

Abstract
Obesity is a major public health problem characterized with high body mass index (BMI). Copy number variations (CNVs) have been identified to be associated with complex human diseases. The effect of CNVs on obesity is unknown. In this study, we explored the association of CNVs with BMI in 597 Chinese Han subjects using Affymetrix GeneChip Human Mapping 500K Array Set. We found that one CNV at 10q11.22 (from 46.36 Mb to 46.56 Mb) was associated with BMI (the raw P=0.011). The CNV contributed 1.6% of BMI variation, and it covered one important obesity gene—pancreatic polypeptide receptor 1(PPYR1). It was reported that PPYR1 was a key regulator of energy homeostasis. Our findings suggested that CNV might be potentially important for the BMI variation. In addition, our study suggested that CNV might be used as a genetic marker to locate genes associated with BMI in Chinese population.
Keywords: 10q11.22, BMI, copy number variation (CNV), PPYR1
INTRODUCTION
Obesity is a major public health problem, and it has been defined by the World Health Organization based on body mass index (BMI, weight/height2, kg/m2).1 BMI is a convenient, simple and popularly adopted method to evaluate obesity. In the Chinese population, BMI of 18.5-23.9 is considered as optimal, 24.0-27.9 as overweight, and 28.0 and above as obese.2,3 Over the years, obesity-related mortality had consistently increased.4
Obesity is a multifactorial and heterogeneous condition that results from alterations of various genes;5 the minimum genetic determination of 40% for human obesity has been established.6 Several genomic regions and candidate genes have been identified to contribute genetic variants for obesity by earlier linkage studies,7 candidate gene studies8 and recent genome-wide association studies.9 However, none of these genes or genomic regions has been found to explain more than 10% of variation in any obesity phenotypes. This leaves largely unknown genetic factors underlying obesity.9
Copy number variation (CNV) is the copy number change of DNA fragments at a range of 1 kilobase (Kb) to several megabases (Mb). A lot of CNVs and several hundred CNV regions have been identified in human populations.10-12 Recent studies showed that CNV occurred frequently in many susceptive individuals who were predisposed to diseases such as mental retardation and autism.13,14 Therefore, investigation of CNVs may contribute to understand the genetic basis of variations in biological functions and phenotypes. However, it is unknown whether CNVs can be used as genetic markers to locate genes associated with BMI.
In this research, we performed a genome-wide CNV analysis in 597 elderly Chinese Han subjects using the Affymetrix GeneChip Human Mapping 500 K Array Set, which had been successfully used to detect the changes of genomic structure.15,16 On the basis of the constructed genome CNVs, for the first time, we performed association analysis to suggest that CNVs may be associated with BMI variation in the Chinese population.
MATERIALS AND METHODS
Research subjects
The study was approved by the local institutional review boards of all the participating institutions. After signing an informed consent, subjects completed a structured questionnaire including anthropometric variables, lifestyles and medical history. The sample for the genome-wide CNV analyses consisted of 597 (258 males and 339 females) elderly Chinese Han subjects. All the subjects were unrelated northern Chinese Han adults living in the city of Xi’an and its vicinity.
Phenotype
Total body weight was measured in a standardized fashion after the removal of shoes and heavy outer clothing using a calibrated balance beam scale. Height was measured after removal of shoes using a stadiometer and recorded to the nearest 0.1 cm. The average weight of the 597 subjects was 59.4 ± 11.4 kg, and the average height was 160.8 ± 8.9 cm. BMI (kg/m2) was calculated as the subject’s weight in kilograms divided by height in meters squared.
