

Abstract
The spatial contextual cueing task (SCCT) (Chun & Jiang, 1998) is an implicit learning task that appears to depend on the medial temporal lobes. This unusual combination has been of interest in functional imaging studies and research with clinical populations, where testing time is at a premium. However, the original version of the SCCT is time-consuming. In this study, 29 young adults (18-22 years) completed the SCCT, in which participants respond to the orientation of a target in arrays containing 11 distractors. Either twelve (original version) or six (abbreviated version) arrays repeated across the experiment, with the remaining novel arrays being generated randomly. Results revealed that the magnitude of learning (faster responses to repeated versus novel arrays) was larger when there were fewer repeated arrays, with no explicit awareness in most participants. Thus, the abbreviated version remained implicit, with the additional benefit of increasing the magnitude of learning.
Spatial context refers to spatial relationships among elements within a scene that persist over time (Chun, 2000). Learning spatial contextual information allows individuals to predict where something is likely to occur. For example, when entering a dark room for the first time, most people know where to start feeling the wall for the light switch because they have learned the spatial relationship between these elements of a room. When spatial contextual regularities are learned without intent or awareness, the learning is implicit.
Implicit learning of spatial context has been examined using the spatial contextual cueing task (SCCT) (Chun & Jiang, 1998). In this task, participants search arrays of distractors (rotated letter L’s) and respond to the orientation of a target (horizontal letter T). Unbeknownst to participants, some arrays repeat across the experiment. With repeated presentations, spatial context learning is seen as faster and/or more accurate responses to repeated arrays compared to arrays that are only seen once (i.e. novel arrays). Learning is implicit in that participants are not explicitly aware that the configuration of distractors predicts the location of the target on repeated arrays.
The SCCT has been of particular interest because, unlike most implicit tasks, it appears to involve the medial temporal lobe (MTL) memory system. Traditionally, the MTL system was thought to mediate explicit forms of learning and memory, with implicit forms of learning relying on other brain regions such as the basal ganglia or cerebellum (Poldrack & Gabrieli, 1997; Squire, 1992). However, early studies using the SCCT in patients with amnesia supported the notion that the hippocampus and/or parahippocampal gyrus (entorhinal, parahippocampal, and perirhinal cortices) were involved. In these studies, amnestic patients, who were known to be impaired on MTL-dependent explicit learning tasks, were also unable to implicitly learn the spatial contextual regularity when damage was confined to the hippocampus (Chun & Phelps, 1999) or extended into other MTL regions (Manns & Squire, 2001). These results sparked an ongoing debate regarding the exact role of the hippocampus in implicit learning, prompting most researchers to shift away from the long held view that the MTL is only involved in tasks with explicit awareness.
Because of its unique features, the SCCT has been used in functional magnetic resonance imaging research that aimed to clarify the contribution of specific MTL structures to learning-versus awareness-related processes during performance of the task. These studies only fueled the debate regarding the role of the MTL/hippocampus in implicit learning by finding learning-related activity (i.e. differential activity to repeated and novel arrays) in the hippocampus in one study (Greene et al., 2007), and perirhinal and entorhinal regions in the other (Preston & Gabrieli, 2008), with the latter study showing that activity in the hippocampus and parahippocampal gyrus was related to awareness (i.e. differential activity for remembered and non-remembered arrays).
The SCCT has also been used in clinical populations to reveal dissociations between implicit learning processes that rely on the MTL memory system and those that rely on the fronto-striatal network. For example, preserved implicit spatial context learning has been reported for individuals with autism spectrum disorders (Barnes et al., 2008), dyslexia (Bennett et al., In press; Howard et al., 2006), and corticobasal syndrome (Negash et al., 2007), consistent with evidence that the MTL is not affected in these condition. In contrast, impaired SCCT learning was seen in individuals with mild cognitive impairment and in healthy older adults with APOE e4 genotype (Negash et al., 2007), in keeping with evidence that MTL structure and/or function is affected in these groups.
