

Abstract
The Majorize-Minimize (MM) optimization technique has received considerable attention in signal and image processing applications, as well as in the statistics literature. At each iteration of an MM algorithm, one constructs a tangent majorant function that majorizes the given cost function and is equal to it at the current iterate. The next iterate is obtained by minimizing this tangent majorant function, resulting in a sequence of iterates that reduces the cost function monotonically. A well-known special case of MM methods are Expectation-Maximization (EM) algorithms. In this paper, we expand on previous analyses of MM, due to [14, 15], that allowed the tangent majorants to be constructed in iteration-dependent ways. Also, in [15], there was an error in one of the steps of the convergence proof that this paper overcomes.
There are three main aspects in which our analysis builds upon previous work. Firstly, our treatment relaxes many assumptions related to the structure of the cost function, feasible set, and tangent majorants. For example, the cost function can be non-convex and the feasible set for the problem can be any convex set. Secondly, we propose convergence conditions, based on upper curvature bounds, that can be easier to verify than more standard continuity conditions. Furthermore, these conditions allow for considerable design freedom in the iteration-dependent behavior of the algorithm. Finally, we give an original characterization of the local region of convergence of MM algorithms based on connected (e.g., convex) tangent majorants. For such algorithms, cost function minimizers will locally attract the iterates over larger neighborhoods than is guaranteed typically with other methods. This expanded treatment widens the scope of MM algorithm designs that can be considered for signal and image processing applications, allows us to verify the convergent behavior of previously published algorithms, and gives a fuller understanding overall of how these algorithms behave.
1 Introduction
This paper pertains to the Majorize-Minimize (MM) optimization technique1 as applied to minimization problems of the form
| (1) |
Here Ψ is a continuously differentiable, but possibly non-convex cost function, and X is a convex feasible subset of ℝp, the space of real, length p column vectors.
The MM technique has a long history in a range of fields. In the statistics literature, a prominent example is the Expectation Maximization (EM) methodology [10] which is an application of MM to maximum likelihood estimation. Further examples can be found in in [16, 17, 22, 24]). The interest in maximum likelihood estimation for tomographic image reconstruction subsequently led to many examples of EM, and more general MM algorithms, in image processing (e.g., [34, 23, 7, 8, 9, 38, 36]). MM has also received considerable attention in the signal processing literature, including [28, 4, 21, 26, 5].
An MM algorithm reduces Ψ monotonically by minimizing a succession of approximations to Ψ, each of which majorizes Ψ in a certain sense. An MM algorithm uses what we call a majorant generator ϕ[·](·) to associate a given expansion point xi with a tangent majorant ϕxi (·). In the simplest case, illustrated for a 1D cost function in Figure 1, a tangent majorant satisfies Ψ(x) ≤ ϕxi (x) for all x ∈ X and Ψ(xi) = ϕxi (xi). That is, ϕxi (·) majorizes Ψ with equality at xi. The constrained minimizer xi+1 ∈ X of ϕxi (·) satisfies Ψ (xi+1) ≤ Ψ(xi). Repeating these steps iteratively, one obtains a sequence of feasible vectors {xi} such that {Ψ (xi)} is monotone non-increasing.
Figure 1.
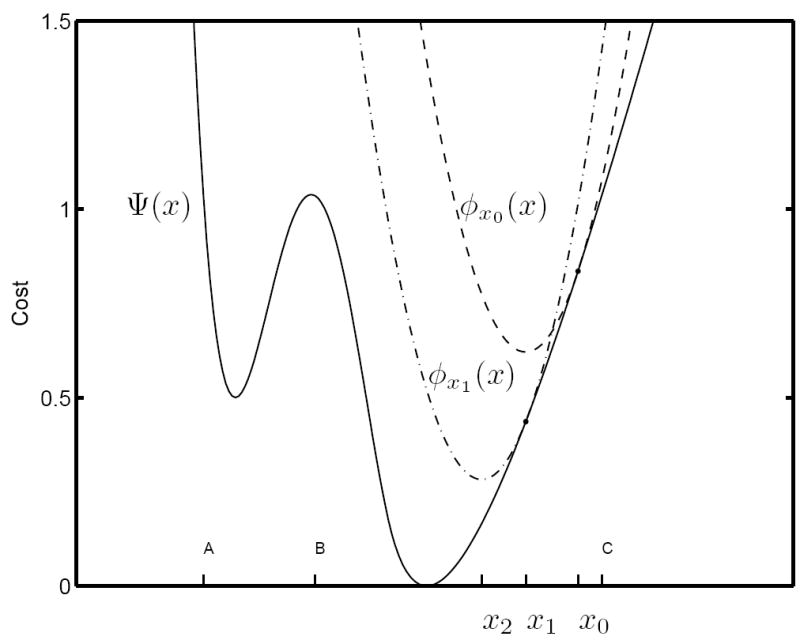
One-dimensional illustration of an MM algorithm.
A more elaborate form of MM was introduced in [14] that allows an iteration-dependent sequence of majorant generators to be used, rather than just a single ϕ[·](·). This generalization allows considerable freedom in choosing the form of the majorant generator at a given iteration. For example, its form can be adaptively determined based on the observed progress of the algorithm over previous iterations. In addition, one can allow the tangent majorants to be functions of i-dependent subsets of the components of x. The latter results in iterative steps that, similar to coordinate descent, reduce Ψ(x) as a function of subsets of the optimization variables. This technique, called block alternation, can simplify algorithm design, because the majorization requirement need be satisfied only with respect to the variables being updated. Furthermore, because the majorization requirement is easier to satisfy, there is empirical evidence that tangent majorants obtained this way may approximate Ψ better (leading to faster convergence) than non-block alternating alternatives. An example of where block alternation led to faster convergence was presented in [14]. Block alternating MM has also seen subsequent use in [28, 30, 12, 4, 21, 26, 5].
The reasons why the MM technique has been attractive to algorithm designers are mixed, and some of the work in this paper may motivate some new reasons. Historically, the main appeal of MM is perhaps that it often leads to algorithms in which the iteration updates are given by simple closed-form formulas (e.g., [34, 7, 8, 11]) and hence, in these cases, tend to be easy to implement. This is in contrast to standard gradient descent methods that employ numerical line searches to ensure global convergence. For large-scale problems, the efficient implementation of line search operations can require complicated customized software implementation, as well as special hardware resources. For example, consider the minimization of the Poisson loglikelihood function encountered in fully 3D Positron Emission Tomography (PET) image reconstruction, e.g., [30]. There, efficiency demands that line searches be implemented in sinogram space. Doing so in turn necessitates considerable RAM, such as would be available on a parallel computing platform. It is likely that, for this reason, investigators in the field of 3D PET have looked to MM alternatives such as [34, 8]. A related reason why MM is attractive is that, when the tangent majorants are computationally simple to manipulate, one might hope for reduced overall CPU time. This benefit is harder to guarantee, because it demands not only that the tangent majorants have a simple form, but also that they provide accurate approximations to Ψ, and these two design requirements can conflict. Hence, one sometimes sees examples of MM in the literature that, although easy to implement, converge quite slowly (e.g., [34]). Conversely, a successful instance of MM acceleration was presented in a logisitic regression example in [24, Example 11]. There, the MM algorithm was found to compare favorably, in terms of convergence rate, with Newton’s method. In this paper (see Section 6), we suggest what might be a third benefit of MM. Namely, we discuss how the unusual local convergence properties of MM might be harnessed by certain non-convex minimization strategies.
