

Abstract
Constructing a rich and continuous visual experience requires computing specific details across views as well as integrating similarities across views. In this paper, we report functional magnetic resonance imaging (fMRI) evidence that these distinct computations may occur in two scene-sensitive regions in the brain, the parahippocampal place area (PPA) and retrosplenial cortex (RSC). Participants saw different snapshot views from panoramic scenes, which represented clearly different views, but appeared to come from the same scene. Using fMRI adaptation, we tested whether the PPA and RSC treated these panoramic views as the same or different. In the panoramic condition, three different views from a single panoramic scene were presented. We did not find any attenuation for panoramic repeats in the PPA, showing viewpoint-specificity. In contrast, RSC showed significant attenuation for the panoramic condition, showing viewpoint-integration. However, when the panoramic views were not presented in a continuous way, both the specificity in the PPA and the integration in RSC were lost. These results demonstrate that the PPA and RSC compute different properties of scenes: the PPA focuses on selective discrimination of different views while RSC focuses on the integration of scenes under the same visual context. These complementary functions of the PPA and RSC enable both specific and integrative representations of scenes across several viewpoints.
Keywords: scene perception, functional magnetic resonance imaging (fMRI), parahippocampal cortex, retrosplenial cortex, navigation, viewpoint specificity
INTRODUCTION
A central task of the human visual system is to maintain a cohesive visual experience from discrete snapshots of retinal input. Multiple physiological constraints limit the amount of visual input, and constant eye and head movements change the retinal projection every moment. Nevertheless, we experience the space around us as continuous and coherent. How do we achieve such an integrated percept of the world while preserving specific information in each individual view? To enable both specificity and invariance, multiple levels of scene representation might co-exist. In this paper, we present fMRI data showing such different kinds of scene representations in the brain. Specifically, we aim to answer whether scene-specific areas in the brain represent specific visual details of each individual scene, or an extended representation that includes multiple successive views.
A recent fMRI study suggests that at least one scene-specific area in the brain represents scenes in a viewpoint-specific way. The parahippocampal place area (PPA) is a scene-specific region in the ventral visual stream (Aguirre, Detre, Alsop, & D’Esposito, 1996; Epstein & Kanwisher, 1998). Using sets of scenes that had viewpoint changes, Epstein, Graham and Downing (2003) demonstrated that the PPA treated scenes with viewpoint changes as different scenes. This suggests that this area represents scenes as individual snapshots of each view rather than as a broader scene that integrates multiple similar snapshots.
However, a number of recent studies have shown that people represent integrative, expansive space (McNamara, Rump, & Werner, 2003; Tversky, 2002). For example, learning spaces or routes for navigation requires associating a current scene or self to a larger scale environment (McNamara et al., 2003). Viewpoint selective responses provide information about the relative position of a viewer in a scene layout. But to navigate through a broader, global environment, viewers need a more expansive representation of the space beyond what is currently in view, based on associations with views that were seen before. The PPA may not be sufficient for such integrative functions: a study that directly tested navigation function in the PPA showed that the PPA does not play a role in guiding navigation through the immediate environment (Epstein, Harris, Stanley, & Kanwisher, 1999).
Instead, another scene-specific area in the brain, the retrosplenial cortex (RSC), has been highlighted as an area important for navigation and route learning (Cain, Humpartzoomian, & Boon 2006; Cooper & Mizumori, 2001; Maguire, Frackowiak, & Frith, 1997; Maguire, Burgerss, Donnett, Frackowiak, Frith, & O’Keefe, 1998; Maguire, 2001; O’Craven & Kanwisher, 2000). For example, patients who have retrosplenial cortex damage were able to identify scenes or landmarks, but lost the ability to use these landmarks to orient themselves or to navigate through a larger environment (Aguirre & D’Esposito, 1999; Maguire, 2001; Valenstein et al., 1987). This contrasts with patients who have damage to their parahippocampal area and could not identify scenes or landmarks at all (Mendez & Cherrier, 2003).
In addition to such neurological evidence, number of recent fMRI results suggest that the PPA and RSC may play distinct roles in object and scene perception (Bar & Aminoff, 2003; Epstein & Higgins, 2007; Epstein, Parker, & Feiler, 2007; Henderson, Larson, & Zhu, 2008). For example, Bar and Aminoff (2003) proposed that RSC represents abstracted prototypical properties of an object context, while the PPA processes physical properties of an object context. Epstein’s group (2007) also reported that the PPA processes visual details of a scene, while RSC processes each scene as part of a broader frame or memory. The results of the current study to these recent fMRI findings will be discussed more extensively in the discussion.
These neurological and fMRI studies suggest that the PPA and RSC might encode different kinds of scene representations. More specifically, the PPA may represent physical details of the scenes such as landmarks, while RSC may represent the navigationally relevant properties of the scene, such as the association of the current scene or objects with other related scenes. In sum, we hypothesized that the scene representation in RSC may have a viewpoint-invariant scene representation used to create a more integrative cognitive map of the environment.
We measured repetition attenuation to test the nature of scene representations in the PPA and RSC. fMRI can reveal the properties of scene-specific representations, as activity is lower for repeated items compared to novel items (Schacter & Buckner, 1998; Wiggs & Martin, 1998). This repetition attenuation can reveal if a particular neuronal population treats two stimuli as the same or different from each other (Grill-Spector & Malach, 2001). For example, the fMRI response in the PPA shows less activity for repeated scenes than for novel scenes (Epstein, Graham, & Downing, 2003; Park et al., 2007; Yi & Chun, 2005).
We presented panoramic scene stimuli (Figure 1a). Three sections were taken from a single panoramic image of a scene, producing three spatially continuous snapshots of a single space. These three scenes were presented in contiguous order, each overlapping 66% with the previous section (in other words, the 1st and the 3rd scene overlapped 33%). Thus, when these scenes were consecutively presented, a strong sense of continuity was achieved through the visual overlap across repetition and the coherent temporal order in which they appeared. This panoramic presentation resembles our usual survey of the environment, sampling views of scenes through successive eye movements. If scene representation in a brain region is viewpoint-specific, these three scenes will be treated as different from each other and will result in no attenuation for panoramic repetition. On the other hand, if the scene representation is viewpoint-independent, the brain will treat these scenes as one integrated scene, just as we experience everyday, and will show attenuation for panoramic repetition.
Figure 1.

a, Panoramic 1st and Panoramic 3rd image were taken from a single panoramic view. Panoramic 1st, 2nd, and 3rd images were sequentially presented one at a time at fixation. The 1st and the 3rd image overlapped in 33% of its physical details. b, A schematic illustration of the panoramic repeat condition, shown with three event trials (TR=2s) and jittered inter trial interval.
METHODS
Experiment 1 directly tested two contrasting hypotheses about the functions of the PPA and RSC in scene perception. Since scene representation in the PPA is sensitive to details of individual scenes, we hypothesized that there would be little panoramic repetition attenuation in the PPA. In contrast, if RSC serves a more integrative function, associating a number of panoramically-related scenes as a single scene, then we should expect panoramic repetition attenuation in RSC. Experiment 2 asked what kind of visual cues help our visual system integrate multiple snapshots as a single scene. In the real world, such cues as the perception of continuous time help the viewer to have an integrated percept of the world (Burke, 1952; Flombaum & Scholl, 2006; Flombaum, Kundy, Santos & Scholl, 2004). The integration of multiple views in the brain might also be sensitive to the presence of continuity cues such as visual similarity, spatial proximity, temporal sequencing, or motion path momentum. For instance, continuity cues affect whether identical-looking faces are treated as the “same” or not in fusiform cortex (Yi, Turk-Browne, Flombaum, Kim, Scholl, & Chun, 2008). Experiment 2 tested the effects of continuity cues on scene representation by interrupting continuity with a number of unrelated scenes between scene repetitions. Thus, the panoramic scene condition no longer mimicked the perception of continuous scanning. If the temporal sequencing is a critical cue that helps RSC integrate across multiple views, then we should expect no panoramic attenuation in RSC with the interleaved images. However, if scene integration in RSC does not necessarily benefit from continuity, then we should expect panoramic repetition attenuation regardless of whether the images were interleaved with others or successively presented.