Finally, the SCCT has been used to examine the development and aging of the MTL memory system. Here, studies have suggested that the underlying MTL regions are not fully mature in school-age children who show less systematic implicit spatial context learning than college-age adults (Vaidya et al., 2007), and that these regions are not affected by healthy aging because preserved learning is seen in healthy older adults (Howard et al., 2004).
Though the SCCT has been used successfully in the research cited above, there are at least two ways in which the task could be improved. First, the original version takes a long time to complete (∼45 minutes), which is not ideal for research where testing time is at a premium. For example, a shorter testing session is often preferred in functional imaging studies and behavioral studies of patient groups, children, and older adults. Second, learning on the original version of the SCCT is sometimes hard to replicate (e.g., Hunt & Thomas, 2007; Jiang et al., 2005, Day 2; Lleras & Von Muhlenen, 2004, Experiment 2).
To address these factors, an abbreviated version of the SCCT was created by decreasing the number of repeated arrays, or contexts, to be learned; a manipulation referred to here as contextual memory load. Participants completed either the original version of the SCCT with 12 repeated arrays (High Load) or the shortened version with 6 repeated arrays (Low Load). The primary aim was to determine whether the Low Load condition, with half the number of trials as the High Load condition, would yield significant learning without increasing awareness of the spatial contextual regularity.
A secondary aim was to determine whether contextual memory load affects the magnitude of implicit spatial context learning, with better learning in the Low versus High Load condition. Such a finding would have theoretical implications, suggesting that decreasing contextual memory load may reduce MTL processing demands (e.g., reducing the number of associative memory representations that need to be formed via hippocampal-dependent binding of the spatial context in arrays), leading to improved learning.
Method
Participants
Thirty-seven Georgetown University undergraduate students (19.6 ± 1.1 years; 10 males) were randomly assigned to the High (n = 19) and Low (n = 18) Load conditions. All participants provided informed consent and received payment or course credit.
Stimuli and Procedure
Spatial contextual cueing task (SCCT)
Participants viewed 12-item arrays that each contained a single target and 11 distractors presented in white on a gray background, with each item subtending approximately 1.1° of visual angle at a 56 cm viewing distance. The target was a horizontal letter “T” rotated 90°, and distractors were the letter “L” rotated 0°, 90°, 180°, or 270°. The leg of the distractor “L” was offset by 3 pixels to increase similarity between the target and distractors (Chun & Phelps, 1999, Experiment 2). Arrays were generated by randomly placing the 12 items into cells of an invisible grid (6 rows × 8 columns), with items repositioned by ± 3 pixels along each axis to avoid colinearity. Target location was balanced for distance from the center and side of the screen, and no target appeared in the four center or corner cells.
On each trial, a white fixation dot appeared for 1 s followed by an array that remained on the screen for up to 10 s until a response was made. Participants were instructed to locate the target and respond to its orientation as quickly as possible by pressing the “z” (for left facing targets) or “/” (for right facing targets) on the keyboard, making no more than 1 or 2 errors per block. Auditory feedback of a high-pitch tone followed a correct response, and a low-pitch tone followed trials with an incorrect response or no response within the 10 s time-out period.
A spatial contextual regularity is embedded in the SCCT, in that half of the arrays repeat across blocks. In repeated arrays, the locations of the distractors predicted the location of the target, but not its orientation (left versus right). Therefore, this regularity could be used to predict the target location, but not the correct response. Remaining arrays for each block also had a fixed set of target locations, but with novel configurations of distractors across the experiment. The order of repeated and novel arrays was randomized within each block. Each participant received a different set of repeated and novel arrays.
Contextual memory load was manipulated by varying the number of arrays to be learned. The High Load condition was identical to the original SCCT, in which participants completed 24 practice trials, followed by 30 24-trial blocks, with 12 repeated and 12 novel trials per block (Chun & Jiang, 1998). In the Low Load condition, participants completed 12 practice trials, followed by 30 12-trial blocks, with 6 repeated and 6 novel trials per block. Thus, the High Load condition had twice as many arrays to be learned as the Low Load condition, but the ratio of repeated-to-novel arrays was constant.
