

Abstract
Cross-sectional studies of neighborhood context and health are subject to upward bias due to unobserved heterogeneity and to downward bias due to overadjustment for potential mediators in the pathway between neighborhood context and health. In this study, the authors employed two strategies that addressed these two sources of bias. First, to mitigate overadjustment of mediators, they adjusted for baseline characteristics observed just prior to the measurement of neighborhood context, using a combined propensity score and regression strategy. Second, to mitigate underadjustment of unmeasured confounders, they employed a fixed-effects modeling strategy to account for unobserved non-time-varying heterogeneity. Analyses were based on a nationally representative sample of the nonimmigrant US population from the Panel Study of Income Dynamics (1980–1997) in which respondent-rated health was regressed on neighborhood poverty. The samples consisted of approximately 6,000 respondents for the propensity score/regression models and 45,000 person-years for the fixed-effects models. Both modeling strategies yielded significant estimates of neighborhood poverty and supported a causal link between neighborhood context and health.
Keywords: causality, health status disparities, poverty, residence characteristics, social class
Place and health are intimately linked, given that goods and services, exposure to hazards, and the availability of opportunities are all spatially distributed. Studies based on observational data generally support a link between neighborhood economic conditions and a wide range of health outcomes, including mortality, chronic disease, mental health, and health behaviors (1–5), although there are a few exceptions (6, 7). These associations remain significant after adjustment for individual-level factors.
However, causal inferences from these studies can be interpreted as tenuous; differences in health across neighborhoods may be due to neighborhood composition rather than neighborhood context, because individuals tend to sort into different types of neighborhoods based on both observed and unobserved characteristics (8). Failure to account for differences in individual-level characteristics across neighborhoods (i.e., composition) may cause investigators to spuriously attribute health differences to neighborhood context. Extant studies, largely relying on cross-sectional data, attempt to account for neighborhood composition by controlling for observed individual-level characteristics in regression models. However, the set of covariates considered is often limited and cannot account for all potential factors. For example, persons who are more likely to engage in risky health behaviors (e.g., substance use) may also seek out neighborhoods in which these activities are more widespread—neighborhoods which also tend to be poorer. Not accounting for these characteristics would cause investigators to spuriously attribute health differences to neighborhood context. Consequently, the reliance on cross-sectional data and a handful of individual-level variables to control for all of the compositional heterogeneity across neighborhoods makes the assumption of (conditional) exogenous variation in neighborhood context difficult to justify.
While neighborhood-health studies exclude relevant confounders, these studies are also susceptible to bias from overadjustment (9–11). Neighborhood environments in childhood and early adulthood are likely to have influenced present-day educational attainment, labor force attachment, and behavioral norms (12–15), which subsequently predict future neighborhood characteristics and health. Consequently, some individual-level characteristics may be considered both mediators and confounders, and adjusting for these factors may yield overly conservative estimates of neighborhood effects.
Using longitudinal data, we employed two modeling strategies that address the two aforementioned sources of bias in neighborhood-health studies. First, to mitigate overadjustment of mediators, we adjusted for baseline individual-level characteristics observed just prior to the period in which neighborhood context was observed (strategy 1). Second, to account for unobserved non-time-varying heterogeneity, we employed a fixed-effects modeling strategy (strategy 2).
MATERIALS AND METHODS
Data
Analyses were based on data from selected years (1980–1997) of the Panel Study of Income Dynamics (PSID). The PSID is a panel study of a nationally representative sample of the nonimmigrant US population. From 1968 to 1997, PSID investigators collected data on an extensive list of socioeconomic variables annually and sporadically collected data on health measures. We used a geocoded version of the PSID that included respondents' census tracts of residence at the time of each interview. The sample was further restricted to non-Hispanic Black and White household heads/spouses who were aged 18 years or over by the time of the 1984 survey. These restrictions resulted in a sample size of approximately 6,000 respondents for the propensity score/regression models and 45,000 person-years for the fixed-effects models.
Neighborhood context
Using 2000 US Census tract identifiers geocoded from residential addresses for each respondent in the PSID data, we linked census tract poverty measures to each respondent-year. Neighborhood poverty levels were derived from the Neighborhood Change Database of GeoLytics, Inc. (GeoLytics, Inc., East Brunswick, New Jersey), which contains decennial census-tract-level data for the years 1980, 1990, and 2000—normalized to 2000 tract boundaries (16). Neighborhood poverty rates between decennial census years within a tract were calculated by simple linear interpolation. Because tract boundaries change across decennial censuses, we used normalized tract boundaries to minimize our chances of spuriously attributing variations in tract characteristics to compositional changes in tract poverty when variations were due to boundary changes. Further, since the United States was not fully tracted until 1990, we restricted our analyses to person-year observations of persons who had resided in areas that had at least 75 percent tract coverage at the time of interview. This led to an approximately 7 percent attrition rate due to missing or undercovered tract areas.
