

Abstract
In Experiment 1 ERPs were recorded while French-English bilinguals read pure language lists of French and English words that differed in terms of the number of orthographic neighbors (many or few) they had in the other language. That is the number of French neighbors for English target words was varied and the number of English neighbors for French target words was varied. These participants showed effects of cross-language neighborhood size in the N400 ERP component that arose earlier and were more widely distributed for English (L2) target words than French (L1) targets. In a control experiment that served to demonstrate that these effects were not due to any other uncontrolled for item effects, monolingual L1 English participants read only the list of English targets that varied in the number of French (an unknown L) neighbors. These participants showed a very different pattern of effects of cross-language neighbors. These results provide further crucial evidence showing cross-language permeability in bilingual word recognition, a phenomena that was predicted and correctly simulated by the bilingual interactive-activation model (BIA+).
Keywords: ERPs, bilingualism, orthographic neighborhood, N400
1. Introduction
A long-standing debate in the literature on bilingual language comprehension concerns the relative permeability of the representations dedicated to processing each language. Traditionally, this debate has opposed proponents of early language-selective processing with proponents of a non-selective access to a set of representations shared by both languages. The language-selective hypothesis is typically associated with the notion of a switching mechanism that guides the linguistic input to the appropriate set of language-specific lexical representations (Macnamara, 1967). According to this hypothesis, there should be no cross-language interference when the language of the incoming information is completely predictable (i.e., in a monolingual context). When this is the case, information extracted from the stimulus is sent directly to the appropriate set of language-specific representations.
The non-selective access hypothesis proposes, on the other hand, that the initial feed-forward sweep of information from the linguistic input can make contact with lexical representations from both languages as a function of their orthographic or phonological overlap with the input. This is the central hypothesis of the Bilingual Interactive-Activation model (Grainger & Dijkstra, 1992; van Heuven, Dijkstra, & Grainger, 1998), and its successor the BIA+ model (Dijkstra & van Heuven, 2002). As a consequence, word representations from both languages are activated and they compete with each other due to lateral inhibition at the word level. Therefore the model predicts not only within-language interference but also cross-language interference effects.
Evidence in favor of language-selective access to language-specific representations, was first provided by language switching experiments (Macnamara & Kushnir, 1972; Soares & Grosjean, 1984; Beavillain & Grainger, 1987; Thomas & Allport, 2000; Alvarez, Holcomb, and Grainger, 2003). All of these studies have shown that switching languages incurs a processing cost compared to a situation where there is no language switch. Thus, for example, in Grainger's and Beauvillain's (1987) study, lexical decision responses to words in one language were slower when the word on the preceding trial was from the other language compared with a word from the same language. Although switch costs have traditionally been taken as evidence for language-selective access, Grainger and Dijkstra (1992) provided an interpretation within the framework of a non-selective access model. Language switch costs are therefore not necessarily diagnostic of language-selective access.
Evidence in favor of non-selective access to a common set of representations was provided by experiments demonstrating cross-language interference using bilingual versions of the Stroop task (Dyer, 1973), the flanker task (Guttentag, Haith, Goodman, & Hauch 1984), experiments showing evidence for co-activation of non-target language representations during the processing of cross-language homographs (Beauvillain & Grainger, 1987; De Groot, Delmar & Lupker, 2000; Dijkstra, Grainger, & van Heuven, 1999; Dijkstra, Timmermans, & Schriefers, 2000; Jared & Szucs, 2002; van Heuven et al., in press) and cross-language homophones (Brysbaert, Van Dyck, & Van de Poel, 1999; Nas, 1983; Dijkstra et al., 1999), and experiments showing differential processing of cognate words compared with non-cognate words (e.g., de Groot & Nas, 1991; van Hell & de Groot, 1998; van Hell & Dijskstra, 2002). These cross-language influences have generally been interpreted as showing that bilinguals cannot block interference from the irrelevant language. However, proponents of selective access have argued that the mere presence of words in the irrelevant language (as is the case in Stroop and Flanker interference experiments) is enough to prevent processing in a pure “monolingual” mode (e.g., Grosjean, 1988). The same critique can be leveled against research examining processing of cross-language homographs, homophones, and identical cognates, since these stimuli are also words in the other language. In order to provide more convincing evidence in favor of non-selective access, cross-language interference must be demonstrated in conditions where there is no explicit activation of the irrelevant language.
These conditions were respected in two studies, one investigating spoken word recognition (Marian & Spivey, 2003), and the other investigating visual word recognition (van Heuven et al., 1998). Critically, and contrary to all prior research, these studies did not explicitly manipulate the presence or absence of other language stimuli. Rather, they manipulated the presence of potential cross-language interference in the form of phonologically or orthographically similar words from the other language. To do so, Marian and Spivey (2003) applied the visual world paradigm (see Tanenhaus, Magnuson, Dahan, & Chambers, 2000, for a description of this technique). In one version of this paradigm, participants are requested to pick up one of four objects placed in front of them. The instructions are delivered auditorily (e.g., “pick up the candle”) and eye movements are recorded. The standard finding is that a significant proportion of eye movements are made to objects whose name is phonologically similar to the target (e.g., “candy”), suggesting at least partial access to the distracter's lexical representation during target word processing. In Marian and Spivey's (2003) study, the phonological similarity of targets and distracters was manipulated within and between languages in bilingual participants. As well as the standard within-language effect, they also found a significant percentage of eye movements to distracter objects in the cross-language condition, but only for targets in L2. Thus, in the absence of any overt presentation of L1 words, comprehension of words in L2 would appear to be influenced by implicit activation of phonologically similar L1 words.
Most relevant for the present study is van Heuven et al.'s (1998) investigation of cross-language neighborhood effects in bilinguals (applying Coltheart, Davelaar, Jonasson, & Besner's, 1977, definition of an orthographic neighbor). Prior work has shown that within-language manipulations of this variable significantly affects performance in standard word recognition tasks (e.g., Andrews, 1989; Carreiras, Perea, & Grainger, 1997; Grainger, 1990; Grainger, O'Regan, Jacobs, & Segui, 1989). Van Heuven et al. (1998) found a significant effect of number of orthographic neighbors both within languages and across languages in bilingual participants (see also Grainger & Dijkstra, 1992). Most important, the cross-language neighborhood effects disappeared in an experiment testing monolingual participants with the same materials. Therefore, as predicted by the BIA model, the cross-language neighborhood effect found in bilingual participants suggests that the processing of a given word (among a list of words from one language only) generates activation in orthographically similar words not only within that language but also in the other language.
