

Abstract
Two eye-tracking experiments examine whether adults and 4 and 5 year old children use the presence or absence of accenting to guide their interpretation of noun phrases (e.g., the bacon) with respect to the discourse context. Unaccented nouns tend to refer to contextually accessible referents, while accented variants tend to be used for less accessible entities. Experiment 1 confirms that accenting is informative for adults, who show a bias toward previously-mentioned objects beginning 300 msec after the onset of unaccented nouns and pronouns. But contrary to findings in the literature, accented words produced no observable bias. In Experiment 2, 4 and 5 year olds were also biased toward previously-mentioned objects with unaccented nouns and pronouns. This builds on findings of limits on children’s on-line reference comprehension (Arnold, Brown-Schmidt, & Trueswell, in press), showing that children’s interpretation of unaccented nouns and pronouns is constrained in contexts with one single highly accessible object.
Learning to understand language involves more than just words and grammatical rules. Children must learn to interpret words and sentences by connecting them with the preceding discourse and the larger context – and to do so very rapidly, as each word and sentence comes at them. This study investigates young children’s ability to generate on-line hypotheses about the referent of expressions like the bagel, with a focus on understanding whether children utilize the presence or absence of an accent to guide these hypotheses. Unaccented words tend to refer to information that is highly accessible in the discourse, while accented words tend to refer to less accessible information (e.g., Venditti & Hirschberg, 2003). Research has shown that adults are highly sensitive to this information, and use it rapidly to guide their interpretation of the nominal referring expression (Dahan, Tanenhaus, & Chambers, 2002). It is not known how accenting is used by children during reference comprehension. Furthermore, what is known about reference comprehension in children presents conflicting information about their ability to integrate linguistic referring expressions with the discourse context.
Reference comprehension and interpretation of accents: Adults
When adults interpret spoken referential expressions, they rapidly utilize detailed information about the linguistic expression to identify the most likely referent, This process is embedded in discourse processing mechanisms whereby adults maintain a mental representation of the entities in the current discourse situation (e.g., van Dijk & Kintsch, 1983; Kintsch, 1988; Johnson-Laird, 1983; Bransford, Barclay & Franks, 1972, Bower & Morrow, 1990; Sanford & Garrod 1981; Zwaan & Radvansky 1998). Those entities that are more central, or salient to the situation are represented as more cognitively accessible (see Arnold, in press; Gundel, Hedberg, & Zacharski, 1993; Sanford & Garrod, 1981), possibly by means of greater activation in the mental model of the discourse (Arnold, 1998). Modulations in referent accessibility have been explained in terms of how people allocate attention differentially to discourse characters (e.g., Arnold & Lao, 2007; Morrow & Bower, 1990; see also Foraker & McElree, 2007). Those entities that attract the listeners’ attentional resources are often termed “in focus”. However, this term should not be confused with the linguistic term focus (as opposed to topic/theme).
Referent accessibility is a critical factor guiding reference interpretation. It is easier to resolve expressions when the referent is contextually accessible, in particular when the expression is lexically or acoustically attenuated. For example, pronominal expressions are initially assumed to refer to the most accessible entity in the discourse that matches their features (e.g., Arnold, Eisenband, Brown-Schmidt, & Trueswell, 2000; Gordon, Grosz, & Gilliom, 1993; Grosz, Joshi, & Weinstein, 1995).
There are a variety of discourse and non-discourse factors that influence the accessibility of discourse entities, but in general listeners focus on things that have been mentioned recently, in particular those mentioned in prominent syntactic or thematic positions (see Arnold, 1998; for a review); acoustic prominence has also been argued to increase the activation of entity representations in the discourse model for subsequent reference (Foraker, Nusbaum, & Schoeneman, 2007). One well-established tendency is for adults to perceive the entity appearing in first-mentioned or subject position as more accessible (e.g., Gernsbacher & Hargreaves, 1989; Kaiser & Trueswell, 2007). For example, Arnold et al. (2000) monitored participants’ eye movements as they viewed a picture and decided if it matched a story, e.g. Donald is bringing some mail to Minnie…. She’s carrying an umbrella…. In situations like this example, where the pronoun only matched one character’s gender, adults began looking at the referent of the pronoun around 200 msec after the pronoun’s offset, indicating a rapid use of gender information to interpret the pronoun. In another condition, Minnie was replaced with Mickey, which required listeners to use information from the discourse context to infer which character was more prominent in the story, and assign the pronoun to that character. Adults looked at the target character just as quickly as in the gender-disambiguated case, but only when it referred to the first-mentioned/subject character from the context sentence (Arnold et al., 2000). This first-mentioned/subject bias is a robust finding with adults (Gernsbacher, 1989; Gordon, et al., 1993; Järvikivi, van Gompel, & Hyönä, 2005; Kaiser & Trueswell, 2007; see Arnold, 1998, for a review).
A similar bias occurs when adults interpret unaccented nominal referring expressions. Spoken words can be pronounced with or without a pitch accent, which is a phonological feature that signals prominence, usually with pitch movement and a local pitch maximum or minimum; in English accents also correlate with longer durations and greater acoustic intensity (e.g., Ladd, 1996). Although the location of accents in an utterance is heavily determined by the linguistic focus structure of the sentence, it also correlates with discourse status. It is frequently claimed that accented words refer to things that are new to the discourse, whereas unaccented words are for given (previously mentioned) information (e.g., Brown, 1983; Chafe, 1987). However, recent evidence suggests that a more precise characterization is that accenting occurs with relatively inaccessible referents, both given and new, and unaccented forms are reserved for highly accessible referents (Hirschberg, 1993; Hirschberg & Pierrehumbert, 1986; for a review see Venditti & Hirschberg, 2003). For example, unaccented variants tend to occur when the referent was mentioned in the previous clause in a parallel syntactic position to the current referring expression (Terken & Hirschberg, 1994). The effect of discourse status on the acoustic properties of a word is not limited to accenting, per se. Even accented words are systematically acoustically attenuated when they refer to entities that have been previously mentioned (Bard & Aylett, 1999, see also Fowler & Housum, 1987; Bard et al., 2000; Bard & Aylett, 2004), especially those in salient discourse positions (Watson & Arnold, 2005).
The above patterns mean that accenting and acoustic prominence could signal the listener about the discourse status of the referent – an unaccented and attenuated expression is likely to have a highly accessible referent, while an accented expression is likely to refer to something less accessible, or discourse new.1 Thus, unaccented variants can direct the listener to look for the referent in the discourse model, whereas accented tokens may suggest the construction of a new discourse representation.
There is substantial evidence that adults do use accenting and acoustic prominence during reference comprehension. Terken & Nooteboom (1987) reported faster comprehension for unaccented words with given (previously-mentioned) referents, and for accented words with new referents. Similarly, listeners in Bock & Mazzella’s (1983) study understood sentences faster when the new information was accented, and the given information was unaccented. In both of these studies, the preference for unaccented tokens occurred when the referent had been mentioned in a parallel syntactic position as the referring expression, for both subject and nonsubject positions. Listeners can also have more specific interpretations for different kinds of pitch accents, as has been found for German (Baumann & Hadelich, 2003; Baumann & Grice, 2004, in press.).
Moreover, adults can use accenting information extremely rapidly. Dahan, et al. (2002) monitored participants’ eye movements using a visual world paradigm (Tanenhaus et al., 1995). In their experiment 1, participants saw displays similar to Figure 1, and followed instructions like Put the candle/candy below the triangle. Now put the CANDLE/candle above the square. The target instruction was the second one, in which the theme noun was either accented or unaccented. The expression was either anaphoric, in which case it referred to the object previously-mentioned in the highly salient position of theme in the first utterance, or it was nonanaphoric, referring to a previously unmentioned entity.
Figure 1.

Sample visual display for Experiment 1.
Dahan et al.’s (2002) study capitalized on the fact that objects like candy/candle and bacon/bagel have names termed cohort competitors, which are words that overlap at their onset, creating a temporary ambiguity (Marslen-Wilson, 1987). This causes listeners to fixate the competitor objects at the onset of the target word on some proportion of the trials (e.g., Allopenna et al., 1998; Tanenhaus et al., 1995). Critically, the level of competition depended on the accenting of the expression and the discourse status of the referent: If the competitor had been previously mentioned, participants looked at it more often when the expression was unaccented, and if the competitor was new, participants looked at it more often in the accented condition. This difference began to emerge around 300 msec after the onset of the referring expression, revealing that adults detected the presence or absence of an accent extremely rapidly, and used it to guide their first hypotheses about the word’s referent.
It is important to note that the interpretation of accented and unaccented expressions never occurs in a vacuum. Variation in accenting necessarily co-occurs with other prosodic changes to an utterance, since accenting is realized partially in comparison with other nearby elements. For example, in Dahan et al’s (2002) study the unaccented condition always used a prominently accented preposition (Now put the candle ABOVE the square). Thus, the effects of accenting (or lack of it) may be in fact the result of a combination of acoustic features in an utterance. Likewise, Birch and Clifton (1995) demonstrate that listeners consider the entire phrase when assessing the meaningful interpretation of accenting.
Reference comprehension in young children
In contrast with adults, the literature offers mixed evidence about whether preschoolers use the discourse context to guide their initial interpretation of referring expressions. There are no prior studies of how accenting guides children’s reference comprehension. The most relevant information about preschoolers’ reference comprehension skills comes from pronoun studies, which provide mixed findings about children’s sensitivity to the discourse context.
Arnold, et al. (2007, experiment 2) examined how children interpret pronouns on-line, examining their earliest hypotheses about the pronoun referent. In the same task as used by Arnold et al. (2000), the eye movements of 4 and 5-year-olds were monitored as they viewed a picture and listened to stories (e.g., Donald is bringing some mail to Mickey…He…). When the pronoun was disambiguated by gender, children identified the referent just as quickly as adults. However, they were not systematically biased toward the first-mentioned character in same-gender items. Results from an offline task with 3 to 5 year olds (experiment 1) were consistent with the online results, revealing no tendency to associate the pronoun with the first-mentioned character.
