

Abstract
Adaptation of the motor system to sensorimotor perturbations is a type of learning relevant for tool use and coping with an ever-changing body. Memory for motor adaptation can take the form of savings: an increase in the apparent rate constant of readaptation compared with that of initial adaptation. The assessment of savings is simplified if the sensory errors a subject experiences at the beginning of initial adaptation and the beginning of readaptation are the same. This can be accomplished by introducing either 1) a sufficiently small number of counterperturbation trials (counterperturbation paradigm [CP]) or 2) a sufficiently large number of zero-perturbation trials (washout paradigm [WO]) between initial adaptation and readaptation. A two-rate, linear time-invariant state-space model (SSMLTI,2) was recently shown to theoretically produce savings for CP. However, we reasoned from superposition that this model would be unable to explain savings for WO. Using the same task (planar reaching) and type of perturbation (visuomotor rotation), we found comparable savings for both CP and WO paradigms. Although SSMLTI,2 explained some degree of savings for CP it failed completely for WO. We conclude that for visuomotor rotation, savings in general is not simply a consequence of LTI dynamics. Instead savings for visuomotor rotation involves metalearning, which we show can be modeled as changes in system parameters across the phases of an adaptation experiment.
INTRODUCTION
Perturbations to either environment or physical plant, as well as direct experimental manipulations of sensory feedback, can induce sensory error: a discrepancy between observed and predicted sensory feedback. Motor adaptation refers to when sensorimotor mappings change to reduce sensory error over successive movements. Adaptation can be modeled with state-space models (Cheng and Sabes 2006) that have sensory error (or perturbation) as input, sensorimotor mappings as hidden variables (states), and adaptation responses as output. Adaptation may reflect how the CNS establishes and maintains sensorimotor mappings throughout normal life (Kording et al. 2007). Memory for a newly learned mapping/state can take at least two forms: aftereffects [persistence of the adapted state into readaptation (Yamamoto et al. 2006)] and savings [a faster rate of readaptation compared with that of initial adaptation (Kojima et al. 2004; Krakauer et al. 2005)]. To assess savings independently of aftereffects, starting states for initial adaptation and readaptation should be equated. Thus far only two studies that meet this requirement have shown savings—one of saccadic adaptation (Kojima et al. 2004) and our previous study of rotation adaptation for reaching movements (Krakauer et al. 2005). Aftereffects were eliminated in the saccade study by inserting counterperturbation trials between initial adaptation and readaptation (counterperturbation paradigm [CP]). Aftereffects were eliminated in the rotation study by inserting instead sufficient zero-perturbation trials to washout memory of the initial adaptation phase (washout paradigm [WO]).
Motivated by findings from the saccadic adaptation study (Kojima et al. 2004), Smith and colleagues (2006) demonstrated via simulation that a linear time-invariant (LTI) state-space model (Cheng and Sabes 2006; Donchin et al. 2003; Thoroughman and Shadmehr 2000) with two states (slow and fast) produces savings in CP. It is helpful to understand that this model (which we will refer to as SSMLTI,2), as well as any LTI SSM used to model adaptation, can be mathematically represented in various ways. For example, Smith and colleagues (2006) chose to express output in terms of net sensorimotor mapping. However, output can be equivalently expressed in terms of sensory error. Likewise, input can be expressed either in terms of sensory error or perturbation. The point here is that, regardless of the specific form, an LTI system obeys superposition: the output to a sum of inputs equals the sum of the outputs to the individual inputs. Therefore no matter whether adaptation is expressed in terms of sensorimotor mapping or sensory error, savings produced by SSMLTI,2 in CP results not from a change in system parameters between initial adaptation and readaptation, but rather from superposition of the adaptation responses to the perturbations corresponding separately to the 1) initial adaptation, 2) counterperturbation, and 3) readaptation phases of CP (Fig. 1).
FIG. 1.

Illustration of superposition for two-rate, linear time-invariant state-space model (SSMLTI,2) [aslow = 0.992, bslow = 0.02, afast = 0.59, bfast = 0.21, taken from the empirical estimates reported by Smith and colleagues (2006)] in the counterperturbation paradigm (CP). See Eq. 2 in the main text for the state-space model. The left column shows the input perturbation functions (abscissa is movement number n), whereas the right column shows both the outputs [equivalently in terms of directional error (red) and net sensorimotor map (black)] and the state variables [slow (blue) and fast (green)]. The rows correspond to a decomposition of the net input [(from top): initial adaptation stimulus, counterperturbation stimulus, readaptation stimulus, summed inputs]. As a consequence of superposition, the shaded plot in the bottom right corner is equal to both 1) the sum of the outputs to the separate inputs (sum down right column) and 2) the output to the summed inputs (transform from left to right in the bottom row). In the CP paradigm, superposition leads to obvious savings (i.e., a faster apparent rate of adaptation during the readaptation phase compared with the initial adaptation phase). Perturbation function for this CP paradigm: 0° for 1 ≤ n ≤ 10, 30° for 11 ≤ n ≤ 100, −30° for 101 ≤ n ≤ 103, 30° for 104 ≤ n ≤ 150.
Given that LTI systems obey superposition, we reasoned that the SSMLTI,2 could not explain savings in a WO paradigm: Assuming a stable LTI SSM, application of some fixed, nonzero perturbation causes the state (i.e., the sensorimotor map) to change trial by trial such that sensory error is reduced. If from some trial onward, the perturbation is set to zero (i.e., washout trials are applied), the sensorimotor map must approach in the limit the same value it had prior to the initial adaptation. Thus with a sufficient number of washout trials the sensorimotor map will be arbitrarily close to this initial, naive value (corresponding to elimination of aftereffects). Therefore respecting superposition, the larger the number of washout trials, the closer the net adaptation response during the readaptation phase of a WO paradigm will be to the adaptation response (time-shifted, of course) to the initial adaptation. Thus in the limit there would be no savings. The same point was made by Smith and colleagues (2006) in that they showed via simulation for SSMLTI,2 that as the number of washout trials inserted between the counterperturbation and readaptation phases in CP increased (i.e., as CP was converted into WO), the amount of savings tended to zero. Figure 2 illustrates the adaptation responses of the SSMLTI,2 in a WO paradigm when the number of washout trials was sufficient to effectively “isolate” the adaptation response during the readaptation phase from that of the initial adaptation phase, leading to a lack of appreciable savings.
FIG. 2.

Illustration of superposition for SSMLTI,2 in the washout paradigm (WO). Formatting and system constants are the same as in Fig. 1. The rows correspond to a decomposition of the net input [(from top) initial adaptation stimulus, washout phase, readaptation stimulus, summed inputs]. Because a sufficient number of washout trials was inserted between the initial adaptation and readaptation stimuli to bring the state vector close to its naive value of (in this case) 0, the apparent rates of adaptation during the readaptation and initial adaptation phases are not nearly as distinguishable as in CP (Fig. 1). However, the directional error output (and thus savings) in response to the summed perturbations can be predicted simply from the superposition of the directional errors caused by the individual perturbations (this superposition being the red curve in the shaded plot), without additional concern for the values of the slow and fast components of the state vector (blue and green curves, respectively, in shaded plot). Perturbation function for this WO paradigm: 0° for 1 ≤ n ≤ 10, 30° for 11 ≤ n ≤ 100, 0° for 101 ≤ n ≤ 200, 30° for 201 ≤ n ≤ 280.
