

Abstract
Purpose
The purpose was to determine whether semantic set size, a measure of the number of semantic neighbors, influenced word learning, and whether the influence of semantic set size was broad, showing effects on multiple measures both during and after learning.
Method
Thirty-six preschool children were exposed to 10 nonobjects, varying in semantic set size, paired with 10 nonwords, controlling phonotactic probability and neighborhood density. Nonobject – nonword pairs were presented in a game format. Learning was measured in naming and referent identification tasks administered before, during, and one-week after training.
Results
Results showed no differences in naming or identifying the referents of the nonobject – nonword pairs with small versus large semantic set sizes before and during training. However, one-week after training, children named and identified the referents of nonobject – nonword pairs with small set sizes more accurately than those with large set sizes.
Conclusions
Similarity to known representations appears to influence word learning, regardless of whether the similarity involves lexical or semantic representations. However, the direction of the effect of similarity to known representations on word learning varies depending on the specific type of representation involved. Specifically, lexical similarity speeds learning, whereas semantic similarity slows learning.
Keywords: word learning, vocabulary, semantic set size
When a child encounters a novel sound form paired with a novel object, the child must recognize that a new word was heard and initiate the process of learning that word. Assuming that the phonemes of the novel word are known (e.g., correctly perceived and/or articulated), learning the novel word presumably involves activating known phonological representations, specifically mental representations of the individual phonemes that compose the word (e.g., Gupta & MacWhinney, 1997; Storkel, Armbruster, & Hogan, 2006). Activated phonological representations, in turn, spread activation to known lexical representations, the mental representation of the whole-word sound form as an integrated unit (e.g., Gupta & MacWhinney, 1997; Storkel et al., 2006). However, none of the known lexical representations will exactly match the novel word. In complement, the novel object will activate known semantic representations, the mental representation of the characteristics of the referent (e.g., Gupta & MacWhinney, 1997; Storkel et al., 2006). Like known lexical representations, none of the known semantic representations will exactly match the novel object. As a result, creation of a new lexical and semantic representation likely will be initiated (e.g., Storkel et al., 2006). In addition, associations or connections will be created between the new lexical and semantic representations and between the new representations and similar existing representations (e.g., Gupta & MacWhinney, 1997; Storkel et al., 2006). This suggests the possibility that existing similar representations of known words may influence the learning of a novel word.
Emerging evidence suggests that phonological and lexical similarity do influence word learning. One index of phonological similarity is phonotactic probability, the likelihood of occurrence of a given phoneme in a given word position and/or of a given pair of adjacent phonemes in a given word position. One index of lexical similarity is neighborhood density, the number of words that differ by one phoneme from a given word. These two measures of phonological and lexical similarity have tended to be studied in tandem because of the reported positive correlation between phonotactic probability and neighborhood density (Storkel, 2004b; Vitevitch, Luce, Pisoni, & Auer, 1999). That is, low probability sound sequences tend to be phonologically similar to few other words in the language, thus residing in low density neighborhoods. In complement, high probability sound sequences tend to be phonologically similar to many other words in the language, residing in high density neighborhoods. Word learning research has shown that typically developing preschool children tend to learn high probability/high density novel words more rapidly than low probability/low density novel words (Storkel, 2001, 2003, 2004a; Storkel & Maekawa, 2005; Storkel & Rogers, 2000).
Similar to the research with phonotactic probability, semantic research demonstrates that children extract semantic regularities from the ambient language and that these regularities, in turn, influence word learning. For example, toddlers appear to extend novel words referring to count nouns (i.e., individuated solid items such as “car”) on the basis of shape, presumably because they have extracted the regularity that count noun categories tend to refer to items sharing shape (see Smith, 1999; 2000 for review). Moreover, toddlers tend to learn novel words better when the shape of the novel object is reinforced by an appropriate gesture (Capone & McGregor, 2005). In addition, toddlers extend novel words referring to mass nouns (i.e., non-individuated non-solid items such as “water”) on the basis of material because it is precisely this feature that is shared across members of the same category (e.g., Samuelson & Smith, 1999; Soja, 1992; Soja, Carey, & Spelke, 1991). Taken together, children appear to extract semantic regularities and use these regularities to extend the use of a novel word to other exemplars. Furthermore, highlighting these regularities appears to facilitate novel word learning.
Unlike research with lexical representations, semantic research in word learning has not yet considered how the number of similar known representations may influence word learning. That is, no word learning studies have considered the impact of a semantic variable that parallels neighborhood density. However, such a variable does exist and has been extensively studied in the adult memory literature and, to a lesser extent, in the adult language processing literature. Semantic set size refers to the number of words that are meaningfully related to or frequently associated with a given word and often is determined through a discrete association task (Nelson, McEvoy, & Schreiber, 1998). In a discrete association task, a spoken or printed word is presented and the participant reports the first word that comes to mind that is meaningfully related to or frequently associated with the word. Any word reported by two or more participants is considered a semantic neighbor of the given word, and semantic set size is determined by tallying the total number of semantic neighbors.
In adult memory research, semantic set size has typically been examined in recall and recognition tasks where the participant is given a list of known words to study and later prompted to recall the items on the list or asked to recognize the items on the list from a field of choices (see Nelson & Zhang, 2000 for review). Generally, recall is superior for words with a small set size (i.e., few semantic neighbors) than words with a large set size (e.g., Nelson, Bennett, Gee, Schreiber, & McKinney, 1993; Nelson, McKinney, Gee, & Janczura, 1998; Nelson, Schreiber, & McEvoy, 1992). In this case, it is thought that words with a large set size lead to confusability between studied words and other known words at test, resulting in poorer recall or recognition of words with large set sizes compared to those with small set sizes. However, a different pattern is observed in language processing by adults. Specifically, in lexical decision of visually presented words, words with a large set size are responded to more quickly than words with a small set size (Buchanan, Westbury, & Burgess, 2001; Yates, Locker, & Simpson, 2003). Here, it is thought that activating a larger network of words (i.e. a large set size) spreads greater activation to the target word facilitating recognition of the visually presented target word. To our knowledge, the effect of semantic set size on word learning has not been investigated in either adults or children.
How might semantic set size influence novel word learning? According to Samuelson and Smith (2000), knowledge in children and adults can be thought of as a dynamic combination of perceiving and remembering. For word learning, this means that when a novel word is perceived, relevant known words, objects, concepts, and experiences are remembered, allowing integration of the current novel word with already learned information. This also allows past learned patterns to influence new word learning, as in the case of the previously discussed shape bias. This view of knowledge suggests that semantic set size may be relevant for word learning. When a novel word is encountered, semantically similar words would be recalled, potentially influencing learning of the novel word. Some novel words might lead to recall of only a few known words, namely a small set size, whereas others might lead to recall of many known words, namely a large set size. The direction of the influence of semantic set size on word learning is unclear. On the one hand, a small set size might facilitate word learning relative to a large set size because there would be less confusion between the newly formed semantic representation and other known semantic representations. This would be consistent with set size findings from the adult memory literature. On the other hand, a large set size might facilitate word learning because integration of the newly formed semantic representation with many known semantic representations may enhance the semantic representation of the new word. This would be consistent with neighborhood density findings from the child and adult word learning literature.
The purpose of this study was to establish whether semantic set size influenced word learning by preschool children and to compare these results to past studies of neighborhood density to determine whether similarity to known representations exerts a parallel influence across lexical and semantic representations. To this end, preschool children participated in a word learning task that varied the semantic set size of the nonobjects to be learned while holding the phonotactic probability and neighborhood density of the nonword names of these nonobjects constant. Analysis of the main effect of set size addresses this question.
