

Abstract
The biosynthetic gene cluster for the enediyne antitumor antibiotic maduropeptin (MDP) from Actinomadura madurae ATCC 39144 was cloned and sequenced. Cloning of the mdp gene cluster was confirmed by heterologous complementation of enediyne polyketide synthase (PKS) mutants from the C-1027 producer Streptomyces globisporus and the neocarzinostatin producer Streptomyces carzinostaticus using the MDP enediyne PKS and associated genes. Furthermore, MDP was produced, and its apo-protein isolated and N-terminal sequenced; the encoding gene, mdpA, was found to reside within the cluster. The biosynthesis of MDP is highlighted by two iterative type I PKSs – the enediyne PKS and a 6-methylsalicylic acid PKS; generation of (S)-3-(2-chloro-3-hydroxy-4-methoxyphenyl)-3-hydroxypropionic acid derived from L-α-tyrosine; a unique type of enediyne apo-protein; and a convergent biosynthetic approach to the final MDP chromophore. The results demonstrate a platform for engineering new enediynes by combinatorial biosynthesis and establish a unified paradigm for the biosynthesis of enediyne polyketides.
Keywords: Actinomadura madurae, biosynthesis, chromoprotein, enediyne apo-protein, maduropeptin, polyketide synthase
Introduction
Maduropeptin (MDP) from Actinonomadura madurae ATCC 39144 belongs to the enediyne family of antitumor antibiotics.1–4 Similar to all chromoprotein enediynes, which include C-10275 and neocarzinostatin (NCS),6 MDP is isolated as a noncovalent complex consisting of an apo-protein and a reactive nine-membered enediyne chromophore (Figure 1). Upon release from the apo-protein, the enediyne chromophore can undergo a rearrangement to form a benzenoid diradical species that can abstract hydrogen atoms from DNA to initiate a cascade of DNA breakage, ultimately leading to cell death.7,8 While this mode of action has attracted interest in using the enediynes for cancer treatment, high cytotoxicity has delayed the application of enediynes as therapeutic agents.9 However, the development of NCS conjugates with poly(styrene-co-maleic acid) or its various alkyl esters10 and a monoclonal-antibody derivative of the ten-membered enediyne calicheamicin (CAL)11 under the trade name Mylotarg® have alleviated toxicity allowing the drugs to reach the markets in Japan and the USA, respectively, providing the inspiration that the engineering and discovery of new enediynes will facilitate anticancer drug development.
Figure 1.
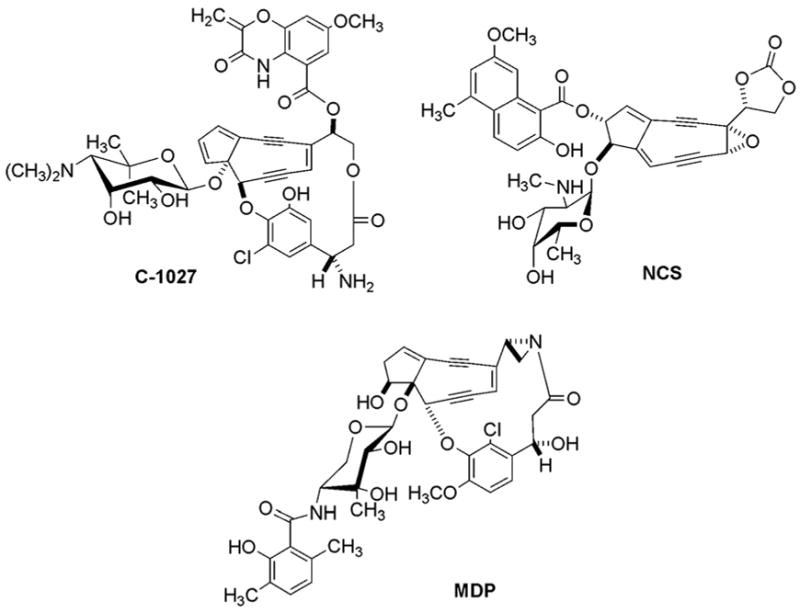
Structures of the 9-membered enediynes C-1027, NCS, and MDP.
The central feature of the enediyne chromophores is their exotic nine- or ten-membered ring structure consisting of a characteristic diyne conjugated to a double bond, otherwise referred to as the enediyne core. The majority of the nine-membered enediyne chromophores, like NCS,12 C-1027,13 and MDP (Figure 1), contain additional structural features that enhance the chemistry, which in turn modulates the biological activity. The MDP chromophore, the structure of which was solved in 1994,14 also contains a 3,6-dimethylsalicylic acid moiety, an aminosugar previously named madurose, and an (S)-3-(2-chloro-3-hydroxy-4-methoxyphenyl)-3-hydroxypropionic acid moiety. Similar to NCS and C-1027, MDP is isolated as a chromoprotein complex, although a new method had to be developed to release the chromophore from the apo-protein for structural characterization.15 Furthermore, the MDP apo-protein was deemed a new type of enediyne apo-protein with no homology to CagA6 or NcsA,5 the C-1027 and NCS apo-proteins, respectively, although only the approximate amino acid composition – and not the primary sequence – was reported.16 The so-called histone-specific proteolytic activity of the apo-proteins for the chromoprotein enediynes, which included the MDP apo-protein,17 has now been generally accepted as an artifact that resulted from adventitious proteases contaminating the apo-protein or chromoprotein preparation.17–20
The 9-membered NCS or 10-membered CAL enediyne chromophores require an external trigger, such as a base or reducing agent, respectively, to initiate an electronic rearrangement to form the benzenoid diradical species (via a Bergman or Myers rearrangement), which in turn abstracts hydrogen atoms from the deoxyribose of DNA, leading to the eventual DNA damage.10 In contrast, the MDP enediyne chromophore, like that of C-1027, is relatively unstable, and attempts to isolate the nascent MDP enediyne chromophore were unsuccessful.14 Instead, a C5-methoxy adduct was structurally elucidated, along with the aromatized product (Figure 2B). Comparisons of these structures and computational modeling led to a proposal where the MDP-OCH3 adduct, hypothesized to be an artifact of the purification process, is first reconverted to MDP by intramolecular ring contraction to form the aziridine, while simultaneously eliminating methanol via double bond migration and anti-elimination. The conjugated diyne form of MDP is now primed to undergo Bergman rearrangement, leading to formation of the benzenoid diradical intermediate that, upon coupling with hydrogen atoms, results in the aromatized product. This proposal was in part substantiated upon chemical synthesis of a MDP-OCH3 adduct mimic, which verified that the exocyclic C4-C13 double bond is labile to rearrangement, resulting in the characteristic aziridine moiety of MDP.21
Figure 2.
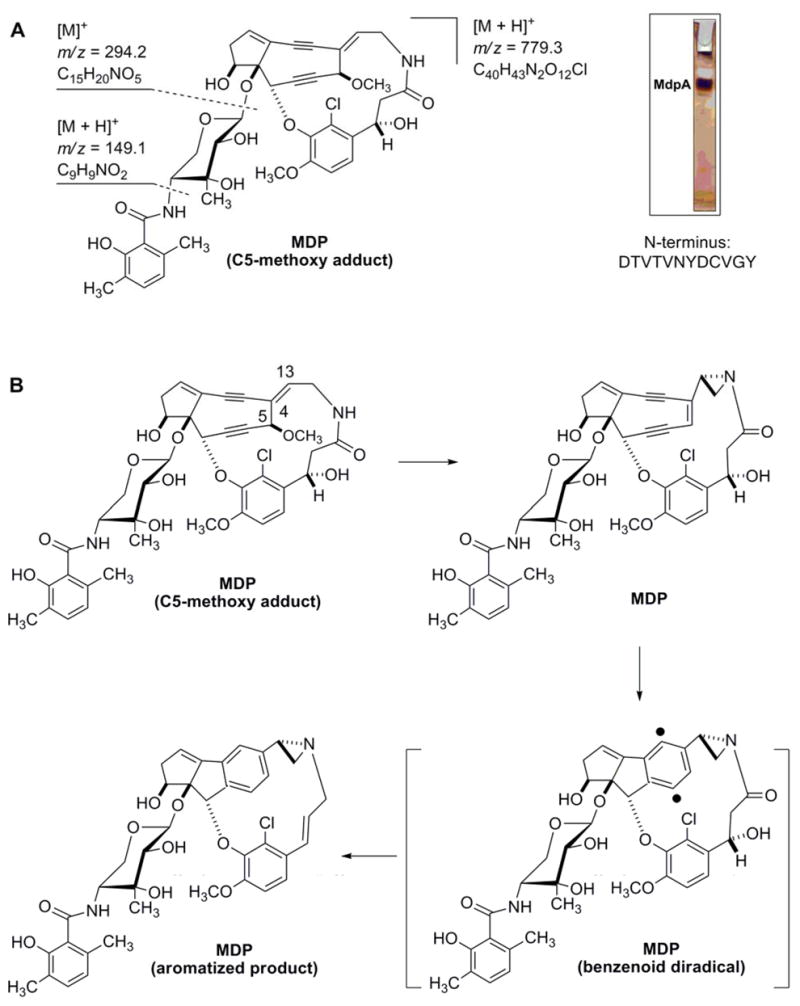
Isolation of MDP chromophore and binding protein, MdpA. (A) The chromophore was purified and confirmed by MS giving the characteristic MDP-OCH3 adduct and associated mass fragments as reported previously;14 the MDP binding protein was purified and confirmed by N-terminal sequencing. (B) Isolation of MDP as a MDP-OCH3 adduct, its rearrangement to the aziridine form MDP, subsequent Bergman rearrangement to afford the MDP-benzenoid diradical, and final formation of the MDP-aromatized product after addition of two hydrogen atoms as described previously.14
Concurrent with our studies regarding the chromoproteins C-102722 and NCS,23 we chose to clone and sequence the mdp biosynthetic gene cluster to facilitate biosynthetic studies of the enediynes, to establish the apo-protein sequence for MDP, and to solidify the unifying paradigm for enediyne biogenesis.24,25 In this paper, we report the identification of the MDP biosynthetic gene cluster from A. madurae ATCC 39144 and propose a convergent biosynthetic pathway leading to the MDP chromophore by sequence analysis of the open reading frames (ORFs) and comparisons to the other cloned enediyne gene clusters, C-1027,22,26 NCS,23 and CAL.27 To expedite the confirmation of the cluster identity, a C-1027 enediyne polyketide synthase (PKS) mutant strain Streptomyces globisporus SB100522 and an NCS enediyne PKS mutant strain Streptomyces carzinostaticus SB500223 were utilized for heterologous complementation with the MDP enediyne PKS. Furthermore, the MDP chromprotein complex was isolated from A. madurae ATCC 39144. The MDP chromophore was confirmed as the MDP-OCH3 adduct by mass spectrometry (MS) analysis, and the MDP apo-protein was N-terminal sequenced, confirming that the mdpA gene, which encodes the apo-protein, was indeed localized within the cloned mdp cluster. The results provide the first experimental evidence for a unified enediyne biosynthetic paradigm and establish a new enediyne binding protein, MdpA, with no sequence homologs in the protein databanks. Together the results lay the groundwork for future enzymatic characterizations of the MDP biosynthetic pathways and provide the basis for combinatorial biosynthesis to generate new enediyne natural products.
