

Abstract
Previously, we have proposed a method for three-class receiver operating characteristic (ROC) analysis based on decision theory. In this method, the volume under a three-class ROC surface (VUS) serves as a figure-of-merit (FOM) and measures three-class task performance. The proposed three-class ROC analysis method was demonstrated to be optimal under decision theory according to several decision criteria. Further, an optimal three-class linear observer was proposed to simultaneously maximize the signal-to-noise ratio (SNR) between the test statistics of each pair of the classes provided certain data linearity condition. Applicability of this three-class ROC analysis method would be further enhanced by the development of an intuitive meaning of the VUS and a more general method to calculate the VUS that provides an estimate of its standard error. In this paper, we investigated the general meaning and usage of VUS as a FOM for three-class classification task performance. We showed that the VUS value, which is obtained from a rating procedure, equals the percent correct in a corresponding categorization procedure for continuous rating data. The significance of this relationship goes beyond providing another theoretical basis for three-class ROC analysis—it enables statistical analysis of the VUS value. Based on this relationship, we developed and tested algorithms for calculating the VUS and its variance. Finally, we reviewed the current status of the proposed three-class ROC analysis methodology, and concluded that it extends and unifies decision theoretic, linear discriminant analysis, and psychophysical foundations of binary ROC analysis in a three-class paradigm.
Keywords: Ideal observer, receiver operating characteristic (ROC) analysis, three-class classification
I. Introduction
PREVIOUSLY, we have developed a three-class decision model which produces a 2-D receiver operating characteristic (ROC) surface in a 3-D ROC space. The volume under the three-class ROC surface (VUS) was proved to be a figure-of-merit (FOM) for three-class task performance [1]. Having explored the decision theoretic and linear discriminant analysis (LDA) foundations of three-class ROC analysis [2], [3], this paper aims at exploring the psychophysical foundation of this proposed three-class ROC analysis, which is inspired by the two-alternative forced-choice (2AFC) procedure and its relationship to binary ROC analysis [4], [5]. This relationship provides the psychophysical foundation for binary ROC analysis, and will be extended in a three-class paradigm in the present paper. The significance of the extension of this relationship goes beyond providing another theoretical basis for three-class ROC analysis—it enables statistical analysis of VUS value. We present and test algorithms for calculating VUS and its variance. At the end of this paper, we provide a short discussion of the current status of the proposed three-class ROC methodology.
II. Background
As a method to evaluate binary classification task performance, conventional ROC analysis has been extensively studied [4]-[11]. A binary classification task can be performed using two procedures: a rating procedure, whose performance is described by area under an ROC curve (AUC), or a 2AFC procedure, whose performance is described by the percent correct. We briefly introduce these two procedures and their relationship.
A medical diagnostic task is often modeled as a classification task using a rating procedure. In such a procedure, the observer is presented with one of two mutually exclusive alternatives (e.g., signal-present image versus signal-absent image) at one time. In other words, the rating procedure has one observation interval [5]. The observer is then asked to rate his confidence level of which alternative is presented. Any number of responses may be used to rate the confidence level. For example, in a human observer signal detection task, a set of five confidence level responses is often used. Alternatively, an observer might be asked to use a continuous rating scale. An ROC curve is then traced out by calculating the sensitivity/specificity (TPF/TNF) pair for each confidence level. The area under this ROC curve gives the AUC value, which serves as a figure-of-merit for describing the task performance using a rating procedure.
A forced-choice design is a psychophysical procedure that can be used to avoid the problem of determining the observer's criterion (or confidence level) [5]. In a 2AFC procedure, two observation intervals are provided, i.e., two images, one from each alternative, are shown at the same time, e.g., a signal-absent image and a signal present image. The observer is instructed to categorize one of the images as signal-present and the other as signal absent. Note that since there are only two classes, this is equivalent to selecting which of the images has the signal present. The probability of correctly identifying which of the two stimuli is “signal-present” and which is “signal-absent” is defined as the percent correct.
In a binary classification task, Green and Swets showed the percent correct of a forced-choice procedure equals the AUC value in a rating procedure [5], [6]. This equivalence is of particular importance in binary ROC analysis [4]. It indicates that, for a given data source, the performance of a binary classification task could be identically determined using either a rating procedure or a 2AFC procedure. Further, both procedures result in the same scalar value that summarizes classification performance. In particular, when an investigator calculates the AUC value from a rating procedure, “he is in fact, or at least in mathematical fact, reconstructing random pairs of images, one from a diseased subject and one from a normal subject, and using the reader's separate ratings of these two images to simulate what the reader would have decided if theses two images had in fact been presented together as a pair in a 2AFC experiment” [4]. Bamber showed that this “probability of correctly ranking a (normal, abnormal)” pair is connected with the quantity calculated in the Wilcoxon or Mann–Whitney (M-W) statistical test [6]. As a result, the extensively-studied properties of M-W test can be used to predict the statistical properties of the area under a ROC curve.
Furthermore, this relationship enables us to study the AUC value and its properties without assumptions either on the distributions of the data or on the properties of the decision variable. Therefore, the AUC value obtained from a nonideal and non-Hotelling observer, e.g., a human observer, is interpretable in the sense of 2AFC.
III. Theory
Scurfield has previously investigated “n-event, m-dimensional” forced-choice tasks [12]. In that work, Scurfield first reformulated the two-class decision rules by introducing, for mathematical convenience, two dummy parameters which do not play a role in the observer's decision. As a natural extension of the reformulated two-class decision rules, a three-class decision rule was introduced which also added dummy parameters that do not play a role in the observer's decision. The resulting decision space is 2-D, and the decision structure has the same shape as the decision structure we derived under the ideal observer framework [1]. Scurfield proved that the volume under a 123-ROC surface (i.e., a surface in the 3-D space with axes T1F, T2F, and T3F, where TiF is the probability of correctly classifying the ith class, or the sensitivity of the ith class) equals the percent correct of an I3A6 (three interval, six-alternative) task. Since Scurfield's decision structure is identical to the decision-theory based one we have previously proposed, Scurfield's proof can be applied readily to this work. However, Scurfield's proof is very hard to follow, and it is not couched in terms that are familiar to the imaging community.
