

Abstract
Three experiments examine how the peripheral visual field (PVF) mediates the development of spatial representations. In Experiment 1 participants learned and were tested on statue locations in a virtual environment while their field-of-view (FOV) was restricted to 40°, 20°, 10°, or 0° (diam). As FOV decreased, overall placement errors, estimated distances, and angular offsets increased. Experiment 2 showed large compressions but no effect of FOV for perceptual estimates of statue locations. Experiment 3 showed an association between FOV size and proprioception influence. These results suggest the PVF provides important global spatial information used in the development of spatial representations.
Keywords: visual field loss, peripheral visual field, spatial representation, memory-guided walking, distance perception
Previous studies have provided valuable information about the quality of visual spatial representations used for task completion (Aivar et al., 2005; Hayhoe et al., 2003; Hollingworth & Henderson, 2002; Irwin & Zelinsky, 2002), the neurological basis of spatial representations (Burgess, 2006; Committeri et al., 2004; Epstein & Kanwisher, 1998; Hartley et al., 2003; Shelton & McNamara, 2001), and the effect of environmental conditions on their development (Cutting & Vishton, 1995; Norman et al., 2005; Sheth & Shimojo, 2001; Wu et al., 2004). However, there is another important factor that has received little attention: the role different regions of the visual field play in mediating the type of information that is processed and the way in which this processing occurs. The topography of the retina, which is composed of rods and cones, is known to vary systematically with distance from the fovea (Osterberg, 1935). Based on the changing ratio of rods to cones, the human visual field is often divided into two components: the central visual field and the peripheral visual field. For the purposes of this study the central visual field is defined as the area within 10° eccentricity of the fovea and the peripheral visual field as the remaining region of the visual field, based on the model proposed by Bishop (1971).
To date, a few studies (Creem-Regehr et al., 2005; Wu et al., 2004) have been conducted looking at the role of field of view (FOV) size on the representation of distance via the use of field restricting goggles. Yet, field restricting goggles can only control the amount of visual stimulation at any given point in time and not where that stimulation is occurring upon the retina. There are, however, two studies which have explicitly tested the influence of the central and peripheral visual fields on the nature of spatial localization during online perception. The first, completed by Turano & Schuchard (1991), had participants with normal vision, peripheral field losses, or central field losses make relative distance judgments while sitting in one location. Results of this study found that participants with either type of field loss exhibited higher levels of spatial localization error than normal vision participants. However, due to the fact that multidimensional scaling was used to analyze the data, it is not possible to determine whether there were any systematic trends in the errors exhibited by the participants with field losses. The second study (Temme et al., 1985) examined perceived eccentricity in observers with normal vision and observers with early stages of retinitis pigmentosa (RP), a retinal disease that leads to peripheral field losses. Using a Goldmann perimeter to measure the perceived eccentricity of flashes of light, Temme and colleagues discovered that the eccentricity participants perceived to be 25% of the distance from fixation to the boundary of their visual fields was in fact a magnification of the true eccentricity. More importantly, however, the true eccentricity was significantly different between the two groups, with normal-vision participants judging points lying 16% of the distance from fixation to reside at the quarter mark while similar judgments were made by the participants with RP for points lying only 8% of the distance from fixation. In other words, decreasing visual field size led to an expansion of space around the point of fixation.
Understanding the role that the central and peripheral visual fields play in the development of spatial representations is important for three reasons. First, spatial information is processed and/or perceived differently depending on the region of the retina where it is received (Banks et al., 1991; Goldstein, 2002; Mullen et al., 2005). The loss of one region may therefore alter the initial development of any spatial representation. Second, the central and peripheral visual fields also differ in terms of their cortical representations in primary occipital cortex (Horton & Hoyt, 1991; Johnston, 1986; Wandell et al., 2005) and in higher processing areas such as the dorsal and ventral visual streams (Baizer et al., 1991; Portin & Hari, 1999; Stephen et al., 2002). Thus, loss of the peripheral visual field may not only lead to sensory deficits, it may also affect the development of spatial representations over time leading to increased distortions in spatial representations that are not apparent in perception. Finally, it is known that individuals with peripheral visual field losses from retinal diseases show marked deficits in their ability to carry out daily life activities, such as driving a car or navigating in unfamiliar environments (Szlyk et al., 1997; Turano et al., 1998). Understanding any systematic changes in spatial representations following loss of the peripheral visual field may help to shed light on the mechanisms underlying such deficits.
The current study sought to investigate the effect that decreasing visual field size has on the nature of short-term spatial representations of objects within a three-dimensional environment. In order to do so it was necessary to create a new paradigm in which the amount of stimulation to the central and peripheral visual fields could be systematically controlled. The solution to this problem involved the use of an immersive virtual reality system that allows for gaze-contingent FOV masking while still allowing participants the ability to move around the environment. A virtual replication of the laboratory was created in order to provide participants with a familiar sense of scale within the virtual environment and six replicas of the same statue, each differing in terms of size and color, were placed throughout the room. The degree to which the participants’ peripheral visual fields were stimulated was systematically controlled by restricting each participant’s FOV to one of four sizes (0°, 10°, 20°, or 40° in diameter) throughout the experiment. Thus, by the operational definition used in the present study, participants in the 10° FOV condition were required to complete the task with only their central visual field while participants in the 20° and 40° FOV conditions were afforded the use of part of their peripheral visual fields. The group with a 0° FOV served as a control group. After learning the locations of the statues by walking around the environment, the statues were removed and participants were required to walk to the locations they believed each statue had been located using the same FOV restriction that they had during the learning phase. Given the results of studies in which participants walk without vision to remembered target locations (Loomis et al., 1992; Loomis & Knapp, 2003), this method should result in spatial representations approaching a Euclidean metric under full FOV conditions as all statues were located within 13m of the starting position and external visual cues provided by the global structure of the environment were available throughout the testing phase. However, based on results from studies investigating the effects of peripheral field losses on perceptual spatial localization ability (Temme et al., 1985; Turano & Schuchard, 1991), it was predicted that decreases in FOV would lead to increasingly distorted representations of the statue locations.
EXPERIMENT 1
Methods
Participants
Twenty-eight healthy volunteers (seventeen women) participated in the current study. The mean age of the participants was 29 years old (SD = 9.23), with a range of 20 to 53 years old. No participant had any ocular diseases or muscular-skeletal disorders. All participants were compensated for their time and this research followed the tenets of the Declaration of Helsinki.
Visual function (visual acuity and contrast sensitivity) was tested binocularly with participants wearing their normal corrective lenses to ensure each participant had normal vision. The pupillary distance of each participant was measured and used to adjust the position of the displays in the headset to obtain a stereo view of the environment.
Stimuli
An immersive virtual replication of the laboratory (see Fig. 1) was created using 3D Studio Max software (Discreet, Montreal, CANADA). The replication was used in order to give the participants a familiar sense of scale in the environment and to prevent the experimenter from having to interfere with the participant’s walking patterns during the testing phase, as all of the walls and support columns present in the real laboratory were represented in the same locations in the virtual environment. Six copies of the same statue were used as targets. The statues all differed in their size, ranging from 1.6m to 3m tall, and in their colors. In order to assure their colors were easily discriminable, the statues were colored red, purple, dark blue, cyan, green, and yellow, corresponding to the three primary hues and their complements (Palmer, 1999). The statues were placed throughout the environment and their distance from the starting position ranged from 2.7m to 11.1m. The program was exported to a graphics engine developed in-house with C++ and Microsoft’s DirectX. The graphics program used the output from a HiBall head tracker (3rd Tech, Chapel Hill, NC) attached to the top of the head-mounted display (HMD) together with the imported scene to determine the subject’s current point of view in the environment. Perspective views of the environment were displayed in the HMD using a GeForce FX graphics board (nVIDIA, Santa Clara, CA).
Figure 1. The virtual environment.