These results initially appear to be at odds with Song and Fisher’s (2005) findings. In their eyetracking experiments, 3-year-olds viewed pictures and listened to stories. The context segment of the stories were longer, and established a clear discourse topic by mentioning the first-mentioned character more than once and, in most experiments, by pronominalizing reference to the discourse topic prior to the critical reference, e.g.: Meet the crocodile and the toad. The crocodile went on vacation with the toad. And she swam in the sea with the toad. This was followed by a target sentence, She/The crocodile walked along the beach with the toad. Their participants showed a bias to look at a picture in which the pronoun referred to the first-mentioned character, although this bias did not show up until a full second after pronoun onset. Similar findings were reported by Pyykkönen, Matthews, and Järvikivi (2007), whose 3-year-old subjects showed evidence of a subject/first-mention bias but not until 2 seconds after pronoun onset.
One interpretation for these contrasting results builds on the observation that discourse accessibility varies along a continuum. In Song and Fisher’s (2005) study, multiple mechanisms clearly established one character as highly accessible, for example repeated mention, first mention, and pronominalization. In this situation, children linked the pronoun to the more accessible character (although not as quickly as adults). By contrast, Arnold et al. (2007) manipulated accessibility through a simple order-of-mention contrast. Although this is a robust cue for adults, it is a probabilistic cue and by itself did not guide children’s initial interpretations (for further discussion, see Arnold et al., in press).
Thus, the literature on children’s pronoun comprehension suggests that children have some ability to interpret referential expressions with respect to the discourse context. At the same time, their ability to do so is limited to situations where a single character is clearly and redundantly marked as the most accessible one, and they may not be able to use accessibility to guide their very earliest interpretations.
Does accenting guide preschoolers’ reference interpretation?
The current study seeks to extend our understanding of preschoolers’ moment-by-moment processes of interpreting spoken referential expressions, by investigating their understanding of accented and unaccented referential expressions. There is no currently available data about children’s use of accenting during reference comprehension. The only evidence of children’s sensitivity to the relationship between accenting and discourse status comes from production studies, which show that English-speaking preschoolers produce adult-like accenting in their own speech, preferring accented tokens for new referents, and unaccented ones for given referents (Wieman, 1976; Hornby & Hass, 1970; MacWhinney & Bates, 1978). However, these findings do not mean that children can also use accenting during comprehension. If children produce unaccented variants for accessible referents because of production-internal facilitation (cf claims by Bard et al., 2000), they may not know that other speakers use accenting systematically as well.
The literature on children’s pronoun comprehension suggests that children would stand the best chance of utilizing accenting if the discourse situation established a clear distinction in accessibility. The following study therefore examines accenting in a context where one candidate referent is previously-mentioned and highly accessible, and the other is new (unmentioned). Previously mentioned referents are usually more accessible than unmentioned ones, in that discourse participants can presume such information to be known and accessible to all other discourse participants (Clark & Marshall, 1981). By contrast, there is less information about whether one’s interlocutors are focusing their attention on unmentioned objects, even if they are visible in the discourse context. The performance of 4 and 5 year old children is examined, given the contrasting predictions for this age group that emerge from the literature on pronoun comprehension.
The following two experiments examined adults’ and children’s use of accenting during on-line reference comprehension, using the same experimental design as Dahan et al. (2002, experiment 1). Participants viewed a display with four objects, two of which had names that were cohort competitors (e.g., bagel/bacon), and followed instructions like in Table 1. The context sentence (e.g., Put the bacon on the star) established a clear contrast in accessibility: the bacon was previously mentioned and in the highly accessible theme position. Also, since the theme of the first instruction is the only object manipulated, we know with relative certainty that the participant is focusing on it at the onset of the second instruction. The bagel, by contrast, is unmentioned and therefore far less accessible than the bacon. If accenting guides on-line comprehension as in Dahan et al.’s experiment, unaccented expressions should result in faster target looks in the anaphoric (given target) condition, and accented expressions should result in faster target looks in the nonanaphoric (new target) condition. As a control condition, we also examined the comprehension of pronominal instructions, Now put it…. Experiment 1 establishes adult performance in this task, and Experiment 2 investigates performance on the same task by 4 and 5 year old children.
Table 1.
Example auditory instructions for Experiments 1 and 2. Capitalization indicates the critical accenting manipulation. Accents also fell on the theme and destination in the context sentence, and on the words Now and the destination shape in the second sentence.
| Instructions | |
|---|---|
| Nonanaphoric, Accented | Put the bacon on the star. Now put the BAGEL on the square. |
| Nonanaphoric, Unaccented | Put the bacon on the star. Now put the bagel on the square. |
| Anaphoric, Accented | Put the bacon on the star. Now put the BACON on the square. |
| Anaphoric, Unaccented | Put the bacon on the star. Now put the bacon on the square. |
| Anaphoric, Pronominal | Put the bacon on the star. Now put it on the square. |
NOTE: In Experiment 1 accent on Now was manipulated as a third variable, but only the
accented-Now conditions are reported here, for direct comparison with Experiment 2.
The experiment used cohort competitors to establish a temporary ambiguity, providing an ideal method for identifying listeners’ earliest hypotheses about the referent. If listeners can identify the word as accented or unaccented during the first syllable of the word, they may integrate the accenting with the temporarily ambiguous input. The first looks after the onset of the target word thus indicate listeners’ biases during reference interpretation.
Predictions
Adults prefer to interpret both pronouns and unaccented nouns as coreferential with highly accessible information. This predicts that children’s interpretation of unaccented noun phrases should use similar mechanisms as their interpretation of pronouns. If the above interpretation of the pronoun literature is right, then children should be able to link unaccented expressions with the more accessible referent, if there is only one highly accessible entity in the context. Furthermore, on some views of language development, the order in which children acquire processing skills is related to the amount of information available in the input, where stronger patterns, with more substantial and reliable evidence, are learned earlier (Arnold et al., 2007; Trueswell & Gleitman, 2004). This would predict an early use of accenting patterns for on-line comprehension if these patterns are robust in child-directed speech. Indeed, there is substantial information available in the speech input about the distribution of unaccented and accented expressions. The adult pattern of using unaccented expressions for given and accessible referents is present in child-directed speech as well (Fisher and Tokura, 1995). More generally, speech to children tends to have attenuated pronunciations for words that are predictable from the discourse or physical context (Bard & Anderson, 1983,1994). If children can detect and categorize tokens by acoustic prominence, they should have amassed a large database of accented and unaccented words at a very young age.
However, evidence from pronoun comprehension suggests that 4–5 year old children may not be able to integrate pragmatic biases with discourse accessibility quickly enough to affect their initial interpretation of the referential expression. While children interpret gender-disambiguated pronouns as quickly as adults (Arnold et al., 2007), manipulations of accessibility either have not influenced young children’s interpretations (Arnold et al., 2007), or have done so only a second or two after the critical expression (Pyykkönen et al., 2007; Song & Fisher, 2005).
Experiment 1: Adults
Method
Participants
49 native English-speaking students at the University of North Carolina at Chapel Hill participated in exchange for course credit. Data from 13 were excluded: 7 because of technical problems, 5 because of calibration problems of track loss, and 1 because the participant had to leave before finishing the experiment. This left 36 participants in the analysis.
Method and Materials
Participants were asked to wear a visor for the purposes of monitoring their eye movements. They viewed pictures on a computer screen, as in Figure 1. 135 of 176 pictures were drawn from a colorized version of the Snodgrass and Vanderwart (1980) database of pictures (Rossion & Purtois, 2001); the rest were from other clipart databases. On each trial, two of the objects had names that were cohort competitors, meaning that they overlapped during the initial segments, like bagel/bacon or candle/candy. The pictures always appeared on a grid, with the same four shapes in the corners on all trials. Participants followed recorded instructions to move objects onto the shapes with the mouse. There were two instructions for each visual stimulus, e.g. Put the bacon on the star. Now put the bacon on the square (see Table 1).
The object in the second instruction was the referring expression of interest, e.g. bacon in this example. The other cohort object (i.e., the one with an overlapping name, e.g., the bagel) was the competitor. The first instruction mentioned either the target (the anaphoric condition) or the competitor (the nonanpahoric condition). We also manipulated the form of the target referring expression, which was accented, unaccented, or pronominal (Now put it…); the pronoun was always anaphoric. For an example of auditory stimuli, see Table 1. There were two sets of items with identical visual stimuli, but the opposite mapping of objects to target and competitor roles (e.g., for Figure 1 the target was bagel in set a and bacon in set b). Thus, any idiosyncratic characteristics of the stimuli were counterbalanced across lists.
The auditory stimuli were recorded by the author, and the same soundfiles were used for both experiments. A single context instruction was recorded for each anaphoric and nonanaphoric condition for each item in cohort set a. These same context instructions were used for cohort set b, but swapped (i.e., the anaphoric context instruction from set a became the nonanaphoric one for set b, and the nonanaphoric one for set a became the anaphoric one in set b). A single recording was created for each target instruction in each condition. All context sentences ended with rising intonation, following Dahan et al.’s (2002) stimuli. This signaled that the speaker wasn’t finished, encouraging participants to interpret the second instruction in the context of the first.
