

Abstract
In this paper, we propose an automated approach for the joint detection of major sulci on cortical surfaces. By representing sulci as nodes in a graphical model, we incorporate Markovian relations between sulci and formulate their detection as a maximum a posteriori (MAP) estimation problem over the joint space of major sulci. To make the inference tractable, a sample space with a finite number of candidate curves is automatically generated at each node based on the Hamilton–Jacobi skeleton of sulcal regions. Using the AdaBoost algorithm, we learn both individual and pairwise shape priors of sulcal curves from training data, which are then used to define potential functions in the graphical model based on the connection between AdaBoost and logistic regression. Finally belief propagation is used to perform the MAP inference and select the joint detection results from the sample spaces of candidate curves. In our experiments, we quantitatively validate our algorithm with manually traced curves and demonstrate the automatically detected curves can capture the main body of sulci very accurately. A comparison with independently detected results is also conducted to illustrate the advantage of the joint detection approach.
Keywords: Index Terms, AdaBoost, boosted prior, cortex, graphical model, major sulci, shape prior
I. INTRODUCTION
One of the most intriguing and difficult problems in brain imaging is identifying and registering the convolution patterns of the cortex. It is generally agreed that a set of major sulci are relatively stable [1] and they have been used as landmark curves for registration and locating structural and functional areas on cortices [2], [3]. On the other hand, the automated detection of these sulci is still a challenging problem due to the complexity and variability of the convolution patterns and the different forms these sulci may have in the folding patterns. Thus, manual annotation remains the gold standard in brain mapping practice. In this paper, we propose a novel approach for the joint detection of major sulci via the solution of an inference problem on graphical models [4], which we construct with boosting techniques [5] to incorporate prior knowledge from manual tracing.
Previous work on sulcal detection mostly focused on detecting each sulcus separately. Curvature features were first used to develop semi-automated algorithms [6]–[8] with user specification of start/end points. Depth features with respect to a shrink wrap surface were also used to study sulcal regions on cortical surfaces [9] or find their line representations [10]. Based on the idea of skeletons [11], [12] and digital topology [13]–[15], medial models, or sulcal ribbons, of sulcal regions were constructed from volume images [16]–[21], but user inputs are still required to label specific sulcus from these results.
To automate the sulcal detection process, prior models were introduced to alleviate the difficulty of the problem. The principal component analysis (PCA) of point sets [22] was used to model the centroids of sulcal basins and help with the labeling [23]. Based on spherical maps of cortical surfaces, a hierarchical contour evolution scheme was developed using a PCA model of major sulci [24]. Graphical models were constructed with neural networks in [25] for simple surfaces, which are subsets of major sulci, computed with the skeletonization algorithm in [16], and then annealing techniques were used to label them. Based on a learning technique called probabilistic boosting trees [26], an automated approach was proposed in [27] to detect sulci from volume images, but each curve was treated separately.
In this work, we propose a joint detection approach that realizes sulcal detection via inference over graphical models of major sulci. We assume that each major sulcus is represented as a continuous curve on the cortical surface following a manual tracing protocol [28]. While this assumption may omit some interruptions over gyral regions, it is useful in improving the regularity when these curves are used to guide the mapping of cortical surfaces across population [3]. Based on boosting techniques, we not only incorporate the individual shape prior of each sulcal curve, but also model joint shape priors between neighboring sulci and integrate this information through belief propagation. From the practice of manual annotation, the use of pairwise shape priors seems a natural idea. For example, the precentral sulcus usually needs to cross a gyrus to ensure it follows a route as parallel as possible to the central sulcus. In fact, such local dependencies are utilized fairly commonly to handle complicated situations in protocols for manual tracing [28].
As an illustration, we provide an overview of our method in Fig. 1. In this example, the goal is to detect a set of eight major sulci on a cortical surface: the central sulcus (CS), precentral sulcus (PreCS), postcentral sulcus (PostCS), superior–frontal sulcus (SF), inferior–frontal sulcus (IF), intraparietal sulcus (IP), sylvian fissure (Sylvian), and the superior–temporal sulcus (ST). An undirected graphical model of eight nodes is used to represent the Markovian relations of these sulci. Since the random variable at each node is a sulcal curve that lives in an infinitely dimensional shape space, it is generally difficult to perform inference directly over such spaces. We overcome this challenge by constructing a sample space containing a finite number of candidate curves, as plotted over each node in the graph in Fig. 1, greatly reducing the search range for each variable. To incorporate both individual and pairwise shape priors, we use boosting techniques to learn discriminative shape models and use them to define potential functions on the graphical model. Finally the max-product algorithm of belief propagation is used to find the MAP estimation from the joint sample spaces of the eight sulci as the sulcal detection results.
Fig. 1.

An overview of our joint sulcal detection approach. The automatically detected sulci are plotted over the cortical surface with the color map on the right.
Compared with PCA models adopted in previous work [23], [24], the boosting approach we use does not need to impose the Gaussian assumption on shape models and can automatically select and fuse a large set of informative features to model both individual and pairwise shape priors. Our prior models are learned automatically from training data and there is no parameter to tune for different sulcal curves. Our method also works directly on cortical surfaces and does not need spherical maps of cortical surfaces [24].
Our work is most related to the sulci labeling algorithm proposed in [25], where the nodes of the graph are simple surfaces that oversample the major sulci and their labeling is realized by matching with a template graph learned from training data. In our work, we model each major sulcus as a continuous curve. In addition, the learning techniques and inference algorithms used in our work are different.
The rest of the paper is organized as follows. In Section II, we first present the general framework for joint sulcal detection. After that, we develop the algorithm for generating sample spaces of candidate sulcal curves in Section III. A learning-based approach for constructing potential functions of graphical models is proposed in Section IV to model priors of sulcal curves. Experimental results are presented in Section V on a data set of 40 surfaces. Finally, we discuss possible future extensions in Section VI.
II. Joint Detection Framework
In this section, we present our general framework for the joint detection of major sulci on cortical surfaces. By using a graphical model to represent Markovian relations of neighboring sulci, we realize automated sulcal detection by performing a MAP estimation over the sample spaces of sulcal lines.
Let ℳ denote the cortical surface and C1, C2,…, CN be the set of major sulci to be detected on ℳ. To represent the Markovian relation among these sulci, we use an undirected graphical model G = (V, E), where V = {C1, C2,…, CN} are the set of nodes, and E is the set of edges in the graph. As an example, a graphical model is shown in Fig. 1 for the eight major sulci: CS (C1), PreCS (C2), PostCS (C3), SF (C4), IF (C5), IP (C6), Sylvian (C7), and ST (C8). As the number of major sulci is typically small, we can construct such graph structures easily to encode desirable Markovian priors and it only needs to be done once for the same detection task.
Besides the graph structure, we need to specify the sample space for the random variable defined at each node and the potential functions to completely characterize the probabilistic graphical model. At each node in V, the random variable is a sulcal line and it can take values in a shape space of curves that is generally infinitely dimensional and difficult to analyze. One possible solution is to use dimension reduction techniques such as PCA models of curves [22] to generate each sulcal line as a linear combination of several basis functions. But the PCA models make the restrictive assumption of Gaussian distributions and there is no guarantee that the generated parametric curves will follow the sulcal regions. To overcome this problem, we develop a novel algorithm, which will be described in detail in Section III, to automatically generate a set of candidate curves for each node by combining geometric features of sulcal regions and machine learning techniques. These curves are guaranteed to be on the cortical surface and they span a wide variety of possible routes for each sulcus of interest. With these candidate curves as the sample space Si of each node Ci, we convert the sulcal detection problem to a tractable inference problem over a set of discrete random variables with the goal of selecting the best from the candidate curves.