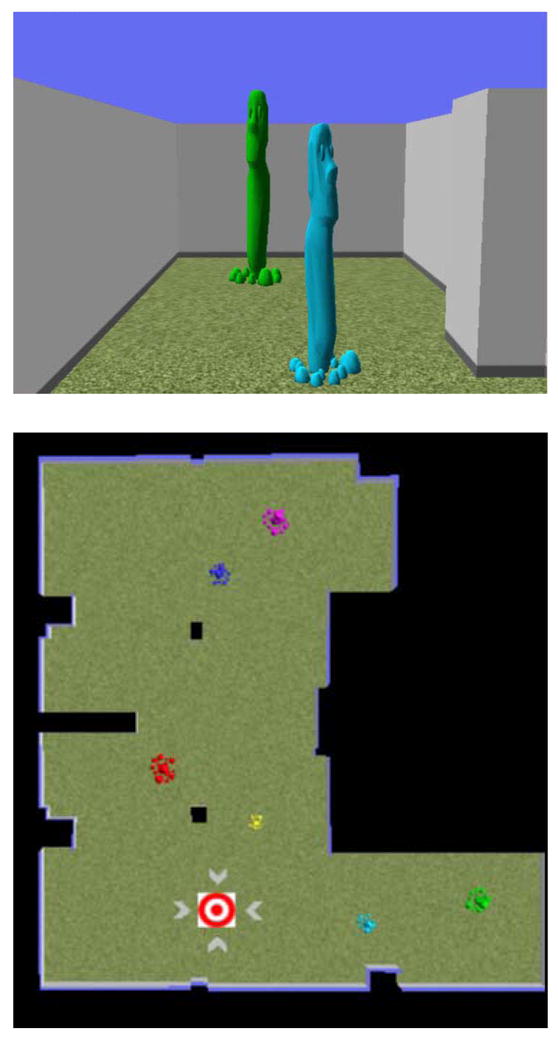
The top panel shows a first-person view of one end of the environment. The bottom panel shows a top-down view of the environment. The starting position is the red and white bull’s-eye and the two black rectangles represent support columns that were present in the real and virtual environments.
FOV restrictions of 40°, 20°, or 10° (diameter) were created using the gaze-contingent display concept of Geisler and Perry (2002) together with the programmable functionality of the nVIDIA GeForce FX5900 GPU (software by co-author JH; see (Fortenbaugh et al., in press). A mask of a certain visual field size was created as a monochrome bitmap, where the intensity of each pixel indicated the degree to which the view was blurred at that point. The center position of the mask was tethered to the participant’s center of gaze, which was determined from an online analysis of the participant’s eye images. The mask was partitioned into 8 grey level bins, and the 2D perspective view of the scene was down-sampled iteratively to produce a corresponding set of 8 increasingly blurred images, which were multiplied with the mask levels and combined to produce the final image.
Apparatus
Head and eye tracking
A HiBall-3000 Optical Tracker (3rd Tech, Chapel Hill, NC) was used to monitor head position and orientation. Infra-red LEDs were housed on the ceiling tiles of the testing room and their signals were detected by optical sensors mounted in a holder that was attached to the top of the headset. Head position and orientation were sampled every 7ms. Tracker resolution is reported to be 0.2mm, with an angular precision less than 0.03°. The output of the head tracker was filtered using an exponential smoothing function with an 80ms time constant. Point of view was calculated from the head position and orientation data collected. Daubechies wavelet transform of the sixth order, Db6 (Ismail & Asfour, 1999), was applied to the data from the head-tracker to filter out the oscillations associated with gait and to determine walking path.
Eye tracking was performed using software developed in-house by co-author LH on the output of cameras housed within the headset in front of each eye. The sampling rate of the eye tracking system is 60Hz and the average spatial variability has been measured at 0.52°. To minimize processing time, pupil tracking was performed with the identification of the centre of mass of a threshold value within a specified region-of-interest. A 5-point calibration was performed prior to beginning the learning phase. This involved presenting the participants with a screen containing five crosses, one at the center and one by each corner of the screen. Participants made fixations to each cross and this position was recorded. Drift-correction calibrations were performed every few minutes or as needed during the experiment by waiting until the participant returned to the starting position during the task and then briefly showing the calibration crosses and having the participant fixate on the center cross. As the participants’ eyes were displayed on a computer screen throughout testing, it was possible to continuously monitor movement of the headset.
Head-mounted display
The display device was a head-mounted display system (a modified Low Vision Enhancement System developed by Robert Massof at the Wilmer Eye Institute). The headset contained two color microdisplays (SVGA, 800 × 600 3D OLED Microdisplay, Emagin Corp). Each display was 51° (H) × 41° (V), with spatial resolution approximately 0.06°/pixel. The displays have a refresh rate of 60 Hz. Spatially offset images were sent to each display producing a stereo view with 100% overlap.
Design and Procedure
After visual testing was completed, the participants were brought into the laboratory and fitted with the headset. In order to assure that the participants were able to fuse the images, a blank screen with a red dot in the center was shown. Participants adjusted the resolution for each screen and the experimenter adjusted the placement of each screen in front of the participants’ eyes until the participants successfully fused the two dots. Participants were asked to point in the direction of the dot in order to check that they perceived the dot at their midlines (i.e. that the headset was centered in front of their eyes). All of the participants except those in the 0° FOV control group were given three practice trials in an unrelated environment in order for them to become accustomed to walking in a virtual environment and help recalibrate their motor systems to any perceptual distortions resulting from the virtual reality system. The practice trials were completed without any FOV restriction, thereby only allowing participants to accommodate to being in an immersive virtual environment and not the loss of their peripheral vision.
A between-subjects design was used to prevent any order effects from occurring. After the practice trials were completed, the participants were led to the starting position by the experimenter, and the initial calibration for the eye tracking was performed (with the exception of the blind-walking control group who performed the entire task without any images on the display). The starting position was marked on the floor with a red and white bulls-eye that was visible throughout the experiment and could serve as a cue to the starting position. All participants were told to pay attention to both the environment and the objects located within it as they would be asked about them later. Participants were also informed that when they walked to a statue they should walk to the center (inside) of each statue at which point the display of the headset would begin flashing the color of the statue.
The experiment consisted of a Learning Phase and a Testing Phase (see Table 1). During the Learning Phase participants completed a predetermined walking path. First, the participants walked from the starting position to each statue and back, in order to learn where the statues were located relative to the starting position. Then the participants walked from each statue to every other statue and the starting position such that each distance was traversed exactly once. This gave the participants a chance to learn where the statues were located relative to one another. For the latter part, two distinct walking patterns were used and alternated across participants within each of the four FOV conditions tested. Participants in the blind-walking control group were led along the exact same paths as the participants in the other groups by one of the experimenters. At each stop the experimenter said the name of the object at that location (either the color of the statue or “the starting position”). To assure that the participants walked to the correct locations, the experimenters monitored the current position of the participants in the virtual environment on two monitors in the laboratory.
Table 1.
Outline of Experimental Designs
| Learning Phase | Number of Statues | Response Type | Effect of FOV? | |
|---|---|---|---|---|
| Experiment 1 | Walk | 6 | Walk | Yes |
| Experiment 2 | Stand | 6 | Verbal | No |
| Walk | 1 | Blind Walk | No | |
| Experiment 3 | Stand | 6 | Blind Walk | Yes |
| Walk | 6 | Blind Walk | No |
Once the Learning Phase was completed, the participants were turned away from the statues and the experimenter pressed a button to make the statues disappear. The participants were then turned back to the starting orientation and required to walk out from the starting position and stand where they thought each statue had been located in a predetermined order. After walking to each location the participant stood still and told the experimenter that they were standing in the correct location, at which time the experimenter pressed a button to make the statue appear in that location and to record the location of the statue. After placing each statue the participants returned to the starting position and orientation before placing the next statue. Again, the participants in the blind-walking control group performed the same task as participants in the other conditions. However, the experimenter led the participants in this condition back to the starting position and orientation after placing each statue. An experimenter walked next to the participants throughout the experiment to assure that they did not walk too close to any of the walls in the real environment. No participant had to be redirected by an experimenter during the Testing Phase. Two orders for placing the six statues were alternated across participants in each of the four FOV conditions tested. After all six statues had been placed the participants had the opportunity to move any of the statues they thought were incorrectly located. This was done in order to allow the participants to use the statues as reference points for one another and to help prevent any order effects from occurring due to the fact that statues early in the pattern were placed without the benefit of the other statues being visible.
Results
Behavioral Measures
Figure 2 shows the average estimated locations of the six statues for the four FOV sizes tested. Placement errors, the distance between the estimated statue location and the true statue location, were calculated for each statue. A one-way ANOVA calculated for mean placement errors with FOV as a between-subjects factor showed a significant effect of FOV, F(3,24) = 5.67, p < 0.01. A trend analysis showed a significant linear relationship with placement errors increasing monotonically with decreasing FOV size, F(1,2) = 14.67, p < 0.01.