EXPERIMENT 1
Experimental design and procedure
Seventeen participants (10 females, 21-31 years old) from the Yale University community participated for financial compensation. All had normal or corrected-to-normal vision. Informed consent was obtained, and the study protocol was approved by the Yale University Human Investigation Committee at the School of Medicine.
Participants completed two runs of scene viewing in the scanner with 128 trials per run. Each event-related trial began with a white fixation point for 1 s, followed by a 500 ms blank interval (See Figure 1b). A scene (24° × 18°) was then presented for 500 ms. Participants were instructed to memorize the overall layout and details of the scene. Participants did not make any responses during the main experiment, and their memory for the scenes was tested after they finished the main experiment and came out of the scanner. The scene was followed by a white fixation dot that remained for 0, 2, or 4 seconds.
There were two repetition conditions and two novel conditions. The two repetition conditions included (1) a panoramic repeat condition and (2) an identical repeat condition. In these two conditions, three scenes were consecutively presented. In the panoramic repetition condition, the three scenes depicted different views of the same panoramic space (see Figure 1a). Each presentation of a scene (1st, 2nd and 3rd) overlapped 66% with its previous presentation (e.g., the 2nd image overlapped 66% with the 1st image; the 3rd image overlapped 66% with the 2nd image). Thus, the 1st and the 3rd scene only overlapped by 33% in physical details. The three scenes were presented in order, providing spatial and temporal continuity across them. The presentation mimicked a steady viewer’s scanning of space with eye and head movements. Movements were counterbalanced so that half of the trials had left to right translation, and the other half had right to left translation.
There were 96 scene image sets (48 image sets per each run), and 32 face images total (thus 16 faces per run). The 96 scene image sets were divided into three groups of 32 image sets that were assigned across the panoramic repeat, the identical repeat, and the novel scene conditions. Image assignments were counterbalanced across every three participants so that each scene appeared equally in each condition. Each image set consisted of three snapshots of a single panoramic scene. In the panoramic repeat condition, three physically different panoramic snapshots were presented (half the times from left to right; half the times from right to left); in the identical repeat condition, the first image from an image set was presented three times without any changes in viewpoints. For both panoramic and identical repetition conditions, the average lag between the 1st and the 3rd presentation was 8 seconds, constant across all conditions (all ts < 1. all Ps > 0.5). The lag between the 1st and the 2nd presentation, as well as the 2nd and the 3rd presentation varied between 0, 2, 4 seconds. Each presentation of a scene was considered to be a single event (e.g., panorama 1st, panorama 2nd, panorama 3rd; Identical 1st, Identical 2nd, Identical 3rd), and modelled as separate conditions in the fMRI analysis. Indoor and outdoor scene categories were counterbalanced across conditions.
The two novel conditions were (1) a novel scenes condition and (2) a novel faces condition. These novel scene and face trials were included to localize scene specific regions in the brain. In the novel scene condition, a single novel scene was presented once. There were no repeats for this condition. Likewise, in the novel faces condition, a single novel face was presented once. The set of faces included both men and women, all with neutral emotion and presented in color. A total of 16 novel scenes and 16 novel faces were used.
When participants came out of the scanner, they participated in an additional behavioral scene recognition test. Two scenes were presented side by side and participants indicated as to which had appeared in the main experiment (one was always completely new). Thirty-two scenes from each of the panoramic repeat, identical repeat, and novel scene conditions appeared (for a total of 96 scenes) paired with 96 new scenes that never appeared in the main experiment. Since the test presented two scenes side by side on a single screen, the visual angle for each was scaled down to 13° × 10°. For scenes that belonged to the panoramic repeat condition in the main experiment, only the third image from the panoramic repetition set was presented.
fMRI data acquisition
Participants were scanned in a Siemens Trio 3T scanner with a standard birdcage head coil. Anatomical images were acquired using conventional parameters. Functional images were acquired with a gradient echo-planar T2* sequence using BOLD contrast. Each functional volume comprised 19 axial slices (2 s repetition time; 25 ms echo time; 80° flip angle; 7 mm thickness with no gap) acquired parallel to the anterior commissure - posterior commissure line. The main experiment was conducted in two functional scan runs, each acquiring 240 image volumes. No separate scene localizers were used, and the novel scenes condition and the novel faces condition within the main experiment were used to localize the PPA and RSC. The first five image volumes of each functional scan were discarded to allow for T1 equilibration effects. Stimuli were presented through an LCD projector on a rear-projection screen.
fMRI data analysis
Image preprocessing and statistical analyses were conducted using SPM2 (Wellcome Department of Cognitive Neurology, Institute of Neurology, London, UK). The two scene-specific regions of interest (ROIs), the PPA and RSC, were functionally localized for individual participants based on the novel scenes-novel faces contrast in the main experiment (See Figure 2).
Figure 2.
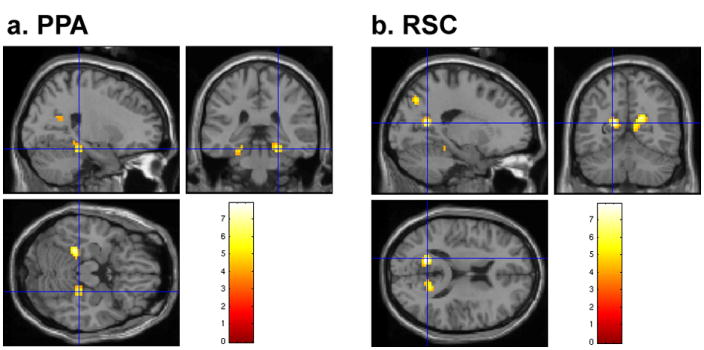
The PPA and RSC are shown on a representative participant’s brain. a, The crosshair indicates the right PPA (24, -33, -23). b, The crosshair indicates left RSC (-18, -59, 13).
A linear contrast (P < 0.0001, uncorrected, cluster threshold = 5 voxels) was used to identify clusters of voxels in bilateral ventral visual areas that responded significantly more to scenes than to faces (Epstein & Kanwisher, 1998). Then, a maximally scene-selective voxel was localized for each hemisphere within the functionally and anatomically defined parahippocampal gyrus and the retrosplenial area: the PPA (average Montreal Neurological Institute (MNI) space coordinates: -27 –46 –15; 30 –44 -14) and RSC (-16 –64 13; 20 –63 17). These coordinates were then entered into the MarsBar toolbox (Brett, Anton, Valabregue, & Polin, 2002) to create spherical ROIs around the maximum voxel (4-mm radius). The bilateral PPA and RSC were found in fifteen out of seventeen participants examined, and data from two participants were excluded because one did not have any activation for either the PPA or RSC in the localizer contrast, and the other did not have any RSC activation. All eight events (panorama 1st, panorama 2nd, panorama 3rd; Identical 1st, Identical 2nd, Identical 3rd, novel scenes, novel faces) were modelled using 13 finite impulse response (FIR) functions with six motion parameters as covariates of no interest. For each ROI of each participant, the mean time courses for the eight main events were extracted across voxels. To determine the time point to include in the ANOVA, the time courses were averaged across conditions and hemispheres, and the numerical peak was compared to each of the other time points. After the comparison of time points, the peak of the PPA response included only the time point at 6 s after the trial onset, and the peak of RSC included both the time points 4 and 6, which were significantly different from the others (t-test, P < 0.05 one-tailed) (Epstein, Graham, & Downing, 2003; Marois, Yi, & Chun, 2004). To test the effect in the entire hemodynamic response, we also modelled the data with a standard HRF including time derivatives, which confirmed major effects we found with the FIR analysis (See Supplementary method)
Whole-brain analyses were conducted to compare panoramic and identical scene repetition effects outside of our ROIs. The fMRI data were modelled with an HRF including time derivatives, and used as regressors in a multiple regression analysis, along with six movement parameter regressors. Contrasts specified a priori include: (1) panoramic 1st vs. panoramic 3rd (panoramic repetition condition attenuation) (2) identical 1st vs. identical 3rd (identical repetition condition attenuation), (3) panoramic condition attenuation vs. identical condition attenuation (panoramic & identical repetition condition interaction). These within-subject contrasts were combined into group random-effects analyses using SPM2 with a threshold of p < 0.001 (uncorrected; cluster threshold = 5 voxels). The threshold follows prior convention for exploratory whole-brain analyses (Epstein, Higgins, Jablonksi, & Feiler, 2007; Johnson, Mitchell, Raye, D’Esposito, & Johnson, 2007; Yi, Turk-Browne, Flombaum, Kim, Scholl, & Chun, 2008).