Genome-wide genotyping
Genomic DNA was extracted from peripheral blood leukocytes using standard protocols. Affymetrix Human Mapping 500 K array sets (Affymetrix, Santa Clara, CA, USA), which consisted of two chips (Nsp and Sty) with ∼250 000 single nucleotide polymorphisms (SNPs) each, were used to genotype each subject from the Chinese sample according to the Affymetrix protocol. Briefly, ∼250 ng of genomic DNA was digested with the restriction enzyme NspI or StyI. Digested DNA was adaptor-ligated and PCR-amplified for each enzyme-digested sample. Fragmented PCR products were then labeled with biotin, denatured and hybridized to the arrays. Arrays were then washed and stained using phycoerythrin on Affymetrix Fluidics Station FS450, and scanned using the GeneChip Scanner 3000 7G. Data management and analyses were conducted using Affymetrix GeneChip Operating System. Genotyping calls were determined from the fluorescent intensities using the Dynamic Modeling algorithm with a 0.33 P-value setting,17 as well as the Bayesian Robust Linear Model with Mahalanobis Distance (BRLMM) algorithm.18 Because of the efforts of repeated experiments, all the samples had a call rate of ≥95% and were thus all were included in the subsequent analyses. The final mean Bayesian Robust Linear Model with Mahalanobis Distance call rates reached a high level of 99.02%.
Assessment of genetic background
The program, STRUCTURE 2.2,19 and the method of genomic control20 were applied to detect possible population stratification of the Chinese sample. Two thousand SNPs tested to be in Hardy-Weinberg equilibrium were randomly selected genome wide to cluster all the subjects. The program uses a Markov Chain Monte Carlo algorithm to cluster individuals into different cryptic subpopulations based on multilocus genotype data. Potential substructure was estimated under a priori assumption of K=2 discrete subpopulations. For genomic control, we estimated the inflation factor (λ) on the basis of genome-wide SNP information.
CNVs and CNVRs determination
DNA CNVs were calculated by Affymetrix GeneChip Chromosome Copy Number Analysis Tool 4.0, which implements a Hidden Markov Model on the basis of an algorithm to identify chromosomal gains and losses by comparing the signal intensity of each SNP probe set for each test subject against a reference set. As an initial analysis, we used 299 random subjects as the reference set. In calculating CNVs for the 299 random subjects, when an individual subject was the test sample, he/she was excluded from the reference set. CNVs were defined when there were at least three consecutive SNPs showing consistent deletion or duplication. As it was not possible to pinpoint the boundaries of each CNV using genome-wide SNP genotyping arrays, we used the positions of SNPs as boundary approximates. After putative variant intervals of CNVs were identified in each individual, we used the following criteria to determine the boundaries of CNV region (CNVR). If two individual CNVs overlapped we merged them as a CNVR using the SNPs selected from these two CNVs with a maximum interval as the boundaries. When the interval of the next overlapping individual CNV exceeded this CNVR, the boundaries would extend accordingly.21 Briefly, a CNVR represented a union of overlapping CNVs.
Association analysis between CNV and BMI
For association analyses, we used the following procedure to redefine the CNVs (for those with frequencies exceeding 5%) contained in the CNVRs. We divided complex CNVR (illustrated in Plot C in Figure 1), including individual CNVs with discordant boundaries but overlapping regions, into several sub-CNVRs, so that the resultant sub-CNVRs had the same configurations as in Plot A or B in Figure 1. Thus, all CNVRs or sub-CNVRs contained only one kind of CNV with the same boundaries as their corresponding CNVR or sub-CNVR. CNVs with frequencies >5%, defined by the above procedure, were selected for association analyses. Multiple regression analyses were used to evaluate the effects of assumed covariates (sex, age, sex*age and age2) and only significant items (age and age2, P<0.05) were included as covariates to adjust the raw value for the subsequent association analyses. We used SPSS software (SPSS Inc., Chicago, IL, USA) to perform analysis of variance test to find the associations between CNVs and BMI. P-values <0.05 in our study were considered nominally significant, and were further subjected to Bonferroni correction to account for multiple comparisons.
Figure 1.

