

SUMMARY
The analysis of covariance provides a common approach to adjusting for a baseline covariate in medical research. With Gaussian errors, adding random covariates does not change either the theory or the computations of general linear model data analysis. However, adding random covariates does change the theory and computation of power analysis. Many data analysts fail to fully account for this complication in planning a study. We present our results in five parts. (i) A review of published results helps document the importance of the problem and the limitations of available methods. (ii) A taxonomy for general linear multivariate models and hypotheses allows identifying a particular problem. (iii) We describe how random covariates introduce the need to consider quantiles and conditional values of power. (iv) We provide new exact and approximate methods for power analysis of a range of multivariate models with a Gaussian baseline covariate, for both small and large samples. The new results apply to the Hotelling-Lawley test and the four tests in the “univariate” approach to repeated measures (unadjusted, Huynh-Feldt, Geisser-Greenhouse, Box). The techniques allow rapid calculation and an interactive, graphical approach to sample size choice. (v) Calculating power for a clinical trial of a treatment for increasing bone density illustrates the new methods. We particularly recommend using quantile power with a new Satterthwaite-style approximation.
Keywords: multivariate analysis of covariance, univariate approach to repeated measures, Hotelling-Lawley trace, Huynh-Feldt test, Geisser-Greenhouse test, Box test
1. INTRODUCTION
1.1. Motivation
Medical studies often use a random baseline covariate to increase precision and statistical power. Although of no consequence in data analysis, including any random predictors substantially complicates the theory and computation of power. Failing to account for randomness of predictors may distort power analysis and lead to a poor choice of sample size.
Regression and analysis of variance (ANOVA) models express a random response as a function of one or more predictors. Describing each predictor as fixed or random requires careful consideration of the study design. A scientist decides what values fixed predictors have before the study begins. For example, dose levels of a drug are usually fixed. In contrast, a scientist discovers values of random predictors only after collecting the data. Although errors in measurement could introduce additional randomness in both fixed and random predictors, we assume that the scientist measures all predictors without appreciable error.
In general, random predictors require more complex theory than do fixed predictors [1]. Optimal parameter estimates and hypothesis tests result from treating all of the predictors fixed. However, power analysis used to plan future studies must account for the random distribution of predictors. Computing the average power over all possible realizations of a particular study design [1] leads to what may be called unconditional power. Power calculated for a particular set of predictor values is described as (a particular) conditional power. With random predictors, the non-centrality parameter is a random variable. Quantile power equals the conditional power value that corresponds to a non-centrality value of specified probability. Each non-centrality value typically encompasses many predictor configurations.
1.2. Literature review
Power analysis with a baseline covariate, or any other type of random predictor, has received little attention. Univariate linear models of Gaussian responses and random discrete predictors have been popular in genetics [2] Soller and Genizi [3, 4] suggested large sample power approximations for such studies. Sampson [1] reviewed the relationships between correlation theory and regression models with multivariate Gaussian responses and predictors, defined unconditional power, and provided expressions for power in the univariate case. Gatsonis and Sampson [5] provided computational formulae and tables for exact (small sample) power of the test of zero multiple correlation with Gaussian predictors and response.
Many authors have studied the power of tests of independence between two sets of Gaussian variables. Most results involve asymptotic properties and use zonal polynomial forms [6-16].
Muller et al. [17] reviewed power calculations for the general linear multivariate model (GLMM) with fixed predictors. They recommended approximations due to Muller and Peterson [18] and Muller and Barton [19]. O'Brien and Shieh (Pragmatic, unifying algorithm gives power probabilities for common F tests of the multivariate general linear hypothesis, unpublished manuscript, University of Florida, 1992) suggested some modifications. The various approximations achieve roughly two decimal places of accuracy [19] (O'Brien and Shieh, unpublished manuscript as before).
1.3. Why not run a simulation?
Computer simulations provide a general tool for power analysis. However, the approach has many disadvantages, including programming time and the burden of certifying the accuracy of the results. Power analysis simulation can never be easier than data analysis. Equally importantly, power analysis typically involves considering an extensive range of design variations. Each change requires a new simulation. The common desire for the hundreds or thousands of power values needed for plots makes simulations troublesome at best. Although we use simulations for power analysis on occasion, it stands as our last resort.
1.4. Why worry about random predictors?
The following example illustrates the many concerns that may arise with random predictors. Cystic fibrosis typically decreases bone mineral density (BMD). Ontjes (unpublished proposal, University of North Carolina at Chapel Hill, 1994) planned to measure spine BMD at baseline, six months, and one year. Stratified by gender, patients were randomly assigned to treatment with a drug designed to increase bone density. Clearly baseline BMD has great appeal as a covariate. Without knowing exactly what values of BMD will occur, how can power be calculated? Is knowing the distribution sufficient? What if the study involves a few tens of subjects, as typically happens in phase I and II clinical trials? What impact do covariates have on the power of tests of fixed effects, such as drug dose? Do repeated measures or multivariate tests change the conclusions? Are there important interactions between two or more such complications? The new results allow answering these questions for many situations.