Figure 2. Behavioral measures for Experiment 1.

Mean estimated locations of the six statues for each of the four FOV conditions tested. The black square is the starting position and the black circles represent the true statue locations. Error bars represent ±1 SEM.
As distance estimates are the most common measure used in studies examining the metric of visual space (Creem-Regehr et al., 2005; Loomis et al., 1992; Loomis & Knapp, 2003; Philbeck et al., 2004; Wagner, 1985), the placement errors were converted into polar coordinates with the starting position as the origin and two measures were assessed: distance errors and angular offset errors relative to the starting position. Distance errors were defined as the difference between the estimated distance and the true distance from the starting position to each statue. As previous research (Wagner, 1985) has shown that errors in perceptual estimates increase with distance from an observer and all statue location estimates were made from the starting position, the statues were also divided into two groups: Near-Space statues (the three closest statues under 5m from the starting position) and Far-Space statues (the three farthest statues over 7m from the starting position). This allowed for the inspection of a FOV × Distance interaction while controlling for the location of the statues relative to the global structure of the environment. The mean distance errors for the four FOV sizes tested for the Near- and Far-Space statues are shown in Figure 3a. A 4(FOV) × 2(Statue Distance) mixed-design ANOVA calculated for the distance errors showed the same pattern of results seen for placement errors with a significant effect of FOV, F(3,24) = 3.36, p = 0.04. Also, a significant effect of Statue Distance was observed, F(1,24) = 48.82, p < 0.01. The FOV × Statue Distance interaction did not reach significance, F(3,24) = 2.89, p = 0.06, but inspection of Figure 3a shows a tendency for distances to the statues to be increasingly underestimated as FOV decreases for the Far-Space statues but not the Near-Space statues1.
Figure 3. Behavioral measures for Experiment 1.
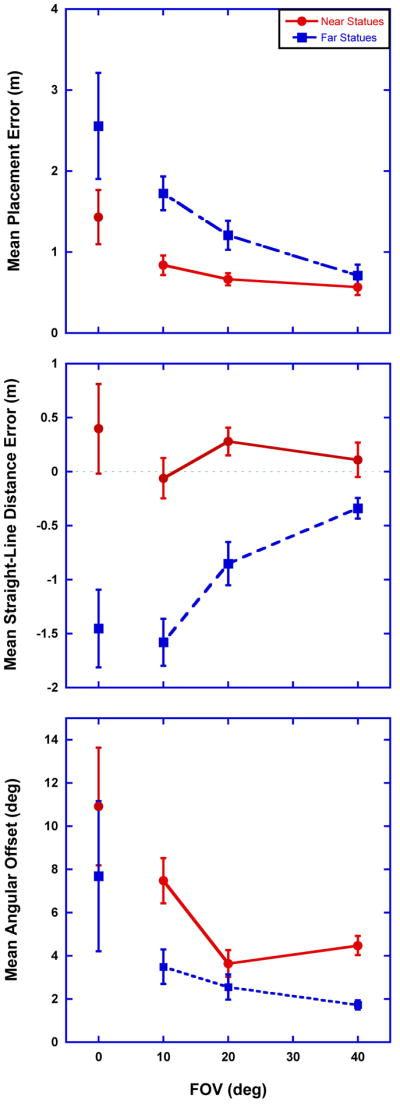

(a) Mean distance errors in meters as a function of FOV and Statue Distance (Near, Far). Positive y-values indicate an overestimation of distance and negative y-values indicate distances were underestimated. (b) Mean absolute angular offsets in degrees as a function of FOV and Statue Distance. Error bars represent ±1 SEM and FOV is in degrees of visual angle.
In order to asses whether the errors in estimated statue distances represented significant compressions, the means for the eight conditions were compared to hypothetical means of zero using a Sidak-Bonferroni correction for multiple testing (αS-B = 0.0064). Results of two-tailed t-tests showed that mean distance errors were not significantly different than zero for the Near-Space statues (p > 0.07 for all FOV sizes) but were significantly less than zero for the Far-Space statues in all FOV conditions except the 40° FOV condition (p < 0.005 for the 0°, 10°, and 20° FOV conditions; p = 0.012 for the 40° FOV condition).
Figure 3b shows the mean angular offsets for the FOV sizes tested as a function of Statue Distance. Results of another 4(FOV) × 2(Statue Distance) mixed-design ANOVA showed a significant effect of FOV, F(3,24) = 4.218, p = 0.02, with mean angular offsets increasing with decreasing FOV size. A significant increase in mean angular offsets for Near-Space statues relative to Far-Space statues was also found, F(1,24) = 10.34, p < 0.01. No FOV × Statue Distance interaction was found, F(3,24) = 0.51, p > 0.68.
Gaze Strategies
In order to investigate whether participants in different conditions attempted to compensate for the loss of their peripheral vision with different sampling strategies, all objects in the environment were classified into five groups: statues, walls, ground, columns, and sky. To control for individual differences in walking speed, and thus the number of fixations made over the course of the experiment, the proportion of fixations made to each of the five categories was calculated for every participant. Figure 4 shows the mean proportion of fixations for each category as a function of FOV for the Learning Phase. Because the data for these measures are ipsative (sum of proportions across categories must equal 1), the analyses were focused on the a priori question of changes in mean proportion of statue fixations. If participants stopped using cues from the global structure of the environment (i.e. switched from an allocentric coding strategy to a more egocentric-direction one) it was predicted that the proportion of statue fixations would increase with decreasing FOV size. Overall, the opposite pattern was observed with the proportion of statue fixations decreasing with FOV size. However, a one-way ANOVA calculated for the proportion of statue fixations did not show a significant effect of FOV, F(2,18) = 2.73, p = 0.09.
Figure 4. Gaze strategies for Experiment 1.

Mean proportion of fixations made to each of the five object categories (statues, walls, ground, columns, and sky) as a function of FOV for the Learning Phase. Error bars represent ±1 SEM and FOV is in degrees of visual angle.
Discussion
Overall, the results illustrate the important role the peripheral visual field plays in the development of spatial representations and demonstrates that increasing loss of the peripheral visual field leads to greater distortions in representations of remembered target locations as measured by overall placement errors. Further analyses showed the distortion to be present in both the representation of the distances to the statues and the statue orientations relative to the starting position. While there was no systematic distortions in the estimated distances to the Near-Space statues, distance estimates to the Far-Space statues were significantly compressed across all FOV sizes tested with the exception of the 40° FOV condition, which approached significance. This suggests a heterogeneous compression of distances that increased with the true distances to the statues. Though the increase in angular offset errors with decreasing FOV size for the Far-Space statues is consistent with this interpretation, angular offset errors were also seen to increase with decreasing FOV size for the Near-Space statues. Some angular offset error is expected from the participants’ paths due to idiosyncratic walking patterns, with larger angular offsets for the Near-Space statues for a given lateral displacement. The large angular errors seen for the 0° FOV control group can, for the most part, be attributed to the performance of one participant in particular whose angular offsets for two statues were approximately 40° and 60°. These large offsets far exceeded those of the other participants in the control group (range of 1° to 20°) and the participants in the other groups (range 0.05° to 21°). Inspection of the angular offsets errors for the Near Space statues for the 10°, 20°, and 40° FOV conditions show a much shallower increase with decreasing FOV and thus, the majority of the increase in placement errors with decreasing FOV size appears to be attributable to the heterogeneous compression of distance.
Given that the participants with smaller FOV sizes could in theory have sampled the same amount of visual information over the course of multiple fixations and the differences in gaze patterns across FOV sizes did not reach significance, the present results suggest that there is something about the information received by the peripheral visual field that is critical for the development of accurate spatial representations. What the results cannot immediately address is when in the development of spatial representations does the loss of visual input to the peripheral visual field result in distortions of the kind presently observed.
Spatial representations arise from the integration of information obtained over time, and thus, over multiple fixations. Therefore, errors observed in the representations themselves could occur either at the level of perception or in memory. As a result of this, another question that needs to be addressed is whether the measures used in the present study reveal distortions in the participants’ on-line perceptions of space while completing the task or if the observed distortions occurred later. This question is inherent in many paradigms, such as those employed by Loomis and colleagues (Loomis et al., 1993; Loomis et al., 1999; Loomis & Knapp, 2003; Philbeck et al., 2004) where participants are required to walk without vision to the remembered location of a target, and is important to consider because Sheth and Shimojo (2001) argue that visual space is compressed in memory. Specifically, Sheth and Shimojo found during a localization task that participants estimated target locations to be closer to salient landmarks or compressed target locations towards the fovea if an external landmark was absent. However, given that the participants in Sheth and Shimojo’s study viewed targets on a 2-D computer screen and were only required to briefly remember the location of one target at a time it is not clear if their results are comparable to the distortions found in the present study.
