

Abstract
Peer video modeling was compared to self video modeling to teach 3 children with autism to respond appropriately to (i.e., identify or label) novel letters. A combination multiple baseline and multielement design was used to compare the two procedures. Results showed that all 3 participants met the mastery criterion in the self-modeling condition, whereas only 1 of the participants met the mastery criterion in the peer-modeling condition. In addition, the participant who met the mastery criterion in both conditions reached the criterion more quickly in the self-modeling condition. Results are discussed in terms of their implications for teaching new skills to children with autism.
Keywords: autism, skill acquisition, textual responses, video modeling
Children with autism typically have difficulties with social interaction, deficits in language, and problems with pretend play skills (American Psychiatric Association, 1994). One way to improve behavior and increase skills in these children is to teach imitation (DeQuinzio, Townsend, Sturmey, & Poulson, 2007). Video modeling involves a child watching a video that depicts someone performing a task that is targeted for acquisition by the child. A number of studies have shown that video modeling can be used to effectively teach a variety of skills to children with autism. These include teaching social skills (Wert & Neisworth, 2003), play skills (D'Ateno, Mangiapanello, & Taylor, 2003), and purchasing skills (Haring, Kennedy, Adams, & Pitts-Conway, 1987).
Video modeling might be more advantageous than in vivo modeling for a number of reasons. First, the cost of making videotapes can be lower than the cost of bringing therapists into homes, schools, or centers to serve as models. Also, a videotape can be used in a variety of settings; a video can be taken anywhere and played at any time. In addition, a video can be played repeatedly, giving the child a chance to watch the video more closely and practice a skill. Finally, tasks on video can be shown and taught in a standardized way, which might make a skill easier to learn (Charlop-Christy, Le, & Freeman, 2000).
One variation of video modeling is self video modeling, which involves the target child observing him- or herself perform some task or engage in some skill on the video. To create the video, the child is typically prompted to engage in certain behaviors at appropriate times or in response to appropriate stimuli. Those prompts are then removed from the tape prior to using the tape for modeling. Self video modeling has also been shown to be effective in teaching children with autism a variety of skills, including spontaneous requesting (Wert & Neisworth, 2003) and initiating interactions with peers (Buggey, 2005).
Only one study has compared peer video modeling to self video modeling. Sherer et al. (2001) compared the two procedures to teach conversation skills to 5 children with autism. Each child was either shown a video in which the participant was depicted engaging in a conversation or a peer was depicted engaging in a conversation. On later measures of conversation, one of the children performed better after watching the self model and another child performed better after watching the peer model. There were no differences between the two conditions for the other 3 children.
The purpose of the current study was to add to existing research that has compared peer video modeling to self video modeling. Specifically, we compared peer video modeling to self video modeling to teach children with autism to respond appropriately to (i.e., identify or label) novel items. Greek and Arabic letters were used to control for the effects of prior exposure to stimuli.
METHOD
Participants and Setting
A 4-year-old boy (Brian), a 9-year-old girl (Mandy), and a 9-year-old boy (Matt) participated in the study. All participants had a diagnosis of autism, spoke in multiple-word sentences, and could imitate others. All participants had received in-home behavioral services when they were younger and attended school at the time of the study. Sessions took place in a small private room in the child's home (Mandy and Matt) or preschool (Brian). Toys and other potentially distracting stimuli were removed from the rooms during sessions.
Materials
Greek and Arabic letter cards
To control for a history of prior exposure (as well as incidental exposure during the course of the study) to stimuli being taught, Greek and Arabic letters written in black ink on index cards (10.2 cm by 15.2 cm) were used. The following are examples of the Arabic letters used: 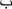 (ba),
(ba),  (jeem),
(jeem),  (ta). Greek letters used included Ω (omega), σ (sigma), and Ξ (xi). For Mandy and Matt, a series of three Greek and Arabic letters was used instead of a single letter. This was done to prevent a ceiling effect; it was hypothesized that Mandy and Matt would easily learn single letters regardless of the video condition.
