

Abstract
Classification using high-dimensional features arises frequently in many contemporary statistical studies such as tumor classification using microarray or other high-throughput data. The impact of dimensionality on classifications is largely poorly understood. In a seminal paper, Bickel and Levina (2004) show that the Fisher discriminant performs poorly due to diverging spectra and they propose to use the independence rule to overcome the problem. We first demonstrate that even for the independence classification rule, classification using all the features can be as bad as the random guessing due to noise accumulation in estimating population centroids in high-dimensional feature space. In fact, we demonstrate further that almost all linear discriminants can perform as bad as the random guessing. Thus, it is paramountly important to select a subset of important features for high-dimensional classification, resulting in Features Annealed Independence Rules (FAIR). The conditions under which all the important features can be selected by the two-sample t-statistic are established. The choice of the optimal number of features, or equivalently, the threshold value of the test statistics are proposed based on an upper bound of the classification error. Simulation studies and real data analysis support our theoretical results and demonstrate convincingly the advantage of our new classification procedure.
Keywords: Classification, feature extraction, high dimensionality, independence rule, misclassification rates
1 Introduction
With rapid advance of imaging technology, high-throughput data such as microarray and proteomics data are frequently seen in many contemporary statistical studies. For instance, in the analysis of Microarray data, the dimensionality is frequently thousands or more, while the sample size is typically in the order of tens (West et al., 2001; Dudoit et al., 2002). See Fan and Ren (2006) for an overview. The large number of features presents an intrinsic challenge to classification problems. For an overview of statistical challenges associated with high dimensionality, see Fan and Li (2006).
Classical methods of classification break down when the dimensionality is extremely large. For example, even when the covariance matrix is known, Bickel and Levina (2004) demonstrate convincingly that the Fisher discriminant analysis performs poorly in a minimax sense due to the diverging spectra (e.g., the condition number goes to infinity as dimensionality diverges) frequently encountered in the high-dimensional covariance matrices. Even if the true covariance matrix is not ill conditioned, the singularity of the sample covariance matrix will make the Fisher discrimination rule inapplicable when the dimensionality is larger than sample size. Bickel and Levina (2004) show that the independence rule overcomes the above two problems. However, in tumor classification using microarray data, we hope to find tens of genes that have high discriminative power. The independence rule, studied by Bickel and Levina (2004), does not possess this kind of properties.
The diffculty of high-dimensional classification is intrinsically caused by the existence of many noise features that do not contribute to the reduction of misclassification rate. Though the importance of dimension reduction and feature selection has been stressed and many methods have been proposed in the literature, very little research has been done on theoretical analysis of the impacts of high dimensionality on classification. For example, using most discrimination rules such as the linear discriminants, we need to estimate the population mean vectors from the sample. When the dimensionality is high, even though each component of the population mean vectors can be estimated with accuracy, the aggregated estimation error can be very large and this has adverse effects on the misclassification rate. Therefore, when there is only a fraction of features that account for most of the variation in the data such as tumor classification using gene expression data, using all features will increase the misclassification rate.
To illustrate the idea, we study independence classification rule. Specifically, we give an explicit formula on how the signal and noise affect the misclassification rates. We show formally how large the signal to noise ratio can be such that the effect of noise accumulation can be ignored, and how small this ratio can be before the independence classifier performs as bad as the random guessing. Indeed, as demonstrated in Section 2, the impact of the dimensionality can be very drastic. For the independence rule, the misclassification rate can be as high as the random guessing even when the problem is perfectly classifiable. In fact, we demonstrate that almost all linear discriminants can not perform any better than random guessing, due to the noise accumulation in the estimation of the population mean vectors, unless the signals are very strong, namely the population mean vectors are very far apart.
The above discussion reveals that feature selection is necessary for high-dimensional classification problems. When the independence rule is applied to selected features, the resulting Feature Annealed Independent Rules (FAIR) overcome both the issues of interpretability and the noise accumulation. One can extract the important features via variable selection techniques such as the penalized quasi-likelihood function. See Fan and Li (2006) for an overview. One can also employ a simple two-sample t-test as in Tibshirani et al.(2002) to identify important genes for the tumor classification, resulting in the nearest shrunken centroids method. Such a simple method corresponds to a componentwise regression method or a ridge regression method with ridge parameters tending to ∞ (Fan and Lv, 2007). Hence, it is a specific and useful example of the penalized quasi-likelihood method for feature selection. It is surprising that such a simple proposal can indeed extract all important features. Indeed, we demonstrate that under suitable conditions, the two sample t-statistic can identify all the features that efficiently characterize both classes.
Another popular class of the dimension reduction methods is projection. They have been widely applied to the classification based on the gene expression data. See, for example, principal component analysis in Ghosh (2002), Zou et al. (2004), and Bair et al.(2004); partial least squares in Nguyen and Rocke (2002), Huang and Pan (2003), and Boulesteix (2004); and sliced inverse regression in Chiaromonte and Martinelli (2002), Antoniadis et al.(2003), and Bura and Pfeiffer (2003). These projection methods attempt to find directions that can result in small classification errors. In fact, the directions found by these methods usually put much more weights on features that have large classification power. In general, however, linear projection methods are likely to perform poorly unless the projection vector is sparse, namely, the effective number of selected features is small. This is due to the aforementioned noise accumulation prominently featured in high-dimensional problems, recalling discrimination based on linear projections onto almost all directions can perform as bad as the random guessing.
As direct application of the independence rule is not efficient, we propose a specific form of FAIR. Our FAIR selects the statistically most significant m features according to the componentwise two-sample t-statistics between two classes, and applies the independence classifiers to these m features. Interesting questions include how to choose the optimal m, or equivalently, the threshold value of t-statistic, such that the classification error is minimized, and how this classifier performs compared with the independence rule without feature selection and the oracle-assisted FAIR. All these questions will be formally answered in this paper. Surprisingly, these results are similar to those for the adaptive Neyman test in Fan (1996). The theoretical results also indicate that FAIR without oracle information performs worse than the one with oracle information, and the difference of classification error depends on the threshold value, which is consistent with the common sense.
There is a huge literature on classification. To name a few in addition to those mention before, Bai and Saranadasa (1996) dealt with the effect of high dimensionality in a two-sample problem from a hypothesis testing viewpoint; Friedman (1989) proposed a regularized discriminant analysis to deal with the problems associated with high dimension while performing computations in the regular way; Dettling and Bühlmann (2003) and Bühlmann and Yu (2003) study boosting with logit loss and L2 loss, respectively, and demonstrate the good performances of these methods in high-dimensional setting; Greenshtein and Ritov (2004), Greenshtein (2006) and Meinshausen (2005) introduced and studied the concept of persistence, which places more emphasis on misclassification rates or expected loss rather than the accuracy of estimated parameters.