There is, however, some variability in the effects of orthographic neighborhood reported in monolingual studies using behavioral measures, with some studies showing facilitatory effects (i.e., faster responses and/or lower error rates to words with large numbers of neighbors compared with words with few neighbors), and others showing inhibitory effects (see Andrews, 1997; Grainger & Jacobs, 1996, for review and discussion of possible mechanisms). These discrepancies in prior behavioral research were the primary motivation for Holcomb, O'Rourke, and Grainger's (2002) study. These authors investigated the effects of orthographic neighborhood density in English using event-related potentials (ERPs). In one experiment, participants had to read words presented in isolation and press a response button whenever they saw an animal name (randomly appearing in 19.5% of trials). The amplitude of the N400 ERP component, a negative going waveform that peaks around 400ms post-target onset, was found to vary significantly with the neighborhood density of target words. Words with large numbers of orthographic neighbors generated greater N400 amplitudes (i.e., more negative-going waveforms in the 300-500 ms time window). Most critically, and unlike prior behavioral findings, these effects of orthographic neighbor on ERP amplitudes did not depend on the task that participants had to perform (semantic categorization or lexical decision).
One ERP study has examined neighborhood effects in bilingual participants. Rüschemeyer et al. (2008) examined the effects of phonological neighborhood during L2 processing. They found ERP effects in the same direction as Holcomb et al. (i.e., items from larger neighborhoods elicit greater N400 amplitudes).
Holcomb and Grainger (2007) have proposed a tentative mapping of ERP components onto underlying processes involved in visual word recognition, couched with the framework of a generic interactive-activation model. Based primarily from evidence obtained with the masked priming paradigm, these authors suggested that much of the mapping of form onto meaning arises as early as 200 ms post-target onset (the beginning of the N250 component found in masked priming) and culminating in the N400. This processing would initially involve the mapping of prelexical form representations onto whole-word representations, with the N400 reflecting the mapping of whole-word form representations onto semantics. In the interactive-activation framework adopted by Holcomb and Grainger (2007), competition between whole-word form representations is thought to be the primary cause of inhibitory effects of orthographic and phonological neighbors. Thus the greater negativity to words with many orthographic neighbors reported by Holcomb et al. (2002), would reflect inhibition operating across lexical representations leading to increased difficulty in settling on a unique form-meaning association. The bilingual version of interactive-activation (the BIA model and its successor the BIA+ model) predicts similar effects of cross-language neighbors due to lexical competition operating within an integrated lexicon of word forms from both languages.
1.1. Experiment 1
The present study provides a further investigation of cross-language neighborhood effects using ERP recordings. We combine the basic manipulation of cross-language neighborhood in the van Heuven et al. (1998) study with the procedure used in the Holcomb et al. (2002) study. In Experiment 1 bilingual participants saw pure lists of French and English words that varied in terms of the number of orthographic neighbors in the other language (many or few). Given the number of items per condition required for an ERP study we did not manipulate within-language neighborhood, although this was equated (see Holcomb et al., 2002, for a within-language ERP investigation of neighborhood effects). The participants tested in Experiment 1 were L1 French and had a relatively high level of proficiency in their L2 (English). They were tested in an L1 context, that is, in France although these participants reported using their L2 on a daily basis for work or study. On the basis of the non-selective access hypothesis and prior ERP effects of neighborhood density found in monolinguals, it was predicted that the N400 would be sensitive to the number of neighbors in the non-presented language, with larger amplitudes for items with many other-language neighbors compared with items with few other-language neighbors.
1.2. Experiment 2
Although within language neighborhood size was carefully controlled in Experiment 1, our words with many and few neighbors could differ by chance on some other within-language dimension. In order to be absolutely sure that it is non-target language activation that is driving the cross-language neighborhood effects, it is important to show that these effects are not a result of some other uncontrolled for property of the words. Monolingual L1 English participants with no or little exposure to French as an L2 should show no effect of French orthographic neighborhood size during the processing of L1 (English) target words. If, on the other hand, it is an uncontrolled L1 variable that is driving the effect, then the results should resemble the pattern found in the bilingual participants tested with English words in Experiment 1. This prediction was tested in Experiment 2.
1.3. Simulation study
Finally, a simulation study was run on the BIA+ model (Dijkstra & van Heuven, 2002). The model was tested with exactly the same stimuli as used in Experiments 1 and 2 in order to evaluate its ability to account for the precise pattern of cross-language neighborhood effects found in the present experiments.
2. Results
2.1. Experiment 1 results
2.1.1. Visual inspection of ERPs
The ERP grand mean waveforms for English targets for 12 scalp sites are plotted in Figure 1a while the grand mean waveforms for French targets are plotted in Figure 2a. Figures 1b (L2) and 2b (L1) contain voltage maps computed by subtracting ERPs for items with few cross-language neighbors from ERPs for items with many cross-language neighbors. We included these to better visualize the scalp distribution of neighborhood size effects at three points in time. The first includes voltages at the center of the early analysis window (275 ms), while the second and third are centered at early (350 ms) and later (450 ms) in the N400 window. As can be seen in these figures, for all ERPs anterior to the occipital sites the first visible component was a negative-going deflection between 90 and 150 ms after stimulus onset (N1). This was followed by a positive deflection occurring at approximately 200 ms (P2). A negativity followed the P2 peaking around 400 ms (N400). At occipital sites the first observable component is the P1, which peaked near 100 ms and was followed by the N1 at 190 ms and a broad P2 between 250 and 300 ms. The P2 was followed by the N400 between 400 and 600 ms.
Figure 1.

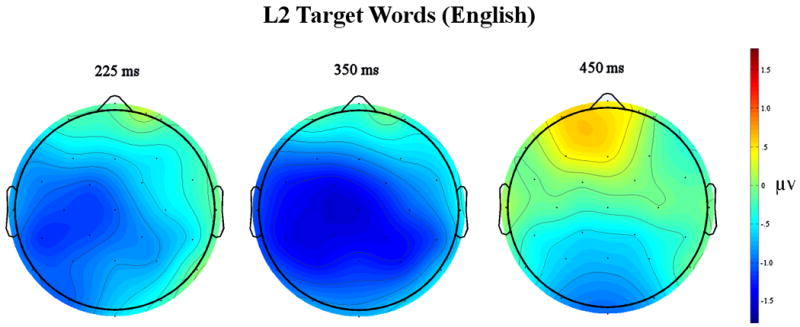
Figure 1a. Results of bilinguals reading English (L2) targets with either many orthographic neighbors in French (L1) or few orthographic neighbors in French.
