

Abstract
People talk to be understood, and so they should produce utterances that are easy for their listeners to understand. I begin this chapter by describing evidence showing that speakers rarely avoid sentences that are ambiguous, even though ambiguity is a factor that is well known to cause difficulty for listeners. Instead, speakers seem to choose utterances that are especially easy for them to say, specifically by producing more accessible, easy-to-think-of material sooner, and less accessible, harder-to-think-of material later. If speakers produce utterances that are easy to say but not utterances that are easy to understand, how is it that we understand each other? A third line of evidence shows that even when sentences are structurally ambiguous, they’re likely to include enough information for comprehenders to figure out what they mean. This suggests that speakers produce ambiguous utterances simply because they can -- because the grammar of their language will only let them produce utterances that are unambiguous enough to be understood most of the time anyway. And so, we understand each other because speakers produce utterances efficiently even if they’re not optimally understandable; addressees do what they need to to understand their speakers; and the grammar makes sure everything works out properly.
1. Introduction
When someone speaks, it is usually with the goal of being successfully understood. Such successful communication comes from a particular division of labor between speaker and listener. A speaker can expend little effort when constructing an utterance (“the thing”), leaving much of the burden for understanding to their listener. Or, speakers can work harder (“the red Honda on your left”), leaving less work for their addressees. The question of interest here is, given the cognitive capabilities of speakers and listeners, and the nature of the languages they speak, what is the actual division of labor that leads to the communicative success we experience everyday?
To understand the division of labor for communicative success, we must understand the behavior of speakers: Why do speakers produce utterances in the ways that they do? Producing an utterance involves a sequence of processing steps. First, a speaker must settle upon the meaning they wish to express. This meaning is a nonlinguistic entity, and is often termed a message. The message is fed to a set of processes that are collectively termed grammatical encoding. Here, we focus on two aspects of grammatical encoding: Speakers must choose the words that describe the people, places, things, actions, and so forth in their messages, and they must arrange those words into grammatical sequences that convey who did what to whom. Grammatical encoding processes feed their products into articulatory processes, which direct muscle movements that cause the now linguistically encoded messages to be presented as perceptible signals to an addressee.
Interestingly, grammatical encoding often involves choices: A speaker can express a given message with different words or with different arrangements of words. Barry Bonds hit his 762 (and counting) home runs with a “bat” or with a “baseball bat.” If a particular acquaintance ran a 26.2-mile event, it could be described as “Steve ran a marathon” or “a marathon was run by Steve.” These choices are interesting because as far as production is concerned, they are a valuable resource -- the flexibility to say “bat” or “baseball bat,” or “Steve ran a marathon” or “a marathon was run by Steve” can be exploited to achieve different goals. One general goal such flexibility can be exploited to achieve is to make comprehension easier, if speakers say “baseball bat” or “a marathon was run by Steve” when the alternative would be harder to understand. If this is what speakers do, then the division of labor for communicative success is such that speakers have to work to produce optimally comprehensible utterances. A different general goal that the flexibility in production can be exploited to achieve is to make production easier, if speakers say “baseball bat” or “a marathon was run by Steve” when the alternative would be more difficult to produce. If this is what speakers do, then the division of labor for communicative success is such that speakers do not have the responsibility of crafting especially easy-to-understand sentences; rather, speakers should produce utterances quickly and efficiently, and addressees simply need to do what is necessary to understand those sometimes sub-optimal utterances.
In my lab, we have explored these issues mostly by investigating a rather useful sentence structure termed a sentence-complement structure, as in “I saw that Steve ran a marathon.” In sentence-complement structures, a main verb like “see” takes an embedded clause argument (a full sentence, at least including a subject and verb) like “Steve ran a marathon.” Critically, sentence complement structures allow speakers to mention or omit a “that,” termed a complementizer, immediately after the main verb: “I saw that Steve ran a marathon” or “I saw Steve ran a marathon.” The mention versus omission of the optional “that” is subtle, and likely has very little effect on the meaning of the sentences (though some speculations have been offered -- e.g., Bolinger, 1972; Thompson & Mulac, 1991; Yaguchi, 2001). As such, this optional “that” is very useful; if its mention is weakly (or not at all) determined by meaning, then its mention can only be determined by grammatical encoding proper. Thus, by investigating why speakers mention the optional “that,” we can determine how grammatical encoding processes use a source of flexibility to achieve communicative success, and in particular, whether this flexibility is exploited to produce easier-to-understand sentences or easier-to-produce sentences. The former possibility I term listener-centered grammatical encoding, and the latter I term speaker-centered grammatical encoding.
2. Listener-centered grammatical encoding: “That” as disambiguator
The primary job of the language comprehension system is to try to recover the words speakers used and how those words are arranged, so that it can in turn recover the message the speaker intended. Accordingly, any property of an utterance that hinders this recovery process challenges the comprehension system and thus threatens communicative success. A primary hindrance to such recovery is ambiguity -- when a given linguistic utterance is able to convey more than one meaning. The newspaper headline, “Hospital sued by seven foot doctors” is ambiguous, because it can mean that seven podiatrists sued a hospital, or that some very tall doctors sued a hospital.
A specific kind of ambiguity that can be especially disruptive is termed a temporary ambiguity or a garden path; this is when the first part of an utterance seems to convey one meaning that is then rendered impossible by the remainder of the utterance. Take the sentence, “The reporter believed the president lied.” The beginning of the sentence -- “the reporter believed the president…” implies that “the president” is the direct object of the verb “believed” (which suggests that the reporter thought the president to be honest). Upon being presented with the word “lied,” however, it becomes apparent that the reporter in fact did not believe the president at all; rather, the reporter believed a fact about the president -- that the president was not honest. With this interpretation, “the president” is not the direct object of “believed,” but instead is the subject of the verb “lied” -- what is termed an embedded subject. Generally speaking, when hearing ambiguous fragments like “the reporter believed the president,” comprehenders tend to adopt a direct object interpretation of “the president” because it is simpler (Frazier & Fodor, 1978) and more common (MacDonald, Pearlmutter, & Seidenberg, 1994). Then, when “the president” turns out to be an embedded subject, this original direct object interpretation must be discarded and the correct embedded-subject interpretation recovered. This garden path represents a notable disruption to the comprehension process, as has been documented in hundreds of experiments exploring language comprehension (for reports on this specific kind of garden path, see F. Ferreira & Henderson, 1990; Trueswell, Tanenhaus, & Kello, 1993).
Because garden paths seem to pose measurable difficulties for comprehenders, if speakers design utterances to be maximally comprehensible, they should avoid them. In fact, the optional “that” is capable of allowing speakers to avoid just this ambiguity. Specifically, in the fragment, “The reporter believed that the president…,” the above-noted garden-path is absent, because “the president” cannot be interpreted as a direct object. Rather, the “that” is a strong signal that the subsequent noun phrase is an embedded subject. Upon being presented with “lied,” addressees do not have to discard an incorrect interpretation, and can maintain their (ultimately correct) original embedded-subject interpretation. As a result of the mention of the optional that, comprehension proceeds more smoothly. Indeed, the optional “that” in sentence-complement structures are sufficiently disambiguating that they are typically used as control conditions in studies looking at this ambiguity.
This analysis raises an interesting question, however: If “that” can disambiguate structures for addressees, why do speakers leave them out at all? From the perspective of listener-centered grammatical encoding, the answer might be that some structures are unambiguous even without the optional “that.” Take the sentence, “The reporter believed I had lied.” Even though this utterance omits the optional “that,” the resulting structure does not include a garden path. This is because “I” is a subject pronoun and so can only be interpreted as a subject (to be a direct object, the fragment would have to be “the reporter believed me…”). Overall, this analysis thus brings us to a specific prediction: If the grammatical-encoding process uses the flexibility available to it to craft utterances that are optimally comprehensible, then speakers should use “that” more in just those sentences that otherwise would include garden paths.
2.1 Pronoun and verb-suffix ambiguity
Ferreira and Dell (2000) explored this question in six experiments (three of which will be discussed at this point). In Experiment 1, we had speakers produce sentences like, “The coach knew (that) I missed practice” and “The coach knew (that) you missed practice.” In the former sentence, the embedded subject is the unambiguous subject pronoun “I,” and so this sentence is unambiguous even when it does not include the optional “that.” In the latter sentence, the embedded subject is an ambiguous pronoun “you,” which can either be a direct object (“The coach knew you well”) or an embedded subject (“The coach knew you missed practice”). Thus, the latter sentence requires the optional “that” to not include a garden path. We asked 96 subjects to each produce 48 such critical sentences. To get speakers to produce these sentences, we presented them as part of a memory task. Subjects read and encoded into memory these critical sentences, along with one or two filler sentences. Then, speakers were prompted (in an unpredictable order) to produce each sentence back. It is well known that memory for the specific forms of sentences is poor (e.g., Sachs, 1967); instead, people largely remember the meaning or ‘gist’ of a sentence, and upon recall, regenerate the sentence from that gist (for especially convincing evidence on this front, see Lombardi & Potter, 1992). In the original sentences that speakers encoded into memory, half had the optional “that” and half did not (counterbalanced with all other factors). Across all experiments, speakers’ memory for the originally presented “that” was approximately 65%; though significantly better than chance, this level of memory for the “that” leaves plenty of room for other factors -- for example, the potential ambiguity of the eventual sentence -- to influence the use or omission of the “that.” And so, if grammatical encoding is listener-centered, we should see that speakers mention “that” in their recalled sentences more when they would otherwise cause a garden path -- “the coach knew (that) you missed practice” -- compared to when they would not -- “the coach knew (that) I missed practice.”
The results for this experiment (as well as two follow-up experiments) are shown in Figure 1. The graph plots along the horizontal axis the percentage of “that” speakers produced in sentences that were unambiguous regardless of inclusion of “that” (top bar) or that are disambiguated with the “that” (bottom bar). Speakers barely produced “that” more often (by 2.3%) in sentences that would otherwise be ambiguous. Despite testing 96 subjects each producing 48 sentences (yielding a 95% confidence interval of the difference of ±3.1%), this 2.3% difference was not significant. Figure 1 also reports the results of Experiment 2, which replicated Experiment 1, only replacing the pronoun “I” (which is unambiguously a subject) with the pronouns “she” and “he” (which are also unambiguously subjects). This experiment was conducted because the first-person pronoun “I” might be special in some way, and so the third-person pronouns “she” and “he” could make for a tighter comparison to “you.” Experiment 2 again revealed a small (2.2%) difference, which (despite testing 48 subjects each producing 48 critical sentences, yielding a confidence interval of ±4.3%) was not significant.