Although many other choices have practical value, we restrict attention to continuous predictors with Gaussian distributions. The restriction reffects particular interest in models with a baseline covariate.
2. A TAXONOMY OF MODELS AND HYPOTHESES
2.1. The GLMM(F, G, D)
We introduce a taxonomy in order to simplify discussion and separate known power results from those remaining to be discovered. Write the GLMM(F, G, D) as
| (1) |
in which qF, qG and qD are the number of columns of fixed, Gaussian and random discrete variables, respectively. Here qF + qG + qD = q. The N rows of Y, X and 𝔼 correspond to independent sampling units, referred to as subjects, for convenience. We assume that X and each of its submatrices, F, G and D, have full rank, that B contains fixed parameters (which are known for power analysis), and that 𝓔([Y G 𝔼])=[FBF 0 0]. Rows of G and 𝔼 are assumed to independently follow non-singular (finite) Gaussian distributions. As in [1], and imply . Also
| (2) |
For fixed ΣG and ΣY, diagonal elements of diagonal elements of Σ𝔼 decrease with increasing correlation between the outcomes and the predictors. If qG =1, then write g and rather than G and ΣG.
Depending on the choice of predictors and distributional assumptions, several different simplifications of the full model arise. The classical GLMM has only fixed predictors, and in our notation is called the GLMM(F). Similarly, we call a model with fixed and multivariate Gaussian predictors a GLMM(F, G), and so on.
For the BMD example, both gender and drug treatment represent fixed effects, while the baseline BMD measure serves as a random predictor. Let dj indicate a vector of bone mineral density measurements at month j ∈ {0, 6, 12}. With m for male, f for female, t for treatment, and p for placebo, a reference cell coding allows writing the model as
| (3) |
In this design there are no random categorical predictors (D does not exist) and
| (4) |
2.2. The General Linear Hypothesis (GLH)
With both fixed and random predictors, hypothesis tests may involve only random, only fixed, or both fixed and random predictors. Assume C, U and Θ0 are fixed and known, with C of full row rank and U of full column rank. With Θ=CBU, an a × b matrix, every general linear hypothesis may be stated as H0:Θ=Θ0. For the GLMM(F, G), a GLH(F) has C =[CF 0], with CF a × qF. The GLH(G) has C =[0CG] with CG a × qG. A test of both random and fixed predictors, the GLH(F, G), has C =[CF CG].
Power may be computed in terms of a small collection of intermediate expressions, especially
| (5) |
| (6) |
| (7) |
| (8) |
s= min(a, b), and s* =rank(Ω) ≤ s. Also define a measure of discrepancy from sphericity used for repeated measures tests. See reference [17] for more details. For power analysis, assume that C , B, U, Θ0, ΣG and ΣY are known constants. If any component of X is random, then so are M, H and Ω.
The cystic fibrosis study focused on the test of gender-by-treatment interaction. Using a MANOVA approach asks if the interaction predicts any linear combination of the BMD at six or twelve months, adjusting for baseline. Define C=[0 0 0 1 0], U =I2, Θ0 =0. This is a GLH(F), which is often the most interesting sort of test in a clinical trial.
3. SMALL SAMPLE POWER
3.1. Known results for fixed predictor power and conditional power
Any method giving power for fixed predictors also gives power for models including a particular realization of random predictors. For example, in the BMD study, consider computing power using baseline values from a previous study. Hence power for fixed predictors equals conditional power, as defined earlier. We consider the multivariate Hotelling-Lawley trace statistic (HLT), as well as the tests for the univariate approach to repeated measures (Geisser-Greenhouse, Huynh-Feldt, Box conservative, and uncorrected). See the Appendix for detailed formulae. All reduce to the usual univariate test if b=1, which requires either only one outcome measure, or a univariate contrast among responses. As an example, for the BMD study, testing only the linear trend across the repeated measures gives b=1.
The O'Brien and Shieh modification of the Muller and Peterson [18] approximation for conditional power of the HLT uses McKeon's [20] F-approximation for the null. If t1 = (N - q)2 - (N - q)(2b + 3) + b(b + 3), t2 =(N - q)(a + b + 1) - (a + 2b + b2 - 1), then d:f :(H)=4 + (a + b + 2)t1/t2. Let and . Conditional power is approximated by 1 - FF[fcrit,H; ab,d.f.(H), ωH].