The overall endeavour of this paper is to revisit and expand the MM convergence analysis of [15]. The scope of [15] is the only one that we know of that includes simultaneously the case where the majorant generator sequence can vary non-trivially with i and, furthermore, where minima may lie at constraint boundaries. Our treatment makes three principal contributions to the work begun there. (In the course of our analysis, we also remedy an error in [15], see Remark 4.5).
Our first contribution is to rework the analysis of iteration-dependent MM while relaxing many specific structural assumptions made in [15] on the form of the constraints, the cost function Ψ, and the tangent majorants. For example, in [15], only non-negativity constraints were considered, whereas in this paper, X can be any convex set or, in the case of block alternating MM, any convex set appropriately decomposable into a Cartesian product. Furthermore, in [15], Ψ and the tangent majorants were both assumed to be strictly convex. Here, we consider cases in which neither of the two are even convex. Flexibility is also introduced in the domain over which the tangent majorants are defined. In [15], the tangent majorant domains were assumed to be all of X, whereas here, the domains can be strict subsets of X. It is not uncommmon for tangent majorants to have smaller domains than Ψ. It is true, for example of the ML-EM algorithm of [34] (see Section 5) and also for the algorithm designs that we proposed (see [19] and [18, Section 6.6]) for a motion-corrected PET image reconstruction application. Lastly, in [15], the tangent majorants were assumed twice-differentiable, whereas in our analysis, only once-differentiability is assumed. These generalizations widen the range of applications to which [15] is applicable and provide a more flexible framework for algorithm design. Moreover, they allow us to verify the convergence (or at least the asymptotic stationarity) of some previously published block alternating MM algorithms not encompassed by the convergence analysis in [15]. Among these are the algorithm proposed in [12, Section 6] and those in [19] and [18, Section 6.6]. The convergence analysis in [15] does not apply to these examples at minimum because they involve non-convex Ψ. The line of proof used in [15] depended critically on the strict convexity of the cost function. Also, as discussed above, some of these algorithms use tangent majorants having domains that are not the entire set X. Further motivating examples for these generalizations are discussed in [20, Section 6].
Our second contribution is an alternative set of convergence conditions requiring local upper curvature bounds. In the MM literature involving iteration-independent majorant generators (e.g., [35, 23, 29]), convergence proofs usually invoke an assumption that the are continuous (jointly in both arguments). This continuity assumption admits an analysis using Zangwill’s convergence theorem [37, p. 91]. In [15], this line of analysis was generalized to iteration-dependent majorant generators under certain additional conditions, and the present paper continues to study these. In addition, however, we show that the continuity condition can be relaxed in favor of a requirement that the tangent majorant curvatures are uniformly locally upper bounded in the region of the expansion points. This latter condition is sometimes more easily verifiable than the standard continuity-based ones. Furthermore, this alternative condition admits considerable freedom in the iteration-dependent behavior of the algorithm (see Remark 4.6).
Our third contribution is an original characterization of the local region of convergence of MM algorithms to local minima. This branch of our analysis is restricted to tangent majorants that are connected (e.g., convex), which is a common practical case. Usually, algorithm developers design tangent majorants that are convex to facilitate their minimization. Our results show that the associated MM algorithm will be attracted to a strict local minima from essentially any point within a basin-like region surrounding that minimum. The same is not generally true of standard gradient algorithms. This property has important implications for the tendency of common kinds of MM designs to become trapped at local minima in non-convex minimization problems. However, we also discuss how this property might be harnessed by some established non-convex minimization strategies.
The rest of the paper is organized as follows. In Section 2, we formalize the class of MM algorithms considered in this paper. Next, in Section 3, we give a few additional mathematical preliminaries and describe various conditions imposed in the subsequent analysis. Our analysis begins in Section 4, where we study the global convergence of both block alternating and nonblock alternating MM. In this section, the principal step is showing the stationarity of MM limit points under conditions alluded to above. (This asymptotic stationarity property is often used as a definition for “convergence” in the nonlinear optimization literature.) Once asymptotic stationarity is established, convergence of MM in norm can be proved (Theorem 4.4) in a standard way by imposing discreteness assumptions2 on the set of stationary points of (1). In Section 5, we discuss EM algorithms as a special case of MM algorithms and how certain EM algorithms from the tomographic imaging literature relate to our framework. Finally, Section 6 gives our analysis of the local region of convergence for MM, and its relation to capture basins. A concluding summary follows in Section 7.
2 Mathematical Description of MM Algorithms
In this section, we describe the class of MM algorithms considered in this paper. With no loss of generality, we assume that the feasible set X is a Cartesian product of M ≤ p convex sets, i.e.,
| (2) |
where Xm ⊂ ℝpm, m = 1, …, M and . Since X is assumed convex, such a representation is always at least trivially accomplishable with M = 1.
To facilitate discussion, we first introduce some indexing conventions. Given x = (x1, …, xp) ∈ X, we can represent x as a vertical concatenation3 of vector partitions x = (x1, x2, …, xM) where xm ∈ Xm, m = 1, …, M. We shall refer to any subsequence S = (m1, m2, …, mq) of (1, …, M) as a block index, and use the notation
to indicate certain Cartesian sub-products and their elements. Thus, one has xS ∈ XS ⊂ ℝS. The block index formed from the complement of S in (1, …, M) shall be denoted S͂. It will be necessary at times to view Ψ(x) as a function of xS only with the components of xS͂ held fixed. We use the notation
for this purpose, where z ∈ XS and y ∈ X.
Given a block index S and a point-to-set mapping D(·) such that yS ∈ D(y) ⊂ XS for all y ∈ X, we define a majorant generator ϕ[·] (·) as a function mapping each y ∈ X to what we call a tangent majorant, a function ϕy(·) : D(y) ⊂ XS → ℝ satisfying
| (3) |
We call y the expansion point of the tangent majorant. We then also have ϕ[·](·) : D → ℝ, in which
denotes the domain of the majorant generator. The simplest case is when D = XS and D = XS × X.
To design an MM algorithm, one selects an initial point x0 ∈ X, a sequence of block indices , and a sequence of majorant generators with domains
where the Di(·) ⊂ XSi are point-to-set mappings of the type described above. Once the majorant generators are chosen, the MM algorithm is implemented by generating an iteration sequence satisfying,
| (4) |
| (5) |
Here, we assume that the set of minimizers in (4) is non-empty. We shall refer to the sequence produced this way as an MM sequence. In the simplest case, in which one chooses for all i, (4) and (5) become a generalization of block coordinate descent (e.g., [1, p. 267]), in which the coordinate blocks are not necessarily disjoint. By virtue of (3) and (4), {Ψ(xi)} is monotonically non-increasing.
