

Abstract
We study semiparametric varying-coefficient partially linear models when some linear covariates are not observed, but ancillary variables are available. Semiparametric profile least-square-based estimation procedures are developed for parametric and nonparametric components after we calibrate the error-prone covariates. Asymptotic properties of the proposed estimators are established. We also propose the profile least-square-based ratio test and Wald test to identify significant parametric and nonparametric components. To improve accuracy of the proposed tests for small or moderate sample sizes, Wild bootstrap version is also proposed to calculate the critical values. Intensive simulation experiments are conducted to illustrate the proposed approaches.
Keywords: Ancillary variables, de-noise linear model, errors-in-variable, profile least-square-based estimator, rational expectation model, validation data, Wild bootstrap
1 Introduction
Various efforts have been made to balance the interpretation of linear models and flexibility of nonparametric models. Important results from these efforts include semiparametric varying-coefficient partially linear models (SVCPLM), in which the response variable Y depends on variables Z, X and U in the form of
| (1.1) |
where Θ is a p-dimensional vector of unknown parameters, α(·) is a q-variate vector of unknown functions, U is a vector of nonparametric components, which may be multivariate, and the model error ε has mean zero and finite variance. For notational simplicity, we assume that U is scalar. αT(U)X is referred to as a nonparametric component since α(U) is nonparametric.
Model (1.1) permits the interaction between the covariates U and X in such a way that a different level of covariate U is associated with a different linear model about ΘTZ, and allows one to examine the extent to which covariates X interact. This model presents a novel and general structure, which indeed covers many well-studied important semiparametric regression models. For example, when Z = 0, (1.1) reduces to varying-coefficient models, which were originally proposed by Hastie and Tibshirani (1993), and studied by Fan and Zhang (1999), Xia and Li (1999), and Cai, Fan and Li (2000). When q = 1 and X = 1, model (1.1) reduces to well-known partially linear models, in which Y depends on Z in a linear way but is related to another independent variable U in an unspecified form. There is a great deal of literature on the study of partially linear models (e.g., Engle et al., 1986;, Robinson, 1988; and Speckman, 1988). A survey of partially linear models was given by Härdle, Liang and Gao (2000). The study of SVCPLM has been investigated by Zhang, Lee and Song (2002), and Fan and Huang (2005) among others. Zhang, Lee and Song (2002) developed the procedures for estimation of the linear and nonparametric parts of the SVCPLM. Fan and Huang (2005) proposed a profile likelihood technique for estimating parametric components and established the asymptotic normality of their proposed estimator.
All studies of the SVCPLM are limited to considerations of exactly observed data. However, in biomedical research observations are measured with error. Simply ignoring measurement errors, known as the naive method, will result in biased estimators. Various attempts have been made to correct for such bias, see Fuller (1987) and Carroll et al. (2006) for extensive discussions and examples of linear and nonlinear models with measurement errors. In this paper, we are concerned with the situation where some components (ξ) of Z are unobserved directly, but auxiliary information is available to remit ξ. Let Z = (ξT, WT)T, where ξ is a p1 × 1 vector and W is a vector of the remaining observed components. We assume that ξ is related to observed η and V through the relationship ξ = E(η|V). Thus, we study the following model
| (1.2) |
where E(ε|Z, X, U) = 0, E(ε2|Z, X, U) = σ2(Z, X, U), and e is an error with mean zero and positive finite covariance matrix Σe = E(eeT). The four covariates V, W, X and U are different. In our structure, we allow that V and (X, W, U) may overlap. Model (1.2) is flexible enough to include a variety of models of interest. We give three examples to illustrate its flexibility.
Example 1.1
(Errors-in-variable models with validation data) Z is a p-variate variable vector and is not observed. Z̃ is an another p-variate vector and is observed associated with vector Z. Assume that we have primary observations {Yj, Z̃j, Uj, j = 1, ···, n}, and n0 independent validation observations {Zj, Z̃j, Ui, i = n + 1, ···, n + n0}, which are independent of the primary observations. Let V = (Z̃T, U)T. The partial errors-in-variable model with validation data is written as
| (1.3) |
This model has been studied by Sepanski and Lee (1995), Sepanski and Carroll (1993), and Sepanski, Knickerbocker and Carroll (1994). Taking X = 1, θ = 0, η = Z, and ξ = E(Z|V) in model (1.2), we know that model (1.3) is a sub-model of (1.2).
Example 1.2
(De-noise linear model) The relation between the response variable Y and covariates (ξ, W) is described by Y = βTξ + θTW + ε, where β and θ are parametric vectors respectively. The covariate ξ is measured with error since instead of observing ξ directly we observe its surrogate η. This forms a de-noise linear model:
| (1.4) |
where ξ = ξ(t) is subject to measurement error at time t and the measurement errors ε and e are independent of each other at each time t.
Cai, Naik and Tsai (2000) used this model to estimate the relationship between awareness and television rating points of TV commercials for certain products. Cui, He and Zhu (2002) proposed an estimator of the coefficients and established asymptotic results of the proposed estimator. It is easy to see that model (1.2) embeds (1.4).
Example 1.3
(Rational expectation model) Consider the following rational expectation model:
| (1.5) |
where ηt − E(ηt|Vt) is the expectation payoff for price variable ηt given historical information Vt. In this model, (Yt, St, ηt, Vt) except E(ηt|Vt) can be observed directly.
Beside estimation and inference of γ and ζ, within the econometric community, the following model is of interest.
| (1.6) |
It is worthy to note that model (1.6) is a sub-model of (1.2). An interesting question is to test whether the model (1.6) satisfies the rational expectation model (1.5), that is to test following hypothesis:
| (1.7) |
In the econometric literature, regressing unobserved covariates is also called generated regression. This topic has been widely studied. Pagan (1984) gave a comprehensive review on the estimation of parametric models with generated regression. Ai and Mcfadden (1997) presented a procedure for analyzing a partially specified nonlinear regression model in which the nuisance parameter is an unrestricted function of a subset of regressors. Ahn and Powell (1993) and Powell (1987) considered the case with the generated regressors in the nonparametric part of the model. Li (2002) considered the problems of estimating a semiparametric partially linear model for dependent data with generated regressors. Their models are special cases of the rational expectation model.
Various procedures similar to generated regression have been proposed to reduce the bias due to mis-measurement. Regression calibration and simulation extrapolation have been developed for measurement errors models (Carroll et al., 2006). Liang, Härdle and Carroll (1999) studied a special case of (1.2), partially linear errors-in-variables models, and proposed an attenuated estimator of the parameter based on the semiparametric likelihood estimate. Wang and Pepe (2000) used a pseudo-expected estimating equation method to estimate the parameter in order to correct the estimation bias.
In an attempt to develop a unified estimation procedure for model (1.2), we propose a profile-based procedure, which is similar to regression calibration method in spirit. The procedure consists of two steps. In the first step, we calibrate the error-prone covariate ξ by using ancillary information and applying nonpara-metric regression techniques. In the second step, we use profile least-square-based principle for estimating the parametric and nonparametric components. Under the mild assumptions, we derive the asymptotic representives of the proposed estimators, and use the representives to establish asymptotic normality. We also propose the profile least-square-based ratio test and Wald test for the parametric part of model (1.2), and a goodness-of-fit test for the varying coefficients in the nonparametric part. The asymptotic distribution of the proposed test statistics is derived. Wild bootstrap versions are introduced to calculate the critical values for those tests.
The paper is organized as follows. In Section 2, we focus on the estimation of the parameters and nonparametric functions, and on the development of asymptotic properties of the resulting estimators. The error-prone covariates are first calibrated. Bandwidth selection strategy is also discussed. In Section 3, we develop profile least-square-based ratio tests for parametric and nonparametric components. Wild bootstrap methods are proposed to calculate the critical values. The results of applications to simulated and real data are reported in Section 4. Section 5 gives a conclusion. Regularity assumptions and technical proofs are relegated to the Appendix.
2 Estimation of the parametric and nonparametric components
When ξ is observed, estimators of β and α(u), and associated tests have been developed to study model (1.2). These estimators and tests cannot be used directly when ξ is unobservable. We first need to calibrate ξ by using ancillary variables and V because a direct replacement of ξ by η will result in bias.