EXPERIMENT 2
In Experiment 1, we presented panoramic scenes consecutively. Although, our presentation parameters do not directly mimic the experience of surveying the environment views across eye movements, not do they produce apparent motion, they do support a sense of spatio-temporal continuity across the views. However, is such continuity necessary to observe panoramic integration in RSC? Experiment 2 tested this possibility by interrupting the continuity cue by interleaving a number of unrelated scenes between repetitions. Although the discontinuous condition introduces both a longer lag and intervening items, this better represents the type of discontinuity experienced in everyday vision.
Experiment 2 compared continuous and non-continuous blocks of trials (Figure 3). The continuous block was identical to Experiment 1: 1st, 2nd, and 3rd scenes were always consecutively repeated with no intervening items in between. The average lag between the 1st and the 3rd presentation was 8 seconds. In the non-continuous block, 1st, 2nd, and 3rd scenes were always interleaved with more than one unrelated item in between. No panoramic or identical scenes were repeated consecutively. The average lag between the 1st and the 3rd presentation was 22 seconds. The average lag could vary from 6 to 63 seconds, and the number of intervening items ranged from 3 to 12 items. Thus, the continuous block aimed to replicate results from Experiment 1. The non-continuous block allowed us to test whether the continuity cue across repetition is necessary for the viewpoint-invariant, integrative representation observed in RSC. The methods were identical to that of Experiment 1 except as specified below.
Figure 3.

A schematic illustration of the continuous and non-continuous blocks in Experiment 2. Trials with green underlines indicate the panoramic condition; blue underlines indicated the identical condition; gray underlines indicated the unrelated condition.
Experimental design and procedure
20 participants (13 females, 18-30 years old) from the Yale University community participated for financial compensation.
Participants completed four runs of scene viewing in the scanner with 108 trials per run. Two of the four runs were continuous blocks and the other two were non-continuous blocks. The order of blocks was counterbalanced across subjects. The presentation time and instructions for each trial were identical with Experiment 1.
Each block consisted of three repetition conditions: panoramic, identical, and unrelated conditions. Panoramic and identical conditions were the same as those in Experiment 1. The unrelated condition was a newly added control condition, which presented three unrelated novel scenes. We included the unrelated condition for two reasons. First, we wanted to rule out the possibility that RSC representation was so abstract that it showed attenuation to consecutive repetition of any scene-like stimuli. Second, we used the unrelated condition as filler trials in the non-continuous block, to fill in the number of intervening items between the 1st, 2nd and 3rd scene repetition. There were 240 independent scene image sets total (an image set included three snapshots of a single panoramic image). 24 image sets each were used in the continuous panoramic repeat condition, the non-continuous panoramic repeat condition, the continuous identical repeat condition, and the non-continuous identical repeat condition, each condition presenting three identical or panoramically related scenes from the image set. The remaining 144 image sets were used in the continuous unrelated and non-continuous unrelated conditions. The continuous unrelated and non-continuous unrelated conditions, by definition, presented three unrelated novel images. Thus, three single snapshots each taken from three individual images sets were used to compose an unrelated condition trial, so 72 image sets (24 × 3) each were used for the continuous unrelated and non-continuous unrelated conditions. Image sets for the continuous panoramic, the non-continuous panoramic, the continuous identical, the non-continuous identical conditions were counterbalanced across four participants. Image sets for the continuous unrelated and the non-continuous unrelated conditions were separately counterbalanced within the two unrelated conditions.
To reduce the complexity of the main experiment, a separate scene localizer was used. The localizer run presented alternating blocks of scenes and faces, and participants performed a repetition detection of scenes and faces (Park et al., 2007; Yi et al., 2004). There were six scene blocks and six face blocks, each block presenting 12 images. The PPA and RSC were defined by contrasting brain activities for scene blocks versus face blocks.
When participants came out of the scanner, they participated in an additional behavioral scene recognition test. The procedure for the recognition test was identical to Experiment 1, except that 24 scenes from each of the panoramic, identical, and novel repeat conditions of the continuous and non-continuous blocks were presented.
fMRI data acquisition
Each functional volume comprised 26 axial slices (2s repetition time; 25 ms echo time; 90° flip angle; 5 mm thickness with no gap) acquired parallel to the anterior commissure-posterior commissure line. The main experiment was conducted in four functional scan runs, each acquiring 204 image volumes. A separate scene localizer was used, acquiring 250 image volumes. The first five image volumes of each functional scan were discarded to allow for T1 equilibration effects.
fMRI data analysis
The PPA and RSC were functionally localized for individual participants based on the contrast of scenes and faces in an independent localizer. A maximally scene-selective voxel was localized for each hemisphere and spherical ROIs (4mm radius) were created around maximal voxels: the PPA (average MNI coordinates: -27 -52 -8;28 -47 -9) and RSC (18 -62 15; 20 -57 17). Continuous and non-continuous blocks were modelled separately, using 13 finite impulse response (FIR) functions, with nine events for each block (panorama 1st, panorama 2nd, panorama 3rd, identical 1st, identical 2nd, identical 3rd, novel 1st, novel 2nd, novel 3rd) and six motion parameters. For each ROI of each participant, average time courses for the eight main events were extracted. The statistical peak of both the PPA and RSC included both time points 4 and 6. Whole-brain contrasts specified a priori were identical to that of Experiment 1, except that the contrasts were defined separately for the continuous and non-continuous blocks.
RESULTS
EXPERIMENT 1
ROI analyses
Repeated-measures ANOVA and paired t-tests between conditions were performed on the averages of the peak amplitude responses in the PPA and RSC ROIs. There was no main effect of hemisphere in any of the ROIs, and hemisphere did not interact with any combination of the other factors. Thus, both hemispheres were collapsed for analysis (Fs < 4, P > 0.1).
Repeated-measures ANOVA with region (PPA or RSC), condition (panoramic repeat, identical repeat), and repetition (1st or 3rd) revealed a significant main effect of region (F1,14 = 11.7, P < 0.01) and scene repetition (F1,14 = 15, P < 0.01), the latter providing evidence for neural attenuation. We restricted our main analysis to the 1st and the 3rd presentation, in order to simplify the measure of attenuation and to maximize the physical differences across scenes. There was a significant overall interaction between condition and repetition (collapsing across regions), suggesting different patterns of attenuation in the panoramic and identical repetition conditions (F1,14 = 5.5, P < 0.05). Furthermore, there was a significant overall three-way interaction across region, condition, and repetition (F1,14 = 5, P < 0.05), suggesting that attenuation effects for each condition differed across regions.
To examine these effects more specifically, repeated-measures ANOVA with condition (panoramic repeat, identical repeat) and repetition (1st and 3rd) was conducted separately for the PPA and RSC. In the PPA, there were no main effect of condition (F1,14 = 2.2, P = 0.16), but there was a significant main effect of repetition (F1,14 = 10.8, P < 0.01), suggesting a repetition attenuation effect. There was a significant interaction between condition and repetition (F1,14 = 5, P < 0.05), suggesting that the repetition attenuation effect was significantly larger in the identical repeat condition. In RSC, there were no significant main effect of condition (F1,14 = 0.3, P = 0.6), but a significant main effect of repetition (F1,14 = 14.8, P < 0.05). Most importantly, in contrast to the PPA, there was no significant interaction between condition and repetition in RSC (F1,14 = 0.9, P = 0.35), suggesting that both the panoramic repeat and identical repeat conditions had significant repetition attenuation effects.