A further issue addressed by this study was the breadth of the influence of semantic set size on word learning. Specifically, the effect of semantic set size was examined in two tasks and at two time points. In terms of tasks, the two tasks varied in the demand placed on the newly formed lexical and semantic representations. In the naming task, children were shown one nonobject and had to produce the nonword name. It was hypothesized that this task placed greater demands on the lexical representation because the child must retrieve the word form from memory to successfully name the nonobject (e.g., Hoover & Storkel, 2005; Storkel, 2001). In the referent identification task, children heard one nonword and had to select the corresponding nonobject from a field of choices. It was hypothesized that this task placed greater demands on the semantic representation because the child must retrieve the word’s referent from memory and match it to one of the choices (e.g., Hoover & Storkel, 2005; Storkel, 2001). If the effect of semantic set size is narrow, then it likely would be detected only in one task, presumably the referent identification task with its heavier demands on the newly formed semantic representation. In contrast, if the effect of semantic set size is broad, then it would be detected in both tasks. Analysis of the interaction of semantic set size and task addresses this question. Past research on the effect of correlated phonotactic probability and neighborhood density has shown a broad impact on word learning with the influence of phonotactic probability/neighborhood density being observed in both naming and referent identification tasks (Storkel, 2001, 2003; Storkel & Maekawa, 2005).
In terms of time, both learning and retention of the stimuli were examined by administering the naming and referent identification tasks immediately following training and one week after training. It was assumed that testing immediately following training would index the effect of semantic set size on the formation of new representations and new connections between representations, whereas testing one week after training would tap the retention of these new representations and connections. If the effect of semantic set size is narrow, then it would only be detected at one test point. In contrast, if the effect of semantic set size is broad, then it would be detected at both test points. Analysis of the interaction of semantic set size and time addresses this question. Past research has shown that phonotactic probability/neighborhood density impacts both learning and retention, although the effect may be stronger at retention (Storkel, 2001, 2003, 2004a; Storkel & Maekawa, 2005).
Method
Participants
Thirty-six preschool children participated (M = 4; 8; SD = 7 months; range 4; 0 – 6; 5). All children were monolingual English-speakers with no known history of speech, language, cognitive, or developmental delays based on parent report. Children passed a hearing screening and performed within normal limits on standardized articulation and vocabulary tests (ASHA, 1997; Dunn & Dunn, 1997; Goldman & Fristoe, 2000; Williams, 1997). Specifically, the mean standard score on the Goldman-Fristoe Test of Articulation – 2 was 110 (SD = 7, range 94–120). The mean standard score on the Peabody Picture Vocabulary Test – 3 was 107 (SD = 10, range 90–135) and on the Expressive Vocabulary Test was 105 (SD = 10, range 89–127).
Stimuli
Stimuli consisted of 10 nonobjects varying in semantic set size and 10 nonwords holding phonotactic probability and neighborhood density constant.
Nonobjects
The 10 nonobjects were selected from a set of 88 black and white nonobject line drawings developed by Kroll and Potter (1984) and normed for semantic set size by Storkel and Adlof (2007). The nonobjects were “created by tracing parts of drawings of real objects and regularizing the resulting figures” (Kroll & Potter, 1984, p. 41). No additional details were provided about nonobject construction in the original article. The nonobjects are presented in the appendix of the original article and are identified by number in that appendix. All references to the nonobjects follow this original numbering convention. Storkel and Adlof (2007) determined the semantic neighbors of the full set of 88 nonobjects for 82 adults and then for a subset of 47 nonobjects for 92 preschool children. For both age groups, a discrete association task was used to determine the neighbors of each nonobject. Adults and children were shown each nonobject picture and asked to report the first word that came to mind that was meaningfully related to or frequently associated with the picture. Responses reported by two or more participants within a group (adult or child) were considered semantic neighbors of the nonobject. The number of different semantic neighbors was tallied for each nonobject for each group (adult or child), yielding the semantic set size for that group.
The underlying hypothesis in using these discrete association norms to select the nonobjects for this word learning study is that the discrete association task taps a similar process of perceiving and remembering as word learning. That is, when the nonobject is presented, either in a discrete association or a word learning task, the same known words are remembered, provided that the presentation conditions are similar. The presentation of the nonobjects in this study is similar to that of the discrete association study (Storkel & Adlof, 2007), as described in the training script below. This logic is similar to that of the adult memory literature manipulating semantic set size (e.g., Nelson et al., 1993; Nelson, McKinney et al., 1998; Nelson et al., 1992).
The nonobjects for this study originally were selected based on the adult semantic set size because the child semantic set size data were being collected while this study was being prepared. Child semantic set size data were examined after data collection began for this study. Selected nonobjects are shown in Table 1. “Small” and “large” semantic set sizes were defined based on the percentiles for adult semantic set size for the full set of 88 nonobjects. Specifically, small semantic set sizes were those between the 10th and 25th percentiles (i.e., adult semantic set size 7–9), and large semantic set sizes were those between the 50th and 75th percentiles (i.e., adult semantic set size 11–12). In addition, nonobjects with small and large semantic set sizes were matched on objectlikeness ratings provided by Kroll and Potter (1984). Objectlikeness ratings were collected from 100 undergraduates who rated the degree to which the nonobject resembled a real object on a 7-point scale. A rating of 1 indicated that the nonobject “looked very much like a real object,” whereas a rating of 7 indicated that the nonobject “looked nothing like a real object” (Kroll & Potter, 1984, p. 60). Nonobjects with a small semantic set size had objectlikeness ratings from 3.1 to 4.6 and nonobjects with a large semantic set size had comparable objectlikeness ratings from 3.3 to 4.8.
Table 1.
Objectlikeness ratings, adult and child semantic set sizes and neighbors for nonobjects with small and large semantic set sizes.
| Nonobject1 | Adult Characteristics | Child Characteristics | |||
|---|---|---|---|---|---|
| Objectlikeness Rating1 | Semantic Set Size2 | Semantic Neighbors (Strength)2 | Semantic Set Size2 | Semantic Neighbors (Strength)2 | |
| Small Semantic Set Size | |||||
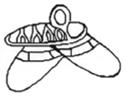
71 |
4.6 | 7 | shoe (0.49), slippers (0.09), dance (0.07), feet (0.06), ballet (0.05), footwear (0.02), sandal (0.02) | 8 | shoe (0.45), slippers (0.12), ballet shoe (0.04), crocodile (0.04), hat (0.04), alligator (0.02), pants (0.02) scissors (0.02) |
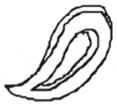
75 |
3.3 | 8 | ear (0.27), hear (0.07), ring (0.05), leaf (0.04), loop (0.04), key (0.02), o (0.02), tree (0.02) | 9 | ear (0.09), raindrop (0.04), circle (0.02), clip (0.02), ham (0.02), horseshoes (0.02), o (0.02), pretzel (0.02) tape (0.02) |
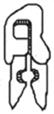
48 |
3.1 | 8 | tool (0.15), wrench (0.07), pliers (0.06), scissors (0.06), key (0.05), cut (0.04), vice (0.04), maze (0.02) | 6 | scissors (0.13), cut (0.02), hair (0.02), knife (0.02), rocket (0.02), tooth (0.02) |
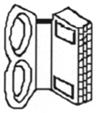
68 |
3.2 | 8 | book (0.16), computer (0.11), type (0.10), keyboard (0.09), read (0.05), glasses (0.02), knowledge (0.02), radio (0.02) | 10 | computer (0.21), house (0.08), book (0.05), door (0.05), refrigerator (0.04), cup holder (0.02), glasses (0.02), milk (0.02), pancake (0.02), roof (0.02) |
