

Abstract
Background
Gene networks are considered to represent various aspects of molecular biological systems meaningfully because they naturally provide a systems perspective of molecular interactions. In this respect, the functional understanding of the transcriptional regulatory network is considered as key to elucidate the functional organization of an organism.
Results
In this paper we study the functional robustness of the transcriptional regulatory network of S. cerevisiae. We model the information processing in the network as a first order Markov chain and study the influence of single gene perturbations on the global, asymptotic communication among genes. Modification in the communication is measured by an information theoretic measure allowing to predict genes that are 'fragile' with respect to single gene knockouts. Our results demonstrate that the predicted set of fragile genes contains a statistically significant enrichment of so called essential genes that are experimentally found to be necessary to ensure vital yeast. Further, a structural analysis of the transcriptional regulatory network reveals that there are significant differences between fragile genes, hub genes and genes with a high betweenness centrality value.
Conclusion
Our study does not only demonstrate that a combination of graph theoretical, information theoretical and statistical methods leads to meaningful biological results but also that such methods allow to study information processing in gene networks instead of just their structural properties.
Background
The advent of high-throughput technologies in molecular biology has initiated an avalanche of data that possess considerable challenges to quantitative sciences providing statistical analysis methods [1]. Due to the fundamental insight that biological processes should be studied holistically [2-4] instead of reductionistically, systems based approaches are of central importance in this respect [5]. For this reason, it is no surprise that network related studies experience an enormous interest starting with the investigation of small-world [6,7] and scale-free [8,9] networks in the mid 1990's followed by numerous studies devoted to the analysis of complex network topologies and their properties in general [8,10-14]. It is interesting to note that many apparently different networks have similar properties. Most prominent example is the degree distribution. For example, the World-Wide Web, the Internet or biological networks are found to be scale-free [8,10,11,15,16] with respect to their degree distribution. In molecular biology, metabolic, transcriptional regulatory, signaling and protein networks have been studied extensively during the last years [4,17-19] to shed light on the functional organization of these complex gene networks [20]. In this context, functional robustness is considered a key player for our understanding regarding the interplay of network structure and network dynamics leading to the emergence of life as omnipresent around us [9,21-23].
For general networks, one of the first studies that has thoroughly investigated structural robustness of systems that can be represented as networks is from ALBERT et al. [24]. ALBERT studied the error and attack tolerance of synthetic as well as real world networks and compared random and scale-free networks, e.g., the World-Wide Web or the Internet. By using purely graph theoretical measures – the diameter of the network and the size of the largest connected component – they found that scale-free networks are much more robust against random errors than random networks but more vulnerable against directed attacks. In the context of gene networks the interest shifts from the structural robustness of the networks to their functional robustness because the ultimate goal is of course to gain insights into the function of a living cell or an organism respectively. On a time scale of a living organism the question of functional robustness has been addressed by [25-28]. For example, in [27] the dynamics of Boolean networks [29,30] were studied serving as a simplified model for the signal processing taking place in gene networks. As major result [27] found that fluctuations occurring inevitably within the system, e.g., due to the inherent noise present on a molecular level [31,32], can be suppressed by a suitable design of the overall network topology [27]. On an evolutionary time scale the functional robustness of gene networks has been studied by [33-35] considering directly the role selective pressure might play during evolution leading to observable patterns of, e.g., protein structures, gene expression or network structures as present in current organisms. In this paper we tie up with previous studies aiming to analyze the functional robustness of networks on a time scale of living organisms. By pointing out the time scale we want to emphasize that we do not investigate the evolutionary robustness of an organism. Instead, the major objective of this paper is to investigate the functional robustness of the transcriptional regulatory network (TRN) of S. cerevisiae with respect to single gene perturbations. As quantitative measure of functional robustness we suggest to use an information theoretic measure [36], previously used to study synthetic networks, that does not focus directly on structural changes of the network topology due to the perturbations but on the alterations of information flow, modeled as Markov Chain [37], within the network as consequence of the structural modifications. The advantage of information theoretic measures [38-40] is that the concrete underlying dynamics does not need to be specified precisely, instead, a qualitative model is enough to gain principle insights into common working mechanisms with regard to more elaborate biological models. General entropy measures for quantifying structural information in networks have been developed in [41,42]. For our study, we use the transcriptional regulatory network of yeast [43,44] and apply our information theoretic measure to identify genes that are crucial for the functioning of the organism in the sense that disruptions of the transcriptional regulatory network are experienced strongest by these genes. For this reason we call these genes fragile. In this paper, we quantify our results by connecting these to the list of known so called essential genes of yeast [45] to demonstrate that our predictions are biologically meaningful.