Here we measured savings as a change in rate constants rather than as a change in rates, to further avoid contamination by aftereffects. When modeling rate constant savings, there is an important distinction to be made (as implied earlier) between apparent rate constants (the empirical rate constant evident during a particular phase of an adaptation experiment) and system rate constants (model parameters that determine the input–output relationship of the system). Our goal for modeling rate constant savings, then, was to determine whether changes in apparent rate constants were best explained with a system whose parameters do (varying-parameter SSM: SSMVP) or do not (SSMLTI) change with experience. A system displaying savings as a result of a change in parameters would correspond to metalearning. We first demonstrated rate constant savings for both CP and WO using the same task (planar reaching movements) and the same type of perturbation (visuomotor rotation). Then, in each paradigm, for the one- and two-rate SSMLTI and SSMVP, we 1) assessed the ability of each SSM to explain rate constant savings and 2) quantified model parsimony with the information-theoretic measure Akaike Information Criterion (AIC) (Akaike 1974; Bozdogan 1987; Burnham and Anderson 2002) to ensure that any potential superiority of SSMVP over SSMLTI with regard to explanation of savings was not offset by overparameterization.
METHODS
Subjects
A total of 14 right-handed subjects volunteered for the study. All were naive to the purpose of the study, signed an institutionally approved consent form, and were paid to participate. They were randomly assigned to either the CP [n = 6; mean age (SD) = 25.8 (6.6) yr; 3 M] or the WO [n = 8; mean age (SD) = 22.1 (0.6) yr; 6 M] experiments.
General experimental protocol
Subjects sat and moved a hand cursor by making planar reaching movements with the shoulder and elbow over a horizontal surface positioned at shoulder level. A center start position and a single target (45° clockwise from the 12 o'clock position, diameter 2 cm, 6 cm from start position) was projected onto a computer screen positioned above the arm. This same, single target position was used throughout the entire experiment in both CP and WO paradigms (i.e., target position was not varied across trials, subjects, or paradigms). A mirror, positioned halfway between the computer screen and the table surface, reflected the computer display, producing a virtual image of the screen cursor and the target in the horizontal plane of the finger tip. Hand positions calibrated to the position of the finger tip were monitored using a Flock of Birds (Ascension Technology, Burlington, VT) magnetic movement recording system at a frequency of 120 Hz. Anterior–posterior translation of the shoulder was prevented with a rigid frame around the trunk. The wrist, hand, and fingers were immobilized with a splint and the forearm was supported on an air-sled system. An opaque shield prevented subjects from seeing their arms and hands at all times.
Visuomotor rotation paradigms
There were two experimental paradigms, which involved the insertion of either counterperturbation (CP) or washout (WO) trials between initial adaptation and readaptation, respectively. A single target position was used in both paradigms (see General experimental protocol). The sign convention used for rotation was that counterclockwise rotation corresponded to positive angles. In both paradigms subjects were first familiarized with 40 baseline trials (0° rotation). In CP they then performed 80 trials of a +30° rotation (initial adaptation) followed by 8 trials of a −30° rotation (counterrotation) followed by another 80 trials of the +30° rotation (readaptation). In WO, after the baseline trials subjects performed 80 initial adaptation trials with a +45° rotation followed by 40 trials of 0° rotation (washout) followed by 80 readaptation trials with +45°. The reason we chose a rotation magnitude of 45° for the WO paradigm was to increase the signal-to-noise ratio of the adaptation data relative to our previous study, which used 30° (Hinder et al. 2007; Kojima et al. 2004; Krakauer et al. 2005). We would have chosen a 45° rotation magnitude for CP as well, but chose not to because a +45° rotation would have meant an initial error of −90° in the deadaptation phase; errors of this size may provoke cognitive strategies (Imamizu et al. 1995), which we sought to avoid. We empirically address this potential confound of different rotation magnitudes early in the results section.
Measurement of savings
In both CP and WO paradigms, apparent first-order rate constants were estimated (via nonlinear least squares) per subject separately for initial adaptation and readaptation from the first 30 values of directional error e[n] according to
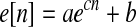 |
(1) |
where n is movement number, c is the rate constant (in units of movements−1), and a and b are additional free parameters (both in units of degrees). Src was defined as cinitial adaptation minus creadaptation. Rate constant savings would correspond to Src >0. This method is reasonable to the extent that the early phase of adaptation can be well approximated by first-order behavior, even though the best model for the net data might be of higher order (Smith et al. 2006).
To assess the degree to which the various SSMs captured Src, Eq. 1 was also fit to the various SSM fits. That is, the SSM fits (see State-space modeling) were simply treated as e[n] and fit by Eq. 1, again, per subject and separately for the initial adaptation and readaptation phases. The basic logic is that if a given SSM fits the data well, the fit of Eq. 1 to the fit of the SSM should capture Src well. We note that our variance estimator for Src comes from the variation in estimated Src across subjects (not the “residual” variation about each fit) and, in such a case, statistical inference will be valid even when “fitting to fits.”
State-space modeling
SSMs describe the entire e[n] movement series for a given experiment, and (unlike Eq. 1) are not fit separately to the initial adaptation and readaptation phases. The parameters of each type of SSM of interest (described in the following text) were estimated separately in each subject. Linear, discrete-time SSMs for modeling motor learning data have been discussed by Cheng and Sabes (2006). The SSMs we use correspond to their Eq. 3.9 and we use their notation (except that we use lowercase boldface for vectors, uppercase boldface for matrices, and italics for scalars). Perturbation (visuomotor rotation angle in degrees) r[n] and the output (reach direction at peak velocity relative to the target direction in degrees) y[n] were scalars (e[n] = r[n] − y[n]). The state vector on movement n, x[n] (={xslow[n] xfast[n]}T) represents the components of the sensorimotor transformation, i.e., the angular discrepancy between the target direction and movement direction, on trial n. Therefore xslow and xfast are also in units of degrees. The state update equation is
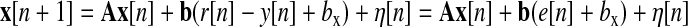 |
(2) |
where
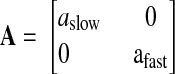 |
is the matrix of dimensionless retention rates, b = [bslow bfast]T is the vector of dimensionless learning rates, bx is sensorimotor bias (degrees), and the state noise vector η ∼ N(0, σstate2I). The equation for the reach direction on trial n + 1 is
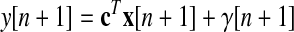 |
(3) |
with the output noise γ ∼ N(0, σoutput2), and c = [1 0]T for one-rate models or [1 1]T for two-rate models. For one-rate models afast and bfast were constrained to be zero. Equation 2 can easily be reparameterized to have r be the input instead of e, and in figures we will use perturbation as the input (because it is under direct experimental control). Likewise, we will discuss the output in terms of both y and e.
The initial state was set equal to its steady-state value under zero perturbation from −∞, which is
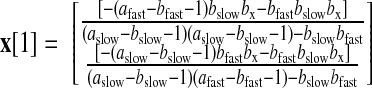 |
The variance of x[1] was σinitial2I.
