

Abstract
The mechanisms of chain selection and assembly of fibril-associated collagens with interrupted triple helices (FACITs) must differ from that of fibrillar collagens, since they lack the characteristic C-propeptide. We analyzed two carboxyl-terminal noncollagenous domains, NC2 and NC1, of collagen XIX as potential trimerization units and found that NC2 forms a stable trimer and substantially stabilizes a collagen triple helix attached to either end. In contrast, the NC1 domain requires formation of an adjacent collagen triple helix to form interchain disulfide bridges. The NC2 domain of collagen XIX and probably of other FACITs is responsible for chain selection and trimerization.
The fibril-associated collagens with interrupted triple helices (FACIT2 collagens) include type IX, XII, XIV, XVI, XIX, XX, XXI, and XXII. Collagen IX is a heterotrimer composed of three different α-chains, and all others are homotrimers whose α-chains are characterized by short collagenous (COL) domains interrupted by several noncollagenous (NC) domains (1, 2). Unlike the fibril-forming collagens, the FACITs have significantly shorter carboxyl-terminal NC domains (NC1 domains): 37 residues for collagen XIV, 20-25 residues for collagen IX, and even fewer than 20 residues for collagen types XII and XIX (based on human sequences). In contrast, the carboxyl-terminal NC domains of fibrillar collagens (C-propeptides) are of a different type and contain about 260 residues. The FACITs share a remarkable sequence homology at their COL1/NC1 junctions, each having two strictly conserved cysteine residues separated by four residues in their NC1 domain. Several studies suggest that the COL1 domain and the NC1 domain are involved in the mechanism of chain selection in the assembly of collagens XII and XIV (3-6). Contrary to these studies, very recent studies on collagen IX show that three α-chains can associate in the absence of the COL1 and NC1 domains to form a triple helix, although the COL2-NC2 region alone is not sufficient for trimerization (7). This suggests that folding and chain selection of collagen IX is a cooperative process involving multiple COL and NC domains (7). It has also been hypothesized that the NC2 domain of all FACIT collagens is able to form an α-helical coiled-coil, thus bearing an ability to trimerize those collagens (8), but no experimental evidence has been reported so far.
Collagen XIX was identified from independently isolated clones from a human rhabdomyosarcoma cell line (9, 10). The type XIX chain is composed of a 268-residue, noncollagenous amino terminus, an 832-residue discontinuous collagenous region, and a 19-residue carboxyl-terminal peptide (10-12). It is by far the least abundant collagen so far purified, with a composition of ∼10-6% of the dry weight of umbilical cord (13). Several features in the type XIX sequence place this collagen in the largest subclass of the nonfibrillar group, the FACIT collagens. These include a ∼250-residue thrombospondin module at the amino terminus, the position of two 2-amino acid interruptions in the collagenous subdomain closest to the carboxyl terminus, and a Cys-Xaa4-Cys motif situated at the junction of the collagenous region and carboxyl peptide (COL1/NC1 junction) (11, 12).
Characterization of mice harboring null or structural mutations in the collagen XIX (Col19a1) gene has revealed the critical contribution of this matrix protein to muscle physiology and differentiation (14). The phenotype includes smooth muscle motor dysfunction and a hypertensive sphincter. Mice without collagen XIX also display impaired smooth-to-skeletal muscle cell conversion in the abdominal segment of the esophagus (14). Electron microscope images of protein purified from human umbilical cord revealed a sharply kinked and highly polymorphic collagenous region as well as higher order complexes (13). The higher order complexes involve the aminoterminal domain, which is responsible for intermolecular disulfide linkages and contains a heparin-binding site (13).
To explore the trimerization abilities of collagen XIX at the biophysical level, we have studied the NC1 and NC2 domains in their isolated form as well as in conjunction with a triple helix. We show that the folding and the interchain disulfide bridge formation in the NC1 domain is driven by the triple helix formation; in other words, the triple helix formation in the COL1 domain is necessary for the folding of the NC1 domain. The artificial triple helical sequence (GPO)6, which forms a triple helix by itself, efficiently induces the folding of the NC1 domain. The NC2 domain alone is an effective trimerization domain. It forms a stable trimer and substantially stabilizes the triple helical domains attached to it.