EXPERIMENT 2
In order to try and dissociate whether the distortions observed in the present study were related to perceptual deficits associated with loss of visual input to the peripheral visual field or if the distortions arose during the consolidation of visual information into a representation of the environment, a second experiment was conducted. This experiment attempted to isolate two components. First, in order to directly test whether loss of the peripheral visual field causes distortions in the on-line perception of distance, participants were required to make verbal distance and height judgments while viewing statues with one of three restricted FOV sizes. In the second part of the experiment, a blind walking paradigm (Loomis et al., 1993; Loomis et al., 1999; Loomis & Knapp, 2003; Philbeck et al., 2004) was employed in order to test whether distortions are present in memory immediately following target viewing. While it has been argued that this paradigm taps into perceptual distortions of distance, the fact that participants must walk to estimated target locations without vision suggests a memory component. Furthermore, as other researchers (Diedrichsen et al., 2004; Werner & Diedrichsen, 2002) have shown distortions in remembered target locations as soon as 50ms after viewing targets on a computer screen, it may be that distortions of target locations occur during encoding in short-term memory and, thus, should manifest by the time participants walk to a specific location.
Methods
Participants
Six healthy volunteers (three women) participated in the study. The mean age of the participants was 35 years (SD = 11.16), with a range of 24 to 52 years. As in Experiment 1, the participants reported no ocular diseases or muscular-skeletal disorders and were tested to assure that they had normal vision. The participants were compensated for their time and gave written consent.
Stimuli
The same environment as in Experiment 1 was used here. However, because a within-subject design was utilized, three unique statue configurations were created for the statues’ locations in order to prevent learning across blocks. Also, the sizes of the statues were varied in order to prevent the participants from using the relative size of the statues as a distance cue from one block to another. The heights of the statues ranged from 1.01m to 3.37m across all three configurations. To allow for direct comparison across the three configurations, each configuration was designed such that there was always a statue located 2.2m, 4m, and 6.9m away from the starting position (the remaining three statues distances varied but the distance to the starting position was always between 2m and 7.7m). For the 2.2m, 4m, and 6.9m statues, the size, color, and angular offset of the statues relative to the starting position and orientation were also varied across the three configurations. This was done to help prevent participants from noticing that certain distances were repeated.
Apparatus
The same equipment used in Experiment 1 was used here.
Design and Procedure
No practice trials were completed for this experiment and the same environment from Experiment 1 was used here. A within-subjects design was used with participants completing each of the three blocks with one of three FOV sizes (10°, 20°, or 40° deg). In each block there were six statues of different heights and colors located in the environment. Though the same six colors were used in each block, the sizes and locations of the statues varied across the blocks. Each block consisted of two tasks (see Table 1). For the first task, the participants estimated the distance to and height of each statue when prompted by the experimenter. Then, the participants were required to estimate the distance between six pairs of statues. Throughout the first part of each block, participants were allowed to move their eyes and heads freely or rotate their bodies to the right or left in order to align themselves towards a statue but they were not allowed to take a step in any direction. Participants were asked to give their estimates in feet and round their estimates to the nearest tenth or fraction of a foot (e.g. “5.5 feet” or “5 and 1/2 feet”). Participants were shown a 12″ ruler before putting on the headset and also reminded that they would be the same height in the virtual environment that they are in the real world.
For the second task, the screen of the headset was blanked. The experimenter then said the color of a statue and the environment reappeared with only that statue visible (in its original location). The participants then had 5sec to find the statue. After 5sec, the screen of the headset was blanked again and the participants were required to walk out from the starting position and stand where they thought the statue had been located. When the participant reached the estimated location they verbally signaled to the experimenter who pushed a button to record the estimated location. The experimenter then guided the participant back to the starting position and orientation. This “blind walking” was completed for the three statues that were placed 2.2m, 4m, and 6.9m from the starting position.
The order in which the FOV sizes were tested was partially-counterbalanced across participants. The order in which the three statue configurations were paired with the three FOV sizes tested was controlled such that each FOV size was tested with each configuration twice.
Results
Perceptual Estimates
Figure 5a shows the mean errors for the distance estimates as a function of FOV and Statue Distance. A 3 (FOV) × 2 (Statue Distance) repeated-measures ANOVA was calculated on the mean distance errors using the same Near Space versus Far Space criterion established in Experiment 1. The FOV × Statue Distance interaction, F(2,10) = 0.39, p = 0.69 was not significant and there was no main effect of FOV, F(2,10) = 0.95, p = 0.42. A significant effect of distance was found with larger underestimations for the three Far-Space statues than the three Near-Space statues, F(1,5) = 19.76, p < 0.01. In order to assess whether the mean distance errors were significant compressions of the true distances, the means were compared to hypothetical means of zero using two-tailed t-tests and a Sidak-Bonferroni correction for multiple testing (αS-B = 0.0085). In all six conditions significant compressions of distances were observed (p < 0.002 for all).
Figure 5. Experiment 2.

(a) Mean distance errors in meters for the perceptual estimates as a function of FOV and Statue Distance. (b) Mean height errors in meters for the perceptual estimates as a function of FOV and Statue Distance. (c) Mean errors in meters for the perceptual estimates of distances between pairs of statues as a function of FOV. (d) Mean placement errors in meters for the three blind-walks as a function of Statue Distance and FOV. Error bars represent ±1 SEM and FOV is in degrees of visual angle.
Figure 5b shows the mean errors for the height estimates as a function of FOV and Statue Distance. A 3 (FOV) × 2 (Statue Distance) repeated-measures ANOVA was calculated on the mean height errors. No FOV × Statue Distance interaction was found, F(2,10) = 0.56, p = 0.59. There was also no main effect of FOV, F(2,10) = 1.54, p = 0.26, or Statue Distance, F(1,5) = 1.30, p = 0.31. Tests of the mean height errors against hypothetical means of zero using two-tailed t-tests and a Sidak-Bonferroni correction for multiple testing (αS-B = 0.0085) showed no evidence for systematic errors in height estimates (p > 0.40 for all conditions).
Figure 5c shows the mean errors for the judgments of the distances between pairs of statues as a function of FOV. A repeated-measures ANOVA was calculated for the mean distance-between errors across the three FOV sizes tested. No effect of FOV was found, F(2,10) = 0.157, p = 0.86. When tested against hypothetical means of zero using two-tailed t-tests and a Sidak-Bonferroni correction for multiple testing (αS-B = 0.017), significant compressions of the estimated distances between statues was found for all three FOV sizes (p < 0.01 for all).
Path Integration
Figure 5d shows the mean placement errors for the three blind walks completed by the participants. A 3 (FOV) × 3 (Path Distance) repeated-measures ANOVA was run on the placement errors for all nine conditions. No interaction was found between FOV and Path Distance, F(4,20) = 1.95, p = 0.14. There was no main effect of FOV, F(2,10) = 0.35, p = 0.71, but there was a main effect of Path Distance, F(2,10) = 11.98, p < 0.01, with placement errors increasing as the true distance increased.
Interestingly, when the placement errors were broken into distance errors and angular offset errors, no main effects of FOV and Path Distance or FOV × Path Distance interactions were found (p > 0.10 for all). The mean distance errors for each condition were tested against a hypothetical mean of zero using two-tailed t-tests and applying a Sidak-Bonferroni correction for multiple testing (αS-B = 0.006). Only the distance errors for the 2.2m statue in the 20° FOV condition was found to be significantly different than zero (p = 0.006 for 20° FOV at 2.2m statue; p > 0.02 for all others).
Discussion
The results of Experiment 2 showed no overall effect of FOV in any of the measurements taken. Significant compressions of estimated distances were observed in the perceptual judgments for distances to the statues from the starting position and distances between pairs of statues. Also, the distance errors showed the same pattern of compression observed in the first experiment, with larger underestimations for the Far-Space statues relative to the Near-Space statues. On the other hand, height estimates were found to be relatively accurate across all three fields of view tested. Collectively, these results are consistent with previous studies showing a general compression of perceptual distance estimates in virtual environments (Creem-Regehr et al., 2005; Loomis & Knapp, 2003; Messing & Durgin, 2005; Sahm et al., 2005; Witmer & Kline, 1998) and psychophysical studies in real environments showing increases in error with increasing target distances (Wagner, 1985).
