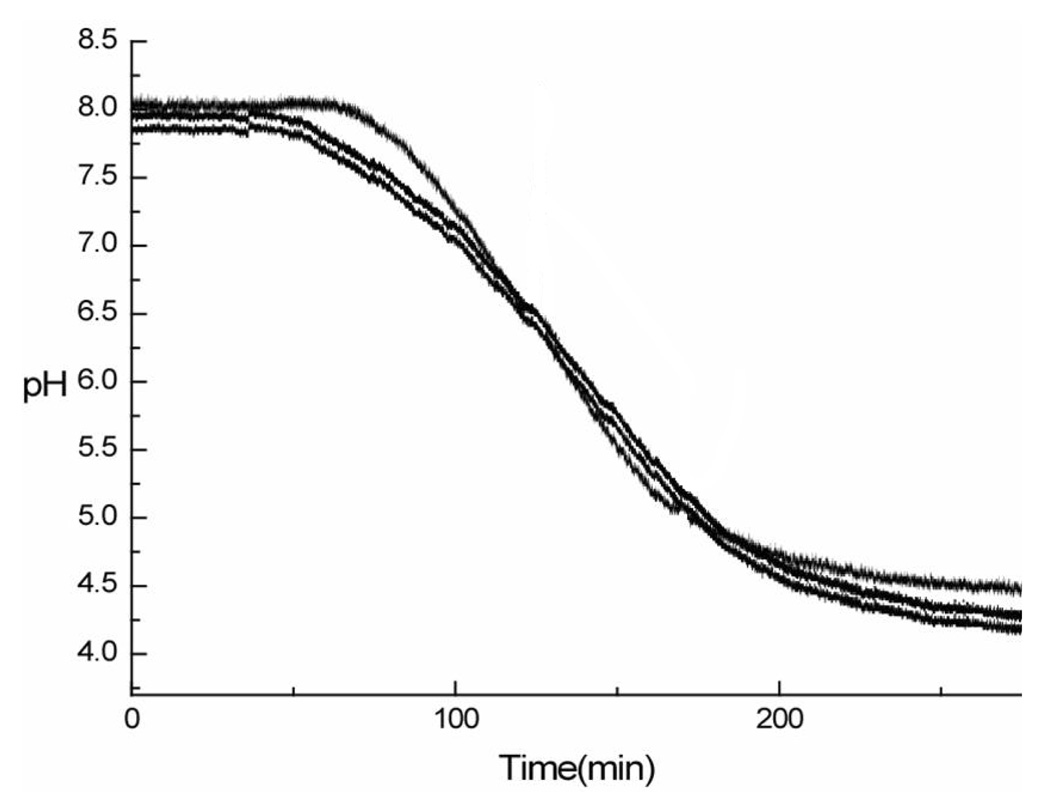
pH gradient obtained by micro-CF
3.2. Separation and identification of proteins using nano ESI-LC-MS
3.2.1. nano-ESI-LC-MS
The proteins separated by micro-CF were collected into pH fractions and digested into peptides using trypsin. The peptides from each fraction were further analyzed using nano-flow HPLC-ESI-MS/MS. The proteins from the pH fractions and the salt gradient were analyzed in these experiments. Figure 2 shows the base peak chromatogram for three pH fractions of a microCF/nano-HPLC-ESI MS/MS of the peptides detected in a human ovarian cancer cell line (TOV112D). Though there are some overlapping peptide peaks from high abundance proteins across adjacent pH ranges, low abundance proteins such as p53 were still identified based upon the reverse phase separation and MS/MS analysis. The reproducibility of the peptide separation and identification was tested using the combined microCF/nano-HPLC-ESI MS/MS in multiple runs of tryptic digest samples. Two consecutive experiments were performed for two different analyses from repeat micro-CF experiments with the same pH range (pH 5.6-5.4). There is only a small difference in elution times of the peptides from the fractionated solution, usually <0.2min. Figure 3 illustrates the base peak chromatogram and tandem mass spectrometry of the sample solution. Mass spectra were generated for the peptide K. MEKETAENYLGHTAK.N from GRP75 (Stress-70 protein, mitochondrial precursor) at 19.47min from Figure 4B and 19.33min in Figure 4D, respectively. Figure 3 demonstrates the reproducibility of the combined micro-CF/nano-HPLC-ESI-MS/MS method.
Figure 2.

Base Peak Chromatogram in TOV112D, (A) fr6, (B) fr7, (C) fr8.
Figure 3.

Reproducibility test for the integrated Micro-CF/nano-HPLC-ESI-MS/MS. Equal amounts of the sample were analyzed. The tandem mass spectrum obtained at 19.43 min in (A) is shown in (C). The tandem mass spectrum obtained at 19.33 min in (B) is shown in (D).
Figure 4.