2.1 Covariate calibration
For notational simplicity, we assume V is univariate in the remainder of this paper. Let ηi,k be the kth entry of vector η, and Lb(·) = L(·/b)/b, b = bk (k = 1, 2, ···, p1) is a bandwidth for the kth component of η. Assume throughout the paper that ξk(υ) has r + 1 derivatives and we approximate ξk(υ) by a r-order polynomial within the neighborhood of υ0 via Taylor expansion
Denote
Wυ = diag{Lb(V1 − υ), ···, Lb(Vn − υ)}. The local polynomial estimator (Fan and Gijble, 1996) of (a0,k, …, ar,k)T can be expressed as . As a consequence, ξk(v) is estimated by , for k = 1, …, p1, where ζ1 is a (r + 1) × 1 vector with 1 in the first position and 0 in other positions.
In what follows, we denote A⊗2 = AAT, μj = ∫ ujL(u)du, νj = ∫ ujL2(u)du, Su = (μj+l)0≤j,l≤r, and cp = (μr+1, ···, μ2r+1)T. fυ(υ) is the density function of V.
Under the assumptions given in the Appendix, we can prove (Fan and Gijbels, 1996, pp 101–103 or Carroll et al., 1997, pp 486) that
| (2.1) |
uniformly on υ ∈
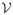 . This fact will be used for proving the main results in the Appendix.
. This fact will be used for proving the main results in the Appendix.
2.2 Estimation of the parametric component
Let (Yi, ηi, Vi, Wi, Xi, Ui), i = 1, 2 ···, n, be the observations from model (1.2). The unknown covariates ξi are substituted by their estimators given in the above section. We therefore have following “new” model:
| (2.2) |
where are still treated as errors. If ξ̂i would be an unbiased estimator of ξi, then Eε̂i = 0.
Approximate αj(U) within the neighbors of u by aj(u) + bj(u)(U − u) for j = 1, …, q. Write and Θ = (βT, θT)T. Following the profile likelihood based procedure proposed by Fan and Huang (2005), our profile least-square-based estimator of Θ is defined as
| (2.3) |
where Z̃ = (I − S)Ẑ, I is the n × n identity matrix,
and Y = (Y1, …, Yn)T, Wu = diag{Kh(U1 − u), …, Kh(Un − u)}n×n, Ẑ = (Ẑ1, ···, Ẑn)T, 0q is the q×1 vector with all the entries being zero, K(·) is a kernel function, h is a bandwidth and Kh(·) = K(·/h)/h.
We now give a representation of Θ̂n. This representation can be used to obtain the asymptotic distribution of , which we give in Theorem 2. This result extends the method of Fan and Huang (2005) to a SVCPLM with generated regressors.
Write Φ(U) = E(XZT|U), Γ(U) = E(XXT|U), B(V) = E[{Z − ΦT(U)Γ−1(U)X}|V], ψ(Z, X, U) = Z − ΦT(U)Γ−1(U)X, and Σ = E(ZZT) − E{ΦT(U) Γ−1(U)Φ(U)}.
Theorem 1
Under Assumptions 1–5 in Appendix, we have
where .
Theorem 2
Let nb2(r+1) → 0. Under Assumptions 1–5 in Appendix, converges to a normal distribution with mean zero and covariance matrix Σ1, where Σ1= Σ−1DΣ−1,
Furthermore, if e is independent of ε given (Z, X, U, V), and ε is independent of (Z, X, U), the asymptotic covariance can be simplified as Σ−1(σ2Σ + E[(eTβ)2{B(V)}⊗2])Σ−1. If e is also independent of V, the asymptotic covariance can further be simplified as σ2Σ−1 + βTΣeβΣ−1E{B(V)⊗2Σ−1.
The proof of Theorem 2 can be completed by using Theorem 1. We omit the details.
The asymptotic variance has a similar structure to that of Das (2005). The first term of asymptotic variance can be viewed as the variance from the first stage estimation without measurement error/missing data, the second one is the variance of the second stage for estimating unobserved variable and the third one is the covariance of two stage estimators. If e = 0 in model (1.2), i.e., the covariate can be exactly observed, the variance of Θ̂n is the same as that of Fan and Huang (2005). To achieve the root-n estimator of Θ, Theorem 2 indicates that undersmoothing is required in estimating ξ(υ), and the optimal bandwidth does not satisfy the condition of Theorem 2.
Example 1.1 (con.) Let β̂n be the estimator of β in model (1.3). Assume n0/n → λ. Checking the conditions of Theorem 2, we can conclude that where Σ⋆ = Σ−1{σ2 + λβTE[E{Z − E(Z|U)|V}]⊗2β} and Σ = E[{ξ − E(ξ|U)}⊗2].
Example 1.2 (con.) For the de-noised models introduced in Section 1, we apply Theorem 2 to derive the asymptotic distribution of the estimator, Θ̂ = (β̂T, θ̂T)T, given by Cui, He, and Zhu (2002), and obtain that .
The asymptotic covariance of Θ̂n can be consistently estimated by Σ̂n = nΣ̂− 1σ̂2 + Σ̂− 1Q̂Σ̂−1, where Σ̂−1 = (Z̃TZ̃)−1Z̃T(I−S)T(I−S)Z̃(Z̃TZ̃)−1, , and , and B̂(v) = Ẑ − Ê{ΦT(U)Γ−1(U)X|V = v} and Ê{ΦT(U)Γ−1(U)X|V = v} is a nonparametric regression estimator of ΦT(U)Γ−1(U)X on V. α̂(·) will be given in the next section.
Generally Σ̂n is difficult to calculate. However, implementation will become simpler in some cases. For example, in the errors-in-variables model with validation data, a direct simplification yields B(V) = Z − ΦT(U)Γ−1(U)X, D = {βTE(eeT|V)β}Σ, and the asymptotic covariance matrix equals Σ−1{σ2 + λβTE(eeT|V)β}. This matrix can be estimated by a standard sandwich procedure. The similar situation also applies for the asymptotic covariance matrix, Σ−1{σ2 + βTE(eeT|V)β}, of the de-noise model.
2.3 Estimation of the nonparametric components
After obtaining estimates Θ̂n, we can estimate aj(u) and bj(u) for j = 1, …, q, and then αj(u). Write Ψ(u) = {a1(u), …, aq(u), b1(u), …, bq(u)}T. An estimator of the nonparametric components Ψ(u) is defined as
| (2.4) |
Correspondingly, a(u) is estimated by , where Iq is the q×q identity matrix, H = diag(1, h)⊗Iq. We have the following asymptotic representation for the resulting estimator.
Theorem 3
Under Assumptions 1–5 given in Appendix, we have
Based on this representation, we can derive the asymptotic normality of the proposed nonparametric estimators of the varying coefficient functions. The proof is straightforward but tedious. We omit the details.
For notational simplicity, we assume that ε is independent of (Z, X, U) and e is independent of (V, U) in the remaining part of this paper.
Theorem 4
Under Assumptions 1–5, we have
as n → ∞, where
and
in which , Λ(u0) = {E[{E(X|V)}|U = u0]}⊗2 q0 = μ2/(μ2 − μ1), .
Furthermore, if nhb2r+2 → 0, then
where ,
The first term of Σ2 is the asymptotic covariance of the usual profile likelihood estimator (Cai, Fan, and Li 2000) when ξj is observed. The second term is attributed to calibrating the error-prone covariates. In the error-in-variable model with validation data, if X is independent of V and E(X) = 0, the measurement errors have no impact on the effect of the covariance Σ2. Theorem 4 also indicates that if n1/2 max(h5/2, br+1) → 0, the bias of α̂(u) tends to zero and α̂(u) is asymptotically normally distributed with rate (nh)1/2.
After obtaining Θ̂n and α̂(u), one can easily give an estimator of the variance σ2 of the error ε:
In our simulation, a simple version of is used. Note that S depends only on the observations , and we can derive a “synthetic linear model”, that is, Y − ZΘ = M + ε, where M = αT(U)X. A straight-forward derivation yields (I − S)Y = (I − S)ZΘ + (I − S)ε. Standard regression gives the least square estimates Θ̂ and then M̂ = S(Y − ZΘ̂). Note that Z is not always observed. Replacing Z by its estimates, we obtain a consistent estimator M̂ of M; that is, M̂ = S(Y − ẐΘ̂). A consistent estimator σ2 may be defined as , where M̂i is the ith element of M̂.
