

Abstract
This theoretical scheme is intended to formulate a potential method for high fidelity synthesis of Nucleic Acid molecules towards a few thousand bases using an enzyme system. Terminal Deoxyribonucleotidyl Transferase, which adds a nucleotide to the 3′OH end of a Nucleic Acid molecule, may be used in combination with a controlled method for nucleotide addition and degradation, to synthesize a predefined Nucleic Acid sequence. A pH control system is suggested to regulate the sequential activity switching of different enzymes in the synthetic scheme. Current practice of synthetic biology is cumbersome, expensive and often error prone owing to the dependence on the ligation of short oligonucleotides to fabricate functional genetic parts. The projected scheme is likely to render synthetic genomics appreciably convenient and economic by providing longer DNA molecules to start with.
Keywords: Long DNA synthesis, Enzyme system modelling, Synthetic gene, pH regulated synthesis, Terminal deoxyribonucleotidyl transferase, Genetic parts fabrication
Introduction
To a great extent the progress in biotechnology and basic biomedical research has been centralized on the major advances in DNA synthesis and sequencing. Elucidation of the genetic code (Khorana 1968), production of synthetic gene (Agarwal et al. 1974), widespread use of PCR (Kleppe et al. 1971; Saiki et al. 1988), sequencing of the human genome (Venter et al. 2001; Lander et al. 2001), and the synthesis of whole genome of a microorganism (Gibson et al. 2008) are powerful examples. These applications along with many others have pivotally depended on the ability to synthesize short oligonucleotides, used as primers, typically ssDNA 10–80 base in length (Caruthers 1985).
The widespread application of synthetic biology is essentially limited by the complexity and cost of assembling short oligonucleotides into longer functional DNA (Endy 2005). In addition to whole genomes (Hutchison et al. 1999; Smith et al. 2003; Gibson et al. 2008), construction of entire biochemical pathways (Martin et al. 2003; Mehl et al. 2003; Kodumal et al. 2004) and genetic circuitry (Elowitz and Leibler 2000; Sprinzak and Elowitz 2005) are illustrative of synthetic biology requiring synthesis of far more than a single gene. Therefore, the rapid availability of predefined DNA, more than 1 Mb in length at a cost per base comparable to or less than oligonucleotides is greatly appealing. Despite important progress in this direction through building large numbers of genes by harnessing the massively parallel form of oligonucleotide synthesis to produce microarrays (Richmond et al. 2004; Tian et al. 2004), still the procedures depend on the chemical synthesis of short oligos. Thus the availability of longer DNA molecules is in principle restricted by the inherent limit of the chemical processes for oligonucleotide synthesis.
The error rate of synthesizing oligonucleotides is also of immense importance. At an error rate of 1 in 600 bp, it is required to sequence 10 clones to get a DNA construct of 1 Kb and 100 clones for 2 Kb (Baedeker and Schulz 1999; Withers-Martinez et al. 1999; Hoover and Lubkowski 2002; Chalmers and Curnow 2001). Thus large target fabrication is extremely difficult and error prone at this rate (Cello et al. 2002). The error was reduced to 1 in 1,400 bp by Tian et al. (2004) using microchip based multiplex synthesis. Protein mediated error correction has been utilized to reduce the rate further to 1 in 10,000 bp (Carr et al. 2004).
If the starting material is precise DNA molecules 1–10 Kb in length rather than ~50 bases, the speed and over all efficiency of synthetic genomics would tremendously increase because synthesis of longer constructs would be possible with fewer clones and sequencing. An extensive application of synthetic genes would be possible with a more convenient and reliable process for their fabrication. Thus an investigation for an efficient synthetic scheme is worth pursuing.