Figure 4 illustrates mean peak hemodynamic responses for panoramic 1st, 2nd, 3rd and identical 1st, 2nd, 3rd conditions in each of the ROIs. In the PPA (Figure 4a), when scenes were repeated panoramically, there was no attenuation at all for the 1st and 3rd scene presentation (t14 < 1, P = 0.98). Confirming past findings, the PPA treated two views of a same scene as two very different scenes, even when 33% of physical details overlapped. Most interestingly, in striking contrast to the PPA, RSC (Figure 4b) treated panoramic scenes as the same (t14 = 3.9, P < 0.01). When physically different, yet panoramically related scenes were continuously repeated, RSC showed a significant attenuation from the 1st to the 3rd scene presentation even when they only overlapped 33% in their physical properties. This means that a population of neurons in RSC responded as if these scenes belonged to the same scene, in other words, in a viewpoint-independent manner. Importantly, there was a significant interaction across region (PPA and RSC) and repetition (1st and 3rd) for the panoramic condition (F1,14 = 5, P < 0.05). Thus, scene representations in the PPA and RSC are distinct. The PPA is sensitive to small physical changes even when there are apparent continuity cues across scene repetition. On the other hand, RSC is invariant to physical changes and treats these physically different but panoramically connected scenes as the same.
Figure 4.

Repetition attenuation for panoramic images in RSC but not in the PPA. Mean peak hemodynamic responses for panoramic 1st, 2nd, 3rd and identical 1st, 2nd, 3rd images are shown for each ROI in Experiment 1. Error bars indicate ± SEM. a, Parahippocampal place area (PPA). Paired comparisons between panoramic 1st and 3rd images show no attenuation, while paired comparisons between identical 1st and 3rd images show significant neural attenuation. Differences between the amount of attenuation across the two conditions was significant. b, Retrosplenial cortex (RSC). Paired comparisons between panoramic 1st and 3rd images showed significant neural attenuation. The amount of attenuation in RSC for the panoramic condition was significantly larger than the amount of attenuation in the PPA for the panoramic condition. Differences between the amount of attenuation for the panoramic condition across the PPA and RSC were significant. Paired comparisons between identical 1st and 3rd images showed significant neural attenuation as well. c, Examples of each condition are illustrated. Panoramic repeat condition repeated three different views taken from a single panoramic image; Identical repeat condition repeated three identical images.
When identical scenes were repeated, the PPA showed significant attenuation (t14 = 5, P < 0.001). This contrasts with the absence of attenuation for the panoramic repetition condition. There was a significant interaction between condition and repetition in the PPA (F1,14 = 9, P < 0.01). This suggests that the PPA is tuned to exact perceptual matches across scenes. RSC also showed significant attenuation for identical scene repetition (t14 = 2.6, P < 0.05). There was no interaction across condition and repetition in RSC (F1,14 < 1, P = 0.35). This suggests that RSC is also sensitive to perceptual matches like the PPA. However, unlike the PPA, RSC has a unique integrative function that binds different snapshots of panoramic scenes into one representation, at least when visually overlapping scenes were continuously presented in temporal sequence.
Whole-brain Analyses
Random-effects analyses were conducted primarily to test what regions outside our primary ROIs revealed identical 1st to 3rd scene repetition attenuation, panoramic 1st to 3rd scene repetition attenuation, and an interaction of these two conditions. Attenuation effects (1st - 3rd) for identical scenes were found in the left and right PPA (MNI coordinates: -27 -39 -24; 30 -39 -15) and the left parietal-occipital junction near the temporal occipital sulcus (TOS; -39 -87 24), another region known to be responsive to scene stimuli (Epstein, Higgins, & Thompson-Schill, 2005; Hasson, Harel, Levy, & Malach, 2003). We also observed identical scene attenuation in the right middle temporal gyrus (63 -51 0) and left inferior frontal gyrus (-55 27 18), regions that have been demonstrated to exhibit repetition reduction effects in a number of studies using a variety of different stimulus materials (Buckner, Goodman, Burock, Rotte, Koutstaal, Schacter, Rose, & Dale, 1998; Demb, Desomond, Wagner, Vaidya, Glover, & Gabrieli, 1995). Attenuation effects (1st - 3rd) for panoramic scenes were also found in similar frontal areas that have been previously shown to exhibit repetition reduction effects, such as superior frontal gyri (-12 6 60; 6 9 66), left dorsal prefrontal gyrus (-21 30 57), and anterior cingulate gyrus (6 12 54) (Buckner et al., 1998). In posterior regions of interest, attenuation effects (1st - 3rd) for panoramic scenes were found in the left and right RSC (-9 -55 2; 11 -56 19), but not in the PPA. Brain regions that revealed a significant interaction between panoramic and identical attenuation include the left RSC (-13 -52 17) and the precentral gyrus near the primary motor area (36 -18 55).
Scene Recognition Performance
When participants came out of the scanner, they performed a behavioral scene recognition test. The average recognition accuracy was 84.5 %, suggesting that participants were paying attention to scenes in the scanner. The recognition accuracy was 84% for the panoramically repeated scenes, 86% for the identically repeated scenes, and 83% for the novel scenes. The accuracy did not differ across conditions (all ts < 1, all Ps > 0.5).
EXPERIMENT 2
There was no main effect or interaction effects involving hemisphere in the ROIs, thus, both hemispheres were collapsed for analysis (Fs < 2, Ps > 0.17)). Repeated-measures ANOVA with region (PPA or RSC), continuity (continuous or non-continuous), condition (panoramic, identical, novel), and repetition (1st or 3rd) revealed a significant main effect of region (F1,19 = 34, P < 0.001), condition (F2,38 = 5, P < 0.05), and scene repetition (F1,19 = 14, P < 0.005). There was a significant overall four-way interaction across region, continuity, condition, and repetition (F2,38 = 6, P < 0.01), suggesting that the scene repetition attenuation in the PPA and RSC were affected differently by perceptual continuity.
To examine these effects more specifically, repeated-measures ANOVA with condition (panoramic, identical, novel) and repetition (1st and 3rd) was conducted separately for continuous and non-continuous blocks. Figure 5 illustrates mean peak hemodynamic responses for panoramic 1st, 2nd, 3rd; identical 1st, 2nd, 3rd; and novel 1st, 2nd, 3rd conditions separately for each block within each ROI. Paired t-tests were also conducted on the 1st and 3rd peak amplitudes. When identical scenes were repeated, both the PPA and RSC showed significant attenuation regardless of the continuity manipulation (ts > 2.5, Ps < 0.05). When unrelated scenes were consecutively presented, none of the areas showed any attenuation at all (ts < 1.2). This indicates that the attenuation observed in these areas was not due to the mere repetition of any scene-like images.
Figure 5.