In the following, we first define a forced-choice procedure in a three-class paradigm; we then introduce the three-class decision model that has been proved to extend and unify the decision theoretic and LDA foundations of binary ROC analysis [1]-[3]. Next, we elaborate on the underlying connections between the proposed decision model and a three-class categorization procedure, and prove the equivalence of the percent correct and VUS in a different, and, we believe, more easily understood way. Based on this relationship, we propose methods and algorithms for calculating the VUS value and its standard deviation.
In the following, scalar variables are denoted with italic fonts, and functions are in regular fonts. For example, in T1F = T1F (x, y), T1F is a variable, and T1F is a function.
A. Definition of the Three-Class Categorization Procedure
We now define a three-class categorization procedure that is analogous to the 2AFC procedure. In this procedure, three randomly sampled objects, one from each of the three distinct classes, are presented to the observer simultaneously. The observer's task is to categorize the three objects into each of the three hypotheses. The observer is said to make a correct decision when, and only when, all three objects are correctly categorized.
B. Decision Model for Three-Class ROC Analysis
We have derived the optimal decision variables and decision rules for practical three-class ROC analysis using a rating procedure [1]. For a given data vector , two decision variables (rating values), LR13, and LR23, are computed, i.e.,
and
| (1) |
where Hi (i = 1, 2, 3) denotes the ith hypothesis, is the data vector, and is the likelihood of the data vector under the ith hypothesis, Hi. To make a decision, a pair of ratings are calculated and compared to a decision structure centered on a critical point, which is determined by prior information (i.e., the decision utilities and prior probabilities of the classes, or predetermined sensitivity pairs). Fig. 1(a) shows the three-class decision plane and decision structure that was proved to be optimal under certain decision criteria in two previous papers [1], [2].
Fig. 1.

Decision plane of the three-class decision model and a three-class ROC surface. (a) Decision plane spanned by (log LR13, log LR23). (b) Decision plane spanned by (x, y). (c) Example of three-class ROC surface.
In order to relate the decision model to a corresponding categorization procedure, where any pairs of decision variables might be used, we provide the following mathematical treatment for the decision model. Since the result to be presented in this paper does not depend on the use of the decision variables, we replace log LR13 and log LR23 with a pair of general decision variables, x and y, as shown in Fig. 1(b). The general decision variables, (x, y), might be any pair of possible decision variables representing a pair of ratings assigned to each object. Note that for the same classification problem, if the decision variables that span the decision plane are different, the distributions on the decision plane would also be different.
The rating pair distributions of the three classes on this general decision plane can thus be represented by f1(x, y), f2(x, y), and f3(x, y), respectively. Fig. 1(c) shows a typical ROC surface. The volume under the ROC surface is given by
| (2) |
where TiF(i = 1, 2, 3) is the probability that class i can be correctly classified. It can be seen that TiF is a function of x and y, i.e.,
| (3) |
C. Mathematical Treatment of the Three-Class Categorization Procedure
In order to relate the three-class categorization procedure to the rating procedure described above, we now analyze the categorization procedure mathematically as a three-step process.
Step 1) Present a triplet of randomly grouped class 1, class 2, and class 3 objects to the observer.
Step 2) Rate each object independently as in a rating procedure, resulting in a rating pair, (x, y), for each object as in the rating procedure.
Step 3) Test the three rating pairs associated with each object to see if the differences among the rating pairs lead to them being correctly categorized according to the decision rules suggested by the decision structure in Fig. 1. That is to say, a triplet can be correctly classified if there exists a decision structure position (defined by a critical point) such that all three rating pairs are correctly classified. Note here that the outcome of this test depends only on the relative positions of the rating pairs on the decision plane.
The described procedure is illustrated graphically in Fig. 2, where the triangle, square, and disk represent the randomly sampled objects, with one from each rating pair distributions f1(x, y), f2(x, y), and f3(x, y), respectively. Fig. 2(a) illustrates a case when at least one decision structure position exists that results in correctly categorizing these three rating pairs, and Fig. 2(b) illustrates a case when no such position exists. Note that the underlying assumption here is that the rating procedure and the categorization procedure use the same decision structure and decision variables. By repeating this procedure and computing the ratio of correct to total trials, we can thus estimate the percent correct for this categorization procedure from the rating data produced by a rating procedure.
Fig. 2.
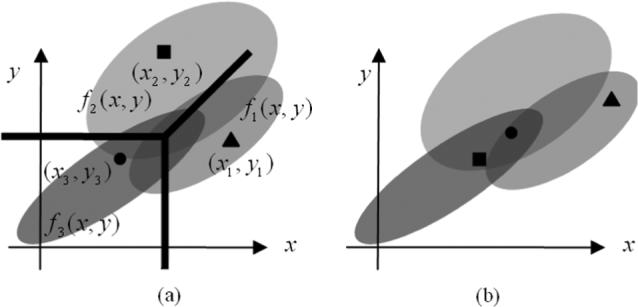
Illustration of a mathematical treatment of the categorization procedure that is equivalent to a rating procedure. Ellipses with different shadings schematically represent the distributions of decision variables for the three classes. Triangle is a random sample from class 1, the square is a random sample from class 2, and the disk represents a random sample from class 3. (a) Illustration of a case where the triplet can be correctly categorized. (b) Illustration of a case where correct categorization is not possible for any position of the proposed decision structure.
D. Equivalence of VUS in a Rating Procedure and Percent Correct in a Categorization Procedure
Given the above mathematical treatment, we can compute the percent correct (PC) as the integration of the product of the probability distributions of the rating pairs for the three classes over all the combinations that can give correct decisions. The formulation of PC is thus obtained by finding a strategy such that a complete set of correctly classified triplets is obtained without counting any triplet more than once, and then integrating the probabilities of all possible correct classifications. In the Appendix, we prove that such a formulation of percent correct leads to the same expression for VUS, i.e.,
| (4) |
Note that the proof is done for continuous rating data. In other words, samples of rating values from the continuous distributions cannot give rise to rating triplets at identical positions in the decision space.