An attempt to delineate the necessary properties of a successful long DNA synthesis process leads to some salient features. Firstly, the error rate should be less than 10−4 in order to allow convenient synthesis of DNA constructs around 105 bp in length. Second, the maximum synthesizable length of DNA should be greater than 105 as current protocols allow transformation with DNA constructs of up to 3 × 105 − 20 × 105 bp in length (Glick and Pasternak 2003). These features indicate that preferably an enzymatic system might be successful. Moreover, enzymatic systems would in principle be more specific and efficient than chemical processes (Sitnitsky 2006). However, the enzymes those can synthesize DNA without templates are not controlled. For example TdT will add a homopolymeric tract of nucleotides when provided with a primer and a single type of NTP (Bollum 1978; Ratliff 1981). When provided with a mixture of nucleotides and a primer, TdT act as a random-sequence generator (Bollum 1978; Ratliff 1981). The physiological role of TdT conform to this random sequence generation as it provides additional variations in hematopoetic cells through acting as a somatic mutator, diversifying the amino acid sequence in the variable region of immunoglobulin molecules (Ratliff 1981).
TdT has already been utilized in genomics. It has been used for the production of synthetic homo and heteropolymers (Bollum 1974), homopolymeric tailing of linear duplex DNA (Deng and Wu 1983; Eschenfeldt et al. 1987), oligodeoxyribonucleotide and DNA labeling (Deng and Wu 1983; Tu and Cohen 1980; Vincent et al. 1982; Kumar et al. 1988; Igloi and Schiefermayr 1993), rapid amplification of cDNA ends (Frohman et al. 1988) and in situ localization of apoptosis (Gorczyca et al. 1993). Scheele and Fukuoka (1992, 1997) used TdT to add homopolymeric oligo dC tract to 3′ end of ss linear DNA in order to facilitate synthesis of ds linear DNA using oligo dG primer. However, no attempt to use TdT to synthesize a defined DNA sequence has been reported. Perhaps the random sequence generation by TdT in an uncontrolled system has prevented this.
Here a theoretical model for predefined long DNA synthesis based on TdT is proposed. The scheme depends on the addition of 3′AcdNTP to the 3′-OH end of a DNA. The Ac group is suggested to prevent polymer formation and thus prevent the chain extension to a single base in each cycle (Fig. 1). After extension the pH of the system is decreased to activate AE and AP while TdT would be deactivated. AP would hydrolyze excess 3′AcdNTP while AE would remove the Ac groups. Then dialysis would render the small molecules out of the system. Dialysis would also elevate the pH to activate TdT and deactivate AE and AP. Thus a new cycle of extension can be initiated by addition of 3′AcdNTP. Theoretical analysis based on available data suggests the scheme to be highly promising in synthesizing long DNA molecules.
Fig. 1.

Simplified scheme for TdT based DNA synthesis
Methods
The scheme
Synthesis of a predefined DNA sequence requires the addition of a single known nucleotide at each step to a given nucleic acid polymer. Thus the problem is essentially reduced to formulating a system such that:
 |
is allowed, while:
 |
is forbidden. Also the allowed reaction should be virtually complete such that no unextended DNA can go through the second round. Searching for enzymes able to extend DNA molecules in the BRENDA enzyme database (Schomburg et al. 2002, 2004; Barthelmes et al. 2007) TdT (EC: 2.7.7.31) was selected to be a potential enzyme because it can add nucleotides to the 3′-OH group of DNA several Kb long and can add modified bases.
In order to prevent formation of a homopolymeric tract the 3′-OH group of the incoming nucleotide should be blocked. Methyl and acetyl groups are extensively used as OH protecting groups. Due to the promising convenience of deprotection by acetylesterase (EC: 3.1.1.6); acetyl group is expected to be a better candidate. Thus, instead of dNTP the DNA primer is to be elongated by addition of a 3′AcdNTP catalyzed by TdT. There is lack of KM and Kcat data of TdT with 3′AcdNTP. Nevertheless, the accommodation of modified bases by TdT indicates a high possibility of addition of a single 3′AcdNTP to 3′-OH end of a DNA.
