

Abstract
To what extent do speaker-external communicative pressures versus speaker-internal cognitive pressures affect utterance form? Four experiments measured speakers’ references to privately known (i.e., privileged) objects when naming mutually known (i.e., common ground) objects. Although speaker-external communicative pressures demanded that speakers avoid references to privileged objects, two experiments showed that speakers often ignored this demand when it co-existed with a speaker-internal pressure to attend to those privileged objects. We hypothesize that this was due to increased salience of privileged objects (a speaker-internal pressure). Experiment 3 showed that directly boosting the salience of privileged objects increased the likelihood that speakers will inappropriately refer to those objects. Experiment 4 showed that the salience-sensitive mechanism in Experiments 1 and 2 is likely related to the mechanism causing such references in Experiment 3. Thus, the language production system is especially sensitive to cognitive pressures even when communicative harm results.
The form any utterance takes is the result of pressures from sources both external to and internal to the speaker. Speaker-external pressures are communicative in nature – for example, how speakers’ word choices convey different messages to addressees. Speaker-internal pressures are cognitive in nature – for example, how speakers’ word choices are influenced by the allocation of attention. Often, speaker-external and speaker-internal pressures converge; for example, allocation of attention might compel speakers to make word choices that are optimally tailored to particular addressees (i.e., if a speaker’s attention is drawn to something, his or her addressee’s attention likely is as well, so that commenting on attention-drawing elements is will be communicative). Sometimes, however, speaker-external and speaker-internal pressures diverge, when speaker-external communicative pressures dictate that speakers design utterances tailored for addressee needs, whereas speaker-internal cognitive pressures can make production of tailored utterances difficult.
The process of tailoring utterances to addressee needs is generally referred to as audience design (Clark, 1996; Clark & Carlson, 1982; Clark & Murphy, 1982). Exactly how interlocutors engage in audience design is controversial (Brown & Dell, 1987; Horton & Gerrig, 2002; Horton & Keysar, 1996; Keysar & Horton, 1998; Lockridge & Brennan, 2002; Polichak & Gerrig, 1998b; Schober & Brennan, 2003). However, speakers do take the needs of their addressees into account in some ways. Some examples of generic-partner adjustments are that adults use exaggerated prosody when speaking to children and non-native speakers (DePaulo & Coleman, 1986; Fernald & Mazzie, 1991); when giving directions, speakers provide more information if the direction seeker appears to be from out-of-town (Kingsbury, 1968 as cited in Krauss & Fussell, 1991); speakers revise their content when provided with evidence that addressees are having difficulty understanding (Garvey, 1975); speakers continue to use the same term to refer to the same entity even if the term is overly specific in a new context, but with a new partner, speakers revert more quickly back to basic-level terms (Brennan & Clark, 1996); and speakers modify their utterances when they estimate that their addressees have more limited processing capacity such as when speaking to cognitively-impaired addressees (DePaulo & Coleman, 1986).
An example of a particular-partner adjustment is that speakers take into account whether to-be-discussed information is information that a particular addressee knows about. The information that speakers and addressees both know that they both know makes up common ground (Clark & Marshall, 1981), and the information that speakers and addressees know only one person knows makes up that person’s privileged ground (Stalnaker, 1978). To communicate effectively, speakers should adhere to a speaker-external communicative demand to avoid inappropriate references to privileged ground (Grice, 1975). For example, imagine a situation where speakers can see two heart shapes, one of which is smaller than the other and is the intended referent or target. Addressees, however, can only see the one target heart. If speakers describe the target with “The smaller heart,” the result may be confused addressees who are wondering whether the heart they can see is the target. For speakers to tailor their speech to an addressee’s knowledge, they must keep track of common versus privileged information.
Here, we use a referential communication task to assess just this sort of situation. The goal of referential communication is to successfully refer: to produce an utterance with a form that allows addressees to determine exactly which referent, out of all referents in some implicit or explicit contrast set, is intended (e.g., one person out of all people in the world, or one card out of a particular set). And so, referring to a single visible heart with just “heart” is likely to successfully refer, whereas under certain circumstances (established in the experiments below), referring to that single heart with “small heart” may not successfully refer, if addressees are able to think that “small heart” could refer to something other than the intended target.
In the referential communication task used in the experiments below, two experimentally naïve participants, a speaker and an addressee, were shown sets of four line drawings of objects (see Figure 1). Sets consisted of pairs of objects of the same form type that differed only in size, and single objects that were the only object of that form type in the set. Both participants could see three of the objects in the set (i.e., they were in common ground). At the beginning of each trial, the speaker occluded the fourth object so that it was not visible to the addressee (by placing a blank opaque picture frame in front of the object). As such, the fourth object’s privileged ground status was naturalistically marked because it was visible only to the speaker. After occluding the privileged object, the speaker named a particular target object. On contrasting trials, the target was the same type of object as the privileged object, but contrasted in size (i.e., a common ground heart with a size-contrasting privileged heart foil). On non-contrasting trials, the target was unique. Our measure was the percentage of trials in an experimental condition on which speakers used size-contrasting modifiers (i.e., big or small) to refer to the target object (e.g., when speakers called the target heart “small heart”), comparing their rate of use on contrasting trials (when they could reflect comparison to the privileged ground object) to non-contrasting trials (when they must have been produced for reasons other than comparison to privileged ground). In tasks like these, speakers tend to use such adjectives more on contrasting than non-contrasting trials (see Wardlow Lane, Groisman, & Ferreira, 2006), revealing that privileged information does sometimes intrude upon speakers’ referring expressions.
Figure 1.
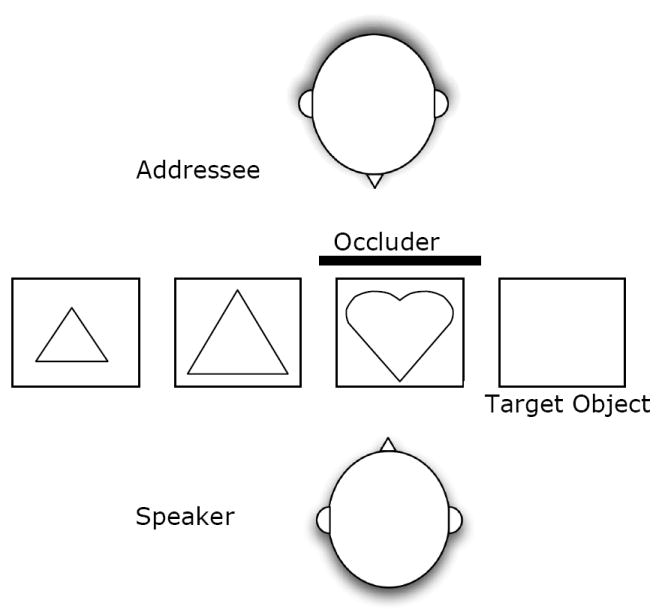
Example experimental set up for Experiments 1 & 2
From the perspective of speaker-external versus speaker-internal influences on language production, we can ask why such references to privileged ground happen at all. Recall that speaker-external forces hinge upon communicative success. This suggests that perhaps speakers refer to privileged information when doing so will not threaten communicative success. That is, perhaps a speaker calls a mutually visible heart “small heart” in the context of a privileged larger heart only when doing so will still allow the addressee to pick out the correct heart. This speaker-external explanation makes a prediction: If speakers are placed under conditions where referring to privileged ground will result in communicative failure – when a speaker-external threat is imposed – they should refer to privileged ground less.
By contrast, recall that speaker-internal forces are those that reflect the cognitive mechanisms involved in assembling utterances irrespective of any direct communicative impact. For example, as speakers formulate utterances, their attention might be drawn to certain features of their thoughts or the environment. (Of course, such speaker-internal forces may operate in service of speaker-external forces, for example, if representations of communicative impact can direct attention to result in more communicatively successful utterances. This possibility is set aside for the purposes of the present definition of “speaker-internal.”) This suggests an alternative explanation for why speakers sometimes refer to privileged information: Perhaps their attention is drawn to that information regardless of the communicative impact of describing it. This speaker-internal-explanation makes its own prediction: If speakers’ attention is drawn to privileged information, then regardless of the communicative consequences, speakers should be more likely to refer to that information.
These different explanations can be couched in terms of current models of language production (see Ferreira & Slevc, 2007, for a recent account). Generally speaking, production is considered to proceed through three stages. At message encoding, the production system selects non-linguistic, meaning-based representations that are to be linguistically encoded. These selected features are called a message. At grammatical encoding, the production system selects the lexical and syntactic features that can express the selected message features. Finally, at phonological and phonetic encoding, the selected lexical and syntactic features are encoded into articulatory representations, in preparation for eventual motor execution.
Within this model, when speakers refer to privileged information, it is because the included a bit of meaning – the contrast between the mutually visible heart and the privileged larger heart – is encoded into their to-be-expressed message. This suggests that referring to (or not referring to) privileged information is a phenomenon that operates at the message encoding stage. Within message encoding, the speaker-external force – the threat to communicative success – can be hypothesized to derive from a representation of the communicative impact of incorporating (or not incorporating) certain meaning features into a message. Such a representation of communicative impact could involve a model of the listener (e.g., Dell & Brown, 1991), which represents what an addressee does and does not know, and how additional information will change that knowledge. In the current task, this model could represent that the addressee does not know the privileged information, and that under conditions of communicative threat, references to that privileged information would lead the addressee to a knowledge state at variance with speakers’ intentions.
Also at the stage of message encoding, the speaker-internal force – the allocation of attention to certain features of meaning – can be hypothesized to reflect the relative accessibility or “activation” of a message-level representation. That is, certain cognitive strategies or environmental events can act to heighten attention to certain features (presumably through working-memory mechanisms), thereby increasing the accessibility or activation of those features. Within the current task, attention can be drawn directly to privileged information in a manner at odds with communicative success, or in a communicatively irrelevant manner (see Experiments 1 and 3 below respectively); if so, and if speaker-internal forces are critical, speakers should be more likely to refer to that privileged information.