Figure 1.

Percentage of sentences with optional “that” and full relative clauses produced in unambiguous and ambiguous sentence structures. Data from Ferreira and Dell (2000).
At this point, a concern was that though the above-described garden path caused by sentence-complement structures is well attested, it is relatively weak. And so, perhaps the reason that only small nonsignificant tendencies to avoid garden paths with sentence-complement structures were observed is because sentence-complement structures only cause small garden paths. If this is correct, then if we ask speakers to produce sentences that could include more disruptive garden paths, they should avoid them more consistently. Experiment 3 (also shown in Figure 1) assessed this possibility. Here, speakers produced sentences that could include the well-known reduced relative garden path, as in the celebrated example “The horse raced past the barn fell” (Bever, 1970). In reduced relatives, the first verb (“raced”) is initially interpreted as a main verb (“the horse raced past the barn quickly”). However, this verb is not the main verb, but is instead part of a relative clause that modifies the subject noun. Speakers can avoid this disruptive garden path by producing optional material before the ambiguous verb -- “the horse that was raced past the barn fell.” If grammatical encoding is listener-centered -- if speakers use syntactic flexibility to avoid garden paths -- this optional material should be used in sentences that would otherwise cause disruptive garden paths.
To test this, speakers produced sentences that require the optional material to avoid the garden path, like, “The astronauts (who were) selected for the missions made history,” as well as sentences that do not include a garden path even without the optional material, like “The astronauts (who were) chosen for the missions made history.” In the latter sentence, the first verb has an unambiguous “-en” suffix that requires it to be part of a relative clause, blocking the main verb interpretation (for evidence, see Trueswell, Tanenhaus, & Garnsey, 1994). The prediction is that if speakers only weakly (and nonsignificantly) avoided garden paths in the first two experiments because the sentence-complement garden paths are only mildly disruptive, they should produce the optional material (yielding a full relative clause) significantly more often in ambiguous (“selected”) than unambiguous (“chosen”) relative clause structures, because these structures are more profoundly disruptive. Results showed that if anything, the nonsignificant differences observed in Experiments 1 and 2 are eliminated with the more disruptive garden path (with a 0.3% difference in the wrong direction; Experiment 3 tested 48 subjects each producing 24 critical sentences, yielding a confidence interval of ±5.1%).
In sum, the first three experiments in Ferreira and Dell (2000) provided no evidence that speakers use “that” as a disambiguator, in turn suggesting that grammatical encoding is not listener-centered. However, it is important to recognize that Ferreira and Dell established a quite specific test for ambiguity avoidance, namely, whether speakers produced “that” more in sentences that were ambiguous, relative to sentences that were disambiguated either by specific features of pronouns (that “you” is ambiguous whereas “I” is not) or verb suffixes (that “-ed” is ambiguous whereas “-en” is not). Speakers’ mention of “that” may in fact be generally sensitive to the potential ambiguity of their utterances, but it just happens to be insensitive to the disambiguating properties of pronouns or verb suffixes.
2.2 Plausibility and verb bias
Ongoing research in my lab is assessing the effect of two other factors that are known to be relevant to ambiguity. Both factors, originally explored in comprehension research by Susan Garnsey and her colleagues (Garnsey, Pearlmutter, Myers, & Lotocky, 1997) are continuous in nature, increasing or decreasing the degree to which sentence-complement structures are ambiguous. One factor is plausibility. This refers to real-world knowledge, in this case, regarding whether the ambiguous noun-phrase can be reasonably interpreted as a direct object. For example, in “The talented photographer accepted the money could not be spent yet,” “the money” is an embedded subject that seems plausible as a direct object -- it’s something a talented photographer would reasonably accept. But in “The talented photographer accepted the fire could not be prevented,” “the fire” is a less plausible direct object -- it’s something that a talented photographer would be less likely to accept. Ambiguous noun phrases that are plausible direct objects are more ambiguous, because they encourage the ultimately incorrect direct-object interpretation of the ambiguous fragment. In fact, Garnsey et al. (1997) showed that such plausibility can affect comprehension, such that ambiguous sentences (ones without the “that”) took longer to read when the ambiguous noun phrase was a more plausible direct object. The question for language production, then, is whether speakers say the optional “that” more in sentences that have embedded subjects that are more plausible as direct objects; if so, this would be evidence for listener-centered grammatical encoding.
The second factor explored in these experiments (also following Garnsey et al., 1997) was verb bias. This refers to how often in everyday language use particular verbs are used in particular ways. Here, this refers to whether the main verb in a sentence complement structure more often is followed by a direct object, an embedded clause, or some other type of linguistic constituent. For example, “accepted” in “The talented photographer accepted the fire could not be prevented” is a verb that commonly occurs with a direct object, compared to “announced” in “The proud mother announced the flowers would be delivered soon.” Verbs like “accepted” that commonly occur with direct objects make sentence-complement structures more ambiguous, because again, they more encourage the ultimately incorrect direct-object interpretation. Again, this was shown by Garnsey et al. (1997), in that comprehenders took longer to read ambiguous sentence-complement structures with verbs that had a direct-object verb bias, compared to ones with verbs that had a sentence-complement verb bias or that were “equibiased,” which were midway between these extremes. The question for production is whether speakers say optional “that” more in sentences including verbs with direct-object verb bias, compared to in sentences including verbs that have sentence-complement verb bias (and sentences with equibiased verbs should be in between).
Three experiments (two of which will be discussed at this point) assessed whether plausibility and verb bias affect speakers’ mention of the optional “that” in sentence complement structures. The first experiment used a memory-based sentence production procedure much like that used by Ferreira and Dell (2000). The second experiment used what has been called a “Post-to-Times” task (Bradley, Fernandez, & Taylor, 2003). Here, speakers are given a pair of simpler sentences, and asked to combine them into a single more complex sentence that expresses about the same amount of information. (Subjects are given a cover story that they are practicing to adapt stories from the New York Post, which by reputation uses simpler language, to be published in the New York Times, which by reputation uses more complex language, thus giving the procedure its name.) Here, speakers were given simpler sentences like, “The talented photographer accepted something,” and “The money could not be spent yet,” and were asked to combine them; sentence-complement structures (“The talented photographer accepted (that) the money could not be spent yet”) were the overwhelmingly common product of such combination.
Figure 2 reports the results of both experiments. Experiment 1 included an equibiased verb-bias condition that Experiment 2 did not, because Experiment 2 had speakers produce more sentences in the two more extreme verb-bias conditions. Considering plausibility first, it is evident that in both experiments, speakers had no consistent tendency to use “that” more in sentences with embedded subjects that were more plausible as direct objects (open bars) than in sentences with embedded subjects that were less plausible as direct objects (grey bars). In contrast, verb bias did have a consistent and predicted effect on “that” mention: Speakers said “that” most in sentences that included verbs that more often take direct objects (the top sets of bars in both graphs), least in sentences that least often take direct objects (the bottom sets of bars in both graphs), and (in Experiment 1) sentences with equibiased verbs were between these extremes (the middle set of bars in the top graph).
Figure 2.
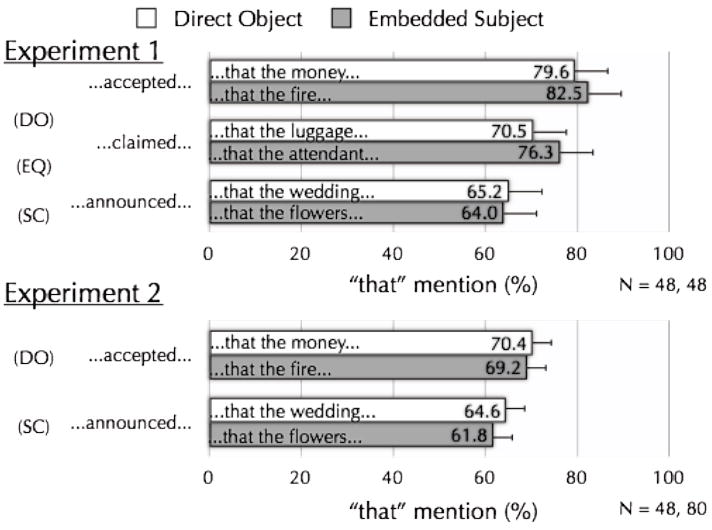
Percentage of sentences with optional “that” produced in sentences with direct-object biased (DO), equibiased (EQ), and sentence-complement biased (SC) verbs (on vertical axes) and embedded subjects that were plausible (white bars) or implausible (dark bars) as direct objects. Data from in-progress experiments.
What do these results mean? First, when the plausibility of a sentence magnified ambiguity, speakers failed to avoid that ambiguity any more often. Note that plausibility was a very reasonable factor that might have caused ambiguity avoidance. Because plausibility is grounded in real-world knowledge (rather than, say, the ambiguity of a pronoun or a verb suffix), it is something that speakers should have intuitive access to. Furthermore, the plausibility of a sentence fragment -- essentially, an aspect of the meaning of that sentence fragment -- is available to speakers before they choose particular sentence structures. (In the terms used above, plausibility is a feature of messages, which serve as input to grammatical encoding.) Thus, in terms of intuitiveness to speakers and processing flow, plausibility could have readily influenced speakers’ choices about sentence structure. Yet it did not.
On the other hand, verb bias did affect “that” mention in a manner predicted by a listener-centered grammatical-encoding mechanism -- speakers said “that” more often in sentences including verbs that commonly occur with the incorrect direct-object interpretation. Why might verb bias have exerted this effect, when other factors (pronoun or verb-suffix ambiguity, or plausibility) did not? One possibility is that verb bias may represent a more static or fixed information source regarding the strength of an ambiguity, relative to other sources of information. That is, plausibility is highly contextual, in that a given sentence may be differently plausible in different contexts or contingent upon very diverse properties of that sentence. Similarly, the ambiguity of a pronoun or verb suffix is likely not usually relevant to its interpretation (most pronouns and verbs are likely produced in unambiguous contexts). Verb bias, on the other hand, is more consistent: Any sentence complement structure with a particular verb will be more or less ambiguous depending upon verb bias every single time. This may allow the production system to employ a more “brute force” ambiguity avoidance strategy: With verbs that are misleading because of their verb bias, use “that” more often.