Muller and Barton [19] described approximations for conditional power of the conservative, Geisser-Greenhouse, Huynh-Feldt and uncorrected tests. The tests estimate ε as 1/b, , and 1, respectively, with and the MLE and Huynh-Feldt estimates. For test T∈{C, GG, HF, Un}, define , with m(T) equal to 1/b, an approximate value of 𝓔(), an approximate value of 𝓔(), or 1. Conditional power is approximated by 1 - FFt[fcrit,T; abε, b(N - q)ε ωU], with ωU = εtr(H)/tr(Σ*). The uncorrected test and power calculations are exact whenever sphericity holds (ε=1).
Examination of the conditional power approximations allows concluding that they depend on random predictors only through scalar non-centrality values. In particular, ωH and ωU become random variables as functions of random X. Hence unconditional power may be computed by deriving the density of the random non-centrality parameter and integrating over all possible values.
3.2. New results for unconditional power: distributions of non-centrality for qG =1
The special case with qG = 1 and qD = 0 reduces the design matrix to
| (9) |
and also implies
| (10) |
with C and CF assumed to be of rank a and cg of rank 0 or 1. For example, the test of treatment effect in the BMD study analysis is a special case. In turn, the presence of random g in
| (11) |
and
| (12) |
makes both random.
Lemma 1
Assume hH,1 and hU,1 are constant, and q1 q2, q3H and q3U are scaled χ2 random variables. For a GLMM(F, g), and a GLH(F, g) or a GLH(F), the random non-centrality for power approximation for the HLT test is exactly
| (13) |
and for the `univariate' approach to repeated measures tests is exactly
| (14) |
See the Appendix for details of the notation and a proof. Standard results for quadratic forms allow proving that q1 is independent of q2, q3H, and q3U, while q2 is not independent of q3H or q3U. Also, neither q3H nor q3U are independent of q1 + q2.
Lemma 2
The non-centralities described in Lemma 1 may each be expressed exactly as weighted sums of independent χ2 random variables. See the Appendix for a proof.
3.3. Unconditional power approximations
Theorem 1
For a GLMM(F, g) and a GLH(F, g) or a GLH(F), with C and CF of rank a, ωH is absolutely continuous, with Pr{0≤hH,0≤ωH≤hH,1}=1. Hence the unconditional power for the Hotelling-Lawley trace may be approximated by
| (15) |
The power may be approximate for three reasons. Conditional power is approximate for s = min(a, b)>1. Numerical calculation of the integral may reduce accuracy. Finally, an approximation (as in Section 3.5) may be preferred to Davies' [21] method for calculating FωH(t) if s*>1. The results are exact (except for inaccuracy due to numerical integration) if s=1. This special case arises in comparing only two groups, as in many clinical trials. If s* =1 then FωH(t) can be expressed exactly in terms of a possibly non-central F CDF, even if s>1.
Theorem 2
Let T index the conservative, Geisser-Greenhouse or Huynh-Feldt test. For a GLMM(F, g), and a GLH(F, g), with C and CF of rank a, the approximate unconditional power for the univariate approach to repeated measures statistics is given by
| (16) |
The logic and most details of the proof are the same as for theorem 1 (see the Appendix).
The power may be approximate for three reasons. Conditional power is approximate if b>1. Numerical integration may introduce some inaccuracy. Finally, an approximation (as in Section 3.5) may be preferred for calculating FωH(t) if s*>1. The results are exact (except for inaccuracy due to numerical integration) if b=1. This case arises with hypotheses involving only one response dimension, such as a linear trend, and any univariate hypothesis. If s* = 1 then FωU(t) can be expressed exactly in terms of a possibly non-central F CDF, even if s>1.
3.4. Quantile power approximations
In addition to unconditional power, quantile power is of interest. Let ωHq be a number such that Pr{ωH<ωHq}=FωH(ωHq)=q. A non-centrality parameter that small or smaller occurs in only 100q per cent of all realizations of possible experiments. Define quantile power for the Hotelling-Lawley test to be the power obtained conditional on observing a non-centrality parameter of ωHq:
| (17) |
Quantile powers for the four tests with the `univariate' approach to repeated measures are defined similarly.
3.5. Computational techniques and approximations
Calculating a numerical value for quantile power will be illustrated by considering the Hotelling-Lawley test:
Fix q. For example, to nd the 25th percentile, q=0:25.
Find the qth percentile of non-centrality, , by numerical inversion of the equation FωH(ωHq)=q. A simple bisection method works, with Davies' algorithm for exact calculation of the CDF's of ωH and ωU.
Compute Pq,H with equation [17]. The QUAD function [22] or algorithm 5.1.2 in Thisted (reference [23], p. 271) were used for integration. Davies' algorithm was used to calculate exact CDF's of ωH and ωU.
