

Abstract
Purpose
The purpose of this study was to examine the influence of phonotactic probability, the frequency of different sound segments and segment sequences, on the overall fluency with which words are produced by preschool children who stutter (CWS), as well as to determine whether it has an effect on the type of stuttered disfluency produced.
Method
A 500+ word language sample was obtained from 19 CWS. Each stuttered word was randomly paired with a fluently produced word that closely matched it in grammatical class, word length, familiarity, word and neighborhood frequency, and neighborhood density. Phonotactic probability values were obtained for the stuttered and fluent words from an online database.
Results
Phonotactic probability did not have a significant influence on the overall susceptibility of words to stuttering, but it did impact the type of stuttered disfluency produced. In specific, single-syllable word repetitions were significantly lower in phonotactic probability than fluently produced words, as well as part-word repetitions and sound prolongations.
Conclusions
In general, the differential impact of phonotactic probability on the type of stuttering-like disfluency produced by young CWS provides some support for the notion that different disfluency types may originate in the disruption of different levels of processing.
Keywords: Stuttering, Language, Phonotactic Probability, Children
Phonotactic probability refers to the frequency with which different sound segments and segment sequences occur in the lexicon (Jusczyk, Luce, & Charles-Luce, 1994; Storkel, 2001, 2003; Vitevitch, 2002b; Vitevitch, Armbrüster, & Chu, 2004). Some phonological segments, such as /b/, and segment sequences, such as /bl/, tend to occur more commonly in language and, thus, are considered to have high phonotactic probability. By comparison, other phonological segments, such as /ð/, and segment sequences, such as /ðכ/, are less commonly occurring or lower in phonotactic probability. Research suggests that children are sensitive to differences in phonotactic frequency relatively early in development, and this sensitivity increases with age and vocabulary growth (Aslin & Smith, 1988; Coady & Aslin, 2004; Edwards, Beckman, & Munson, 2004; Munson, Kurtz, & Windsor, 2005; Storkel, 2001). This increase in sensitivity to phonotactic probability over development suggests that children’s lexical representations may become increasingly more segmental in nature (Aslin & Smith, 1988; Munson & Babel, 2005; Walley, 1988, 1993). Accordingly, as new words are added into the lexicon, children’s lexical entries assume increasing amounts of segmental information, enabling them to be differentiated more efficiently among phonologically similar representations. Thus, as children acquire more segmental detail into their lexical entries, they will presumably become increasingly sensitive to differences in phonotactic frequency.
While segmental details in children’s lexical entries may become more elaborate during language development, research suggests that children’s early lexical representations contain at least some segmental detail. This is largely evidenced by the fact that phonotactic probability does have an impact on the accuracy of speech production in toddlers and preschool children (Coady & Aslin, 2004; Storkel, 2001; Zamuner, Gerken, & Hammond, 2004). If this is the case, then one might posit that phonotactic probability would have a similar effect on the fluency with which words are produced by young children who stutter (CWS). This speculation is based, in part, on the observation that stuttering tends to be constrained by many of the same linguistic factors as speech errors.1 For example, children tend to produce more stuttering and speech errors on words that are less frequently occurring in language (Anderson, 2007; German & Newman, 2004; Palen & Peterson, 1982; Stemberger, 1984) and longer in length (Coady & Aslin, 2003; Dworzynski, Howell, & Natke, 2003; Howell & Au-Yeung, 1995). Providing further support for this speculation, some studies have found evidence to suggest that CWS may have delays or difficulties with aspects of phonological processing (e.g., Byrd, Conture, & Ohde, 2007). Thus, the overall purpose of this study is to explore the potential role of phonotactic probability on the fluency of speech production in young CWS. To provide background, findings from studies of phonological processing in CWS are reviewed, followed by a discussion of the effect of phonotactic probability in speech production, as well as its hypothesized effect on stuttering.
Phonological Encoding Processes in Children Who Stutter
It has been suggested that the increasing ability to differentiate words in the lexicon from detailed segmental information allows children to speak more rapidly, thereby facilitating more fluent, accurate speech production (Brooks & MacWhinney, 2000; cf. Wijnen, 1992). In a recent study, Byrd et al. (2007) found evidence to support this presumed association between speech fluency and the ability to process individual sound segments. In specific, Byrd and colleagues examined the holistic (a unit of speech at the size of a syllable) and segmental (a word as individual sounds/phonemes from beginning to end) processing abilities of 3-and 5-year-old CWS (n = 26) and children who do not stutter (CWNS; n = 26) using a picture-naming auditory priming paradigm. Children were shown pictures that were preceded by auditory primes that were either holistic or segmental in nature and asked to name each picture “as soon as [they] see it.” Findings indicated that 3-year-old CWNS exhibited significantly faster naming latencies for holistic processing than 5-year-old CWNS, but 5-year-old CWNS were significantly faster than 3-year-old CWNS in segmental processing. By comparison, both 3-and 5-year-old CWS were faster in the holistic approach, suggesting that CWS may be slower to develop a segmental approach to processing than their normally-fluent peers.
Arnold et al. (2006) recently extended the speech reaction time findings of Byrd and colleagues (2007) by simultaneously recording electroencephalography activity, in the form of evoked-response potentials (ERPs), during the time period between the auditory prime and the onset of the child’s naming response. In addition to replicating Byrd et al.’s finding that CWS (both 3-and 5-year-olds) were faster in the holistic than incremental priming condition, Arnold et al. found that both early (perceptual) and later (cognitive/linguistic) components of the ERP signal differ between the two priming conditions. These findings suggest, according to the authors, that the holistic and incremental priming conditions have a behavioral, as well as cognitive/linguistic “reality.”
Melnick, Conture, and Ohde (2003) also found evidence to suggest that CWS may have delays and/or difficulties in processes associated with phonological encoding. The authors used a picture-naming auditory priming paradigm to examine the speed of phonological encoding in 36 preschool CWS and CWNS. Results revealed that both CWS and CWNS demonstrated faster naming latencies when presented with an auditory prime that had the same onset as the target word than when presented with an incongruent phonological prime. However, when picture naming latencies were compared to scores on a measure of speech sound articulation (Goldman-Fristoe Test of Articulation-2; GFTA-2; Goldman & Fristoe, 2000), results indicated that CWNS demonstrated a significant negative correlation while CWS did not. That is, CWNS with shorter naming latencies demonstrated greater articulatory mastery, whereas those with longer naming latencies demonstrated less articulatory mastery. In contrast, CWS did not exhibit an association between speech sound articulation and naming latencies. The authors took these findings to suggest that the phonological encoding systems of CWS may be less developed or organized than their normally-fluent peers. However, it is not clear how the authors arrived at this interpretation, as they did not provide an unambiguous explanation for why the absence of a negative correlation for CWS would indicate that they have a less organized phonological encoding system.
Melnick et al. (2003) speculated that less efficient phonological organization may result from CWS having “…less complete information in that part of their mental lexicon that stores (the) phonological code…” (p. 1440). However, inefficiencies in phonological organization could be related to the ability of CWS to hold phonological information in memory, rather than to the specificity of their phonological representations. Evidence in support of this position comes from a study by Hakim and Ratner (2004), in which 4-to 8-year-old CWS were found to perform more poorly than their age-matched normally-fluent peers on a nonword repetition task designed to measure phonological working memory skills. The authors concluded that CWS may have a deficiency in their ability to hold novel phonological sequences in memory for a sufficient period of time and, subsequently, in their ability to adequately reproduce those novel sequences. More recently, Anderson, Wagovich, and Hall (2006) partially replicated and extended these findings to include a younger group of children between the ages of 3 to 5 years. They found that CWS not only performed more poorly than CWNS on the same nonword repetition task used by Hakim and Ratner, but unlike their normally-fluent peers, they also exhibited a significant, positive relationship between performance on a test of articulation (GFTA-2) and the nonword repetition task. The authors interpreted these findings to suggest that CWS may have difficulty with rehearsal mechanisms involved in processing phonological information.
The Effect of Phonotactic Probability in Speech Production
From this review, it would appear that there may be a relationship between the ability to process individual sound segments and the ability to engage in fluent speech production, as Brooks and MacWhinney (2000) suggested. As previously mentioned, several investigators have posited that the ability to process individual sound segments is acquired gradually over development (e.g., Walley, 1988, 1993). According to this view, children’s earliest words are stored holistically, in terms of some unit larger than the individual phoneme, but then segmental detail is gradually added to the holistic representations until the lexicon has been fully restructured. However, when, in development, this holistic-to-segmental transformation takes place has been a matter of debate in the child language literature. Some researchers maintain that children’s early words are stored holistically until they experience a rapid increase in lexical growth at around 18-20 months of age (e.g., Ferguson, 1986; Locke, 1988; cf. Coady & Aslin, 2004), whereas others suggest that holistic representations are still present in the lexicons of children throughout the early school years (Jusczyk, 1986; Metsala & Walley, 1998; Walley, 1993).
Although it may be the case that children’s earliest words are stored holistically, evidence has accumulated to suggest that the lexical representations of children as young as 2 to 3 years of age do contain at least some fine-grained phonemic detail (Coady & Aslin, 2004; Gerken, Murphy, & Aslin, 1995; Storkel, 2001; Zamuner et al., 2004). Much of this evidence comes from studies in which the effects of phonotactic probability on the accuracy with which (non)words are recognized or produced are examined using experimental tasks, such as nonword repetition (Beckman & Edwards, 1999; Coady & Aslin, 2004; Munson et al., 2005; Storkel & Rogers 2000; Zamuner et al., 2004) and picture naming (e.g., Storkel, 2001, 2003; Storkel & Maekawa, 2005). Findings from these studies generally indicate that children are better able to recognize and produce sounds and sound sequences that are more commonly occurring in language than those that are less commonly occurring.