The target instruction sentences were analyzed with Praat (Boersma & Weenik, 2007) to identify the average duration and pitch of each critical word, and the accent pattern of the target words was transcribed in the ToBI labeling system (Beckman & Elam, 1997). In the accented condition, the target word (the theme in the second instruction) carried a pitch accent, had greater pitch movement, and was acoustically prominent and relatively long (avg. 701 ms). In the unaccented condition, the target word carried no pitch accent, and was acoustically attenuated, with a shorter duration (avg. 337 ms), and no boundary tone. The pronoun was also unaccented and acoustically attenuated, average duration 92 ms. In all accented conditions, the target word had a L+H* accent, followed by an L-H% boundary tone. The result was an extremely prominent sounding accent, giving the impression that the speaker was being deliberate and explicit. This established a clear contrast between the accented and unaccented conditions. Table 2 presents the ToBI transcription of the typical accent pattern; Table 3 presents the average acoustic properties of the target words in each condition. Sample acoustic files can be found at www.unc.edu/~jarnold/pages/publications.html.
Table 2.
ToBI transcription of accent pattern in context and stimulus sentences.
| Instructions | |
|---|---|
| Context sentence | Put the bacon on the star. |
| H* L+H* H−H% | |
| Pronoun target sentence | Now put it on the square. |
| L+H* H* L−L% | |
| Unaccented target sentence | Now put the bacon on the square. |
| L+H* H* L−L% | |
| Accented target sentence | Now put the BACON on the square. |
| L+H* L+H* L−H% H* L−L% |
Table 3.
Experiment 1: Acoustic characteristics of the target word in each condition
| Accented | Unaccented | Pronoun | |
|---|---|---|---|
| Target word duration | 701 ms | 337 ms | 92 ms |
| Pause after target word | 191 ms | 14 ms | 0 ms |
| Maximum pitch | 289 Hz. | 190 Hz. | 185 Hz. |
| Minimum pitch | 145 Hz. | 164 Hz. | 167 Hz. |
The focus here is on the different acoustic properties of the target word, but it is important to note that accenting on any particular word is not independent from the prosodic characteristics of the rest of the utterance. In all conditions the destination location also received a prominent pitch excursion. Apart from the presence of pitch accents, other acoustic characteristics of stimuli with accented targets were also systematically different. The target instructions in all conditions had an accent on the initial word Now. However, as shown in Table 4, the initial three words (Now put the) were longer and/or more likely to have a following pause in the accented condition compared with both unaccented and pronominal conditions. The accented and unaccented conditions both used a prominent accent on the destination shape (e.g., on the TRIANGLE). This pattern was deemed most natural because the most contrastive element of the sentence (apart from the target) was the destination shape, which was always different across the two instruction. This pattern differed from Dahan et al.’s unaccented condition, which instead used a prominent accent on the preposition following the target word (2002, p. 298). However, Dahan et al.’s accented condition was very similar to the one used here, with a prominent accent and boundary tone on the target word.
Table 4.
Experiment 1: Average duration for the initial words in each condition (ms)
| Accented | Unaccented | Pronoun | |
|---|---|---|---|
| Now duration | 310 | 257 | 314 |
| Pause after Now | 53 | 49 | 0 |
| Put duration | 105 | 88 | 108 |
| Pause after Put | 65 | 38 | 0 |
| The duration | 121 | 85 | -- |
This experiment also included an additional manipulation of the prosody on the word Now. In half the items Now carried a large acoustic prominence, and in half the items it was relatively de-emphasized. This variable did not affect the results substantially, and therefore will not be discussed further. The experiment with children (Experiment 2) only used the prominent Now conditions, so only those items are presented here (i.e., 15 out of the 30 items viewed by each participant).
The basic experimental design was thus 2 (anaphoric vs. nonanaphoric) x 2 (accented vs. unaccented target), plus a pronominal/anaphoric condition. These 5 conditions occurred either with an accented Now or an unaccented Now, for a total for 10 conditions. There were 30 experimental items in 10 conditions, so each participant heard 3 critical items in each experimental condition. The critical items were combined with 12 fillers into 10 lists. As an additional control, there was a second set of 10 lists in which the items that were assigned to target and competitor were swapped; e.g. the example in Table 1 became Put the bagel on the circle. Now put the bacon on the square. Before each list there were two practice items, in one the target expression was accented, in the other it was unaccented; both referred to a different object than was mentioned in the first instruction.
All 12 filler items also included a pair of objects whose names were members of a cohort set. These were never mentioned in the context instruction, and were mentioned in six fillers as the theme of the second instruction. The fillers thus served to reduce the expectation that one of the two objects with overlapping names would be mentioned in the first instruction, as well as the expectation that if one of these objects was mentioned, the other would be too. Out of the 12 fillers and 2 practice items, the target noun was anaphoric in 4 items and nonanaphoric in 10; 7 target expressions were accented, and 7 were unaccented. Across all stimulus and filler/practice items, there were an equal number of anaphoric and nonanaphoric items on each list.
On critical items, the target and competitor objects occurred equally in all four positions in the display. On all items, the target and competitor were placed either diagonally or vertically from each other on the initial display. The experiment was designed so that the first instruction would always result in the object being moved to the shape immediately next to it, because of methodological constraints on coding direction of eye gaze in Experiment 2. However, due to a programming error, all the objects on the bottom half of the screen were moved to the bottom shape on the opposite half of the screen. This did not affect our ability to identify eye movements for this experiment.
Procedure and Apparatus
We monitored participants’ eye movements with an Eyelink II head mounted eyetracker. After the task was explained, the visor with cameras was arranged on the participant’s head, and calibrated. Participants completed two practice items, were given a chance to ask questions, and then went on to do the experimental task.
The visual and auditory stimuli were presented on a PC computer running the ExBuilder software (Longhurst, 2006). Each trial was preceded by a screen with a dot, which participants needed to fixate on and click. This enabled the eyetracker to perform a drift correction, and encouraged participants to attend as each trial began. As soon as the participants clicked on the dot, the visual stimulus appeared and the soundfile began to play. The instruction began within 150 msec of the onset of the soundfile. The Eyelink II sampled participants’ eye movements once every 2 or 4 milliseconds; the data were analyzed with a 4-msec time window for each data point.
If participants behave as those in Dahan et al.’s (2002) experiment 1, the unaccented condition should produce more and earlier looks to the previously-mentioned object than the accented condition. The pronominal condition can only be interpreted as anaphoric, and is expected to produce similar results as the unaccented/anaphoric condition.
Results and Discussion
Three types of analyses are reported: 1) Descriptive data establishing the speed and frequency of eye movements in this task, for comparison with children in Experiment 2; 2) Action errors in moving the objects, and 3) Eye movements to target objects. Eye movements are analyzed in terms of the average number of looks; each look begins at the onset of a saccade to an object, and lasts until the participant makes a saccade to a new object. Saccades within the same object are categorized as a single look. Saccades are grouped together with following fixations because they are ballistic, so the saccade reflects the participant’s decision to look at that object.
In both this and experiment 2, the pronoun condition is presented for comparison with the unaccented condition, but the primary analysis is the comparison of the four conditions resulting from a cross between accent and anaphoricity. All analyses of variance were conducted over both participant and item means. The items analyses always included Item Group (i.e., the class of items that rotates together through the conditions across lists) as a predictor variable; this captures differences between the participants who contribute to the different conditions for a particular item. There were no effects or interactions with Item Group except where noted. All analyses using proportion data were performed twice, once with the raw data and once with arcsin-transformed proportions (arcsine (2*p − 1). The raw analyses are reported for transparency of interpretation; the arcsine-transformed analyses provided the same pattern of results unless noted. Trials were excluded from time-window analyses if there was greater than 33% track loss during the critical period; 11 trials (3%) were excluded from Exp. 1, and 3 trials (1.3%) were excluded from Exp. 2.
Descriptive Data
Two dimensions were measured with the primary purpose of comparing adults and children in terms of the speed with which they moved their eyes and responded to the linguistic input in this task. The speed with which adults change their point of regard was measured in terms of the average amount of time spent on each look, which was 530 msec (SE = 12). That is, on average every 530 msec adults launched a saccade to look at a new region on the screen. Their response to the linguistic input was measured as the time lapse between the onset of the target word and the next saccade to a new object, which averaged 330 msec (SE = 17).
Errors
The presentation software recorded trials on which the participant initially moved the wrong object. Six participants made one error, and always in the unaccented nonanaphoric condition; these errors occurred on four different items (average 5.6% across participant means). There were no errors in any of the other conditions.
Eye movements
Eye movements to display objects were time-locked with the onset of the target referring expression for each item, for each participant. Figure 2 presents the average looks to display objects in both the pronominal and unaccented/anaphoric conditions, starting at the onset of the target expression. Of primary interest are eye movements occurring during the target expression and immediately after. These are the eye movements that are likely to reflect listeners’ initial hypotheses about what the word refers to, as they hear the phonetic input accrue over the course of the word. As predicted, both pronouns and unaccented anaphors yielded an early target preference: looks to the target began to diverge from looks to the competitor very rapidly, about 300 msec after the onset of the referring expression. Although there were slightly more looks to the target in the pronominal condition, the conditions were not reliably different from one another, with either target or competitor looks as the dependent variable (all F’s < 1). This similarity occurs despite the fact that pronouns are substantially shorter, suggesting suggests that the first syllable of the unaccented noun provides enough information for listeners to begin to resolve the reference. This is consistent with the expected anaphoric bias for the unaccented condition.
Figure 2.

Experiment 1 results: Proportion looks to target and competitor objects in the unaccented/anaphoric and pronominal conditions. The graph begins at the onset of the critical expression for each item. Proportions are calculated out of all looks, including track loss.
But the critical question is whether the unaccented condition would have a greater anaphoric bias than the accented condition. As Figure 3 illustrates, it does. The proportion of looks to the previously-mentioned (given) objects, both targets and competitors, is calculated out of all looks to cohort objects, collapsing across target condition. This takes advantage of the temporary ambiguity of the target word, which initially is consistent with both target and competitor objects. Thus, early eye movements may have been programmed before the disambiguating information was available. Beginning around 300 msec after the onset of the unaccented referring expression, there is an increase in looks to the previously mentioned object. In the accented condition, by contrast, the rate of looking at the previously mentioned cohort steadily decreases.