Wardlow Lane et al. (2006) reported an experiment relevant to these issues that used the above-described task. Speakers described mutually visible shapes (e.g., a heart) when privileged shapes (an occluded card) were contrasting (a larger heart) or not contrasting (some other shape). In baseline blocks, speakers and addressees performed the basic task. They kept scores, such that every correct choice by the addressee gave both participants a point. In conceal blocks, speakers and addressees performed the same task with an additional instruction: Addressees were permitted at their discretion to guess the identity of the privileged card – the card the addressee could not see. Note that if speakers referred to privileged information, it effectively signals to the addressee the identity of the privileged card (hearing “small heart” when no other heart is mutually visible suggests that the hidden object might be a larger heart). If addressees guessed correctly, they received an extra point (but speakers did not). Speakers in turn were instructed not to hint at the identity of the hidden shape, so that addressees would not get additional points and win. Thus, speakers were given an incentive to conceal the hidden shape – that is, an incentive to avoid referring to privileged information. If references to privileged information can be controlled by speakers in light of communicative incentives, speakers should use modifiers less in the conceal block than in the baseline block. Results however showed the opposite: Speakers used modifiers more in the conceal block than in the baseline block.
With respect to the current issues, this raises two facts to explain. First, why don’t speakers refer to privileged information less when given an incentive to do so? One possible answer is that even if speaker-external forces directly influence speakers’ references to privileged information, the production system may not be sensitive to the specific communicative pressure that Wardlow Lane et al. (2006) tested. In that experiment, speakers had two goals: a primary goal of successfully referring to targets, and, a secondary goal of not providing information about privileged objects. When speakers ground references to targets in privileged information (i.e., when they say “small heart” to name a common ground heart when there was a larger heart in privileged ground) their primary goal of conveying which was the target object was not threatened (because only mutually visible shapes could be targets); only their secondary goal of concealing the hidden shape was threatened. And so, the production system may not be particularly sensitive to whether inclusion of some feature in an utterance (such as a modifier) threatens a more remote (secondary) goal, especially when that goal is unrelated to the primary goal of successful reference.
In Experiment 1 below, we manipulate communicative success in a more fundamental way. Here, speakers have only one goal: To successfully refer to a target object so that addressees can identify it. In one condition, speakers must avoid referring to privileged objects when naming common ground objects (e.g., avoid saying “small heart”), because doing so could be misinterpreted, thereby threatening the success of that reference. In another condition, even if speakers referred to privileged objects when naming common ground objects (by saying “small heart”), it was impossible to misinterpret the utterance, and so the reference would be successful anyway. (Below, we describe how we allowed or blocked the potential for such misinterpretation.) If speakers are sensitive to this external pressure (a threat to successful reference), then they should refer to privileged ground less when doing so threatened the success of the reference. In this way, we have made the more general communicative pressure to avoid inappropriate references to privileged information primary. Now, instead of only (perhaps) causing momentary confusion because of an inappropriate reference to privileged information, these references can actually result in utterances with forms that do not allow addressees to identify the intended target.
The second fact to be explained from the Wardlow Lane et al. (2006) experiment is why speakers referred to privileged information more in conceal blocks than in baseline blocks. This may be explained as resulting from a speaker-internal force. Specifically, the instruction and incentive to avoid mentioning privileged information in the original experiment may have incidentally heightened speakers’ attention to privileged objects, and such heightened attention might have led to increased references to those privileged objects. If so, this would suggest that when speakers produce utterances that refer to privileged information, it is because speaker-internal pressures drive such references.
In Experiment 1, we include both a speaker-external communicative pressure and a speaker-internal cognitive pressure that work to opposite ends. Specifically, we include a speaker-external pressure that creates a threat-to-referential success when speakers refer to privileged information at the same time as it creates a speaker-internal pressure demanding attention to privileged information. We explore in more detail the role that such attention-paying plays in references to privileged ground in later experiments, and tie this notion explicitly to our implementation of threat-to-referential success.
Experiment 1
Experiment 1 tests the influences of a simultaneous threat-to-referential-success and heightened attention to privileged information. We implemented these pressures by making privileged information either ignorable or relevant to the communicative situation. The ignorability and relevance of privileged information were implemented by manipulating the location of targets on filler trials. In the privileged-ignorable condition, all targets on all trials (filler and critical) were in common ground; that is, speakers were never asked to identify hidden objects. The effect of this is twofold: First, speakers were able to completely ignore privileged information for the entire session because they never had to refer to that information or take it into account when speaking. This should make it easy to pay little or no attention to that privileged information. Second, speakers knew that addressees need only ever consider the three common ground objects when trying to determine which object speakers referred to, because addressees knew speakers never were asked to identify privileged objects. This implies that if speakers named a target object heart or small heart (when the privileged object was a larger heart), addressees would have no difficulty determining the intended referent, because there is only one heart for them to consider. As such, there is no referential penalty when speakers use modifiers, even if those modifiers implicitly refer to privileged information and even though use of a modifier violates the communicative pressure to avoid providing privileged information.
Contrastingly, in the privileged-relevant condition, some targets were in privileged ground, though only on certain filler trials. Using Figure 1 as an example, speakers in the privileged-relevant condition may have been instructed to name the hidden heart. The effect of this design is again twofold: First, speakers cannot completely ignore privileged information across the entire experiment, because on some filler trials they have to identify a privileged object. This could act to interfere with speakers’ ability to pay less attention overall to privileged information. Second, on any given trial, speakers knew that addressees had to consider all four objects when they tried to determine the target. This requirement placed pressure on speakers to avoid making implicit references to privileged objects when naming common ground targets (i.e., to avoid saying small heart to name a common ground heart when there was a larger heart in privileged ground) because doing so does not uniquely identify the target rather than the privileged object. For example, if speakers named a common ground target a small heart because there was a larger heart in privileged ground, addressees would not know whether small heart referred to the single visible heart, or another heart that was occluded (which, only in the privileged-relevant condition, is a possible target). Instead, speakers should just say “heart,” as an utterance of this form would uniquely identify the only common ground heart addressees could see. In short, use of a modifier to describe a common ground target threatened the referential success of references only in the privileged-relevant condition. 1
If speakers are especially sensitive to speaker-internal pressures, we expect to find that the privileged-relevant condition should make privileged information difficult to ignore, thereby causing more references to privileged information in the privileged-relevant condition, despite the communicative harmfulness of the modifier use in that condition. If, however, speakers are especially sensitive to speaker-external pressures dictating the form utterances should take, we expect to find that the referential threat that arises in the privileged-relevant condition should cause fewer references to privileged information in the privileged-relevant condition, despite the (hypothetical) heightened attention that is drawn to privileged information in that condition.
Method
Participants
Participants were 24 native English speaking undergraduates at the University of California, San Diego. Each participated as both a speaker and an addressee. One speaker was excluded due to experimenter error.
Materials and Design
Each pair of participants viewed 288 simple line drawings of common objects, four of which were displayed depicted in “cards” drawn on 8 1/2 × 11 inch pages in a binder. All critical targets were medium-sized objects, filling about half of the outlined space. Objects varied in size across and within trials such that the larger (or smaller) object on one trial (relative to the size of the other objects in that set) might be smaller (or larger) on another trial. Each object type was used on only one trial and never occurred with more than one other object of the same type (which was always a different size). Because size manipulations were only made with respect to the other member of a pair, and not other members of the entire set, terms such as “small” and “large” were encouraged to refer to relative rather than to absolute size.
Two manipulations were used: contrast type (contrasting versus non-contrasting) and privileged relevance (privileged-relevant versus privileged-ignorable). Four experimental conditions were assigned to each critical object by crossing the levels of the contrast type and the privileged relevance. Contrast type was manipulated within speakers and items in counterbalanced fashion and privileged relevance was manipulated between speakers and within items in counterbalanced fashion. On critical trials speakers were instructed to describe a particular mutually visible object (hereafter, target) for addressees (e.g., a heart). On contrasting trials the target was paired with a size-contrasting privileged object of the same type (e.g., a larger heart). On non-contrasting trials the target was unique to the set (e.g., a square was privileged, so that the target heart was the only heart in the set).
Speakers in the privileged-ignorable condition named mutually visible targets on all critical and filler trials. Speakers in the privileged-relevant condition named mutually visible targets on all critical trials, but named privileged ground targets on 18 out of 36 filler trials (25% of all trials). Half of filler trials with privileged targets required a modifier (9 out of 18 trials, or 12.5% of all trials) because those privileged targets had size-contrasting common ground pair mates. The other half of filler trials with privileged targets did not require a modifier (9 out of 18 trials, or 12.5% of all trials) because the privileged target was unique to the set. Speakers in the privileged-relevant condition named common ground targets on the other half of filler trials (18 out of 36 trials). Half of these (9 out of 18 trials) did not require a modifier, whereas the other half (9 out of 18 trials) did, to contrast the common ground target from a size-contrasting pair mate also in common ground. Fillers and critical trials were pseudo-randomly interspersed throughout the experimental session.
On all trials, speakers’ use of size-contrasting modifiers was measured. We assume that modifier use on non-contrasting trials were not references to privileged information (because the privileged object did not contrast with the target in size). Thus, however much more speakers use the direction-appropriate size modifier on contrasting than on non-contrasting trials assesses speakers’ references to privileged information. Additionally, speaker utterance initiation latency, addressee target selection latency, and addressee target selection accuracy were all measured and assessed.
Procedure
A coin toss randomly assigned participants to the roles of speaker and addressee. After completing a full set of stimuli in these roles, participants changed roles and completed another full set of stimuli from the other privileged-ground relevance condition. For example, if the first speaker was presented with the privileged-ignorable condition, the second speaker was presented with the privileged-relevant condition and vice-versa. Also, targets that were in the contrasting condition for the first speaker were in the non-contrasting condition for the second speaker and vice versa. Because filler trials were the same across all presentations, after the participant role changed, stimuli groupings (each set of four objects) were the same on half of trials as in the first presentation whereas the groupings were different on half of trials (the critical trials). Therefore, participants could not easily rely on their memory of the stimuli from the first round to aid them in the second round, as they would be just as likely to make a mistake using this strategy as not. Participants were informed that some of the stimuli groupings would be different in the second round and were instructed not to try to make guesses according to what they might remember about the first round as doing so would not be helpful to their scores (described below). Order of privileged-ground relevance conditions were counterbalanced across pairs.
During the experimental session, participants sat at opposite sides of a table. A standard three-ring binder lay flat in the center of the table between the two participants. The binder was oriented so that all stimuli were facing upwards for the speaker and upside down for the addressee. At the beginning of each trial, addressees closed their eyes while speakers opened the binder to reveal a set of four objects printed across the middle of the first page. Speakers were instructed to look at each of the objects from left to right on the page and then look up at a computer monitor. The monitor display showed four blank squares meant to represent the four objects on the binder page. There was an arrow above one of the boxes with the phrase “block this object”. Speakers then blocked that object by positioning an occluder (a 3-inch × 5-inch picture frame) between the object and addressees so that addressees would not be able to see the object when viewing the display. After another two-second delay, the old arrow disappeared from the computer monitor and a new one appeared with the phrase, “identify this object”. Speakers were instructed to identify that object for addressees without using eye movement, head movement or direction (i.e., “the object on the left”). A voice key measured speakers’ production latencies, measured from the onset of the “identify this object” display.