EXPERIMENTAL PROCEDURES
Synthesis and Purification of Reduced NC1-containing Peptides—Peptides with the NC1 domain were synthesized using the native sequence of mouse collagen XIX from the Swiss Protein Data base (Swiss-Prot number Q0VF58). The peptides were synthesized on an ABI433A peptide synthesizer (Applied Biosystems) with 0.25 mm Fmoc-Gly-PEG-PS resin, a 4-fold excess of Fmoc-amino acids, and O-(7-azabenzotriazol-1-yl)-N,N,N′,N′-tetramethyluronium hexafluorophosphate as activating agent. The Fmoc-amino acids carried the protection groups Cys-Trt, Hyp-t-Bu, Gln-Trt, His-Trt, Ser-t-Bu, Glu-O-t-Bu, Arg-Pbf, Asn-Trt, and Tyr-t-Bu. The peptides were cleaved off of the resin and deprotected for 4 h at room temperature with 90% trifluoroacetic acid, 5% thioanisole, 3% 1,2-ethanedithiol, 2% anisole. Subsequently, the peptides were precipitated in cold ether, redissolved in H2O, and lyophilized. The reduced peptides were then purified by reverse phase HPLC using a C18 column (50 × 250 mm, 10-15-μm particle size, 300-Å pores; Vydac, Hesperia, CA) with an acetonitrile/water gradient and 0.1% trifluoroacetic acid as an ion-pairing agent. Finally, the peptides were characterized by electrospray/quadrupole/time-of-flight mass spectrometry (Q-Tof micro, Waters Associates).
Oxidation of NC1-containing Peptides and Separation of Oligomers—The lyophilized, reduced peptides were dissolved in degassed and N2-saturated 50 mm sodium phosphate buffer, pH 8.0, under N2 atmosphere and were kept at 4 °C for 24 h in order to allow triple helix formation prior to oxidation. Oxidation was induced by the addition of reduced (10 mm) and oxidized (1 mm) glutathione and exposure to atmospheric O2. The pH was raised to 8.3 with a saturated solution of Tris. Oxidation was carried out for 5-7 days, and the peptide mass was periodically analyzed by liquid chromatography/mass spectrometry. To separate covalently linked oligomers, the oxidized crude material was dissolved in deionized 8 m urea containing 0.1% trifluoroacetic acid to prevent disulfide exchange and applied to a sieve column (BioSep-SEC-S 2000, 600 × 20 mm; Phenomenex). Fractions were characterized by electrospray/quadrupole/time-of-flight mass spectrometry. Trimer-containing fractions were pooled and further purified by reverse phase HPLC using a C18 column with an acetonitrile/water gradient and 0.1% trifluoroacetic acid.
Cloning, Expression, and Purification of NC2, (GPP)10NC2, and NC2(GPP)10—To facilitate expression and folding of short peptides containing the NC2 domain of human collagen XIX, they were cloned as part of fusion molecules with a His-tagged minifibritin that has a thrombin cleavage site (HT-mf-thr). Minifibritin is an obligatory trimer with both its amino and carboxyl termini exposed to solvent. The modified version of minifibritin (HT-mf-thr) has recently been used to successfully express, initiate folding, and stabilize a set of collagen fragments (15, 16). The plasmid pET23-HisMf (17) has multiple cloning sites just after the HT-mf-thr gene. The plasmid (clone ID 8322416, NCBI accession number BC113364), containing the full-length human collagen XIX cDNA was purchased from Open Biosystems. The NC2 domain was PCR-amplified using two oligonucleotides: 5′-TGCAGATCTCCGGCTGATGCAGTTTCATTTGAA-3′ (forward primer fNC2; the BglII site is underlined) and 5′-GTCAGTCGACTTAGCCATAAGCTTGGGCAGCCAACATT-3′ (reverse primer rNC2; the SalI site is underlined). Two other constructs for (GPP10)NC2 and NC2(GPP)10 were PCR-amplified in two steps. The DNA fragment coding (GPP10)NC2 was prepared as follows. A synthetic oligonucleotide coding for (GPP)10 (5′-GGTCCGCCTGGCCCACCGGGCCCGCCCGGTCCGCCGGGCCCGCCGGGTCCCCCAGGTCCGCCCGGCCCGCCGGGCCCTCCGGGTCCACCG-3′) was used as a template to amplify the (GPP)10 part, including a complementary end for the NC2 domain, using two oligonucleotides, 5′-TCAGGATCCGGTCCGCCTGGCCCACCGGGC-3′ (forward primer fGPP; the BamHI cloning site is underlined) and 5′-TTCAAATGAAACTGCATCAGCCGGAATCCCGGGTGGACCCGGAGGGCCCGGC-3′ (reversed primer; one half of it is complementary to the end of (GPP)10, and the other half is complementary to the beginning of the NC2 domain). The product of this PCR was purified and used together with the plasmid containing the NC2 domain sequence as a complex annealed template to PCR-amplify the (GPP10)NC2 fragment using two oligonucleotides: fGPP and rNC2. The same strategy was applied to amplify the fragment NC2(GPP)10, using the following primers: 5′-GTTGGCTGCCCAAGCTTATGGGCGGCCGGGTCCGCCTGGCCCACCGGGC-3′ (forward primer; one half of it is complementary to the end of NC2 domain, and the other half is complementary to the beginning of (GPP)10) and 5′-GTCAGTCGACTTACGGTGGACCCGGAGGGCCCGG-3′ (reverse primer rGPP; the SalI site is underlined) for the first step and fNC2 and rGPP for the second step.