Figure 3.
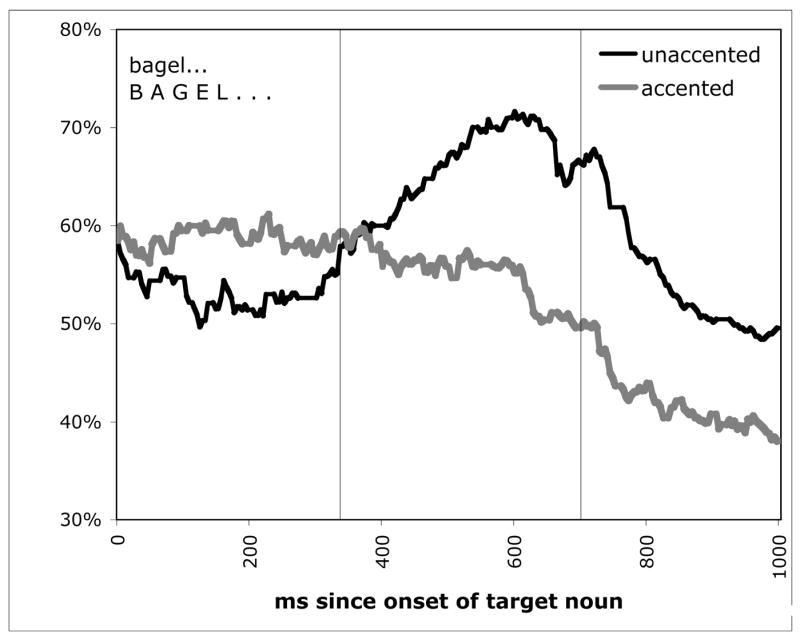
Experiment 1 results: proportion looks to the given (previously-mentioned) object out of all looks to both the given and new cohort objects. The vertical line represents the average offset of the target word. The graph begins at the onset of the critical expression. Proportions are calculated out of all looks, including trackloss.
The reliability of this contrast was assessed in two ways. The simplest way to observe the difference between accented and unaccented conditions is to analyze the average looks to the previously-mentioned object following accented and unaccented target words. This analysis uses the common technique of synchronizing items at the onset of the target word, and analyzing a time window shortly thereafter. The window used here was 300–1000 msec after the onset of the target expression, following Dahan et al. (2002). Looks to the previously-mentioned object were reliably greater in the accented condition (M = 37%, SE = 3), than the unaccented condition (M = 28%, SE = 3). These data were submitted to analyses of variance with participants and items as random effects. Results revealed a main effect of accenting (F1(1,35) = 7.69, p <.01; F2 (1,20) = 7.53, p <.05). This supports the prediction that unaccented expressions have a greater bias toward previously-mentioned referents than accented expressions do.
This contrast is further supported by an examination of participants’ first look after the onset of the target word, which is a likely indication of their initial hypothesis about the referent. As shown in Table 5, unaccented expressions yielded more initial looks to the target in the anaphoric than unanaphoric condition, whereas accented expressions produced equal initial target looks in the two conditions. The measurement of first looks is categorical, analyzed here as looks to target vs. other. These data were therefore modeled with a multilevel logistic regression model, with random effects for both participants and items, using SAS proc glimmix with a Penalized Quasi-Likelihood (PQL) estimator (see Bauer & Curran, 2006). The model included three independent variables: accent, anaphoricity, and accent x anaphoricity. As shown in table 6, the t-value for the odds ratio was significant at the.05 level for the main effect of anaphoricity, and for the accent × anaphoricity interaction.
Table 5.
Experiment 1: Eye movement results across the four conditions: Adult participant means in each condition. Standard Error of the Mean is in parentheses.
| Unaccented Anaphoric | Unaccented Nonanaphoric | Accented Anaphoric | Accented NonAnaphoric | |
|---|---|---|---|---|
| Proportion of first looks after target expression onset to the target object | 37% (6) | 16% (4) | 24% (4) | 23% (4) |
| Proportion looks to target object (300–1000 after target onset) | 51% (4) | 38% (3) | 35% (4) | 39% (3) |
| Proportion looks to competitor object (300–1000 after target onset) | 12% (2) | 23% (3) | 22% (3) | 22% (3) |
Table 6.
Experiment 1 statistical data for analyses across all four conditions. Nonsignificant and marginal effects are shaded.
| Main effect of accenting | Main effect of anaphoricity | Interaction (anaphoricity × accenting) | |
|---|---|---|---|
| Proportion of first looks after target expression onset to the target onset | Odds ratio = 0.45
S.E. =.36 t = 1.26 DF = 347 p =.21 |
Odds ratio = 1.15
S.E. =.34 t = 3.36 DF = 347 p <.001 |
Odds ratio = -1.05
S.E. =.47 t = -2.22 DF = 347 p <.05 |
| Proportion looks to target object (300–1000 after target onset) + * | F1 (1,35) = 6.05
p <.05 |
F1(1,35) = 1.27
p =.127 |
F1(1,35) = 8.08, p <.01 |
| F2(1,20) = 2.18
p =.156 |
F2 (1,20) = 4.19
p =.054 |
F2 (1,20) = 15.74
p =.001 |
|
| Proportion looks to competitor object (300–1000 after target onset) + | F1 (1,35) = 1.86
p =.181 |
F1(1,35) = 2.80
p =.103 |
F1 (1,35) = 6.07
p <.05 |
| F2 (1,20) = 1.05
p =.319 |
F2 (1,20) = 5.07
p <.05 |
F2 (1,20) = 6.19,
p <.05 |
There was also a three-way interaction itemgroup x accent x anaphoricity in the F2 analysis
One cell was missing in the F1 analysis and was replaced by the participant mean.
Comparison with Dahan et al.’s (2002) findings
Since this experiment was closely modeled on that of Dahan et al. (2002), it is worth considering whether their effects were replicated. Table 5 presents the average proportion looks to target and competitor over the time window from 300 to 1000 msec, which was the measure reported by Dahan et al. The means show more target and fewer competitor looks in the unaccented/anaphoric condition than in the other three critical conditions. These data were submitted to a 2(accented vs. unaccented) x 2(anaphoric vs. nonanaphoric) ANOVA, which revealed a significant interaction between anaphoricity and accent. See Table 6 for statistical details.
Our findings replicated the interaction between anaphoricity and accenting that was found by Dahan et al. (2002). However, our findings only clearly replicated Dahan et al.’s anaphoric bias with unaccented nouns. By contrast, participants in the current experiment did not exhibit a strong new-object bias with the accented condition. Separate analyses of target looks in the accented and unaccented conditions revealed a significant effect of anaphoricity for unaccented items (F(1, 25) = 8.08, p <.01; F2 (1, 20) = 18, p <.001)2, but no effect for accented items (F’s < 1)3.
The only evidence that could possibly be interpreted as a new advantage for accented stimuli occurred fairly late. Figure 4 presents the proportion of target looks (out of all looks) for two seconds after the onset of the critical expression. Beginning around 800 msec after the onset of an accented noun, there were more looks to the nonanaphoric than anaphoric target. Since the accented stimuli were longer in duration than the unaccented stimuli, it is worth considering whether reactions to the input simply occur later in time, and that this late new-object bias reflects listeners’ initial biases when hearing accented referring expressions. However, there are two reasons that this conclusion is not justified. First, participants were only slightly slower to launch a new eye movement following the target word onset in the accented (M = 382 msec) than unaccented (M = 328 msec) conditions, but the new-target advantage in the accented condition emerges roughly 500 msec after the advantage for previously-mentioned objects in the unaccented condition.
Figure 4.
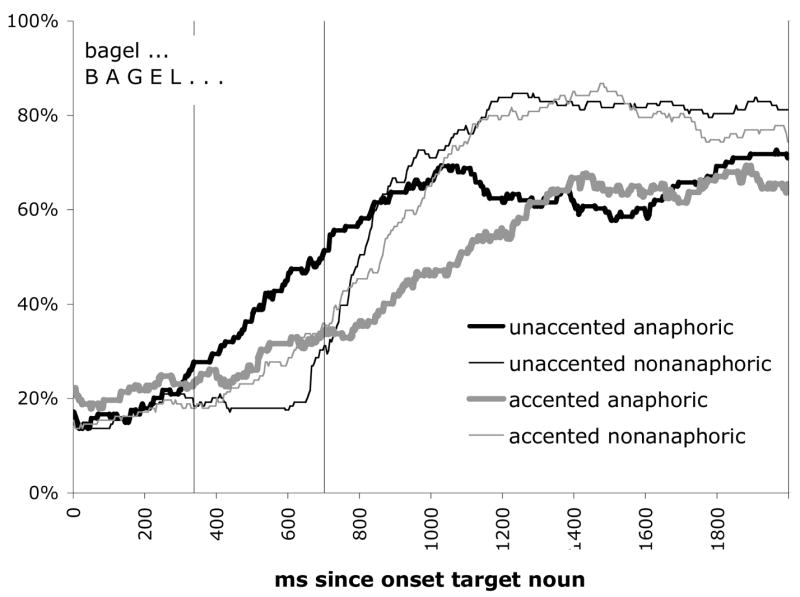
Experiment 1: proportion looks to the target object in the four critical conditions. The vertical line represents the average offset of the target word. The graph begins at the onset of the critical expression. Proportions are calculated out of all looks, including trackloss.
