

Abstract
Feedlot cattle in Alberta, Canada, have been identified as reservoirs for Campylobacter jejuni, an important human pathogen. Oligonucleotide DNA microarrays were used as a platform to compare C. jejuni isolates from feedlot cattle and human clinical cases from Alberta. Comparative genomic hybridization (CGH) analysis was performed on 87 isolates (46 bovine, 41 human) obtained within the same geographical regions and time frame. Thirteen CGH clusters were obtained based on overall comparative genomic profile similarity. Nine CGH clusters contained human and cattle isolates, three contained only human isolates, and one contained only cattle isolates. The study isolates clustered regardless of temporal or geographical frameworks. In addition, array genes (n = 1,399) were investigated on a gene-by-gene basis to see if any were unequally distributed between human and cattle sources or between clusters dominated by either human or cattle isolates (“human enriched” versus “cattle enriched”). Using Fisher's exact test with the Westfall and Young correction for these comparisons, a small number of differentially distributed genes were identified. Our findings suggest that feedlot cattle and human C. jejuni strains are very similar and may be endemic within Alberta. Further, the common distribution of human clinical and bovine C. jejuni isolates within the same genetically based clusters suggests that dynamic and important transmission routes between cattle and human populations may exist.
The Alberta, Canada, beef industry is economically important to the province as the largest source of farm cash receipts from a single agricultural commodity (2005 data) (40). In 2005, Alberta had 2,370,800 cattle on feed, which is 67% of the national total (3). In that same year, campylobacteriosis was the most common (notifiable) bacterial, enteric disease, with a provincial rate of 36.1 cases for every 100,000 people (38a, 41). Because of the relatively high number of human cases and the large numbers of cattle on feed in Alberta, research into the role of feedlot cattle as Campylobacter reservoirs has been ongoing (15, 18-21). Campylobacter jejuni is of public health significance as the most common Campylobacter species isolated from human cases (approximately 85%) (28). Recent Alberta feedlot cattle fecal studies have determined a large proportion (32 to 69%) of Campylobacter-positive samples to be C. jejuni (2, 15, 19, 21), reinforcing the need for continued research into the potential importance of cattle as reservoirs for these human pathogens.
Many campylobacters are commensals in a wide range of warm-blooded hosts and insects, and they can persist and maintain viability in water sources, in biofilm, and during environmental stress (1, 30). While poultry and poultry products are usually considered the main sources of human Campylobacter infections (17), it is possible that other transmission routes exist. Poultry sources have not accounted for 100% of human infections, and typing surveys have found human Campylobacter strains that do not exhibit similarity (do not cluster) with poultry strains (7, 26, 27, 32, 33). Cattle and human Campylobacter isolates have been found to be similar using a variety of molecular typing methods (5, 22, 33), and typing studies have suggested that cattle may play a role in the epidemiology of campylobacteriosis (5, 26, 33). In a study by Nielsen et al., human and cattle C. jejuni isolates were identical based on six molecular typing methods (31). Further, cattle strains have been able to infect poultry (51), suggesting that cattle may be potential Campylobacter reservoirs for poultry as well as people.
In 2000, the genetic sequencing of Campylobacter jejuni (C. jejuni NCTC 11168) by Parkhill et al. (38) led to the development of whole-genome DNA microarrays that could be used to study the comparative genomics of C. jejuni (11). DNA microarrays have been used in comparative genomic hybridization (CGH) surveys to analyze C. jejuni genomic variability (4, 34, 37, 43) and to explore the possibility of using CGH as a tool for epidemiological investigation (24).
The purpose of this study was to perform comparative high-resolution genotyping (CGH analysis) on feedlot cattle and human clinical C. jejuni isolates obtained from the same geographical regions and during the same time frame in order to identify isolates with high levels of genomic similarity. This was a cross-sectional study, and it is not known if the persons represented by the human samples had any contact with cattle. Our goal was to use CGH to generate indirect evidence (preliminary assessment) as to the potential for cattle to be a source of C. jejuni infection for people. Human and feedlot cattle C. jejuni isolates for this study were purposefully collected within specific geographical areas in Alberta in both the winter and summer of 2005 and chosen for DNA microarray testing by using stratified random selection.
MATERIALS AND METHODS
Analytical design.
Fig. 1 describes the pathway of inclusion and exclusion of field isolates, arrays, replicate arrays, and genes throughout the analysis process.
FIG. 1.

Flow diagrams of field strains, genes, and technical replicates through selection and data analysis. C, cattle; H, human; QC, quality control.
C. jejuni isolation from feedlot cattle.
Cattle isolates were collected as part of a prevalence study in seven large commercial feedlots from four regional health authorities (RHAs 1, 2, 3, and 5) in Alberta (15). Preliminary identifications of C. jejuni were made for 1,020 samples based on positive cultures (direct) and positive hippurate hydrolysis testing (15, 29). Fifty-eight isolates from feedlot cattle were randomly selected (using Microsoft Office Excel 2007 [Microsoft Corporation]) after stratification by feedlot and season and confirmed as C. jejuni (based on the hypO gene) using a multiplex PCR as previously described (15, 48). These isolates were then subjected to high-resolution genotyping using DNA microarrays. Only one isolate was allowed per pen.
Human isolates.
Eighty-two viable human isolates, identified as C. jejuni by diagnostic laboratories in Alberta (RHAs 1, 2, and 3) were sent to the Alberta Provincial Laboratory of Public Health. The isolates were screened to ensure that patients had not traveled outside Alberta within 30 days of sample submission and that only one isolate per patient and per household was sent for microarray testing. In Alberta, the campylobacteriosis case definition is based on laboratory confirmation from an appropriate clinical specimen, with or without symptoms in the patient (13). The isolates were couriered to the Vaccine and Infectious Disease Organization (VIDO) on ice along with nonidentifying information (date of birth, gender, date of specimen submission, and RHA). Upon receipt, the isolates were plated onto Mueller-Hinton agar for 48 h at 43°C to ensure a pure culture and then streaked onto three Mueller-Hinton plates and incubated for 16 to 18 h at 37°C (10% CO2, 5% O2, 85% N2). Growth from three plates per strain was then suspended in a 50% brain heart infusion-25% glycerol mixture and frozen to −70°C for genotyping at a later date. Human isolates were stratified by RHA and by season and then randomly sampled. Data from 49 human C. jejuni arrays were initially entered into the analysis.
ORF C. jejuni NCTC 11168 DNA microarray.
A C. jejuni oligonucleotide microarray from the Campylobacter jejuni Genome Oligo Set version 1.0 was purchased from Operon Biotechnologies, Inc. (Huntsville, AL). This product contained 1,601 probes 70 bp in length and represented 1,546 open reading frames (ORFs) from C. jejuni subsp. jejuni NCTC 11168 (GenBank sequence AL111168); 51 ORFs from C. jejuni 81-176 virulence plasmid pVir (GenBank sequence AF226280); and four ORFs from C. jejuni plasmid pCJ01 (GenBank sequence AF301164). All 1,601 probes were designed within ORFs predicted by Operon using their proprietary software. The probes were normalized to melting temperature of 71°C (±5°C). Triplicate spots were included for each ORF on the chip. The microarray slides were produced from this set of oligonucleotides by The Biomedical Genomics Center, University of Minnesota (Minneapolis, MN). The conditions required for the optimal hybridization of these arrays using cyanine dye detection systems are outlined below. For this study, only genes from C. jejuni NCTC 11168 (n = 1,546) were analyzed; plasmid data available on the arrays were not included in the analysis.
Genomic DNA extraction and labeling.