Health measurement
Health was captured with a five-point respondent-rated health measure (poor, fair, good, very good, excellent) that we dichotomized to fair/poor health—henceforth referred to as poor health. Respondent-rated health is a strong predictor of future mortality and morbidity, even net of clinical measures of health status (17, 18). There are further advantages to this measure. First, it is a global measure that captures both physical and mental health. Second, it is a dynamic measure that is nonabsorbing; that is, individuals can lapse in and out of poor health across surveys/time. Use of variables measured over time which enter a state and are not allowed to leave that state (e.g., diagnosed diabetes) may lead to conservative effect estimates, since future variation in predictors will have no effect on the person's state of health. Third, changes in perceived health over time tend to move in the same direction as changes in morbidity (19). The nonabsorbing and time-varying aspects of this measure lend themselves well to a fixed-effects model approach, as well as having it serve as a baseline health measure.
Strategy 1: baseline adjustment framework
Disentangling confounders from mediating factors is especially difficult in neighborhood-effects models because exposure to neighborhood context is lifelong. As such, there is no conventional pretreatment period that allows for adjustment of characteristics at baseline, just prior to exposure. Using a strategy developed by Harding (15), we alleviate these concerns by explicitly demarcating a finite time frame, [to, te], during which the effect of neighborhood context is measured (see figure 1). Persons who reside in high-poverty neighborhoods (≥20 percent on average) during this period are considered to be in the treated group. Conversely, persons who reside in low-poverty areas on average during this period are considered to be in the control group. Comparability is achieved by adjusting for baseline differences between the two groups as observed for up to t years before the beginning of treatment, but not during the time frame of treatment. At the end of the time frame of treatment, te, the two groups are compared with regard to the health outcome. By clearly defining a time frame of treatment, we can adjust for baseline confounders and refrain from readjusting for any possible time-varying mediators (e.g., income) during the exposure period. This model assumes that any differential changes in baseline characteristics at the end of the time frame are due to neighborhood context and should be considered a true neighborhood effect.
FIGURE 1.

Baseline adjustment framework for the propensity score model, Panel Study of Income Dynamics, 1980–1997.
The health outcome is defined as respondent-rated health reported in the last year for which the measure is observed between 1995 and 1997—which we subsequently label as 1995/6/7. The time frame in which neighborhood poverty is measured is 1985–1997 (1985–1995/6/7), inclusive; measurements of neighborhood poverty after the year of health measurement are obviously excluded. Treatment is a binary indicator of residence in a high-neighborhood-poverty environment between 1985 and the year in which respondent-rated health is measured. A high-neighborhood-poverty environment is defined as an average neighborhood poverty rate of 20 percent or more during this time period.
We control for pretreatment baseline characteristics as measured in 1984. These characteristics include: employment status, educational attainment, family poverty income ratio, marital status, indicator for a female-headed household, receipt of public assistance (welfare), age, and wealth. Wealth is composed of the net value of assets, including financial accounts, business value, real estate (excluding primary residence), stocks, and vehicles. Further, we also include 1984 respondent-rated health and 1980–1984 average neighborhood poverty rate as baseline adjustments. Non-time-varying covariates include race and sex. Finally, because this is an unbalanced sample, we include the number of years on which the average neighborhood poverty rates are based.
Statistical adjustment strategy.
In addition to multivariate regression, we use a propensity scoring strategy to control for baseline differences between residents of high-poverty neighborhoods and residents of low-poverty neighborhoods. This approach allows for better comparability between the treated group (residents of high-poverty neighborhoods) and the control group (residents of low-poverty neighborhoods). The propensity score, P(T = 1| X), is defined as the probability that a person with characteristics X is assigned to the treatment group, defined as T = 1. Conditional on the propensity score, the covariate distribution of X is no longer correlated with the treatment assignment (20, 21).
There are several advantages to this approach as compared with standard regression adjustments. First, when differences between groups are large, estimates from parametric regression models may be particularly sensitive to assumptions of model specification, even in the absence of omitted confounders. However, propensity score adjustment is less sensitive to model misspecification (22) and therefore less likely to yield biased estimates. Second, conducting t tests to examine whether any significant differences in covariates between the two groups remain after propensity score adjustment allows for transparency in the quality of covariate balance. Third, when significant differences remain, fitting a regression model weighted by the propensity score offers an additional layer of adjustment that can be more effective than propensity score adjustment alone (23, 24). Finally, the augmented strategy of combining the propensity score with regression adjustment may increase the precision of the neighborhood effect estimate and serves to produce a “doubly robust” estimator, given that the neighborhood effect estimate is consistent if either the propensity or the regression model is correctly specified (24).
