

Abstract
Objective
To incorporate value-based weight scaling into the Fellegi-Sunter (F–S) maximum likelihood linkage algorithm and evaluate the performance of the modified algorithm.
Background
Because healthcare data are fragmented across many healthcare systems, record linkage is a key component of fully functional health information exchanges. Probabilistic linkage methods produce more accurate, dynamic, and robust matching results than rule-based approaches, particularly when matching patient records that lack unique identifiers. Theoretically, the relative frequency of specific data elements can enhance the F–S method, including minimizing the false-positive or false-negative matches. However, to our knowledge, no frequency-based weight scaling modification to the F–S method has been implemented and specifically evaluated using real-world clinical data.
Methods
The authors implemented a value-based weight scaling modification using an information theoretical model, and formally evaluated the effectiveness of this modification by linking 51,361 records from Indiana statewide newborn screening data to 80,089 HL7 registration messages from the Indiana Network for Patient Care, an operational health information exchange. In addition to applying the weight scaling modification to all fields, we examined the effect of selectively scaling common or uncommon field-specific values.
Results
The sensitivity, specificity, and positive predictive value for applying weight scaling to all field-specific values were 95.4, 98.8, and 99.9%, respectively. Compared with nonweight scaling, the modified F–S algorithm demonstrated a 10% increase in specificity with a 3% decrease in sensitivity.
Conclusion
By eliminating false-positive matches, the value-based weight modification can enhance the specificity of the F–S method with minimal decrease in sensitivity.
Introduction
Accurate and efficient record linkage offers numerous benefits to physicians and healthcare organizations, not only by improving the quality of patient care, but also by facilitating clinical research and population-based studies. 1–5 A variety of statistical methods have been applied to the record linkage challenge. One of the more widely used, the Fellegi-Sunter (F–S) method, uses a field-specific weight that is based on the agreement/disagreement between corresponding fields. 6 The F–S method does not, however, leverage the information contained in field-specific values. A value-specific weight derives from the frequency of field-specific values, and provides an opportunity to capture and measure the relative importance of specific values found in a field. We hypothesize that incorporating the value-specific weight into the original agreement/disagreement based F–S method can enhance the record linkage performance.
Background
Healthcare data are captured in many separate healthcare settings. In 2006, alone, patients made an estimated 1.1 billion visits to physician offices, hospital emergency departments and other care settings in the United States, which reflects an average of four visits per person. 7 Moreover, this situation is exacerbated by the fact that patients receive healthcare from many different healthcare settings. 8,9
As a result, records about the same patient are collected at different healthcare systems with unrelated identifiers and patient records collected in an institution may have multiple identifiers referring to the same patient. 10 Data collection systems often lack a standard format for patient identifiers, resulting in incomplete data sharing among healthcare professionals, patients, and data repositories. Furthermore, typographic errors happen routinely and are unavoidable, resulting in inaccurate and inconsistent data. To aggregate and integrate health information, patient record linkage (matching) is a key process for identifying and connecting records belonging to the same patient over extended time periods and across several disparate data sources. 11
Often, probabilistic linkage technology produces more accurate, dynamic, and robust matching than deterministic approach, particularly in matching patient records that lack unique identifiers. 12–15 A widely used probabilistic linkage algorithm is the Fellegi-Sunter (F–S) method. To establish the match or nonmatch status of two records, the F–S method produces a composite likelihood ratio that is the sum of field-specific weights for each record-pair. The field-specific weight is based on a likelihood ratio whose numerator is the probability that a matching field agrees given the comparison pair is a true match; it's denominator is the probability that a matching field agrees given that comparison pair is true nonmatch. 6 This ratio reflects the relative importance of a comparison field in predicting match status. 16 For example, agreement on date of birth receives a higher positive weight than agreement on sex, but disagreement on date of birth receives fewer penalties (a smaller negative weight) than sex receives for disagreement. The sum of all field-specific weights produces the composite match score for a pair.