Figure 1b. Scalp voltage maps at three time points between English words with few French neighbors and many French neighbors (units are in microvolts)
Figure 2.

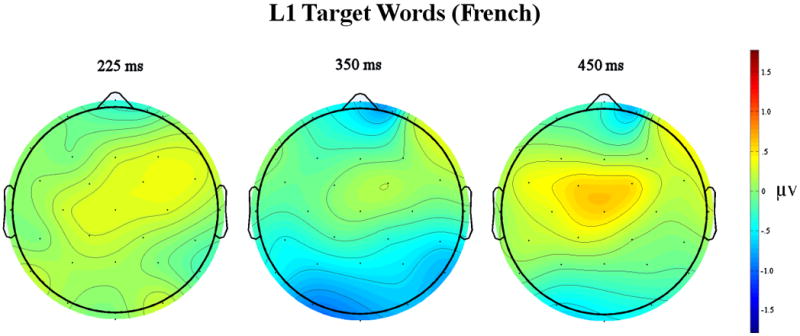
Figure 2a. Results of bilinguals reading French (L1) targets with either many orthographic neighbors in English (L2) or few orthographic neighbors in English.
Figure 2b. Scalp voltage maps at three time points between French words with few English neighbors and many English neighbors.
2.1.2. Analyses of ERP data
2.1.2.1 175-275 ms epoch
As can be seen in Figure 1 differences due to cross-neighborhood-size began to emerge in this epoch. The omnibus ANOVA on the mean amplitude values revealed a marginal main effect of cross-neighborhood-size (F(1,19) = 3.78, p = .067), and a significant language by cross-neighborhood-size interaction (F(1,19) = 4.41, p = .049), the latter indicating a difference in the cross-neighborhood-size effect for the two languages.
Follow-up analyses examining the effects of cross-neighborhood-size separately for the two target languages revealed that English (L2) words with many French orthographic neighbors were more negative-going than English words with few orthographic neighbors in French (main effect of cross-neighborhood-size: F(1,19) = 8.08, p = .01). Moreover, this cross-neighborhood-size effect tended to be larger over the left hemisphere and midline electrode sites than over right hemisphere sites (cross-neighborhood-size × laterality interaction: F(2,38)= 4.49, p = .033 – see Figure 1b, left). There was however, no evidence that French (L1) words were affected by the number of English neighbors in this epoch (all Fs < 1.0 involving cross-neighborhood-size -- see Figure 2).
2.1.2.2. 300-500 ms epoch
As can be seen in Figures 1 and 2 differences due to cross-neighborhood-size continued into this epoch. The omnibus ANOVA produced marginal effects for cross-neighborhood-size (F(1,19) = 3.24, p = .089) and a cross-neighborhood-size × language interaction (F(1,19) = 4.13, p = .056) and importantly a significant cross-neighborhood-size × language × Electrode site interaction (F(3,57) = 3.85, p = .037). This latter interaction indicated differences in the scalp distribution of the cross-neighborhood-size effect for the two languages.
Follow-up analyses examining the effects of cross-neighborhood-size separately for the two target languages demonstrated that English words (L2) with many French (L1) orthographic neighbors were again more negative-going than English words with few French neighbors (main effect of cross-neighborhood-size: F(1,19) = 8.63, p = .008). However, unlike the earlier epoch where the cross-neighborhood-size effect was larger over left and midline sites, in this epoch the effect was more widespread across the head and was bilaterally more symmetrical (see Figure 1b middle and right). Also different from the earlier epoch where there was no evidence of significant cross-neighborhood-size effects for French words, in this window French words with many English orthographic neighbors did produce evidence of more negative-going ERPs than French words with few English neighbors (although the main effect of cross-neighborhood-size was not significant, p > .778). This was revealed in a significant cross-neighborhood-size × Electrode site interaction (F(3,57) = 4.5, p = .029). As can be seen in Figure 2a and b, these effects were not widespread across the scalp and were significant only at the three most posterior sites (occipital cross-neighborhood-size F(1,19) = 5.74, p = .027).
2.1.3. Experiment 1 behavioral results
Participants averaged 17 (SD = 0.94) out of 18 hits in their L1 (95%) and 14 (SD = 1.77) out of 18 hits in their L2 (79%) for probe words. This difference was significant (t(19)= 7.78, p = .001). Participants produced false alarms on an average of 1.8 items (SD = 1.01) in L1 (2.4%) and on 1.9 items (SD = 2.87) in L2 (2.5%). This difference between languages was not significant (p > .9). In a post translation task participants were asked to translate all 74 L2 target words that they had seen in the experiment. The mean number of correct translations was 53 (SD = 9.2) or 71%. The mean number of correct translations of probe items was 15 (SD = 1.88) or 81%.
2.2. Discussion of Experiment 1
The results of Experiment 1 show effects of cross-language orthographic neighborhood density in the ERP waveforms generated during the processing of words in L1 and L2. These cross-language neighborhood effects had an earlier onset and were more widely distributed when the targets were in L2. This is important evidence in favor of initial non-selective access processes in bilingual word recognition, as assumed in the BIA+ model (Dijkstra & van Heuven, 2002). Participants in this study read words in one language only (and knew that they would only receive words in one language in a given list), yet the orthographic characteristics of the words in the non-presented language influenced the way our participants reacted to these stimuli. These results can be explained by a combination of non-selective access (a string of letters activates compatible whole-word orthographic representations in both of a bilingual's languages) and lateral inhibition across word representations in an integrated lexicon. A given stimulus word generates activation in all whole-word orthographic representations that are partly compatible with the stimulus, and these co-activated word representations inhibit processing of the target word itself. The increased difficulty in target word processing is reflected in the greater ERP negativities between 200 and 500 ms, a result similar to that previously reported for neighborhood density in a monolingual context (Holcomb et al., 2002), and compatible with the time-course of component processes in visual word recognition proposed by Holcomb and Grainger (2006, 2007).
2.3 Experiment 2 Results
2.3.1. Analyses of ERP data
2.3.1.1. 175-275 ms epoch
As can be seen in Figure 3 there does not appear to be much of a cross-neighborhood-size effect in this epoch (cross-neighborhood-size main effect: F(1,19) = 2.85, p = .108; cross-neighborhood-size × Electrode site p > 0.2) and this small marginal main effect is actually in the opposite direction compared to the results for English targets in Experiment 1.
Figure 3.