The PCR-amplified fragments NC2, (GPP)10NC2, and NC2(GPP)10 were cut by BglII/BamHI and SalI and cloned into the pET23-HisMf vector using the restriction sites BamHI and SalI, so that all three fragments were a part of the fusion encoding the His6 tag, minifibritin, the flexible linker with the thrombin cleavage site, and the insert.
The DNA inserts were verified by Sanger dideoxy DNA sequencing. The recombinant proteins were expressed at 30 °C in the Escherichia coli BL21(DE3) host strain (Novagen) after isopropyl 1-thio-β-d-galactopyranoside induction (final concentration 1 mm) for 12 h. Purification of the His6-tagged fusion proteins by immobilized metal affinity chromatography on a HisTrap™ HP column (Amersham Biosciences) and separation of the fragments NC2, (GPP)10NC2, and NC2(GPP)10 after thrombin cleavage were carried out as described in the manufacturer's instructions. Thrombin cleavage was performed at 4 °C for 24 h with thrombin protease (ICN) in 50 mm Tris/HCl buffer, pH 8.3, containing 150 mm NaCl. The resulting fragments had two additional amino acid residues, GS, before the native amino acid sequence. The peptides were then purified by reversed phase HPLC using a C18 column with an acetonitrile/water gradient and 0.1% trifluoroacetic acid as an ion-pairing agent. The peptides eluted at a ∼60% acetonitrile concentration, which is highly denaturing. Finally, the peptides were characterized by electrospray/quadrupole/time-of-flight mass spectrometry and amino acid analysis.
Analytical Ultracentrifugation—Sedimentation equilibrium measurements were performed on a Beckman model XL-A analytical ultracentrifuge. Absorbance was measured at 240 nm. Runs were carried out at 20 °C in an An60-Ti rotor using 12-mm cells with Epon two-channel centerpieces.
Circular Dichroism Analysis—CD spectra were recorded on an AVIV model 202 spectropolarimeter (AVIV Instruments, Inc.) with thermostatted quartz cells of 0.1-1-mm path length. The spectra were normalized for concentration and path length to obtain the mean molar residue ellipticity after subtraction of the buffer contribution. Thermal scanning curves were recorded at 222 nm for the NC2 peptide to monitor the α-helical secondary structure transition and at 230 nm for (GPP)10NC2 and NC2(GPP)10 to monitor the collagen triple helix transition. Peptide concentrations were determined by amino acid analysis.
Evaluation of the Thermodynamic Data—CD transition curves were interpreted based on a two-state mechanism in which three unfolded chains, u, cross-linked by the NC2 domain, combine to a native collagen triple helix, n: u ↔ n.
The equilibrium constant Ku is as follows,
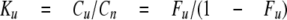 |
(Eq.1) |
where cu and cn are concentrations of
unfolded and native species, and Fu is the fraction of
unfolded species,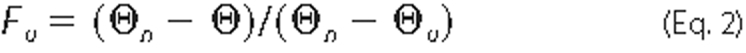
where Θn and Θu are the extrapolated native and unfolded ellipticities in the transition region and Θ is the observed ellipticity at the given temperature.
From Equation 3,
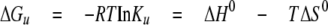 |
(Eq.3) |
and Equation 1, assuming that ΔH0 and ΔS0 are constant, the linear fit of -RTlnKu versus T allowed us to determine the standard enthalpy, ΔH0, and the standard entropy, ΔS0.