Based on the sample spaces of candidate sulcal curves, we define two types of potential functions to complete the construction of the graphical model: the local evidence function φi: Si → ℝ at each node Ci and the compatibility function ψi,j: Si × Sj → ℝ for each edge (Ci, Cj) ∈ E. Given a candidate curve from Si, the local evidence function φi gives the likelihood of this curve being the desirable sulcus to be detected. The compatibility function φi,j, represents joint shape priors for two neighboring sulci (Ci, Cj) and measures how likely any two curves from Si × Sj can co-exist as neighbors. To incorporate such individual and joint shape priors, we propose a discriminative approach based on AdaBoost [5] in Section IV to learn both types of potential functions from manually annotated training data. With the discriminative approach, we can use a flexible and large set of features derived from training data and selectively combine them with boosting techniques to form the potential functions, so there is no need of specifying parametric forms for either the individual or joint shape prior models of sulcal lines.
The undirected graphical model defined above is a Markov random field, so the joint distribution of all the sulci can be factorized as a product of potential functions
| (1) |
where Z is the partition function for normalization. The task of finding the optimal set of curves ( ) in the space S1 × S2 × ··· × SN is then a MAP estimation problem defined as follows:
| (2) |
To solve this inference problem over graphical models, we use the max-product algorithm of belief propagation [4], [29] because it can efficiently compute the optimal solution for tree-structured graphs and also demonstrated very good performance on graphs with cycles in various applications [30], [31]. With belief propagation, each node in the graph receives and sends out messages at every iteration of the algorithm. For a node (Ci, the message it sends to its neighbor Cj is defined as
| (3) |
where 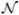 (Ci) are neighbors of Ci in the graph. This message takes into account not only the local evidence φi and the compatibility function ψi,j, but also the messages the node Ci received from its neighbors except Cj. As an illustration, we show in Fig. 2 the flow of messages from the node C6 and C7 to C3, and then to C1 in the graphical model shown in Fig. 1. After the message passing procedure converges, we obtain the final belief at each node of the graph as
(Ci) are neighbors of Ci in the graph. This message takes into account not only the local evidence φi and the compatibility function ψi,j, but also the messages the node Ci received from its neighbors except Cj. As an illustration, we show in Fig. 2 the flow of messages from the node C6 and C7 to C3, and then to C1 in the graphical model shown in Fig. 1. After the message passing procedure converges, we obtain the final belief at each node of the graph as
Fig. 2.
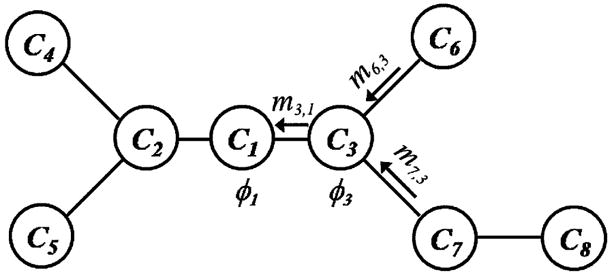
An example of message passing in the graphical model of Fig. 1.
| (4) |
and also the pairwise belief of each edge as
| (5) |
Based on the final beliefs, we find an optimal configuration of major sulci with the following procedure [32], [33].
Start from a node Ci and pick the optimal sulcus at this node as the one that maximizes bi (·).
For each node Ci visited, if it has a neighbor Cj unvisited, find the optimal solution for Cj by maximizing the pairwise belief function . Repeat step 2 until all nodes are visited.
For tree-structured graphs, the above algorithm guarantees to find the globally optimal solution for the MAP estimation problem in (2). It is possible that more than one solution achieves global optimality for MAP estimation over graphs, but in our experience this does not happen in any of our sulci detection experiments. Nevertheless, we choose to fix the starting node as the one corresponding to the central sulcus in step 1 of the above procedure to remove the potential ambiguity that exists theoretically.
III. Sample Space Generation
Given a cortical surface ℳ represented as a genus zero triangular mesh, which we assume is a left hemispheric surface aligned in a standard ICBM space [34] with a nine-parameter affine registration including independent scaling in x-, y-, and z- directions to account for brain size differences, there are four main steps in our algorithm to generate a sample space for each node in the graphical model: 1) extract the skeleton of the sulcal regions; 2) partition the surface into the lateral and medial part; 3) compute a set of possible start/end points and route-control segments of candidate curves with a learning-based approach; 4) generate candidate curves via random walks on a graph built from the start/end points and route-control segments.
A. Sulcal Skeleton Extraction
As a first stage toward sample space generation, we use the algorithm of computing Hamilton–Jacobi skeletons on cortical surfaces [35] to extract the skeleton of sulcal regions on ℳ. For completeness, we briefly describe the main steps of computing the sulcal skeletons as illustrated in Fig. 3. Using the mean curvature of the cortical surface ℳ, it is first partitioned into sulcal and gyral regions using graph cuts [36], [37] and the result is shown in Fig. 3(b). After that, the Hamilton–Jacobi skeleton method [38] is extended to triangular meshes to compute the skeleton of sulcal regions. A pruning process is finally applied to eliminate small branches with length below a specific threshold, which is 10 mm in all our experiments. The sulcal skeletons are decomposed into a set of branches as shown in Fig. 3(c), where we have plotted the main body of the branches in blue and the end points in green. From the results we can see these sulcal skeletons capture the major folding patterns fairly well and provide a compact summary of cortex geometry.
Fig. 3.

Main steps in computing the sulcal skeletons of a cortical surface, (a) The cortical surface, (b) The partition of the surface into sulcal and gyral regions. (c) The Hamilton–Jacobi skeleton of the sulcal regions. End points of each branch are marked as green dots.
B. Lateral/Medial Side Partition
In the second stage we partition the hemispheric cortical surface ℳ into lateral and medial parts with a graph-cut algorithm. The resulting boundary between the lateral and medial side is then used to compute a set of features with the aim of providing intrinsic information about sulcal features in addition to absolute coordinates (in millimeter) in the ICBM space and improving the robustness to pose variations.
Before we apply the graph-cut algorithm, we first find a set of seed points for both the lateral and medial side. Since ℳ is a left hemispheric surface in the ICBM space, where the x-coordinate increases from left to right, we find a set of seed points Xl for the lateral side as vertices visible from the left side, i.e., the “x” direction, using the Z-buffer algorithm for visible surface determination in computer graphics. Similarly, the set of seed points Xm for the medial side are determined as vertices visible from the right side, i.e., the “-x” direction.
Because there are hidden regions invisible from either the left or right side, the two sets Xl and Xm do not form a complete partition of the surface. To achieve this goal, we minimize the following energy function to separate ℳ into the lateral side Rl and the medial side Rm:
| (6) |
where 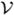 i and
j are vertices on ℳ, K is the total number of vertices, dℳ(·, ·) denote the geodesic distance between two point sets on ℳ that can be computed numerically with the fast marching algorithm on triangular meshes [39], and the delta function δ is defined as one when
i and
j, a vertex in its one-ring neighborhood (
i), belong to different regions and zero otherwise. The first two energy terms require Rl and Rm to be close to their seed points, the third energy term provides regularization for boundary smoothness and the nonnegative parameter λ controls the weight of regularization. To minimize the energy, the same graph-cut algorithm used in stage one for partitioning ℳ into sulcal and gyral regions is applied to find the solution. Since this is a binary optimization problem, the graph-cut technique ensures the global optimality of the separation result [36], [37].
i and
j are vertices on ℳ, K is the total number of vertices, dℳ(·, ·) denote the geodesic distance between two point sets on ℳ that can be computed numerically with the fast marching algorithm on triangular meshes [39], and the delta function δ is defined as one when
i and
j, a vertex in its one-ring neighborhood (
i), belong to different regions and zero otherwise. The first two energy terms require Rl and Rm to be close to their seed points, the third energy term provides regularization for boundary smoothness and the nonnegative parameter λ controls the weight of regularization. To minimize the energy, the same graph-cut algorithm used in stage one for partitioning ℳ into sulcal and gyral regions is applied to find the solution. Since this is a binary optimization problem, the graph-cut technique ensures the global optimality of the separation result [36], [37].