During the blind-walking task only the distance estimates for the 2.2m statue for participants in the 20° FOV condition showed significant compressions. The lack of an overall effect of FOV and the general tendency for participants to underestimate the distances to the statues suggests that the compression seen in this condition is probably more related to sampling noise than any systematic differences across FOV sizes. This is not what would be predicted based on the results of previous studies using this paradigm in a virtual environment. While it is known that persons with normal vision can accurately walk to targets up to 20m away in a blind-walking task under normal viewing conditions (Loomis & Knapp, 2003), it was thought that a general compression might be observed due to the use of a virtual environment and the fact that participants were not given the chance to recalibrate their perception of distances by walking around the environment before testing. It could be that the extensive viewing time participants had while making perceptual estimates of the statue locations and the relatively close locations of the statues (all were under 7m from the starting position), may have played a role in the participants performance.
Given that the same environment and statues were used in both experiments, these results suggest that the distortions related to loss of input to the peripheral visual field seen in Experiment 1 did not solely arise from the participants’ inability to accurately perceive the locations of the targets within the environment. However, due to the differences between the tasks used in the two experiments, the possibility of perceptual distortions cannot be ruled out yet. In particular, the results from a study (Wu et al., 2004) using goggles to restrict FOV (i.e. creating head-based FOV restrictions as opposed to eye-based FOV restrictions) suggest that when participants are required to make distance judgments without the use of head movements, estimates show significant compressions. However, when participants are allowed to systematically sample the ground surface texture on a flat terrain from near to far (i.e. close to their feet and then out to the target along a radial line) distance estimates are accurate out to a distance of 20m. While the nature of the restrictions in Wu et al.’s (2004) experiment and the present study are fundamentally different, it is possible that by using similar strategies participants in Experiment 2 were able to compensate for any compression that resulted from the loss of their peripheral vision. If this were the case, it might be that this difference in strategies is what led to differences in the participants’ performances in Experiment 1 and Experiment 2.
An important difference between the two paradigms used here is the number of judgments required after viewing the statues. In Experiment 1, all of the statues were removed after the Learning Phase and participants had to place the statues without viewing the original configuration again while in Experiment 2 participants either made perceptual judgments that did not require short-term memory or they completed blind walks immediately after viewing each statue individually. Recent neurological work (Todd & Marois, 2004; Xu & Chun, 2006) has found evidence that capacity limits of VSTM are related to the ability of areas in the posterior parietal cortex to encode object locations, not just the objects themselves. It could be that the increasing distortions in Experiment 1 are related to task difficulty and that VSTM capacities were more overwhelmed as FOV size decreased when six statue locations needed to be remembered rather than just one.
Finally, it could also be that the availability of proprioception feedback, either during the Learning or Testing phases of Experiment 1 played a role in the FOV effect. During the course of the Learning Phase participants walked all of the possible paths connecting the statues and starting position to one another. Under normal viewing conditions incoming visual input regarding self-motion (i.e. optic flow) is well calibrated with proprioception cues from muscles and the vestibular system and these cues can be used for assessing distances traveled (Mittelstaedt & Mittelstaedt, 2001). In Experiment 1 the mean distance errors ranged from −1.58m to −0.34m for the Far-Space statues while perceptual estimates of the distances to the Far-Space statues in Experiment 2 ranged from −2.13m to −2.39m. The large increase in compression of distance estimates in Experiment 2 may therefore represent a floor effect. If this is the case, the compression due to the lack of proprioception feedback to help recalibrate incoming visual spatial information in the virtual environment, in conjunction with the compression of distance estimates that occurs during stationary viewing, may have obscured any influence the loss of the peripheral field had on distance estimates.
EXPERIMENT 3
Given that the tasks used in the first two experiments differed in terms of the availability of proprioception cues, the number of statue locations to be remembered, and the type of response (walk, verbal, blind walk), a final experiment was conducted. This experiment controlled for both the memory-load component (6 statues) and the type of response (blind walk only) while varying the availability of proprioception cues during the Learning Phase (viewing the statues from the starting position vs. walking to their locations). This was done in order to assess whether the availability of proprioception feedback interacts with FOV size when the locations of all six statues must be remembered. Only two FOV sizes were tested (10° and 40°). A Task × FOV × Distance interaction was predicted in which the distance estimates of participants would show greater levels of compression with a 10° FOV than a 40° FOV in the Walk condition but not in the Stand condition, though errors should be larger in the Stand conditions overall. Moreover, it was predicted that distance errors would increase with Statue Distance but that this increase would be larger for the 10° FOV Walk condition than the 40° FOV Walk condition.
Methods
Participants
Eight healthy volunteers (five women) participated in the study. The mean age of the participants was 28 years old (SD = 9.27), with a range of 21 to 50 years old. As in the previous experiments, all participants reported no ocular diseases or muscular-skeletal disorders and were tested to assure that they had normal vision. The participants were compensated for their time and gave written consent.
Stimuli
The same environment from Experiment 1 was used here. Four unique configurations were created for the locations and sizes of the six colored statues. However, in each configuration, the distances from the starting position to the statues were always 2m, 3.5m, 5m, 6.5m, 8m, and 9.5m. The color and size of the statue corresponding to each distance were varied across the four configurations and the exact locations of the statues (i.e. angular offsets) were also varied. As in Experiment 2, this was done to prevent the participants from noticing that the distances to the statues from the starting position remained constant across the configurations.
Apparatus
The same equipment used in Experiment 1 was used here.
Design and Procedure
A 2(FOV) × 2(Task) × 6(Statue Distance) within-subject design was used (see Table 1). Participants learned the locations of the six statues by either viewing the statues from the starting position (Stand condition) or by walking from the starting position to the location of each statue and back (Walk condition). No practice trials were completed for this experiment. In the Stand blocks, participants were given an unlimited amount of time to learn the locations of the six statues by viewing them from the starting position. Participants were allowed to turn in any direction but could not take a step forward. In the Walk condition, participants learned the locations of the statues by walking from the starting position to the location of a statue and then returning to the starting position and orientation before walking to the next statue. Participants were told which statue to walk to and this order was held constant across participants. For both the Stand and Walk conditions, the Learning Phase was completed with the participants’ FOV restricted to either 10° or 40°. A different statue configuration was used for each condition for a total of four configurations. Across all blocks, after participants were given the opportunity to learn the locations of the statues, the displays in the headset were blanked and participants were required to walk from the starting position and stand where they thought each statue had been located. When the participants reached the estimated statue location, the position was recorded and the experimenter guided the participant back to the starting position and orientation before moving on to the next statue. This is similar to the blind-walking paradigm used in Experiment 2 except that participants were required to remember the locations of all six statues and were not given the opportunity to re-view each statue before walking to the estimated location. The Walk condition was similar to the paradigm used in Experiment 1 except that participants had to place the statues without vision in the Testing Phase.
The order in which the two FOV sizes were tested was alternated across participants, and the two task conditions (Stand, Walk) were completed before the other FOV was tested. The order in which the two task conditions were completed for each FOV was also alternated across participants. This assured that, overall, each task and FOV combination was tested an equal number of times across the four blocks and participants never completed the same task (with a different FOV) across two successive blocks. The pairing of the four statue configurations with the four conditions was partially counterbalanced across the eight participants.
Results
Figure 6 shows the mean distance errors for the Walk and Stand Conditions across the two FOV sizes. The results of a 2(FOV) × 2(Task) × 6(Statue Distance) repeated-measures ANOVA calculated on the distance errors did not show a significant three-way interaction, F(5,35) = 0.43, p = 0.83. However, a significant FOV × Task interaction was observed, F(1,7) = 7.11, p = 0.03. The greatest compressions were seen when participants completed the Stand condition with a 10° FOV, with a mean error of −1.2m, relative to the other three conditions where mean errors were all approximately −0.8m. The Task × Distance interaction was also significant, F(5,35) = 4.28, p < 0.01. The FOV × Distance interaction was not significant, F(5,35) = 1.03, p = 0.42. There was no overall effect of FOV, F(1,7) = 2.04, p = 0.20, or Task, F(1,7) = 0.61, p = 0.46. There was a significant effect of Statue Distance with participants increasingly underestimating the distances to the statues as the true statue distances increased in all conditions, F(5, 35) = 5.54, p < 0.01.