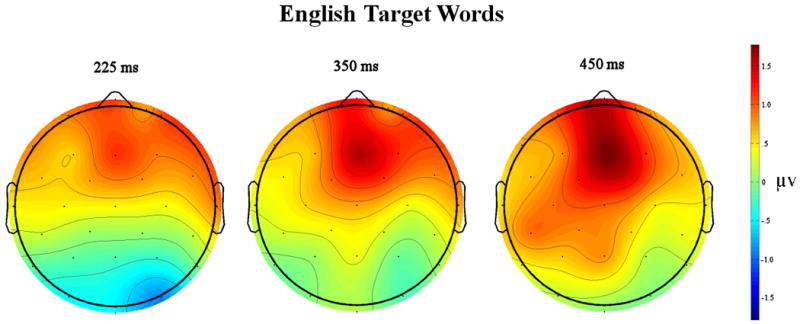
Figure 3a. Results of the monolinguals reading English targets with either many orthographic neighbors in French or few orthographic neighbors in French.
Figure 3b. Scalp voltage maps showing the difference at three time points between English words with few French neighbors and many French neighbors.
2.3.1.2. 300-500 ms epoch
As can be seen in Figure 3, there is only a small effect of cross-neighborhood-size in this epoch (F(1,19) = 3.00, p = .100; cross-neighborhood-size × Electrode site p > 0.2) and importantly this marginal main effect is in the opposite direction compared to the results for English targets in Experiment 1 as in the previous epoch.
2.3.2. Experiment 2 behavioral results
Participants averaged 84% (SD = 9.5%) hit rate for probe words.
2.3.3. Combined analysis Experiments 1 and 2
A between participants analysis was carried out, comparing the English list of the L1 French participants in Experiment 1 with the English list of the monolingual participants in Experiment 2 to insure that our effects, showing the influence of cross-language neighborhood on word recognition, are not due to any properties of the English items that we may not have effectively controlled. While there was no main effect of cross-neighborhood-size in either epoch (both p > .260), there was a significant interaction of cross-neighborhood-size by experiment in both epochs (early: F(1,38) = 10.69, p = .002; late: F(1, 38) = 11.26, p = .002).
2.4. Discussion of Experiment 2
The results of Experiment 2 demonstrate that the pattern of effects seen in these monolinguals is not similar to those of bilinguals when processing a list of English words in which cross-language orthographic neighborhood size varies. This implies that the effects of cross-language neighborhood size that was found in the bilinguals in Experiment 1 are not due to some confound or uncontrolled property of the English list. If that had been the case, we should have seen very similar effects of this variable in Experiment 2.
Our results clearly indicate that when bilinguals read lists of words in one of their languages, the brain's reaction to these word stimuli is influenced by the orthographic characteristics of the words in the other (non-presented) language. The BIA+ model (Dijkstra & van Heuven, 2002) accounts for such cross-language influences in terms of non-selective activation of word representations in both of the bilingual's languages. In a simulation study we put the BIA+ model to test with the stimuli used in the present experiments.
2.5. Simulation study results
The mean number of cycles to reach the identification threshold for the different experimental conditions in Experiments 1 and 2 are presented in Table 1. We conducted separate analyses for Experiment 1 (bilinguals) and Experiment 2 (English monolinguals). The data of the bilinguals revealed a significant effect of Language (F(1,144)=23.42, p < .001), Cross-Neighborhood-Size (F(1,144)=4.41, p < .05), and importantly a significant interaction between these factors (F(1,144)=5.21, p < .05). This interaction is due to a significant inhibition effect (0.7 cycles) of cross-language neighborhood size for English words (F(1,72)=8.51, p < .01) and not for French words (F(1,72) < 1). As expected, the data of the English monolinguals did not show any effect of cross-language neighborhood size (F(1,72) < 1).
Table 1.
Simulated response times of French-English bilinguals and English monolinguals in the BIA+ model for the different experimental conditions tested in Experiments 1 (Bilingual participants) and 2 (Monolingual participants). Average number of cycles to reach the word identification threshold for English words with many French neighbors (High French) or few French neighbors (Low French) and French words with many English neighbors (High English) or few English neighbors (Low English).
| Neighborhood Size | Bilinguals | Monolinguals | |
|---|---|---|---|
| English Targets | High French | 21.1 | 20.1 |
| Low French | 20.4 | 20 | |
| 0.7 | 0.1 | ||
| French Targets | High English | 20 | |
| Low English | 20.1 | ||
| -0.1 | |||
2.6. Simulation study discussion
The results of the simulation study show that the BIA+ model correctly predicts an influence of cross-language orthographic neighborhood size. The effect of cross-language neighbors was significant in the simulation of bilinguals recognizing L2 words. As expected, no effect of cross-language neighborhood size was found in the simulation of English monolinguals. The BIA+ model therefore simulates the pattern of cross-language neighborhood effects for French-English bilinguals and English monolinguals that, overall, mimics the effects found in our ERP experiments. The simulation study revealed a significant interaction between cross-language neighborhood size and language, thus correctly accounting for the stronger effects that were found in L2 than in L1 in Experiment 1.
3. General discussion
In the present study French-English bilinguals were shown pure-language lists of words that varied in terms in the number of orthographic neighbors they had in the other language (the number of cross-language neighbors). French native speakers who were relatively proficient in English were found to be sensitive to the cross-language neighborhood density of words in both their L1 (French) and their L2 (English). Words with many cross-language neighbors generated a more negative-going ERP waveform in the region of the N400 than words with few cross-language neighbors. This cross-language neighborhood effect appeared earlier (in the 175-275ms epoch) and was more widely distributed across the scalp when the target words were in English (L2) and the neighbors in L1. Effects of cross-language neighborhood on French (L1) words only appeared in the 300-500ms epoch and were limited to the most posterior electrode sites. The strong effects of L1 (French) neighbors on processing L2 (English) words cannot be attributed to any properties of the English items apart from their French neighborhood size because English monolingual participants did not show the same pattern of ERPs to these stimuli.
These results provide considerable support for the non-selective access hypothesis embodied in the BIA+-model (Dijkstra & van Heuven, 2002), and contradict the notion of early language-specific selection in bilingual language comprehension. Our participants saw lists of words in one language only and were therefore in appropriate conditions for using language-specific selection processes. The results clearly indicate that such selection processes were not effective in blocking the activation of word representations in the irrelevant language. We found evidence for early activation of non-target language representations that influenced the processing of target words.
The more negative-going waveforms found for words with large numbers of cross-language neighbors is interpreted as reflecting a greater difficulty in settling on a single form-meaning interpretation of the stimulus (Holcomb et al., 2002). Words with more cross-language neighbors suffer from the co-activation of the lexical representations of these neighbors, as reflected in the typically longer RTs found to these stimuli in behavioral studies (Grainger & Dijkstra, 1992; van Heuven et al., 1998).