Copy number variation (CNV) redefined for association analyses. CNV regions (CNVRs) were divided into several sub-CNVRs with the same configuration as A or B, thus all the sub-CNVRs contained only one kind of CNV for association analyses. (A) All the individual CNVs in a CNVR had the same boundaries. (B) All the individual CNVs in a CNVR had at most one single nucleotide polymorphism (SNP) difference in each side of the boundaries. (C) CNVR with complex overlapping regions. This kind of CNVRs was divided into several sub-CNVRs with the same configuration as A or B. (D) Precise structure of redefined CNV 10q11.22. The numbers at the start and the end of CNVs were the physical positions on Chromosome 10 of each CNV.
RESULTS
Basic characteristics of the Chinese sample, including age, weight, height and BMI were summarized in Table 1. The STRUCTURE program showed that all Chinese subjects were clustered together as one homogeneous sample. The estimated inflation factor (λ) value was 1.03. These results indicated that there was no detectable significant population stratification in the Chinese sample.
Table 1. Basic characteristics of the Chinese sample.
| Trait | Total (N=597) | Male (N=258) | Female (N=339) |
|---|---|---|---|
| Age (year) | 70.4 (7.4) | 71.1 (6.8) | 69.7 (7.8) |
| Weight (kg) | 59.4 (11.4) | 63.6 (11.1) | 56.3 (10.7) |
| Height (cm) | 160.8 (8.9) | 167.8 (6.9) | 155.5 (6.3) |
| BMI (kg/m2) | 22.9 (3.8) | 22.5 (3.4) | 23.2 (4.0) |
Note: Data were shown as mean (s.d.).
Combining all CNVs data of each subject, we selected 24 CNVs (Table 2) with frequencies of .more than 5% from the total 1395 CNVs for association analyses between BMI and CNVs. The selected 24 CNVs covered ∼9 Mb with a mean length of 387 kb. One of the twenty-four CNVs was associated with BMI with nominal significance (P=0.011). However, it did not remain significant after strict Bonferroni correction. This CNV, illustrated in Plot D in Figure 1, was located in 10q11.22 with the physical position from 46 363 383 bp to 46 557 002 bp (named CNV 10q11.22 at Table 2).
Table 2. Characteristics of the 24 selected CNV for association analyses with BMI in the Chinese population.
| CNV no. | Chromosome | Start (bp) | End (bp) | Frequency (%) | P-value |
|---|---|---|---|---|---|
| 1/CNV | chrom10 | 46 363 383 | 46 557 002 | 5.025 | 0.011 |
| 10q11.22 | |||||
| 2 | chrom1 | 141 510 591 | 141 521 671 | 9.715 | 0.051 |
| 3 | chrom4 | 69 067 201 | 69 172 267 | 30.151 | 0.057 |
| 4 | chrom1 | 147 188 028 | 147 218 095 | 24.121 | 0.067 |
| 5 | chrom2 | 89 066 885 | 89 387 125 | 11.725 | 0.138 |
| 6 | chromx | 55 706 970 | 56 979 440 | 5.695 | 0.158 |
| 7 | chrom15 | 21 873 330 | 22 393 551 | 6.198 | 0.168 |
| 8 | chrom16 | 16 540 862 | 16 576 405 | 7.873 | 0.207 |
| 9 | chrom22 | 23 971 025 | 24 344 094 | 6.365 | 0.209 |
| 10 | chrom15 | 18 427 103 | 18 451 755 | 71.357 | 0.221 |
| 11 | chromx | 80 296 786 | 80 433 322 | 9.548 | 0.245 |
| 12 | chrom3 | 196 743 561 | 199 063 671 | 6.030 | 0.303 |
| 13 | chrom5 | 688 709 | 972 497 | 7.538 | 0.390 |
| 14 | chrom19 | 32 651 846 | 32 855 288 | 8.040 | 0.425 |
| 15 | chromx | 107 710 661 | 108 444 141 | 8.375 | 0.503 |
| 16 | chrom9 | 41 217 099 | 41 262 379 | 25.126 | 0.570 |
| 17 | chrom2 | 87 250 325 | 87 344 242 | 8.208 | 0.614 |
| 18 | chrom5 | 45 615 550 | 46 419 092 | 18.425 | 0.633 |
| 19 | chrom22 | 14 433 758 | 14 490 036 | 18.760 | 0.683 |
| 20 | chrom14 | 105 032 574 | 106 356 482 | 12.060 | 0.730 |
| 21 | chrom21 | 9 887 804 | 9 941 889 | 17.085 | 0.791 |
| 22 | chrom8 | 12 039 387 | 12 040 126 | 12.563 | 0.876 |
| 23 | chrom14 | 19 272 965 | 19 309 319 | 55.276 | 0.884 |
| 24 | chromx | 79 800 610 | 80 174 885 | 7.035 | 0.998 |
Abbreviations: BMI, body mass index; CNV, copy number variation.