Figure 6. Experiment 3.

Mean distance errors in meters as a function of Statue Distance and FOV for the Stand and Walk conditions, respectively. Error bars represent ±1 SEM and FOV is in degrees of visual angle.
A trend analysis was performed on the mean distance errors for each task in order to examine the nature of the Task × Distance interaction. For the Walk condition, a significant linear trend was observed, F(1,7) = 26.98, p < 0.01, and this relationship did not interact with FOV, F(1,7) = 0.06, p = 0.82. In the Stand condition, there was not a significant linear trend, F(1,7) = 2.36, p = 0.17, and FOV size did not interact with the linear contrast, F(1,7) = 0.15, p = 0.71. However, there was a significant quadratic trend, F(1,7) = 5.56, p = 0.05. The interaction for the quadratic contrast of Statue Distance and FOV did not reach significance, F(1,7) = 4.43, p = 0.07.
Discussion
There are two main findings in Experiment 3. First, mean distance errors increased with the true distances to the statues in all four conditions, and the manner in which these errors occurred differed depending on how participants learned the statue locations. In particular, a linear increase in errors was observed for the Walk condition while the errors for the Stand Condition showed more of a quadratic trend, with errors increasing more rapidly across the three closest statues then leveling off across the farthest ones.
The results also indicate that the availability of proprioception cues during the Learning Phase was influential in the estimates of the statue location when participants completed the task with a 10° FOV. Considering the Walk condition, it was expected that an effect of FOV would be found as it was in Experiment 1, with participants showing the least compression of distance estimates when performing the task with a 40° FOV. Comparison of the mean distance errors in Experiment 1 and Experiment 3 (see Figures 3a and 6) suggests similar levels of compression for statues placed with a 10° FOV but larger compressions for the farther statues placed with a 40° FOV in Experiment 3 relative to Experiment 1. Given that the major difference between the two experiments is that the statues in Experiment 1 were placed with vision, even though FOV was restricted, it appears that the deficit in the performance of the participants when completing the task with a 40° FOV in Experiment 3 is most likely attributable to the lack of visual information during the Testing Phase. In turn, this would suggest that the FOV effect found in Experiment 1 was due, in part, to the participants in the 40° FOV condition using visual information about the global structure of the environment while participants in the 10° FOV condition did not.
The distance errors observed in the Stand condition are also consistent with the distance errors for the blind walks completed in Experiment 2. In Experiment 2, the range of the distances tested was between 2m and 7m and comparison of Figures 5d and 6 shows a similar range of compressions over these distances. The main difference between the Stand condition in Experiment 3 and the blind walks performed in Experiment 2 is the number of statue locations the participants had to keep in memory, with each statue being shown individually prior to the blind walk in Experiment 2 while the locations of all six statues had to be remembered while placing the statues in Experiment 3. The comparable performances of participants these conditions suggests that the increased difficulty associated with holding multiple statue locations in memory cannot account for the lack of an effect of FOV size in the Experiment 2.
General Discussion
Collectively, the results of Experiment 1 showed that loss of input to the peripheral visual field leads to systematic distortions in representations of object locations, and in particular, that decreasing FOV size led to heterogeneous compressions of estimated distances that increased with the true distances to the statues. Further analyses of the gaze patterns of participants showed no significant effect of FOV though the overall mean proportion of statue fixations tended to decrease with FOV size while the proportion of wall fixations increased. This suggests that the distortions in remembered statue locations cannot be accounted for by participants switching from an allocentric coding strategy to a more egocentric-direction strategy when learning the locations of the statues. The results of Experiment 2 showed large compressions in verbal estimates of the distances to the statues when movement was restricted during the Learning Phase, suggesting an important role for proprioception feedback in estimating distances when input to the peripheral visual field is restricted. Moreover, results of Experiment 3 in conjunction with the lack of any significant difference in gaze patterns across FOV sizes during the Learning Phase in Experiment 1 suggest that the superior performance of participants in the 40° FOV condition in Experiment 1 may also have resulted from their use of visual cues provided by the global structure of the environment during the Testing Phase. Given that participants in the 10° FOV condition could have sampled the same visual information over multiple fixations, this suggests that one of the functions of the peripheral visual field is to provide information about the global structure of an environment within each fixation.
There are several possible reasons why the availability of global spatial information from the peripheral visual field might be important for the creation of veridical spatial representations. For example, it is possible that the loss of peripheral vision disrupted the ability of participants in Experiment 1 to execute effective visual searches of the environment. Research on visual search in natural settings has found that visual search patterns are influenced by both bottom-up and top-down processes, such as saliency and context (Brockmole & Irwin, 2005; Chun & Jiang, 1999; Hamker, 2004; Itti et al., 1998; Jiang & Chun, 2001; McPeek et al., 2000; Oliva et al., 2004; Turano et al., 2003; Wolfe, 2003). In order for volitionally driven eye movements to be made in a systematic manner during visual search, individuals need to be able to attend to areas in the parafovea or periphery (Henderson et al., 1989; Kowler & McKee, 1987; Peterson et al., 2004). Based on this theory, it may be that eliminating the peripheral visual field degraded the participants’ abilities to plan effective visual search patterns by reducing the size of the area that participants’ could preview before making future eye movements. As a result of this, the successive pattern of fixations that was stored in VSTM may not have been coherent enough for participants to accurately determine the locations of objects in space relative to each other and to the global structure of the environment.
However, comparison of the participants’ performances across Experiments 1 and 3 suggests that disruptions in visual search patterns following peripheral field loss is unlikely to be the critical mechanism driving the distortion observed in the present study. If one assumes that visual search patterns were increasingly disrupted for participants with smaller FOV sizes during the Learning Phase (i.e. when statue locations were being encoded in memory), the visual search patterns of participants with 40° FOV sizes should have been minimally disrupted. Yet, it was found that the mean distance errors of participants with 10° and 40° FOV sizes were comparable in Experiment 3. Moreover, any disruption in visual search patterns present during the Learning Phase would also be present during the Testing Phase. Thus, if the distortions observed in the performance of participants with 40° FOV sizes in Experiment 3 was attributed to disruptions in visual search patterns during the Learning Phase, one would expect to see comparable distortions even if visual input is available during the Testing Phase, as it was in Experiment 1, unless some other factor was mediating the influence that visual search patterns had on the development of the participants’ spatial representations.
Another possibility is that performance was impacted by the amount of spatial information obtained at any point in time rather than the particular sequence of fixations over time. In order to successfully bind information across successive fixations to create cohesive representations of the external environment two things must occur. First, the system responsible for completing this process must be able to store information from past fixations in VSTM to build up the representation. Second, the system must be able to monitor where the eye currently is and where the eye was prior to the saccade in order to know where the stored pieces of information fit relative to one another. Given the large amount of visual information that could be obtained within a single fixation, it is unlikely that all of the information received by the visual system is stored. In agreement with this view, a recent study by Brockmole and Irwin (2005) suggests that only certain objects and the spatial relationship of these objects relative to each other are stored in VSTM. Based on the results of Experiments 2 and 3, it appears that the distortions observed in Experiment 1 arose from difficulties in storing the locations of the statues within the environment and this can be explained by a reduction in the amount of information that can be used to connect one fixation to the next. An analogy for this would be putting a puzzle together. Whereas the edge pieces of a puzzle provides an absolute framework, or boundary, in which all other pieces can be placed in relation to, the peripheral visual field can be thought of as providing both an edge and a background to visual space. Though attention may be closely tied to the point of fixation and visual information is degraded as eccentricity increases, the awareness of space in the peripheral visual field may provide humans with a spatial framework in which to place the content of the current fixation.
Under this view, the resulting visual spatial representations of participants with larger FOV sizes would benefit from either a more accurate representation of the locations of the statues themselves relative to the starting position and/or the inclusion of more of the global structure of the environment within the spatial representation to serve as landmarks during retrieval. The performance of the participants with 40° FOV sizes in Experiment 3 suggests that the latter alternative is more plausible as one would expect similar performances for these participants relative to the participants with 40° FOV sizes in Experiment 1 if their representations of the statue locations were not coupled with visual cues in the environment, though both could certainly be applicable.