The results of Experiment 1 show that L2 neighbors have a later and less widely distributed effect on L1 target processing than L1 neighbors have on L2 target processing. This is perfectly in line with one major principle implemented in all connectionist models of language processing – that frequency of exposure determines connection strength. Because none of our participants in Experiment 1 were early balanced bilinguals we can assume that exposure to L2 words is overall much lower than exposure to L1 words. This exposure difference is thus reflected in word frequency differences between L1 and L2. Therefore, L2 word representations will on average be more weakly activated by a stimulus than L1 word representations, and this imbalance will be exaggerated in a competitive network where the dominant representation inhibits all others. This therefore accounts for why the effects of L2 neighbors are weaker, less widely distributed (since more time is required for propagation), and appear later than the effects of L1 neighbors. Simulations run on the BIA+ model show effectively that cross-language neighborhood effects are stronger when targets are in L2 compared with targets in L1 (see Table 1).
Experiment 2 of the present study tested monolingual English participants with the same list of English words presented to the French-English bilinguals of Experiment 1. Since these monolingual participants did not show that same pattern of effects of cross-language neighborhood (i.e., of French language neighbors) as the bilinguals, this allows us to reject uncontrolled for within-language variables as the source of the cross-language neighborhood effect found in Experiment 1. Therefore, the present study adds to the behavioral literature on effects of cross-language orthographic and phonological similarity (Marian & Spivey, 2003; van Heuven et al., 1998) showing that the process of word comprehension in bilingual participants presented with words in one of their languages is influenced by the similarity of these words to words in the non-presented language.
The present study provides important information concerning the time-course of cross-language neighborhood effects. The results of Experiment 1 show relatively early influences of L1 orthographic neighbors on the processing of L2 words, emerging as early as 200 ms post-target onset (see Figure 1). Such early influences were not found in the within-language neighborhood manipulation of Holcomb et al. (2002). This can be explained by differences in the relative frequency of target words and their orthographic neighbors in the Holcomb et al. and the present study. Orthographic neighbors will tend to have higher subjective frequencies when these neighbors are L1 words and the target a word in L2 (compared to L1 neighbors of L1 words), and the more frequent the orthographic neighbors are relative to the target word, the more rapidly they can influence target word processing. Furthermore, as processing develops and word recognition is in its final stages (i.e., a stable form-meaning association is established), activation of the target word itself will dominate processing and neighborhood effects disappear.
Furthermore, the precise timing of the effects found in the present study is in line with the time-course analysis of visual word recognition proposed by Holcomb and Grainger (2006, 2007). According to their analysis, form-level (orthographic and phonological) processing of printed words initiates around 200 ms post-target onset with the mapping of prelexical representations onto whole-word forms, and culminates at around 400 ms (the peak of the N400) with the mapping of lexical form onto meaning. Within the generic interactive-activation model adopted by Holcomb and Grainger, effects of orthographic neighborhood are generated by competition arising between co-activated whole-word representations. This lexical-level competition already affects the early mapping of prelexical form representations onto whole-word form representations and further influences processing upstream, increasing the difficulty of mapping whole-word forms onto semantics. Given that orthographic neighborhood correlates highly with phonological neighborhood (e.g., Grainger, Muneaux, Farioli, & Ziegler, 2005), it is likely that part of the effects of orthographic neighborhood are being driven by competition between phonologically similar words. However, this possibility is greatly reduced in a cross-language neighborhood manipulation as used in the present study, given the lower levels of phonological overlap between orthographically similar words from different languages.
In conclusion, the present study provides further evidence for cross-language permeability in bilingual word recognition, in particularly stringent testing conditions. First, following the behavioral study of van Heuven et al. (1998) participants saw words of one language only in a given list, and cross-language interference was evaluated by a manipulation of the number of orthographic neighbors in the non-presented language. Second, our participants had to silently read words for meaning and respond (on non-critical trials) whenever a body part appeared, a procedure that minimizes contamination by decision-related processes. The ERPs generated by target words on critical trials were found to be sensitive to the number of orthographic neighbors of that word in the other language of our bilingual participants. This constitutes perhaps the strongest evidence to date in favor of initial parallel access to representations in both languages when bilinguals are reading in one language.
4. Experimental procedures
4.1. Experiment 1
4.1.1. Participants
Twenty-two participants were recruited and compensated for their time. The data from two participants was not used due to excessive noise in their ERP data. Of the remaining 20, thirteen were women (mean age = 23 years, SD = 4.7), all were right handed (Edinburgh Handedness Inventory – Oldfield, 1971) and had normal or corrected-to-normal visual acuity with no history of neurological insult or language disability.
French was reported to be the first language learned by all participants (L1) and English their primary second language (L2). All participants began their study of English in their sixth year of primary school at approximately the age of 12 years, as is customary in the French school system. Participants' daily use of English, auto-evaluation of English and French language skills and a history of study and of immersion in English were surveyed by questionnaire. Participants reported daily use of English to be on average 42% (SD = 26.8%) of their total language use. On a seven point scale (1 = unable; 7 = expert) participants reported their abilities to read, speak and comprehend English and French as well as how frequently they read in both languages (1 = rarely; 7= very frequently). The overall average of self-reported languages skills in French was 6.9 (SD = 0.32) and in English was 5.7 (SD = 0.95). Our participants reported their average frequency of reading in French as 6.3 (SD = 1.05) and in English as 5.8 (SD = 1.47).
4.1.2. Stimuli
For the selection of stimuli a French lexicon was extracted from the Lexique database (New, Pallier, Brysbaert, & Ferrand, 2004), and an English lexicon from the CELEX database (Baayen, Piepenbrock, & Gulikers, 1995). These lexicons contained only 4 and 5-letter, monosyllabic and bi-syllabic words with at least 1 occurrence per million, and were used to calculate the number of orthographic neighbors of words within and across languages. The final set of stimuli for the study were 74 English and 74 French words between four and five letters in length with half of the items in each language having many orthographic neighbors in the other language and other half having few neighbors in the other language (an orthographic neighbor is defined as a word of the same length having all but one letter in common respecting letter position (Coltheart, Davelaar, Jonasson, & Besner, 1977).