In this study, rather than the more conventional parametric models (21), we use a multivariate nonparametric regression technique called generalized boosted models (25) to estimate the propensity to reside in a high-poverty neighborhood. The propensity scores are then used to calculate observation weights defined as
That is, persons in the treated group are assigned a weight of 1 and persons in the control group are assigned a weight of 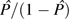 . Persons in the control group who are similar in observed characteristics to the treatment group will have a higher propensity score, and thus a larger weight, than those with dissimilar characteristics. The weighting serves to transform the covariate distribution of the control group to correspond with that of the treatment group, in essence creating a pseudo-population of persons who reside in low-poverty neighborhoods that resembles the population that resides in high-poverty neighborhoods.
. Persons in the control group who are similar in observed characteristics to the treatment group will have a higher propensity score, and thus a larger weight, than those with dissimilar characteristics. The weighting serves to transform the covariate distribution of the control group to correspond with that of the treatment group, in essence creating a pseudo-population of persons who reside in low-poverty neighborhoods that resembles the population that resides in high-poverty neighborhoods.
Propensity score model specification.
With the propensity score adjustment strategy, covariate balance can be explicitly tested. Before propensity score adjustment, residents of high- and low-poverty neighborhoods differ greatly (compare the “high-poverty neighborhood” and “low-poverty neighborhood (no propensity score weighting)” columns in table 1). After propensity score weighting (compare the “high-poverty neighborhood” and “low-poverty neighborhood (after propensity score weighting)” columns in table 1), these differences are reduced considerably, but not entirely. As such, we fit our model with the full set of factors that were included in the propensity score model as an additional protective step against bias.
TABLE 1.
Characteristics (proportion or mean value) of high- and low-poverty residents at baseline, Panel Study of Income Dynamics, 1980–1997
| Characteristic | High-poverty neighborhood | Low-poverty neighborhood (no propensity score weighting) | Low-poverty neighborhood (after propensity score weighting) |
| (n = 1,509) | (n = 4,583) | (n = 4,583) | |
| Female sex | 0.647 | 0.556** | 0.679 |
| Black race | 0.793 | 0.179** | 0.760 |
| Age (years) | 39.252 | 39.008 | 37.903 |
| Economic factors | |||
| Family poverty income ratio | 1.999 | 4.383** | 2.169* |
| Wealth (1984 dollars) | 14,281.469 | 64,276.614** | 12,663.227 |
| Welfare recipient | 0.130 | 0.017** | 0.100 |
| Female-headed household | 0.209 | 0.046** | 0.211 |
| Education | |||
| No high school | 0.463 | 0.178** | 0.429 |
| High school | 0.384 | 0.412 | 0.385 |
| Some college | 0.108 | 0.196** | 0.117 |
| College | 0.031 | 0.137** | 0.048* |
| Graduate school | 0.014 | 0.077** | 0.020 |
| Labor force status | |||
| Employed | 0.545 | 0.728** | 0.629** |
| Unemployed | 0.129 | 0.033** | 0.106 |
| Not in the labor force | 0.326 | 0.239** | 0.265* |
| Marital status | |||
| Single | 0.213 | 0.095** | 0.232 |
| Married | 0.535 | 0.786** | 0.500 |
| Widowed | 0.072 | 0.035** | 0.284 |
| Divorced | 0.097 | 0.062** | 0.322 |
| Separated | 0.083 | 0.022** | 0.256 |
| Baseline neighborhood poverty rate | 27.541 | 9.415** | 25.359** |
| Baseline poor health | 0.272 | 0.104** | 0.402** |
p < 0.05;
p < 0.01 (difference from the high-poverty group in t test for mean/proportion difference).
Strategy 2: fixed-effects model framework
As with regression models, propensity score adjustment can only adjust for measured factors. Hence, causal inference from our first strategy rests on the strong assumption that there exists no omitted variable bias. Neglecting to account for factors that are correlated with both neighborhood poverty and health in the propensity/regression model—henceforth referred to as the propensity model—could cause one to spuriously attribute differences in health outcomes to neighborhood context.
Therefore, our second strategy employs a fixed-effects logistic model (26, 27) to account for possible non-time-varying unobserved confounders. More formally, we maximize the conditional likelihood function
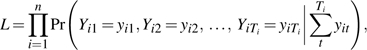 |
where Ti represents the number of waves observed for person i and yit is a time-varying binary indicator of poor health for person i and is a function of both time-varying covariates, xit, and non-time-varying covariates, αi—that is,
By conditioning the likelihood on the sum of each individual's outcomes (i.e.,  ), we ensure that the resulting function is now independent of αi. Consequently, because αi includes both measured and unmeasured factors that do not vary over time, parameter estimates are now purged of any (time-invariant) unobserved individual-level heterogeneity.