To improve calculation speed, we developed an algorithm based on Satterthwaite approximations. For a GLH(F), equations [A6] and [A9] express Pr{ωT≤w}, the CDF of the (random) non-centrality for test statistic T ∈ {H,U}, in terms of the CDF of
| (18) |
Note that the set of λTk are functions of w. Let
| (19) |
| (20) |
and define ν*T2 and λT2 as similar sums over the set {k : λTk<0}, but with λTk replaced by |λTk| Note that ν*T1, ν*T2, λ*T1 and λ*T2 all depend on w through the set of λTk. If {k: λTk>0} is empty, FωT(w)=0, and if {k: λTk<0} is empty, FωT(w)=1. Otherwise, a Satterthwaite type of approximation is given by
| (21) |
The approximation can be used for both unconditional and quantile power.
4. LARGE SAMPLE POWER
For all of the multivariate tests, conditional power approaches 1 as sample size approaches ∞ (reference [14], p. 330). In turn, unconditional power also approaches 1, since it is an average conditional power. Here we focus on quantized limits, in the spirit of those in Anderson (reference [14], p. 330). See the Appendix for details. For a positive integer, m, define N(m)=mN, with N fixed. Evaluation of quantized limits centres on local Pitman-type alternatives (reference [14], p. 330; reference [24], p. 238). This leads to basing the test statistics on B/√{N (m)},(Θ - Θ0)/√{N (m)}, and HLA = H/N(m), and considering N(m)→∞.
With W and Fe as defined in the Appendix, asymptotic limits of the approximations to unconditional power may be expressed in terms of and
| (22) |
Lemma 3
For a GLMM(F, g) and a GLH(F, g), under a sequence of Pitman local alternatives indexed by m
| (23) |
See the Appendix for a proof.
Theorem 3
Consider the limits of the unconditional power approximations given in theorems 1 and 2 under a sequence of Pitman local alternatives indexed by m. Define and ωU,LA =bε tr(QLA)/tr(Σ*), and let be the 1 - α quantile of a χ2 variable with ν degrees of freedom. Then the limits of the unconditional power approximations for the tests are given in Table I. See the Appendix for a proof.
Table I.
Limits of unconditional power under local alternatives
| Test | Limit | |
|---|---|---|
| Univariate | Conservative | 1 - Fχ2 [bεccrit(a); abε, ωU, LA] |
| Geisser-Greenhouse | 1 - Fχ2 [ccrit(abε); abε, ωU, LA] | |
| Huynh-Feldt (unbounded) | 1 - Fχ2 t[ccrit(abε); abε, ωU, LA] | |
| Multivariate | All tests coincide | 1 - Fχ2 [ccrit(ab); ab, ωH, LA] |
5. NUMERICAL RESULTS
We conducted a number of simulations to assess the accuracy of the approximations and to compare the speed of calculations to a Monte Carlo approach. Unconditional and quantile power, with s* =1 and s*>1, for HLT and the Geisser-Greenhouse tests were evaluated.
We illustrate the results with a simulation based on p=4, qF = 3 and qG = 1. Cell mean coding for a balanced design gave Fe = IqF and F=IqF ⊗1N/qF. This led to
| (24) |
We chose ΣY = Ip, , BF = Δg(1,2,0qF-2), and . The hypothesis involved α=0:05, C =[-1qF-1 IqF-1 0], U =Ip and Θ0 = 0, which gave Ω two non-zero eigenvalues. The parameter Δ scales differences between two group intercepts (and means), while ρ is the slope for the covariate. We chose ρ=0:5 and N ∈ {15, 75, 150}. For each N, we selected three values of Δ so that exact median quantile power, pq,H, was 0.20, 0.50 or 0.80. We also calculated the Satterthwaite approximate 0.50 quantile power (PS,0.50,H).
Table II contains numerical power values and times. All calculations allowed a maximum error of 0.001. To find empirical quantile power, for fixed values of N, Σg, ΣY, Δ and ρ, we generated 1000 values of g. The SAS NORMAL function [22] produced pseudo-random spherical Gaussian data which were transformed to obtain realizations of g. For each g, we generated 1000 values of Y, and calculated 𝔼. Then LINMOD [25] was used to calculate test statistics and p-values. For each g, the empirical quantile power was the total number of times that the null hypothesis was rejected, divided by 1000. The empirical quantile power was the median of the 1000 empirical powers. Times for both quantile and unconditional power illustrate the dramatic speed advantage of the new methods over simulation, and the approximations over exact. For the examples considered, the results for non-centrality CDF's differ from those calculated with Davies' algorithm only in the third decimal place. All other inaccuracy arose from the conditional power approximations. The univariate approach to repeated measures conditional power approximations introduced errors as large as 0.05 for some cases with N = 15.