When the block indices Si are not all equal to (1, …, M), we say that the algorithm is block alternating (cf. [14, 15]). When the algorithm is not block alternating, i.e., if all Si = (1, …, M), then (3) simplifies to
| (6) |
| (7) |
Observe in (6) that when Ψ(y) = ϕy(y) (something we could always ensure by adding a y-dependent constant to ϕy(·)), one has ϕy(z) ≥ Ψ(z) with equality at z = y. That is, ϕy(·) majorizes Ψ and is tangent to it at y. This is the reason for our choice of the terminology tangent majorant.
The technique of block alternation can be advantageous because it can be simpler to derive and minimize tangent majorants satisfying (3), which involve functions of fewer variables, than tangent majorants satisfying (6). Block alternation can also provide faster alternatives to certain non-block alternating algorithm designs [14]. To apply block alternation, X must be decomposable into the Cartesian product form (2) with M > 1.
3 Mathematical Preliminaries and Assumptions
In this section, we overview mathematical ideas and assumptions that will arise in the analysis to follow.
3.1 General Mathematical Background
A closed d-dimensional ball of radius r and centered at u ∈ ℝd is denoted
where ∥ · ∥ is the standard Euclidean norm. For the minimization problem (1), we shall also use the notation
to denote certain constrained balls. Given a set G ⊂ ℝd, the notation cl(G), ri(G), and aff(G) shall denote the closure, relative interior, and affine hull of G, respectively. For a more leisurely discussion of these concepts, see [1, 33]. The notation ∂G will denote the relative boundary, cl(G) \ ri(G).
A function f : D ⊂ ℝd → ℝ is said to be connected on a set D0 ⊂ D if (see [31, p. 98]), given any u, v ∈ D0, there exists a continuous function g : [0, 1] → D0 such that g(0) = u, g(1) = v, and
for all α ∈ (0, 1). A set C ⊂ ℝd is said to be path-connected if, given any u, v ∈ C there exists a continuous function g : [0, 1] → C such that g(0) = u and g(1) = v. Convex and quasi-convex functions are simple examples of connected functions with g(α) = αv + (1 − α)u. Also, it has been shown (e.g., Theorem 4.2.4 in [31, p. 99]) that a function is connected if and only if its sublevel sets are path-connected.
A key question in the analysis to follow is whether the limit points of an MM algorithm (i.e., the limits of subsequences of {xi}) are stationary points of (1). By a stationary point of (1), we mean a feasible point x* that satisfies the first order necessary optimality condition,
| (8) |
Here 〈·, ·〉 is the usual Euclidean inner product. If an algorithm produces a sequence {xi} whose limit points (if any exist) are stationary points of (1), we say that the algorithm and the sequence {xi} are asymptotically stationary.
3.2 Assumptions on MM Algorithms
Throughout the article, we consider cost functions Ψ and tangent majorants ϕy(·) that are continuously differentiable throughout open supersets of X and D(y) respectively. For every y, the domain D(y) is assumed convex. In addition, for a given MM algorithm and corresponding sequence , we impose conditions that fall into one of two categories. Conditions in the first category, listed next, are what we think of as regularity conditions. In this list, a condition enumerated (Ri.j) denotes a stronger condition than (Ri), i.e., (Ri.j) implies (Ri). Typical MM algorithms will satisfy these conditions to preclude certain degenerate behavior that could otherwise be exhibited.
-
(R1)Feasibility of the algorithm. We assume that the sequence {xi} lies in a closed subset of X. Thus, any limit point of {xi} is feasible. There are a variety of standard conditions under which (R1) will hold. The simplest case is if X is itself closed. Alternatively, (R1) will hold if one can show that the sublevel sets of Ψ are closed, which is often a straightforward exercise. For example, the closure of sublevel sets often follows if Ψ is coercive, i.e., tends to infinity at the boundary of X and at infinity. In such cases then, with τ0 = Ψ(x0), the sublevel set sublevτ0 Ψ is closed, and because {Ψ(xi)} is montonically non-increasing, it follows that the entire sequence {xi} is contained in this set.
-
(R1.1)Feasibility/boundedness of the algorithm. The sequence {xi} is contained in a compact subset of X. Similar to (R1), if X (or just sublevτ0 Ψ) is compact, then (R1.1) holds. This again is often the case when Ψ is coercive.
-
(R1.1)
-
(R2)
Agreement and continuity of first derivatives. The gradient of every tangent majorant agrees with that of Ψ at its expansion point. Formally, for every i and y ∈ X,
(9) Because Ψ is continuously differentiable, it follows from (9) that ∇ϕyi(ySi) is continuous with respect to y.
-
(R3)
Minimum size of tangent majorant domains. Each tangent majorant is defined on a feasible neighborhood of some minimum size around its expansion point. Formally, there exists an r > 0 such that for all i. The simplest scenario is when Di(x) = XSi for all i and x ∈ X, in which case (R3) holds with any r > 0.
Remark 3.1 Equation (9) is, in fact, implied by (3) whenever aff(Di(y)) = aff(XSi) and ySi ∈ ri(Di(y)). For details, see [20, Note A.2].
Remark 3.2 As discussed in [20, Note A.3], Condition (R2) can be weakened when XSi is of measure zero in ℝSi.
Aside from the above regularity conditions, most results will require specific combinations of the following technical conditions. Similar to before, a condition denoted (Ci.j) implies (Ci).
-
(C1)
Connected tangent majorants. Each tangent majorant is connected on its respective domain Di(xi). The typical case is when the tangent majorants are convex.
-
(C2)
Finite collection of majorant generators. The elements of the sequence are chosen from a finite set of majorant generators.
-
(C3)
Continuity of majorant generators in both arguments. For each i, the majorant generator is continuous on its domain Di. In addition, for any closed subset Ƶ of X, there exists an rƵi > 0 such that the set lies in a closed subset of Di. This is a generalization of the joint continuity condition for EM proposed in [35].
-
(C4)
Regular updating of coordinate blocks. Every sub-vector xm ∈ Xm, m = 1 … M of x is updated by the algorithm at least once in every sequence of J iterations. Formally, for each m, there exists a block index S(m) containing m, so that the set Im = {i : Si = S(m)} satisfies,
A simple case is when the block indices simply cycle over (1, …, M) according to Si = i mod M + 1.
-
(C5)Diminishing differences. The sequence xi satisfies . This condition has frequently been encountered in the study of feasible direction methods (e.g., [31, p. 474]). In the MM context, this condition is implied by the following, often readily verifiable condition,
-
(C5.1)Uniform strong convexity. The sequence {xi} has at least one feasible limit point. Also, there exists a γ− > 0, such that for all i and z, w ∈ Di (xi),In other words, the are strongly convex with curvatures that are uniformly lower bounded in i. The fact that (C5.1) implies (C5) is proved in [20, Section 6.3.3]. Essentially, the proof is done by using Lemma 3.3(b) in this paper with u = xi+1, v = xi, and f = ϕxi(·). Condition (C5.1) generalizes [15, Condition 5].
-
(C5.1)
-
(C6)
Uniform upper curvature bound. In addition to (R3), there exists a γ+ ≥ 0, such that for all i and (here r is as in (R3)),
In other words, the curvatures of the tangent majorants are uniformly upper bounded along line segments emanating from their expansion points. The line segments must extend to the boundary of a feasible neighborhood of size r around the expansion points. When the tangent majorants are twice differentiable, this is equivalent to saying that the second derivatives are locally bounded by γ+.