Implicitness measures
After the SCCT, participants completed a recognition task and interview to assess their explicit knowledge of the spatial regularity. In the recognition task (Chun & Jiang, 2003), participants viewed repeated arrays from the test blocks and an equal number of novel arrays (6 or 12 depending on the Load condition) where the targets were replaced by distractors, and indicated which quadrant of the screen would most likely have contained the target. For the interview, participants were asked if they noticed that certain arrays repeated across trials and if they could describe any of the repeated arrays.
Results
Implicit Spatial Context Learning
For each participant, median reaction times for correct trials and percentage of correct responses were calculated separately for each block, and then averaged into six, five-block epochs. Mean of median reaction times (see Figure 1) and mean accuracy scores were analyzed separately in Load (High, Low) x Array (Repeated, Novel) x Epoch (1-6) repeated measures ANOVAs, with Load as a between-subject variable, and Array and Epoch as within-subject variables.
Figure 1.
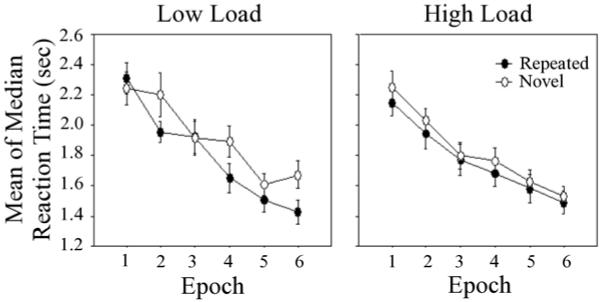
Mean of median reaction time (sec) is plotted separately for repeated (closed circle) and novel (open circle) arrays for the Low Load (left) and High Load (right) conditions.
For reaction time, visual search skill learning was seen as a significant main effect of Epoch, F (5, 175) = 82.28, p < .001, ηp2 = .70, in which responses became faster with practice. Spatial context learning was revealed by significant Array, F (1, 35) = 5.70, p < .03, ηp2 = .14, and Array x Epoch, F (5, 175) = 2.27, p < .05, ηp2 = .06, effects. Participants responded faster to Repeated versus Novel arrays, and this difference increased across epochs. The main effect of Load was not significant, p > .60, indicating that overall speed did not differ for High versus Low Load, and thus search efficiency did not vary as a function of the Load manipulation. However, contextual memory load did influence the magnitude of learning as seen by a significant Load x Array x Epoch interaction, F (5, 175) = 2.28, p < .05, ηp2 = .06.
This three-way interaction was further examined with Array x Epoch ANOVAs conducted separately for each Load condition. Spatial context learning was seen in the Low Load condition with a marginally significant main effect of Array, F (1, 17) = 3.56, p < .08, ηp2 = .17, and a significant Array x Epoch interaction, F (5, 85) = 2.81, p < .03, ηp2 = .14. However, these effects did not attain significance in the High Load condition, p’s > .17. When the Array x Epoch ANOVAs were limited to Epochs 4-6, the main effect of Array was significant for the Low Load, F (1, 17) = 7.70, p < .02, ηp2 = .31, but not High Load condition, p > .22. Thus, spatial context learning was greater when there were fewer arrays to be learned. This effect of contextual memory load on learning was also seen at the individual level, with greater magnitudes of learning for participants in the Low versus High Load condition (see Figure 2).
Figure 2.
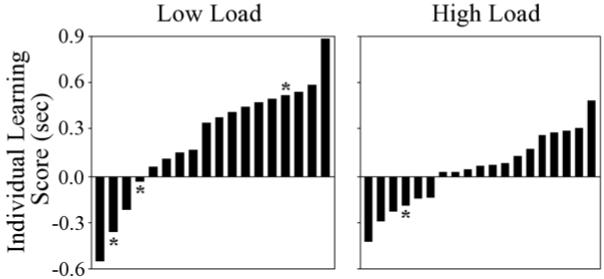
Individual learning scores (sec), calculated by averaging the difference in median reaction time for repeated versus novel arrays across the five blocks in the last epoch, are plotted separately for each participant in the Low Load (left) and High Load (right) conditions. Stars denote participants who were able to accurately describe one of the repeated arrays.