In one such study, Zamuner et al. (2004) examined the effects of phonotactic probability on 2-year-old children’s production of coda consonants. Children repeated consonant-vowel-consonant (CVC) nonwords containing the same coda in high versus low phonotactic probability environments. The authors reported that children were more likely to produce the same coda accurately in high phonotactic probability nonwords than in low phonotactic probability nonwords. In an earlier study, Storkel (2001) examined the effect of phonotactic probability on 3-to 6-year-old children’s ability to learn novel words using a word learning task, in which eight CVC nonwords varying in phonotactic probability (high versus low) were paired with eight object referents. Children were exposed to the nonword-object referent pairings in the context of a story narrative and learning was assessed using multiple measures, including a picture naming task. In the picture naming task, children were shown pictures of each object referent and were asked to verbally express the name of the nonword that corresponded to the pictured object. Results revealed that nonwords with more common sound sequences were named more accurately than those with less common sound sequences. Taken together, findings from these studies suggest that the probabilistic phonotactic information of the language has an influence on children’s word learning and sound segments that occur more frequently in language have a facilitative effect on phonological processing.
Storkel (2001) also examined the effect of phonotactic probability on the type of errors (semantic versus unrelated errors) children produced in the picture naming task. Semantic errors occurred when the child produced the nonword name of a semantically related object referent from the story, whereas unrelated errors occurred when the child produced the nonword name of a semantically unrelated object referent. Results revealed that children produced more semantic errors on nonwords composed of rare sound sequences than common sound sequences. The author hypothesized that holistic or intact semantic representations, consisting of semantic category information but not enough detail to distinguish category members, tend to be associated with common rather than rare sound sequences. However, she also found that when children substituted an unrelated nonword for a target nonword, the unrelated nonword tended to be composed of rare as opposed to common sound sequences, irrespective of the target nonword’s phonotactic frequency. These latter findings indicated, according to the author, that the children had a lexical representation of the rare sound sequences, but they could not make an association between these sequences (or lexical representations) and a semantic representation. Storkel concluded that the facilitative effect of common sound sequences on phonological processing serves to strengthen the association between lexical and semantic representations, thereby increasing the speed with which lexical items are acquired.
The Potential Effect of Phonotactic Probability in Stuttering
If, as has been suggested (e.g., Byrd et al., 2007), stuttering is related to difficulty processing phonological segments, then one might hypothesize that stuttered words would be lower in phonotactic probability than fluently produced words, as low phonotactic probability words are more vulnerable to errors or disruptions. On the other hand, it is also conceivable that the overall susceptibility of words to stuttering will not be at all influenced by phonotactic probability. Accordingly, if CWS have difficulty processing phonological segments, then their lexical representations may not contain as much detailed segmental information, making them less sensitive to differences in the phonotactic structure of the lexicon. Thus, in this case, no differences in phonotactic probability would be expected to occur between words that are stuttered on and those that are fluently produced.
As previously mentioned, phonotactic probability also appears to have an influence on children’s error patterns, providing insights into the nature and development of children’s lexical and semantic representations (see Storkel, 2001). Thus, it seems logical to assume that phonotactic probability might also influence the production of specific types of stuttered disfluencies. Findings from a recent study by Anderson (2007) provide some support for this assumption. In specific, Anderson reported that preschool CWS tended to produce part-word repetitions and sound prolongations on words that were lower in frequency and/or neighborhood frequency (the frequency of a target word’s phonological neighbors) than their fluently produced words. These frequency variables, however, did not have an effect on the production of single-syllable word repetitions. The author interpreted these findings to suggest that part-word repetitions and/or sound prolongations may result from word-form or phonological segment disruptions, whereas difficulties at some other (non-phonological) level may result in the production of single-syllable word repetitions.
Thus, if words containing part-word repetitions and sound prolongations arise from difficulties with phonological encoding processes, as suggested by Anderson (2007), then one might hypothesize that they will be lower in phonotactic probability than fluently produced words and words with single-syllable word repetitions. However, if single-syllable word repetitions occur as a result of difficulties at some other level of processing, then they will presumably not be differentiated from fluent words in phonotactic probability. These hypotheses are based on the aforementioned finding that words that are lower in phonotactic probability tend to be more vulnerable to disruption than those that are higher in phonotactic probability. On the other hand, it is equally possible that only words containing single-syllable word repetitions will be susceptible to the effects of phonotactic probability. In this way, if single-syllable word repetitions are related to processing difficulties at a non-phonological level of processing, then their phonological representations should be sufficiently robust in segmental detail, making them sensitive to differences in phonotactic frequency. In contrast, if the phonological representations of words containing part-word repetitions and sound prolongations are insufficient in segmental detail, then they will not be sensitive to differences in phonotactic probability and, thus, be comparable to words that are fluently produced.
In sum, the purpose of the present investigation is to examine the effect of phonotactic probability on the susceptibility of words to stuttering in the naturalistic speech of young CWS, as well as to determine whether phonotactic probability has an influence on the type of stuttered disfluency (part-word repetitions, single-syllable word repetitions, or sound prolongations) produced. This investigation will provide further insight into the phonological encoding processes of young CWS, processes which have been identified in other studies as a potential source of difficulty for CWS (e.g., Byrd et al., 2007; Hakim & Ratner, 2004). In addition, because phonotactic probability is examined within the context of naturalistic speech, it is anticipated that this study may further our understanding of any potential mechanisms that may be involved in the moment of stuttering. Indeed, by focusing on naturalistic speech production, the present study differs from most other speech production studies, since the effect of phonotactic probability on the accuracy of word production has, as of this date, only been examined using laboratory-based experimental tasks (Storkel, 2001, 2003; Zamuner et al., 2004).
The fact that phonotactic probability effects have not been examined in naturalistic speech production is rather surprising, as this methodology has been used to examine the effects of other lexical factors, such as word frequency and neighborhood density, in speech production (e.g., German & Newman, 2004; Gordon, 2002; Vitevitch, 1997). Furthermore, research has demonstrated that error data collected in naturalistic speech samples are similar in “ecological validity” to error data induced in laboratory controlled situations (Stemberger, 1992; see Vitevitch, 2002a and Voss, 1984 for a similar comparison in spoken word recognition). Thus, it would seem that the use of naturalistic speech samples to examine the effects of phonotactic probability on stuttering is not only a valid and reliable alternative to the use of controlled, laboratory-based samples, but also promises to yield data that is truly reflective of the environment in which stuttering typically occurs (i.e., conversation; cf. Storkel, 2004a).
Method
Participants
Participants included 19 CWS (14 males, 5 females) between the ages of 3;0 and 5;8 (years; months) (Mean age = 48.89 months, SD = 7.69). All participants were native speakers of American English and had no history of hearing, intellectual, neurological, or speech-language problems (except for stuttering), based on parental reports and examiner observation. Fourteen of the 19 children in this study had been participants in a previous study conducted by the first author (Anderson, 2007). Participants were recruited through advertisements placed in local news periodicals in Bloomington, IN and surrounding areas.
Inclusion and Classification Criteria
To participate, children were required to score within normal limits on four standardized speech-language measures, pass a hearing screening, and meet the minimum criteria established for CWS classification based on a conversational speech sample (see Table 1). Participants were assessed on a single occasion for 1 to 1½ hours in the Speech Disfluency Laboratory at Indiana University.
Table 1.
Participant Characteristics
| Participant | Age (months) | Gender | PPVT-III | EVT | TELD-3 | GFTA-2 | TSO | % SLD | SSI-3 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 48 | M | 101 | 97 | 90 | 90 | 24 | 3.2 | 20 |
| 2 | 51 | M | 104 | 115 | 123 | 100 | 15 | 3.5 | 23 |
| 3 | 58 | F | 119 | 120 | 129 | 92 | 20 | 3.9 | 20 |
| 4 | 51 | F | 97 | 107 | 109 | 111 | 27 | 7.4 | 29 |
| 5 | 51 | M | 123 | 107 | 124 | 102 | 9 | 10.9 | 23 |
| 6 | 50 | M | 94 | 91 | 91 | 109 | 24 | 3.8 | 28 |
| 7 | 42 | F | 116 | 119 | 119 | 94 | 7 | 4.9 | 20 |
| 8 | 43 | M | 126 | 111 | 134 | 103 | 6 | 15.5 | 31 |
| 9 | 43 | F | 93 | 113 | 101 | 124 | 20 | 5.9 | 26 |
| 10 | 56 | M | 109 | 102 | 96 | 93 | 12 | 4.8 | 24 |
| 11 | 51 | M | 108 | 103 | 99 | 97 | 9 | 3.0 | 18 |
| 12 | 57 | M | 116 | 133 | 113 | 118 | 33 | 3.1 | 15 |
| 13 | 36 | M | 93 | 98 | 102 | 117 | 3 | 7.4 | 16 |
| 14 | 41 | M | 96 | 112 | 122 | 99 | 2 | 4.8 | 20 |
| 15 | 40 | M | 95 | n/a* | n/a* | 104 | 21 | 7.6 | 23 |
| 16 | 42 | M | 105 | 122 | 140 | 120 | 7 | 7.5 | 21 |
| 17 | 49 | F | 121 | 125 | 131 | 95 | 29 | 4.5 | 16 |
| 18 | 52 | M | 119 | 124 | 124 | 113 | 16 | 11.0 | 29 |
| 19 | 68 | M | 111 | 114 | 117 | 86 | 32 | 8.0 | 20 |
| MEAN (SD) | 48.89 (7.69) | n/a | 107.68 (11.18) | 111.83 (11.05) | 114.67 (15.25) | 103.37 (11.42) | 16.63 (9.87) | 6.35 (3.31) | 22.21 (4.69) |
Note. PPVT-III = Peabody Picture Vocabulary Test-III (standard score); EVT = Expressive Vocabulary Test (standard score); TELD-3 = Test of Early Language Development-3 (standard score); GFTA-2 = Goldman-Fristoe Test of Articulation-2 (standard score); TSO = parent-reported time since initial onset of stuttering (months); %SLD = mean frequency of stuttering-like disfluencies (percent) per 100 words; SSI-3 = Stuttering Severity Instrument-3 (total score); = test scores could not be obtained, because the participant refused to cooperate with further testing.