While the F–S algorithm leverages more information in the data than other approaches and typically produces accurate results, it does not explicitly accommodate the notion of a value-specific weight. As a result, each field receives the identical agreement weight for all record pairs regardless of the relative importance of the specific values being compared for that field. Some specific values are less common than others. Theoretically, the relative frequency (either rare or common) of a field-specific value should be incorporated into the matching process because agreement on a common value should not be scored the same as agreement on an uncommon value for that field. For instance, agreement on a common surname (e.g., “Smith”) should adjust the surname weight downward for that record pair, while an uncommon surname (e.g., “Zilwicki”) should adjust the surname weight upward. 17
Probabilistic matching processes often use a match threshold to establish the match status: a pair with a score above the threshold is a match, while a pair with a score below the threshold is a nonmatch. The matching status is most uncertain for pairs with scores close to the threshold because both uncertain links and uncertain nonlinks exist in greatest density near the threshold and these links may lack sufficient information to be correctly classified. 18 Potential matches may be misclassified in two ways: a false-positive occurs when truly nonmatching records are declared to be the same entity; a false-negative occurs when truly matching records are not declared to be the same entity. A false-positive match can yield incorrectly aggregated patient information and can subsequently lead to incorrect diagnosis and treatment as well as potential loss of patient confidentiality. A false-negative match leads to an incomplete patient information, which is another common reason for treatment errors and cost inefficiency. 19
The existing solutions to minimize these two misclassifications include the following: applying clerical review for uncertain pairs, increasing the number of matching fields, combining deterministic strategies, or shifting the threshold according to the tolerance for false positives and false negatives. Value-specific frequencies can adjust the field-specific weight by leveraging the information contained in the values stored for a specific field, and thus it is a potential strategy to enhance the F–S algorithm's performance. 20,21 To our knowledge, this approach has not been implemented and evaluated in a real world, operational clinical setting. In this study, we created a frequency-based, weight scaling modification of the F–S algorithm using an information theoretical model. We also formally evaluated the effectiveness of this modification by linking a statewide newborn screening data to registration data from an operational health information exchange. We hypothesize that this frequency-based modification can enhance the F–S method's performance.
Methods
Data Sources and Settings
Robust patient matching is a core health information exchange function required for aggregating patient data across disparate systems. One specific linkage use case involves improving newborn screening follow-up by identifying infants who may lack screening. It is well-known that not all infants are appropriately screened for harmful or potentially fatal disorders that are otherwise unapparent at birth. Although public health authorities can link vital records data with newborn screening results to identify unscreened infants, such processes may be delayed and some cases may remain undetected by this process. 22 To improve detection of unscreened infants, we have developed an algorithm to link records from Indiana's statewide newborn screening registry to the Indiana Network for Patient Care (INPC). 23 The INPC is a regional health information exchange that has served five major hospital systems (24 hospitals) in Indianapolis for more than ten years. This system aggregates and delivers a variety of standardized patient data in electronic form including registration records, laboratory tests, radiology reports, diagnosis, and administrative data. 24,25
For this analysis we extracted 51,361 newborn screening records from Jul 1, 2007 to Dec 31, 2007, and 80,089 HL7 messages for patients less than 1 month of age from the INPC for the same time period. These two datasets share the following fields: Medical Record Number (MRN), patient's surname and given name, gender, telephone, Zip code, city, date of birth (year, day, and mo), next of kin's surname and given name, and doctor's surname and given name.
Data Preprocessing
We preprocessed the data before matching to eliminate invalid values from both the newborn screening and INPC transactions. Punctuation and digits were removed from text fields. Nonspecific “placeholder” given names such as “INFANT” and “BABY” are often used when newborns are first registered. These monikers can lead to false-positive matches for two reasons. First, when present in a blocking field, they produce a high proportion of nonmatching potential pairs, which increase the likelihood of a false match. Second, when placeholder values agree between non-blocking fields, that agreement raises the match score, increasing the likelihood that a pair will be classified as a match, incorrectly. Therefore, we removed placeholder and invalid values for given names (e.g., “INFANT”, “BABY”, “AAA”, “BOO” and “NEWBORN”) and gender (e.g., “sex”, “u”). The year of birth field was excluded because all values for year of birth in this study were “2007”, which added no additional information. Zip codes were converted to five digits and trailing zeros were eliminated. Default values, such as 999-999-9999 for missing telephone numbers, were identified and removed from both datasets.
Blocking
More than 4 billion (51,369 × 80,089) comparisons would be required to compare all possible newborn screening and INPC record pairs. To reduce the total number of comparisons, we used a blocking scheme. Blocking schemes partitioned the full Cartesian product of possible record pairs into smaller subsets where blocking fields agree, and then the candidate matches are examined in detail to identify true matches. Blocking fields should have high variety of values and a low missing value rate. This strategy ideally increases the proportion of true matches among possible pairs while decreasing the number of comparisons. 26 Each of the blocking schemes identified unique true matches, and their union ideally captured most of the true matches.