The SSM described by Eqs. 2 and 3 with fixed [aslow bslow afast bfast] is LTI (and so referred to as SSMLTI). We also used a version of the above-cited SSM in which [aslow bslow afast bfast] were allowed to take on different values for the experimental phases of initial adaptation, counterperturbation for CP (or washout for WO), and readaptation. We refer to these SSMs as “varying-parameter” SSMs (abbreviated as SSMVP). SSMVP are non-LTI (or, more precisely, not necessarily LTI) because they need not satisfy superposition. The idea behind using SSMVP is that the experience of a perturbation during an early experimental phase (e.g., initial adaptation) might change the system parameters during a later phase (e.g., readaptation): Consider a particular system initially (i.e., in the absence of prior nonzero input) displaying LTI behavior. Let r1[n] be a perturbation function taking on a particular nonzero value for 0 ≤ n ≤ N and a value of zero everywhere else, and let the response of the system to r1[n] be y1[n]. Let r2[n] = r1[n − L] with L > N, and let the response of the system to r2[n] be y2[n]. Let r3[n] = r1[n] + r2[n], and let the response of the system to r3[n] be y3[n]. If the occurrence of the perturbation reflected in r1[n] changes the parameters of the system, then y3[n] will not equal y1[n] + y2[n]. This is because y2[n] = y1[n − N], whereas the response to r2[n] having been preceded by r1[n] (i.e., to r2[n] as a component of r3[n]) will not equal y1[n − N] as [aslow bslowafastbfast] will have been changed as a consequence of r1[n]. Thus representing the system transform as T(r), we would have T(r1[n] + r2[n]) = T(r3[n]) = y3[n] ≠ y1[n] + y1[n − N] = y1[n] + y2[n] = T(r1[n]) + T(r2[n]), and thus T(r) would be a non-LTI system.
The reason we use the abbreviation SSMVP for these varying-parameter SSMs as opposed to simply SSMnon-LTI is that SSMVP is one very particular type of non-LTI SSM among many. We chose SSMVP from among the immense class of non-LTI models because although it can manifest experience dependence, it is LTI within phase, which is congruent with our impressions of directional error data from previous visuomotor rotation paradigms (Krakauer et al. 2005).
We considered one- and two-rate versions of the SSMLTI and the SSMVP. Numbers of free parameters (k) per SSM were as follows: k = 6 for SSMLTI,1; k = 8 for SSMLTI,2; k = 10 for SSMVP,1; and k = 16 for SSMVP,2. An explicit form for the likelihood f(e|p) of the directional error e = r − y = {r[Ninitial] − y[Ninitial], r[Ninitial + 1] − y[Ninitial + 1],… , r[Nmax] − y[Nmax]}T) for each of the four SSMs was derived from Eqs. 2 and 3. For SSMLTI, p = [aslow bslow afast bfast bx σinitial2 σstate2 σoutput2]T; p was similar for SSMVP except that the values of [aslow bslow afast bfast] were allowed to be different during the three phases of both CP and WO. Ninitial = 31 and Nmax = 160; for CP, Ninitial = 31 and Nmax = 190 for WO (see next paragraph for the reason that all 240 movements were not used). These values were chosen to allow fitting from the last 10 zero perturbation trials before the initial adaptation up until 30 trials into the readaptation. The form of loge [f(y|p)] corresponding to Eqs. 2 and 3 was derived such that, unlike expectation-maximization (Cheng and Sabes 2006; Shumway and Stoffer 1982), the states were not explicitly represented; thereby, maximum likelihood estimates (MLEs; Shao 2003) p̂ of p were obtained from e of each subject for each of the four SSMs by minimizing −loge [f(y|p)] with respect to p using the MATLAB 7.4a (The MathWorks, Natick MA) routine fmincon via the method of Levenberg–Marquardt. Fits were also obtained to across-subject averages of e, but these fits were used for display only, not for model selection (see AIC). The following linear constraints were used to reduce the occasion of nonconvergence: 0 ≤ aslow, afast ≤ 1.1; 0 ≤ bslow, bfast ≤ 0.8; −30 ≤ bx ≤ 30; 1 ≤ σinitial2 ≤ 200; 0.1 ≤ σstate2 ≤ 200; 1 ≤ σoutput2 ≤ 200; aslow − bslow ≥ 0.001; afast − bfast ≥ 0.001. All fits were initialized with the values pinitial = [0.990.050.40.20 101010]T.
In expectation-maximization, one iteratively maximizes (with respect to p) the expectation of loge [f(x, y|p)] (with respect to x conditioned on y and p); for SSMLTI, this expectation has a computationally simple form (Cheng and Sabes 2006; Shumway and Stoffer 1982). However, we did not use the expectation-maximization method of obtaining the MLE of p because we were not sure how to implement this method with SSMVP. Instead, for both SSMLTI and SSMVP, we maximized the more complicated loge [f(y|p)]; the computational expense of determining loge [f(y|p)] was the only reason the entire 240 movement data sets were not used to obtain MLEs.
Obtaining MLEs of e (both for plotting and for assessment of explanation of savings) involved substituting the expression for y[n] from Eq. 3 into Eq. 2, eliminating all random terms, and substituting p̂ for p
 |
(4) |
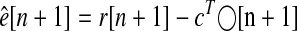 |
(5) |
This fit ê is purely a function of p̂ and the deterministic r, and so (by virtue of the r we used in either paradigm) is not “bumpy”: ê represents our best estimate of the expected value of e[n] given p̂ and r. This can be contrasted with Kalman filtering (not used here), which yields the best estimate of the expected value of e[n] given p̂, r, and e[n − 1] (Shumway and Stoffer 1982), which would tend to be “bumpy.” Although this latter type of fit better follows the data, it is not limited to the estimated deterministic response of the system, which is all that is of interest here.
AIC
Because the four different SSMs described earlier have different numbers of free parameters (k), model parsimony becomes an issue. This is because simply increasing k will improve apparent model fit (i.e., increase loge [f(y|p̂)]), even if the extra parameters are irrelevant to the true process generating the data. Thus the SSM with more parameters might conceivably appear to explain more savings than another, but in a manner not “worth” the extra parameters because adding extra parameters tends to reduce the stability of fits over repeated measurements (Stone 1977). The AIC provides a way to rank a set of candidate models in terms of how well they fit the data (Akaike 1974; Bozdogan 1987; Burnham and Anderson 2002) while accounting for the effect of varying k. The AIC for the ith candidate model is
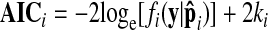 |
(6) |
and it is in units of information (Burnham and Anderson 2002). Let ui equal the expectation (with respect to the data sample) of the Kullbach–Leibler mean information for discrimination between candidate model i and the true data generating process; ui is the risk function (i.e., the function to be minimized over i) for information-theoretic model selection and is related to total prediction error (Akaike 1974; Bozdogan 1987; Burnham and Anderson 2002). AICi − AICj is an approximately unbiased estimator of ui − uj (Akaike 1974; Bozdogan 1987; Burnham and Anderson 2002). That is, the AIC difference between two candidate models is an approximately unbiased estimator of their difference in information-theoretic model selection risk. However, the AIC is known to demonstrate a bias with respect to model selection risk toward selection of more overparameterized models (Hurvich and Tsai 1991), which will temper our inferences accordingly.
Since the difference in AIC between two models is only an estimator of their difference in risk, to control the false-positive rate when comparing the risk between models using the AIC would require a statistical test. Here, the null hypothesis of zero difference between pairs of SSMs in the population average risk was assessed via paired t-test using a two-tailed α = 0.05. Because AIC differences do not have normal distributions, the use of t-test is not formally correct; however, parametric tests tend to be robust to violations of normality (Kirk 1982). Nevertheless, the Shapiro–Wilk W test (Shapiro and Wilk 1968) was used to assess the assumption of normality on the AIC differences for each of the six SSM pairings in both CP and WO paradigms; a threshold of α = 0.05 for each W test was used as a criterion for deciding whether the violation of the normality assumption was acceptable.