2.4 Bandwidth selection
The proposed procedure involves two bandwidths, h and b, to be selected. To derive asymptotic distributions of the proposed estimators, we theoretically impose the rates of convergence for the bandwidths. It is worthy to point out that undersmoothing is necessary when we estimate ξ and the optimal bandwidth for b is then violated.
As mentioned before, the optimal bandwidth for b cannot be obtained because undersmoothing the nonparametric estimators of the covariates is needed. The consequence of undersmoothing ξ is that the bias is kept small and precludes the optimal bandwidth for b. The asymptotic variances of the proposed estimators for constant coefficients depend on neither the bandwidth nor the kernel function. Hence, we can use the similar method of mixture of higher-order theoretical expansions, proposed by Sepanski, Knicherbocker and Carroll (1994) or the typical curves approach by Brookmeyer and Liao (1992) to select the bandwidth b. As done by Sepanski, et al. (1994), the suitable bandwidth is b = Cn−1/3, where C is a constant depending on unknown function ξ(υ) and its twice derivatives. In practice, one can use a plug-in rule to estimate the constant C. A useful and simple candidate C is σ̂V, the sample deviation of V. This method is fairly effective and easy to implement. In our simulation example, the bandwidth is b = σ̂υn−1/3. Based on the asymptotic analysis and empirical experience for fixed time case (i.e. de-noise models), we suggest a simple rule of thumb as follows: the smoothing parameter b is so chosen that intervals of size 2b would contain around 5 points for n up to 100 and between 8−1n1/3 and 4−1n1/3 points for larger n.
We use “leave-one-sample-out” method to select the bandwidth h. This method has been widely applied in practice, for example Cai, et al. (2000) and Fan and Huang (2005). We define the cross-validation score for h as , where Θ̂n,−i is the estimated profile least-square-based estimator defined by (2.3), and computed from the data with measurements of the i-th observation deleted and α̂h,−i(·) is the estimator defined in (2.4) with Θ̂n replaced by Θ̂n,−i. The likelihood cross-validation smoothing parameter hcυ is the minimizer of CV(h). That is, hcυ = arg minh CV(h).
3 Tests for parametric and nonparametric components
3.1 Test for parametric components
An interesting question is to consider the following hypothesis
| (3.1) |
where A is a given l × p full rank matrix.
Let be the estimators of Θand α̂0(·) be the estimator of α(u) under the null hypothesis. Denote . RSS0 can be further expressed as , where Θ̂0 = Θ̂ − (Z̃TZ̃)−1AT{A(Z̃TZ̃)−1AT}− 1AΘ̂, and Θ̂ = (Z̃TZ̃)−1Z̃TỸ, an estimator of Θ without the restriction, with Z̃ = (I − S)Ẑ and Ỹ = (I − S)Ŷ.
Similarly, let and α̂1(·) be the estimators of Θ and α(·) under the alternative hypothesis, respectively. Denote , which can be expressed as . Following Fan and Huang (2005), we define a profile least-square-based ratio test by
Under their set-up, Fan and Huang (2005) showed that statistic Tn is the profile likelihood ratio when the error distribution is normally distributed. In the present situation, because of effect of measurement error on variables, no central χ2-distribution as that of Fan and Huang (2005) is available. However, we can still prove that 2Tn has the asymptotic noncentral χ2 distribution under the alternative hypothesis of (3.1), which we summarize in the following theorem.
Theorem 5
Suppose that Assumptions 1-5 in Appendix are satisfied and nb2r+2 → 0, as n → ∞. Under the alternative hypothesis of (3.1),
where ωi for 1 ≤ i ≤ l are the eigenvalues of and is the central χ2 distribution with degree of freedom 1. Furthermore, let Σ̂1 and Σ̂ be the consistent estimators of Σ1 and Σ, respectively. Then , where is noncentral χ2 distribution with degrees of freedom l, and the noncentral parameter λ = σ−2ϱ limn→∞ nΘTAT(AΣ−1AT)−1AΘ with .
In a similar way, we may construct the Wald test for hypothesis (3.1) as Wn =Θ̂TAT(AΣ̂1AT)−1AΘ̂ and demonstrate that Wn and 2ϱnTn have the same asymptotic distribution under the alternative hypothesis. These properties can therefore be used to calculate power of the proposed tests.
Example 1.3 (con.) Generalize (1.6) to a more flexible model:
Write Θ = (βT, ζT, γT)T and . The hypothesis (1.7) is equivalent to
| (3.2) |
where A = (1p1, −1p1, 0), 1p1 is p1-variate vector with all entries 1. This is an expression of (3.1). As a consequence, the proposed profile least-square-based ratio test and Wald test can be applied to test this hypothesis.
For hypothesis (3.2), one may also propose a Wald-type statistic: Wn(h) = Θ̂TAT(AΣ̂hAT)−1AΘ̂, where Σ̂h = Σ̂−1(σ̂2 + β̂TΣ̂eβ̂). It can be proved that 2ϱnTn and Wn have the same asymptotic χ2 distribution.
3.2 Tests for the nonparametric part and Wild bootstrap version
It is also of interest to check whether the varying-coefficient functions α(u) in model (1.2) are parametric functions. Specifically speaking, we consider the following hypothesis:
where γ is an unknown vector, αi(·, ·) is a known function, i = 1, 2, ···, q.
For simplicity of presentation, we test the homogeneity:
| (3.3) |
Let α̃1, ···, α̃q and Θ̃ be the profile estimator under H0. The weighted residual sum of squares under H0 is , where wi(·) are weighted functions such that , and wi ≥ 0. In general, the weight function w has a compact support, designed to reduce the boundary effects on the test statistics. When σ2(Z, X, U) = υ(Z, X, U)σ2 for some known function υ(Z, X, U), we may choose wi = υ−1(Zi, Xi, Ui). See Fan, Zhang, and Zhang (2001) for a similar argument.
Under the general alternative that all the varying-coefficient functions are allowed to be varying of random variable U, we use the local likelihood method to obtain estimator β̂ and α̂(U). Therefore, the corresponding weighted residual sum of squares is
In a similar way as in Section 3.1, we propose a generalized likelihood ratio (GLR) statistic:
| (3.4) |
Under mild assumptions, one can derive the asymptotic distribution of TGLR. This distribution can be used to gain the empirical level. See Fan, Zhang and Zhang (2001) for a related discussion.
These arguments can be applied to the following partially parametric null hypothesis:
The difference is only the definition of RSS(H0), for which we use the profile likelihood procedure to estimate constant coefficient αi, i = 1, 2, ···, r and Θ, and use the profile linear procedure to estimate the nonparametric component αi(·), i = r + 1, ···, q under the null hypothesis.
Although the asymptotic level of TGLR is available, TGLR may not perform well when sample sizes are small. For this reason and for practical purposes, we suggest using a bootstrap procedure. To be specific, let
be the residuals based on estimators (2.3) and (2.4) for parametric and nonparametric parts, respectively. We use the Wild bootstrap (Wu, 1986; Härdle and Mammen, 1993) method to calculate the critical values for test TGLR. Let τ be a random variable with a distribution function F(·) such that Eτ = 0, Eτ2 = 1 and E|τ|3 < ∞. We generate the bootstrap residual , where τi is independent of ε̂i. Define bootstrap version like TGLR based on the bootstrap sample ( ), where for i = 1, 2 ···, n. On a basis of the distribution of , we have the (1 − α) quantile and reject the parametric hypothesis if .
4 Numerical Examples
4.1 Performance of the proposed estimators
In this section, we conducted simulation experiments to illustrate the finite sample performances of the proposed estimators and tests. Our simulated data were generated from the following model:
| (4.1) |
W1 and W2 are bivariate normal with marginal mean zero, marginal variance 1 and correlation , while X1 and X2 are independent and normal with mean zero and variance 0.8. The unobserved covariate ξ is related to auxiliary variable (η, V) through ξ(V) = 3V − 2 cos(4πV) and η = ξ(V) + e. V is a uniform random variable on [0, 1] and U is a uniform random variable on [0, 3]. The errors ε and e are independent each other, and normal variables with mean 0 and variances and , respectively. The varying-coefficient functions are
| (4.2) |
| (4.3) |
| (4.4) |
where , and ϱ is chosen one from the set {0.0, 0.2, 0.5, 0.7, 1.0}.