The English items from large French neighborhoods had a mean number of French neighbors of 5.9 (range = 4 – 13, SD = 2.2). For the English items with few French neighbors the mean number of French neighbors was 1.1 (range = 0 – 3, SD = 1.1). These means were significantly different (t(72) = 4.58, p = 0.036). The means of within language neighbors for these two groups of English words were 6.5 (SD = 3.4) for items with many French neighbors and 6.9 (SD = 3.6) for items with few French neighbors. These means were not significantly different (t(72) = 1.29, p = 0.26). The mean frequency per million, of English words with many French neighbors was 12.9 (SD = 13.9) while for items with few French neighbors the mean frequency was 12.8 (SD = 13.0). These means were not significantly different (t(72) = 0.04, p = 0.97). The mean number of letters for English items was not significantly different for the two conditions (see table 2 for mean lengths, t(72) = 0.73, p = 0.47).
Table 2.
Stimulus characteristics for the two languages and the two conditions.
| Mean number of cross language neighbors | Mean number of w/in language neighbors | Mean frequency count per million | Mean length | ||
|---|---|---|---|---|---|
| English targets | Many | 5.9 (2.2) | 6.5 (3.4) | 12.9 (13.9) | 4.4 (0.5) |
| Few | 1.1 (1.1) | 6.9 (3.6) | 12.8 (13.0) | 4.3 (0.5) | |
| French targets | Many | 7.8 (3.6) | 6.6 (3.1) | 15.2 (15.0) | 4.4 (0.5) |
| Few | 0.7 (1.0) | 4.7 (3.3) | 14.2 (11.9) | 4.5 (0.5) |
The French items from large English neighborhoods had a mean number of English neighbors of 7.8 (= 5 – 19, SD = 3.6). For the French items with few English neighbors the mean number of English neighbors was 0.7 (range = 0 – 5, SD = 1.0). These means were significantly different (t(72) = 25.62, p < 0.001). The means of within language neighbors for these two groups of French words were 6.6 (SD = 3.1) for items with many English neighbors and 4.7 (SD = 3.3) for items with few English neighbors. These means were not significantly different (t(72) = 0.50, p = 0.48). The mean frequency per million, of French words with many English neighbors was 15.2 (SD = 15.0) while for items with few English neighbors the mean frequency was 14.2 (SD = 11.9). These means were not significantly different (t(72) = 0.30, p = 0.76). The mean number of letters for French items was not significantly different for the two conditions (, t(72) = 1.41, p = 0.16). Mean lengths can be seen in table 2.
Two lists were formed, one with the 74 English words in a pseudorandom order and one with the 74 French words in a pseudorandom order. Intermixed in each list was a second group of 18 probe words which were all members of the semantic category of “body parts” (probes were English words in the English list and French words in the French list). The order of the list, blocked by language was counter-balanced across participants.
4.1.4. Procedure
The word stimuli in each list were presented as white letters centered vertically and horizontally on a black background on a 15 inch color monitor (Toshiba Tekbright). Presentation of all visual stimuli and digitizing of the EEG was synchronized with the vertical retrace interval (60 Hz refresh rate) of the stimulus PCs video card (ATI Radeon) to assure precise time marking of ERP data. The participants were seated so that their eyes were at a distance of approximately 1.5 meters from the screen. The maximum height and width of the stimuli were such that no saccades would be required during reading of the single word stimuli (i.e., the width of the word filled less than 2 degrees of the participant's visual field). Participant responses were made using a button box held in the lap throughout the experiment. A go/no-go semantic categorization task was used in which participants were instructed to read all words but to press a button whenever they saw a word referring to a body part. Eighteen trials in each language block were body part words (19.5% of all trials). As can be seen in Figure 4, each trial began with the onset of a fixation cross which remained on screen for 200ms and was followed by 300ms of blank screen. A target word then appeared for a duration of 300ms was followed by 1000ms of blank screen. Each trial ended with a screen indicating that it was permissible to move or blink the eyes [( - - )]. This screen had a duration of 2500 ms. The next trial began after 500ms of blank screen with the fixation cross.
Figure 4. Schematic of two trials in the English block, one with a target word (grape) and another with a probe word requiring a button pressing response (foot).

4.1.4. EEG recording
Participants were seated in a comfortable chair in a sound attenuating room and were fitted with an elastic cap equipped with 29 tin electrodes (Electro-cap International -- see Figure 5 for the location of electrodes). Two additional electrodes were used to monitor for eye-related artifact (blinks and vertical or horizontal eye movement); one below the left eye (VE) and one horizontally next to the right eye (HE). All electrodes were referenced to an electrode placed over the left mastoid (A1). A final electrode was placed over the right mastoid (A2 -- used to determine if there was any asymmetry between the mastoids; none was observed). The 32 channels of electrophysiological data were amplified using an SA Instruments Bio-amplifier system with 6db cutoffs set at .01 and 40Hz. The output of the bio-amplifier was continuously digitized at 200 Hz throughout the experiment.
Figure 5. Electrode Montage and analysis sites (in grey).
After electrode placement instructions for the experimental task were given in French then a short practice list (in the language of the first block) was presented to assure good performance during experimental runs and to accustom the participant to the coming language. A practice list was also run before the second block in the language of the second block. The order of language blocks was counterbalanced across participants. There were three pauses within each block; the length of these pauses was determined by the participant. Each language block typically required 15 minutes. At the end of the ERP experiment participants were asked to give a translation of the 92 English words that they had seen during the experiment (74 critical items and 18 body parts). These post-translations were graded for accuracy and reported as behavioral results.
4.1.5. Data analysis
ERPs were averaged separately for English target words that had many or few orthographic neighbors in French, and French target words that had many or few orthographic neighbors in English. Only trials contaminated by eye movement activity were rejected prior to averaging (7.1 % of trials). Because we did not assume that translation performance is equivalent to L2 word representation all French items were averaged regardless of post-translation results. All target items were baselined to the average of activity in the 40 ms pre-target period and were lowpass filtered at 15 Hz.1 The ERPS were then quantified by measuring the mean amplitude in two latency windows: 175-275 ms to capture pre-N400 activity, and 300-500 ms to capture the N400 itself. In order to analyze the scalp distribution of the various ERP components omnibus repeated measures analyses of variance (ANOVAs) were carried out for 12 electrode sites from representative frontal (FC1, Fz and FC2) middle (C3, Cz and C4), parietal (CP1, Pz and CP2) and occipital (O1, Oz, and O2) locations. This arrangement allowed for a single omnibus ANOVA with factors of Language (French vs. English), cross-neighborhood-size (many vs. few), electrode-site (F vs. C vs. CP vs. O) and laterality (left vs. medial vs. right). Significant interactions in the omnibus analyses involving language and cross-neighborhood-size were decomposed with followed-up ANOVAs looking at each language (French/English) separately. The Geisser-Greenhouse (1959) correction was applied to repeated measures with more than one degree of freedom in the numerator.2
4.2 Experiment 2
4.2.1. Participants
Twenty participants (11 women) were recruited and compensated for their time (mean age = 20 years, SD = 1.3). All were right handed (Edinburgh Handedness Inventory – Oldfield, 1971) with normal or corrected-to-normal visual acuity and no history of neurological insult or language disability. All participants reported to be monolingual native English speakers and to have had no classroom exposure to French as an L2.