For accuracy, visual search skill learning was seen as a significant main effect of Epoch, F (5, 175) = 3.79, p < .01, ηp2 = .10, in which accuracy improved with practice. There was also a trend for more accurate performance in the High (M = 98.7%, SD = .02) versus Low (M = 98.0%, SD = .03) Load condition, as revealed by a marginal main effect of Load, F (1, 35) = 3.76, p < .07, ηp2 = .10. No other main effects or interactions reached significance, p’s > .11, which is not surprising given that overall accuracy was near ceiling (M = 98.3%, SD = .02).
Implicitness
For the recognition task, the percentage of times each participant selected the correct target quadrant was calculated separately for Repeated and Novel arrays. A Load x Array ANOVA revealed no significant main effects or interactions (p’s > .24)(High Load-Repeated, 29.8 ± 15.3%; High Load-Novel, 25.0 ± 12.7%; Low Load-Repeated, 27.8 ± 19.0%; Low Load-Novel, 30.6 ± 19.2%). Further, recognition accuracy was not significantly different from chance (25%) in any Load-Array condition (p’s > .18), indicating that neither group was able to identify where the target would occur in repeated configurations.
For the interview, three Low Load and one High Load participant (marked with asterisks in Figure 2) reported noticing that certain arrays repeated and accurately described one of the repeated arrays. Importantly, learning in the Low Load condition did not depend on awareness of the regularity because Array, F (1, 14) = 5.15, p < .04, ηp2 = .27, and Array x Epoch, F (5, 70) = 2.36, p < .05, ηp2 = .14, effects remained significant when these three participants were removed from the ANOVA for the reaction time measure.
Discussion
The present study varied the number of repeated arrays to be learned in the SCCT using the original version with 12 repeated arrays (High Load) and an abbreviated version with 6 repeated arrays (Low Load). The primary aim was to determine whether the shortened version would yield significant learning without affecting implicit awareness. In line with this aim, results revealed significant learning in the Low Load condition, with no explicit awareness of the spatial contextual regularity in most participants. A secondary aim, assessing whether contextual memory load affected the magnitude of implicit spatial context learning, was confirmed with a significant three-way interaction for reaction time that revealed more learning in the Low versus High Load condition.
Significant learning was seen across Load conditions in the omnibus ANOVA, with Array and Array x Epoch effects for the reaction time measure showing faster responses to repeated arrays compared to novel arrays. When analyzed separately, these findings remained significant for the Low Load condition, indicating that spatial context learning can be acquired with the abbreviated SCCT. In contrast, when the High Load condition was analyzed alone, the learning effect did not attain significance: a result that was unexpected, but not unprecedented. Previous research in young adults using the original SCCT (i.e., the High Load condition) has yielded significant learning effects in some studies (Howard et al., 2004; Jiang et al., 2005) but not others (Jiang et al., 2005, Day 2; Lleras & Von Muhlenen, 2004, Experiment 2). These inconsistent results may result from individual differences in the magnitude of learning. For example, previous SCCT studies have identified “reverse learners” who show the opposite pattern of responding faster to novel versus repeated arrays (Hunt & Thomas, 2007; Lleras & Von Muhlenen, 2004). It is unclear exactly what reverse learners are learning about the spatial contextual regularity, but their inclusion in group-level analyses certainly affects the ability to detect significant learning effects. In the present study, slightly more reverse learners were seen in the High versus Low Load condition (see Figure 2). These individual data also revealed substantially larger magnitudes of learning for participants in the Low Load condition, despite having half the number of trials as the High Load condition. Together, these findings highlight an additional benefit of the abbreviated SCCT; fewer reverse learners and larger magnitudes of learning.