Upon hearing the description, addressees opened their eyes and looked at the display. After determining which object they thought was the target, addressees pressed a number (1, 2, 3 or 4) on a keyboard in front of them, allowing addressees’ response times to be measured (relative to the onset of speakers’ productions). They were instructed to press the number that corresponded to the position of the object they wanted to select (the left-most object corresponded to the number 1 and the object directly to the right of number 1 was number 2, etc). After pressing the number on the keyboard, addressees were instructed to point to the object that they thought was the target. The explanation given to addressees was that speakers could not see which button was pressed, so addressees should also point to an object to so that speakers could tell them whether they were right or wrong.
After addressees pointed to an object, speakers removed the occluder so that addressees could see all objects, and indicated to addressees whether the choice was correct. An experimenter tracked the number of correct choices made as well as documented how the speaker described the target. A point was given to pairs whenever addressees correctly identified targets. Speakers and addressees were asked to maximize this score across the experiment. Questions and comments were allowed and encouraged during the practice session, but discouraged during the real trials.
Analyses
For the primary dependent variable of interest, how speakers described targets, the percentage of targets described with direction-appropriate size-contrasting modifiers was computed for each subject. These percentages were submitted to repeated measures analyses of variance (ANOVAs) using subjects (F1) and items (F2) as random factors. (For all analyses on proportional data reported below, additional analyses carried out using arcsine-transformed proportions yielded the same pattern of significance as reported here.) The ANOVA design was 2 × 2, with the factors of contrast type and privileged relevance. All significant effects achieved the .05 level unless otherwise specified. We report variability with repeated measures 95% confidence-interval half-widths (CIs) based on single-degree-of-freedom comparisons (Loftus & Masson, 1994). We analyzed speakers’ production latencies and addressees’ selection latencies with analogous ANOVAs. However, due to wide variability, no reliable effects on any latency measure was observed, and so we do not discuss these measures further.
Results
For Experiment 1, we report four sets of results. Following the primary analyses of speakers’ target descriptions, we consider whether the patterns of target descriptions were modulated by whether trials were early versus late in the experiment, and by whether speakers acted first, after acting as addressees. Then, we consider how accurately addressees were able to select targets.
Target descriptions
Figure 2 shows the mean percentages of target descriptions that included specified modifiers (i.e., “small triangle”) as a function of contrast-type and privileged-ground relevance. Speakers modified most when the target had a size-contrasting match in privileged ground and speakers sometimes had to identify privileged objects, as compared to when speakers never had to identify privileged objects. In contrast, speakers rarely used modifiers when the target object was unique to the set regardless of whether they had to identify privileged objects.
Figure 2.
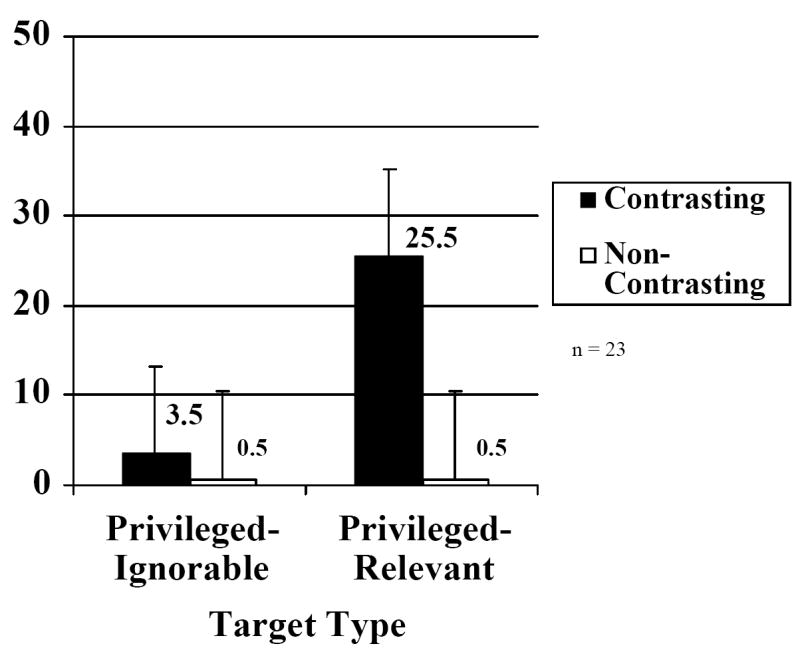
Experiment 1. Percentages of target descriptions including foil-contrasting modifiers as a function of whether the foil and target were the same (contrasting trials) or different shapes (non-contrasting trials), and whether speakers were required to name some privileged ground targets on filler trials. Error bars illustrate 95% confidence interval of the interaction by speakers.
Statistical analyses support these observations. The main effect of contrast type was significant: Speakers produced significantly more modifiers in the contrasting condition (14.5%) than in the non-contrasting condition (0.5%), F1(1,21) = 8.1, CI = ±10.2%; F2(1,35) = 85.4, CI = ±3.1%. The main effect of privileged relevance was also significant. Speakers produced significantly more modifiers in the privileged-relevant condition (13.0%) than in the privileged-ignorable condition (2.0%), F1(1, 21) = 4.81, CI = ±10.4%; F2(1,35) = 48.1, CI = ±3.2%. The interaction between these two factors was also significant, F1(1, 21) = 5.0, CI = ±14.8%; F2(1,35) = 48.4, CI = ±4.6%. In the privileged-relevant condition, speakers modified target descriptions 25.0% more often on contrasting trials (25.5%) than on non-contrasting trials (0.5%), whereas in the privileged-ignorable condition, speakers modified only 3.0% more on contrasting trials (3.5%) than on non-contrasting trials (0.5%).
Trial order
To test whether speakers’ use of modifiers changed over the course of the experiment, we reconducted the analyses after introducing a trial order factor, dividing trials into groups depending on whether they were presented in the first or second half of the experiment. Speakers used modifiers on 9.4% of critical trials in the first half of the experiment and they used modifiers on 5.6% of critical trials in the second half of the experiment, an effect that was marginally significant by subjects, F1(1, 21) = 3.4, p = .08, CI = ±6.1%, and significant by items, F2(1,34) = 5.6, CI = ±2.4%. This overall diminution of modifier use appeared about equally in the two privileged-ground relevance conditions. On first half trials in the privileged-relevant condition, speakers modified target descriptions 29.5% more often on contrasting trials (30.6%) than on non-contrasting trials (0.9%), whereas in the privileged-ignorable condition, speakers modified only 4.0% more on contrasting trials (5.0%) than on non-contrasting trials (1.0%). On second half trials in the privileged-relevant condition, speakers modified target descriptions 20.4% more often on contrasting trials (20.4%) than on non-contrasting trials (0.0%), whereas in the privileged-ignorable condition, speakers modified only 2.0% more on contrasting trials (2.0%) than on non-contrasting trials (0.0%). This left the interaction between trial order, contrast-type and privileged-ground relevance as nonsignificant, F1(1, 21) = 1.1, CI = ±7.4 %; F2(1,34) = 1.4, CI = ±6.4%.
Speaker order
Because participants acted as both speakers and addressees in this experiment, half of participants acted as speakers only after acting as addressees, whereas the other half acted as speakers naively, at the beginning of the experimental session. It is possible that participants who acted as speakers second might have performed differently, because of their previous experience as addressees. However, note that when participants switched roles from speaker to addressee (or vice versa), the assignment of privileged relevance also switched. This implies that if participants who acted as speakers second perform differently, it cannot be because they learned something particular about the privileged-ground relevance condition they participated in as speakers, because their previous experience as addressees was in the opposite relevance condition.
Introducing a speaker order factor showed that speakers’ overall modification rates tended to vary according to speaker order, such that participants used modifiers less when acting as speakers in the second half of the experiment (11.3% vs. 3.8%), an effect that was marginally significant by subjects, F1(1, 19) = 3.2, CI = ±8.8% and significant by items F2(1,35) = 36.8, CI = ±2.6%. Most interestingly, the above-observed overall interaction between contrast type and privileged relevance was caused by participants who acted as speakers first (with a 43.4% difference between contrasting and non-contrasting trials for privileged-relevant speakers but a reversed 0.1% corresponding difference for privileged-ignorable speakers). Participants who acted as speakers second showed no such interaction: Privileged-relevant speakers used modifiers on 7.4% more trials in the contrasting than in the non-contrasting condition, whereas privileged-ignorable speakers used modifiers on 7.8% more trials in the contrasting than in the non-contrasting condition. As such, the interaction between contrast-type, privileged-ground relevance and speaker order was significant, F1(1, 19) = 6.8, CI = ±17.2%; F2(1,35) = 60.9, CI = ±5.9%.
The disappearance of the overall interaction for speakers who acted second came about because privileged-relevant speakers acting second, who acted as privileged-ignorable addressees first, produced modifiers far less than privileged-relevant speakers who acted first (7.4% vs. 43.4%), whereas privileged-ignorable speakers who acted second, who were privileged-relevant addressees in the first half of the experiment, produced modifiers far more than privileged-ignorable speakers who acted first (7.8% vs. 0%). Note that privileged-relevant speakers who acted second and so produced relatively fewer modifiers themselves heard no modifiers (on critical trials) as addressees, whereas privileged-ignorable speakers who acted second and so produced relatively more modifiers heard nearly half of all critical trials described with modifiers. One interpretation of this difference is that there may be a cross-role priming effect: Speakers’ use of modifiers when they acted second was influenced by how often they heard modifiers when they previously acted as addressees2. Important for current purposes, however, is that when there is an effect (for speakers who act first), it appears to reflect a speaker-internal pressure (more modifiers in the privileged-relevant condition). This effect can be wiped out, but still, the pattern that would be expected if speakers were sensitive to the speaker-external factor is not apparent, as even speakers who acted second did not produce fewer modifiers when in the privileged-relevant compared to the privileged-ignorable condition.