IV. Statistical Analysis
Given the equivalence of VUS and percent correct, we now propose methods for statistical analysis of VUS value.
A. Calculation of the VUS Value
Since, as described above and proved in the Appendix, the VUS equals the percent correct in the corresponding three-class categorization task, we can thus estimate PC as a substitute for estimating the VUS. With sample sizes of n1, n2, and n3 from continuous class 1, class 2, and class 3 distributions, respectively, the rating procedure will result in nk rating pairs for class k (where k = 1, 2, 3). We denote each rating pair as , where i = 1 ... ni refers to the ith sample in the kth class. The corresponding categorization procedure, at least conceptually, consists of making all possible n1 · n2 · n3 comparisons among the ratings from the three classes and summing the score, , for each comparison according to the rule
| (5) |
where l, m, and n are the lth, mth, and nth samples from classes 1, 2, and 3, respectively. In (5), correct categorization is said to occur when there exists a critical point (this is a position for the decision structure) such that falls into the area for a class 1 decision, falls into the area for a class 2 decision, and falls into the area for a class 3 decision. The percent correct, PC, is then estimated by averaging the {U} over all n1 · n2 · n3 comparisons, i.e.,
| (6) |
where the caret above PC indicates that it is an estimate. Given the equivalence between the VUS and PC, VUS can be evaluated using (6).
Equation (5) is very similar to its counterpart in the 2AFC procedure, as described in [4]. In the binary case, when discrete rating data are used, it is possible for two samples from different classes to be identical, and the decision rule will assign a value of 0.5 for percent correct calculation [4]. One may note (5) does not include a contingency for the case where some of the ratings are the same. This is because, in this paper we only proved VUS = PC for a continuous rating scale, where we do not need to consider the case where random samples of the ratings are identical. The possible relationship between VUS and PC for three-class discrete rating scale is more complicated than in the binary case and is beyond the scope of this paper.
B. Estimation of the Variance of the VUS Value
We have implemented two methods for variance estimation. The first method is based on Dreiseitl's extension [13] of Lehmann's nonparametric approach [14]. In Dreiseitl's work, algorithms for estimating the volume under the surface value and its variance were proposed for Mossman's three-class decision model. Dreiseitl's algorithms for volume-under-the-surface estimation are very similar to (5) and (6). The only difference lies in the definition of correct categorization in (5). This is because Mossman's decision model uses different decision structures, requiring a different correct categorization test. However, this difference does not affect the formulation for VUS and its variance, and Dreiseitl's variance calculation algorithm can be readily applied to this work as explained below.
In this method, the variance is given by [13]
| (7) |
In (7), , cov(Uijk, Umnl) = E(UijkUmnl) - θ2, where E() is the expectation operation, , and θ = E(Uijk), which is the true percent correct. Note that E(UijkUmnl) is the probability that both Uijk and Umnl are 1. Expanding (7), as described in [13] results in the following formula for variance of the VUS
| (8) |
Note that the elements in each expectation in (8) have at least one identical subscript, e.g., the two elements in E(UijkUIJk) have subscripts ijk and IJk, respectively. E(UijkUIJk) is de fined as
| (9) |
Other expectations in (8) have analogous definitions.
The calculation of each E(UijkUmnl) in (8) requires four or five nested loops, which, as will be demonstrated later, takes a long time when the number of rating pairs is large. Therefore, we propose to implement a second method using a bootstrap approach [15], [16] to estimate the variance. The steps involved in this method are as follows.
Step 1) Formulate three empirical probability rating pair distributions, , to estimate the real rating pair distribution, , where I represents the ith class. For a standard Bootstrap approach, is expressed as a discrete distribution such that each of the ni samples from from class i has a probability of 1/ni. Despite the fact that is discrete, each rating pair is a sample from the continuous rating distribution, fi(x, y). In cases where the sample size is small, one might want to fit the distribution of the data with a normal distribution as is done in binary ROC analysis. However, we have not yet been able to derive a three-class counterpart of the binormal ROC curve fitting. Thus we provide an alternative approach using a simple parametric Bootstrap method, where the available experimental samples are used to fit bivariate Gaussian distributions to estimate , and , respectively. To be specific, using the experimentally obtained rating pairs of the ith class, we compute the mean, variance and the covariance of x and y, and then use these parameters to formulate the empirical probability distribution of the rating pairs of the ith class. Note that the parametric bootstrap approach is not essential, but does have the advantage of handling the case for discrete ratings and, to the extent the data are described by bivariate Gaussian distributions, more precise estimates of the VUS and its variance.
Step 2) Take n1 random samples from , n2 random samples from , and n3 random samples from with replacement.
Step 3) Make all possible n1 · n2 · n3 comparisons among the random samples from each class. Calculate the fraction, Γ, of the samples of comparisons that result in a correct categorization using (5)-(6).
Step 4) Repeat Steps 2 and 3 B times, to create B bootstrap samples. This results in a set of estimates of the percent correct Γ1, Γ2, Γ3, ..., ΓB.
Step 5) The distribution of Γ estimates the distribution of PC, which estimates the distribution of the VUS value. The variance of the VUS is estimated by the variance of Γ.
V. Experiments
We have implemented the algorithms for estimating the VUS and its variance. To test the algorithms, we used a set of data from a previous experiment on dual-isotope myocardial perfusion SPECT (MPS) image quality evaluation described in [17], [18], where the rest-stress MPS images were obtained from a simulated population of normal patients and patients with reversible or fixed defects. For each of the three classes, a total of 432 rating pairs were generated. Fig. 3(a) shows the decision plane and Fig. 3(b) shows the corresponding three-class ROC surface.
Fig. 3.