Speech and Language Measures and Hearing Screening
All participants scored less than one standard deviation below the mean on four standardized speech-language measures: (a) Peabody Picture Vocabulary Test-III (PPVT-III; Dunn & Dunn, 1997); (b) Expressive Vocabulary Test (EVT; Williams, 1997); (c) Test of Early Language Development-3 (TELD-3; Hresko, Reid, & Hammill, 1999); and (d) the “Sounds-in-Words” subtest of the GFTA-2.2 Participants also passed a hearing screening, which included bilateral pure tone testing at 20dB SPL for 500, 1000, 2000, and 4000 Hz and impedance audiometry at +400 to -400 daPa (ASHA, 1990).
Parent-Child Conversational Interaction
The conversational interaction consisted of having the parent and child seated at a small table with age-appropriate toys. A 500+ word language sample (mean sample size = 824.21 words, SD = 321.53) was obtained for each child as he/she verbally interacted with his/her parent(s). Each child’s language sample was analyzed for mean frequency of stuttering-like disfluencies (part-word repetitions, single-syllable word repetitions, sound prolongations, blocks, and tense pauses) per 100 words (Yairi & Ambrose, 1992, 1999, 2005)3 and stuttering severity, as measured by the Stuttering Severity Instrument-3 (SSI-3; Riley, 1994).
To be classified as CWS, participants had to: (a) have a mean frequency of three or more stuttering-like disfluencies; (b) receive a score of 12 or higher on the SSI-3 (3 participants were classified as having “mild” stuttering, 12 were “moderate”, and 4 were “severe”); and (c) have a parent(s) who was concerned about his/her stuttering. One child had received treatment for stuttering in the 9 months prior to participating in this study. The time since onset of each child’s stuttering, which was determined using the “bracketing” procedure described by Yairi and Ambrose (1992; cf. Anderson, Pellowski, Conture, & Kelly, 2003), was 16.63 months (SD = 9.87 months; Range = 2-33 months).
Procedures
Transcript Analysis
The conversational interaction was videotaped using two color video cameras (EV1-D30), Unipoint AT853 Rx Miniature Condenser Microphone, and a Panasonic DVD/HD video recorder (Model N. DMR-HS2). The videotaped language sample collected for each participant was subsequently transcribed into the computer using the Systematic Analysis of Language Transcripts software program (Miller & Chapman, 1998). For classification purposes, all instances of stuttering-like disfluencies (part-word repetitions, single-syllable word repetitions, sound prolongations, blocks, and tense pauses) were identified in each child’s transcript and analyzed for the mean frequency of stuttering-like disfluencies per 100 words and stuttering severity, as measured by the SSI-3 (see above).
For all subsequent analyses, however, only words containing part-word repetitions (e.g., “b* b* but,” “ba* ba* baby”), single-syllable word repetitions (e.g., “but-but-but,” “you-you-you”), and sound prolongations (e.g., “wwwwhat,” “mmmmommy”) were included in the data corpus. In other words, all other stuttering-like disfluencies (blocks and tense pauses), as well as “normal” disfluencies (multisyllable/phrase repetitions, revisions, and interjections; Yairi & Ambrose, 1992, 1999, 2005) were excluded from the data corpus. Blocks were excluded because they occurred relatively infrequently across participants—only 3 of the 19 participants (15.8%) exhibited blocks during conversational speech (a frequency consistent with studies of early stuttering; see Yairi, 1997, for review). Tense pauses were excluded because they occur between words and are often difficult to reliably discern in young children’s speech (Yairi & Ambrose, 1992, 1999, 2005). Finally, all other (“normal”) disfluencies were excluded from the data corpus, because the focus of the present study was on the lexical characteristics of words that tend to be associated with stuttering (i.e., stuttering-like disfluencies). A total of 827 words containing part-word repetitions, single-syllable word repetitions, and/or sound prolongations were obtained from the 19 participants’ transcripts.
Word Pair Matching
Each word containing a stuttering-like (or stuttered) disfluency (part-word repetitions, single-syllable word repetitions, and sound prolongations) was randomly paired with the first subsequently produced fluent (control) word that matched it exactly by grammatical class (function or content) and number of syllables and, as closely as possible, by number of phonemes, word familiarity, word frequency, neighborhood density, and neighborhood frequency (see below for additional word matching details). This matching procedure was employed in order to control for the potential effect of these lexical variables on phonotactic probability (e.g., Storkel, 2001; Vitevitch, 2003).
Values for word frequency, word familiarity, neighborhood density, and neighborhood frequency were obtained from an online database (the Hoosier Mental Lexicon [HML]), which contains the transcriptions of 20,000 words from Webster’s Pocket Dictionary (Luce & Pisoni, 1998; Nusbaum, Pisoni, & Davis, 1984; http://128.252.27.56/neighborhood/Home.asp). Word frequency (the number of times a given word occurs in a language) and neighborhood frequency (the frequency of a given word’s neighbors) values in this database are based on the counts of Kučera and Francis (1967), whereas all other lexical values are from Luce and Pisoni (1998). Word familiarity, a subjective rating of how well-known a given word is to a listener, has values in this database ranging from 1 (“don’t know the word”) to 7 (“know the word and know its meaning”; see Nusbaum, Pisoni, & Davis, 1984). The neighborhood density values in this database were obtained by calculating the number of words in the dictionary that differed from a given word by the substitution, addition, or deletion of a single phoneme (see Luce & Pisoni, 1998).
Although values in the HML are based on the adult lexicon, research has demonstrated that they are highly and positively correlated with child values, making it appropriate to use in this present study (Dale, 2001; Gierut & Storkel, 2002; Jusczyk et al., 1994; Maekawa & Storkel, 2006; Moe, Hopkins, & Rush, 1982; Walley & Metsala, 1992). However, because the database of 20,000 words is relatively small compared to the entirety of the lexicon, not all stuttered and control words were found in the database (Luce & Pisoni, 1998). Thus, the neighborhood values for the 42 words that were not in the HML database were obtained from a phonetic database maintained by Dr. Michael Vitevitch in the Department of Psychology at the University of Kansas. The Kučera and Francis frequency values (1967) for these 42 words were obtained from the MRC Psycholinguistic Database (Wilson, 1988; http://www.psy.uwa.edu.au/mrcdatabase/uwa_mrc.htm).
The stuttered and control words were first matched exactly by grammatical class and number of syllables. Next, each word pair was matched, as closely as possible, by number of phonemes and word familiarity. In particular, the control word had to be within 0-2 phonemes of the stuttered word and have a familiarity rating of 6.0 or higher. The stuttered and control words were then matched for word frequency using a median split value of 2439, with high frequency words having a frequency value of 2439 or higher and low frequency words having values below 2439. A control word was considered to be an acceptable match for a stuttered word if they both had either high or low frequency values. Word pairs were matched for neighborhood density using a density value of 10, with high density words having a density value of 10 or higher and low density words having values below 10 (see Morrisette & Gierut, 2002 for a similar operational definition of high versus low density values). A control word was matched to a stuttered word if they both had high or low density values. Finally, each word pair was matched for neighborhood frequency in a manner similar to that described for word frequency, except the median split value for this variable was 365.1. If, at any point, the control word failed to meet any of the matching criteria, then the next fluently produced word with the same grammatical class and number of syllables as the stuttered word was selected and the matching process began anew. This matching procedure resulted in a total of 684 useable word pairs across all participants, of which 204 (29.8%) were content words and 480 (70.2%) were function words. Of the 684 word pairs, 630 (92.1%) were single-syllable words, 50 (7.3%) were two-syllable words, and 4 (0.60%) were three-syllable words.
Matching Analysis
The 684 stuttered and control words were statistically analyzed to ensure that they were comparably matched in number of phonemes, word familiarity, word frequency, neighborhood density, and neighborhood frequency. Nonparametric statistics were used for these analyses because samples were drawn from highly-skewed distributions, and thus, violated the normality assumption for parametric tests (attempts to power transform the data also failed to correct the distribution).
Each word pair was matched, as closely as possible, for number of phonemes, with stuttered words having a mean value of 2.74 (SD = 0.96) phonemes and control words having a mean of 2.75 (SD = 0.93) phonemes. Of the 684 usable word pairs, 381 (55.7%) had the exact same number of phonemes, 282 (41.2%) differed by only one phoneme, and 21 (3.1%) differed by two phonemes. A Wilcoxon signed-ranks test revealed no significant difference between the two groups of words in the number of phonemes, z = -.54, p = .59. In addition, the stuttered words (M = 6.91, SD = 0.19) were not significantly different from the control words (M = 6.92, SD = 0.19) in word familiarity, z = -.27, p = .79. The mean frequency of the stuttered words was 7305.88 (SD = 11819.53), while the mean frequency of the control words was 7913.01 (SD = 14529.72), a difference that was not statistically significant, z = -.75, p = .45. The stuttered and control words were also found to be comparable in neighborhood density, with the stuttered words having a mean density value of 17.40 (SD = 9.54) and the control words having a mean of 17.77 (SD = 9.50). A Wilcoxon signed-ranks test revealed that the two groups of words were not significantly different in neighborhood density, z = -1.19, p = .23. Finally, the mean neighborhood frequency of the stuttered words (M = 839.43, SD = 1744.25) did not significantly differ from the control words (M = 906.09, SD = 1572.93), z = -1.12, p = .26.
Findings from this matching analysis indicate that, in addition to being matched exactly by grammatical class and number of syllables, the stuttered and control words were comparable in their number of phonemes, word familiarity, word frequency, neighborhood density, and neighborhood frequency. Thus, any potential difference between the stuttered and control words in phonotactic probability cannot be readily attributed to these other potentially confounding lexical variables.
Phonotactic Probability Analysis
Phonotactic probability estimates for the stuttered and control words were calculated using an online database, the Phonotactic Probability Calculator (Vitevitch & Luce, 2004). This database contains phonotactic probability values for phonological segments (referred to as positional segment frequency—the probability of occurrence of a particular sound in a particular word position) and segment sequences (referred to as biphone frequency—the probability of co-occurrence of two adjacent sounds within a word) for 20,000 words from an online version of Webster’s Pocket Dictionary. All stuttered and control words were phonetically transcribed and then translated into a computer-readable transcription (referred to as “Klattese”) prior to obtaining their log-based values for positional segment and biphone frequency from the database (Vitevitch & Luce, 2004). This database, like the aforementioned HML, has been previously used in the literature to compute phonotactic probability in children, as well as infants and adults (e.g., Jusczyk et al., 1994; Storkel, 2001, 2003).