Methods
In this section we present the information theoretic measure we use to analyze the transcriptional regulatory network of yeast to study its functional robustness.
Markov chains
We approximate the information flow in the network as a Markov chain. A Markov chain is a Markov process that is discrete in time and space. We define a Markov process by using a given network topology G and the plausible assumption that all possible interactions are equal likely. Plausible in this context does not necessarily mean that this corresponds best to the real situations, it means that it is the most simple and unbiased assumption one can make. For simplicity, we further assume the Markov process to be of first-order
| T(Xt+1 = j|Xt = it, ..X1 = i1) = T(Xt+1 = j|Xt = it). | (1) |
That means, the transition probability T depends only on the last state and not on states that are further in the past.
Definition 1: The transition probability T for a Markov chain of first-order for a network G with adjaceny matrix A is defined by
 |
(2) |
for all i, j ∈ V.
Here ki = ∑j Aji is the degree of node (gene) i in the network and Aij is a component of the adjacency matrix indicating if node i is connected with node j (Aij = 1) or unconnected (Aij = 0). V denotes a set comprising all genes.
Single gene perturbations
In this paper we study the effect of single gene perturbations on the information processing in the transcriptional regulatory network of yeast. Formally, we define perturbations in the following way.
Definition 2: (Single gene perturbations) If a gene k in network G is perturbed than all outgoing and incoming edges from this gene are deleted. In addition, one self-connection is introduced.
In Fig. 1 and 2 we visualize a single gene perturbation. One can see that the perturbed gene (shown in red) does no longer participate in the information processing in the network. However, the remainder of the network is still structurally intact and capable to transmit signals. Hence, a single knockout can be considered as a perturbation and the modified communication among the remaining genes can be studied principally provided there is a measure to quantify these alterations. This measure is given in the next subsection.
Figure 1.

A graph depicts the flow of information in the network.
Figure 2.

Perturbing the node shown in red leads to a breakdown of communication between the red node and all other nodes. However, there is still an information flow in the remaining network.
Asymptotic Communication
The information theoretic measure we use to capture the asymptotic behavior of information processing evaluates the deviation of the unperturbed (or normal (n)) state from the perturbed (p) state caused by the perturbation of gene k. We use the the relative entropy also known as Kullback-Leibler (KL) divergence D [46,47] to quantify this deviation. Our asymptotic measure is given by the following definition.
Definition 3: (Asymptotic information change)
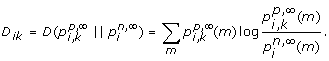 |
(3) |
Here  and
and  are stationary distributions obtained by
are stationary distributions obtained by
| (4) |
| (5) |
The Markov chain given by Tk corresponds to the process obtained by perturbing gene k in the network. The stationary distribution of the perturbed (p) network obtained by perturbing gene k and starting from the initial distribution,
| (6) |
depends on i because we use the Kronecker delta, which is one for i = m and zero otherwise, as initial condition. The reason therefore is we consider i as starting point for the spread of information in the network. The interpretation for the unperturbed (normal (n)) distribution is correspondingly. We want to note that due to the directedness of the network the Markov process is not ergodic which results in a dependence of the asymptotic distributions and on the initial distribution  . For this reason it is important to use |V| - 1 (starting from k is excluded because the perturbed gene has no longer outgoing edges) different initial distributions to evaluate Dik. That means Eq. 3 defines the components of a matrix and the interpretation of Dik is that the index k correspond to the deletion of gene k and index i referes to the initial distribution = δi, m. The diagonal elements Dik (i = k) are not defined.
. For this reason it is important to use |V| - 1 (starting from k is excluded because the perturbed gene has no longer outgoing edges) different initial distributions to evaluate Dik. That means Eq. 3 defines the components of a matrix and the interpretation of Dik is that the index k correspond to the deletion of gene k and index i referes to the initial distribution = δi, m. The diagonal elements Dik (i = k) are not defined.