Weight Scaling
We proposed the following general scaling factor for each field, which yields values less than one for frequently occurring items while producing values greater than one for uncommon values. 27
| (1) |
(Eqn 1) where:
T k= the total number of the values for the field (constant for the field)
Q k = the total number of *unique* values for the field (constant for the field)
I k= the field-specific frequency of the current value (varies for each unique value)
Since T k and Q k were constant for each field, equation (1) is re-written as:
| (2) |
(Eqn 2) where:
, and is constant for each field. It represents the average frequency for the field across both datasets to be linked. For field values having a frequency (I k) equal to the average frequency (Ak) for that field, the scaling factor equals one.
Under the conditional probability independence assumption, the F–S model of record linkage sums the component weights of each identifier in the j th record pair 6 :
| (3) |
(Eqn 3) where, for the k th identifier in the j th record pair:
n = number of identifiers per record
γ k = observed agreement/disagreement status (1=agree, 0= disagree)
m k = estimated identifier agreement rate among links
u k = estimated identifier agreement rate among non links
Incorporating the scaling factor from Eqn (2) into Eqn (3), we obtained the following modified F–S equation:
| (4) |
(Eqn 4) We calculated likelihood scores with and without the weight scaling modification using equations, 4,3 respectively.
Selective Scaling Approaches
Our initial analysis scaled all fields for each record. We were uncertain how the degree of commonality for specific values would influence the algorithm performance and hypothesized that selectively scaling values of greater and lesser frequency would yield different matching performance characteristics. To study the effect of selectively scaling common or uncommon values, we examined a variety of approaches that selectively scaled specific field values using predefined cutoff percentiles based on field value frequency. We applied this strategy to all fields for a given cutoff percentile. For example, in one analysis we scaled only the 5% least common values for each field and evaluated the accuracy of that approach. Other scaling approaches we used were 10% least common values only; 10% most common values only; 10% least and most common values; below average common values; above average common values; below median common values; and above median common values.
Parameter Estimation
Exact values for the parameters p (proportion of true matches), m, and u for each comparison field are unknown for a given dataset. To accurately estimate these parameters, we applied the expectation maximization (EM) algorithm with random sampling. 23,28 We defined empty fields as disagreeing by default to avoid agreement between two empty fields. We also used EM to estimate the proportion of true matches to establish the match/nonmatch threshold. We performed separate EM analyses for record pairs created by each of the three blocking schemes. Consequently, distinct values for matching parameters and score threshold were estimated for each blocking scheme.
Evaluating Performance
We randomly sampled and manually reviewed 10% of the potential pairs from each block to detect links and nonlinks. Informed by the EM parameter estimates, we compared the modified weight-scaling F–S method to the original F–S method using a gold standard of manually reviewed matches. All potential pairs were assigned to one of four categories: true-positive match (TP, classified as a match when it truly is a match), true-negative match (TN, classified as a nonmatch when it truly is not a match), false-positive match (FP, classified as a match when it truly is not a match), false-negative match (FN, classified as a nonmatch when it truly is a match). 29 To evaluate the performance of the F–S method with and without weight scaling, we used three measurements. These were sensitivity (SENS), specificity (SPEC) and positive predictive value (PPV).
Results
Data Cleaning, Selection of the Blocking Variable and Parameter Estimation
The field characteristics, including the percentage of missing value and the number of unique values, informed our choice of blocking variables (▶). Using these two field characteristics, we selected three blocking schemes, which included medical record (MRN), surname and given name (LNFN) and telephone number (TEL). For the INPC dataset we invalidated 44,365 first names, 63 telephone numbers, 424 gender codes, and 222 Zip codes; in the newborn screening dataset we invalidated 29,431 first names. After removing invalid values from both datasets, more than half of the given name fields were empty, and thus the given name field was considered a weak identifier in both datasets. However, the combination of given name and surname fields remained an informative blocking scheme. The blocking schemes generated 31,871 pairs for MRN, 15,252 pairs for LNFN, and 63,347 pairs for TEL. Using the union of these three fields produced 80,661 unique potential pairs. The blocking schemes reduced the total number of comparisons from greater than 4 billion to less than 110,000. ▶ summarizes the number of matched pairs for each blocking scheme and the number of overlapping pairs identified by multiple blocking schemes. ▶ shows the proportion of true matches and threshold for each blocking scheme, which were informed by EM.