4.2.2. Stimuli and procedure
Materials and experimental task were the same as in Experiment 1 but only the English list was presented to these participants.
4.2.3. Data analysis
Trials contaminated by eye movement activity were rejected prior to averaging (8.9 %). ERPs were averaged for English target words that had many or few orthographic neighbors in French. All target items were baselined to the average of activity in the 40 ms pre-target period and were lowpass filtered at 15 Hz. The ERPs were then quantified, as in Experiment 1, by measuring the mean amplitude in two latency windows: 175-275 ms and 300-500 ms. The analysis approach was identical to Experiment 1, but the factor of target language was eliminated as these monolingual participants only read words in their L1.
4.3. Simulation Study
The model was implemented with a 4 and 5-letter French word lexicon extracted from the Lexique database (New et al., 2004), and a 4 and 5-letter English word lexicon from the CELEX database (Baayen et al., 1995). Only words with at least 2 occurrences per million (opm) were included in the lexicons. The bilinguals of Experiment 1 were not perfectly balanced bilinguals, therefore word frequencies (implemented as resting-level activations of word nodes in the BIA+ model) were adjusted to simulate such unbalanced high proficiency bilinguals (see Dijkstra & van Heuven, 1998). The resting-level activations of French (L1) were scaled between the default word node resting-level activation values of the Interactive Activation (IA) model (McClelland & Rumelhart, 1981). Thus, the resting-level activation of the most frequent word was set to 0 and the resting-level activation of the least frequent words (2 opm) was set to -0.92. Other word nodes were assigned resting-level values between -0.92 and -0.01 based on their word frequency. The resting-level activations of the English (L2) words were scaled for the bilinguals between -1.20 and 0. To simulate the English monolingual data of Experiment 2 we conducted simulations with only English words with resting-level activations between -0.92 and 0. Parameters of the BIA+ model with 4-letter words were identical to those of the IA model. Parameters for the simulations with the 5-letter word lexicons were identical to the simulation of the 4-letter words except for the letter-to-word excitation parameter, which was reduced from 0.07 to 0.06 as in the simulations of Grainger and Jacobs (1996). Target words were presented to the model until the target word reached the word identification threshold of 0.70.
Acknowledgments
This research was supported by grant numbers HD25889 and HD043251. The authors would like to thank Courtney Brown for her help in data collection.
Footnotes
A 40 ms baseline was chosen because using the more traditional 100 pre-stimulus baseline resulted in a substantial difference between conditions in the first 50 ms after target word onset.
We performed a first pass analysis including the factor of order to test for differential effects of which target language block occurred first. There were no interactions involving the order and language or cross-neighborhood-size factors (all Fs < 2). In all of the analyses reported we collapsed across this factor.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Alvarez RP, Holcomb PJ, Grainger J. Accessing word meaning in two languages: An event-related brain potential study of beginning bilinguals. Brain Language. 2003;87(2):290–304. doi: 10.1016/s0093-934x(03)00108-1. [DOI] [PubMed] [Google Scholar]
- Andrews S. Frequency and neighborhood effects on lexical access: Activation or search? Journal of Experimental Psychology: Learning, Memory, and Cognition. 1989;15(5):802–814. [Google Scholar]
- Andrews S. The effect of orthographic similarity on lexical retrieval: Resolving neighborhood conflicts. Psychonomic Bulletin Review. 1997;4(4):439–461. [Google Scholar]
- Baayen RH, Piepenbrock R, Gulikers L. The celex lexical database. Philadelphia, PA: Linguistic Data Consortium; 1995. [Google Scholar]
- Beauvillain C, Grainger J. Accessing interlexical homographs: Some limitations of a language-selective access. Journal of Memory and Language. 1987;26(6):658–672. [Google Scholar]
- Brysbaert M, Van Dyck G, Van de Poel M. Visual word recognition in bilinguals: Evidence from masked phonological priming. Journal of Experimental Psychology: Human Perception and Performance. 1999;25(1):137–148. doi: 10.1037//0096-1523.25.1.137. [DOI] [PubMed] [Google Scholar]
- Carreiras M, Perea M, Grainger J. Effects of the orthographic neighborhood in visual word recognition: Cross-task comparisons. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1997;23(4):857–871. doi: 10.1037//0278-7393.23.4.857. [DOI] [PubMed] [Google Scholar]
- Coltheart M, Davelaar E, Jonasson JT, Besner D. Access to the internal lexicon. In: Dornic S, editor. Attention and Performance. VI. London: Academic Press; 1977. pp. 535–555. [Google Scholar]
- de Groot AM, Delmaar P, Lupker SJ. The processing of interlexical homographs in translation recognition and lexical decision: Support for non-selective access to bilingual memory. Quarterly Journal of Experimental Psychology A: Human Experimental Psychology. 2000;53A(2):397–428. doi: 10.1080/713755891. [DOI] [PubMed] [Google Scholar]
- de Groot AM, Nas GL. Lexical representation of cognates and noncognates in compound bilinguals. Journal of Memory and Language. 1991;30(1):90–123. [Google Scholar]
- Dijkstra T, Grainger J, van Heuven WJB. Recognition of cognates and interlingual homographs: The neglected role of phonology. Journal of Memory and Language. 1999;41:496–518. [Google Scholar]
- Dijkstra T, Timmermans M, Schriefers H. On being blinded by your other language: Effects of task demands on interlingual homograph recognition. Journal of Memory and Language. 2000;42(4):445–464. [Google Scholar]
- Dijkstra T, van Heuven WJB. The BIA model and bilingual word recognition. In: Grainger J, Jacobs AM, editors. Localist connectionist approaches to human cognition. Mahwah, NJ: Lawrence Erlbaum Associates; 1998. pp. 189–225. [Google Scholar]