(ta). Greek letters used included Ω (omega), σ (sigma), and Ξ (xi). For Mandy and Matt, a series of three Greek and Arabic letters was used instead of a single letter. This was done to prevent a ceiling effect; it was hypothesized that Mandy and Matt would easily learn single letters regardless of the video condition.
Videotapes
Two videotapes were created for each child: a peer videotape and a self videotape. The peer video depicted a typically developing child answering the therapist's question. According to each participant's parent, the child depicted in the video was the participant's friend. That is, the peer and the participant had a history of interacting with each other. In the video, the therapist said “What letter is it?” and the child named the Greek or Arabic letter or series of letters. The self video depicted the participant answering the therapist's question. The therapist said “What letter is it?” and the participant named the letter or letters. This videotape was created by editing raw footage of the therapist and participant. To prevent any learning that may have occurred during the creation of the self video, the participants never saw the index cards with the letters on them. Participants were simply prompted by the therapist to say the name of the letter or letters. A scene in which the therapist held up the card and said “What letter is it?” was then filmed and edited; the participant's response was inserted immediately after the therapist's question. All of the nonverbal and verbal prompts the therapist used to evoke the correct response from the participant were removed from the video. Delivery of verbal praise by the therapist after the participant responded correctly was shown on the video. However, the praise was actually delivered contingent on another behavior unrelated to the target response and edited to appear as if it occurred immediately after the target response in the video. For both the peer and self videotapes, a total of five trials, with each trial depicting a different letter or series of letters, were depicted on the video.
Data Collection and Experimental Design
The dependent variable was a correct trial, which was defined as a vocal response which matched the letter or letters depicted on the index card presented by the therapist. The percentage of trials with correct responding during each session was then calculated by dividing the number of correct trials by the total number of trials (five) and multiplying by 100%. Interobserver agreement data were collected on responding by each participant on a trial-by-trial basis during at least 35% of sessions. An agreement was defined as both observers recording a correct or an incorrect response. Agreement between the two observers was calculated by dividing the number of agreements by the number of agreements plus disagreements and converting this ratio to a percentage. Interobserver agreement was at least 98% for baseline and video modeling conditions for all participants.
A measure of the integrity of the independent variable was also collected. A checklist was given to parents so that they could check off each time they showed the video to the participant during the initial 2-day viewing of each video (see below). All parents recorded that they presented the video to their child on 100% of appropriate occasions.
A combination multiple baseline design and multielement design was used to compare the two types of video modeling. Participants received the video modeling comparison condition in a staggered fashion once baseline data were stable.
Procedure
Baseline
During baseline, the therapist held up the index cards with the Greek or Arabic letters and asked the participant “What letter is it?” No feedback on correct or incorrect responses was provided during this phase. Each participant was exposed to 10 letters (or series of letters). One of the 10 letters (or one series) was randomly presented during each trial of every baseline session. After baseline and before the videotapes were created, five letters that had been presented in baseline were randomly assigned to the self video condition, and five were randomly assigned to the peer video condition. These same five letters in each condition were depicted on the videos and throughout trials during the video comparison phase.
Postvideo preparation probe
To be sure that no learning occurred during the creation of the videos, an additional baseline session was conducted after the videos had been prepared for each participant. This session was identical to baseline sessions, in that no feedback was delivered.
Comparison of video modeling
Parents were given a viewing schedule and were instructed to show either the self (Brian and Matt) or peer (Mandy) videotape to their child three times a day over 2 consecutive days before sessions began. Parents were instructed to show the child the video in the morning before school (about 7:30 a.m.), immediately after school (about 3:00 p.m.), and before bedtime (about 7:30 p.m.). The therapist called each day to remind the parents to show the video at the appropriate time, and parents recorded the time at which the video was shown.
After 2 days, one session (the first session of the video-modeling comparison phase) was conducted by the therapist with the five letters depicted on the first videotape (peer for Mandy, self for Brian and Matt). Next, the other videotape (self for Mandy, peer for Brian and Matt) was shown on the same schedule for 2 days. After viewing the second video for 2 days, one session (second session of the video modeling comparison phase) was conducted by the therapist with the five letters depicted on the second video. The order in which participants were shown the videotapes during these initial 4 days was randomly determined. Participants viewed each video for 2 days before sessions began so that they would acclimate to the videos.
