

Abstract
Purpose
Graph theory and the new science of networks provide a mathematically rigorous approach to examine the development and organization of complex systems. These tools were applied to the mental lexicon to examine the organization of words in the lexicon and to explore how that structure might influence the acquisition and retrieval of phonological word-forms.
Method
Pajek, a program for large network analysis and visualization (V. Batagelj & A. Mvrar, 1998), was used to examine several characteristics of a network derived from a computerized database of the adult lexicon. Nodes in the network represented words, and a link connected two nodes if the words were phonological neighbors.
Results
The average path length and clustering coefficient suggest that the phonological network exhibits small-world characteristics. The degree distribution was fit better by an exponential rather than a power-law function. Finally, the network exhibited assortative mixing by degree. Some of these structural characteristics were also found in graphs that were formed by 2 simple stochastic processes suggesting that similar processes might influence the development of the lexicon.
Conclusions
The graph theoretic perspective may provide novel insights about the mental lexicon and lead to future studies that help us better understand language development and processing.
Keywords: graph theory, mental lexicon, phonological neighborhood
In the present analysis, graph theoretic techniques were used to examine the complex cognitive system known as the mental lexicon. Graph theory is a branch of mathematics used by physicists, computer scientists, and other researchers interested in the “new” science of networks (Watts, 2004) to study the structure of a diverse array of complex systems in the real world. Complex systems are comprised of a large number of individual units that interact in relatively simple ways. Despite the simple, predictable nature of the individual components on a local level, these large systems often exhibit behaviors that may appear unpredictable at a global level.
Although graphs simply describe the structure of a system, the way in which a system is organized has important implications for the type of processing that can be carried out in that system (Strogatz, 2001; Ward, 2002). For example, Montoya and Solé (2002) used the techniques of graph theory to create a graph (or network) of various ecosystems by representing the animals in an ecosystem as nodes (sometimes called vertices or actors) and the predator–prey relationship between animals as links (sometimes called edges or ties) to examine how the extinction of a given species might affect the rest of the ecosystem. The present graph theoretic analyses examined the organization of phonological word-forms in the adult lexicon to explore how the structure of the mental lexicon might influence the process of lexical retrieval.
The current structure of a system has been influenced by (among other things) the growth and development of that system. Certain constraints on development may result in the emergence of one type of structure but not in the emergence of some other type of structure. By studying the current structure of a system, one might gain insight into the constraints that could have led to that type of structure. Although several different constraints may produce the same final structure, analyses of the current structure do serve to rule out some possible developmental mechanisms. Therefore, structural analyses employing graph theoretic techniques may help other research endeavors to focus their investigations on a more reasonably sized search space of possible developmental mechanisms. The present graph theoretic analyses examined the current structure of phonological word-forms in the adult lexicon to also gain some insight on the constraints that may influence lexical acquisition and word learning.
Some readers might be familiar with the terms node, link, and network in the context of connectionist models, or artificial neural networks. However, it is important to note that the networks discussed in the present work are not artificial neural networks. That is, the nodes in the present networks do not have activation states or rules to change activation states like the nodes in an artificial neural network. Furthermore, the links in the present networks do not have weights associated with them or a learning rule (e.g., back-propagation of error) to change the connection weights between nodes. In other words, the present networks are not artificial neural networks that model a cognitive process. Rather, the present investigation employed graph theoretical analysis techniques to examine the global structure or organization of phonological word-forms that might appear in the mental lexicon of a typically developing adult. Although increased understanding of the structure of phonological word-forms in the mental lexicon might lead to insights related to the processing of phonological word-forms during the perception or production of speech and to insights related to the mechanisms that might influence word learning, it is important to emphasize that the present graph theoretical analysis is not a model of any language process.
Several researchers have used graph theoretic techniques to examine semantic relationships among words in the mental lexicon. Similar conclusions about the structure of semantically related words were reached even though several different definitions of “semantically related” were used, including words that were free associates of each other, synonym pairs, core words from dictionary definitions, or co-occurring words in text (Albert & Barabási, 2002; Batagelj, Mrvar, & Zaveršnik, 2002; Ferrer i Cancho & Solé, 2001b, Motter, de Moura, Lai, & Dasgupta, 2002; Steyvers & Tenenbaum, 2005; Wilks & Meara, 2002; Wilks, Meara, & Wolter, 2005). Given the arbitrary relationship between semantic and phonological representations (Saussure, 1916/1966), it is unclear whether the same network structure found in a network of semantic representations will be found in a network of phonological word-forms.
In the present graph theoretic analysis, the nodes in the network represented phonological word-forms in the English language (i.e., lexemes), and a link was placed between two nodes if they were phonological neighbors of each other (e.g., Luce & Pisoni, 1998). That is, the links in the present network were not directed and were not weighted. More complex relationships among nodes can be modeled by incorporating directed or weighted links. In a network with directed links (sometimes called arcs), connections between two nodes are not necessarily reciprocal. For example, X may buy a good from Y, but Y does not buy a good from X. See Harary, Norman, and Cartwright (1965) for an introduction to graphs with directed links. In a graph with weighted links, the relationship between some nodes might be stronger or weaker than the relationship between other nodes. For example, X and Y might be lifelong friends, so the link between them might be weighted with a 1. In contrast, X and Z may simply be acquaintances, so the link between them might be weighted with a .25. See Roberts (1976) for an introduction to graphs with weighted links.
Although more complex networks can be constructed, the present investigation analyzed simple network models to explore the most fundamental characteristics that might shape the mental lexicon. Some of the characteristics that shape the development of the lexicon might be common to other types of systems that have been explored with these techniques, whereas other characteristics may be unique to the lexicon. By starting out with a simple yet mathematically precise model, we can explore how well a few basic mechanisms can account for the structure found in the mental lexicon and, perhaps, shed some light on additional assumptions that may be required to account for the structure found in the mental lexicon.
Method
To represent the adult lexicon, the phonological transcriptions of approximately 20,000 words (N = 19,340) were examined with Pajek, a program for large network analysis and visualization (Batagelj & Mrvar, 1998). The sample of words was obtained from the 1964 Merriam-Webster Pocket Dictionary. Although the entries were those from the Merriam-Webster Pocket Dictionary, the pronunciations were derived, checked, and edited by several researchers at the Massachusetts Institute of Technology, including Dennis Klatt, Dave Shipman, Meg Withgott, and Lori Lamel. Numerous studies have used this same sample of words to derive estimates of neighborhood density and phonotactic probability in English (e.g., Luce & Pisoni, 1998; Nusbaum, Pisoni, & Davis, 1984; Vitevitch & Luce, 2004, 2005). Although the number of words in this sample is slightly larger than the 17,000 base words that comprise the vocabulary of a well-educated adult native speaker of English (Goulden, Nation, & Read, 1990), it constitutes a reasonable approximation of the adult lexicon.
A node in the network corresponded to each of the phonological representations from the Merriam-Webster Pocket Dictionary. A link was placed between two nodes if the two words were phonologically similar (cf. Batagelj et al., 2002, in which a link connected two nodes if the words were semantically related). Phonological similarity was operationally defined by substituting, adding, or deleting a single phoneme in a given word to form a “phonological neighbor” (e.g., Greenberg & Jenkins, 1967; Landauer & Streeter, 1973; Luce & Pisoni, 1998). For example, the words hat, cut, cap, scat, and _at were considered phonologically similar to the word cat (cat has other words as neighbors, but only a few were listed for illustrative purposes). In the present network, links would connect the nodes that corresponded to those words to the word cat (and to each other as appropriate).
The same definition of phonological similarity has been used in numerous psycholinguistic studies. The results of these studies have shown that the number of phonological neighbors activated in the lexicon influences various language processes: (a) the acquisition of sounds in children (Gierut, Morrisette, & Champion, 1999); (b) the acquisition of words in children (Charles-Luce & Luce, 1990, 1995; Coady & Aslin, 2003; Dollaghan, 1994; Storkel, 2004; Vicente, Castro, & Walley, 2003); (c) spoken word recognition in young adults with no history of speech, language, or hearing impairment in English and in Spanish (Luce & Pisoni, 1998; Vitevitch, 2002b; Vitevitch & Luce, 1998, 1999; Vitevitch & Rodriguez, 2005), in older adults with no history of speech, language, or hearing impairment (e.g., Sommers, 1996), and in postlingually deafened adults who use a cochlear implant (Kaiser, Kirk, Lachs, & Pisoni, 2003), and of accented speech (Imai, Walley, & Flege, 2005); (d) spoken word production in children who stutter (Arnold, Conture, & Ohde, 2005), in young adults with fluent speech in English and in Spanish (Munson & Solomon, 2004; Vitevitch, 1997, 2002a; Vitevitch & Stamer, 2006), in older adults with fluent speech (Vitevitch & Sommers, 2003), and in individuals with aphasia (Gordon & Dell, 2001); and even (e) reading by young adults with no history of speech, language, or hearing impairment (Yates, Locker, & Simpson, 2004).
