

Abstract
Although an unambiguous and consistent representation is the foundation of data reuse, a locally developed documentation system such as nursing flowsheets often fails to meet the requirement. This article presents the domain modeling process of the ICU nursing flowsheet to clarify the meaning that its contents represent and the lessons learned during the activity. This study has been done as a first step toward reusing the data documented in a computerized nursing flowsheet for an algorithmic decision making. Following the ontology development processes proposed by other researchers a conceptual model was developed using Protégé. Then the existing information model was refined by fully specifying the embedded information structures and by establishing linkages to the conceptual model at the finest-grained concept level. Domain knowledge that the experienced nurses provided was critical to correctly interpret the meaning of the flowsheet contents as well as to verify the newly developed models. This study reassured the importance of the roles of a nurse informatician to develop a computerized nursing documentation system that accurately represents the information needs in nursing practice.
Keywords: Domain Modeling, Standardized Knowledge Representation, Data Reuse, Computerized Nursing Flowsheets
Introduction
Patient data should be consistently and unambiguously represented in order to be repeatedly used for various purposes such as clinical decision making, quality assurance, and research.1-3 For example, detailed patient data documented in nursing flowsheets should be used for patient acuity estimation; nursing diagnoses; and outcome research. A flowsheet is a common approach to frequent documentation of discrete and detailed patient data obtained in the course of nursing care. Flowsheet data is feasible to index and retrieve, as its level of granularity is in atomic and the contents are relatively well standardized and structured. Therefore, nursing flowsheet is considered as a potential rich source of atomic level data that can be reused to serve the various purposes described above.
However a locally developed documentation system like a nursing flowsheet often represents its data with highly local terms i.e., interface terms4 (a.k.a. application terms or colloquial terms) which are developed and used by local users. Usually, the semantic relations among the data are embedded in nested information hierarchies thus are presented only implicitly. Accordingly, only local human users can understand the data contents and the data is not suitable for algorithmic processing for sharing and reusing. It will be extremely challenging to reuse flowsheet data unless they are unambiguously represented with standardized terms and clearly defined domain models i.e., a conceptual model and an information model.
Both a conceptual model and an information model are critical in representing a domain unambiguously. Although the closely intertwined roles and relationships between the two models have continuously been active subjects of informatics research the boundary between them still remains unclear. However, in general, an information model shows what data and information are important in a particular domain and how they are organized and stored in the system.10, 11 As shown in Figure 1, an information model does not provide details on terminological knowledge of the concepts used in the domain such as semantic relations among the concepts and the contextual information of the terms used in the domain. In the given example, “tender,” “soft,” and “firm” are the values that may describe the findings of the data item Abdominal Assessment. However, the model does not describe the detailed semantic relations between the values and the data item such as “assessing texture,” and “assessing shape.” Such knowledge is essential to correctly interpret the meaning of the value as well as to inference the presented data, and is usually represented with a conceptual model (Figure 1).12-14
Figure 1.

Linking the conceptual model to the information model – a schematic view.
A number of researchers have developed domain models to facilitate the use of clinical data stored in the local information system.5-9 In most of the studies, the domain models were developed as an effort to design a new clinical application rather than to clarify the domain contents of an existing system, which had been converted from a legacy system that has no sharable conceptual or information model. Although several of them addressed issues with standardized term representations by conducting term mapping to selected terminology systems no conceptual model that would have provided comprehensive contextual information of the individual terms in the domain was developed. In addition, the term mapping was done in an individual term level without considering the context surrounding the term usage.6, 8, 9
The purpose of this study was to produce unambiguous domain models of the ICU nursing flowsheet of Mayo Clinic as a first step toward reusing its contents for the secondary purpose of patient acuity estimation. The specific aims were to
Build a conceptual model that unambiguously represents the terminological properties of the interface terms used in the ICU nursing flowsheets in terms of 1) key terms and their standardized representations and 2) subsumptive semantic relations among them.
Implement existing approaches in ontology development as a reverse engineering method of a conceptual modeling, which can be applied to disambiguate the domain contents of the other structured documentation forms that have been built without a sharable schema of the domain
Clarify the information structure of the ICU nursing flowsheets by 1) teasing out the nested information hierarchies and 2) linking the concepts used in the information model to those of the conceptual model to inherit their terminological properties.