RESULTS
Sequences of the NC1 and NC2 Domains of FACIT Collagens—All FACIT collagens except human type XX have at least two collagenous domains, COL1 and COL2, and two noncollagenous domains, NC1 and NC2 (Fig. 1), where the NC2 domain is positioned between COL2 and COL1. Sequence analysis shows no significant sequence homology either among NC1 or NC2 domains, with the exception of the cysteine pattern at the junction between COL1 and NC1. The length of the NC1 domain varies from 19 to 37 residues (collagens XII/XIX and XIV, respectively), assuming that the first cysteine in the conserved cysteine pattern belongs to COL1. The length of NC2 domains, including one GXY triplet on both ends, varies from 37 to 50 residues (Fig. 1).
FIGURE 1.

Sequence alignment of the NC2 and NC1 domains of human FACIT collagens. Types IX (chains α1, α2, and α3), XII, XIV, XVI, XIX, XXI, and XXII (Swiss-Prot numbers P20849, Q14055, Q14050, Q99715, Q05707, Q07092, Q14993, Q96P44, and Q8NFW1) are included. No significant sequence homology is detected in either the NC2 domain or the NC1 domain, except the conserved cysteine pattern Gly-Xaa-Cys-(Xaa)4-Cys at the junction region of COL1-NC1 (those cysteines are highlighted). The α1, α2, and to some extent the α3 chain of type IX collagen show some sequence homology in the NC2 domain. Collagens XII and XIV also show high sequence homology in the NC2 domain.
Folding and Oxidation of the NC1 Domain—Formation of covalently cross-linked trimers is chosen as an indicator of the correct folding of the NC1 domain. To test the ability of the NC1 domain alone to form a covalently linked trimer, we oxidized the NC1 peptide (Table 1). Mass spectrometry analysis of oxidation products revealed the presence of only two peaks corresponding to a monomer and a dimer. Those products were separated on a sieve column under denaturing conditions. Two prominent peaks (Fig. 2A) were determined to be the dimer and the monomer by mass spectrometry. No trimer was detected.
TABLE 1.
Amino acid sequences of peptides used in this study
Shown is the amino acid sequence of the NC1 and NC2 peptides (where O represents (4R)-hydroxyproline).

FIGURE 2.

Separation of oxidative products of the NC1 containing peptides on a sieve column under denaturing conditions. Oxidized samples were run in 8 m urea containing 0.1% trifluoroacetic acid. 1, 2, and 3 indicate monomeric, dimeric, and trimeric species as determined by mass spectrometry. A, NC1 peptide; B, h1NC1 peptide; C, (GPO)2h1NC1 peptide.
The h1NC1 peptide (Table 1) contains the last uninterrupted segment of the collagenous domain and the full-length NC1 domain. The length of this helix appeared insufficient to form a triple helix by itself at 4 °C, since no thermal transition was monitored by CD. The oxidation at 4 °C produced only monomers and dimers, as in the case with the NC1 peptide. Interestingly, the oxidation experiments of the h1NC1 peptide performed at -20 °C in the presence of 30% methanol to avoid freezing as described in Ref. 5 were more successful. In addition to monomeric and dimeric oxidative forms, a small fraction (∼15-20%) of a trimer was formed (Fig. 2B). The purified trimeric form showed the formation of a moderately stable collagen triple helix (Table 2). This led us to the idea that the collagen triple helix formation might be a prerequisite for the correct folding and oxidation of the NC1 domain. Indeed, the addition of two GPO triplets to the beginning of the h1NC1 peptide dramatically changed the efficiency of the NC1 domain oxidative folding. The reduced (GPO)2h1NC1 peptide showed collagen triple helix formation (Table 2), and the consequent oxidation produced about 90% of the correctly oxidized trimeric product (Fig. 2C).
TABLE 2.