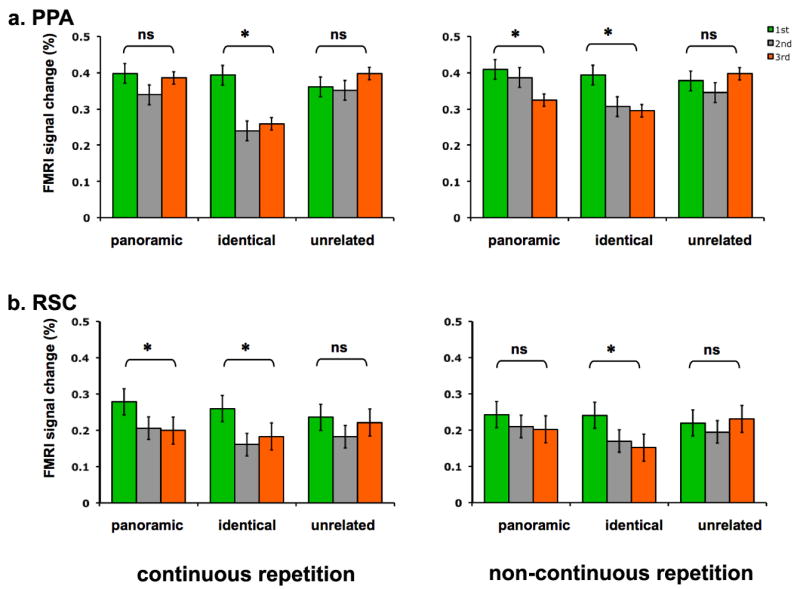
Mean peak hemodynamic responses for panoramic 1st, 2nd, 3rd; identical 1st, 2nd, 3rd; unrelated 1st, 2nd, 3rd images are shown separately for the continuous repetition block (left panel) and the non-continuous repetition block (right panel) in Experiment 2. Error bars indicate ± SEM. a, Parahippocampal place area (PPA). b, Retrosplenial cortex (RSC).
We’ll now focus on the results of the panoramic repetition conditions in each block, the conditions of primary interest. The continuous block exactly replicated the results of Experiment 1. When panoramic scenes were consecutively repeated, there was no attenuation in the PPA (t19 < 0.3, P = 0.83) and significant attenuation in RSC (t19 = 3.3, P < 0.005). There was a significant interaction in the amount of panoramic attenuation across regions, suggesting distinctive modes of scene representation across the PPA and RSC (F1,19 = 6.9, P < 0.05). These results confirm that the scene representation in the PPA is viewpoint-specific while the scene representation in RSC is integrative of multiple continuous views -- at least when these scenes are continuously presented.
However, the critical question is what happens when the panoramic scene presentation is discontinuous. Is RSC still able to integrate scenes that lack continuity cues to link them? RSC, previously viewpoint-invariant, now showed no attenuation for panoramic repetition (t19< 1, P = 0.4), meaning that RSC treated panoramic scenes as different when there was more than one interleaving item in between. Interestingly, when panoramic scenes appeared without continuity (non-continuous block), both the specificity of the PPA and invariance of RSC were affected. The PPA, previously viewpoint-specific, now showed panoramic repetition attenuation (t19 = 3, P < 0.01). In other words, the PPA treated scenes with viewpoint changes as the same when there were intervening items in between them. Thus, continuity across views is an important cue for RSC to make associations across views, and for the PPA to detect physical differences across views.
These results may be initially puzzling, but they make more sense when we consider the advantages and disadvantages of continuous scene presentation. The PPA focuses on the analysis of specific differences across each view. Therefore, when scenes are continuously presented, the shift and physical changes across views become apparent, making it easier for the PPA to detect these changes. However, when scenes are presented discontinuously with interfering items in between them, it becomes harder to compare details across repetition because of the rapid decay of representations and interference from other items (Potter, Staub, Rado, & O’Connor, 2002, Potter, Staub, & O’Connor, 2004).
On the other hand, RSC makes associations between the current view and previous views, creating an integrated representation over view changes. When scenes are consecutively presented, the continuity and the relevance of the previous scene to the current scene is very apparent, thus it is easier for RSC to link these views. However, when scenes are presented with multiple intervening items in between, these associations are lost and interrupted by other items, making it harder for RSC to maintain an integrated representation. In other words, disruption of continuity cues causes a “regression to the mean” form of representation. PPA responses that were specific for continuous panoramic views become less specific, while RSC responses that integrated continuous panoramic views become less effective at linking the views, resulting in more specific representations.
Whole-brain Analyses
Random-effects analyses were conducted to test what regions outside the ROIs revealed identical 1st to 3rd repetition attenuation, panoramic 1st to 3rd scene repetition attenuation, or an interaction of these two types of repetition (p < 0.001, uncorrected; cluster threshold = 5). The continuous and non-continuous blocks were analyzed separately for these effects. When identical scenes were repeated consecutively (the continuous block), identical repetition attenuation effects (1st - 3rd) were found in the left and right PPA (-36 -45 -12; 17 -36 -15), left inferior frontal gyrus (-39 33 18) and the inferior temporal-occipital junction (45 -57 -12). Similarly, when identical scenes were discontinuously repeated, repetition attenuation effects were found in the left and right PPA (-33 -42 -12; 33 -39 -15). When panoramic scenes were continuously repeated, attenuation was found in the medial frontal gyrus (9 57 9); when panoramic scenes were discontinuously repeated, attenuation effects were found in the left middle frontal gyrus (-15 9 69), left precuneus (-18 -51 0), left anterior cingulate gyrus (-9 48 -6), and right middle occipital gyrus (15 -99 6). No brain regions revealed a significant interaction between panoramic and identical attenuation for continuous presentation. Right superior frontal gyrus (21 15 66), the middle temporal gyrus (54 -15 -12), and the cingulate cortex (-6 -6 54) showed an interaction between panoramic and identical attenuation for non-continuous presentation. The larger involvement of frontal regions in the non-continuous scene condition partly suggests that scene recognition over a long delay might involve higher level memory representations of the scene, such as the gist or conceptual information, compared to scene recognition over a brief delay, which might involve more perceptual representations of the scene.
Scene Recognition Performance
The average recognition accuracy was 81% for scenes from the continuous panoramic repeat condition, and 80% for scenes from the non-continuous panoramic repeat condition. The average recognition accuracy was 80% for scenes from the continuous identical repeat condition, and 76% for scenes from the non-continuous identical repeat condition. The accuracy did not differ across lags or conditions (all ts < 1. all Ps > 0.5).
DISCUSSION
The current study tested whether two major scene-selective regions in the brain represent scenes in a viewpoint-specific way or a more integrative, viewpoint-invariant way. The results suggest that viewpoint-specific and invariant representations co-exist in these scene recognition networks of the brain. Furthermore, perceptual continuity across repetition is important for both discriminating and associating different views of the same scene. When viewpoint changes occur continuously, allowing for easy comparison across changing views, the PPA is viewpoint-specific, that is, sensitive to the differences in the physical details of each view, while RSC is viewpoint-invariant, that is, responsive to the similarity across views. These complementary functions of the PPA and RSC may assist in building a coherent and richly detailed representation of a scene across several viewpoints.
Recent studies on object recognition also suggest that the viewpoint-specific and invariant representation of objects might co-exist. The nature of visual representation has been long debated in the object recognition literature (Biederman, 1987; Biederman & Gerhardstein, 1993; Biederman & Bar, 1999; Tarr, Williams, Hayward, & Gauthier, 1998; Hayward & Tarr, 2000). However, despite this prolonged debate on whether object representations are viewpoint-specific (Ullman, 1989, Tarr et al., 1998), or viewpoint-invariant (Biederman, 1987, Hummel & Biederman, 1992), there is growing behavioral and neurophysiological evidence that viewpoint-specific and viewpoint-invariant representations might co-exist (Booth & Rolls, 1998; Burgund & Marsolek, 2000; Vuilleumier, Henson, Driver & Dolan, 2002). For example, Vuilleumier and colleagues (2002) showed that the right fusiform region represents objects in a viewpoint-specific manner, while the left fusiform region represents objects in a viewpoint-invariant manner and treats objects as the same regardless of viewpoint changes. Booth and Rolls (1998) found viewpoint-specific and viewpoint-invariant representations coexisting within the macaque temporal visual cortex (IT). Similar lines of neurophysiological research suggest that the adult human visual system is relatively plastic, and visual representations in the brain are not defined as viewpoint-specific or invariant, but instead change with experience or task demands (Cox, Meier, Oertelt & DiCarlo, 2005; Kourtzi & DiCarlo, 2006).