Genomic DNA isolation was performed using a modification of the hexadecyltrimethyl ammonium bromide (CTAB) procedure (50). Briefly, cells were suspended in 567 μl of TE (10 mM Tris HCl and 1 mM EDTA [pH 8.0]). Proteinase K and sodium dodecyl sulfate were added to a final concentration of 100 μg/ml and 0.5%, respectively. After incubation for 1 h at 37°C, 100 μl of 5 M NaCl was added, and the suspension was mixed thoroughly. Eighty microliters of 10% CTAB in 0.7 M NaCl was added, and the mixture was incubated at 65°C for 10 min. An equal volume of chloroform/isoamyl alcohol (24:1) was added, and after thorough mixing, the CTAB-protein/polysaccharide complex was removed by centrifugation. The aqueous supernatant was transferred to a fresh tube, and the remaining protein was extracted with phenol-chloroform/isoamyl alcohol (25:24:1). The supernatant was precipitated with 0.6 volumes of isopropanol, and the precipitate was dissolved in 250 μl of water.
Three microliters of random primers (Invitrogen Corporation, Carlsbad, CA) were added to approximately 6 μg of genomic C. jejuni DNA (Cy3 for reference strain NCTC 11168, Cy5 for the test strain) in 1.5-ml amber tubes (Diamed Lab Supplies, Inc., Mississauga, ON, Canada). Distilled water was then added so that each tube contained a total of 40.5 μl. The contents were then denatured at 95 to 97°C for 6 min, cooled on ice for 2 min, and then left at room temperature for 5 min. Five microliters of 10× Klenow reaction buffer (USB Corporation, Cleveland, OH), 1.5 μl Cy-labeled dCTP (Amersham Biosciences, Inc., Sunnyvale, CA), 1 μl deoxynucleoside triphosphate (Amersham Biosciences, Inc.), and 20 units exonuclease-free Klenow (USB Corporation) were added and the tubes incubated at 37°C for 2 h. Then, 2.5 μl of 0.5 M EDTA was added to each tube and left for 1 min at room temperature. The tubes were then heated at 95 to 97°C for 2 min, kept on ice for 5 min, and left to sit at room temperature for 5 min. The cleanup of probes was carried out using the Qiagen MinElute reaction cleanup kit as per the manufacturer's specifications (catalog no. 28206; Qiagen, Inc., Mississauga, ON, Canada) with a final elution volume of 13 μl distilled H2O. The labeled DNA was quantified using a spectrophotometer (Ultrospec 3000; Pharmacia Biotech) to calculate the number of pmol/μl in each tube. In a fresh 1.5-ml amber tube, 40 pmol of both the reference strain (Cy3) and the test strain (Cy5) were combined, and distilled H2O was added to bring the total volume to 20 μl.
Microarray hybridization.
Each array was submerged in warm prehybridization solution (Genicon Sciences Corporation, now part of Invitrogen Corporation) and incubated for 30 min at 42°C. Each array was then washed in fresh distilled H2O 10 times and in 100% isopropanol 10 times. The arrays were then dried with filtered air. Lifter slips (#25x601-2-4789; Erie Scientific Co., Portsmouth, NH) were washed in distilled H2O followed by 100% ethanol and left to dry. Damp paper towels were placed onto a metal leveling block in a large plastic container. The arrays were then labeled and placed, with the probes facing upward, on the paper towels and the lifter slips added. SlideHyb Buffer #2 (55 μl; Ambion, Austin, TX) was then added to the 20 μl tube from the quantification step and mixed gently, and the tube was placed in the heat block for 5 min (65 to 67°C). In a darkened room, the entire contents of the tube was then pipetted along one edge of the lifter slip to wick up the slide. The lid was then placed on the container, and it was incubated at 42°C in the humidified chamber for 18 to 24 h. After incubation, the lifter slips were removed, and the arrays were immersed in fresh wash solution 1 (1× sodium chloride-sodium citrate [SSC; 1× SSC is 0.15 M NaCl plus 0.015 M sodium citrate]/0.1% sodium dodecyl sulfate) at 42°C for 5 min. This step was then repeated twice. The arrays were then immersed in wash solution 2 (1× SSC) at 42°C for 5 min (repeated twice) and then in wash solution 3 (0.1× SSC) at 42°C for 5 min (repeated twice). The slides were then rinsed in warm distilled H2O (42°C), dried with filtered air, placed into clean slide mailers, and protected from direct light until scanned.
Scanning, data acquisition, and preliminary data analysis.
The arrays were scanned using GenePix Pro version 4.1 (GenePix 4000B scanner; MDS Analytical Technologies, Mississauga, ON, Canada) or Jaguar 2.0 (ArrayScanner 428; Affymetrix, Inc., Santa Clara, CA). Cy3 and Cy5 were scanned at wavelengths of approximately 532 nm and 635 nm, respectively, both with 100% power. Primary image analysis (ArrayVision, version 8.0, rev. 3.0; Imaging Research, Inc.) and global loess normalization (ArrayPipe) (16) were performed. The background was then subtracted from the raw spot intensity for both the reference and test strains, giving a net intensity for each spot. Prior to all subsequent analyses, anomalous spots resulting from printing errors were removed from the data set. The average net intensity data in the reference and test channels for each ORF on the array were then obtained by averaging the net intensities of the remaining replicate spots.
Quality control and gene absence/divergence analysis.
Taboada et al. previously showed that low-intensity CGH data may behave less reliably than high intensity data upon the subsequent analysis of gene divergence/absence (47). Preliminary analysis of our data set revealed that low-intensity data reduced the concordance of data from replicate arrays (see the description in the “Global cluster analysis and validation of clustering results” section below). A custom script was written in Visual Basic for Applications for Microsoft Office Excel (Microsoft Corporation) to test pixel intensity cutoffs from 200 to 1,200 pixel units (in 20-unit increments) while monitoring the concordance of replicate data. This analysis allowed us to determine intensity and log ratio cutoffs which would maximize the amount of reliable data retained for subsequent analysis and minimize the adverse effects of low-signal data on replicate concordance. The ORFs and arrays in which greater than 5% of the data yielded less than 500 pixel units in the reference channel were excluded from subsequent analysis. A log ratio or log2 (net test signal/net reference signal) threshold of −1.1 was chosen to differentiate divergent/absent from present genes. Spots were categorized as “divergent/absent” if log ratios were <−1.1, or “conserved” if log ratios were ≥−1.1. The log ratio was calculated for each ORF in each array that passed quality control (1,399 ORFs; 119 arrays). Raw and processed log ratio data for these data sets are available at NCBI's Gene Expression Omnibus website (http://www.ncbi.nlm.nih.gov/projects/geo/) under accession number GSE13228. Log ratio data were visualized and analyzed in TIGRs MultiExperiment Viewer (TMEV) version 3.1 (39).
Global cluster analysis and validation of clustering results.
Average linkage hierarchical clustering (12) was used to cluster samples based on the similarity of binarized gene conservation profiles and was performed in TMEV (39) using Euclidean distance as a distance metric. Support tree bootstrapping within TMEV (500 bootstrap resamplings) (39) was then used to test the reliability of the clustering patterns. Tree data were coded into Newick format prior to visualization using Treeview version 1.6.6 (35).
Arrays from 90 study C. jejuni isolates and replicate arrays from 23 randomly selected isolates stratified by source (human or bovine) were included in the preliminary cluster analysis. Six self-self arrays (laboratory strain NCTC 11168) and six arrays comparing the reference NCTC 11168 strain to the laboratory test strain RM1221 (hereafter referred to as RM1221) were also included in the data set. These technical replicate arrays were used to validate our data based on the expectation that replicates should group together on the dendrogram. Three isolates for which replicate arrays showed low concordance were identified and removed from subsequent analyses. The remaining 87 field isolates were included in the final global clustering and gene association analyses.
Statistical analyses of gene association.