In addition to being widely used (by many researchers and over several decades), work by Luce and Large (2001; see also Cutler, Sebastian-Galles, Soler-Vilageliu, & van Ooijen, 2000) provides some evidence for the psychological validity of the one-phoneme metric as a measure of phonological similarity. In Experiment 2 of Luce and Large (2001), participants heard a nonsense word, such as /fin/, and were asked to produce the first real word that came to mind that sounded like the nonword stimulus item. Over 70% of the responses involved a change of one phoneme in the nonword to form a real word (e.g., mean, fun, feet). Eighteen percent of the responses involved a two-phoneme change (either CV, C_C, or VC), and the remaining 11% of the responses consisted of various types of changes involving the addition of a single segment (or the addition of a syllable). These results suggest that the operational definition of phonological similarity used in the present analysis also captures, to a large extent, the definition of phonological similarity that speakers may have.
By employing the same psychologically valid metric that has been used in many psycholinguistic experiments in the present graph theoretic analysis, psychologically valid insight about the mental lexicon might be obtained. Analyses of complex cognitive systems comprised of nodes that are connected in a manner that is not motivated by psycholinguistic research may be interesting mathematical exercises, but they are unlikely to provide significant insight into questions of interest to language researchers.
The same techniques used by physicists and computer scientists (e.g., Albert & Barabási, 2002) were used in the current graph theoretic analysis to examine the network structure of the phonological word-forms in the mental lexicon. Different mechanisms lead to different network structures, so identification of the structure of a given network can provide some insight into the mechanisms that might have influenced the development of the observed network. In conventional graph theoretic analyses, identification of the structure of a given network is accomplished by comparing several measurements from the graph of interest to the same measurements made in a random network with the same number of nodes and the same average number of connections per node as the graph of interest. Random graphs consist of a network in which links are randomly placed between nodes. They have been widely studied and are mathematically well understood (see Erdos & Rényi, 1960, for pioneering work on random graphs) and, therefore, provide a good baseline for comparisons. These conventional graph theoretic analyses were supplemented in some cases by additional comparisons to measurements obtained from a sample of random graphs generated by the Pajek program.
The following measurements were made in the present graph theoretic analysis of the phonological word-forms in the mental lexicon: average path length (ℓ), clustering coefficient (C), degree distribution, and the extent of assortative mixing by degree in the network. The average path length of a network refers to the average distance between every node in the network and every other node in the network (Watts & Strogatz, 1998). The clustering coefficient characterizes the extent to which nodes connected to another node are also connected to each other. A clustering coefficient of 0 implies that none of the neighbors of a node are connected to the other neighbors of that node. A clustering coefficient of 1 implies that all of the neighbors of a node are connected to each other. Values between 0 and 1 imply that a number of neighbors of a node are also neighbors of each other (Watts & Strogatz, 1998).
The number of connections per node is also referred to as the degree of the node, or k. The degree distribution refers to the proportion of nodes [P(k)] that have a given number of links. In a degree distribution that resembles a normal bell-shaped distribution (i.e., a Poisson or Gaussian distribution), a small number of nodes will have fewer than the average number of connections per node, and a small number of nodes will have more than the average number of connections per node, but most nodes will have the average number of connections per node. This type of degree distribution is found in a random network. In a degree distribution that resembles a power-law, many nodes have a small degree (or a few connections), and a few nodes have a large degree (or many connections). This type of degree distribution has been found in graphs of many real-world systems, including graphs depicting connections among Web pages on the Internet (e.g., Albert & Barabási, 2002); the mechanisms that lead to the development of this special type of network structure will be described later. Typically a logarithmic transformation is applied to the degree distribution to reduce variability in the data and aid in the identification of the network structure.
Assortative mixing by degree refers to the probability of a highly connected node being connected to other nodes that are also highly connected (Newman, 2002; Newman & Park, 2003). In other words, there is a positive correlation between the degree of a node and the degree of its neighbors. In a network with disassortative mixing by degree, nodes that have many connections tend to be connected to nodes with few connections, producing a negative correlation between the degree of a node and the degree of its neighbors. In a random network, where connections are placed at random, the correlation between the degree of a node and the degree of its neighbors is zero (Newman, 2002). The implications of these different types of mixing by degree will be addressed later.
Results and Discussion
After connecting the nodes in the phonological network using the similarity metric employed in previous psycholinguistic studies, I calculated the average path length and the clustering coefficient by using the Pajek program. Note that the average path length, or distance between any two nodes in a network, can be computed only on a fully connected network. In the case of the mental lexicon, there were many “ lexical hermits” (n = 10,265), or words that had no phonological neighbors, such as spinach and obtuse. These hermits were not connected to the large group of words that were highly connected to each other, referred to as the largest component of the network. There were also a number of words in the lexicon (n = 2,567) that had a few neighbors, but neither the word nor the neighbors were similar to a word in the largest component of the network. These “lexical islands” contained words like converse, convert, and converge that were connected to each other but were not connected to any of the words in the largest component. The calculations of the network characteristics were, therefore, based on the 6,508 words in the largest component of the phonological lexicon.
Average Path Length (ℓ)
The average path length (ℓ) obtained from Pajek for the phonological network was 6.05. That is, on average, approximately six links had to be traversed to connect any two nodes in the (largest component of the) network. For example, to get from the word cat to the word dog, one can traverse the links between the nodes corresponding to the words bat, bag, and bog. The value obtained from the phonological network was compared with the average path length obtained from a comparably sized and connected random network, ℓran. Because of the well-studied nature of random graphs, the convention in graph theoretic analyses (e.g., Albert & Barabási, 2002) is to estimate the value of ℓran using Equation 1:
| (1) |
where n refers to the number of nodes in the network and <k> refers to the mean degree. In the phonological network, the largest component contained 6,508 nodes (n), and the mean degree (<k>) of the nodes in the largest connected component was 9.105; therefore, ℓran = 3.975.
The computationally derived value of ℓran approximates the estimate of ℓran obtained from 100 Erdos-Rényi random networks that were constructed in Pajek and contained the same number of nodes (n = 6,508) and the same average degree (<k> = 9.105) as the phonological network. The mean value of the average path length (ℓ100) from the sample of 100 random networks was 4.22 (SD = 0.01; 95% confidence interval = 4.20–4.24).
Although the average path length for the phonological network (ℓ = 6.05) was somewhat larger than the derived value of ℓran and the estimated value of ℓ100, the conventions used in graph theoretic analyses would consider these values comparable (Watts & Strogatz, 1998). To further demonstrate the comparability of these values, compare them to the average path length of a similarly sized ordered network (ℓord). In an ordered network, each node is linked to its nearest neighboring nodes. The average path length of an ordered network can be estimated by using Equation 2:
| (2) |
where, again, n refers to the number of nodes in the network, and <k> refers to the mean degree. Given n = 6,508 nodes, and <k> = 9.105, ℓord = 357.386. The value of the average path length obtained from the phonological network (ℓ) was much closer to and of the same order of magnitude as the value obtained for ℓran compared with the value obtained for ℓord, further suggesting that the average path length of the phonological network is comparable to the average path length of a similarly sized random network.
Clustering Coefficient
As is the convention in graph theoretic analyses, the clustering coefficient (C) obtained from the (largest component of the) phonological network was compared with the value of the clustering coefficient that would be obtained from a comparably sized and connected random network (Cran). The value of the clustering coefficient (C) obtained from Pajek for the largest component of the phonological network was .126. That is, neighbors of a given word have a tendency to also be neighbors of each other (see Vitevitch, 2006, for work on how the clustering coefficient may influence spoken word recognition).
Because of the well-studied nature of random graphs, the convention in graph theoretic analyses (e.g., Albert & Barabási, 2002) is to estimate the value of Cran by using Equation 3:
| (3) |
where n refers to the number of nodes in the network, and <k> refers to the mean degree. Given n = 6,508 nodes, and <k> = 9.105, the value of Cran obtained from Equation 3 is .0014, which is about 90 times smaller than the value of C obtained in the phonological network. The value of Cran was also calculated from the same 100 Erdos-Rényi random networks used in the analyses of the average path length. The mean value of C from the 100 random networks (C100) was .00056 (SD = .00006; 95% confidence interval = .00044–.00067). The value of C100 is similar in magnitude to the derived value, Cran, but both values are smaller in magnitude than the value of C obtained from the phonological network. In other words, C ≫ Cran (Watts & Strogatz, 1998).
Analyses of the average path length and the clustering coefficient are often used to determine whether a given network can be classified as a small-world network. As described in Watts and Strogatz (1998; Watts, 1999), a small-world network has (a) an average path length that is comparable to the average path length of a random network, but (b) a clustering coefficient that is much greater than the clustering coefficient of a random network with the same number of nodes and the same average degree. Small-world networks are so called because the pattern of connections that yields Characteristics A and B makes the network easy to traverse.1 That is, the very large system has the appearance of being relatively small. The results of the present analyses suggest that the phonological network has the characteristics of a small-world network, a structure that is shared with the semantic networks that have been previously investigated (e.g., Albert & Barabási, 2002; Batagelj et al. 2002; Ferrer i Cancho & Solé, 2001b) and with many other real-world systems. To further examine the structure of the phonological network, I performed additional analyses, including an examination of the degree distribution and the extent to which the phonological network exhibits assortative mixing by degree.