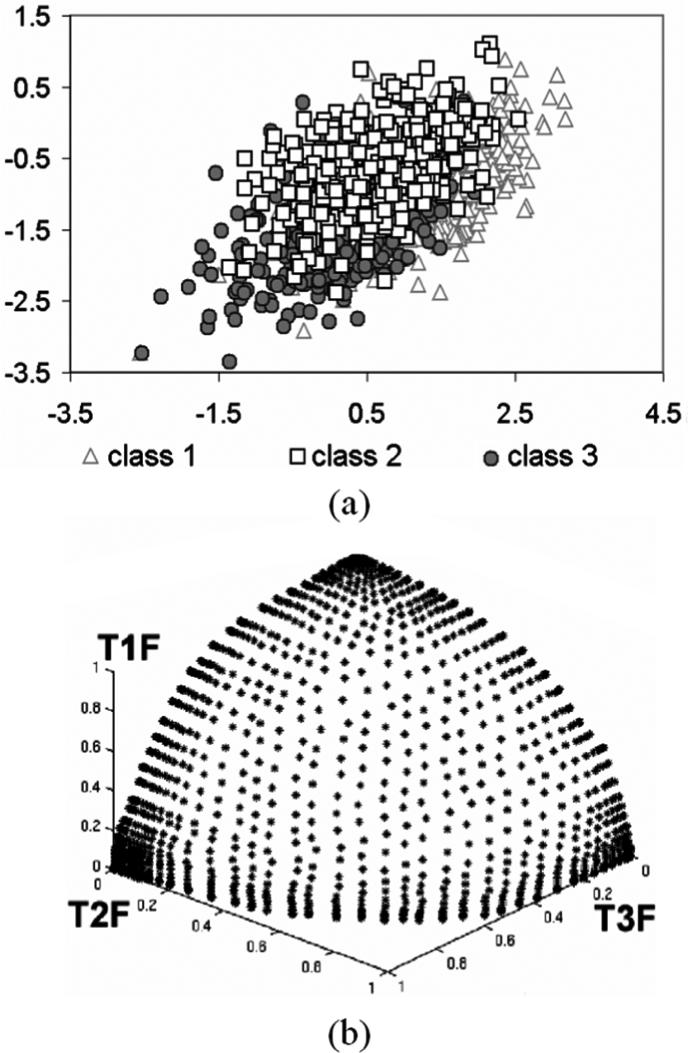
Decision planes and the ROC surface obtained for simulated dual-isotope MPS images. (a) Decision plane. (b) ROC surface traced out by moving the decision structure on the decision plane and compute the sensitivity triplets.
To validate the VUS calculation algorithm proposed, we developed an ad hoc VUS calculation algorithm, as illustrated in Fig. 4. The rating pair distributions were sampled on a grid with very small grid spacing [Fig. 4(a)]. In the ROC space, a relatively large bin size was defined on the (T1F, T2F) plane [Fig. 4(b)]. Moving the decision structure in the decision plane with very small grid spacing produced several T3F values in each of the (T1F, T2F) bin in the ROC space. For each (T1F, T2F) bin in the ROC space, we average the T3F values to produce an ROC histogram. An estimate of the VUS value was obtained by averaging the histogram for all (T1F, T2F) bins. The accuracy of the VUS can be increased by decreasing the grid spacing.
Fig. 4.
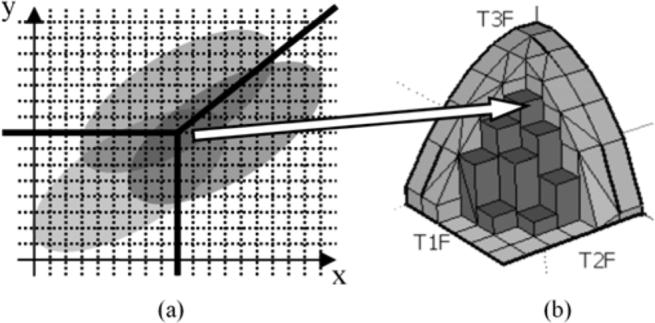
Calculation of the VUS. (a) Sample the distributions with very small grid spacing in the decision plane. (b) For each (T1F, T2F) bin in the ROC space, we average the T3F values to produce an ROC histogram.
The experimentally obtained data were too sparse to enable small grid spacing in the experimental decision plane. We thus fit the three rating pair distributions to bivariate Gaussian distributions for the ad hoc algorithm. This was done based on our previous unpublished study of the normality of the rating pairs. Note that the ad hoc method is a very coarse method, its resulting VUS value is affected by the bin sizes on both the decision plane and the histogram. We developed this ad hoc method only to obtain a rough idea of the magnitude of the VUS value to test whether the theoretical method provides a VUS that is similar. For the method based on (6), we did not use the bivariate Gaussian fitting. Table I shows the parameters of the fitted bivariate Gaussian distributions for the three classes. To validate the variance calculation, we simply compared the estimate from Dreiseitl's extension [13] in (8) and the proposed Bootstrap method. We also compared the computational times for (8) and the Bootstrap method.
TABLE I.
Parameters of the Fitted Bivariate Gaussian Distributions for the Three Classes
| μ x | σ x | μ y | σ y | ρ | |
|---|---|---|---|---|---|
| Class 1 | 1.340 | 0.643 | −0.878 | 0.386 | 0.532 |
| Class 2 | 0.688 | 0.520 | −0.642 | 0.328 | 0.492 |
| Class 3 | 0.187 | 0.557 | −1.358 | 0.390 | 0.528 |
Since the data were obtained from 432 triplets of rating values, we used n1 = n2 = n3 = 432 in calculating VUS using (6). The results are shown in Table II, where we see that methods based on VUS = PC agreed well with the ad hoc method for estimating the VUS value. To calculate the variance using the Bootstrap method, we used B = 1000 repetitions. It can be seen from Fig. 5 that VUS and its variance were well-converged after 200 repetitions. The resulting standard deviation using the Bootstrap method after 1000 iterations was 0.181 (Fig. 5), which is in the same order as the one obtained using (8). However, the algorithm for obtaining standard deviation using (8) took approximately eight days. This is because, as described above, each E(UijkUmnl) in (8) involves a nested summation loop four or five levels deep [an example is given in (9)]. The five level deep loops dominate the computational time. Thus, when n = n1 = n2 = n3, the nested summation loops result in a computational time that is roughly proportional to n5. For example, using a 2.13 GHz AMD Opteron processor, when n = 100, it took 418 s to compute the variance, while when n = 200, it took 13, 358 s, approximately 31.96 times longer. In our study, with n = 432, the computational time was about eight days. The Bootstrap method, on the other hand, required only 15 min for 200 repetitions, as shown in Table II.