Experimental Procedures
Bacterial Strains, Plasmids, and Sequence Analysis
A. madurae ATCC 39144 and S. carzinostaticus ATCC 15944 wild-type strains producing MDP and NCS, respectively, were obtained from American Type Culture Collection (Rockville, MD). The S. globisporus wild-type22 and S. globisporus SB100522 and S. carzinostaticus SB500223 mutant strains, in which the sgcE and ncsE enediye PKS genes have been inactivated, respectively, were described previously. Gigapack III XL and E. coli XL1-Blue MR cells were obtained from Stratagene (La Jolla, CA). pGEM-T Easy and pGEM-3zf(+) were from Promega (Madison, WI). SuperCos1 was from Stratagene. pANT841,23 pSET152,29 pUWL201PW,29 and pWHM7930 were described previously. The C-1027 and NCS enediyne PKS expression constructs pBS101922 (that overexpresses sgcE under the ErmE* promoter29) and pBS502023 (that overexpress ncsE5, ncsE, and ncsE10 under the ErmE* promoter29) were reported previously. DIG-labeling kit and calf intestinal phosphatase were from Roche (Indianapolis, IN). Ligations were performed with T4 DNA ligase from Promega. Restriction enzymes were from New England Biolabs (Ipswich, MA) or Invitrogen (Carlsbad, CA). The shotgun library of pBS10002 for DNA sequencing of the mdp cluster was prepared by Lucigen (Madison, WI). DNA sequencing was carried out at the University of Wisconsin Biotechnology Center (Madison, WI). Sequence analysis was carried out using BLASTN available from NCBI and contiguous DNA was compiled using Lasergene (DNASTAR Inc., Madison, WI). ORFs were predicted using ORFinder from NCBI, and protein sequences were analyzed using PSI-BLAST (NCBI), SignalP, and Vector NTI (Invitrogen). Protein sequence identity and similarity were calculated using the Vector NTI program AlignX.
Biochemicals, Chemicals, and Media
Biochemicals, chemicals, media, and other molecular biology reagents were from standard commercial sources and used without further purification.
Cosmid DNA Library Construction
Recombinant DNA manipulations in E. coli28 and Streptomyces29 were carried out following standard protocols. The general procedure for cloning the enediyne PKS gene and associated ORFs was previously described.25 A 3.5 kb-DNA fragment covering most of mdpE5/E4/E3 was PCR amplified from total genomic DNA using Platinum Taq DNA polymerase (Invitrogen, Carlsbad, CA). Reactions were performed following the manufacturer’s protocol with 5% DMSO added, an annealing temperature of 62 °C for 30 sec, and the following primers: (forward) 5′-GGMTTCCACCAGGCGTACTTC-3′ / (reverse) 5′-SCCGARRTTCGASGGGTTCAT-3′, where M = A or C; S = C or G; and R = A or G. The DNA fragment was inserted into pGEM-T Easy following the provided protocol to yield pBS10001. After confirmation of the insert by DNA sequencing, pBS10001 was digested with PstI to yield a 1.2-kb fragment (one PstI site was within the MCS of pGEM-T Easy and the other within mdpE4), which was used to prepare a DIG-labeled probe (Probe-1) following the provided instructions (Roche) (Figure 3A).
Figure 3.

The MDP biosynthetic gene cluster from A. madurae ATCC 39144. (A) Restriction map of the 85-kb DNA region encompassed by three overlapping cosmids represented by pBS10002, pBS10003, and pBS10004. Solid black indicates the region whose gene products are predicted to be involved in MDP biosynthesis (62.8 kb). P, PstI. Probe-1 and –2 were used to localize the overlapping cosmids covering the MDP cluster. (B) Genetic organization of the MDP biosynthetic gene cluster. Proposed functions for individual orfs are color-coded and summarized in Table 1.
A cosmid library was constructed by partially digesting A. madurae ATCC 39144 chromosomal DNA with Sau3A1 followed by dephosphorylation with calf intestinal phosphatase. A modified version of SuperCos1 was prepared by digestion with Eco47III and re-ligation to eliminate the kanamycin resistance gene to yield SuperKos as described previously.31 After an overnight ligation at 16 °C, the mixture was packaged using Gigapack III XL and used to transfect E. coli XL1 Blue MR cells following the instructions provided (Stratagene). Colony hybridization was performed using Probe-1 with Hybond-N from Amersham Bioschences (Piscataway, NJ). Ten clones that hybridized with Probe-1 were chosen, and the cosmids were isolated and their inserts were end-sequenced using the primers (forward) 5′-GGGAATAAGGGCGACACGG-3′ and (reverse) 5′-GCTTATCGATGATAAGCGGTC-3′ to determine the best candidate for complete sequencing.
A single cosmid (pBS10002) was identified to harbor DNA regions encoding the enediyne PKS24 and a second, distinct PKS (Figure 3A) and was used to generate a shotgun library for complete DNA sequence determination. The resultant DNA sequences were compiled and assembled into contigs, and gaps were filled in by primer walking or by subcloning fragments covering the gaps into pGEM-3zf(+) and subsequently sequencing the cloned fragments using the M13 universal primers.
After complete sequencing of pBS10002, a second probe (Probe-2) was prepared using PCR amplification with pBS1002 as a template and the following primers: (forward) 5′-GGTGCTGCTGACCACCTTCC-3′ / (reverse) 5′-CGACGTCCACCGTGACGACGACC-3′ to give a 1.5-kb fragment near the upstream end of pBS1002 (Figure 3A) and used to re-screen the A. madurae cosmid library. Cosmid pBS10003 was chosen as the best candidate to contain the most upstream boundary on the basis of end-sequencing of the DNA insert. Alternatively, pBS1004, which hybridized with Probe-1, was chosen to likely contain the downstream boundary based on end-sequencing of the DNA insert. The final DNA sequence of the entire mdp cluster was obtained by chromosomal walking from pBS10002 directly into pBS10003 and pBS10004, combined with subcloning of selected fragments from pBS10003 and pBS10004 into pGEM-3zf(+) and sequencing using M13 universal primers.
Culturing of A. madurae ATCC 39144
The culture conditions of A. madurae ATCC 39144 for genomic DNA isolation were previously described.24 A. madurae spores were isolated according to standard procedures upon culturing on ISP4 plates at 28 °C for 5–7 days.29 Production and isolation of the MDP chromoprotein complex was essentially the same as described previously.14,15 Purification of the MDP chromophore from the chromoprotein was carried out according to the literature procedure,14 and the resultant MDP chromophore was subjected to atmospheric pressure chemical ionization-mass spectrometry (APCI-MS) analysis using an Agilent 1100 LC-MSD mass spectrometer (Agilent Technologies, Palo Alto, CA) with a Phenomenex Luna C18 column (5 μ, 4.6 x 100 mm) (Torrance, CA) and an isocratic mobile phase of 80% methanol in water at 1 mL/min.
Heterologous Complementation
To construct the mdp enediyne PKS gene cassette expression vector pBS10005, a 9.5-kb PstI-BamHI fragment, containing the mdpE5, mdpE, mdpE10, and mdpE6 genes, was recovered from pBS10004 and cloned into the same sites of pANT841 to yield pBS10006. This cassette was then isolated as a 9.5-kb HindIII-BamHI fragment from pBS10006 and co-ligated with a 0.45-kb EcoRI-HindIII fragment of the ErmE* promoter from pWHM79 into the BamHI and EcoRI sites of pSET152 to yield pBS10005.