Now the completion of the reaction remains a problem. TdT has Km value of 3 × 10−4 mM for oligonucleotide primers at pH 8.2 in the presence of Mn+2 (Coleman 1977) and turnover number 0.833 for ATP (Bollum 1974). Thus TdT should be present in a high molar ratio with respect to primers in order to ensure the completeness of the reaction. Further, the polymerization reaction would be energetically favorable as pyrophosphate may be quickly removed by hydrolysis.
A new cycle of base addition must be preceded by removal of excess 3′AcdNTP and deprotection of the 3′OH group of the extended DNA. Acid phosphatase (EC: 3.1.3.2) is a suitable candidate for hydrolysis of excess 3′AcdNTP while acetylesterase is preferred for deprotection.
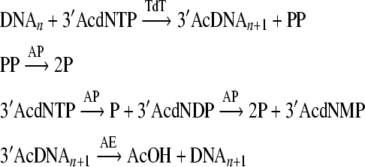 |
However the process raises problem regarding precise temporal order. As depicted in Fig. 2, if the protective Ac group is removed before complete hydrolysis of 3′AcdNTP, additional bases may add to the extended DNA. Moreover AE deacetylates wide range substrates. Thus 3′AcdNTP may become deacetylated before incorporation into DNA. This event would also fail the objective. Thus TdT must be inactive when AE is active and vice versa. Bovine TdT has a pH optimum at 7.5 and has limited activity below pH 6.9 (Coleman 1977) however it is stable at pH down to 4.5. On the other hand Aspergillus niger AE has a pH optimum of 5.5 with limited activity over pH 6 (Kormelink et al. 1993). A. niger AE is however stable at pH 8. Therefore, the elongation step should be catalyzed by TdT at pH 7.5 while the deprotection step should take place at pH 5.5.
Fig. 2.

Lack of precise temporal order in removal of excess modified NTP and deacetylation may lead to unintended chain elongation
Penicillium chryrsogenum acid phosphatase has pH optimum at pH 5.5 (Haas et al. 1991). Therefore it is expected to be an efficient scavenger of excess 3′AcdNTP after elongation. E. coli inorganic diphosphatase (EC: 3.6.1.1) has pH optimum at pH 7.5 (Vainonen et al. 2005). Thus it can be utilized to hydrolyze pyrophosphate formed during elongation by TdT.
 |
The rapid change is pH demanded by such a pH controlled system would be very difficult to achieve in a traditional reactor system. A nanoreactor would provide distinctive advantage of rapid condition alteration. Thus, the enzyme system in a nanoreactor coupled with pH regulation is a promising one for template free long DNA synthesis.
Thermodynamics of the scheme
The free energy of the intended reactions would depend on the concentration of the reactants and products. The choice of reactant concentration is determined by the intended concentration of the product. DNA concentration of 10−12 M is enough for most molecular biology protocols (Sambrook and Russel 2001). In order to synthesize sufficient amount of DNA for molecular biology protocols, here we arbitrarily set the intended product concentration to be 10−9 M. For the sake of the completeness of the reaction the initial concentrations in Table 1 are proposed.
Table 1.
Proposed initial concentration of reactants in the synthetic scheme
| Species | Initial concentration (M) |
|---|---|
| Primer (DNAn) | 10−9 |
| 3′AcdNTP | 10−8 |
| TdT | 10−8 |
| PP | <10−12 |
| P | <10−12 |
| 3′AcDNAn+1 | <10−15 |
| DNAn+1 | <10−15 |
| AcOH | 10−8 |
| H2O | 55.5 |
| 3′AcdNMP | 10−8 |
| TdT | 10−8 |
In the reaction:
 |
A phosphodiester bond is synthesized while an ester bond between α and β phosphate of the 3′AcdNTP is hydrolyzed. The ΔGo/ of synthesizing a phosphodiester bond is +22.2 KJ mol−1 (Dickson et al. 2000) while ΔGo/ of hydrolyzing bond between α and β phosphate of nucleotides is −32.2 KJ mol−1 (Voet and Voet 2004). Thus the ΔGo/ of the above reaction would be very close to −10 KJ mol−1. For the concentrations of reactants in table (1) the value of ΔG is −69.3 KJ mol−1.