This article is organized as follows. In Section 2, we demonstrate the impact of dimensionality on the independence classification rule, and show that discrimination based on projecting observations onto almost all linear directions is nearly the same as random guessing. We establish, in Section 3, the conditions under which two sample t-test can identify all the important features with probability tending to 1. In Section 4, we propose FAIR and give an upper bound of its classification error. Simulation studies and real data analyses are conducted in Section 5. The conclusion of our study is summarized in Section 6. All proofs are given in the Appendix.
2 Impact of High Dimensionality
Consider the p-dimensional classification problem between two classes C1 and C2. Suppose that from class Ck, we have nk observations Y k1, ⋯, Y knk in . The j-th feature of the i-th sample from class Ck satisfies the model
| (2.1) |
where μkj is the mean effect of the j-th feature in class Ck and ϵkij is the corresponding Gaussian random noise for i-th observation. In matrix notation, the above model can be written as
where μk = (μk1, ⋯, μkp)′ is the mean vector of class Ck and ϵki = (ϵki1, ⋯, ϵkip)′ has the distribution N (0, Σk). We assume that all observations are independent across samples and in addition, within class Ck, observations Yk1, ⋯, Yknk are also identically distributed. Throughout this paper, we make the assumption that the two classes have compatible sample sizes, i.e., c1 ≤ n1/n2 ≤ c2 with c1 and c2 some positive constants.
We first investigate the impact of high dimensionality on classification. For simplicity, we temporarily assume that the two classes C1 and C2 have the same covariance matrix Σ. To illustrate our idea, we consider the independence classification rule, which classifies the new feature vector x into class C1 if
where μ = (μ1 + μ2)/2 and D = diag(Σ). This classifier has been thoroughly studied in Bickel and Levina (2004). They showed that in the classification of two normal populations, this independence rule greatly outperforms the Fisher linear discriminant rule under broad conditions when the number of variables is large.
The independence rule depends on the marginal parameters μ1, μ2 and . They can easily be estimated from the samples:
and
where is the sample variance of the j-th feature in class k and . Hence, the plug-in discrimination function is
Denote the parameter by θ = (μ1, μ2, Σ). If we have a new observation X from class C1, then the misclassification rate of is
| (2.2) |
where
and Φ(·) is the standard Gaussian distribution function. The worst case classification error is
where Γ is some parameter space to be defined. Let n = n1 + n2. In our asymptotic analysis, we always consider the misclassification rate of observations from C1, since the misclassification rate of observations from C2 can be easily obtained by interchanging n1 with n2 and μ1 with μ2. The high dimensionality is modeled through its dependence on n, namely pn → ∞. However, we will suppress its dependence on n whenever there is no confusion.
Let R = D-1/2 ΣD-1/2 be the correlation matrix, and λmax(R) be its largest eigenvalue, and α ≡ (α1, ⋯, αp)′ = μ1 - μ2. Consider the parameter space
where Cp is a deterministic positive sequence that depends only on the dimensionality p, and b0 is a positive constant. Note that α′D-1α corresponds to the overall strength of signals, and the first condition α′D-1α ≥ Cp imposes a lower bound on the strength of signals. The second condition λmax(R) ≤ b0 requires that the maximum eigenvalue of R should not exceed a positive constant. But since there are no restrictions on the smallest eigenvalue of R, the condition number can still diverge. The third condition ensures that there are no deterministic features that make classification trivial and the diagonal matrix D is always invertible. We will consider the asymptotic behavior of and .
Theorem 1
Suppose that log p = o(n), n = o(p) and nCp → ∞. Then (i) The classification error W (δ, θ) with θ ϵ Γ is bounded from above as
(ii) Suppose p/(nCp) → 0. For the worst case classification error W (δ), we have
Specifically, when with C0 a nonnegative constant, then
In particular, if C0 = 0, then .
Theorem 1 reveals the trade-off between the signal strength Cp and the dimensionality, reflected in the term when all features are used for classification. It states that the independence rule would be no better than the random guessing due to noise accumulation, unless the signal levels are extremely high, say, for some B > 0. Indeed, discrimination based on linear projections to almost all directions performs nearly the same as random guessing, as shown in the theorem below. The poor performance is caused by noise accumulation in the estimation of μ1 and μ2.
Theorem 2
Suppose that a is a p-dimensional uniformly distributed unit random vector on a (p - 1)-dimensional sphere. Let λ1, ⋯, λp be the eigenvalues of the covariance matrix Σ. Suppose and with τ a positive constant. Moveover, assume that p-1α′α → 0. Then if we project all the observations onto the vector a and use the classifier
| (2.3) |
the misclassification rate of satisfies
where the probability is taken with respect to a and X ϵ C1.
3 Feature Selection by Two-Sample t-Test
To extract salient features, we appeal to the two sample t-test statistics. Other componentwise tests such as the rank sum test can also be used, but we do not pursue those in detail. The two-sample t-statistic for feature j is defined as
| (3.1) |
where and are the same as those defined in Section 1. We work under more relaxed technical conditions: the normality assumption is not needed. Instead, we assume merely that the noise vectors ϵki,i = 1, ⋯, nk are i.i.d. within class Ck with mean 0 and covariance matrix Σk, and are independent between classes. The covariance matrix Σ1 can also differ from Σ2.
To show that the t-statistic can select all the important features with probability 1, we need the following condition.
Condition 1
Assume that the vector α = μ1 - μ2 is sparse and without loss of generality, only the first s entries are nonzero.
Suppose that ϵkij and satisfy the Cramér's condition, i.e., there exist constants ν1, ν2, M1 and M2, such that and for all m = 1, 2, ⋯.
Assume that the diagonal elements of both Σ1 and Σ2 are bounded away from 0.
The following theorem describes the situation under which the two sample t-test can pick up all important features by choosing an appropriate critical value. Recall that c1 ≤ n1/n2 ≤ c2 and n = n1 + n2.
Theorem 3
Let s be a sequence such that log(p - s) = o(nγ) and for someβn → ∞ and . Suppose that . Then under Condition 1, for x ~ cnγ/2 with c some positive constant, we have
In the proof of Theorem 3, we used the moderate deviation results of the two-sample t-statistic (see Cao, 2007 or Shao, 2005). Theorem 3 allows the lowest signal level to decay with sample size n. As long as the rate of decay is not too fast and the sample size is not too small, the two sample t-test can pick up all the important features with probability tending to 1.