We remark that although performing parametric statistical tests on independent and identically distributed samples of AICs is not a very common procedure, and was frowned on by Burnham and Anderson (2002), we cannot see any fundamental problem or contradiction in doing so. Indeed, we see it as a strength, given the likely variability between subjects in the relative risk between models, variability that is explicitly accounted for in statistical testing.
Using the AIC for model selection is different from statistical hypothesis testing of additional SSM parameters (one possible alternative to the AIC for model selection), which controls type I error rate (α) for a null hypothesis. Arguments against using hypothesis testing to perform model selection include the arbitrary selection of α, the multiple-comparison problem, the dependence of results on the order of entering variables in stepwise regression, and the philosophical issue of whether any null hypothesis can ever be true (Akaike 1974; Bozdogan 1987; Burnham and Anderson 2002).
RESULTS
Adaptation curves
The directional errors for both CP and WO manifested the essential qualitative behavior expected from previous studies of adaptation to visuomotor rotation (Krakauer et al. 1999, 2000; Wigmore et al. 2002). CP directional error data averaged across subjects (n = 6) is shown in Fig. 3A (data from a randomly selected single subject is shown in Supplemental Fig. S1A).1 With respect to the CP data averaged across subjects, directional error on the first trial during the initial adaptation phase was on average +33°, which is very close to the value of the perturbation value (+30°) after taking into account a small sensorimotor bias, which led to a +4° offset during baseline trials. As expected, directional error decreased throughout the course of initial adaptation, approaching an asymptotic level of adaptation of approximately +6°. The first trial of counterrotation (−30°) had a directional error of −54°, as expected from the asymptotic level of directional error during initial adaptation, which then increased to −23° on the eighth movement with counterrotated feedback. The first trial of readaptation had a directional error of +36° (i.e., within 3° of the first trial of initial adaptation, which indicates that aftereffects were to a good approximation eliminated). By visual inspection, the apparent rate constant of readaptation was substantially more negative (i.e., smaller decay time constant) than that of initial adaptation.
FIG. 3.

The perturbation r[n] (thick gray line), across-subject averaged directional error e[n] (open diamonds) and SSM MLE fits (black line: SSMLTI,1, green line: SSMLTI,2, blue line: SSMVP,1, red line: SSMVP,2) for the (A) CP and (B) WO paradigms.
Figure 3B shows the directional error data averaged across subjects (n = 8) for WO (data from a randomly selected single subject are shown in Supplemental Fig. S1B). This paradigm yielded qualitatively very similar results to those of CP, accounting for the larger magnitude of the perturbation (+45° for WO vs. +30° for CP). Also, as expected, the directional error during the first trial of washout was approximately −36°, which is less than the magnitude of the 45° perturbation during initial adaptation (whereas in contrast, in CP the directional error during the first trial of counterrotation was −54°, which is substantially larger in magnitude than the corresponding value of the perturbation during initial adaptation). As in CP, aftereffects were successfully eliminated. Also as in CP, visual inspection suggests that the apparent rate constant of readaptation was substantially more negative than that of initial adaptation.
A potential confound in comparing and contrasting rate constant savings, Src, in the CP and WO paradigms was that they were associated with different rotation (perturbation) amplitudes during initial adaptation (+30° for CP and +45° for WO; see Visuomotor rotation paradigms, in methods), which could possibly be associated with different rate constants of adaptation. To assess this possibility, we compared the rate constants of initial adaptation between CP and WO. A single exponential (Eq. 1) was fit to the first 30 movements of the initial adaptation data from each subject in each paradigm to obtain an estimate of the apparent adaptation rate constant. The exponential rate constants (in units of movements−1) during the initial adaptation phase were (mean ± SD) −0.16 ± 0.14 for CP and −0.17 ± 0.16 for WO, which were not significantly different [t(12) = −0.13, two-tailed P = 0.90]. This shows that, on average, rate constants of initial adaptation were very similar between CP and WO (which is what would be expected under a LTI system), despite the different magnitudes of visuomotor rotation. For completeness, we note that this implies that their rates of initial adaptation (in units of degrees·movements−1) were different (greater for WO).
Besides the requirement for the LTI system to have a single rate constant regardless of perturbation amplitude, the output amplitude must also be strictly proportional to perturbation amplitude. This was supported as the average ratio of estimated output amplitude (i.e., a in Eq. 1) to perturbation amplitude was very similar [t(12) = 0.08, two-tailed P = 0.94] for CP (0.922 ± 0.011) and WO (0.916 ± 0.029). This finding provides further support for an LTI system being a reasonable approximation to initial adaptation. It also implicitly provides evidence against adaptation having appreciable saturation or supralinear (two other types of nonlinear SSMs distinct from SSMVP) characteristics in this perturbation range because this ratio would have been different between CP and WO if it did.
Initial adaptation: one-rate or two-rate?
In the immediately preceding text, we approximated the first 30 trials of initial adaptation as a single exponential to estimate apparent adaptation rate constants. However, this does not mean that the adaptation curves do not have multirate behavior. Therefore a preliminary question we sought to address is whether initial adaptation to a visuomotor rotation is a better fit by SSMLTI,1 or SSMLTI,2 (SSMVP values were not relevant here because initial adaptation constitutes only one phase). Data reported for adaptation to a viscous-curl force field suggested a multirate (e.g., two-rate) system during initial adaptation (Smith et al. 2006). Determining whether there are similarly two rates present during initial adaptation to a visuomotor rotation will be important for interpreting how the various SSM models fit CP and WO directional error data in their entirety.
Initial adaptation data were fit better by a SSMLTI,1 than by a SSMLTI,2, significantly in CP [for AIC1-rate LTI minus AIC2-rate LTI: t(5) = −37.9, two-tailed P < 0.001] and only as a trend for WO [for AIC1-rate LTI minus AIC2-rate LTI: t(5) = −2.10, two-tailed P = 0.07]. (The extremely high t-value for the former comparison was mainly due to very small variability across subjects in [AIC1-rate LTI minus AIC2-rate LTI] for initial adaptation in CP; the average values of [AIC1-rate LTI minus AIC2-rate LTI] for initial adaptation were −3.70 and −1.58 for CP and WO, respectively.) These results show that, ostensibly unlike adaptation to viscous-curl force fields (Smith et al. 2006), initial adaptation to either a +30° (in CP) or +45° (in WO) visuomotor rotation is better fit by a SSMLTI,1 than a SSMLTI,2. As a technical aside, we emphasize that these SSM fits were to the initial adaptation phase only, in contrast to the SSMVP fits to all three phases we report later (see SSM fits) that, despite allowing for different learning and retention rates in each of the three paradigm phases, have a single sensorimotor bias parameter.