In the next reaction:
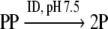 |
An ester bond between two phosphate groups of a pyrophosphate is hydrolyzed. ΔGo/ of this reaction is −33.5 KJ mol−1(Voet and Voet 2004). For the concentrations of reactants in table (1) the value of ΔG is −115.1 KJ mol−1.
The following reaction:
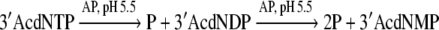 |
Two high energy phosphate bonds are hydrolyzed. The ΔGo/ of this reaction is −65.7 KJ mol−1 (Voet and Voet 2004). For the concentrations of reactants in table (1) the value of ΔG is −181.4 KJ mol−1.
The following reaction:
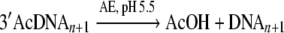 |
breaks an ester bond and a H–OH bond while creates a CH3C(O)–OH and a RO–H bond. The bond dissociation energies of ester, H–OH, CH3C(O)–OH and RO–H bonds are 433.1, 497.4, 456.2 and 425.1 KJ mol−1 respectively (Luo 2007). Thus ΔHo of this reaction would be close to +49.2 KJ mol−1. Both the products of the reaction are soluble in water, thus the entropy of the reaction would be positive in aqueous media. Therefore, ΔGo of this reaction would be less than ΔHo. For the concentrations of reactants in table (1) the value of ΔG should be less than −44.2 KJ mol−1. Moreover, the activation energy of hydrolysis of acetate ester in water is around +40 KJ mol−1 at temperature 35–37°C (Aksnes and Libanu 1991). Therefore, the reactants would be kinetically stable in absence of an active catalyst.
Results
The study on enzyme properties and possible combinations suggests that an enzymatic synthesis of predefined long DNA molecule is theoretically plausible. Based on the available data the process depicted in Fig. 3 is expected to be successful. AcOH would be added to decrease the pH to 5.5 while dialysis in a buffer of pH 7.5 would serve multiple functions, including removal of AcOH, phosphate groups, nucleosides and other small molecules in addition to restoring the pH to 7.5.
Fig. 3.

Proposed protocol for DNA synthesis utilizing the scheme
Incubation time T1 would depend on the relative concentration of TdT, primer, 3′AcdNTP and ID. The total time required for completing a step of the synthetic scheme would be determined according to the following equation:
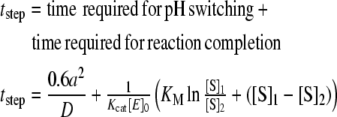 |
1 |
where, a is radius of the reactor, Kcat is turnover number of the enzyme, D is diffusion coefficient of H+ ions, [S]1 is initial substrate concentration, [S]2 is intended final substrate concentration, [E]0 is initial concentration of enzyme, KM is Michaelis constant of the enzyme for the substrate.
In order to complete pH switching within less than 0.1 s the radius of the reactor should be less than 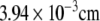 with a volume less than
with a volume less than 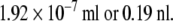 As an enzyme catalyzed reaction is designed to take place in nano liter volume, the reactor is named nanobioreactor. Use of nanobioreactors would greatly reduce the time of pH switching and thus lead to faster synthesis.
As an enzyme catalyzed reaction is designed to take place in nano liter volume, the reactor is named nanobioreactor. Use of nanobioreactors would greatly reduce the time of pH switching and thus lead to faster synthesis.
Incubation time T2 would depend on the size of the reactor, Kcat[AP] and Kcat[AE]. The smaller the reactor the less time would be necessary to activate AE and AP through shift in pH. Moreover, a slow pH shift may lead to a transitory period with both TdT, ID and AP, AE enzyme pairs active; thus increase error rate. Therefore a rapid pH change essential. Higher enzyme activity would decrease the time required for complete hydrolysis of excess bases and deprotection of 3′-OH groups. Incubation time T3 would depend mostly on the time required to restore the pH back to 7.5. Thus the size of the reactor would again be an important factor.