Second, the new-target advantage also occurs in the unaccented conditions. Thus, this pattern seems to reflect a general tendency to spend less time fixating targets when they have been previously mentioned, probably because they had already visually examined the previously mentioned object. We assessed this by examining the length of time spent on the first look at the target object after the onset of the target expression onset, which revealed that people look longer at nonanaphoric than anaphoric targets, in both unaccented and accented conditions (unaccented/anaphoric: M = 790 msec, SE = 38; unaccented/nonanaphoric; M = 946, SE, = 49; accented/anaphoric: M = 892, SE = 73; accented/nonanaphoric: M = 1135, SE = 49). This contrast is evident in the results of a 2×2 ANOVA, which revealed a main effect of anaphoricity (F1 (1,35) = 21.46, p <.001; F2 (1,20) = 19.5, p <.001), a main effect of accenting (F1 (1,35) = 4.97, p <.05; F2(1,20) = 5.96, p <.05), and no interaction (F’s < 1).
In sum, the accented condition produced less of a bias toward previously-mentioned objects than the unaccented condition did, but there was little evidence that adults have an initial bias towards low-accessible referents when they hear accented expressions. While there may be a later bias, it is indistinguishable from a general interest in looking at previously unmentioned objects.
This lack of a clear nonanaphoric bias in the accented condition is surprising, given claims in the literature that the L+H* invokes a contrastive interpretation (e.g., Pierrehumbert & Hirschberg, 1990), and can lead to the inference of a contrast set (e.g., Sedivy et al., 1995). Stimuli like Put the bacon…. Now put the BA-, should suggest a contrast with the object of the previous put action. One possibility is that the contrastive interpretation is there, but that unrelated factors lead participants to fixate previously-mentioned entities more quickly (for example, as suggested by an anonymous reviewer, if such items are better represented in visual memory), irrespective of accenting condition. However, it is notable that Dahan et al. (2002) did find a nonanaphoric bias for interpreting accented expressions with the same task. Thus, while the current results are not inconsistent with claims that accenting creates a contrastive interpretation, they suggest that in the context used here, this interpretation is either weaker, or occurs relatively late compared with the anaphoric bias in the unaccented condition.
This asymmetry in the results is consistent with how accenting occurs in speech. Unaccented expressions have a strong probability of being used to refer to something highly accessible and given in the discourse context. Accented definite NPs, on the other hand, seem to be less specialized. They can felicitously be used to refer to something that has not been previously mentioned, as long as the referent is identifiable (see Chafe, 1976, Prince, 1992; Gundel et al., 1993). At the same time, they can refer to something given, particularly if its referent is not highly accessible in memory. For example, 52% of words with given referents were accented in Hirschberg’s (1993) sample (and 87% of words with new referents). Related evidence comes from Watson and Arnold’s (2005) experiment 1, in which acoustically prominent tokens were frequently produced for reference to both unmentioned and given but relatively inaccessible entities. Similarly, Terken & Hirschberg (1994) found accenting when the referent was given but not in a syntactically parallel position. It is also worth noting that Dahan et al’s (2002) data also support the conclusion that the anaphoric bias with unaccented forms is stronger than the nonanaphoric bias with accented forms. The new bias reported in their experiment 1 only affected competitor looks, and their experiment 2 revealed a preference to interpret accented expressions as co-referential with previously mentioned but less accessible entities.
Nevertheless, the important finding from experiment 1 was that adults distinguished between accented and unaccented referring expressions. Adults were more biased toward an anaphoric interpretation with unaccented expressions than accented expressions. Indeed, unaccented expressions were interpreted very much like pronouns. Experiment 2 investigated whether 4 and 5 year old children would also use the presence or absence of an accent to guide their initial referential interpretations.
Experiment 2: 4 and 5 year old children
Method
Participants
27 children in the Chapel Hill/Durham area participated in the experiment in exchange for a small toy; their parent received $5 for each child participating. 7 participants were excluded from analysis: 3 because of technical problems, 2 because they did not attend to the task (e.g. talking during the critical items), and 2 because they were confused about many items or made too many mistakes on the context instruction. This left 20 participants in the analysis; 11 were girls, 9 were boys. The average age was 59 months (range: 48–68 months).
Method and Materials
Half the items from Experiment 1 (n=15) were used, with the same recorded instructions and pictures. The average acoustic characteristics of this subset of items is shown in Table 7, and the durations for Now, put, and the for this subset of items are shown in Table 8. This subset of items had the same pattern of acoustic characteristics as the full set of items used in Experiment 1. The target/competitor pair for one filler (gun/gum) was inadvertently included at first; it was changed to clown/cloud after a few participants because it was inappropriate for the age group4.
Table 7.
Experiment 2: Acoustic characteristics of the target word in each condition
| Accented | Unaccented | Pronoun | |
|---|---|---|---|
| Target word duration | 726 | 342 | 95 |
| Following pause | 198 | 8 | 0 |
| Maximum pitch | 290 | 185 | 179 |
| Minimum pitch | 147 | 161 | 165 |
Table 8.
Experiment 2: Average duration for the initial words in each condition
| Accented | Unaccented | Pronoun | |
|---|---|---|---|
| Now duration | 320 | 272 | 329 |
| Pause after Now | 56 | 49 | 0 |
| Put duration | 105 | 89 | 121 |
| Pause after Put | 69 | 41 | 0 |
| The duration | 113 | 80 | -- |
Only the accented Now conditions were used (i.e., those conditions reported above for experiment 1). Thus, there were four conditions resulting from the cross between givenness and accenting, plus the pronominal condition, each of which occurred 3 times per list. These five conditions were rotated through the 15 critical items, and combined with 6 filler items into five lists. As before, the target/competitor assignment to each member of a target/competitor pair was counterbalanced across two versions of each list, one with item a as the target, one with item b as the target. This resulted in 10 lists, each of which had a forward and backward order.
In all items, the first instruction had the child move the object to the shape immediately next to its original position. This preserved the spatial distinction between all four objects at the onset of the second instruction, such that one was in each corner of the display. This was necessary because of the video-based method for monitoring eye movements. On each list, the target and competitor objects on the 15 experimental items were as evenly distributed across the four positions as possible. The display was similar to that in Figure 1, except that the target and competitor object were always horizontal from each other. This orientation was used to encourage a high rate of looks to the competitor, since horizontal eye movements are more frequent than vertical or diagonal ones (Dahan, Tanenhaus, & Salverda, in press).
Procedure and coding
Children performed the same task as in Experiment 1, except that the pictures were displayed on a magnet board, instead of on a computer. The four shapes were painted onto the corners of the board, and the pictures for each object were connected to magnets and placed on the board for each trial. The board stood at a slight incline off vertical, and the child stood in front of the board, looking down at it. The pictures were in easy reach, so children could carry out each instruction by moving the magnetic picture with their hands.
Children’s eye movements were monitored using a digital camcorder that was trained on their face through a hole in the middle of the board (for a similar methodology, see Snedeker & Trueswell, 2004). This image was sent to a frame-accurate Sony DSR-30 digital VCR, which recorded 30 images per second. Because the camera was placed behind the pictures, experimenters could code the video while blind to the location of the target and competitor objects.
The instructions were played out of a different computer, running the same software as used in Experiment 1. The sound played from a speaker near the child. Sound was recorded either through a microphone that was connected to the digital VCR (the first few subjects), or through a direct line from the computer into the digital VCR. Both methods yielded frame-accurate sound, so the coder could identify eye movements with respect to critical words in the auditory input.
Before each experiment began, the parent and child (or children) were welcomed to the lab and introduced to the experimenters. While the parent filled out the consent form and lab questionnaire, the experimenters showed the child(ren) the equipment and explained the task. Each child completed two practice items, and was given a chance to ask questions before going on to do the experiment. Each child was tested with only the parent and experimenters in the room.
If the child made an error on any of the critical trials (e.g., moving the wrong object or moving it to the wrong shape), it was recorded by an experimenter on a sheet of paper. The same experimenter recorded events that invalidated the trial, e.g. if the child talked during the critical instruction, or made a mistake on the first instruction by either moving the wrong object or moving an object to the wrong shape.
Each frame of the video record was later inspected to determine the child’s direction of gaze, beginning at the onset of the second (critical) instruction. Coders first went through the tape, listening for the onset of Now, and marking the time of onset on a spreadsheet. The sound was then turned off, so coders would be blind to the experimental condition while coding eye movements. Gazes were coded in one of the following categories: upper left, upper right, lower left, lower right, center, other, or trackloss. Following the same method of analysis as in Experiment 1, coders identified the onset of each saccade, and grouped it with the following fixation. Trackloss could be the result of blinks or other obstructions of the eye image, for example if the child moved their head away from the video camera. Frames with trackloss due to blinks were grouped as part of the following fixation.
Gazes to each of the four corners were later categorized as gazes to the target object, competitor object, or unrelated objects, based on where each object had been on a particular item. Recall that the first instruction always resulted in an object being placed on the shape immediately next to it. This meant that gazes to each corner were ambiguous between looks to an object or a shape. However, looks to the target and competitor objects were not likely to be much influenced by looks to the shape in the same corner, because the location shape in the second instruction (the most likely location shape to be fixated) was never the same as either the location of either the target or competitor object. Furthermore, there is no evidence of increased looks to the destination corner (compared with the other unrelated item) until quite late (from target onset: 1600 ms in accented conditions; 1400 ms in unaccented conditions, and 900 ms in pronominal conditions).
Two research assistants coded the eye movement data. They double-coded the data of one participant who was outside the age range of this study, and therefore not reported here. The two coders achieved 94% agreement on the location of the gazes; agreement on the location of the onset of the critical words Now was within ±0.06 frames, and the onset of the target word was ± 0.77 frames.
Results and Discussion
20 items (or 7% of the total) were excluded from analysis because of technical problems (n=5), too much trackloss (n=1), the child moved the wrong object on the first instruction (n=6), or the trial was interrupted by someone saying something, including when the child asked for clarification after the first instruction (n=8). 10 subjects had at least one item excluded. An additional 3 items were excluded from time-window analyses because there was greater than 33% trackloss during the critical period.