Savings
The presence of Src in both CP and WO paradigms was confirmed by comparing the apparent rate constants from the initial adaptation and readaptation phases. This method of measuring savings did not explicitly involve assuming any SSM but simply relied on the qualitative impression that at least the first few trials of motor adaptation to a constant perturbation is reasonably well modeled by Eq. 1 (Caithness et al. 2004; Krakauer et al. 2005; Mazzoni and Krakauer 2006), although this would correspond to the response of SSMLTI,1 to a constant perturbation. The rate constant c was significantly more negative (corresponding to faster learning, i.e., Src) for the readaptation than for the initial adaptation phase in both CP [t(5) = 3.05, one-tailed P = 0.014] and WO [t(7) = 3.73, one-tailed P = 0.004]. Furthermore, the magnitude of Src was not significantly different between CP and WO [cinitial adaptation minus creadaptation (mean ± SD) = 0.48 ± 0.39 for CP and 0.47 ± 0.36 for WO; t(12) = −0.056, two-tailed P = 0.96]. Also, we keep in mind the finding that apparent rate constants of initial adaptation were very similar between CP and WO (see Adaptation curves). Thus the two adaptation paradigms CP and WO did not appreciably differ from one another either in terms of Src (which was robust in both) or rate constants of initial adaptation (despite different perturbation magnitudes).
SSM fits
MLE fits of the four SSMs to e[n] (simultaneously to all three phases of either the CP or WO paradigms; see State-space modeling in methods) were computed separately in each subject. The across-subject averages of the parameter estimates are provided in Table 1. To collectively illustrate the character of the fits, MLEs of the SSMs were also determined for the across-subject averaged time courses for both CP (Fig. 3A) and WO (Fig. 3B). Although quantitative comparisons between SSMs based on the fits obtained per subject are provided subsequently, a qualitative impression of the across-subject averaged fits is provided here: SSMLTI,1 did a poor job of explaining savings in both paradigms, yielding initial adaptation that was too fast and readaptation that was too slow; this SSM also poorly fit the sensorimotor bias. SSMLTI,2 did a reasonable job in CP but did a very poor job in the WO paradigm in which it manifested the same problem as SSMLTI,1: initial adaptation that was too fast and readaptation that was too slow. Although the SSMVP,1 did a reasonable job fitting WO, it did a much less reasonable one in CP in which it clearly misfit the baseline offset. We speculate this misfitting of the baseline offset was due to a competition between the sensorimotor bias term, on the one hand, and the learning and retention rates during initial adaptation, on the other, both of which determine the offset from zero directional error in baseline trials. Similar misfitting of the baseline offset by this SSM was also apparent in five of six of the individual subject fits (data not shown). SSMVP,2 fit the data well overall in both paradigms.
TABLE 1.
Across-subject averages of the maximum likelihood estimates of SSM parameters
|
CP |
WO
|
|||||||
|---|---|---|---|---|---|---|---|---|
| SSMLTI,1 | SSMLTI,2 | SSMVP,1 | SSMVP,2 | SSMLTI,1 | SSMLTI,2 | SSMVP,1 | SSMVP,2 | |
| Phase 1 | ||||||||
| aslow | 0.924 (0.043) | 0.991 (0.012) | 0.971 (0.028) | 0.986 (0.016) | 0.960 (0.031) | 0.983 (0.025) | 0.979 (0.016) | 0.986 (0.016) |
| bslow | 0.137 (0.057) | 0.062 (0.016) | 0.081 (0.039) | 0.112 (0.057) | 0.245 (0.099) | 0.159 (0.046) | 0.149 (0.078) | 0.116 (0.048) |
| afast | N/A | 0.629 (0.102) | N/A | 0.369 (0.350) | N/A | 0.519 (0.318) | N/A | 0.492 (0.324) |
| bfast | N/A | 0.158 (0.051) | N/A | 0.003 (0.005) | N/A | 0.193 (0.104) | N/A | 0.077 (0.076) |
| Phase 2 | ||||||||
| aslow | N/A | N/A | 0.779 (0.150) | 0.946 (0.140) | N/A | N/A | 0.846 (0.102) | 0.891 (0.099) |
| bslow | N/A | N/A | 0.093 (0.089) | 0.064 (0.058) | N/A | N/A | 0.242 (0.141) | 0.144 (0.127) |
| afast | N/A | N/A | N/A | 0.573 (0.263) | N/A | N/A | N/A | 0.480 (0.284) |
| bfast | N/A | N/A | N/A | 0.120 (0.079) | N/A | N/A | N/A | 0.230 (0.181) |
| Phase 3 | ||||||||
| aslow | N/A | N/A | 0.834 (0.077) | 0.792 (0.388) | N/A | N/A | 0.955 (0.038) | 0.975 (0.034) |
| bslow | N/A | N/A | 0.318 (0.187) | 0.170 (0.123) | N/A | N/A | 0.375 (0.137) | 0.330 (0.170) |
| afast | N/A | N/A | N/A | 0.400 (0.347) | N/A | N/A | N/A | 0.548 (0.365) |
| bfast | N/A | N/A | N/A | 0.175 (0.256) | N/A | N/A | N/A | 0.088 (0.114) |
| Sensorimotor bias | ||||||||
| bx | 2.707 (5.330) | −3.405 (2.233) | 3.189 (43.382) | −4.101 (1.758) | −3.065 (10.986) | −4.071 (8.599) | 2.562 (28.544) | −3.098 (13.398) |
| Hyperparameters | ||||||||
| σinitial2 | 36.107 (34.135) | 1* (0.00) | 48.071 (43.382) | 1* (0.00) | 1* (0.00) | 1* (0.00) | 12.209 (28.544) | 5.737 (13.398) |
| σoutput2 | 13.358 (4.537) | 12.791 (3.604) | 17.417 (4.702) | 14.925 (5.970) | 13.680 (10.986) | 7.482 (8.599) | 17.699 (12.473) | 16.469 (12.408) |
| σstate2 | 6.378 (3.550) | 2.530 (1.643) | 1.255 (2.270) | 1.167 (2.479) | 9.911 (5.504) | 8.195 (7.624) | 3.539 (2.953) | 2.123 (1.644) |
Values are means, with SDs in parentheses. Due to our parameterization of the SSMs, the initial state and state noise variance estimates for two-rate models need to be multiplied by 2 to be comparable to the corresponding variance estimates for one-rate models. That the average and SD of phase 1 aslow are the same in CP and WO to three decimal places for SSMVP,2 is not a typographical error. An asterisk denotes that all subjects in that sample had estimates equal to a bound placed in that parameter. N/A, parameter not applicable for that SSM.
Table 2 shows the percentage of Src explained by the various SSMs in both paradigms. The SSMLTI,1 was unable to explain Src in either paradigm. The SSMLTI,2 was able to explain a nontrivial amount Src in CP but, as expected, negligibly explained Src in WO. Both of the SSMVP explained substantial amounts of Src in both CP and WO, although the SSMVP,1 overestimated Src in CP.
TABLE 2.
Percentage of savings explained by state-space model
| SSMLTI,1 | SSMLTI,2 | SSMVP,1 | SSMVP,2 | |
|---|---|---|---|---|
| CP | 3.6 × 10−5 ± 2.9 × 10−4 (8.5 × 10−5) | 64.8 ± 57.0 (46.8) | 156.6 ± 81.3 (152.2) | 109.3 ± 81.3 (113.2) |
| WO | −9.1 × 10−5 ± 3.2 × 10−4 (0.0) | 1.5 ± 2.1 (0.18) | 87.5 ± 29.1 (87.8) | 86.1 ± 22.8 (82.6) |
Values are means ± SD; median values are in parentheses.