3.3 Lemmas
We now give several lemmas that facilitate the analysis in this paper. Most of these lemmas are slight generalizations of existing results. Their proofs are straightforward and are given in [20, Section 6.3.3].
Lemma 3.3 (Functions with curvature bounds) Suppose f : D ⊂ ℝd → ℝ is a continuously differentiable function on a convex set D and fix v ∈ D.
-
If 〈∇f(u) − ∇f(v), u−v〉 ≤ γ+∥u − v∥2 for some γ+ > 0 and ∀u ∈ D, then likewise
-
If 〈∇f(u) − ∇f(v), u−v〉 ≥ γ−∥u − v∥2 for some γ− > 0 and ∀u ∈ D, then likewise
Lemma 3.4 (Implications of limit points) Suppose that {xi} is an MM sequence with a limit point x* ∈ X. Then
{Ψ(xi)} ↘ Ψ(x*).
If x** ∈ X is another limit point of {xi}, then Ψ(x**) = Ψ(x*).
If (C5.1) also holds then, .
Lemma 3.5 (Convergence to isolated stationary points) Suppose {xi} is a sequence in a compact set K ⊂ X and whose limit points S ⊂ K are stationary points of (1). Let C denote the set of all stationary points of (1) in K. If either of the following is true,
C is a singleton, or
Condition (C5) holds and C is a discrete set,
then {xi} in fact converges to a point in C.
4 Asymptotic Stationarity and Convergence to Isolated Stationary Points
In this section, we establish conditions under which MM algorithms are asymptotically stationary. Convergence in norm is then proved under standard supplementary assumptions that the stationary points are isolated (see Theorem 4.4). Theorem 4.1, our first result, establishes that non-block alternating MM sequences are asymptotically stationary under quite mild assumptions. Two sets of assumptions are considered. One set involves (C3), a continuity condition similar to that used in previous MM literature (e.g., [35, 15, 29]). The continuity condition is motivated by early work due to Zangwill [37, p. 91], which established a broadly applicable theory for monotonic algorithms.
In the second set, the central condition is (C6), which requires a uniform local upper bound on the tangent majorant curvatures. To our knowledge, we are the first to consider such a condition in the context of MM methods.4 Condition (C6) can be easier to verify than (C3). For example, the algorithm of [11] is an example of MM based on separable quadratic tangent majorants. The optimal choice of curvatures for these quadratics is derived in [11], and is given by a complicated formula. It is much easier to show that these curvatures are uniformly bounded than to show that they are continuous.
Theorem 4.1 (Stationarity without block alternation) Suppose that all Si = (1,…, M), that {xi} is an MM sequence generated by (7), and that the regularity conditions (R1), (R2), and (R3) hold. Suppose further that either (C6) or the pair of conditions {(C2), (C3)} holds. Then any limit point of {xi} is a stationary point of (1).
Proof. Suppose x* ∈X is a limit point of {xi} (it must lie in X due to (R1)) and, aiming for a contradiction, let us assume that it is not a stationary point. Then there exists x′ ≠ x* ∈ X such that
| (10) |
Since ∇Ψ is continuous, then, with (R2) and (R3), it follows that there exists a constant c < 0 and a subsequence {xik} satisfying, for all k,
| (11) |
where r is as in (R3), and
| (12) |
Define the unit-length direction vectors
and, for t ∈ [0, t̄], the scalar functions
| (13) |
Due to (R3) and (11), all hk are well-defined on this common interval. The next several inequalities follow from (7), (6), and Lemma 3.4(a), respectively,
| (14) |
| (15) |
The remainder of the proof addresses separately the cases where {(C6)} and {(C2), (C3)} hold.
First, assume that (C6) holds. This, together with Lemma 3.3(a), implies that for t ∈ [0, t̄],
However, hk(0) = Ψ(xik), while ḣk(0) ≤ c due to (12). These observations, together with (15), leads to
Passing to the limit in k,
Finally, dividing this relation through by t and letting t ↘ 0 yields c ≥ 0, contradicting the assumption that c < 0, and completing the proof for this case.
Now, assume {(C2), (C3)}. In light of (C2), we can redefine our subsequence {xik} so that, in addition to (11) and (12), equals some fixed function ϕ̂·([·]) for all k. That and (14) give, for t ∈ [0, t̄],
| (16) |
| (17) |
From (R1), we know that {xik} lies in a closed subset Ƶ of X. With (C3), there therefore exists a positive rƵ ≤ t̄ such that hk(t) as given in (16), converges as k → ∞ to for all t ∈ [0, rƵ]. Letting k → ∞ in (17) therefore yields,
| (18) |
The function h*(t) is differentiable at t = 0 due to (R2). Now, hk(0) = Ψ(xik), so that in the limit, h*(0) = Ψ(x*). Thus, we have that (18) holds with equality at t = 0, from which it follows that
| (19) |
However, ḣk(0) ≤ c due to (12). Furthermore, since ∇ϕyi(ySi) is continuous in y due to (R2), we have that ḣk(0) converges to ḣ*(0) as k → ∞. With (19), these observations lead to c ≥ lim infk ḣk(0) ≥ 0, contradicting again the assumption that c < 0.
The following example provides a simple illustration of how an MM algorithm can be non-asymptotically stationary when the assumptions of Theorem 4.1 are not met.
Example 4.2 Consider the 1D problem X = [0, 1.5], and Ψ(x) = 2 − x. Take x0 = 0 and let {xi} be the sequence generated via (7) with majorant generator
The resulting sequence of iterates {xi} and tangent majorants ϕxi(·) are depicted for several iterations in Figure 2. By induction, one can show that xi = 1 − 2−i. Hence, {xi} converges to 1 which is not a stationary point. This presents no conflict with Theorem 4.1, however. The tangent majorants do not satisfy condition (C6), since the tangent majorant curvatures {c(xi) = 2i} tend to infinity. Also, ϕy(x) is discontinuous at y = 1, so (C3) is not satisfied. Consequently, the hypothesis of Theorem 4.1 does not hold.
Figure 2.
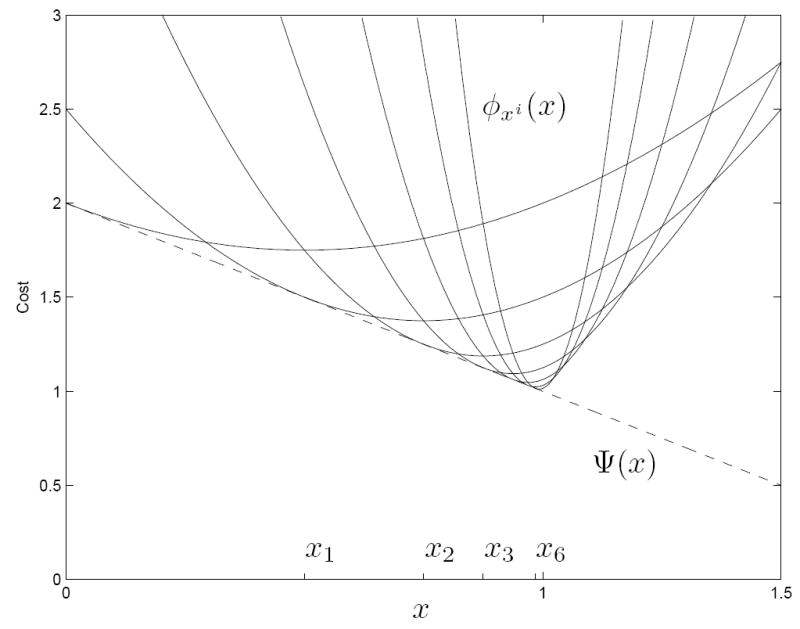
Illustration of Example 4.2. The MM sequence {xi} converges to a non-stationary point. This is possible since the conditions of Theorem 4.1 are not satisfied.