As an example, we show in Fig. 4 the partition results for the surface in Fig. 3(a). Choosing a proper regularization parameter ensures there will be no holes in Rl and Rm and their boundary is a simple curve. In our experience, the parameter λ = 10 gives very robust performance. With this parameter, our algorithm is able to successfully partition all of the 40 cortical surfaces used our experiments into only two connected components corresponding to the lateral and medial parts.
Fig. 4.

The result of partitioning the cortical surface in Fig. 3(a) into the lateral(bright) and medial(dark) side, (a) The lateral view, (b) The medial view. The boundary between the two regions is divided into three curves: BC1 (green), BC2 (blue), and BC3 (cyan), (c) The landmark curves from 40 cortical surfaces.
Once we have the partition results Rl and Rm, we find three boundary vertices, shown as red dots in Fig. 4, that have the largest y-coordinate, the smallest y-coordinate, and the smallest z-coordinate, respectively, and use them to divide the boundary between Rl and Rm into three curves BC1, BC2, BC3 shown as the green, blue, and cyan curve in Fig. 4(a) and (b). We have also plotted the three curves from all 40 surfaces used in our experiments in Fig. 4(c). We can see these curves are clustered fairly closely in the ICBM space and this helps demonstrate the robustness of our partition algorithm. Using these three curves, we can compute the landmark context feature [40] defined at each vertex as LC = [dBC1, dBC2, dBC3] to provide an intrinsic characterization of locations on ℳ, where dBCj (j = 1,2,3) is the geodesic distance to the curve BCj. While the landmark context feature is not necessarily unique over the surface, it provides very intuitive characterizations of the intrinsic locations of major sulci on the cortical surface using distances to the three curves. For example, the distance to the curve BC1 is useful in describing the almost parallel path to the medial wall the SF sulcus usually takes. This distance is also useful to describe the medial-to-lateral trend of the CS, PreCS, and PostCS. The distance to the curve BC2 is valuable in characterizing the intrinsic location of the frontal part of the SF, IF, ST sulcus and the sylvian fissure. With the distance to the curve BC3, we can quantify effectively the almost parallel relation between the ST sulcus and the sylvian fissure. In the next stage, we will use both the ICBM coordinate and the landmark context feature to characterize relative locations on ℳ for the learning algorithms.
C. Compute Start/End Points and Route-Control Segments
By computing the skeleton of sulcal regions, we greatly reduce the search range for the start point
and end point
of a sulcal curve Ci. Let us denote the set of end points for the branches of sulcal skeletons, i.e., the green dots in Fig. 3(c), as 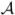 . For each branch of the skeleton, we also divide it into ⎣ℒ/10⎦ segments of equal length around 10 mm, where ℒ is the length of the branch and ⎣x⎦ represents the largest integer less than or equal to x. We denote the set of such segments from all the branches as ℬ. In this third stage of our sample space generation algorithm, we use classifiers learned from training data to pick out a set of candidate points from the set for
and
, and a set of segments from ℬ, which we denote as route-control segments, that help better control the intermediate path the sample curves should follow from
to
.
. For each branch of the skeleton, we also divide it into ⎣ℒ/10⎦ segments of equal length around 10 mm, where ℒ is the length of the branch and ⎣x⎦ represents the largest integer less than or equal to x. We denote the set of such segments from all the branches as ℬ. In this third stage of our sample space generation algorithm, we use classifiers learned from training data to pick out a set of candidate points from the set for
and
, and a set of segments from ℬ, which we denote as route-control segments, that help better control the intermediate path the sample curves should follow from
to
.
To train these classifiers, we derive training data from a set of  cortical surfaces with manually traced sulci and use AdaBoost [5] as our learning algorithm because it is easy to implement, flexible to incorporate various features, and robust to over fitting. As listed in Table I, the main idea of boosting is to form a strong classifier by combining a series of weak classifiers with their weights chosen adaptively based on their classification performance. In order to train the classifier for the start/end point of a sulcal curve Ci, we form the training data as follows by using the start point of Ci as an example. For each of the cortical surfaces in the training data, we compute the set of end points of sulcal skeletons. On each surface there is a manually labeled start point for the sulcal curve Ci and we compute the distance between this point and all points in . For each point in , if this distance is less than 5 mm, we assign the label +1. For all other points in , we assign a label −1. Combining all the results from the P surfaces, we form the training data for the start point of the sulcal curves Ci. The training data for its end point can be formed similarly. The features we use in our learning algorithm include the ICBM coordinate, the landmark context, and their individual components. For 1-D features, we learn a decision stump as the weak classifier. For 3-D features, we learn a perception using the pocket algorithm with rachet [41] as the weak classifier. Both the decision stump and perceptron are linear classifiers in the form
cortical surfaces with manually traced sulci and use AdaBoost [5] as our learning algorithm because it is easy to implement, flexible to incorporate various features, and robust to over fitting. As listed in Table I, the main idea of boosting is to form a strong classifier by combining a series of weak classifiers with their weights chosen adaptively based on their classification performance. In order to train the classifier for the start/end point of a sulcal curve Ci, we form the training data as follows by using the start point of Ci as an example. For each of the cortical surfaces in the training data, we compute the set of end points of sulcal skeletons. On each surface there is a manually labeled start point for the sulcal curve Ci and we compute the distance between this point and all points in . For each point in , if this distance is less than 5 mm, we assign the label +1. For all other points in , we assign a label −1. Combining all the results from the P surfaces, we form the training data for the start point of the sulcal curves Ci. The training data for its end point can be formed similarly. The features we use in our learning algorithm include the ICBM coordinate, the landmark context, and their individual components. For 1-D features, we learn a decision stump as the weak classifier. For 3-D features, we learn a perception using the pocket algorithm with rachet [41] as the weak classifier. Both the decision stump and perceptron are linear classifiers in the form
TABLE I.
AdaBoost Algorithm [5]
Given training data: (x1,y1,
), · · ·,(xn,yn,
) where xi are the sample data, yi ∈ {−1, 1} are the corresponding class labels, and
are the initial weights.For t = 1, · · ·, T
|
| (7) |
where x is the feature in ℝ1 for the decision stump, and ℝ3 for the perception. For the decision stump, (μ, ξ) are coefficients of a 1-D linear classifier. In the case of the perceptron, they are coefficients of a 3-D linear classifier. While the perceptron seems sufficient for 3-D features such as the ICBM coordinates and landmark context, we have chosen to also include the decision stump for the individual components of these 3-D features because the training data is noisy and the 3-D classifier may not be as specific as the 1-D classifier in learning information that can be better captured by 1-D features. So the decision stump can be viewed as a robust version of the perceptron useful to learn explicitly 1-D information such as the distance to the medial wall. The AdaBoost algorithm is then used to selectively combine information from these features and form the final classifier.