Target selection accuracy
A critical question is whether addressees indeed performed worse when speakers modified critical targets with reference to a privileged card, and furthermore, whether such modifiers only harmed performance in the privileged-relevant condition (which was assumed to introduce the communicative threat). In fact, across all addressees in the privileged-ignorable condition, only two incorrect target selections were made, both on filler trials. Furthermore, in both cases the target selection errors occurred after a speaker used an inappropriate modifier to describe a target (i.e., the speaker said “small triangle” to describe the large member of a pair of triangles). In contrast, across all addressees in the privileged-relevant condition, 42 incorrect target selections were made, 19 on filler items, 2 on non-contrasting items and 21 on contrasting items. Of these 21 incorrect target selections on contrasting items, 20 were made when targets were described with a modifier. Note that addressees in the privileged-ignorable condition heard only 7 contrasting targets described with a modifier, whereas addressees in the privileged-relevant condition heard a total of 55 contrasting targets described with a modifier. Most important then is that addressees in the privileged-relevant condition made 20 out of 55 incorrect selections when hearing critical contrasting targets described with modifiers, whereas addressees in the privileged-ignorable condition made 0 out of 7 incorrect selections when hearing critical contrasting targets described with modifiers.
We conducted statistics on the proportion of all trials involving a modified target description where addressees made an incorrect selection, excluding any subject who never heard a modified target selection. Addressees in the privileged-relevant condition made more incorrect selections upon hearing modified target descriptions (0.44 incorrect selections per subject) than addressees in the privileged-ignorable condition (0 incorrect selections per subject), F(1,12) = 5.22, CI = ±.42 incorrect selections per subject. This confirms the assumption that by making privileged ground relevant, speakers’ use of a modifier indeed causes communicative failure.
Additionally, recall that participant pairs kept scores, receiving a point whenever the addressee correctly guessed the card speakers intended to describe. Revealingly, decreased target selection accuracy in the privileged-relevant condition affected pairs’ scores such that speakers earned fewer overall points in the privileged-relevant condition as compared to the privileged-ignorable condition. The average score for a pair of participants in the privileged-ignorable condition was 71.1 points, whereas the average score for a pair of participants in the privileged-relevant condition was 68.0 points (each out of a maximum possible score of 72), a difference that was significant F(1,21) = 9.8, CI = ±2.04 points.
Discussion
The results of Experiment 1 showed that speakers made more references to privileged information when they had to cope with both a speaker-external pressure to avoid such references and a speaker-internal pressure that made privileged information salient. Our analysis of trial order suggests that speakers may have learned the communicative contingencies and were able to lessen their use of modifiers in the second half of the experiment as compared to the first half of the experiment. However, it is important to note that speakers’ modifier use continued to show the same overall pattern in both first and second halves. That is, speakers used the most modifiers on contrasting privileged-relevant trials as compared to all other trial types in both first and second halves of the experiment.
Our analysis of speaker order showed that participants who acted as speakers first and participants who acted as speakers second displayed the same overall pattern of modifier use, even if speakers who acted second used modifiers less overall. That is, both groups of speakers used more modifiers on contrasting than non-contrasting trials. That said, there is a consistent tendency that as speakers gained more experience with the task, overall, they used modifiers less. This could reflect an increased sensitivity to the privileged-common distinction and thus greater sensitivity to the knowledge states of their addressees, though it is worth noting that at no point did speakers modify less on privileged-relevant than on privileged-ignorable trials, as would be expected if speakers’ decisions regarding utterance form were dictated specifically by addressee needs.
Importantly, our analysis of target selection accuracy and pairs’ scores showed that modifier use on critical trials was only harmful to pairs’ scores and to addressees’ ability to select the correct target in the privileged-relevant condition. This finding, coupled with the finding that speakers used modifiers most often in the privileged-relevant condition, suggests that our speaker-external pressure to avoid referring to privileged information did not act to decrease such references, at least not when paired with a speaker-internal pressure that worked to the opposite end. The observed pattern suggests that speakers are highly sensitive to speaker-internal pressures even at the expense of successful communication.
Upon hearing a modified description of a critical target, addressees made errors 20 out of 55 times, or 36.4% of the time. This is a sizable error rate, though it is likely better than chance (50%, if addressees took modified descriptions to be equally likely to refer to common or privileged information). This may be because across the experiment, common objects were targets much more often (63 trials) than privileged objects (9 trials). Addressees thus may have become sensitive to this target distribution, choosing common objects more (which would be correct on target trials). Another possibility is that addressees were sensitive to more subtle cues from speakers, such as where their gaze was directed (e.g., Hanna & Tanenhaus, 2004; note however that addressees’ eyes were closed as the utterance was produced, so that only eye-gaze after production could be influential).
Overall, Experiment 1 suggests that when a manipulation heightens attention to privileged ground, speakers are only more likely to refer to that privileged ground. However, an alternative explanation for the pattern observed in Experiment 1 is that speakers in the privileged-relevant condition may have used more modifiers because they were unable to develop an effective referential strategy, due to the complexity of the task. Specifically, speakers might have been confused about how to name privileged objects when those objects had pair mates that were visible to addressees (i.e., it was difficult to name a privileged heart when there was another heart in common ground). This confusion may have carried over into their descriptions of common ground objects.
To illustrate, imagine that speakers are asked to identify a privileged ground heart (i.e., occluded from the addressee’s view) when a smaller heart and two circles are mutually visible. Speakers can either say, “heart,” or “large heart” to name the privileged target. If speakers say, “heart,” addressees should assume that the target is the visible (common ground) heart, as they have no a priori reason to think that there is another heart in the set. This would of course be an incorrect selection, and so saying just “heart” to name the privileged ground target when it has a size-contrasting pair mate in common ground does not implement a communicatively successful strategy. Contrastingly, if speakers instead say “large heart” to name the privileged heart, now the reference may be successful. Yet in order for it to be successful, addressees will have to guess whether the target is the visible (common ground) heart (which in our experiments was always medium-sized) or the hidden object (this is the penalty or threat to referential success that was part of the design of this condition). (Of course, from a Gricean perspective [i.e., Grice, 1975], the correct strategy is to call the privileged heart ‘large heart,’ as including the extra information with respect to common ground should compel addressees to seek additional information, which in this context would naturally be the privileged-ground heart. Nonetheless, interlocutors are not always perfectly Gricean [see Engelhardt, Bailey, & Ferreira, 2006]).
Importantly, to be maximally effective across trials, speakers must consistently name common ground targets without the use of a modifier (e.g., “heart”) and privileged ground targets that have size-contrasting common ground pair mates with the use of a modifier (e.g., “large heart”). This evidently was difficult for speakers, as reflected by their 25% modification rate under these conditions. Or, speakers may have determined that because they sometimes violated this general strategy (say, because speaker-internal pressures sometimes caused them to erroneously compare a common ground object to a hidden object), the entire strategy was undermined and so they chose not to pursue the strategy at all. In either case, the fact that speakers sometimes had to describe privileged-ground objects that had size-contrasting matches in common ground may have made it more difficult for speakers to determine or implement the optimal description strategy. Experiment 2 tests this possibility.
Experiment 2
In order to test whether the results of Experiment 1 were due to participant confusion, Experiment 2 required all speakers to name privileged targets on some filler trials and manipulated (between subjects) whether those privileged target objects had pair mates in common ground or whether they were unique to the set. Privileged target referents that have pair mates in common ground (i.e., when speakers are asked to name a privileged heart when there is another heart in common ground) must be consistently grounded with size-contrasting information (just as in Experiment 1). Privileged target referents that are unique do not – if speakers are asked to name a privileged circle when no other circle exists in the set, they need only say “circle.”
The effect of this manipulation is that it provides half of speakers with a simple strategy for referring to privileged objects (just name the unique object) and the other half with a more difficult strategy (name the unique object with a modifier, and make sure that common-ground targets with privileged-ground pair mates are never named with a modifier). If the results of Experiment 1 are due to the difficulty in determining a referential strategy, speakers who are required to name privileged ground targets that have size-contrasting pair mates in common ground should produce more modifiers than those that do not have the same requirement.
Experiment 2 used a slightly different procedure for presenting subjects with stimuli. Unlike Experiment 1, in which outlines of cards were printed on binder pages, Experiment 2 used actual individual cards. This superficial difference in procedure should not affect the referential demands of the task; if it in fact does not, then we should see comparable performance between Experiment 1 and Experiment 2, at least in the analogous conditions (i.e., when speakers in Experiment 2 must identify privileged-ground cards that have shape matches in common ground).
Method
Participants
Participants were 56 undergraduates at the University of California, San Diego, 28 as speakers and 28 as addressees. Data were excluded from one pair due to experimenter error. All participants were native speakers of English.
Materials and Design
Each pair of participants viewed 288 different cards. Each card displayed one simple line drawing of a familiar object (the same objects used in Experiment 1). Cards were placed on a table between speakers and addressees in sets of four as described in Experiment 1.
Two manipulations were used: contrast-type (contrasting versus non-contrasting) and privileged-uniqueness (privileged-paired versus privileged-unique). Contrast-type was manipulated within subjects and items in counterbalanced fashion. Contrasting and non-contrasting trials were as described in Experiment 1. Privileged-uniqueness was manipulated between subjects and within items in counterbalanced fashion. Speakers in both privileged-uniqueness conditions were required to name some filler targets that were privileged. Speakers in the privileged-paired condition were required to name privileged filler targets that had size-contrasting pair mates in common ground, whereas speakers in the privileged-unique condition were required to name privileged filler targets that were unique to the set. (Note that naming the privileged object in the privileged-unique condition does not require the use of a modifier, although modifier use should not cause referential failure -- calling a privileged object ‘small circle’ when addressees cannot see any circle at all should still lead addressees to choose the privileged object.) For all speakers, 18 out of 36 filler trials included privileged ground targets. In all, 72 trials were administered.
Procedure
A coin toss randomly assigned participants to the roles of speaker and addressee. Participants sat at opposite sides of a table such that the speaker could see a computer monitor, but the addressee could not. At the beginning of each trial, the addressee closed his or her eyes while the experimenter placed four cards on the table. The speaker then looked at a computer monitor that displayed a schematic of four blank cards, one of which had an arrow above it with the instruction, Block this card. The speaker then blocked the corresponding actual card by positioning an occluder (a 5-inch × 5-inch picture frame) between the card and the addressee so that the addressee would not be able to see the card when viewing the display. Next, the speaker looked back at the computer monitor that displayed a new schematic of four blank cards. This time one of the cards had an arrow above it with the instruction, Identify this card. Speakers were instructed to identify the object on that card as in Experiment 1. Points were awarded as in Experiment 1.
Analyses
We report speakers’ overall target-description performance as a function of the primary experimental conditions. The supplemental analyses are not reported, both because we did not measure all relevant aspects of performance (e.g., production latencies) and because Experiment 1 did not reveal informative effects in those analyses (e.g., effects of trial order). The analyses that are reported are like those in Experiment 1.