It is important to consider the number of SSM parameters in addition to how well an SSM seems to fit the data overall. Model selection risk corresponds to net prediction error, which includes both systematic and random sources of misfitting (Akaike 1974). All other things being equal, increasing the number of parameters increases model selection risk. The AIC is an approximately unbiased estimator of model selection risk in that the AIC not only penalizes systematic misfitting by the model [through a dependence on loge (likelihood)] but also corrects in a theoretically reasoned way (Akaike 1974) for the number of model parameters. The across-subject average AICs (not the AICs corresponding to fits to the across-subject average data) of the various candidate SSMs to CP (trials 31–160) and WO (trials 31–190) are shown in Fig. 4, A and B, respectively. Plotted together with the AICs are the −2 loge (likelihood) values (like AIC, the smaller the better). The −2 loge (likelihood) values (which do not penalize the number of parameters) decrease necessarily as the number of nested SSM model parameters k increases (Burnham and Anderson 2002). In contrast, the AIC, which equals −2 loge (likelihood) + 2k, does not have to decrease as k increases (e.g., Fig. 4B).
FIG. 4.

The across-subject averaged Akaike Information Criterion (AIC, black) and −2 loge (likelihood) (gray) values (to within an additive constant) of the candidate models for the (A) CP and (B) WO paradigms. Both measures assess model fit, but only the AIC penalizes for the number of parameters. For each measure, it is only the differences between models (within paradigm) that are meaningful. The units of both the AIC and −2 loge (likelihood) are information, in the information-theoretic sense.
For descriptive purposes, for each SSM pairing the proportion of subjects with AIC differences in a given direction are provided in Tables 3 and 4 for CP and WO, respectively. To compare the population average model selection risk between SSMs, paired t-tests on the AIC values from different SSM pairings were performed (two-tailed α = 0.05). The Shapiro–Wilk W test was used to assess the t-test assumption of normality on the AIC differences for each of the six SSM pairings in both CP and WO paradigms; none of the W values for any of the pairings in either paradigm was significant at α = 0.05 (12 W tests: median P value = 0.49, P value range = 0.09–0.93), indicating insufficient evidence to reject the null hypothesis of normality for any of the pairings. We therefore proceeded with the use of t-test. The AIC of the SSMLTI,2 was significantly better than that of the SSMLTI,1 in both CP [t(5) = 4.24, two-tailed P = 0.008] and WO [t(7) = 2.58, two-tailed P = 0.036]. The AIC of the SSMVP,2 was better (although not significantly so at two-tailed α = 0.05) than the SSMLTI,2 in both the CP [t(5) = 1.76, two-tailed P = 0.138] and WO [t(7) = 1.44, two-tailed P = 0.192]. That the AIC was better (albeit not significantly) for SSMVP,2 than for SSMLTI,2 in CP, is a pivotal finding. This is because if the SSMLTI,2 was a good approximation to the true data generating process in CP, its model selection risk in CP would be better than that of SSMVP,2 (because SSMVP,2 has more parameters than SSMLTI,2). However, we keep in mind the bias of AIC toward overfitting with respect to model selection risk (Hurvich and Tsai 1991).
TABLE 3.
Number of subjects showing AIC differences in a particular direction in CP
| SSMLTI,1 | SSMLTI,2 | SSMVP,1 | SSMVP,2 | |
|---|---|---|---|---|
| SSMLTI,1 | N/A | 6/6 | 6/6 | 5/6 |
| SSMLTI,2 | — | N/A | 4/6 | 5/6 |
| SSMVP,1 | — | — | N/A | 3/6 |
| SSMVP,2 | — | — | — | N/A |
The value of each cell is the proportion of subjects whose AIC is lower (i.e., better) for the SSM of the column relative to the SSM of that row.
TABLE 4.
Number of subjects showing AIC differences in a particular direction in WO
| SSMLTI,1 | SSMLTI,2 | SSMVP,1 | SSMVP,2 | |
|---|---|---|---|---|
| SSMLTI,1 | N/A | 7/8 | 6/8 | 6/8 |
| SSMLTI,2 | — | N/A | 6/8 | 6/8 |
| SSMVP,1 | — | — | N/A | 2/8 |
| SSMVP,2 | — | — | — | N/A |
The value of each cell is the proportion of subjects whose AIC is lower (i.e., better) for the SSM of the column relative to the SSM of that row.
The AICs of SSMVP,1 and SSMVP,2 were not substantially different in CP [AIC1-rate varying-parameter minus AIC2-rate varying-parameter: t(5) = 0.34, two-tailed P = 0.749], although the former trended toward being favored over the latter in WO [AIC1-rate varying-parameter minus AIC2-rate varying-parameter: t(7) = −2.29, two-tailed P = 0.056]. Because these results did not indicate that SSMVP,2 was providing a consistently (i.e., in both CP and WO) better fit than SSMVP,1, we were curious to see how multirate behavior was manifested, if at all, in any phase of either paradigm. To this end, we plotted the fast and slow state (Eq. 2) estimates from SSMVP,2 fit to the across-subject averaged e[n], for both CP and WO. For CP, it appears that the fast state is substantial only during the counterperturbation phase (Fig. 5). Analogously, for WO the fast state is most apparent during the washout phase. This absence of a salient fast system during initial adaptation is expected based on our finding that the initial adaptation phase is best fit by a SSMLTI,1 (see Initial adaptation: one-rate or two-rate?). Figure 5 furthermore suggests essentially one-rate behavior for both CP and WO during readaptation, which indicates that Src relies almost entirely on a change in the parameters of the dominant, slow state. It may be that for adaptation to visuomotor rotation, fast states emerge substantially only when the net state is returning to 0°, as occurs during counterperturbation and washout.
FIG. 5.

The fast (red line), slow (green line), and net = fast + slow (black line) state variables estimated from the fit of SSMVP,2 to the across-subject averaged directional error e[n] are plotted for the (A) CP and (B) WO paradigms. The perturbation r[n] (thick gray line), i.e., the deterministic input to the system, is also plotted.
DISCUSSION
To provide a more pure assessment of savings than that of most previous studies we eliminated aftereffects via either CP or WO, and we also used Src rather than rate savings. Comparable Src was observed for CP and WO. SSMLTI,2 was able to explain on average 65% of Src in CP but only 1.5% of Src in WO. In terms of SSMLTI,2, this is because the fast and slow states, when subjected to enough washout trials, will both (aside from any sensorimotor bias) get arbitrarily close in expectation to zero (and this is true of any arbitrary order of LTI model, not just second-order). Since SSMLTI parameters are fixed, the bringing of its state variables close to initial conditions will make its net output response during a second rotational perturbation look much like that during initial adaptation, and increasingly so with increasing numbers of washout trials. Given the empirical rate of initial adaptation, the 40 washout trials used in WO were sufficient to well approximate complete washout, making it impossible for a SSMLTI to explain Src in WO. In contrast, both SSMVP,1 and SSMVP,2 (which can be non-LTI in the perturbation inputs) explained >85% of Src in both CP and WO. Furthermore, as measured by the AIC both SSMVP,1 and SSMVP,2 fit the overall adaptation movement series data better than either SSMLTI in both CP and WO (although population-level inference was not significant). Together, these empirical findings lead to the following conclusions for adaptation to visuomotor rotation: 1) Src can occur even with complete elimination of aftereffects via washout between initial adaptation and readaptation, confirming a previous report (Krakauer et al. 2005); 2) this savings cannot be reasonably explained by a SSMLTI,2 (and from theory, not by any SSMLTI); and 3) Src seen with counterperturbation as well as Src seen with washout are both more parsimoniously explained as the consequence of experience-dependent changes in learning and retention parameters (as a result of initial adaptation) rather than as a property of a multirate LTI system.