Table II.
Calculated and empirical HLT power
| N | Δ | Median |
Unconditional (mean) |
||||
|---|---|---|---|---|---|---|---|
| Exact | Approximate | Empirical | Exact | Approximate | Empirical | ||
| 15 | 0.4997 | 0.200 | 0.200 | 0.194 | 0.195 | 0.195 | 0.193 |
| 0.8076 | 0.500 | 0.500 | 0.502 | 0.487 | 0.487 | 0.491 | |
| 1.0976 | 0.800 | 0.800 | 0.809 | 0.784 | 0.784 | 0.796 | |
| 75 | 0.1651 | 0.200 | 0.200 | 0.199 | 0.198 | 0.198 | 0.200 |
| 0.2623 | 0.500 | 0.500 | 0.498 | 0.497 | 0.497 | 0.500 | |
| 0.3508 | 0.800 | 0.800 | 0.798 | 0.797 | 0.797 | 0.798 | |
| 150 | 0.1142 | 0.200 | 0.200 | 0.200 | 0.199 | 0.199 | 0.200 |
| 0.1813 | 0.500 | 0.500 | 0.498 | 0.498 | 0.498 | 0.499 | |
| 0.2424 | 0.800 | 0.800 | 0.798 | 0.802 | 0.798 | 0.798 | |
| Total CPU minutes | 0.063 | 0.001 | 627.461 | 24.223 | 0.130 | 627.461 | |
A limited number of cases were examined to assess the formulae given for asymptotic unconditional power. In those cases, a sample size of at least 1000 was required to ensure roughly two digits of accuracy. The same accuracy can apparently be achieved by using, for HLT for example, the rst term, and neglecting the integral term, in equation [15]. The integral term was never seen to be more than roughly 0.05.
6. POWER ANALYSIS EXAMPLE
A power analysis was conducted for the cystic fibrosis example using our new methods. Plausible values for BG, ΣY and ΣG were based on pilot data in the grant proposal [20]. It was assumed that the variances of the baseline, six and twelve month BMD's were equal, and that the correlation between any pair of measurements was equal. Sample sizes of 13 and 39 were considered, and a range of differences between means examined.
At the small sample size, substantial differences can be seen in Figure 1 among unconditional power, the lower 0.025 quantile (corresponding to a 95 per cent confidence level), and the traditional conditional power approximation based on adjusting the error covariance. The upper 0.975 quantile points lie roughly at the same values as the conditional approximation.
Figure 1.
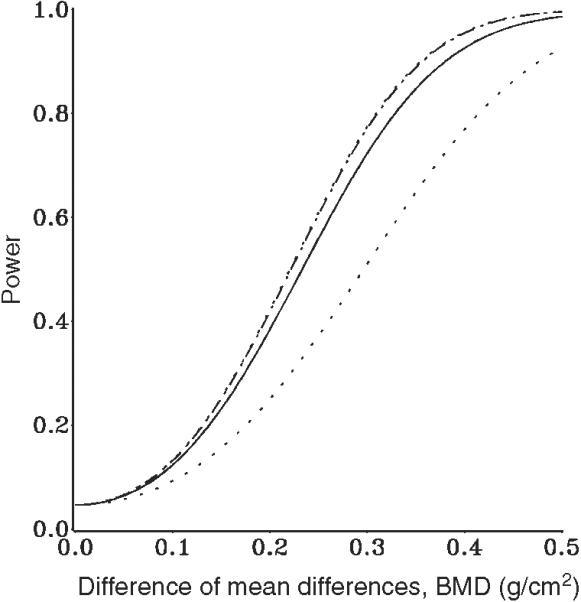
Geisser-Greenhouse power for gender × treatment, N = 13: … 95 per cent Cl; —unconditional; — - —conditional.
For N = 39 (see Figure 2), for the hypothesis and sample size of interest, the choice of quantile has a modest effect on power. Similar results were found for a range of related designs, tests and hypotheses.
Figure 2.

Geisser-Greenhouse power for gender × treatment, N = 39: … 95 per cent Cl; —unconditional; — - —conditional.
7. CONCLUSIONS
The presence of a baseline covariate substantially complicates power calculations of treatment effects in univariate and multivariate ANCOVA settings. New exact and approximate results allow conveniently computing power in the presence of a Gaussian covariate. We recommend computing quantile power for studies with random predictors. The choice of which quantile depends on the ethical and monetary features of the application.