Number of possible cycles N would depend on the error rate, which would in turn depend on the completeness of reaction at each step. As reaction of each step in the cycle is thermodynamically favorable, the completeness is in principle warranted, provided with sufficient time. Since the KM of TdT for oligonucleotide primer is in the range of 10−4, at equivalent molar ratio with primer TdT is expected to make less than 1 in 10,000 errors. The error rate may however increase if incubation time T1 is longer due to slow pH shift. Thus faster pH shift would maintain high fidelity.
Discussion
The scheme proposed here is a potentially efficient enzymatic method for de novo DNA synthesis. From available data on the thermodynamics of the reactions and properties of the involved enzymes, the scheme is theoretically feasible. However, experimental demonstration would be crucial for its practical application.
A major difficulty may be the low turnover number of TdT with 3′AcdNTP as substrate. From the reported results of incorporation of modified bases by TdT (Deng and Wu 1983; Tu and Cohen 1980; Vincent et al. 1982; Kumar et al. 1988; Igloi and Schiefermayr 1993), it is inferred that TdT would accommodate an acetyl group. Recombinant enzymes are likely to be available to circumvent the problem in case native TdT does not incorporate 3′AcdNTP. Recombinant enzymes may also lead to a TdT with higher affinity to primers further limiting the error rate.
Nanobioreactors with capabilities of rapid change in pH would offer great advantage not only for this scheme but also for synthetic methods requiring sequential temporal activity switching of different sets of enzymes. Enzymatic correction (Carr et al. 2004) may be used on the longer DNA sequences. This combination may limit the error further down to 1 in 150,000. The availability of longer DNA for gene assembly would significantly increase the power and range of synthetic genomics. Not only small microorganism genomes, large genomes of higher organisms may also become amenable to synthesis with longer starting material.
Acknowledgement
This study was carried out with support from Ashtabhuj Systems.
Conflict of interest The author declares that he has no conflict of interest.
Open Access This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Abbreviations
- 3′AcdN
3′ Acetyl deoxyribo nucleoside
- 3′AcdNA
3′ Acetyl deoxyribo nucleic acid
- 3′AcdNDP
3′ Acetyl deoxyribo nucleoside di phosphate
- 3′AcdNMP
3′ Acetyl deoxyribo nucleoside mono phosphate
- 3′AcdNTP
3′ Acetyl deoxyribo nucleoside tri phosphate
- Ac
Acetyl group
- AcOH
Acetic acid (in equilibrium with acetate)
- AE
Acetylesterase, deacetylase (EC: 3.1.1.6)
- AP
Acid phosphatase (EC: 3.1.3.2)
- DNA
Deoxyribo nucleic acid
- dNTP
Deoxyribo nucleoside tri phosphate
- ds
Double strand
- ID
Inorganic diphosphatase (EC: 3.6.1.1)
- Kb
Kilobase
- Mb
Megabase
- NA
Nucleic acid
- NTP
Ribo nucleoside tri phosphate
- P
Phosphate group
- PCR
Polymerase chain reaction
- RNA
Ribo nucleic acid
- ss
Single strand
- TdT
Terminal deoxynucleotidyl transferase, DNA nucleotidyl exotransferase (EC: 2.7.7.31)
References