Note: P-value was estimated by analysis of variance.
CNV 10q11.22 included four genes; SYT15 (synaptotagmin XV), GPRIN2 (G protein regulated inducer of neurite outgrowth 2), PPYR1 (pancreatic polypeptide receptor 1) and LOC728643 (heterogeneous nuclear ribonucleoprotein A1 pseudogene). In our sample, 12 subjects had CNV 10q11.22 loss (CN=0 or 1) and 18 subjects had CNV 10q11.22 gain (CN=3, 4 or more). Association analyses showed that the CNV 10q11.22 loss was significantly associated with higher BMI. Compared with the 567 subjects with two gene copy numbers (normal diploid), subjects with CNV 10q11.22 loss had 12.4% higher BMI value, and subjects with CNV 10q11.22 gain had 5.4% lower BMI value (Figure 2). Regression analysis showed that CNV 10q11.22 contributed 1.6% of BMI variation.
Figure 2.
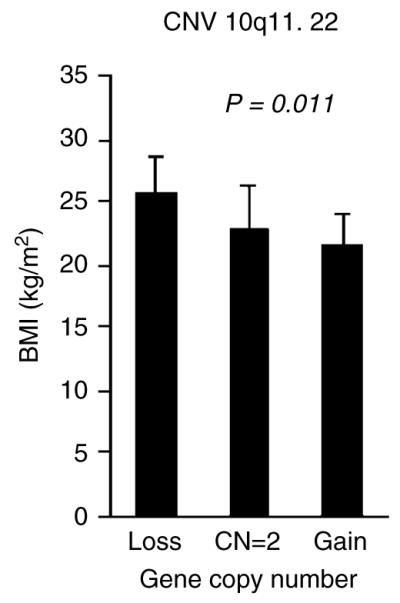
Comparisons of body mass index (BMI) value for copy number variation (CNV) 10q11.22 in the Chinese sample. P-value was estimated by analysis of variance.
DISCUSSION
In our study, we tested the association between CNVs and BMI. We discovered that CNV 10q11.22 as a genetic marker was associated with BMI. And CNV 10q11.22 overlapped with an earlier reported CNVs data from Database of Genomic Variants (http://projects.tcag.ca/variation/). Wong et al.,22 Sebat et al.,10 Pinto et al.23 and Jakobsson et al.24 reported the existence of CNVs in this region using array comparative genomic hybridization, representational oligonucleotide microarray analysis, Affymetrix 500K SNP Mapping Array and Illumina HumanHap Map 550 SNP Array.
CNV 10q11.22 covers four genes; PPYR1, SYT15, GPRIN2 and LOC728643. It is well established that PPYR1 is related to obesity. The PPYR1 gene was a key regulator of energy homeostasis and directly involved in the regulation of food intake.25 PPYR1, also named as neuropeptide Y receptor or pancreatic polypeptide 1, was a member of the seven transmembrane domain-G-protein coupled receptor family. Genetic variation studies have reinforced the potential influence of PPYR1 on body weight in humans.26 Pancreatic polypeptide is the preferential PPYR1 agonist.27 Peripheral administration of pancreatic polypeptide inhibits gastric emptying and decreases food intake in humans.28,29 Currently, 7TM Pharma company (Horsholm, Denmark) reported that a selective PPYR1 agonist peptide, TM30339, had effect on the reduction of food intake and weight loss.26 These findings indicate a promising role of PPYR1 and its agonist in the treatment of human obesity. On the basis of the findings, a patent has been filed in Europe to use this gene as a potential target to treat human obesity (European Patent EP1362926). The different expression of copy number variant genes may lead to phenotypic variation.30 In our study, PPYR1 gene copy number gain was associated with lower BMI. Subjects with PPYR1 copy numbers gain may produce more expression products, which will regulate energy homeostasis through agonists or other pathways to inhibit obesity.