A different possibility, of course, is that the effect of verb bias is not due to its effect on ambiguity at all, but rather is due to some other factor that also varies with verb bias. The third experiment in this project distinguishes these possibilities, and is discussed further below.
Thus far then, not much evidence suggests that grammatical encoding is listener-centered (except possibly for the effect of verb bias just discussed). However, an important feature of the experiments presented so far is that isolated speakers (speakers did not speak to any actual person in the experiments) produced isolated sentences (the sentences were not part of a discourse or conversation). Of course, the whole point of listener-centered grammatical encoding is that speakers produce sentences that are easy for a listener. If speakers aren’t addressing an actual listener, why avoid ambiguity?
This is not to say that the evidence cited thus far is wholly uninformative. The experiments in Ferreira and Dell (2000) and the in-progress experiments just described used memory-based production and Post-to-Times tasks because they were designed to assess the reasonable possibility that speakers might automatically avoid ambiguities during production. Such automatic ambiguity avoidance appears not to hold. Still, an interesting alternative possibility is that listener-center grammatical encoding is only invoked as a kind of speech register -- that when a speaker produces natural sentences for an actual listener, they might better avoid ambiguity.
2.3 Speaking to listeners
One experiment in Ferreira and Dell (2000), Experiment 6, was designed to assess part of this issue. Speakers still produced isolated sentences from memory, but this time to actual addressees (who were themselves real experimental participants, not confederates). Addressees were instructed to listen to speakers’ utterances and rate them for how easy they were to understand, and speakers were instructed to maximize these clarity ratings. Speakers produced four different types of sentences, varying in terms of whether the main subject and embedded subject was “I” or “you”:
I knew (that) I would miss the flight.
I knew (that) you would miss the flight.
You knew (that) I would miss the flight.
You knew (that) you would miss the flight.
(The reason these four sentence types in particular were elicited is described further below.) Without the optional “that,” of these four sentence types, only (2) includes a garden path. Sentences like (1) and (3) do not include a garden path because the embedded subject pronoun “I” cannot be an object (as was the case for Experiment 1 of Ferreira and Dell, described above). Sentences like (4) do not include a garden path for more complex reasons. In particular, the embedded subject “you” cannot be interpreted as a direct object in the same clause as another phrase before it referring to the same entity; instead, such a pronoun would have to be reflexive (“You knew yourself…”). This implies that when both the main and embedded subjects are “you,” a comprehender can be certain that the pronoun is an embedded subject even without the “that.” And so, because only sentences like (2) contain an ambiguity, if speakers use “that” to avoid ambiguity, they should say them more in sentences like (2), compared to the other three sentence types.
Figure 3 reveals results from this experiment, when speakers addressed addressees (top graph) and when they did not (bottom graph). Speakers did not produce “that” most in ambiguous sentences like (2). In fact, they produced “that” just as often in sentences like (3), even though such sentences had “I” as embedded subjects and so were unambiguous. Furthermore, the same pattern is observed regardless of whether speakers addressed an actual addressee (top panel) or not. Speakers did say “that” overall more when addressing real addressees (by about 7%), however, they increased “that”-mention just as much in unambiguous sentences like (1), (3), and (4) as in unambiguous sentences like (2). Thus, it appears that addressing an actual person by itself is not enough to cause grammatical encoding to be listener centered, at least in terms of avoiding ambiguity.
Figure 3.

Percentage of sentences with optional “that” produced in sentences with different main and embedded subjects with addressees (top graph) or without (bottom graph). Data from Ferreira and Dell (2000).
However, though Ferreira and Dell’s (2000) Experiment 6 assessed the possibility that speakers might avoid ambiguity more when addressing a real addressee, it was still the case that Ferreira and Dell’s speakers produced isolated sentences -- individual sentences from memory, rather than sentences that were part of a discourse or conversation. Ongoing work with Melanie Hudson is exploring whether speakers might avoid ambiguity more effectively when producing conversationally situated sentences to real addressees. To get speakers to produce sentences like (1) to (4) above, pairs of experimentally naïve subjects were told that they would read each other passages that included statements describing one of them observing one of them behaving in some manner, and then a question asking what kind of emotion that behavior might correspond to. For example, one subject would ask the other (from a script), “You notice I am stamping my feet. What do you believe about me?” The other subject was asked to answer in a complete sentence, and so might say something like “I believe (that) you are angry.” We then manipulated who did the observing and who did the behaving, and so elicited all sentence types (1) through (4) above. For example, an answer to “I notice I am smiling from ear to ear. What do I believe about myself?” would be something like, “You believe you are ecstatic.” (We began the experiment by describing a theory of emotion to subjects suggesting that we may not always have direct access to our emotional states, so that sometimes, we infer even our own emotional states based on our behaviors. This allowed responses like “I believe (that) I am ecstatic” and “you believe (that) you are ecstatic” to seem reasonable.)
Figure 4 reports the results of two experiments using this methodology. The first graph reports results from the just-described basic paradigm. If speakers use “that” to disambiguate otherwise ambiguous sentences, as a listener-centered grammatical-encoding mechanism would predict, they should say “that” most in sentences like “I believe (that) you are angry.” Rather, we observed that speakers produced “that” least in such sentences. The bottom graph reports results from another experiment in which on some filler trials, subjects answered questions that elicited responses like “I believe you,” in which the pronoun “you” was a direct object. This assessed the possibility that speakers failed to avoid ambiguity in the first experiment because all responses in the experimental situation were sentences with “you” as embedded subjects, possibly making such embedded subjects effectively unambiguous. Still, the observed result was that speakers said “that” least often in the ambiguous case. In sum, these experiments provide no evidence that speakers avoid ambiguity more effectively when producing communicatively situated sentences for actual addressees. (It is worth noting that though the data reported in Figure 4 shows speakers mentioning “that” least in ambiguous sentences, the pattern is rather unlike that revealed by Ferreira & Dell Experiment 6 that was just discussed, despite the fact that the same sorts of sentences were produced in the studies. This point is considered further below.)
Figure 4.

Percentage of sentences with optional “that” produced by speakers in interactive dialogue in sentences with different main and embedded subjects in a basic referential communication paradigm (top graph) and when fillers included direct objects (bottom graph). Data from in-progress experiments.
To sum up: Through the mention of the optional “that,” grammatical encoding processes have the opportunity to produce less ambiguous, easier-to-understand utterances to addressees. A series of investigations looking at this possibility revealed little evidence that grammatical encoding processes do this, however. Speakers did not use “that” more in sentences that were ambiguous because they include an ambiguous pronoun; they did not produce disambiguating full relative clauses more in sentences that had ambiguous verb suffixes; they did not produce “that” more in sentences that had real-world meaning that encouraged an incorrect interpretation; and they did not say “that” more often in ambiguous compared to unambiguous sentences when addressing real addressees, even in naturalistic, interactive conversational settings. One effect suggests ambiguity avoidance: Speakers did say “that” more in sentences that include verbs that commonly occur with the misleading direct-object interpretation, compared to in sentences that include verbs that commonly occur with the intended embedded-subject interpretation, an effect that is explored further below.
The weight of this evidence suggests that grammatical encoding is not listener-centered -- that when speakers have flexibility in how to express a message, they do not choose a form that is easier for their listener to comprehend. This suggests that the division of labor for communicative success may be such that speakers use flexibility to produce easy-to-formulate sentences. Evidence for this is discussed next.
3. Speaker-centered grammatical encoding: “That” as syntactic pause
Of course, speakers have the job not only of saying things their addressees can understand (even if as suggested by the evidence in the previous section, perhaps not things their addressees can optimally understand), but also to say things quickly and efficiently. In fact, such an “efficiency mandate” is likely very important -- it is not clear that a speaker who takes an inappropriately long time to craft a perfect utterance benefits the communicative process more than a speaker who gets his or her utterance out quickly, even if that utterance isn’t perfect. This is closely related to what Clark (1996) calls the temporal imperative -- speakers are responsible for the time that they use in a conversation, and so need to use that time judiciously (despite what many of us may think during faculty meetings). The experiments reviewed next were designed to assess whether speakers use syntactic flexibility to promote such efficiency of production.
3.1 Accessibility-sensitive production
One strategy that has been argued to promote the efficiency of production is based on a kind of first-in-first-out principle (Bock, 1982). The idea is that a major challenge to efficient production is variability in retrieving from memory the words to be included in a sentence; some words are retrieved quickly, whereas others are retrieved more slowly. Meanwhile, utterances are largely sequential structures -- sentences are produced one word after another in certain constrained orders. An inefficient production strategy would be to commit to producing a word at a particular point in a sentence irrespective of when it is retrieved from memory. For example, if speakers commit to producing a word early in a sentence that is difficult to retrieve, the production of the whole sentence will need to wait until the retrieval of that word is complete. More efficient would be for speakers to produce sentences such that easy-to-retrieve material is positioned early in the sentence whereas hard-to-retrieve material is positioned later. If easy-to-retrieve material is positioned early, the production of the sentence can begin sooner, whereas delaying the mention of hard-to-retrieve material to later in the sentence buys time for the successful retrieval of that material. This strategy is here termed accessibility-based syntactic production: Choose syntactic structures that allow more accessible material to be mentioned sooner.
The classic experimental demonstration of accessibility-based syntactic production comes from Bock (1986). She investigated the influence of priming on sentence production, that is, the fact that people retrieve words from memory more quickly when they previously process related words. On target trials in Bock’s experiment, speakers described simple line-drawn scenes that allowed for active- and passive-structure descriptions like “lightning is striking the church” or “the church is being struck by lightning.” Before describing such pictures, speakers heard and repeated individual words that were similar in meaning to one element of the picture or another, thereby priming the names of such elements -- for example, “thunder” (priming “lightning”) or “worship” (priming “church”). Results showed that speakers used active or passive sentence structures in order to position the primed word earlier in their sentences, so that they tended to say “lightning struck the church” when they previously heard and repeated “thunder,” but “the church was struck by lightning” when they previously heard and repeated “worship.” This is accessibility-based sentence production: Speakers chose sentence structures that allowed accessible material to be spoken sooner.