Summary of biophysical data of the NC1-containing peptides
The number of residues, calculated molecular masses (in Da), molecular masses of the reduced and oxidized peptides determined by mass spectrometry (in Da), and midpoint transition temperatures Tm of the triple helix of the reduced and oxidized peptides at a 1 mg/ml concentration in 50 mm sodium acetate buffer, pH 4.5, are shown. NA, not applicable; ND, not detected.
| Number of residues | Mass (calc.) | Mass (reduced) | Mass (oxidized) | Tm (reduced) | Tm (oxidized) | |
|---|---|---|---|---|---|---|
| Da | Da | Da | °C | °C | ||
| NC1 | 28 | 2844.1 | 2843.0 | 2842.0 + 5685.5 | NA | NA |
| h1NC1 | 40 | 3908.2 | 3908.5 | 3907.5 + 7813.5 + 11,718.5 | ND | 29 |
| (GPO)2h1NC1 | 46 | 4442.8 | 4442.5 | 13,319.0 | 19 | 45 |
| (GPO)6NC1 | 43 | 4180.6 | 4180.0 | 12,538.5 | 26 | 72 |
| (GPO)6NC1Δ | 33 | 3182.4 | 3181.5 | 9540.5 | 27 | 67 |
To analyze the importance of the triple helical sequence composition on the trimer formation, we substituted the native sequence with (GPO)6 (Table 1, peptide (GPO)6NC1), which is known to form a stable triple helix. The yield of the correctly oxidized product of the (GPO)6NC1 peptide was even slightly higher (data not shown). Thus, the oxidative folding of the NC1 domain does not depend on the composition of the triple helical sequence.
The sequence of the NC1 domain is rather short, being only 19 amino acids long. To test its importance on oxidative folding, we synthesized a peptide, (GPO)6NC1Δ, where the last 10 residues of the NC1 domain are deleted (Table 1). The yield of the correctly oxidized trimer was the same as for the (GPO)6NC1 peptide. The comparison of the triple helix stability in the oxidized form of the two peptides shows a difference of 5 °C (Table 2). Thus, the missing part of the NC1 domain might be important for additional stabilization of the triple helix, either via a direct interaction of the missing part with the triple helix or by sterically restricting the dynamics of the disulfide knot.
Trimeric Structure of the NC2 Domain—Fig. 3A shows an SDS-polyacrylamide gel of the expressed NC2 domain, (GPP)10NC2 and NC2(GPP)10. The far ultraviolet CD spectrum shows that the NC2 domain has predominantly an α-helical structure (Fig. 3B) at 20 °C. The oligomeric state of the NC2 domain was investigated by analytical ultracentrifugation. Sedimentation equilibrium runs revealed a molecular mass of 15.7 ± 3.0 kDa, which is consistent with a trimeric structure (calculated molecular mass of the single chain is 5.3 kDa) (Table 3). Thermal transition curves monitored at 222 nm showed that the NC2 domain forms a highly stable structure that requires a substantial concentration of guanidine hydrochloride for thermal unfolding (Fig. 4). The reversibility of unfolding is shown by the gain of the signal upon reverse temperature scanning of the NC2 domain in a buffer supplemented with 3 m guanidine hydrochloride. Without the denaturant, the α-helical structure was stable up to 90 °C.
FIGURE 3.

Gel electrophoresis and secondary structure of the NC2-containing peptides. A, the purified peptides were subjected to 4-12% SDS-PAGE and analyzed by Coomassie staining. Lane 1, (GPP)10NC2; lane 2, NC2(GPP)10; lane 3, NC2. B, CD spectra of peptides NC2 (in blue), (GPP)10NC2 (in red), and NC2(GPP)10 (in green) recorded in 50 mm sodium phosphate buffer, pH 8.0, using 0.2 mm peptide concentrations and a 0.1-mm path length quartz cuvette equilibrated at 20 °C. C, calculated spectra of the collagen triple-helical part of (GPP)10NC2 (in red) and NC2(GPP)10 (in green).
TABLE 3.
Summary of biophysical data of the NC2-containing peptides
The calculated molecular masses, molecular masses determined by analytical ultracentrifugation (AUC) in 50 mm sodium phosphate buffer, pH 8.0, containing 150 mm NaCl, midpoint transition temperatures Tm of the triple helix, and thermodynamics values ΔH0 and ΔS0 are shown. NA, not applicable.
| Mass | AUC | Tm | ΔH0 | ΔS0 | |
|---|---|---|---|---|---|
| kDa | kDa | °C | kJ mol−1 | J mol−1 K−1 | |
| NC2 | 5.3 | 15.7 ± 3.0 | NA | NA | NA |
| (GPP)10NC2 | 8.0 | 22.1 ± 4.3 | 68 | −501.4 ± 4.7 | −1470 ± 12 |
| NC2 (GPP)10 | 8.1 | 26.6 ± 4.7 | 55 | −392.4 ± 3.9 | −1196 ± 12 |
FIGURE 4.