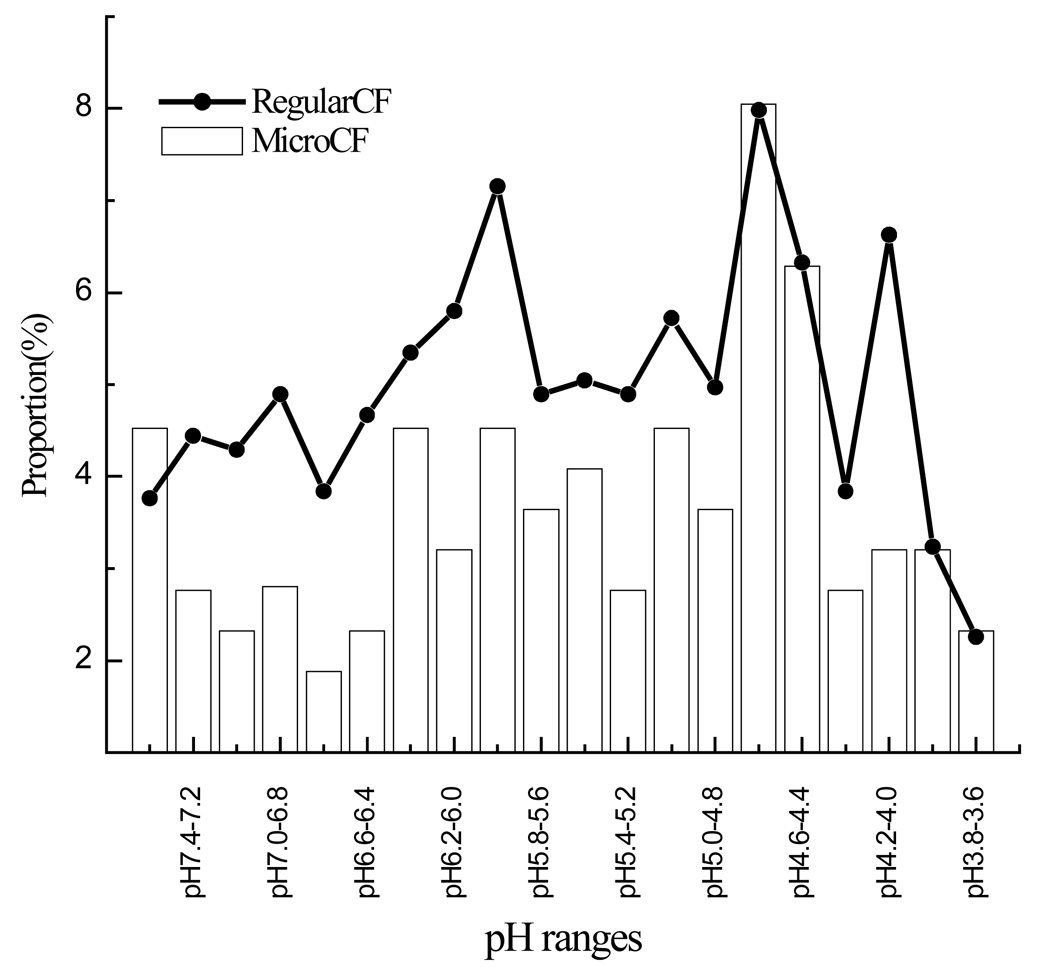
pI distribution in both Analytical CF and Micro-CF using MDAH2774 cell line.
3.2.2 Comparison of ovarian cancer cell line proteins
In the integrated micro-CF/nano HPLC-ESI-MS/MS approach, 700–800 proteins were detected using 10µg of sample in each of two cell lines. Each of these samples was run three times to increase the number of total proteins detected. However, after the second run the number of proteins detected did not increase substantially. The pI distribution and location of the identified proteins is illustrated in Figure 4 and 5 respectively. The pI distribution of proteins using micro-CF is similar to that obtained from analytical scale CF. As can be seen, most of the proteins are located in the Cytosol and Nuclear compartments. There was little difference in the location of the proteins in the two ovarian endometrioid cell lines.
Figure 5.
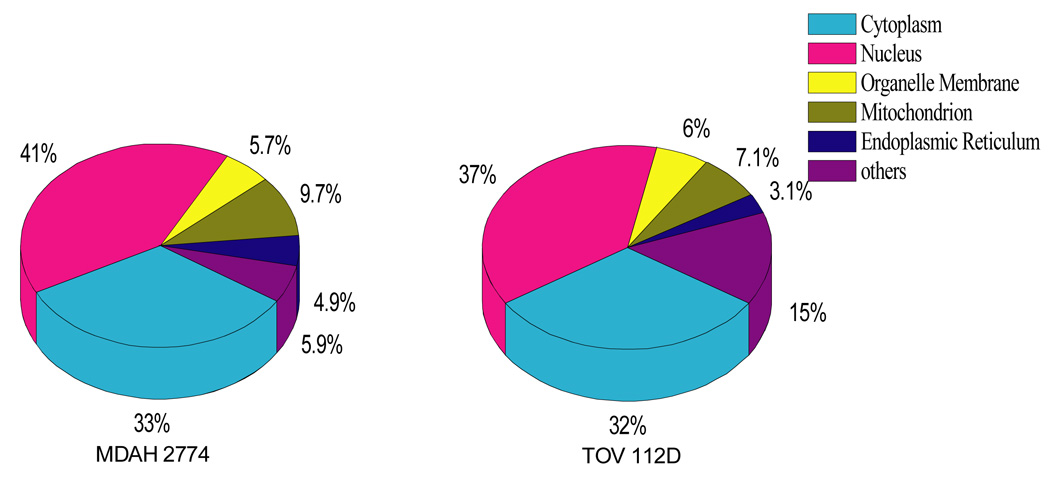
The comparison of cellular composition of identified proteins from two ovarian cancer cell lines (MDAH2774, TOV112D).
Table 1 lists 173 proteins common to both the MDAH 2774 and TOV 112D cell lines. This Table also contains quantitative information on protein expression based upon the spectral counting method. For example, structural proteins such as Keratin 9, 19, 22 and the Histones AA, BA are found with a high Xcorr score from the ESI-MS/MS Sequest database search result. It should be noted that there are large differences in expression between the histones and keratins between the cell lines, where the presence of the different keratins is often used as a marker of the type of cancer [29, 30]. Of the common proteins in both cell lines Table 1 shows that less than half of the proteins undergo pI shifts. Also, approximately 25% of the proteins in Table 1 are shifted to acidic pH compared to the database value. According to the nano HPLC-ESI/MS/MS result, half of the proteins with a pI shift toward the acidic range showed possible phosphorylations, while the remainder showed possible methionine oxidation or no PTM present. Many of these proteins have been studied in previous work using analytical scale chromatofocusing in breast cancer cell lines and showed distinctive phosphorylations in aggressive cancers [13]. Some of these proteins include the four histones detected, which have a strong shift towards lower pI compared to that expected. In addition, other proteins such as elongation factor1-alpha1 and arginine splice factor have been studied by these methods and shown to be multiply-phosphorylated in cancer cells. Interestingly, proteins with a pI shift toward the acidic range appear to be involved in protein binding at the molecular function level such as ATP binding. This may indicate that these proteins play a role in signal pathways involved in cancer.
Table 1.