Results and discussion
Data
For our analysis we use the transcriptional regulatory network of yeast [43,44] which is a directed, unweighted network. From this network we extract the weakly connected component consisting of 3357 genes and 7230 interactions. The weakly connected component of a network is defined as the subnetwork that connects every pair of nodes by at least one directed path. That means for every pair of genes the weakly connected component ensures that communication (at least in one direction) between these genes is in principle enabled. This is an important characteristic because in our analysis we are aiming to quantify modifications of the communication among genes due to perturbations. Hence, if there would be no path between genes such an analysis would not be sensible.
On a practical note, we want to remark that our theoretical analysis described in detail in the next section is computationally expensive because we perform single gene perturbations for all genes in the network. That means, we do not just analyze one network with our method but as many as genes in the network. Hence, the results presented in this article are obtained by analyzing 3357 networks. It is clear that this is getting more and more demanding computationally by increasing the number of genes in the network. From our simulations we found that networks with several thousand nodes can be studied within reasonable time whereas larger networks would require more algorithmic attention to reduce the computation time.
Results
Now we study the asymptotic behavior of the transcriptional regulatory network of yeast regarding information propagation under the influence of single gene perturbation.
For the normal (unperturbed) and perturbed network topology of the transcriptional regulatory network we determine Markov chains from which we calculate the stationary distributions. The perturbations correspond to single gene perturbations and the Markov chains are obtained as described in the methods section. From the resulting stationary distributions of the Markov chains we calculate the Kullback-Leibler divergence Dik = D (||) for all genes i ∈ V and perturbations k ∈ V with i ≠ k. We want to note that due to the directedness of the network the resulting Markov process is no longer ergodic. Hence, information sent from different genes can results in different stationary distributions. For this reason, we use all N genes consecutively as sender gene. This is reflected by the index i in Eq. 3 corresponding to the gene from which the information was sent initially. On a mathematical note we want to remark that the network does not need to be disconnected to result in a non-ergodic Markov chain. However, the need to consider different initial conditions to study the behavior of the resulting stationary distributions meaningfully remains also true in this case.
We begin our analysis by investigating if the asymptotic results summarized by Dik can be connected to local, structural properties of the genes in the network. For this reason we determine all genes with
| (7) |
and calculate the correlation with the in- and out-degree vector of the network. More precisely, we calculate Spearman's rank-order correlation coefficient [48] between the rank ordered vectors to decide if the order in these vectors is statistically preserved. For the in-degrees we obtain a correlation of r = -0.39 and p = 6 × 10-9, for the out-degrees r = 0.33 and p = 1 × 10-6. Using a significance level of α = 0.05 indicates that both rank correlations are statistically significant implying that, e.g., high out-degrees correspond to high values of Di. These results seem plausible considering the following situation: For a given gene that is connected to all other genes (outgoing edges) it is clear, that an arbitrary knockout of a single gene effects with probability one an outgoing edge of this gene. Hence, this knockout will have an influence on the information processing of this gene. The strength of this influence can not be easily predicted given just this information, however, we will have an influence with probability one. Instead, a gene having very few outgoing connections has a lower probability that a single knockout effects one of its outgoing edges (Pr = kout/Np with Np the number of genes that can be perturbed). However, it is possible that the knocked out gene destroys some communication paths (secondary- or even higher-order effect if measured as Dijkstra distance [49]) and, hence, can still have a strong impact on the information processing. It seems to be reasonable to assume that the further away the knockout gene is from the starting gene (in Dijkstra distance [49]) the less the impact will be. This is a strong indicator that information processing on a systems level depends crucially on the information processing in a local environment of the gene that sends the information. We want to remark that in our analysis the number Di, given in Eq. 7, is a global measure, whereas the degree vector is a local measure. This result is interesting because it demonstrates that the local properties of genes, given by their local connectedness, which can be roughly summarized by their degrees, are not averaged away with respect to the stationary distribution of the Markov process. That means the local connectivity signature is still detectable in the asymptotic behavior. We will come back to this point in the discussions section because this is a non-trivial point.