The same three types of analyses are reported as for Experiment 1: 1) Descriptive data, 2) Action errors, and 3) Eye movement data.
Descriptive Data
Children spent more time looking at objects than adults did, averaging 665 msec per look (SE = 27.6); 135 msec slower than adults. Children may spend more time looking at an object before moving on to a new region, perhaps because they devote more time to visually exploring the display in this task than adults, who are probably motivated by personal time constraints to efficiently and quickly finish the experiment. Children’s eye movements were also slower to respond to the target linguistic expression: it took an average of 574 msec to launch the first new look after the target expression (SE = 31); 244 msec slower than adults). This means that any effect of the manipulations in experiment 2 is likely to show up during a later time window compared with experiment 1.
Action Errors
On some trials children moved the wrong object, and like adults this was most likely to occur in the unaccented/nonanaphoric condition (M = 16%, SE = 5%; total N=10), compared with 1.7% (SE = 1.7) errors in each of the two accented conditions (N=1 in each condition), and 0 errors in the unaccented/anaphoric condition. All of the errors in the unaccented nonanaphoric condition involved moving the cohort competitor object, supporting the idea that unaccented expressions are preferentially assigned an anaphoric interpretation. Both trials with errors in the accented conditions involved moving a non-cohort object.
Eye movements
Figure 5 reveals that children were like adults in their response to the unaccented/anaphoric and pronominal conditions, both of which resulted in early looks to the target. Since children’s eye movements occurred slightly later (by about 200 msec) than adults in this task, it was expected that any effect of the manipulations should occur slightly later as well. For this reason, the critical time window examined was 500–1200 msec after target onset. Although children were more likely to look at the competitor with an unaccented noun anaphor than with a pronoun (F1(1,19) = 11.98, p <.005; F2(1,14) = 18.13, p <.001), they were equally likely to look at the target for both anaphor types (F’s < 1). This suggests that like adults, children have an anaphoric bias for unaccented nouns that is similar to the anaphoric bias for pronouns.
Figure 5.

Experiment 2 results: proportion looks to the target following unaccented/anaphoric and pronominal conditions. The vertical lines represent the average offset of the target word. The graph begins at the onset of the critical expression for each item. Proportions are calculated out of all looks, including trackloss.
As before, the critical question was whether accented and unaccented expressions would result in different preferences for anaphoric or nonanaphoric interpretations. Figure 6 demonstrates that it does. From 500–1200 msec after target onset, children have a greater preference to look at previously-mentioned objects in the unaccented (M = 43, SE = 3) than the accented condition (M = 32, SE = 4). This difference is supported by analyses of variance, which revealed a main effect of accenting (F1(1,19) = 5.46, p <.05; F2 (1,14) = 7.88, p <.05).
Figure 6.

Experiment 2 results: proportion looks to the target following unaccented (top panel) and accented nouns (bottom panel). The vertical line represents the average offset of the target word. The graph begins at the onset of the critical expression for each item. Proportions are calculated out of all looks, including trackloss.
Both experiments used nearly identical stimuli and procedures, allowing a direct comparison of the results. Analysis of variance compared the proportion of looks to previously-mentioned objects across experiments (including only the items used in experiment 2 for the items analysis), and found a main effect of accenting (F1(1,54) = 13.18, p =.001; F2(1,14) = 12.89, p <.005). There was a marginal effect of experiment in the F2 analysis only (F1(1,54) = 1.83, p =.18; F2(1,14) = 3.41, p =.09), which reflected the fact that adults looked somewhat less at the previously-mentioned object in the accented condition. There were no other effects or interactions with experiment, supporting the conclusion that adults and children make a broadly similar distinction between accented and unaccented references during comprehension.
Further support for the effect of accenting is evident in the proportion of first looks to the target object across the four conditions. As for adults, the unaccented condition led children to look at the target object more often in for anaphoric (M = 46, SE = 5) than nonanaphoric (M = 13, SE = 5) expressions, whereas the accented condition did not have as great a preference for looking at the target in the anaphoric (M = 30, SE = 5) than nonanpahoric (M = 23, SE = 6) conditions. This contrast emerged as a significant interaction between anaphoricity and accenting in a multilevel logistic regression model, with random effects for both participants and items (Odds ratio = −1.36, SE =.65, DF = 186, t = −2.1, p <.05).
These data suggest that 4–5 year old children already distinguish unaccented and accented expressions during on-line processing. An examination of children’s first looks after the target word indicates that they prefer anaphoric interpretations of unaccented tokens. The accented condition, by contrast, does not result in a strong initial preference for either the anaphoric or nonanphoric target. Although this contrasts with claims in the literature of a new-object bias with accented tokens (Dahan et al., 2002), it is consistent with how adults performed on the same task. As for adults, the only preference to look at the nonanaphoric target occurred quite late, around 1200 msec after target onset, and for both accented and unaccented stimuli (see Figure 7). That is, children also tend to spend less time fixating previously-mentioned targets. This is supported by an analysis of the duration of the first look to the target after the critical noun, which revealed longer looks for nonanaphoric (M = 1007 ms, SE = 60) than anaphoric targets (M = 658, SE = 37). An analysis of variance revealed a main effect of anaphoricity (F15 = 29.91, p <.001; F2 = 20.83, p =.001). There was also a marginal effect of accenting in the participants analysis only (F1(1,19) = 3.30, p =.085; F2 =.09, p =.77), and no interaction (F’s<1).
Figure 7.

Experiment 2: proportion looks to the target object in the four critical conditions. The vertical line represents the average offset of the target word. The graph begins at the onset of the critical expression. Proportions are calculated out of all looks, including trackloss.
In sum, 4 and 5 year old children were adult-like in that they responded differently to accented and unaccented tokens during spoken reference comprehension, both in their eye movements and final responses. Like adults, children had a greater anaphoric bias in the unaccented than accented condition. The contrast between accented and unaccented expressions also emerged immediately, on the children’s first new look after they heard the beginning of the target word. This suggests that accenting – or the lack of it -- does guide children’s initial hypotheses about what a word refers to. Both children and adults were also most likely to make an error when an unaccented noun referred to a new object. In this condition children instead moved the previously-mentioned object, demonstrating an anaphoric bias for unaccented stimuli.
Children also exhibited pragmatically appropriate interpretations of pronouns, which were rapidly interpreted as co-referential with the previously moved object. The similarity between the pronominal and unaccented/anaphoric conditions suggests that children interpret both expressions with a similar discourse bias. The results from this experiment contrast with Arnold et al.’s (2007) findings, where children did not use referent accessibility to guide interpretation of an ambiguous pronoun. This difference may stem from the stronger evidence of accessibility in the current experiment. While Arnold et al.’s (2007) experiment, the only evidence of accessibility in the same-gender context was the order of mention in the context sentence. In the current experiment, children critically also moved the first-mentioned object following the context instruction, ensuring that they focused their attention on it. This is consistent with the assumption that children should be most likely to map pronouns to accessible referents when accessibility is robustly established through multiple mechanisms.
General Discussion
The results presented here reveal that 4 and 5 year old children are fairly adept at using accenting information during their on-line interpretation of referential expressions. Unaccented expressions were more likely than accented ones to lead children to initially look at objects that were previously-mentioned and highly accessible – the same pattern as observed for adults. Furthermore, children were most likely to pick up the wrong object when an unaccented expression did the pragmatically odd thing, referring to a relatively inaccessible object.
The results from both experiments support findings from the literature that accenting and acoustic prominence drive listeners’ initial interpretation of referential expressions (Dahan et al., 2002; Terken & Nooteboom, 1987). However, in contrast with earlier studies, the current experiments did not find strong evidence for a bias toward a nonanaphoric interpretation of accented expressions, for either adults or children.
The findings presented here are consistent with the conclusion that both adults and 4–5 year old children are sensitive to the pragmatic specialization of accenting. Under this interpretation, accenting is instrumental in directing the listener to either associate the referring expression with an already given and accessible entity, or to retrieve a less accessible representation, possibly one that has to be built for the first time, based on the speech input (Dahan et al., 2002; Terken & Nooteboom, 1987). This discourse bias is integrated in parallel with the unfolding acoustic information, directing listeners’ hypotheses about the most likely referent at each point in time. While previous studies found that accented expressions produced a specific bias toward an object that was relatively less accessible, the current results suggest that accenting may have a less specific result, where accented expressions are acceptable for both previously-mentioned and accessible referents, and referents that have not already been mentioned. This is broadly consistent with the way accenting is used in production: unaccented and attenuated expressions are restricted to situations where the expression is highly accessible. Accented expressions, by contrast, can be used for a wider range of discourse statuses. For example, Watson & Arnold (2005) examined the production of references to objects along a continuum of discourse accessibility, and found that while acoustic prominence varied systematically, almost all tokens were accented. Given this pattern, an unaccented expression is a very good indication that the referent is highly accessible, whereas an accented expression provides less information.
However, because the current experiments failed to replicate the new-object bias for accented expressions, we must consider whether an alternate explanation could account for the data. Is it possible that both adults and children interpret expressions with only a general bias towards given information, and no sensitivity to accenting? Since unaccented expressions are less acoustically explicit, they contain less bottom-up information. If this leads to any doubt about the identity of the word, listeners might be forced to rely instead on their top-down knowledge, i.e. by linking it with the more familiar object. Since accented expressions contain more bottom-up information, top-down information is not necessary. On this view, it is the ambiguity of the input that drives the contribution of any discourse biases, and not the specific knowledge that attenuated expressions are used more often with accessible referents (Bard & Anderson, 1994). However, the results of both experiments give reason to doubt this interpretation. As the accented expression unfolds over time, it is also temporarily ambiguous –and in fact, is ambiguous for a longer time than the unaccented expression. If listeners were initially biased towards the most accessible referent for all expressions, we should see a bias toward the previously-mentioned object in the accented condition, just as in the unaccented condition. Yet we see no preference for either object in the accented condition until quite late. This is consistent with the proposal that listeners quickly identify the acoustic prominence of the token, but that it does not result in an initial bias.