TABLE II.
Resulting VUS Values and the Standard Deviations Using Different Approaches
Fig. 5.

Convergence of VUS (a) and its standard deviation (b) using the Bootstrap method.
VI. Discussion
Current Status of the Proposed Three-Class ROC Analysis
Binary ROC analysis has been a standard method for assessing diagnostic performance. However, there are an increasing number of diagnostic tasks of interest for which binary classification is not sufficient. In particular, in many cases diagnosing disease using imaging techniques requires both detection and characterization of the disease instead of disease detection alone; analysis of these cases requires ROC analysis techniques for analyzing multi-class diagnoses. However, multiclass ROC analysis is a theoretical problem whose solution has been eluded the community ever since the introduction of the binary ROC in the 1950s [19], [20]. Much work has been devoted to understanding the nature of a multiclass classification problem, and many metrics have been proposed to assess the performance of a multiclass classification task [12], [13], [19]-[32].
Motivated by the medical problem of cardiac perfusion defect evaluation using simultaneous dual-isotope myocardial perfusion SPECT (MPS), where the assessment of a three-class diagnostic task is required to evaluate and optimize MPS imaging techniques, we have carried out a series of studies on the theoretical foundations for a practical three-class ROC analysis method. The present paper results in both an additional theoretical justification for the proposed method, and a practical method to calculate its figure of merit, the volume under a three-class ROC surface. In the following, we review the previous developments in order to present a more complete picture of the theoretical framework.
Model Development
We first developed an optimal three-class decision model that maximizes the expected utility under decision theory by assuming that incorrect decisions have equal utilities under the same hypothesis (the equal error utility assumption). This decision model produces a 2-D ROC surface in a 3-D ROC space and the volume under this surface (VUS) is a figure-of-merit for three-class task performance. We have compared the proposed three-class ROC analysis with conventional binary ROC analysis and concluded that they share many similar properties and that three-class ROC analysis reduces to binary ROC analysis for certain special cases [1].
Decision Theoretic Foundation
We thoroughly investigated the decision theoretic foundations of the proposed three-class ROC analysis and proved the optimality of the three-class ideal observer (3-IO) according to several decision theoretic criteria. In particular, we found that the 3-IO and the proposed decision model maximizes the expected utility (MEU) under equal error utility assumption, maximizes the probability of making correct decisions, provides the maximum likelihood (ML) decision, and satisfies the Neyman-Pearson (N-P) criterion in the sense that, given the sensitivities of two classes, the sensitivity of the third class is maximized [2]. We believe that the optimality with respect to N-P criterion is of particular importance for clinical applications, as explained in [2] and [3].
Linear Discriminant Analysis (LDA) Foundation
We then investigated the LDA foundation of three-class ROC analysis. We have shown that the conventional multiclass extension of LDA has significant limitations. In particular, the L-class Hotelling trace, which has been used as a figure-of-merit for multiclass task performance, cannot distinguish cases where all classes are perfectly classified from cases where only one of the classes can be correctly classified [33]. Using the proposed three-class ROC analysis method, we have found that when the data follow multivariate Gaussian distribution with equal covariance matrices, in addition to the optimality mentioned above, the proposed three-class decision model maximizes the SNR between each pairs of the classes, and likelihood ratios can be computed using a linear observer, i.e., the three-class Hotelling observer (3-HO) [3]. When the data are not Gaussian distributed, we have shown that 3-HO still maximizes the SNR between each pair of the classes given a certain data linearity condition [3].
Psychophysical Foundation
In this paper, we have investigated the relationship between a three-class rating procedure and the corresponding categorization procedure. The equivalence of VUS and the percent correct extends the psychophysical foundation of binary ROC analysis to the proposed three-class ROC analysis.
From the above, we conclude that the proposed three-class ROC analysis method extends and unifies the decision theoretic, linear discriminant analysis, and psychophysical foundations of binary ROC analysis in a three-class paradigm. The proposed three-class ROC methodology is practical mathematically in the sense that a figure-of-merit (FOM) was proposed along with practical numerical methods to obtain the FOM and its statistical properties [1]-[3]. Additionally, the proposed methodology might also prove to be a reasonable model of clinical decision making, as described in [2] and [3].
VII. Conclusion
In this paper, we investigated the psychophysical foundation of a previously-proposed three-class ROC methodology by presenting an intuitive meaning for the VUS value, i.e., the percent correct in a three-class categorization procedure for continuous rating data. This equivalence is neither dependent on the decision variables used, nor dependent on the actual distributions of the three classes. In other words, no matter what decision variables are used, the VUS obtained always equals the percent correct in a corresponding three-class categorization procedure when using the decision rules defined by the decision structure used in this work. Based on this psychophysical foundation, we developed and tested algorithms for calculating the VUS and its variance.
In light of this connection to the proposed psychophysical task, we reviewed the current status of the proposed three-class ROC analysis methodology, and concluded that it extends and unifies decision theoretic, linear discriminant analysis, and psychophysical foundations of binary ROC analysis in a three-class paradigm.
Acknowledgment
The authors would like to thank their colleagues Dr. D. S. Graff, Dr. J. M. Links, and Dr. B. M. W. Tsui for their helpful comments and thought-provoking discussions with regard to this work and manuscript.
This work was supported by the National Institutes of Health (NIH) under Grant K99-EB007620, Grant R01-EB000288, and Grant R01-HL068575. The content of this work is solely the responsibility of the authors and does not necessarily represent the official view of the NIH or its various institutes.