Table 1.
Table 1 The number and percentage of missing values and number of unique values for each identifier in the Newborn Screening data and the INPC data
| Field Name | Newborn Screening Data (N = 51,361) |
INPC Data (N = 80,089) |
||||
|---|---|---|---|---|---|---|
| Number of Missing Values(Percentage) | Number of Unique Values | Number of Missing Values (Percentage) | Number of Unique Values | |||
| MRN | 557 | (2.0%) | 44,366 | 106 | (0.1%) | 18,794 |
| Telephone Number | 2,580 | (5.0%) | 42,693 | 20,806 | (26.0%) | 14,542 |
| Surname | 1 | (< 0.1%) | 17,115 | 2,352 | (2.9%) | 9,008 |
| Kin's surname | 49 | (0.1%) | 16,792 | 46,584 | (58.2%) | 7,131 |
| Kin's given name | 196 | (0.4%) | 6,983 | 46,676 | (58.3%) | 3,746 |
| Given name | 29,441 | (57.3%) | 5,299 | 45,243 | (56.5%) | 6,255 |
| Doctor's surname | 43 | (0.1%) | 2,047 | 22,386 | (28.0%) | 1,390 |
| Doctor's given name | 892 | (1.7%) | 971 | 21,304 | (26.6%) | 1,417 |
| Zip code | 679 | (1.3%) | 1,256 | 15,999 | (20.0%) | 816 |
| Day of birth | 1 | (< 0.1%) | 31 | 3,826 | (4.8%) | 31 |
| mo of birth | 0 | (0.1%) | 6 | 3,826 | (4.8%) | 7 |
| Gender | 618 | (1.2%) | 2 | 3,920 | (4.9%) | 2 |
INPC = Indiana Network for Patient Care; MRN = medical record number.
Figure 1.

The number of potential pairs for the three blocking schemes and the number of overlapping pairs (TEL block alone contributed 46.96% of total 80,661 potential pairs in the union of three blocking schemes).
Table 2.
Table 2 The total number of pairs per blocking scheme, EM-estimated proportion of true matches (p), and the match threshold score for each block
| Block Scheme Block | Total Number of Pairs | p (%) | Threshold Score |
|---|---|---|---|
| MRN | 31,871 | 98.6 | 0.33 |
| TEL | 63,347 | 97.6 | 0.61 |
| LNFN | 15,252 | 92.1 | 3.33 |
EM = expectation maximization; LNFN = surname and given name; MRN = medical record number; TEL = telephone number.
Sensitivity/Specificity/PPV
We randomly sampled (with replacement) 10% of the records from each block (3,187 pairs for MRN block, 1,525 pairs for LNFN block, and 6,334 pairs for TEL block) and labeled them as a link or non-link based on manual review. The number of true links for the samples from the MRN, LNFN, and TEL blocks were 3,158, 1,461, and 6,242, respectively. The union of all blocking schemes yielded 9,145 true matches and 162 true nonmatches out of a total of 9,307 pairs. For the bulk of this analysis we used the union of all three blocking schemes. ▶ shows the performance of various selective weight scaling approaches. Weight scaling all values for all fields produced sensitivity, specificity, and positive predictive values of 95.4, 98.8 and 99.9%, respectively. Compared with no weight scaling, the modified F–S algorithm produced a 10% increase in specificity with a small 3% decrease in sensitivity.
Table 3.
Table 3 Sensitivity, specificity, and positive predictive value for the union of all blocking schemes across different weight scaling approaches
| Scaling Approach | TP | FN | FP | TN | SENS (%) | SPEC (%) | PPV (%) |
|---|---|---|---|---|---|---|---|
| No scaling | 8,991 | 154 | 18 | 144 | 98.3 | 88.9 | 99.8 |
| Scale bottom 5% | 9,082 | 63 | 18 | 144 | 99.3 | 88.9 | 99.8 |
| Scale bottom 10% | 9,082 | 63 | 18 | 144 | 99.3 | 88.9 | 99.8 |
| Scale below median | 9,082 | 63 | 18 | 144 | 99.3 | 88.9 | 99.8 |
| Scale below mean | 9,082 | 63 | 18 | 144 | 99.3 | 88.9 | 99.8 |
| Scale top and bottom 10% | 8,989 | 156 | 15 | 147 | 98.3 | 90.7 | 99.8 |
| Scale top 10% | 8,723 | 422 | 2 | 160 | 95.4 | 98.8 | 99.9 |
| Scale above median | 8,723 | 422 | 2 | 160 | 95.4 | 98.8 | 99.9 |
| Scale above mean | 8,723 | 422 | 2 | 160 | 95.4 | 98.8 | 99.9 |
| Scale all | 8,725 | 420 | 2 | 160 | 95.4 | 98.8 | 99.9 |
FN = false-negative; FP = false-positive; PPV = positive predictive value; SENS = sensitivity; SPEC = specificity; TN = true-negative; TP = true-positive.