Power methods vary substantially in convenience and speed. Simulations were the slowest, with methods based on numerical integration being next slowest. The Satterthwaite-style approximation is essentially as fast as the simple adjustment with conditional power methods, while being nearly as accurate in the integration technique. Hence the simple adjustment should be avoided, except possibly in large samples. We recommend using the Satterthwaite-style approximation as the best combination of accuracy and computational speed.
Many unanswered questions remain for power analysis with random covariates. In particular, the test of interaction between a random continuous predictor and a fixed predictor seems very important, but is not covered by known results. In the BMD example, testing for equality of baseline slopes in each treatment group falls into this category. More generally, non-Gaussian predictors seem important for practice, yet are not covered by known results.
ACKNOWLEDGEMENTS
Glueck's work was supported in part by grant T32HS00058-04 from the Agency for Health Care Policy and Research to the University of Medicine and Dentistry of New Jersey, Robert Wood Johnson Medical School. The contents are solely the responsibility of the authors and do not necessarily represent the views of AHCPR. A portion of the work reported here was described in the dissertation submitted by D. H. Glueck in partial fulfillment of the requirements for the PhD degree in Biostatistics at the University of North Carolina at Chapel Hill. Muller's work supported in part by NCI program project grant P01 CA47 982-04. The authors gratefully acknowledge guidance from an anonymous reviewer that led to substantial improvements.
Contract/grant sponsor: Agency for Health Care Policy and Research; contract/grant number: T32HS00058-04 Contract/grant sponsor: NCI; contract/grant number: P01 CA47 982-04
APPENDIX
A.1. Distributions and approximations
As needed, a matrix is described as constant, random, or a realization of a random matrix. The Kronecker product is A⊗B = {aij·B}. Graybill's (reference [26], p. 309) definition for vec is used. Let Dg({λ1,λ2,…,λn}) indicate a diagonal matrix. Let χ2(ν,ω) indicate a chi-squared random variable with ν degrees of freedom and non-centrality ω (reference [27], chapter 28). Write the cumulative distribution function (CDF) of random variable Z as FZ(z; θ1, θ2,…, θp), with pth quantile . For the non-central F (reference [27], chapter 30) this gives FF(x; a, b, ω).
Let K be the number of groups of subjects in F, with Nk subjects in each group. Assume that K, Nk and the maximum entry in F are all finite. The actual variables of interest are assumed to be available, and no surrogate variables are used. None of the data may be missing.
Proof of Lemma 1
A standard result for the inverse of a partitioned matrix (reference [28], p. 67) gives
| (A1) |
with B11 =(F′F)-1 + (F′F)-1F′gb22g′F(F′F)-1, b12 =-(F′F)-1F′gb22 and . Then, with P =CF(F′F)-1F′ and g* =Pg - cg
| (A2) |
Using the Bartlett formula for the inverse of a partitioned matrix (reference [28], p. 69), define , and
| (A3) |
If and , then
| (A4) |
Independence among some qj's may be proven as follows. If z ~ NN(0, IN), then, . If mg =P′ (PP′)-1cg and mz = mg/σg then g* = P (g - mg) = σgP(z - mz). Define symmetric and psd A1 = I - F(F′F)-1F′, A2 = P′ T1P, and . Here A1 is idempotent, rank ν1 = N - qF, A2 is idempotent, rank a and A3H is not idempotent, with rank of s*≤s. Also , and proving that each qj is a quadratic form in independent Gaussians. Hence A1A2 = A1A3H = 0, and A2A3H ≠ 0 implies independence of corresponding qj pairs [29].
For the univariate tests, hU,1 = bεtr-1(Σ*)tr[(Θ - Θ0)′T1(Θ - Θ0)]. Replacing by bεtr-1(Σ*)Ib defines A3U in lieu of A3H, which in turn leads to q3U in lieu of q3H. Therefore
| (A5) |
Proof of Lemma 2
Let FωH(w)=Pr{ωH≤w} and b0=1 - w/hH,1, with 0≤b0≤1. Then
| (A6) |
Define AdH =(b0A2 - A3H). The fact that A1A2 = A1A3H = 0 implies A1AdH = 0. With and , it follows that
| (A7) |
If VdH+ = P′FT1VsH, then and AdHVdH+ = VdH+[b0Ia - Dg(λsH)]. Hence the first a eigenvectors of AdH are VdH+. Also AdH has at most a non-zero eigenvalues, namely {b0 - λsH,k}. Define . Then
| (A8) |
with all χ2 random variables independent of each other, which completes the proof. All coefficients are positive unless b0 - λsH,1>0, which implies w>hH,0 =hH,1(1 - λsH,1).