- Agarwal KL, Buchi H, Caruthers MH, Gupta N, Khorana HG, Kleppe K, Kumar A, Ohtsuka E, Rajbhandary UL, Van de Sande JH et al (1974) Total synthesis of the gene for an alanine transfer ribonucleic acid from yeast. Nature 227:27–34. doi:10.1038/227027a0 [DOI] [PubMed]
- Aksnes G, Libanu FO (1991) Temperature dependence of ester hydrolysis in water. Acta Chem Scand 45:463–468. doi:10.3891/acta.chem.scand.45-0463 [DOI]
- Baedeker M, Schulz GE (1999) Overexpression of a designed 2.2 kb gene of eukaryotic phenylalanine ammonia-lyase in Escherichia coli. FEBS Lett 457:57–60. doi:10.1016/S0014-5793(99)01000-5 [DOI] [PubMed]
- Barthelmes J, Ebeling C, Chang A, Schomburg I, Schomburg D (2007) BRENDA, AMENDA and FRENDA: the enzyme information system in 2007. Nucleic Acids Res. doi:10.1093/nar/gkl972 [DOI] [PMC free article] [PubMed]
- Bollum FJ (1974) Terminal deoxynucleotidyl transferase. In: Boyer PD (ed) The enzymes, vol 10, 3rd edn. Academic Press, New York, pp 145–171
- Bollum FJ (1978) Terminal deoxynucleotidyl transferase: biological studies. Adv Enzymol Relat Areas Mol Biol 47:347–374 [DOI] [PubMed]
- Carr PA, Park JS, Lee YJ, Yu T, Zhang S, Jacobson JM (2004) Protein-mediated error correction for de novo DNA synthesis. Nucleic Acids Res. doi:10.1093/nar/gnh160 [DOI] [PMC free article] [PubMed]
- Caruthers MH (1985) Gene synthesis machines: DNA chemistry and its uses. Science 230:281–285. doi:10.1126/science.3863253 [DOI] [PubMed]
- Cello J, Paul AV, Wimmer E (2002) Chemical synthesis of poliovirus cDNA: generation of infectious virus in the absence of natural template. Science 297:1016–1018. doi:10.1126/science.1072266 [DOI] [PubMed]
- Chalmers FM, Curnow KM (2001) Scaling up the ligase chain reaction-based approach to gene synthesis. Biotechniques 30:249–252 [DOI] [PubMed]
- Coleman MS (1977) Terminal deoxynucleotidyl transferase: characterization of extraction and assay conditions from human and calf tissue. Arch Biochem Biophys 182:525–532. doi:10.1016/0003-9861(77)90533-1 [DOI] [PubMed]
- Deng GR, Wu R (1983) Terminal transferase: use in the tailing of DNA and for in vitro mutagenesis. Methods Enzymol 100:96–116. doi:10.1016/0076-6879(83)00047-6 [DOI] [PubMed]
- Dickson KS, Burns CM, Richardson JP (2000) Determination of the free-energy change for repair of a DNA phosphodiester bond. J Biol Chem 275:15828–15831. doi:10.1074/jbc.M910044199 [DOI] [PubMed]
- Elowitz MB, Leibler S (2000) A synthetic oscillatory network of transcriptional regulators. Nature 403:335–338. doi:10.1038/35002125 [DOI] [PubMed]
- Endy D (2005) Foundations for engineering biology. Nature doi:10.1038/nature04342 [DOI] [PubMed]
- Eschenfeldt WH et al (1987) Homopolymeric tailing. Methods Enzymol 152:337–342. doi:10.1016/0076-6879(87)52040-7 [DOI] [PubMed]
- Frohman MA et al (1988) Rapid production of full-length cDNAs from rare transcripts: amplification using a single gene-specific oligonucleotide primer. Proc Natl Acad Sci USA 85:8998–9002. doi:10.1073/pnas.85.23.8998 [DOI] [PMC free article] [PubMed]
- Gibson DG, Benders GA, Andrews-Pfannkoch C, Denisova EA, Baden-Tillson H, Zaveri J, Stockwell TB, Brownley A, Thomas DW, Algire MA, et al (2008) Complete chemical synthesis, assembly and cloning of a Mycoplasma genitalium genome. Science doi:10.1126/science.1151721 [DOI] [PubMed]