To cross-complement the sgcE:ermE mutation in S. globisporus with mdpE, pBS10005 was introduced into S. globisporus SB100522 by intergenetic conjugation according to the previously described procedure with pBS1019 similarly introduced as a positive control.22 To cross-complement the ncsE:ermE mutation in S. carzinstaticus with mdpE, pBS10005 was introduced into S. carzinostaticus SB500223 by PEG-mediated protoplast transformation as described previously with pBS5020 similarly introduced as a positive control.23 The resultant recombinant strains S. globisporus SB1011 [i.e., SB1005 (pBS10005)] and SB1010 [i.e., SB1005 (pBS1019)] were cultured and analyzed for C-1027 production by HPLC analysis as described previously22 with the S. globisporus wild-type strain as a control (Figure 7A). C-1027 production was confirmed by matrix-assisted laser desorption ionization-mass spectrometry (MALDI-MS), yielding a characteristic [M + H]+ at m/z = 844.259 and 846.273, consistent with the molecular formula of C43H42N3O13Cl (enediyne form calculated 843.241) and C43H44N3O13Cl (aromatized form calculated 845.256), respectively. Similarly, the S. carzinostaticus recombinant strains SB5007 [i.e., SB5002 (pBS10005)] and SB5003 [i.e., SB5002 (pBS5020)] were cultured and analyzed for NCS production by HPLC analysis following the published procedure23 with the S. carzinostaticus ATCC 15944 wild-type strain as a control (Figure 7B). The identity of NCS was confirmed by liquid chromatograghy-electrospray ionization-mass spectrometry (LC-ESI-MS), yielding a characteristic [M + H]+ at m/z = 660.3, consistent with the molecular formula of C35H33NO12 (calculated 659.2).
Figure 7.

Heterologous complementation of C-1027 and NCS enediyne PKS mutants by the MdpE enediyne PKS cassette. (A) Complementation of C-1027 enediyne polyketide synthase mutant (SB1005) with empty vector (II), sgcE, plasmid pBS1019 (III), and mdpE/E5/E6/E10, plasmid pBS3010 (IV). For comparisons, production of C-1027 from wild-type producer is shown (I). (B) Complementation of NCS enediyne polyketide synthase mutant (SB5002) with ncsE, plasmid pBS5019 (I); empty vector (II); and mdpE/E5/E6/E10, plasmid pBS10005 (III). Symbols are (●) for C-1027 in the enediyne form, (○) for C-1027 aromatized product, and (◆) for NCS.
Isolation of the MDP Apo-protein from A. madurae ATCC 39144 and Confirmation of Its Identity as MdpA
The MDP apo-protein MdpA was purified from A. madurae ATCC 31944 following the described procedure except for the inclusion of 5 mM EDTA in all solutions.15 After binding to DEAE cellulose anion exchange resins, the MDP chromoprotein complex was eluted with 50 mM Tris-HCl, pH 8.0, containing 0.5 M NaCl, and the resultant chromoprotein complex was precipitated by addition of (NH4)2SO4 to 70% saturation. After centrifugation at 30,000 × g at 4 oC for 30 min, the pellet was collected, re-suspended in 50 mM HEPES, pH 7.5, with 5 mM EDTA, and dialyzed overnight in the same buffer. The MDP chromoprotein complex was further purified using anion exchange chromatography as described except a 5 mL HiTrapQ column (GE Healthcare; Piscataway, NJ) was used to substitute for the TSK Gel DEAE 3SW column.16 The fractions were analyzed by SDS-PAGE and native PAGE with 15% acrylamide and visualized using non-destructive silver staining.32 The gel was soaked with gentle agitation for 24 h increments in H2O, acetic acid:MeOH:H2O (10:30:60, v/v), acetic acid:H2O (10:90, v/v), and H2O. The protein band was electro-eluted onto Hybond-P (GE Healthcare) and sequenced at Tufts University Core Facility (Boston, MA). The first 12 amino acid residues of the purified apo-protein were determined as DTVTVNYDXVGY using automated Edman Degradation. The residue “X” is predicted to be a cysteine based on the encoding DNA sequence and was not detected by N-terminal sequencing.
Cloning of mdpC4 and mdpC1 for E. coli Expression
The genes for mdpC4 and mdpC1 were amplified by PCR using Expand Long Template PCR System from Roche (Indianapolis, IN) with 1X supplied buffer, 250 μM dNTPs, 5% DMSO, 20 ng pBS10002, 5 U DNA polymerase, and 15 μM each of the following primer pairs: mdpC4 (forward) 5′-GGTATTGAGGGTCGCATGAAGGTGACTCAGACCGAG-3′/(reverse) 5′-AGAGGAGAGTTAGAGCCTCAGCGCAGCTCGACGCC-3′; and mdpC1 (forward) 5′-GGTATTGAGGGTCGCATGACTGCGATCGGAACGGC-3′/(reverse) 5′-AGAGGAGAGTTAGAGCCTCACCTTCACTCCGATCGCTC-3′. The PCR program included an initial hold at 96 °C for 2 min., followed by 30 cycles of 96 °C for 10 s, 56 °C for 30 s, and 68 °C for 40 s per kb of desired product. The gel-purified PCR product was inserted into pET-30 Xa/LIC using ligation-independent cloning as described by Novagen (Madison, WI), affording pBS10007 (for mdpC4), and pBS10008 (for mdpC1); and sequenced to confirm PCR fidelity.
Subcloning of mdpC4 and mdpC1 for Streptomyces lividans Expression
Plasmids pBS10007 and pBS10008 were digested with NdeI-EcoRI, and the 1.7-kb (mdpC4) and 3.5-kb (mdpC1) DNA fragments were purified and ligated to the identical sites of pUW201PW to give pBS10009 and pBS10010, respectively. Plasmids were transformed into S. lividans TK-64 by PEG mediated protoplast transformation following standard procedure. After 16 h, the transformation plates were overlaid with 1 mL water supplemented with 50 μg/mL thiostrepton. Single colonies were picked 3 days after overlay and transferred to a fresh R2YE-agar plate containing 50 μg/mL thiostrepton for a second round of antibiotic selection. For protein production, a loopful of mycelium was inoculated into 5 mL liquid R2YE medium supplemented with 25 μg/mL thiostrepton and grown for 2 days at 28 °C. After homogenizing the mycelia, 1 mL was used to inoculate 50 mL liquid R2YE medium in a 250-mL baffled flask containing 4 g of glass beads and 25 μg/mL thiostrepton, and the resulting culture was incubated at 28 °C for 3 days at 250 rpm prior to harvesting.
Purification of His6-MdpC4 from S. lividans (pBS1007) and His6-MdpC1 from S. lividans (pBS1008)
Cells were resuspended in 100 mM Tris-HCl, pH 8.0, 300 mM KCl, and 5 mM β-mecraptoethanol and lysed using a French Press with 2 passes at 15000 psi. After centrifugation, the supernatent was loaded onto a column containing Ni-NTA agarose and the proteins purified as described by Qiagen (Valencia, CA) using a 20 mM imidazole wash and elution buffer containing 250 mM imidazole. Protein was desalted into 20 mM Tris-HCl, pH 8, and 0.5 mM DTT using PD-10 columns (GE Healthcare) and stored as 50% glycerol stocks at –20 °C. A dominant band corresponding to the expected molecular weight of MdpC4 (63 kD) and MdpC1 (122 kD) was detected using 10% SDS-PAGE.
Activity of His6-MdpC4 and His6-MdpC1
Activity assays for MdpC1 were performed and analyzed as described for SgcC1.54,55 Activity assays for MdpC4 were performed as described for SgcC4,51,52 and the reactions were analyzed using C18 reverse-phase HPLC with an analytical Apollo C18 column (250 x 4.6 mm, 5 μ; Grace Davison, Deerfield, IL). A series of linear gradients was developed from 0.1% trichloroacetic acid in 10% acetonitrile (A) to 0.1% trichloroacetic acid in 90% acetonitrile (B) in the following manner (beginning time and ending time with linear increase to % B): 0–2 min, 5% B; 2–19 min, 50% B; 19–24 min, 100% B; 24–32 min, 100% B; and 32–35 min, 5% B. The flow rate was kept constant at 1.0 mL/min and elution was monitored at 280 nm. Peaks corresponding to L-α-tyrosine and (S)-β-tyrosine were identified by comparison to authentic standards (Sigma-Aldrich, St. Louis, MO and Peptech Corporation, Burlington, MA, respectively) and with comparisons to SgcC4 activity assays.
Results
Cloning, Sequencing, and Organization of the mdp Gene Cluster
Degenerate primers designed according to conserved regions found in the known NCS, C-1027, and CAL enediyne PKS and the associated upstream ORF were used to amplify the MDP enediyne PKS gene fragment from A. madurae ATCC 39144 genomic DNA.24 The amplified fragment, exemplified by Probe-1 containing portions of mdpE and mdpE5 (Figure 3A), was subsequently used to screen a cosmid library of A madurae, with several cosmids resulting in positive hits from Southern hybridization. Of the positive clones, a single cosmid pBS10002 was chosen because end-sequencing of the DNA insert revealed sequences whose deduced gene products – MdpB at one end and MdpE2 at the other end – showed similarities to the chlorothricin 6-methylsalicylic acid synthase (an iterative type I PKS)43 and an unknown protein associated with all known enediyne PKSs, respectively (Figure 3A). pBS10002 was fully sequenced by a shotgun approach, and the primary sequence of the DNA insert was reconstructed. Analysis of the potential ORFs revealed numerous gene products with similarity to proteins contained within the C-102722 and NCS23 gene clusters. A second cosmid, pBS10003, was subsequently identified using Probe-2 from pBS10002 to re-screen the A. madurea cosmid library to obtain the upstream boundary, and a third cosmid (pBS10004) hybridizing to Probe-1 was chosen to complete the downstream boundary. Together the three overlapping cosmids cover 85 kb of contiguous DNA encompassing the entire mdp gene cluster (Figure 3A).