Critical for present purposes is that accessibility-based sentence production might affect not just the choice between an active versus passive structure, but also the mention of the optional “that.” The optional “that” itself should be especially easy to retrieve for production: It is very common (the 17th most frequent word in the language, according to the CELEX database, Baayen, Piepenbrock, & van Rijn, 1993), it has a simple sound structure, and its production may even come essentially “for free” as part of a syntactic selection process (V. S. Ferreira, 2003). This implies that when speakers mention an easy-to-retrieve “that,” they delay the retrieval and production of the subsequent material. Thus, if accessibility-based syntactic production applies to “that” mention, speakers should mention “that” when the retrieval of the subsequent material is more difficult (thereby mentioning difficult-to-retrieve material later), and they should omit “that” when the retrieval of subsequent material is easier (thereby mentioning easy-to-retrieve material sooner).
Is “that” mention in fact sensitive to the accessibility of sentence material in this fashion? Current evidence is consistent with this. Above, I described Experiment 6 from Ferreira and Dell (2000), in which speakers produced sentences like the following (repeated from above):
I knew (that) I would miss the flight.
I knew (that) you would miss the flight.
You knew (that) I would miss the flight.
You knew (that) you would miss the flight.
In the description above, it was noted that sentences like (2) are ambiguous whereas sentences like (1), (3), and (4) are not. However, sentences (1) through (4) also vary in a way that likely affects accessibility. In particular, in sentences (1) and (4), the main and embedded subjects are identical: They are the same word, referring to the same entity (they are coreferential, linguistically speaking). The fact that the embedded subject is identical to the main subject in these sentences should make retrieval of that main subject easier: When speakers need to produce the embedded subject, they simply need to repeat a word they used two or three words previously. In contrast, in sentences (2) and (3), the main and embedded subjects are different words referring to different entities (they are not coreferential). This implies that retrieval of the embedded subject should be more difficult in these sentences, because a speaker can’t simply repeat a word retrieved two or three words previously. Thus, if “that” mention is accessibility based, speakers should say the “that” less in sentences like (1) and (4), compared to in sentences like (2) and (3).
This was tested first in Experiment 4 of Ferreira and Dell (2000). (Note that Experiment 6, reported above, was a replication of Experiment 4 manipulating the presence of an addressee.) The result of Experiment 4 is shown in the top graph in Figure 5. Speakers indeed produced “that” less in sentences like (1) and (4), in which the embedded subject is identical to the main subject, compared to in sentences like (2) and (3), in which the embedded subject differs from the main subject. Re-inspection of Figure 3 above reveals that the same pattern was also observed in Experiment 6, regardless of whether speakers addressed addressees. This suggests that speakers mention “that” in response to the accessibility of the material in their sentences. This should make production easier, in turn suggesting that the grammatical encoding process operates in a speaker-centered rather than listener-centered way.
Figure 5.

Percentage of sentences with optional “that” produced by speakers under different conditions of greater or lesser accessibility. In the bottom graph, underlining indicates material used as the recall prompt in the memory-based sentence-production task. Data from Ferreira and Dell (2000).
Of course, it is possible that the repetition (or coreferentiality) manipulated in Experiments 4 and 6 of Ferreira and Dell (2000) affected “that” mention for reasons other than accessibility. However, other experiments provide converging evidence that accessibility indeed affects “that” mention in the predicted manner. Experiment 5 in Ferreira and Dell assessed the effect of accessibility directly. Speakers were presented with sentences like “I suspected (that) you felt uncomfortable” in a memory based task. The primary manipulation was of the cue used to prompt production of the critical sentence. Specifically, speakers were cued to produce critical sentences either with the main subject and verb of the sentence (“I suspected”) or with the embedded subject and verb (“you felt”). When cued with the embedded subject and verb, the retrieval of that embedded subject and verb should be especially easy -- after all, the material is literally given to speakers. If “that” mention is sensitive to the accessibility of subsequent material, speakers should say the “that” less when cued with the embedded subject and verb (“I felt”) -- the material after that “that” -- compared to when cued with the main subject and verb (“I suspected”) -- the material before the “that.” The bottom graph in Figure 5 shows that in fact, when prompted with the embedded subject and verb, speakers say “that” significantly less often than when prompted with the main subject and verb, as predicted by an accessibility-based syntactic production mechanism (the experiment included yet one more manipulation of ambiguity, illustrated in the graph, just to give the ambiguity-avoidance prediction one more chance; once again, ambiguity was uninfluential).
More converging evidence that accessibility per se affects “that” mention comes from a study by Ferreira and Firato (2002). There, we explored the effect of proactive interference on sentence production. Proactive interference refers to difficulty retrieving information from memory because of previous memory retrievals, which is greater to the extent that the current and previously retrieved material is more similar. For example, imagine someone attempted to retrieve the lists of words “author, poet, biographer, writer” and “author, poet, biographer, golfer.” Because “writer” is more similar in meaning to “author,” “poet,” and “biographer” than “golfer” is, “writer” should be relatively harder to retrieve from memory. In fact, in a list-recall experiment, Ferreira and Firato revealed just this effect. Now, consider sentences (5) and (6) below:
-
(5)
The author, the poet, and the biographer recognized (that) the writer was boring.
-
(6)
The author, the poet, and the biographer recognized (that) the golfer was boring.
If speakers are asked to remember and produce these sentences, because “writer” should be harder to remember in sentence (5) than “golfer” is in sentence (6), speakers should be more likely to produce “that” in (5) than in (6). (Note that materials were counterbalanced so that for a different group of subjects, “golfer” was presented with three semantically similar words and “writer” with three semantically different words.) Figure 6 reports the results of the experiment. Speakers in fact did produce “that” more in sentences with embedded subjects that were similar in meaning to main subjects, compared to in sentences with embedded subjects that were different in meaning to the main subjects. This fits with an accessibility-based prediction, assuming that the similar embedded subjects elicited greater proactive interference. Interestingly, not only did speakers say “that” more in sentences like (5) (with similar-meaning embedded subjects), but they also produced more disfluencies in sentences like (5), such as “ums,” “uhs,” repetitions, restarts, and so forth. This is consistent with the claim that similar-meaning embedded subjects engendered proactive interference and so greater retrieval difficulty.
Figure 6.
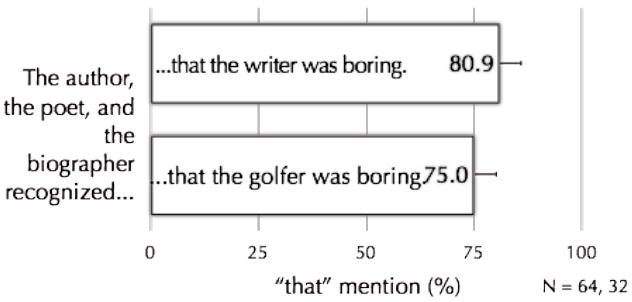
Percentage of sentences with optional “that” produced by speakers when embedded subjects suffered from more (top bar) or less (bottom bar) proactive interference. Data from Ferreira and Firato (2002).
3.2 Other production-based influences
Two results that were presented in the experiments described above assessing listener-centered grammatical encoding were left hanging, and at this point can be resolved. First, the experiments that manipulated plausibility and verb bias revealed that though ambiguity as magnified by plausibility failed to influence “that” mention, ambiguity as magnified by verb bias did. In particular, speakers produced “that” more in sentences with verbs that commonly took direct objects compared to in sentences with verbs that commonly took embedded clauses. The ambiguity-avoidance explanation emphasizes that verbs that commonly take direct objects encourage an incorrect direct-object interpretation and so can use the “that” as a disambiguator, whereas verbs that rarely take direct objects do not encourage an incorrect direct object interpretation and so don’t need the “that” as a disambiguator. There is another explanation for this effect, however. One could equally emphasize the complementary characterization: Verbs that commonly take direct objects rarely take embedded clauses, and so may be hard to produce as embedded clause structures, whereas verbs that rarely take direct objects commonly take embedded clauses, and so may be easy to produce as embedded clause structures. If we assume that in general, when production is more difficult, speakers use strategies that make production easier, then speakers should use “that” more in sentences with direct-object biased verbs, but not because the ambiguity of the direct-object biased verbs, but because producing embedded-clause structures with verbs that rarely take embedded-clause structures is more difficult.
A third experiment in this series was conducted to test this possibility. Here, sentences with three types of verbs were compared: Verbs that commonly take direct objects (“Jenny anticipated (that) the turn would be extremely sharp”), verbs that commonly take embedded clauses (“Kevin assumed (that) the blame was going to head his way”), and verbs that commonly take neither (because they take other sorts of arguments instead; “Amy confirmed (that) the rumor had been passed on to others”). If speakers say “that” more in sentences with verbs that commonly take direct objects because of the ambiguity that is encouraged by such verbs, then they should say “that” less in verbs that take neither direct-objects nor embedded clauses; because such verbs rarely take direct objects, they don’t encourage ambiguity, and so don’t require the “that” as disambiguator. But if speakers say “that” more in sentences with verbs that commonly take direct objects because it is harder to produce embedded-clause structures with such verbs (because speakers produce embedded-clause structures with direct-object biased verbs less), then speakers should also say “that” often with verbs that take neither direct objects nor embedded clauses, because verbs that take neither type of argument are rarely produced with embedded clause structures and so should also be harder to produce. Figure 7 reports the results of a Post-to-Times experiment testing these predictions. Speakers produced “that” often both in sentences with verbs that commonly take direct objects as well as in sentences with verbs that take neither direct objects nor embedded clauses, relative to sentences with verbs that commonly take embedded subjects. Thus, speakers say “that” less only in sentences with verbs that are usually produced with embedded clauses; how commonly verbs take direct objects was irrelevant. This suggests that difficulty of production and not ambiguity is why speakers say “that” more in sentences with direct-object biased verbs. Thus, the only suggestion above that speakers avoid ambiguity appears in fact not to be about ambiguity, but rather, about difficulty of production. This is further evidence that grammatical encoding operates in a speaker-centered rather than listener-centered way.
