

Abstract
Measurement error occurs in many biomedical fields. The challenges arise when errors are heteroscedastic since we literally have only one observation for each error distribution. This paper concerns the estimation of smooth distribution function when data are contaminated with heteroscedastic errors. We study two types of methods to recover the unknown distribution function: a Fourier-type deconvolution method and a simulation extrapolation (SIMEX) method. The asymptotics of the two estimators are explored and the asymptotic pointwise confidence bands of the SIMEX estimator are obtained. The finite sample performances of the two estimators are evaluated through a simulation study. Finally, we illustrate the methods with medical rehabilitation data from a neuro-muscular electrical stimulation experiment.
Keywords: Smooth distribution function, Measurement errors, Kernels, Deconvolution, Fourier method, SIMEX, Heteroscedasticity, Confidence bands
1. Introduction
Many practical problems involve estimation of distribution functions or density functions from indirect observations. For example, in low level microarray data from either the complementary DNA (cDNA) microarray or the Affymetrix GeneChip system, each observation is an original signal coupled with a background noise. To obtain an expression measure, the goals often include developing better statistical tools or enhancing algorithms for background correction so that the disease genes can be detected accurately and efficiently. In medical image analysis, observable outputs are often blurred images. In astronomy, due to great astronomical distances and atmospheric noise, most data are subject to measurement errors. Statistical analyses that ignore measurement errors could be misleading. Measurement error model is an active, rich research field in statistics. There is an enormous literature on this topic in linear regression, as summarized by Fuller (1987) and in nonlinear models, as summarized by Carroll et al. (2006). In this paper, we investigate estimation methods of smooth distribution function from data contaminated with heteroscedastic measurement errors.
Nonparametric kernel type methods have been widely used in estimating density functions and their derivatives or in regression. Kernel smoothing is also an important tool for distribution function estimation. The kernel estimate of a distribution function, first introduced by Nadaraya (1964), has been investigated by many authors (Azzalini, 1981; Reiss, 1981; Sarda, 1993; Bowman et al., 1998). The kernel smooth estimator, which has good statistical properties, can be expressed as
| (1) |
where X1, X2, …, Xn are independent random variables with the common distribution function FX and the density function fX. The function L is defined from a kernel K as , where K(·) is some bounded density function with K(t) = K(−t) for all t ∈ ℝ and hn > 0 is the smoothing parameter with hn → 0 and nhn → ∞ as n → ∞. The conventional empirical distribution function (EDF) can be obtained by letting hn → 0, when L(·) is replaced by an indictor function I(Xi ≤ x). It is noted that F̂ in (1) can be written as
where f̂ is the well-known kernel density estimator.
In real data applications, there are many examples where observable data are contaminated with measurement errors and it is not realistic to assume that the errors are homoscedastic. The measurement process might be subjective and differs among all individuals. Fuller (1987) had an early consideration of this problem. Cheng and Riu (2006) discussed the point estimation of the parameters in a linear measurement error (heteroscedastic errors in variables) model. Kulathinal et al. (2002) considered estimation problem of an errors-in-variables regression model when the variances of the measurement errors vary between observations in the analysis of aggregate data in epidemiology. Sun et al. (2002) studied a measurement error model with application to astronomical data that came with information on their heteroscedastic errors. In the research of density estimation with measurement errors, the literature is vast; see for example, Fan (1991); Zhang (1990); Stefanski and Carroll (1990); Carroll and Hall (1989); Delaigle and Gijbels (2004). They focused on the study of the deconvoluting kernel density estimation through an inverse Fourier transform with the case of homoscedastic errors. Until very recently, Delaigle and Meister (2008) studied the deconvoluting kernel estimator under the heteroscedastic setting. Staudenmayer et al. (2008) addressed a different type of model, where the observable data with heteroscedastic measurement errors were assumed normally distributed. A Monte Carlo Markov chain and a random-walk Metropolis-Hastings algorithm were proposed to estimate the unknown density.
Estimating cumulative distribution functions with measurement errors was also of interest. The sample cumulative distribution function is a nonlinear function of data and is biased when it is estimated ignoring measurement errors. Stefanski and Bay (1996) studied the estimation of a discrete population cumulative distribution function when data were contaminated with measurement errors. Using the method of simulation extrapolation (SIMEX) (Cook and Stefanski, 1994; Stefanski and Cook, 1995), they proposed a bias-adjusted estimator that reduced much of the bias. Later, Cordy and Thomas (1996) considered an expectation-maximization algorithm for estimating a distribution function when data were from a mixture of a finite number of known distribution. Nusser et al. (1996) presented a method for estimating distributions with additive normal errors with application to a study of daily dietary intakes. Their approach differed from the kernel estimators in that they assumed that a transformation existed such that both the original observations and the measurement errors were normally distributed. Most recently, Hall and Lahiri (2008) studied Fourier-type estimation of distributions, moments, and quantiles with homoscedastic errors.
Challenges of estimation problems arise when errors are heteroscedastic where we literally have only one observation for each error distribution. In this paper, we study two types of methods to recover the unknown smooth distribution function: a Fourier-type deconvolution method and a SIMEX method, when data are contaminated with heteroscedastic errors. In section 2, we first extend Hall and Lahiri’s (2008) Fourier-type estimator to the case of heteroscedastic errors and then generalize the work of Stefanski and Bay (1996) to estimate the smooth distribution function with heteroscedastic errors using SIMEX. The asymptotics of the two estimators are studied and the asymptotic pointwise confidence bands of the SIMEX estimator are obtained. In section 3, we conduct a simulation study to compare the finite sample performances of the two estimators. In section 4, we apply our proposed method to real data in a medical rehabilitation study. In section 5, we close this paper with a discussion.