In Fig. 3 we show the components of the asymptotic information change Dik for which Di ≥ 0.1 holds (149 genes). Blue corresponds to low values (zero) and cyan to high values of Dik (the maximal value of Dik is 20.47). The vertical stripes indicate that the knockout of a few genes effects many other genes whereas most knockouts have only a minor effect on other genes. This is also the reason why we do not show Dik for N = 3357 genes because in this case the figure would appear essentially blue.
Figure 3.

Asymptotic information change Dik for all genes with Di ≥ 0.1.
In Fig. 4 we show the histogram of Di. From this figure one can see that the distribution of Di has a heavy tail and that most values are around zero. This indicates that our measure has the desirable property to be very selective by evaluating most perturbations as minor. This corresponds to experimental results showing that only about 10% of all genes in yeast are categorized as essential [50] which means that their knockout has a catastrophic influence on the organism.
Figure 4.

Histogram of Di for all genes with Di > 0.
To point out the properties of our measure we show in Fig. 5 results connecting genes with high Di values quantitatively to the appearance of essential genes from gene-deletion experiments in yeast [45]. Figure 5 shows Ne/Nc in dependence on ΘD. Nc is the number of genes found for which Di > ΘD holds and Ne is the number of essential genes found in this set,
Figure 5.

Ne/Nc in dependence on ΘD.
| Sc = {i|Di > ΘD}, | (8) |
| Nc = #Sc, | (9) |
| Se = {i|i ∈ Sc and i is essential}, | (10) |
| Ne = #Se. | (11) |
The highest values found by this comparison are over 40%. A natural question arising now is if this occurred just by chance or is this high coverage unlikely to happened accidentally. Figure 6 provides information regarding this question. There we show pD in dependence on ΘD. The probability pD is the sum of a hypergeometric distribution p(k; N, NE, n) giving the probability to observe exactly k essential genes in a set of size n = Nc(ΘD) when the total number of genes is N containing NE essential genes.
Figure 6.

pD in dependence on ΘD. The dotted line corresponds to 0.05.
Hence,
 |
(12) |
is the probability to observe k or more essential genes in the set Nc. From Fig. 6 one can see that for ΘD ∈ [8,15] the probability pD < 0.05 (the dotted line corresponds to 0.05). This result suggests that the peaks observed in Fig. 5 do not appear by chance. Further, we obtain possible cut-off values for our gene set to be considered which corresponds to the interval ΘD ∈ [8,15]. From these results we decided to choose  = 12 as cut-off value because for this value Ne/Nc assumes a maximum value. We call all genes for which Di > holds fragile genes.
= 12 as cut-off value because for this value Ne/Nc assumes a maximum value. We call all genes for which Di > holds fragile genes.
In table 1 we show a list of 12 genes found by setting = 12 for which pD = 0.0039. These genes are ordered according to their out-degree dout in descending order. The first column gives the name of the gene. The second and third, the out- correspondingly in-degree of the gene in the TRN. The forth column gives the value of Di and the fifth column indicates if the gene is found to be essential (Y) or non-essential (N) according to [45]. As one can see, the first gene (YNL216W) is a hub because dout = 240. However, all other genes are not. Interestingly, YNL216W is not an essential gene according to [45]. The results in table 1 demonstrate that our measure does not prefer to select hub genes because only one hub was selected.
Table 1.
Genes obtained for = 12.
| gene | d out | d in | D i | essential |
| YNL216W | 240 | 2 | 17.5 | N |
| YKL043W | 92 | 1 | 17.9 | N |
| YML007W | 89 | 2 | 13.0 | N |
| YFR034C | 73 | 2 | 14.0 | N |
| YER040W | 44 | 1 | 17.8 | Y |
| YBR112C | 26 | 1 | 13.6 | Y |
| YPL177C | 23 | 2 | 13.3 | N |
| YOL148C | 13 | 1 | 20.4 | N |
| YGL207W | 12 | 2 | 18.1 | N |
| YLR399C | 9 | 3 | 12.2 | Y |
| YDR138W | 5 | 1 | 15.6 | Y |
| YPR072W | 4 | 1 | 16.1 | Y |
The first column gives the name of the gene.