), we ensure that the resulting function is now independent of αi. Consequently, because αi includes both measured and unmeasured factors that do not vary over time, parameter estimates are now purged of any (time-invariant) unobserved individual-level heterogeneity.
The fixed-effects sample consists of multiple measurements of neighborhood poverty and self-reported health between 1984 and 1997. With the exception of three variables, all time-varying socioeconomic factors that were included in the propensity model presented above are also entered into the fixed-effects model, including: marital status, age, education, indicator for a female-headed household, receipt of public assistance, labor force status, and family poverty income ratio. Baseline health, baseline neighborhood poverty, and baseline wealth, although they are theoretically time-varying characteristics, are constant measures in the model because they refer to baseline values. Consequently, they are absorbed by the specification of the individual-level fixed effects.
Because descriptive analyses revealed that most of the within-person neighborhood poverty variation was due to residential relocation, which may be correlated with changes in individual characteristics that also affect health, an indicator for whether the respondent has moved during the previous year is also included in the model. Specifically, intraperson variation in neighborhood poverty is more than 3.5 times greater among movers (one third of the study population) than among nonmovers. Lastly, we also include a complete set of year dummies to adjust for unobserved factors peculiar to each year.
Several specifications of neighborhood poverty are explored: categorical, linear, and log-linear. Finally, as a basis of comparison, we also fit non-fixed-effects models (pooled logistic regression) using the 1984–1997 sample with the same set of covariates in the fixed-effects models, with sex and race as additional adjustments. Given that there are multiple observations per individual, the pooled logistic regression models adjust the standard errors for nonindependence of observations within individuals (28–30). The pooled logistic model represents the more conventional cross-sectional modeling strategy in which unobserved individual heterogeneity is ignored.
Table 2 summarizes the three modeling strategies: 1) baseline adjustment framework, 2) fixed-effects framework, and 3) pooled logistic regression.
TABLE 2.
Model specifications and sample sizes used for the baseline adjustment, fixed-effects, and pooled logistic regression strategies, Panel Study of Income Dynamics, 1980–1997
| Strategy | Sample size | Adjustments |
| Baseline adjustment strategy | 6,092 | 1984 baseline: employment status, educational attainment, family poverty income ratio, marital status, indicator for a female-headed household, receipt of welfare, age, race, sex, wealth, respondent-rated health, and 1980–1984 average neighborhood poverty |
| Fixed-effects strategy | 45,351 | At time t: employment status, educational attainment, family poverty income ratio, marital status, indicator for a female-headed household, receipt of welfare, and age |
| 1984–1997 (non-fixed-effects) pooled logistic regression strategy | 129,595 | At time t: employment status, educational attainment, family poverty income ratio, marital status, indicator for a female-headed household, receipt of welfare, age, race, and sex |
RESULTS
Results from strategy 1: baseline adjustment framework
Propensity score model estimates are presented in table 3. The sample size is indicative of the adult household-head/spouse population of respondents. Model 1 is the unconditional weighted logistic regression model and yields an estimate of average neighborhood poverty for the period 1985–1997 of 1.74 (odds ratio (OR) = 1.74, 95 percent confidence interval (CI): 1.33, 2.27). Again, this estimate is obtained using the propensity score-weighted analysis discussed above in Materials and Methods. On average, the odds of reporting poor health are 1.74 times greater among residents of high-poverty neighborhoods than among residents of low-poverty neighborhoods. However, this estimate is expected to be biased, since there remain significant baseline differences between residents of high- and low-poverty neighborhoods, as evidenced in table 1. Model 2 adds the five covariates for which balance was not achieved. The estimate (OR = 1.63, 95 percent CI: 1.21, 2.19) is slightly attenuated but remains significant and relatively stable, as measured by the width of the confidence interval. On average, the odds of reporting poor health are 1.63 times greater for a person who resides in a high-poverty neighborhood than for a comparable person in a low-poverty neighborhood. Model 3 adds the full set of factors that were also included in the propensity score weighting. The inclusion of the remaining covariates in the regression model does not significantly alter the neighborhood estimate or the width of the confidence interval. The stability of the neighborhood poverty estimate is reassuring, since the additional covariates should no longer be correlated with neighborhood poverty after propensity score weighting. As aforementioned, the inclusion of the full set of covariates also serves to produce a “doubly robust” estimator.
TABLE 3.