Proteins identified from both cell lines, TOV112D, and MDAH2774.
| Access No. | Protein Name | Expression change(fold)Theritical Experimental pI | ||||
|---|---|---|---|---|---|---|
| TOV112D | MDAH2774 | pI | TOV 112D | MDAH 2774 | ||
| P31947 | 14-3-3 protein sigma | 98.4 | 4.68 | pH4.6-4.4 | pH4.4-4.2 | |
| P62736 | Actin, aortic smooth muscle | 6.3 | 5.24 | pH5.6-5.4 | pH5.2-5.0 | |
| P60709 | Actin, cytoplasmic 1 | 3.6 | 5.29 | pH5.6-5.4 | pH5.2-5.0 | |
| P63261 | Actin, cytoplasmic 2 (Gamma-actin) | — | — | 5.31 | abovepH7.5 | abovepH7.5 |
| P12814 | Alpha-actinin-1 (Alpha-actinin cytoskeletal isoform) | 1.1 | 5.25 | pH5.2-5.0 | pH4.2-4.0 | |
| O43707 | Alpha-actinin-4 (Non-muscle alpha-actinin 4) | — | — | 5.27 | abovepH7.5 | above pH 7.5 |
| Q9H2P0 | Activity-dependent neuroprotector | 3.1 | 6.97 | pH6.2-6.0 | pH6.8-6.6 | |
| P51825 | AF4/FMR2 family member 1,Proto-oncogene AF4 | 2.7 | 9.26 | abovepH7.5 | abovepH7.5 | |
| Q16352 | Alpha-internexin | — | — | 5.34 | abovepH7.5 | salt washing |
| P02768 | Serum albumin [Precursor] | 8.9 | 5.67 | pH5.6-5.4 | pH5.6-5.4 | |
| Q01484 | Ankyrin-2 | — | — | 5.03 | pH5.0-4.8 | pH5.2-5.0 |
| Q86YR6 | Ankyrin repeat domain-containing protein 21 | 2.6 | 6.32 | pH6.6-6.4 | pH7.0-6.8 | |
| P50995 | Annexin A11 (Annexin XI) | — | — | 7.53 | salt washing | salt washing |
| P07355 | Annexin A2 | 7.2 | 7.56 | pH5.8-5.6 | pH6.0-5.8 | |
| P12429 | Annexin A3 | 8.8 | 5.63 | pH5.6-5.4 | pH5.6-5.4 | |
| Q9NR81 | Rho guanine nucleotide exchange factor 3 | 4.4 | 6.03 | pH4.8-4.6 | pH4.4-4.2 | |
| Q68CP9 | AT-rich interactive domain-containing protein 2 | 3.2 | 7.08 | pH7.2-7.0 | pH7.2-7.0 | |
| P06576 | ATP synthase subunit beta, mitochondrial precursor | 15.5 | 5 | pH5.6-5.4 | pH5.6-5.4 | |
| O75173 | ADAMTS-4 [Precursor] | 3.2 | 8.23 | pH4.6-4.4 | abovepH7.5 | |
| Q8WWM7 | Ataxin-2-like protein | 2.7 | 8.7 | above pH7.5 | abovepH7.5 | |
| Q8IY92 | BTB/POZ domain-containing protein 12 | 1.5 | 5.32 | pH6.2-6.0 | abovepH7.5 | |
| Q05682 | Caldesmon (CDM) | 1.8 | 5.63 | abovepH7.5 | abovepH7.5 | |
| P62158 | Calmodulin (CaM) | 6.7 | 4.09 | pH4.4-4.2 | pH4.4-4.2 | |
| P83916 | Chromobox protein homolog 1 | — | — | 4.85 | above pH7.5 | abovepH7.5 |
| P47902 | Homeobox protein CDX-1 | 3.3 | 9.58 | pH6.2-6.0 | pH6.0-5.8 | |
| P49454 | Centromere protein F | 1.7 | 5.03 | pH4.8-4.6 | pH4.6-4.4 | |
| Q86VQ0 | Uncharacterized protein C6orf152 | 1.7 | 7.31 | pH6.6-6.4 | pH6.6-6.4 | |
| Q9HAC7 | Uncharacterized protein C7orf10 | 2.6 | 8.54 | salt washing | salt washing | |
| Q9P2M7 | Cingulin | 2.2 | 5.46 | pH7.2-7.0 | pH7.2-7.0 | |
| P53618 | Coatomer subunit beta | 4.3 | 5.72 | pH4.8-4.6 | pH4.6-4.4 | |
| Q92828 | WD repeat-containing protein 2 | 2 | 8.24 | pH5.6-5.4 | pH6.0-5.8 | |
| Q8IVV8 | Protein FAM77A | 3.2 | 5.43 | above pH7.5 | abovepH7.5 | |
| Q14118 | Dystrophin-associated glycoprotein 1 | 2.4 | 9.31 | above pH7.5 | above pH7.5 | |
| Q9UIK4 | Death-associated protein kinase 2 | 28.5 | 6.45 | pH6.8-6.6 | abovepH7.5 | |
| P16989 | DNA-binding protein A | 27 | 9.77 | above pH7.5 | pH7.2-7.0 | |
| Q13561 | Dynactin subunit 2 (Dynactin complex 50 kDa subunit) | 11.9 | 5.1 | pH5.2-5.0 | pH4.6-4.4 | |
| P17661 | Desmin | 2.6 | 5.21 | pH5.4-5.2 | pH5.4-5.2 | |
| O00273 | DNA fragmentation factor subunit alpha | 1.4 | 4.68 | pH4.8-4.6 | PH4.8-4.6 | |
| O60469 | Down syndrome cell adhesion molecule [Precursor] | 1.7 | 7.81 | pH5.2-5.0 | pH5.2-5.0 | |
| Q8TE73 | Ciliary dynein heavy chain 5 | 2.4 | 5.79 | pH4.8-4.6 | pH4.8-4.6 | |
| Q8WXU2 | Dyslexia susceptibility 1 candidate gene 1 protein | 1.2 | 8.95 | pH5.2-5.0 | pH5.2-5.0 | |
| P68104 | Elongation factor 1-alpha 1 | 35.8 | 9.1 | pH7.6-7.4 | pH7.6-7.4 | |
| P26641 | Elongation factor 1-gamma (EF-1-gamma) | 1 | 6.27 | pH5.2-5.0 | pH4.6-4.4 | |
| P13639 | Elongation factor 2 | 3.2 | 6.42 | 6.2-6.0 | pH6.0-5.8 | |
| Q14677 | Clathrin interactor 1 (Epsin-4) (Epsin-related protein) | 1.7 | 6.01 | pH6.2-6.0 | pH6.2-6.0 | |