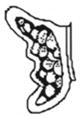
79 |
3.6 | 8 | ear (0.13), food (0.07), bowl (0.05), butterfly (0.05), pea (0.05), marble (0.02), pie (0.02), vase (0.02) | 9 | ball (0.04), bowling balls (0.03), butterfly (0.03), pea (0.03), bathtub (0.02), bead (0.02), mouth (0.02), pie (0.02), wing (0.02) |
| X | 3.6 | 8 | 8 | ||
| SD | 0.6 | 0.5 | 1.5 | ||
| Large Semantic Set Size | |||||
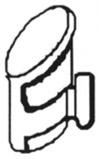
29 |
3.3 | 12 | can (0.26), mug (0.07), open (0.07), coffee (0.05), trash (0.05), can opener (0.04), cup (0.04), drum (0.02), pot (0.02), soda (0.02), trash can (0.02), turn (0.02) | 11 | can (0.20), cup (0.16), trash can (0.05), drum (0.04), jar (0.03), can opener (0.02), coffee (0.02), coffee cup (0.02), door handle (0.02), drawer (0.02), drink (0.02) |
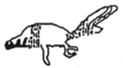
59 |
4.3 | 11 | animal (0.17), rabbit (0.16), kangaroo (0.09), bug (0.05), dinosaur (0.05), run (0.05), beaver (0.04), squirrel (0.04), Australia (0.02), fly (0.02), insect (0.02) | 17 | dinosaur (0.11), dog (0.09), squirrel (0.05), animal (0.04), fish (0.04), skunk (0.04), hand (0.03), raccoon (0.03), anteater (0.02), beaver (0.02), bee (0.02), bug (0.02), crab (0.02), fox (0.02), lizard (0.02), mouse (0.02), turtle (0.02) |
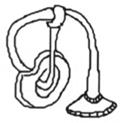
52 |
3.3 | 12 | lamp (0.16), horn (0.11), light (0.05), instrument (0.04), music (0.04), band (0.02), clean (0.02), loop (0.02), play (0.02), shower (0.02), vacuum (0.02), water (0.02) | 12 | vacuum (0.11), horn (0.08), light (0.08), hose (0.04), sink (0.04), trumpet (0.04), ear (0.03), instrument (0.03), lamp (0.03), shower (0.03), faucet (0.02), car (0.02) |
80 |
4.8 | 12 | trumpet (0.07), instrument (0.06), music (0.06), horn (0.05), ghost (0.04), tool (0.04), twist (0.04), band (0.02), butterfly (0.02), gun (0.02), stick (0.02), stuck (0.02) | 11 | trumpet (0.05), airplane (0.04), car (0.03), music (0.03), tool (0.03), eye (0.02), head (0.02), horn (0.02), instrument (0.02), person (0.02), tuba (0.02) |
13 |
3.6 | 12 | can (0.07), rope (0.07), fire (0.04), scar (0.04), art (0.02), detach (0.02), dress (0.02), instrument (0.02), jaw (0.02), neck (0.02), trap (0.02), vase (0.02) | 16 | bag (0.05), drum (0.05), cake (0.04), dress (0.04), apple (0.03), bone (0.03), can (0.03), cup (0.03), horn (0.03), boot (0.02), hat (0.02), ice (0.02), maraca (0.02), paper (0.02), scarf (0.02), sock (0.02) |
| X | 3.9 | 12 | 13 | ||
| SD | 0.7 | 0.5 | 2.9 | ||
Reprinted from Kroll, J. F., & Potter, M. C. (1984). Recognizing words, pictures, and concepts: A comparison of lexical, object, and reality decisions. Journal of Verbal Learning and Verbal Behavior, 23, 39–66, with permission from Elsevier. Note that lower objectlikeness ratings indicate a nonobject that looks more like a real object, whereas higher ratings indicate a nonobject that looks less like a real object.
Storkel & Adlof (2007). Neighbors are listed in order from strongest to weakest. Child neighbors that are adult neighbors are in italics.
Although nonobjects were originally selected based on adult data, child data were examined when they became available. As shown in Table 1, child semantic set sizes yielded non-overlapping sets of nonobjects with small (i.e., 6–10 semantic neighbors) versus large semantic set sizes (i.e., 11–17 semantic neighbors).
Storkel and Adlof (2007) reported a significant negative correlation between semantic set size and neighbor strength. Neighbor strength is the proportion of participants who reported the word as a neighbor of the nonobject out of the total number of participants. For adults and children, Storkel and Adlof (2007) found that the strength of the first and possibly second strongest neighbors was significantly negatively correlated with semantic set size. Thus, nonobjects with a small semantic set size tended to have stronger first and possibly second neighbors than nonobjects with a large semantic set size. Said differently, nonobjects with small semantic neighborhoods tended to have one to two more dominant neighbors than nonobjects with large semantic neighborhoods (see also Buchanan et al., 2001 for a similar finding with real words). This pattern also held for the selected nonobjects in this study where adult strength of the first strongest neighbor for nonobjects with small set sizes (M = 0.24, SD = 0.15, range = 0.13 – 0.49) tended to be higher than the adult strength of the first strongest neighbor for nonobjects with large set sizes (M = 0.15, SD = 0.08, range = 0.07 – 0.26). However, note that three of the five nonobjects in each condition had similar strength values for the first strongest neighbor (i.e., small set size nonobject 75 and large set size nonobject 29; 48 and 52; 68 and 59). This suggests that the negative correlation between neighbor strength and set size was somewhat minimized in this set of stimuli. Adult strength of the second strongest neighbor was similar across small and large set sizes (M = 0.08, SD = 0.02, range 0.07 – 0.11 for small; M = 0.09, SD = 0.04, range 0.06 – 0.16 for large). Child strength comparisons showed a similar pattern. Adult and child neighbor strength for the selected nonobjects is reported in Table 1.
Digital files of the nonobjects were obtained from the original creators (Kroll & Potter, 1984) and were converted to bmp file format, the required file format for the experimental control software (i.e., DirectRT, Jarvis, 2002).
Nonwords
Ten nonwords were selected from a pool of all possible consonant-vowel-consonant (CVC) nonwords composed of early acquired consonants (Smit, Hand, Freilinger, Bernthal, & Bird, 1990). Phonotactic probability and neighborhood density were computed based on an adult dictionary of 20,000 words (Webster’s Seventh Collegiate Dictionary, 1967). Two measures of phonotactic probability were computed: positional segment sum and biphone sum. Positional segment sum was computed by summing the log frequencies of all of the words in the dictionary containing the target phoneme in the target word position and then dividing by the sum of the log frequencies of all the words in the dictionary that had any phoneme in the target word position (Storkel, 2004b). This was computed for each phoneme in the word, and then these individual values were summed. Biphone sum was computed by summing the log frequencies of all the words in the dictionary containing the target phoneme pair in the target word position and then dividing by the sum of the log frequencies of all the words in the dictionary that had any phoneme in the target word position (Storkel, 2004b). This was computed for each phoneme pair in the word, and then these individual values were summed. The 50th percentile and standard deviation were then determined for the full set of nonword CVCs. Nonwords were selected such that the positional segment sum and biphone sum were within half of a standard deviation of the 50th percentile (i.e., 0.11–0.15 for positional segment sum; 0.002–0.006 for biphone sum). Adult positional segment sum and biphone sum for the selected nonwords are shown in Table 2.
Table 2.
Adult and child positional segment sum, biphone sum, and neighborhood density for Set A and Set B nonwords and their nonobject pairings.
| Nonword | Adult Characteristics | Child Characteristics | Nonobject Pairing1 | |||||
|---|---|---|---|---|---|---|---|---|
| Positional Segment Sum | Biphone Sum | Neighborhood Density | Positional Segment Sum | Biphone Sum | Neighborhood Density | Small Set Size | Large Set Size | |
| Set A Nonwords | ||||||||
| hεg | 0.13 | 0.006 | 13 | 0.14 | 0.007 | 13 | 48, 71 | 13, 52 |
| fip | 0.12 | 0.003 | 13 | 0.13 | 0.005 | 11 | 79, 48 | 80, 13 |
| jeɪn | 0.13 | 0.003 | 12 | 0.15 | 0.006 | 8 | 68, 79 | 29, 80 |
| Maɪf | 0.11 | 0.004 | 11 | 0.11 | 0.006 | 9 | 75, 68 | 59, 29 |
| Goʊm | 0.12 | 0.004 | 11 | 0.13 | 0.004 | 8 | 71, 75 | 52, 59 |
| X | 0.12 | 0.004 | 12 | 0.13 | 0.006 | 10 | ||
| SD | 0.01 | 0.001 | 1 | 0.02 | 0.001 | 2 | ||
| Set B Nonwords | ||||||||
| meɪb | 0.11 | 0.005 | 13 | 0.12 | 0.006 | 8 | 48, 71 | 13, 52 |
| Jʌt | 0.11 | 0.003 | 12 | 0.14 | 0.004 | 11 | 79, 48 | 80, 13 |
| boʊg | 0.12 | 0.003 | 12 | 0.15 | 0.005 | 11 | 68, 79 | 29, 80 |
| wun | 0.14 | 0.003 | 11 | 0.17 | 0.003 | 11 | 75, 68 | 59, 29 |
| pig | 0.13 | 0.003 | 11 | 0.13 | 0.004 | 12 | 71, 75 | 52, 59 |
| X | 0.12 | 0.003 | 12 | 0.14 | 0.005 | 11 | ||
| SD | 0.01 | 0.001 | 1 | 0.02 | 0.001 | 2 | ||
When Set A Nonwords were paired with nonobjects with a small semantic set size, Set B Nonwords were paired with nonobjects with a large semantic set size, and vice-versa.