Functional differences between the PPA and RSC are an important focus of current study in the scene perception literature (Bar & Aminoff, 2003; Bar, 2004; Epstein and Higgins, 2007; Epstein, Parker, & Feiler, 2007; Henderson, Larson, & Zhu, 2008). Epstein and Higgins (2007) measured PPA and RSC activation for three types of scene identification: specific familiar location identification (e.g., “Penn bookstore”), general place category identification (e.g., “kitchen”), or general situational categories (e.g, “party”). The PPA and RSC were both preferentially involved in specific location identification compared to general category or situation identification. However, RSC showed a more extreme preference for the specific location identification condition over the other two conditions. The specific location identification condition particularly required participants’ familiarity with the individual scene and where it was specifically located relative to a bigger cognitive map. Thus, both the PPA and RSC represent the visuo-spatial structure of an individual scene, but RSC seems to be particularly involved in representing an individual scene as a part of a larger spatial layout, which is important for navigation.
Another test of viewpoint selectivity in the PPA and RSC found that overall PPA and RSC responses were viewpoint-specific, although the right RSC showed marginally significant viewpoint-invariant attenuation, similar to our results (Epstein, Higgins, Jablonksi, & Feiler, 2007). The critical difference between the current study and the Epstein et al. study was the steadiness of the viewer’s location within the environment. The viewpoint change in our experiment was more similar to a steady viewer’s translation of views from left to right or right to left. Thus, the head orientation information changed, but the location of the viewer in the environment did not change. On the other hand, the viewpoint change in the Epstein et al. study was generated by viewer movement within the environment, viewing the same scene from one position and then at another angle viewed from a different position. In other words, their viewpoint change required the translation of the viewer’s location, implying both changes in the head orientation and the place information of where the viewer stands in the environment. Thus, it is possible that the integration of multiple viewpoints in RSC is sensitive not only to the continuity, but also to the viewer’s placement or movement within the environment. In fact, it would be very informative to directly compare the two types of viewpoint changes: the type that involves recognizing a single view from multiple viewer standpoints to the type involving integrating multiple views from a single viewer standpoint.
Other lines of fMRI research using objects have also suggested different roles of the PPA and RSC in representing contextual properties of objects. Bar and Aminoff (2004) found RSC to be equally active for objects that have a strong contextual association to a specific place (e.g., oven) and objects that have a weak contextual association to a specific place (e.g., baby bottle); while the PPA much preferred objects that were strongly associated to a specific place. They have concluded that RSC processes contexts in a more abstracted gist-like manner, while the PPA processes physical properties of object contexts. Such functional dissociation of PPA and RSC strongly corresponds to our current finding that the PPA represents specific details of each views of a scene, while RSC represents an abstracted scene that encompass multiple views.
Computational models of hippocampal function (O’Keefe & Burgess, 1996; Kumaran & Maguire, 2009) and a recent high-resolution fMRI study of hippocampal subfields (Bakker et al., 2008) suggest that the division of labor that we observed across the PPA and RSC may exist within the hippocampus. Pattern separation, a process of amplifying small differences in patterns of input and creating distinct representations may occur in the dentate gyrus; while pattern completion, a process that reconstructs a stored pattern with partial input may occur in the recurrent connections of the CA3 region of the hippocampus (Bird & Burgess, 2008; Best, White & Minai, 2001; Morris, 1984; Kumaran & Maguire, 2009; O’Keefe & Nadel, 1978; Taube, 1998). A recent study on human hippocampus suggests that retrosplenial cortex complements the hippocampal function of creating a cognitive map by mediating the transformation of one frame of reference to another as the reference frame changes (Iaria, Chen, Guariglia, Ptito,& Petrides, 2007). Other studies suggested that the parahippocampal gyrus (PHG) processes egocentric spatial information, while the retrosplenial cortex might process allocentric spatial information, such as knowing where the landmark is in relation to a broader allocentric map (Rosenbaum, Ziegler, Winocur, Grady, & Moscovitch, 2004; Vann & Aggleton, 2004). Although it is hard to make any direct analogy to these studies, especially those using rodents, the complementary function within the hippcampus or across the hippocampus and retrosplenial cortex seem to correspond to the complementary functions of specificity and integration across the PPA and RSC.
In addition to finding dissociable types of representation, our results suggest that the lag between repeated presentations is important. We observed two different types of panoramic repetition attenuation: RSC showed attenuation when scenes were immediately and consecutively repeated, while the PPA showed attenuation when scenes were repeated with a long lag and multiple intervening items. We propose that these results reflect two different types of attenuation, the former reflecting the immediate habituation to the perceptual properties of scenes (Grill-Spector et al., 1999; Grill-Spector, Henson, & Martin, 2006; Sawamura, Orban, & Vogels, 2006), and the latter reflecting the revival of old perceptual representations that are mediated by re-entrance of conceptual properties of scenes in memory (Grill-Spector et al., 2006; Henson et al., 2002). Behavioral studies of scene memory showed that the perceptual details of a scene representation fade away as the time delay between the encoding and the test becomes longer, however, the conceptual information of a scene, or a scene gist, persists longer (Potter et al., 2002; 2004). Thus, when the panoramic view of the same scene is presented after a long interval with intervening items, the revival of the original scene might rely more on the conceptual gist of the scene, and less on the decayed perceptual representation of the scene. A recent study proposed a similar argument regarding different types of scene attenuation over time in the PPA and RSC (Epstein et al., 2007). When different views of the same place were repeated within a session, the PPA and RSC showed viewpoint specific responses, but when repeated across a session, both these areas showed viewpoint-invariant responses, similar to the long lag panoramic attenuation in the PPA observed here. Note that there were critical differences in the type of viewpoint change used in the Epstein et al. and the current study, as discussed earlier, which might explain specific differences in our results. Yet, both their study and ours converge on the finding that repetition lag or intervening items influence the specificity of representation in the PPA and RSC.
The current design could not dissociate effects of temporal lag and intervening items. One might question that intervening items may have conceptually masked scenes in the long lag block, interfering with the recognition of repeated stimuli. However, comparable subsequent memory performance for the continuous and non-continuous blocks suggests argue against conceptual masking. Although it is more ecological to have intervening items covary with increased temporal lag, it could be useful to study the effects of lag per se by eliminating intervening items. Another interesting future study would be to test if the PPA and RSC interact over the timecourse of encoding and retrieval. For example, the PPA may encode novel additions to the scene as the view changes, while RSC may retrieve familiar aspects of the scene that is common across the views. The current design did not distinguish such specific stages, but it would be interesting to test how the PPA and RSC may be differentially involved in initial encoding and subsequent retrieval.
In summary, the present study along with prior work to date permit an important conclusion. The PPA and RSC play different roles in scene perception: the PPA selectively discriminates different views while RSC integrates similar scenes that are continuously presented. The selective function in the PPA may facilitate the perception of our exact placement in relation to the environment. The integrative function in RSC may facilitate the perception of a continuous world from multiple snapshots arising from eye and head movements.