The sample size was 100. We generated 500 data sets in each case, applying to each simulated sample the bootstrap test proposed for the parametric part based on 500 bootstrap repetitions. The Gaussian kernel has been used in this example. The optimal bandwidth h were chosen by the leave-one-out cross-validation method described in Section 2.4 and the bandwidth b was selected as b = συn−1/3, where συ is the sample deviation of V.
We consider four scenarios. In the first three scenarios and .
β = (0, c − 1, 1)T for c ∈ {0, 0.1, 0.2, 0.25, 0.5, 0.7, 1.0} and α1(u) and α2(u) are given in (4.2) and (4.4);
β = (0, −0.8, 1)T and α1(u) and α2(u) are given in (4.3) and (4.4) with ϱ ∈ {0.0, 0.2, 0.5, 0.7, 1.0};
β = (0.2, −1, 1)T and α1(u) and α2(u) are the same as in (ii).
The setting is the same as that of (iii). But the signal-noise ratio ( ) varies from 0.3 to 0.8 by 0.1.
The corresponding results are presented in Tables 1–4, in which we display the estimated values and associated standard errors, standard derivations, and coverage probabilities based on the benchmark estimator (i.e., all covariate measured exactly), the proposed estimator and the naive estimator (ηi directly used as the covariates). We summarize our findings as follows.
When β1 = 0 (scenario (i) and (ii)), all estimates are close to the true values regardless of the non-parametric functions α1(u) and α2(u). The differences among the estimated values based on three methods are slight and can be ignored. However, when β1 = 0.2, the estimates of β1 based on the naive method have severe biases and the associated coverage probabilities are also substantially smaller than 0.95. These biases were not improved when the sample size was increased (not listed here). But the proposed estimation procedure performs well. On the other hand, the estimates of β2 and β3 are similar based on the three methods. From Table 4, we can see that the naive estimator of β1 has zero coverage probabilities when r = 0.3, while the proposed estimator has fairly reasonable coverage probabilities. With increase of r, it is readily seen that coverage probabilities of the proposed estimator are closer to the nominal level, which indicates the proposed method is promising.
Table 4.
Results of simulation study for scenario (iv).
| β1 |
β2 |
β3 |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r | Est. | SE | SD | COV | Est. | SE | SD | COV | Est. | SE | SD | COV | |
| 0.30 | B | 0.194 | 0.038 | 0.046 | 0.970 | −0.987 | 0.145 | 0.159 | 0.980 | 1.005 | 0.149 | 0.156 | 0.980 |
| P | 0.173 | 0.040 | 0.042 | 0.850 | −0.986 | 0.150 | 0.152 | 0.970 | 1.005 | 0.150 | 0.149 | 0.970 | |
| N | 0.073 | 0.025 | 0.025 | 0.000 | −0.976 | 0.159 | 0.137 | 0.920 | 0.996 | 0.153 | 0.135 | 0.920 | |
| 0.40 | B | 0.199 | 0.043 | 0.044 | 0.950 | −1.002 | 0.123 | 0.147 | 0.970 | 1.002 | 0.131 | 0.147 | 0.980 |
| P | 0.185 | 0.045 | 0.041 | 0.890 | −1.003 | 0.124 | 0.144 | 0.970 | 0.999 | 0.130 | 0.144 | 0.980 | |
| N | 0.096 | 0.029 | 0.028 | 0.060 | −1.002 | 0.127 | 0.134 | 0.970 | 1.002 | 0.135 | 0.134 | 0.960 | |
| 0.50 | B | 0.199 | 0.043 | 0.042 | 0.960 | −0.981 | 0.134 | 0.142 | 0.960 | 1.020 | 0.122 | 0.143 | 0.970 |
| P | 0.190 | 0.044 | 0.040 | 0.920 | −0.981 | 0.133 | 0.139 | 0.950 | 1.019 | 0.127 | 0.141 | 0.950 | |
| N | 0.116 | 0.033 | 0.030 | 0.200 | −0.988 | 0.137 | 0.133 | 0.930 | 1.020 | 0.132 | 0.135 | 0.930 | |
| 0.60 | B | 0.194 | 0.035 | 0.040 | 0.970 | −0.993 | 0.136 | 0.141 | 0.950 | 1.025 | 0.137 | 0.138 | 0.930 |
| P | 0.192 | 0.038 | 0.040 | 0.950 | −0.994 | 0.140 | 0.140 | 0.950 | 1.025 | 0.138 | 0.137 | 0.910 | |
| N | 0.131 | 0.028 | 0.032 | 0.450 | −0.998 | 0.152 | 0.137 | 0.910 | 1.020 | 0.138 | 0.134 | 0.940 | |
| 0.70 | B | 0.198 | 0.038 | 0.039 | 0.960 | −1.018 | 0.137 | 0.133 | 0.970 | 1.004 | 0.140 | 0.131 | 0.930 |
| P | 0.194 | 0.040 | 0.038 | 0.950 | −1.017 | 0.138 | 0.132 | 0.960 | 1.004 | 0.142 | 0.131 | 0.930 | |
| N | 0.152 | 0.038 | 0.033 | 0.660 | −1.021 | 0.142 | 0.130 | 0.920 | 1.004 | 0.144 | 0.128 | 0.920 | |
| 0.80 | B | 0.203 | 0.036 | 0.038 | 0.950 | −1.001 | 0.142 | 0.132 | 0.930 | 1.005 | 0.136 | 0.132 | 0.960 |
| P | 0.203 | 0.038 | 0.038 | 0.950 | −1.002 | 0.143 | 0.131 | 0.940 | 1.005 | 0.135 | 0.132 | 0.960 | |
| N | 0.172 | 0.035 | 0.035 | 0.870 | −1.002 | 0.147 | 0.131 | 0.920 | 1.000 | 0.136 | 0.131 | 0.930 | |
4.2 Performance of the proposed tests
We now explore the numerical performance of the proposed tests. Firstly, we want to test hypothesis of the parametric component of form:
| (4.5) |
where A = (1, 1, 1)T, c is a value from the set {0, 0.1, 0.2, …, 0.7, 1}, β = (0.2, c − 1.2, 1)T, α1(·) and α1(·) are the same those as scenarios (i). The same models and error distribution as in section 4.1 are used.
The power to detect H1 were calculated by using the critical values from chi-squared approximation and Wild bootstrap approximation. To compare test performances, the powers of the tests based on the benchmark estimator, the proposed estimator and the naive estimator are presented. In implementing the Wild bootstrap method, we generated 500 bootstrap samples from the model
here, is a wild bootstrap residual; i.e., , with ε̂i = Yi − {β̂1ξ̂i + β̂2W1i + β̂3W2i + α̂1(Ui)Z1i + α̂2(Ui)Z2i}, and with probability and with . Using this bootstrap sample ( ), we can calculate the and , and get the 95% percentiles as the critical values for the proposed tests at the significance level 0.05.
The power of Tn associated to scenario (iii) is presented in Table 5 for β1 = 0.2. Note that the power is actually the empirical level when c = 0. All empirical levels close nominal level 0.05 and the empirical level based on the Wild bootstrap procedure are consistently smaller than those based on the χ2 approximation and are closer to the nominal level. These facts apply for β1 = 0 (not listed here). As c increases to 0.7, the powers of two tests based on χ2 approximation is greater than 0.92. Similar conclusions can be drawn for the Wald test, whose simulation results are also given in Table 5.
Table 5.