| P15311 | Ezrin (p81) (Cytovillin) (Villin-2) | 4.7 | 5.95 | pH6.0-5.8 | pH6.0-5.8 | |
| Q5JRC9 | Protein FAM47A | 2.6 | 9.15 | above pH7.5 | above pH7.5 | |
| Q96AY3 | FK506-binding protein 10 [Precursor] | 3.8 | 5.26 | pH5.4-5.2 | pH5.4-5.2 | |
| Q16595 | Frataxin, mitochondrial [Precursor] | 6.8 | 5.94 | pH4.8-4.6 | pH4.6-4.4 | |
| Q5H8C1 | FRAS1-related extracellular matrix protein 1 [Precursor] | 2.7 | 5.5 | pH4.6-4.4 | salt washing | |
| P32455 | Interferon-induced guanylate-binding protein 1 | 1.2 | 5.97 | pH7.6-7.4 | pH7.2-7.0 | |
| Q8IWJ2 | GRIP and coiled-coil domain-containing protein 2 | 1.3 | 5.08 | above pH7.5 | abovepH7.5 | |
| Q02153 | Guanylate cyclase soluble subunit beta-1 (GCS-beta-1) | 3.7 | 5.2 | salt washing | pH5.4-5.2 | |
| Q96N19 | Integral membrane protein GPR137 | 2.5 | 8.78 | salt washing | pH4.8-4.6 | |
| P38646 | Stress-70 protein, mitochondrial [Precursor] | 150.7 | 5.44 | pH5.6-5.4 | pH5.6-5.4 | |
| P11021 | 78 kDa glucose-regulated protein precursor | 2.7 | 5.01 | pH5.2-5.0 | pH5.2-5.0 | |
| P28001 | Histone H2A type 1-E | 244 | 11.05 | pH6.8-6.6 | pH7.6-7.4 | |
| P0C0S8 | Histone H2A type 1 | 531.9 | 10.9 | above 7.5 | pH7.2-7.0 | |
| P62807 | Histone H2B type 1-C/E/F/G/I | 100 | 10.32 | pH7.6-7.4 | pH7.6-7.4 | |
| P62805 | Histone H4 | 46.2 | 11.36 | pH7.6-7.4 | pH7.6-7.4 | |
| P82979 | Nuclear protein Hcc-1 | 2.6 | 6.12 | pH4.6-4.4 | pH4.6-4.4 | |
| Q16836 | Hydroxyacyl-coenzyme A dehydrogenase, mitochondrial | 1.1 | 8.38 | pH7.4-7.2 | pH7.0-6.8 | |
| Q8TBE9 | N-acylneuraminate-9-phosphatase(NANP_human) | 9.7 | 6.01 | pH4.6-4.4 | pH6.2-6.0 | |
| P31943 | Heterogeneous nuclear ribonucleoprotein H (hnRNP H) | 58.6 | 5.89 | pH5.8-5.6 | pH5.6-5.4 | |
| P52597 | Heterogeneous nuclear ribonucleoprotein F (hnRNP F) | 2 | 5.38 | pH5.6-5.4 | pH5.6-5.4 | |
| P61978 | Heterogeneous nuclear ribonucleoprotein K (hnRNP K) | 1.8 | 5.39 | pH5.2-5.0 | pH4.8-4.6 | |
| O43390 | Heterogeneous nuclear ribonucleoprotein R (hnRNP R) | 1.1 | 8.23 | salt washing | salt washing | |
| P34931 | Heat shock 70 kDa protein 1L | 15.3 | 5.76 | pH5.8-5.6 | pH5.6-5.4 | |
| P07900 | Heat shock protein HSP 90-alpha | 13.8 | 4.94 | pH6.6-6.4 | pH4.4-4.2 | |
| P08107 | Heat shock 70 kDa protein 1 | 7.7 | 5.48 | pH5.4-5.2 | pH5.2-5.0 | |
| P54652 | Heat shock-related 70 kDa protein 2 | 6 | 5.56 | pH5.6-5.4 | pH5.6-5.4 | |
| P34932 | Heat shock 70 kDa protein 4 | 1.2 | 5.18 | pH5.2-5.0 | pH4.8-4.6 | |
| P11142 | Heat shock cognate 71 kDa protein | 7.8 | 5.37 | pH5.6-5.4 | pH5.6-5.4 | |
| Q9Y3Y2 | Uncharacterized protein C1orf77 | 1.6 | 12.24 | above pH7.5 | 7.6-7.4 | |
| Q7Z6Z7 | E3 ubiquitin-protein ligase HUWE1 | 2.2 | 5.1 | above pH7.5 | above pH7.5 | |
| P20810 | Calpastatin | 4.5 | 4.98 | above pH7.5 | above pH7.5 | |
| P63241 | Eukaryotic translation initiation factor 5A-1 | 1.4 | 5.08 | pH5.0-4.8 | pH5.0-4.8 | |
| P01563 | Interferon alpha-2 [Precursor] | 1.3 | 5.99 | pH6.0-5.8 | pH6.0-5.8 | |
| Q12906 | Interleukin enhancer-binding factor 3 | 1.3 | 8.86 | salt washing | pH5.2-5.0 | |
| Q14643 | Inositol 1,4,5-trisphosphate receptor type 1 | 2.3 | 5.71 | pH5.8-5.6 | pH5.8-5.6 | |
| P29375 | Histone demethylase JARID1A | 1.1 | 6.42 | above pH7.5 | pH7.0-6.8 | |
| O94953 | JmjC domain-containing histone demethylation protein 3B | 34.1 | 6.72 | pH6.8-6.6 | above pH7.5 | |
| Q9HCJ3 | Ribonucleoprotein PTB-binding 2 | 1.4 | 7.12 | pH7.0-6.8 | above pH7.5 | |
| P13645 | Keratin, type I cytoskeletal 10 | 34 | 5.13 | pH5.8-5.6 | pH6.0-5.8 | |
| P13646 | Keratin, type I cytoskeletal 13 | 3.6 | 4.91 | pH7.6-7.4 | pH7.6-7.4 | |
| P08779 | Keratin, type I cytoskeletal 16 | 3.7 | 4.98 | pH7.6-7.4 | pH5.2-5.0 | |
| P12035 | Keratin, type II cytoskeletal 3 | 2.1 | 8.16 | pH5.6-5.4 | pH5.6-5.4 | |
| P05787 | Keratin, type II cytoskeletal 8 | 30 | 5.52 | pH5.6-5.4 | pH5.6-5.4 | |
| P00568 | Adenylate kinase isoenzyme 1 | 11.1 | 8.73 | above 7.5 | pH7.2-7.0 | |
| O95069 | Potassium channel subfamily K member 2 | 1.4 | 8.46 | above pH7.5 | pH7.2-7.0 | |