4 Features Annealed Independence Rules
We apply the independence classifier to the selected features, resulting in a Features Annealed Independence Rule (FAIR). In many applications such as tumor classification using gene expression data, we would expect that elements in the population mean difference vector α are sparse: most entries are small. Thus, even if we could use t-test to correctly extract out all these features, the resulting choice is not necessarily optimal, since the noise accumulation can even exceed the signal accumulation for faint features. This can be seen from Theorem 1. Therefore, it is necessary to further single out the most important features that help reduce misclassification rate.
To help us select the number of features, or the critical value of the test statistic, we first consider the ideal situation that the important features are located at the first m coordinates and our task is to merely select m to minimize the misclassification rate. This is the case when we have the ideal information about the relative importance of features, as measured by |αj|/σj, say. When such an oracle information is unavailable, we will learn it from the data. In the situation that we have vague knowledge about the importance of features such as tumor classification using gene expression data, we can give high ranks to features with large |αj|/σj.
In the presentation below, unless otherwise specified, we assume that the two classes C1 and C2 are both from Gaussian distributions and the common covariance matrix is the identity, i.e., Σ1 = Σ2 = I. If this common covariance matrix is known, the independence classifier becomes the nearest centroids classifier
If only the first m dimensions are used in the classification, the corresponding features annealed independence classifier becomes
where the superscript m means that the vector is truncated after the first m entries. This is indeed the same as the nearest shrunken centroids method of Tibshirani et al. (2002).
Theorem 4
Consider the truncated classifier for a given sequence mn. Suppose that as mn → ∞. Then the classification error of is
where n = n1 + n2 as defined in Section 2.
In the following, we suppress the dependence of m on n when there is no confusion. The above theorem reveals that the ideal choice on the number of features is
It can be estimated as
where . The expression for m0 quantifies how the signal and the noise affect the misclassification rates as the dimensionality m increases. In particular, when n1 = n2, the express reduces to . The term reflects the trade-off between the signal and noise as dimensionality m increases.
The good performance of the classifier depends on the assumption that the largest entries of α cluster at the first m dimensions. An ideal version of the classifier is to select a subset and use this subset to construct independence classifier. Let m be the number of elements in . The oracle classifier can be written as
The misclassification rate is approximately
| (4.1) |
when and m → ∞. This is straightforward from Theorem 4. In practice, we do not have such an oracle, and selecting the subset is difficult. A simple procedure is to use the feature annealed independence rule based on the hard thresholding:
We study the classification error of FAIR and the impact of the threshold b on the classification result in the following theorem.
Theorem 5
Suppose that and with . Moreover, assume that and . Then
Notice that the upper bound of in Theorem 5 is greater than the classification error in Theorem 4, and the magnitude of difference depends on . This is expected as estimating the set increases the classification error. These results are similar to those in Fan (1996) for high-dimensional hypothesis testing.
When the common covariance matrix is different from the identity, FAIR takes a slightly different form to adapt to the unknown componentwise variance:
| (4.2) |
where Tj is the two sample t-statistic. It is clear from (4.2) that FAIR works the same way as that we first sort the features by the absolute values of their t-statistics in the descending order, and then take out the first m features to classify the data. The number of features can be selected by minimizing the upper bound of the classification error given in Theorem 1. The optimal m in this sense is
where is the largest eigenvalue of the correlation matrix Rm of the truncated observations. It can be estimated from the samples:
| (4.3) |
Note that the factor in (4.3) increases with m, which makes usually smaller than .
5 Numerical Studies
In this section we use a simulation study and three real data analyses to illustrate our theoretical results and to verify the performance of our newly proposed classifier FAIR.
5.1 Simulation Study
We first introduce the model. The covariance matrices Σ1 and Σ2 for the two classes are chosen to be the same. For the distribution of the error ϵij in (2.1), we use the same model as that in Fan, Hall and Yao (2006). Specifically, features are divided into three groups. Within each group, features share one unobservable common factor with different factor loadings. In addition, there is an unobservable common factor among all the features across three groups. For simplicity, we assume that the number of features p is a multiple of 3. Let Zij be a sequence of independent N(0, 1) random variables, and be a sequence of independent random variables of the same distribution as with the Chi-square distribution with degrees of freedom d. In the simulation we set d = 6.
Let {aj} and {bj} be factor loading coefficients. Then the error in (2.1) is defined as
where aij = 0 except that a1j = aj for j = 1, ⋯, p/3, a2j = aj for j = (p/3) + 1, ⋯, 2p/3, and a3j = aj for j = (2p/3)+1, ⋯, p. Therefore, ϵij = 0 and var(ϵij) = 1, and in general, within group correlation is greater than the between group correlation. The factor loadings aj and bj are independently generated from uniform distributions U(0, 0.4) and U(0, 0.2). The mean vector μ1 for class C1 is taken from a realization of the mixture of a point mass at 0 and a double-exponential distribution:
where c ϵ (0, 1) is a constant. In the simulation, we set p = 4, 500 and c = 0.02. In other words, there are around 90 signal features on an average, many of which are weak signals. Without loss of generality, μ2 is set to be 0. Figure 1 shows the true mean difference vector α, which is fixed across all simulations. It is clear that there are only very few features with signal levels exceeding 1 standard deviation of the noise.
Figure 1.
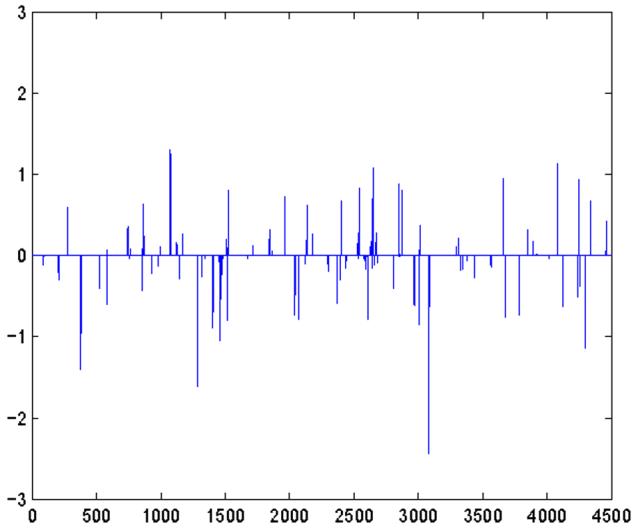
True mean difference vector α. x-axis represents the dimensionality, and y-axis shows the values of corresponding entries of α.