Animal experiments showed complicated results. Sainsbury A et al.25 reported that PPYR1 knockout mice displayed lower body weight and reduced white adipose tissue accompanied with increased plasma levels of pancreatic polypeptide. However, deletion of the PPYR1 on the ob/ob background mice had no effect on the hyperphagia, obesity or type II diabetic phenotype.25,31,32
The difference between human study and mice experiments can be elucidated by the following reasons. First, mice may not be the most appropriate model to understand the function of PPYR1 in human, as mice expressed a functional Y6 receptor and this receptor was also used to interpret receptor knockout results.27 Second, the mice PPYR1 amino acid sequence is 76% identical to human PPYR1;33 the highly variable PPYR1 across species may explain why its exact roles differ among species.27 Third, compared with the 597 studied subjects, PPYR1 knockout (PPYR1-/-) mice have neither copy of the gene nor corresponding gene expression products.
The other three genes, SYT15, GPRIN2 and LOC728643, have not been reported to have relation with any obesity phenotypes. And it was unknown whether the interactions of the four genes may lead to the BMI variation. Further functional studies are needed to identify their potential role on obesity.
In conclusion, our genome-wide CNV study suggested one CNV may be associated with obesity variation in the Chinese Han population. An important obesity-related gene, PPYR1, is located in this CNV. Our results suggested that CNV might be potentially important for BMI variation and CNV might be used as a genetic marker to locate genes associated with BMI in the Chinese population.
ACKNOWLEDGEMENTS
We thank all the participants for taking part in this research. Investigators of this project were funded in part by grants from the National Natural Science Foundation of China (30230210, 30771222, 30731160618), Xi’an Jiaotong University and the Ministry of Education of China, Huo Ying Dong Education Foundation, Hunan Province and Hunan Normal University. HWD was supported by Dickson/Missouri endowment from University of Missouri—Kansas City and by grants from NIH (R01 AR050496, R21 AG027110, R01 AG026564, P50 AR055081 and R21 AA015973). We declare that we have no conflict of interest. The genome-wide genotype data will be deposited online soon to be freely available for non-commercial use.
References
- 1.Mascie-Taylor G, Goto R. Human variation and body mass index: a review of the universality of BMI cut-offs, gender and urban-rural differences, and secular changes. J. Physiol. Anthropol. 2007;26:109–112. doi: 10.2114/jpa2.26.109. [DOI] [PubMed] [Google Scholar]
- 2.Zhou B. Predictive values of body mass index and waist circumference for risk factors of certain related diseases in Chinese adults—study on optimal cut-off points of body mass index and waist circumference in Chinese adults. Biomed. Environ. Sci. 2002;15:83–95. [PubMed] [Google Scholar]
- 3.Zhou B. Effect of body mass index on all-cause mortality and incidence of cardiovas-cular diseases—report for meta-analysis of prospective studies open optimal cut-off points of body mass index in Chinese adults. Biomed. Environ. Sci. 2002;15:245–252. [PubMed] [Google Scholar]
- 4.Rosmond R. Aetiology of obesity: a striving after wind? Obes. Rev. 2004;5:177–181. doi: 10.1111/j.1467-789X.2004.00151.x. [DOI] [PubMed] [Google Scholar]