- Glick BR, Pasternak JJ (2003) Molecular biotechnology: principles and applications of recombinant DNA, 3rd edn. ASM Press, Washington DC, p 81
- Gorczyca W et al (1993) Detection of DNA strand breaks in individual apoptotic cells by the in situ terminal deoxynucleotidyl transferase and nick translation assays. Cancer Res 53:1945–1951 [PubMed]
- Haas H, Redl B, Leitner E, Stöffler G (1991) Penicillium chrysogenum extracellular acid phosphatase: purification and biochemical characterization. Biochim Biophys Acta 1074:392–397 [DOI] [PubMed]
- Hoover DM, Lubkowski J (2002) DNA works: an automated method for designing oligonucleotides for PCR-based gene synthesis. Nucleic Acids Res 30:e43. doi:10.1093/nar/30.10.e43 [DOI] [PMC free article] [PubMed]
- Hutchison CA, Peterson SN, Gill SR, Cline RT, White O, Fraser CM, Smith HO, Venter JC (1999) Global transposon mutagenesis and a minimal Mycoplasma genome. Science 286:2165–2169. doi:10.1126/science.286.5447.2165 [DOI] [PubMed]
- Igloi GL, Schiefermayr E (1993) Enzymatic addition of fluorescein- or biotin-riboUTP to oligonucleotides results in primers suitable for DNA sequencing and PCR. Biotechniques 15:486–497 [PubMed]
- Khorana HG (1968) Nucleic acid synthesis in the study of the genetic code. In: Nobel lectures: physiology or medicine (1963–1970). Elsevier Science Ltd, Amsterdam, pp 341–369
- Kleppe K, Ohtsuka E, Kleppe R, Molineux I, Khorana HG (1971) Studies on polynucleotides XCVI. Repair replications of short synthetic DNA’s as catalyzed by DNA polymerases. J Mol Biol 56:341–361. doi:10.1016/0022-2836(71)90469-4 [DOI] [PubMed]
- Kodumal SJ, Patel KG, Reid R, Menzella HG, Welch M, Santi DV (2004) Total synthesis of long DNA sequences: synthesis of a contiguous 32-kb polyketide synthase gene cluster. Proc Natl Acad Sci USA 101:15573–15578. doi:10.1073/pnas.0406911101 [DOI] [PMC free article] [PubMed]
- Kormelink FJM, Lefebvre B, Strozyk F, Voragen AGJ (1993) Purification and characterization of an acetyl xylan esterase from Aspergillus niger. J Biotechnol 27:267–282. doi:10.1016/0168-1656(93)90090-A [DOI]
- Kumar A et al (1988) Nonradioactive labeling of synthetic oligonucleotide probes with terminal deoxynucleotidyl transferase. Anal Biochem 169:376–382. doi:10.1016/0003-2697(88)90299-0 [DOI] [PubMed]
- Lander ES, Linton LM, Birren B, Nusbaum C, Zody MC, Baldwin J, Devon K, Dewar K, Doyle M, FitzHugh W et al (2001) Initial sequencing and analysis of the human genome. Nature 409:860–921. doi:10.1038/35057062 [DOI] [PubMed]
- Luo Y-R (2007) Comprehensive handbook of chemical bond energies. CRC Press, Boca Raton, pp 255–338
- Martin VJ, Pitera DJ, Withers ST, Newman JD, Keasling JD (2003) Engineering a mevalonate pathway in Escherichia coli for production of terpenoids. Nat Biotechnol 21:796–802. doi:10.1038/nbt833 [DOI] [PubMed]
- Mehl RA, Anderson JC, Santoro SW, Wang L, Martin AB, King DS, Horn DM, Schultz PG (2003) Generation of a bacterium with a 21 amino acid genetic code. J Am Chem Soc 125:935–939. doi:10.1021/ja0284153 [DOI] [PubMed]
- Ratliff RL (1981) Terminal deoxyribonucleotidyl transferase. In: Boyer PD (ed) The enzymes, vol 14, 3rd edn. Academic Press, New York, pp 105–118