Empirical power of profile least square ratio test Tn and the Wald test Wn at level 0.05 for hypothesis (4.5). Data were generated from models (4.1) with β = (0.2, c − 1.2, 1)T and c ∈ {0, 0.1, 0.2, 0.25, 0.5, 0.7, 1} and α1(u) and α2(u) given by (4.2) and (4.4), respectively. The methods used are “Asm” for the asymptotic version, and “Boot” for the bootstrap version.
| Tn |
Wald
|
||||||
|---|---|---|---|---|---|---|---|
| c | B | P | N | B | P | N | |
| 0 | Aym | 0.060 | 0.070 | 0.080 | 0.050 | 0.050 | 0.080 |
| Boot | 0.050 | 0.060 | 0.060 | 0.060 | 0.060 | 0.060 | |
| 0.10 | Aym | 0.150 | 0.140 | 0.150 | 0.130 | 0.130 | 0.150 |
| Boot | 0.130 | 0.100 | 0.080 | 0.130 | 0.120 | 0.080 | |
| 0.20 | Aym | 0.190 | 0.220 | 0.120 | 0.150 | 0.150 | 0.120 |
| Boot | 0.170 | 0.160 | 0.080 | 0.190 | 0.180 | 0.080 | |
| 0.25 | Aym | 0.350 | 0.340 | 0.240 | 0.320 | 0.310 | 0.240 |
| Boot | 0.290 | 0.280 | 0.180 | 0.310 | 0.300 | 0.180 | |
| 0.50 | Aym | 0.740 | 0.710 | 0.530 | 0.670 | 0.660 | 0.530 |
| Boot | 0.700 | 0.630 | 0.500 | 0.720 | 0.630 | 0.500 | |
| 0.70 | Aym | 0.940 | 0.940 | 0.870 | 0.930 | 0.920 | 0.870 |
| Boot | 0.920 | 0.890 | 0.800 | 0.930 | 0.890 | 0.800 | |
| 1.00 | Aym | 1.000 | 1.000 | 1.000 | 0.990 | 0.990 | 1.000 |
| Boot | 0.990 | 0.990 | 0.960 | 0.990 | 0.990 | 0.960 | |
We further study the numerical performance of the test by checking the nonparametric component. We consider the following hypothesis:
| (4.6) |
The simulation results obtained by using the Wild bootstrap approximation method to choose critical value are shown in Table 6. When ϱ = 0, the results are the empirical levels, which are close to the nominal level. The power is greater than 0.99 when ϱ = 0.5. Table 6 also indicates that the power is a monotone increasing function of ϱ.
Table 6.
Empirical power of level 0.05 for hypothesis (4.6) using the Wild bootstrap procedure. Data were generated from (4.1) and (4.3) with β = (0.2, −1, 1)T and ϱ ∈ {0, 0.5, 0.10, 0.15, 0.5, 0.7}.
| ϱ | B | P | N |
|---|---|---|---|
| 0 | 0.060 | 0.050 | 0.080 |
| 0.05 | 0.110 | 0.140 | 0.160 |
| 0.10 | 0.240 | 0.260 | 0.250 |
| 0.15 | 0.410 | 0.360 | 0.360 |
| 0.20 | 0.520 | 0.510 | 0.500 |
| 0.50 | 0.990 | 0.990 | 1.000 |
| 0.70 | 1.000 | 1.000 | 1.000 |
4.3 Real data example
To illustrate the proposed estimation method, we consider a dataset from Duchenne Muscular Dystrophy (DMD) study. See Andrews and Herzberg (1985) for a detailed discussion on the dataset. The dataset contains 209 observations corresponding to blood samples on 192 patients (17 patients have two samples) collected from a project to develop a screening program for female relatives of boys with DMD. The program’s goal was to inform a woman of her chances of being a carrier based on serum markers as well as her family pedigree. Another question of interest is whether age should be taken into account in the analysis. Enzyme levels were measured in known carriers (75 samples) and in a group of non-carriers (134 samples). The serum marker creatine kinase ( ck) is inexpensive to obtain, while the marker lactate dehydrogenase ( ld) is very expensive to obtain. It is of interest to predict the value ld by using the level of ck, carrier status and age of patient.
We consider the following model: Y = β0 + β1Z1 + β2Z2 + g(U), where Z1 = ck is measured with errors, and Z2 = carrierstatus is exactly measured, U is age and Y denotes the observed level of lactate dehydrogenase. We justify the measurement error of Z1 by regressing Z1 on U. The estimates and associated standard errors based on the naive and proposed methods are as follows: β̂0,naive = 4.6057(0.113), β̂1,naive = 0.1509(0.027), β̂2,naive = 0.2269(0.055); β̂0,n = 4.4296(0.329), β̂1,n = 0.1775(0.042), and β̂2,n = 0.3702(0.050). The estimated curves of the nonparametric function g(u) are provided in Figure 1. Accounting for measurement errors, the estimate of β1 increases about 17.2%, and the associated standard error also increases 55%. The estimate of β2 also increases when measurement errors are taken into account. The patterns of the nonparametric curve are similar, and shows slight difference.
Figure 1.

Estimated curves of the nonparametric function for the DMD study. The solid, dotted lines were obtained using the naive and proposed method, respectively.
5 Discussion
We developed estimation and inference procedures for the SVCPLM when parts of the parametric components are unobserved. The procedures are derived by incorporating ancillary information to calibrate the mismeasured variables, and by applying the profile least-square-based principle.
In some case we may not have an auxiliary variable η, but we can observe two or more independent replicates of V. For instance, when two measurements V1 and V2, which satisfy that V1 = ξ + u1 and V2 = ξ + u2, and E(u1|V2) = 0 and E(u2|V1) = 0, are available, we can estimate ξ by
because E(V1|V2 = υ) = E(V2|V1 = υ) = E(ξ|V = υ). The proposed procedure applies to this situation as well, and similar results to those presented in this paper can be obtained for the resulting estimator.
It is of interest to extend the proposed methodology to a more general semiparametric model:
where G(·) is a link function. The study of this model with mismeasured components of Z needs further investigation and is beyond the scope of this paper.
Table 1.
Results of simulation study for scenario (i)
| β1 |
β2 |
β3 |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ϱ | Est. | SE | SD | COV | Est. | SE | SD | COV | Est. | SE | SD | COV | |
| 0 | B | −0.000 | 0.030 | 0.027 | 0.912 | −0.990 | 0.133 | 0.125 | 0.938 | 1.000 | 0.138 | 0.126 | 0.924 |
| P | −0.001 | 0.031 | 0.028 | 0.918 | −0.990 | 0.133 | 0.125 | 0.936 | 1.000 | 0.139 | 0.126 | 0.930 | |
| N | −0.001 | 0.026 | 0.024 | 0.904 | −0.990 | 0.133 | 0.125 | 0.940 | 0.999 | 0.138 | 0.126 | 0.926 | |
| 0.1 | B | 0.002 | 0.028 | 0.027 | 0.920 | −0.890 | 0.139 | 0.126 | 0.910 | 1.003 | 0.129 | 0.126 | 0.936 |
| P | 0.003 | 0.030 | 0.028 | 0.938 | −0.890 | 0.139 | 0.126 | 0.912 | 1.003 | 0.129 | 0.126 | 0.938 | |
| N | 0.003 | 0.025 | 0.024 | 0.938 | −0.890 | 0.140 | 0.126 | 0.912 | 1.004 | 0.129 | 0.126 | 0.938 | |
| 0.2 | B | 0.000 | 0.029 | 0.027 | 0.936 | −0.802 | 0.144 | 0.126 | 0.894 | 0.991 | 0.138 | 0.126 | 0.932 |
| P | −0.000 | 0.030 | 0.028 | 0.934 | −0.802 | 0.145 | 0.126 | 0.898 | 0.991 | 0.138 | 0.126 | 0.940 | |
| N | −0.001 | 0.027 | 0.024 | 0.912 | −0.801 | 0.145 | 0.126 | 0.896 | 0.992 | 0.138 | 0.125 | 0.934 | |
| 0.25 | B | −0.001 | 0.029 | 0.027 | 0.930 | −0.749 | 0.128 | 0.127 | 0.936 | 0.990 | 0.138 | 0.127 | 0.940 |
| P | −0.000 | 0.031 | 0.028 | 0.928 | −0.748 | 0.129 | 0.127 | 0.938 | 0.990 | 0.139 | 0.127 | 0.938 | |
| N | −0.000 | 0.024 | 0.024 | 0.948 | −0.749 | 0.128 | 0.126 | 0.938 | 0.990 | 0.138 | 0.126 | 0.940 | |
| 0.5 | B | −0.002 | 0.029 | 0.027 | 0.926 | −0.513 | 0.143 | 0.126 | 0.918 | 1.000 | 0.131 | 0.126 | 0.936 |
| P | −0.002 | 0.031 | 0.028 | 0.928 | −0.513 | 0.143 | 0.126 | 0.920 | 1.001 | 0.131 | 0.126 | 0.936 | |
| N | −0.001 | 0.026 | 0.024 | 0.926 | −0.513 | 0.143 | 0.126 | 0.918 | 1.001 | 0.131 | 0.126 | 0.936 | |
| 0.7 | B | 0.000 | 0.029 | 0.027 | 0.936 | −0.299 | 0.140 | 0.127 | 0.916 | 0.996 | 0.138 | 0.127 | 0.924 |
| P | 0.001 | 0.029 | 0.028 | 0.930 | −0.298 | 0.140 | 0.127 | 0.920 | 0.997 | 0.138 | 0.127 | 0.926 | |
| N | 0.001 | 0.025 | 0.024 | 0.934 | −0.299 | 0.140 | 0.126 | 0.914 | 0.996 | 0.138 | 0.126 | 0.926 | |
| 1 | B | 0.001 | 0.030 | 0.027 | 0.934 | 0.002 | 0.137 | 0.127 | 0.942 | 1.008 | 0.144 | 0.127 | 0.908 |
| P | 0.001 | 0.031 | 0.028 | 0.934 | 0.002 | 0.137 | 0.127 | 0.938 | 1.008 | 0.145 | 0.127 | 0.906 | |
| N | 0.001 | 0.026 | 0.024 | 0.928 | 0.002 | 0.138 | 0.127 | 0.938 | 1.007 | 0.144 | 0.127 | 0.908 | |
Note: “Est” is the simulation mean; “SE” is the mean of the estimated standard error; “SE” is the mean of the estimated standard deviation; and “COV” is the coverage probability of a nominal 95% confidence interval. The methods used are “B” for the benchmark method, “P” for the proposed method, and “N” for the naive method.