Degree Distribution
The degree distribution of a graph provides additional information about the structure of that system. To maintain consistency with traditional graph theoretic analyses, as well as with the present analyses of the average path length and the clustering coefficient, the degree distribution of the largest component of the phonological lexicon—instead of the entire lexicon—was examined.
One type of network structure that has received much attention is a scale-free network (Barabási & Albert, 1999). In a scale-free network, many nodes in the network have few links, but there are a few nodes with many links. That is, a scale-free network can be identified by the presence of a power law function in the degree distribution. A power-law relationship appears as a straight line in a log-log plot of the degree distribution (Albert & Barabási, 2002). The degree exponent, γ, or slope of the line in the log-log plot of the degree distribution, in most scale-free networks is 2 < γ < 3; however, Montoya and Solé (2002) found several examples of scale-free networks that had values for γ much less than 2 (one as low as 1.05).
An alternative method to determine whether a network is a scale-free network is to plot the cumulative degree distribution in a log-log scale (Newman, 2006) or the cumulative degree distribution in a linear-log scale (Amaral, Scala, Barthélémy, & Stanley, 2000). In a log-log scale, the cumulative degree distribution would again show a straight line if a power-law function existed, but this time with a slope of γ – 1 = 1.5 (Newman, 2006). In a linear-log plot, a power-law distribution would be evident if the line fitting the data had an upward bend to it, whereas a straight line would indicate an exponential relationship in the degree distribution instead of a power-law relationship (Amaral et al., 2000). Both the degree distribution and the cumulative degree distribution will be used to examine the structure of the phonological network.
Figure 1 shows the degree distribution for the 6,508 connected word-forms in the largest component of the phonological lexicon on a log-log scale. The best fitting power-law and exponential lines were computed over all of the data points and are also plotted in the figure. The root-mean-square error (RMSE) measure of fit shows that the observed data fit an exponential distribution (Y = .141 * e−.123*X, RMSE = .005) better than a power-law distribution (Y = .672 * X−1.489, RMSE = .089). Given the poor fit of the power-law function, the degree exponent, γ, was not calculated.
Figure 1.
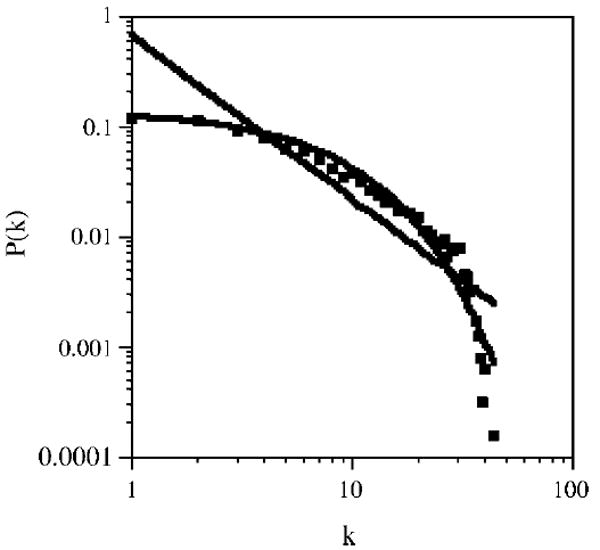
The degree distribution for the 6,508 word-forms in the largest fully connected component of the phonological network in a log-log plot (the solid squares). The best fitting power-law (straight line) and exponential functions (curved line) are also displayed for comparison.
Figure 2 shows the cumulative degree distribution of the phonological network in a log-log scale (Newman, 2006), with the best fitting power-law (Y = 21.524 * X−2.13) and exponential (Y = 2.807 * e−.181*X) lines also plotted in the figure. Figure 3 shows the cumulative degree distribution of the phonological network in a linear-log scale (Amaral et al., 2000), with the best fitting power-law and exponential lines also plotted in the figure. The RMSE measure of fit shows that the observed data again fit an exponential distribution (RMSE = .335) better than a power-law distribution (RMSE = 3.198). Given the poor fit of the power-law function, the degree exponent, γ, was not calculated. Both methods of evaluation—degree distribution and cumulative degree distribution—show that the degree distribution of the phonological network is better characterized as an exponential function than as a power-law function.
Figure 2.
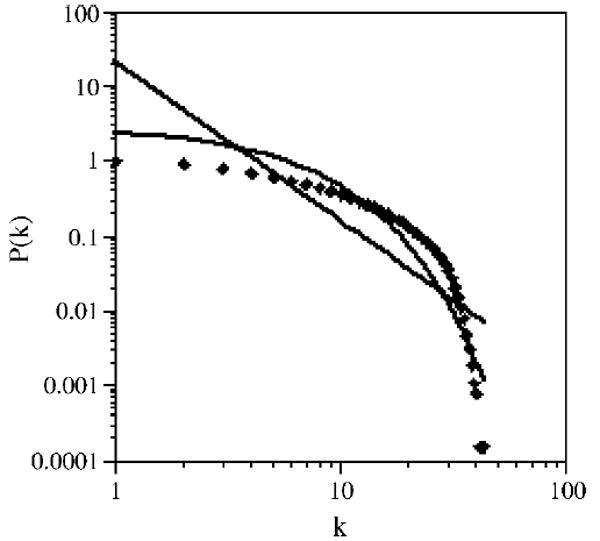
The cumulative degree distribution for the 6,508 word-forms in the largest fully connected component of the phonological network in a log-log plot (the solid diamonds). The best fitting power-law (straight line) and exponential (curved line) functions are also displayed for comparison.
Figure 3.
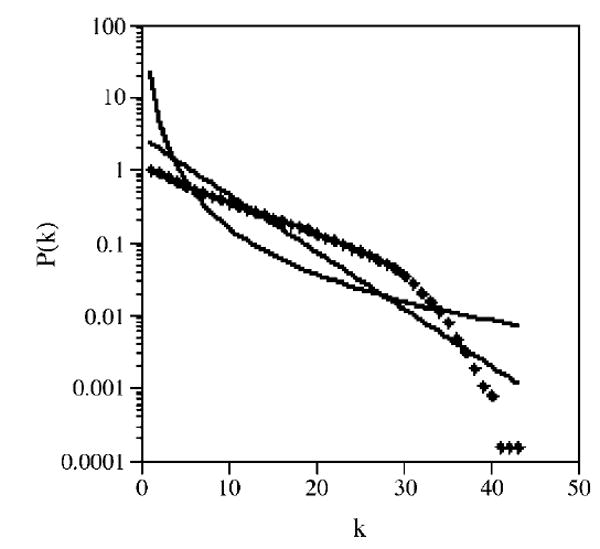
The cumulative degree distribution for the 6,508 word-forms in the largest fully connected component of the phonological network in a linear-log plot (the solid diamonds). The best fitting power-law (upward curving line) and exponential (straight line) functions are also displayed for comparison.
Assortative Mixing
A final analysis was performed to determine whether the phonological network showed assortative mixing or disassortative mixing by degree (Newman, 2002; Newman & Park, 2003). In a network with assortative mixing by degree, the nodes that have many connections tend to be connected to other nodes that have many connections. In other words, there is a positive correlation between the degree of a node and the degree of its neighbors. In a network with disassortative mixing by degree, nodes that have many connections tend to be connected to other nodes with few connections—a negative correlation between the degree of a node and the degree of its neighbors. Examination of the type of mixing by degree that occurs in a network is of interest because Newman (2002) discussed different processing implications for networks with assortative and disassortative mixing by degree (a point that will be discussed later in the context of the phonological network).
The number of connections, or degree, of each of the 6,508 nodes in the fully connected component was correlated with the degree of each of its neighbors. The resulting Pearson’s r (29,613) = .62, p < .0001, shows a positive correlation. That is, nodes with many connections tend to be connected to nodes that also have many connections, whereas nodes with few connections tend to be connected to nodes that also have few connections. Said another way, words with dense phonological neighborhoods tend to have neighbors that also have dense phonological neighborhoods, whereas words with sparse phonological neighborhoods tend to have neighbors that also have sparse phonological neighborhoods; therefore, the phonological network exhibits assortative mixing by degree.
What Advantages Does This Structure Afford the Mental Lexicon?
The analyses of the average path length and the clustering coefficient suggested that the phonological network had the characteristics of a small-world network (Watts & Strogatz, 1998). Although such networks may be very large and sparsely connected, processing on networks with a small-world structure occurs rapidly, accurately, and robustly. Given the small-world characteristics observed in the network of phonological word-forms, it is perhaps not a coincidence that language processes are also rapid, accurate, and robust.