- 5.Ichihara S, Yamada Y. Genetic factors for human obesity. Cell Mol. Life Sci. 2008;65:1086–1098. doi: 10.1007/s00018-007-7453-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Bell C, Walley A, Froguel P. The genetics of human obesity. Nat. Rev. Genet. 2005;6:221–234. doi: 10.1038/nrg1556. [DOI] [PubMed] [Google Scholar]
- 7.Ciullo M, Nutile T, Dalmasso C, Sorice R, Bellenguez C, Colonna V, et al. Identification and replication of a novel obesity locus on chromosome 1q24 in isolated populations of Cilento. Diabetes. 2008;57:783–790. doi: 10.2337/db07-0970. [DOI] [PubMed] [Google Scholar]
- 8.Boutin P, Dina C, Vasseur F, Dubois S, Corset L, Seron K, et al. GAD2 on chromosome 10p12 is a candidate gene for human obesity. PLoS. Biol. 2003;1:E68. doi: 10.1371/journal.pbio.0000068. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Liu Y, Liu X, Wang L, Dina C, Yan H, Liu J, et al. Genome-wide association scans identified CTNNBL1 as a novel gene for obesity. Hum. Mol. Genet. 2008;17:1803–1813. doi: 10.1093/hmg/ddn072. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Sebat J, Lakshmi B, Troge J, Alexander J, Young J, Lundin P, et al. Large-scale copy number polymorphism in the human genome. Science. 2004;305:525–528. doi: 10.1126/science.1098918. [DOI] [PubMed] [Google Scholar]
- 11.Conrad D, Andrews T, Carter N, Hurles M, Pritchard J. A high-resolution survey of deletion polymorphism in the human genome. Nat. Genet. 2006;38:75–81. doi: 10.1038/ng1697. [DOI] [PubMed] [Google Scholar]
- 12.Redon R, Ishikawa S, Fitch K, Feuk L, Perry G, Andrews T, et al. Global variation in copy number in the human genome. Nature. 2006;444:444–454. doi: 10.1038/nature05329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Marshall C, Noor A, Vincent J, Lionel A, Feuk L, Skaug J, et al. Structural variation of chromosomes in autism spectrum disorder. Am. J. Hum. Genet. 2008;82:477–488. doi: 10.1016/j.ajhg.2007.12.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Madrigal I, Rodriguez-Revenga L, Armengol L, Gonzalez E, Rodriguez B, Badenas C, et al. X-chromosome tiling path array detection of copy number variants in patients with chromosome X-linked mental retardation. BMC. Genomics. 2007;8:443. doi: 10.1186/1471-2164-8-443. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Woo J, Sun G, Haverbusch M, Indugula S, Martin L, Broderick J, et al. Quality assessment of buccal versus blood genomic DNA using the Affymetrix 500K GeneChip. BMC. Genet. 2007;8:79. doi: 10.1186/1471-2156-8-79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Hua J, Craig D, Brun M, Webster J, Zismann V, Tembe W, et al. SNiPer-HD: improved genotype calling accuracy by an expectation-maximization algorithm for high-density SNP arrays. Bioinformatics. 2007;23:57–63. doi: 10.1093/bioinformatics/btl536. [DOI] [PubMed] [Google Scholar]
- 17.Di X, Matsuzaki H, Webster T, Hubbell E, Liu G, Dong S, et al. Dynamic model based algorithms for screening and genotyping over 100K SNPs on oligonucleotide microarrays. Bioinformatics. 2005;21:1958–1963. doi: 10.1093/bioinformatics/bti275. [DOI] [PubMed] [Google Scholar]
- 18.Rabbee N, Speed T. A genotype calling algorithm for affymetrix SNP arrays. Bioinformatics. 2006;22:7–12. doi: 10.1093/bioinformatics/bti741. [DOI] [PubMed] [Google Scholar]
- 19.Pritchard J, Stephens M, Donnelly P. Inference of population structure using multilocus genotype data. Genetics. 2000;155:945–959. doi: 10.1093/genetics/155.2.945. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Devlin B, Roeder K. Genomic control for association studies. Biometrics. 1999;55:997–1004. doi: 10.1111/j.0006-341x.1999.00997.x. [DOI] [PubMed] [Google Scholar]