After the initial 4 days of video watching (2 days per video), videos were shown only once immediately before sessions, which were conducted in the late afternoon 3 to 4 days per week. The therapist was responsible for showing each video and conducting subsequent trials. Participants were shown each of the videos on the same day, and the order in which participants viewed the videotapes each day was alternated (i.e., peer video first on Day 1, self video first on Day 2, peer video first on Day 3, etc.). Immediately after each video was shown, the therapist conducted the five trials with the letters depicted in that video. For example, each time Brian saw the peer video, he viewed a peer correctly responding to 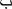 (ba),
(ba),  (jeem), Ω (omega), σ (sigma), and Ξ (xi). He then received five trials in which the therapist asked him to identify these same five letters, one per trial. The order in which the therapist presented the letters varied and was randomly determined. Immediately after the five trials, the other video was shown, and the therapist then conducted the five trials with the letters depicted in that video.
(jeem), Ω (omega), σ (sigma), and Ξ (xi). He then received five trials in which the therapist asked him to identify these same five letters, one per trial. The order in which the therapist presented the letters varied and was randomly determined. Immediately after the five trials, the other video was shown, and the therapist then conducted the five trials with the letters depicted in that video.
During sessions, data collectors sat in the corner of the room, behind the participant. A trial began when the therapist held up the index card and asked the child “What letter is it?” If the child did not answer within 10 s, the therapist asked the question again. If the child again did not answer within 10 s, the observer recorded an incorrect response, and the therapist told the child the correct response once. If the child responded within 10 s, but the response was incorrect, the therapist told the child the correct response once. Verbal praise was delivered to the child for each correct response. Sessions continued until each participant scored at least 80% (i.e., four of the five trials) correct over three consecutive sessions in one of the two video modeling conditions. After criterion for one of the conditions was attained, five additional sessions in the other condition were conducted to give the participant an opportunity to reach the criterion in that condition. If the criterion in the other condition was met in fewer than five sessions, sessions were discontinued at that point.
RESULTS AND DISCUSSION
Figure 1 presents the percentage of correct responses per session for each participant. During baseline and the postvideo preparation probe, no correct responses occurred for any of the participants. During the video comparison condition, all participants' correct responding improved. Within 13 sessions, Brian performed at 100% correct in the self-modeling condition and at 80% correct in the peer-modeling condition. However, he did not meet criterion (i.e., at least 80% correct across three consecutive sessions) in the peer-modeling condition.
Figure 1.

Percentage of trials with correct responses across baseline and video modeling conditions for Brian (top), Mandy (middle), and Matt (bottom).
Mandy's performance improved from 0% correct in baseline to 100% correct in the self-modeling condition and 80% correct in the peer-modeling condition. She reached criterion in both conditions but reached criterion earlier (i.e., within 16 sessions) in the self-modeling condition. It took her 19 sessions to reach criterion in the peer-modeling condition. Matt reached 100% correct in the self-modeling condition and 80% in the peer-modeling condition. It took him 30 sessions to reach criterion in the self-modeling condition. He did not meet the criterion in the peer-modeling condition.
The results of this study indicate that all 3 participants reached the criterion in the self-modeling condition, whereas only 1 participant reached the criterion in the peer-modeling condition. In addition, Mandy, who was the only participant to reach the criterion in both the self and peer conditions, reached the criterion in the self-modeling condition more quickly. These data add to the existing literature comparing self and peer video modeling in children with autism by suggesting that self video modeling may be superior to peer video modeling for teaching textual responses.
Anecdotally, the participants seemed to like watching the self videos more than the peer videos. All 3 participants requested the self videos often, even though their access to the videos was restricted. In addition, the participants' parents reported that they asked for the self video after the study concluded. Future research should collect data on engagement with (i.e., attending to) the videos to obtain a more objective measure of preference.
One reason for the relatively poor effects of the peer- modeling condition could be related to the peer used in the video. That is, it is possible that the peer in the videos might not have been a highly preferred peer. Although the parents of all participants reported that the peers were their child's friends, this might not have actually been the case. Future research should assess more objectively the extent to which the peers used in peer video modeling are preferred.