Figure 7.
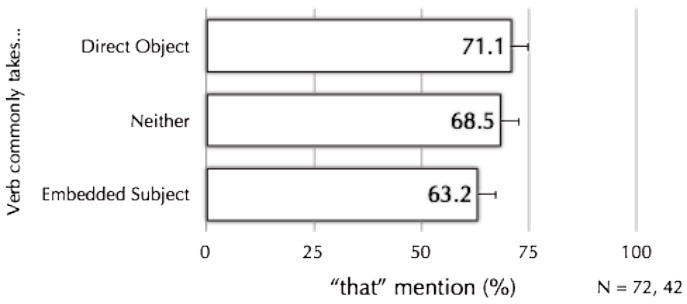
Percentage of sentences with optional “that” produced by speakers in sentences with verbs that commonly take direct objects (top bar), embedded subjects (bottom bar), or neither (middle bar). Data from in-progress experiment.
The second hanging result was from the experiments investigating interactive dialogue. It was noted that though speakers said “that” least in sentences that would otherwise be ambiguous (disconfirming an ambiguity-avoidance prediction), the results of the experiments were different from that observed in Ferreira and Dell (2000). That is, Ferreira and Dell found that when pronouns were repeated (or coreferential), speakers said “that” less than when pronouns were unrepeated (see Figures 3 and 5). In contrast, the experiment investigating interactive dialogue found two main effects: Speakers said “that” less when the main subject was “I” than when the main subject was “you,” and speakers said “that” less when the embedded subject was “you” than when the embedded subject was “I” (see Figure 4). Why did these two sets of experiments observe different results despite the similarity of the materials?
Here, it turns out to be important exactly how sentences are elicited for production, because retrieval difficulty can manifest in different ways depending on exactly how speakers generate the material to be produced. In memory-based sentence production (Ferreira & Dell, 2000), what is likely especially difficult to remember are all of the words (and their meanings) in a sentence. If a pronoun is repeated, it means that there is one fewer word (or referent) to keep track of, which should make retrieval of sentence material easier. In the interactive dialogue situation, however, speakers did not have to hold sentences in memory. Instead, speakers had to generate sentence content by answering their partners’ questions concerning which emotion might correspond to a particular observed behavior. This implies that in the interactive dialogue situation, factors that make it easy or hard to think of which emotion corresponds to particular behaviors should determine retrieval difficulty.
In particular, consider the difference between sentences with “I” versus “you” main subjects: “I believe (that) you are angry” versus “You believe (that) you are angry.” To produce the first sentence, a speaker must take his or her own perspective (“If I noticed my partner stamping her feet, what emotion would I believe that corresponds to?”). To produce the second sentence, a speaker must take his or her partner’s perspective (“If my partner noticed herself stamping her feet, what emotion would she believe that corresponds to?”). The latter process -- taking someone else’s perspective -- is likely more difficult than the former process -- taking ones own perspective. So, speakers may have said “that” more in sentences with “I” as a main subject compared to in sentences with “you” as a main subject because the sentences with “I” as a main subject were easier to produce. The difference between sentences with “I” versus “you” as embedded subjects is more subtle (and the effect of the embedded subject is less stable), but here, it may be that it is more difficult to attribute an emotion to oneself (based on observing a behavior) than it is to attribute an emotion to others. This reasoning is based on the well-known actor-observer discrepancy in the domain of attribution, whereby people make so-called dispositional attributions (attributions about someone’s personality) less to themselves (when they are actors) than to others (when they observe others behaving). Thus, speakers may say “that” less when “you” is the embedded subject because it is easier to think of what emotion might correspond to a behavior when evaluating others’ behavior, whereas when “I” is the embedded subject, it is more difficult to think of what emotion might correspond to one’s own behavior.
Two experiments sought to confirm this explanation. In one, a third party was introduced to the dialogue situation, namely, the experimenter. Now, subjects could say any of the nine sentences, “I/you/she believe (that) I/you/she is angry,” with “she” referring to the experimenter. If the above explanation is correct, “she” should pattern with “you” both as main and embedded subjects (it should be just as difficult to adopt the experimenter’s perspective as the speakers’ partners’ perspective, and it should be just as easy to attribute an emotion to the experimenter as it is to attribute an emotion to one’s partner). In fact, the results exhibited a pattern very much like this. In a second experiment, the specific sentences speakers produced in the original experiment (with the results reported in Figure 4 above) were taken, cleaned up (removing “ums” and so forth), and then given to an independent group of 48 subjects to produce from memory. If the above explanation is correct, then when speakers produce the sentences from memory, the original pattern observed in Ferreira and Dell should return, with “that” produced less when the pronouns were repeated. This prediction was confirmed. Note that this latter result demonstrates an important point, because it shows that “that” mention is not tied to the linguistic properties of speakers’ utterances -- the same set of sentences exhibited very different patterns of “that” mention when produced from memory, versus when produced in interactive dialogue. This suggests that “that” mention is sensitive to the cognitive states of speakers -- in particular what causes greater versus less retrieval difficulty -- rather than to the the features of speakers’ sentences per se.
In sum, the weight of the evidence reviewed thus far suggests that speakers do not use the flexibility that is available to them (in the form of being able to use or omit an optional “that”) to produce easier-to-comprehend sentences; instead, they use that flexibility to produce easier-to-produce sentences. This portrays a grammatical encoding process that is speaker-centered and not listener-centered. Why might this be the case? A general answer to this question comes from Levinson (2000). He notes that for a variety of reasons, production is likely to be more difficult than comprehension. If so, then communication as a whole would proceed more efficiently if speakers are freed to produce utterances as efficiently as they can, even if the utterances are missing some information or are not optimally comprehensible. Then, given listener’s relatively smaller communicative burden, they can bring a powerful inferencing process to bear on the suboptimal utterances they are presented with, filling in missing information or plowing through relatively difficult-to-understand structures. The data presented here are consistent with this general picture. However, this analysis begs the question of why producing an easier-to-comprehend sentence is difficult in the first place. Next, we consider ambiguity avoidance in particular, and why it might hard for producers to do.
4. Why don’t speakers avoid ambiguity?
Though it is sometimes claimed that speakers should (Grice, 1975) or in fact do avoid ambiguity (e.g., Haywood, Pickering, & Branigan, 2005; Temperley, 2003), it often seems that frank ambiguities go unnoticed even by comprehenders, let alone by speakers. Groucho Marx’s famous line, “I once shot an elephant in my pajamas” is likely not humorous to those who first hear it until he follows it up with, “how he got in my pajamas I’ll never know.” The likely frequency with which ambiguity goes unnoticed suggests an important fact: Detecting ambiguity is often difficult (and interestingly, may not threaten successful communication -- more on that below).
Why might it be difficult to detect ambiguity? The forms of ambiguity that have been considered thus far are termed linguistic ambiguities. They occur because accidents in the language or limitations of linguistic encoding (i.e., how particular features of meaning are mapped onto words and structures) cause a linguistic utterance to be interpretable in (at least) two otherwise unrelated ways. “I once shot an elephant in my pajamas” is ambiguous because the order of words in a sentence does not completely determine the syntactic structure of that sentence, and so “in my pajamas” can be syntactically interpreted as modifying the verb (meaning that the shooting happened while in pajamas) or as modifying the noun (meaning that the elephant was in pajamas). The same holds for “the reporter believed the president…,” though only temporarily. A simpler form of linguistic ambiguity occurs with homophones: Words with different meanings that happen to sound the same, like “bat” (which can either refer to an instrument for hitting baseballs or cricket balls, or a flying mammal). In this case, it’s simply an accident of English that two distinct meanings are sometimes expressed with identical-sounding words.
Now, consider what a speaker must do to detect that “bat” is ambiguous, given how production processes in general operate. A speaker begins with some meaning they wish to express -- say, the meaning of a flying mammal. The speaker then must formulate a linguistic description for that meaning: the word “bat.” Then, the speaker must assess that linguistic description for whether it could be interpreted in some other way -- a way that the speaker does not intend to express, and that is not systematically related to the meaning that the speaker does intend to express. This process describes a kind of “production U-turn”: To detect ambiguity, speakers must take a meaning, formulate a candidate expression, and compare it back against meaning (other meanings) to determine whether it is ambiguous. Like a U-turn in real life, executing such a U-turn would seem inefficient and difficult.
4.1 Avoiding lexically ambiguous descriptions
Ferreira, Slevc, and Rogers (2005) sought to determine what conditions must hold for speakers to be able to successfully carry out this “production U-turn.” They tested speakers in a referential communication task, where they were presented with four line drawings, and were asked to describe one or more of them so that an addressee could pick them out. On critical trials, speakers were asked to describe target objects that could be labeled with homophone names, for example, a flying mammal. On some critical trials, such targets were presented in contexts that created linguistic ambiguity, because one of the three other objects in the display, termed the foil object, was the homophone counterpart of the target object, and so could be described with the same name. For example, the flying mammal was accompanied by a baseball bat (along with two other unrelated objects, like a swan and a magician), so that “bat” could legitimately describe either object. On other trials, targets were presented in control contexts, where all three other objects in the display were completely unrelated to the target (so a flying mammal was accompanied by a goat, a swan, and a magician). The question of interest was, under what circumstances could a speaker detect that a description like “bat” might be ambiguous? To the extent that speakers can detect ambiguity, they should use potentially ambiguous bare-homophone labels like “bat” less in ambiguous contexts (when the flying mammal is accompanied by a baseball bat) than in control contexts.
A first experiment confirmed that speakers are able to avoid linguistic ambiguities at all. When speakers were presented with the display of four pictures, they saw an arrow indicating the target picture, which they were to describe as soon as they saw the arrow. On half of trials, this arrow appeared simultaneously with the pictures; on the other half of trials, the pictures appeared and remained on the screen for five seconds before the arrow appeared, giving speakers a lengthy preview of the whole display. The results, shown in the top panel of Figure 8, reveal that speakers were able to avoid ambiguity (by avoiding a bare-homophone description) 22% more often with preview than without. Furthermore, without preview, speakers hardly avoided ambiguity at all, using potentially ambiguous bare-homophone labels (like “bat”) only 11% less often in ambiguous contexts compared to in control contexts.