Background
Nursing Flowsheets
A flowsheet is a local view of a domain often developed by a team of clinicians of a local health organization. It is developed typically to facilitate efficient data entry and easy review of temporal patterns of data at a point of care.15 In order to support prompt documentation and easy review of the data patterns, flowsheets often employ a structured approach to documenting key information of a particular domain using a set of predefined terms. For instance, with computerized nursing flowsheets, documentation is usually done by selecting an appropriate value from a pick-list provided with each data item and augmented with options for free text.
Typically, nursing flowsheets are structured into a nested information hierarchy. They consist of multiple domains that cover specific nursing areas, which often reflect higher level of conceptual and theoretical perspectives on the target phenomena in nursing. For example, nursing flowsheets of Mayo Clinic consist of a number of nursing domains including tissue perfusion, integument condition, sensory and perceptual status, coping and safety, neurological and circulatory status, home health maintenance, nutrition, and elimination. Each domain contains a set of data items on nursing observation and intervention that needs to be documented. Many of these domains are further divided into multiple sections (or sub-domains) depending on the complexity of the domain and the amount of the data that needs to be documented.
Figure 2 shows how a data item Dressing is presented in the ICU nursing flowsheets of Mayo Clinic. As illustrated, many critical semantic relations among the terms are only implied and no consistent subsumptive relation is maintained across the information hierarchy. The information hierarchy of this example implies that “Drainage” is a section of the domain WOUND and Dressing is a data item that conveys information on “Drainage.” The data item Dressing is associated with the drainage tube insertion site, which is treated as a type of wound in the flowsheets. The data item Dressing contains multiple kinds of information such as intervention status, dressing condition, and dressing types, which are not clearly demarcated in the presented view. Also, many pick-list options are presented with locally created lexical forms such as “Sec w/Tape” and “TranspDrsg,” which mean “secured with tape” and “transparent dressing” respectively.
Figure 2.
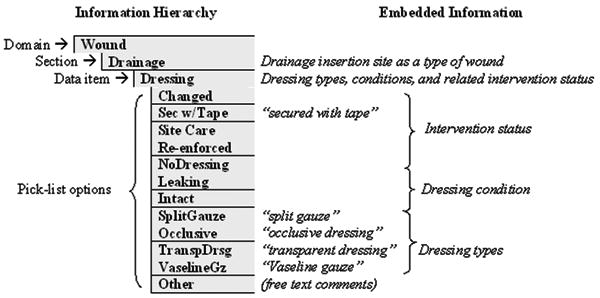
An example of the information embedded in the ICU nursing flowsheets.
Consistently and unambiguously representing domain contents is critical to the algorithmic data processing for data retrieval, reasoning, and transfer, which are the mandatory steps for data sharing and reusing. The example shown in Figure 2 indicates that the locations of the terms in the information structure provide important clues for interpreting the meaning of the terms. However, as shown in the pick-list options, terms are listed without any structural information and even represented with inappropriate lexical forms. Therefore, the knowledge and rules that the local human users share regarding the domain and documentation are critical to correctly interpreting the contents of this flowsheet. Algorithmically processing the data provided in the example will be extremely difficult because of the representational problems that cannot be easily handled by machine.
General Approaches to Conceptual Modeling
Several researchers have recommended methods and procedures to develop a conceptual model of a domain. Rassinoux et al. described two approaches in concept modeling, which are usually jointly involved in the process.16 The top-down approach starts from identifying the key concepts of a domain. They are then organized into a backbone structure. More detailed concepts are filled into the structure next. In the bottom-up approach, collecting all the detailed concepts is the first step. Then they are categorized, labeled, and arranged into a hierarchical structure. Step by step procedures of developing a domain ontology for a computer application have been described by several researchers.12, 17, 18 Significant overlaps exist in their descriptions but the six steps of iterative approach described by Stevens et al. provides an overarching framework of the key ideas. The six steps are described next.