Many special cases arise. If cg = 0 then all χ2's are central. Note that b0 ∈(0,1) and λsH,k ∈(0,1). If λsH,k ≡ λsH>b0, which is guaranteed by s* = 1, then Pr{SH≤0} can be expressed in terms of the CDF of a possibly doubly non-central F. If cg = 0, s* = 1 and N* = N - qF + a - 1, then λsH = 1, , f* = w/[N*(hH,1 - w)] and Pr{SH≤0} = FF(f*;N*,1).
Replacing by bεtr-1(Σ*)Ib gives the parallel result for ωU. In particular
| (A9) |
With , the first a eigenvectors of AdU=(b0A2 - A3U) are P′FT1VsU. If then
| (A10) |
Proof of Theorem 1
Unconditional power equals the expected value of conditional power over all possible realizations of the experiment. Using the law of total probability, unconditional power can be approximated by integrating approximate conditional power with respect to ωH.
For any G, implies hH,1 ≥q3H/(q1 + q2). Also, qj ≥ 0 and q3H/(q1 + q2) ≥ 0. Finite N, Θ, CF and 0<|Σ*|<∞ ensure finite hH,1. Hence ∞>hH,1 ≥ q3H/(q1+q2) ≥ 0, which implies hH,1 ≥ ωH ≥ 0. See the proof of lemma 2 for the derivation of hH,0. As a smooth function of absolutely continuous random variables, ωH is also absolutely continuous (and has a density). Use an expression for ∂FF(f;ν1,ν2,t)=∂t [30, 30.46] and integration by parts to complete the proof.
A.2. Local alternatives and quantized limits
In a GLMM(F), the experimenter decides a priori to select a certain number of subjects from each of K groups. Write the predictor matrix as
| (A11) |
with fk a qF × 1 vector of values for a subject in group k. Define the essence matrix, Fe, as that matrix which contains one and only one copy of each unique row of F [31]:
| (A12) |
Let W be a diagonal K × K matrix with diagonal entries {N1/N,N2/N,…,Nk/Nt}. Then and .
For a positive integer m, let N(m)= mN. As m →∞, then N(m)→∞ in a sequence of quantized steps, each of size N, a quantized limit process. The sequences used in the limits here are in the same spirit as those in Anderson (reference [14], p. 330). Also define F(m) = F ⊗ 1m. Then . Note that W, Fe and N remain fixed as N (m) increases.
We assume rowi(Gm)′ = NN(m)(0,ΣG), with independent rows. Both F(m) and Gm increase by N rows at each step, which corresponds to drawing a larger random sample for Gm.
Proof of Lemma 4
Consider
| (A13) |
First
| (A14) |
Next write
| (A15) |
and use lemma 19.9 of Arnold (reference [32], p. 365) to show As the Gaussian in q2 converges in probability to a point mass, . Finally
| (A16) |
with . Since the Gaussian vector in converges in probability to a point mass
| (A17) |
and the result follows.
Proof of Theorem 3
For the HLT, approximate unconditional power is defined in equation (15). By lemma 4, . Thus . The result follows by lemma 1 in Glueck and Muller [33]. For the univariate tests, convergence of HLA implies that limN(m)→∞ωU=ωU,LA, and the CDF of non-centrality becomes a point mass. Similar arguments apply to the Pillai-Bartlett and Wilks' tests. Hence they have the same asymptotic unconditional power under local alternatives.
REFERENCES
- 1.Sampson AR. A tale of two regressions. Journal of the American Statistical Association. 1974;69:682–689. [Google Scholar]
- 2.Jayakar AD. On the detection and estimation of linkage between a locus influencing a quantitative character and a marker locus. Biometrics. 1970;26:451–464. [PubMed] [Google Scholar]
- 3.Soller M, Genizi A. The efficiency of experimental designs for the detection of linkage between a marker locus and a locus affecting a quantitative trait in segregating populations. Biometrics. 1978;34:47–55. [Google Scholar]
- 4.Genizi A, Soller M. Power derivation in an ANOVA model which is intermediate between the `fixed-effects' and the `random-effects' models. Journal of Statistical Planning and Inference. 1979;3:127–134. [Google Scholar]
- 5.Gatsonis C, Sampson AR. Multiple correlation: exact power and sample size calculations. Psychological Bulletin. 1989;106:516–524. doi: 10.1037/0033-2909.106.3.516. [DOI] [PubMed] [Google Scholar]
- 6.Constantine AG. Some non-central distribution problems in multivariate analysis. Annals of Mathematical Statistics. 1963;34:1270–1285. [Google Scholar]
- 7.Pillai KCS, Jayachandran K. Power comparisons of tests of two multivariate hypotheses based on four criteria. Biometrika. 1967;54:195–210. [PubMed] [Google Scholar]