Propensity score-weighted regression estimates for poor health in 1997 (n = 6,092), Panel Study of Income Dynamics, 1980–1997
| Propensity score-weighted estimate |
||||||
| Model 1 |
Model 2 |
Model 3 |
||||
| OR* | 95% CI* | OR | 95% CI | OR | 95% CI | |
| 1985–1997 average tract poverty (%) | ||||||
| <20 | 1.00 | 1.00 | 1.00 | |||
| ≥20 | 1.74 | 1.33, 2.27 | 1.63 | 1.21, 2.19 | 1.64 | 1.19, 2.24 |
| Race/ethnicity | ||||||
| White | 1.00 | |||||
| Black | 1.08 | 0.81, 1.43 | ||||
| Sex | ||||||
| Female | 0.80 | 0.60, 1.08 | ||||
| Male | 1.00 | |||||
| Age | 1.10 | 1.03, 1.16 | ||||
| Age squared | 1.00 | 1.00, 1.00 | ||||
| Family poverty income ratio (%) | ||||||
| ≤100 | 1.32 | 0.86, 2.02 | 1.65 | 1.02, 2.68 | ||
| >100–200 | 1.34 | 0.94, 1.91 | 1.59 | 1.07, 2.37 | ||
| >200–300 | 1.29 | 0.91, 1.85 | 1.49 | 1.03, 2.18 | ||
| >300 | 1.00 | 1.00 | ||||
| Socioeconomic characteristics | ||||||
| Female-headed household | 0.81 | 0.51, 1.29 | ||||
| Welfare recipient | 1.62 | 0.99, 2.64 | ||||
| Quintile of family wealth | ||||||
| 1 | 1.08 | 0.63, 1.88 | ||||
| 2 | 0.83 | 0.48, 1.44 | ||||
| 3 | 0.86 | 0.49, 1.48 | ||||
| 4 | 1.00 | |||||
| Education (years) | ||||||
| <12 | 2.26 | 1.71, 3.00 | 1.62 | 1.18, 2.23 | ||
| 12 | 1.00 | 1.00 | ||||
| 13–15 | 0.74 | 0.51, 1.08 | 0.82 | 0.56, 1.21 | ||
| 16 | 0.46 | 0.23, 0.95 | 0.48 | 0.23, 1.00 | ||
| ≥17 | 0.96 | 0.38, 2.46 | 0.67 | 0.27, 1.66 | ||
| Labor force status | ||||||
| Employed | 1.00 | 1.00 | ||||
| Unemployed | 1.06 | 0.72, 1.57 | 1.15 | 0.78, 1.71 | ||
| Not in the labor force | 1.40 | 1.02, 1.92 | 1.14 | 0.79, 1.65 | ||
| Baseline health | ||||||
| Fair/poor | 4.99 | 3.69, 6.75 | 3.68 | 2.64, 5.13 | ||
| Not fair/poor | 1.00 | 1.00 | ||||
| Baseline neighborhood poverty rate (%) | ||||||
| <10 | 1.00 | 1.00 | ||||
| 10–<20 | 0.95 | 0.69, 1.31 | 0.83 | 0.59, 1.17 | ||
| ≥20 | 0.76 | 0.57, 1.01 | 0.67 | 0.48, 0.92 | ||
OR, odds ratio; CI, confidence interval.
Results from strategy 2: fixed-effects models
With strategy 2, we focus on both the contrasts between fixed-effects models (A models) and non-fixed-effects models (B models) and the variations in the functional form of the neighborhood poverty measurements. The sample size in the non-fixed-effects models represents the pooled 1984–1997 person-year data, based on the approximately 6,000 adults used for strategy 1; the sample size in the fixed-effects regressions is a subset of these person-year observations but is restricted to those who exhibit variation in both neighborhood poverty and health over time. The fixed-effects estimate for the binary neighborhood poverty specification (table 4, model 4A) is not significant, probably because of insufficient intraperson variation across categories. On the other hand, using a finer gradation in categories (model 5A) demonstrates a significant association for areas with a poverty rate of 40 percent or more. In addition, the linear and log-linear poverty specifications (models 6A and 7A, respectively) indicate that neighborhood poverty significantly increases the likelihood of reporting poor health. For example, in the raw (linear) specification, a 10-percentage-point increase in neighborhood poverty increases the odds of reporting poor health by a factor of 1.05. Though both estimates for the continuous neighborhood poverty measures (linear and log-linear) are relatively stable, with neither ratio of 95 percent confidence limits (upper:lower) exceeding 1.2, the lower 95 percent confidence limits for both estimates fall precariously close to 1. Consequently, although results from the fixed-effects models support a causal link between neighborhood poverty and health, the evidence is far from definitive.
TABLE 4.