Additional analyses showed that the network of phonological word-forms exhibited assortative mixing by degree. Newman (2002) examined several real-world networks and discussed the implications that assortative and disassortative mixing by degree might have on “processing” in those systems. The assortative mixing observed in the structure of the phonological network may have similar implications for the process of retrieving word-forms from the mental lexicon. The following discussion, however, should not be viewed as a proposal for a model of lexical processing. Rather, it is simply an exploration of how the structure of the phonological network might affect its function (Strogatz, 2001; Ward, 2002).
To examine how the structure of the phonological word-forms might influence lexical processing, consider how a common metaphor for lexical processing—activation from acoustic–phonetic input spreading to phonologically related words—might be affected by a network exhibiting disassortative versus assortative mixing by degree. In a network with disassortative mixing by degree, the distribution of highly connected nodes throughout the network would result in activation spreading among many, if not all, of the word-forms in the mental lexicon. A large number of potential lexical candidates would then have to be rejected during each attempt at lexical retrieval, perhaps making the process of word recognition slow, resource intensive, and—especially in listening conditions that are less than ideal—very laborious.
However, in a network with assortative mixing by degree, highly connected nodes tend to be clustered together, thereby restricting the spread of activation to a more circumscribed region of the network (forming what Newman, 2002, referred to as a “reservoir” in the context of disease transmission). In this case, activation from acoustic–phonetic input would spread among a smaller set of potential candidates, even in the case of words that have many phonological neighbors (see Norris, 1994, for a processing model instead of a structural model that leads to a “short list” of lexical candidates). The spread of activation to a more restricted set of candidates means that not every word in the lexicon would have to be considered and rejected as a potential lexical candidate as it would in a network with disassortative mixing, ensuring rapid, seemingly automatic retrieval of the correct lexical candidate from the lexicon, even in less than ideal listening conditions. The assortative mixing found in the phonological network also suggests that models of spoken word retrieval may not have to postulate a special ad hoc mechanism that prevents the entire lexicon from being activated whenever any acoustic-phonetic input is received, as the very structure of the phonological network may prevent this from happening.
Suppose now that the correct word-form in the lexicon does not receive enough activation to cross the threshold necessary for successful lexical retrieval. That is, the node is (temporarily) removed from the network. What are the implications for processing when a node is removed from a system that exhibits disassortative or assortative mixing by degree? In the case of the mental lexicon, how might the structure of the system influence recovery from a failed attempt at retrieving a phonological word-form? In a network with disassortative mixing by degree, the removal of one of the highly connected nodes that are distributed throughout the network is likely to result in the fracturing of the fully connected network into smaller components. If the mental lexicon were structured in this way, the reduced connectivity in the system caused by the removal of that node may make it difficult for activation to spread to another lexical candidate, resulting in catastrophic failure of the lexical retrieval process. In other words, if the correct phonological word-form is not retrieved, then nothing is retrieved.
In a network with assortative mixing by degree, the removal of one of the highly connected nodes from the cluster of highly connected nodes does little to break up the network, as the numerous “redundant” pathways found in the cluster of highly connected nodes maintain the connectivity of the network. The alternative pathways enable activation to spread to another (albeit, incorrect) candidate. Thus, if the correct word-form is not retrieved in a network with assortative mixing, catastrophic failure does not occur. Rather, the system experiences graceful degradation (McClelland, Rumelhart, & Hinton, 1986) and finds another item that best matches the input. Evidence from studies of speech perception errors (Vitevitch, 2002b) and speech production errors (e.g., Vitevitch, 1997) suggests that catastrophic failure is not likely to occur when the lexical retrieval process fails. Instead, the system experiences graceful degradation, retrieving at least partial information about a word (e.g., interlopers, or the first letter or syllable of a word that is on the “tip of the tongue”; Vitevitch & Sommers, 2003). The graceful degradation that occurs during lexical retrieval failures may in part be due to the assortative mixing by degree found in the structure of the phonological network.
Furthermore, Newman (2002) found that 5 to 10 times more nodes that were highly connected had to be removed from a network with assortative mixing than from a network with disassortative mixing to destroy the connectivity of the network. This finding suggests that the assortative mixing found in the phonological network may also contribute to the robustness of language processing in the face of more permanent damage to the system stemming from stroke or other injury to language-related areas of the brain. Only in the case of massive damage to the system, when a large number of highly connected nodes in the system are removed, is the connectivity of the network likely to be compromised, perhaps leading to catastrophic processing failures. In the case of lexical processing, conditions of catastrophic failure, such as pure word deafness, may be the result of massive damage to the lexicon that removes a large number of highly connected nodes from the system.
Although the present graph theoretic analyses simply examined the structure that was observed among phonological word-forms in the mental lexicon, the nature of that organization has important implications for the type of processing carried out in that system (Strogatz, 2001; Ward, 2002). The present discussion highlighted how the small-world nature and the assortative mixing by degree found in the phonological network might, in part, account for the speed, accuracy, and robustness of lexical processing. The following discussion considers the mechanisms that might lead to certain network structures and explores the implications of those mechanisms for the acquisition of phonological word-forms.
What Leads to This Structure in the Mental Lexicon?
Certain mechanisms lead to the formation of certain types of network structures. Therefore, the analyses of the degree distribution of a network can be used to help identify the structure of a given network and to shed some light on the mechanisms that may have led to its formation. The mechanisms that lead to the formation of certain network structures might be viewed as mechanisms that operate on a longer time scale, akin to evolution, or as mechanisms that operate on shorter time scales, akin to development or learning. Indeed, some researchers have argued that evolution, development, and learning might differ in the time scales in which they operate, but they are all subject to a similar underlying mechanism (Dickins & Levy, 2001). Given the possibility that a similar mechanism might govern evolution, development, and learning, the following discussion will examine the mechanisms that might lead to the formation of certain network structures and will explore the implications of those mechanisms for word learning.
Much attention—even in the popular press (Barabási, 2002)—has focused on the apparent ubiquity of networks with a scale-free structure. The interest in scale-free networks might, in part, be related to the power-law relationship found in the degree distribution, as power-law distributions have also been associated with the phenomenon of self-organized criticality (Bak, Tang, & Wiesenfeld, 1988). Barabási and Albert (1999; Barabási, Albert, & Jeong, 1999) suggested that two mechanisms lead to the emergence of scale-free networks: growth and preferential attachment. Growth refers to the addition of new nodes to the network over time. Preferential attachment is a constraint that makes it more likely for new nodes being added to the system to connect to nodes that are already highly connected. Barabási and Albert (1999; Barabási et al., 1999) found that both growth and preferential attachment were necessary to create the power-law degree distribution in scale-free networks (however, see Ferrer i Cancho & Solé, 2001a, for evidence that a process that optimizes the distance between nodes and the number of links per node may also lead to a power-law degree distribution).
In the case of phonological word forms in the mental lexicon, there is some evidence for growth and preferential attachment. First, consider that the mental lexicon grows over time. Although learning new word-forms is something that is typically associated with and primarily studied in children (e.g., Storkel, 2001, 2003), it is not controversial to state that adults also learn new words. In other words, the mental lexicon continues to grow over time.
Now consider preferential attachment, or the tendency for a new node to attach to a node that is connected to many rather than to few nodes in the system. In the case of the mental lexicon, a novel word-form that is phonologically similar to many known words (i.e., with a dense phonological neighborhood) should be acquired more easily than a novel word-form that is phonologically similar to few known words (i.e., with a sparse phonological neighborhood). Indeed, Storkel (2001, 2003; see also Beckman & Edwards, 2000; Gathercole, Hitch, Service, & Martin, 1997; Storkel & Morrisette, 2002) found that preschool-age children learned novel words that had common sound sequences (which are correlated with word-forms with dense phonological neighborhoods; Vitevitch, Luce, Pisoni, & Auer, 1999) more rapidly than novel words that had rare sound sequences (i.e., sparse neighborhoods). Similarly, Storkel, Armbrüster, and Hogan (2006) found that college-age adults learned novel words with dense neighborhoods more rapidly than novel words that had sparse neighborhoods, further suggesting that a mechanism like preferential attachment may influence the growth of the mental lexicon.
Furthermore, work by Page (2000; see also Grossberg, 1972) illustrates how a localist neural network with a competitive learning algorithm (i.e., not the type of network examined in the present investigation) might exhibit behavior that resembles growth via preferential attachment. In a localist neural network, an individual node represents a given concept or, in the case of the phonological lexicon, a word-form. When a novel word-form is presented to the localist network, several uncommitted nodes become partially activated by the input and compete with each other to become the node that will be committed to representing that input pattern in the future. Each node will adapt its weights to better match the input pattern. Eventually, one node will match the input pattern better than the other competing nodes and will become committed to representing that word. The “losing” nodes remain uncommitted (i.e., they do not represent a known word), but because of the previous competition, their weights are in an excellent position to represent a new input pattern that is similar to the previously learned input pattern. Such a mechanism not only accounts for the advantage found in word learning for similar sounding words (i.e., words with dense neighborhoods) over unique words (i.e., words with sparse neighborhoods) but also illustrates how a connectionist model could exhibit behavior that resembles preferential attachment.