The second and third, the out-correspondingly in-degree of the gene in the TRN. The fourth column gives the value of Di and the fifth column indicates if the gene is found to be essential (Y) or non-essential (N) according to [45]. For this set pD = 0.0039.
This underlines the non-trivial characteristics of our measure. For reasons of completeness we show in table 2 the top four knockout genes that cause the largest influence, as measured by
Table 2.
Top four knockout genes that have the largest impact on other genes.
| gene | d out | d in | D k | essential |
| YML027W | 314 | 2 | 26.8 | N |
| YGL096W | 248 | 0 | 97.4 | N |
| YDL056W | 129 | 0 | 149.8 | Y |
| YHR206W | 128 | 0 | 27.8 | N |
First column: gene name. Second column: out-degree. Third column: in-degree. Fourth column: Dk. Fifth column: essential genes (yes (Y) or no (N)).
| (13) |
on other genes. The genes are again ranked according to their out-degrees. All of these genes are hubs. Considering the top 50 genes reveals that in this set 20 genes have an out-degree below 25 and even genes with an out-degree one and two are among these. Again, this demonstrates that hubness is no sufficient property to characterize these genes.
Next, we analyze the structure of the TRN containing our 12 genes shown in table 1. We find that each gene pair is connected (both ways) via a directed path. This implies that the subgraph formed from these 12 genes is part of the strongly connected component of the TRN. As side note we remark that for ΘD ≤ 9 the resulting set of genes is no longer strongly connected and that also for ΘD = 10 this gene set does not correspond to the entire strongly connected component of the whole TRN comprising Nsc = 36 genes. Analysis of the strongly connected component of the whole TRN shows that it contains only 8 essential genes. From this we calculate the probability to find 8 or more essential genes by chance in the strongly connected component. By summing up the probabilities from a hypergeometric distribution we find psc = 0.021. This shows that essential genes are enriched in the strongly connected component, however, due to pD (ΘD = 12) <<psc the strongly connected component represents a less favorable set to identify essential genes than the set found by our method. Fig. 7 shows Dik for the strongly connected component. In contrast to Fig. 3 the influence of the perturbations is now much more severe as can be seen by the many non-blue dots. As a remark we want to remind that the diagonal of Dik is not defined as explained in the methods section.
Figure 7.

Asymptotic information change Dik for all genes in the strongly connected component of the transcriptional regulatory network.
Finally, we test for the transcriptional regulatory network if our measure and betweenness centrality are similar by calculating Spearman's rank sum correlation coefficient. For the genes in table 1 we obtain a correlation coefficient r = 0.0139 and a p-value of 0.965 indicating that the results of both measures are not correlated. Further, we find that among the top 100 ranked genes of both measures only two genes are selected by both measures.
Discussion
In table 3 we provide some information about the biological processes the genes in table 1 are involved in. All genes found by our measure belong to the category 'regulation of transcription, DNA-dependent'. Further, some additional categories are listed for each gene in table 3. It is apparent that involvement in transcription regulation is the dominating category. This is interesting because the genes listed in the bottom of the table have a fairly low out-degree (see table 1). From our results we hypothesize that the genes found by our method, who have not been declared 'essential' by [45], should be 'fragile' in the sense that they are influenceable quite severely by the malfunctioning of many other genes. Here, 'fragile' should not necessarily be equalized with 'essential' but the organism may be viable, however, it's overall function substantially impaired. It is also important to bear in mind that the list of essential genes used in our analysis is not necessarily complete. After intense literature research we found that YGL207W (also known as SPT16 – subunit of the heterodimeric FACT complex (Spt16p-Pob3p), facilitates RNA Polymerase II transcription elongation) is reported to be essential by [51] confirming our findings.
Table 3.
Biological processes the genes provided in table 1 participate.
| gene | biological process |
| YNL216W | chromatin silencing at telomere, ribosome biogenesis |
| YKL043W | pos. regulation of trans. from RNA polymerase II promoter |
| YML007W | regulation of trans. from RNA polymerase II promoter in response to oxidative stress |
| YFR034C | response to starvation, |
| YER040W | positive regulation of transcription |
| YBR112C | negative regulation of transcription, chromatin remodeling |
| YPL177C | cellular copper ion homeostasis |
| YOL148C | chromatin modification, mitotic cell cycle |
| YGL207W | DNA repair, chromatin modification |
| YLR399C | DNA repair, chromatin remodeling |
| YDR138W | response to DNA damage stimulus |
| YPR072W | protein ubiquitination |
In addition to the listed biological processes, all genes are involved in the category 'regulation of transcription, DNA-dependent'.