Functional Assignments of Genes within the mdp Cluster
The mdp gene cluster consists of minimally forty-two orfs spanning a 52-kb contiguous DNA region responsible for biosynthesis, resistance, and transport of the MDP chromoprotein comples (Figure 3B and Table 1). Sequence analysis by BLAST comparison of gene products within the mdp cluster provided functional assignments that are consistent with five ORFs (MdpA1 through MdpA5) responsible for aminosugar production, three ORFs (MdpB through MdpB2) for 3,6-dimethylsalicylyl-CoA biosynthesis, eight ORFs (MdpC through MdpC8, excluding MdpC5) for (S)-3-(2-chloro-3-hydroxy-4-methoxyphenyl)-3-hydroxypropionic acid production, twelve ORFs (MdpE through MdpE11) for production of the enediyne core, three ORFs (MdpA6, MdpB3, and MdpC5) for the final convergence of the four building blocks into the MDP chromophore, and five ORFs (MdpR1 through MdpR4) responsible for transport, regulation, and resistance, including one putative ORF (MdpA) containing the expected amino acid composition for the MDP apo-protein. The DNA sequence of the entire cluster, including predicted genes and functional assignments for the gene products have been deposited in GenBank under accession number AY271660.
Table 1.
Deduced functions of ORFs in the Maduropeptin Biosynthetic Gene Cluster
| Gene | Sizea | Putative function | Homologb | Identity%/Similarity% |
|---|---|---|---|---|
| orf(-5) | 444 | Dioxygenase | SimC5 (AAK06796) | 41/52 |
| orf(-4) | 403 | Dioxygenase | SimC5 (AAK06796) | 31/42 |
| orf(-3) | 226 | Transcriptional repressor | CmaC (AAK44709) | 37/50 |
| orf(-2) | 557 | Methylmalonyl-CoA decarboxylase | Sim11 (NP_823479) | 64/76 |
| orf(-1) | 162 | Glyoxylase/dioxygenase superfamily | SCO2237 (NP_626487) | 47/62 |
| Predicted upstream boundary of the mdp cluster | ||||
| mdpA1 | 344 | dTDP-1-glucose synthase | SgcA1 (AAL06657) | 53/74 |
| mdpL | 460 | Epoxide hydrolase | UbiH (AAM78003) | 51/64 |
| mdpC8 | 340 | Zn-dependent alcohol dehydrgosenase | AdhP (NP_396172) | 54/68 |
| mdpA4 | 406 | C-Methyltransferase | McmC (CAK50790) | 58/74 |
| mdpC | 539 | Monooxygenase | SgcC (AAL06674) | 71/81 |
| mdpA3 | 328 | Glucuronic acid decarboxylase | UXS1 (Q96V00) | 53/62 |
| mdpA2 | 447 | NDP-glucose dehydrogenas | AlgD (AAB01487) | 52/64 |
| mdpA5 | 403 | Aminotransferase | ArnB (Q8ZNF3) | 54/68 |
| mdpJ | 148 | Unknown | SgcJ (AAL06676) | 63/80 |
| mdpD2 | 394 | Oxidoreductase | SgcD2 (AAL06685) | 67/79 |
| mdpB1 | 348 | C-Methyltransferase | RemG (CAE51172) | 28/43 |
| mdpB | 1747 | 6-Methylsalicylic acid synthase | ChlB1 (AAZ77673) | 51/63 |
| MdpB2 | 548 | Adenylate Ligase | NcsB2 (AAM77987) | 44/53 |
| MdpB3 | 285 | Putative Hydrolase | PlaP6 (ABB69740) | 33/42 |
| mdpA6 | 466 | Glycosyltransferase | SgcA6 (AAL06670) | 43/57 |
| mdpR4 | 245 | DNA alkylation repair | RBE_0692 (YP_537862) | 36/56 |
| mdpU1 | 409 | P-450 oxidoreductase | CypX (AAC25766) | 42/57 |
| mdpU2 | 381 | Hypothetical protein | nfa43920 (BAD59241) | 33/47 |
| mdpU3 | 411 | P-450 oxidoreductase | Cyp28 (NP_828645) | 42/56 |
| mdpC7 | 461 | Aminotransferase | BioA (Q47862) | 38/55 |
| mdpA | 167c | Apo-Protein | No | --- |
| mdpR3 | 525 | Transmembrane efflux protein | Pur8 (P42670) | 48/xx |
| mdpH | 442 | Hydroxylase | SgcH (AAL06669) | 48/63 |
| mdpC5 | 460 | NRPS condensation enzyme | SgcC5 (AAL06671) | 45/58 |
| mdpC3 | 518 | Halogenase | SgcC3 (AAL06656) | 54/65 |
| mdpC4 | 537 | Aminomutase | SgcC4 (AAL06680) | 72/82 |
| mdpC1 | 1115 | NRPS adenylation enzyme | SgcC1 (AAL06681) | 50/59 |
| mdpC2 | 95 | NRPS peptidyl carrier protein | SgcC2 (AAL06679) | 38/52 |
| mdpC6 | 198 | O-Methyltransferase | FkbG (AAF86386) | 42/54 |
| mdpE11 | 267 | Unknown | SgcE11 (AAL06691) | 60/73 |
| mdpM | 365 | Unknown | SgcM (AAL06686) | 29/35 |
| mdpE9 | 552 | Oxidoreductase | SgcE9 (AAL06693) | 74/81 |
| mdpE8 | 189 | Unknown | SgcE8 (AY048670) | 53/66 |
| mdpR1 | 337 | Regulatory protein | StrR (CAA55579) | 48/60 |
| mdpR2 | 251 | Transcription regulatory protein | SgcR2 (AAL06696) | 49/64 |
| mdpE7 | 464 | P-450 hydroxylase | SgcE7 (AAL06697) | 60/69 |
| mdpE6 | 183 | Flavin reductase | SgcE6 (AAL06698) | 50/59 |
| mdpE10 | 152 | Type II thioesterase | SgcE10 (AAL06692) | 72/84 |
| mdpE | 1944 | Enediyne PKS | SgcE (AAL06699) | 56/63 |
| mdpE5 | 330 | Unknown | SgcE5 (AAL06700) | 70/78 |
| mdpE4 | 678 | Unknown | SgcE4 (AAL06701) | 56/67 |
| mdpE3 | 300 | Hypothetical | SgcE3 (AAL06702) | 47/56 |
| mdpE2 | 331 | Unknown | SgcE2 (AAL06703) | 55/61 |
| Predicted dowmstream boundary of the mdp cluster | ||||
| orf1 | 500 | Aldehyde dehydrogenase | PutA (CAB71240) | 51/65 |
| orf2 | 162 | Acetyltransferase | blr0463 (BAC45728) | 21/30 |
| orf3 | 525 | Alcohol dehydrogenase | BetA (CAB51051) | 43/57 |
| orf4 | 208 | Unknown | COG2096 (1NOG_A) | 27/43 |
| orf5 | 523 | Predicted peptidase | Iap (NP_251629) | 36/48 |
Numbers are in amino acids.
Given in parentheses are NCBI accession numbers; references, if not in the text, can be found therein.
Contains a 34-amino acid leader peptide
The mdp Cluster Boundaries and Unassigned Gene Products
The mdp gene cluster is proposed to start at mdpA1 and conclude at mdpE2 (Table 1). The orfs upstream of mdpA1 have gene products predicted to be involved in cell membrane biogenesis or possibly secondary metabolism of a distinct natural product, and the orfs downstream of mdpE2 have gene products with similarities to enzymes involved in ATP biosynthesis. Furthermore, the gene products of mdpA1 and mdpE2 also represent the furthest upstream and downstream sequence homologs with respect to the C-1027,22 NCS,23 or CAL27 gene clusters, although orfs outside the proposed boundary cannot be discounted precluding the development of a genetic system for A. madurae. Within the gene cluster, two P-450 oxidoreductases (MdpU1 and MdpU3) and an unknown protein MdpU2 that form a putative operon have not been assigned specific functions with respect to MDP biosynthesis. However, these ORFs are likely involved in aziridine formation to further process the enediyne core.
Resistance, Regulation, and Transport
Four genes (mdpR1 through mdpR4) are predicted to be involved in resistance, regulation, and transport. Three of the four gene products, MdpR1, MdpR2, and MdpR3, have homologs within the C-102722 and NCS23 gene clusters. MdpR1 has sequence homology to the StrR family of regulatory proteins33 and MdpR2 to the large family of AraC-type transcriptional regulatory proteins.34 MdpR3 is homologous to Pur8, which is a transmembrane protein that, when expressed in S. lividans, was implicated in late stage efflux of the antibiotic puromycin.35,36 MdpR4 has sequence similarity to conserved hypothetical proteins involved in DNA alkylation repair, although all of these protein homologs have putative assignments that are not based on definitive function.
The MDP apo-Protein MdpA
Bioinformatics analysis of the mdp gene cluster revealed a single gene product – MdpA – had characteristics of the MDP apo-protein,16 including no homology to CagA5 or NcsA,6 a predicted leader peptide of 34 amino acids, no Y, H, R, and K residues in the mature protein, and a low isoelectric point (predicted pI of 3.7 with and 3.0 without the leader peptide). The mdpA gene is translated as a 166-amino acid protein, and SignalP analysis predicted a leader peptide that is cleaved between A32 and D33, resulting in a 133-amino acid protein with a predicted molecular weight of 12,928 Da and having no significant similarities to any protein deposited at NCBI.