Previous studies (Intraub, 2002; Intraub et al., 2006; Intraub & Richardson, 1989) on memory for pictures of natural scenes have shown a robust tendency for participants to remember more of a scene’s background than was originally present during encoding, a phenomenon called boundary extension. It has been suggested that boundary extension is an adaptive, automatic process that may aid the development of cohesive visual spatial representations from discrete samples (i.e. fixations) of the environment (Intraub et al., 2006). What is of interest to the present study is the implication from the boundary extension literature that the visual system uses heuristics about the stability and continuity of an external environment to extrapolate beyond the limits of current sensory input. In other words, while the amount of external visual information received within a single fixation differed across the FOV sizes tested here, the awareness of the participants that the environment persisted in a stable and continuous manner beyond their current view did not. Thus, it may be that while the on-line perception of the statue locations did not differ across FOV sizes, as shown by the results of Experiment 2, the resulting spatial representations that the participants relied on to place the statues in the testing phases of Experiments 1 and 3 may have contained unique distortions that were dependent on FOV size, with participants in the 10° FOV conditions extrapolating more of the space around the statue locations and thus failing to incorporate changes in the true global structure of the environment that could be used as landmarks in the Testing Phases. However, given the design of the present study it is not possible to determine whether the incorporation of landmarks and other global aspects of an environment are inherently more difficult to incorporate into a spatial representation when FOV size is reduced or if the nature of the tasks used and the instructions given to the participants influenced the types of information they attended to. More work is needed in this area to determine the relationship between FOV size and the ability to encode global spatial information.
In conclusion, the results of the present study demonstrate the important role the peripheral visual field plays in creating spatial representations and point to the need for further research to investigate the mediation of incoming spatial information across the retina. For while the central visual field may play a starring role in many aspects of visual processing, when it comes to representing the external world in a cohesive fashion and creating the spatial representations that allow humans to effectively interact with their environments, the peripheral visual field is by no means an expendable player.
Acknowledgments
The authors would like to thank Thomas Wickens for helpful comments on the data analysis. This work was funded by a grant from NIH/National Eye Institute EY07839 to author K.A.T.
Footnotes
It should be noted that when all of the behavioral measure analyses in this experiment were calculated with the data from the blind control group excluded, the FOV × Statue Distance was found to be significant for the mean distance errors (F(2,18) = 5.05, p = 0.02). The significance of the results from all other analyses did not change.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Aivar MP, Hayhoe MM, Chizk CL, Mruczek REB. Spatial memory and saccadic targeting in a natural task. Journal of Vision. 2005;5(3):177–193. doi: 10.1167/5.3.3. [DOI] [PubMed] [Google Scholar]
- Baizer JS, Ungerleider LG, Desimone R. Organization of visual inputs to the inferior temporal and posterior parietal cortex in macaques. The Journal of Neuroscience. 1991;17:166–190. doi: 10.1523/JNEUROSCI.11-01-00168.1991. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Banks MS, Sekuler AB, Anderson SJ. Peripheral spatial vision: Limits imposed by optics, photoreceptors, and receptor pooling. Journal of the Optical Society of America: A. 1991;8:1775–1787. doi: 10.1364/josaa.8.001775. [DOI] [PubMed] [Google Scholar]
- Bishop PO, Henry GH. Spatial vision. Annual Review of Psychology. 1971;22:119–160. doi: 10.1146/annurev.ps.22.020171.001003. [DOI] [PubMed] [Google Scholar]
- Brockmole JR, Irwin DE. Eye movements and the integration of visual memory and visual perception. Perception & Psychophysics. 2005;67(3):495–512. doi: 10.3758/bf03193327. [DOI] [PubMed] [Google Scholar]
- Burgess N. Spatial memory: How egocentric and allocentric combine. Trends Cogn Sci. 2006;10(12):551–557. doi: 10.1016/j.tics.2006.10.005. [DOI] [PubMed] [Google Scholar]
- Chun MM, Jiang Y. Top-down attentional guidance based on implicit learning of visual covariation. Psychological Science. 1999;10:360–365. [Google Scholar]
- Committeri G, Galati G, Paradis AL, Pizzamiglio L, Berthoz A, LeBihan D. Reference frames for spatial cognition: Different brain areas are involved in viewer-, object-, and landmark-centered judgments about object location. J Cogn Neurosci. 2004;16(9):1517–1535. doi: 10.1162/0898929042568550. [DOI] [PubMed] [Google Scholar]
- Creem-Regehr SH, Willemsen P, Gooch AA, Thompson WB. The influence of restricted viewing conditions on egocentric distance perception: Implications for real and virtual environments. Perception. 2005;34:191–204. doi: 10.1068/p5144. [DOI] [PubMed] [Google Scholar]
- Cutting JE, Vishton PM. Perceiving layout and knowing distances: The integration, relative potency, and contextual use of different information about depth. In: Rogers WES, editor. Handbook of perception and cognition. Vol. 5. San Diego: Academic Press; 1995. pp. 69–117. [Google Scholar]
- Diedrichsen J, Werner S, Schmidt T, Trommershauser J. Immediate spatial distortions of pointing movements induced by visual landmarks. Perception & Psychophysics. 2004;66(1):89–103. doi: 10.3758/bf03194864. [DOI] [PubMed] [Google Scholar]
- Epstein RA, Kanwisher N. A cortical representation of the local visual environment. Nature. 1998;392:598–601. doi: 10.1038/33402. [DOI] [PubMed] [Google Scholar]
- Fortenbaugh FC, Hicks JC, Hao L, Turano KA. A technique for simulating visual field losses in virtual environments to study human navigation. Behavior Research Methods. doi: 10.3758/bf03193025. (in press) [DOI] [PubMed] [Google Scholar]
- Geisler WS, Perry JS. Real-time simulation of arbitrary visual fields. Paper presented at the Eye Tracking Research & Applications Symposium (ACM).2002. [Google Scholar]
- Goldstein EB. Sensation and perception. 6. Pacific Grove, CA: Wadsworth Group; 2002. [Google Scholar]
- Hamker FH. A dynamic model of how feature cues guide spatial attention. Vision Research. 2004;44:501–521. doi: 10.1016/j.visres.2003.09.033. [DOI] [PubMed] [Google Scholar]
- Hartley T, Maguire EA, Spiers HJ, Burgess N. The well-worn route and the path less traveled: Distinct neural bases of route following and wayfinding in humans. Neuron. 2003;37:877–888. doi: 10.1016/s0896-6273(03)00095-3. [DOI] [PubMed] [Google Scholar]
- Hayhoe MM, Shrivastava A, Mruczek R, Pelz JB. Visual memory and motor planning in a natural task. Journal of Vision. 2003;3:49–63. doi: 10.1167/3.1.6. [DOI] [PubMed] [Google Scholar]
- Henderson J, Pollatsek A, Rayner K. Covert visual attention and extrafoveal information use during object identification. Perception & Psychophysics. 1989;45(3):196–208. doi: 10.3758/bf03210697. [DOI] [PubMed] [Google Scholar]
- Hollingworth A, Henderson JM. Accurate visual memory for previously attended objects in natural scenes. Journal of Experimental Psychology: Human Perception and Performance. 2002;28(1):113–136. [Google Scholar]
- Horton JC, Hoyt WF. The representation of the visual field in human striate cortex: A revision of the classic holmes map. Archives of Ophthalmology. 1991;109:816–824. doi: 10.1001/archopht.1991.01080060080030. [DOI] [PubMed] [Google Scholar]
- Intraub H. Anticipatory spatial representation of natural scenes: Momentum without movement? Visual Cognition. 2002;9:93–119. [Google Scholar]