Results
Figure 3 shows the mean percentages of target descriptions that included specified modifiers as a function of contrast-type and privileged-uniqueness. Speakers were just as likely to use size-contrasting modifiers when a target had a size-contrasting match in privileged ground regardless of whether on filler trials speakers had to identify privileged targets that were unique to the set or privileged targets that had size-contrasting matches in common ground.
Figure 3.

Experiment 2. Percentages of target descriptions including foil-contrasting modifiers as a function of whether the foil and target were the same (contrasting trials) or different shapes (non-contrasting trials), and whether speakers were asked to identify privileged objects that had pair mates in common ground (privileged-paired trials) or that were unique to the set (privileged-unique trials). Error bars illustrate 95% confidence interval of the interaction by speakers.
Statistical analyses support this observation. The main effect of contrast-type was significant. Speakers produced significantly more modifiers in the contrasting condition (25.9%) than in the non-contrasting condition (3.6%), F1(1,26) = 10.5, CI = ±10%; F2(1,70) = 60.5, CI = ±5.1%. The main effect of privileged-uniqueness was not significant. Speakers produced modifiers equally often in the privileged-paired condition (14.5%) as in the privileged-unique condition (15.0%), F1(1, 26) < 1, CI = ±10%; F2(1,70) < 1, CI = ±5.1%. The interaction between these two factors was also not significant, F1(1, 26) < 1, CI = ±14.1%; F2(1,70) < 1, CI = ±7.7%. In the privileged pair condition, speakers produced modifiers 21.8% more on contrasting trials (25.4%) than on control trials (3.6%), whereas in the privileged unique condition, they produced modifiers 22.7% more on contrasting trials (26.3%) than on non-contrasting trials (3.6%).
Discussion
The results of Experiment 2 show that modification rate was not influenced by whether a privileged ground target had a pair mate in common ground (making it difficult to develop a referential strategy) or was unique to the set (making it easy to develop a referential strategy). This suggests that speakers’ use of modifiers in Experiment 1 was not influenced by any difficulty determining an effective referential strategy that is caused by having privileged-ground objects contrast in size with common-ground objects. Rather, any time speakers are required to sometimes name privileged cards on filler trials, they heavily increase their tendency to implicitly refer to privileged cards on critical trials. Together, the results of Experiments 1 and 2 suggest that a manipulation specifically designed to raise a threat to communicative success (a speaker-external pressure) did not lead to fewer references to privileged ground when that threat co-existed with an internal pressure that caused speakers to allocate more attention to privileged ground.
The equivalent performance in the privileged-paired and privileged-unique conditions supports an additional important point, which is that performance in Experiment 1 in the privileged-relevant condition (and in the formally identical privileged-paired condition in Experiment 2) did not come out as it did because speakers failed to learn the communicative contingencies of the task. That is, the fact that speakers modified at very similar rates in the privileged-paired and privileged-unique conditions suggests the effect is caused by the need to sometimes name the privileged-ground object, and not by any additional effect of learning how paired cards are distributed across common and privileged ground.
Experiment 2 suggests that the requirement to name privileged objects, which was necessary to establish our speaker-external pressure of a threat to referential success (at least in the way it is currently implemented), caused the presence of privileged objects to become highly salient to speakers. Highly salient privileged objects represent a speaker-internal cognitive pressure, because they demand attention. With respect to this task, the more highly salient privileged information became, the more difficult it may have been for speakers to avoid referring to it. Likewise, and as mentioned above, increased salience may be the reason that speakers’ references to privileged information increase with explicit instruction to avoid such references (Wardlow Lane et al. 2006).
Of course, having speakers sometimes name privileged objects is not an obviously face-valid manipulation of a speaker-internal pressure that increases the salience of privileged-ground objects. For instance, note that even when speakers sometimes had to name privileged objects on filler trials, speakers did not have any special pressure to process privileged objects on target trials. Therefore, a demonstration that speakers’ references to privileged information are sensitive to a more face-valid manipulation of attention is warranted. Experiment 3 included such a more face-valid manipulation, increasing the salience of privileged objects by drawing speakers’ attention to those privileged objects immediately before utterance production on critical trials. Specifically, on high salience contrasting trials, speakers were required to recognize the privileged object immediately before producing their reference to a common object. If increased salience of privileged information increases the likelihood that that information will be mentioned, we should see an increased use of context-relevant modifiers in the high salience condition. This manipulation was neutral with respect to conversational pressure.
Note also that Experiments 1 and 2 exhibited very similar performance, despite the slight differences in procedure (Experiment 1 using a binder presentation with “cards” on a page, Experiment 2 using actual cards). The binder presentation is more efficient to implement, and so is used in subsequent experiments.
Experiment 3
Experiment 3 was designed to directly test whether a speaker-internal pressure, increased attention to privileged objects, increases the likelihood that speakers will refer to that privileged information. To do this, Experiment 3 required speakers to identify common targets under low salience or high salience conditions. In the low salience condition, speakers were shown which object to name in a straightforward manner, as in Experiment 1: The experimenter indicated which object was the target by pointing to it. In the high salience condition, the identity of the target was revealed in a different way: Speakers opened a page in a binder that displayed instructions regarding which object to name. The instructions on the binder page were of the sort, “1 to the right of,” next to a reference object (i.e., a picture of one of the objects in the set). As shown in Figure 4, the instructions might say “1 to the right of” next to a picture of the large heart.
Figure 4.
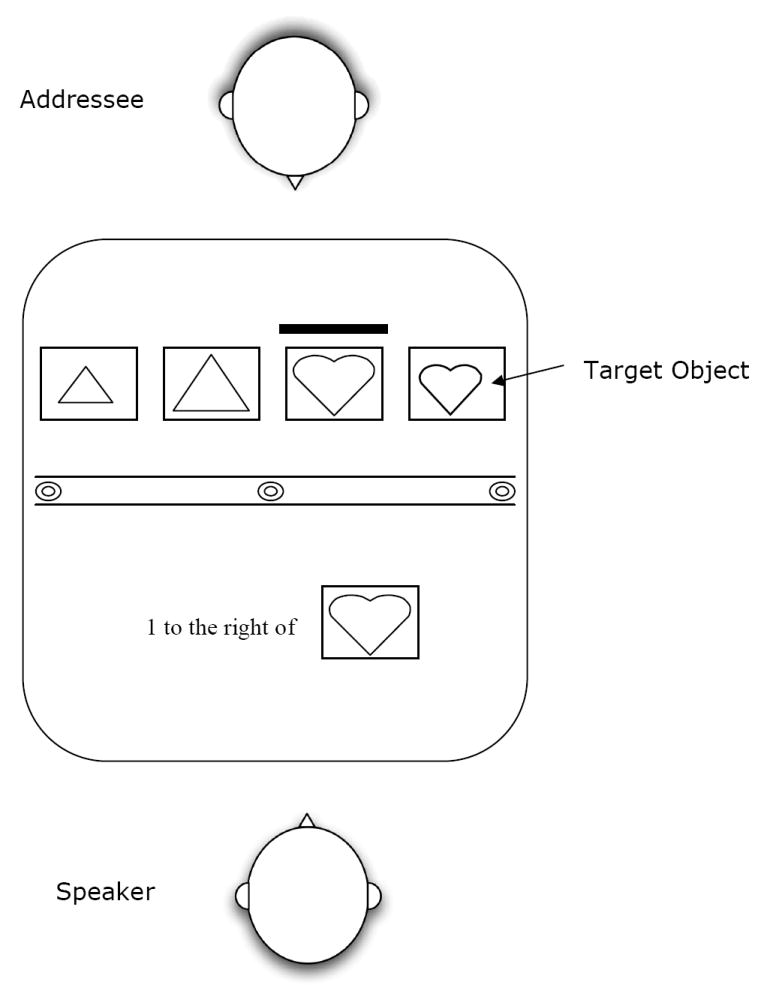
Example experimental set up for Experiments 3 and 4. Note that the binder was angled such that the instructions were only visible to the speaker.
On all contrasting trials in the high salience condition, the reference object was the privileged object. Therefore, in order to determine which object was the target, speakers first had to recognize and locate the privileged object, thereby attending to it. Thus, speakers’ attention to privileged objects was higher in the high-salience condition than in the low-salience condition. If attention to privileged objects, a speaker-internal cognitive pressure, causes increased mention of those objects when speakers name common targets, we should see an increased use of context-relevant modifiers in the high salience condition.
Method
Participants
Participants were 74 native English-speaking undergraduates from the University of California, San Diego who participated for experimental credit. Four participants were excluded due to experimenter error.
Materials and Design
The materials and presentation format were the same as those described in Experiment 1. The stimuli binder, a standard three-ring binder, was laid flat on a table so that there was a top sheet and a bottom sheet of paper, both visible to speakers and addressees.
Two manipulations were used: contrast-type (contrasting versus non-contrasting) and attention-type (low salience versus high salience). Contrast-type and attention-type were manipulated within subjects and items in counterbalanced fashion. Contrasting and non-contrasting trials were the same as in the previous experiments, intermixed on a trial-by-trial basis. Attention-type was blocked, with order of blocks counterbalanced across participants. On low salience trials, the experimenter pointed to an object to indicate that it was the target. On high salience trials, the speaker unfolded the bottom sheet of the binder to reveal instructions. Instructions were typed across the bottom page and indicated a reference point, which was one of the objects on the top page. To the left of the indicated object were instructions such as “1 to the left of” or “2 to the right of,” revealing the identity of the target only in relation to the indicated object. On experimental trials the indicated object was the privileged object. Thus, in order to determine which object to identify, speakers first needed to look at the privileged object, increasing its salience.
Procedure
The instructions, read by the experimenter at the beginning of the experiment, informed participants that they would never have to name the hidden object. Furthermore, the instructions outlined the procedure stating that for half of trials, the experimenter would point to an object to indicate that it should be named, and on the other half of trials the participant would unfold a piece of paper to reveal which object should be named. The instructions were modified according to presentation group so that participants were told which of these procedures would occur in the first half of the experiment and which in the second half. No motivation for the procedural differences was provided to participants.
The procedure was the same as that described in Experiment 1, except for the implementation of the high salience condition as described. Addressees were instructed to close their eyes, after which speakers turned the page in the binder to reveal a set of objects. Once the page was turned, the top sheet of paper displayed a set of four objects. Speakers were instructed to keep their eyes on the set of objects. An experimenter waited about two seconds and then pointed to an object. Speakers placed a 3 × 5 picture frame between that object and the addressee so that speakers could see the object but addressees would not be able to see the object when their eyes were open.