Given the evidence for growth and preferential attachment in the mental lexicon, it is somewhat surprising that a power-law relationship was not observed in the analysis of the degree distribution of phonologically similar words in the mental lexicon (cf. Albert & Barabási, 2002; Batagelj et al., 2002; Ferrer i Cancho & Solé, 2001b; Motter et al., 2002; Steyvers & Tenenbaum, 2005). Instead, an exponential function provided a better fit to the degree distribution of the phonological network.
Also note that Newman (2002) found that the Barabási and Albert (1999) scale-free network had neither assortative nor disassortative mixing by degree; rather, the correlation of the degrees of connected nodes, perhaps counterintuitively, was 0. Recall that assortative mixing by degree was observed in the phonological network. The exponential degree distribution and the presence of assortative mixing by degree suggest that it is unlikely that the phonological network is a scale-free network like those examined by Barabási and Albert (1999). What mechanisms might lead to the network characteristics observed in the phonological network: a degree distribution that does not follow a power-law and assortative mixing by degree?
In addition to showing that growth and preferential attachment lead to a scale-free network with a power-law degree distribution, Barabási and Albert (1999) also demonstrated that a system that does not grow or that grows without preferential attachment is not likely to exhibit a power-law degree distribution. Recall, however, that the mental lexicon does grow over time and does seem to be influenced by a mechanism that resembles preferential attachment. Perhaps additional constraints on the formation of the network—and by implication, on the acquisition of novel words—led to the characteristics observed in the phonological network.
Amaral et al. (2000) found that if there is a cost associated with the attachment of a new node (i.e., the node may be able to accommodate only a fixed number of links), then a power-law degree distribution, like that in the scale-free model proposed by Barabási and Albert (1999), is not likely to be observed. In the case of phonological word-forms, restrictions on word length, on the sounds used in that language (i.e., phonemic inventory), and on the sequencing of those sounds in a word (i.e., phonotactic constraints) may limit the number of new nodes that can link to an already existing node. The costs associated with adding a new link in the phonological lexicon may, in part, account for the failure to find a degree distribution that follows a power law (see also Krapivsky, Redner, & Leyvraz, 2000, for the influence of nonlinear preferential attachment on the degree distribution). Although additional constraints on preferential attachment may produce degree distributions that do not follow a power law (e.g., an exponential degree distribution), it is not clear whether they will also lead to assortative mixing by degree or to the presence of lexical hermits—nodes that were not connected to any other node in the system—as was observed in the phonological network.
One type of growing network that does exhibit all of these characteristics—exponential degree distribution, assortative mixing by degree, and the presence of isolated nodes and islands—is the randomly grown network examined by Callaway, Hopcroft, Kleinberg, Newman, and Strogatz (2001). These characteristics emerged in the growing network examined by Callaway et al. because of two stochastic processes: (a) new connections are placed between randomly chosen pairs of nodes, and (b) new nodes that are added to the system are not required to attach to a preexisting node. Do such processes also influence the acquisition of phonological word-forms?
Consider the first stochastic process described by Callaway et al. (2001), in which new connections are placed between randomly chosen pairs of nodes in the network. In the phonological network, there is some probability that a new node might link to an already existing node in the network. In terms of the mental lexicon, a new word might be phonologically similar to an already known word. Callaway et al. also noted that older nodes, or those items that had been in the network for some time, tended to have a higher degree, or more connections than more recently added nodes. That is, it is also likely that the already existing node will have a high degree, or in terms of the mental lexicon, it is likely that the already known word will have a dense phonological neighborhood. Consistent with this prediction, Storkel (2004) found a positive correlation between age of acquisition and neighborhood density, such that words learned early in life tended to sound similar to many words (i.e., they had a higher degree) than a word learned later in life. The resemblance between the network model examined by Callaway et al. and the mental lexicon regarding the relationship between age of acquisition and neighborhood density is quite striking.
It is important to note, however, that the relationship observed by Storkel (2004) is correlational in nature and, therefore, could be the result of several possibilities. For example—as implied by the first stochastic process in the network model examined by Callaway et al. (2001)—the first words that are learned may lay a lexical foundation that makes it more likely that some words (i.e., those that are similar to known words) but not others (i.e., those that are not similar to known words) will be acquired in the future. Another possibility—as the results of laboratory-based word-learning experiments by Storkel and others might suggest (Storkel 2001, 2003; Storkel et al. 2006; see also Beckman & Edwards, 2000; Gathercole et al., 1997)—is that words with dense neighborhoods are easier to learn and are therefore acquired earlier in life than words with sparse neighborhoods. Alternatively, a third variable may be responsible for the apparent relationship between age of acquisition and neighborhood density. In the case of the mental lexicon, the frequency with which a word occurs in the language is correlated with both age of acquisition and neighborhood density. Finally, a combination of some or all of these possibilities might be at work. The exact nature of the relationship between age of acquisition and neighborhood density is an interesting question that cannot be definitively answered by the present analyses and must, therefore, be left for future research to address.
Consider further the first stochastic process described by Callaway et al. (2001): New connections are placed between randomly chosen pairs of nodes in the network. This stochastic process also implies that there is some probability that a link may be placed between two preexisting nodes in the network. That is, two known words that were not previously identified as being phonologically similar may, at a subsequent point in time, become phonologically similar. How can two words that were not previously phonologically similar become phonologically similar at a later point in time? Perhaps the lexical restructuring hypothesis proposed by Metsala and Walley (1998) might account for the later emergence of links between nodes in the lexicon. Metsala and Walley suggested that continued vocabulary growth leads to the internal restructuring of lexical representations. That is, lexical representations gradually become more detailed throughout early and middle childhood. Such a process may lead to changes in phonological similarity between previously unrelated items and may account for the subsequent placement of a link between two preexisting nodes.
To illustrate how the lexical restructuring hypothesis might account for the subsequent placement of a link between two preexisting nodes, imagine that the lexicon of a child at an early point in time consisted only of the words cat and dog. With such a small vocabulary, very abstract representations of those word-forms that lack much detail might be sufficient to distinguish between those two word-forms. Abstract representations for cat and dog might consist of the first segment in each word and some general information indicating that (perhaps, a certain number of) additional speech sounds follow; suppose something like /k–/ and /d–/.
If a new node with the abstract representation /d–/, corresponding to the recently learned word doll, was added to the network, one would no longer be able to distinguish between the word-forms for dog and doll. More detail would need to be added to the phonological representations for dog and doll (perhaps /d-[stop]/ and /d-[glide]/) in order to distinguish between those similar words. The subsequent addition of this more detailed information might result in a link being placed between these two preexisting yet similar nodes at some later point in time.
Although there is some evidence to support the lexical restructuring hypothesis (e.g., Edwards, Beckman, & Munson, 2004; Munson, Swenson, & Manthei, 2005; Storkel, 2002; Walley, 1993), it has been articulated only in very general terms and is not without its critics (e.g., Swingley, 2003; Swingley & Aslin, 2002). Admittedly, there are still some open questions regarding the lexical restructuring hypothesis, including whether the addition of more detailed information to lexical representations may result in two words that were previously considered similar to each other to no longer be phonological neighbors. This possibility might correspond to the removal of a link between two nodes in a network. However, such a mechanism is not present in the model proposed by Callaway et al. (2001). Despite the lack of specific details in the lexical restructuring hypothesis, such a mechanism makes it at least plausible that the simple stochastic process proposed by Callaway et al. not only contributes to the structure observed in the randomly grown network that they examined, but may also contribute to the structure observed in the phonological network.
Consider now the second stochastic process described by Callaway et al. (2001): New nodes added to the system are not required to attach to a preexisting node in the network. Accidental gaps and various restrictions (e.g., on word length, on the phonemic inventory, or on phonotactic sequencing) have resulted in numerous word-forms that are not phonologically related to any other extant word. The process of adding new nodes to the system without requiring them to attach to a preexisting node in the network can account for the presence of these lexical hermits in the phonological network. This would not be true in the scale-free network model proposed by Barabási and Albert (1999), in which a new node has to also connect to a preexisting node. In that model, there is no way to account for the presence of lexical hermits as observed in the phonological network. Thus, this simple stochastic process not only contributes to the structure observed in the randomly grown network examined by Callaway et al., but may also contribute to the structure observed in the phonological network.
It is quite striking that these two simple stochastic processes can account for several nontrivial results related to the acquisition and subsequent organization of phonological word-forms in the mental lexicon. The present analyses certainly do not prove that (only) these two stochastic processes caused the structure observed in the phonological network, nor do they account for all of the patterns that were observed, but they do suggest that a long list of complicated and detailed constraints that capture the microscopic details of language may not be necessary to produce the structure observed in the phonological network. Future simulations and graph theoretic analyses will further investigate which mechanisms led to the structure that was observed in the phonological network examined here.