Thermal transition curves of the NC2 domain. Transition curves were recorded in 50 mm sodium phosphate buffer, pH 8.0, supplemented with 0 m (squares), 2 m (circles), 3 m (triangles), 4 m (diamonds), and 5 m (inverted triangles) guanidine hydrochloride using 0.08 mm peptide concentrations and a 1-mm path length cell. The change inα-helical content was monitored at 222 nm with a scan rate of 0.5 °C/min. Heating and cooling transition curves are shown for the sample with 3 m guanidine hydrochloride to demonstrate the reversibility of the transition.
The NC2 Domain Stabilizes the Triple Helix—The single chain peptide with the sequence (PPG)10 is able to form a collagen triple helix of moderate stability. The midpoint transition temperature (Tm) for (PPG)10 is a concentration-dependent value and is about 25 °C at 1 mg/ml concentration in phosphate-buffered saline (18). It has been previously shown that the Tm value of (GPP)10 can be sufficiently increased by fusion to an obligatory stable trimer (19) or by covalent cross-linking of all three chains (18, 20). Stabilization of the (GPP)10 triple helix by forcing trimerization is possible from both amino- and carboxyl-terminal ends, although the effectiveness is highly varied (18).
Far ultraviolet CD spectra of both (GPP)10NC2 and NC2(GPP)10 are similar in shape and deviate significantly from the CD spectrum of the isolated NC2 domain (Fig. 3B). Equimolar subtraction of the NC2 domain spectrum from either (GPP)10NC2 or NC2(GPP)10 and subsequent adjustment of the mean molar ellipticity demonstrates the presence of the collagen triple helical structure in both peptides (Fig. 3C). The (GPP)10 part in the (GPP)10NC2 peptide has higher content of triple helix then in NC2(GPP)10. Thermal transition curves monitored at 230 nm, at which the collagen triple helix transitions can be observed, show a substantial stabilization of the triple helix in both cases (Fig. 5). The Tm values are 68 and 55 °C for (GPP)10NC2 and NC2(GPP)10, respectively. The thermal range of the triple helical transitions is below the melting point of the NC2 domain (Fig. 5A); thus, the chains remain associated by the NC2 domain. The difference in the Tm values also correlates with the difference in the extent of the triple helical content. Both heating and cooling transition curves are shown to demonstrate a known effect of hysteresis observed for collagen transitions (16, 21-22). Unfolding of the collagen triple helices observed in both peptides should be considered as a monomolecular reaction, since three chains remain linked by the NC2 domain. A thermodynamic analysis of the transitions shows that the absolute values of ΔH0 and ΔS0 are smaller for the NC2(GPP)10 peptide compared with the (GPP)10NC2 peptide (Fig. 5B and Table 3).
FIGURE 5.

Thermal transition curves of the NC2 containing peptides. A, transition curves of NC2 (diamonds), (GPP)10NC2 (circles), and NC2(GPP)10 (squares) recorded in 50 mm sodium phosphate buffer, pH 6.5, supplemented with 150 mm sodium chloride. The change of collagen triple-helical content was monitored at 230 nm. To emphasize the hysteresis of the collagen transition, heating and cooling curves are plotted for (GPP)10NC2 and NC2(GPP)10, where cooling curves show lower apparent values of the melting temperature. The scan rate was 0.5 °C/min. B, linear fit of ΔGu versus T for the collagen transition in (GPP)10NC2 (circles) and NC2(GPP)10 (squares) to establish ΔH0 and ΔS0.
DISCUSSION
Oxidative refolding experiments performed on the peptides containing the NC1 domain (Table 1) of collagen XIX demonstrate that a stable triple helical region is absolutely required for the correct disulfide knot formation in the junction region between the COL1 and NC1 domains. The full-length NC1 domain together with the preceding 9 residues of the COL1 domain is not capable of trimerization and disulfide knot formation. The presence of a sequence that can form a stable collagen triple helix is enough to initiate disulfide knot formation. The nature of the amino acid sequence in the triple helix is not important for disulfide knot formation; indeed, the natural sequence can be successfully substituted with the artificial (GPO)6 sequence. Furthermore, the deletion of the carboxyl-terminal half of the NC1 domain sequence has no effect on the yield of the correctly oxidized trimers. The same features are observed in the collagen III carboxyl-terminal disulfide knot (16, 23). The presence of the correctly formed disulfide knot significantly increases the thermal transition temperature of the collagen triple helix. This is very important for all FACIT collagens, since the carboxyl-terminal collagenous region COL1 has a number of interruptions that should significantly destabilize the triple helix. The presence of the disulfide knot just at the end of the last collagen domain serves as a covalent clamp preventing the carboxyl-terminal end of the collagen triple helix from “breathing” or “fraying.”