- Richmond KE, Li MH, Rodesch MJ, Patel M, Lowe AM, Kim C, Chu LL, Venkataramaian N, Flickinger SF, Kaysen J et al (2004) Amplification and assembly of chip-eluted DNA (AACED): a method for high-throughput gene synthesis. Nucleic Acids Res 32:5011–5018. doi:10.1093/nar/gkh793 [DOI] [PMC free article] [PubMed]
- Saiki RK, Gelfand DH, Stoffel S, Scharf SJ, Higuchi R, Horn GT, Mullis KB, Erlich HA (1988) Primer-directed enzymatic amplification of DNA with a thermostable DNA polymerase. Science 239:487–491. doi:10.1126/science.2448875 [DOI] [PubMed]
- Sambrook J, Russel D (2001) Molecular cloning: a laboratory manual, vol 2, 3rd edn. Cold Harbor Laboratory Press, Cold Spring Harbor, pp 8.18–8.25
- Scheele G, Fukuoka S-I (1992) Synthesis of full-length double-stranded DNA from a single-stranded linear DNA template. US Patent 5162209
- Scheele G, Fukuoka S-I (1997) Synthesis of full-length double-stranded DNA from a single-stranded linear DNA template. US Patent 5643766
- Schomburg I, Chang A, Schomburg D (2002) BRENDA, enzyme data and metabolic information. Nucleic Acids Res 30:47–49. doi:10.1093/nar/30.1.47 [DOI] [PMC free article] [PubMed]
- Schomburg I, Chang A, Ebeling C, Gremse M, Heldt C, Huhn G, Schomburg D (2004) BRENDA, the enzyme database: updates and major new developments. Nucleic Acids Res 32:D431–D433. doi:10.1093/nar/gkh081 [DOI] [PMC free article] [PubMed]
- Sitnitsky AE (2006) Dynamical contribution into enzyme catalytic efficiency. Physica A doi:10.1016/j.physa.2006.03.039
- Smith HO, Hutchison CA, Pfannkoch C, Venter JC (2003) Generating a synthetic genome by whole genome assembly: ΦX174 bacteriophage from synthetic oligonucleotides. Proc Natl Acad Sci USA 100:15440–15445. doi:10.1073/pnas.2237126100 [DOI] [PMC free article] [PubMed]
- Sprinzak D, Elowitz MB (2005) Reconstruction of genetic circuits. Nature. doi:10.1038/nature04335 [DOI] [PubMed]
- Tian J, Gong H, Sheng N, Zhou X, Gulari E, Gao X, Church GM (2004) Accurate multiplex gene syntheses from programmable DNA chips. Nature 432:1050–1053. doi:10.1038/nature03151 [DOI] [PubMed]
- Tu C-PD, Cohen SN (1980) 3’-end labeling of DNA with [alfa-32P]cordycepin-5’-triphosphate. Gene 10:177–183. doi:10.1016/0378-1119(80)90135-3 [DOI] [PubMed]
- Vainonen JP, Vorobyeva NN, Rodina EV, Nazarova TI, Kurilova SA, Skoblov JS, Avaeva SM (2005) Metal-free PPi activates hydrolysis of MgPPi by an Escherichia coli inorganic pyrophosphatase. Biochemistry (Mosc) 70:69–78 [PubMed]
- Venter JC, Adams MD, Myers EW, Li PW, Mural RJ, Sutton GG, Smith HO, Yandell M, Evans CA, Holt RA et al (2001) The sequence of the human genome. Science 291:1304–1351. doi:10.1126/science.1058040 [DOI] [PubMed]
- Vincent C et al (1982) Synthesis of 8-(2, 4-dinitrophenyl-2, 6-aminohexyl)aminoadenosine-5’-triphosphate: biological properties and potential uses. Nucleic Acids Res 10:6787–6796. doi:10.1093/nar/10.21.6787 [DOI] [PMC free article] [PubMed]
- Voet D, Voet JG (2004) Biochemistry, 3rd edn. Wiley, New York, p 566
- Withers-Martinez C, Carpenter EP, Hackett F, Ely B, Sajid M, Grainger M, Blackman MJ (1999) PCR-based gene synthesis as an efficient approach for expression of the A + T-rich malaria genome. Protein Eng 12:1113–1120. doi:10.1093/protein/12.12.1113 [DOI] [PubMed]