With the parameters and model above, for each simulation, we generate n1 = 30 training data from class C1 and n2 = 30 training data from C2. In addition, separate 200 samples are generated from each of the two classes in each simulation, and these 400 vectors are used as test samples. We apply our newly proposed classifier FAIR to the simulated data. Specifically, for each feature, the t-test statistic in (3.1) is calculated using the training sample. Then the features are sorted in the decreasing order of the absolute values of their t-statistics. We then examine the impact of the number of features m on the misclassification rate. In each simulation, with m ranging from 1 to 4500, we construct the feature annealed independence classifiers using the training samples, and then apply these classifiers to the 400 test samples. The classification errors are compared to those of the independence rule with the oracle ordering information, which is constructed by repeating the above procedure except that in the first step the features are ordered by their true signal levels, |α|, instead of by their t-statistics
The above procedure is repeated 100 times, and averages and standard errors of the misclassification rates (based on 400 test samples in each simulation) are calculated across the 100 simulations. Note that the average of the 100 misclassification rates is indeed computed based on 100 × 400 testing samples.
Figure 2 depicts the misclassification rate as a function of the number of features m. The solid curves represent the average of classification rates across the 100 simulations, and the corresponding dashed curves are 2 standard errors (i.e. the standard deviation of 100 misclassification rates divided by 10) away from the solid one. The misclassification rates using the first 80 features in Figure 2(a) are zoomed in Figure 2(b). Figures 2(c) and 2(d) are the same as 2(a) and 2(b) except that the features are arranged in the decreasing order of |α|, i.e., the results are based on the oracle-assisted feature annealed independence classifier. From these plots we see that the classification results of FAIR are close to those of the oracle-assisted independence classifier. Moreover, as the dimensionality m grows, the misclassification rate increases steadily due to the noise accumulation. When all the features are included, i.e. m = 4500, the misclassification rate is 0.2522, whereas the minimum classification errors are 0.0128 in plot 2(b) and 0.0020 in plot 2(d). These results are consistent with Theorem 1. We also tried to decrease the signal levels, i.e., the mean of the double exponential distribution, or to increase the dimensionality p, and found that the classification error tend to 0.5 when all the dimensions are included. Comparing Figures 2(a) and 2(b) to Figures 2(c) and 2(d), we see that the features ordered by t-statistics has higher misclassification rates than those ordered by the oracle. Also, using t-statistics results in larger minimum classification errors (see plots 2(b) and 2(d)), but the differences are not very large.
Figure 2.
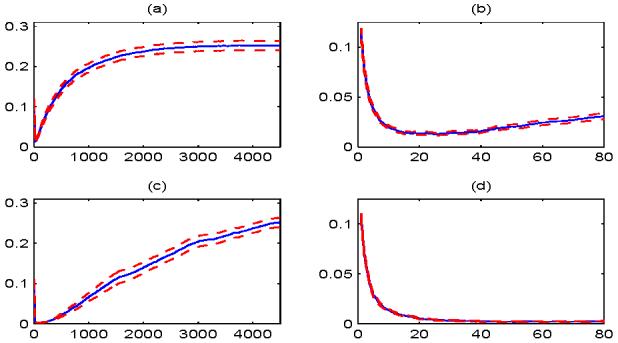
Number of features versus misclassification rates. The solid curves represent the averages of classification errors across 100 simulations. The dashed curves are 2 standard errors away from the solid curves. The x-axis represents the number of features used in the classification, and the y-axis shows the misclassification rates. (a) The features are ordered in a way such that the corresponding t-statistics are decreasing in absolute values. (b) The amplified plot of the first 80 values of x-axis in plot (a). (c) The same as (a) except that the features are arranged in a way such that the corresponding true mean differences are decreasing in absolute values. (d) The amplified plot of the first 80 values of x-axis in plot (c).
Figure 3 shows the classification errors of the independence rule based on projected samples onto randomly chosen directions across 100 simulations. Specifically, in each of the simulations in Figure 2, we generate a direction vector a randomly from the (p - 1)-dimensional unit sphere, then project all the data in that simulation onto the direction a, and finally apply the Fisher discriminant to the projected data (see (2.3)). The average of these misclassification rates is 0.4986 and the corresponding standard deviation is 0.0318. These results are consistent with our Theorem 2.
Figure 3.
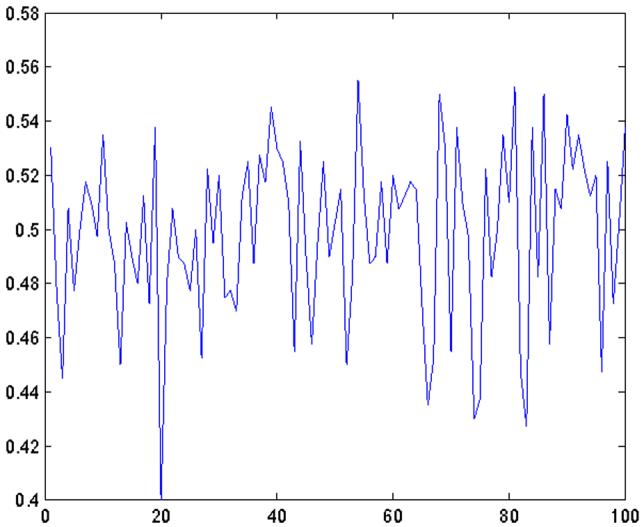
Classification errors of the independence rule based on projected samples onto randomly chosen directions over 100 simulations.
Finally, we examine the effectiveness of our proposed method (4.3) for selecting features in FAIR. In each of the 100 simulations, we apply (4.3) to choose the number of features and compute the resulting misclassification rate based on 400 test samples. We also use the nearest shrunken centroids of Tibshirani et al. (2003) to select the important features. Figure 4 summarizes these results. The thin curves correspond to the nearest shrunken centroids method, and the thick curves correspond to FAIR. Figure 4(a) presents the number of features calculated from these two methods, and Figure 4(b) shows the corresponding misclassification rates. For our newly proposed classifier FAIR, the average of the optimal number of features over 100 simulations is 29.71, which is very close to the smallest number of features with the minimum misclassification rate in Figure 2(d). The misclassification rates of FAIR in Figure 4(b) have average 0.0154 and standard deviation 0.0085, indicating the outstanding performance of FAIR. Nearest shrunken centroids method is unstable in selecting features. Over the 100 simulations, there are several realizations in which it chooses plenty of features. We truncated Figure 4 to make it easier to view. The average number of features chosen by the nearest shrunken centroids is 28.43, and the average classification error is 0.0216, with corresponding standard deviation 0.0179. It is clear that nearest shrunken centroids method tends to choose less features than FAIR, but the misclassification rates are larger.