For each sulcus Ci, we also use AdaBoost to train a classifier to pick out a set of route-control segments from the set ℬ that should be on the sample curves. For each of the P cortical surface in the training data, we first compute the set ℬ of skeleton segments. For every segment in ℬ, we then compute its Hausdorff distance to the manually traced curve on this surface. If the Hausdorff distance is less than 5 mm, we assign a label +1 to this segment; otherwise, a label −1 is assigned. Repeating the above procedure for all the P cortical surfaces, we form the training data for the route-control segments of Ci. For each segment, we compute the mean and difference of the ICBM coordinates, the landmark context features, and their individual components at its two end points as the features used for classification. The same learning algorithm described above is then used to learn the classifier for route-control segments.
D. Candidate Curve Generation via Random Walks
In this fourth stage, we generate sample curves based on random walks over a directed graph constructed from the candidate start/end points and route-control segments for a major sulcus Ci. Given a pair of candidate start point and end point , we order all the route-control segments of Ci according to their geodesic distance to , which we denote as RC = {Q1, Q2, … QJ} and a segment Qj1 is closer to than Qj2 if jl < j2. Similarly, we also order the two end points of a segment Qj and denote them as and such that , where dℳ(·,·) denotes the geodesic distance between two points on ℳ as in (6).
The directed attributed graph G⃗ = (V⃗, E⃗) for generating sample curves from to is composed of a set of nodes and a set of direct edges . Then set are directed edges from to all the segments in RC and their weights are defined as . The set are directed edges from all the segments in RC to and their weights are defined as . The set are composed of directed edges between segments in RC. To ensure there are no loops in the graph, we require the end point of Qj1 to be closer to than the start point of Qj2. The weights for edges in are defined as .
To generate a sample curve, we perform a random walk in G⃗ to find a path from to . Starting from the node , we pick the next node by randomly choosing an edge from all the direct edges starting from with a probability in proportion to the weights of these edges. The process is repeated until we reach the node . Because we have defined the weights of edges inversely proportional to the geodesic distance between neighboring nodes, edges connecting closer nodes will have a higher chance of being visited in the random walk. Since there are no loops in G⃗ and all the router-control segments are connected to and , any random walk starting from is guaranteed to stop at . By repeating the random walk multiple times, we can generate sample curves covering various routes from the start point to the end point. This is important as the major sulci are not necessarily the shortest path from to .
Suppose the path of the random walk in the graph G⃗ is , we generate the sample curve by connecting a series of curve segments: , where (·, ·) represents a weighted geodesic path connecting two points on ℳ. Because it is possible to jump from a curve segment to a relatively far away curve segment during the random walk, we need to design the weighted geodesies to ensure the path connecting them passes through sulcal regions whenever possible. Thus, we define the weight function for computing the geodesic as
| (8) |
where D is the distance transform of the sulcal skeletons, so points closer to the skeleton will have higher speeds. To find each path numerically, we use the fast marching algorithm on triangular meshes [39] to solve the Eikonal equation on ℳ:
| (9) |
and trace backward along the gradient direction of dw to find the geodesic path.
As an example, we show in Fig. 5(b) the sample curves between a start point (the red dot) and end point (the green dot) generated with random walks on the graph constructed with the route-control segments shown in Fig. 5(a). For each pair of start/end points, we typically generate 30 candidate curves in our experiments. In this case, there are five start and five end points, so we obtain a sample space of 750 candidate curves as shown in Fig. 5(c). Similarly, we can generate the sample space for other major sulci of interest. The sample spaces of the eight sulci in the graphical model of Fig. 1 are plotted in Fig. 5(d) with the color map in Fig. 1. In this case, the usefulness of the random walking process can be best illustrated in the sample space generated for the IF sulcus as the shortest path is clearly not the most desirable. It is clear that most of the sample curves shown in Fig. 5(d) are not neuro-biologically valid sulci. There are also overlaps between candidate curves of different sulci as it is possible for some curve segments being classified as route-control segments by multiple sulci. To ensure that the belief propagation algorithm can handle these cases correctly, we learn the potential functions of the graphical model from training data to incorporate prior knowledge about individual and neighboring sulci.
Fig. 5.

The process of sample space generation, (a) The candidate start (red) and end (green) points of the precentral sulcus, and its route-control segments whose both ends are marked as yellow dots, (b) The sample curves generated with 30 random walks between a pair of start and end points of the precentral sulcus. (c) The sample space of precentral sulcus as composed of curves connecting all the start and end points, (d) The sample spaces of all eight major sulci in the graphical model of Fig. 1 are plotted with the same color map in Fig. 1.
IV. Learning Potential Functions
In this section, we describe our learning-based approach to construct both the local evidence functions φi and compatibility functions ψi,j over the sample spaces of sulcal curves. For each potential function, we compute a large set of features and let the boosting technique automatically pick out the most informative features to model the individual and pairwise shape priors. Using the classifier learned by AdaBoost, we then define the potential function based on its connection to logistic regression [42].
For both the local evidence functions and compatibility functions, we assume a training data set of cortical surfaces in the ICBM space with manually labeled sulcal lines. For each surface, we compute the sample space Si for each node Ci in the graphical model.
A. Local Evidence Functions
To learn the local evidence function φi for a sulcus Ci, we form its training data as follows. We assign all the manually traced curves on the surfaces the label +1. For a curve from Si of each surface, we assign it the label −1 if more than 50% of the points on the curve have a minimum distance of 10 mm to the corresponding manually traced sulcus.
To characterize these curves, we use the Haar wavelet transform to compute a set of multiscale features. More specifically, we uniformly sample each curve into LHarr = 32 points. The Haar wavelet transform is then computed for the ICBM coordinates, landmark context features, and their individual components defined at these uniformly sample points. As a result, we have 2LHaar 3-D features from the ICBM coordinates and landmark context features, and 6LHaar 1-D features from their individual components. This large set of features provides a multi-scale description of the location and orientation of the curves.
Using these features, the AdaBoost algorithm combines a series of weak classifiers to form a final decision function for a curve Ci ∈ Si
| (10) |
where ht is the tth weak classifier, which is a decision stump for 1-D features and perceptron for 3-D features, αt is the weight for this classifier, and T is the total number of weak classifiers. It is shown in [42] that AdaBoost approximates logistic regression and the learned decision function can be used to estimate the probability of a class label, thus we follow [42] and define the local evidence function as
| (11) |
The range of the local evidence function is between (0,1) and it approaches 1 when f(Ci) is large for a curve Ci ∈ Si, which suggests this curve bears strong similarity to manually traced sulcal lines in the training data. On the other hand, it approaches zero for curves with negative decision function values.
B. Compatibility Functions
For two nodes Ci, and Cj in the graphical model G, we follow a similar process to learn their compatibility function ψi,j, but with a different set of features to capture their joint shape priors. Given a cortical surface, we generate the sample spaces Si and Sj for these two sulci, and the value ψi,j(Ci, Cj) measures how compatible a pair of curves (Ci, Cj) ∈ Si × Sj being the two major sulci. The training data to learn ψi,j thus are also composed of curve pairs (Ci, Cj) that we form as follows. For the pairs of manually traced sulci for Ci and Cj on the surfaces in the training data, we assign a label +1. For each of the surface, we compute the sample space Si and Sj and assign a label −1 for the set of curve pairs (Ci, Cj) generated by associating each curve Ci ∈ Si with a randomly picked curve Cj ∈ Sj with the goal of representing possible cases of incompatible curves. By repeating the above procedure for each edge in the graphical model G, we can generate different training data for other neighboring sulci.