Table 2.
Results of simulation study for scenario (ii)
| β1 |
β2 |
β3 |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ϱ | Est. | SE | SD | COV | Est. | SE | SD | COV | Est. | SE | SD | COV | |
| 0 | B | 0.000 | 0.034 | 0.033 | 0.920 | −0.795 | 0.154 | 0.153 | 0.948 | 0.995 | 0.160 | 0.154 | 0.946 |
| P | 0.001 | 0.036 | 0.035 | 0.922 | −0.795 | 0.154 | 0.154 | 0.950 | 0.995 | 0.159 | 0.154 | 0.950 | |
| N | 0.000 | 0.030 | 0.029 | 0.928 | −0.794 | 0.154 | 0.153 | 0.948 | 0.994 | 0.160 | 0.154 | 0.950 | |
| 0.05 | B | 0.002 | 0.028 | 0.027 | 0.920 | −0.790 | 0.139 | 0.125 | 0.910 | 1.003 | 0.129 | 0.126 | 0.936 |
| P | 0.003 | 0.030 | 0.028 | 0.938 | −0.790 | 0.139 | 0.125 | 0.908 | 1.004 | 0.129 | 0.126 | 0.938 | |
| N | 0.003 | 0.025 | 0.024 | 0.938 | −0.790 | 0.140 | 0.125 | 0.908 | 1.004 | 0.129 | 0.126 | 0.938 | |
| 0.1 | B | 0.000 | 0.029 | 0.027 | 0.936 | −0.802 | 0.144 | 0.126 | 0.894 | 0.991 | 0.138 | 0.125 | 0.928 |
| P | −0.000 | 0.030 | 0.028 | 0.936 | −0.802 | 0.144 | 0.126 | 0.898 | 0.991 | 0.138 | 0.126 | 0.938 | |
| N | −0.001 | 0.027 | 0.024 | 0.916 | −0.801 | 0.145 | 0.125 | 0.896 | 0.992 | 0.138 | 0.125 | 0.932 | |
| 0.15 | B | −0.001 | 0.029 | 0.027 | 0.932 | −0.799 | 0.128 | 0.126 | 0.936 | 0.990 | 0.138 | 0.126 | 0.938 |
| P | −0.000 | 0.031 | 0.028 | 0.930 | −0.798 | 0.128 | 0.126 | 0.938 | 0.990 | 0.138 | 0.126 | 0.938 | |
| N | −0.000 | 0.024 | 0.024 | 0.950 | −0.799 | 0.128 | 0.126 | 0.938 | 0.990 | 0.138 | 0.126 | 0.936 | |
| 0.2 | B | −0.002 | 0.029 | 0.027 | 0.926 | −0.813 | 0.143 | 0.126 | 0.918 | 1.001 | 0.131 | 0.126 | 0.934 |
| P | −0.002 | 0.031 | 0.028 | 0.932 | −0.813 | 0.143 | 0.126 | 0.918 | 1.001 | 0.131 | 0.126 | 0.934 | |
| N | −0.001 | 0.026 | 0.024 | 0.924 | −0.813 | 0.143 | 0.126 | 0.916 | 1.001 | 0.131 | 0.126 | 0.934 | |
| 0.5 | B | 0.000 | 0.029 | 0.027 | 0.936 | −0.799 | 0.140 | 0.126 | 0.916 | 0.996 | 0.138 | 0.126 | 0.924 |
| P | 0.001 | 0.029 | 0.028 | 0.930 | −0.798 | 0.140 | 0.126 | 0.922 | 0.997 | 0.138 | 0.127 | 0.926 | |
| N | 0.001 | 0.025 | 0.024 | 0.934 | −0.799 | 0.140 | 0.126 | 0.914 | 0.996 | 0.138 | 0.126 | 0.926 | |
| 0.7 | B | 0.001 | 0.030 | 0.027 | 0.932 | −0.798 | 0.137 | 0.127 | 0.942 | 1.008 | 0.144 | 0.127 | 0.906 |
| P | 0.001 | 0.031 | 0.028 | 0.934 | −0.798 | 0.137 | 0.127 | 0.938 | 1.008 | 0.145 | 0.127 | 0.906 | |
| N | 0.001 | 0.026 | 0.024 | 0.930 | −0.798 | 0.138 | 0.126 | 0.938 | 1.007 | 0.144 | 0.126 | 0.908 | |
Table 3.
Results of simulation study for scenario (iii)
| β1 |
β2 |
β3 |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ϱ | Est. | SE | SD | COV | Est. | SE | SD | COV | Est. | SE | SD | COV | |
| 0 | B | 0.200 | 0.034 | 0.035 | 0.936 | −0.995 | 0.154 | 0.162 | 0.956 | 0.995 | 0.160 | 0.163 | 0.964 |
| P | 0.195 | 0.038 | 0.038 | 0.920 | −0.995 | 0.158 | 0.167 | 0.958 | 0.994 | 0.163 | 0.168 | 0.958 | |
| N | 0.156 | 0.031 | 0.030 | 0.684 | −0.995 | 0.158 | 0.160 | 0.952 | 0.995 | 0.165 | 0.160 | 0.946 | |
| 0.05 | B | 0.202 | 0.028 | 0.029 | 0.948 | −0.990 | 0.139 | 0.138 | 0.938 | 1.003 | 0.129 | 0.138 | 0.950 |
| P | 0.197 | 0.032 | 0.032 | 0.944 | −0.994 | 0.144 | 0.144 | 0.938 | 1.004 | 0.139 | 0.144 | 0.948 | |
| N | 0.159 | 0.026 | 0.025 | 0.602 | −0.991 | 0.149 | 0.133 | 0.910 | 1.004 | 0.140 | 0.133 | 0.926 | |
| 0.1 | B | 0.200 | 0.029 | 0.029 | 0.950 | −1.002 | 0.144 | 0.138 | 0.924 | 0.991 | 0.138 | 0.138 | 0.956 |
| P | 0.194 | 0.032 | 0.033 | 0.948 | −1.005 | 0.151 | 0.144 | 0.922 | 0.991 | 0.147 | 0.144 | 0.954 | |
| N | 0.155 | 0.028 | 0.025 | 0.560 | −1.004 | 0.153 | 0.133 | 0.904 | 0.991 | 0.148 | 0.133 | 0.912 | |
| 0.15 | B | 0.199 | 0.029 | 0.029 | 0.950 | −0.999 | 0.128 | 0.138 | 0.960 | 0.990 | 0.138 | 0.138 | 0.960 |
| P | 0.194 | 0.033 | 0.032 | 0.938 | −0.998 | 0.135 | 0.144 | 0.958 | 0.986 | 0.144 | 0.144 | 0.956 | |
| N | 0.155 | 0.025 | 0.025 | 0.542 | −0.997 | 0.138 | 0.133 | 0.938 | 0.989 | 0.145 | 0.133 | 0.948 | |
| 0.2 | B | 0.198 | 0.029 | 0.029 | 0.948 | −1.013 | 0.143 | 0.138 | 0.942 | 1.001 | 0.131 | 0.138 | 0.958 |
| P | 0.193 | 0.033 | 0.032 | 0.936 | −1.012 | 0.148 | 0.144 | 0.938 | 0.997 | 0.136 | 0.144 | 0.954 | |
| N | 0.155 | 0.027 | 0.025 | 0.536 | −1.016 | 0.154 | 0.133 | 0.920 | 0.998 | 0.141 | 0.133 | 0.932 | |
| 0.5 | B | 0.200 | 0.029 | 0.029 | 0.956 | −0.999 | 0.140 | 0.138 | 0.954 | 0.996 | 0.138 | 0.138 | 0.944 |
| P | 0.195 | 0.032 | 0.032 | 0.952 | −1.000 | 0.147 | 0.144 | 0.954 | 0.993 | 0.144 | 0.144 | 0.956 | |
| N | 0.157 | 0.026 | 0.025 | 0.582 | −1.000 | 0.153 | 0.133 | 0.898 | 0.996 | 0.145 | 0.133 | 0.920 | |
| 0.7 | B | 0.201 | 0.030 | 0.029 | 0.952 | −0.998 | 0.137 | 0.139 | 0.958 | 1.008 | 0.144 | 0.139 | 0.938 |
| P | 0.196 | 0.033 | 0.033 | 0.946 | −0.997 | 0.143 | 0.145 | 0.962 | 1.008 | 0.146 | 0.145 | 0.956 | |
| N | 0.157 | 0.028 | 0.025 | 0.594 | −1.000 | 0.146 | 0.134 | 0.932 | 1.006 | 0.151 | 0.134 | 0.912 | |
Acknowledgments
Zhou’s research was partially supported by Funds of National Natural Science (No.10471140 and No. 10571169) of China. Liang’s research was supported by NIH/NIAID grants AI62247, AI59773, and AI50020. The authors thank the Co-Editors, the former Co-Editor Professor Jianqing Fan, and the referees for constructive comments that substantially improved an earlier version of this paper.