Figure 4.
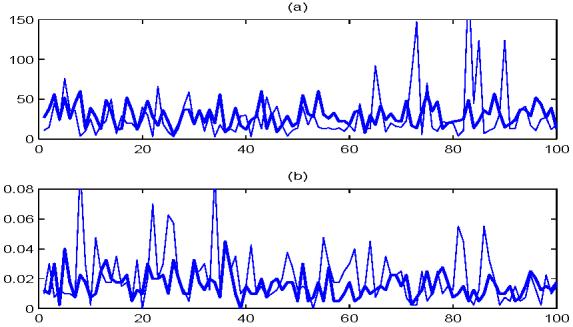
The thick curves correspond to FAIR, while the thin curves correspond to the nearest shrunken centroids method. (a) The numbers of features chosen by (4.3) and by the nearest shrunken centroids method over 100 simulations. (b) Corresponding classification errors based on the optimal number of features chosen in (a) over 100 simulations.
5.2 Real Data Analysis
5.2.1 Leukemia Data
Leukemia data from high-density Affymetrix oligonucleotide arrays were previously analyzed in Golub et al.(1999), and are available at http://www.broad.mit.edu/cgi-bin/cancer/datasets.cgi. There are 7129 genes and 72 samples coming from two classes: 47 in class ALL (acute lymphocytic leukemia) and 25 in class AML (acute mylogenous leukemia). Among these 72 samples, 38 (27 in class ALL and 11 in class AML) are set to be training samples and 34 (20 in class ALL and 14 in class AML) are set as test samples.
Before classification, we standardize each sample to zero mean and unit variance as done by Dudoit et al. (2002). The classification results from the nearest shrunken centroids (NSC hereafter) method and FAIR are shown in Table 1. The nearest shrunken centroids method picks up 21 genes and makes 1 training error and 3 test errors, while our method chooses 11 genes and makes 1 training error and 1 test error. Tibshirani et al.(2002) proposed and applied the nearest shrunken centroids method to the unstandardized Leukemia dataset. They chose 21 genes and made 1 training error and 2 test errors. Our results are still superior to theirs.
Table 1.
Classification errors of Leukemia data set
| Method | Training error | Test error | No. of selected genes |
|---|---|---|---|
| Nearest shrunken centroids | 1/38 | 3/34 | 21 |
| FAIR | 1/38 | 1/34 | 11 |
To further evaluate the performance of the two classifiers, we randomly split the 72 samples into training and test sets. Specifically, we set approximately 100γ% of the observations from class ALL and 100γ% of the observations from class AML as training samples, and the rest as test samples. FAIR and NSC are applied to the training data, and their performances are evaluated by the test samples. The above procedure is repeated 100 times for γ = 0.4, 0.5 and 0.6, respectively, and the distributions of test errors of FAIR, NSC and the independence rule without feature selection are summarized in Figure 5. In each of the splits, we also calculated the difference of test errors between NSC and FAIR, i.e., the test error of FAIR minus that of NSC, and the distribution is summarized in Figure 5. The top panel of Figure 6 shows the number of features selected by FAIR and NSC for γ = 0.4. The results for the other two values of γ are similar so we do not present here to save the space. From these figures we can see that the performance of independence rule improves significantly after feature selection. The classification errors of NSC and FAIR are approximately the same. As we have already noticed in the simulation study, NSC is not good with feature selection, that is, the number of features selected by NSC is very large and unstable, while the number of features selected by FAIR is quite reasonable and stable over different random splits. Clearly, the independent rule without feature selection performs poorly.
Figure 5.
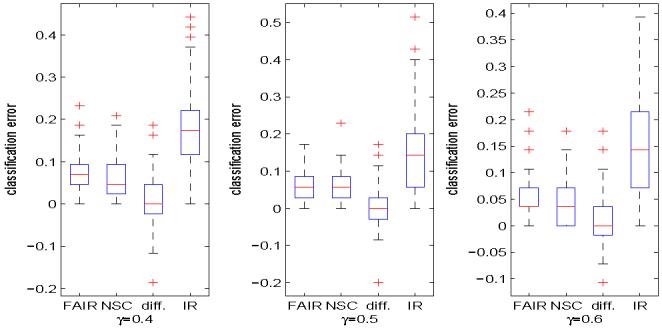
Leukemia data. Boxplots of test errors of FAIR, NSC and the independence rule without feature selection over 100 random splits of 72 samples, where 100γ% of the samples from both classes are set as training samples. The three plots from left to right correspond to γ = 0.4, 0.5 and 0.6, respectively. In each boxplot above, “FAIR” refers to the test errors of the feature annealed independent rule; “NSC” corresponds to the test errors of nearest shrunken centroids method; “diff.” means the difference of the test errors of FAIR and those of NSC; and “IR” corresponds the test errors of independence rule without feature selection.
Figure 6.
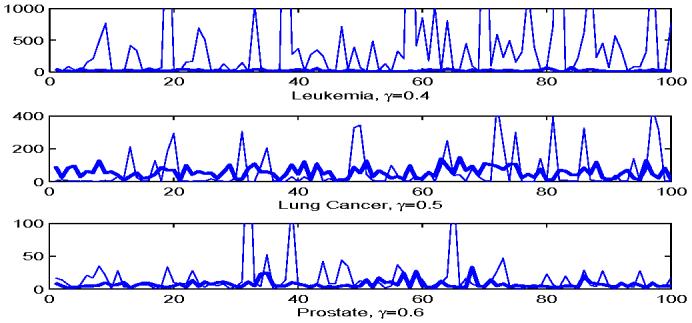
Leukemia, Lung Cancer, and Prostate data sets. The number of features selected by FAIR and NSC over 100 random splits of the total samples. In each split, 100γ% of the samples from both class are set as training samples, and the rest are used as test samples. The three plots from top to bottom correspond to the Leukemia data with γ = 0.4, the Lung Cancer data with γ = 0.5 and the Prostate cancer data with γ = 0.6, respectively. The thin curves show the results from NSC, and the thick curves correspond to FAIR. The plots are truncated to make them easy to view.