Another possible reason for the poor effects of the peer video modeling condition is that the models were in some way dissimilar to the participants. Previous research on modeling and imitation by Bandura, Ross, and Ross (1961) noted that individuals are more likely to imitate what they see when the model is very similar to the learner. It is possible that the model in the peer video modeling condition was not similar to the participant in some important way (e.g., articulation). Future research should employ models who are as similar to participants as possible in many different ways.
Sherer et al. (2001) found few differences between self- and peer-modeling conditions. One reason for the difference in findings between the current study and the findings of Sherer et al. could be the type of task examined. Sherer et al. used a task that involved teaching conversation skills. It is possible that conversing with others is best taught using a peer model. Future research should compare self and peer video modeling to teach other tasks.
Some limitations of this study should be noted. First, feedback was provided only during the video modeling conditions. Although this does not affect the comparison between video modeling conditions, it does introduce an independent variable other than the one of interest (videos) when comparing baseline to video modeling. Future research on video modeling should include identical components across baseline and treatment conditions. Second, although a number of steps were taken to reduce the likelihood of creating a history of prior exposure to stimuli during the creation of the self video, it is nevertheless possible that participants acquired textuals more quickly in the self video condition as a result of having emitted the response vocally during video creation. Future research should control for this potential confounding effect by having participants vocally emit the letters depicted in the peer video condition as well. Finally, novel Greek and Arabic letters were used to compare the two types of video modeling; thus, history effects that may have been associated with more educationally relevant stimuli were controlled. However, because using socially relevant stimuli may have offered advantages (e.g., response generalization) without compromising the experiment's internal validity, future research could replicate these procedures using stimuli that are educationally appropriate.
Acknowledgments
This report is based on a thesis submitted by the first author in partial fulfillment of the requirements for the master of science degree in applied behavior analysis at the Florida Institute of Technology.
REFERENCES
- American Psychiatric Association. Diagnostic and statistical manual of mental disorders (4th ed.) Washington, DC: Author; 1994. [Google Scholar]
- Bandura A, Ross D, Ross S. Transmission of aggression through imitation of aggressive models. Journal of Abnormal and Social Psychology. 1961;63:575–582. doi: 10.1037/h0045925. [DOI] [PubMed] [Google Scholar]
- Buggey T. Video self-modeling applications with students with autism spectrum disorder in a small private school setting. Focus on Autism and Other Developmental Disabilities. 2005;20:52–63. [Google Scholar]
- Charlop-Christy M, Le L, Freeman K. A comparison of video modeling and in vivo modeling for teaching children with autism. Journal of Autism and Developmental Disorders. 2000;20:537–552. doi: 10.1023/a:1005635326276. [DOI] [PubMed] [Google Scholar]
- D'Ateno P, Mangiapanello K, Taylor B. Using video modeling to teach complex play sequences to a preschooler with autism. Journal of Positive Behavior Interventions. 2003;5:5–11. [Google Scholar]
- DeQuinzio J.A, Townsend D.B, Sturmey P, Poulson C.L. Generalized imitation of facial models by children with autism. Journal of Applied Behavior Analysis. 2007;40:755–759. doi: 10.1901/jaba.2007.755-759. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haring T, Kennedy C, Adams M, Pitts-Conway V. Teaching generalization of purchasing skills across community settings to autistic youth using videotape modeling. Journal of Applied Behavior Analysis. 1987;20:89–96. doi: 10.1901/jaba.1987.20-89. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sherer M, Pierce K.I, Paredes S, Kisacky K.L, Ingersoll B, Schreibman L. Enhancing conversation skills in children with autism via video technology: Which is better, “self” or “other” as a model. Behavior Modification. 2001;25:140–158. doi: 10.1177/0145445501251008. [DOI] [PubMed] [Google Scholar]
- Wert B, Neisworth J. Effects of video self modeling on spontaneous requesting in children with autism. Journal of Positive Behavior Interventions. 2003;5:30–34. [Google Scholar]