The NC2 domain alone forms a highly stable trimer with a Tm value higher than 90 °C under physiological conditions. This is the first time that the trimerization abilities of the NC2 domain were demonstrated experimentally. The NC2 domain has an α-helical structure and might adopt a coiled-coil structure, as suggested by McAlinden et al. (8). Coiled-coils are versatile motifs that can form a variety of different oligomeric states, including parallel and anti parallel arrangements of chains (24). Coiled-coil proteins contain a characteristic seven-residue sequence repeat whose positions are designated a to g. The interacting surface between α-helices in a classical coiled-coil is formed by interspersing nonpolar side chains at the a and d positions with hydrophilic residues at the flanking e and g positions (25). The heptad repeat patterns in the NC2 domains of FACIT collagens have interruptions and unusual distribution of apolar and polar residues (8). The NC2 domain is located between two adjacent collagenous domains, and its structure might resemble the staggered conformation of triple helices. Thus, the unusual heptad repeat pattern might be a way to form a staggered coiled-coil. There are a few known examples of natural and designed α-helical parallel coiled-coils having four or seven chains with shifted register (26-28), although none of them would resemble the collagen triple-helical staggered packing. Mapping of NC2 residues on a theoretical α-helical wheel shows preferential distribution of polar side chains on one side that could possibly interact with two other chains to form a hydrophobic core. The trimerization properties and stabilization of the collagen triple helix on either end of the NC2 domain suggests a universal role for this domain in chain selection, chain registration, and initiation of the triple helix formation in all FACIT collagens. This is somewhat in contradiction with studies on collagen IX, where others believe that the COL2-NC2 region alone is not sufficient for trimerization (7). Although this might reflect a different role of the NC2 domain in type IX collagen, a more detailed analysis is required. In future studies, we will investigate if the NC2 domain of type IX collagen is responsible for chain selection of the only heterotrimeric FACIT collagen. Since no mutations are described in NC2 domains of FACITs, it remains to be elucidated what residues are important for folding, stability, and especially for chain selection. To verify the proposed staggered conformation of the NC2 domain, the determination of an atomic structure by x-ray crystallography or NMR is required.
Acknowledgments
We thank Lynn Sakai for motivation to study the NC1 domain of mouse collagen XIX and Kerry Maddox, Jessica Hacker, and Jesse Vance for peptide synthesis, peptide purification, mass spectrometry, amino acid analysis, and DNA sequencing.
This work was supported by a grant from Shriners Hospital for Children. The costs of publication of this article were defrayed in part by the payment of page charges. This article must therefore be hereby marked “advertisement” in accordance with 18 U.S.C. Section 1734 solely to indicate this fact.
Footnotes
The abbreviations used are: FACIT, fibril-associated collagen with interrupted triple helices; COL, collagenous; NC, noncollagenous; Fmoc, N-(9-fluorenyl)methoxycarbonyl; HPLC, high pressure liquid chromatography.