As inputs to the weak classifiers used in AdaBoost, we design a set of multiscale features to model the joint configuration for each pair of curves (Ci, Cj). Let ϒ denote the maximum number of levels we want to compute the features. We resample each curve Ci and Cj into 2ϒ + 1 equally spaced points. Let p0, p1, … p2ϒ be the 2ϒ +1 points on Ci, we then approximate it with a set of 2n straight line segments at the level 0 ≤ η ≤ ϒ
| (12) |
where denote the line segment connecting the two points pk2ϒ−η and p(k+1)2ϒ−η. As shown in Fig. 6, line segments at the coarse scale captures the global trend of each curve, while the line segments at finer scales provide more local information. Similarly, the curve Cj is also decomposed into the same number of levels and we use the relation between line segments from these two curves to characterize their configuration at each level. More specifically, for each line segment LS1 of Ci and LS2 of Cj at a level η, we compute the angle between them and the shortest displacement vector from points on LS1 to LS2. Repeat this procedure for all levels, we obtain a set of multiscale features to describe the relative position of curves. The AdaBoost algorithm is then used to learn a strong classifier for the curve pair (Ci, Cj). Similar to the definition of local evidence functions, we define the compatibility function between Ci and Cj as
Fig. 6.
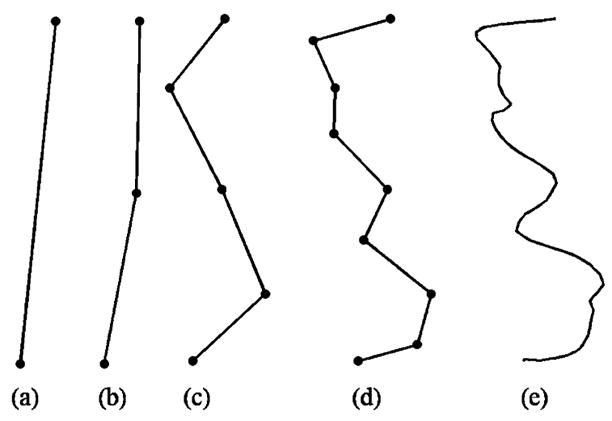
The multilevel decomposition of a curve, (a) η = 0. (b) η = 1. (c) η= 2. (d) η= 3. (e) The original curve.
| (13) |
where f(·, ·) is the decision function learned with AdaBoost using features described above.
Applying the above learning algorithms to each node and every pair of neighboring sulci in a graphical model, we can learn all the local evidence and compatibility functions, which complete the construction of the graphical model. After that, the belief propagation algorithm can be applied to detect sulci jointly on cortical surfaces from the sample spaces of major sulci.
V. Experimental Results
In this section, we present experimental results to demonstrate our joint sulcal detection algorithm on a data set of 40 left hemispheric surfaces. These surfaces represent the boundary between the gray matter and cerebrospinal fluid (CSF), and were generated from MRI images in the ICBM space using a surface extraction algorithm [43] and they all have genus zero topology. While these surfaces may not capture the deepest parts of sulcal regions, the regularity they share makes it easier to compare across population and perform group studies. More details on the MRI imaging and postprocessing protocols can be found in [44]. A set of eight major sulci were manually labeled on each surface for training and validation, which include the central sulcus (CS), precentral sulcus (PreCS), postcentral sulcus (PostCS), superior–frontal sulcus (SF), inferior–frontal sulcus (IF), intraparietal sulcus (IP), sylvian fissure (Sylvian), and the superior–temporal sulcus (ST).
In our experiments, we use the graphical model in Fig. 1 to demonstrate the joint detection method. As a common practice in graph-based estimation, belief propagation is also often applied to graphs with loops. This may allow us to incorporate more neighboring priors between sulcal curves, but no theoretical guarantee of global optimality exists for graphs with loops. So there is a tradeoff between using more complicated models and the tractability in obtaining the optimal solution. We have chosen to use tree-structured graphical models in our experiments as this allows us to focus more on the construction of sample spaces of candidate curves and shape priors.
In the first experiment, we learn from a set of training data the classifiers used in sample space generation and the potential functions in the graphical model, and then demonstrate the sulcal detection algorithm on surfaces in the training data. After that we apply the joint detection algorithm to a set of testing data and validate its performance quantitatively. In our third experiment, we demonstrate the advantage of the joint detection approach by comparing with results obtained without using the graphical model.
A. Graphical Model Training
Among the 40 surfaces in our data we randomly pick 20 surfaces, together with their manually traced sulci, as the training data. As an illustration, we show three examples from the training data in Fig. 7(a)–(c). The other 20 surfaces are used as the testing data to evaluate the performance of the joint sulcal detection algorithm.
Fig. 7.

Three surfaces in the training data, (a)–(c) Cortical surfaces with manually traced sulcal curves. (d)–(f) Sample spaces of the eight sulci. (g)–(i) Automatically detected sulcal curves plotted on surfaces. (All curves are plotted with the color map in Fig. 1).
In this learning stage, we first compute the sulcal skeletons for all the surfaces in the training data. After that the landmark context features derived from the boundary of the lateral/medial partition are computed with the graph-cut approach developed in Section III-B. Using results obtained in these two steps, the AdaBoost algorithm is applied to learn the classifiers for the start/end points and route-control segments of each sulcal curve as described in Section III-C. On every surface, we then run the random-walk algorithm in Section III-D for each sulcal curve, or node of the graphical model, to generate its sample space of candidate curves. For the surfaces in Fig. 7(a)–(c), the corresponding sample spaces of the eight major sulci are plotted in Fig. 7(d)–(f). Finally the potential functions in the graphical model are learned following the procedure in Section IV.
As a first step to examine the graphical model we learned from training data, we perform MAP estimation on the sample spaces of each surface in training data using the belief propagation algorithm described in Section II. By presenting results from the training data, we demonstrate the ability of our learning-based approach in capturing shape priors from manual tracing. These results will also be used to compare with results from the testing data to illustrate the generalization ability of our method. For the three examples in Fig. 7, we have plotted in Fig. 7(g)–(i) the detected sulci. Compared with the manually traced curves in Fig. 7(a)–(c), we can see the detected sulci travel mostly along the same routes through sulcal regions. The geometric relations of neighboring sulci, such as the junctions between the IF and PreCS, are also correctly followed because both angle and displacement features are used in modeling the compatibility functions of these neighboring sulci.
Besides the visual results, we next present more detailed quantitative measures to compare automatically detected sulci with manual results. In previous works [19], [24], [27], statistics such as the mean and standard deviation of distances between points on detected sulci and manually traced curves were used. We extend these measures and use more detailed quantile statistics in our experiments. With quantile statistics, we can characterize how well the detected curves align with the main body of the major sulci at different levels, which maybe anatomically more reasonable considering the difficulty and the resulting variability in deciding the starting and ending parts of sulcal curves even for human tracers.
To compute the quantile statistics, we first calculate two distances between automatically detected curves and manual results. For each point on an automatically detected curve, we compute its minimum distance to the corresponding manually traced curve and denote this kind of distance as dam. For each point on the manually traced curve, we also compute its minimum distance to the automatically detected curve and denote this distance as dma. For each major sulcus, we use the 20 pairs of automatically detected and manually traced curves on all the surfaces in training data to compute the quantile statistics of dam and dma at the 50th, 70th, and 90th percentile.
The results for all eight sulci are listed in Table II. Each distance value in the table represents a cut-point on the cumulative distribution function (CDF) of either dam or dma for a certain sulcus. For example, the last number in the column of central sulcus means that 90% of points on the manually traced curve have a distance dma ≤ 2.09 mm to the automatically detected curve. For all eight sulci, we can see the 50th percentile of both dam and dma are less than 1.5 mm, and the 70th percentile are less than 3.5 mm. Even for highly variable sulci such as PostCS and IF, the 90th percentile of both dam and dma are around 10 mm. So the results in Table II show that very good alignment has been achieved between the main body of automatically detected curves and manually traced ones.
TABLE II.