Discussion
We have three main findings from this study. First, when scaling all values for all fields, the weight scaling modification increased specificity with only a small decrease in sensitivity. Second, false positives were largely eliminated by selective scaling the most common field values (as seen in ▶). Third, using value-based frequency, the scaling factor leverages additional information and tailors the original F–S weight. These enhancements improve the overall performance of the F–S method as tested using real-world clinical data.
Specificity Improvement
We evaluated the modified F–S method using sensitivity, specificity, and positive predictive value across a variety of scaling approaches. When weight scaling common values, specificities for MRN, LNFN, TEL blocks and their union were near 100%, meaning that every nonlink was accurately identified by the algorithm (▶). In addition, for most scaling approaches sensitivities did not dramatically decrease and when selectively scaling less common values, sensitivity increased slightly (▶). The specificity increased from 88.9% with no weight scaling to 98.8% for scaling all values. At the same time, sensitivity decreased from 98.3 to 95.4%, and the PPV for all scaling approaches were nearly equal (▶). Manual review confirmed that all blocking schemes produced a high true-link rate (99.1% for MRN block, 95.8% for LNFN block, and 98.5% for TEL block). Although prevalence of true links does not directly influence an algorithm's sensitivity and specificity, changes in population prevalence can reflect different population characteristics that may in turn affect sensitivity and specificity. 30,31 This is the case for record linkage because the measurement, in this case the match score, is a function of multiple underlying population traits. Since this distribution of traits also determines the prevalence of links in the population, diagnostic misclassification as reflected in sensitivity and specificity are related to prevalence of links for this category of measurement. As is the case with any matching approach, the performance characteristics of the algorithm depend on the underlying characteristics of the data, and this may limit the generalizability of this study's findings. To confirm the specificity improvement of the modified algorithm and to further evaluate the positive predictive value, we will evaluate the algorithm performance using different datasets with lower prevalence of true links.
Figure 2.

Specificity of each blocking scheme and the union of all blocking schemes ordered by weight scaling approaches.
Figure 3.

Sensitivity of each blocking scheme and the union of all blocking schemes ordered by weight scaling approaches.
We used SENS, SPEC, and PPV to assess the algorithm performance. It is important to note that data quality factors such as missing values and error rates of data also influence the algorithm's performance. Besides the common data quality issues, the datasets used for our study have additional unique challenges. The infant name may change after newborn screening. In addition, the INPC data are collected by numerous providers across more than 20 hospitals in central Indiana resulting in increased variability in data capture. In this study, the modified F–S algorithm has improved specificity from 88 to 98% while minimally reducing the sensitivity from 98 to 95%. The improved specificity is important for our specific use case, which is to identify newborns that lack universal screening at birth. When no match for the INPC encounter record is found in the newborn screening database, the appropriate public health stakeholders should be alerted. Thus, from a public health perspective, it is better to minimize false positives and err on the side of false negatives. In this case increasing specificity is useful because we would rather falsely conclude a patient lacks screening (and generate an alert) than to incorrectly say a patient has been screened (and generate no alert). Overall, the modified F–S algorithm is a more effective approach for linking newborn screening data to INPC data, and it is a potential approach to linking other types of data with INPC records for both clinical practice and research purposes.
Efforts to Eliminate the False-Positive Matches
Compared with the unmodified algorithm, the modified F–S algorithm eliminated 16 out of 18 false-positive matches from the union of the three blocking schemes. These false-positive matches were found to have a common given name, common Zip code, common month of birth, or common doctor's name. Because these specific values were common, the scaling factor lowered the match score so that it was below the match thresholds. Two nonmatches were incorrectly categorized as true matches because their original scores were well above the match score threshold. Both pairs had the same value for the field of telephone number, month of birth and day of birth, but have different values for gender and other fields.