On a mathematical note we want to remark that the fact that rank(Di) and rank(dout) respectively rank(din) are correlated, as shown in the beginning of the results section, does not imply that our measure approximates or is even identical to the ranking of the degrees. This can be seen in table 1 because, e.g., the five bottom genes have dout < 20, however, in the whole transcriptional regulatory network are 79 genes that have an out-degree larger than 20. But only seven of them appear in the list.
From a perspective of information processing the connection between asymptotic information change and local network structure represented by their degrees is interesting because it indicates that a local subgraph may be sufficient to study information processing in the overall network. This dissection is interesting because it would allow to reduce the computational complexity considerably that arises studying genomes like yeast or even organisms with more genes. In a former study [27], a similar idea has been proposed in a different methodological framework.
Finally, we want to remark that we repeated the analysis using Dk = ∑i Dik as fragility measure of genes. However, for Dk we did not obtain meaningful results regarding the enrichment of essential genes. That means that the information captured by Dik is asymmetric, as one would expect from it's construction.
Conclusion
In this paper we analyzed the influence that single gene perturbations have on the asymptotic communication abilities of the transcriptional regulatory network of yeast [43,44] to learn about the functional robustness of this network. To study the influence of the perturbations we used an information theoretic measure [36] and approximated the information propagation as a first order Markov chain directly defined for a given network topology. Our numerical studies obtained three major results. First, the asymptotic distributions for the perturbed and unperturbed network states carry implicitly information about their local origin from which the initial signal was transmitted. This confirms results previously found for synthetic networks [36]. Second, using our measure of asymptotic information change we could demonstrate that the predicted set of fragile genes contains a statistically significant enrichment of so called essential genes that are experimentally found to be necessary to ensure vital yeast. Third, a structural analysis of the transcriptional regulatory network revealed that there are significant differences between fragile genes, hub genes and genes with a high betweenness centrality value.
In addition to these findings we consider it to be important to emphasize that we employed graph theoretical, information theoretical as well as statistical methods [52] because the biological information processing in gene networks is unlikely to be treated correctly in a deterministic framework. This demonstrates the power of interdisciplinary approaches and is at the heart of computational systems biology.
Authors' contributions
All authors contributed to all aspects of the article.
Acknowledgments
Acknowledgements
We would like to thank Michael Drmota for fruitful discussions.
Contributor Information
Frank Emmert-Streib, Email: v@bio-complexity.com.
Matthias Dehmer, Email: dehmer@math.uc.pt.
References
- Emmert-Streib F, Dehmer M, Eds . Analysis of Microarray Data: A Network Based Approach. Wiley VCH; 2008. [Google Scholar]
- Alon U. An Introduction to Systems Biology: Design Principles of Biological Circuits. Chapman & Hall/CRC; 2006. [Google Scholar]
- Kitano H. Foundations of Systems Biology. MIT Press; 2001. [Google Scholar]
- Palsson BO. Systems Biology. Cambridge University Press; 2006. [Google Scholar]
- von Bertalanffy L. General System Theory: Foundation, Development, Application. New York, George Braziller; 1968. [Google Scholar]
- Watts D, Strogatz S. Collective dynamics of 'small-world' networks. Nature. 1998;393:440–442. doi: 10.1038/30918. [DOI] [PubMed] [Google Scholar]