Neighborhood density also was computed for this same pool of CVC nonwords using the same adult dictionary. Neighborhood density was computed by counting the number of words in the dictionary that differed by a one phoneme substitution, addition, or deletion in any word position. Again, the 50th percentile and standard deviation were determined for the full set of CVC nonwords. Nonwords were selected such that the neighborhood density was within half of a standard deviation of the 50th percentile (9–15). Adult neighborhood density for the selected nonwords is shown in Table 2.
After the nonwords were selected, positional segment sum, biphone sum, and neighborhood density were computed using the same procedures described above on an approximately 5,000 word child database developed by the first author. The child database consists of words and frequency counts from the spoken language of first grade (Moe, Hopkins, & Rush, 1982) and kindergarten (Kolson, 1960) children. Child values for the selected nonwords are shown in Table 2.
Nonwords were audio recorded in a soundproof booth by a female native speaker of English. Multiple recordings (at least three) were made of each nonword. These recordings were digitized and edited. Durations were measured, and notes were made concerning recording quality. One token of each nonword was selected based on its duration and recording quality. All selected nonword tokens were correctly transcribed by two naïve listeners, under the same listening conditions as the participants.
Nonobject-Nonword Pairings
Nonwords were divided into two sets (A vs. B) of five nonwords. Table 2 shows the two sets of nonwords. The two sets were matched on adult positional segment sum, biphone sum, and neighborhood density. The child values for these three variables were also quite similar across sets. In addition, durations were similar for each set (M = 561 ms, SD = 73 ms, range 479 – 646 ms for Set A; M = 563 ms, SD = 57 ms, range 497 – 631 ms for Set B). Four pairings of nonobjects with nonwords were created. In two of the pairings, nonobjects with a small semantic set size were paired with Set A nonwords, and nonobjects with a large semantic set size were paired with Set B nonwords. In the remaining two pairings, nonobjects with a small semantic set size were paired with Set B nonwords, and nonobjects with a large semantic set size were paired with Set A nonwords. Table 2 shows the four pairings of nonobjects and nonwords. The use of these four pairings was counterbalanced across participants, guarding against any confounding of nonword characteristics with semantic set size.
Training script
The training script was the same for each nonword. The script was recorded by the same female speaker that recorded the nonwords under the same recording conditions. The sentences in the script were digitized and edited. The nonwords were inserted into the script during administration of the word learning task by the experimental control software (i.e., DirectRT, Jarvis, 2002). The script was as follows: This is a nonword. Say nonword. Yes, that’s a nonword or Listen closely, that’s a nonword. Remember, it’s a nonword. We’re going to play a game. Find the nonword. That’s the nonword or That’s not it. This is the nonword. Say nonword. Don’t forget the nonword. Thus, the exposure script provided eight exposures to the nonword, including two repetition prompts (one with feedback and one without) and one nonobject matching prompt (with feedback).
Word Learning Procedures
Each participant was seated in front of a laptop computer that presented visual stimuli via the laptop screen and auditory stimuli via table-top speakers. Participant responses were audio and video recorded as well as noted by the examiner on a score sheet and with number pad or mouse input to the computer. Presentation of the auditory and visual stimuli was controlled by the computer using DirectRT software (Jarvis, 2002).
The first word learning session began with baseline testing of the word learning measures. Two tasks were used to measure word learning: naming and referent identification. These measures always were administered in a fixed order with naming followed by referent identification. In the naming task, a nonobject was presented on the computer screen and the child was asked to name it. During baseline testing, children were encouraged to guess the name of the nonobject. Any response was audio recorded, phonetically transcribed using broad transcription, and scored. A response was scored as correct if it exactly matched the target nonword (i.e., 3 of 3 phonemes produced correctly in the correct order). The order of presentation of the nonobjects was randomized by the DirectRT software.
In the referent identification task, all 10 nonobjects were presented on the computer screen in two rows of five nonobjects with a number (i.e., 0–9) next to each picture. The location of the nonobjects was randomized by the DirectRT software. A nonword was presented via the speakers and the child was asked to guess which nonobject corresponded to the nonword. Children indicated their response by pointing to the nonobject on the screen. The examiner recorded the number of the child’s selection on a response sheet and also entered it on the number pad connected to the computer. A response was scored as correct if the correct nonobject was selected. The order of presentation of the nonobjects was randomized by the DirectRT software.
Following baseline testing, the first training cycle was initiated. The order of presentation of the nonobject – nonword pairs was randomized by the DirectRT software. The nonobject was shown centered in the middle of the computer screen throughout the entire exposure. The first portion of the training script and corresponding nonword were played over the speakers (i.e., This is a nonword. Say nonword.). Following the production prompt, the examiner scored the child’s repetition attempt on-line as correct (i.e., left mouse click) or incorrect (i.e., right mouse click). The examiner’s scoring determined the delivery of the appropriate feedback (i.e., for a correct response: Yes, that’s a nonword; for an incorrect response: Listen closely, that’s a nonword.). Following the nonobject matching prompt (Remember, it’s a nonword. We’re going to play a game. Find the nonword.), a matching game was played off-line. This game varied by training cycle. For the first training cycle, the game was a card slap game. The examiner had a deck of 10 cards corresponding to the 10 nonobjects. The examiner dealt each card face-up one on top of the other, and the child was to slap the card with the target nonobject when it appeared. Note that the picture of the target nonobject remained on the computer screen while the card game was being played, making this a relatively simple matching task. The examiner scored the child’s matching attempt on-line as correct (i.e., left mouse click) or incorrect (i.e., right mouse click). The examiner’s scoring determined the delivery of the appropriate feedback (i.e., for a correct response: That’s the nonword; for an incorrect response: That’s not it. This is the nonword.). A second repetition prompt was played (i.e., Say nonword) and scored by the examiner, but the following exposure sentence was the same regardless of the accuracy of the child’s repetition (i.e., Don’t forget the nonword.). Once the exposure was completed for a given nonobject – nonword pair, the next pair was presented, following the same procedures until all 10 pairs were presented.
Upon completion of the first training cycle, the naming and referent identification tasks were re-administered following the same procedures as baseline testing, except that participants were encouraged to remember the nonobjects and corresponding nonwords from the game rather than being encouraged to guess. Administration of these measures is referred to as the first test cycle.
Additional training-testing cycles were completed following these same procedures unless the following two criteria were met. The first criterion was that the child had to name at least 3 of the 10 nonobjects correctly. This specific criterion was chosen because it was in-line with naming performance in past studies of phonotactic probability/neighborhood density (Storkel, 2001, 2003, 2004a; Storkel & Maekawa, 2005). The second criterion was that the child had to correctly identify at least 5 of the 10 referents correctly. This specific criterion was chosen because it represents a significant difference from chance performance (i.e., chance = 10%; p < 0.01). Note that when meeting the overall criterion, it is still possible to show (or not show) a difference in performance between nonobjects with a small versus a large set size. For example, the following patterns would be possible if a child correctly identified 5 of the 10 referents: 5 small set size correct – 0 large set size correct; 4 small – 1 large; 3 small – 2 large; 2 small – 3 large; 1 small – 4 large; 0 small – 5 large. Most importantly, these criteria are overall performance criteria (i.e., total correct responses/total number of items) rather than condition-specific criteria (i.e., accuracy for small vs. larger set size). The impact of this is that the number of exposures to the stimuli varied across participants depending on how quickly they learned the words. This was necessary because there was variability between participants in age and scores on standardized vocabulary tests. Setting overall performance criteria helped to ensure that all children were at a similar overall level of performance (i.e., above the floor but below the ceiling) when training was discontinued. However, it is important to emphasize that all stimuli, both those with small and those with large set sizes, were always trained together. Thus, within a given participant, the number of exposures to nonobjects with a small versus a large set size was exactly the same. In this way, any differences in learning of nonobjects with small versus large set sizes can be attributed to semantic set size, rather than differences in the number of exposures.