Quantile Statistics of dam and dma From Sulci Detected in Training Data. All Distances are in Millimeters
| CS | PreCS | PostCS | SF | IF | IP | Sylvian | ST | ||
|---|---|---|---|---|---|---|---|---|---|
| dam | 50th percentile | 0.70 | 1.05 | 1.01 | 1.24 | 1.15 | 0.97 | 0.93 | 1.04 |
| 70th percentile | 0.98 | 1.91 | 1.86 | 2.25 | 3.28 | 2.01 | 1.58 | 1.94 | |
| 90th percentile | 1.66 | 6.35 | 9.76 | 8.92 | 8.26 | 6.87 | 4.60 | 8.54 | |
| dma | 50th percentile | 0.75 | 1.18 | 1.14 | 1.38 | 1.31 | 1.12 | 1.05 | 1.26 |
| 70th percentile | 1.14 | 2.30 | 2.19 | 2.55 | 3.34 | 2.18 | 1.95 | 2.56 | |
| 90th percentile | 2.09 | 8.15 | 12.75 | 9.29 | 8.62 | 7.35 | 6.62 | 11.21 | |
B. Validation With Testing Data
In our previous experiment, we demonstrated very good sulcal detection results in Fig. 7 and Table II. For practical purposes, however, it is more important to examine the generalization abilities of the algorithm, i.e., its performance on testing data. In this experiment, we apply our algorithm to the 20 surfaces in the testing data and evaluate the results quantitatively with manually labeled sulcal lines.
There are two main steps in applying our algorithm to testing data. In the first step, we generate a sample space of candidate curves for each sulcus on a cortical surface. During this stage, the classifier for start/end points and route-control segments learned from training data are used. After that, belief propagation is applied to pick out the best combination of sulcal curves from their sample spaces. Using the classifiers learned from training data, there are very few parameters to tune when we apply the two steps to the testing data. The only parameter we need to adjust is the number of sample curves to generate for each pair of start/end points of a sulcal curve at the first step. When we increase this number, we get larger sample spaces covering more routes a sulcal curve can follow, but it also increases the computational cost because more random walks need to be performed. In our experiments, we set this parameter to 30 curves as in the example shown in Section III-D. This usually generates a sample space containing around 1000 curves for each major sulcus. No significant gains are observed if we further increase this parameter. As an illustration, we visualize the results from these two steps on three surfaces in the testing data, as shown in Fig. 8(a)–(c). The sample spaces generated for each of the eight major sulci are plotted on the surfaces in Fig. 8(d)–(f) using the same color map in Fig. 1. The detected sulcal curves are plotted on the surfaces in Fig. 8(g)–(i). By comparing the automatically detected sulci with manually traced curves in Fig. 8(a)–(c), we can see the automatically detected curves overall capture the main body of the sulci and agree with manual results very well.
Fig. 8.

Sulcal detection results on three cortical surfaces in the testing data, (a)–(c) Cortical surfaces with manually traced sulci. (d)–(f) Sample spaces of the eight sulci. (g)–(i) Automatically detected sulcal curves plotted on surfaces. (All curves are plotted with the color map in Fig. 1.)
To measure quantitatively the performance of our sulcal detection algorithm on testing data, we compute the same statistics as in the first experiment. For each major sulcus, we use the 20 pairs of automatically detected and manually traced curves in testing data to calculate the quantile statistics of dam and dma at the 50th, 70th, and 90th percentile. The results for the eight sulci are listed in Table III. For all eight sulci, the 50th percentile of both dam and dma are less than 2 mm, and the 70th percentile are less than or around 5 mm. Besides the central sulcus, the 90th percentile of dam and dma are around 10 mm, which is slightly worse than the performance on training data and this is mainly due to the high variability in the starting and ending parts of sulcal curves. One good example in illustrating this difficulty is the superior end of the PostCS. Following the tracing protocol [28], the manual tracer is able to consistently pick the posterior route whenever there are more than one choices in determining this part of the PostCS such as the example in Fig. 7(a). Our automated approach, however, may sometimes get confused and follow a posterior route that actually jumps across a gyrus as in Fig. 8(h). Another example is the difficulty in capturing the frontal part of the IF sulcus that usually bends backward. This is mainly because that the IF sulcus does not necessarily follow a weighted geodesic that we use to generate candidate curves. These kinds of situations contribute to the largest errors in the quantile statistics and point out directions of future improvements.
TABLE III.
Quantile Statistics of dam and dma From Sulci Detected Jointly in Testing Data. All Distances Are in Millimeters
| CS | PreCS | PostCS | SF | IF | IP | Sylvian | ST | ||
|---|---|---|---|---|---|---|---|---|---|
| dam | 50th percentile | 0.70 | 1.23 | 1.05 | 1.46 | 1.55 | 0.92 | 1.34 | 1.33 |
| 70th percentile | 0.97 | 2.42 | 2.11 | 3.25 | 3.99 | 1.74 | 2.84 | 2.75 | |
| 90th percentile | 1.70 | 8.07 | 9.32 | 8.98 | 9.17 | 8.60 | 7.36 | 7.64 | |
| dma | 50th percentile | 0.74 | 1.44 | 1.23 | 1.63 | 1.97 | 1.12 | 1.77 | 1.66 |
| 70th percentile | 1.14 | 3.32 | 2.93 | 3.38 | 5.16 | 2.24 | 4.13 | 4.19 | |
| 90th percentile | 2.38 | 9.06 | 10.77 | 9.44 | 11.50 | 11.05 | 11.02 | 10.75 | |
Overall the results in Table III show that our algorithm generalizes very well on testing data and the detected curves are able to capture the main body of major sulci accurately, which is especially encouraging for those sulci (PostCS, IF) that are highly variable.
C. Comparison With Sulci Detected Separately
In this experiment, we compare the joint detection results in Section V-B with sulci detected separately without taking into account pairwise priors between neighboring sulci, which is realized by choosing the curve in each sample space that maximizes the associated local evidence function.
For the three surfaces in Fig. 8(a)–(c), we plot the independently detected sulci in Fig. 9(a)–(c), respectively. To highlight the differences between the detection results in Figs. 8 and 9, we have annotated with a dotted circle to identify one place on each surface in Fig. 9 where the independently detected curve failed to locate the corresponding sulcus accurately. On the contrary, these kinds of mistakes were avoided in the results shown in Fig. 8(g)–(i) because pairwise priors are incorporated. This demonstrates the value of the compatibility functions in improving sulci detection with joint shape priors.
Fig. 9.

Sulcal detection results without using graphical models. (All curves are plotted with the color map in Fig. 1).
Following the quantitative evaluation procedure in Section V-B, we also compare independently detected sulci with manually annotated sulcal curves on the 20 surfaces in our testing data by computing the same quantile statistics. The results are listed in Table IV. From the numbers in Tables III and IV, we can clearly see the advantage of the joint detection approach as it performs better on 40 of the 48 distance measures. For the 6 measures that the independent detection approach generated better results, it outperforms the joint detection method only by a slight margin of less than 0.1 mm. The performance gain with the use of the graphical model is especially significant for more variable sulci such as the PostCS and IF as demonstrated by their quantile statistics at the 70th percentile for both dam and dma in Tables III and IV.
TABLE IV.