Appendix
We denote the rating pair distributions as f1(x, y), f2(x, y), and f3(x, y) for each of the three classes, respectively, and the corresponding true class fractions as
| (A1) |
| (A2) |
and
| (A3) |
Note that scalar variables are represented using italic fonts while functions are in regular fonts. In the following, we prove the equivalence of the VUS and the PC with respect to a categorization procedure.
A. Preparing Necessary Partial Derivatives and Three Lemmas
Before proving the equivalence of the VUS and the PC in a categorization procedure, we first introduce three lemmas and derive the partial derivatives of T2F(x, y) and T3F(x, y), which will be used later in the proof.
1) The Three Lemmas
Lemma 1
The purpose of Lemma 1 is to change the bound of the integrals, and is expressed as
| (A4) |
Proof:
where Θ is the Heaviside step function. Now let y′ = y - x + a
Let y = y′
Lemma 2
Lemma 2 is very similar to Lemma 1, and is expressed as
| (A5) |
Proof:
where Θ is the Heaviside step function, let x′ = x - y + b
Let x = x′
Lemma 3
The purpose of Lemma 3 is to change the order of the double integral, and is expressed as
| (A6) |
Proof:
where Θ (y) is the Heaviside step function. Now the order of the integration can be changed.
2) Partial Derivatives of T2F (x, y)
For a decision structure centered on (x, y), T2F(x, y) is expressed in (A2), and the partial derivative of T2F(x, y) with respect to x is thus
| (A7) |
To calculate the partial derivative of T2F(x, y) with respect to y, we note that T2F(x, y) is an integral over a region bounded below by a horizontal ray extending from the origin of the decision structure to -∞ and a second ray from the origin of the decision structure along the 45° line from the origin of the decision structure toward (∞, ∞). We use the observation above to rewrite T2F(x, y) as
| (A8) |
Applying Lemma 1 in (A4) to the second term of (A8), T2F(x, y) can be expressed as
| (A9) |
Using this we find that
| (A10) |
3) Partial Derivatives of T2F(x, y)
For a decision structure centered on (x, y), T3F(x, y) is given by (3). Its partial derivatives with respect to x and y are thus
and
| (A11) |
B. Strategy for Computing the Percent Correct
We now describe the strategy for computing percent correct; a full mathematical derivation based on this strategy will be given in the next section. The percent correct on a three-class categorization procedure is given by
| (A12) |
where c = c(x1, y1, x2, y2, x3, y3) is 1 if there exists a position of the decision structure such that the triplet of rating pairs ((x1, y1), (x2, y2), (x3, y3))can be correctly classified, and is 0 otherwise. Rearranging (A12), we obtain
| (A13) |
Examination of (A13) reveals that the outermost double integral can be expressed as
| (A14) |
where
| (A15) |
Here, p(c = 1|x3, y3) is the probability density for a correct classification over all possible (x1, y1) and (x2, y2) combinations for the given (x3, y3). Similarly, p(c = 1|x3, y3) can be expressed as
| (A16) |
where p(c = 1|x2, y2, x3, y3) is the probability density for correct classification over all possible (x1, y1) for the given (x2, y2) and (x3, y3) combination, and is expressed as
| (A17) |
Equations (A14), (A16), and (A17) provide a natural strategy to evaluate the six-dimensional integral in (A12). We first select a (x3, y3) pair. Next, we recognize that all (x2, y2) for which correct classifications are possible will necessarily have y2 > y3, as seen in Fig. 6(a). For such pairs, the maximum region containing (x1, y1) that is correctly classifiable will be obtained if the decision structure is positioned such that the selected (x2, y2) and (x3, y3) lie on the rays comprising the decision structure. For a given (x3, y3), there are three subsets of (x2, y2) for which correct classification is possible, as described in Table III and shown in Fig. 6(b)–(d), depending on which of the rays the two pairs of decision variables are located on. Thus, what we need to do is to add the probability density for correct classification for each of these subsets. Integrating over all the (x2, y2) pairs for a given (x3, y3) and then over all the (x3, y3) will give the percent correct.
Fig. 6.

For a particular (x3, y3), (a)–(d) illustrates the strategies for finding correctly classifiable triplet. (a) We divide all (x2, y2) that may form a correct classification with (x3, y3), i.e., y2 > y3, into three mutually exclusive subsets, Subset 1, Subset 2, and Subset 3, respectively. Here, (b)–(d) shows examples of the set of (x1, y1), indicated by the shaded region, which will result in correct classification for the particular (x3, y3) and a (x2, y2) from each subset, respectively.
TABLE III.
Definition of the Three Subsets
| Subset 1 | {x2 < x3, y2 > y3} |
| Subset 2 | {x2 ≥ x3, y2 > y3, y2 - x2 ≥ y3 - x3} |
| Subset 3 | {x2 ≥ x3, y2 > y3, y2 - x2 < y3 - x3} |
C. Computing the Percent Correct
First consider p(c = 1|x3, y3) for a particular (x3, y3). Note that
| (A18) |
Thus, (A16) can also be written as
| (A19) |
where the double integral is over the half plane where y2 > y3. As described above, there are three nonintersecting subsets of (x2, y2) that satisfy y2 > y3, defined by their relative locations; we label these Subset 1, Subset 2 and Subset 3, respectively, as shown in Table III and illustrated in Fig. 6(a).