As in any system development activity, 1) identifying purposes and scopes is critical first step as they specify a set of requirements that an ontology should satisfy. An ontology is designed, evaluated, and utilized according to the specifications. Next step is 2) knowledge acquisition, where the key domain knowledge that needs to be modeled is collected from various resources such as literatures, domain experts' opinions, and other existing ontologies. The process of incorporating the contents and the structures of an existing ontology is especially referred as 3) integration. 4) Conceptualization is the process of framing domain contents in terms of key objects, semantic relations, and the constraints hold between them. In order to conceptualize the domain contents, the domain knowledge is categorized, labeled, and characterized according to the core properties it carries. Categorizing domain concepts into relevant semantic types is helpful to clarify the domain contents with a complex conceptual structure.19 Semantic types also provide “hook-concepts” based on which individual concepts with similar semantic characteristics are grouped into a common concept class.17
The conceptualized domain knowledge is then 5) encoded with a knowledge representation language. Among various knowledge representation languages, formalisms like frame, conceptual graph, and description logics are especially popular, as they provide a ground to inference domain contents.16, 20, 21 Although each of these formalisms has its own strengths and weaknesses, they are considered as equivalent in terms of the ability to represent domain knowledge.16, 21, 22 The final step is to 6) evaluate the ontology based on the set of predefined criteria and specifications. If certain criteria or specifications are not met, the related modeling step is revisited. Usually, these development processes are iterated as necessary.
Protégé
Protégé is a comprehensive environment to build a knowledge-based system. It was developed by the Medical Informatics group at Stanford University. Its main function is building a frame-based ontology where an object (i.e., a key concept) of a domain is described as a class and its attributes are further specified as slots filled with relevant values.27 Protégé supports various additional functions including ontology comparison, database connectivity, inference, and ontology visualization via various plug-in programs.23 It is a highly recognized tool in the area of ontology development in terms of performance, user-friendliness, and availability.24 As such this tool has been utilized in various modeling activities.
Methods
Investigating the Current Flowsheet Structure
This study targeted the flowsheets used in the adult ICUs for general internal medicine, general surgery, cardiology, neurology and trauma. The computerized ICU nursing flowsheets of Mayo Clinic were constructed based on system loading forms, which are in Microsoft Excel spreadsheets. Many semantic relations among data items and values are not fully specified in the forms. Therefore, we first disambiguated the meaning that each data item and value pair is intended to convey by teasing out the semantic structures embedded in the information hierarchy presented in the system loading forms. Three local nurses with at least three years of clinical experiences and who are in charge of training new nurses for nursing documentation provided inputs on interpreting many ambiguous cases. For example, they verified that a combination of the data item Patient's Activity Level and the value “up as tolerated” should be interpreted as “patient can perform any activity as long as they can tolerate it.”
Building a Conceptual Model of the Flowsheets
We first constructed a conceptual model of the ICU flowsheets using Protégé (version 2.1.1). As a top-down approach we first identified the key high-level concepts that would reasonably encompass and categorize the detailed concepts of the flowsheets. In addition to considering the current information structure of the flowsheets we also referred to the concept hierarchies of the existing reference terminologies such as International Classifications of Nursing Practice (beta version)25 and Systematic Nomenclature of Medicine Clinical Terms (July, 2003 release)26 for this task. Then we organized the identified key high-level concepts into a subsumptive hierarchy in order to lay out the backbone structure of the conceptual model.
Once the backbone structure of the conceptual model was established, lower level classes and instances were filled into them. We first extracted the terms that appeared in the flowsheets in the finest grained level and normalized them into a singular nominal form when applicable, to denote the concept that the term represents. We then assigned a semantic type to each individual concept. Semantic types were derived from three sources. First source was the Unified Medical Language System Semantic Network (UMLS version 2004AA)27. We found that the granularity of the semantic types in the UMLS is uneven; very specific for certain concepts but too general for the others. Therefore, when an appropriate semantic type was not found in the UMLS, we referred to the second source – SNOMED-CT – and borrowed the name of the super-class of the corresponding concept as a surrogate semantic type. Finally, when neither system provided adequate semantic types, we created our own semantic types considering the consistency and relevancy in the overall conceptual structure.