Most participants in the present study were not explicitly aware of the spatial contextual regularity. Participants in both Load conditions were no more accurate at recognizing the correct target quadrant for repeated arrays than for novel arrays. In the post-experiment interview, one High Load and three Low Load participants were able to accurately describe one of the repeated arrays. Importantly, when these participants were removed from the analyses, the pattern of results was unchanged. These findings are consistent with assessments of implicitness in previous SCCT studies (Chun & Jiang, 2003; Lleras & Von Muhlenen, 2004; Smyth & Shanks, 2008), indicating that spatial contextual regularities can be learned without explicit awareness.
The finding that contextual memory load influenced the magnitude of learning, as revealed by the three-way interaction, is consistent with cross-experiment comparisons from two SCCT studies in which numerically larger learning effects were seen when there were fewer repeated arrays. In Chun & Jiang’s initial study (1998), Experiment 1 used the original SCCT containing 12 repeated arrays with 12 items per array (1 target, 11 distractors), while Experiment 4 used a variation that contained four repeated arrays at each of three different set sizes (8, 12, or 16 items per array). Though no statistical comparison was conducted across these experiments, the learning effect was approximately 40 ms larger when there were four 12-item repeated arrays (∼130 ms) versus twelve 12-item repeated arrays (∼80 ms). This comparison is confounded because the distractor set size manipulation in Experiment 4 may have facilitated learning by making the arrays more distinct. Nonetheless, similarly large learning effects (∼200 ms) were observed in another study that contained only 8 repeated arrays (Hunt & Thomas, 2007), further supporting the view that decreasing the number of arrays to be learned increases the magnitude of learning in the SCCT.
One interpretation of the contextual memory load effect on learning is that it reduces demands on underlying MTL-dependent processes. The hippocampus is involved in binding multiple elements of a stimulus or event into an associative memory representation regardless of awareness (O’Reilly & Rudy, 2001; Rose et al., 2004; Schendan et al., 2003). Accordingly, learning repeated arrays in the SCCT likely results from hippocampal-dependent binding of the target location and distractor configuration. Thus, decreasing the number of repeated arrays to be learned in the Low Load condition may reduce the number of associative memory representations that need to be formed, leading to improved learning. Similar effects of memory load have been observed in paired-associate learning paradigms that also involve MTL structures (Meltzer & Constable, 2005; Small et al., 2001). In these studies, faster reaction times and/or higher accuracy were seen with fewer word pairs (Carroll & Burke, 1965) or digit-letter pairs (Calfee & Atkinson, 1965; Carroll & Burke, 1965) to be learned. Having fewer stimulus pairs to learn in a paired-associate learning task may be functionally similar to having fewer repeated arrays to learn in the Low Load condition of the SCCT in that they both place fewer demands on associative binding processes.
An alternative interpretation is that differences between the Load conditions, beyond contextual memory load, affected implicit spatial context learning. For example, there were more trials in the High versus Low Load condition (720 versus 360 trials). This cannot be controlled in the present data because comparing the first half of the High Load condition to the full-length of the Low Load condition would confound the number of repetitions of each repeated array (15 repetitions of 12 repeated arrays in the High Load condition versus 30 repetitions of 6 repeated arrays in the Low Load condition). Nonetheless, overall reaction times continued to improve during the last three epochs in the High Load condition (see Figure 1), suggesting that the load-dependent findings are not due to fatigue in the full-length SCCT.
In conclusion, the present study demonstrated that implicit spatial context learning can be obtained with an abbreviated version of the SCCT that requires half the time of the original task (∼25 versus ∼45 minutes) and yields larger learning effects without affecting the implicit nature of the task. The shortened Low Load condition seems preferable to the original High Load condition, especially for studies using special populations and experimental designs in which a shorter testing session is particularly important.
Acknowledgments
This research was funded by grants R37 AG15450 and F31 AG030874 from the National Institute on Aging/National Institutes of Health. The authors want to thank Meghan Shapiro for assisting with data collection and Dr. Chandan Vaidya for comments on earlier drafts of this paper. Preliminary findings from this project were presented at the 19th Annual Convention of the Association for Psychological Sciences in Washington, DC in May 2007.