Supplementary Material
Acknowledgments
This work was supported by National Institutes of Health Grants to M. M. C. (EY014193 and P30 EY000785)
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Aguirre GK, Detre JA, Alsop DC, D’Esposito M. The parahippocampus subserves topographical learning in man. Cereb Cortex. 1996;6:823–829. doi: 10.1093/cercor/6.6.823. [DOI] [PubMed] [Google Scholar]
- Aguirre GK, D’Esposito M. Topographical disorientation: a synthesis and taxonomy. Brain. 1999;122:1613–1628. doi: 10.1093/brain/122.9.1613. [DOI] [PubMed] [Google Scholar]
- Bar M, Aminoff E. Cortical analysis of visual context. Neuron. 2003;38:347–358. doi: 10.1016/s0896-6273(03)00167-3. [DOI] [PubMed] [Google Scholar]
- Bar M. Visual objects in context. Nat Rev Neurosci. 2004;5:617–629. doi: 10.1038/nrn1476. [DOI] [PubMed] [Google Scholar]
- Best PJ, White AM, Minai A. Spatial processing in the brain: the activity of hippocampal place cells. Annu Rev Neurosci. 2001;24:459–486. doi: 10.1146/annurev.neuro.24.1.459. [DOI] [PubMed] [Google Scholar]
- Biederman I. Recognition-by-components: a theory of human image understanding. Psychol Rev. 1987;94:115–147. doi: 10.1037/0033-295X.94.2.115. [DOI] [PubMed] [Google Scholar]
- Biederman I, Gerhardstein PC. Recognizing depth rotated objects: evidence and conditions for three-dimensional view point invariance. J Exp Psychol Hum Percept Perform. 1993;19:1162–1182. doi: 10.1037//0096-1523.19.6.1162. [DOI] [PubMed] [Google Scholar]
- Biederman I, Bar M. One-shot viewpoint invariance in matching novel objects. Vision Res. 1999;39:2885–2899. doi: 10.1016/s0042-6989(98)00309-5. [DOI] [PubMed] [Google Scholar]
- Booth MC, Rolls ET. View-invariant representations of familiar objects by neurons in the inferior temporal visual cortex. Cereb Cortex. 1998;8:510–523. doi: 10.1093/cercor/8.6.510. [DOI] [PubMed] [Google Scholar]
- Buckner RL, Goodman J, Burock M, Rotte M, Koutstaal W, Schacter D, Rosen B, Dale AM. Functional-anatomic correlates of object priming in humans revealed by rapid presentation event-related fMRI. Neuron. 1998;20:285–296. doi: 10.1016/s0896-6273(00)80456-0. [DOI] [PubMed] [Google Scholar]
- Burgess N, Maguire EA, Spiers HJ, O’Keefe J. A temporoparietal and prefrontal network for retrieving the spatial context of lifelike events. Neuroimage. 2001;14:439–453. doi: 10.1006/nimg.2001.0806. [DOI] [PubMed] [Google Scholar]
- Burgund ED, Marsolek CJ. Viewpoint-invariant and viewpoint-dependent object recognition in dissociable neural subsystems. Psychon Bull Rev. 2000;7:480–489. doi: 10.3758/bf03214360. [DOI] [PubMed] [Google Scholar]
- Burke L. On the tunnel effect. Quarterly Journal of Experimental Psychology. 1952;4:121–138. [Google Scholar]
- Brett M, Anton JL, Valabregue R, Poline JB. Region of interest analysis using an SPM toolbox. NeuroImage. 2002;16 available on CD-ROM. [Google Scholar]
- Cain DP, Humpartzoomian R, Boon F. REtrosplenial cortex lesions impair water maze strategies learning or spatial place learning depending on prior experience prior experience of the rat. Behav Brain Res. 2006;170:316–325. doi: 10.1016/j.bbr.2006.03.003. [DOI] [PubMed] [Google Scholar]
- Cooper BG, Mizumori SJY. Temporary inactivation of the retrosplenial cortex causes a transient reorganization of spatial coding in the hippocampus. Journal of Neurosci. 2001;21:3986–4001. doi: 10.1523/JNEUROSCI.21-11-03986.2001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox DD, Meier P, Oertelt N, DiCarlo JJ. ‘Breaking’ position-invariant object recognition. Nature Neurosci. 2005;8:1145–1147. doi: 10.1038/nn1519. [DOI] [PubMed] [Google Scholar]
- Demb JB, Desmond JE, Wagner AD, Vaidya CJ, Glover GH, Gabrieli JD. Semantic encoding and retrieval in the left inferior prefrontal cortex: a functional MRI study of task difficulty and process specificity. J Neurosci. 1995;15:5870–5878. doi: 10.1523/JNEUROSCI.15-09-05870.1995. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Epstein R, Kanwisher N. A cortical representation of the local visual environment. Nature. 1998;392:598–601. doi: 10.1038/33402. [DOI] [PubMed] [Google Scholar]
- Epstein R, Harris A, Stanley D, Kanwisher N. The parahippocampal place area: Recognition, navigation, or encoding? Neuron. 1999;23:115–125. doi: 10.1016/s0896-6273(00)80758-8. [DOI] [PubMed] [Google Scholar]
- Epstein R, Graham KS, Downing PE. Viewpoint-specific scene representations in human parahippocampal cortex. Neuron. 2003;37:865–876. doi: 10.1016/s0896-6273(03)00117-x. [DOI] [PubMed] [Google Scholar]
- Epstein RA, Higgins JS, Thompson-Schill SL. Learning places from views: variation in scene processing as a function of experience and navigational ability. Journal of Cognitive Neuroscience. 2005;17:73–83. doi: 10.1162/0898929052879987. [DOI] [PubMed] [Google Scholar]
- Epstein RA, Parker WE, Feiler AM. Where am I now? Distinct roles for parahippocampal and retrosplenial cortices in place recognition. Journal of Neuroscience. 2007;27:6141–6149. doi: 10.1523/JNEUROSCI.0799-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Epstein RA, Higgins JS, Jablonksi K, Feiler AM. Visual scene processing in familiar and unfamiliar environments. Journal of Neurophysiology. 2007;97:3670–3683. doi: 10.1152/jn.00003.2007. [DOI] [PubMed] [Google Scholar]
- Epstein RA, Higgins JS. Differential parahippocampal and retrosplenial involvement in three types of visual scene recognition. Cerebral Cortex. 2007;17:1680–1693. doi: 10.1093/cercor/bhl079. [DOI] [PubMed] [Google Scholar]
- Flombaum JI, Kundey S, Santos LR, Scholl BJ. Dynamic object individuation in rhesus macaques: a study of the tunnel effect. Psychological Science. 2004;15:795–800. doi: 10.1111/j.0956-7976.2004.00758.x. [DOI] [PubMed] [Google Scholar]
- Flombaum JI, Scholl BJ. A temporal same-object advantage in the tunnel effect: Facilitated change detection for persisting objects. Journal of Experimental Psychology: Human Perception & Performance. 2006;32(4):840–853. doi: 10.1037/0096-1523.32.4.840. [DOI] [PubMed] [Google Scholar]
- Grill-Spector K, Kushnir T, Edelman S, Avidan G, Itzchak Y, Malach R. Differential processing of objects under various viewing conditions in the human lateral occipital complex. Neuron. 1999;24:187–203. doi: 10.1016/s0896-6273(00)80832-6. [DOI] [PubMed] [Google Scholar]
- Grill-Spector K, Henson R, Martin A. Repetition and the brain: neural models of stimulus-specific effects. Trends in Cognitive Sciences. 2005;10(1):14–23. doi: 10.1016/j.tics.2005.11.006. [DOI] [PubMed] [Google Scholar]
- Grill-Spector K, Malach R. fMR-adaptation: a tool for studying the functional properties of human cortical neurons. Acta Psychol. 2001;107:293–321. doi: 10.1016/s0001-6918(01)00019-1. [DOI] [PubMed] [Google Scholar]
- Hasson U, Harel M, Levy I, Malach R. Large-scale mirror-symmetry organization of human occipito-temporal object areas. Neuron. 2003;37:1027–1041. doi: 10.1016/s0896-6273(03)00144-2. [DOI] [PubMed] [Google Scholar]
- Hayward WG, Tarr MJ. Differing views on views: comments on Biederman and Bar (1999) Vision Res. 2000;40:3895–3899. doi: 10.1016/s0042-6989(00)00179-6. [DOI] [PubMed] [Google Scholar]
- Henderson JM, Larson CL, Zhu DC. Full scenes produce more activation than close-up scenes and scene-diagnostic objects in parahippocampal and retrosplenial cortex: An fMRI study. Brain and Cognition. 2008;66:40–49. doi: 10.1016/j.bandc.2007.05.001. [DOI] [PubMed] [Google Scholar]