Fixed-effects and cross-sectional model estimates of the effect of neighborhood poverty on poor health, Panel Study of Income Dynamics, 1980–1997*
| Model | Neighborhood poverty specification | Fixed-effect models (n = 45,351) |
Non-fixed-effects models (n = 129,595) |
||
| OR† | 95% CI† | OR | 95% CI | ||
| Categorical measures of neighborhood poverty | |||||
| Model 4A/B | Neighborhood poverty rate (%) | ||||
| <20 | 1.00 | ||||
| ≥20 | 0.97 | 0.87, 1.09 | 1.25 | 1.16, 1.36 | |
| Model 5A/B | Neighborhood poverty rate (%) | ||||
| <5 | |||||
| 5–<10 | 1.14 | 0.96, 1.34 | 1.21 | 1.08, 1.35 | |
| 10–<20 | 1.19 | 0.98, 1.43 | 1.37 | 1.22, 1.53 | |
| 20–<40 | 1.11 | 0.91, 1.35 | 1.62 | 1.43, 1.83 | |
| ≥40 | 1.32 | 1.03, 1.68 | 1.48 | 1.26, 1.73 | |
| Continuous measures of neighborhood poverty | |||||
| Model 6A/B | Linear poverty | 1.05 | 1.01, 1.11 | 1.09 | 1.06, 1.12 |
| Model 7A/B | Log poverty | 1.09 | 1.01, 1.18 | 1.21 | 1.15, 1.27 |
Odds ratios for the linear and log measures of neighborhood poverty represent a hypothetical change of 10 percentage points.
OR, odds ratio; CI, confidence interval.
For comparison, results from non-fixed-effects analyses (pooled logistic regression) based on 1984–1997 data are also presented in table 4. Expectedly, estimates from the non-fixed-effects regression models, having not been adjusted for unobserved individual heterogeneity, are consistently significant and larger than those from comparable fixed-effects models. In sum, all estimates of neighborhood poverty effects from the non-fixed-effects models, regardless of specification, are statistically significant.
DISCUSSION
In this study, we addressed two sources of bias: unobserved heterogeneity and overadjustment of mediators. Models addressing each source of bias produced significant neighborhood effect estimates, supporting a causal link between neighborhood poverty and respondent-rated health. In short, while some portion of previously attributed neighborhood effects on health uncovered using cross-sectional observational data is probably due to compositional differences between neighborhoods, context plays a significant role in determining the health of individuals, even under our more restrictive model conditions. However, there was a rather broad range in the estimates of effects between our two models, suggesting that the true magnitude may lie somewhere between these estimates.
The propensity score estimate (OR = 1.64, 95 percent; CI: 1.19, 2.24) is substantially larger than the linear neighborhood poverty fixed-effects model estimate (OR = 1.05, 95 percent CI: 1.01, 1.11). However, the two estimates are not directly comparable, as the propensity score estimate reflects an average threshold effect at the 20 percent poverty level while the fixed-effects model assumes a linear relation and reflects a 10-percentage-point change in neighborhood poverty rate. A rough proxy for the difference in poverty rates between the two categories in the propensity model is the difference in the mean value of each category. The average poverty rates within the low-poverty and high-poverty neighborhoods are 8.6 percent and 31.7 percent, respectively. Hence, the 64 percent increase in the odds of reporting poor health in the propensity score model corresponds approximately to a 23 percent increase in the neighborhood poverty rate. For an equivalent change in neighborhood poverty rate in the fixed-effects model, this equates to increased odds of approximately 12 percent for reporting poor health. Even with this interpretation in mind, the propensity score estimate is still quite a bit larger than the fixed-effects estimate.
The relative magnitudes of the propensity score, fixed-effects, and non-fixed-effects model estimates are in the expected order. The propensity score model yielded larger neighborhood estimates than the non-fixed-effects model (model 4B), since it adjusted for only baseline factors and refrained from overadjusting for possible mediators. Conversely, the fixed-effects models, accounting for unobserved heterogeneity, were expected to show an attenuated link between neighborhood poverty and health, as compared with the non-fixed-effects models. Though the fixed-effects models do not account for unobserved time-varying factors, the significant results from the fixed-effects models are especially noteworthy because the models adjust for mediating factors that clearly lie in the pathway between neighborhood and health, probably yielding more conservative estimates.
However, the findings should also be interpreted with caution, especially in light of results from the Moving to Opportunity (MTO) Study—one of the largest quasi-experiments yet undertaken to examine the impact of neighborhood poverty on individual outcomes, including health. The MTO Study did not find any significant neighborhood effects on respondent-rated health (31). One possible explanation for the divergent results is the shorter time frame of the MTO experiment. Respondent-rated health was measured 4–7 years after enrollment in the MTO Study, versus 14 years in this study. Moreover, approximately 40 percent of those in the MTO Study who were offered housing vouchers restricted to low-poverty neighborhoods lived less than 5 years in their neighborhood (31). Consequently, the salutary effects of residing in a low-poverty environment may not have had sufficient time to manifest. One promising finding from the MTO experiment is the significant effects found for a summary measure of physical health for younger adults (age <33 years). This suggests the possibility that significant effects on respondent-rated health may be found in future follow-up studies.