Next, in the low salience condition, the experimenter waited approximately another two seconds and then pointed to the to-be-named target. In the high salience condition, the paper on the bottom half of the binder, when unfolded, indicated which object was the target object. When folded, the paper appeared blank. After an object was occluded, in the high salience condition, speakers unfolded the bottom piece of paper to reveal the instructions to find the target object. After speakers read the instructions but before they named a target (and thus before addressees opened their eyes), speakers folded the paper back up so that addressees would not be able to see the instructions when their eyes were open.
Analyses
Analyses were conducted as in the previous experiments.
Results
Figure 5 shows the mean percentages of target descriptions that included specified modifiers as a function of contrast type and attention type. Speakers used modifiers most when the target had a size-contrasting match in privileged ground and when the location of the target was revealed by its relationship to the privileged object -- the high-salience condition -- as compared to when the location of the target was indicated by the experimenter -- the low-salience condition. Speakers never used modifiers when the target was unique to the set regardless of how the location of the target was revealed.
Figure 5.
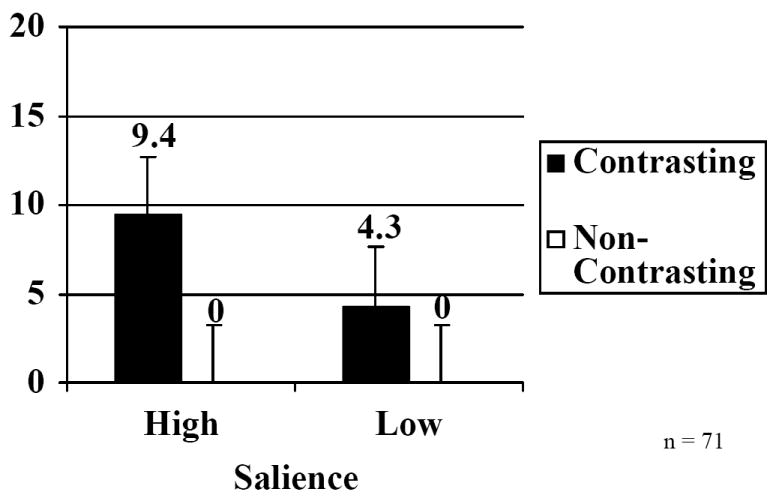
Experiment 3. Percentages of target descriptions including foil-contrasting modifiers as a function of whether the foil and target were the same (contrasting trials) or different shapes (non-contrasting trials), and whether speakers were shown the target by a point (low salience trials) or through the use of a picture of the privileged object (high salience trials). Error bars illustrate 95% confidence interval of the interaction by speakers.
Statistical analyses support these observations. The main effect of contrast type was significant. Speakers produced significantly more modifiers in the contrasting condition (6.8%) than in the non-contrasting condition (0%), F1(1,69) = 25.0, CI = ± 2.7%; F2(1,35) = 27.6, CI = ± 2.6%. The main effect of salience was also significant. Speakers produced significantly more modifiers in the high salience condition (4.9%) than in the low salience condition (2.1%), F1(1, 69) = 5.4, CI = ± 2.3%; F2(1,35) = 10.8, CI = ± 1.9 %. The interaction between these two factors was also significant, F1(1, 69) = 3.3, CI = ± 3.3%; F2(1,35) = 6.6, CI = ± 2.6%. In the high-salience condition, speakers used modifiers 9.4% more on contrasting trials (9.4%) than on non-contrasting trials (0%), whereas in the low salience condition, speakers used modifiers only 4.3% more on contrasting trials (4.3%) than on non-contrasting trials (0%).
Discussion
Experiment 3 replicates the first two experiments in that speakers used more context-relevant modifiers when they named targets that had size-contrasting pair mates in privileged ground than when they named targets that were unique to the set. Importantly, this effect was larger in the high salience condition, when speakers’ attention was drawn to the privileged object immediately before utterance production. This shows that increasing the salience of privileged ground objects, which produces a speaker-internal cognitive pressure, results in more references to privileged information.
Although we claim that Experiment 3 embodies a more face-valid manipulation of salience as compared to the privileged-relevance manipulation in Experiment 1, the proportion of modifiers speakers used on contrasting trials was lower overall in Experiment 3 than in Experiment 1. Evidently, although the salience manipulation in Experiment 3 more obviously tested the hypothesized role of the salience of privileged information, the manipulation itself did not serve to make privileged information as salient as the privileged-relevant condition in Experiment 1. One difference between the manipulations of Experiments 1 and 3 is that in the privileged-relevant condition of Experiment 1, speakers had to fully encode privileged objects on the filler trials where they named those privileged objects (though they need not have on target trials). This is not the case in the high salience condition of Experiment 3. This may have made the attentional effect more potent in Experiment 1. Another difference between the salience manipulations in Experiments 1 and 3 is that the privileged-relevant condition in Experiment 1 made privileged information relevant both to speakers and to addressees, whereas the high-salience condition in Experiment 3 made privileged ground relevant only to speakers. It may be that speakers are more sensitive to manipulations of the salience of privileged ground that involve their addressees. This may be an interesting demonstration that speakers are sensitive to the knowledge states of their addressees, as much as they are sensitive to their own knowledge states.
With respect to the results of Experiment 1, we cannot yet claim that the speaker-internal manipulation of attention to privileged information used in Experiment 3 involves the same cognitive mechanism as the speaker-internal manipulation of attention used in Experiment 1. If these mechanisms are different, then Experiment 3, though successfully demonstrating that attention to privileged information can increase references to that information, does not necessarily demonstrate that the manipulation used in Experiment 1 increased references to privileged information because it increased attention to privileged information. To test whether the manipulation of attention to privileged information used in Experiment 3 and the manipulation of attention to privileged information used Experiment 1 are the same, Experiment 4 will introduce the manipulation used in Experiment 3 under circumstances where attention to privileged information was (hypothetically) already increased through the manipulation used in Experiment 1. If the cognitive bases of the two manipulations are independent, then the manipulation used in Experiment 3 should still be effective, even when attention to privileged information is already increased as was done in Experiment 1 (in the privileged-target condition); in fact, we would expect the same size effect of the manipulation in Experiment 4 as was observed in Experiment 3. However, if we find that the salience manipulation influences performance differently in Experiment 4 versus Experiment 3, it would suggest that the cognitive bases of the two salience manipulations are somehow related to one another.
Experiment 4
Method
Participants
Participants were 72 undergraduate native English speakers from the University of California, San Diego. Each participated as both speaker and addressee. Five participants were excluded due to experimenter error.
Materials and Design
Materials were the same as those used in Experiment 3. The only difference in design between Experiments 3 and 4 was that speakers identified privileged ground objects (that were unique to the set) on six filler trials (8% of all trials) in Experiment 4 whereas they never identified privileged objects in Experiment 3.
Two manipulations were used: contrast-type (contrasting versus non-contrasting) and attention-type (low salience versus high salience). Contrast-type and attention-type were manipulated within subjects and items in counterbalanced fashion. Contrasting and non-contrasting trials were the same as in the previous experiments. Low and high salience trials were the same as in Experiment 3.
Procedure
The procedure was the same as in Experiment 3.
Analyses
Analyses were conducted as in the previous experiments.
Results
Figure 6 shows the mean percentages of target descriptions that included specified modifiers as a function of contrast type and attention type. Speakers’ use of modifiers when the target had a size-contrasting match in privileged ground was not influenced by whether the location of the target was revealed by its relationship to the privileged object or whether the location of the target was indicated by the experimenter. Speakers never used modifiers when the target was unique to the set regardless of how the location of the target was revealed.
Figure 6.
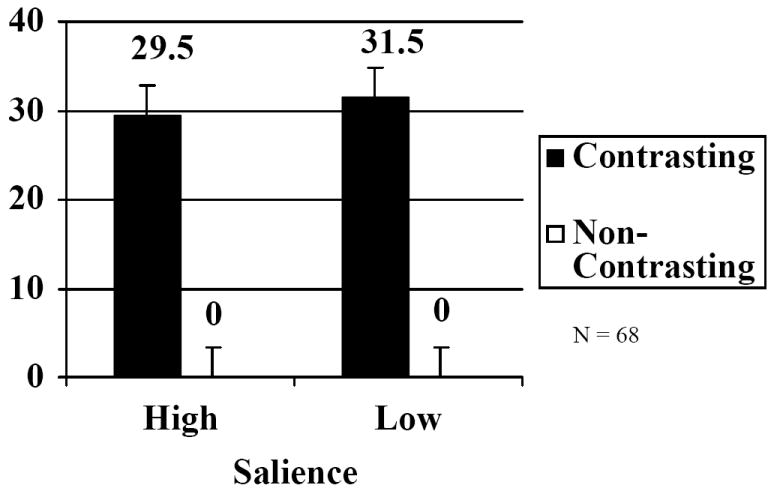
Experiment 4. Percentage of target descriptions including foil-contrasting modifiers as a function of whether the foil and target were the same (contrasting trials) or different shapes (non-contrasting trials), and whether speakers were shown the target by a point (low salience trials) or through the use of a picture of the privileged object (high salience trials). Error bars illustrate 95% confidence interval of the interaction by speakers.
Statistical analyses support these observations. The main effect of contrast-type was significant. Speakers produced significantly more modifiers in the contrasting condition (31.0%) than in the non-contrasting condition (0%), F1(1,66) = 44.5; CI = ± 9.0%; F2(1, 35) = 305.4, CI = ± 3.6%. The main effect of attention-type was not significant. Speakers produced about equal numbers of modifiers in the high salience condition (15.0%) as in the low salience condition (16.0%), F1(1,66) = < 1; CI = ±3.2%; F2(1, 35) = <1, CI = ± 3.4%. The interaction between these two factors was also not significant, F1(1,66) < 1; CI = ±4.6 %; F2(1, 35) < 1, CI = ±4.9%. In the high-salience condition, speakers used modifiers 29.5% more often on contrasting trials (29.5%) than on non-contrasting trials (0%), whereas in the low salience condition, speakers used modifiers 31.5% more often on contrasting trials (31.5%) than on non-contrasting trials (0%).
To determine whether performance in Experiment 3 versus Experiment 4 was statistically different, we examined only the contrasting trials in a combined analysis of the two experiments. The ANOVA design was 2 × 2, with the factors salience (high vs. low) and experiment (3 vs. 4). If the 5.1% difference observed between salience conditions in Experiment 3 was larger than the 2.0% reversed difference observed in Experiment 4, this ANOVA should reveal a significant interaction. In fact, the interaction was significant, F1(1,135) = 6.5, CI = ±3.9%, F2(1, 70) = 8.1, CI = ±3.5%.