False positives are more likely to occur as datasets increase in size. 32 An important cause of false-positive matches is the combination of a limited number of comparison fields and large file size. Too few fields or insufficient variation within fields can decrease discriminating power, which increases the likelihood that multiple fields will agree due to chance between different patient records. 33 Consequently, agreement on multiple fields yields a high matching score, so that records from different patients are incorrectly classified as false positives. However, while common values occur more frequently when data size increases, the average frequency for a field remains relatively stable. The modified algorithm can leverage more information about these common values to avoid false-positive matches.
Scaling Factor
The scaling factor takes into account the distinguishing power of a specific value when two fields agree. A frequently occurring value may have less distinguishing power than a less frequently occurring value. 34 To illustrate the scaling factor, we use two hypothetical datasets with single field of given name, each with ten records. The combination of these two datasets has five “Gina” and fifteen “Mary”. Therefore, the average frequency (AK) for given name is 10 (20/2 = 10), and the scaling factors are 0.81 (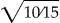 ) for “Mary” and 1.41(
) for “Mary” and 1.41(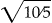 ) for “Gina”. Mathematically, when the given name field agrees between these two files, we conclude that a record pair with “Mary” has approximately 50% (0.81/1.41) less probability to be a true link than a record with “Gina”.
) for “Gina”. Mathematically, when the given name field agrees between these two files, we conclude that a record pair with “Mary” has approximately 50% (0.81/1.41) less probability to be a true link than a record with “Gina”.
The F–S approach calculates field specific weights based on agreement and disagreement. 35 The scaling factor adds additional information related to the frequency of a specific value and this information is not directly accounted by the F–S algorithm. As an example, in our study the scaling factor for surname ranged from 0.067 for the most commonly occurring name to 2.45 for names occurring only once. We applied field-specific weight and scaling factor as conditionally independent for this study; that their multiplication more accurately informs the relative importance for a specific field value.
A focus of this study was to evaluate the feasibility and utility of using frequency distributions derived from the data being matched. The rationale for this approach is based on the assumption that the frequencies from the actual data most closely reflect the actual distribution of the data being matched. However, there are other sources for name frequency data that may be similarly used when it is infeasible to generate statistics from the data being matched. The United States Census Bureau publishes name frequency lists 36 and future work will assess the feasibility and utility of such data to improve matching accuracy.
To better understand how the weight scaling influences the total matching score, we analyzed the change in corresponding match scores between the modified F–S algorithm and the original F–S algorithm. ▶ illustrates the distribution of matching score with and without weight scaling modification for MRN, LNFN and TEL block when every value in those blocks is scaled. Because common values dominate in the two datasets used for our study, the contribution of unique values in a field are generally canceled out when records have a common value for other fields. In most cases, the scaling factor decreases the overall matching score; along with the same threshold of the nonweight scaling approach, these lower matching scores largely eliminated the false-positive matches. However, a small percentage (about 1% in each blocking scheme) of match scores increased even when scaling all the values, which can potentially improve sensitivity by reducing false-negative matches. We will investigate these increased scores in future work.
Figure 4.

Matching score distribution with (ws) and without (nws) weight scaling modification for each blocking scheme.
Limitations
This study has two main limitations. First, we did not separate singleton and twin births in our study. Linking twins is more complicated because twins share almost all the same information. The discriminating fields, such as order of birth, birth weight, time of the birth and the Apgar's score, are often missing in healthcare transactions. Consequently, we rely on accurate values for given name to distinguish twins. However, twins' names are commonly recorded as infantA/infantB and girlA/boyB in newborn screening data, and these nonspecific values were nullified in this study as any other invalid values for the given name field. Further, although the MRN is a highly discriminating field, it is not perfect for distinguishing twins because MRN may be attributed to the wrong twin in subsequent healthcare encounters; in addition, not all healthcare transactions contain an MRN. It is unlikely that there is sufficient information for the F–S model to distinguish twin records as nonlinks, with or without the scaling factor, unless twin's records have valid and accurate values for the given name field.