- Watts D. Small Worlds: The Dynamics of Networks between Order and Randomness. Princeton University Press; 1999. [Google Scholar]
- Albert R, Jeong H, Barabasi AL. Diameter of the world wide web. Nature. 1999;401:130–131. doi: 10.1038/43601. [DOI] [Google Scholar]
- Jeong H, Tombor B, Albert R, Oltvai ZN, Barabasi AL. The large-scale organization of metabolic networks. Nature. 2000;407:651–654. doi: 10.1038/35036627. [DOI] [PubMed] [Google Scholar]
- Albert R, Barabasi A. Statistical Mechanics of Complex Networks. Rev of Modern Physics. 2002;74:47–97. doi: 10.1103/RevModPhys.74.47. [DOI] [Google Scholar]
- Newman MEJ. The Structure and Function of Complex Networks. SIAM Review. 2003;45:167–256. doi: 10.1137/S003614450342480. [DOI] [Google Scholar]
- Ravasz E, Somera AL, Mongru DA, Oltvai ZN, Barabasi AL. Hierarchical Organization of Modularity in Metabolic Networks. Science. 2002;297:1551–1555. doi: 10.1126/science.1073374. [DOI] [PubMed] [Google Scholar]
- Schwikowski B, Uetz P, Fields S. A network of protein-protein interactions in yeast. Nat Biotechnol. 2000;18:1257–1261. doi: 10.1038/82360. [DOI] [PubMed] [Google Scholar]
- Soinov LA, Krestyaninova MA, Brazma A. Towards reconstruction of gene networks from expression data by supervised learning. Genome Biology. 2003;4:R6. doi: 10.1186/gb-2003-4-1-r6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bornholdt S, Schuster H, Eds . Handbook of Graphs and Networks: From the Genome to the Internet. Wiley-VCH; 2003. [Google Scholar]
- van Noort V, Snel B, Huymen MA. The yeast coexpression network has a small-world, scale-free architecture and can be explained by a simple model. EMBO reports. 2004;5:280–284. doi: 10.1038/sj.embor.7400090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friedman N. Inferring cellular networks using probabilistic graphical models. Science. 2004;303:799–805. doi: 10.1126/science.1094068. [DOI] [PubMed] [Google Scholar]
- Margolin A, Nemenman I, Basso K, Wiggins C, Stolovitzky G, Dalla Favera R, Califano A. ARACNE: an algorithm for the reconstruction of gene regulatory networks in a mammalian cellular context. BMC Bioinformatics. 2006;7:S7. doi: 10.1186/1471-2105-7-S1-S7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Werhli A, Grzegorczyk M, Husmeier D. Comparative evaluation of reverse engineering gene regulatory networks with relevance networks, graphical gaussian models and bayesian networks. Bioinformatics. 2006;22:2523–31. doi: 10.1093/bioinformatics/btl391. [DOI] [PubMed] [Google Scholar]
- Barabasi AL, Oltvai ZN. Network Biology: Understanding the Cell's Functional Organization. Nature Reviews. 2004;5:101–113. doi: 10.1038/nrg1272. [DOI] [PubMed] [Google Scholar]
- Kitano H. Biological robustness. Nat Rev Genet. 2004;5:826–37. doi: 10.1038/nrg1471. [DOI] [PubMed] [Google Scholar]
- Stelling J, Sauer U, Szallasi Z, Doyle F, III, Doyle J. Robustness of Cellular Functions. Cell. 2004;118:675–685. doi: 10.1016/j.cell.2004.09.008. [DOI] [PubMed] [Google Scholar]
- Kitano H. Towards a theory of biological robustness. Mol Syst Biol. 2007;3:137. doi: 10.1038/msb4100179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Albert R, Jeong H, Barabasi AL. Error and attack tolerance of complex networks. Nature. 2000;406:378–482. doi: 10.1038/35019019. [DOI] [PubMed] [Google Scholar]
- Li F, Long T, Lu Y, Ouyang Q, Tang C. The yeast cell-cycle network is robustly designed. Proc Natl Acad Sci USA. 2004;101:4781–6. doi: 10.1073/pnas.0305937101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ingolia N. Topology and robustness in the Drosophila segment polarity network. PLoS Biol. 2004;2:e123. doi: 10.1371/journal.pbio.0020123. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klemm K, Bornholdt S. Topology of biological networks and reliability of information processing. PNAS. 2005;102:18414–18419. doi: 10.1073/pnas.0509132102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilhelm T, Behre J, Schuster S. Analysis of structural robustness of metabolic networks. Syst Biol. 2004;1:114–120. doi: 10.1049/sb:20045004. [DOI] [PubMed] [Google Scholar]