- Intraub H, Hoffman JE, Wetherhold J, Stoehs S. More than meets the eye: The effect of planned fixations on scene representation. Perception & Psychophysics. 2006;68:759–769. doi: 10.3758/bf03193699. [DOI] [PubMed] [Google Scholar]
- Intraub H, Richardson M. Wide-angle memories of close-up scenes. Journal of Experimental Psychology: Learning, Memory and Cognition. 1989;15:179–187. doi: 10.1037//0278-7393.15.2.179. [DOI] [PubMed] [Google Scholar]
- Irwin DE, Zelinsky GJ. Eye movements and scene perception: Memory for things observed. Perception & Psychophysics. 2002;64(6):882–895. doi: 10.3758/bf03196793. [DOI] [PubMed] [Google Scholar]
- Ismail AR, Asfour SS. Discrete wavelet transform: A tool in smoothing kinematic data. Journal of Biomechanics. 1999;32:317–321. doi: 10.1016/s0021-9290(98)00171-7. [DOI] [PubMed] [Google Scholar]
- Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1998;20:1254–1259. [Google Scholar]
- Jiang Y, Chun MM. Selective attention modulates implicit learning. Quarterly Journal of Experimental Psychology. 2001;54A:1105–1124. doi: 10.1080/713756001. [DOI] [PubMed] [Google Scholar]
- Johnston A. A spatial property of the retino-cortical mapping. Spatial Vision. 1986;1:319–331. doi: 10.1163/156856886x00115. [DOI] [PubMed] [Google Scholar]
- Kowler E, McKee S. Sensitivity of smooth eye movement to small differences in target velocity. Vision Research. 1987;27:993–1015. doi: 10.1016/0042-6989(87)90014-9. [DOI] [PubMed] [Google Scholar]
- Loomis JM, Da Silva JA, Fujita N, Fukusima SS. Visual space perception and visually directed action. Journal of Experimental Psychology: Human Perception and Performance. 1992;18:906–921. doi: 10.1037//0096-1523.18.4.906. [DOI] [PubMed] [Google Scholar]
- Loomis JM, Klatzky RL, Golledge RG, Cicinelli JG, Pellegrino JW, Fry PA. Nonvisual navigation by blind and sighted: Assessment of path integration ability. Journal of Experimental Psychology: General. 1993;122:73–91. doi: 10.1037//0096-3445.122.1.73. [DOI] [PubMed] [Google Scholar]
- Loomis JM, Klatzky RL, Golledge RG, Philbeck JW. Human navigation by path integration. In: Golledge RG, editor. Wayfinding behavior: Cognitive mapping and other spatial processes. Baltimore, MD: Johns Hopkins University Press; 1999. pp. 125–151. [Google Scholar]
- Loomis JM, Knapp JM. Visual perception of egocentric distance in real and virtual environments. In: Hettinger LJH, editor. Virtual and adaptive environments. Mahwah, NJ: Erlbaum; 2003. pp. 21–46. [Google Scholar]
- McPeek RM, Skavenski AA, Nakayama K. Concurrent processing of saccades in visual search. Vision Research. 2000;40:2499–2516. doi: 10.1016/s0042-6989(00)00102-4. [DOI] [PubMed] [Google Scholar]
- Messing R, Durgin FH. Distance perception and the visual horizon in head-mounted displays. ACM Transactions in Applied Perception. 2005;2:234–250. [Google Scholar]
- Mittelstaedt ML, Mittelstaedt H. Idiothetic navigation in humans: Estimation of path length. Experimental Brain Research. 2001;139:318–332. doi: 10.1007/s002210100735. [DOI] [PubMed] [Google Scholar]
- Mullen KT, Sakurai M, Chu W. Does l/m cone opponency disappear in human periphery? Perception. 2005;34:951–959. doi: 10.1068/p5374. [DOI] [PubMed] [Google Scholar]
- Norman JF, Crabtree CE, Clayton AM, Norman HF. The perception of distances and spatial relationships in natural outdoor environments. Perception. 2005;34:1315–1324. doi: 10.1068/p5304. [DOI] [PubMed] [Google Scholar]
- Oliva A, Wolfe JM, Arsenio HC. Panoramic search: The interaction of memory and vision in search through a familiar scene. Journal of Experimental Psychology: Human Perception and Performance. 2004;30:1132–1146. doi: 10.1037/0096-1523.30.6.1132. [DOI] [PubMed] [Google Scholar]
- Osterberg GA. Topography of the layer of rods and cones in the human retina. Acta Ophthalmology. 1935;(Suppl VI) [Google Scholar]
- Palmer S. Vision science: Photons to phenomenology. Cambridge, MA: Bradford Books/MIT Press; 1999. [Google Scholar]
- Peterson MS, Kramer AF, Irwin DE. Covert shifts of attention precede involuntary eye movements. Perception & Psychophysics. 2004;66:398–405. doi: 10.3758/bf03194888. [DOI] [PubMed] [Google Scholar]
- Philbeck JW, O’Leary S, Lew AL. Large errors, but no depth compression, in walked indications of exocentric extent. Perception & Psychophysics. 2004;66:377–391. doi: 10.3758/bf03194886. [DOI] [PubMed] [Google Scholar]
- Portin K, Hari R. Human parieto-occipital visual cortex: Lack of retinotopy and foveal magnification. Proceedings: Biological Sciences. 1999;266:981–985. doi: 10.1098/rspb.1999.0733. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sahm CS, Creem-Regehr SH, Thompson WB, Willemsen P. Throwing versus walking as indicators of distance perception in similar real and virtual environments. ACM Transactions in Applied Perception. 2005;2:35–45. [Google Scholar]
- Shelton AL, McNamara TP. Systems of spatial reference in human memory. Cognitive Psychology. 2001;43:274–310. doi: 10.1006/cogp.2001.0758. [DOI] [PubMed] [Google Scholar]
- Sheth BR, Shimojo S. Compression of space in visual memory. Vision Research. 2001;41:329–341. doi: 10.1016/s0042-6989(00)00230-3. [DOI] [PubMed] [Google Scholar]
- Stephen JM, Aine CJ, Christner RF, Ranken D, Huang M, Best E. Central versus peripheral visual field stimulation results in timing differences in dorsal stream sources as measured with meg. Vision Research. 2002;42:3059–3074. doi: 10.1016/s0042-6989(02)00415-7. [DOI] [PubMed] [Google Scholar]
- Szlyk JP, Fishman GA, Alexander KR, Revelins BI, Derlack DJ, Anderson RJ. Relationship between difficulty in performing daily activities and clinical measures of visual function in patients with retinitis pigmentosa. Archives of Ophthalmology. 1997;115:53–59. doi: 10.1001/archopht.1997.01100150055009. [DOI] [PubMed] [Google Scholar]
- Temme LA, Maino JH, Noell WK. Eccentricity perception in the periphery of normal observers and those with retinitis pigmentosa. American Journal of Optometry & Physiological Optics. 1985;62:736–743. doi: 10.1097/00006324-198511000-00003. [DOI] [PubMed] [Google Scholar]
- Todd JJ, Marois R. Capacity limit of visual short-term memory in human posterior parietal cortex. Nature. 2004;428:751–754. doi: 10.1038/nature02466. [DOI] [PubMed] [Google Scholar]
- Turano KA, Geruschat DR, Baker FH. Oculomotor strategies for the direction of gaze tested within a real-world activity. Vision Research. 2003;43:333–346. doi: 10.1016/s0042-6989(02)00498-4. [DOI] [PubMed] [Google Scholar]
- Turano KA, Geruschat DR, Stahl JW. Mental effort required for walking: Effects of retinitis pigmentosa. Optometry and Vision Science. 1998;75:879–886. doi: 10.1097/00006324-199812000-00010. [DOI] [PubMed] [Google Scholar]
- Turano KA, Schuchard RA. Space perception in observers with visual field loss. Clinical Vision Sciences. 1991;6:289–299. [Google Scholar]
- Wagner M. The metric of visual space. Perception & Psychophysics. 1985;38:483–495. doi: 10.3758/bf03207058. [DOI] [PubMed] [Google Scholar]
- Wandell BA, Brewer AA, Dougherty RF. Visual field map clusters in human cortex. Philosophical Transactions of the Royal Society of London: B. 2005;360:693–707. doi: 10.1098/rstb.2005.1628. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Werner S, Diedrichsen J. The time course of spatial memory distortion. Memory & Cognition. 2002;30:718–730. doi: 10.3758/bf03196428. [DOI] [PubMed] [Google Scholar]
- Witmer BG, Kline PB. Judging perceived and traversed distance in virtual environments. Presence. 1998;7:144–167. [Google Scholar]
- Wolfe JM. Moving towards solutions to some enduring controversies in visual search. Trends in Cognitive Science. 2003;7:70–76. doi: 10.1016/s1364-6613(02)00024-4. [DOI] [PubMed] [Google Scholar]
- Wu B, Ooi TL, He ZJ. Perceiving distance accurately by a directional process of integrating ground information. Nature. 2004;428:73–77. doi: 10.1038/nature02350. [DOI] [PubMed] [Google Scholar]
- Xu Y, Chun MM. Dissociable neural mechanisms supporting visual short-term memory for objects. Nature. 2006;440:91–95. doi: 10.1038/nature04262. [DOI] [PubMed] [Google Scholar]