Limitations
While the propensity score model framework mitigates bias due to overadjustment for time-varying mediating factors, substantial downward bias probably remains. The youngest respondent in the sample was aged 18 years. By this age, the largest impacts of neighborhood context probably have already been realized through educational attainment and the development of behavioral norms. Adjusting for baseline factors in adulthood effectively eliminates the impact of childhood neighborhood environment, which arguably may be most influential for adult health. This is especially noteworthy since the baseline adjustment included respondent-rated health. Further, adjusting for baseline factors such as education that do not change much after one's educational career is completed is tantamount to a contemporaneous control that is commonly employed with cross-sectional data sets. Consequently, estimating the effects of neighborhood context experienced during a small window of time in adulthood is probably a conservative approach to estimating the full impact of neighborhood context on adult health over the life course. Nonetheless, unobserved heterogeneity in the propensity score model may be a serious threat to causal inference and may lead to upward bias in the neighborhood effect estimates. And while the fixed-effects models control for unobserved non-time-varying factors, they cannot adjust for time-varying unobserved characteristics.
Several other limitations are worth noting. First, respondent-rated health is a measure that may be sensitive to response factors such as recall and social desirability. Second, the conventional usage of single census tracts to define neighborhood boundaries ignores the impact of surrounding communities (i.e., nonresidential poverty exposure). Recent work suggests that estimates of neighborhood effects that considered only the tract of residence may have underestimated the total effects of neighborhoods on health (32). Third, both respondent-rated health and neighborhood poverty are broad measures that preclude discerning specific mechanisms through which neighborhood affects health. More research, using more objective health measures and specific neighborhood characteristics that are theoretically linked to the health measure in question, is needed to gain more insight into the pathways through which neighborhoods affect health.
Conclusions
Despite the above limitations, this study represents a substantial step towards obtaining causal estimates of neighborhood effects on health. The analyses used a nationally representative US sample and employed two complementary techniques to examine the relation between neighborhood poverty and respondent-rated health. While our fixed-effects estimates might represent the lower bound of the effect of neighborhood poverty over a short period of time in adulthood, our propensity score approach might also be downwardly biased because of overcontrol for mediators that are well-established in adulthood (e.g., education). However, it is clear from this study that even short-term effects of neighborhoods have significant and direct effects on health. In future research, investigators should begin to utilize similar methods, combined with theoretically nuanced arguments, to pin down the actual contribution of neighborhood context to population health and health disparities over the life course.
Acknowledgments
This research was supported by the Kellogg Health Scholars Program (grant P0117943), the National Institutes of Health Predoctoral Ruth L. Kirschstein National Research Service Award (grant 1-F31-HD051032-01), and an R21 award from the National Institute of Child Health and Human Development (grant 1R21HD055612).
Conflict of interest: none declared.
Glossary
Abbreviations
- CI
confidence interval
- MTO
Moving to Opportunity
- OR
odds ratio
- PSID
Panel Study of Income Dynamics
References
- 1.Ellen IG, Mijanovich T, Dillman KN. Neighborhood effects on health: exploring the links and assessing the evidence. J Urban Aff. 2001;23:391–408. [Google Scholar]
- 2.Yen IH, Syme SL. The social environment and health: a discussion of the epidemiologic literature. Annu Rev Public Health. 1999;20:287–308. doi: 10.1146/annurev.publhealth.20.1.287. [DOI] [PubMed] [Google Scholar]
- 3.Kawachi I, Berkman L. New York, NY: Oxford University Press; 2003. Neighborhoods and health. [Google Scholar]
- 4.Pickett KE, Pearl M. Multilevel analyses of neighbourhood socioeconomic context and health outcomes: a critical review. J Epidemiol Community Health. 2001;55:111–22. doi: 10.1136/jech.55.2.111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Robert SA. Socioeconomic position and health: the independent contribution of community socioeconomic context. Annu Rev Sociol. 1999;25:489–516. [Google Scholar]