References
- Barnes KA, Howard JH, Jr., Howard DV, Gilotty L, Kenworthy L, Gaillard WD, et al. Intact implicit learning of spatial context and temporal sequences in childhood autism spectrum disorder. Neuropsychology. 2008;22:563–570. doi: 10.1037/0894-4105.22.5.563. doi:10.1037/0894-4105.22.5.563. [DOI] [PubMed] [Google Scholar]
- Bennett IJ, Romano JC, Howard JHJ, Howard DV. Two forms of implicit learning in young adults with dyslexia. Annals of the New York Academy of Sciences. 2008;1145:184–198. doi: 10.1196/annals.1416.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calfee RC, Atkinson RC. Paired-associate models and the effects of list length. Journal of Mathematical Psychology. 1965;2:254–265. doi:10.1016/0022-2496%2865%2990004-0. [Google Scholar]
- Carroll JB, Burke ML. Parameters of paired-associate verbal learning: length of list, meaningfulness, rate of presentation, and ability. Journal of Experimental Psychology: General. 1965;69:543–553. doi: 10.1037/h0022006. doi:10.1037/h0022006. [DOI] [PubMed] [Google Scholar]
- Chun MM. Contextual cueing of visual attention. Trends in Cognitive Science. 2000;4:170–178. doi: 10.1016/s1364-6613(00)01476-5. doi:10.1016/S1364-6613%2800%2901476-5. [DOI] [PubMed] [Google Scholar]
- Chun MM, Jiang Y. Contextual cueing: implicit learning and memory of visual context guides spatial attention. Cognitive Psychology. 1998;36:28–71. doi: 10.1006/cogp.1998.0681. doi:10.1006/cogp.1998.0681. [DOI] [PubMed] [Google Scholar]
- Chun MM, Jiang Y. Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2003;29:224–234. doi: 10.1037/0278-7393.29.2.224. doi:10.1037/0278-7393.29.2.224. [DOI] [PubMed] [Google Scholar]
- Chun MM, Phelps EA. Memory deficits for implicit contextual information in amnestic subjects with hippocampal damage. Nature Neuroscience. 1999;2:844–847. doi: 10.1038/12222. doi:10.1038/12222. [DOI] [PubMed] [Google Scholar]
- Greene AJ, Gross WL, Elsinger CL, Rao SM. Hippocampal differentiation without recognition: an fMRI analysis of the contextual cueing task. Learning & Memory. 2007;14:548–554. doi: 10.1101/lm.609807. doi:10.1101/lm.609807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Howard JH, Jr., Howard DV, Dennis NA, Yankovich H, Vaidya CJ. Implicit spatial contextual learning in healthy aging. Neuropsychology. 2004;18:124–134. doi: 10.1037/0894-4105.18.1.124. doi:10.1037/0894-4105.18.1.124. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Howard JHJ, Howard DV, Japikse KC, Eden GF. Dyslexics are impaired on implicit higher-order sequence learning but not on implicit spatial context learning. Neuropsychologia. 2006;44:1131–1144. doi: 10.1016/j.neuropsychologia.2005.10.015. doi:10.1016/j.neuropsychologia.2005.10.015. [DOI] [PubMed] [Google Scholar]
- Hunt RH, Thomas KM. Hippocampal recruitment in implicit learning: neuroimaging evidence from a visual search task. Cognitive Neuroscience Society. 2007 [Google Scholar]
- Jiang Y, Song JH, Rigas A. High-capacity spatial contextual memory. Psychonomic Bulletin & Review. 2005;12:524–529. doi: 10.3758/bf03193799. [DOI] [PubMed] [Google Scholar]
- Lleras A, Von Muhlenen A. Spatial context and top-down strategies in visual search. Spatial Vision. 2004;17:465–482. doi: 10.1163/1568568041920113. doi:10.1163/1568568041920113. [DOI] [PubMed] [Google Scholar]