Given the subsets defined in Table III, (A19) is expressed as
| (A20) |
Fig. 6 provides an intuitive illustration of the three subsets [Fig. 6(a)] and the corresponding strategies for identifying p(c = 1|x2, y2, x3, y3) for a (x2, y2) sampled from each subsets [Fig. 6(b)–(d)]. In particular, Fig. 6(b) shows the strategy for identifying p(c = 1|x2, y2, x3, y3) for a (x2, y2)sampled from Subset 1. We wish to find all (x1, y1) that may be correctly classified with this particular (x2, y2) and (x3, y3). To accomplish this, the decision structure should be moved toward x = -∞, y = +∞ to include as many (x1, y1)as possible. However, as shown in Fig. 6(b), the vertical line of the decision structure should not exceed x = x3, and the horizontal line should not exceed y = y2. Otherwise, incorrectly classified triplets will be counted. As a result, the shaded area in Fig. 6(b) includes all (x1, y1) that form correct classification triplet with the particular (x2, y2), and (x3, y3) shown in Fig. 6(b). For this particular (x2, y2) and (x3, y3), p(c = 1|x2, y2, x3, y3) is obtained by integrating f1(x1, y1) in the shaded area. Fig. 6(c)–(d) illustrate the strategies for identifying for p(c = 1|x2, y2, (x3, y3) for (x2, y2) belonging to Subsets 2 and 3, respectively. It can be seen that the first, second and third term in (A20) are the probability densities for correct classification given a (x3, y3) for each of the three subsets of potentially-correctly-classifiable (x2, y2). In the following, we consider the computation of each of the three terms in (A20).
Let the first term be
| (A21) |
Now note that the true class 1 fraction, T1F(x, y), when the decision structure is located at (x, y) is equal to p(c = 1|x2, y2, (x3, y3), i.e.,
| (A22) |
Thus, referring to Fig. 6(b) for the computation of A(x3, y3), we see that A(x3, y3) can be expressed as
| (A23) |
Rearranging (A23) gives
| (A24) |
Similarly, the second term in (A20), is
| (A25) |
Referring to Fig. 6(c) and again recognizing the true class 1 fraction, we see that we can rewrite this as
| (A26) |
We now apply Lemma 1 [given in (A2)] to change the bounds of the integrals in B(x3, y3), obtaining
| (A27) |
Thus, the sum of the first two terms of (A20) is
| (A28) |
Comparing (A28) and (A10) reveals that the line integral inside the square brackets in (A28) is equivalent to the negative of the partial derivative of T2F with respect to y2.
Similarly, referring to Fig. 6(c), the third term in (A20) can be expressed as
| (A29) |
Applying Lemma 2 [given in (A3)] to change the limits of integration, (A29) becomes
| (A30) |
Inside the square brackets is the line integral of f2(x, y) along the line of identity in Fig. 6(d), and function T1F is an area integration of f1(x, y) over the shaded area. Comparing (A30) and (A7) reveals that the line integral inside the bracket in (A30) is the partial derivative of T2F with respect to x2.
Substituting the partial derivatives of T2F given in (A7) and (A10), p(c = 1|x3, y3) in (A20) is given by
| (A31) |
Substituting (A31) into (A14), we obtain an expression for PC, i.e.,
| (A32) |
Equation (A32) shows that the percent correct is a sum of two terms. For notational simplicity, we replace all the x3 with x, y3 with y, x2 with x′, and y2 with y′. We first rewrite the first term as
| (A33) |
Applying the Lemma 3 [given in (A4)] to the expression inside the square bracket in, (A33) becomes
| (A34) |
Comparing (A11) and (A34) reveals that the term inside the parentheses is the partial derivative of T3F with respect to x. Substituting (A11) into (A34), gives
| (A35) |
Applying Lemma 3 and the expression for the partial derivative of T3F in (A11) to the second term of (A32) in a similar fashion gives
| (A36) |
For notational simplicity, we rewrite (A35) and (A36) so that they are both integrals of x and y. Thus, (A32) becomes
| (A37) |
Inspection of (A37) reveals that the determinant is the Jacobian for the change of variables from (T2F, T3F) to (x, y). Noting that these fractions become 0 and 1, respectively, as the rating values move from -∞ to ∞, we thus have
| (A38) |
where T1F, T2F, and T3F are defined in (A1). Equation (A38) is the expression for VUS, and we thus have that
| (A39) |
Contributor Information
Xin He, Department of Radiology, Johns Hopkins School of Medicine, 601 N. Caroline Street, Baltimore, MD 21287 USA..
Eric. C. Frey, Department of Radiology, Johns Hopkins School of Medicine, Baltimore, MD 21287 USA (e-mail: efrey@jhmi.edu)..
REFERENCES
- 1.He X, Metz CE, Links JM, Tsui BM, Frey EC. Three-class ROC analysis—A decision theoretic approach under the ideal observer framework. IEEE Trans. Med. Imag. 2006 May;25(5):571–581. doi: 10.1109/tmi.2006.871416. [DOI] [PubMed] [Google Scholar]
- 2.He X, Frey EC. Three-class ROC analysis—The equal error utility assumption and the optimality of three-class ROC surface/hypersurface with the ideal observer. IEEE Trans. Med. Imag. 2006 May;25(5):979–986. doi: 10.1109/tmi.2006.877090. [DOI] [PubMed] [Google Scholar]
- 3.He X, Frey EC. An optimal three-class linear observer derived from decision theory. IEEE Trans. Med. Imag. 2007 Jan.26(1):77–83. doi: 10.1109/TMI.2006.885335. [DOI] [PubMed] [Google Scholar]
- 4.Hanley JA, McNeil BJ. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology. 1982;143:29–36. doi: 10.1148/radiology.143.1.7063747. [DOI] [PubMed] [Google Scholar]
- 5.Green DM, Swets JA. Signal Detection Theory and Psychophysics. Krieger; Huntington, NY: 1973. [Google Scholar]