| Q9NQT8 | Kinesin-like protein KIF13B | 3.4 | 5.56 | pH7.2-7.0 | above pH7.5 | |
| P46013 | Antigen KI-67 | 1.1 | 9.49 | above pH7.5 | pH6.6-6.4 | |
| O00139 | Kinesin-like protein KIF2A | 6.8 | 6.04 | pH6.2-6.0 | above pH7.5 | |
| Q9BVG8 | Kinesin-like protein KIFC3 | 4.3 | 7.62 | pH7.4-7.2 | pH7.2-7.0 | |
| P05455 | Lupus La protein | 2.3 | 6.68 | pH6.0-5.8 | pH5.6-5.4 | |
| P20700 | Lamin-B1 | 5.4 | 5.11 | pH5.2-5.0 | pH5.0-4.8 | |
| P02545 | Lamin-A/C | 16.3 | 6.57 | pH6.2-6.0 | pH5.6-5.4 | |
| Q14847 | LIM and SH3 domain protein 1 | 1.6 | 6.61 | pH6.8-6.6 | pH4.6-4.4 | |
| Q6JVE6 | Epididymal-specific lipocalin-10 [Precursor] | 1.5 | 10.25 | above pH7.5 | above pH7.5 | |
| P07195 | L-lactate dehydrogenase B chain | 4.3 | 5.72 | pH6.2-6.0 | pH5.6-5.4 | |
| Q7L1W4 | Leucine-rich repeat-containing protein 8D | 1.5 | 7.76 | 7.6-7.4 | pH5.2-5.0 | |
| Q9NX58 | Cell growth-regulating nucleolar protein | 1.3 | 9.57 | pH4.8-4.6 | pH6.0-5.8 | |
| Q9UPN3 | Microtubule-actin cross-linking factor 1, isoforms 1/2/3/5 | 1.6 | 5.27 | pH7.0-6.8 | above pH7.5 | |
| P27816 | Microtubule-associated protein 4 | 1 | 5.32 | pH5.0-4.8 | pH4.6-4.4 | |
| P43243 | Matrin-3 | 2.8 | 5.87 | pH4.8-4.6 | pH4.8-4.6 | |
| P41594 | Metabotropic glutamate receptor 5 [Precursor] | 2.9 | 8.09 | pH5.8-5.6 | pH5.6-5.4 | |
| P19105 | Myosin regulatory light chain 2, nonsarcomeric | 2.3 | 4.67 | pH4.8-4.6 | pH4.8-4.6 | |
| P49006 | MARCKS-related protein | 4 | 4.68 | pH4.6-4.4 | pH4.6-4.4 | |
| P60660 | Myosin light polypeptide 6 | 22.2 | 4.56 | above pH7.5 | pH4.8-4.6 | |
| Q15746 | Myosin light chain kinase, smooth muscle | — | — | 5.85 | pH6.20-6.0 | above pH7.5 |
| O95251 | Histone acetyltransferase MYST2 | 1.4 | 9.01 | pH4.8-4.6 | pH7.0-6.8 | |
| P15531 | Nucleoside diphosphate kinase A | 3 | 5.83 | pH5.6-5.4 | pH5.2-5.0 | |
| P20929 | Nebulin | 1.4 | 9.1 | salt washing | pH5.2-5.0 | |
| P82970 | Nucleosome-binding protein 1 | 1.8 | 4.5 | pH4.4-4.2 | pH4.4-4.2 | |
| Q9UNZ2 | NSFL1 cofactor p47 | 1.2 | 4.99 | pH4.6-4.4 | pH4.6-4.4 | |
| Q02818 | Nucleobindin-1 [Precursor] | 6 | 5.09 | pH5.2-5.0 | pH5.2-5.0 | |
| Q96KK4 | Olfactory receptor 10C1 | — | — | 8.64 | above pH7.5 | above pH7.5 |
| Q9Y4L1 | Hypoxia up-regulated protein 1 [Precursor] | 1.2 | 5.07 | pH5.0-4.8 | pH4.8-4.6 | |
| Q9Y6V0 | Protein piccolo | 1.4 | 6.12 | pH6.2-6.0 | pH6.2-6.0 | |
| O95831 | Apoptosis-inducing factor 1, mitochondrial [Precursor] | 5.5 | 6.86 | pH6.2-6.0 | pH5.2-5.0 | |
| P30101 | Protein disulfide-isomerase A3 [Precursor] | 6.9 | 5.61 | pH5.6-5.4 | pH5.6-5.4 | |
| P41219 | Peripherin | 1.6 | 5.37 | above pH7.5 | above pH7.5 | |
| O43933 | Peroxisome biogenesis factor 1 | — | — | 5.91 | pH4.6-4.4 | pH7.2-7.0 |
| Q9NQP4 | Prefoldin subunit 4 | 3 | 4.42 | pH4.4-4.2 | pH4.4-4.2 | |
| P78562 | Phosphate-regulating neutral endopeptidase | 1.8 | 8.91 | salt washing | pH5.2-5.0 | |
| Q9ULU4 | Protein kinase C-binding protein 1 | 1.8 | 6.83 | 7.4-7.2 | pH7.2-7.0 | |
| Q96MT3 | Prickle-like protein 1 | 4.1 | 5.84 | pH5.2-5.0 | pH5.2-5.0 | |
| P17980 | 26S protease regulatory subunit 6A | 13.3 | 5.13 | pH5.2-5.0 | pH7.6-7.4 | |
| Q15678 | Tyrosine-protein phosphatase non-receptor type 14 | — | — | 8.45 | above pH7.5 | above pH7.5 |
| P11498 | Pyruvate carboxylase, mitochondrial [Precursor] | 1.1 | 6.14 | pH6.8-6.6 | pH7.0-6.8 | |
| Q7Z5J4 | Retinoic acid-induced protein 1 | 16.5 | 9.03 | pH5.6-5.4 | pH7.2-7.0 | |
| P43487 | Ran-specific GTPase-activating protein | 4.6 | 5.19 | pH5.2-5.0 | pH5.0-4.8 | |
| O76081 | Regulator of G-protein signaling 20 | 5.4 | 6.48 | pH6.6-6.4 | pH6.6-6.4 | |
| Q99729 | Heterogeneous nuclear ribonucleoprotein A/B | 1.5 | 9.04 | above pH7.5 | ph4.8-4.6 | |
| P62263 | 40S ribosomal protein S14 | 1.3 | 10.08 | pH6.2-6.0 | pH7.6-7.4 | |
| Q92545 | Transmembrane protein 131 [Fragment] | 1.8 | no info | pH7.2-7.0 | abovepH7.5 | |
| Q15413 | Ryanodine receptor 3 | — | — | 5.45 | pH7.2-7.0 | abovepH7.5 |
| Q92562 | SAC domain-containing protein 3 | 1.5 | 6.46 | pH7.2-7.0 | above pH7.5 | |