5.2.2 Lung Cancer Data
We evaluate our method by classifying between malignant pleural mesothelioma (MPM) and adenocarcinoma (ADCA) of the lung. Lung cancer data were analyzed by Gordon et al.(2002) and are available at http://www.chestsurg.org. There are 181 tissue samples (31 MPM and 150 ADCA). The training set contains 32 of them, with 16 from MPM and 16 from ADCA. The rest 149 samples are used for testing (15 from MPM and 134 from ADCA). Each sample is described by 12533 genes.
As in the Leukemia data set, we first standardize the data to zero mean and unit variance, and then apply the two classification methods to the standardized data set. Classification results are summarized in Table 2. Although FAIR uses 5 more genes than the nearest shrunken centroids method, it has better classification results: both methods perfectly classify the training samples, while our classification procedure has smaller test error.
Table 2.
Classification errors of Lung Cancer data
| Method | Training error | Test error | No. of selected genes |
|---|---|---|---|
| Nearest shrunken centroids | 0/32 | 11/149 | 26 |
| FAIR | 0/32 | 7/149 | 31 |
We follow the same procedure as that in Leukemia example to randomly split the 181 samples into training and test sets. FAIR and NSC are applied to the training data, and the test errors are calculated using the test data. The procedure is repeated 100 times with γ = 0.4, 0.5 and 0.6, respectively, and the test error distributions of FAIR, NSC and the independence rule without feature selection can be found in Figure 7. We also present the difference of the test errors between FAIR and NSC in Figure 7. The numbers of features used by FAIR and NSC with γ = 0.5 are shown in the middle panel of Figure 6. Figure 7 shows again that feature selection is very important in high dimensional classification. The performance of FAIR is close to NSC in terms of classification error (Figure 7), but FAIR is stable in feature selection, as shown in the middle panel of Figure 6. One possible reason of Figure 7 might be that the signal strength in this Lung Cancer dataset is relatively weak, and more features are needed to obtain the optimal performance. However, the estimate of the largest eigenvalue is not accurate anymore when the number of features is large, which results in inaccurate estimates of m1 in (4.3).
Figure 7.
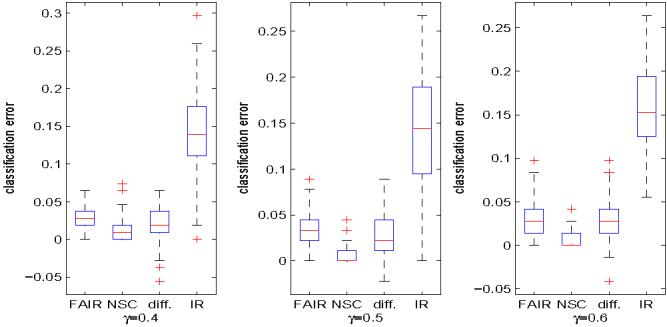
Lung cancer data. The same as Figure 5 except that the data set is different.
5.2.3 Prostate Cancer Data
The last example uses the prostate cancer data studied in Singh et al.(2002). The data set is available at http://www.broad.mit.edu/cgi-bin/cancer/datasets.cgi. The training data set contains 102 patient samples, 52 of which (labeled as “tumor”) are prostate tumor samples and 50 of which (labeled as “Normal”) are prostate samples. There are around 12600 genes. An independent set of test samples is from a different experiment and has 25 tumor and 9 normal samples.
We preprocess the data by standardizing the gene expression data as before. The classification results are summarized in Table 3. We make the same test error as and a bit larger training error than the nearest shrunken centroids method, but the number of selected genes we use is much less.
Table 3.
Classification errors of Prostate Cancer data set
| Method | Training error | Test error | No. of selected genes |
|---|---|---|---|
| Nearest shrunken centroids | 8/102 | 9/34 | 6 |
| FAIR | 10/102 | 9/34 | 2 |
The samples are randomly split into training and test sets in the same way as before, the test errors are calculated, and the number of features used by these two methods are recorded. Figure 8 shows the test errors of FAIR, NSC and the independence rule without feature selection, and the difference of the test errors of FAIR and NSC. The bottom panel of Figure 6 presents the numbers of features used by FAIR and NSC in each random split for γ = 0.6. As we mentioned before, the plots for γ = 0.4 and 0.5 are similar so we omit them in the paper. The performance of FAIR is better than that of NSC both in terms of classification error and in terms of the selection of features. The good performance of FAIR might be caused by the strong signal level of few features in this data set. Due to the strong signal level, FAIR can attain the optimal performance with small number of features. Thus, the estimate of m1 in (4.3) is accurate and hence the actual performance of FAIR is good.
Figure 8.
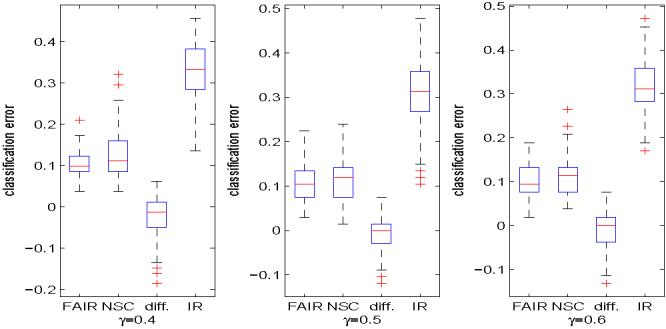
Prostate cancer data. The same as Figure 5 except that the data set is different.
6 Conclusion
This paper studies the impact of high dimensionality on classifications. To illustrate the idea, we have considered the independence classification rule, which avoids the difficulty of estimating large covariance matrix and the diverging condition number frequently associated with the large covariance matrix. When only a subset of the features capture the characteristics of two groups, classification using all dimensions would intrinsically classify the noises. We prove that classification based on linear projections onto almost all directions performs nearly the same as random guessing. Hence, it is necessary to choose direction vectors which put more weights on important features.
The two-sample t-test can be used to choose the important features. We have shown that under mild conditions, the two sample t-test can select all the important features with probability one. The features annealed independence rule using hard thresholding, FAIR, is proposed, with the number of features selected by a data-driven rule. An upper bound of the classification error of FAIR is explicitly given. We also give suggestions on the optimal number of features used in classification. Simulation studies and real data analysis support our theoretical results convincingly.