Up to two additional training-testing cycles (Cycles 2 and 3) could be completed during the first word learning session. These training-testing cycles followed the procedures already outlined except that the training games differed. During the second training-testing cycle, the off-line game was a sticker hiding game. Before training began, the examiner laid out all 10 nonobject cards face-up and, while the child’s eyes were closed, hid a sticker under two of the nonobject cards: one with a small semantic set size and one with a large semantic set size. Then the training was initiated. When the child was instructed to match one of the cards to the nonobject on the computer screen, the child selected a card and looked under the selected card to determine whether a sticker was present.
During the third training-testing cycle, the off-line game was a bingo game. Before training began, the examiner laid out a bingo board consisting of three pictures of each of the 10 nonobjects arranged randomly (i.e., 5 pictures × 6 pictures bingo board). Then the training was initiated. When the child was instructed to match one of pictures on the bingo board to the nonobject on the computer screen, the child selected only one of the pictures on the bingo board and placed a colored bear on that picture. The goal of the game was to get six bears in a column.
If the training criteria were not met after three training-testing cycles (i.e., Cycles 1–3), training was continued on a different day, approximately 1 week later. During the second word learning session, up to three additional training-testing cycles could be completed (Cycles 4–6), following the same procedures as the first word learning session. Thus, the maximum number of training-testing cycles was six. If the criteria were not met after six cycles, training was discontinued. Note that a child need not meet both criteria during the same cycle. That is, a child could meet the naming criterion on one cycle (e.g., Cycle 2) and meet the referent identification criterion on a different cycle (e.g., Cycle 3). In this case, training would be discontinued after the cycle when the last criterion was met (e.g., Cycle 3 in this example). In terms of the naming criterion (i.e., at least 3 of 10 correct), the following percent of children met the naming criterion on the identified cycle: 0% of children met criterion on Cycle 1, 8% on Cycle 2, 0% on Cycle 3, 11% on Cycle 4, 3% on Cycle 5, 8% on Cycle 6. The remaining 69% never met the naming criterion. In terms of the referent identification criterion (i.e., at least 5 of 10 correct), the following percent of children met the referent identification criterion on the identified cycle: 11% of children met criterion on Cycle 1, 14% on Cycle 2, 8% on Cycle 3, 8% on Cycle 4, 6% on Cycle 5, 6% on Cycle 6. The remaining 47% never met criterion. To determine whether performance differed between children who met criterion versus those who did not, data from each task were visually inspected comparing the two groups. The observed patterns were similar across children who met criterion and those who did not. Thus, only the full group analysis is reported in the results section.
Once the criteria were met or training was discontinued, the child returned for a final word learning session to test retention of the nonobject – nonword pairs. This session occurred approximately one week (M = 9 days, SD = 5, range 5–28 days) after the criteria were met or training was discontinued and consisted of administration of the naming and referent identification tasks, following the procedures already described.
Dependent Variables
One dependent variable was computed to examine differences between nonobjects with small versus large semantic set sizes prior to training. The prediction was that there would be no difference between small versus large semantic set sizes on this variable so that any difference between small versus large semantic set sizes on the word learning dependent variables could be attributed to word learning processes, rather than other factors. This control dependent variable was the percentage of correct responses on the word learning naming baseline and word learning referent identification baseline for nonobjects with small versus large semantic set sizes. This dependent variable identifies any a priori response biases that could favor the nonobjects with small or large semantic set sizes, particularly in the referent identification task where guessing is possible.
One dependent variable was computed to address the purpose of the study. This was the percentage of correct responses in the word learning naming and referent identification tasks for nonobjects with small versus large semantic set sizes. This dependent variable was computed at two time points: the cycle when criterion was met for the task (or the final cycle if criterion was never met for the task) and the one week retention test.
Reliability
Consonant-to-consonant transcription reliability was computed for transcription of the real words produced by the child on the Goldman-Fristoe Test of Articulation-2 and the nonwords produced during the word learning task (i.e., repetition and naming) for 22% of the participants. Interjudge transcription reliability was 96% (SD = 2.7, range 93–100%) for real words and 98% (SD = 2.0, range 95–100%) for nonwords.
Procedural reliability for administration of the word learning protocol was computed for 25% of the participants. A reliability judge viewed the video tape for the selected participants and scored protocol administration (e.g., correct version of protocol administered, tasks administered in the correct order, correct directions and feedback provided, correct on-line scoring) as well as equipment and set-up (e.g., appropriate audio and video quality, appropriate speaker loudness, computer malfunctions, data collection forms completed correctly). Procedural reliability was 94% (SD = 4.2, range 87–100%). The majority of errors noted (i.e., 67%) related to equipment issues such as poor sound quality on either the audio or video recording due to a problem with positioning of the microphone or equipment malfunction.
Scoring reliability was computed for the word learning naming and referent identification tasks for 31% of the participants. Interjudge scoring reliability was 99% (SD = 3.9, range 87–100%).
Results
The first analysis compared the percentage of correct responses to nonobjects with small versus large semantic set sizes at baseline testing. Figure 1 shows this baseline accuracy for each type of nonobject (small vs. large set size) in each task (naming vs. referent identification). For the naming task, all children were 0% accurate naming nonobjects with small versus large semantic set sizes. Thus, no statistical analyses could be completed because there was no variability in the data. Baseline referent identification performance for nonobjects with small versus large semantic set sizes was compared using a t test. Results showed no significant difference in identifying nonobjects with small (M = 12%, SD = 14, range 0–40%) versus large semantic set sizes (M = 15%, SD = 15, range 0–40%), t (35) = −0.82, p > 0.40. Children did not appear to have an a priori response bias to select nonobjects with small or large semantic set sizes.
Figure 1.

Mean percent correct for nonobjects with a small set size (open symbols) and nonobjects with a large set size (filled symbols) in the word learning naming (squares) and referent identification tasks (circles) at baseline, criterion cycle (or last cycle if criterion never met), and one-week retention. Error bars depict the standard error.
The second analysis examined the percent of correct responses in the word learning task using a 2 semantic set size (low vs. high) × 2 task (naming vs. referent identification) × 2 time (criterion/last cycle vs. retention test) repeated measures ANOVA. Figure 1 shows the corresponding data for this analysis. The main effect of semantic set size approached significance, F (1, 35) = 3.32, p = 0.08, ηp2 = 0.09. Responses to nonobjects with small semantic set sizes (M = 27%, SD = 23) tended to be more accurate than responses to nonobjects with large semantic set sizes (M = 23%, SD = 24). The main effect of task was significant, F (1, 35) = 48.70, p < 0.001, ηp2 = 0.58. Responses in the referent identification task (M = 36%, SD = 23) were more accurate than responses in the naming task (M = 14%, SD = 20). This finding was expected given that the naming task uses an open set response format (i.e., recall task), whereas the referent identification task uses a closed set response format (i.e., recognition task). The interaction of semantic set size and time also was significant, F (1, 35) = 4.15, p = 0.05, ηp2 = 0.11. No other main effects or interactions were significant, all Fs (1, 35) < 2.00, all ps > 0.15, all ηp2s < 0.06.
The significant interaction of semantic set size and time was followed up by conducting separate 2 semantic set size (low vs. high) × 2 task (naming vs. referent identification) ANOVAs for each time: criterion/last cycle, retention test. For the criterion/last cycle, the effect of semantic set size was not significant, F (1, 35) = 0.15, p > 0.60, ηp2 < 0.01. Responses to nonobjects with small semantic set sizes (M = 26%, SD = 21) tended to be similar to responses to nonobjects with large semantic set sizes (M = 25%, SD = 24). In contrast, the effect of task was significant, F (1, 35) = 108.33, p < 0.001, ηp2 = 0.76. As was expected given the differences in response format, responses in the closed-set referent identification task (M = 37%, SD = 23) were more accurate than responses in the open-set naming task (M = 15%, SD = 15). The interaction of semantic set size and task was not significant, F (1, 35) = 0.22, p > 0.60, ηp2 = 0.01.