Second, data recording errors are unavoidable in data and should be minimized to improve record linkage accuracy. 37 Coincidental agreement across two datasets resulting from recording errors may cause an erroneous frequency calculation, which can produce an incorrect average frequency for that field. This in turn affects the scaling factor for that field. In addition, if a typographic error occurs for a common value (such as “Xmith” for “Smith”) across both datasets, then this common value will be treated as a unique value. Coincidental agreement caused by typographic errors among corresponding fields occurs more commonly with fields having few unique values, such as gender and month of birth, while coincidental typographic agreement rarely occurs among fields with many unique values. For example, a typographic error in month is more likely to cause a coincident agreement than a typo in a name. We reduced recording errors by validating values for the fields of gender, date of birth, month of birth, Zip code, and telephone number. However, we did not investigate the typographic errors for the given name and surname fields for newborn, next of kin, and doctor because the typographic errors in these fields are unlikely to dramatically influence matching results. In addition, the effect of typographic error also can be mitigated by weight scaling only common values, such as the values with frequency greater than the average or median frequency of corresponding field.
Conclusions
The frequency-based modification enhanced performance of the F–S algorithm by eliminating false-positive matches: specificity was improved. This study empirically demonstrates that the proposed scaling factor accurately adjusts field specific weights based on the F–S probabilistic model. Our results also suggest that we can optimize either sensitivity or specificity using selective scaling approaches: weight scaling common values improves specificity while weight scaling uncommon values improves sensitivity.
Acknowledgments
The authors thank the NLM Medical Informatics Fellowship Program (5T15LM007117), Regenstrief Institute, Inc, the HRSA grant for newborn screening (U22MC06969), and the Clinical Investigator Translational Education Program, School of Medicine at Indiana University.
References
- 1.Shapiro JS, Kasnnry J, Andrew W, Kushniruk G. Kuperman emergency physicians' perceptions of health information exchange J Am Med Inform Assoc 2007;14(6):700-705. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Møller S, Jensen MB, Ejlertsen B, Bjerre KD, et al. The clinical database and the treatment guidelines of Danish Breast Cancer Cooperative Group (DBCG): It's 30-year experience and future promise Acta Oncol 2008;47(4):506-524. [DOI] [PubMed] [Google Scholar]
- 3.Nitsch D, Morton S, DeStavola BL, Clark H, Leon DA. How good is probabilistic record linkage to reconstruct reproductive histories?. Results from the Aberdeen children of the 1950s study. BMC Med Res Methodol 2006;6(15):1-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Hall SE, Holman CD, Finn J, Semmens JB. Improving the evidence base for promoting quality and equity of surgical care using population-based linkage of administrative health records Int J Qual Health Care 2005;17(5):415-420. [DOI] [PubMed] [Google Scholar]
- 5.Dean JM, Vernon DD, Cook L, Nechodom P, Reading J, Suruda A. Probabilistic linkage of computerized ambulance and inpatient hospital discharge records: A potential tool for evaluation of emergency medical services Ann Emerg Med 2001;37(6):616-626. [DOI] [PubMed] [Google Scholar]
- 6.Fellegi ISA. A theory for Record linkage J Am Stat Assoc 1969;64:1183-1201. [Google Scholar]
- 7.Schappert SM, Rechtsteiner EA. Ambulatory medical care utilization estimates for 2006 CDC, National Center for Health Statistics 2008:832. [PubMed]
- 8.John T, Finnell MJ, Mc Overhage CJ. Donald. In support of emergency department health information technology. AMIA Symp 2005:246-250. [PMC free article] [PubMed]
- 9.John T, Finnell JM, Overhage PR, et al. Donald. Community clinical data exchange for emergency medicine patients. AMIA Symp 2003:235-238. [PMC free article] [PubMed]
- 10.McDonald CJ. The barriers to electronic medical record systems and how to overcome them J Am Med Inform Assoc 1997;4(3):213-221. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Newcombe HB. Handbook of Record Linkage: Methods for Health and Statistical Studies, Administration and BusinessOxford: Oxford University Press; 1988.