Appendix
In this Appendix, we list assumptions and outline proofs of the main results. The following technical assumptions are imposed.
A.1 Assumptions
The random variable U has a bounded support
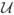 . Its density function fu(·) is Lipschitz continuous and bounded away from 0 on its support. The density function of random variable V, fυ(v), is continuously differentiable and bounded away 0 and infinite on its finite support
. {αi(u), i = 1, 2, ···, q} have continuous second derivative.
. Its density function fu(·) is Lipschitz continuous and bounded away from 0 on its support. The density function of random variable V, fυ(v), is continuously differentiable and bounded away 0 and infinite on its finite support
. {αi(u), i = 1, 2, ···, q} have continuous second derivative.The q × q matrix E(ZZT|U) is non-singular for each U ∈
. All elements of the matrixes E(ZZT|U), E(ZZT|U)−1 and E(ZXT|U) are Lipschitz continuous.The kernel functions K(·) and L(·) are density functions with compact support [−1, 1].
-
There is an s > 2 such that E||Z||2s < ∞ and E||X||2s < ∞ and for some δ < 2 − s−1 such that n2δ−1h → ∞, n2δ−1bk → ∞ and , k = 1, 2, ···, p1 where bk is the bandwidth parameter in polynomial estimator ξ̂k(·) of ξk(·).
5. nh8 → 0 and nh2/(log n)2 → ∞.
A.2 Preliminary Lemmas
Write .
Lemma A.1
Suppose that (Zi, Xi, Ui), i = 1, 2, ···, n are i.i.d random vector. E|g(X, Z, U)| < ∞ and E[g(·, ·, u)|U = u] has continuous second derivative on u. Further assume that E(|g(X, Z, U)|s|Z = z, X = x) < ∞. Let K be a bounded positive function with a bounded support, satisfying Lipschitz condition. Given that n2δ−1h → ∞ for some δ < 1 − s−1, then we have
Furthermore, Assume that E[εi|Zi, Xi, Ui] = 0, E[|εi|s|Zi, Xi, Ui)] < ∞, then
Proof
The first result follows an argument similar to that of Lemma A.2 of Fan and Huang (2005). The second result follows the first result and an argument similar to Xia and Li (1999).
Lemma A.2
Suppose that E[g(Z, X, u)|U = u] has continuous second derivative on u and E|g(X, Z, U)|s < ∞. Under Assumptions 1–5, we have
and
where h(·) is a twice continuous differentiable function.
Proof
Note that can be decomposed as
By Lemma A.1, the first term equals fu(u)E{g(X, Z, u)ξ|U = u}μk + O(cn1) uniformly on u ∈
in probability. Recalling the asymptotic expression given in (2.1) and using Lemma A.1, one can show that the second term is O(cn2). This completes the proof of Lemma 2.
Lemma A.3
g(·, ·, u) has continuous second derivative on u and E|g(X, Z, U)| < ∞. Under Assumptions 1–5, and are of order O(cn) a.s.
Proof
The proof follows from (2.1) and arguments similar to Lemma A.2.
Lemma A.4
Under Assumptions 1–5, we have
in probability.
Proof
We first prove that
| (A.1) |
A direct calculation yields
| (A.2) |
On the other hand, Lemma A.3 implies
| (A.3) |
A combination of (A.2) and (A.3) implies
| (A.4) |
and then
| (A.5) |
It follows from these arguments that , and (A.1) follows.
Note that . The second term, J2, is by Lemma A.3. Write Z̃* = (I − S)Z. We have . It follows from (2.1) that
By an argument similar to that of (A.5), we derive
where ρ̃(Zl, Xl, Ul) can be expressed as
Denote by ρ(Zl, Xl, Ul) the main term of the right hand side of the above formula. Note that E{ρ (Zl, Xl, Ul)|Ul} = 0. By Lemma 3 of Chen, Choi and Zhou (2005) we have
| (A.6) |
Furthermore, we can show, in a similar way as that for (A.6), that
These arguments imply that
| (A.7) |
We now deal with the term . Note that equals , which can be further decomposed as
This completes the proof of Lemma A.4.
Lemma A.5
Under Assumptions 1–5, we have Z̃T(I −S)(I −S)TZ̃/n → Σ in probability and Σ̂ = n(Z̃TZ̃)−1Z̃T(I −S)(I −S)Z̃(Z̃TZ̃T)−1 → Σ.
Proof
The proof of the first result can be finished by arguments similar to those of Lemmas A.2–A.4, while the second one can be proved by arguments similar to Lemma 7.3 of Fan and Huang (2005).
Lemma A.6
Under Assumptions 1–5, we have .
Proof
The proof follows (A.5) and an argument similar to that of Lemma 7.4 of Fan and Huang (2005).
Lemma A.7
g (·) and h(·) are two continuous function vectors. Under Assumptions 1–5, we have and in probability.
Proof
The proof follows from arguments similar to those of Lemma A.2.
Lemma A.8
Under Assumptions 1–5, we have , where ε= (ε1, ···, εn)T.
Proof
Note that . By the same argument as those for (A.3), we have
This formula along with (A.2) yields . A combination of these arguments with Lemma A.7 finishes the proof of Lemma A.8.
A.3 Proof of Theorem 1
Note that Θ̂n can be expressed as (Z̃TZ̃)−1Z̃T(I −S)ZΘ+ (Z̃TZ̃)−1Z̃T(I −S)M + (Z̃TZ̃)−1Z̃T(I −S)ε. By Lemma A.8, the third term equals . The first term equals, via Lemma A.4,
By Lemma A.6 and (A.1), it follows that the second term of Θ̂n’s expression is of order in probability. These arguments imply that
This completes the proof of Theorem 1.
A.4 Proof of Theorem 3
By the definition of Ψ̂ (u), we have
where and . It is easy to show that Rn = o(n−1/2) in probability. Note that
It follows from (A.2) that
| (A.8) |
and
Furthermore, (A.3) implies that
| (A.9) |
We therefore have , where Mu = α(u)TX.
By Taylor expansion and a direct simplification, we have
Hence,
| (A.10) |
It follows from (A.8)–(A.10) that can be represented as
By the similar argument of Lemma A.8, we have
The proof of Theorem 3 is completed.