For the retention test, the effect of semantic set size was significant, F (1, 35) = 8.65, p < 0.01, ηp2 = 0.20. Responses to nonobjects with small semantic set sizes (M = 27%, SD = 23) were more accurate than responses to nonobjects with large semantic set sizes (M = 21%, SD = 24). Likewise, the effect of task was significant, F (1, 35) = 13.56, p = 0.001, ηp2 = 0.28. As expected, responses in the referent identification task (M = 34%, SD = 23) were more accurate than responses in the naming task (M = 14%, SD = 23). The interaction of semantic set size and task was not significant, F (1, 35) = 2.44, p > 0.10, ηp2 = 0.07. However, the trend was for a smaller difference between small and large semantic set sizes in the naming task as compared to the referent identification task (see Figure 1).
Discussion
The purpose of this study was to determine whether semantic set size influenced word learning by preschool children and whether this influence was similar to that previously reported for neighborhood density. A related question was whether the influence of semantic set size would be broad, showing effects on multiple measures of word learning both immediately after learning and at a later retention test. Differences in learning names for nonobjects with small versus large semantic set sizes did emerge, but not until 1 week after training was completed. Specifically, nonobjects with small semantic set sizes were named and identified more accurately than nonobjects with large semantic set sizes at the retention test. These findings have implications for understanding how similarity to known representations influences word learning as well as the breadth of this influence.
Role of Similarity to Known Semantic Representations in Word Learning
The finding of a significant effect of semantic set size on word learning by preschool children suggests that the number of similar known semantic representations does influence the learning of a novel word. This finding is similar to past research showing that the number of similar known lexical representations influences word learning (Storkel, 2001, 2003, 2004a; Storkel & Maekawa, 2005; Storkel & Rogers, 2000). Thus, it appears that similarity to known representations influences novel word learning regardless of the type of representation examined (i.e., lexical, or semantic). However, there is an important difference in the influence of similarity to lexical versus semantic representations. For lexical representations, novel words that are similar to many lexical representations (i.e., high neighborhood density) are learned more readily than novel words that are similar to few lexical representations (i.e., low neighborhood density). In contrast, the opposite pattern is observed for semantic representations. Specifically, novel words that are similar to few semantic representations (i.e., small semantic set size) are learned more readily than novel words that are similar to many semantic representations (i.e., large semantic set size). What can account for this apparent discrepancy between lexical and semantic similarity in word learning? One possibility is to consider how past accounts of the effect of similarity to known lexical representations on word learning could be altered to explain the semantic data. A second possibility is to generate new accounts based on other semantic research. A third possibility is to consider the influence of other unmeasured or uncontrolled variables.
Past accounts of similarity to known lexical representations
Previous accounts of the effect of similarity to known lexical representations on word learning have suggested two possible mechanisms that may offer a viable account of the semantic data (Storkel et al., 2006). The first interpretation from past lexical research focuses on the role of known representations in forming new representations and new connections between representations (Storkel et al., 2006). In many models of spoken language, connections between representations of the same type are inhibitory (or non-existent), whereas connections between representations of different types are excitatory (e.g., Auer, 1993; McClelland & Elman, 1986). Thus, facilitory effects typically arise through an interaction between representations of different types. In terms of lexical facilitation in word learning, it has been hypothesized that initial exposure to a new word initiates the formation of a new lexical representation and links to known representations, although this representation and links might be incomplete or weak (Storkel et al., 2006). Upon subsequent exposure to the novel word, the new lexical representation would be activated and would spread activation to known phonological representations, which would spread activation to known lexical representations. The known lexical representations would then spread activation back to known phonological representations, which in turn would spread activation back to the new lexical representation. This interactive process presumably strengthens the connections between the new lexical representation and known phonological representations. The more connections available, as would be the case in a high density neighborhood, the greater the spread of activation with a corresponding increase in the strength of the new lexical representation and links between the new lexical representation and known phonological representations. This process arguably would speed the creation and/or retention of strong representations for novel words that are similar to many known lexical representations (i.e., high density neighborhood) as compared to novel words that are similar to few known lexical representations (i.e., low density neighborhood). Crucially, this account depends on the interaction of lexical representations and smaller word-form representations, namely phonological representations. If it is assumed that semantic representations interact with smaller meaning representations, such as representation of semantic features (e.g., Gasser & Smith, 1998; Samuelson, 2002), then we would expect the same type of facilitation of similarity to many representations. Alternatively, if it is assumed that semantic representations do not interact with representations of smaller units of meaning either because smaller units of meaning are not represented or because the connections are not bidirectional (e.g., Gupta & MacWhinney, 1997), then the same type of facilitative mechanism for novel words that are similar to many known semantic representations is not available. In this case, there would only be inhibitory direct connections between known semantic representations, impeding learning and/or retention of a novel word that is similar to many known semantic representations (i.e., large semantic set size). Thus, the findings from the current study could be accounted for using the same mechanisms that have been proposed for lexical representations by hypothesizing a lack of interaction between semantic representations and smaller units of meaning. This hypothesis could be verified by examining the effect of semantic set size in other tasks where interaction between semantic representations and smaller units of meaning would be critical.
A second possible interpretation from past lexical research relates to the influence of similarity on triggering of word learning. That is, a person must recognize that a novel word was presented to engage the process of creating a new representation. In past lexical research, it has been hypothesized that phonotactic probability, rather than similarity to known lexical representations, plays a critical role in triggering learning of the form of a novel word with low probability sound sequences facilitating detection of novelty more readily than high probability sound sequences (Storkel et al., 2006). It is possible that similarity to known semantic representations serves this function for meaning. Specifically, a novel object that is similar to few other known objects, as in a small set size, may be more readily recognized as novel than an object that is similar to many other known objects, as in a large set size. Consequently, learning may be triggered immediately for nonobjects with a small set size. This bears some resemblance to the novel name-nameless category principle (Golinkoff, Mervis, & Hirsh-Pasek, 1994), which states that children have a bias to attach new word forms to unnamed objects, but further suggests that phonotactic probability influences what counts as a novel name, whereas semantic set size influences what counts as a nameless category. This hypothesis could be tested by more clearly differentiating triggering of learning from other aspects of word learning.
New accounts based on past semantic research
The effect of similarity to known semantic representations on word learning may be accounted for by some mechanism that has not been previously considered in the past lexical research. Numerous studies of adult long-term memory suggest a possible mechanism to account for the effect of semantic set size on word learning. Specifically, adult memory research shows that known words that are similar to many semantic representations compete with those similar representations, leading to performance decrements in recognition or recall of known words with a large semantic set size when compared to known words with a small semantic set size (Nelson et al., 1993; Nelson, Bennett, & Leibert, 1997; Nelson & Schreiber, 1992; Nelson et al., 1992; Nelson & Zhang, 2000). It is plausible that precisely this type of competition was induced with the current word learning paradigm. Specifically, when viewing the nonobject, semantic representations in long-term memory may have been activated creating competition between the semantic representation being created and the already known semantic representations. Novel words that are similar to many semantic representations (i.e., large semantic set size) would engender greater competition than those that are similar to few semantic representations (i.e., small semantic set size), impeding the creation and/or retention of an accurate, complete, and detailed semantic representation. This type of competition may not have occurred in past lexical research because of the transient presentation of the nonwords, which may have minimized the activation of existing representations in long-term memory during exposure. Under this hypothesis, the difference in the contribution of lexical and semantic similarity to word learning would relate to differences in the engagement of long-term memory during exposure to the novel words due to the specific paradigm used. This hypothesis could be tested by altering the word learning paradigm to similarly engage long-term memory for both types of representations (e.g., transient presentation of both the nonword and the novel object).