Discussion
Experiment 4 found that speakers were equally likely to make references to privileged objects when their attention was drawn to those privileged objects immediately before utterance production (high salience condition) as when it was not (low salience condition). This finding is in contrast to the results of Experiment 3 where rate of privileged ground references increased in the high salience condition. Furthermore, a combined analysis of Experiment 3 and Experiment 4 revealed that the tendency to modify more in the high-salience condition was greater in Experiment 3 than in Experiment 4. In short, introducing a privileged ground target eliminated the salience manipulation. This suggests that the hypothetical manipulation of attention in Experiment 1 (requiring subjects to sometimes name privileged cards on filler trials) and the more face-valid manipulation of attention in Experiment 3 indeed relied on interrelated cognitive mechanisms. If the two manipulations were completely distinct, then each manipulation should have affected the use of size-contrasting modifiers independently. This suggests that subjects in the privileged-ground target condition of Experiment 1 used size-contrasting modifiers more because the requirement to sometimes name privileged-ground targets specifically heightened attention to privileged-ground information overall. Presumably because the privileged-relevance manipulation so powerfully affects speakers’ attention (perhaps for the reasons outlined above), this places attentional influences at an effective ceiling so that the privileged-relevant condition washes out the influence of the direct salience manipulation.
General Discussion
Summarizing, Experiment 1 showed that the presence of a speaker-external pressure (a threat to referential success) to avoid inappropriately mentioning privileged information did not reduce the rate at which speakers made such references when it co-existed with a speaker-internal pressure that caused privileged information to be more salient. In fact, when both pressures co-existed, speakers used modifiers at a higher rate. Experiment 2 ruled out the possibility that privileged ground references were made because speakers were confused about how to identify privileged objects that had size-contrasting matches in common ground, narrowing the effect specifically to the need to sometimes name privileged-ground items. Experiment 3 showed that a direct manipulation of a speaker-internal cognitive pressure (increased attention to privileged information) results in more references to privileged information. This implies that the high rate of privileged ground references in Experiments 1 and 2 could indeed have occurred because the speaker-external communicative demand (a threat to referential success) served to increase a speaker-internal pressure by increasing the attention speakers allocated to privileged objects. Lastly, Experiment 4 suggest that the mechanisms responsible for the high rate of privileged ground references in Experiments 1, 2 and 3 were likely related. Taken together, these experiments suggest that the more salient privileged information is, the more difficult it is for speakers to exclude it from their utterances, even when inclusion of privileged information threatens the fundamental goal of forming a referentially successful utterance.
In terms of models of language production, these results carry implications for the processes at work at the level of message encoding. In particular, when message-encoding processes include privileged information in messages, it is not because they have ascertained the communicative impact of doing so (e.g., only doing so when it is not communicatively harmful). In turn, this implies that at least as far as including references to privileged information is concerned, message-encoding processes do not consult representations of addressees’ knowledge and how it will be influenced by including (or not including) a particular bit of information, as instantiated by a model of the listener, for example. Instead, message-encoding processes evidently include privileged information in messages as directly determined by salience irrespective of communicative impact.
To give speakers the strongest chance of performing in a laboratory context as they do in everyday conversations, we incorporated a number of features into our experimental setting to increase naturalness while allowing for a tightly controlled experimental setting. Following the recent emphasis in psycholinguistics on the importance of situating language users in naturalistic contexts where speakers produce their utterances for another naïve participant (Lockridge & Brennan, 2002), we included both a naïve speaker and naïve addressee in our task (i.e., we did not use confederate participants). Additionally, we made our stimuli physically co-present because of the suggestion that speakers will be more likely to properly encode the distinction between common and privileged information if there is physical co-presence of stimuli (Clark & Marshall, 1981; Polichak & Gerrig, 1998a). Furthermore, we had speakers themselves make objects privileged, and the way privileged status was indicated was with an obvious physical barrier. As such, we attempted to give speakers every advantage to take the distinction between common and privileged knowledge into account so that they could exclude privileged information from their utterances. Nonetheless, we continued to see higher rates of references to privileged information whenever speakers’ attention was drawn to that privileged information.
When speakers make references to privileged information, they have failed in some sense to take into account the differences between what they know and what their partner knows (or, at the very least, they have failed to use that information properly when designing their utterances). Perhaps it is not surprising that speakers sometimes make this mistake, given the complexity of taking knowledge differences into account and the various speaker-internal and speaker-external pressures that may be present (Brennan, 2005; Metzing & Brennan, 2003). The complexity of taking knowledge differences into account is revealed by the various theories that attempt to explain this process. To date there are two general processing theories that explain how speakers are able to determine the common versus privileged status of information and use that determination in real-time language production.
One theory, often called monitoring and adjustment, argues for a modularized and specialized two-stage processing strategy (Horton & Keysar, 1996; Keysar & Barr, 2002). The first stage is quick and automatic, wherein interlocutors take their own perspective on a given situation (i.e., speakers consider all information including both common and privileged ground). Thus, speakers initially design their utterances without taking into account that some information is likely privileged. In a task like the one used in the present experiments, speakers’ initial utterance form would be something such as, “large triangle,” even when the smaller triangle is privileged knowledge. Forming an “egocentric” utterance is presumably easy because speakers obviously have ready access to the information that they know themselves. The second stage, however, is an effortful and controlled monitoring stage in which interlocutors attempt to correct for their unique perspective, if given adequate time and resources. After correction for the fact that the smaller triangle is privileged knowledge, speakers’ utterances should be of the form, “triangle.” Evidence for the dual-process model is that speakers produce more egocentric utterances – utterances that do not take perspective into account – when they are speeded (Horton & Keysar, 1996) and when they are under an increased cognitive load (Roßnagel, 2000).
A second theory takes a non-modular probabilistic approach to the problem of determining common ground. This theory claims that the distinction between common and privileged ground is only one of many linguistic and non-linguistic constraints that speakers use when formulating utterances. In contrast to monitoring and adjustment, a probabilistic approach claims that whether information is in common or privileged ground has a partial but immediate effect on utterance form. The production system is said to integrate information from multiple sources using cue-weighting mechanisms that provide probabilistic evidence for alternative interpretations (such as whether a given piece of information should be included in an utterance) that are activated in parallel. These constraints are weighted according to their salience and reliability and their effects are related to the probability that each cue will be important for communication (Hanna & Tanenhaus, 2004; Hanna, Tanenhaus, & Trueswell, 2003). These sources serve to update the common ground versus privileged ground distinction continuously as the interlocutor is engaged in conversation (Nadig & Sedivy, 2002).
Furthermore, recent work supporting this theory suggests that successful communication falls out of more general cognitive functions (Horton & Gerrig, 2005a; Horton & Gerrig, 2005b). Horton and Gerrig (2005a) showed that speakers produced utterances in accordance with addressee knowledge only when necessary memory representations were readily accessible. This suggests that the appearance of audience design can be explained by appealing to ordinary cognitive processing, specifically to the accessibility of memory representations, without the necessity of specialized and modular processing mechanisms.
The present results have implications for both of these general processing theories. First, the present results are consistent with the general spirit of monitoring-and-adjustment theories, in that monitoring-and-adjustment theories predict that utterance formation involves a measurable egocentric component. Because heightening speakers’ attention to privileged information caused them to refer more to that privileged information (rather than making them better able to respect the privileged status of that information), the present results reveal a form of egocentricism. That said, it is important to note that the most distinctive aspect of monitoring-and-adjustment is that it predicts a time-course to speaker-based versus addressee-based influences on production; given enough time, speakers should be able to accommodate their addressees’ distinct perspectives. In our experiments, we did not impose any time pressure on speakers, and thus, even according to monitoring-and-adjustment, speakers should have been able to consistently accommodate their addressees’ distinct perspectives. This was in fact not observed, as speakers included references to privileged information up to 30% of the time (in conditions of heightened attention). (We note that our production-latency evidence did not reveal that speakers took longer to formulate utterances where they did not produce a modifier and therefore “adjusted,” by this theory. Latency data were noisy, however, precluding drawing any firm conclusion.)
Also, the present results extend in informative ways the account of Horton and Gerrig (2006), suggesting that audience design emerges from general cognitive mechanisms. Horton and Gerrig focused on the effects of memory retrieval, showing that when a cue to memory retrieval (namely, a particular conversational participant) was highly effective for retrieving partner-specific information, speakers produced utterances in accordance with addressee knowledge. The present results instead focus on a different general cognitive mechanism, namely attention allocation. Experiments 1 and 2 showed that when an environmental cue (namely, a visual occluder) is a highly effective cue to reducing attention (because speakers can always ignore information so cued – in the privileged-ignorable target conditions of Experiments 1), speakers successfully excluded privileged information. But when that same cue was not a highly effective cue to reducing attention (because speakers could not always ignore the cued information – in the privileged-relevant target conditions of Experiments 1, 2, and 4), speakers less successfully excluded privileged information. In short, just as the reliability of retrieval cues can affect speakers’ ability to engage in audience design, so too does the reliability of attentional cues.
Interestingly, it seems that the harder we try to get speakers to exclude privileged information, the more they include it (Wardlow Lane et al, 2006). However, what the manipulations we have used have in common is that they all increase the salience of privileged information. This finding is important for researchers investigating speakers’ propensities to include privileged information in their utterances. Subtle aspects of experimental design that act to draw speakers’ attention to privileged information may interfere with speakers’ abilities to exclude that information causing an elevated rate of such references.
The results of these experiments might be taken to show that speakers are quite poor at taking the distinction between shared and privileged knowledge into account during utterance production. This position might further suggest that the production system is suboptimal. However, it should be noted that a system that forced speakers to tailor each utterance according to particular addressee needs might instead be suboptimal. Because addressees can often signal their understanding to speakers and speakers can take an active role in establishing reference (Clark & Brennan, 1991), there is perhaps no need for speakers to shoulder the entire cognitive burden. Furthermore, given that it is likely that comprehending language is at least somewhat less demanding than producing language, it should be more efficient to allow comprehenders to carry a larger burden for effective communication (Levinson, 2000).