General Discussion
Although graph theoretic concepts have been used for some time to study social interactions and social networks (e.g., Kochen, 1989; Wasserman & Faust, 1994; Wellman & Wortley, 1990), their use has been conspicuously absent from studies of cognitive processing (see Sporns, Chialvo, Kaiser, & Hilgetag, 2004, for the application of graph theory to neuroscience). The present work (see also Steyvers & Tenenbaum, 2005) suggests that these techniques can also be used to increase our understanding of complex cognitive systems, such as the mental lexicon. Speech-language pathology, psycholinguistics, and cognitive science more generally might obtain great insights by viewing complex cognitive systems from this alternative perspective.
Alternative perspectives, such as connectionist modeling, have, in the past, reshaped and advanced our understanding of various psychological processes—including the influence of evolution, development, and learning on those processes—in significant ways (e.g., Elman, Bates, Johnson, Karmiloff-Smith, Parisi, & Plunkett, 1996). Looking at the mental lexicon in graph theoretic terms may have similar consequences, as it places the lexicon, and other complex psychological systems, in a broader context and allows us to see that cognitive systems may be governed by the same underlying principles—such as those that led to small-world structures—that govern other complex systems found in the world. If complex cognitive systems are subject to the same constraints as other real-world systems, then ad hoc specific mechanisms may not be needed to account for processes like word learning and word retrieval (e.g., Markson & Bloom, 1997).
Callaway et al. (2001) stated, “We do not claim that our model is an accurate reflection of any particular real-world system, but we find that studying a model that exhibits network growth in the absence of other complicating features leads to several useful insights” (p. 1). The present analyses employed simple models, like those explored by Callaway et al. These networks with uncomplicated features indeed provided several useful insights regarding lexical access and acquisition. Specifically, a few simple stochastic processes may lead to a structure that significantly influences the learning and retrieval of word-forms in the mental lexicon.
Although the quantitative fit between the phonological network and the graph theoretic models was not perfect (e.g., the faster-than-exponential decay in Figure 3), the qualitative similarity of the phonological network, a real-world cognitive system, to the model examined by Callaway et al. (2001) may offer a unique opportunity for each field to learn from and contribute to the development of the other. Cross-disciplinary analyses of the mental lexicon might lead to the discovery of various parameters that influence the development of network structures in many real-world systems. The study of the structure observed in the mental lexicon might also lead to the development of new techniques to better classify different types of networks. Indeed, several experts in network analysis recently discussed 10 topics that future research should focus on (“Virtual Round Table,” 2004). First among those research topics was the following question: Are there formal ways of classifying the structure of different growing models? The present analyses have revealed a number of puzzles that might stimulate such cross-disciplinary investigation.
One puzzle that might capture the attention of researchers relates to the amount of assortative mixing by degree that was observed in the phonological network. Recall that the analysis of assortative mixing by degree in the phonological network found a correlation of .62. The value of the correlation coefficient obtained in the present analyses, however, is much greater than that reported by Newman (2002) for other real-world networks (a maximum of .363 for a coauthorship network of physicists) and is greater than the value predicted by the randomly grown network examined by Callaway et al. (2001; less than .4). It is not clear that any of the network models that were examined in the present analysis can account in any way for this observation.
What could lead to a greater amount of assortative mixing by degree? Perhaps somewhat counterintuitively, such a situation might emerge in the phonological network because of numerous restrictions or constraints on word formation. With some constraints on what constitutes a legal word in a given language, one might imagine that maximally dissimilar word-forms would populate the lexicon to limit confusability among the items and to facilitate the transmission of information. With many more constraints, however, the lexicon that emerges might instead resemble a group of individuals wearing a uniform of some sort. That is, the options for what shirt and what pants to wear (or what segments can co-occur) are so limited that everyone ends up looking very similar, like students in a Catholic school, employees in a fast food restaurant, soldiers in the military, or words that are morphologically related to each other.
In addition to leading to greater assortative mixing by degree, additional constraints on word formation, such as those imposed by morphology, might also underlie another anomaly that was observed in the phonological network, namely, the existence of a rather large island of related word-forms. Recall that the phonological network consisted of many words in a large interconnected component, many lexical hermits, and a number of islands containing several words that were related to each other but not to anything else. Although the processes proposed by Callaway et al. (2001) predict the existence of hermits and of islands of various sizes, additional analyses (that were not reported here) suggest that it is not very likely that an island containing over 50 nodes, as was observed in the phonological network, should exist in a network of this size and connectivity. (Because approximately two thirds of the words in this group contain the morphologically relevant sequence of segments /shin/, such as faction, fiction, and fission, I facetiously refer to this group of words as the island of the “shunned.”) Further research is required to determine how to best represent additional constraints on word formation, like those imposed by morphology, in a network model, and to determine whether analogous constraints also influence other real-world systems.
Although there is much to be gained from such opportunities for interdisciplinary research, future research focusing on the mental lexicon may also benefit from the application of graph theoretical techniques. Advances in our understanding of language processing and language-related disorders might be made by examining the lexicon of individual children, instead of an “average” lexicon as was done in the present analyses, to determine whether language acquisition is proceeding along a typical trajectory. One might also employ graph theoretic approaches to help identify certain words in the vocabulary of an individual child that might facilitate the diffusion of sound change throughout the lexicon (e.g., Gierut, 2001).
Future graph theoretic analyses of the lexicon could also use more complex graphs to examine other structural characteristics that might influence language processing. For example, a network with weighted links might be used to examine how overlapping words like cap and captain might influence lexical retrieval (however, see Newman, Sawusch, & Luce, 2005). Alternatively, a graph that allows multiplexity (two or more links of different types might exist between nodes; see Koehly & Pattison, 2005) could be used to examine how semantic information might interact with phonological information during lexical processing. The present analysis shows some of the potential that graph theory and the new science of networks (Watts, 2004) hold for understanding cognitive processing. In short, graph theory offers a new and useful set of mathematically rigorous tools to increase our understanding of language-related processes and other complex cognitive systems.
Acknowledgments
This work was supported in part by grants from the National Institutes of Health to the University of Kansas through the Schiefelbusch Institute for Life Span Studies (R01 DC 006472), the Mental Retardation and Developmental Disabilities Research Center (P30 HD002528), and the Center for Biobehavioral Neurosciences in Communication Disorders (P30 DC005803). I would like to thank Ed Auer, Albert-László Barabási, Steven B. Chin, John Colombo, Mark Steyvers, Daniel B. Stouffer, Steven Strogatz, and Holly Storkel for helpful comments, suggestions, and discussions. I would also like to thank Douglas Kieweg, Mircea Sauciuc, and Brad Torgler for their assistance with several analyses.
Footnotes
The “small-world” concept may be familiar to many because of the classic work on the social “distance” between any two people in the United States (Milgram, 1967). In this study, a randomly chosen person received the name and address of a target individual and a set of instructions directing them to deliver a packet to the target individual. If the randomly chosen person knew the target individual, they could send the packet directly to the target. If the randomly chosen person did not know the target individual, they were to send the packet to someone they knew on a first name basis who was more likely to know the target individual. The process of sending the packet to someone that was more likely to know the target was repeated until the target individual finally received the packet. Milgram found that approximately six intermediate acquaintances were required to get the packet from the randomly chosen person to the target individual. This work contributed to the notions that we live in a “small world” and that there are only “six degrees of separation” between any two people on the planet (see also the work of Granovetter, 1973).