Figure 8.
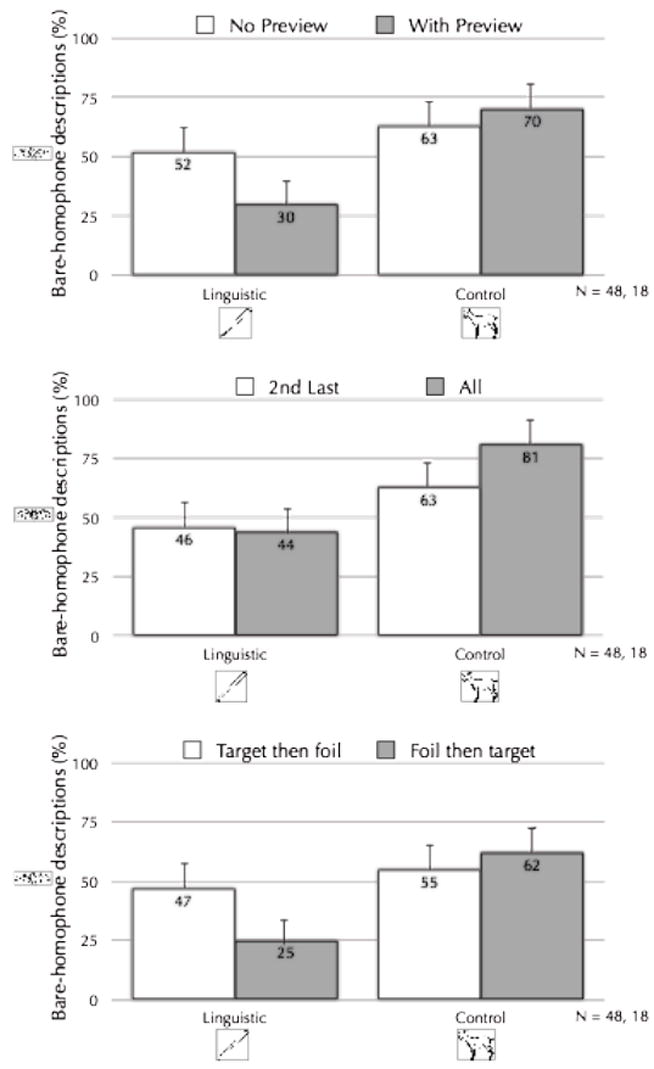
Percentage of bare homophones produced under linguistic ambiguity and control conditions with and without preview (top graph), when ambiguity-causing foils were only looked at or were about to be named (middle graph), and when ambiguity causing foil was named after or before target (bottom graph). Data from Ferreira et al. (2005).
So, when under time pressure, speakers don’t avoid ambiguity very well. But, when given enough time (five seconds -- an eternity to a system that can produce words at a rate of 3 to 4 per second), speakers can avoid linguistic ambiguities. The question of interest is, what does it take for speakers to in fact do so? The answer to this question should give us insight into what sorts of processing steps are necessary for speakers to make the “production U-turn” described above. The starting point for the remaining experiments, which were designed to answer this question, was that speakers must somehow “activate” the foil object -- they must somehow access the representation of the baseball bat in a way that allows it to be recognized as describable by the same name (“bat”) as the target object. Or, put another way, perhaps what was happening without preview in the top graph of Figure 8 is that speakers didn’t have the resources to process the baseball bat sufficiently to detect that it could be described by the candidate description “bat”; with preview, speakers were able to do something more with the foil object that allowed its threat of ambiguity to be detected. The crucial question is, what specifically could speakers do with preview that they couldn’t do without preview?
The simplest possibility is that without preview, speakers simply didn’t see or attend to the foil objects at all -- that when the arrow appeared simultaneously with the pictures, speakers looked at the arrow, then immediately directed their attention to the target, describing it with a bare-homophone label like “bat” while remaining wholly oblivious to the ambiguity caused by the foil. Perhaps if speakers simply could look at or draw their attention to the foil before initiating description of the target, the threat caused by that foil could be appreciated. A more extensive possibility is that looking at or drawing attention to the foil object isn’t sufficient to recognize its ambiguity-causing potential. Rather, perhaps speakers need to process the foil in a way that involves naming it, or applying an ’intention to speak’ to the object. The idea is that if speakers need to name not just the target (the flying mammal) but also the foil (the baseball bat), this should compel them to recognize that “bat” is a description that could apply to both objects.
To assess this, the task was modified so that instead of an arrow appearing that indicated the target object, a dot appeared and bounced from object to object in the display. On all critical trials, the dot appeared and bounced from a filler object (the swan) to the target object (the flying mammal) to the foil object (the baseball bat), so that the target object was always indicated second-last and the foil object last. On non-critical trials, the dot would appear and sometimes bounce to just two objects and other times would bounce to all four objects, so speakers could never anticipate how many objects would be indicated in total. On half of all trials, the speaker was instructed to name only the second-last indicated object (which on critical trials was in fact the target object). Note that overall, speakers cannot know until all dots have bounced which is the second-last object (because two, three, or four objects could be indicated in total). This means that on these second-last trials, speakers had to look at all indicated objects, including the foil object, before knowing which was the target object. On the other half of trials, speakers had to name all indicated objects. This means that speakers had to prepare to name not just the target object (which was the second-last description to be provided), but also the foil object (which was the last description to be provided), all in a fluent utterance (by saying something like “swan, [flying] bat, and [baseball] bat”). So here, speakers described target objects under circumstances where speakers have applied an “intention to name” to the ambiguity-causing foil, and in fact, will describe it with the words that immediately follow the target description. The question of interest is, is looking at the foil object enough to cause speakers to appreciate that it causes ambiguity? If so, then speakers should avoid ambiguity effectively in the second-last condition -- about as effectively as they did with preview in the first experiment. Or, is looking not enough -- do speakers have to look at and prepare to name the foil object to recognize that it causes ambiguity? If so, then performance in the second-last condition should pattern as in the no-preview condition (with speakers barely avoiding bare-homophone ambiguous descriptions), whereas productions in the all condition should include bare-homophone productions less often (about as rarely as speakers did with preview).
The middle graph in Figure 8 reports the results. Speakers produced bare homophone labels 46% of the time when instructed to name only the second-last-indicated picture, and they produced bare homophone labels 44% of the time when instructed to name all indicated pictures. Thus, they didn’t avoid ambiguous descriptions any better when applying an “intention to name” to the ambiguity-causing foil, compared to when they just had to look at that ambiguity-causing foil. However, consider speakers’ overall performance relative to the first experiment (top graph): Speakers in Experiment 2 only avoided ambiguity 7% better than speakers in Experiment 1 did without preview (52% vs. 45%). That is, looking at foils, or looking at and preparing to name foils (with the very next words that a speaker is about to produce) allowed for only a small amount of additional ambiguity detection (compared to, say, the effect of full preview, which was 22% -- 52% vs. 30%). This places quite serious limits on speakers’ ability to detect ambiguity -- they only weakly detected that a description like “bat” is ambiguous, even when they are just about to describe another object that such a description is ambiguous with respect to.
(Two quick notes about this experiment: First, performance differed quite strongly between conditions in the control condition. This reveals a puzzling observation: Speakers were better able to detect that a potentially ambiguous description like “bat” was not a threat in the all condition compared to in the second-last condition -- they used descriptions like “bat” when ambiguity was not at issue more in the all-instruction condition. Why this was observed is unclear. Second, this experiment also included two addressee conditions: speakers addressed either a real addressee who was asked to indicate with pen-and-paper which objects were described and in which order, or addressees were hypothetical. Qualitatively, subjects performed the same in these two cases, though they did use bare homophone descriptions less overall -- even in the control condition -- when addressing real addressees, likely because they adopted a strategy of being over-descriptive [describing the flying mammal with expressions like, “the animal bat with its wings open,” providing far more information than is needed to distinguish the target from the foil].)
The performance in this experiment surprised us. How could speakers not effectively avoid ambiguous labels like “bat,” even when they were just about to describe two consecutive but distinct objects that could be described with “bat”? When we inspected speakers’ actual utterances, it turned out that they frequently produced utterances like “swan, bat, and baseball bat” -- in other words, they described the target object with an ambiguous label (“bat”), but then they described the foil object with an unambiguous label (“baseball bat”). Based on performance in another condition, we knew speakers didn’t consider this descriptive strategy to be optimal. That is, when we gave speakers displays with two identical objects that differed only in (say) size, like with a bigger and smaller flying mammal, speakers never produced utterances like “swan, bat, and bigger bat,” instead nearly always producing utterances like “swan, smaller bat, and bigger bat.” This shows that speakers avoid ambiguity with their first description when they can. Thus, the preponderance of utterances like “swan, bat, and baseball bat” led us to conclude that speakers could avoid ambiguity largely after-the-fact -- that only once speakers were about to use the same label to describe two different referents were they able to recognize the ambiguity of that label. Two final experiments, the results of one of which are shown in the bottom of Figure 8, confirm that this is the case. Speakers described displays with bouncing dots, but this time, either the target object was indicated before the foil, or the target was indicated after the foil. Speakers were instructed to always describe all objects, so that they either described targets before foils (like in the experiment shown in the middle graph) or after foils. As shown in the graph, speakers described targets with potentially ambiguous bare-homophone labels much less often when they described targets after foils than when they described targets before foils. Concretely, speakers produced utterances like “swan, bat, and flying bat” when they described targets after foils, but they produced utterances like “swan, bat, and baseball bat” when they described targets before foils (like they did in the previous experiment). This confirms that speakers can only maximally avoid ambiguity after the fact: Once they’ve formulated and described one object with a potentially ambiguous label, and they are about to apply that same label to another object -- once they’re about to say “swan, bat, and…” -- they can recognize that the label can actually apply to two different objects.