The next result addresses the block alternating case, but requires additional conditions, namely (C4) and (C5). (Although, Condition (C2) is no longer required.) These conditions, however, are no stronger than those invoked previously in [15]. Condition (C4) is a generalization of [15, Condition 6]. Condition (C5) is an implied condition in [15], as shown in Lemma 3 in that paper.
Theorem 4.3 (Stationarity with block alternation) Suppose that {xi} is an MM sequence generated by (4) and (5). As in Theorem 4.1, assume that (R1), (R2), (R3), and either (C6) or the pair of conditions {(C2), (C3)} hold. In addition, suppose that (C4) and (C5) hold. Then any limit point of{xi} is a stationary point of (1).
Proof. Suppose x* ∈ X is a limit point of {xi} (it must lie in X due to (R1)) and, aiming for a contradiction, let us assume that it is not a stationary point. In light of (2), there therefore exists x′ ≠ x* ∈ X and m ∈ {1, …, M}, such that
| (20) |
and such that , ∀m̃ ≠ m. Then, with S(m) as in (C4), it follows from (20) that,
| (21) |
Now, consider a subsequence {xik} converging to x*. We can assume that Sik = S(m), for otherwise, in light of (C4), we could construct an alternative subsequence {xik+Jk}, Jk ≤ J which does have this property. Furthermore, this alternative subsequence would also converge to x* due to (C5).
Similar to the proof of Theorem 4.1, we can also choose {xik} so that,
and, in light of (21) and (R2), so that
for some c < 0. Now define
and, for t∈ [0, t̄]
Manipulations of this hk(t) verbatim to those in the proof of Theorem 4.1 lead to the contradiction c ≥ 0, and complete the proof of this theorem, as well.
The following theorem establishes convergence in norm by adding discreteness assumptions on the stationary points of (1).
Theorem 4.4 (Convergence in norm) Suppose {xi} is an MM sequence satisfying (R1.1) and the conditions of either Theorem 4.1 or Theorem 4.3. Suppose, in addition, that either of the following is true.
The problem (1) has a unique solution as its sole stationary point, or
Condition (C5) holds and (1) has a discrete set of stationary points.
Then {xi} converges to a stationary point. Moreover, in case (a), the limit is the unique solution of (1).
Proof. Under (R1.1), {xi} lies in a compact subset of X. Moreover, the limit points of {xi} are all guaranteed to be stationary by either Theorem 4.1 or Theorem 4.3. The result then follows from Lemma 3.5.
Remark 4.5 (An error remedied) The analysis in [15] of MM convergence is less general than stated there due to an error in the proof of Lemma 6 in that paper. The error occurs where it is argued “if then ”. This argument would be valid only if, in addition to what was already assumed, ϕ(k)(·; xi) were a function of a single variable. Due to the analysis in the present paper, however, we can claim that the conclusions of [15] are indeed valid, even if the arguments are not. This follows from Theorem 4.4(a) above, which implies convergence under conditions no stronger than those assumed in [15].
Remark 4.6 (Curvature and iteration-dependence) In Theorems 4.1 and 4.3, when the curvature upper bound (C6) holds, there is very little restriction on how can depend on i, as compared to when {(C2), (C3)} are invoked.
This is useful, for example, if one wishes to use majorant generators that change adaptively based on several previous iterations of the algorithm sequence {xi}. For example, one strategy that can be helpful for certain cost functions is to use a block alternating MM algorithm that monitors the gradient sequence {∇Ψ(xi)}. When certain gradient components are persistently larger than others over several iterations, one switches to a majorant generator that updates only the variables corresponding to those components, thereby conserving computation. Such majorant generator sequences will not generally satisfy Condition (C2), and so one could not invoke Theorem 4.3 with {(C2), (C3)}. However, could well be made to satisfy (C6).
5 EM as a Special Case of MM
As discussed in Section 1, the family of Expectation Maximization (EM) algorithms is a prominent special case of MM algorithms for minimizing the negative loglikelihood Ψ(x) = − logpx(u) of a random measurement vector U. In the classical set-up, one develops an EM algorithm by devising a so-called complete data random vector V whose joint distribution with U is of the form5
| (22) |
i.e., the conditional distribution of U given V is independent of the unknown parameter vector x. An EM algorithm is then just an MM algorithm based on the majorant generator,
| (23) |
where KL [f ∥ g] is the Kullback-Leibler (KL) divergence between two probability distributions f and g. For discrete U and V, this is
| (24) |
For continuous random variables, the sum is to be replaced by an integral. A straightforward consequence of Jensen’s inequality is that KL [f ∥ g] ≥ 0 with equality iff f = g. It follows that (23) satisfies the majorization property (6), which in turn ensures the monotonicity of the algorithm.
The term “Expectation Maximization” comes from the fact that
which one can readily show by combining (23) with (22). Thus, processing the tangent majorant in each iteration is equivalent to taking a conditional expectation and maximizing the result.
A well established convergence condition for EM is the joint continuity assumption proposed in [ 35], a forerunner to our Condition (C3). A hazard in the design of MM algorithms can arise due to the singularity in the integrand in (24) at f = g = 0. Thus, unless px(u |v) is bounded away from zero as a function of x, this singularity may translate into singularities in the tangent majorant(23), so that Condition (C3) is violated. Algorithms such as these therefore do not satisfy standard regularity conditions for EM (or MM) convergence. Such algorithms would also violate Condition (C6), since curvatures in the neighbourhood of a singularity are unbounded.
Examples of these pathological cases are to be seen in certain EM algorithms that have been proposed for emission tomographic imaging. A widely considered statistical model for emission tomography projection measurements is
where xj ≥ 0 denote unknown image voxel values, aij ≥ 0 are system matrix elements, and ri ≥ 0 are mean background radiation measurements. An EM algorithm investigated in [32] was based on the complete data choice,
for which (23) becomes,
| (25) |
| (26) |
In the particular case ri = 0, this algorithm reduces to the ML-EM algorithm of algorithm of [34]. Clearly this ϕ[·](·) can approach singularities as (xj, yj) → (0, 0), and hence (C3) and (C6) are violated. Although the algorithm has been proven to converge for ri = 0, existing analyses (e.g., [3]) are difficult and very specific to the structures of Ψ and ϕ. The algorithm has not, to our knowledge, been shown to converge for the more general case ri ≥ 0, although some relevant analysis was done in [13].