Src observed here in WO for single target adaptation is consistent with the savings described in a our previous work for multitarget rotation adaptation (Krakauer et al. 2005). Hinder and colleagues reported absence of savings in a WO paradigm (Hinder et al. 2007) but savings was determined from the fits of a power function to directional error (e[n] = c1n2c), which is a poor approximation because empirical adaptation curves tend not to asymptote at zero, whereas power functions must (a nonzero asymptote can be accommodated by, say, a SSMLTI,1 by having a retention rate <1 and/or a sensorimotor bias). Perhaps this is why no savings was detected for WO even though visual inspection of their raw adaptation data (Fig. 2b from that report) suggests otherwise. Thus at the present time it would seem that savings can indeed occur even after washout eliminates aftereffects. This does not preclude the possibility that prolonged washout might eliminate savings, which is another potential explanation for the lack of savings reported by Hinder and colleagues (2007) and in the study by Kojima and colleagues (2004), where savings was not seen after counterperturbation followed by washout trials.
Recently, in a perturbation/counterperturbation/error-clamp adaptation paradigm using viscous-curl force fields, it was demonstrated that SSMLTI,2 could explain spontaneous recovery, a transient excursion of motor output during movements under error clamp in the same direction as that seen during adaptation to the initial perturbation (Smith et al. 2006). The early component of spontaneous recovery in SSMLTI,2 is attributable to the rapid decay of the fast state, whereas the sluggish decay back to baseline is attributable to the slow decay (i.e., better retention) of the slow system. Spontaneous recovery has also been observed with saccades (Kojima et al. 2004). Smith and colleagues also showed via simulation that SSMLTI,2 produces Src for CP. A heuristic explanation of savings for the SSMLTI,2 in CP (with the convention that the initial perturbation is positive) is that the movements with counterrotated feedback eventually (when the net state reaches zero) bring the fast state to take on a substantial negative value (with the slow state having a value that is equal in magnitude but positive). That the fast system has a value substantially away from zero on the first readaptation trial (unlike the first initial adaptation trial) in conjunction with the fact that the fast system retention parameter is smaller than that of the slow system, allow the fast system to respond with a more rapid correction to the perturbation during readaptation than to the perturbation during initial adaptation (Smith et al. 2006). However, perhaps a more clear way to understand the Src produced by SSMLTI,2 in CP is that it is simply the result of the superposition of the separate adaptation responses to the initial adaptation, counterperturbation, and readaptation perturbations (critically with the latter necessarily being identical to that for initial adaptation). Thinking in terms of superposition, we can also understand why SSMLTI,2 cannot produce savings in WO without worrying explicitly about the slow and fast systems: the net output seen during readaptation will be a superposition of the separate adaptation responses to the initial adaptation, washout, and readaptation perturbations; the system response to the initial adaptation, however, has decayed essentially to nil during the washout phase (and will continue to decay), the response to the washout trials themselves is nil, and the response attributable to the readaptation stimulus must simply be a shifted version of the response to the initial adaptation stimulus.
Given that SSMLTI,2 is able to explain spontaneous recovery in a viscous-curl force field (Smith et al. 2006), we need to ask why SSMLTI,2 did not do a better job of explaining savings in CP compared with SSMVP,2. A sufficient answer lies in our finding that for the initial adaptation phase, the fit of SSMLTI,1 was superior to that of a SSMLTI,2 in both CP and WO, which means that there was no appreciable two-rate behavior during initial adaptation in our data. Thus SSMLTI,2 could not satisfactorily explain savings even in CP because (under SSMLTI,2) two-rate behavior is not something that can suddenly emerge at readaptation. Rather, it must be evident even at initial adaptation. In contrast to the lack of two-rate behavior during initial adaptation in our visuomotor rotation data, the viscous-curl force-field data reported by Smith and colleagues (Fig. 3d from that report) manifest clear two-rate behavior during initial adaptation (Smith et al. 2006). A possible explanation for this discrepancy is the difference in the nature of perturbations used in the two experiments. Viscous-curl force-field perturbations have a proprioceptive component, whereas visuomotor rotations do not. Malfait and Ostry (2004) showed that salient viscous-curl force-field perturbations led to interlimb transfer of adaptation in extrinsic coordinates, whereas more gradual perturbations led only to intralimb transfer in joint-centered coordinates. They suggested that the salient perturbation engaged a cognitive/explicit mechanism distinct from the implicit mechanisms thought to underlie adaptation in joint-centered coordinates. Similarly, it has recently been shown that there is a form of response to sudden force-field perturbations that appears to be categorical rather than scaled to the size of the error (Fine and Thoroughman 2006). In contrast, we have shown that explicit strategies do not contribute to rotation learning (Mazzoni and Krakauer 2006). Perhaps then the two-rate behavior evident in force-field adaptation is due to an explicit component absent in rotation learning. Therefore at the current time we must restrict our finding that SSMLTI,2 is worse at explaining savings in CP than SSMVP,2 to visuomotor rotation.
The AIC was used here to assess parsimony of the candidate SSMs in the contexts of the CP and WO paradigms. The AIC does not measure the ability of the models to explain savings per se (which is why we also directly assessed savings). Rather, the AIC estimates the overall closeness, in terms of Kullbach–Leibler mean information for discrimination, of the estimated, candidate model to the true but unknown data-generating process (Akaike 1974; Burnham and Anderson 2002); this closeness does not solely depend on the ability to explain savings. All other things being equal, however, a model that explains more savings than another should be closer in terms of Kullbach–Leibler information to the truth and therefore have a lower AIC. As it turned out, direct measurements of the amount of savings explained by the various SSMs were grossly consonant with the AICs, with the SSMVP explaining more savings as well as having better AICs (albeit, not significantly) than those of the SSMLTI. The use of the AIC complemented the direct measurement of savings because the former takes into account increasing instability in the estimated fit associated with increasing parameter number, whereas the latter does not. Thus that the SSMVP did not have significantly worse model selection risk (and even trended toward being better) than the SSMLTI suggests that the SSMVP made up for their larger number of parameters by the extent to which they reduced model bias (i.e., fit systematic aspects of the data). In contrast, if we had included a highly overparameterized candidate model, it might have explained savings the best of all, but its AIC would likely have been the worst of all. However, a caveat of model selection with AIC is that it is known to be biased toward selecting overparameterized models when the ratio of the number of observations to the number of parameters is low (Hurvich and Tsai 1991); we do not know the size of this bias for the problem we investigated here.
The appeal of SSMLTI,2 in the context of motor adaptation is that with a small number of static parameters it is nonetheless capable of producing a fairly rich array of behavioral phenomena (Smith et al. 2006). That savings in WO cannot be explained by such a model is in a sense unfortunate. However, a more subtle yet perhaps more interesting aspect of the current findings is that they underscore the fact that the ability of a model to theoretically produce a certain phenomenon (in this case, Src in CP) does not imply that the model can actually explain the empirical phenomenon. The paradox is resolved by realizing that it is not just the choice of model type, but also the values of the model parameters that determine the input–output behavior of a system. So, although SSMLTI,2 can produce Src in CP, it does so appreciably only when its parameter values are such that two-rate behavior is sufficiently salient. It so happened that, empirically, two-rate behavior during initial adaptation was weak, which made the SSMLTI,2 fit to the Src effects in CP mediocre. The situation in WO was different because there it can be understood from superposition that it is impossible for SSMLTI,2 to substantially explain Src.