Why, then, are there other reports in the literature that accenting leads to specific pragmatic biases (Dahan et al., 2002; Terken & Nooteboom, 1987)? One possible explanation is offered by Dahan et al.’s experiment 2, which suggests that accented expressions are preferentially interpreted as co-referential with something that has been previously mentioned, but not in a highly accessible position. The present experiments used target expressions that were initially consistent with both the most highly accessible object, and a far-less accessible, unmentioned object. Thus, as an accented expression was initially encountered, the “preferred” interpretation of a middle-accessible referent was unavailable. This may have led listeners to equally consider both objects that matched the input.
Thus, the most plausible interpretation of the data in experiments 1 and 2 is that children, like adults, distinguish between accented and unaccented tokens, pursuing an anaphoric interpretation for unaccented expressions more readily than for accented expressions. Moreover, 4 and 5 year old children, like adults, are able to utilize the form of both nominal and pronominal referring expressions rapidly enough to guide their initial hypotheses about their referent.
The results of this study, along with others in the literature (Bock & Mazzella, 1983; Dahan et al., 2002; Terken & Nooteboom, 1987) are most simply described as a contrast between accented and unaccented tokens. However, prosody is a linguistic feature that does not affect each word independently, and accenting choices on each word in an utterance cannot help but affect the acoustic characteristics of other words. The experimental conditions used here differed by more than just the presence or absence of accent on the target word. The accented condition also included an intonational phrase break following the target word, as well as longer durations on other words in the utterance. As in natural speech situations, listeners in experiments 1 and 2 may have used any or all of these sources of information alone or in concert.
Children’s relatively adult-like comprehension in the current experiment stands in contrast to other reports in the literature, where children do not use discourse accessibility to constrain their interpretation of pronouns (Arnold et al., in press), or do not do so immediately (Song & Fisher, 2005; Pyykkönen, et al., 2007). Children’s comparative success in the current study reflects the prediction that children should show greater success when there is a large difference in the accessibility of potential referent entities. Here the previously-mentioned object was highly salient, being the only object moved on the previous trial, whereas unmentioned new objects were not brought to the attention of the participants at all. While Song & Fisher’s study also used a strong manipulation of accessibility, their participants used it more slowly, most probably because of their young age (3 years). In sum, the current experiments establish the ability of young children to rapidly use accenting and discourse accessibility to constrain on-line reference comprehension.
Acknowledgments
This research was supported by NIH grant HD-41522 to the author. Many thanks to all of the adult participants in Experiment 1, and to the parents and children who came to campus to participate in Experiment 2. I am grateful to Rebecca Altmann for her extensive work on a pilot version of Experiment 1; to Shin-Yi Lao for her invaluable help with experiment 2; to Joyce McDonough and Jennifer Venditti for discussion of the ToBI transcriptions presented here; and to Daniel Bauer and Daniel Serrano for statistical consultation. Many thanks also to Alex Christodoulou, Glenn Kern, Li Yi, Tatiana Meteleva, and Daniel Peterson for their help collecting and coding the data, and to Bob McMurray for the use of his data analysis program. Humberto Gutiérrez-Rivas generously helped construct the magnet board display for experiment 2.
Appendix A
Target and competitor objects for critical items
| Both Experiment 1 and Experiment 2: | Experiment 1 only: |
|---|---|
| bacon, bagel | whistle, windmill |
| cake, cape | beaker, beetle |
| camel, camera | cloud, clown |
| candy, candle | coat, comb |
| fish, fist | dollar, dolphin |
| hammer, hanger | harp, heart |
| horse, horn | spider, spiral |
| lemon, leopard | rooster, ruler |
| mouth, mouse | carrot, carriage |
| mushroom, moustache | spool, spoon |
| peacock, peanut | paddle, padlock |
| pencil, penguin | plate, plane |
| sandwich, sandal | picture, pickle |
| snail, snake | turkey, turtle |
| watermelon, waterfall | bandaid, banjo |
Footnotes
While it is clear that accenting and acoustic prominence can affect comprehension, it is a matter of debate whether acoustic prominence is produced explicitly as a signal to the listener or is instead a function of constraints on the production system (see, e.g., Arnold, in press; Bard et al., 2000; Bard & Aylett, 2004; Gregory, Healy, & Jurafsky, 2004).
There was a significant interaction between anaphoricity and item group in the raw analysis, but not the arcsine-transformed analysis.
There was a significant interaction between anaphoricity and item group in the arcsin-transformed analysis, but not the raw analysis.
I am grateful to Alessandra Gutiérrez-Arnold (age 4 at time of participation) for bringing this to my attention.
Two cells were replaced by the participant mean in the participants analysis.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Allopenna PD, Magnuson JS, Tanenhaus MK. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language. 1998;38:419–439. [Google Scholar]
- Arnold JE. Reference form and discourse patterns (Doctoral dissertation, Stanford University, 1998) Dissertation Abstracts International. 1998;59:2950. [Google Scholar]
- Arnold JE. Reference production: Production-internal and addressee-oriented processes. Language and Cognitive Processes in press. [Google Scholar]
- Arnold JE, Brown-Schmidt S, Trueswell JC. Children’s use of gender and order-of-mention during pronoun comprehension. Language and Cognitive Processes in press. [Google Scholar]
- Arnold JE, Eisenband JG, Brown-Schmidt S, Trueswell JC. The rapid use of gender information: Evidence of the time-course of pronoun resolution from eyetracking. Cognition. 2000;76:B13–B26. doi: 10.1016/s0010-0277(00)00073-1. [DOI] [PubMed] [Google Scholar]
- Arnold JE, Griffin Z. The effect of additional characters on choice of referring expression: Everyone competes. Journal of Memory and Language. 2007;56:521–536. doi: 10.1016/j.jml.2006.09.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arnold JE, Lao SC. The role of attention during pronoun comprehension. Paper presented at the 48th Annual meeting of the Psychonomic Society; Long Beach, CA. Nov 15–18, 2007.2007. [Google Scholar]
- Bard EG, Anderson AH. The unintelligibility of speech to children. Journal of Child Language. 1983;10(2):265–292. doi: 10.1017/s0305000900007777. [DOI] [PubMed] [Google Scholar]
- Bard EG, Anderson AH. The unintelligibility of speech to children: Effects of referent availability. Journal of Child Language. 1994;21:623–648. doi: 10.1017/s030500090000948x. [DOI] [PubMed] [Google Scholar]
- Bard EG, Anderson AH, Sotillo C, Aylett M, Doherty-Sneddon G, Newlands A. Controlling the intelligibility of referring expressions in dialogue. Journal of Memory and Language. 2000;42:1–22. [Google Scholar]
- Bard EG, Aylett MP. The dissociation of deaccenting, givenness and syntactic role in spontaneous speech. In: Ohala J, Hasegawa Y, Ohala M, Granville D, Bailey AC, editors. Proceedings of the XIVth International Congress of Phonetic Science. San Francisco: 1999. pp. 1753–1756. [Google Scholar]
- Bard EG, Aylett MP. Referential form, word duration, and modeling the listener in spoken dialogue. In: Trueswell JC, Tanenhaus MK, editors. Approaches to studying world-situated language use: Bridging the language-as-product and language-as-action traditions. Cambridge, MA: MIT Press; 2004. pp. 173–191. [Google Scholar]
- Baumann S, Grice M. Accenting accessible information. Proceedings from Speech Prosody 2004, Nara, Japan. 2004:21–24. [Google Scholar]
- Baumann S, Grice M. The intonation of accessibility. Journal of Pragmatics in press. [Google Scholar]
- Baumann S, Hadelich K. Accent type and givenness: An experiment with auditory and visual priming. Proceedings of the 15th ICPhS, Barcelona, Spain. 2003:1811–1814. [Google Scholar]
- Bauer DJ, Curran PJ. Multilevel modeling of hierarchical and longitudinal data using SAS Course Notes. Cary, NC: SAS Institute Inc; 2006. [Google Scholar]
- Beckman ME, Elam GA. Guidelines for ToBI labelling, Version 3. The Ohio State University Research Foundation. 1997 Available: http://www.ling.ohio-state.edu/~tobi/ame_tobi/labelling_guide_v3.pdf.