- Hochberg J. Perception. 2. Prentice-Hall; 1978. [Google Scholar]
- Hochberg J. Representation of motion and space in video and cinematic displays. In: Boff KJ, Kaufman L, Thomas JP, editors. Handbook of Perception and Human Performance. Vol. 1. Wiley; 1986. pp. 22:1–22:64. [Google Scholar]
- Hummel JE, Biederman I. Dynamic binding in a neural network for shape recognition. Psychol Rev. 1992;99:480–517. doi: 10.1037/0033-295x.99.3.480. [DOI] [PubMed] [Google Scholar]
- Iaria G, Chen JK, Guariglia C, Ptito A, Petrides M. Retrosplenial and hippocampal brain regions in human navigation: complementary functional contributions to the formation and use of cognitive maps. European Journal of Neuroscience. 2007;25(3):890–899. doi: 10.1111/j.1460-9568.2007.05371.x. [DOI] [PubMed] [Google Scholar]
- Johnson MR, Mitchell KJ, Raye CL, D’Esposito M, Johnson MK. A brief thought can modulate activity in extrastriate visual areas: Top-down effects of refreshing just-seen visual stimuli. NeuroImage. 2007;37:290–299. doi: 10.1016/j.neuroimage.2007.05.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kourtzi Z, DiCarlo JJ. Learning and neural plasticity in visual object recognition. Current Opinion in Neurobiology. 2006;16:152–158. doi: 10.1016/j.conb.2006.03.012. [DOI] [PubMed] [Google Scholar]
- Marois R, Yi D-J, Chun MM. The neural fate of consciously perceived and missed events in the attentional blink. Neuron. 2004;41:465–472. doi: 10.1016/s0896-6273(04)00012-1. [DOI] [PubMed] [Google Scholar]
- McNamara TP, Rump B, Werner S. Egocentric and geocentric frames of reference in memory of large-scale space. Psychonomic Bulletin and Review. 2003;10:589–595. doi: 10.3758/bf03196519. [DOI] [PubMed] [Google Scholar]
- Maguire EA, Frackowiak RSJ, Frith CD. Recalling routes around London: Activation of the right hippocampus in taxi drivers. J Neurosci. 1997;17:7103–7110. doi: 10.1523/JNEUROSCI.17-18-07103.1997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maguire EA, Burgess N, Donnett JG, Frackowiak RSJ, Frith CD, O’Keefe J. Knowing where and getting there: A human navigation network. Science. 1998;280:921–924. doi: 10.1126/science.280.5365.921. [DOI] [PubMed] [Google Scholar]
- Maguire EA. The retrosplenial contribution to human navigation: A review of lesion and neuroimaging findings. Scand J Psychol. 2001;42:225–238. doi: 10.1111/1467-9450.00233. [DOI] [PubMed] [Google Scholar]
- Malach R, Reppas JB, Benson RR, Kwong KK, Jiang H, Kennedy WA, Ledden PJ, Brady TJ, Rosen BR, Tootell RBH. Object-related activity revealed by functional magnetic resonance imaging in human occipital cortex. Proc Natl Acad Sci U S A. 1995;92:8135–8139. doi: 10.1073/pnas.92.18.8135. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mendez MF, Cherrier MM. Agnosia for scenes in topographagnosia. Neuropsychologia. 2003;41:1387–1395. doi: 10.1016/s0028-3932(03)00041-1. [DOI] [PubMed] [Google Scholar]
- Morris R. Developments of a water-maze procedure for studying spatial learning in the rat. J Neurosci Methods. 1984;11(1):47–60. doi: 10.1016/0165-0270(84)90007-4. [DOI] [PubMed] [Google Scholar]
- O’Craven KM, Kanwisher N. Mental imagery of faces and places activates corresponding stimulus-specific brain regions. J Cognitive Neurosci. 2000;12:1013–1023. doi: 10.1162/08989290051137549. [DOI] [PubMed] [Google Scholar]
- O’Keefe, Nadel . The hippocampus as a cognitive map. Oxford UP; Oxford: 1978. [Google Scholar]
- Park S, Intraub H, Widders D, Yi DJ, Chun MM. Beyond the edges of a view: boundary extension in human scene-selective visual cortex. Neuron. 2007;54(2):335–342. doi: 10.1016/j.neuron.2007.04.006. [DOI] [PubMed] [Google Scholar]
- Potter MC, Staub A, Rado J, O’Connor DH. Recognition memory for briefly-presented pictures: The time course of rapid forgetting. Journal of Experimental Psychology: Human Perception and Performance. 2002;28:1163–1175. doi: 10.1037//0096-1523.28.5.1163. [DOI] [PubMed] [Google Scholar]
- Potter MC, Staub A, O’Connor DH. Pictorial and conceptual representation of glimpsed pictures. Journal of Experimental Psychology: Human Perception & Performance. 2004;30(3):478–489. doi: 10.1037/0096-1523.30.3.478. [DOI] [PubMed] [Google Scholar]
- Rosenbaum RS, Ziegler M, Winocur G, Grady CL, Moscovitch M. “I have often walked down this street before”: fMRI studies on the hippocampus and other structures during mental navigation of an old environment. Hippocampus. 2004;14(7):826–35. doi: 10.1002/hipo.10218. [DOI] [PubMed] [Google Scholar]
- Sawamura H, Orban G, Vogels R. Selectivity of Neuronal Adaptation Does Not Match Response Selectivity: A Single-Cell Study of the fMRI Adaptation Paradigm. Neuron. 2006;49:307–318. doi: 10.1016/j.neuron.2005.11.028. [DOI] [PubMed] [Google Scholar]
- Schacter DL, Buckner RL. Priming and the brain. Neuron. 1998;20:185–195. doi: 10.1016/s0896-6273(00)80448-1. [DOI] [PubMed] [Google Scholar]
- Tarr MJ, Williams P, Hayward WG, Gauthier I. Three-dimensional object recognition is viewpoint dependent. Nat Neurosci. 1998;1:275–277. doi: 10.1038/1089. [DOI] [PubMed] [Google Scholar]
- Taube JS. Head direction cells and the neurosphyciological basis for a sense of direction. Prog Neurobiol. 1998;55:225–256. doi: 10.1016/s0301-0082(98)00004-5. [DOI] [PubMed] [Google Scholar]
- Tversky B. Functional significance of visuospatial representations. In: Shah P, Miyake A, editors. Handbook of higher-level visuospatial thinking. Cambridge University Press; Cambridge: in press. [Google Scholar]
- Ullman S. Aligning pictorial descriptions: An approach to object recognition. Cognition. 1989;32:193–253. doi: 10.1016/0010-0277(89)90036-x. [DOI] [PubMed] [Google Scholar]
- Valenstein E, Vowers D, Verfaellie M, Heilman KM, Day A, Watson RT. Retrosplenial amnesia. Brain. 1987;110:1631–1646. doi: 10.1093/brain/110.6.1631. [DOI] [PubMed] [Google Scholar]
- Vann SD, Aggleton JP. Selective dysgranular retrosplenial cortex lesions in rats disrupt allocentric performance of the radial-arm maze task. Behav Neurosci. 2005;119(6):1682–1686. doi: 10.1037/0735-7044.119.6.1682. [DOI] [PubMed] [Google Scholar]
- Vuilleumier P, Henson RN, Driver J, Dolan RJ. Multiple levels of visual object constancy revealed by event-related fMRI of repetition priming. Nat Neurosci. 2002;5:491–499. doi: 10.1038/nn839. [DOI] [PubMed] [Google Scholar]
- Wiggs CL, Martin A. Properties and mechanisms of perceptual priming. Curr Opin Neurobiol. 1998;8:227–233. doi: 10.1016/s0959-4388(98)80144-x. [DOI] [PubMed] [Google Scholar]
- Yi D-J, Chun MM. Attentional modulation of learning-related repetition attenuation effects in human parahippocampal cortex. J Neurosci. 2005;25:3593–3600. doi: 10.1523/JNEUROSCI.4677-04.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yi D-J, Turk-Browne NB, Flombaum JI, Kim M-S, Scholl BJ, Chun MM. Spatiotemporal object continuity in human ventral visual cortex. PNAS. 2008:105. doi: 10.1073/pnas.0802525105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yi D-J, Woodman GF, Widders D, Marois R, Chun MM. Neural fate of ignored stimuli: Dissociable effects of perceptual and working memory load. Nature Neuroscience. 2004;7(9):992–996. doi: 10.1038/nn1294. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.