Measurement Reliability
Stuttering-like disfluency measures
Intra-and interjudge reliability was assessed for the three stuttering-like disfluency types (part-word and single-syllable word repetitions, as well as sound prolongations) assessed in this study. Four participants’ conversational speech samples were randomly selected, which included a total of 2,989 words and represented 19% of the total data corpus (there were 15,660 total words across all participants). For intrajudge reliability, a trained graduate student re-observed the videotape recordings of the 4 children on two separate occasions, separated by a period of 1 month, and re-identified all instances of each stuttering-like disfluency type within each sample. Interjudge reliability was achieved by having the first author and a trained graduate student independently observe the four recordings and then identify each stuttering-like disfluency type. Sander’s (1961) point-by-point agreement index (number of agreements/[number of agreements + disagreements] × 100) was used to calculate intra-and interjudge reliability percentages. Intrajudge measurement reliability was 90% for part-word repetitions, 93% for single-syllable word repetitions, and 88% for sound prolongations. Interjudge measurement reliability was 86% for part-word repetitions, 90% for single-syllable word repetitions, and 81% for sound prolongations.
SALT transcripts
The SALT transcripts from the four conversational speech samples used in the stuttering-like disfluency reliability analysis were also assessed for transcription accuracy. Intrajudge reliability was achieved by having a trained graduate student transcribe the videotaped speech samples of the 4 participants on two separate occasions, separated by one month. Interjudge reliability was achieved by having two trained students independently transcribe each sample using SALT. Point-to-point (i.e., word-to-word) comparisons were made by noting whether the two samples agreed or disagreed with each other for each transcribed word. Sander’s (1961) agreement reliability formula was used to establish intrajudge (92.8%) and interjudge (90.0%) reliability for words in the SALT transcripts.
Results
Influence of Phonotactic Probability on Stuttering
The purpose of this analysis was to determine whether phonotactic probability has an effect on the overall susceptibility of words to stuttering in naturalistic speech production. To this aim, the positional segment and biphone frequency values of words containing stuttering-like disfluencies (part-word repetitions, single-syllable word repetitions, and sound prolongations) were compared to those that were fluently produced. Mean positional segment and biphone log-based frequency values for the stuttered and control words were calculated for each participant (N = 19), and then analyzed using matched-pairs t-tests. The effect size indicator partial eta square (partial eta2) is reported for each statistical comparison as a measure of the strength of the association, with a partial eta2 of .14 representing a “large” effect, .06 a “medium” effect, and .01 a “small” effect (Cohen, 1988).
As depicted in Figure 1, a matched-pairs t-test revealed no significant difference between the stuttered (M = .119, SD = .020) and control words (M = .125, SD = .021) in positional segment frequency, t (18) = -1.57, p =.14, partial eta2 = .12, power = .32. Similarly, there was no significant difference between the stuttered (M = .007, SD = .002) and control words (M = .007, SD = .002) in biphone frequency, t (18) = -.05, p = .96, partial eta2 = .001, power = .05 (Figure 2). Thus, contrary to initial expectations, results indicate that phonotactic probability does not have a significance influence on the fluency with which words are produced, although power was low for these analyses.
Figure 1.
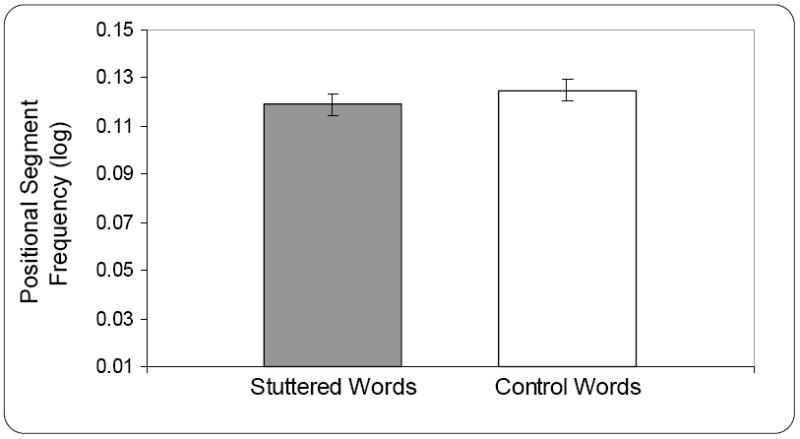
Mean (and standard error of the mean) positional segment frequency for stuttered and control words for 19 children who stutter between the ages of 3;0 and 5;8 (years;months).
Figure 2.
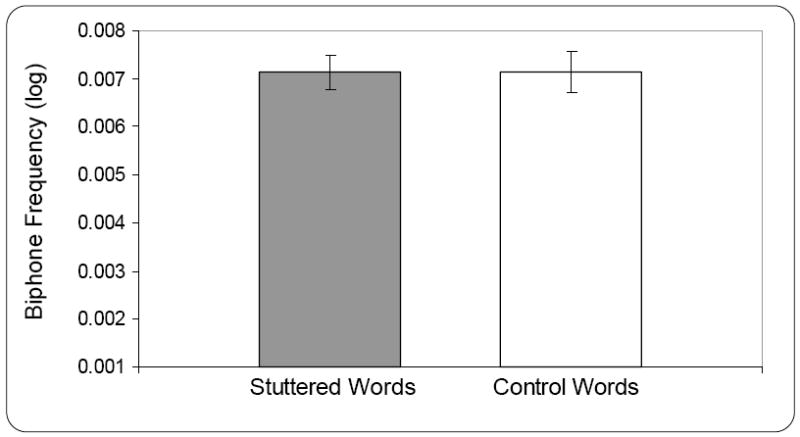
Mean (and standard error of the mean) biphone frequency for stuttered and control words for 19 children who stutter between the ages of 3;0 and 5;8 (years;months).
Influence of Phonotactic Probability on Types of Stuttering
The purpose of this analysis was to examine whether phonotactic probability influences specific types of stuttering-like disfluency produced in spontaneous speech. Accordingly, the positional segment and biphone frequency values for each stuttering-like disfluency type were compared to their corresponding control words, as well as across stuttering-like disfluency types. For these analyses, words containing more than one type of stuttering-like disfluency (e.g., “Wh* wh* wh* where where does that horsie go?”) were removed from the data corpus. This resulted in the removal of 19 words from the initial corpus of 684 stuttered words for a total of 665 words. Of these 665 words, 302 contained part-word repetitions, 280 single-syllable word repetitions, and 83 sound prolongations. There were fewer instances of sound prolongations in the data corpus, because 5 children did not produce any sound prolongations during conversational speech and 7 children produced only one or two instances of sound prolongations.
The stuttered words for each type of stuttering-like disfluency were paired with the same control words used in the previous analyses, which had been matched exactly by grammatical class and number of syllables and, as closely as possible, by number of phonemes, word familiarity, word frequency, neighborhood density, and neighborhood frequency. Wilcoxon signed-ranks tests revealed no significant difference between the stuttered and control words in number of phonemes, word familiarity and frequency, and neighborhood density and frequency for each stuttering-like disfluency type, with p-values ranging from .07 to .94. Mean positional segment and biphone frequency values for words containing part-word and single-syllable word repetitions and their corresponding control words were calculated for each participant (N = 19). Mean phonotactic probability values were also calculated for sound prolongations and their control words. However, because there were fewer instances of sound prolongations across participants, mean positional segment and biphone frequency values were only calculated for the seven children who produced at least three or more of these stuttering-like disfluency types, along with their corresponding control words. The sound prolongations and their control words were also removed from the omnibus significance tests and analyzed separately, as their inclusion had the effect of substantially reducing the sample size for statistical analyses. Partial eta2 is again reported as the effect size indicator for each statistical analysis and Bonferroni adjustments were applied to alpha, where appropriate, to maintain the familywise potential for Type I error at .05.
Positional Segment Frequency
Figure 3 depicts the positional segment frequency values for each stuttering-like disfluency type and their corresponding controls. A two-way repeated measures analysis of variance revealed significant main effects for stuttering-like disfluency type (part-word and single-syllable word repetitions), F (1, 18) = 29.68, p < .01, partial eta2 = .62, and word group (stuttered and control words), F (1, 18) = 4.75, p < .05, partial eta2 = .21, on positional segment frequency, but no significant type × word group interaction, F (1, 18) = 2.10, p = .16, partial eta2 = .10, power = .28. A follow-up matched-pairs t-test (Bonferroni corrected), however, revealed that words with single-syllable word repetitions (M = .094, SD = .021) were significantly lower in positional segment frequency than their corresponding control words (M = .113, SD = .025), t (18) = -2.72, p < .05, partial eta2 = .29, indicating that single-syllable word repetitions occur on words with less frequently occurring phonological segments than those produced fluently. There was no significant difference in positional segment frequency between words containing part-word repetitions (M = .134, SD = .025) and their corresponding controls (M = .136, SD = .032), t (18) = -.262, p = .80, partial eta2 = .004, as well as between words containing sound prolongations (M = .139, SD = .054) and their controls (M = .139, SD = .034), t (6) = .04, p = .97, partial eta2 = .001, although statistical power was determined to be low for these analyses (power = .06 and .05, respectively).
Figure 3.
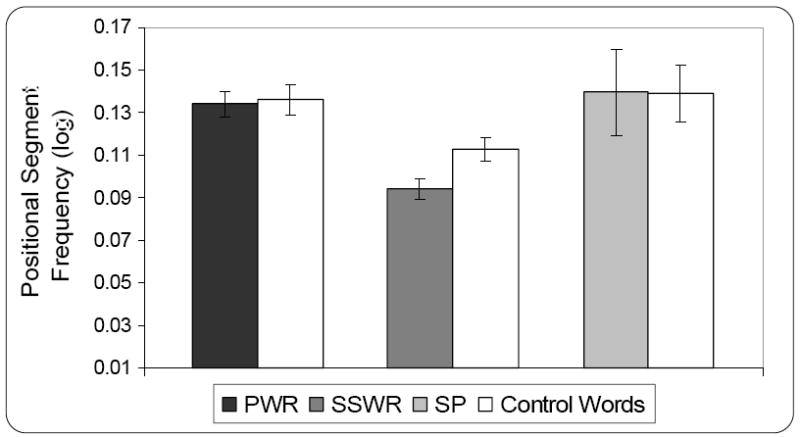
Mean (and standard error of the mean) positional segment frequency for words containing part-word repetitions (PWR) and control words (n = 19), single-syllable word repetitions (SSWR) and control words (n = 19), and sound prolongations (SP) and control words (n = 7) for children who stutter between the ages of 3;0 and 5;8 (years;months).