- 6.Bamber D. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. J. Math. Psych. 1975;12:387–415. [Google Scholar]
- 7.Barrett HH, Abbey CK, Clarkson E. Objective assessment of image quality. III. ROC metrics, ideal observers, and the likelihood-generating functions. J. Opt. Soc. Amer. 1998;15:1520–1535. doi: 10.1364/josaa.15.001520. [DOI] [PubMed] [Google Scholar]
- 8.Barrett HH, Myers KJ. Foundations of Image Science. Wiley; New York: 2003. [Google Scholar]
- 9.Metz CE. Basic principles of ROC analysis. Sem. Nucl. Med. 1978;8:283–298. doi: 10.1016/s0001-2998(78)80014-2. [DOI] [PubMed] [Google Scholar]
- 10.Metz CE. ROC methodology in radiologic imaging. Invest. Radiol. 1986;21:720–733. doi: 10.1097/00004424-198609000-00009. [DOI] [PubMed] [Google Scholar]
- 11.Thompson ML, Zucchini W. On the statistical analysis of ROC curves. Statist. Med. 1989;8:1277–1290. doi: 10.1002/sim.4780081011. [DOI] [PubMed] [Google Scholar]
- 12.Scurfield BK. Generalization of the theory of signal detectability to n-event m-dimensional forced-choice tasks. J. Math. Psych. 1998;42:5–31. doi: 10.1006/jmps.1997.1183. [DOI] [PubMed] [Google Scholar]
- 13.Dreiseitl S, Ohno-Machado L, Binder M. Comparing three-class diagnostic tests by three-way ROC analysis. Med. Decis. Making. 2000;20:323–331. doi: 10.1177/0272989X0002000309. [DOI] [PubMed] [Google Scholar]
- 14.Lehmann EL. Nonparametrics: Statistical Methods Based on Ranks. McGraw-Hill; New York: 1975. [Google Scholar]
- 15.Pierre C. M.S. thesis. Dept. Elect. Eng., Virginia Polytechnic Inst. State Univ.; Blacksburg: 1997. Confidence interval estimation for distribution systems power consumption by using the bootstrap method. [Google Scholar]
- 16.Efron B, Tsibshirani RJ. An Introduction to the Bootstrap. Chapman & Hall; London, U.K.: 1993. [Google Scholar]
- 17.Song X, Frey EC, He X, Segars WP, Tsui BMW. A mathematical observer study for evaluation of a model-based compensation method for crosstalk in simultaneous dual isotope SPECT. IEEE Med. Imag. Conf.; Portaland, OR. 2003. [Google Scholar]
- 18.He X, Frey EC, Links JM, Tsui BMW. Three-class ROC analysis and three-class hotelling observer for myocardial perfusion SPECT optimization and evaluation. J. Nucl. Med. 2004;45:42P–42p. [Google Scholar]
- 19.Swets J, Pickett R. Evaluation of Diagnostic Systems: Methods from Signal Detection Theory. Academic; New York: 1982. [Google Scholar]
- 20.Swets JA, Birdsall TG. The human use of information. 3. decision-making in signal-detection and recognition situations involving multiple alternatives. IRE Trans. Inf. Theory. 1956;2:138–165. [Google Scholar]
- 21.Scurfield BK. Multiple-event forced-choice tasks in the theory of signal detectability. J. Math. Psychol. 1996;40:253–269. doi: 10.1006/jmps.1996.0024. [DOI] [PubMed] [Google Scholar]
- 22.Edwards DC, Lan L, Metz CE, Giger ML, Nishikawa RM. Estimating three-class ideal observer decision variables for computerized detection and classification of mammographic mass lesions. Med. Phys. 2004;31:81–90. doi: 10.1118/1.1631912. [DOI] [PubMed] [Google Scholar]
- 23.Edwards DC, Metz CE. Restrictions on the three-class ideal observer's decision boundary lines. IEEE Trans. Med. Imag. 2005 Dec.24(12):1566–1573. doi: 10.1109/TMI.2005.859212. [DOI] [PubMed] [Google Scholar]
- 24.Edwards DC, Metz CE. Analysis of proposed three-class classification decision rules in terms of the ideal observer decision rule. J. Math. Psychol. 2006;50:478–487. [Google Scholar]
- 25.Edwards DC, Metz CE, Kupinski MA. Ideal observers and optimal ROC hypersurfaces in n-class classification. IEEE Trans. Med. Imag. 2004 Jul.23(7):891–895. doi: 10.1109/TMI.2004.828358. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Edwards DC, Metz CE, Nishikawa RM. The hypervolume under the ROC hypersurface of “near-guessing” and “near-perfect” observers in n-class classification tasks. IEEE Trans. Med. Imag. 2005 Mar.24(3):293–299. doi: 10.1109/tmi.2004.841227. [DOI] [PubMed] [Google Scholar]
- 27.Chan H-P, Sahiner B, Hadjiiski LM, Petrick N, Zhou C. Design of three-class classifiers in computer-aided diagnosis: Monte carlo simulation study. Proc. SPIE. 2003;5032:567–578. [Google Scholar]
- 28.Mossman D. Three-way ROCs. Med. Decision Making. 1999;19:78–89. doi: 10.1177/0272989X9901900110. [DOI] [PubMed] [Google Scholar]
- 29.Nakas CT, Yiannoutsos CT. Ordered multiple-class ROC analysis with continuous measurements. Statist. Med. 2004;23:3437–3449. doi: 10.1002/sim.1917. [DOI] [PubMed] [Google Scholar]
- 30.Xiong C, van Belle G, Miller JP, Morris JC. Measuring and estimating diagnostic accuracy when there are three ordinal diagnostic groups. Statist. Med. 2006;25(7):1251–1273. doi: 10.1002/sim.2433. [DOI] [PubMed] [Google Scholar]
- 31.Sahiner B, Chan H-P, Hadjiiski LM. Performance analysis of 3-class classifiers: Properties of the 3-D ROC surface and the normalized volume under the surface. Proc. SPIE. 2006;6146 doi: 10.1109/TMI.2007.905822. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Sahiner B, ChanL HP, Hadjilski M. Performance analysis of three-class classifers: Properties of a 3–D ROC surface and the normalized volume under the surface for the ideal observer. IEEE Trans. Med. Imag. 2008 Feb.27(2):215–227. doi: 10.1109/TMI.2007.905822. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.He X, Frey EC. Describing three-class task performance: Three-Class volume under ROC surface (VUS) and three-class hotelling trace (3-HT) as figures of merit. Proc. SPIE: Image Perception, Observer Performance, Technol. Assessment. 2007;6515 [Google Scholar]