The genuine identity of the MDP apo-protein was elucidated by fermentation of the A. madurae ATCC 39144 strain, isolation of the MDP chromoprotein complex as described previously using a bioassay against Micrococcus luteus as guidance,15 and direct characterization of the MDP chromoprotein complex. Thus, a portion of the purified MDP chromoprotein complex was extracted with methanol-ethyl acetate (1:1 ratio), and the resultant MDP chromophore was subjected to APCI-MS analysis yielding a pair of [M+H]+ ions at m/z = 779.3 and m/z = 781.3 with a 3:1 ratio, consistent with the molecular formula of C40H43N2O12Cl expected for the mono-chlorinated MDP-OCH3 adduct (calculated 779.3 and 781.3).14 Also, two prominent [M]+ fragment ions were observed at m/z of 149.1 and 294.2, consistent with the benzamide (molecular formula C9H9NO2, calculated 149.0) and the entire ribopyranose moiety (molecular formula C15H20NO5, calculated 294.0), respectively (Figure 2A).14 The remaining complex was analyzed by native PAGE, and the only detected band was acid-washed and eluted onto PVDF membrane for N-terminal sequencing using standard Edman degradation (Figure 2A). The N-terminal sequence of the first 12 residues matched that of the predicted mature protein, confirming MdpA as the elusive MDP apo-protein and simultaneously providing the first evidence that the mdp gene cluster was localized and cloned.
Aminosugar Biosynthesis
The biosynthesis of the aminosugar of MDP consists of five enzymatic steps beginning from D-glucose-1-phosphate prior to attachment to the enediyne core (Table 1 and Figure 4A). MdpA1 is highly homologous to SgcA1, a biochemically characterized α-D-glucopyranosyl-1-phosphate thymidyltransferase, and catalyzes the formation of TDP-glucose.37 MdpA2, similar to the family of UDP-glucose dehydrogenases that includes Pseudomonas aeruginose AlgD, catalyzes the net four-electron oxidation of TDP-glucose to form TDP-glucuronic acid.38 MdpA3 is similar to the family of UDP-glucuronic acid decarboxylases and catalyzes oxidative decarboxylation of TDP-glucuronic acid to form thymidyl 5′-β-L-threo-pentapyranosyl-4″-ulose diphosphate.39,40 MdpA4 is homologous to a C-methyltransferase family that includes McmC and TylC3, which are necessary for mycarose biosynthesis in mithramycin from Streptomyces argillaceus and tylosin from Streptomyces fradiae, respectively.41 Therefore, MdpA4 catalyzes the incorporation of a methyl group from S-adenosylmethionine (SAM) with concomitant hydroxyl epimerization to form thymidyl 5′-3-methyl-α-D-erythro-pentapyranosyl-4″-ulose diphosphate. Finally, MdpA5, similar to Salmonella typhimurium ArnB implicated in lipid A biosynthesis,42 catalyzes a transamination leading to TDP-4-amino-4-deoxy-3-methyl-β-D-ribose.
Figure 4.

Proposed biosynthetic pathway for MDP chromophore: (A) aminosugar; (B) β-hydroxy acid; (C) 3,6-dimethylsalicylyl-CoA; and (D) enediyne core and convergent biosynthesis of four components to yield MDP chromophore.
3,6-Dimethylsalicylyl-CoA Biosynthesis
Three genes, mdpB through mdpB2, were identified within the mdp gene cluster that encode proteins with functions that would support their involvement in the biosynthesis of the 3,6-dimethylsalicylic acid moiety of MDP (Table 1 and Figure 4C). The gene for mdpB encodes a PKS with 5 known domains: a ketosynthase (KS), an acyltransferase (AT), a dehydrates (DH), a ketoreductase (KR), and an acyl carrier protein (ACP). MdpB is most similar to ChlB1, an iterative type I PKS involved in 6-methylsalicylic acid production during chlorothricin biosynthesis,43,44 but is also similar to NcsB, responsible for the production of 2-hydroxy-5-methyl-1-napthoic acid moiety of neocarzinostatin (Figure 5A).23,45 This newly discovered family of bacterial iterative type I PKSs46 has identical domain organization to Aspergillus terreus and other fungal 6-methylsalicylic acid synthase (6-MSAS) that catalyze 3 rounds of decarboxylative condensation to afford an tetraketide.47 As a consequence of these comparisons, MdpB is proposed to catalyze the synthesis of 6-methylsalicylic acid through 3 iterations with the regiospecific ketoreduction at position 5 that is seen with 6-MSAS. MdpB1 contains an S-adenosylmethionine binding motif found in several O-, N-, and C-methyltransferase,48 and is proposed to catalyze C-methyltransferase activity to generate 3,6-dimethylsalicylic acid. The closest homologs of MdpB1, RemG and RemH, are implicated in the unprecedented geminal bis-methylation of the aromatic polyketide resistomycin from Streptomyces resistomycificus,49 supporting the proposed role for MdpB1. Finally, MdpB2 utilizes the free acid to generate the 3,6-dimethylsalicylyl-CoA thioester. The closest homolog of MdpB2, NcsB2, has recently been characterized as a naphthoic acid-CoA ligase supporting the proposed assignment for this enzyme.50
Figure 5.

Comparisons of MdpB with selected bacterial iterative type I PKSs and MdpE with selected enediyne PKSs. (A) Domain organization of MdpB, a 6-methylsalicylic acid synthase (6-MSAS) and comparisons to NcsB involved in naphthoic acid biosynthesis and ChlB1 involved in 6-methylsalicylic acid biosynthesis. (B) Domain organization of MdpE and comparison to the enediyne PKS NcsE and SgcE. Abbreviations are KS, ketosynthase; AT, acyltransferase; ACP, acyl carrier protein; KR, ketoreductase; DH, dehydratase; and PPTase, phosphopantetheinyl transferase. The number of amino acids used for comparisons are given above and below the numbers of % identity / % similarity.
(S)-3-(2-Chloro-3-Hydroxy-4-Methoxyphenyl)-3-Hydroxypropionic Acid Biosynthesis
Eight genes (mdpC to mdpC8 excluding mdpC5) were identified to process L-α-tyrosine to form the (S)-3-(2-chloro-3-hydroxy-4-methoxyphenyl)-3-hydroxypropionic acid moiety of MDP (Table 1 and Figure 4B). MdpC through MdpC5 had closest sequence homology with enzymes involved in the biosynthesis of (S)-3-chloro-5-hydroxy-β-tyrosine of C-1027, with sequence identities ranging from 38% to 72%.22 The initial step is catalyzed by MdpC4, a 4-methylideneimidazole-5-one (MIO)-containing aminomutase similar to SgcC4, to generate (S)-β-tyrosine from L-α-tyrosine,51–53 Loading of (S)-β-tyrosine to a free-standing peptidyl carrier protein (PCP) (MdpC2) is then achieved by a discrete adenylation enzyme, MdpC1, which has closest homology to the C-1027 biosynthetic homolog SgcC1 that has been recently characterized and shown to prefer (S)-β-tyrosine as a substrate.54,55 Following activation and tethering of the (S)-β-Tyr as the (S)-β-tyrosyl-S-MdpC2 intermediate, a transamination occurs to eliminate the β-amino group catalyzed by the PLP-dependent transaminase MdpC7, homologous to the aminotransferase BioA family involved in cofactor metabolism.56 The 4′-hydroxyphenyl-3-ketopropionic acid, thioester-tethered to MdpC2, is next modified by a hydroxylase MdpC (similar to SgcC),22 an O-methyltransferase MdpC6,57 and a halogenase MdpC3 (similar to SgcC3).58 The (S)-β-hydroxy functionality is subsequently formed by stereospecific reduction of the β-carbonyl group, the most likely candidate for which is MdpC8, a homolog of a family of hypothetical zinc-dependent alcohol dehydrogenases with unknown function.
MdpC4 and MdpC1 Enzyme Activity
Activity of MdpC4 and MdpC1 was tested to confirm the origin of the (S)-3-(2-chloro-3-hydroxy-4-methoxyphenyl)-3-hydroxypropionic acid moiety of MDP and to demonstrate this biosynthetic pathway mimics the assembly of the (S)-3-chloro-4,5-dihydroxy-β-phenylalanine moiety found in C-1027. Recombinant MdpC4 was first purified from S. lividans, and the purified enzyme was incubated with L-α-tyrosine under the assay conditions as described for SgcC4.51,52 Using HPLC analysis with the free acids, a new peak appeared eluting before substrate, and this new peak had an identical retention time to authentic (S)-β-tyrosine, which was confirmed by co-injections and comparisons using SgcC4-catalyzed reactions (Figure 6A). Similar to SgcC4, the MdpC4-catalyzed reaction is reversible with a 7:3 ratio of (S)-β-tyrosine:L-α-tyrosine observed at equilibrium (Figure 6A). All hypothetic α-amino acid substrates, such as L-4-methoxyphenylalanine, L-3-chlorotyrosine, and L-3-hydroxytyrosine, were not recognized by MdpC4.
Figure 6.

Activty of MdpC4 and MdpC1. (A) HPLC profile of authentic L-α-tyrosine (I), L-α-tyrosine incubated 30 min with MdpC4 (II), L-α-tyrosine incubated overnight with MdpC4 (III), and authentic (S)-β-tyrosine (IV). Shown in the inset is the overnight incubation of (S)-β-tyrosine with MdpC4, which gives the identical profile and peak ratio compared to the forward reaction (III). Symbols are (●) for L-α-tyrosine and (◆) for (S)-β-tyrosine. (B) Amino acid-dependent ATP-PPi exchange assay for MdpC1 comparing L-α-tyrosine with β-tyrosine analogs where R is the respective substituent.
Recombinant MdpC1 was partially purified from S. lividans, and the enzyme was subjected to the same preliminary analysis as that described for SgcC1.54,55 Using the amino acid-dependent ATP-PPi exchange assay, MdpC1 was unable to recognize L-α-tyrosine, but activity was observed when MdpC1 was incubated with (S)-β-tyrosine (Figure 6B). Similarly to SgcC1, MdpC1 was active with other β-amino acid substrates including (R)-β-tyrosine (75%), 3-hydroxy-β-tyrosine (39%), and 3-chloro-β-tyrosine (24%).