A one-way analysis of variance was also conducted to examine differences in positional segment frequency between part-word and single-syllable word repetitions. Prior to performing the analysis, however, the two groups of words were analyzed to determine whether they were comparable in grammatical class, word length (number of phonemes and syllables), word familiarity, word frequency, neighborhood density, and neighborhood frequency. A Wilcoxon signed-ranks test indicated that words containing part-word repetitions were higher in phoneme number (M = 2.82, SD = .29), z = -2.94, p < .01, and lower in frequency (M = 6119.70, SD = 2758.15), z = -2.94, p < .01, and neighborhood frequency (M = 627.31, SD = 217.10), z = -2.85, p < .01, than words containing single-syllable word repetitions (phonemes: M = 2.39, SD = .34; frequency: M = 9731.16, SD = 4650.45; neighborhood frequency: M = 1108.21, SD = 619.13). A chi-square analysis also revealed a significant difference in the proportion of content and function words between the two stuttering-like disfluency types, χ2(1) = 21.54, p < .001, with words containing part-word repetitions having a higher proportion of content words and a lower proportion of function words than words containing single-syllable word repetitions. Values for all other lexical factors (number of syllables, word familiarity, and neighborhood density) were not significantly different between part-word and single-syllable word repetitions, with p-values ranging from . 08 to .85.
Because words containing part-word repetitions and single-syllable word repetitions were not comparable in grammatical class, number of phonemes, word frequency, and neighborhood frequency, these lexical variables were included as covariates in the analysis of variance. Preliminary testing of the assumptions of the analysis of covariance, including homogeneity of variance and regression slopes, was found to be satisfactory. After adjusting for the lexical factors, results revealed a significant difference between words containing part-word and single-syllable word repetitions in positional segment frequency, F (1, 32) = 4.36, p < .05, partial eta2 = .12. In specific, words containing single-syllable word repetitions (adjusted M = .105, n = 19) were significantly lower in positional segment frequency than words containing part-word repetitions (adjusted M = .122, n = 19).
A one-way repeated measures analysis of variance was also used to examine differences in positional segment frequency between words containing part-word repetitions and sound prolongations. However, no covariates were included in the analysis, because the two groups of words did not significantly differ in any of the aforementioned lexical variables (p-values ranged from .07 to .87). Results revealed no significant difference between words containing part-word repetitions (M = .134, SD = .03) and sound prolongations (M = .139, SD = .05) in positional segment frequency, F (1, 6) = .96, p =.37, partial eta2 = .14, power = .13. These findings indicate that part-word repetitions and sound prolongations are comparable in the frequency of their phonological segments (findings should, however, be viewed with caution, given the low statistical power and reduced sample size).
Biphone Frequency
Figure 4 shows the biphone frequency values for each stuttering-like disfluency type and their corresponding controls. A two-way repeated measures analysis of variance revealed a significant main effect for stuttering-like disfluency type (part-word and single-syllable word repetitions), F (1, 18) = 8.45, p < .01, partial eta2 = .32, but no significant word group (stuttered and control words), F (1, 18) = .41, p = .53, partial eta2 = .02, power = .09, or type × word group interaction, F (1, 18) = 1.08, p = .31, partial eta2 = .065, power = .17. A separate matched-pairs t-test also revealed no significant difference between words containing sound prolongations (M = .009, SD = .005) and their control words (M = .008, SD = .004) in biphone frequency, t (6) = .78, p = .47, partial eta2 = .09, power = .10. These findings indicate that the frequency of occurrence of different phonological segment sequences in children’s naturalistic speech does not have a significant influence on the production of different types of stuttering-like disfluencies. These findings should, nevertheless, be viewed with caution given the low power.
Figure 4.
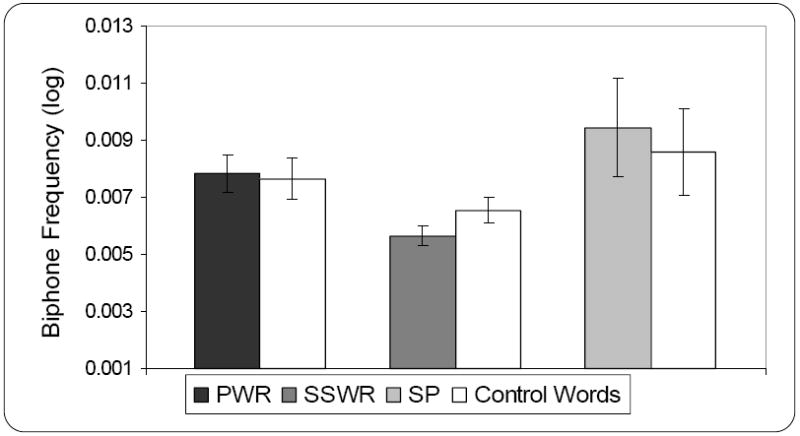
Mean (and standard error of the mean) biphone frequency for words containing part-word repetitions (PWR) and control words (n = 19), single-syllable word repetitions (SSWR) and control words (n = 19), and sound prolongations (SP) and control words (n = 7) for children who stutter between the ages of 3;0 and 5;8 (years;months).
A one-way analysis of covariance was also used to examine differences in biphone frequency between part-word and single-syllable word repetitions, with grammatical class, number of phonemes, word frequency, and neighborhood frequency included as covariates. Preliminary checks were conducted to ensure that there were no violations of the assumptions of the ANCOVA. After adjusting for the lexical factors, results revealed that although words containing single-syllable word repetitions (adjusted M = .006, n = 19) were lower in biphone frequency than words containing part-word repetitions (adjusted M =.007, n = 19), this difference was not statistically significant, F (1, 32) = .59, p = .45, partial eta2 = .02, power = .12. A one-way analysis of variance also revealed no significant difference in biphone frequency between part-word repetitions (M = .008, SD = .003) and sound prolongations (M = .009, SD = .005), F (1, 24) = 1.16, p = .29, partial eta2 = .20, power = .18.
Discussion
The purpose of this study was to assess the influence of phonotactic probability on the overall fluency with which words are produced by preschool CWS in naturalistic speech, as well as to examine whether these variables have an effect on the type of stuttering-like disfluency produced. In general, results indicated that while phonotactic probability does not have an appreciable influence on the overall susceptibility of words to stuttering, it does have an effect on the type of stuttering-like disfluency produced. The significance of these findings will be discussed further below, but to provide a context, the locus of phonotactic probability effects in speech production will first be considered.
The Locus of Phonotactic Probability Effects in Speech Production
Findings from studies of speech production in adults and children generally suggest that phonotactic information is stored in phonological representations (also referred to as sublexical or segmental representations), which correspond to phonological segments and segment sequences (Storkel, 2001, 2004b; Vitevitch & Luce, 2005; Vitevitch et al., 2004; cf. Storkel & Morrisette, 2002). Thus, in an interactive spreading activation model, such as the two-step model of lexical access proposed by Dell and his colleagues (e.g., Dell, Schwartz, Martin, Saffran, & Gagnon, 1997), phonotactic probability presumably has its primary effect on phonological retrieval processes. According to this model, lexical access is hypothesized to result from bidirectional, excitatory spreading activation within a network of three interconnected layers consisting of semantic (concept or meaning), lexical (word or lemma), and sublexical (phonemes) features (e.g., Dell, Chang, & Griffin, 1999; Dell et al., 1997; Schwartz et al., 2006). This model does not include a separate layer for the word form or lexeme, but rather this information is presumed to be represented in the connection between lexical and sublexical layers (Schwartz et al., 2006).
Dell and his colleagues posit that lexical access involves two separate, but interconnected steps: word (or lemma) retrieval and phonological retrieval (Dell, Lawler, Harris & Gordon, 2004; Dell et al., 1997; Foygel & Dell, 2000; Schwartz et al., 2006). The word retrieval step begins when a target word’s semantic features are activated by either seeing, hearing, or thinking of the word (see Schwartz et al., 2006). This activation will spread throughout the network—from semantic features to words, words to phonemes, and back again—until the most activated word unit with the appropriate syntactic category is selected. The selected word is then given a boost of activation, marking the beginning of the phonological retrieval step. Activation will again spread throughout the network in a top-down and bottom-up manner until the most activated phonemes are selected. The selected phonemes are then linked to positions in a phonological frame, denoting the end of the phonological retrieval step.
Based on this model, the facilitative effects of phonotactic probability can be explained by considering that phonological segments that have a higher frequency of occurrence will be initially more highly activated, as they are frequently accessed in language (Vitevitch et al., 2004). As a result, the access paths for these segments may be more firmly established in the lexicon and/or their sublexical representations may be more robust in phonological detail (see Garlock, Walley, & Metsala, 2001; Metsala & Walley, 1998; Morrisette & Gierut, 2002; cf. Anderson, 2007). Thus, high frequency phonological segments will be more accurately and quickly retrieved. In contrast, phonological segments that are lower in frequency of occurrence will be initially less highly activated, as they are not commonly accessed in language (Vitevitch et al., 2004). As a result, these low frequency segments may have less firmly established access paths and/or less specified segmental compositions, causing them to be retrieved more slowly and less accurately than their high frequency counterparts. In sum, phonotactic probability can be said to originate from different levels of activation in phonological representations, such that commonly occurring segments have higher levels of activation and infrequently occurring segments have lower levels of activation (Vitevitch et al., 2004).