References
- Albert R, Barabási AL. Statistical mechanics of complex networks. Review of Modern Physics. 2002;74:47–97. [Google Scholar]
- Amaral LAN, Scala A, Barthélémy M, Stanley HE. Classes of small-world networks. Proceedings of the National Academy of Sciences. 2000;97:11149–11152. doi: 10.1073/pnas.200327197. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arnold HS, Conture EG, Ohde RN. Phonological neighborhood density in the picture naming of young children who stutter: Preliminary study. Journal of Fluency Disorders. 2005;30:125–148. doi: 10.1016/j.jfludis.2005.01.001. [DOI] [PubMed] [Google Scholar]
- Bak P, Tang C, Wiesenfeld K. Self-organized criticality. Physical Review A. 1988;38:364–374. doi: 10.1103/physreva.38.364. [DOI] [PubMed] [Google Scholar]
- Barabási AL. Linked: The new science of networks. Cambridge, MA: Perseus; 2002. [Google Scholar]
- Barabási AL, Albert R. Emergence of scaling in random networks. Science. 1999 October 15;286:509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- Barabási AL, Albert R, Jeong H. Mean-field theory for scale-free random networks. Physica A. 1999;272:173–187. [Google Scholar]
- Batagelj V, Mrvar A. Pajek: A program for large network analysis. Connections. 1998;21:47–57. [Google Scholar]
- Batagelj V, Mrvar A, Zaveršnik M. Network analysis of texts. In: Tomǎ E, Gros J, editors. Proceedings of the 5th International Multi-Conference Information Society—Language Technologies. Ljubljana: Slovenia: Multi-Conference Information Society; 2002. pp. 143–148. [Google Scholar]
- Beckman ME, Edwards J. The ontogeny of phonological categories and the primacy of lexical learning in linguistic development. Child Development. 2000;71:240–249. doi: 10.1111/1467-8624.00139. [DOI] [PubMed] [Google Scholar]
- Callaway DS, Hopcroft JE, Kleinberg JM, Newman MEJ, Strogatz SH. Are randomly grown graphs really random? Physical Review E: Statistical, Nonlinear, and Soft Matter Physics. 2001;64(4 Pt 1) doi: 10.1103/PhysRevE.64.041902. [DOI] [PubMed] [Google Scholar]
- Charles-Luce J, Luce PA. Similarity neighborhoods of words in young children’s lexicons. Journal of Child Language. 1990;17:205–215. doi: 10.1017/s0305000900013180. [DOI] [PubMed] [Google Scholar]
- Charles-Luce J, Luce PA. An examination of similarity neighborhoods in young children’s receptive vocabularies. Journal of Child Language. 1995;22:727–735. doi: 10.1017/s0305000900010023. [DOI] [PubMed] [Google Scholar]
- Coady JA, Aslin RN. Phonological neighborhoods in the developing lexicon. Journal of Child Language. 2003;30:441–469. [PMC free article] [PubMed] [Google Scholar]
- Cutler A, Sebastian-Galles N, Soler-Vilageliu O, van Ooijen B. Constraints of vowels and consonants on lexical selection: Cross-linguistic comparisons. Memory & Cognition. 2000;28:746–755. doi: 10.3758/bf03198409. [DOI] [PubMed] [Google Scholar]
- Dickins TE, Levy JP. Evolution, development and learning: A nested hierarchy? In: French RM, Sougné JP, editors. Connectionist models of learning, development and evolution: Proceedings of the Sixth Neural Computation and Psychology Workshop. London: Springer-Verlag; 2001. pp. 263–270. [Google Scholar]
- Dollaghan CA. Children’s phonological neighborhoods: Half empty or half full? Journal of Child Language. 1994;21:257–271. doi: 10.1017/s0305000900009260. [DOI] [PubMed] [Google Scholar]
- Edwards J, Beckman ME, Munson B. The interaction between vocabulary size and phonotactic probability effects on children’s production accuracy and fluency in nonword repetition. Journal of Speech, Language, and Hearing Research. 2004;47:421–436. doi: 10.1044/1092-4388(2004/034). [DOI] [PubMed] [Google Scholar]
- Elman JL, Bates EA, Johnson MH, Karmiloff-Smith A, Parisi D, Plunkett K. Rethinking innateness: A connectionist perspective on development. Cambridge, MA: MIT Press; 1996. [Google Scholar]
- Erdos P, Rényi A. On the evolution of random graphs. Publication of the Mathematical Institute of the Hungarian Academy of Sciences. 1960;5:17–61. [Google Scholar]
- Ferrer i Cancho R, Solé RV. Optimization in complex networks. Santa Fe, NM: Santa Fe Institute; 2001a. Nov, Working Paper No. 01-11-068. [Google Scholar]
- Ferrer i Cancho R, Solé RV. The small world of human language. Proceedings of the Royal Society of London B: Biological Sciences. 2001b;268:2261–2266. doi: 10.1098/rspb.2001.1800. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gathercole SE, Hitch GJ, Service E, Martin AJ. Phonological short-term memory and new word learning in children. Developmental Psychology. 1997;33:966–979. doi: 10.1037//0012-1649.33.6.966. [DOI] [PubMed] [Google Scholar]
- Gierut JA. A model of lexical diffusion in phonological acquisition. Clinical Linguistics & Phonetics. 2001;15:19–22. doi: 10.3109/02699200109167624. [DOI] [PubMed] [Google Scholar]
- Gierut JA, Morrisette ML, Champion AH. Lexical constraints in phonological acquisition. Journal of Child Language. 1999;26:261–294. doi: 10.1017/s0305000999003797. [DOI] [PubMed] [Google Scholar]
- Gordon JK, Dell GS. Phonological neighborhood effects: Evidence from aphasia and connectionist modeling. Brain and Language. 2001;79:21–23. [Google Scholar]
- Goulden R, Nation P, Read J. How large can a receptive vocabulary be? Applied Linguistics. 1990;11:341–363. [Google Scholar]
- Granovetter MS. The strength of weak ties. American Journal of Sociology. 1973;78:1360–1380. [Google Scholar]
- Greenberg JH, Jenkins JJ. Studies in the psychological correlates of the sound system of American English. In: Jacobivits LA, Miron MS, editors. Readings in the psychology of language. Englewood Cliffs, NJ: Prentice-Hall; 1967. pp. 186–200. [Google Scholar]
- Grossberg S. Neural expectation: Cerebellar and retinal analogy of cells fired by learnable or unlearnable pattern classes. Kybernetik. 1972;10:49–57. doi: 10.1007/BF00288784. [DOI] [PubMed] [Google Scholar]
- Harary F, Norman RZ, Cartwright D. Structural models: An introduction to the theory of directed graphs. New York: Wiley; 1965. [Google Scholar]
- Imai S, Walley AC, Flege JE. Lexical frequency and neighborhood density effects on the recognition of native and Spanish-accented words by native English and Spanish listeners. The Journal of the Acoustical Society of America. 2005;117:896–907. doi: 10.1121/1.1823291. [DOI] [PubMed] [Google Scholar]
- Kaiser AR, Kirk KI, Lachs L, Pisoni DB. Talker and lexical effects on audiovisual word recognition by adults with cochlear implants. Journal of Speech, Language, and Hearing Research. 2003;46:390–404. doi: 10.1044/1092-4388(2003/032). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kochen M. The small world: A volume of recent research advances commemorating Ithiel de Sola Pool, Stanley Milgram, Theodore Newcomb. Norwood, NJ: Ablex Publishing; 1989. [Google Scholar]
- Koehly LM, Pattison P. Random graph models for social networks: Multiple relations or multiple raters. In: Carrington PJ, Scott J, Wasserman S, editors. Models and methods in social network analysis. New York: Cambridge University Press; 2005. pp. 162–191. [Google Scholar]
- Krapivsky PL, Redner S, Leyvraz F. Connectivity of growing random networks. Physical Review Letters. 2000;85:4629–4632. doi: 10.1103/PhysRevLett.85.4629. [DOI] [PubMed] [Google Scholar]
- Landauer TK, Streeter LA. Structural differences between common and rare words: Failure of equivalence assumptions for theories of word recognition. Journal of Verbal Learning and Verbal Behavior. 1973;12:119–131. [Google Scholar]
- Luce PA, Large NR. Phonotactics, density and entropy in spoken word recognition. Language and Cognitive Processes. 2001;16:565–581. [Google Scholar]
- Luce PA, Pisoni DB. Recognizing spoken words: The neighborhood activation model. Ear and Hearing. 1998;19:1–36. doi: 10.1097/00003446-199802000-00001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Markson L, Bloom P. Evidence against a dedicated system for word learning in children. Nature. 1997 February 27;385:813–815. doi: 10.1038/385813a0. [DOI] [PubMed] [Google Scholar]
- McClelland JL, Rumelhart DE, Hinton GE. The appeal of parallel distributed processing. In: Rumelhart DE, McClelland JL, editors. Parallel distributed processing: Explorations in the microstructure of cognition: Volume 1 Foundations. Cambridge, MA: MIT Press; 1986. pp. 3–44. [Google Scholar]
- Metsala JL, Walley AC. Spoken vocabulary growth and the segmental restructuring of lexical representations: Precursors to phonemic awareness and early reading ability. In: Metsala J, Ehri L, editors. Word recognition in beginning literacy. Vol. 4. Mahwah, NJ: Erlbaum; 1998. pp. 89–120. [Google Scholar]
- Milgram S. The small-world problem. Psychology Today. 1967;2:60–67. [Google Scholar]
- Montoya JM, Solé RV. Small world patterns in food webs. Journal of Theoretical Biology. 2002;214:405–412. doi: 10.1006/jtbi.2001.2460. [DOI] [PubMed] [Google Scholar]
- Motter AE, de Moura APS, Lai YC, Dasgupta P. Topology of the conceptual network of language. Physical Review E: Statistical, Nonlinear, and Soft Matter Physics. 2002;65(6 Pt 2):065102. doi: 10.1103/PhysRevE.65.065102. Retrieved February 18, 2003, from http://prola.aps.org/pdf/PRE/v65/i6/e065102. [DOI] [PubMed]