Enediyne Core Biosynthesis and Convergent Biosynthesis for the MDP Chromophore
The MDP enediyne core is assembled by an iterative type I PKS – MdpE – that has high sequence homology and identical domain organization to other known enediyne PKS (Figure 5B).22–25 Four domains are evident by sequence analysis, including a KS, AT, dehydratase (DH), and KR. Two additional domains have been proposed for the enediyne PKS family, a central ACP and a C-terminal phosphopantetheinyltransferase (PPTase) domain.
MdpE is envisioned to assemble a nascent linear polyunsaturated polyketide backbone that is further modified by tailoring enzymes, including a minimum of 10 additional proteins (MdpE2 through MdpE11) (Table 1 and Figure 4D).24,25,46 Comparison to the C-102722 and NCS23 gene clusters suggests MdpH, MdpJ, MdpL, and MdpM – a hydroxylase, an unknown protein, an epoxide hydrolase, and an unknown protein, respectively – are also required for processing the MDP enediyne core. Upon formation of the enediyne core intermediate, the aminosugar madurose is attached via MdpA6, a glycosyltransferase; the 3,6-dimethylsalicylic acid via MdpB3, a putative acyltransferase/esterase; and the (S)-3-(2-chloro-3-hydroxy-4-methoxyphenyl)-3-hydroxypropionic acid via MdpC5, a condensation enzyme, although the timing of the coupling steps is still unclear.
Heterologous Complementation Using MdpE
To circumvent the difficulty in developing a genetic system for A. madurea, heterologous complementation of the respective enediyne PKS for C-1027 production in S. globisporus and NCS production in S. neocarzinostaticus was chosen to confirm the cloning and localization of the mdp gene cluster. Enediyne PKS inactivated mutant strains for C-1027, S. globisporus SB1005,22 and NCS, S. carzinostaticus SB2002,23 have been previously constructed and chosen for cross-complementation using mdpE and its associate genes. The mdpE enediyne PKS expression vector pBS10007 was constructed in the integrative vector pSET15229 that can be stably maintained in A. madurae via site specific integration into its chromosome. pBS10007, in which the expression of mdpE, together with its immediate upstream gene mdpE5 and downstream genes mdpE10 and mdpE6, is under the control of the constitutive ErmE* promoter,29 was introduced into SB1005 and SB2002, with pBS1019 (an sgcE expression construct) and pBS2020 (an ncsE5-ncsE-ncsE10 expression construct) as positive controls, respectively.
The resulting S. globisporus SB1010 and SB1011 recombinant strains were cultured and examined for C-1027 production by HPLC analysis with the S. globisporus wild-type strain as a positive control (Figure 7A). Similarly, the resulting S. carzinostaticus SB5003 and SB5007 recombinant strains were cultured and examined for NCS production by HPLC analysis with the S. carzinostaticus wild-type strain as a positive control (Figure 7B). Production of C-1027 in SB1011 and NCS in SB5007 was restored to a detectable level, albeit to around 20% level of C-1027 in SB1010 and 50% level of NCS in SB5003, respectively (Figure 7). The HPLC fraction containing the expected C-1027 chromophore and its aromatized product from the SB1011 recombinant strain was analyzed by high resolution MALDI-MS, yielding the characteristic [M+H]+ ions at m/z = 844.259 and m/z = 846.273, consistent with the molecular formula of C43H42N3O13Cl (enediyne form calculated 843.241) and C43H44N3O13Cl (aromatized form calculated 845.256), respectively and identical to that isolated from the S. globisporus wild-type strain.22 Likewise, LC-ESI-MS was used to confirm the NCS chromophore from the SB5007 recombinant strain, giving an [M+H]+ ion at m/z = 660.3, consistent with the molecular formula of C35H33NO12 (calculated 659.2) and identical to that found from the S. carzinostaticus wild-type strain.23 In total, the data show that the cloned mdpE enediyne PKS gene can functionally cross-complement the sgcE or ncsE enediyne PKS gene for C-1027 or NCS biosynthesis in their native producer, respectively.
Discussion
The biosynthetic gene clusters for C-1027 and NCS, two prominent members of the 9-membered enediyne family, have been cloned, sequenced, and the gene products functionally assigned based on bioinformatics analysis and biochemical studies.22–26,37,50–55,58 A third 9-membered enediyne, MDP, was targeted to provide further evidence for our proposed unifying paradigm for enediyne biosynthesis and to facilitate metabolic engineering of the enediyne family for novel analogs. Despite varying degrees of structural uniqueness, all three members share a virtually identical enediyne core (Figure 1), and therefore the gene clusters were hypothesized to harbor genes encoding a similar enediyne PKS and associated enzymes.22–27 Indeed, knowledge of the shared minimal enediyne PKS gene cassettes for the previously cloned enediyne clusters was successfully employed to probe DNA libraries in order to isolate other enediyne producers including to locate the MDP enediyne PKS locus.24,25 This approach was used here as a starting point for chromosomal walking to ultimately lead to the isolation of the three overlapping cosmids covering the entire mdp gene cluster (Figure 3).
Consistent with the characterization of C-102722 and NCS23 gene clusters, the biosynthesis of the MDP chromophore occurs by the assembly of individual components before convergence to form the final enediyne chromophore. As expected the biosynthesis of the aminosugar moiety begins by the conversion of glucose-1-phosphate to the nucleotide sugar diphosphate. Based on high sequence identity to SgcA1, which is involved in C-1027 deoxy aminosugar biosynthesis and has been characterized biochemically,37 the nucleotide is proposed to be TTP. The two subsequent steps involve formation of a C6-carboxylic acid followed by oxidative decarboxylation to generate a 4-keto-pentapyranose. These two enzymatic steps are unusual for natural product biosynthesis, but have been proposed and characterized for the production of lipid A that is implicated in polymyxin resistance of gram-negative bacteria such as S. typhimurium and E. coli.39,40 After production of the 4-keto-pentapyranose, C-methylation and hydroxyl epimerization at C3 occurs through an enolate intermediate, and the overall conversion has been demonstrated for the homolog TylC3 involved in tylosin biosynthesis.59 The final step before addition to the aglycon is transamination, an enzymatic step that is commonly seen in the biosynthesis of monosaccharides in secondary metabolism.
The MDP chromophore contains two monocyclic aromatic moieties in addition to the enediyne core (Figure 2), and subsequently the gene cluster was found to contain a second iterative type I PKS that is distinct from the MdpE enediyne PKS. Although MdpB is most similar to ChlB1, a bacterial 6-MSAS in the chlorothricin gene cluster,43,44 MdpB also has sequence similarity to NcsB, which is responsible for the naphthoic acid moiety of NCS23,45 (Figure 5A). However, unlike NcsB, MdpB is expected to catalyze only three rounds of decarboxylative condensation with regiospecific ketoreduction at C5 instead of five iterations and ketoreduction at C5 and C9 as proposed for NcsB. Despite this variance in chain length, MdpB has a higher identity to NcsB (48% identity/64% similarity) than the functionally equivalent fungal 6-MSAS counterpart (41% identity/56% similarity). The addition of MdpB to this rapidly growing family of bacterial iterative type I PKS, which now consists of minimally five enzymes,43,44,46 should ultimately aid in deciphering the molecular details inherent in the iterative type I PKSs that control the chain length, regiospecific reduction, and hence the structure of final aromatic polyketides in bacteria.
The second monocyclic aromatic moiety of MDP is the (S)-3-(2-chloro-3-hydroxy-4-methoxyphenyl)-3-hydroxypropionic acid, the origin of which only became evident using comparative genomic analysis. The moiety originates from L-α-tyrosine, as deciphered from the discovery of homologs with >50% identity (excluding only MdpC2) to the biosynthetic enzymes involved in production of the β-amino acid of C-1027.22 The majority of the pathway to the β-amino acid moiety in C-1027 has now been reconstituted using recombinant enzymes,51–55,58 and the two initial steps for MDP biosynthesis have been shown here to be identical: MdpC4 is a L-α-tyrosine aminomutase and MdpC1 is an (S)-β-tyrosine –activating adenylation enzyme. In both cases, L-α-tyrosine is first converted to the (S)-β-tyrosine by a growing family of MIO-containing aminomutases using no exogenous cofactors, now consisting of four enzymes,51–53,60,61 followed by activation and loading of the resultant (S)-β-tyrosine onto the free-standing MdpC2 PCP. While further transformations are paralleled, the halogenation and hydroxylation of the (S)-β-tyrosyl-S-MdpC2 intermediate differ in regiochemistry; MDP biosynthesis also requires three additional reactions: transamination, carbonyl reduction, and O-methylation. The timing of these events is currently under investigation.