The concepts were then grouped by the semantic types. The semantic types were modeled as the lowest level classes i.e., leaf classes and the individual concepts were specified as their instances. The leaf classes with similar semantic features were grouped together, and an appropriate super-class that can encompass them was created. For example, a class VISUAL PROPERTY was created to encompass the leaf classes Appearance and Shape, Colors, and Clarity. The leaf classes were defined with a number of property slots. “ByName” is a basic slot that takes a normalized lexical representation of the flowsheet concept as a value. We created several optional slots that contain the standardized terms and codes of the terminology systems to which the instance concepts had been mapped. The three ICU nurses, who had provided inputs for interpreting ambiguous flowsheet contents, also verified the quality of the concept representations of the model in terms of concept coverage and concept uniqueness.
Refining the Information Model of the Flowsheets
The original ICU nursing flowsheets consist of sixteen main domain areas, seven of which were further divided into multiple sections. We identified a total of 217 data items and more than 1,300 unique terms that serve as pick-list options. Each flowsheet domain was constructed as a top level class, and the sections were constructed as their direct subclasses.
Several structural modifications were inevitable for clear representation of the contents. They were mostly done by dividing the original structures into more granular ones. For example, ANXIETY/COPING and SAFTY, which had been combined as one domain in the original flowsheet supposedly due to the relatively small number of data items they contain, were separated into two individual domains i.e., ANXIETY & COPING, and SAFTY. Data items with pick-list options containing different kinds of information were also divided into multiple data items so that each of them can deliver a distinct kind of information. The example provided in Figure 2 is one of such cases. In this case, we split the data item Dressing into Dressing Management Status, Dressing Condition, and Dressing Types.
The data items were formed as leaf classes and the associated pick-list options were specified as instances. The leaf classes of the information model were also defined with multiple property slots. A slot “ByName” shows a lexical representation of an instance as appeared in the flowsheets. Several optional slots were added to represent the semantic information that an instance concept conveys. These semantic slots reflect the names of the classes in the conceptual model whose instance concepts serve as the potential values of the corresponding slot of the information model. Figure 1 illustrates how the Abdominal Assessment class and its values in the information model were defined using the semantic slots that provide linkages to the concepts in the conceptual models. The refined information model was reviewed by the three ICU nurses.
Institutional Review Process
An institutional review process was not required, as this study did not utilize any actual patient data.
Results
The Models
The conceptual model was constructed with ten top level classes, 36 subclasses, and 169 leaf classes. Under the leaf classes a total of 1,458 direct instances were created. The information model was refined with 21 top level classes representing the main flowsheet domains; 49 subclasses representing the sections under them; 339 leaf classes representing the data items; and 2,447 instances representing the pick-list options. The top-level classes of each model are presented in Figure 3. The nurse reviewers verified that the data contents and the structures of the both models adequately reflect those of the ICU nursing flowsheets. As the verification was done with open review and discussion we did not test the level of agreement among the reviewers.
Figure 3.

Ten top level classes of the conceptual model (a) and 21 top level classes of the information model (b)
Overall Procedures of Developing the Models
We found that the previously described methods and procedures of ontology development were viable strategies to develop the conceptual model of the ICU nursing flowsheets. In this study, the scope of the conceptual modeling was limited to the adult ICU nursing flowsheets of Mayo Clinic, and the purpose was to generate unambiguous and consistent representations of the flowsheet contents so that they can be reused for the secondary purpose of patient acuity estimation. In the knowledge acquisition phase, we retrieved key atomic concepts and the semantic relations from the flowsheet loading forms. Conceptualization and integration were done by assigning semantic types to the concepts retrieved in the previous phase and constructing a concept hierarchy by referring to several standardized terminology systems. Then they were encoded with a frame-based tool called Protégé. Evaluation was done by obtaining face validity from three nurse reviewers.
Building the information model was relatively simpler than building the conceptual model. While most of the structures and the data organizations of the current flowsheets were retained, several information layers (i.e., sections) and data items were added in order to clarify many ambiguous data representations in the original flowsheets. The pick-list options of the original flowsheets were instantiated in the information model by utilizing the instance concepts of the conceptual model as the values for the semantic slots of the information model.