A multistep process was used to investigate genes which might be differentially distributed between human and cattle sources. Genome-wide gene association analyses were conducted using an in-house Microsoft Excel script developed to compare conservation rates for each array gene (n = 1,399) in groups of strains using the two-tailed Fisher exact test (46). The 87-field-isolate set was separated by source, and the number of absent and conserved genes between cattle and human isolates was compared on a gene-by-gene basis. Because of obvious clonality present in the data, it was then decided to analyze CGH clusters that might have the potential for niche adaptation. The comparative genomic hybridization clusters were combined based on their apparent affinity for either human or cattle hosts. The first group comprised CGH clusters composed mainly of cattle isolates (CGH1, CGH8, CGH10; 24 cattle and 3 human isolates) and designated “cattle enriched” (CGH CE). The second group was comprised of CGH clusters composed mainly of human isolates (CGH3, CGH5, CGH11, CGH13; 4 cattle and 20 human isolates) and designated “human enriched” (CGH HE). A third group, not used for analytical purposes, was comprised of CGH clusters composed of similar numbers of cattle and human isolates (CGH2, CGH4, CGH6, CGH7, CGH10; 14 cattle and 13 human isolates) and designated “intermediate” (CGH I) (Fig. 2). For each gene (n = 1,399), we tested the null hypothesis that there would be a similar distribution between CGH HE and CGH CE groups and the alternate hypothesis that the gene would have an unequal distribution between groups by using Fisher's exact test (P ≤ 0.05). Fisher's exact test P values from both of the above analyses (cattle versus human and CGH CE versus CGH HE) were adjusted for multiple comparisons using the Westfall and Young correction (WY; P ≤ 0.05) (49) based on 20,000 bootstrap resamplings (SAS version 9.2; SAS Institute, Inc., Cary, NC).
FIG. 2.

Distribution of human (light gray shading) and cattle (dark gray shading) C. jejuni isolates (n = 79; isolates that did not cluster are not shown) within all comparative genomic hybridization clusters and designation into HE or CE groups for gene association testing.
RESULTS
Assessment of clustering results using technical replicates.
Technical replicates were included in the study (Fig. 1). The inclusion of these arrays was a means of validating our data as replicate arrays should form clusters. Initially, 25 replicate sets were included in the analysis, representing 11 human and 12 cattle field isolates and two laboratory strains (NCTC 11168 and RM1221). The field isolates each had two replicates and the two laboratory strains (NCTC 11168 and RM1221) each had six replicates.
As expected, most replicate sets grouped within the same CGH cluster (22/25 sets). Three replicate pairs from three field isolates, however, did not group within the same CGH cluster, and these isolates were removed from all subsequent analyses. A dendrogram representing 119 arrays (87 field isolates: 67 with single arrays, 20 with duplicate arrays; two laboratory strains each with six replicate arrays) is shown in Fig. 3.
FIG. 3.

Dendrogram of validated C. jejuni technical replicates, laboratory strains, and field isolates. Heavy black branch lines indicate greater than 75% bootstrap support. Gray brackets join the 20 sets of field isolate replicates on the dendrogram. Boxes denote the two sets of laboratory strain replicates. There were 119 arrays.
Cluster analysis of human and cattle isolates.
Forty-one arrays from human C. jejuni isolates (24 male, 17 female; ages 1 to 81 years old) and 46 arrays from cattle C. jejuni isolates were included in the final study data set (Table 1). Of the 87 field isolates studied, eight isolates did not cluster with others, and isolate #4121 (CGH 7) clustered only with the RM1221 laboratory strain. Of the 13 CGH clusters identified, nine contained both human and cattle isolates, three contained only human isolates, and one contained only cattle isolates (Fig. 2 and 4; see also Table S1 in the supplemental material).
TABLE 1.
Human and feedlot cattle C. jejuni isolate information (order same as the dendrogram in Fig. 4)
| CGH clustera | Isolate no. | No. of replicates | Populationb | Seasonc | Feedlot or straind | RHA | Submission or sampling date | Gendere | Age (yr) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 773 | 1 | B | W | D | 1 | 25 Aug 2005 | − | − |
| 2106 | 1 | B | S | B | 1 | 25 Aug 2005 | − | − | |
| 2808 | 1 | B | S | G | 3 | 13 Sep 2005 | − | − | |
| 4151 | 0 | H | S | − | 3 | 5 Aug 2005 | M | 34 | |
| 2719 | 0 | B | S | F | 5 | 12 Sep 2005 | − | − | |
| 2046 | 0 | B | S | B | 1 | 25 Aug 2005 | − | − | |
| 1006 | 0 | B | W | F | 5 | 31 Jan 2005 | − | − | |
| 1046 | 0 | B | W | F | 5 | 31 Jan 2005 | − | − | |
| 1133 | 0 | B | W | F | 5 | 31 Jan 2005 | − | − | |
| 213 | 0 | B | W | B | 1 | 18 Jan 2005 | − | − | |
| 2 | 356 | 0 | B | W | B | 1 | 18 Jan 2005 | − | − |
| 4189 | 0 | H | S | − | 1 | 3 Jul 2005 | F | 43 | |
| 1302 | 1 | B | W | G | 3 | 1 Feb 2005 | − | − | |
| 1393 | 0 | B | W | G | 3 | 1 Feb 2005 | − | − | |
| 442 | 0 | B | W | C | 1 | 19 Jan 2005 | − | − | |
| 4197 | 1 | H | W | − | 1 | 7 Jan 2005 | F | 41 | |
| 4194 | 0 | H | W | − | 1 | 17 Dec 2004 | F | 30 | |
| NC | 4122 | 1 | H | W | − | 3 | 8 Nov 2004 | M | 57 |
| 3 | 4125 | 0 | H | W | − | 3 | 15 Nov 2004 | F | 74 |
| 4137 | 0 | H | W | − | 3 | 11 Jan 2005 | F | 1 | |
| 4 | 4145 | 0 | H | S | − | 3 | 1 Aug 2005 | M | 64 |
| 4332 | 0 | B | S | G | 3 | 13 Sep 2005 | − | − | |
| 84 | 1 | B | W | A | 2 | 17 Jan 2005 | − | − | |