Another consequence of the singularities in KL is that, when all yj > 0, the domain D(y) of the tangent majorant(26) is the interior of the non-negative orthant, which is normally a strict subset of the feasible set X. Normally, there are feasible images x in which some of the voxel values are zero (e.g., when for all i, the mean background radiation terms ri > 0) and such images are excluded from the domain of (26). From similar considerations, one can also see that the tangent majorant fails to satisfy Condition (R3) at y near the boundary of the non-negative orthant.
A modification called ML-EM-3 was proposed in [15] that remedies the singularity issue in most practical cases. ML-EM-3 is based on complete data,
where mj ≥ 0 are parameters chosen to satisfy Σj mj ≤ ri. With this complete data, (23) becomes,
In practice, one generally has ri > 0 for all i, and hence can choose mj > 0 for all j. In this case, ϕ[·](·) satisfies both (C3) and (C6). Moreover, the domain of these tangent majorants is the entire non-negative orthant. So, by Theorem 4.1, we can conclude that ML-EM-3 is asymptotically stationary.
In summary, although EM algorithms are special cases of MM, the applicability of the MM theory of this paper and its forerunners (e.g., [35]) depends on the choice of complete data.
6 Region of Local Convergence for Connected Tangent Majorants
In the study of minimization algorithms, one often wishes to know over what surrounding region of a strict local minimizer an algorithm is guaranteed to converge to that minimizer. In this section, we characterize regions of capture and convergence for MM algorithms that use connected (e.g., convex) tangent majorants. It is a prevalent design choice to make the tangent majorants convex, since this facilitates their minimization. We show in Theorem 6.4 that such algorithms are captured in any basin-shaped region in the graph of Ψ. If the basin contains a minimizer, then with suitable additional conditions (see Theorem 6.5), the entire basin is a region of convergence to that minimizer.
This is to be contrasted with the standard theory of gradient methods (e.g., steepest descent, Newton’s, Levenberg-Marquardt). General gradient methods are driven by the minimization of quadratic approximations to Ψ. These approximations may not majorize Ψ as tangent majorants do. Standard analyses of regions of capture for gradient methods (e.g., [1, p. 51, Proposition 1.2.5] and [1, p. 90, Proposition 1.4.1(a)]) guarantee capture only in a neighbourhood where the derivatives of Ψ are sufficiently similar to the derivatives at the minimum. In Example 6.6, we illustrate how this region of capture can be a strict subset of a basin-shaped region around the minimizer. Thus, our findings suggest that connected tangent majorants lead to larger regions of capture/convergence for MM than for (non-MM) gradient methods. This property has various practical implications that we shall discuss.
To proceed with our analysis, we require a formal mathematical definition of a “basin”. The following definition generalizes usual notions of a basin-shaped region.
Definition 6.1 We say that a set G ⊂ X is a generalized basin (with respect to the minimization problem (1)) if, for some x ∈ G, the following is never violated
| (27) |
Moreover, we say that x is well-contained in G.
Thus, a point is well-contained in G if it has lower cost than any point x̃ in the common boundary cl(G) ⋂ cl(X \ G) between G and its complement.
Remark 6.2 (Special Cases of Basins) Definition 6.1 is worded so that cl(G) ⋂ cl(X \ G) can be empty. Thus, for example, the whole feasible set X always constitutes a generalized basin, provided that it contains some x. This is because cl(X) ⋂ cl(X \ X) is empty, implying that (27) can never be violated by any x.
Any sublevel set G = {x ∈ X : Ψ (x) ≤ τ} is a generalized basin so long as τ is not the global minimum value of Ψ over X. Moreover, any global minimizer x* is well-contained in G. For further discussion of the basic properties of generalized basins, see [18, pp. 104-5,136-7].
The following proposition lays the foundation for the results of this section. It asserts that, if the expansion point of a connected tangent majorant is well-contained in a generalized basin G, then any point that decreases the cost value of that tangent majorant (relative to the expansion point) is likewise well-contained in G.
Proposition 6.3 Suppose that ϕy(·) is a tangent majorant that is connected on its domain D(y) ⊂ XS and whose expansion point y ∈ X is well-contained in a generalized basin G. Suppose, further, that x ∈ X satisfies
| (28) |
Then x is likewise well-contained in G.
Proof. It is sufficient to show that x ∈ G. For taking any x̃ ∈ cl(G) ⋂ cl(X \ G), and then combining (28), (3), and the fact that y is well-contained in G,
| (29) |
implying that x is also well-contained in G. Aiming for a contradiction, suppose that x ∈ X \ G. Since ϕy(·) is connected on D (y), there exists a continuous function g : [0, 1] → X with g(0) = y, g(1) = x, and such that, for all α ∈ (0, 1), one has
| (30) |
where the equality in (30) is due to (28). Also, since g(0) = y ∈ G,
is well-defined. Finally, let w = g(α*). Combining the definitions of g() and α*, the continuity of g(), and the fact that x ∈ X \ G, one can readily show that w ∈ cl(G) ⋂ cl(X \ G).
Therefore, from the rightmost inequality in (29), we have, with x̃ = w,¡
| (31) |
With (3), this implies that ϕy([g(α*)]S) > ϕy(yS), contradicting (30).
The following consequence of Proposition 6.3 articulates a capture property for MM sequences.
Theorem 6.4 (Capture property of MM) Suppose that {xi} is an MM sequence generated by (4) and (5). In addition, suppose that some iterate xn is well-contained in a generalized basin G and that the tangent majorant sequence satisfies (C1). Then likewise xi is well-contained in G for all i > n.
Proof. The result follows from Proposition 6.3 and an obvious induction argument.
Finally, we obtain the principal result of this section.
Theorem 6.5 (Region of Convergence) In addition to the assumptions of Theorem 6.4, suppose that the conditions of either Theorem 4.1 or Theorem 4.3 are satisfied. Suppose further that G is bounded and cl(G) contains a single stationary point x*. Then {xi} converges to x*.
Proof. Since G is bounded, it follows from Theorem 6.4 that the sequence lies in the compact set K = cl(G). Moreover, all limit points of {xi} are stationary, as assured by either Theorem 4.1 or Theorem 4.3. The conclusions of the theorem then follow from Lemma 3.5(a).
Example 6.6 (Gradient Methods with Ad Hoc Steps) Here we illustrate how gradient algorithms with ad hoc step size choices may have a radius of capture that does not cover the entire basin surrounding a minimum. Consider the following 1D cost function, also depicted in Figure 3,
Figure 3.