Acknowledgments
Financial support from the NSF grants DMS-0354223 and DMS-0704337 and NIH grant R01-GM072611 is gratefully acknowledged. The authors acknowledge gratefully the helpful comments of referees that led to the improvement of the presentation and the results of the paper.
7 Appendix
Proof of Theorem 1
For θ ∈ Γ, Ψ defined in (2.2) can be bounded as
| (7.1) |
where we have used the assumption that λmax(R) ≤ b0. Denote by
We next study the asymptotic behavior of .
Since Condition 1(b) in Section 3 is satisfied automatically for normal distribution, by Lemma 2 below we have , where oP(1) holds uniformly across all diagonal elements. Thus, the right hand side of (7.1) can be written as
We first consider the denominator. Notice that it can be decomposed as
| (7.2) |
where is the j-th diagonal entry of D, , is the j-th diagonal entry of , and . Notice that . By singular value decomposition we have
where QR is orthogonal matrix and be the eigenvalues of the correlation matrix R. Define , then . Hence,
Since and for all i = 1, ⋯, p, we have . By weak law of large number we have
| (7.3) |
Next, we consider I1. Note that I1 has the distribution . Since and
we have . This together with (7.2) and (7.3) yields
| (7.4) |
Now, we consider the numerator. It can be decomposed as
Denote by . Note that
| (7.5) |
Define , then for all j. For the normal distribution, we have the following tail probability inequality
Since , by the above inequality we have
with C some positive constant, for all x > 0 and j = 1,⋯, p. By Lemma 2.2.10 of van de Vaart and Wellner (1996, P102), we have
where K is some universal constant. This together with (7.5) ensures that
Hence,
| (7.6) |
Now we only need to consider . Note that . Since the variance term can be bounded as
By the assumption that and λmax(R) is bounded, we have . Combining this with (7.6) leads to
We now examine I4 and I5. By the similar proof to (7.3) above we have
Thus the numerator can be written as
and by (7.4)
Since is an increasing function of x and , in view of (7.1) and the definition of the parameter space Γ, we have
If p/(nCp) → 0, then . Furthermore, if with C0 some constant, then
This completes the proof.
Proof of Theorem 2
suppose we have a new observation X from class C1. Then the posterior classification error of using is
Where is the standard Gaussian distribution function, and Ea means expectation taken with respect to a. We are going to show that
| (7.7) |
which together with the continuity of ·(.) and the dominated convergence theorem gives
Therefore, the posterior error is no better than the random guessing.
Now, let us prove (7.7). Note that the random vector a can be written as
where Z is a p-dimensional standard Gaussian distributed random vector, independent of all the observations Y ki and X. Therefore,
| (7.8) |
where and . By the singular value decomposition we have
where Q is an orthogonal matrix and is a diagonal matrix. Let , then is also a p-dimensional standard Gaussian random vector. Hence the denominator of Ψa can be written as
where is the j-th entry of . Since it is assumed that and for some positive constant τ, by the weak law of large numbers, we have
| (7.9) |
Next, we study the numerator of Ψa in (7.8). Since , the first term of the numerator converges to 0 in probability, i.e.,
| (7.10) |
Let and , then has distribution N(0, I) and is independent of . The second term of the numerator can be written as
Since , it follows from the weak law of large number that
This together with (7.8), (7.9), and (7.10) completes the proof.
We need the the following two lemmas to prove Theorem 3.
Lemma 1
[Cao (2005)] Let n = n1 + n2. Assume that there exist 0 < c1 ≤ c2 < 1 such that c1 ≤ n1/n2 ≤ c2. Let . Then for any satisfying x → ∞ and x = o(n1/2),
If in addition, if we have only and , then
where and O(1) is a finite constant depending only on c1 and c2. In particular,
uniformly in .
Lemma 2
Suppose Condition 1(b) holds and log p = o(n). Let be the sample variance defined in Section 1, and be the variance of the j-th feature in class Ck. Suppose min is bounded away from 0. Then we have the following uniform convergence result
Proof of Lemma 2
For any , we know when nk is very large,
| (7.11) |
It follows from Bernstein's inequality that
and
Since log p = o(n), we have I1 = o(1) and I2 = o(1). These together with (7.11) completes the proof of Lemma 2.
Proof of Theorem 3
We devidte the proof into two parts. (a) Let us first look at the probability . Clearly,
| (7.12) |
Note that for all j > s, αj = μj1 - μj2 = 0. By Condition 1(b) and Lemma 1, the following inequality holds for 0 ≤ x ≤ n1/6/d,
where C is a constant that only depends on c1 and c2, and
with the j-th diagonal element of . For the normal distribution, we have the following tail probability inequality
This together with the symmetry of Tj gives
Combining the above inequality with (7.12), we have
Since log(p - s) = o(nγ) with , if we let , then
which along with (7.12) yields
(b) Next, we consider P (minj≤s |Tj| ≤ x). Notice that for j ≤ s, αj = μ1j - μ2j ≠ 0. Let and define
Then following the same lines as those in (a), we have
It follows from Lemma 2 that,
Hence, uniformly over j = 1, ⋯, s, we have
Therefore,
with c2 defined in Theorem 3. Let . Then it follows that
By part (a), we know that x ~ cnγ/2 and log(p-s) = o(nγ). Thus if for some , then similarly to part (a), we have
Combination of part (a) and part (b) completes the proof.
Proof of Theorem 4
The classification error of the truncated classifier is
We first consider the denominator. Note that . It can be shown that
which together with the assumptions gives
Next, let us look at the numerator. We decompose it as
| (7.13) |
Since the second term above has the distribution , it follows from the assumption that
The third term in (7.13) can be written as
Hence the numerator is
Therefore, the classification error is
This concludes the proof.
Proof of Theorem 5
Note that the classification error of is
We divide the proof into two parts: the numerator andthe denominator.
(a) First, we study the numerator of ΨH. It can be decomposed as
where and with the complementary of the set . Note that
Since , it follows from the normal tail probability inequality that for every and ,
| (7.14) |
where M is a generic constant. Thus for every ε > 0, if and , we have
which tends to zero. Hence,
| (7.15) |
We next consider I2,2. Since , and , we have
which converges to 0. Therefore,
| (7.16) |
Then, we consider I2,3. Since c1 ≤ n1/n2 ≤ c2 and , by (7.14) we have for every ε > 0,
where M is some generic constant. Thus, . Combination of this with (7.15) and (7.16) entails
We now deal with I1. Decompose I1 similarly as
We first study I1,2. By using , it can be shown that
| (7.17) |
since , we have . Therefore,
Next, we look at I1,1. For any ε > 0,
When n is large enough, the above probability can be bounded by
which along with the assumption gives
It follows that the numerator is bounded from below by
(b) Now, we study the denominator of Ψ. Let
We first show that . Note that . Thus,
This together with (7.14) and the assumption that yields as . Now we study term J1. By (7.17), we have
Hence the denominator is bounded from a above by . Therefore,
It follows that the classification error is bounded from above by
This completes the proof.