| 4196 | 0 | H | W | − | 1 | 20 Dec 2004 | M | 23 | |
| 5 | 4147 | 0 | H | S | − | 3 | 2 Aug 2005 | F | 63 |
| 4153 | 1 | H | S | − | 3 | 7 Aug 2005 | M | 2 | |
| 4142 | 1 | H | S | − | 2 | 28 Jun 2005 | M | 50 | |
| 4186 | 1 | H | S | − | 1 | 29 Jun 2005 | M | 28 | |
| 4134 | 0 | H | W | − | 3 | 13 Dec 2004 | M | 81 | |
| 4138 | 0 | H | S | − | 2 | 5 Jul 2005 | F | 28 | |
| 2202 | 1 | B | S | E | 1 | 6 Sep 2005 | − | − | |
| 4199 | 0 | H | W | − | 1 | 12 Jan 2005 | F | 1 | |
| 4176 | 0 | H | S | − | 1 | 8 Jun 2005 | M | 19 | |
| 4132 | 0 | H | W | − | 3 | 6 Dec 2004 | M | 7 | |
| 4450 | 0 | B | S | G | 3 | 13 Sep 2005 | − | − | |
| 4123 | 0 | H | W | − | 3 | 14 Nov 2004 | F | 3 | |
| NCTC 11168 | 5 | Laboratory strain | |||||||
| 4143 | 0 | H | S | − | 2 | 1 Jun 2005 | M | 23 | |
| 697 | 0 | B | W | D | 1 | 24 Jan 2005 | − | − | |
| 4158 | 0 | H | S | − | 3 | 11 Aug 2005 | M | 40 | |
| NC | 4129 | 0 | H | W | − | 3 | 3 Dec 2004 | M | 23 |
| NC | 4195 | 0 | H | W | − | 1 | 19 Dec 2004 | M | 49 |
| 6 | 1645 | 0 | B | S | D | 1 | 22 Aug 2005 | − | − |
| 4163 | 1 | H | S | − | 3 | 15 Aug 2005 | F | 77 | |
| 4173 | 0 | H | S | − | 1 | 7 Jun 2005 | F | 34 | |
| 2603 | 0 | B | S | F | 5 | 12 Sep 2005 | − | − | |
| 4140 | 0 | H | S | − | 2 | 13 Sep 2005 | M | 43 | |
| 2650 | 0 | B | S | F | 5 | 12 Sep 2005 | − | − | |
| 7 | 4121 | 0 | H | W | − | 3 | 9 Dec 2004 | F | 64 |
| RM1221 | 5 | Laboratory strain | |||||||
| 8 | 2360 | 0 | B | S | E | 1 | 6 Sep 2005 | − | − |
| 2409 | 1 | B | S | A | 2 | 8 Sep 2005 | − | − | |
| 1676 | 1 | B | S | D | 1 | 22 Aug 2005 | − | − | |
| 4200 | 1 | H | W | − | 1 | 27 Jan 2005 | M | 3 | |
| 1716 | 0 | B | S | D | 1 | 22 Aug 2005 | − | − | |
| 4413 | 0 | B | S | G | 3 | 13 Sep 2005 | − | − | |
| 4190 | 0 | H | S | − | 1 | 5 Jul 2005 | M | 32 | |
| 2497 | 0 | B | S | A | 2 | 8 Sep 2005 | − | − | |
| 4330 | 0 | B | S | G | 3 | 13 Sep 2005 | − | − | |
| 2548 | 0 | B | S | A | 2 | 8 Sep 2005 | − | − | |
| NC | 2515 | 0 | B | S | A | 2 | 8 Sep 2005 | − | − |
| 9 | 1826 | 0 | B | S | C | 1 | 23 Aug 2005 | − | − |
| 2371 | 0 | B | S | E | 1 | 6 Sep 2005 | − | − | |
| 381 | 0 | B | W | B | 1 | 18 Jan 2005 | − | − | |
| 2326 | 0 | B | S | E | 1 | 6 Sep 2005 | − | − | |
| 4127 | 0 | H | W | − | 3 | 21 Nov 2004 | M | 47 | |
| 4128 | 0 | H | W | − | 3 | 22 Nov 2004 | M | 19 | |
| 4193 | 0 | H | W | − | 1 | 17 Dec 2004 | M | 57 | |
| 4141 | 0 | H | S | − | 2 | 11 Sep 2005 | F | 28 | |
| NC | 1243 | 0 | B | W | G | 3 | 1 Feb 2005 | − | − |
| 10 | 179 | 1 | B | W | A | 2 | 17 Jan 2005 | − | − |
| 2699 | 1 | B | S | F | 5 | 12 Sep 2005 | − | − | |
| 1016 | 0 | B | W | F | 5 | 31 Jan 2005 | − | − | |
| 321 | 0 | B | W | B | 1 | 18 Jan 2005 | − | − | |
| 875 | 0 | B | W | E | 1 | 25 Jan 2005 | − | − | |
| 100 | 1 | B | W | A | 2 | 17 Jan 2005 | − | − | |
| 791 | 0 | B | W | D | 1 | 24 Jan 2005 | − | − | |
| 11 | 4167 | 0 | H | S | − | 3 | 16 Aug 2005 | F | 25 |
| 4177 | 0 | H | S | − | 1 | 9 Jun 2005 | M | 18 | |
| 1888 | 0 | B | S | C | 1 | 23 Aug 2005 | − | − | |
| 4188 | 1 | H | S | − | 1 | 30 Jun 2005 | M | 45 | |
| 4149 | 0 | H | S | − | 3 | 3 Aug 2005 | F | 40 | |
| NC | 4198 | 0 | H | W | − | 1 | 9 Jan 2005 | F | 24 |
| 12 | 1111 | 0 | B | W | F | 5 | 31 Jan 2005 | − | − |
| 4170 | 1 | H | S | − | 3 | 26 Aug 2005 | F | 48 | |
| 13 | 4136 | 0 | H | W | − | 3 | 3 Jan 2005 | M | 33 |
| 4144 | 0 | H | S | − | 2 | 8 Aug 2005 | M | 47 | |
| NC | 122 | 0 | B | W | A | 2 | 17 Jan 2005 | − | − |
| NC | 4427 | 0 | B | S | G | 3 | 13 Sep 2005 | − | − |
n = 89 C. jejuni isolates (87 field and 2 laboratory strains). NC, isolates that did not cluster with any other field or laboratory strains.
B, bovine; H, human.
S, summer; W, winter.
-, not applicable.
M, male; F, female.
FIG. 4.
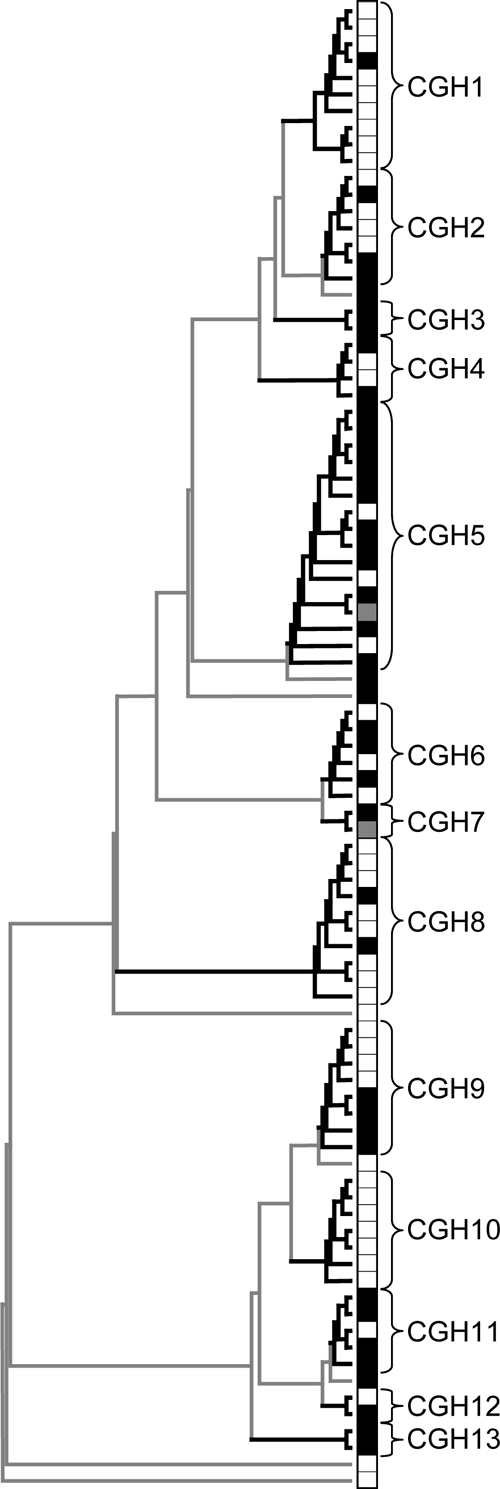
Global clustering dendrogram of feedlot cattle and human clinical C. jejuni isolates. Heavy black lines indicate greater than 75% bootstrap support. The figure includes 87 field isolate arrays (white squares indicate bovine isolates, and black squares indicate human isolates) and two laboratory strain arrays (gray squares).
Molecular epidemiological analysis of temporal distribution.
Nine of 13 CGH clusters contained C. jejuni isolates from both the summer and winter seasons, and of these, three clusters contained both cattle and human isolates from both winter and summer (Fig. 5). Further, five clusters (CGH 2, 5, 6, 9, and 11) contained both human and cattle isolates submitted/collected within 2-week time frames (Table 1).
FIG. 5.

Distribution of summer (n = 47) and winter (n = 40) feedlot cattle (n = 46) and human (n = 41) clinical C. jejuni isolates within all CGH clusters. NC, isolates that did not cluster with any other field or laboratory strains.
Molecular epidemiological analysis of geographical distribution.
Two or more feedlots were represented in 8 of the 13 CGH clusters, and 3 of the 13 CGH clusters contained cattle isolates from four or more feedlots (Fig. 6). Only one CGH cluster was composed of isolates from a single RHA (CGH3; n = 2). Another cluster, CGH7, contained a single field isolate and the laboratory strain RM1221 (one field and one laboratory strain). The other 11 CGH clusters contained isolates from two or more RHAs, and one cluster (CGH6) contained isolates from all four RHAs (Fig. 7).
FIG. 6.

Distribution of feedlots within all C. jejuni comparative genomic hybridization clusters. Legend at the right gives the feedlot designation. NC, isolates that did not cluster with any other field or laboratory strains. The figure includes feedlot cattle C. jejuni isolates only (n = 46).
FIG. 7.