Quantile Statistics of dam and dma From Sulci Detected Separately in Testing Data. All distances Are in Millimeters
| CS | PreCS | PostCS | SF | IF | IP | Sylvian | ST | ||
|---|---|---|---|---|---|---|---|---|---|
| dam | 50th percentile | 0.69 | 1.23 | 1.56 | 1.71 | 2.34 | 0.88 | 1.33 | 1.34 |
| 70th percentile | 0.99 | 2.96 | 7.52 | 4.87 | 7.29 | 1.65 | 2.86 | 3.24 | |
| 90th percentile | 2.04 | 10.32 | 13.68 | 11.13 | 11.56 | 10.59 | 9.15 | 8.63 | |
| dma | 50th percentile | 0.74 | 1.54 | 1.90 | 1.83 | 2.42 | 1.13 | 1.71 | 1.78 |
| 70th percentile | 1.15 | 4.01 | 9.02 | 4.57 | 8.46 | 2.29 | 4.27 | 4.87 | |
| 90th percentile | 2.82 | 10.95 | 16.42 | 11.10 | 13.52 | 12.61 | 11.79 | 11.65 | |
VI. Discussion and Conclusion
In this paper, we proposed a joint detection framework for the automated labeling of major sulci on cortical surfaces. By generating sample spaces of candidate curves for the major sulci, we are able to convert sulcal detection into a tractable inference problem over discrete random variables. To capture both individual and joint shape priors of sulcal curves, we use graphical models in our framework to encode Markovian relations between neighboring sulci and learn the potential functions automatically with AdaBoost.
With the aim of providing stable landmark curves for the mapping of cortical surfaces across population, we represent each major sulcus as a continuous curve in our work, which is useful for the analysis of anatomical quantities defined on cortical surfaces such as gray matter densities. On the other hand, this assumption simplifies the interruptions of the sulci over gyral regions that exist naturally. So when the sulcal anatomy is the target of analysis, it might be beneficial to study the detailed configuration of sulcal regions directly.
In our experiments, we demonstrated the training of a graphical model and applied it to automatically detect a set of eight major sulci on hemispheric cortical surfaces. These sulci are on the lateral surface of the cortex, but our method is general and can also be applied to detect other major sulci on the medial surface such as the calcarine sulcus. For the detection of secondary sulci that may or may not be present, for example the secondary cingulate sulcus, however, we cannot apply our method directly. A model selection process might be necessary to first determine the proper graphical model to use and then apply the joint detection algorithm we develop here.
As noted in our experiments, there are still difficulties in accurately detecting sulcal lines that tend to bend backward. To address this problem, we will improve in the future work the sample space generation algorithm for these sulci to ensure their sample spaces contain valid candidate curves. For example, we can train an additional classifier for the IF sulcus to detect a route-control segment corresponding to the most frontal part of the sulcal line and use it to capture the bending between the start and end points.
A large set of features derived from the ICBM coordinates and landmark context features have been combined with AdaBoost to model shape priors of sulcal curves in our current work. The ability of this approach in modeling joint shape priors was demonstrated via comparisons with results detected without using graphical models. An interesting direction of future research is to include a feature selection process [45], [46] in our algorithm as many features contain redundant information. This may improve the effectiveness of our model. For example, this process could make the compatibility function of the PostCS and IP sulcus more sensitive to the spatial configuration between the closest line segments in their multilevel decompositions and help eliminate artifacts such as the slight overlap of these two sulcal curves in Fig. 8(h).
We have chosen to use tree-structured graphical models in our experiments because the belief propagation algorithm can efficiently compute the globally optimal solution on such models. This is, however, at the expense of leaving out potentially useful neighboring priors. To incorporate more joint shape priors, we will study the use of graphical models with loops in our future work. The same learning process developed here can still be used to construct the sample spaces of candidate curves and potential functions on such models, but the belief propagation algorithm has to be used with caution as there is no guarantee of global optimality anymore. More sophisticated optimization strategies such as the tree-reweighted message passing algorithm [47] and the primal-dual graph cut algorithm [48] will be investigated for MAP estimation on these graphical models with loops.
Acknowledgments
This work was supported by the National Institutes of Health through the NIH Roadmap for Medical Research, Grant U54 RR021813 entitled Center for Computational Biology (CCB). Information on the National Centers for Biomedical Computing can be obtained from http://nihroadmap.nih.gov/bioinformatics.
Footnotes
Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org.
References
- 1.Ono M, Kubik S, Abarnathey C. Atlas of the Cerebral Sulci. New York: Thieme Medical Publishers; 1990. [Google Scholar]
- 2.Van Essen DC. A population-average, landmark- and surface-based (PALS) atlas of human cerebral cortex. NeuroImage. 2005;28(3):635–662. doi: 10.1016/j.neuroimage.2005.06.058. [DOI] [PubMed] [Google Scholar]
- 3.Thompson PM, Hayashi KM, Sowell ER, Gogtay N, Giedd JN, Rapoport JL, de Zubicaray GI, Janke AL, Rose SE, Semple J, Doddrell DM, Wang Y, van Erp TGM, Cannon TD, Toga AW. Mapping cortical change in alzheimer’s disease, brain development, and schizophrenia. NeuroImage. 2004;23:S2–S18. doi: 10.1016/j.neuroimage.2004.07.071. [DOI] [PubMed] [Google Scholar]
- 4.Perl J. Probabilistic Reasoning in Intelligent Systems. San Mateo, CA: Morgan Kaufman; 1988. [Google Scholar]
- 5.Freund Y, Schapire R. A decision-theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci. 1997;55(1):119–139. [Google Scholar]
- 6.Khaneja N, Miller M, Grenander U. Dynamic programming generation of curves on brain surfaces. IEEE Trans Pattern Anal Mach Intell. 1998 Nov;20(11):1260–1265. [Google Scholar]
- 7.Bartesaghi A, Sapiro G. A system for the generation of curves on 3-D brain images. Human Brain Mapp. 2001;14:1–15. doi: 10.1002/hbm.1037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Lui LM, Wang Y, Chan TF, Thompson PM. Automatic landmark and its application to the optimization of brain conformal mapping. Proc Comput Vision Pattern Recognit. 2006;2:1784–1792. [Google Scholar]
- 9.Rettmann ME, Han X, Xu C, Prince JL. Automated sulcal segmentation using watersheds on the cortical surface. NeuroImage. 2002;15(2):329–244. doi: 10.1006/nimg.2001.0975. [DOI] [PubMed] [Google Scholar]
- 10.Kao C, Hofer M, Sapiro G, Stern J, Rehm K, Rotternberg D. A geometric method for automatic extraction of sulcal fundi. IEEE Trans Med Imag. 2007 Apr;26(4):530–540. doi: 10.1109/TMI.2006.886810. [DOI] [PubMed] [Google Scholar]
- 11.Blum H, Nagel R. Shape description using weighted symmetric axis features. Pattern Recognit. 1978;10(3):167–180. [Google Scholar]