- Munson B, Solomon NP. The effect of phonological neighborhood density on vowel articulation. Journal of Speech, Language, and Hearing Research. 2004;47:1048–1058. doi: 10.1044/1092-4388(2004/078). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Munson B, Swenson CL, Manthei SC. Lexical and phonological organization in children: Evidence from repetition tasks. Journal of Speech, Language, and Hearing Research. 2005;48:108–124. doi: 10.1044/1092-4388(2005/009). [DOI] [PubMed] [Google Scholar]
- Newman MEJ. Assortative mixing in networks. Physical Review Letters. 2002;89:208701. doi: 10.1103/PhysRevLett.89.208701. Retrieved December 18, 2006, from http://arxiv.org/abs/cond-mat/0205405. [DOI] [PubMed]
- Newman MEJ. Power laws, Pareto distributions and Zipf ’s law. Contemporary Physics. 2006;46:323–351. [Google Scholar]
- Newman MEJ, Park J. Why social networks are different from other types of networks. Physical Review E: Statistical, Nonlinear, and Soft Matter Physics. 2003;68(3 Pt 2):036122. doi: 10.1103/PhysRevE.68.036122. Retrieved December 18, 2006, from http://prola.aps.org/pdf/PRE/v68/i3/e036122. [DOI] [PubMed]
- Newman RS, Sawusch JR, Luce PA. Do postonset segments define a lexical neighborhood? Memory & Cognition. 2005;33:941–960. doi: 10.3758/bf03193204. [DOI] [PubMed] [Google Scholar]
- Norris D. Shortlist: A connectionist model of continuous speech recognition. Cognition. 1994;52:189–234. [Google Scholar]
- Nusbaum HC, Pisoni DB, Davis CK. Research on Speech Perception Progress Report No. 10. Bloomington: Indiana University; 1984. Sizing up the Hoosier mental lexicon: Measuring the familiarity of 20,000 words; pp. 357–376. [Google Scholar]
- Page M. Connectionist modeling in psychology: A localist manifesto. Behavioral and Brain Sciences. 2000;23:443–512. doi: 10.1017/s0140525x00003356. [DOI] [PubMed] [Google Scholar]
- Roberts FS. Discrete mathematical models. Englewood Cliffs, NJ: Prentice-Hall; 1976. [Google Scholar]
- Saussure Fde. In: Course in general linguistics. Wade Baskin., translator. New York: McGraw-Hill; 1966. Original work published 1916. [Google Scholar]
- Sommers MS. The structural organization of the mental lexicon and its contribution to age-related declines in spoken word recognition. Psychology and Aging. 1996;11:333–341. doi: 10.1037//0882-7974.11.2.333. [DOI] [PubMed] [Google Scholar]
- Sporns O, Chialvo DR, Kaiser M, Hilgetag CC. Organization, development and function of complex brain networks. Trends in Cognitive Sciences. 2004;8:418–425. doi: 10.1016/j.tics.2004.07.008. [DOI] [PubMed] [Google Scholar]
- Steyvers M, Tenenbaum J. The large scale structure of semantic networks: Statistical analyses and a model of semantic growth. Cognitive Science. 2005;29:41–78. doi: 10.1207/s15516709cog2901_3. [DOI] [PubMed] [Google Scholar]
- Storkel HL. Learning new words: Phonotactic probability in language development. Journal of Speech, Language, and Hearing Research. 2001;44:1321–1337. doi: 10.1044/1092-4388(2001/103). [DOI] [PubMed] [Google Scholar]
- Storkel HL. Restructuring of similarity neighborhoods in the developing mental lexicon. Journal of Child Language. 2002;29:251–274. doi: 10.1017/s0305000902005032. [DOI] [PubMed] [Google Scholar]
- Storkel HL. Learning new words: II. Phonotactic probability in verb learning. Journal of Speech, Language, and Hearing Research. 2003;46:1312–1323. doi: 10.1044/1092-4388(2003/102). [DOI] [PubMed] [Google Scholar]
- Storkel HL. Do children acquire dense neighborhoods? An investigation of similarity neighborhoods in lexical acquisition. Applied Psycholinguistics. 2004;25:201–221. [Google Scholar]
- Storkel HL, Armbrüster J, Hogan TP. Differentiating phonotactic probability and neighborhood density in adult word learning. Journal of Speech, Language, and Hearing Research. 2006;49:1175–1192. doi: 10.1044/1092-4388(2006/085). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Morrisette ML. The lexicon and phonology: Interactions in language acquisition. Language, Speech, and Hearing Services in Schools. 2002;33:24–37. doi: 10.1044/0161-1461(2002/003). [DOI] [PubMed] [Google Scholar]
- Strogatz SH. Exploring complex networks. Nature. 2001 March 8;410:268–276. doi: 10.1038/35065725. [DOI] [PubMed] [Google Scholar]
- Swingley D. Phonetic detail in the developing lexicon. Language and Speech. 2003;46:265–294. doi: 10.1177/00238309030460021001. [DOI] [PubMed] [Google Scholar]
- Swingley D, Aslin RN. Lexical neighborhoods and the word-form representations of 14-month-olds. Psychological Science. 2002;13:480–484. doi: 10.1111/1467-9280.00485. [DOI] [PubMed] [Google Scholar]
- Vicente S, Castro SL, Walley A. A developmental analysis of similarity neighborhoods for European Portuguese. Journal of Portuguese Linguistics. 2003;2:115–133. [Google Scholar]
- Virtual round table on ten leading questions for network research [Editorial] European Physical Journal, B. 2004;38:143–145. [Google Scholar]
- Vitevitch MS. The neighborhood characteristics of malapropisms. Language and Speech. 1997;40:211–228. doi: 10.1177/002383099704000301. [DOI] [PubMed] [Google Scholar]
- Vitevitch MS. The influence of phonological similarity neighborhoods on speech production. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2002a;28:735–747. doi: 10.1037//0278-7393.28.4.735. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS. Naturalistic and experimental analyses of word frequency and neighborhood density effects in slips of the ear. Language and Speech. 2002b;45:407–434. doi: 10.1177/00238309020450040501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS. The clustering coefficient of phonological neighborhoods influences spoken word recognition; Poster presented at the 4th Joint Meeting of the Acoustical Society of America and the Acoustical Society of Japan; Honolulu, HI. 2006. November–December, [Google Scholar]
- Vitevitch MS, Luce PA. When words compete: Levels of processing in spoken word perception. Psychological Science. 1998;9:325–329. [Google Scholar]
- Vitevitch MS, Luce PA. Probabilistic phonotactics and neighborhood activation in spoken word recognition. Journal of Memory and Language. 1999;40:374–408. [Google Scholar]
- Vitevitch MS, Luce PA. A web-based interface to calculate phonotactic probability for words and nonwords in English. Behavior Research Methods, Instruments, and Computers. 2004;36:481–487. doi: 10.3758/bf03195594. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS, Luce PA. Increases in phono-tactic probability facilitate spoken nonword repetition. Journal of Memory and Language. 2005;52:193–204. [Google Scholar]
- Vitevitch MS, Luce PA, Pisoni DB, Auer ET. Phonotactics, neighborhood activation and lexical access for spoken words. Brain and Language. 1999;68:306–311. doi: 10.1006/brln.1999.2116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS, Rodríguez E. Neighborhood density effects in spoken word recognition in Spanish. Journal of Multilingual Communication Disorders. 2005;3:64–73. doi: 10.1080/14769670400027332. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS, Sommers MS. The facilitative influence of phonological similarity and neighborhood frequency in speech production in younger and older adults. Memory & Cognition. 2003;31:491–504. doi: 10.3758/bf03196091. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS, Stamer MK. The curious case of competition in Spanish speech production. Language and Cognitive Processes. 2006;21:760–770. doi: 10.1080/01690960500287196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Walley AC. The role of vocabulary development in children’s spoken word recognition and segmentation ability. Developmental Review. 1993;13:286–350. [Google Scholar]
- Ward LM. Dynamical cognitive science. Cambridge, MA: MIT Press; 2002. [Google Scholar]
- Wasserman S, Faust K. Social network analysis: Methods and applications. New York: Cambridge University Press; 1994. [Google Scholar]
- Watts DJ. Small worlds: The dynamics of networks between order and randomness. Princeton, NJ: Princeton University Press; 1999. [Google Scholar]
- Watts DJ. The “new” science of networks. Annual Review of Sociology. 2004;30:243–270. [Google Scholar]
- Watts DJ, Strogatz SH. Collective dynamics of “small-world” networks. Nature. 1998 June 4;393:440–442. doi: 10.1038/30918. [DOI] [PubMed] [Google Scholar]
- Wellman B, Wortley S. Different strokes from different folks: Community ties and social support. American Journal of Sociology. 1990;96:558–588. [Google Scholar]
- Wilks C, Meara P. Untangling word webs: Graph theory and the notion of density in second language word association networks. Second Language Research. 2002;18:303–324. [Google Scholar]
- Wilks C, Meara P, Wolter B. A further note on simulating word association behaviour in a second language. Second Language Research. 2005;21:359–372. [Google Scholar]
- Yates M, Locker L, Jr, Simpson GB. The influence of phonological neighborhood on visual word perception. Psychonomic Bulletin & Review. 2004;11:452–457. doi: 10.3758/bf03196594. [DOI] [PubMed] [Google Scholar]