Distribution of Alberta RHAs within all C. jejuni CGH clusters for cattle (n = 46) and humans (n = 41). NC, isolates that did not cluster with any other field or laboratory strains.
Gene association testing to compare cattle and human isolates.
The comparison of all human (n = 41) and cattle (n = 46) isolates originally identified 25 of 1,399 genes in our data set having an unequal distribution between the two groups (genes absent more in one group than the other, P ≤ 0.05). The WY correction was used to account for the testing of multiple comparisons and adjusted Fisher's exact test P values to minimize the possibility of false-positive results. In gene-by-gene comparisons of the cattle and human clinical C. jejuni isolates (with WY correction), only three genes were identified with statistically significant differences in presence/absence between the two groups: Cj0617, encoding a hypothetical protein; Cj0628, encoding a putative lipoprotein; and Cj1668, encoding a putative periplasmic protein. It was observed that seven CGH clusters were dominated by either cattle or human isolates (Fig. 2). We hypothesized that there could be potentially meaningful genetic differences between the human-dominated or cattle-dominated clusters and decided to investigate these source-biased groupings further. CGH clusters predominantly composed of human isolates (CGH HE) and those predominantly composed of cattle isolates (CGH CE) were compared using gene association testing. This focused cluster comparison identified 37 of 1,399 genes unequally distributed between these two groups using both Fisher's exact test and the WY correction (P ≤ 0.05) (Table 2).
TABLE 2.
Results of C. jejuni gene association testing for comparison of CGH CE and HE groupsa
| Gene | No. absent from CGH CE clusters (n = 27) | No. absent from CGH HE clusters (n = 24) | CGH CE vs HE P value
|
Gene product | |
|---|---|---|---|---|---|
| Unadjusted | WY | ||||
| Cj0202 | 27 | 14 | 0.00015 | 0.00210 | Hypothetical protein |
| Cj0300 | 19 | 24 | 0.00464 | 0.05000 | Putative molybdenum transport ATP-binding protein |
| Cj0302 | 16 | 24 | 0.00033 | 0.00400 | Putative molybdenum-pterin binding protein |
| Cj0303 | 11 | 24 | <0.00001 | <0.00001 | Putative molybdate-binding lipoprotein |
| Cj0304 | 15 | 24 | 0.00013 | 0.00135 | Putative biotin synthesis protein |
| Cj0399 | 17 | 24 | 0.00081 | 0.01145 | Colicin V production protein homolog |
| Cj0485 | 13 | 21 | 0.00352 | 0.03890 | Putative oxidoreductase |
| Cj0617 | 27 | 6 | <0.00001 | <0.00001 | Hypothetical protein |
| Cj0628 | 0 | 8 | 0.00116 | 0.01525 | Putative lipoprotein |
| Cj1051 | 2 | 12 | 0.00118 | 0.01555 | Restriction modification enzyme |
| Cj1136 | 3 | 16 | 0.00005 | 0.00055 | Putative glycosyltransferase |
| Cj1137 | 4 | 17 | 0.00006 | 0.00085 | Putative glycosyltransferase |
| Cj1138 | 5 | 17 | 0.00023 | 0.00325 | Putative glycosyltransferase |
| Cj1139 | 10 | 22 | 0.00010 | 0.00115 | β-1,3-Galactosyltransferase |
| Cj1140 | 9 | 19 | 0.00172 | 0.01970 | α-2,3-Sialyltransferase |
| Cj1141 | 3 | 17 | 0.00001 | 0.00005 | Sialic acid synthase (N-acetylneuraminic acid synthetase) |
| Cj1142 | 6 | 18 | 0.00023 | 0.00360 | Putative UDP-N-acetylglucosamine 2-epimerase |
| Cj1143 | 2 | 16 | 0.00002 | 0.00010 | Two-domain bifunctional protein (β-1,4-N-acetylgalactosaminyltransferase/CMP-Neu5Ac synthase) |
| Cj1144 | 6 | 16 | 0.00194 | 0.02315 | Hypothetical protein |
| Cj1145 | 5 | 16 | 0.00066 | 0.00885 | Coding sequence merged with Cj1144 |
| Cj1146 | 12 | 22 | 0.00038 | 0.00455 | Putative glucosyltransferase |
| Cj1150 | 19 | 24 | 0.00464 | 0.05000 | d-β-d-Heptose 7-phosphate kinase/d-β-d-heptose 1-phosphate adenylyltransferase |
| Cj1297 | 10 | 19 | 0.00424 | 0.04385 | Hypothetical protein |
| Cj1389 | 1 | 16 | <0.00001 | <0.00001 | Pseudogene (putative C4-dicarboxylate anaerobic carrier |
| Cj1421 | 6 | 18 | 0.00023 | 0.00360 | Putative sugar transferase |
| Cj1422 | 7 | 20 | 0.00006 | 0.00080 | Putative sugar transferase |
| Cj1428 | 10 | 20 | 0.00145 | 0.01710 | GDP-l-fucose synthetase |
| Cj1429 | 6 | 19 | 0.00007 | 0.00090 | Hypothetical protein |
| Cj1430 | 8 | 18 | 0.00191 | 0.02225 | Putative dTDP-4-dehydrorhamnose 3,5-epimerase |
| Cj1432 | 3 | 16 | 0.00005 | 0.00055 | Putative sugar transferase |
| Cj1433 | 2 | 17 | <0.00001 | <0.00001 | Hypothetical protein |
| Cj1434 | 5 | 19 | 0.00002 | 0.00025 | Putative sugar transferase |
| Cj1435 | 8 | 19 | 0.00105 | 0.01410 | Putative phosphatase |
| Cj1439 | 0 | 15 | <0.00001 | <0.00001 | UDP-galactopyranose mutase |
| Cj1440 | 6 | 16 | 0.00194 | 0.02315 | Putative sugar transferase |
| Cj1520 | 9 | 20 | 0.00054 | 0.00665 | Removed from coding sequences |
| Cj1729 | 1 | 13 | 0.00007 | 0.00150 | Flagellar hook subunit protein |
All genes are statistically significant (P ≤ 0.05) based on the unadjusted Fisher's exact test P values and the WY corrected P values; 1,399 genes were tested. The gene product information is from reference 14.
DISCUSSION
This study describes the use of DNA microarray as a high-resolution genotyping tool for the molecular epidemiological investigation of C. jejuni. This set of data represents the largest published comparison of human and feedlot cattle C. jejuni isolates using DNA microarrays and focuses on feedlot cattle because of their potential as Campylobacter reservoirs. The isolates tested by DNA microarray in this study were purposefully collected within a defined geographical and temporal framework in order to generate data on the presence and persistence of strains in feedlot cattle and people in Alberta.
Although the microarray-based CGH approach described is not used in routine molecular epidemiology due to high cost and low throughput compared to conventional genotyping methods, it has the potential to provide an unprecedented level of discriminatory power (10, 25, 44). In a recent study, CGH was able to differentiate C. jejuni strains within highly related multilocus sequence typing (MLST) profiles (45). Further, analysis by DNA microarray-based CGH has recently been shown to correlate with clonal complexes identified by MLST, the “gold standard” in molecular typing, in Streptococcus pneumoniae (6) and in C. jejuni (45). Data obtained from genomic DNA microarray studies can not only create high-resolution genetic profiles for global clustering but can also be directly applied in gene association studies to look at potential genotype-phenotype links. These advantages are reflected in a recent investigation of C. jejuni strains implicated in Guillain-Barré and Miller Fisher syndromes (46). In the past, finding associations using conventional molecular typing methods between neuropathogenic C. jejuni typing markers and clinical phenotypes has been difficult (9). With the use of data obtained from microarray-based CGH, it has been possible to extend applications beyond lineage diversity to successfully identify factors commonly shared by neuropathogenic strains using a gene association approach.