| Q9Y5Y9 | Sodium channel protein type 10 subunit alpha | 2.8 | 5.67 | pH6.4-6.2 | pH6.4-6.2 | |
| Q9H190 | Syntenin-2 | 17.8 | 9.15 | pH7.6-7.4 | pH4.0-3.8 | |
| O43175 | D-3-phosphoglycerate dehydrogenase | 159.5 | 6.31 | pH6.6-6.4 | pH5.2-5.0 | |
| O15047 | Histone-lysine N-methyltransferase | 1.5 | 5.07 | pH5.2-5.0 | pH5.2-5.0 | |
| P23246 | Splicing factor, proline- and glutamine-rich | 1.3 | 9.45 | pH6.4-6.2 | pH6.2-6.0 | |
| P84103 | Splicing factor, arginine/serine-rich 3 | 1.1 | 11.64 | above pH7.5 | pH5.2-5.0 | |
| Q13813 | Spectrin alpha chain, brain | 7 | 5.22 | pH5.0-4.8 | pH5.4-5.2 | |
| Q01082 | Spectrin beta chain, brain 1 | 4 | 5.39 | pH5.0-4.8 | pH6.2-6.0 | |
| Q13748 | Tubulin alpha-2 chain | 2 | 4.98 | pH5.2-5.0 | pH5.0-4.8 | |
| Q71U36 | Tubulin alpha-1A chain | 2.7 | 4.94 | pH5.0-4.8 | pH5.0-4.8 | |
| O75764 | Transcription elongation factor A protein 3 | — | — | 9.32 | abovepH7.5 | pH5.6-5.4 |
| P48643 | T-complex protein 1 subunit epsilon | 1.7 | 5.45 | pH5.6-5.4 | pH5.2-5.0 | |
| P49368 | T-complex protein 1 subunit gamma | 1.2 | 6.1 | pH4.6-4.4 | pH5.6-5.4 | |
| Q9UNS1 | Timeless homolog | 2.3 | 5.26 | pH5.6-5.4 | pH5.6-5.4 | |
| P11388 | DNA topoisomerase 2-alpha | 1.4 | 8.82 | above pH7.5 | pH7.2-7.0 | |
| P55327 | Tumor protein D52 | 1.1 | 4.94 | pH5.0-4.8 | pH4.8-4.6 | |
| O43399 | Tumor protein D54 | 3 | 5.26 | pH5.0-4.8 | pH5.0-4.8 | |
| P09493 | Tropomyosin-1 alpha chain | 1.6 | 4.69 | pH4.4-4.2 | pH4.4-4.2 | |
| P07951 | Tropomyosin beta chain | 21.7 | 4.66 | pH4.8-4.6 | pH4.8-4.6 | |
| P06753 | Tropomyosin alpha-3 chain | 1.4 | 4.68 | pH4.8-4.6 | pH4.8-4.6 | |
| Q9Y4A5 | Transformation/transcription domain-associated protein | 1.4 | 8.49 | above pH7.5 | above pH7.5 | |
| P26368 | Splicing factor U2AF 65 kDa subunit | 1.5 | 9.19 | salt washing | pH4.8-4.6 | |
| Q00341 | Vigilin | 3.2 | 6.43 | pH6.6-6.4 | pH 6.6-6.4 | |
| P08670 | Vimentin | 1.3 | 5.06 | pH4.8-4.6 | pH4.8-4.6 | |
| P18206 | Vinculin | 8.3 | 5.51 | pH5.2-5.0 | pH5.6-5.4 | |
| Q9P1Q0 | Vacuolar protein sorting-associated protein 54 | 2.7 | 6.1 | pH5.6-5.4 | pH5.2-5.0 | |
| P04275 | Von Willebrand factor [Precursor] | 2.6 | 5.06 | pH5.2-5.0 | pH5.2-5.0 | |
| Q9P2L0 | WD repeat protein 35 | 1.1 | 5.98 | pH5.2-5.0 | pH4.2-4.0 | |
| Q8NI36 | WD repeat protein 36 | 21.6 | 7.33 | pH7.4-7.2 | abovepH7.5 | |
| O15213 | WD repeat protein 46 | 23.7 | 9.69 | pH7.6-7.4 | abovepH7.5 | |
| Q8IZP6 | RING finger protein 113B | 1.1 | 7.54 | pH5.6-5.2 | pH7.6-7.4 | |
| Q5TAX3 | Zinc finger CCHC domain-containing protein 11 | 1.2 | 8.3 | pH7.0-6.8 | pH7.6-7.4 | |
| Q9H4I2 | Zinc fingers and homeoboxes protein 3 | 2.5 | 5.73 | pH7.6-7.4 | pH7.0-6.8 | |
| Q9UL59 | Zinc finger protein 214 | 3.7 | 8.89 | pH7.6-7.4 | pH7.2-7.0 | |
| O15015 | Zinc finger protein 646 | 1.1 | 6.97 | pH7.0-6.8 | above pH7.5 | |
3.3 Ovarian cancer cell lines-Pathway proteins detected
Two ovarian endometrioid adenocarcinoma (OEA) cell lines have been studied to gain insight into the progression of disease through potential proteomic studies of cell signaling pathways. Among the signal pathways, the Wnt signaling pathway has been known to play a critical role in cell proliferation, regulating morphology, and cell fate at the cellular level[31] and is known to be deregulated in endometrioid ovarian cancer [32]. Moreover, mutations such as the CTNNB1 gene mutation and the PTEN tumor suppressor gene have also been shown to be involved in this pathway [33]. The CTNBB1 gene encodes beta-catenin which is regulated by a multi-protein complex (Beta-catenin -Axin-adenomatous polyposis coli (APC)-glycogen synthase kinase (GSK-3β)). In this protein complex, GSK-3β phosphorylates NH2-terminal β-catenin, producing beta-catenin for ubiquitination and proteasome degradation. With the Wnt signal, beta-catenin degradation is inhibited allowing β-catenin to enter the nucleus, activating the TCF/LEF complex including Bcl-9, PYCO, CBP and turning on genes such as c-Myc and cyclin-D.