References
- 1.Myllyharju, J., and Kivirikko, K. I. (2004) Trends Genet. 20 33-43 [DOI] [PubMed] [Google Scholar]
- 2.Ricard-Blum, S., and Ruggiero, F. (2005) Pathol. Biol. 53 430-442 [DOI] [PubMed] [Google Scholar]
- 3.Mazzorana, M., Gruffat, H., Sergeant, A., and van der Rest, M. (1993) J. Biol. Chem. 268 3029-3032 [PubMed] [Google Scholar]
- 4.Mazzorana, M., Giry-Lozinguez, C., and van der Rest, M. (1995) Matrix Biol. 14 583-588 [DOI] [PubMed] [Google Scholar]
- 5.Lesage, A., Penin, F., Geourjon, C., Marion, D., and van der Rest, M. (1996) Biochemistry 35 9647-9660 [DOI] [PubMed] [Google Scholar]
- 6.Mazzorana, M., Cogne, S., Goldschmidt, D., and Aubert-Foucher, E. (2001) J. Biol. Chem. 276 27989-27998 [DOI] [PubMed] [Google Scholar]
- 7.Jäälinoja, J., Ylöstalo, J., Beckett, W., Hulmes, D. J. S., and Ala-Kokko, L. (2008) Biochem. J. 409 545-554 [DOI] [PubMed] [Google Scholar]
- 8.McAlinden, A., Smith, T. A., Sandell, L. J., Ficheux, D., Parry, D. A. D., and Hulmes, D. J. S. (2003) J. Biol. Chem. 278 42200-42207 [DOI] [PubMed] [Google Scholar]
- 9.Yoshioka, H., Zhang, H., Ramirez, F., Mattei, M. G., Moradi-Ameli, M., van der Rest, M., and Gordon, M. K. (1992) Genomics 13 884-886 [DOI] [PubMed] [Google Scholar]
- 10.Myers, J. C., Sun, M. J., D'Ippolito, J. A., Jabs, E. W., Neilson, E. G., and Dion, A. S. (1993) Gene (Amst.) 123 211-217 [DOI] [PubMed] [Google Scholar]
- 11.Inoguchi, K., Yoshioka, H., Khaleduzzaman, M., and Ninomiya, Y. (1995) J. Biochem. (Tokyo) 117 137-146 [DOI] [PubMed] [Google Scholar]
- 12.Myers, J. C., Yang, H., D'Ippolito, J. A., Presente, A., Miller, M. K., and Dion, A. S. (1994) J. Biol. Chem. 269 18549-18557 [PubMed] [Google Scholar]
- 13.Myers, J. C., Li, D., Amenta, P. S., Clark, C. C., Nagaswami, C., and Weisel, J. W. (2003) J. Biol. Chem. 278 32047-32057 [DOI] [PubMed] [Google Scholar]
- 14.Sumiyoshi, H., Mor, N., Lee, S. Y., Doty, S., Henderson, S., Tanaka, S., Yoshioka, H., Rattan, S., and Ramirez, F. (2004) J. Cell Biol. 166 591-600 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Bachmann, A., Kiefhaber, T., Boudko, S., Engel, J., and Bächinger, H. P. (2005) Proc. Natl. Acad. Sci. U. S. A. 102 13897-13902 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Boudko, S. P., and Engel, J. (2004) J. Mol. Biol. 335 1289-1297 [DOI] [PubMed] [Google Scholar]
- 17.Boudko, S. P., Kuhn, R. J., and Rossmann, M. G. (2007) J. Mol. Biol. 366 1538-1544 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Frank, S., Boudko, S., Mizuno, K., Schulthess, T., Engel, J., and Bächinger, H. P. (2003) J. Biol. Chem. 278 7747-7750 [DOI] [PubMed] [Google Scholar]
- 19.Frank, S., Kammerer, R. A., Mechling, D., Schulthess, T., Landwehr, R., Bann, J., Guo, Y., Lustig, A., Bächinger, H. P., and Engel, J. (2001) J. Mol. Biol. 308 1081-1089 [DOI] [PubMed] [Google Scholar]
- 20.Barth, D., Kyrieleis, O., Frank, S., Renner, C., and Moroder, L. (2003) Chemistry 9 3703-3714 [DOI] [PubMed] [Google Scholar]
- 21.Engel, J., and Bächinger, H. P. (2000) Matrix Biol. 19 235-244 [DOI] [PubMed] [Google Scholar]
- 22.Persikov, A. V., Xu, Y., and Brodsky, B. (2004) Protein Sci. 13 893-902 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Mechling, D. E., and Bächinger, H. P. (2000) J. Biol. Chem. 275 14532-14536 [DOI] [PubMed] [Google Scholar]
- 24.Burkhard, P., Stetefeld, J., and Strelkov, S. V. (2001) Trends Cell Biol. 11 82-88 [DOI] [PubMed] [Google Scholar]
- 25.Lupas, A. (1996) Trends Biochem. Sci. 21 375-382 [PubMed] [Google Scholar]
- 26.Deng, Y., Liu, J., Zheng, Q., Yong, W., and Lu, M. (2006) Structure 14 889-899 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Liu, J., Zheng, Q., Deng, Y., Cheng, C., Kallenbach, N. R., and Lu, M. (2006) Proc. Natl. Acad. Sci. U. S. A. 103 15457-15462 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Liu, J., Deng, Y., Zheng, Q., Cheng, C., Kallenbach, N. R., and Lu, M. (2006) Biochemistry 45 15224-15231 [DOI] [PubMed] [Google Scholar]