In our study, the global clustering of isolates based on whole-genome profiles identified a high degree of similarity between cattle and human C. jejuni isolates. The distribution of isolates from both sources within most of the 13 CGH clusters suggests that both people and cattle may have access to the same transmission routes. Nine out of 13 CGH clusters contained both bovine and human isolates, and within five clusters, genetic clones (isolates with high genomic similarity and belonging to the same CGH cluster) were identified from both cattle and people within very confined temporal periods (2 weeks). Often the C. jejuni isolates within a cluster represented multiple geographical regions and feedlots, both seasons, and both cattle and human sources. It is not known if human campylobacteriosis patients in our study had contact with feedlot cattle or were from urban or rural backgrounds. Specifically designed epidemiological studies would be required to link cattle contact to human cases. However, our findings, although indirect, suggest that the transmission of C. jejuni strains may be occurring between people and feedlot cattle and that the distribution of C. jejuni strains able to cause human disease may be widespread geographically.
Clonality was a prominent feature observed in our data set. One known campylobacteriosis outbreak occurred in RHA3 during the course of our study. However, isolates from this outbreak were not included in order to maximize genetic variability in our data set. CGH cluster 5, in which 12 of 15 field isolates were of human origin, was an important strain in the data set, as isolates with this genetic profile were persisting, widespread, and clearly pathogenic. Patients infected with this C. jejuni strain sought clinical care over a 44-week period (7 months) in three different RHAs. Our finding of clonal groups that were dominated by either human or cattle sources is consistent with MLST studies which have suggested that niche adaptation may play a role in the overrepresentation of sources within clonal groups (7, 8). While it is possible that sampling issues could play a role in our findings, some of the genotypic clusters identified in our study may represent phenotypic separations within the data set. It is plausible that C. jejuni, which is commensal in cattle but usually pathogenic in people, could have differential infection and colonization rates between host species based on differences in strain attributes or exposure patterns.
While global clustering gives an overview of the similarity between isolates, it does not specify which parts of the genomes are similar or different. The ability to mine microarray data using gene association testing, in addition to global clustering, is one of the main advantages of the DNA microarray platform. A limitation of the CGH technology is that it is not possible to identify novel genomic sequences when comparing strains; only known genes present on the microarray are evaluated. Even though only genes from the NCTC 11168 strain were incorporated, the microarray used in this study included several hundred genes with high intraspecies variability (43) which should achieve a level of resolution that surpasses that of the current conventional typing method. Future studies using “pan-genomic” microarrays containing genes from multiple C. jejuni strains would allow relationships among isolates to be explored with even greater levels of accuracy and resolution.
Our comparison of human and bovine C. jejuni isolates using gene association testing identified only three of 1,399 genes with statistically significant differences in conservation rates between sources. Because it is possible that the small number of genes identified resulted from confounding factors or lack of power, in addition to similarity between human and cattle isolates, it was decided to explore source-biased clusters more thoroughly. Our comparison of CE and HE clusters identified 37 of 1,399 genes with unequal distribution between these clonal groupings. This still represents a very small number of differences and supports the overall similarity between human and cattle isolates. Interestingly, some genes identified with unequal conservation rates using gene association testing are involved in the biosynthesis of lipooligosaccharide (LOS) and capsular polysaccharide (CPS). In contrast with the strains from the CE clusters, a high proportion of strains from the HE clusters generated little to no hybridization signal to some of the LOS and CPS genes represented in the microarray. These human strains likely contained a combination of sequence variants and/or genes that were unique to specific CPS (23) or LOS (36) types and different from those present in the NCTC 11168 strain used to construct the array. The concept of feedlot niche adaptation may be plausible based on our findings of clonal groupings dominated by particular host sources and is interesting, from an epidemiological perspective, as the genetic composition of different clonal strains may have potential clinical relevance.
The feedlot environment seems a dynamic and important niche in the epidemiology of campylobacters. Our results supported our expectation that C. jejuni strains collected within a feedlot would be similar and would group within the same CGH cluster. Seven CGH clusters were found to contain two or more isolates from the same feedlot. However, it was surprising that individual feedlots contained so many genetically diverse strains. Three or more strains (CGH clusters) were identified within each of the seven feedlots. Multiple strains within each feedlot niche are most likely the result of a combination of influences, including human, wild bird, insect, other reservoir host, fomite, and water exposures. Further, clones from both the winter and summer collections were identified within individual feedlots (B and F). Our findings suggest that some genotypic clones can persist over the course of the year in the feedlot environment and that C. jejuni genomic profiles are relatively stable and not undergoing major recombination events. They also suggest that cattle may be exposed to multiple strains of C. jejuni over time.
Human samples were acquired from diagnostic laboratories within three RHAs in Alberta. As protocols for C. jejuni isolation are not standardized across the province, it is possible that a variety of isolation methods were used for the human isolations and that these were different from protocols for the isolation of bovine strains. This may have resulted in selection pressure for certain strains based on the isolation conditions used, resulting in an underrepresentation of isolate genetic variability.
Both cattle and human isolates were collected in winter and summer 2005 from three geographical areas (RHA 1, 2, and 3) in Alberta. In order to include more bovine isolates, cattle in a fourth area (RHA 5) were sampled over the same time frame. The clustering of C. jejuni strains did not seem to be influenced by season, as 9 of 13 CGH clusters contained isolates from both the summer and winter. The RHA was also not a segregating factor, as 11 of 13 CGH clusters contained C. jejuni isolates from two or more RHAs. These findings suggest that the movement of strains between the different geographical regions may be occurring and common within the province.
Alberta patients are provided with medical treatment, including laboratory services, under Canada's universal, publicly insured health care plan. Community and hospital physician services are accessed within RHAs, and while patients have the option to access these services outside of RHAs, the majority of primary care and laboratory services are accessed within the RHA of residence. While it was assumed that the RHA submitting the human isolate was the same region in which the patient lived, it is possible that regional misclassification may have occurred if the patient saw a physician outside of their area of residence or if the samples were sent to diagnostic laboratories in a different RHA.
This study used the DNA microarray as a platform to investigate C. jejuni isolates from feedlot cattle and people in Alberta. From our experience and based on time, labor, and cost factors, conducting whole-genome CGH studies using the DNA microarray platform is likely not conducive for time-sensitive outbreak investigation or detection surveys. As a result, the DNA microarray may be advantageous for use in molecular epidemiological contexts that require comprehensive genetic data but not immediate reporting. Further, the advantages of DNA microarray technology in generating high-resolution data useful for both global clustering and gene association studies represent significant added value compared to those of other molecular typing techniques (45, 46). The present molecular study enabled the description of genetic variability between human and cattle isolates, both globally and gene by gene. Study isolates clustered regardless of temporal or geographical frameworks, suggesting that C. jejuni strains may be endemic and stable over time. Further, the common distribution of human clinical and bovine C. jejuni isolates within the same genetically based clusters suggests that dynamic and important transmission routes between cattle and human populations in Alberta may exist.
Supplementary Material
Acknowledgments
Financial support for this study has been provided by the Agriculture Council of Saskatchewan through the Advancing Canadian Agriculture and Agri-Food Saskatchewan (ACAAFS) program. Funding for the ACAAFS program is provided by Agriculture and Agri-Food Canada. We also gratefully acknowledge funding and support from the Natural Sciences and Engineering Research Council (NSERC; A.P. holds an NSERC senior industrial research chair in food and water safety vaccines), B.C. Cattlemen's Association, Vétoquinol, and Western College of Veterinary Medicine interprovincial graduate student fellowship.
Special thanks to P. Tilley and S. Cook (Alberta Provincial Laboratory of Public Health), the diagnostic laboratory and administrative staff from the Calgary, Chinook and Palliser RHAs, K. Hokamp (ArrayPipe), M. Eliasziw (Department of Community Health Sciences, University of Calgary), and C. Reiman, G. Crockford, and N. Rawlyk (VIDO) for technical assistance.
Footnotes
Published ahead of print on 26 November 2008.
Supplemental material for this article may be found at http://jcm.asm.org/.