In this work, two ovarian endometrioid cell lines (MDAH2774, TOV112D) were studied. MDAH2774 and TOV112D are cultured cell lines derived from human ovarian endometrioid adenocarcinomas. TOV112D harbors the β-catenin mutation, Wnt pathway defect and MDAH2774 has an Axin1 mutation, also a Wnt pathway defect. The effect of these mutations is an increase in the cellular level of beta-catenin and subsequent transcription of Wnt target genes. In considering the Wnt pathway, no Wnt antagonists e.g. secreted frizzled-related proteins (SFRPs) or Wnt-inhibit-factor-1 (WIF-1) were observed in either cell line at detectable levels with the capability of our current experiment. However, the Receptor (Frizzled-1[precursor]) and low density lipoprotein receptor for Wnt ligand were detected in each cell line, which suggests the activation of the cytoplasmic protein disheveled (Dsh, Dvl). The mechanism for Dsh/Dvl activation is not clear yet, but CSK21 (casein kinase II subunit alpha) found in TOV112D has been suggested as being involved in this process.[34] Dishevelled proteins have been shown to recruit GSK-3 binding protein (GBP), detected in both cell lines herein to the multiprotein complex. The resulting complex in both cell lines (TOV112D, MDAH2774) was expected to lead to activation of the TCF/LEF target since the mutations of CTNNB1 (TOV112D) and Axin1(MDAH2774) have been shown in prior work[32]. Bcl-9, and CBP (CREB-binding protein), which were detected in TOV112D, are a part of the β-catenin complex (LEF/TCF- β-catenin-Bcl9-CBP) in the nucleus. This finding may support the higher activation of TCF-dependent transcription in TOV112D obtained compared to MDAH2774. Also p53 was found in MDAH2774, which could provide an alternate pathway for tumor activation in this cell line.
Since both cell lines have different mutations, different cellular behavior may result according to protein expression. Compared with MDAH2774, the TOV112D cell line expresses a higher number of proteins involved with cell activation, for example, T-cell surface antigens CD2, CD4, and the Wiskott-Aldrich syndrome protein family member 3(WASF3). Also detected was p85A (phosphatidylinositol 3-kinase regulatory subunit alpha) which is necessary for the insulin-stimulated increase in glucose uptake and glycogen synthesis in insulin-sensitive tissues. In terms of glucose transport, GTR4 (Solute carrier family 2, facilitated glucose transporter member 4) was found in TOV112D. Raf1 protein was detected which is involved in B-cell receptor signaling and IL-6 signaling where IL6 (Interleukin-6 [Precursor]) was detected. Several proteins (M3K9, M3K10 and M3K11) involved in the MAPKinase signal pathway were also more often observed in TOV112D than in MDAH2774. Although these cell lines are both endometrioid cancers, there may be different pathways at work that are responsible for their aggressiveness and pathologies.
4. Conclusion
It is shown that cell lysates can be analyzed using the combined method, micro-CF/nano-HPLC-ESI-MS/MS, where only limited amounts of sample are available. The micro-CF method involves separation of intact proteins where the pI information can be used for identifying the potential presence of PTMs and also the change in PTM content between cell lines. The method can identify large numbers of proteins (700–800) with only 10–20µg total protein where the proteins observed can be associated with protein pathways. The proteins identified can be associated with known genetic defects in these cancer cell lines and these pathways can potentially be associated with the aggressiveness or the progression of disease.
5. Acknowledgement
This work received was supported in part by the National Cancer Institute under grant NCI R01 CA100104 and the National Institute of General Medical sciences under R01 GM49500 and also received support from Eprogen, Inc.(Darien, IL).