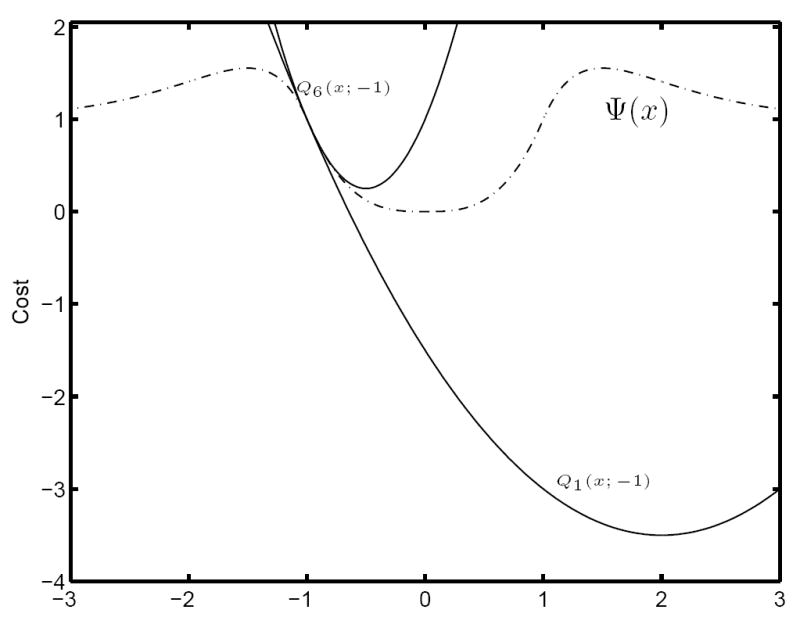
Comparing the capture properties of MM with gradient methods.
From Figure 3, one can see that the open interval (−1.5, 1.5) is a generalized basin in which all points are well-contained. It will be useful to note also that
| (32) |
Consider now the family of quadratic expansions,
| (33) |
The minimizer xk+1 of Qsk(·; xk) is given by the gradient algorithm step,
| (34) |
Suppose we choose an arbitrary and constant step size parameter sk = 1. From (32), it then follows that if xk lies in the interval |x| ≤ 2/3, the gradient step (34) cannot cross the origin to a point more distant from the origin than xk. Consequently, all subsequent iterations of (34) remain trapped in the region |x| ≤ 2/3 and hence also in the larger basin-like interval (−1.5, 1.5). (One can also show that the algorithm converges monotonically to the minimum when initialized in |x| < 2/3, but this is tangential to the point of this example.)
This capture property does not hold, however, for all starting points in (−1.5, 1.5). In particular, if |xk| = 1, then . With sk = 1, this means that the gradient step (34) will be large enough to put xk+1 in the region |x| > 1.5. Not only does this step escape from the basin (−1.5, 1.5), but the gradient algorithm will also never return there. For, once |xk+1| > 1.5 the direction of the gradient will carry all subsequent iterations of (34) off toward infinity.
This example is to be contrasted with the choice sk = 6. The iterations are then driven by the minimizations of the functions Q6(·; xk) which are not only convex, but are also tangent majorants. The latter can be verified, for instance, using Lemma 3.3(a) with γ+ = 6 and f = Ψ. Theorem 6.4 therefore applies and shows that if xk lies in (−1.5, 1.5), then all subsequent iterations of the algorithm will as well.
The distinction between these two cases is also illustrated graphically in Figure 3 with xk = −1. There, we see that, since Q6(·; −1) majorizes Ψ, its minimum is constrained by the graph of Ψ to lie in (−1.5, 1.5). Conversely, since Q1(·; −1) does not majorize Ψ, its minimum is not constrained in this way.
The above example illustrates how non-MM gradient methods with constant step sizes can escape from a basin. However, it is also easy to see how this would be true even when conventional line search algorithms are used. Generally, line search methods can find any 1D stationary point along the search line and different 1D stationary points can lie in different generalized basins. For example, in Figure 1, the stationary points in the intervals [A, B] and [B, C] clearly lie in different generalized basins. The MM steps in Figure 1 respect the basin boundaries, consistent with Theorem 6.4, whereas a line search algorithm would not be expected to.
There are both positive and negative practical implications to Theorem 6.5. Since it is common to use convex (and hence connected) tangent majorants, it is essential for MM algorithm designers to be aware of these implications. A positive consequence is that global minimizers will, as a special case, attract the iterates over larger distances. Thus, if a moderately good initial guess of the solution is available, the chances of getting pulled toward the global solution may be higher. A negative consequence is that sub-optimal local minimizers will also attract the iterates over larger distances. Thus, if not even a moderately good initial guess is available, the chances of becoming trapped at a sub-optimal local minimum can be high, depending on the preponderance of different minima in the graph of Ψ.
A potential application of Theorem 6.5 is to non-convex optimization strategies that decompose the problem into a sequence of local minimization steps. These include a method due to [2] called Graduated Non-Convexity (GNC), in which a parametric family of approximations to the cost function Ψ are locally minimized at successive increments of the parameter. Another example is the strategy of selecting a mesh of initial points and locally minimizing Ψ around each point so as to probe for the global minimum. In these strategies, MM with connected tangent majorants seem an appropriate tool for implementing the local minimization steps since, of course, local minimization tasks benefit from a wide region of convergence.
7 Summary
In this paper, we have revised the analysis of [15] in an expanded framework, introduced alternative convergence conditions, and provided original insights into the locally convergent behavior of iteration-dependent MM. In the course of doing so, we also remedied an error in the previous convergence proof (see Remark 4.5). The core results of our global convergence analysis were Theorems 4.1 and 4.3, which proved asymptotic stationarity for non-block alternating and block alternating MM respectively. The core result of our local convergence analysis was Proposition 6.3, which proved a fundamental property of MM algorithms employing connected tangent majorants, namely that they remain in basin-like regions of the cost function. Our treatment here, we believe, provides enhanced insight into the behavior of MM, as well as a highly broad and flexible framework for MM algorithm design. The results have been useful in verifying the convergence of previously proposed algorithms for different PET imaging applications [12, 19, 18].
An unresolved theoretical question is whether MM will converge in norm when the stationary points of the optimization problem are non-isolated. It is rare to be able to prove this behavior for iterative optimization algorithms in general. However, it has been proven for the EM algorithm of Shepp and Vardi [34], a prominent example of MM in the field of emission tomography. Thus, it is tempting to think that this behavior may be provable in wider generality within the class of MM algorithms. Our preliminary work on this question in [20] may be a starting point for future analysis.
Acknowledgments
The authors would like to thank the reviewers for the time that they have invested in this article, as well as for their many helpful suggestions for its improvement.
Footnotes
The term MM was coined in [24]. The technique has gone by various other names as well, such as optimization transfer, SAGE, and iterative majorization.
Non-discrete stationary points are not generally stable (cf. [1, p. 22]) under perturbations of Ψ, and so are mainly of theoretical interest.
In this paper, (a, b, c, …) will always denote the vertical concatentation of vectors/scalars a, b, c, ….
Curvature bounds also arise in the convergence theory of trust-region methods, e.g., [6, pp. 121-2].