- Birch S, Clifton C., Jr Focus, accent, and argument structure: Effects on language comprehension. Language and Speech. 1995;33:365–391. doi: 10.1177/002383099503800403. [DOI] [PubMed] [Google Scholar]
- Bock JK, Mazzella JR. Intonational marking of given and new information: Some consequences for comprehension. Memory and Cognition. 1983;11:64–76. doi: 10.3758/bf03197663. [DOI] [PubMed] [Google Scholar]
- Boersma P, Weenink D. Praat: Doing phonetics by computer (Version 4.6.29) [Computer program]. Amsterdam: Institute of Phonetic Sciences. 2007 Retrieved from http://www.praat.org/
- Bower GH, Morrow DG. Mental models in narrative comprehension. Science. 1990;247(4938):44–48. doi: 10.1126/science.2403694. [DOI] [PubMed] [Google Scholar]
- Bransford JD, Barclay JR, Franks JJ. Sentence memory: A constructive versus interpretive approach. Cognitive Psychology. 1972;3(2):193–209. [Google Scholar]
- Brown G. Prosodic structure and the given/new distinction. In: Cutler A, Ladd R, editors. Prosody: Models and measurements. New York: Springer-Verlag; 1983. pp. 67–77. [Google Scholar]
- Chafe WL. Givenness, contrastiveness, definiteness, subjects, topics, and point of view. In: Li CN, editor. Subject and topic. New York: Academic Press; 1976. pp. 25–56. [Google Scholar]
- Chafe W. Cognitive constraints on information flow. In: Tomlin R, editor. Coherence and grounding in discourse. Amsterdam: John Benjamins; 1987. pp. 20–51. [Google Scholar]
- Clark HH, Marshall CR. Definite reference and mutual knowledge. In: Joshi AK, Webber BL, Sag IA, editors. Elements of discourse understanding. Cambridge: Cambridge University Press; 1981. pp. 10–63. [Google Scholar]
- Dahan D, Tanenhaus MK, Chambers CG. Accent and reference resolution in spoken language comprehension. Journal of Memory and Language. 2002;47:292–314. [Google Scholar]
- Dahan D, Tanenhaus MK, Salverda AP. The influence of visual processing on phonetically-driven saccades in the “visual world” paradigm. In: van Gompel RPG, Fischer MH, Murray WS, Hill RL, editors. Eye movements: A window on mind and brain. Oxford: Elsevier; in press. [Google Scholar]
- Fisher C, Tokura H. The given-new contract in speech to infants. Journal of Memory and Language. 1995;34:287–310. [Google Scholar]
- Foraker S, McElree B. The role of prominence in pronoun resolution: Active vs. passive representations. Journal of Memory and Language. 2007;56:357–383. [Google Scholar]
- Foraker S, Nusbaum H, Schoeneman S. Re-accessing representations: Specificity of meaning for prominent and non-prominent concepts. Talk presented at the 20th annual CUNY conference on human sentence processing; San Diego, CA. 2007. [Google Scholar]
- Fowler C, Housum J. Talkers’ signaling of “new” and “old” words in speech and listeners’ perception and use of the distinction. Journal of Memory and Language. 1987;26:489–504. [Google Scholar]
- Gernsbacher MA. Mechanisms that improve referential access. Cognition. 1989;32:99–156. doi: 10.1016/0010-0277(89)90001-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gernsbacher MA, Hargreaves DJ, Beeman M. Building and accessing clausal representations: The advantage of first mention versus the advantage of clause recency. Journal of Memory and Language. 1989;28(6):735–755. doi: 10.1016/0749-596X(89)90006-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gordon PC, Grosz BJ, Gilliom LA. Pronouns, names, and the centering of attention in discourse. Cognitive Science. 1993;17:311–347. [Google Scholar]
- Gregory ML, Healy AF, Jurafsky D. Common ground in production: Effects of mutual knowledge on word duration. University of Colorado; Boulder: 2004. Unpublished manuscript. [Google Scholar]
- Grosz BJ, Joshi AK, Weinstein S. Centering: A framework for modeling the local discourse. Computational Linguistics. 1995;21(2):203–225. [Google Scholar]
- Gundel JK, Hedberg N, Zacharski R. Cognitive status and the form of referring expressions in discourse. Language. 69(2):274–307. [Google Scholar]
- Hirschberg J. Pitch accent in context: Predicting intonational prominence from text. Artificial Intelligence. 1993;63:305–340. [Google Scholar]
- Hirschberg J, Pierrehumbert JB. Proceedings from the 24th annual meeting of the Association for Computational Linguistics. San Francisco: M. Kaufmann; 1986. The intonational structuring of discourse; pp. 136–144. [Google Scholar]
- Hornby PA, Hass WA. Use of contrastive stress by preschool children. Journal of Speech and Hearing Research. 1970;13:395–399. doi: 10.1044/jshr.1302.395. [DOI] [PubMed] [Google Scholar]
- Järvikivi J, van Gompel RPG, Hyönä J. Ambiguous pronoun resolution: Contrasting the first-mention and subject-preference accounts. Psychological Science. 2005;16(4):260–264. doi: 10.1111/j.0956-7976.2005.01525.x. [DOI] [PubMed] [Google Scholar]
- Johnson-Laird PN. Mental models: Toward a cognitive science of language, inference and consciousness. Cambridge, MA: Harvard University Press; 1983. [Google Scholar]
- Kaiser E, Trueswell JC. Investigating the interpretation of pronouns and demonstratives in Finnish: Going beyond salience. In: Gibson E, Pearlmutter N, editors. The processing and acquisition of reference. Cambridge, MA: MIT Press; 2007. [Google Scholar]
- Kintsch W. The role of knowledge in discourse comprehension: A constructive-integration model. Psychological Review. 1988;95:163–182. doi: 10.1037/0033-295x.95.2.163. [DOI] [PubMed] [Google Scholar]
- Ladd R. Intonational phonology. Cambridge, U.K: Cambridge University Press; 1996. [Google Scholar]
- Longhurst E. ExBuilder. 2006. Computer program. [Google Scholar]
- MacWhinney B, Bates E. Sentential devices for conveying givenness and newness: A cross-cultural developmental study. Journal of Verbal Learning and Verbal Behavior. 1978;17:539–558. [Google Scholar]
- Marslen-Wilson W. Linguistic structure and speech shadowing at very short latencies. Nature. 1973;244(5417):522–523. doi: 10.1038/244522a0. [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson W. Sentence perception as an interactive parallel process. Science. 1975;189:226–228. doi: 10.1126/science.189.4198.226. [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson W. Functional parallelism in spoken word recognition. Cognition. 1987;25:71–102. doi: 10.1016/0010-0277(87)90005-9. [DOI] [PubMed] [Google Scholar]
- Pierrehumbert J, Hirschberg J. The meaning of intonational contours in the interpretation of discourse. In: Cohen PR, Morgan J, Pollack ME, editors. Intentions in Communication. Cambridge, MA: MIT Press; 1990. pp. 271–311. [Google Scholar]
- Prince E. The ZPG letter: Subjects, definiteness, and information-status. In: Thompson S, Mann W, editors. Discourse description: Diverse analyses of a fund raising text. Philadelphia: John Benjamins B.V; 1992. pp. 295–325. [Google Scholar]
- Pyykkönen P, Matthews D, Järvikivi J. Children’s online comprehension of pronouns in spoken language: The role of verb semantics. Poster presented at the 20th annual CUNY conference on human sentence processing; San Diego, CA. 2007. [Google Scholar]
- Rossion B, Pourtois G. Revisiting Snodgrass and Vanderwart’s object database: Color and texture improve object recognition [On-line] Journal of Vision. 2001;1:413a. doi: 10.1167/1.3.413. Abstract from: http://journalofvision.org/1/3/413. [DOI]
- Sanford AJ, Garrod SC. Understanding written language. Chichester: Wiley; 1981. [Google Scholar]
- Sedivy J, Tanenhaus M, Spivey-Knowlton M, Eberhard K, Carlson G. Proceedings of the 17th Annual Conference of the Cognitive Science Society. Hillsdale, NJ: Erlbaum; 1995. Using intonationally-marked presuppositional information in on-line language processing: Evidence from eye movements to a visual model; pp. 375–380. [Google Scholar]
- Snedeker J, Trueswell J. The developing constraints on parsing decisions: The role of lexical-biases and referential scenes in child and adult sentence processing. Cognitive Psychology. 2004;49(3):238–299. doi: 10.1016/j.cogpsych.2004.03.001. [DOI] [PubMed] [Google Scholar]
- Snodgrass JG, Vanderwart M. A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Human Learning & Memory. 1980;6:174–215. doi: 10.1037//0278-7393.6.2.174. [DOI] [PubMed] [Google Scholar]
- Song H, Fisher C. Who’s “she”? Discourse prominence influences preschoolers’ comprehension of pronouns. Journal of Memory and Language. 2005;52:29–57. [Google Scholar]
- Tanenhaus MK, Spivey-Knowlton MJ, Eberhard KM, Sedivy JC. Integration of visual and linguistic information during spoken language comprehension. Science. 1995;268:1632–1634. doi: 10.1126/science.7777863. [DOI] [PubMed] [Google Scholar]
- Terken J, Hirschberg J. Deaccentuation of words representing “given” information: Effects of persistence of grammatical function and surface position. Language and Speech. 1994;37:125–145. [Google Scholar]
- Terken J, Nooteboom SG. Opposite effects of accentuation and deaccentuation on verification latencies for given and new information. Language and Cognitive Processes. 1987;2:145–163. [Google Scholar]
- Trueswell JC, Gleitman L. Children’s eye movements during listening: Developmental evidence for a constraint-based theory of sentence processing. In: Henderson JM, Ferreira F, editors. The interface of language, vision, and action: Eye movements and the visual world. New York, NY: Psychology Press; 2004. pp. 319–346. [Google Scholar]
- Trueswell JC, Sekerina I, Hill NM, Logrip ML. The kindergarten-path effect: Studying on-line sentence processing in young children. Cognition. 1999;73:89–134. doi: 10.1016/s0010-0277(99)00032-3. [DOI] [PubMed] [Google Scholar]
- Van Dijk TA, Kintsch W. Strategies of discourse comprehension. New York: Academic Press; 1983. [Google Scholar]
- Venditti JJ, Hirschberg J. Intonation and discourse processing. Proceedings of the 15th ICPhS 2003; Barcelona, Spain. 2003. [Google Scholar]
- Watson D, Arnold JE. Not just given and new: The effects of discourse and task-based constraints on acoustic prominence; 2005, March; Poster presented at the 18th annual CUNY conference on human sentence processing; Tuscon, AZ. [Google Scholar]
- Watson DG, Arnold JE, Tanenhaus MK. Tic tac TOE: Effects of predictability and importance on acoustic prominence in language production. University of Illinois; Urbana-Champaign: 2007. Unpublished manuscript. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wieman LA. Stress patterns of early child language. Journal of Child Language. 1976;3:283–286. [Google Scholar]
- Zwaan RA, Radvansky GA. Situation models in language comprehension and memory. Psychological Bulletin. 1998;123(2):162–185. doi: 10.1037/0033-2909.123.2.162. [DOI] [PubMed] [Google Scholar]