These results provide insight into how speakers do the ’production U-turn’ noted above that is necessary to detect ambiguity. In fact, the results suggest that to maximally avoid ambiguity, speakers don’t do the U-turn at all. They can only apply formulation processes in the forward direction, first formulating a description for one meaning (“bat” for the flying mammal), then once they’re about to formulate that same description for another meaning (“bat” for the baseball bat), they can detect the possibility of the same label applying to both meanings. Note that the ambiguity caused by homophones is tightly circumscribed: The whole ambiguity exists with just one (often short) label. The ambiguity caused by syntactic indeterminacies -- for example, “I once shot an elephant in my pajamas” -- is much more extended in time, and thus is likely even harder to appreciate with this “apply production processes to two separate meanings” strategy.
4.2 Other evidence for ambiguity avoidance
All of this said, some reports have suggested that speakers produce utterances in certain ways in order to avoid ambiguity. It may be, however, that more production-centered forces or simpler strategies are at work in these reported situations. For example, Temperley (2003) suggested that speakers’ use of optional “that” in object-relative clauses like “the lawyer that companies hire…” is motivated by ambiguity avoidance, because in part of a corpus of utterances, “that” is more common when without the “that,” the sequence could be interpreted as a single noun phrase. So, “the lawyer companies hire…” could be interpreted as a noun phrase (including the compound noun “lawyer companies”) followed by a main verb “hire”; in a fragment like “the lawyer the companies hire…,” the “that” isn’t needed for disambiguation, because “lawyer the companies” cannot be interpreted as a single noun phrase. However, this pattern could also be explained by accessibility: In “the lawyer the companies hire…”, the “the” in “the companies” -- the word after the optional “that” -- is likely easier to retrieve from memory than “companies” is immediately after the optional “that” in “the lawyer companies hire…” If the “the” is easier to retrieve, it’ll be ready for production sooner, and so should be uttered sooner, and so the “that” is omitted.
In another report, Haywood, Pickering, and Branigan (2005), showed that speakers mentioned optional “that” more in sentences that would be ambiguous given a current nonlinguistic context compared to the same sentences when the nonlinguistic context eliminated the ambiguity. However, it may be that the contexts that tolerated the ambiguity were perceptually conspicuous in a manner that has been shown to affect production irrespective of ambiguity per se (Kraljic & Brennan, 2005). If so, then the pattern would be consistent with speakers trying to produce utterances that are easier to understand, but not in response to ambiguity per se; rather, they could be sensitive to an ambiguity-independent factor that is correlated with actual linguistic ambiguity.
Finally, Snedeker and Trueswell (2003) showed that speakers modified the prosody (rhythm and pitch) of their sentences to avoid ambiguity. However, only speakers who were consciously aware of the ambiguity avoided it This raises the possibility that such avoidance may have been closely tied to the experimental context in which it was assessed.
To sum up, given what speakers must do to detect ambiguity, it is not surprising that they don’t do so. Speakers have difficulty formulating a candidate description of an utterance and then doubling back, comparing it to some open-ended set of unrelated and unintended alternative meanings an addressee may light upon. This may seem to raise a troubling prospect: If speakers have great difficulty detecting (and therefore avoiding) ambiguity, how do we understand one another at all?
5. How ambiguous is language really?
The question of the actual potential ambiguity of language was addressed by work by Doug Roland and colleagues (Roland, Elman, & Ferreira, 2006). We took the British National Corpus, which includes over 100 million words (and is thus a large corpus), and used an automatic procedure to parse it into grammatically structured sentences. Though automatic parsing is not flawless (a point I return to shortly), given the size of the corpus, we assumed that the power that would come from having a large number of observations would outweigh the noise added by having some inaccurate parses in the database. We then extracted from the corpus all sentences that began with a noun-phrase, a verb, and then a noun-phrase, such as “The old man felt the restaurant bill…,” which in principle could be analyzed either as a subject-verb-direct-object sequence or as a subject-verb-embedded-subject sequence. We then removed any fragment that included disambiguating information, such as direct object pronouns like “me” (and note too that no sequences included the disambiguating “that”). This left approximately 250,000 structurally ambiguous noun-phrase-verb-noun-phrase sequences; of these, the automatic parsing procedure analyzed about 182,000 as subject-verb-direct-object sequences and about 68,000 as subject-verb-embedded-subject sequences. We measured any relatively easily measurable property of each part of these sequences, including the length of the first and second nouns and noun phrases (in characters, since that was readily available and should be highly correlated with any other measure of length), the frequency of the first and second nouns and noun phrases (based on counts of the words in the British National Corpus itself), and an approximation of the semantic content of the two nouns and noun phrases (based on Latent Semantic Analysis, Landauer & Dumais, 1997). We also took into account the specific verb that was in the sequence. These statistics for each sequence was entered into a kind of regression model (a logistic regression model) whereby the structure of the sequence -- whether it was a subject-verb-direct-object sequence versus a subject-verb-embedded-subject sequence -- was predicted from the length, frequency, semantics, and verb statistics. In everyday terms, this procedure boils down to assessing whether readily available properties of structurally ambiguous sequences (how long and common parts of the sequences are, the semantic properties of parts of the sequence, and which verb is involved) can provide good information about what the actual structure of the sequence is.
In fact, the regression model was highly successful at predicting the estimated structure (as determined by the automatic parse) of the otherwise structurally ambiguous sequences, as about 86% of all such sequences were accurately predicted to be either subject-verb-direct-object sequences versus subject-verb-embedded-subject sequences. However, it turns out that the performance of the regression model was even better than this. Recall that the automatic procedures used to parse large corpora such as these are imperfect. When we sampled sentences from our parsed observation set at random, and determined their actual structure by hand, it turned out that about 10% of the sentences were incorrectly categorized, so that either a subject-verb-direct-object sequence was analyzed as a subject-verb-embedded-subject sequence or vice versa. This means that 10% of sentences could not have been accurately predicted in the first place. So, of the 90% of sentences that the regression model had a chance to accurately predict the structure of, it got 86% of them right.
It is important to note that it has not been shown that language comprehenders are in fact sensitive specifically to the factors that we measured. Still, this result suggests that in principle, language may in fact be massively unambiguous. If language comprehenders are sensitive to readily accessible properties of the utterances they are presented with, including how long parts of those utterances are, how frequent the words in parts of those utterances are, certain coarse meaning properties of parts of those utterances, and what verb is being used, then even when those utterances are structurally ambiguous, comprehenders can still determine the correct structure of those utterances in an a very large percentage of cases. This brings the analyses presented here full circle: The question we started out with was, do speakers use certain linguistic devices, especially the mention of the optional “that,” to avoid presenting comprehenders with ambiguous structures. The bulk of the evidence suggested that speakers in fact do not do this. Now we see why this may be the case: Speakers don’t use certain linguistic devices to structurally disambiguate their sentences because their sentences likely are not ambiguous to comprehenders in the first place. In the overwhelming majority of cases, even when speakers leave out the “that,” addressees have all the information they need to be able to correctly determine the structures of the utterances they are presented with. When this observation is combined with the one from the previous section, that it is likely very tricky for speakers to detect (let alone avoid) ambiguity, it does not seem surprising at all that a communicative system would operate in this fashion.
6. Why are speakers’ utterances so unambiguous?
The analysis in the preceding section could be seen as pinning communicative success rather too heavily on good fortune. Speakers’ utterances happen to have enough information so that even when they are structurally ambiguous, addressees can figure out what their intended structure is. Presumably, if this were not the case -- if speakers produced impoverished structurally ambiguous utterances -- communication would be hindered. So, what ensures that speakers provide their addressees with rich enough utterances so that those utterances can be easily understood?
The answer to this question is: the grammar of language. In general, the grammar of a language describes the rules or guidelines that distinguish well-formed from ill-formed utterances. In English, our grammar dictates that “Steve ran a marathon” is grammatical, but “ran Steve marathon a” is not. A rich controversy in the study of language concerns where the “problem space” of the grammar comes from -- what makes it so that the world’s languages realize certain grammatical possibilities rather than others (specifically debating whether some innate or genetic component is necessary to explain the structure of this problem space). However, setting aside that thorny problem, another question is, what determines what part of the problem space is carved out by a particular language’s grammar? So, for example, in English, our grammar has settled (at least for now) on the prescription that in many structures, the complementizer “that” is optional. Why does the grammar permit that optionality?
To explore this issue, consider a more extreme example. One of the general (and graded) ways that the world’s languages are categorized is as fixed versus free word order. English is a fixed word-order language, because the roles of subject, object, and so forth are determined by relative order information. For example, in an active transitive sentence like “Steve bought a present,” the noun phrase before the verb (“Steve”) is the subject and the noun phrase after the verb (“present”) is the object. If these are reversed -- “The present bought Steve” -- a very different meaning is conveyed. Japanese is a free word-order language, because noun phrase arguments can be more freely ordered, so that for example in an active transitive sentence, the subject can precede or follow the object. The reason this is so is because the roles of subject, object, and so forth in free word-order languages are generally conveyed by suffixes or case markers. For example, “Steve-ga purezento-o katta” means “Steve bought a present”; the case-marker “ga” indicates that “Steve” is the subject of the sentence and the case-marker “o” indicates that “purezento” is the object. Because the case markers convey subject and object roles, “purezento-o Steve-ga katta,” with the object before the subject, also means “Steve bought a present.”
What is worth noting is that few (if any) languages exist that have relatively free word order and do not use case-markers to indicate grammatical roles like subject and object. The reason such an arrangement is so unusual is that any language that permitted free ordering of arguments and did not have case marking would be rampantly (and likely fatally) ambiguous. In such a language, in the sentences “Steve teased Kim” and “Kim teased Steve,” one person (Steve or Kim) should clearly be the subject (the teaser) and the other the object (the one being teased); obviously, this is not the case. And so, grammars of languages use one device or the other (word order or case marking) to disambiguate what would otherwise be impossibly ambiguous utterances. Considering the optional “that” again, this analysis suggests that the reason English permits the “that” to be optional is because in the heavy majority of utterances in which it could be left out, those utterances still have plenty of information for addressees to still efficiently determine speakers’ intended structure, consistent with the Roland et al. (2006) results described above. (In this vein, it is interesting to note that one place where the “that” is obligatory is where it would be consistently misleading, namely, in noun phrases with active subject-relative clauses like “the book that fell on the floor…” Without the “that,” the noun phrase would be “the book fell on the floor,” which presumably nearly always will be interpreted as a subject-main-verb sequence.)