Contributor Information
Jianqing Fan, Princeton University.
Yingying Fan, Harvard University.
REFERENCES
- ANTONIADIS A, LAMBERT-LACROIX S, LEBLANC F. Effective dimension reduction methods for tumor classification using gene expression data. Bioinformatics. 2003;19:563–570. doi: 10.1093/bioinformatics/btg062. [DOI] [PubMed] [Google Scholar]
- BAI Z, SARANADASA H. Effect of high dimension : by an example of a two sample problem. Statistica Sinica. 1996;6:311–329. [Google Scholar]
- BAIR E, HASTIE T, DEBASHIS P, TIBSHIRANI R. Prediction by supervised principal components. The Annals of Statistics. 2007 to appear. [Google Scholar]
- BICKEL PJ, LEVINA E. Some theory for Fisher's linear discriminant function, “naive Bayes”, and some alternatives when there are many more variables than observations. Bernoulli. 2004;10:989–1010. [Google Scholar]
- BOULESTEIX A. PLS Dimension reduction for classification with microarray data. Statistical Applications in Genetics and Molecular Biology. 2004;3:1–33. doi: 10.2202/1544-6115.1075. [DOI] [PubMed] [Google Scholar]
- BÜHLMANN P, YU B. Boosting with the L2 loss: regression and classification. Journal of the American Statistical Association. 2003;98:324–339. [Google Scholar]
- BURA E, PFEIFFER RM. Graphical methods for class prediction using dimension reduction techniques on DNA microarray data. Bioinformatics. 2003;19:1252–1258. doi: 10.1093/bioinformatics/btg150. [DOI] [PubMed] [Google Scholar]
- CAO HY. Moderate deviations for two sample t-statistics. Probability and Statistics. 2007 Forthcoming. [Google Scholar]
- CHIAROMONTE F, MARTINELLI J. Dimension reduction strategies for analyzing global gene expression data with a response. Mathematical Biosciences. 2002;176:123–144. doi: 10.1016/s0025-5564(01)00106-7. [DOI] [PubMed] [Google Scholar]
- DETTLING M, BÜHLMANN P. Boosting for tumor classification with gene expression data. Bioinformatics. 2003;19(9):1061–1069. doi: 10.1093/bioinformatics/btf867. [DOI] [PubMed] [Google Scholar]
- DUDOIT S, FRIDLYARD J, SPEED TP. Comparison of discrimination methods for the classification of tumors using gene expression data. Journal of the American Statistical Association. 2002;97:77–87. [Google Scholar]
- FAN J. Test of significance based on wavelet thresholding and Neyman's truncation. Journal of the American Statistical Association. 1996;91:674–688. [Google Scholar]
- FAN J, HALL P, YAO Q. To how many simultaneous hypothesis tests can normal, student's t or Bootstrap calibration be applied? Manuscript. 2006 [Google Scholar]
- FAN J, LI R. Statistical challenges with high dimensionality: feature selection in knowledge discovery. In: Sanz-Sole M, Soria J, Varona JL, Verdera J, editors. Proceedings of the International Congress of Mathematicians. Vol. III. 2006. pp. 595–622. [Google Scholar]
- FAN J, REN Y. Statistical analysis of DNA microarray data. Clinical Cancer Research. 2006;12:4469–4473. doi: 10.1158/1078-0432.CCR-06-1033. [DOI] [PubMed] [Google Scholar]
- FAN J, LV J. Sure independence screening for ultra-high dimensional feature space. Manuscript. 2007 doi: 10.1111/j.1467-9868.2008.00674.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- FRIEDMAN JH. Regularized discriminant analysis. Journal of the American Statistical Association. 1989;84:165–175. [Google Scholar]
- GHOSH D. Singular value decomposition regression modeling for classification of tumors from microarray experiments. Proceedings of the Pacific Symposium on Biocomputing. 2002:11462–11467. [PubMed] [Google Scholar]
- GREENSHTEIN E. Best subset selection, persistence in high dimensional statistical learning and optimization under l1 constraint. Ann. Statist. 2006 to appear. [Google Scholar]
- GREENSHTEIN E, RITOV Y. Persistence in high-dimensional linear predictor selection and the virtue of overparametrization. Bernoulli. 2004;10:971–988. [Google Scholar]
- HUANG X, PAN W. Linear regression and two-class classification with gene expression data. Bioinformatics. 2003;19:2072–2978. doi: 10.1093/bioinformatics/btg283. [DOI] [PubMed] [Google Scholar]
- LIN Z, LU C. Limit Theory for Mixing Dependent Random Variables. Kluwer Academic Publishers; Dordrecht: 1996. [Google Scholar]
- MEINSHAUSEN N. Relaxed Lasso. Computational Statistics and Data Analysis. 2007 to appear. [Google Scholar]
- NGUYEN DV, ROCKE DM. Tumor classification by partial least squares using microarray gene expression data. Bioinformatics. 2002;18:39–50. doi: 10.1093/bioinformatics/18.1.39. [DOI] [PubMed] [Google Scholar]
- SHAO QM. Self-normalized Limit Theorems in Probability and Statistics. Manuscript. 2005 [Google Scholar]
- TIBSHIRANI R, HASTIE T, NARASIMHAN B, CHU G. Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proc. Natl. Acad. Sci. 2002;99:6567–6572. doi: 10.1073/pnas.082099299. [DOI] [PMC free article] [PubMed] [Google Scholar]
- VAN DER VAART AW, WELLNER JA. Weak Convergence and Empirical Processes. Springer-Verlag; New York: 1996. [Google Scholar]
- WEST M, BLANCHETTE C, FRESSMAN H, HUANG E, ISHIDA S, SPANG R, ZUAN H, MARKS JR, NEVINS JR. Predicting the clinical status of human breast cancer using gene expression profiles. Proc. Natl. Acad. Sci. 2001;98:11462–11467. doi: 10.1073/pnas.201162998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- ZOU H, HASTIE T, TIBSHIRANI R. Sparse principal component analysis. Technical report. 2004 [Google Scholar]