- Kauffman S. Metabolic stability and epigenesis in randomly constructed genetic nets. Journal of Theoretical Biology. 1969;22:437–467. doi: 10.1016/0022-5193(69)90015-0. [DOI] [PubMed] [Google Scholar]
- Kauffman S. Origins of Order: Self-Organization and Selection in Evolution. Oxford University Press; 1993. [Google Scholar]
- McAdams HH, Arkin A. Stochastic Mechanisms in Gene Expression. Proc Natl Acad Sci USA. 1997;94:814–819. doi: 10.1073/pnas.94.3.814. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tu Y, Stolovitzky G, Klein U. Quantitative noise analysis for gene expression microarray experiments. Proc Natl Acad Sci USA. 2002;99:14031–6. doi: 10.1073/pnas.222164199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wagner A. Robustness against mutations in genetic networks of yeast. Nature Genetics. 2000;24:355–61. doi: 10.1038/74174. [DOI] [PubMed] [Google Scholar]
- Wagner A. Robustness, Neutrality, and Evolvability. FEBS Letters. 2005;579:1772–1778. doi: 10.1016/j.febslet.2005.01.063. [DOI] [PubMed] [Google Scholar]
- Wagner A. Robustness and Evolvability in Living Systems. Princeton University Press; 2007. [Google Scholar]
- Emmert-Streib F, Dehmer M. Fault Tolerance of Information Processing in Gene Networks. Physica A. 2009;388:541–548. doi: 10.1016/j.physa.2008.10.032. [DOI] [Google Scholar]
- Norris J. Markov Chains. Cambridge University Press; 1998. [Google Scholar]
- Gallager R. Information Theory and Reliable Communication. Wiley, New York; 1968. [Google Scholar]
- MacKay D. Information theory, inference and learning algorithms. Cambridge University Press; 2003. [Google Scholar]
- Shannon C, Weaver W. The Mathematical Theory of Communication. University of Illinois Press; 1949. [Google Scholar]
- Dehmer M, Emmert-Streib F. The Structural Information Content of Chemical Networks. Zeitschrift für Naturforschung A. 2008;63a:155–158. [Google Scholar]
- Dehmer M, Borgert S, Emmert-Streib F. Entropy Bounds for Hierarchical Molecular Networks. PLoS ONE. 2008;3:e3079. doi: 10.1371/journal.pone.0003079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luscombe N, Badu M, Yu H, Snyder M, Teichmann S, Gerstein M. Genomic analysis of regulatory network dynamics reveals large topological changes. Nature. 2004;431:308–312. doi: 10.1038/nature02782. [DOI] [PubMed] [Google Scholar]
- Yu H, Kim P, Sprecher E, Trifonov V, Gerstein M. The importance of bottlenecks in protein networks: Correlation with gene essentiality and expression dynamics. PLoS Computational Biology. 2007;3:e59. doi: 10.1371/journal.pcbi.0030059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Giaever G, et al. Functional profiling of the Saccharomyces cerevisiae genome. Nature. 2002;418:387–391. doi: 10.1038/nature00935. [DOI] [PubMed] [Google Scholar]
- Kullback S, Leibler R. On information and sufficiency. Ann Math Stat. 1951;22:79–86. doi: 10.1214/aoms/1177729694. [DOI] [Google Scholar]
- Kullback S. Information theory and statistics. Wiley, New York; 1959. [Google Scholar]
- Sheskin DJ. Handbook of Parametric and Nonparametric Statistical Procedures. 3. RC Press, Boca Raton, FL; 2004. [Google Scholar]
- Dijkstra E. A note on two problems in connection with graphs. Numerische Math. 1959;1:269–271. doi: 10.1007/BF01386390. [DOI] [Google Scholar]
- Deutscher D, Meilijson I, Schuster S, Ruppin E. Can single knockouts accurately single out gene functions. BMC Systems Biology. 2008;2:50. doi: 10.1186/1752-0509-2-50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Orphanides G, et al. The chromatin-specific transcription elongation factor FACT comprises human SPT16 and SSRP1 proteins. Nature. 1999;400:284–288. doi: 10.1038/22350. [DOI] [PubMed] [Google Scholar]
- Emmert-Streib F, Dehmer M, Eds . Information Theory and Statistical Learning. Springer, New York; 2008. [Google Scholar]