This general framework thus suggests that it is not the job of speakers to ensure that the sentences they produce are sufficiently unambiguous that they can be efficiently understood. That job belongs to the grammar of the language speakers speak, by only allowing speakers to have options that most of the time (often enough so that communication isn’t broadly hindered) include enough information so that addressees can efficiently understand them. By restricting speakers’ grammatical options just to those that are relatively likely to succeed, the flexibility that comes from having those options can be exploited for the other important communicative imperative: Speakers should choose options that allow them to produce sentences most efficiently. If an option that is more efficient for speakers happens to be less efficient for addressees, that is likely acceptable -- because the grammar generally won’t allow options that are too ambiguous, addressees should have the resources available to easily enough understand the less-than-optimally-comprehensible utterance.
(An interesting question is how languages might come to allow only those options that are not generally too ambiguous. It seems a likely candidate mechanism is language acquisition, and the related mechanisms of language change. That is, aspects of a language that are too ambiguous to use are likely too ambiguous to learn as well. If language learners don’t pick up on aspects of grammars that are too ambiguous, those aspects would get filtered out, leaving only those aspects that are sufficiently unambiguous. These speculations go beyond the scope of the current presentation, but may be an interesting basis for future research.)
7. Conclusion: A Division of Labor for Communicative Success
Together, all of these considerations suggest a rather tidy division of labor for communicative success. This division involves three parties: Speakers, addressees, and the grammar of the language they speak. The division is:
Grammar: Allow for a space of possible utterances within a particular language that given the information at addressees’ disposal, can be easily enough understood most of the time.
Speakers: Exploit the flexibility within the space of possible utterances defined by the grammar to optimize the efficiency of the formulation and articulation process.
Addressees: Do the work necessary to understand the utterances that your speakers produce.
This division is useful, because it helps to frame our explanations for why speakers or listeners seem to adopt particular linguistic strategies, or why the grammar might have the features that it does. For example, it is often claimed that certain patterns found in language are motivated by an imperative to make comprehension more efficient. Take heavy NP-shift, referring to the fact that noun phrase objects can be moved from their typical locations when they are especially long (or heavy): “I drove to the store the car that was old and falling apart” (cf., “I drove to the store the car.”). Why is shifting a noun phrase in this manner more acceptable when it is heavy? One explanation (Hawkins, 1994) can be motivated by comprehension preferences: Without the shift, the heavy noun phrase delays the presentation of any part of the subsequent prepositional phrase (“to the store”). When that prepositional phrase is eventually presented, a listener must recall over a now long interval of time and material what the verb was that the preposition modified. By shifting the heavy noun phrase to later in the utterance, the prepositional phrase is presented immediately after the verb it modifies, and the heavy noun phrase object itself is presented relatively sooner after the verb (because the prepositional phrase is shorter). The current framework, by contrast, compels a different explanation: Perhaps speakers tend to shift heavy noun phrases until later because they take longer to formulate (i.e., they are relatively less accessible), and so by delaying their mention, more accessible material (the shorter prepositional phrase) can be mentioned sooner, and speakers can buy time to formulate the more difficult heavy noun phrase (see also Wasow, 1997; Yamashita & Chang, 2001). Note that this latter explanation, by appealing to speakers’ preferences rather than listeners’ preferences, also does not need to explain how it is that speakers -- the creators of the heavy-NP shift pattern -- encode comprehension preferences that are sufficiently subtle that they take many sentences to describe in a paper like this. In short, the division of labor for communicative success proposed here suggests that language researchers should not be too quick to posit explanations for patterns of language use in terms of what is easy for comprehenders. Such explanations are less parsimonious compared to explanations in terms of production efficiency (because they must also describe how it is that speakers know what is efficient for comprehenders, a challenge analogous to the above question of how speakers can detect ambiguity), and they overlook the very important mandate speakers have to produce utterances efficiently.
Overall then, the body of work reviewed in this chapter suggests that communication succeeds because speakers do what they need to do to produce utterances efficiently, addressees do what they need to do to understand what their speakers are saying, and the grammar makes sure that it all works out.
References
- Baayen RH, Piepenbrock R, van Rijn H. The celex lexical database. Philadelphia: Linguistic Data Consortium; 1993. [Google Scholar]
- Bever TG. The cognitive basis for linguistic structures. In: Hayes JR, editor. Cognition and the development of language. New York: John Wiley; 1970. [Google Scholar]
- Bock JK. Toward a cognitive psychology of syntax: Information processing contributions to sentence formulation. Psychological Review. 1982;89:1–47. [Google Scholar]
- Bock JK. Meaning, sound, and syntax: Lexical priming in sentence production. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1986;12:575–586. [Google Scholar]
- Bolinger D. That’s that. The Hague: Mouton; 1972. [Google Scholar]
- Bradley D, Fernandez EM, Taylor D. Prosodic weight versus information load in the relative clause attachment ambiguity. Paper presented at the CUNY Conference on Human Sentence Processing; Boston, MA. 2003. [Google Scholar]
- Clark HH. Using language. Cambridge, England: Cambridge University Press; 1996. [Google Scholar]
- Ferreira F, Henderson JM. Use of verb information in syntactic parsing: Evidence from eye movements and word-by-word self-paced reading. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1990;16:555–568. doi: 10.1037//0278-7393.16.4.555. [DOI] [PubMed] [Google Scholar]
- Ferreira VS. The persistence of optional complementizer production: Why saying “that” is not saying “that” at all. Journal of Memory and Language. 2003;48(2):379–398. [Google Scholar]
- Ferreira VS, Dell GS. Effect of ambiguity and lexical availability on syntactic and lexical production. Cognitive Psychology. 2000;40(4):296–340. doi: 10.1006/cogp.1999.0730. [DOI] [PubMed] [Google Scholar]
- Ferreira VS, Firato CE. Proactive interference effects on sentence production. Psychonomic Bulletin & Review. 2002;9:795–800. doi: 10.3758/bf03196337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferreira VS, Slevc LR, Rogers ES. How do speakers avoid ambiguous linguistic expressions? Cognition. 2005;96:263–284. doi: 10.1016/j.cognition.2004.09.002. [DOI] [PubMed] [Google Scholar]
- Frazier L, Fodor JD. The sausage machine: A new two-stage parsing model. Cognition. 1978;6:291–325. [Google Scholar]
- Garnsey SM, Pearlmutter NJ, Myers E, Lotocky MA. The contributions of verb bias and plausibility to the comprehension of temporarily ambiguous sentences. Journal of Memory and Language. 1997;37:58–93. [Google Scholar]
- Grice HP. Logic and conversation. In: Cole P, Morgan JL, editors. Syntax and semantics: Speech act. Vol. 3. New York: Academic Press; 1975. pp. 41–58. [Google Scholar]
- Hawkins JA. A performance theory of order and constituency. Cambridge, England: Cambridge University Press; 1994. [Google Scholar]
- Haywood SL, Pickering MJ, Branigan HP. Do speakers avoid ambiguity during dialogue? Psychological Science. 2005;16:362–366. doi: 10.1111/j.0956-7976.2005.01541.x. [DOI] [PubMed] [Google Scholar]
- Kraljic T, Brennan SE. Prosodic disambiguation of syntactic structure: For the speaker or for the addressee? Cognitive Psychology. 2005;50:194–231. doi: 10.1016/j.cogpsych.2004.08.002. [DOI] [PubMed] [Google Scholar]
- Landauer TK, Dumais ST. A solution to plato’s problem: The latent semantic analysis theory of acquisition, induction and representation of knowledge. Psychological Review. 1997;104(2):211–240. [Google Scholar]
- Levinson SC. Presumptive meanings: The theory of generalized conversational implicature. Cambridge, MA: MIT Press; 2000. [Google Scholar]
- Lombardi L, Potter MC. The regeneration of syntax in short term memory. Journal of Memory and Language. 1992;31:713–733. [Google Scholar]
- MacDonald MC, Pearlmutter NJ, Seidenberg MS. The lexical nature of syntactic ambiguity resolution. Psychological Review. 1994;101(4):676–703. doi: 10.1037/0033-295x.101.4.676. [DOI] [PubMed] [Google Scholar]
- Roland DW, Elman JL, Ferreira VS. Why is that? Structural prediction and ambiguity resolution in a very large corpus of english sentences. Cognition. 2006;98:245–272. doi: 10.1016/j.cognition.2004.11.008. [DOI] [PubMed] [Google Scholar]
- Sachs JS. Recognition of semantic, syntactic, and lexical changes in sentences. Psychonomic Bulletin. 1967;1:17–18. [Google Scholar]
- Snedeker J, Trueswell JC. Using prosody to avoid ambiguity: Effects of speaker awareness and referential context. Journal of Memory & Language. 2003;48(1):103–130. [Google Scholar]
- Temperley D. Ambiguity avoidance in english relative clauses. Language. 2003;79:464–484. [Google Scholar]
- Thompson SA, Mulac A. The discourse conditions for the use of the complementizer that in conversational english. Journal of Pragmatics. 1991;15:237–251. [Google Scholar]
- Trueswell JC, Tanenhaus MK, Garnsey SM. Semantic influences on parsing: Use of thematic role information in syntactic ambiguity resolution. Journal of Memory and Language. 1994;33:285–318. [Google Scholar]
- Trueswell JC, Tanenhaus MK, Kello C. Verb-specific constraints in sentence procesing: Separating effects of lexical preference from garden-paths. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1993;19:528–553. doi: 10.1037//0278-7393.19.3.528. [DOI] [PubMed] [Google Scholar]
- Wasow T. End-weight from the speaker’s perspective. Journal of Psycholinguistic Research. 1997;26:347–361. [Google Scholar]
- Yaguchi M. The function of the non-deictic that in english. Journal of Pragmatics. 2001;33(7):1125–1155. [Google Scholar]
- Yamashita H, Chang F. “long before short” preference in the production of a head-final language. Cognition. 2001;81:B45–B55. doi: 10.1016/s0010-0277(01)00121-4. [DOI] [PubMed] [Google Scholar]