References
- 1.Bertsekas DP. Nonlinear programming. 2. Athena Scientific; Belmont: 1999. [Google Scholar]
- 2.Blake A, Zisserman A. Visual reconstruction. MIT Press; Cambridge, MA: 1987. [Google Scholar]
- 3.Byrne C. Likelihood maximization for list-mode emission tomographic image reconstruction. IEEE Tr Med Im. 2001 October;20(10):1084–92. doi: 10.1109/42.959305. [DOI] [PubMed] [Google Scholar]
- 4.Cadalli N, Arikan O. Wideband maximum likelihood direction finding and signal parameter estimation by using tree-structured EM algorithm. IEEE Trans Sig Proc. 1999 January;47(1):201–6. [Google Scholar]
- 5.Chung PJ, Böhme JF. Comparative convergence analysis of EM and SAGE algorithms in DOA estimation. IEEE Trans Sig Proc. 2001 December;49(12):2940–9. [Google Scholar]
- 6.Conn AR, Gould NIM, Toint P. Trust-region Methods. MPS/SIAM Series on Optimization; Philadelphia: 2000. [Google Scholar]
- 7.De Pierro AR. On the relation between the ISRA and the EM algorithm for positron emission tomography. IEEE Tr Med Im. 1993 June;12(2):328–33. doi: 10.1109/42.232263. [DOI] [PubMed] [Google Scholar]
- 8.De Pierro AR. A modified expectation maximization algorithm for penalized likelihood estimation in emission tomography. IEEE Tr Med Im. 1995 March;14(1):132–137. doi: 10.1109/42.370409. [DOI] [PubMed] [Google Scholar]
- 9.De Pierro AR. On the convergence of an EM-type algorithm for penalized likelihood estimation in emission tomography. IEEE Tr Med Im. 1995 December;14(4):762–5. doi: 10.1109/42.476119. [DOI] [PubMed] [Google Scholar]
- 10.Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J Royal Stat Soc Ser B. 1977;39(1):1–38. [Google Scholar]
- 11.Erdoğan H, Fessler JA. Monotonic algorithms for transmission tomography. IEEE Tr Med Im. 1999 September;18(9):801–14. doi: 10.1109/42.802758. [DOI] [PubMed] [Google Scholar]
- 12.Erdoğan Hakan. PhD thesis. Univ. of Michigan; Ann Arbor, MI, 48109-2122: Jul, 1999. Statistical image reconstruction algorithms using paraboloidal surrogates for PET transmission scans. [Google Scholar]
- 13.Fessler JA, Clinthorne NH, Rogers WL. On complete data spaces for PET reconstruction algorithms. IEEE Trans Nuc Sci. 1993 August;40(4):1055–61. [Google Scholar]
- 14.Fessler JA, Hero AO. Space-alternating generalized expectation-maximization algorithm. IEEE Tr Sig Proc. 1994 October;42(10):2664–77. [Google Scholar]
- 15.Fessler JA, Hero AO. Penalized maximum-likelihood image reconstruction using space-alternating generalized EM algorithms. IEEE Tr Im Proc. 1995 October;4(10):1417–29. doi: 10.1109/83.465106. [DOI] [PubMed] [Google Scholar]
- 16.Heiser WJ. Convergent computation by iterative majorization: theory and applications in multidimensional data analysis. In: Krzanowski WJ, editor. Recent Advances in Descriptive Multivariate Analysis. Royal Statistical Society Lecture Note Series. Oxford University Press; New York: 1995. [Google Scholar]
- 17.Huber PJ. Robust statistics. Wiley; New York: 1981. [Google Scholar]
- 18.Jacobson M. PhD thesis. Univ. of Michigan; Ann Arbor, MI, 48109-2122: 2006. Approaches to motion-corrected PET image reconstruction from respiratory gated projection data. [Google Scholar]
- 19.Jacobson MW, Fessler JA. Joint estimation of image and deformation parameters in motion-corrected PET. Proc IEEE Nuc Sci Symp Med Im Conf. 2003;5:3290–4. [Google Scholar]
- 20.Jacobson MW, Fessler JA. Properties of MM algorithms on convex feasible sets: extended version. Comm. and Sign. Proc. Lab., Dept. of EECS, Univ. of Michigan; Ann Arbor, MI, 48109-2122: Nov, 2004. Technical Report 353. [Google Scholar]
- 21.Johnston LA, Krishnamurthy V. Finite dimensional smoothers for MAP state estimation of bilinear systems. IEEE Trans Sig Proc. 1999 September;47(9):2444–59. [Google Scholar]
- 22.Lange K. A gradient algorithm locally equivalent to the EM Algorithm. J Royal Stat Soc Ser B. 1995;57(2):425–37. [Google Scholar]
- 23.Lange K, Carson R. EM reconstruction algorithms for emission and transmission tomography. J Comp Assisted Tomo. 1984 April;8(2):306–16. [PubMed] [Google Scholar]
- 24.Lange K, Hunter DR, Yang I. Optimization transfer using surrogate objective functions. J Computational and Graphical Stat. 2000 March;9(1):1–20. [Google Scholar]
- 25.Liu CH, Wu YN. Parameter expansion scheme for data augmentation. J Am Stat Assoc. 1999 December;94(448):1264–74. [Google Scholar]
- 26.Logothetis A, Carlemalm C. SAGE algorithms for multipath detection and parameter estimation in asynchronous CDMA systems. IEEE Trans Sig Proc. 2000 November;48(11):3162–74. [Google Scholar]
- 27.Meng XL, van Dyk D. The EM algorithm - An old folk song sung to a fast new tune. J Royal Stat Soc Ser B. 1997;59(3):511–67. [Google Scholar]
- 28.Nelson LB, Poor HV. Iterative multiuser receivers for CDMA channels: an EM-based approach. IEEE Trans Comm. 1996 December;44(12):1700–10. [Google Scholar]
- 29.Nettleton D. Convergence properties of the EM algorithm in constrained parameter spaces. The Canadian Journal of Statistics. 1999;27(3):639–48. [Google Scholar]
- 30.Ollinger JM, Goggin A. Maximum likelihood reconstruction in fully 3D PET via the SAGE algorithm. Proc IEEE Nuc Sci Symp Med Im Conf. 1996;3:1594–8. [Google Scholar]
- 31.Ortega JM, Rheinboldt WC. Iterative solution of nonlinear equations in several variables. Academic; New York: 1970. [Google Scholar]
- 32.Politte DG, Snyder DL. Corrections for accidental coincidences and attenuation in maximum-likelihood image reconstruction for positron-emission tomography. IEEE Trans Med Imag. 1991 March;10(1):82–9. doi: 10.1109/42.75614. [DOI] [PubMed] [Google Scholar]
- 33.Rockafellar RT. Convex analysis. Princeton University Press; Princeton: 1970. [Google Scholar]
- 34.Shepp LA, Vardi Y. Maximum likelihood reconstruction for emission tomography. IEEE Tr Med Im. 1982 October;1(2):113–22. doi: 10.1109/TMI.1982.4307558. [DOI] [PubMed] [Google Scholar]
- 35.Wu CFJ. On the convergence properties of the EM algorithm. Ann Stat. 1983 March;11(1):95–103. [Google Scholar]
- 36.Yu DF, Fessler JA, Ficaro EP. Maximum likelihood transmission image reconstruction for overlapping transmission beams. IEEE Tr Med Im. 2000 November;19(11):1094–1105. doi: 10.1109/42.896785. [DOI] [PubMed] [Google Scholar]
- 37.Zangwill W. Nonlinear programming, a unified approach. Prentice-Hall; NJ: 1969. [Google Scholar]
- 38.Zheng J, Saquib S, Sauer K, Bouman C. Parallelizable Bayesian tomography algorithms with rapid, guaranteed convergence. IEEE Trans Im Proc. 2000 October;9(10):1745–59. doi: 10.1109/83.869186. [DOI] [PubMed] [Google Scholar]