Influence of Phonotactic Probability on Stuttering
In the present study, it was initially hypothesized that CWS would be more susceptible to fluency disruptions on words that are lower in phonotactic probability than fluently produced words. This hypothesis was largely derived from studies that have revealed that (non)words with less common sound sequences tend to be produced less accurately than (non)words with more common sound sequences (e.g., Storkel & Maekawa, 2005; Zamuner et al., 2004). Contrary to this hypothesis, results revealed that stuttered words were comparable in phonotactic probability to those that were fluently produced. This finding, however, is consistent with Throneburg, Yairi, and Paden’s (1994) finding that phonological complexity, measured according to whether words contained late emerging consonants, consonant strings, and/or multiple syllables, had no effect on stuttering in preschool CWS (cf. Howell & Au-Yeung, 1995). On the other hand, in a more recent study, Howell, Au-Yeung, and Sackin (2000) reported that 3-to 11-year-old children tend to stutter more on content words that begin with a late emerging consonant or consonant string. Therefore, if word position had been taken into account in the present study, it is possible that a word initial effect of phonotactic probability may have been found, with stuttering occurring more on words with less commonly occurring initial phonemes. While this possibility warrants further investigation, it does not appear likely, given that most of the stuttered words (70.2%) sampled in this study were function words and Howell et al. did not find a word initial effect of phonological complexity on stuttering in function words.
Present findings should be interpreted with caution, given the low power associated with the analyses, presumably as a result of a relatively limited sample size (see Caveats for further discussion). Nevertheless, if taken at face value, findings provide preliminary support for the second, alternative hypothesis, in which stuttering was not expected to be influenced by phonotactic probability. According to this hypothesis, if CWS are less adept at processing phonological segments, then their lexical entries may contain less segmental detail. As a result, they would be less sensitive to differences in phonotactic probability and, thus, no significant difference in phonotactic probability would be expected to occur between words that are stuttered on and those that are fluently produced. The notion that CWS may be delayed in their ability to access/store segmental representations receives some empirical support from the findings of Byrd et al. (2007). As will be recalled, Byrd et al. found evidence to suggest that, in contrast to their typically developing peers, CWS appear to be slower to shift from a holistic to segmental form of encoding. Thus, as vocabulary growth increases, if CWS have difficulty capitalizing on segmental processing, then they would likely have difficulty disambiguating among phonologically similar representations in their lexicons. This would, at least theoretically, make them more prone to speech disruptions, perhaps taking the form of frequent repetitions or prolongations of sounds and/or words.
Influence of Phonotactic Probability on Specific Types of Stuttering-Like Disfluencies
It was initially predicted, based on findings from speech production studies, that words containing part-word repetitions and sound prolongations would contain less frequently occurring segments and segment sequences relative to words containing no stuttering and those with single-syllable word repetitions. In addition, single-syllable word repetitions were not expected to differ in phonotactic probability from the fluent control words. Present findings, however, did not support this initial hypothesis. In fact, as will be recalled, the phonological segments (but not segment sequences) of words containing single-syllable word repetitions were significantly lower in frequency than fluently produced words and words with part-word repetitions and sound prolongations. Also contrary to initial expectations was the finding that words containing part-word repetitions and sound prolongations were not susceptible to the effects of phonotactic probability.
Thus, present findings appear to provide preliminary support for the second, alternative hypothesis, in which only words with single-syllable word repetitions were expected to be influenced by phonotactic probability. Accordingly, the fact that words with single-syllable word repetitions were susceptible to the effects of phonotactic probability indicates that their phonological representations must have contained enough segmental detail to be sensitive to differences in phonotactic frequency (see Aslin & Smith, 1988; Munson & Babel, 2005; Walley, 1988, 1993). In contrast, words containing part-word repetitions and sound prolongations were not significantly different from their fluent controls in phonotactic probability, suggesting that their phonological representations may have been lacking in segmental detail relative to words containing single-syllable word repetitions. As a result, words containing part-word repetitions and sound prolongations would be relatively impervious to differences in phonotactic frequency.
Of course, as with the discussion of the overall effects of phonotactic probability, these findings with respect to types of stuttering-like disfluencies must be tempered by the fact that power was low for at least some of the analyses. Nevertheless, it is interesting to note that present findings complement those of Anderson (2007). In this respect, findings from the two studies indicate that phonotactic probability influenced the production of single-syllable word repetitions (but not part-word repetitions or sound prolongations), and word frequency and neighborhood frequency variables influence part-word repetitions and/or sound prolongations (but not single-syllable word repetitions). Taken together, these findings provide preliminary evidence to suggest that stuttered disfluencies involving the repetition or prolongation of sounds—that is, part-word repetitions and sound prolongations—may be related to difficulty at the phonological segment level, whereas single-syllable word repetitions may result from a disruption in some other, presumably non-phonological level of processing (see Anderson, 2007, for further discussion).
Caveats and Future Directions
There are several issues that should be taken into consideration when interpreting the findings from this study. First, the sample size used in this study may have been too small to allow for a reliable detection of differences. Although the sample size (N = 19) was smaller than what is typically used in similar studies of typically-developing children (e.g., Storkel, 2001; Storkel & Maekawa, 2005; Zamuner et al., 2004), it is at least comparable to, if not greater than, many other similar studies of CWS (e.g., Anderson & Conture, 2004; Anderson et al., 2006; Arnold, Conture, & Ohde, 2005; Hakim & Ratner, 2004). Nevertheless, the relatively small sample size was particularly problematic for the analyses of different types of stuttering-like disfluencies, especially with respect to sound prolongations. As will be recalled, phonotactic probability values for sound prolongations were only calculated for 7 participants who produced at least three or more of these stuttering-like disfluencies in conversational speech, compared to the 19 participants who contributed values for both part-word and single-syllable word repetitions. Of course, one potential draw-back of utilizing a small sample size is there may not be enough statistical power to detect real differences between groups or, in the case of the present study, between the stuttered and control words (see Jones, Gebski, Onslow, & Packman, 2002 for a discussion of power issues related to stuttering research). Thus, it is possible that, with a larger sample size, differences in phonotactic probability may emerge for some of the null results found in the present study. This possibility appears to warrant further consideration in any future research that seeks to further examine the role of phonotactic probability on the stuttering-like disfluencies of CWS.
A second issue to consider is that the online databases used to calculate the lexical (e.g., familiarity, frequency, etc.) and phonotactic probability values of the stuttered and control words are based on the adult lexicon. Although, as previously indicated, the values in these databases are frequently used in studies of children, because they are highly and positively correlated with child values and tend to result in similar findings when compared to child databases (e.g., Dale, 2001; Gierut & Storkel, 2002; Storkel, 2001, 2003; Walley & Metsala, 1992; Jusczyk et al., 1994), it cannot be assumed that children will always perform similarly to adults. However, even though differences likely exist in adult versus child lexicons, findings from the aforementioned studies suggest that these differences are not likely to be of significant consequence to the present findings. Nevertheless, this possibility may, as with the sample size issue, warrant further consideration in future studies of this nature.
Third, as noted by Ratner (2005), when interpreting findings from studies examining the effect of linguistic characteristics on stuttered words in naturalistic speech, the possibility that the findings reflect the effects of larger units of processing, such as the phrase in which the words are embedded, cannot be completely ruled-out. While this possibility clearly deserves further consideration, it should be noted that the present study is based on evidence from the normal speech production literature suggesting that phonotactic probability does have an effect on the ease with which isolated words are produced (e.g., Storkel, 2001, 2003; Storkel & Maekawa, 2005). Thus, since the effect of phonotactic probability on the speed and accuracy with which isolated words are produced has already been established, it seems relatively safe to say that the present findings are less likely to be interpreted as reflecting the effect of larger units of processing (cf. Anderson, 2007). However, to conclusively eliminate the potential effect of larger units of processing in spontaneous speech production, it might be worthwhile to further match by syntactic complexity and/or clause position in future studies of this nature.
The fourth and final issue to be considered is the possibility that phonotactic probability might have an effect on the grammatical class of stuttered words. As will be recalled, the goal of the present investigation was to examine whether stuttered words—regardless of whether they are function or content words—differ in phonotactic probability from words that are fluently produced. After all, even though young children tend to stutter more on function words (Bernstein, 1981; Bloodstein & Grossman, 1981; Howell, Au-Yeung, & Sackin, 1999; Natke, Sandreiser, van Ark, Pietrowsky, & Kalveram, 2004), they still, nevertheless, stutter on content words. In the present study, grammatical class was controlled by ensuring that each word pair was matched exactly by grammatical class. In future investigations, however, it might be of interest to examine whether phonotactic probability impacts stuttering on function versus content words in young children, and perhaps, across the lifespan.
Conclusion
Findings revealed that stuttered disfluencies, as a whole, were not susceptible to the effects of phonotactic probability, but words containing single-syllable word repetitions were significantly lower in phonotactic probability than fluent controls, as well as words containing part-word repetitions and sound prolongations. This differential impact of phonotactic probability on the type of stuttering-like disfluency produced by young CWS may reflect the underlying representation of these words in the child’s mental lexicon. In this respect, present findings suggest that words that are either partially repeated or prolonged may contain less specified phonological representations. In general, findings from this study motivate the need to further examine the phonological encoding skills of CWS, as such research may provide some insight into potential factors that may be involved in the onset of stuttering. It is equally as important, however, that future research continue to investigate the potential relationship between phonological delays, deficiencies, and/or disorganization and the production of specific types of speech disfluencies.
Acknowledgments
This research was supported by a research grant (DC006805) to Indiana University from the National Institute on Deafness and Other Communication Disorders. The authors would like to thank the parents and children who participated in this study, as well as Andrea Linton and Christie Merten for their help with data collection and reliability. A portion of this research was presented at the annual meeting of the American Speech-Language-Hearing Association, San Diego, CA, November, 2005.
Footnotes
It should be noted that most studies that have examined the linguistic correlates of speech errors have looked primarily at content words, whereas in the current study, the focus is largely on function words, as these words are more likely to be stuttered on by young children (e.g., Bernstein, 1981; Bloodstein & Grossman, 1981; Howell, Au-Yeung, & Sackin, 1999).
EVT and TELD-3 scores were not available for one child (a CWS), as this child refused to cooperate with testing.