A.5 Proof of Theorem 5
The proof is similar to Theorems 3.1 and 3.2 of Fan and Huang (2005). We only give a sketch. We first prove that n−1RSS1 = σ2{1 + oP (1)}.
By a similar procedure as that of Theorem 3.2 in Fan and Huang (2005), we can obtain that , where M̂i0 is the ith element of M̂0 = S(Y −ZΘ̂). A direct calculation yields that
| (A.11) |
By (2.1), Theorem 2 and Jensen inequality, we know that the first term in the right-hand side of (A.11) is bounded by
| (A.12) |
which is op(1). A similar argument can show that the second term in the right-hand side of (A.11) is also op(1). We therefore have n−1RSS1 = σ2{1 + oP (1)}.
Furthermore, RSS0 can be decomposed as , where Q1= {Z̃(Θ̂ − Θ̂0)}T{Z̃(Θ̂ − Θ̂0)}, Q2= (Y − M̂ − ẐΘ̂) {Z̃(Θ̂ − Θ̂0)}, Q3={Z̃(Θ̂ − Θ̂0)}T(Y − M̂ − ẐΘ̂).
Recalling the expression of Θ̂0 and the result given in (A.1), we know that n−1Z̃T Z̃ → Σ in probability, and in distribution. In an analogous way, we can that show Q2 and Q3 are asymptotic negligible in probability. These statement along with the Slutsky theorem imply that in distribution. Finally, following the lines of Rao and Scott (1981), we can prove that the distribution of has the approximate distribution as , and complete the proof of Theorem 5.
Contributor Information
Yong Zhou, Institute of Applied Mathematics, Academy of Mathematics and System Science,Chinese Academy of Science, Beijing, China, 100080.
Hua Liang, Dept. of Biostatistics and Computational Biology, University of Rochester Medical Center, 601 Elmwood Avenue, Box 630 Rochester, NY 14642.
References
- 1.Ahn H, Powell JL. Semiparametric estimation of censored selection models with a nonparametric selection mechanism. J Econometrics. 1993;58:3–29. [Google Scholar]
- 2.Ai C, McFadden D. Estimation of some partially specified nonlinear models. J Econometrics. 1997;76:1–37. [Google Scholar]
- 3.Andrews DF, Herzberg AM. Data. A Collection of Problems for Many Fields for Student and Research Worker. New York: Springer Verlag; 1985. [Google Scholar]
- 4.Brookmeyer R, Liao J. Statistical Models for Reconstructing Infection Curves. In: Jewell NP, Dietz K, Farewell VT, editors. AIDS Epidemiology Issues. Boston: Birkhäuser; 1992. pp. 39–60. [Google Scholar]
- 5.Cai Z, Fan J, Li R. Efficient estimation and inferences for varying-coefficient models. J Amer Statist Asso. 2000;95:888–902. [Google Scholar]
- 6.Cai Z, Naik PA, Tsai CL. De-noised least squares estimators: an application to estimating advertising effectiveness. Statistica Sinica. 2000;10:1231–1241. [Google Scholar]
- 7.Carroll RJ, Fan J, Gijbels I, Wand MP. Generalized partially linear single-index models. J Amer Statist Asso. 1997;92:477–489. [Google Scholar]
- 8.Carroll RJ, Ruppert D, Stefanski LA, Crainiceanu CM. Measurement Error in Nonlinear Models. 2. New York: Chapman and Hall; 2006. [Google Scholar]
- 9.Chen G, Choi Y, Zhou Y. Nonparametric estimation for structural change points in volatility for time series. J Econometrics. 2005;126:79–114. [Google Scholar]
- 10.Cui H, He X, Zhu L. On regression estimators with de-noised variables. Statistica Sinica. 2002;12:1191–1205. [Google Scholar]
- 11.Das M. Instrumental variable estimators of nonparametric models with discrete endogenous regressors. J Econometrics. 2005;124:335–361. [Google Scholar]
- 12.Engle RF, Granger WJ, Rice J, Weiss A. Semiparametric estimates of the relation between weather and electricity sales. J Amer Statist Asso. 1986;80:310–319. [Google Scholar]
- 13.Fan JQ, Gijbels I. Local polynomial modelling and its applications. New York: Chapman and Hall; 1996. [Google Scholar]
- 14.Fan JQ, Huang T. Profile likelihood inferences on semiparametric varying-coefficient partially linear models. Bernoulli. 2005;11:1031–1057. [Google Scholar]
- 15.Fan JQ, Zhang C, Zhang J. Generalized likelihood ratio statistics and Wilks phenomenon. Ann Statist. 2001;29:153–193. [Google Scholar]
- 16.Fan JQ, Zhang W. Statistical estimation in varying coefficient models. Ann Statist. 1999;27:1491–1518. [Google Scholar]
- 17.Fuller WA. Measurement Error Models. John Wiley and Sons; New York: 1987. [Google Scholar]
- 18.Härdle W, Liang H, Gao JT. Partially linear models. Heidelberg: Physica-Verlag; 2000. [Google Scholar]
- 19.Härdle W, Mammen E. Comparing nonparametric versus parametric regression fits. Ann Statist. 1993;21:1926–1947. [Google Scholar]
- 20.Hastie TJ, Tibshirani R. Varying-coefficient models. J Roy Statist Soc, Ser B. 1993;55:757–796. [Google Scholar]
- 21.Lee L, Sepanski JH. Estimation of linear and nonlinear error-in-variables models using validation data. J Amer Statist Asso. 1995;90:130–140. [Google Scholar]
- 22.Li Q. Semiparametric estimation of partially linear models for dependent data with generated regressors. Econ Theory. 2002;19:625–645. [Google Scholar]
- 23.Liang H, Härdle W, Carroll RJ. Estimation in a semiparametric partially linear errors-in-variables model. Ann Statist. 1999;27:1519–1535. [Google Scholar]
- 24.Masry E. Multivariate local polynomial regression for time series: uniform strong consistency and rates. J Time Ser Ann. 1996;17:571–599. [Google Scholar]
- 25.Pagan A. Econometric issues in the analysis of regressions with generated regressors. International Econometric Review. 1984;25:221–247. [Google Scholar]
- 26.Powell JL. Discussion paper, Social System Research Institute. University of Wisconsin; 1987. Semiparametric estimation of bivariate latent variable models. [Google Scholar]
- 27.Rao JNK, Scott AJ. The analysis of categorical data from complex sample surveys: chi-squares tests for goodness of fit and independence in two-way tables. J Amer Statist Asso. 1981;76:221–230. [Google Scholar]
- 28.Robinson P. Root-N-consistent semiparametric regression. Econometrica. 1988;56:931–954. [Google Scholar]
- 29.Severini TA, Staniswalis JG. Quasilikehood estimation in semiparametric models. J Amer Statist Asso. 1994;89:501–511. [Google Scholar]
- 30.Speckman P. Kernel smoothing in partial linear models. J Roy Statist Soc, Ser B. 1988;50:413–436. [Google Scholar]
- 31.Sepanski JH, Carroll RJ. Semiparametric quasi-likelihood and variance function estimation in measurement error models. J Econometrics. 1993;58:223–256. [Google Scholar]
- 32.Sepanski JH, Lee LF. Semiparametric estimation of nonlinear errors-in-variables models with validation study. J Nonparametric Statist. 1995;4:365–394. [Google Scholar]
- 33.Sepanski JH, Knickerbocker R, Carroll RJ. A semiparametric correction for attenuation. J Amer Statist Asso. 1994;89:1366–1373. [Google Scholar]
- 34.Wang CY, Pepe MS. Expected estimating equations to accommodate covariate measurement error. J Roy Statist Soc, Ser B. 2000;62:509–524. [Google Scholar]
- 35.Wu J. Jackknife, bootstrap and other resampling methods in regression analysis. Ann Statist. 1986;14:1261–1343. [Google Scholar]
- 36.Xia Y, Li WK. On the estimation and testing of functional-coefficient linear models. Statistica Sinica. 1999;9:737–757. [Google Scholar]
- 37.Zhang W, Lee SY, Song X. Local polynomial fitting in semiparametric varying coefficient models. J Mult Anal. 2002;82:166–188. [Google Scholar]