REFERENCES
- 1.Adhikari, B., J. H. Connolly, P. Madie, and P. R. Davies. 2004. Prevalence and clonal diversity of Campylobacter jejuni from dairy farms and urban sources. N. Z. Vet. J. 52378-383. [DOI] [PubMed] [Google Scholar]
- 2.Besser, T. E., J. T. LeJeune, D. H. Rice, J. Berg, R. P. Stilborn, K. Kaya, W. Bae, and D. D. Hancock. 2005. Increasing prevalence of Campylobacter jejuni in feedlot cattle through the feeding period. Appl. Environ. Microbiol. 715752-5758. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.CanFax Research Services. 2008. Statistical briefer. CanFax Research Services, Calgary, Alberta, Canada. http://www.canfax.ca/general/StatBrf.pdf.
- 4.Champion, O. L., M. W. Gaunt, O. Gundogdu, A. Elmi, A. A. Witney, J. Hinds, N. Dorrell, and B. W. Wren. 2005. Comparative phylogenomics of the food-borne pathogen Campylobacter jejuni reveals genetic markers predictive of infection source. Proc. Natl. Acad. Sci. USA 4416043-16048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Colles, F. M., K. Jones, R. M. Harding, and M. C. J. Maiden. 2003. Genetic diversity of Campylobacter jejuni isolates from farm animals and the farm environment. Appl. Environ. Microbiol. 697409-7413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Dagerhamn, J., C. Blomberg, S. Browall, K. Sjostrom, E. Morfeldt, and B. Henriques-Normark. 2008. Determination of accessory gene patterns predicts the same relatedness among strains of Streptococcus pneumoniae as sequencing of housekeeping genes does and represents a novel approach in molecular epidemiology. J. Clin. Microbiol. 46863-868. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Dingle, K. E., F. M. Colles, D. R. A. Wareing, R. Ure, A. J. Fox, F. E. Bolton, H. J. Bootsma, R. J. L. Willems, R. Urwin, and M. C. J. Maiden. 2001. Multilocus sequence typing system for Campylobacter jejuni. J. Clin. Microbiol. 3914-23. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Dingle, K. E., and M. C. J. Maiden. 2005. Population genetics of Campylobacter jejuni, p. 43-57. In J. M. Ketley and M. E. Konkel (ed.), Campylobacter: molecular and cellular biology. Horizon Bioscience, Norfolk, United Kingdom.
- 9.Dingle, K. E., N. van den Braak, F. M. Colles, L. J. Price, D. L. Woodward, F. G. Rodgers, H. P. Endtz, A. van Belkum, and M. C. J. Maiden. 2001. Sequence typing confirms that Campylobacter jejuni strains associated with Guillain-Barré and Miller-Fisher syndromes are of diverse genetic lineage, serotype, and flagella type. J. Clin. Microbiol. 393346-3349. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Dorrell, N., S. J. Hinchliffe, and B. W. Wren. 2005. Comparative phylogenomics of pathogenic bacteria by microarray analysis. Curr. Opin. Microbiol. 8620-626. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Dorrell, N., J. A. Mangan, K. G. Laing, J. Hinds, D. Linton, H. Al-Ghusein, B. G. Barrell, J. Parkhill, N. G. Stoker, A. V. Karlyshev, P. D. Butcher, and B. W. Wren. 2001. Whole genome comparison of Campylobacter jejuni human isolates using a low-cost microarray reveals extensive genetic diversity. Genome Res. 111706-1715. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Eisen, M. B., P. T. Spellman, P. O. Brown, and D. Botstein. 1998. Cluster analysis and display of genome-wide expression patterns. Proc. Natl. Acad. Sci. USA 9514863-14868. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Government of Alberta. 2005. Public health notifiable disease management guidelines—campylobacteriosis. Alberta Health and Wellness, Government of Alberta, Edmonton, Alberta, Canada. http://www.health.alberta.ca/documents/ND-Campylobacteriosis.pdf.
- 14.Gundogdu, O., S. D. Bentley, M. T. Holden, J. Parkhill, N. Dorrell, and B. W. Wren. 2007. Re-annotation and re-analysis of the Campylobacter jejuni NCTC11168 genome sequence. BMC Genomics 8162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Hannon, S. J., B. Allan, C. Waldner, M. L. Russell, A. Potter, L. Babiuk, and H. G. G. Townsend. Prevalence and risk factor investigation of Campylobacter species and Campylobacter jejuni in beef cattle feces from seven large commercial feedlots in Alberta, Canada. Can. J. Vet. Res., in press. [PMC free article] [PubMed]
- 16.Hokamp, K., F. M. Roche, M. Acab, M-E. Rousseau, B. Kuo, D. Goode, D. Aeschliman, J. Bryan, L. A. Babiuk, R. E. W. Hancock, and F. S. L. Brinkman. 2004. ArrayPipe: a flexible processing pipeline for microarray data. Nucleic Acids Res. 32W457-W459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Humphrey, T., S. O'Brien, and M. Madsen. 2007. Campylobacters as zoonotic pathogens: a food production perspective. Int. J. Food Microbiol. 117237-257. [DOI] [PubMed] [Google Scholar]
- 18.Inglis, G. D., L. D. Kalischuk, and H. W. Busz. 2003. A survey of Campylobacter species shed in feces of beef cattle using polymerase chain reaction. Can. J. Microbiol. 49655-661. [DOI] [PubMed] [Google Scholar]
- 19.Inglis, G. D., L. D. Kalischuk, and H. W. Busz. 2004. Chronic shedding of Campylobacter species in beef cattle. J. Appl. Microbiol. 97410-420. [DOI] [PubMed] [Google Scholar]
- 20.Inglis, G. D., T. A. McAllister, H. W. Busz, L. J. Yanke, D. W. Morck, M. E. Olson, and R. R. Read. 2005. Effects of subtherapeutic administration of antimicrobial agents to beef cattle on the prevalence of antimicrobial resistance in Campylobacter jejuni and Campylobacter hyointestinalis. Appl. Environ. Microbiol. 713872-3881. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Inglis, G. D., D. W. Morck, T. A. McAllister, T. Entz, M. E. Olson, L. J. Yanke, and R. R. Read. 2006. Temporal prevalence of antimicrobial resistance in Campylobacter spp. from beef cattle in Alberta feedlots. Appl. Environ. Microbiol. 724088-4095. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Johnsen, G., K. Zimmerman, B.-A. Lindstedt, T. Vardund, H. Herikstad, and G. Kapperud. 2006. Intestinal carriage of Campylobacter jejuni and Campylobacter coli among cattle from south-western Norway and comparative genotyping of bovine and human isolates by amplified-fragment length polymorphism. Acta Vet. Scand. 484. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Karlyshev, A. V., O. L. Champion, C. Churcher, J.-R. Brisson, H. C. Jarrell, M. Gilbert, D. Brochu, F. St. Michael, J. Li, W. W. Wakarchuk, I. Goodhead, M. Sanders, K. Stevens, B. White, J. Parkhill, B. W. Wren, and C. M. Szymanski. 2005. Analysis of Campylobacter jejuni capsular loci reveals multiple mechanisms for the generation of structural diversity and the ability to form complex heptoses. Mol. Microbiol. 5590-103. [DOI] [PubMed] [Google Scholar]
- 24.Leonard, E. E., II, T. Takata, M. J. Blaser, S. Falkow, L. S. Tompkins, and E. C. Gaynor. 2003. Use of an open-reading frame-specific Campylobacter jejuni DNA microarray as a new genotyping tool for studying epidemiologically related isolates. J. Infect. Dis. 187691-694. [DOI] [PubMed] [Google Scholar]