- 12.Shaun J, Grannis MJ, Mc Overhage CJ. Donald. Analysis of identifier performance using a deterministic linkage algorithm. AMIA Symp 2002:309. [PMC free article] [PubMed]
- 13.Gill L, Simmons H, Bettley G, Griffith M. Computerised linking of medical records: Methodological guidelinesMG J Epidemiol Community Health 1993;47(4):316-319. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Grannis SJ, Overhage MJ, McDonald C. Real world performance of approximate string comparators for use in patient matching Stud Health Technol Inform 2004;107:43-47. [PubMed] [Google Scholar]
- 15.Shaun J, Grannis JM, Overhage SH, Mc Clement J. Donald. Analysis of a probabilistic record linkage technique without human review. AMIA Symp 2003:259-263. [PMC free article] [PubMed]
- 16.Kevin MC DD, Krupski A. Record linkage software in the public domain a comparison of Link plus, the Link King and a“basic” deterministic algorithm Health Inform J 2008;14(1):5-15. [DOI] [PubMed] [Google Scholar]
- 17.Campbell KM. Impact of record-linkage methodology on performance indicators and multivariate relationships J Substance Abus Treat 2008;5:1-8. [DOI] [PubMed] [Google Scholar]
- 18.Nora Méraya JBR, Anita CJRavellia, Gouke J, Bonsel. Probabilistic record linkage is a valid and transparent tool to combine databases without a patient identification number J Clin Epidemiol 2007;11:1-14. [DOI] [PubMed] [Google Scholar]
- 19.Richard Hillestad JHB, Chaudhry B, Dreyer P, et al. Identity CRISIS: An examination of the costs and benefits of a unique patient identifier for the U.S. Health care system RAND Health 2008:1-97.
- 20.MacLeod M, Kendrick S, Cobbe S. Computers and biomedical research enhancing the power of record linkage involving low quality personal identifiers: Use of the best link principle and cause of death prior likelihoods Comput Biomed Res 1998;31(4):257-270. [DOI] [PubMed] [Google Scholar]
- 21.Howe GR. Use of computerized record linkage in cohort studies Epidemiol Rev 1998;20(1):112-122. [DOI] [PubMed] [Google Scholar]
- 22.Hoff T, Ayoob M, Therrell BL. Long-term follow-up data collection and use in state newborn screening programs Arch Pediatr Adolesc Med 2007;161(10):994-1000. [DOI] [PubMed] [Google Scholar]
- 23.Grannis L, Biondich H, Downs G, et al. Leveraging open-source matching tools and health information exchange to improve newborn screening follow-up Public Health Information Network Annu Symp. Progress. 2008.
- 24.Overhage MJ, McTierney WM, Donald CJ. In: Design and Implementation of the Indianapolis Network for Patient Care and Research Bull Med Libr Assoc 1995;83(1):48-56. [PMC free article] [PubMed] [Google Scholar]
- 25.McDonald CJ, Overhage JM, et al. The Indiana Network for Patient Care: A working local health information infrastructure Health Aff Millwood 2005;24(5):1214-1220. [DOI] [PubMed] [Google Scholar]
- 26.Michelson M, Knoblock CA. Learning blocking schemes for record linkage 2006. Proceedings of the 21St National Conference on Artificial Intelligence (AAAI-06), Boston, MA.
- 27.Pates RD, Scully KW, Einbinder JS, et al. Adding value to clinical data by linkage to a public death registry IMIA 2001:1384-1388. [PubMed]
- 28.Yancey WE. Improving EM Algorithm Estimates for Record Linkage Parameters Research Report Series. US Bureau of Census; 2004.
- 29.Blakely T, Salmond C. Probabilistic Record Linkage and a Method to Calculate the Positive Predictive Value International Epidemiological Association 2002;vol 31:1246-1251. [DOI] [PubMed] [Google Scholar]
- 30.Friis RH. Epidemiology for Public Health PracticeJones and Bartlett Publishing; 2008.
- 31.Brenner H, Gefeller O. Variation of sensitivity, specificity, likelihood ratios and predictive values with disease prevalence Stat Med 1997;16(9):981-991. [DOI] [PubMed] [Google Scholar]
- 32.Cameron CM, Purdie DM, Kliewer EV, McClure RJ, Wajda A. Population health and clinical data linkage: The importance of a population registry Aust N Z J Public Health 2007;31(5):459-463. [DOI] [PubMed] [Google Scholar]
- 33.Winkle WE. Overview of record linkage and current research directions. Research report series. Statistics 2006;2:1-44. [Google Scholar]
- 34.Winkler WE. Methods for record linkage and Bayesian networks. Research report series. Statistics 2002;5:1-29. [Google Scholar]
- 35.Herzog TN, Winkler WE. Data Quality and Record Linkage TechniquesSpringer; 2007.
- 36. Frequently Occurring Names in the U.S. Retrieved May 7, 2009, US Census Bureau, 2000http://www.census.gov/genealogy/names/names_files.html 2007. Accessed:.
- 37.Winkler WE. Matching and Record Linkage U.S. Bureau of the Census 1993;vol 8:1-38. [Google Scholar]