Influence of other variables
Another avenue of reasoning is to consider the influence of other variables that were not systematically controlled. One possibility is that gross measures of similarity that simply count the number of similar known representations may not be sensitive to other important aspects of similarity that influence word learning and that could differ across lexical and semantic representations. That is, fine grain aspects of similarity, such as diversity of similar representations, strength of association between the target and its neighbors, interconnectedness of neighbors, and hierarchical structure, are not captured by neighborhood density or semantic set size. Consider as an example the potential influence of diversity of the similar representations. Examination of the semantic neighbors of the nonobjects in this study (refer to Table 1) shows that the semantic neighbors of the stimuli with small set sizes tended to focus on a few themes, whereas the semantic neighbors of the stimuli with large set sizes tended to focus on more themes (c.f., Storkel & Adlof, 2007). For example, nonobject 79, which has an objectlikeness rating of 3.6, had a small set size. The nine semantic neighbors seem to be decomposed into two themes, round items (i.e., ball, bowling balls, pea, bead) and curved items (i.e., butterfly, wing, bathtub, mouth), and one difficult to classify neighbor (i.e., pie). In comparison, nonobject 13 had the same object likeness rating (i.e., 3.6) but its 16 semantic neighbors could be divided into four themes, clothes (i.e., dress, boot, hat, scarf, sock), food (i.e., cake, apple, ice), containers (e.g., bag, can, cup), and musical instruments (i.e., drum, horn, maraca), and two neighbors that didn’t seem to cohere with the others (i.e., paper, bone). In this case, small set size might facilitate word learning because the similar semantic representations are more cohesive and less diverse, focusing attention on only a few (presumably critical) perceptual or conceptual properties of the novel object. Previous studies of the influence of lexical similarity have not examined or controlled the diversity of the lexical neighbors. However, the definition of a lexical neighbor places a clear upper limit on diversity, particularly when stimuli are limited to consonant-vowel-consonant (CVC) words, as is the case in past research. That is, defining a neighbor as any word that differs by one phoneme limits neighbors of CVC words to five specific types (i.e., onset substitution, vowel substitution, coda substitution, phoneme addition, phoneme deletion). In this way, differences in the effect of the influence of known lexical and known semantic representations on word learning may be attributable to differences in the diversity of lexical versus semantic neighbors (or other fine grain aspects of structure). This hypothesis could be tested by systematically controlling or manipulating more fine grain aspects of lexical and semantic similarity, such as neighbor diversity.
In a related vein, another fine grain aspect of structure is neighbor strength. There is a documented relationship between semantic set size and strength of the first strongest semantic neighbor (Storkel & Adlof, 2007), which also was observed for the current stimuli. This suggests the possibility that the effects observed in this study may actually be attributable to neighbor strength rather than semantic set size. To re-state the results under this interpretation, children learned novel words having a stronger first semantic neighbor better than novel words having a weaker first semantic neighbor. Under this scenario, the discrepancy between similarity to known lexical representations and similarity to known semantic representations in word learning is removed because it is assumed that different aspects of structure were tapped across studies (i.e., the number of similar representations in past lexical research vs. the strength of similar representations in the current semantic study). The influence of neighbor strength could be accounted for by the interactive model previously described, whereby a stronger semantic neighbor would spread greater activation back to the new semantic representation via the representations of smaller units of meaning (e.g., semantic features). Future research disambiguating the effects of neighbor strength and number of neighbors for both lexical and semantic representations would provide a critical test of this hypothesis.
Breadth of Influence of Known Semantic Representations
In terms of the breadth of influence of known representations on word learning, past studies of lexical representations have shown effects of neighborhood density in both naming and referent identification tasks (Storkel, 2001, 2003; Storkel & Maekawa, 2005). Thus, it was hypothesized that similarity to known lexical representations influences learning a new lexical representation, based on the effect on naming, as well as connecting the new lexical representation to a new semantic representation, based on the effect on referent identification. A similar pattern was observed in this study for the effect of semantic set size, where the interaction between semantic set size and task was not statistically significant. Therefore, it appears that similarity to known semantic representations influences learning a new semantic representation as well as connecting the new semantic representation to a new lexical representation.
The above discussion of learning warrants further differentiation of the effect of similarity to known representations on the formation versus retention of new representations and connections. This can be examined more closely by considering the effect of similarity to known representations across time (i.e., criterion/last cycle vs. retention test). Past studies of lexical representations have shown an effect of neighborhood density at both learning and retention test points, although the effect is sometimes stronger (i.e., larger differences) at the retention test point (Storkel, 2001, 2003, 2004a; Storkel & Maekawa, 2005). This suggests that similarity to known lexical representations influences both learning and retention of new representations and new connections between representations, although the effect on retention may be stronger or more robust than the effect on learning. In the current study, the effect of semantic set size was observed only at the retention test point and not during learning. This may indicate that similarity to known semantic representations is more important for later retention of new representations and new connections between representations than for the initial formation of new representations and new connections between representations (cf., Leach & Samuel, 2007; Naigles, 2002). However, this interpretation probably should be avoided because of the methods used in this study. Unlike past studies, this study set overall accuracy criteria for discontinuing training, and learning data were analyzed only when these criteria were met (or the maximum number of training cycles was completed). This may have limited the difference between novel words with small versus large semantic set sizes immediately following training. A different picture may have emerged if accuracy was tracked across training, as has been done in past studies of lexical representations. Replication of this result is warranted before theoretical conclusions can be drawn.
Conclusion
Investigation of the influence of semantic set size on word learning by preschool children showed that children learned novel words that were similar to few known semantic representations more readily than novel words that were similar to many known semantic representations. This finding suggests that similarity to known representations influences word learning, regardless of whether the similarity involves lexical or semantic representations. However, the direction of the effect of similarity to known representations varies depending on the specific type of representation involved. Specifically, similarity to many lexical representations facilitates word learning, whereas similarity to many semantic representations impedes word learning. It is unclear whether the same mechanisms that have been proposed to account for the influence of similarity to known lexical representations on word learning also can account for the effect of similarity to known semantic representations on word learning. Moreover, it is unclear how fine grain aspects of lexical and semantic structure differ from one another as well as how these potential differences might influence the role of each type of representation in word learning. Additional research comparing the influence of lexical and semantic representations on word learning is warranted so that a more detailed model of word learning can be developed.
Acknowledgments
This research was supported by DC 08095, DC 00052, DC 05803, HD02528. The following individuals contributed to stimulus creation, data collection, data processing, and reliability calculations: Andrew Aschenbrenner, Teresa Brown, Deborah Christenson, Andrea Giles, Nicole Hayes, Jennica Kilwein, Jill Hoover, Su-Yeon Lee, Junko Maekawa, Shannon Rogers, Josie Row, Allison Wade, and Courtney Winn.
Footnotes
Holly L. Storkel and Suzanne M. Adlof, Department of Speech-Language-Hearing: Sciences and Disorders, University of Kansas.