Discussion
Lessons Learned
Domain modeling was a feasible approach to clarify many ambiguous data representations of the local ICU nursing flowsheets. However, there were a couple of challenges in implementing this approach. Most of all, building the conceptual model was a labor intensive process depending highly on human judgment. In addition, incomplete concept coverage of the referenced terminology systems25-27 adversely influenced the process of assigning semantic types. A related work on the concept coverage performed in this study was reported elsewhere.28
The ICNP provided many high-level concepts in nursing practice that are also relevant to the flowsheets contents it lacked many detailed descriptive concepts. On the other hand, SNOMED-CT provided detailed descriptive concepts via Observable Entity axis and Qualifier Value axis. It also provided many concepts related to medical devices and products, which are not included in the ICNP. However, its conceptual hierarchy did not fit well with the flowsheets as SNOMED-CT has been structured around diseases and clinical processes rather than the functional domains of a human, which are the main constructs of nursing perspectives. The UMLS covered many detailed concepts of the flowsheets but the semantic types assigned to them were often not adequate for our purpose due to the granularity issues. For example, many descriptive concepts representing color, size, degree, and shape have too general semantic types such as “qualitative concept” or “quantitative concept.”
We observed a number of vaguely defined data items in the original flowsheets, which would ultimately hinder retrieving and inference the information contents they deliver. First type of such case is the data item under containing multiple kinds of information that are loosely grouped without clear logical relations. Such data items contain pick-list options seemingly irrelevant to the data item, which can only be comprehended by the local human users. For example, pick-list options of the data item Wound Color also contain the concepts related to wound healing processes such as “granulating” and “fibrosis” coupled respectively with the color concepts “pink” and “yellow.” Organizing pick-list options this way will cause inaccurate reasoning as well as difficulties in data retrieval, considering that the wound color is not the sole determinant of the wound-healing process.
Data items labeled with “…Status” and “…Condition” are other examples of vaguely defined data items. They do not convey sufficient semantic information on the data they contain thus will also make it difficult to retrieve and inference the data. For instance, in the original flowsheets, a data item Invasive Site Condition contains three kinds of information including conditions of the wound caused by invasive procedure (e.g., bleeding, intact), conditions of the dressing applied to the wound (e.g., marked, dry), and the intervention status (e.g., dressing changed, dressing reinforced, etc). As described in the method section we divided such data items into more specific ones so that each of them can carry a single kind of information.
The modifications we made in this study added four new domains and increased the number of data items by 24 %. At first, we cautiously assumed that such illogical data structure would have been inevitable to minimize the data input burden of nurses. However, the nurses who participated in developing the original computerized flowsheets testified that the problem had originated from the restrictions imposed by the application developers. They asked nurses to provide the data items that need documentation in a way that they could fit to the limited data input interface that the developers designed. Therefore nurses had to omit many information layers and data categories that would have fully specified the logical relations among the data, in order to fit the abundant data items into the limited space allocated to them.
Limitations of the Study
There are several limitations in this study. As the conceptual model and the information model built in this study were derived from the local view of the nursing practice represented in local adult ICU flowsheets, they have limited generalizability. Although the high level structures of the conceptual model are quite generic as they had been built based on the ICNP, the lower level structures including instance concepts may not be sufficient enough to completely represent the other nursing documentation modules.
The conceptual model has been developed as a “thin” model that serves limited purposes including clarifying the subsumptive semantic relations embedded between concepts and providing standardized representations for the interface terms used in the flowsheets by mapping them to the selected standardized terminology systems. Therefore, this model does not fully specify any lexical variation of the terms, synonyms, or non-hierarchical semantic relations that can possibly hold between concepts. In addition, our conceptual model needs to be evaluated with a reasoning-intensive tool such as Renamed A-Box and Concept Expression Reasoner (RACER) 29 in order to be assured of its capability to support algorithmic processing of the data for reuse.
The main goal of the information modeling in this study was to clarify the semantics and the logical relations embedded in the original flowsheet structure. The information model constructed in this study is, therefore, an intermediate step toward a fully functioning information model based on which semantically unambiguous and interoperable computerized flowsheet is constructed. To serve that purpose, our information model will need to be transformed into a workable UML (Unified Modeling Language)30 model where other modeling components such as data types, constraints, and object relationships are fully specified. The model also needs to conform to an existing standard such as HL7 RIM (Reference Information Model) 31 to support messaging the contents of the flowsheets.