The enediynes of the nine-membered family are isolated as a chomoprotein complex, and the genes encoding the apo-protein for C-1027 and NCS both reside within the boundaries for the respective gene cluster.22,23 Likewise, it was hypothesized the MDP apo-protein was also encoded within the gene cluster, although a functional assignment based on bioinformatics alone was inconclusive because (i) the MDP apo-protein is neither homologous to CagA or NcsA, (ii) only the relative abundance of amino acids, not the amino acid sequence of the apo-protein, is known, and (iii) previous reports identified the MDP apo-protein had molecular weights of 22.5 kD by gel filtration,16 32 kD by SDS-PAGE,14 and 13 kD by mass spectrometry.62 Of the forty-two ORFs predicted to be involved in MDP biosynthesis, MdpA was the only logical candidate as the apo-protein based on (i) elimination of other ORFs from functional assignments, (ii) the prediction of a 32-amino acid leader peptide, and (iii) the lack of H, K, W, and R residues, the last of which was reported during the initial characterization of the MDP chromoprotein complex.16
To experimentally identify the MDP apo-protein and to resolve the size ambiguities in the literature, A. madurae was fermented and the MDP chromoprotein complex isolated. The N-terminal sequence of the resultant apo-protein was determined and confirmed to be identical to that of the predicted mature MdpA. Interestingly, while the 9-membered enediyne apo-proteins all share ~40% identity, MdpA has no similarities to proteins deposited at NCBI which includes CagA22 and NcsA.23 Therefore, the discovery of MdpA as the MDP apo-protein not only confirms that we have localized the mdp gene cluster, but also establishes MdpA as a new type of enediyne apo-protein. Furthermore, based on ORF analysis, MdpA is translated as a 16,212 Da-protein, and N-terminal sequencing revealed MdpA is processed to yield a 12,928 Da-protein, which is consistent with the data obtained by mass spectrometry.62
To further verify the identification of the mdp gene cluster, heterologous complementation was chosen to circumvent the difficulty in developing a genetic system for the MDP producer, A. madurae. We have previously shown that (i) inactivation of sgcE and ncsE afforded S. globisporus SB1005 and S. carzinostaticus SB5002 mutant strains whose ability to produce C-1027 and NCS was completely abolished and (ii) C-1027 and NCS production could be restored to the SB1005 and SB5002 mutant strains upon expression of a functional copy of sgcE and ncsE5-ncsE-ncsE10 in trans, respectively.22,23 Upon introduction of the mdpE enediyne cassette expression plasmid pBS10007 to SB1005 or SB5002, production of C-1027 or NCS was indeed successfully restored, respectively, in the resultant recombinant strains (Figure 7). Although yields were low, ranging from 20% for C-1027 in SB1011 and 50% for NCS in SB5007 in comparison with that found from complementation with its cognate enediyne PKS sgcE in SB1010 and ncsE5-ncsE-ncsE10 in SB5003, the results definitively demonstrated that the mdp enediyne PKS cassette can functionally cross-complement the sgcE or ncsE mutation in their respective producer, supporting the cloned gene cluster to encode MDP production.
Of utmost significance for our future combinatorial biosynthesis strategies, cross-complementation between mdpE and sgcE and between mdpE and sgcE is consistent with the biosynthesis of the enediyne core occurring through a common mechanism for the 9-membered enediyne family. Although this unified mechanism for enediyne core biosynthesis has been speculated previously on the basis bioinformatics analysis,24,25 this is for the first time now supported by experimental evidence. Finally, the ability to cross-complement the enediyne biosynthetic machinery suggests S. globisporus and S. carzinostaticus have the appropriate genetic and biochemical traits to facilitate rational genetic engineering to control the chemical features and structural diversity of the enediynes. Therefore, these organisms represent model host organisms for combinatorial biosynthesis to generate new enediyne compounds.63
Conclusion
The gene cluster involved in the biosynthesis, resistance, regulation, and transport of the enediyne MDP was localized and cloned from A. madurea ATCC 39144 and sequenced and functionally annotated. Predictions from bioinformatics analysis were consistent with the expected enzymology with several unusual findings, including the uncovering of a second iterative type I PKS for aromatic polyketide biosynthesis and a pathway to a β-hydroxy acid that mirrors β-amino acid formation in C-1027, featuring a rare MIO-containing aminomutase and a set of discrete adenylation, PCP and condensation enzymes for β-amino or β-hydroxy acid activation and subsequent incorporation into natural products. In a process similar to the other enediynes, the MDP chromophore is formed from the convergence of four building blocks: (i) the enediyne core, (ii) a 3,6-dimethylsalicylyl-CoA, (iii) an aminosugar, and (iv) a halogenated β-phenyl-β-hydroxy propionic acid. Cross-complementation of the sgcE or ncsE enediyne PKS mutants by the mdpE enediyne PKS cassette provided convincing evidence that the MDP gene cluster was identified, and also supported a unifying paradigm for 9-membered enediyne core biosynthesis. By establishing the biosynthetic machinery for three individual enediyne gene clusters (i.e., C-1027, MDP, and NCS), comparative genetics should undoubtedly facilitate combinatorial biosynthesis for the discovery of new enediynes. Finally, the MDP apo-protein, MdpA, was identified by isolation of the MDP chromoprotein complex and N-terminal sequencing of the purified apo-protein. MdpA, like the other apo-proteins for the 9-membered enediyne chromoproteins, is located within the biosynthetic gene cluster. In contrast, however, MdpA represents a new type of apo-protein with no sequence homology to other known proteins, providing new opportunities to explore apo-protein and enediyne chromophore interaction, enediyne chromophore stabilization, and chromoprotein activation.
Acknowledgments
We thank Dr. Y. Li, Institute of Medicinal Biotechnology, CAMS, Beijing, China for the wild-type S. globisporus strain and the AIC of the School of Pharmacy, UW-Madison for support in obtaining MS data. This work is supported in part by NIH grants CA78747 and CA113297. SVL is the recipient of an NIH postdoctoral fellowship (CA1059845).
Abbreviations used
- ACP
acyl carrier protein
- AT
acyltransferase
- CAL
calicheamicin
- DH
dehydratase
- KR
ketoreductase
- KS
ketosynthase
- MDP
maduropeptin
- MIO
4-methylideneimidazole-5-one
- MS
mass spectrometry
- 6-MSAS
6-methylsalicylic acid synthase
- NCS
neocarzinostatin
- ORF
open reading frame
- PCP
peptidyl carrier protein
- PKS
polyketide synthase
- PPTase
phosphopantetheinyltransferase
- SAM
S-adenosylmethionine
Footnotes
Dedicated to the memory of Prof. Ian Scott for his pioneering work on natural product biosynthesis and enzyme reaction mechanism.
References
- 1.Xi Z, Goldberg IH. In: Comprehensive Natural Products Chemistry. Barton D, Nakanishi K, Meth-Cohn O, editors. Elsevier; New York, NY: 1999. pp. 533–592. [Google Scholar]
- 2.Jones GB, Fouad FS. Curr Pharm Des. 2002;8:2415–2440. doi: 10.2174/1381612023392810. [DOI] [PubMed] [Google Scholar]
- 3.Thorson JS, Shen B, Whitwam RE, Liu W, Li Y, Ahlert J. Bioorg Chem. 1999;27:172–188. [Google Scholar]
- 4.Galm U, Hager MH, Van Lanen SG, Ju J, Thorson JS, Shen B. Chem Rev. 2005;105:739–758. doi: 10.1021/cr030117g. [DOI] [PubMed] [Google Scholar]
- 5.Otani T, Yasuhara T, Minami Y, Shimazu T, Zhang R, Xie M. Agri Biol Chem. 1991;55:407–415. [PubMed] [Google Scholar]
- 6.Gibson BW, Herlihy WC, Samy TSA, Hahm K, Maeda H, Meienhofer J, Biemann K. J Biol Chem. 1984;259:10801–10806. [PubMed] [Google Scholar]
- 7.Dedon PC, Goldberg IH. J Biol Chem. 1990;265:14713–14716. [PubMed] [Google Scholar]
- 8.Koide Y, Ito A, Edo K, Ishida N. Chem Pharm Bull. 1986;34:4425–4427. doi: 10.1248/cpb.34.4425. [DOI] [PubMed] [Google Scholar]
- 9.Zhen Y, Ming X, Yu B, Otani T, Saito H, Yamada Y. J Antibiot. 1989;42:1294–1298. doi: 10.7164/antibiotics.42.1294. [DOI] [PubMed] [Google Scholar]
- 10.Doyle TW, Borders DB, editors. Enediyne Antibiotics as Antitumor Agents. Marcel-Dekker; New York, NY: 1995. pp. 1–459. [Google Scholar]