What the above interpretation requires, though, is a dialogue. That is, situations in which addressees can signal their understanding and speakers can use that feedback to make adjustments necessarily rely on two-way verbal communication (i.e., situations that allow for dialogue). However, the reported experiments did not allow for two-way verbal communication, thereby limiting addressees’ ability to signal their misunderstanding. We believe that future work exploring the questions addressed here, but in situations allowing for two-way verbal communication, would be useful in developing our understanding of the processes at work that achieve everyday communicative success. Yet, as that work is undertaken, we feel that it is valuable to understand how speakers behave when they can give only one-shot utterances as was examined in the reported experiments. Not only will this lay a foundation on which to build a more thorough analysis of common ground processing in broader contexts, but it also allows us to examine a particular type of communicative situation that many people find themselves engaged in daily: Namely, one-way communicative situations such as writing, teaching, or radio announcing. Furthermore, even interactive dialogue begins with a one-shot utterance, and it is important to know what speakers do (and don’t do) with that utterance.
Even though speakers failed to take into account the common–privileged distinction relatively often in these one-shot utterances, notice that in Experiments 1 and 3, there was a baseline condition (privileged-ignorable and low salience, respectively) in which speakers were quite good at ignoring privileged information. It was only the conditions where speakers were influenced by the cognitive pressure to pay attention to privileged objects that they often referred to privileged information. Additionally, even in the condition where speakers referred to privileged information most (Experiment 4, low salience condition, 31.5%), they ignored privileged information nearly two-thirds of the time. This means that even with speaker-internal pressures to pay attention to privileged information, speakers avoided mentioning that information a clear majority of the time. In short, speakers are good at producing utterances that are communicatively successful. What is at stake in these theories and experiments is how they are so good, and to learn this, we must break down their performance -- make them less able to ignore privileged information -- so that the forces at play can be identified.
So, how are speakers so good at ignoring privileged information? The present experiments and analyses suggest that it is not because speakers’ production systems actively take addressees’ distinct knowledge states into account when deciding what to include in or omit from an utterance. If so, then heightened attention to privileged ground should only have more sharply marked that knowledge as unavailable to the addressee, and so led to its omission. Instead, these results suggest that heightened attention to information directly promotes the use of that information in an utterance. Evidently, speakers are good at respecting the privileged-common distinction likely because speakers and addressees’ attention systems are drawn to similar information, so that what speakers attend to is likely to be exactly what they should be referring to. Natural, interactive dialogue likely promotes such attentional coordination, and ultimately, communicative success.
Acknowledgments
This research was supported by National Institutes of Health grant R01 MH64733 and R01 HD051030. We thank Shelly Dutt, Brenna Gall, Michelle Groisman, Katie Doyle and Amber Latronica for assistance with data collection and Tamar Gollan, Tanya Kraljik and Bob Slevc and for helpful discussions.
Footnotes
Strictly speaking, this logic goes through if speakers adopt the following (Gricean motivated) strategy: Only give addressees additional information if they need it. So, when a common-ground shape with a privileged-ground size-contrasting match is the target referent, speakers should not add a modifier, because that modifier is unmotivated with respect to the currently known common ground. When a privileged-ground size-contrasting match is the target referent, however, adding the modifier is reasonable, as speakers should assume that when they provide additional information (the modifier), addressees should seek out a motivation for that additional information.
It is possible that this is a communicatively interesting priming effect. Perhaps speakers who frequently heard critical trials described with modifiers assumed that was how such critical trials ought to be described, and vice versa for addressees who never heard critical trials described with modifiers. This could be a rich area for future work.
References
- Brennan SE, Clark HH. Conceptual pacts and lexical choice in conversation. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1996;22(6):1482–1493. doi: 10.1037//0278-7393.22.6.1482. [DOI] [PubMed] [Google Scholar]
- Brennan SE. How conversation is shaped by visual and spoken evidence. In: Trueswell J, Tanenhaus M, editors. Approaches to studying world-situated language use: Bridging the language-as-product and language-as-action traditions. Cambridge, MA: MIT Press; 2005. pp. 95–129. [Google Scholar]
- Brown PM, Dell GS. Adapting production to comprehension: The explicit mention of instruments. Cognitive Psychology. 1987;19:441–472. [Google Scholar]
- Clark HH. Using language. Cambridge, England: Cambridge University Press; 1996. [Google Scholar]
- Clark HH, Brennan SE. Grounding in communication. In: Resnick LB, Levine JM, editors. Perspectives on socially shared cognition. Vol. 13. Washington, D.C.: American Psychological Association; 1991. pp. 127–149. [Google Scholar]
- Clark HH, Carlson TB. Context for comprehension. In: Long J, Baddeley A, editors. Attention and performance. New York, NY: Academic Press; 1982. pp. 1–37. [Google Scholar]
- Clark HH, Marshall C. Definite reference and mutual knowledge. In: Joshi A, Webber B, Sag I, editors. Elements of discourse understanding. Cambridge, England: Cambridge University Press; 1981. pp. 10–63. [Google Scholar]
- Clark HH, Murphy GL. Audience design in meaning and reference. In: Le Ny JF, Kintsch W, editors. Language and comprehension. Amsterdam, Holland: 1982. pp. 287–299. [Google Scholar]
- Dell GS, Brown PM. Mechanisms for listener-adaptation in language production: Limiting the role of the “model of the listener.”. In: Donna Jo Napoli E, Judy Anne Kegl E, et al., editors. Bridges between psychology and linguistics: A swarthmore festschrift for Lila Gleitman. Hillsdale, NJ, USA: 1991. pp. 105–129. [Google Scholar]
- DePaulo BM, Coleman LM. Talking to children, foreigners, and retarded adults. Journal of Personality and Social Psychology. 1986;51:945–959. doi: 10.1037//0022-3514.51.5.945. [DOI] [PubMed] [Google Scholar]
- Engelhardt PE, Bailey KGD, Ferreira F. Do speakers and listeners observe the Gricean Maxim of Quantity? Journal of Memory & Language. 2006;54:554–573. [Google Scholar]
- Fernald A, Mazzie C. Prosody and focus in speech to infants and adults. 1991;27:209–221. [Google Scholar]
- Ferreira VS, Slevc LR. Grammatical encoding. In: Gaskell MG, editor. The oxford handbook of psycholinguistics. Oxford: Oxford University Press; 2007. pp. 453–469. [Google Scholar]
- Garvey C. Requests and responses in children’s speech. Journal of Child Language. 1975;2:41–63. [Google Scholar]
- Grice HP. Logic and conversation. In: Cole P, Morgan JL, editors. Syntax and semantics: Speech act. Vol. 3. New York: Academic Press; 1975. pp. 41–58. [Google Scholar]
- Hanna JE, Tanenhaus MK. Pragmatic effects on reference resolution in a collaborative task: Evidence from eye movements. Cognitive Science. 2004;28(1):105–115. [Google Scholar]
- Hanna JE, Tanenhaus MK, Trueswell JC. The effects of common ground and perspective on domains of referential interpretation. Journal of Memory & Language. 2003;49(1):43–61. [Google Scholar]
- Horton WS, Gerrig R. Speakers’ experiences and audience design: Knowing when and knowing how to adjust utterances to addressees. Journal of Memory & Language. 2002;47:589–606. [Google Scholar]
- Horton WS, Gerrig R. The impact of memory demands on audience design during language production. Cognition. 2005a;96:127–142. doi: 10.1016/j.cognition.2004.07.001. [DOI] [PubMed] [Google Scholar]
- Horton WS, Gerrig RJ. Conversational common ground and memory processes in language production. Discourse Processes 2005b [Google Scholar]
- Horton WS, Keysar B. When do speakers take into account common ground? Cognition. 1996;59(1):91–117. doi: 10.1016/0010-0277(96)81418-1. [DOI] [PubMed] [Google Scholar]
- Keysar B, Barr D. Self anchoring in conversation: Why language users don’t do what they “should”. In: Gilovich T, Griffin DW, Kahneman D, editors. Heuristics and biases: The psychology of judgment. New York, NY: Cambridge University Press; 2002. pp. 150–166. [Google Scholar]
- Keysar B, Horton WS. Speaking with common ground: From principles to processes in pragmatics: A reply to polichak and gerrig. Cognition. 1998;66:191–198. doi: 10.1016/s0010-0277(98)00010-9. [DOI] [PubMed] [Google Scholar]
- Kingsbury D. Manipulating the amount of information obtained from a person giving directions. Harvard University; Cambridge, MA: 1968. [Google Scholar]
- Levinson SC. Presumptive meanings: The theory of generalized conversational implicature. Cambridge, MA: MIT Press; 2000. [Google Scholar]
- Lockridge CB, Brennan SE. Addressees’ needs influence speakers’ early syntactic choices. Psychonomic Bulletin & Review. 2002;9(3):550–557. doi: 10.3758/bf03196312. [DOI] [PubMed] [Google Scholar]
- Loftus GR, Masson MEJ. Using confidence intervals in within-subject designs. Psychonomic Bulletin & Review. 1994;1:476–490. doi: 10.3758/BF03210951. [DOI] [PubMed] [Google Scholar]
- Metzing C, Brennan SE. When conceptual pacts are broken: Partner-specific effects in the comprehension of referring expressions. Journal of Memory and Language. 2003;49:201–213. [Google Scholar]
- Nadig AS, Sedivy JC. Evidence of perspective-taking constraints in children’s online reference resolution. Psychological Science. 2002;13(4):329–336. doi: 10.1111/j.0956-7976.2002.00460.x. [DOI] [PubMed] [Google Scholar]
- Polichak J, Gerrig R. Common ground and everday language use: Comments on horton and keysar (1996) Cognition. 1998a;66:183–189. doi: 10.1016/s0010-0277(98)00011-0. [DOI] [PubMed] [Google Scholar]
- Polichak J, Gerrig R. Common ground and everyday language use: Comments on horton & keysar. Cognition. 1998b;66(2):182–189. doi: 10.1016/s0010-0277(98)00011-0. [DOI] [PubMed] [Google Scholar]
- Roßnagel C. Cognitive load and perspective-taking: Applying the automatic-controlled distinction to verbal communication. European Journal of Social Psychology. 2000;30:429–445. [Google Scholar]
- Schober MF, Brennan SE. Processes of interactive spoken discourse: The role of the partner. In: Graesser AC, Gernsbacher MA, editors. Handbook of discourse processes. Mahwah, NJ: Lawrence Erlbaum Associates, Publishers; 2003. pp. 123–164. [Google Scholar]
- Stalnaker RC. Assertion. In: Cole P, editor. Syntax and semantics 9: Pragmatics. New York, NY: Academic Press; 1978. pp. 315–332. [Google Scholar]
- Wardlow Lane L, Groisman M, Ferreira VS. Don’t talk about pink elephants! Speakers’ control over leaking private information during language production. Psychological Science. 2006;17:273–277. doi: 10.1111/j.1467-9280.2006.01697.x. [DOI] [PMC free article] [PubMed] [Google Scholar]