- 21.de Smith A, Tsalenko A, Sampas N, Scheffer A, Yamada N, Tsang P, et al. Array CGH analysis of copy number variation identifies 1284 new genes variant in healthy white males: implications for association studies of complex diseases. Hum. Mol. Genet. 2007;16:2783–2794. doi: 10.1093/hmg/ddm208. [DOI] [PubMed] [Google Scholar]
- 22.Wong K, deLeeuw R, Dosanjh N, Kimm L, Cheng Z, et al. A comprehensive analysis of common copy-number variations in the human genome. Am. J Hum. Genet. 2007;80:91–104. doi: 10.1086/510560. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Pinto D, Marshall C, Feuk L, Scherer S. Copy-number variation in control population cohorts. Hum. Mol. Genet. 2007;16:R168–R173. doi: 10.1093/hmg/ddm241. [DOI] [PubMed] [Google Scholar]
- 24.Jakobsson M, Scholz S, Scheet P, Gibbs J, VanLiere J, Fung H, et al. Genotype, haplotype and copy-number variation in worldwide human populations. Nature. 2008;451:998–1003. doi: 10.1038/nature06742. [DOI] [PubMed] [Google Scholar]
- 25.Sainsbury A, Schwarzer C, Couzens M, Jenkins A, Oakes S, Ormandy C, et al. Y4 receptor knockout rescues fertility in ob/ob mice. Genes Dev. 2002;16:1077–1088. doi: 10.1101/gad.979102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Kamiji M, Inui A. Neuropeptide y receptor selective ligands in the treatment of obesity. Endocr. Rev. 2007;28:664–684. doi: 10.1210/er.2007-0003. [DOI] [PubMed] [Google Scholar]
- 27.Berglund M, Hipskind P, Gehlert D. Recent developments in our understanding of the physiological role of PP-fold peptide receptor subtypes. Exp. Biol. Med. (Maywood.) 2003;228:217–244. doi: 10.1177/153537020322800301. [DOI] [PubMed] [Google Scholar]
- 28.Batterham R, Le Roux C, Cohen M, Park A, Ellis S, Patterson M, et al. Pancreatic polypeptide reduces appetite and food intake in humans. J. Clin. Endocrinol. Metab. 2003;88:3989–3992. doi: 10.1210/jc.2003-030630. [DOI] [PubMed] [Google Scholar]
- 29.Schmidt P, Naslund E, Gryback P, Jacobsson H, Holst J, Hilsted L, et al. Arole for pancreatic polypeptide in the regulation of gastric emptying and short-term metabolic control. J. Clin. Endocrinol. Metab. 2005;90:5241–5246. doi: 10.1210/jc.2004-2089. [DOI] [PubMed] [Google Scholar]
- 30.Beckmann J, Estivill X, Antonarakis S. Copy number variants and genetic traits: closer to the resolution of phenotypic to genotypic variability. Nat. Rev. Genet. 2007;8:639–646. doi: 10.1038/nrg2149. [DOI] [PubMed] [Google Scholar]
- 31.Parker E, Van H, Stamford A. Neuropeptide Y receptors as targets for anti-obesity drug development: perspective and current status. Eur. J. Pharmacol. 2002;440:173–187. doi: 10.1016/s0014-2999(02)01427-9. [DOI] [PubMed] [Google Scholar]
- 32.Lin E, Sainsbury A, Lee N, Boey D, Couzens M, Enriquez R, et al. Combined deletion of Y1, Y2, and Y4 receptors prevents hypothalamic neuropeptide Y over-expression-induced hyperinsulinemia despite persistence of hyperphagia and obesity. Endocrinology. 2006;147:5094–5101. doi: 10.1210/en.2006-0097. [DOI] [PubMed] [Google Scholar]
- 33.Darby K, Eyre H, Lapsys N, Copeland N, Gilbert D, Couzens M, et al. Assignment of the Y4 receptor gene (PPYR1) to human chromosome 10q11.2 and mouse chromosome 14. Genomics. 1997;46:513–515. doi: 10.1006/geno.1997.5071. [DOI] [PubMed] [Google Scholar]