- Manns JR, Squire LR. Perceptual learning, awareness, and the hippocampus. Hippocampus. 2001;11:776–782. doi: 10.1002/hipo.1093. doi:10.1002/hipo.1093. [DOI] [PubMed] [Google Scholar]
- Meltzer JA, Constable RT. Activation of human hippocampal formation reflects success in both encoding and cued recall of paired associates. Neuroimage. 2005;24:384–397. doi: 10.1016/j.neuroimage.2004.09.001. [DOI] [PubMed] [Google Scholar]
- Negash S, Boeve BF, Geda YE, Smith GE, Knopman DS, Ivnik RJ, et al. Implicit learning of sequential regularities and spatial contexts in corticobasal syndrome. Neurocase. 2007;13:133–143. doi: 10.1080/13554790701401852. doi:10.1080/13554790701401852. [DOI] [PubMed] [Google Scholar]
- Negash S, Petersen LE, Geda YE, Knopman DS, Boeve BF, Smith GE, et al. Effects of ApoE genotype and mild cognitive impairment on implicit learning. Neurobiology of Aging. 2007;28:885–893. doi: 10.1016/j.neurobiolaging.2006.04.004. doi:10.1016/j.neurobiolaging.2006.04.004. [DOI] [PubMed] [Google Scholar]
- O’Reilly RC, Rudy JW. Conjunctive representations in learning and memory: principles of cortical and hippocampal function. Psychological Review. 2001;108:311–345. doi: 10.1037/0033-295x.108.2.311. doi:10.1037/0033-295X.108.2.311. [DOI] [PubMed] [Google Scholar]
- Poldrack RA, Gabrieli JD. Functional anatomy of long-term memory. Journal of Clinical Neurophysiology. 1997;14:294–310. doi: 10.1097/00004691-199707000-00003. [DOI] [PubMed] [Google Scholar]
- Preston AR, Gabrieli JD. Dissociation between explicit memory and configural memory in the human medial temporal lobe. Cerebral Cortex. 2008;29:2192–2207. doi: 10.1093/cercor/bhm245. doi:10.1093/cercor/bhm245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rose M, Haider H, Weiller C, Buchel C. The relevance of the nature of learned associations for the differentiation of human memory systems. Learning & Memory. 2004;11:145–152. doi: 10.1101/lm.67204. doi:10.1101/lm.67204. [DOI] [PubMed] [Google Scholar]
- Schendan HE, Searl MM, Melrose RJ, Stern CE. An FMRI study of the role of the medial temporal lobe in implicit and explicit sequence learning. Neuron. 2003;37:1013–1025. doi: 10.1016/s0896-6273(03)00123-5. [DOI] [PubMed] [Google Scholar]
- Small SA, Nava AS, Perera GM, DeLaPaz R, Mayeux R, Stern Y. Circuit mechanisms underlying memory encoding and retrieval in the long axis of the hippocampal formation. Nature Neuroscience. 2001;4:442–449. doi: 10.1038/86115. doi:10.1038/86115. [DOI] [PubMed] [Google Scholar]
- Smyth AC, Shanks DR. Awareness in contextual cueing with extended and concurrent explicit tests. Memory & Cognition. 2008;36:403–415. doi: 10.3758/mc.36.2.403. [DOI] [PubMed] [Google Scholar]
- Squire LR. Memory and the hippocampus: a synthesis from findings with rats, monkeys, and humans. Psychological Review. 1992;99:195–231. doi: 10.1037/0033-295x.99.2.195. doi:10.1037/0033-295X.99.2.195. [DOI] [PubMed] [Google Scholar]
- Vaidya CJ, Huger M, Howard DV, Howard JH., Jr. Developmental differences in implicit learning of spatial context. Neuropsychology. 2007;21:497–506. doi: 10.1037/0894-4105.21.4.497. doi:10.1037/0894-4105.21.4.497. [DOI] [PubMed] [Google Scholar]