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Alexander H, Stegner AL, Wagner-Mann C, Du Bois GC, Alexander S, Sauter ER. Clinical Cancer Research. 2004;10:7500. doi: 10.1158/1078-0432.CCR-04-1002. [DOI] [PubMed] [Google Scholar]
- 2.Emmert-Buck MR, Bonner RF, Smith PD, Chuaqui RF, Zhuang Z, Goldstein SR, Weiss RA, Liotta LA. Science. 1996;274:998. doi: 10.1126/science.274.5289.998. [DOI] [PubMed] [Google Scholar]
- 3.Gajewski TF. Clinical Cancer Research. 2006;12:2326s. doi: 10.1158/1078-0432.CCR-05-2517. [DOI] [PubMed] [Google Scholar]
- 4.Doss MX, Winkler J, Chen S, Hippler-Altenburg R, Sotiriadou I, Halbach M, Pfannkuche K, Liang H, Schulz H, Hummel O, Hübner N, Rottscheidt R, Hescheler J, Sachinidis A. Genome Biology. 2007;8:R56. doi: 10.1186/gb-2007-8-4-r56. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Chen J, Balgley BM, Devoe DL, Lee CS. Anal. Chem. 2003;75:3145. doi: 10.1021/ac034014+. [DOI] [PubMed] [Google Scholar]
- 6.Pepaj M, Wilson SR, Novotna K, Lundanes E, Greibrokk T. J. Chromatogr. A. 2006;1120:132. doi: 10.1016/j.chroma.2006.02.031. [DOI] [PubMed] [Google Scholar]
- 7.Chen EI, Hewel J, Felding-Habermann B, Yates JR., III Molecular and Cellular Proteomics. 2006;5:53. doi: 10.1074/mcp.T500013-MCP200. [DOI] [PubMed] [Google Scholar]
- 8.Wu R, Hu L, Wang F, Ye M, Zou H. J. Chromatogr. A. 2008;1184:369. doi: 10.1016/j.chroma.2007.09.022. [DOI] [PubMed] [Google Scholar]
- 9.Nesbitt CA, Lo JTM, Yeung KKC. J. Chromatogr. A. 2005;1073:175. doi: 10.1016/j.chroma.2004.09.081. [DOI] [PubMed] [Google Scholar]
- 10.Zhou F, Johnston MV. Electrophoresis. 2005;26:1383. doi: 10.1002/elps.200410125. [DOI] [PubMed] [Google Scholar]
- 11.Metz TO, Jacobs JM, Gritsenko MA, Fonte's G, Qian W-J, Camp DG, II, Poitout V, Smith RD. Journal of Proteome Research. 2006;5:3345. doi: 10.1021/pr060322n. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Motoyama A, Venable JD, Ruse CI, Yates JR., III Anal. Chem. 2006;78:5109. doi: 10.1021/ac060354u. [DOI] [PubMed] [Google Scholar]
- 13.Zhu K, Zhao J, Lubman DM, Miller FR, Barder TJ. Anal. Chem. 2005;77:2745. doi: 10.1021/ac048494w. [DOI] [PubMed] [Google Scholar]
- 14.Xie R, Johnson W, Spayd S, Hall GS, Buckley B. Anal. Chim. Acta. 2006;578:186. doi: 10.1016/j.aca.2006.06.076. [DOI] [PubMed] [Google Scholar]
- 15.Karlsson E, Ryden L, Brewer J. In: Protein Purification. Janson JC, Ryden L, editors. New York: Wiley-VCH; 1998. p. 145. [Google Scholar]
- 16.Yamamoto S, Ishihara T. J. Chromatogr. A. 1999;A852:31. doi: 10.1016/s0021-9673(99)00593-2. [DOI] [PubMed] [Google Scholar]
- 17.Sluyterman LAAE, Elgersma O. J. Chromatogr. 1978;150:17. [Google Scholar]
- 18.Sluyterman LAAE, Wijdenes J. J. Chromatogr. 1978;150:31. [Google Scholar]
- 19.Strong JC, Frey DD. J. Chromatogr. A. 1997;769:129. doi: 10.1016/s0021-9673(96)01049-7. [DOI] [PubMed] [Google Scholar]
- 20.Kang X, Frey DD. Anal. Chem. 2002;74:1038. doi: 10.1021/ac0109319. [DOI] [PubMed] [Google Scholar]
- 21.Shan L, Anderson DJ. J. Chromatogr A. 1998;814:43. [Google Scholar]
- 22.Shan L, Anderson DJ. Anal. Chem. 2002;74:5641. doi: 10.1021/ac020169q. [DOI] [PubMed] [Google Scholar]
- 23.Zhao J, Zhu K, Lubman DM, Miller FR, Barder TJ. Proteomics. 2006;6:3847. doi: 10.1002/pmic.200500195. [DOI] [PubMed] [Google Scholar]
- 24.Wang Y, Wu R, Cho KR, Shedden KA, Barder TJ, Lubman DM. Molecular and Cellular Proteomics. 2006;5:3345. doi: 10.1074/mcp.T500023-MCP200. [DOI] [PubMed] [Google Scholar]
- 25.Yang F, Subramanian B, Nakeff A, Barder TJ, Parus SJ, Lubman DM. Anal. Chem. 2003;75:2299. doi: 10.1021/ac020678s. [DOI] [PubMed] [Google Scholar]
- 26.Nesvizhskii AI, Keller A, Kolker E, Aebersold R. Anal. Chem. 2003;75:4646. doi: 10.1021/ac0341261. [DOI] [PubMed] [Google Scholar]
- 27.Tabb DL, McDonald WH, Yates JR., III Journal of Proteome Research. 2002;1:21. doi: 10.1021/pr015504q. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Wang H, Kachman MT, Schwartz DR, Cho KR, Lubman DM. Proteomics. 2004;4:2476. doi: 10.1002/pmic.200300763. [DOI] [PubMed] [Google Scholar]
- 29.Casanova ML, Bravo A, Martínez-Palacio J, Fernández-Aceñero MJ, Villanueva C, Larcher F, Conti CJ, Jorcano JL. FASEB J. 2004;18:1556. doi: 10.1096/fj.04-1683fje. [DOI] [PubMed] [Google Scholar]
- 30.Trask DK, Band V, Zajchowski DA, Yaswen P, Suh T, Sager R. Proc. Natl. Acad. Sci. U.S.A. 1990;87:2319. doi: 10.1073/pnas.87.6.2319. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Dorsky RI, Moon RT, Raible DW. Nature. 1998;396:370. doi: 10.1038/24620. [DOI] [PubMed] [Google Scholar]
- 32.Wu R, Zhai Y, Fearon ER, Cho KR. Cancer Research. 2001;61:8247. [PubMed] [Google Scholar]
- 33.Polakis P. Genes and Development. 2000;14:1837. [PubMed] [Google Scholar]
- 34.Sakanaka C, Leong P, Xu L, Harrison SD, Williams LT. Proc. Natl. Acad. Sci. U.S.A. 1999;96:12548. doi: 10.1073/pnas.96.22.12548. [DOI] [PMC free article] [PubMed] [Google Scholar]