The authors acknowledge that disagreement exists regarding classification schemes for the measurement of stuttered and nonstuttered speech disfluencies (Einarsdottir & Ingham, 2005; Wingate, 2001). Nevertheless, it should be noted that the classification scheme used in the present study was based on a large scale study (Ambrose & Yairi, 1999) that has since been systematically replicated (Pellowski & Conture, 2002).
Contributor Information
Julie D. Anderson, Indiana University
Courtney T. Byrd, The University of Texas at Austin
References
- Ambrose NG, Yairi E. Normative disfluency data for early childhood stuttering. Journal of Speech, Language, and Hearing Research. 1999;42:895–909. doi: 10.1044/jslhr.4204.895. [DOI] [PubMed] [Google Scholar]
- American Speech-Language-Hearing Association. Guidelines for screening for hearing impairment and middle-ear disorders. ASHA. 1990;32:17–24. [PubMed] [Google Scholar]
- Anderson JD. Phonological neighborhood and word frequency effects in the stuttered disfluencies of children who stutter. Journal of Speech, Language, and Hearing Research. 2007;50:229–247. doi: 10.1044/1092-4388(2007/018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson JD, Conture EG. Language abilities of children who stutter: A preliminary study. Journal of Fluency Disorders. 2000;25:283–304. [Google Scholar]
- Anderson JD, Conture EG. Sentence structure priming in young children who do and do not stutter. Journal of Speech, Language, and Hearing Research. 2004;47:552–571. doi: 10.1044/1092-4388(2004/043). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson JD, Pellowski MW, Conture EG, Kelly EM. Temperamental characteristics of young children who stutter. Journal of Speech, Language, and Hearing Research. 2003;46:1221–1233. doi: 10.1044/1092-4388(2003/095). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson JD, Wagovich SA, Hall NE. Nonword repetition skills in young children who do and do not stutter. Journal of Fluency Disorders. 2006;31:177–199. doi: 10.1016/j.jfludis.2006.05.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arnold H, Conture E, Byrd C, Key A, Mathiesen S, Coulter C. Phonological processing of young children who stutter: Preliminary Behavioral/ERP findings. Poster session presented at the International Fluency Association 5th World Congress; Dublin, Ireland. Jun, 2006. [Google Scholar]
- Arnold HS, Conture EG, Ohde RN. Phonological neighborhood density in the picture naming of young children who stutter: Preliminary study. Journal of Fluency Disorders. 2005;30:125–148. doi: 10.1016/j.jfludis.2005.01.001. [DOI] [PubMed] [Google Scholar]
- Aslin RN, Smith LB. Perceptual development. Annual Review of Psychology. 1988;39:435–473. doi: 10.1146/annurev.ps.39.020188.002251. [DOI] [PubMed] [Google Scholar]
- Beckman ME, Edwards J. Lexical frequency effects on young children’s imitative productions. In: Broe MB, Pierrehumbert JB, editors. Papers in laboratory phonology V. Cambridge, UK: Cambridge University Press; 1999. pp. 208–218. [Google Scholar]
- Bernstein NE. Are there constraints on childhood disfluency? Journal of Fluency Disorders. 1981;6:341–350. [Google Scholar]
- Bloodstein O, Grossman M. Early stuttering: Some aspects of their form and distribution. Journal of Speech and Hearing Research. 1981;24:298–302. [PubMed] [Google Scholar]
- Brooks PJ, MacWhinney B. Phonological priming in children’s picture naming. Journal of Child Language. 2000;27:335–366. doi: 10.1017/s0305000900004141. [DOI] [PubMed] [Google Scholar]
- Byrd CT, Conture EG, Ohde RN. Phonological priming in young children who stutter: Holistic versus incremental processing. American Journal of Speech-Language Pathology. 2007;16:43–53. doi: 10.1044/1058-0360(2007/006). [DOI] [PubMed] [Google Scholar]
- Coady JA, Aslin RN. Phonological neighbourhoods in the developing lexicon. Journal of Child Language. 2003;30:441–469. [PMC free article] [PubMed] [Google Scholar]
- Coady JA, Aslin RN. Young children’s sensitivity to probabilistic phonotactics in the developing lexicon. Journal of Experimental Child Psychology. 2004;89:193–213. doi: 10.1016/j.jecp.2004.07.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen J. Statistical power analysis for the behavioral sciences. 2. Hillsdale, NJ: Lawrence Erlbaum Associates, Inc; 1988. [Google Scholar]
- Dale RA. Unpublished B.A. Honors thesis. Indiana University; 2001. A comparison of lexical databases in computational studies of phonological acquisition. [Google Scholar]
- Dell GS, Chang F, Griffin ZM. Connectionist models of language production: Lexical access and grammatical encoding. Cognitive Science. 1999;23:517–542. [Google Scholar]
- Dell GS, Lawler EN, Harris HD, Gordon JK. Models of errors of omission in aphasic naming. Cognitive Neuropsychology. 2004;21:125–145. doi: 10.1080/02643290342000320. [DOI] [PubMed] [Google Scholar]
- Dell GS, Schwartz MF, Martin N, Saffran EM, Gagnon DA. Lexical access in aphasic and nonaphasic speakers. Psychological Review. 1997;104:801–838. doi: 10.1037/0033-295x.104.4.801. [DOI] [PubMed] [Google Scholar]
- Dunn L, Dunn L. Peabody Picture Vocabulary Test-III (PPVT-III) 3. Circle Pines, MN: American Guidance Service, Inc; 1997. [Google Scholar]
- Dworzynski K, Howell P, Natke U. Predicting stuttering from linguistic factors for German speakers in two age groups. Journal of Fluency Disorders. 2003;28:95–113. doi: 10.1016/s0094-730x(03)00009-3. [DOI] [PubMed] [Google Scholar]
- Edwards J, Beckman ME, Munson B. The interaction between vocabulary size and phonotactic probability effects on children’s production accuracy and fluency in novel word repetition. Journal of Speech, Language, and Hearing Research. 2004;47:421–436. doi: 10.1044/1092-4388(2004/034). [DOI] [PubMed] [Google Scholar]
- Einarsdottir J, Ingham RJ. Have disfluency-type measures contributed to the understanding and treatment of developmental stuttering? American Journal of Speech-Language Pathology. 2005;14:260–273. doi: 10.1044/1058-0360(2005/026). [DOI] [PubMed] [Google Scholar]
- Ferguson CA. Discovering sound units and constructing sound systems: It’s child’s play. In: Perkell S, Klatt DH, editors. Invariance and variability in speech processes. Hillsdale, NJ: Lawrence Erlbaum; 1986. pp. 36–51. [Google Scholar]
- Foygel D, Dell GS. Models of impaired lexical access in speech production. Journal of Memory and Language. 2000;43:182–216. [Google Scholar]
- Garlock VM, Walley AC, Metsala JL. Age-of-acquisition, word frequency, and neighborhood density effects on spoken word recognition by children and adults. Journal of Memory and Language. 2001;45:468–492. [Google Scholar]
- Gerken LA, Murphy WD, Aslin RN. Three-and four-year-olds perceptual confusions for spoken words. Perception & Psychophysics. 1995;57:475–486. doi: 10.3758/bf03213073. [DOI] [PubMed] [Google Scholar]
- German DJ, Newman RS. The impact of lexical factors on children’s word-finding errors. Journal of Speech, Language, and Hearing Research. 2004;47:624–636. doi: 10.1044/1092-4388(2004/048). [DOI] [PubMed] [Google Scholar]
- Gierut JA, Storkel H. Markedness and the grammar in lexical diffusion of fricatives. Clinical Linguistics and Phonetics. 2002;16:115–134. doi: 10.1080/0269920011011287. [DOI] [PubMed] [Google Scholar]
- Goldman R, Fristoe M. Goldman-Fristoe Test of Articulation-2 (GFTA-2) Circle Pines, MN: American Guidance Service, Inc; 2000. [Google Scholar]
- Gordon JK. Phonological neighborhood effects in aphasic speech errors: spontaneous and structured contexts. Brain and Language. 2002;79:21–23. doi: 10.1016/s0093-934x(02)00001-9. [DOI] [PubMed] [Google Scholar]
- Hakim HB, Ratner NB. Nonword repetition abilities of children who stutter: An exploratory study. Journal of Fluency Disorders. 2004;29:179–199. doi: 10.1016/j.jfludis.2004.06.001. [DOI] [PubMed] [Google Scholar]
- Howell P, Au-Yeung J. The association between stuttering, Brown’s factors, and phonological categories in child stutterers ranging in age between 2 and 12 years. Journal of Fluency Disorders. 1995;20:331–344. [Google Scholar]
- Howell P, Au-Yeung J, Sackin S. Exchange of stuttering from function words to content words with age. Journal of Speech, Language & Hearing Research. 1999;42:345–354. doi: 10.1044/jslhr.4202.345. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Howell P, Au-Yeung J, Sackin S. Internal structure of content words leading to lifespan differences in phonological difficulty in stuttering. Journal of Fluency Disorders. 2000;25:1–20. doi: 10.1016/s0094-730x(99)00025-x. [DOI] [PubMed] [Google Scholar]
- Hresko W, Reid D, Hammill D. Test of Early Language Development-3 (TELD-3) Austin, Tx: PRO-ED; 1999. [Google Scholar]
- Jones M, Gebski V, Onslow M, Packman A. Statistical power in stuttering research: A tutorial. Journal of Speech, Language, and Hearing Research. 2002;45:243–255. doi: 10.1044/1092-4388(2002/019). [DOI] [PubMed] [Google Scholar]
- Jusczyk PW. Toward a model of the development of speech perception. In: Perkell JS, Klatt DH, editors. Invariance and variability in speech processes. Hillsdale, NJ: Lawrence Erlbaum; 1986. pp. 1–19. [Google Scholar]
- Jusczyk PW, Luce PA, Charles-Luce J. Infants’ sensitivity to phonotactic patterns in the native language. Journal of Memory and Language. 1994;33:630–645. [Google Scholar]
- Kucera H, Francis WN. Computational analysis of present-day American English. Providence: Brown University; 1967. [Google Scholar]
- Locke JL. The sound shape of early lexical representations. In: Smith MD, Locke JL, editors. The emergent lexicon: The child’s development of a linguistic vocabulary. New York: Academic Press; 1988. pp. 3–22. [Google Scholar]