Kording and colleagues (2007) described an elegant model of sensorimotor adaptation based on Bayesian estimation (“Bayesian learner”). In this model, the brain implements Kalman filtering to obtain a posteriori estimates of sensorimotor perturbation states (“disturbance states” in Kording et al.) associated with different timescales, which it then uses to correct sensorimotor maps (i.e., adapt). This Bayesian learner model can be roughly understood as a generalization of the SSMLTI,2 of Smith and colleagues (2006) that represents perturbations over a wide range of timescales instead of only two. As the Kalman gain approaches steady state, Kalman filtering approaches an SSMLTI. Thus a Bayesian learner that assumes fixed, known state and measurement error covariance matrices will be LTI, and thus obey superposition, at steady state. Therefore like SSMLTI,2, such a Bayesian learner would fail to explain the savings we observed in WO.
In contrast to SSMLTI (Kording et al. 2007; Smith et al. 2006), the SSMVP values investigated here were allowed to change their parameters in an experience-dependent manner and in this way were able to generate the non-LTI behavior required to explain Src in WO. Said in another way, this experience dependence of SSMVP parameters enabled metalearning (i.e., learning to learn; Abraham and Bear 1996). Similarly, the Bayesian learner could also manifest metalearning by allowing its assumed state and/or measurement error covariance matrices to vary (Kording et al. 2007); such a Bayesian learner would also be SSMVP. It would be interesting to determine whether such a varying-parameter Bayesian learner—which estimates rather than assumes state and measurement noise parameters—can explain the savings we observed in WO more parsimoniously than the SSMVP investigated here.
GRANTS
This work was supported by a Gatsby Initiative in Brain Circuitry grant to E. Zarahn and National Institute of Neurological Disorders and Stroke Grant R01-NS-052804 to J. W. Krakauer.
Acknowledgments
We thank Dr. Stefano Fusi for a critical reading of the manuscript. We thank Dr. Robert Sainburg for sharing custom computer software.
The costs of publication of this article were defrayed in part by the payment of page charges. The article must therefore be hereby marked “advertisement” in accordance with 18 U.S.C. Section 1734 solely to indicate this fact.
Footnotes
The online version of this article contains supplemental data.
REFERENCES
- Abraham and Bear 1996.Abraham WC, Bear MF. Metaplasticity: the plasticity of synaptic plasticity. Trends Neurosci 19: 126–130, 1996. [DOI] [PubMed] [Google Scholar]
- Akaike 1974.Akaike H New look at statistical-model identification. IEEE Trans Autom Control 19: 716–723, 1974. [Google Scholar]
- Bozdogan 1987.Bozdogan H Model selection and Akaike Information Criterion (AIC): the general-theory and its analytical extensions. Psychometrika 52: 345–370, 1987. [Google Scholar]
- Burnham and Anderson 2002.Burnham KP, Anderson DR. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach. New York: Springer-Verlag, 2002, p. 488.
- Caithness et al. 2004.Caithness G, Osu R, Bays P, Chase H, Klassen J, Kawato M, Wolpert DM, Flanagan JR. Failure to consolidate the consolidation theory of learning for sensorimotor adaptation tasks. J Neurosci 24: 8662–8671, 2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng and Sabes 2006.Cheng S, Sabes PN. Modeling sensorimotor learning with linear dynamical systems. Neural Comput 18: 760–793, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fine 2006.Fine MS, Thoroughman KA. Motor adaptation to single force pulses: sensitive to direction but insensitive to within-movement pulse placement and magnitude. J Neurophysiol 96: 710–720, 2006. [DOI] [PubMed] [Google Scholar]
- Hinder et al. 2007.Hinder MR, Walk L, Woolley DG, Riek S, Carson RG. The interference effects of non-rotated versus counter-rotated trials in visuomotor adaptation. Exp Brain Res 180: 629–640, 2007. [DOI] [PubMed] [Google Scholar]
- Hurvich and Tsai 1991.Hurvich CM, Tsai CL. Bias of the corrected AIC criterion for underfitted regression and time-series models. Biometrika 78: 499–509, 1991. [Google Scholar]
- Imamizu et al. 1995.Imamizu H, Uno Y, Kawato M. Internal representations of the motor apparatus: implications from generalization in visuomotor learning. J Exp Psychol Hum Percept Perform 21: 1174–1198, 1995. [DOI] [PubMed] [Google Scholar]
- Kirk 1982.Kirk R Experimental Design: Procedures for the Behavioral Sciences. Belmont, CA: Brooks/Cole Publishing, 1982.
- Kojima et al. 2004.Kojima Y, Iwamoto Y, Yoshida K. Memory of learning facilitates saccadic adaptation in the monkey. J Neurosci 24: 7531–7539, 2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kording et al. 2007.Kording KP, Tenenbaum JB, Shadmehr R. The dynamics of memory as a consequence of optimal adaptation to a changing body. Nat Neurosci 10: 779–786, 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krakauer et al. 2005.Krakauer JW, Ghez C, Ghilardi MF. Adaptation to visuomotor transformations: consolidation, interference, and forgetting. J Neurosci 25: 473–478, 2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krakauer et al. 1999.Krakauer JW, Ghilardi MF, Ghez C. Independent learning of internal models for kinematic and dynamic control of reaching. Nat Neurosci 2: 1026–1031, 1999. [DOI] [PubMed] [Google Scholar]
- Krakauer et al. 2000.Krakauer JW, Pine ZM, Ghilardi MF, Ghez C. Learning of visuomotor transformations for vectorial planning of reaching trajectories. J Neurosci 20: 8916–8924, 2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Malfait and Ostry 2004.Malfait N, Ostry DJ. Is interlimb transfer of force-field adaptation a cognitive response to the sudden introduction of load? J Neurosci 24: 8084–8089, 2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mazzoni and Krakauer 2006.Mazzoni P, Krakauer JW. An implicit plan overrides an explicit strategy during visuomotor adaptation. J Neurosci 26: 3642–3645, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shao 2003.Shao J Mathematical Statistics. New York: Springer-Verlag, 2003.
- Shapiro and Wilk 1968.Shapiro SS, Wilk MB. Approximations for null distribution of W statistic. Technometrics 10: 861–866, 1968. [Google Scholar]
- Shumway and Stoffer 1982.Shumway RH, Stoffer DS. An approach to time series smoothing and forecasting using the EM algorithm. J Time Series Anal 3: 253–264, 1982. [Google Scholar]
- Smith et al. 2006.Smith MA, Ghazizadeh A, Shadmehr R. Interacting adaptive processes with different timescales underlie short-term motor learning. PLoS Biol 4: e179, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stone 1977.Stone M An asymptotic equivalence of choice of model by cross-validation and Akaike's criterion. J R Stat Soc B Stat Method 39: 44–47, 1977. [Google Scholar]
- Wigmore et al. 2002.Wigmore V, Tong C, Flanagan JR. Visuomotor rotations of varying size and direction compete for a single internal model in motor working memory. J Exp Psychol Hum Percept Perform 28: 447–457, 2002. [DOI] [PubMed] [Google Scholar]
- Yamamoto et al. 2006.Yamamoto K, Hoffman DS, Strick PL. Rapid and long-lasting plasticity of input–output mapping. J Neurophysiol 96: 2797–2801, 2006. [DOI] [PubMed] [Google Scholar]