- 6.Reijneveld S, Schene A. Higher prevalence of mental disorders in socioeconomically deprived urban areas in the Netherlands: community or personal disadvantage? J Epidemiol Community Health. 1998;52:2–7. doi: 10.1136/jech.52.1.2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Sloggett A, Joshi H. Higher mortality in deprived areas: community or personal disadvantage? BMJ. 1994;309:1470–4. doi: 10.1136/bmj.309.6967.1470. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Oaks JM. The (mis)estimation of neighborhood effects: causal inference for a practicable social epidemiology. Soc Sci Med. 2004;58:1929–52. doi: 10.1016/j.socscimed.2003.08.004. [DOI] [PubMed] [Google Scholar]
- 9.Macintyre S. Place effects on health: how can we conceptualise, operationalise and measure them? Soc Sci Med. 2002;l55:125–39. doi: 10.1016/s0277-9536(01)00214-3. [DOI] [PubMed] [Google Scholar]
- 10.Robert SA. Neighborhood socioeconomic context and adult health: the mediating role of individual health behaviors and psychosocial factors. Ann N Y Acad Sci. 1999;896:465–8. doi: 10.1111/j.1749-6632.1999.tb08171.x. [DOI] [PubMed] [Google Scholar]
- 11.Duncan GJ, Connell JP, Klebanov PK. Conceptual and methodological issues in estimating causal effects of neighborhoods and family conditions on individual development. In: Brooks-Gunn J, Duncan G, Aber J, editors. Neighborhood poverty: context and consequences for children. Vol 1. New York, NY: Russell Sage Publications; 1997. [Google Scholar]
- 12.Wilson WJ. Chicago, IL: University of Chicago Press; 1987. The truly disadvantaged: the inner city, the underclass, and public policy. [Google Scholar]
- 13.Aaronson D. Using sibling data to estimate the impact of neighborhoods on children's educational outcomes. J Hum Resour. 1998;33:915–46. [Google Scholar]
- 14.Cutler DM, Glaeser EL. Are ghettos good or bad? Q J Econ. 1997;112:827–72. [Google Scholar]
- 15.Harding DJ. Counterfactual models of neighborhood effects: the effect of neighborhood poverty on dropping out and teenage pregnancy. Am J Sociol. 2003;109:676–719. [Google Scholar]
- 16.Tatian PA. Washington, DC: Urban Institute; 2003. Neighborhood Change Database (NCDB): 1970 –2000 tract data. Data users' guide, long form release. ( http://www.geolytics.com/pdf/NCDB-LF-Data-Users-Guide.pdf) [Google Scholar]
- 17.Idler EL, Benyamini Y. Self-rated health and mortality: a review of twenty-seven community studies. J Health Soc Behav. 1997;38:21–37. [PubMed] [Google Scholar]
- 18.Benyamini Y, Idler EL. Community studies reporting association between self-rated health and mortality: additional studies, 1995 to 1998. Res Aging. 1999;21:392–401. [Google Scholar]
- 19.Goldberg P, Gueguen A, Schmaus A, et al. Longitudinal study of associations between perceived health status and self reported diseases in the French Gazel cohort. J Epidemiol Community Health. 2001;55:233–8. doi: 10.1136/jech.55.4.233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983;70:41–55. [Google Scholar]
- 21.Rosenbaum PR, Rubin DB. Reducing bias in observational studies using subclassification on the propensity score. J Am Stat Assoc. 1984;79:516–24. [Google Scholar]
- 22.Drake C. Effects of misspecification of the propensity score on estimators of treatment effect. Biometrics. 1993;49:1231–6. [Google Scholar]
- 23.Rosenbaum P. New York, NY: Springer-Verlag, Inc; 2002. Observational studies. [Google Scholar]
- 24.Bang H, Robins JM. Doubly robust estimation in missing data and causal inference models. Biometrics. 2005;61:962–73. doi: 10.1111/j.1541-0420.2005.00377.x. [DOI] [PubMed] [Google Scholar]
- 25.McCaffrey DF, Ridgeway G, Morral AR. Propensity score estimation with boosted regression for evaluating causal effects in observational studies. Psychol Methods. 2004;9:403–25. doi: 10.1037/1082-989X.9.4.403. [DOI] [PubMed] [Google Scholar]
- 26.Chamberlain G. Analysis of covariance with qualitative data. Rev Econ Stud. 1980;47:225–38. [Google Scholar]
- 27.Greene WH. 4th ed. Englewood Cliffs, NJ: Prentice-Hall, Inc; 2000. Econometric analysis. [Google Scholar]
- 28.Huber PJ. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. Vol 1. Berkeley, CA: University of California Press; 1967. The behavior of maximum likelihood estimates under nonstandard conditions; pp. 221–3. [Google Scholar]
- 29.White H. A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica. 1980;48:817–30. [Google Scholar]
- 30.Rogers WH. Regression standard errors in clustered samples. Stata Tech Bull. 1993;13:19–23. [Google Scholar]
- 31.Kling JR, Liebman JB, Katz LF, et al. Cambridge, MA: National Bureau of Economic Research; 2004. Moving to opportunity and tranquility: neighborhood effects on adult economic self-sufficiency and health from a randomized housing voucher experiment. [Google Scholar]
- 32.Inagami S, Cohen D, Finch BK. Non-residential neighborhood exposures suppress neighborhood effects on health. Soc Sci Med. 2007;65:1779–91. doi: 10.1016/j.socscimed.2007.05.051. [DOI] [PubMed] [Google Scholar]