- Luce PA, Pisoni DB. Recognizing spoken words: the Neighborhood Activation Model. Ear and Hearing. 1998;19:1–36. doi: 10.1097/00003446-199802000-00001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maekawa J, Storkel HL. Individual differences in the influence of phonological characteristics on expressive vocabulary development by young children. Journal of Child Language. 2006;33:439–459. doi: 10.1017/s0305000906007458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Melnick K, Conture E, Ohde R. Phonological priming in picture-naming of young children who stutter. Journal of Speech, Language and Hearing Research. 2003;46:1428–44. doi: 10.1044/1092-4388(2003/111). [DOI] [PubMed] [Google Scholar]
- Metsala JL, Walley AC. Spoken vocabulary growth and the segmental restructuring of lexical representations: Precursors to phonemic awareness and early reading ability. In: Metsala JL, Ehri LC, editors. Word recognition in beginning literacy. Mahwah, NJ: Lawrence Erlbaum; 1998. pp. 89–120. [Google Scholar]
- Miller JF, Chapman RS. Systematic Analysis of Language Transcripts (Version 5.0) Madison: University of Wisconsin; 1998. Computer software. [Google Scholar]
- Moe AJ, Hopkins KJ, Rush RT. The vocabulary of first grade children. Thomas; Springfield, IL: 1982. [Google Scholar]
- Morrisette ML, Gierut JA. Lexical organization and phonological change in treatment. Journal of Speech, Language, and Hearing Research. 2002;45:143–159. doi: 10.1044/1092-4388(2002/011). [DOI] [PubMed] [Google Scholar]
- Munson B, Babel M. The sequential cueing effect in children’s speech production. Applied Psycholinguistics. 2005;26:157–174. [Google Scholar]
- Munson B, Kurtz B, Windsor J. The influence of vocabulary size, phonotactic probability, and wordlikeness on nonword repetitions of children with and without specific language impairment. Journal of Speech, Language, & Hearing Research. 2005;48:1033–1047. doi: 10.1044/1092-4388(2005/072). [DOI] [PubMed] [Google Scholar]
- Natke U, Sandreiser P, van Ark M, Pietrowsky R, Kalveram K. Linguistic stress, within-word position and grammatical class in relation to early childhood stuttering. Journal of Fluency Disorders. 2004;29:109–122. doi: 10.1016/j.jfludis.2003.11.002. [DOI] [PubMed] [Google Scholar]
- Nusbaum HC, Pisoni DB, Davis CK. Sizing up the Hoosier mental lexicon. Research on Speech Perception. 1984;10:409–422. [Google Scholar]
- Palen C, Peterson JM. Word frequency and children’s stuttering: The relationship to sentence structure. Journal of Fluency Disorders. 1982;7:55–62. [Google Scholar]
- Pellowski M, Conture E. Characteristics of speech disfluencies and stuttering behaviors in 3-and 4-year-old children. Journal of Speech, Language, and Hearing Research. 2002;45:20–34. doi: 10.1044/1092-4388(2002/002). [DOI] [PubMed] [Google Scholar]
- Ratner NB. Is phonetic complexity a useful construct in understanding stuttering? Journal of Fluency Disorders. 2005;30:337–341. doi: 10.1016/j.jfludis.2005.09.002. [DOI] [PubMed] [Google Scholar]
- Riley GD. Stuttering Severity Instrument for Children and Adults-3 (SSI-3) 3. Austin, Tx: Pro-Ed; 1994. [DOI] [PubMed] [Google Scholar]
- Sander EK. Reliability of the Iowa Speech Disfluency Test. Journal of Speech and Hearing Disorders. 1961;7:21–30. Monograph. [PubMed] [Google Scholar]
- Schwartz MF, Dell GS, Martin N, Gahl S, Sobel P. A case-series test of the interactive two-step model of lexical access: Evidence from picture naming. Journal of Memory and Language. 2006:228–264. doi: 10.1016/j.jml.2006.05.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stemberger JP. Structural errors in normal and agrammatic speech. Cognitive Neuropsychology. 1984;1:281–313. [Google Scholar]
- Stemberger JP. The reliability and replicability of naturalistic speech error data: A comparison with experimentally induced errors. In: Baars BJ, editor. Experimental Slips and Human Error Exploring the architecture of volition. New York, NY: Plenum Press; 1992. pp. 195–215. [Google Scholar]
- Storkel HL. Learning new words: Phonotactic probability in language development. Journal of Speech, Language, & Hearing Research. 2001;44:1321–1337. doi: 10.1044/1092-4388(2001/103). [DOI] [PubMed] [Google Scholar]
- Storkel HL. Learning new words II: Phonotactic probability in verb learning. Journal of Speech, Language, & Hearing Research. 2003;46:1312–1323. doi: 10.1044/1092-4388(2003/102). [DOI] [PubMed] [Google Scholar]
- Storkel HL. Methods for minimizing the confounding effects of word length in the analysis of phonotactic probability and neighborhood density. Journal of Speech, Language, & Hearing Research. 2004a;47:1454–1468. doi: 10.1044/1092-4388(2004/108). [DOI] [PubMed] [Google Scholar]
- Storkel HL. The emerging lexicon of children with phonological delays: Phonotactic constraints and probability in acquisition. Journal of Speech, Language, & Hearing Research. 2004b;47:1194–1212. doi: 10.1044/1092-4388(2004/088). [DOI] [PubMed] [Google Scholar]
- Storkel HL, Maekawa J. A comparison of homonym and novel word learning: the role of phonotactic probability and word frequency. Journal of Child Language. 2005;32:827–853. doi: 10.1017/s0305000905007099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Morrisette ML. The lexicon and phonology: interactions in language acquisition. Language, Speech, and Hearing Services in Schools. 2002;33:24–37. doi: 10.1044/0161-1461(2002/003). [DOI] [PubMed] [Google Scholar]
- Storkel HL, Rogers MA. The effect of probabilistic phonotactics on lexical acquisition. Clinical Linguistics & Phonetics. 2000;14:407–425. [Google Scholar]
- Throneburg RN, Yairi E, Paden EP. Relation between phonologic difficulty and the occurrence of disfluencies in the early stages of stuttering. Journal of Speech and Hearing Research. 1994;37:504–509. doi: 10.1044/jshr.3703.504. [DOI] [PubMed] [Google Scholar]
- Vitevitch MS. The neighborhood characteristics of malapropisms. Language and Speech. 1997;40:211–228. doi: 10.1177/002383099704000301. [DOI] [PubMed] [Google Scholar]
- Vitevitch MS. Naturalistic and experimental analyses of word frequency and neighborhood density effects in slips of the ear. Language & Speech. 2002a;45:407–434. doi: 10.1177/00238309020450040501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS. The influence of phonological similarity neighborhoods on speech production. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2002b;28:735–747. doi: 10.1037//0278-7393.28.4.735. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS. The influence of sublexical and lexical representations on the processing of spoken words in English. Clinical Linguistics and Phonetics. 2003;17:487–499. doi: 10.1080/0269920031000107541. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS, Armbrüster J, Chu S. Sublexical and lexical representations in speech production: effects of phonotactic probability and onset density. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2004;30:514–529. doi: 10.1037/0278-7393.30.2.514. [DOI] [PubMed] [Google Scholar]
- Vitevitch MS, Luce PA. A web-based interface to calculate phonotactic probability for words and nonwords in English. Behavior Research Methods, Instruments, & Computers. 2004;36:481–487. doi: 10.3758/bf03195594. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS, Luce PA. Increases in phonotactic probability facilitate spoken nonword repetition. Journal of Memory and Language. 2005;52:193–204. [Google Scholar]
- Voss B. Slips of the ear: Investigations into the speech perception behavior of German Speakers of English. Tubingen, Germany: Gunter Narr Verlag; 1984. [Google Scholar]
- Walley AC. Spoken word recognition by young children and adults. Cognitive Development. 1988;3:137–165. [Google Scholar]
- Walley AC. The role of vocabulary development in children’s spoken word recognition and segmentation ability. Developmental Review. 1993;13:286–350. [Google Scholar]
- Walley AC, Metsala JL. Young children’s age-of-acquisition estimates for spoken words. Memory and Cognition. 1992;20:171–182. doi: 10.3758/bf03197166. [DOI] [PubMed] [Google Scholar]
- Wijnen F. Incidental word and sound errors in young speakers. Journal of Memory and Language. 1992;31:734–755. [Google Scholar]
- Williams KT. Expressive Vocabulary Test (EVT) Circle Pines, MN: American Guidance Service, Inc; 1997. [Google Scholar]
- Wilson MD. The MRC Psycholinguistic Database: Machine readable dictionary (Version 2) Behavioural Research Methods, Instruments, and Computers. 1988;20:6–11. [Google Scholar]
- Wingate ME. SLD is not stuttering. Journal of Speech, Language, and Hearing Research. 2001;44:381–383. doi: 10.1044/1092-4388(2001/031). [DOI] [PubMed] [Google Scholar]
- Yairi E. Disfluency characteristics of childhood stuttering. In: Curlee RF, Siegel GM, editors. Nature and treatment of stuttering: New directions. 2. Boston, MA: Allyn and Bacon; 1997. [Google Scholar]
- Yairi E, Ambrose N. A longitudinal study of stuttering in children: a preliminary report. Journal of Speech and Hearing Research. 1992;35:755–760. doi: 10.1044/jshr.3504.755. [DOI] [PubMed] [Google Scholar]
- Yairi E, Ambrose N. Early childhood stuttering I: Persistency and recovery rates. Journal of Speech, Language, & Hearing Research. 1999;42:1097–1112. doi: 10.1044/jslhr.4205.1097. [DOI] [PubMed] [Google Scholar]
- Yairi E, Ambrose N. Early Childhood Stuttering. Austin, TX: Pro-Ed; 2005. [Google Scholar]
- Zamuner TS, Gerken L, Hammond M. Phonotactic probabilities in young children’s speech production. Journal of Child Language. 2004;31:515–536. doi: 10.1017/s0305000904006233. [DOI] [PubMed] [Google Scholar]