- 11.Sievers EL, Appelbaum FR, Spielberger RT, Forman SJ, Flowers D, Smith FO, Shannon-Dorcy K, Berger MS, Bernstein ID. Blood. 1999;93:3678–3684. [PubMed] [Google Scholar]
- 12.Edo K, Mizugaki M, Koide Y, Seto H, Furihata K, Otake N, Ishida N. Tetrahedron Lett. 1985;26:331–340. [Google Scholar]
- 13.Yoshida K, Minaomi Y, Azuma R, Saeki M, Otani T. Tetrahedron Lett. 1993;34:2637–2640. [Google Scholar]
- 14.Schroeder DR, Colson KL, Klohr SE, Zein N, Langley DR, Lee MS, Matson JA, Doyle TWJ. Am Chem Soc. 1994;116:9351–9352. [Google Scholar]
- 15.Schroeder DR, Lam KS, Veitch JM. U.S. Patent 5,281,417. 1994
- 16.Hanada M, Ohkuma H, Yonemoto T, Tomita K, Ohbayashi M, Kamei H, Miyaki T, Konishi M, Kawaguchi H. J Antibiot. 1991;44:403–414. doi: 10.7164/antibiotics.44.403. [DOI] [PubMed] [Google Scholar]
- 17.Zein N, Solomon W, Colson KL, Schroeder DR. Biochemistry. 1995;34:11591–11594. doi: 10.1021/bi00036a035. [DOI] [PubMed] [Google Scholar]
- 18.Zein N, Casazza AM, Doyle TW, Leet JE, Schroeder DR, Solomon W, Nadler SG. Proc Natl Acad Sci U S A. 1993;90:8009–8012. doi: 10.1073/pnas.90.17.8009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Zein N, Reiss P, Bernatowicz M, Bolgar M. Chem Biol. 1995;2:451–455. doi: 10.1016/1074-5521(95)90262-7. [DOI] [PubMed] [Google Scholar]
- 20.Heyd B, Lerat G, Adjadj E, Minard P, Desmadril M. J Bacteriol. 2000;182:1812–1818. doi: 10.1128/jb.182.7.1812-1818.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Suffert J, Toussaint D. Tetrahedron Lett. 1997;38:5507–5510. [Google Scholar]
- 22.Liu W, Christenson SD, Standage S, Shen B. Science. 2002;297:1170–1173. doi: 10.1126/science.1072110. [DOI] [PubMed] [Google Scholar]
- 23.Liu W, Nonaka K, Nie L, Zhang J, Christenson SD, Bae J, Van Lanen SG, Zazopoulos E, Farnet CM, Yang CF, Shen B. Chem Biol. 2005;12:1–10. doi: 10.1016/j.chembiol.2004.12.013. [DOI] [PubMed] [Google Scholar]
- 24.Liu W, Ahlert J, Gao Q, Wendt-Pienkowski E, Shen B, Thorson JS. Proc Natl Acad Sci U S A. 2003;100:11959–11963. doi: 10.1073/pnas.2034291100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Zazopoulos E, Huang K, Staffa A, Liu W, Bachmann BO, Nonaka K, Ahlert J, Thorson JS, Shen B, Farnet CM. Nat Biotechnol. 2003;21:187–190. doi: 10.1038/nbt784. [DOI] [PubMed] [Google Scholar]
- 26.Liu W, Shen B. Antimicrob Agents Chemother. 2000;44:382–392. doi: 10.1128/aac.44.2.382-392.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Ahlert J, Shepard E, Lomovskaya N, Zazopoulos E, Staffa A, Bachmann BO, Huang K, Fonstein L, Czisny A, Whitwam RE, Farnet CM, Thorson JS. Science. 2002;297:1173–1176. doi: 10.1126/science.1072105. [DOI] [PubMed] [Google Scholar]
- 28.Sambrook J, Russell DW. Molecular Cloning: A Laboratory Manual. 3. Cold String Harbor Laboratory Press; Cold Spring Harbor, NY: 2002. [Google Scholar]
- 29.Kieser T, Bibb M, Buttner M, Chater KF, Hopwood DA. Practical Streptomyces Genetics. The John Innes Foundation; Norwich, UK: 2000. [Google Scholar]
- 30.Shen B, Hutchinson CR. Proc Natl Acad Sci U S A. 1996;93:6600–6604. doi: 10.1073/pnas.93.13.6600. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Wendt-Pienkowski E, Huang Y, Zhang J, Li B, Jiang H, Kwon HJ, Hutchinson CR, Shen B. J Am Chem Soc. 2005;127:16442–16452. doi: 10.1021/ja054376u. [DOI] [PubMed] [Google Scholar]
- 32.Gharahdaghi F, Weinberg CR, Meagher DA, Imai BS, Mische SM. Electrophoresis. 1999;20:601–605. doi: 10.1002/(SICI)1522-2683(19990301)20:3<601::AID-ELPS601>3.0.CO;2-6. [DOI] [PubMed] [Google Scholar]
- 33.Distler J, Ebert A, Mansouri K, Pissowotzki K, Stockmann M, Piepersberg W. Nucleic Acids Res. 1987;15:8041–8056. doi: 10.1093/nar/15.19.8041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Rhee S, Martin RG, Rosner JL, Davies DR. Proc Natl Acad Sci U S A. 1998;95:10413–10418. doi: 10.1073/pnas.95.18.10413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Tercero JA, Espinosa JC, Lacalle RA, Jimenez A. J Biol Chem. 1996;271:1579–1590. doi: 10.1074/jbc.271.3.1579. [DOI] [PubMed] [Google Scholar]
- 36.Tercero JA, Lacalle RA, Jimenez A. Eur J Biochem. 1993;218:963–971. doi: 10.1111/j.1432-1033.1993.tb18454.x. [DOI] [PubMed] [Google Scholar]
- 37.Murrell JM, Liu W, Shen B. J Nat Prod. 2004;67:206–213. doi: 10.1021/np0340403. [DOI] [PubMed] [Google Scholar]
- 38.Naught LE, Gilbert S, Imhoff R, Snook C, Beamer L, Tipton P. Biochemistry. 2002;41:9637–9645. doi: 10.1021/bi025862m. [DOI] [PubMed] [Google Scholar]
- 39.Breazeale SD, Ribeiro AA, Raetz CRH. J Biol Chem. 2002;277:2886–2896. doi: 10.1074/jbc.M109377200. [DOI] [PubMed] [Google Scholar]
- 40.Bar-Peled M, Griffith CL, Doering TL. Proc Natl Acad Sci U S A. 2001;98:12003–12008. doi: 10.1073/pnas.211229198. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.González A, Remsing LL, Lombó F, Fernández MJ, Prado L, Braña AF, Künzel E, Rohr J, Méndez C, Salas JA. Mol Gen Genet. 2004;264:827–835. doi: 10.1007/s004380000372. [DOI] [PubMed] [Google Scholar]
- 42.Noland BW, Newman JM, Hendle H, Badger J, Christopher JA, Tresser J, Buchanan MD, Wright TA, Rutter ME, Sanderson WE, Müller-Dieckmann HJ, Gajiwala KS, Buchanan SG. Structure. 2002;10:1569–1580. doi: 10.1016/s0969-2126(02)00879-1. [DOI] [PubMed] [Google Scholar]
- 43.Shao L, Qu X, Jia X, Zhao Q, Tian Z, Wang M, Tang G, Liu W. Biochem Biophys Res Comm. 2006;345:133–139. doi: 10.1016/j.bbrc.2006.04.069. [DOI] [PubMed] [Google Scholar]
- 44.Jia XY, Tian ZH, Shao L, Qu XD, Zhao QF, Tang J, Tang GL, Liu W. Chem Biol. 2006;13:575–585. doi: 10.1016/j.chembiol.2006.03.008. [DOI] [PubMed] [Google Scholar]
- 45.Sthapit B, Oh TJ, Lamichhane R, Liou K, Lee HC, Kim CG, Sohng JK. FEBS Lett. 2004;566:201–206. doi: 10.1016/j.febslet.2004.04.033. [DOI] [PubMed] [Google Scholar]
- 46.Shen B. Curr Opin Chem Biol. 2003;7:285–295. doi: 10.1016/s1367-5931(03)00020-6. [DOI] [PubMed] [Google Scholar]
- 47.Fujii I, Ono Y, Tada H, Gomi K, Ebizuka Y, Sankawa U. Mol Gen Genet. 1996;253:1–10. doi: 10.1007/s004380050289. [DOI] [PubMed] [Google Scholar]
- 48.Kozbial PZ, Mushegian AR. BMC Struct Biol. 2005;5:1–26. doi: 10.1186/1472-6807-5-19. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Jakobi K, Hertweck C. J Am Chem Soc. 2004;126:2298–2299. doi: 10.1021/ja0390698. [DOI] [PubMed] [Google Scholar]
- 50.Cooke HA, Zhang J, Griffin MA, Van Lanen SG, Shen B, Bruner SD. J Am Chem Soc. 2007;129:7728–7729. doi: 10.1021/ja071886a. [DOI] [PubMed] [Google Scholar]
- 51.Christenson SD, Liu W, Toney MD, Shen B. J Am Chem Soc. 2003;125:6062–6063. doi: 10.1021/ja034609m. [DOI] [PubMed] [Google Scholar]
- 52.Christenson SD, Wu W, Spies MA, Shen B, Toney MD. Biochemistry. 2003;42:12708–12718. doi: 10.1021/bi035223r. [DOI] [PubMed] [Google Scholar]
- 53.Christianson CV, Montavon TJ, Van Lanen SG, Shen B, Bruner SD. Biochemistry. 2007;46:7205–7214. doi: 10.1021/bi7003685. [DOI] [PubMed] [Google Scholar]
- 54.Van Lanen SG, Dorrestein PC, Christenson SD, Liu W, Ju J, Kelleher NL, Shen B. J Am Chem Soc. 2005;127:11594–11595. doi: 10.1021/ja052871k. [DOI] [PubMed] [Google Scholar]
- 55.Van Lanen SG, Dorrestein PC, Lin S, Kelleher NL, Shen B. J Biol Chem. 2006;281:29633–29640. doi: 10.1074/jbc.M605887200. [DOI] [PubMed] [Google Scholar]
- 56.Wu CH, Chen HY, Shiuan D. Gene. 1996;174:251–258. doi: 10.1016/0378-1119(96)00090-x. [DOI] [PubMed] [Google Scholar]
- 57.Wu K, Chung L, Revill WP, Katz L, Reeves CD. Gene. 2000;251:81–90. doi: 10.1016/s0378-1119(00)00171-2. [DOI] [PubMed] [Google Scholar]
- 58.Lin S, Van Lanen SG, Shen B. J Am Chem Soc. 2007;129 doi: 10.1021/ja072311g. in press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Chen H, Zhao Z, Hallis TM, Guo Z, Liu H. Angew Chem Int Ed. 2001;40:607–610. [PubMed] [Google Scholar]
- 60.Jin M, Fischbach MA, Clardy J. J Am Chem Soc. 2006;128:10660–10661. doi: 10.1021/ja063194c. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Walker KD, Klettke K, Akiyama T, Croteau R. J Biol Chem. 2004;279:53947–53954. doi: 10.1074/jbc.M411215200. [DOI] [PubMed] [Google Scholar]
- 62.Zein N, Schroeder DR. In: Advances in DNA Sequence-Specific Agents. Palumbo M, editor. Vol. 3. Elsevier; Cambridge, MA: 1998. pp. 201–225. [Google Scholar]
- 63.Kennedy DR, Gawron LS, Ju J, Liu W, Shen B, Beerman TA. Cancer Res. 2007;67:773–781. doi: 10.1158/0008-5472.CAN-06-2893. [DOI] [PubMed] [Google Scholar]