- 12.Pizer SM, Fritsch DS, Yushkevich PA, Johnson VE, Chaney EL. Segmentation, registration, and measurement of shape variation via image object shape. IEEE Trans Med Imag. 1999 Oct;18(10):851–865. doi: 10.1109/42.811263. [DOI] [PubMed] [Google Scholar]
- 13.Kong T, Rosenfeld A. Digital topology: Introduction and survey. Comput Vis Graph Image Process. 1989 Dec;48(3):357–393. [Google Scholar]
- 14.Bertrand G, Malgouyres R. Some topological properties of surfaces in Z3. J Math Imag Vis. 1999;11:207–221. [Google Scholar]
- 15.Han X, Xu C, Prince J. A topology preserving level set method for geometric deformable models. IEEE Trans Pattern Anal Mach Intell. 2003 Jun;25(6):755–768. [Google Scholar]
- 16.Mangin JF, Frouin V, Bloch I, Régis J, López-Krahe J. From 3-D magnetic resonance images to structural representations of the cortex topography using topology preserving deformations. J Math Imag Vis. 1995;5(4):297–318. [Google Scholar]
- 17.Lohmann G. Extracting line representations of sulcal and gyral patterns in MR images of the human brain. IEEE Trans Med Imag. 1998 Jun;17(6):1040–1048. doi: 10.1109/42.746714. [DOI] [PubMed] [Google Scholar]
- 18.Vaillant M, Davatzikos C. Finding parametric representations of the cortical sulci using an active contour model. Med Image Anal. 1996;1(4):295–315. doi: 10.1016/s1361-8415(97)85003-7. [DOI] [PubMed] [Google Scholar]
- 19.Goualher G, Procyk E, Collins D, Venugopal R, Barillot C, Evans A. Automated extraction and variability analysis of sulcal neuroanatomy. IEEE Trans Med Imag. 1999 Mar;18(3):206–217. doi: 10.1109/42.764891. [DOI] [PubMed] [Google Scholar]
- 20.Zhou Y, Thompson PM, Toga AW. Extracting and representing the cortical sulci. IEEE Comput Graphics Appl. 1999 May-Jun;19(3):49–55. doi: 10.1109/38.761550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Zeng X, Staib L, Schultz R, Tagare H, Win L, Duncan J. A new approach to 3-D sulcal ribbon finding from MR images. Proc MICCAI. 1999:148–157. [Google Scholar]
- 22.Cootes T, Taylor C, Cooper D, Graham J. Active shape models-their training and application. Computer Vis Image Understand. 1995;61(1):38–59. [Google Scholar]
- 23.Lohmann G, Cramon D. Automatic labelling of the human cortical surface using sulcal basins. Med Image Anal. 2000;4:179–188. doi: 10.1016/s1361-8415(00)00024-4. [DOI] [PubMed] [Google Scholar]
- 24.Tao X, Prince J, Davatzikos C. Using a statistical shape model to extract sulcal curves on the outer cortex of the human brain. IEEE Trans Med Imag. 2002 May;21(5):513–524. doi: 10.1109/TMI.2002.1009387. [DOI] [PubMed] [Google Scholar]
- 25.Rivière D, Mangin JF, Papadopoulos-Orfanos D, Martinez J, Frouin V, Régis J. Automatic recognition of cortical sulci of the human brain using a congregation of neural networks. Med Image Anal. 2002;6:77–92. doi: 10.1016/s1361-8415(02)00052-x. [DOI] [PubMed] [Google Scholar]
- 26.Tu Z. Probabilistic boosting-tree: Learning discriminative models for classification, recognition, and clustering. Proc ICCV. 2005;2:1589–1596. [Google Scholar]
- 27.Tu Z, Zheng S, Yuille A, Reiss A, Dutton RA, Lee A, Galaburda A, Dinov I, Thompson P, Toga A. Automated extraction of the cortical sulci based on a supervised learning approach. IEEE Trans Med Imag. 2007 Apr;26:541–552. doi: 10.1109/TMI.2007.892506. [DOI] [PubMed] [Google Scholar]
- 28.Surface curve protocal [Online] Available: http://www.loni.ucla.edu/~esowell/edevel/new_sulcvar.html.
- 29.Aji SM, McEliece RJ. The generalized distributive law. IEEE Trans Inf Theory. 2000;46:325–343. [Google Scholar]
- 30.Aji SM, Horn G, McEliece RJ, Xu M. Iterative min-sum decoding of tail-biting codes. Proc IEEE Inf Theory Workshop. 1998:68–69. [Google Scholar]
- 31.Freeman WT, Pasztor E. Learning to estimate scenes from images. Proc Neural Inf Process Syst (NIPS) 1998;2:775–781. [Google Scholar]
- 32.Dawid AP. Applications of a general propagation for probabilistic expert systems. Statistics Comput. 1992;2:25–36. [Google Scholar]
- 33.Wainwright M, Jaakkola T, Willsky A. Tree consistency and bounds on the performance of the max-product algorithm and its generalizations. Statistics Comput. 2004:143–166. [Google Scholar]
- 34.Mazziotta JC, Toga AW, Evans AC, Lancaster PTFNDJ, Zilles K, Woods RP, Paus T, Simpson G, Pike B, Holmes CJ, Collins DL, Thompson PM, MacDonald D, Schormann T, Amunts K, Palomero-Gallagher N, Parsons L, Narr KL, Kabani N. A probabilistic atlas and reference system for the human brain: International consortium for brain mapping. Philos Trans R Soc Land B Biol Sci. 2001;356:1293–1322. doi: 10.1098/rstb.2001.0915. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Shi Y, Thompson P, Dinov I, Toga A. Hamilton-Jacobi skeleton on cortical surfaces. IEEE Trans Med Imag. 2008 May;27(5):664–673. doi: 10.1109/TMI.2007.913279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Boykov Y, Jolly MP. Interactive graph cuts for optimal boundary & region segmentation of objects in N-D images. Proc ICCV. 2001;I:105–112. [Google Scholar]
- 37.Boykov Y, Kolmogorov V. An experimental comparison of Min-Cut/Max-Flow algorithms for energy minimization in vision. IEEE Trans Pattern Anal Mach Intell. 2004 Sep;26(9):1124–1137. doi: 10.1109/TPAMI.2004.60. [DOI] [PubMed] [Google Scholar]
- 38.Siddiqi K, Bouix S, Tannebaum A, Zuker S. Hamilton-Jacobi skeletons. Int J Comput Vis. 2002;48(3):215–231. [Google Scholar]
- 39.Kimmel R, Sethian JA. Computing geodesic paths on manifolds. Proc Nat Acad Sci USA. 1998;95(15):8431–8435. doi: 10.1073/pnas.95.15.8431. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Shi Y, Thompson PM, Dinov I, Osher S, Toga AW. Direct cortical mapping via solving partial differential equations on implicit surfaces. Med Image Anal. 2007;11(3):207–223. doi: 10.1016/j.media.2007.02.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Gallant S. Perceptron-based learning algorithms. IEEE Trans Neural Networks. 1990 Jun;1(2):179–191. doi: 10.1109/72.80230. [DOI] [PubMed] [Google Scholar]
- 42.Friedman J, Hastie T, Tibshirani R. Additive logistic regression: A statistical view of boosting. Ann Statist. 2000;28, no. 2:337–407. [Google Scholar]
- 43.MacDonald D. PhD dissertation. McGill Univ; Montreal, QC, Canada: 1998. A method for identifying geometrically simple surfaces from three dimensional images. [Google Scholar]
- 44.Thompson PM, Lee AD, Dutton RA, Geaga JA, Hayashi KM, Eckert MA, Bellugi U, Galaburda AM, Korenberg JR, Mills DL, Toga AW, Reiss AL. Abnormal cortical complexity and thickness profiles mapped in Williams syndrome. J Neurosci. 2005;25(16):4146–4158. doi: 10.1523/JNEUROSCI.0165-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Guyon I, Elisseeff A. An introduction to variable and feature selection. J Mach Learn Res. 2003;3:1157–1182. [Google Scholar]
- 46.Peng H, Long F, Ding C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell. 2005 Aug;27(8):1226–1238. doi: 10.1109/TPAMI.2005.159. [DOI] [PubMed] [Google Scholar]
- 47.Wainwright MJ, Jaakkola TS, Willsky AS. MAP estimation via agreement on trees: Message-passing and linear programming. IEEE Trans Inf Theory. 2005 Nov;51(11):3697–3717. [Google Scholar]
- 48.Komodakis N, Tziritas G. Approximate labeling via graph cuts based on linear programming. IEEE Trans Pattern Anal Mach Intell. 2007 Aug;29(8):1436–1453. doi: 10.1109/TPAMI.2007.1061. [DOI] [PubMed] [Google Scholar]