- Dijkstra T, Van Heuven WJB. Modeling bilingual word recognition: Past, present and future: Reply. Bilingualism: Language and Cognition. 2002;5(3):219–224. [Google Scholar]
- Dijkstra T, Van Heuven WJB, Grainger J. Simulating cross-language competition with the bilingual interactive activation model. Psychologica Belgica. 1998;38(34):177–196. [Google Scholar]
- Dyer FN. The stroop phenomenon and its use in the study of perceptual, cognitive, and response processes. Memory Cognition. 1973;1(2):106–120. doi: 10.3758/BF03198078. [DOI] [PubMed] [Google Scholar]
- Grainger J. Word frequency and neighborhood frequency effects in lexical decision and naming. Journal of Memory and Language. 1990;29(2):228–244. [Google Scholar]
- Grainger J, Beauvillain C. Language blocking and lexical access in bilinguals. Quarterly Journal of Experimental Psychology. 1987;39A:295–319. [Google Scholar]
- Grainger J, Dijkstra T. On the representation and use of language information in bilinguals. In: Harris RJ, editor. Cognitive processing in bilinguals. Amsterdam: North-Holland: 1992. pp. 207–220. [Google Scholar]
- Grainger J, Jacobs AM. Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review. 1996;103(3):518–565. doi: 10.1037/0033-295x.103.3.518. [DOI] [PubMed] [Google Scholar]
- Grainger J, Muneaux M, Farioli F, Ziegler J. Effects of phonological and orthographic neighborhood density interact in visual word recognition. Quarterly Journal of Experimental Psychology. 2005;58A:981–998. doi: 10.1080/02724980443000386. [DOI] [PubMed] [Google Scholar]
- Grainger J, O'Regan J, Jacobs AM, Segui J. On the role of competing word units in visual word recognition: The neighborhood frequency effect. Perception Psychophysics. 1989;45(3):189–195. doi: 10.3758/bf03210696. [DOI] [PubMed] [Google Scholar]
- Greenhouse SW, Geisser S. On methods in the analysis of profile data. Psychometrika. 1959;24:95–112. [Google Scholar]
- Grosjean F. Exploring the recognition of guest words in bilingual speech. Language and Cognitive Processes. 1988;3(3):233–274. [Google Scholar]
- Guttentag RE, Haith MM, Goodman GS, Hauch J. Semantic processing of unattended words by bilinguals: A test of the input switch mechanism. Journal of Verbal Learning Verbal Behavior. 1984;23(2):178–188. [Google Scholar]
- Holcomb PJ, Grainger J. On the time-course of visual word recognition: An ERP investigation using masked repetition priming. Journal of Cognitive Neuroscience. 2006;18(10):1631–1643. doi: 10.1162/jocn.2006.18.10.1631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holcomb PJ, Grainger J. Exploring the temporal dynamics of visual word recognition in the masked repetition priming paradigm using event-related potentials. Brain Research. 2007;1180:39–58. doi: 10.1016/j.brainres.2007.06.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holcomb PJ, Grainger J, O'Rourke T. An electrophysiological study of the effects of orthographic neighborhood size on printed word perception. Journal of Cognitive Neuroscience. 2002;14(6):938–950. doi: 10.1162/089892902760191153. [DOI] [PubMed] [Google Scholar]
- Jared D, Szucs C. Phonological activation in bilinguals: Evidence from interlingual homograph naming. Bilingualism: Language and Cognition. 2002;5:225–239. [Google Scholar]
- Macnamara J. The linguistic independence of bilinguals. Journal of Verbal Learning Verbal Behavior. 1967;6(5):729–736. [Google Scholar]
- Macnamara J, Kushnir SL. Linguistic independence of bilinguals: The input switch. Journal of Verbal Learning Verbal Behavior. 1972;10(5) [Google Scholar]
- McClelland JL, Rumelhart DE. An interactive model of context effects in letter perception: Part i. An account of basic findings. Psychological Review. 1981;88(5):375–407. [PubMed] [Google Scholar]
- Marian V, Spivey M. Competing activation in bilingual language processing: Within- and between-language competition. Bilingualism: Language and Cognition. 2003;6:97–115. [Google Scholar]
- Nas G. Visual word recognition in bilinguals: Evidence for a cooperation between visual and sound based codes during access to a common lexical store. Journal of Verbal Learning Verbal Behavior. 1983;22(5):526–534. [Google Scholar]
- New B, Pallier C, Brysbaert M, Ferrand L. Lexique 2: A new French lexical database. Behavior Research Methods, Instruments & Computers. 2004;36(3):516–524. doi: 10.3758/bf03195598. [DOI] [PubMed] [Google Scholar]
- Oldfield RC. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia. 1971;9(1):97–113. doi: 10.1016/0028-3932(71)90067-4. [DOI] [PubMed] [Google Scholar]
- Ruschemeyer S, Nojack A, Limbach M. A mouse with a roof? Effects of phonological neighbors on processing of words in sentences in a non-native language. Brain and Language. 2008;104(2):113–121. doi: 10.1016/j.bandl.2007.01.004. [DOI] [PubMed] [Google Scholar]
- Soares C, Grosjean F. Bilinguals in a monolingual and a bilingual speech mode: The effect on lexical access. Memory Cognition. 1984;12(4):380–386. doi: 10.3758/bf03198298. [DOI] [PubMed] [Google Scholar]
- Tanenhaus MK, Magnuson JS, Dahan D, Chambers C. Eye movements and lexical access in spoken-language comprehension: Evaluating a linking hypothesis between fixations and linguistic processing. Journal of Psycholinguistic Research. 2000;29(6):557–580. doi: 10.1023/a:1026464108329. [DOI] [PubMed] [Google Scholar]
- Thomas MS, Allport A. Language switching costs in bilingual visual word recognition. Journal of Memory and Language. 2000;43(1):44–66. [Google Scholar]
- van Hell JG, De Groot AMB. Conceptual representation in bilingual memory: Effects of concreteness and cognate status in word association. Bilingualism: Language and Cognition. 1998;1(3):193–211. [Google Scholar]
- van Hell JG, Dijkstra T. Foreign language knowledge can influence native language performance in exclusively native contexts. Psychonomic Bulletin Review. 2002;9(4):780–789. doi: 10.3758/bf03196335. [DOI] [PubMed] [Google Scholar]
- van Heuven WJ, Dijkstra T, Grainger J. Orthographic neighborhood effects in bilingual word recognition. Journal of Memory and Language. 1998;39(3):458–483. [Google Scholar]
- van Heuven WJB, Schriefers H, Dijkstra T, Hagoort P. Language conflict in the bilingual brain. Cerebral Cortex. 2008 doi: 10.1093/cercor/bhn030. [DOI] [PMC free article] [PubMed] [Google Scholar]