Conclusions
This study was the first phase of the larger study aimed to develop a prototype patient acuity system that automatically determines the patient acuity based on the data documented in the nursing flowsheets. We observed a number of potential barriers to reusing the flowsheet data, in the ways they are organized and represented. Via the conceptual modeling and the information modeling, we clarified many ambiguous data representations of the flowsheets.
This study showed that closely investigating the terms and the information structures of a domain is an essential first step to take to clarify any ambiguity posed in the representations of the domain contents, which may hinder reusing its data. Domain knowledge that expert nurses provide is critical not only to correctly interpreting the meaning of the domain contents but also to verifying newly developed models. In order to ensure the accuracy of the data representation and the reusability of the data, nurses with up to date practical nursing knowledge need to be more actively involved in the development and maintenance of a computerized nursing flowsheet. Also, developers of such applications should fully incorporate expert nurses' opinions and minimize any technical constraint that can possibly alter the logical representations of nursing knowledge. Most of all, we think the role of a nurse informatician as a liaison is critical to transfer nurses' domain knowledge to application developers so that computerized nursing documentation systems can correctly reflect the information needs in nursing practice.
Acknowledgments
We thank to Yolanda Jennissen, RN, Jean Higgins, RN, and Jessica Winkels, RN for their inputs as domain experts. This study was supported in part by grant LM R01 07453-01 from National Institute of Health, Marcelline R Harris, Principal Investigator.
References
- 1.Goossen WT, Epping PJ, Dassen T. Criteria for nursing information systems as a component of the electronic patient record an international delphi study. Comput Nurs. 1997;15:307–15. doi: 10.1097/00024665-199711000-00022. [DOI] [PubMed] [Google Scholar]
- 2.Chute CG, Cohn SP, Campbell JR. A framework for comprehensive health terminology systems in the United States. J Am Med Inform Assoc. 1998;5:503–10. doi: 10.1136/jamia.1998.0050503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Androwich IM, editor. Clinical information systems: a framework for reaching the vision. Washington DC: ANA; 2002. [Google Scholar]
- 4.Rosenbloom ST, Miller RA, Johnson KB, Elkin PL, Brown SH. Interface terminologies: facilitating direct entry of clinical data into electronic health record systems. J Am Med Inform Assoc. 2006;13:277–88. doi: 10.1197/jamia.M1957. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Kos RK, van Ginneken Astrid M, de Wilde M, van der Lei Johan. OpenSDE: row modeling applied to generic structured data entry. J Am Med Inform Assoc. 2004;11:162–5. doi: 10.1197/jamia.M1375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.van Ginneken AM. Considerations for the representation of meta-data for the support of structured data entry. Methods Inform Med. 2003;42:226–35. [PubMed] [Google Scholar]
- 7.Goossen WT, Jonker MJ, Heitmann KU, Jongeneel-de Haas IC, De-Jong T, van der Slikke JW, et al. Electronic patient records: domain message information model perinatology. Int J Med Inform. 2003;70:265–76. doi: 10.1016/s1386-5056(03)00054-6. [DOI] [PubMed] [Google Scholar]
- 8.Coyle JF, Rossi Mori A, Huff SM. Standards for detailed clinical models as the basis for medical data exchange and decision support. Int J Med Inform. 2003;69:157–74. doi: 10.1016/s1386-5056(02)00103-x. [DOI] [PubMed] [Google Scholar]
- 9.Liaw S, Sulaiman N, Pearce C, Sims J, Hill K, Grain H, et al. Falls prevention within the Australian general practice data model: methodology, information model, and terminology issues. J Am Med Inform Assoc. 2003;10:425–32. doi: 10.1197/jamia.M1281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Rector AL. The interface between information terminology and inference models. In: Patel VL, Rogers R, Haux R, editors. MEDINFO Proceedings of the 10th World Congress on Medical Informatics; 2001 Sep 2-5; London, UK. Amsterdam: IOS Press; 2001. pp. 246–50. [PubMed] [Google Scholar]