- 25.Leonard, E. E., II, L. S. Tompkins, S. Falkow, and I. Nachamkin. 2004. Comparison of Campylobacter jejuni isolates implicated in Guillain-Barré syndrome and strains that cause enteritis by a DNA microarray. Infect. Immun. 721199-1203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Manning, G., C. G. Dowson, M. C. Bagnall, I. H. Ahmed, M. West, and D. G. Newell. 2003. Multilocus sequence typing for comparison of veterinary and human isolates of Campylobacter jejuni. Appl. Environ. Microbiol. 696370-6379. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Michaud, S., S. Menard, and R. D. Arbeit. 2005. Role of real-time molecular typing in the surveillance of Campylobacter enteritis and comparison of pulsed-field gel electrophoresis profiles from chicken and human isolates. J. Clin. Microbiol. 431105-1111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Moore, J. E., D. Corcoran, J. S. Dooley, S. Fanning, B. Lucey, M. Matsuda, D. A. McDowell, F. Megraud, B. C. Millar, R. O'Mahony, L. O'Riordan, M. O'Rourke, J. R. Rao, P. J. Rooney, A. Sails, and P. Whyte. 2005. Campylobacter. Vet. Res. 36351-382. [DOI] [PubMed] [Google Scholar]
- 29.Morris, G. K., M. R. El Sherbeeny, C. M. Patton, H. Kodaka, G. L. Lombard, P. Edmonds, D. G. Hollis, and D. J. Brenner. 1985. Comparison of four hippurate hydrolysis methods for identification of thermophilic Campylobacter spp. J. Clin. Microbiol. 22714-718. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Murphy, C., C. Carroll, and K. N. Jordan. 2006. Environmental survival mechanisms of the foodborne pathogen Campylobacter jejuni. J. Appl. Microbiol. 100623-632. [DOI] [PubMed] [Google Scholar]
- 31.Nielsen, E. M., J. Engberg, V. Fussing, L. Petersen, C.-H. Brogren, and S. L. W. On. 2000. Evaluation of phenotypic and genotypic methods for subtyping Campylobacter jejuni isolates from humans, poultry, and cattle. J. Clin. Microbiol. 383800-3810. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Nielsen, E. M., J. Engberg, and M. Madsen. 1997. Distribution of serotypes of Campylobacter jejuni and C. coli from Danish patients, poultry, cattle and swine. FEMS Immunol. Med. Microbiol. 1947-56. [DOI] [PubMed] [Google Scholar]
- 33.Nielsen, E. M., V. Fussing, J. Engberg, N. L. Nielsen, and J. Neimann. 2005. Most Campylobacter subtypes from sporadic infections can be found in retail poultry products and food animals. Epidemiol. Infect. 134758-767. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.On, S. L., N. Dorrell, L. Petersen, D. D. Bang, S. Morris, S. J. Forsythe, and B. W. Wren. 2006. Numerical analysis of DNA microarray data of Campylobacter jejuni strains correlated with survival, cytolethal distending toxin and haemolysin analyses. Int. J. Med. Microbiol. 296353-363. [DOI] [PubMed] [Google Scholar]
- 35.Page, R. D. 1996. TreeView: an application to display phylogenetic trees on personal computers. Comput. Appl. Biosci. 12357-358. [DOI] [PubMed] [Google Scholar]
- 36.Parker, C. T., S. T. Horn, M. Gilbert, W. G. Miller, D. L. Woodward, and R. E. Mandrell. 2005. Comparison of Campylobacter jejuni lipooligosaccharide biosynthesis loci from a variety of sources. J. Clin. Microbiol. 432771-2781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Parker, C. T., B. Quinones, W. G. Miller, S. T. Horn, and R. E. Mandrell. 2006. Comparative genomic analysis of Campylobacter jejuni strains reveals diversity due to genomic elements similar to those present in C. jejuni strain RM1221. J. Clin. Microbiol. 444125-4135. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Parkhill, J., B. W. Wren, K. Mungall, J. M. Ketley, C. Churcher, D. Basham, T. Chillingworth, R. M. Davies, T. Feltwell, S. Holryd, K. Jagels, A. V. Karlyshev, S. Moule, M. J. Pallen, C. W. Penn, M. A. Quail, M.-A. Rajandream, K. M. Rutherford, A. H. M. van Vliet, S. Whitehead, and B. G. Barrell. 2000. The genome sequence of the food-borne pathogen Campylobacter jejuni reveals hypervariable sequences. Nature 403665-668. [DOI] [PubMed] [Google Scholar]
- 38a.Public Health Agency of Canada. 1 October 2007, posting date. Notifiable diseases summary (preliminary) (concluded): new cases report from 1 October to 31 December 2006. Can. Communicable Dis. Rep. 3333-34. http://www.phac-aspc.gc.ca/publicat/ccdr-rmtc/07pdf/cdr3311.pdf. [PubMed] [Google Scholar]
- 39.Saeed, A. I., V. Sharov, J. White, J. Li, W. Liang, N. Bhagabati, J. Braisted, M. Klapa, T. Currier, M. Thiagarajan, A. Sturn, M. Snuffin, A. Rezantsev, D. Popov, A. Ryltsov, E. Kostukovich, I. Borisovsky, Z. Liu, A. Vinsavich, and J. Quackenbush. 2003. TM4: a free, open-source system for microarray data management and analysis. BioTechniques 34374-378. [DOI] [PubMed] [Google Scholar]
- 40.Statistics Canada. 2006. Farm cash receipts: agriculture economics statistics, May 2006. Farm Income and Prices Section, Agriculture Division, Statistics Canada, Ottawa, Ontario, Canada. http://www.statcan.ca/english/freepub/21-011-XIE/21-011-XIE2006001.pdf.
- 41.Statistics Canada. 2007. Population by year, by province, by territory. CANSIM Table 051-001. Statistics Canada, Ottawa, Ontario, Canada. http://www40.statcan.gc.ca/l01/cst01/demo02a-eng.htm.
- 42.Reference deleted.
- 43.Taboada, E. N., R. R. Acedillo, C. D. Carrillo, W. A. Findlay, D. T. Medeiros, O. L. Mykytczuk, M. J. Roberts, C. A. Valencia, J. M. Farber, and J. H. E. Nash. 2004. Large-scale comparative genomics meta-analysis of Campylobacter jejuni isolates reveals low level of genome plasticity. J. Clin. Microbiol. 424566-4576. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Taboada, E. N., C. C. Luebbert, and J. H. E. Nash. 2007. Studying bacterial genome dynamics using microarray-based comparative genomic hybridization, p. 223-254. In N. H. Bergman (ed.), Methods in molecular biology. Human Press, Inc., Totowa, NJ. [DOI] [PubMed]
- 45.Taboada, E. N., J. M. MacKinnon, C. C. Luebbert, V. P. J. Gannon, J. H. E. Nash, and K. Rahn. 2008. Comparative genomic assessment of multi-locus sequence typing: rapid accumulation of genomic heterogeneity among clonal isolates of Campylobacter jejuni. BMC Evol. Biol. 8229. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Taboada, E. N., A. van Belkum, N. Yuki, R. R. Acedillo, P. C. R. Godschalk, M. Koga, H. P. Endtz, M. Gilbert, and J. H. E. Nash. 2007. Comparative genomic analysis of Campylobacter jejuni associated with Guillain-Barré and Miller Fisher syndromes: neuropathogenic and enteritis-associated isolates can share high levels of genomic similarity. BMC Genomics 8359. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Taboada, E. N., R. R. Acedillo, C. C. Luebbert, W. A. Findlay, and J. H. Nash. 2005. A new approach for the analysis of bacterial microarray-based comparative genomic hybridization: insights from an empirical study. BMC Genomics 678. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Wang, G., C. G. Clark, T. M. Taylor, C. Pucknell, C. Barton, L. Price, D. Woodward, and F. G. Rodgers. 2002. Colony multiplex PCR assay for identification and differentiation of Campylobacter jejuni, C. coli, C. lari, C. upsaliensis, and C. fetus subsp. fetus. J. Clin. Microbiol. 404744-4747. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Westfall, P. H., and S. S. Young. 1993. Resampling-based multiple testing: examples and methods for p-value adjustment. John Wiley & Sons, Inc., New York, NY.
- 50.Wilson, K., F. M. Ausubel, R. Brent, and R. E. Kingston. 1987. Preparation of genomic DNA from bacteria, p. 2.4.1-2.4.2. In Current protocols in molecular biology. John Wiley and Sons, New York, NY. [DOI] [PubMed]
- 51.Ziprin, R. L., C. L. Sheffield, M. E. Hume, D. L. J. Drinnon, and R. B. Harvey. 2003. Cecal colonization of chicks by bovine-derived strains of Campylobacter. Avian Dis. 471429-1433. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.