- 8.Sugiura N, Fujikoshi Y. Asymptotic expansions of the non-null distributions of the likelihood ratio criteria for multivariate linear hypothesis and independence. Annals of Mathematical Statistics. 1969;40:942–952. [Google Scholar]
- 9.Lee Y-S. Distribution of the canonical correlations and asymptotic expansions for distributions of certain independence test statistics. Annals of Mathematical Statistics. 1971;42:526–537. [Google Scholar]
- 10.Muirhead RJ. On the test of independence between two sets of variates. Annals of Mathematical Statistics. 1972;43:1491–1497. [Google Scholar]
- 11.Nagao H. Non-null distributions of the likelihood ratio criteria for independence and equality of mean vectors and covariance matrices. Annals of the Institute of Statistical Mathematics. 1972;24:67–79. [Google Scholar]
- 12.Fujikoshi Y. Asymptotic formulas for the non-null distributions of three statistics for multivariate linear hypothesis. Annals of the Institute of Statistics. 1975;22:99–108. [Google Scholar]
- 13.Fujikoshi Y. Comparison of powers of a class of tests for multivariate linear hypothesis and independence. Journal of Multivariate Analysis. 1988;26:48–58. [Google Scholar]
- 14.Anderson TW. An Introduction to Multivariate Statistical Analysis. 2nd edn Wiley; New York: 1984. [Google Scholar]
- 15.Kulp RW, Nagarsenker BN. An asymptotic expansion of the non-null distribution of Wilks' criterion for testing the multivariate linear hypothesis. Annals of Statistics. 1984;12:1576–1583. [Google Scholar]
- 16.Sugiyama T, Ushizawa K. Power of largest root in canonical correlation. Communications in Statistics: Simulations. 1992;21:947–960. [Google Scholar]
- 17.Muller KE, LaVange LM, Ramey SL, Ramey CT. Power calculations for general linear multivariate models including repeated measures applications. Journal of the American Statistical Association. 1992;87:1209–1226. doi: 10.1080/01621459.1992.10476281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Muller KE, Peterson BL. Practical methods for computing power in testing the multivariate general linear hypothesis. Computational Statistics and Data Analysis. 1984;2:143–158. [Google Scholar]
- 19.Muller KE, Barton CN. Approximate power for repeated measures ANOVA lacking sphericity. Journal of the American Statistical Association. 1989;84:143–158. correction, 1991; 86:255-256. [Google Scholar]
- 20.McKeon J. F approximations to the distribution of Hotelling's . Biometrika. 1974;61:381–383. [Google Scholar]
- 21.Davies RB. Algorithm AS 155: the distribution of a linear combination of chi-squared random variables. Applied Statistics. 1980;29:323–333. [Google Scholar]
- 22.SAS Institute Inc. SAS/IML User's Guide, Version 8. SAS Institute Inc.; Cary NC: 1999. [Google Scholar]
- 23.Thisted RA. Elements of Statistical Computing. Chapman and Hall; New York: 1988. [Google Scholar]
- 24.Sen PK, Singer JM. Large Sample Methods in Statistics: an Introduction with Applications. Chapman and Hall; New York: 1993. [Google Scholar]
- 25.Christiansen DH, Hosking JD, Helms RW, Muller KE, Hunter KB. LINMOD (3.1) Language Reference Manual. The University of North Carolina at Chapel Hill; Chapel Hill, NC: 1995. Freely available at http://www.bios.unc.edu/∼muller (04/01/2002) [Google Scholar]
- 26.Graybill FA. Matrices with Applications in Statistics. 2nd edn Wadsworth; Belmont, CA: 1983. [Google Scholar]
- 27.Johnson NL, Kotz S. Continuous Univariate Distributions. vol. 2. Houghton Mifflin; Boston: 1970. [Google Scholar]
- 28.Morrison DF. Multivariate Statistical Methods. 3rd edn McGraw Hill; New York: 1990. [Google Scholar]
- 29.Mathai AM, Provost SB. Quadratic Forms in Random Variables: Theory and Applications. Marcel Dekker; New York: 1992. [Google Scholar]
- 30.Johnson NL, Kotz S, Balakrishnan N. Continuous Univariate Distributions. 2nd edn vol. 2. Wiley; New York: 1995. [Google Scholar]
- 31.Helms RW. Comparisons of parameter and hypothesis definitions in a general linear model. Communications in Statistics - Theory and Methods. 1988;17:2725–2753. [Google Scholar]
- 32.Arnold SF. The Theory of Linear Models and Multivariate Analysis. Wiley; New York: 1981. [Google Scholar]
- 33.Glueck DH, Muller KE. On the expected value of sequences of functions. Communications in Statistics - Theory and Methods. 2001;30:363–369. doi: 10.1081/STA-100002037. [DOI] [PMC free article] [PubMed] [Google Scholar]