References
- ASHA. Guidelines for screening for hearing impairment-preschool children, 3–5 years. Asha. 1997;4:IV-74cc–IV-74ee. [Google Scholar]
- Auer ET. Dynamic processing in spoken word recognition: The influence of paradigmatic and syntagmatic states. State University of New York at Buffalo; Buffalo, NY: 1993. Unpublished Dissertation. [Google Scholar]
- Buchanan L, Westbury C, Burgess C. Characterizing semantic space: Neighborhood effects in word recognition. Psychonomic Bulletin and Review. 2001;8:531–544. doi: 10.3758/bf03196189. [DOI] [PubMed] [Google Scholar]
- Capone NC, McGregor KK. The effect of semantic representation on toddlers’ word retrieval. Journal of Speech, Language and Hearing Research. 2005;48:1468–1480. doi: 10.1044/1092-4388(2005/102). [DOI] [PubMed] [Google Scholar]
- Dunn LM, Dunn LM. Peabody picture vocabulary test. 3. Circle Pines, MN: American Guidance Service; 1997. [Google Scholar]
- Gasser M, Smith L. Learning nouns and adjectives: A connectionist account. Language and Cognitive Processes. 1998;13:269–306. [Google Scholar]
- Goldman R, Fristoe M. Goldman-Fristoe Test of Articulation-2. Circles Pines, MN: American Guidance Service; 2000. [Google Scholar]
- Golinkoff RM, Mervis CB, Hirsh-Pasek K. Early object labels: the case for a developmental lexical principles framework. Journal of Child Language. 1994;21:125–155. doi: 10.1017/s0305000900008692. [DOI] [PubMed] [Google Scholar]
- Gupta P, MacWhinney B. Vocabulary acquisition and verbal short-term memory: Computational and neural bases. Brain and Language. 1997;59:267–333. doi: 10.1006/brln.1997.1819. [DOI] [PubMed] [Google Scholar]
- Hoover JR, Storkel HL. Understanding of word learning by preschool children: Insights from multiple tasks, stimulus characteristics, and error analysis. Perspectives on Language Learning and Education (ASHA Division 1 Newsletter), October. 2005:8–11. [Google Scholar]
- Jarvis BG. DirectRT research software (Version 2002) New York, NY: Empirisoft; 2002. [Google Scholar]
- Kolson CJ. The vocabulary of kindergarten children. University of Pittsburgh; Pittsburgh: 1960. Unpublished Doctoral Dissertation. [Google Scholar]
- Kroll JF, Potter MC. Recognizing words, pictures, and concepts: A comparison of lexical, object, and reality decisions. Journal of Verbal Learning and Verbal Behavior. 1984;23:39–66. [Google Scholar]
- Leach L, Samuel AG. Lexical configuration and lexical engagement: When adults learn new words. Cognitive Psychology. 2007;55:306–353. doi: 10.1016/j.cogpsych.2007.01.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McClelland J, Elman J. The TRACE model of speech perception. Cognitive Psychology. 1986;18:1–86. doi: 10.1016/0010-0285(86)90015-0. [DOI] [PubMed] [Google Scholar]
- Moe AJ, Hopkins KJ, Rush RT. The vocabulary of first grade children. Springfield, IL: Thomas; 1982. [Google Scholar]
- Naigles LR. Form is easy, meaning is hard: Resolving a paradox in early child language. Cognition. 2002;86:157–199. doi: 10.1016/s0010-0277(02)00177-4. [DOI] [PubMed] [Google Scholar]
- Nelson DL, Bennett D, Gee N, Schreiber T, McKinney V. Implicit memory: Effects of network size and interconnectivity on cued recall. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1993;19:747–764. doi: 10.1037//0278-7393.19.4.747. [DOI] [PubMed] [Google Scholar]
- Nelson DL, Bennett D, Leibert T. One step is not enough: Making better use of association norms to predict cued recall. Memory & Cognition. 1997;25:785–796. doi: 10.3758/bf03211322. [DOI] [PubMed] [Google Scholar]
- Nelson DL, McEvoy C, Schreiber T. The University of South Florida word association, rhyme, and word fragment norms. 1998 doi: 10.3758/bf03195588. Retrieved Feb 1, 2005, from http://www.usf.edu/FreeAssociation/ [DOI] [PubMed]
- Nelson DL, McKinney V, Gee N, Janczura G. Interpreting the influence of implicitly activated memories on recall and recognition. Psychological Review. 1998;105:299–324. doi: 10.1037/0033-295x.105.2.299. [DOI] [PubMed] [Google Scholar]
- Nelson DL, Schreiber T. Word concreteness and word structure as independent determinants of recall. Journal of Memory and Language. 1992;31:237–260. [Google Scholar]
- Nelson DL, Schreiber T, McEvoy C. Processing implicit and explicit representations. Psychological Review. 1992;99:322–348. doi: 10.1037/0033-295x.99.2.322. [DOI] [PubMed] [Google Scholar]
- Nelson DL, Zhang N. The ties that bind what is known to the recall of what is new. Psychonomic Bulletin and Review. 2000;7:604–617. doi: 10.3758/bf03212998. [DOI] [PubMed] [Google Scholar]
- Samuelson LK. Statistical regularities in vocabulary guide language acquisition in connectionist models and 15–20-month-olds. Developmental Psychology. 2002;38:1016–1037. doi: 10.1037//0012-1649.38.6.1016. [DOI] [PubMed] [Google Scholar]
- Samuelson LK, Smith LB. Early noun vocabularies: Do ontology, category structure and syntax correspond? Cognition. 1999;73:1–33. doi: 10.1016/s0010-0277(99)00034-7. [DOI] [PubMed] [Google Scholar]
- Samuelson LK, Smith LB. Grounding development in cognitive processes. Child Development. 2000;71:98–106. doi: 10.1111/1467-8624.00123. [DOI] [PubMed] [Google Scholar]
- Smit AB, Hand L, Freilinger JJ, Bernthal JE, Bird A. The Iowa Articulation Norms Project and its Nebraska replication. Journal of Speech and Hearing Disorders. 1990;55:779–798. doi: 10.1044/jshd.5504.779. [DOI] [PubMed] [Google Scholar]
- Smith LB. Children’s noun learning: How general learning processes make specialized learning mechanisms. In: MacWhinney B, editor. The Emergence of Language. Mahwah: Lawrence Erlbaum Associates; 1999. pp. 277–304. [Google Scholar]
- Smith LB. Learning how to learn words: An associative crane. In: Golinkoff RM, Hirsh-Pasek K, Akhtar N, Bloom L, Hollich G, Plunkett K, Smith L, Tomasello M, Woodward A, editors. Becoming a Word Learner: A Debate on Lexical Acquisition. London: Oxford Press; 2000. [Google Scholar]
- Soja NN. Inferences about the meanings of nouns: The relationship between perception and syntax. Cognitive Development. 1992;7:29–46. [Google Scholar]
- Soja NN, Carey S, Spelke ES. Ontological categories guide young children’s inductions of word meaning: Object terms and substance terms. Cognition. 1991;38:179–211. doi: 10.1016/0010-0277(91)90051-5. [DOI] [PubMed] [Google Scholar]
- Storkel HL. Learning new words: Phonotactic probability in language development. Journal of Speech, Language, and Hearing Research. 2001;44:1321–1337. doi: 10.1044/1092-4388(2001/103). [DOI] [PubMed] [Google Scholar]
- Storkel HL. Learning new words II: Phonotactic probability in verb learning. Journal of Speech, Language and Hearing Research. 2003;46:1312–1323. doi: 10.1044/1092-4388(2003/102). [DOI] [PubMed] [Google Scholar]
- Storkel HL. The emerging lexicon of children with phonological delays: Phonotactic constraints and probability in acquisition. Journal of Speech, Language, and Hearing Research. 2004a;47:1194–1212. doi: 10.1044/1092-4388(2004/088). [DOI] [PubMed] [Google Scholar]
- Storkel HL. Methods for minimizing the confounding effects of word length in the analysis of phonotactic probability and neighborhood density. Journal of Speech, Language and Hearing Research. 2004b;47:1454–1468. doi: 10.1044/1092-4388(2004/108). [DOI] [PubMed] [Google Scholar]
- Storkel HL, Adlof SM. Adult and child semantic neighbors of the Kroll and Potter (1984) nonobjects. 2007 doi: 10.1044/1092-4388(2009/07-0174). Manuscript submitted for publication. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Armbruster J, Hogan TP. Differentiating phonotactic probability and neighborhood density in adult word learning. Journal of Speech, Language, and Hearing Research. 2006;49:1175–1192. doi: 10.1044/1092-4388(2006/085). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Maekawa J. A comparison of homonym and novel word learning: The role of phonotactic probability and word frequency. Journal of Child Language. 2005;32:827–853. doi: 10.1017/s0305000905007099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Rogers MA. The effect of probabilistic phonotactics on lexical acquisition. Clinical Linguistics & Phonetics. 2000;14:407–425. [Google Scholar]
- Vitevitch MS, Luce PA, Pisoni DB, Auer ET. Phonotactics, neighborhood activation, and lexical access for spoken words. Brain and Language. 1999;68:306–311. doi: 10.1006/brln.1999.2116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Webster’s Seventh Collegiate Dictionary. Los Angeles: Library Reproduction Service; 1967. [Google Scholar]
- Williams KT. Expressive vocabulary test. Circle Pines, MN: American Guidance Services; 1997. [Google Scholar]
- Yates M, Locker L, Jr, Simpson GB. Semantic and phonological influences on the processing of words and pseudohomophones. Memory and Cognition. 2003;31:856–866. doi: 10.3758/bf03196440. [DOI] [PubMed] [Google Scholar]