- 11.Rector AL, Rogers J, Taweel A. Models and inference methods for clinical systems: a principled approach. In: Fieschi M, Coiera E, Li YJ, editors. MEDINFO 2004: Proceedings of the 11th World Congress on Medical Informatics; 2004 Sep 7-11; San Francisco, USA. Amsterdam: IOS Press; 2004. pp. 79–83. [PubMed] [Google Scholar]
- 12.Stevens R, Goble CA, Bechhofer S. Ontology-based knowledge representation for bioinformatics. Brief Bioinform. 2000;1(4):398–414. doi: 10.1093/bib/1.4.398. [DOI] [PubMed] [Google Scholar]
- 13.McCray AT. The Nature of Lexical knowledge. Methods Inform Med. 1998;37(45):353–60. [PubMed] [Google Scholar]
- 14.Matney S, Dent C, Rocha RA. Development of a compositional terminology model for nursing orders. Int J Med Inform. 2004;73:625–30. doi: 10.1016/j.ijmedinf.2004.04.006. [DOI] [PubMed] [Google Scholar]
- 15.Weed L. Knowledge coupling: new premises and new tools for medical care and education (computers in health care) New York: Springer-Verlag; 1991. pp. 127–40. [Google Scholar]
- 16.Rassunoux AM, Miller RA, Baud RH, Scherrer JR. Modeling concepts in medicine for medical language understanding. Method Inform Med. 1998;37:361–72. [PubMed] [Google Scholar]
- 17.Annamalai M, Sterling L. Guidelines for constructing reusable domain ontologies. Proceedings of AAMAS; 2003. [Google Scholar]
- 18.Noy NF, McGuinness DL. Ontology development 101: a guide to creating your first ontology. Technical report: Stanford University Medical Informatics; SMI-2001-0880 [Google Scholar]
- 19.McCray AT, Burgun A, Bodenreider O. Aggregating UMLS semantic types for reducing conceptual complexity. Proc MEDINFO. 2001;10:216–20. [PMC free article] [PubMed] [Google Scholar]
- 20.Sowa JF. A brief introduction to conceptual graphs [monograph on the Internet] [June 24, 2004]; Available from: http://www.cs.uah.edu/∼delugach/CG/Sowa-intro.html.
- 21.Gomez-Perez A, Corcho O, Fernandez-Lopez M. Ontology engineering (advanced information and knowledge processing) London, U.K: Springer-Verlag; 2004. pp. 47–70. [Google Scholar]
- 22.Ingenerf J. On the relationship between description logics and conceptual graphs – with some references to the medical domain. In: Bock HH, Posasek W, editors. 19th Annual Conference of the Gesellschaft für Klassifikation (GfKl); 1995 Mar; Basel, Switzerland. Heidelberg-Berlin: Springer-Verlag; 1996. pp. 355–69. [Google Scholar]
- 23.Stanford University Medical Informatics. Protégé-frame's user's guide. [May 29, 2004]; Available from http://protege.stanford.edu/doc/users guide/index.html.
- 24.Lambrix P, Habbouche M, Perez M. Evaluation of ontology development tools for bioinformatics. Bioinformatics. 2003;19:1564–71. doi: 10.1093/bioinformatics/btg194. [DOI] [PubMed] [Google Scholar]
- 25.International Council of Nurses. International classifications for nursing practice. [Jan 12 2004]; Available from: http://www.icn.ch/icnp.htm.
- 26.SNOMED® International. Systematic Nomenclature of Medicine. http://www.snomed.org/
- 27.National Library of Medicine. Unified Medical Language System. [Jan 15 2004]; Available from: http://umlsks.nlm.nih.gov.
- 28.Kim H, Harris MR, Savova G, Chute CG. Content coverage of SNOMED-CT toward the ICU nursing flowsheets and the acuity indicators. Stud Health Technol Inform. 2006;122:722–6. [PubMed] [Google Scholar]
- 29.Racer Systems GmbH & Co. KG. RacerPro user's guide version 1.9. [Nov 5 2005]; Available from: http://www.racer-systems.com/
- 30.Fowler M, Scott K. UML Distilled: a brief guide to the standard object modeling language. 2nd. Boston: Addison-Wesley Professional; 1999. [Google Scholar]
- 31.Health Level 7. HL7 version 3 resources. [Mar 10 2006]; Available from: http://www.hl7.org.au/HL7-V3-Resrcs.htm.