2. Estimation methods
To investigate the estimation of the smooth distribution function for data contaminated with heteroscedastic errors, we first consider a general heteroscedastic measurement error model. Let Y1, ···, Yn be an observed random sample such that
| (2) |
with the measurement error Uj independent of Xj. Each Uj has its own density fUj, j = 1, ···, n, where fU1, ···, fUn are from a same distributional family, but the measurement error distribution’s parameters vary with the observation index. If fU1 = ··· = fUn = fU, the errors are said to be homoscedastic; otherwise, the errors are heteroscedastic. One is to recover the unknown distribution function of the unobserved continuous random variable X, where fX is the density function of X.
2.1. Fourier-type Deconvolution
Denote the characteristic functions of X and Uj by φX and φUj (j = 1, ···, n), respectively. Through an inverse Fourier transform, Delaigle and Meister’s (2008) deconvolution estimator for the density with heteroscedastic errors can be written as a form of a kernel-type density estimator,
| (3) |
where
and φK is the characteristic function of a symmetric probability kernel, K(·), with a finite variance. It is noted that f̂X,Fourier in (3) becomes the conventional deconvoluting kernel estimator (Stefanski and Carroll, 1990) for homoscedastic errors when fU1= ··· = fUn = fU.
Similarly to Hall and Lahiri (2008), our distribution estimator F̂X,Fourier in the case of heteroscedastic errors is defined as simply the integral of f̂X,Fourier over (−∞, x]. Let
By integrating f̂X,Fourier in (3), we have
| (4) |
We now study asymptotic properties of our estimator. Due to the nature of the deconvolution kernel estimation, similarly as defined in Fan (1991), we consider a slightly different definition of the distribution function estimator as in the following form to derive the asymptotics. For a sequence of positive numbers Mn → ∞ as n → ∞,
Here we included the terms about Mn in the uniform bound. Conventionally, Mn can be selected to be proportional to , similar to that discussed in Fan (1991). Note that the bandwidth hn depends on n when studying the asymptotics. We assume the following conditions:
- For an integer m ≥ 0, 0 < α ≤ 1,
K(x) < D · |x|−m−2 for all x;
φK(t) has support [−1, 1];
Condition C of Delaigle and Meister (2008).
The asymptotic behavior of the estimator is described in the next theorem.
Theorem 1
Assume Conditions (1) – (4). Then, for x0 ∈ ℝ with specifically chosen sequence of numbers Mn → ∞ and bandwidth hn → 0, we have
Remark 1
The last term of the upper bound reflects the effect of the heteroscedastic measurement errors to the estimation of the unknown distribution function. The smoothness of the measurement error distributions influence the convergence rate of the distribution function estimation, as discussed in Fan (1991). In the above theorem, we present a general asymptotic result of our estimator. The specific convergence rate could be obtained similar as in Hall and Lahiri (2008), where they classified the distribution functions of the unobservable random variable and the measurement errors into eight classes.
2.2. SIMEX
SIMEX is a “jackknife”-type bias-adjusted method that has been widely applied in regression problems with measurement errors. Stefanski and Cook (1995) applied the SIMEX algorithm to parametric regression problems. Staudenmayer and Ruppert (2004), Carroll et al. (1999) discussed the nonparametric regression in the presence of measurement errors using SIMEX method. Stefanski and Bay (1996) studied SIMEX estimation of a finite population cumulative distribution function when sample units are measured with errors. Now we generalize Stefanski and Bay’s (1996) method to estimate the smooth distribution function with heteroscedastic Gaussian errors.
Under the model setting (2), we further assume , for j = 1, ···, n. Typically, σj can be obtained from auxiliary data. By the general SIMEX algorithm, estimators are re-computed from a large number B of measurement error-inflated pseudo data sets, , b = 1, ···, B, with
where Zjb are independent, standard normal pseudo-random variables, and λ ≥ 0 is a constant controlling the amount of added errors.
The smooth distribution function estimator from the bth variance-inflated data is
where L(·) is defined from a kernel K(·) as and K(·) is a symmetric kernel with a finite variance such that ∫ K(t)dt = 1, ∫ tK(t)dt = 0, and ∫ t2K(t)dt < ∞.
In the general SIMEX algorithm, the simulation and estimation steps are repeated a large number of times, and the average value of the estimators for each level of contamination is calculated by,
| (5) |
However, it is noted that Ujb = σjZjb, where Zjb are independent, standard normal random variables. With a fixed j (j = 1, ···, n), let h̃j = h/(σjλ1/2), we have
Notice that the smooth distribution estimator is asymptotically unbiased and has the same variance as the EDF. It uniformly converges to the true distribution function with probability one (Nadaraya, 1964). Hence, with a fixed j, conditional on Yj,
where Φ(·) denotes the distribution function of the standard normal distribution.
Therefore, the simulation step can be bypassed in the SIMEX algorithm for the distribution estimation. We use Ĝ* in (6) to replace Ĝ in (5) for our estimation,
| (6) |
The above equation has some similarity with equation (3) in Stefanski and Bay (1996). We further calculate the quantity in (6) for a pre-determined sequence of λ, i.e. 0 ≤ λ1 < λ2 < ··· < λl. The success of SIMEX technique depends on the fact that the expectation of Ĝ* is well-approximated by a nonlinear function of λ (Carroll et al., 2006). Here we consider the conventional quadratic function of λ, i.e.
It is indeed a good approximation when is not very large. The SIMEX estimator for the unknown distribution function FX without measurement error can be obtained by the extrapolation step, i.e. letting λ → −1,
| (7) |
The following proposition shows that, in the case of heteroscedastic Gaussian errors, our estimator (7) is an asymptotically unbiased estimator for the unknown distribution function FX, if the extrapolant is exact.
Proposition 1
Assume (a) the polynomial extrapolant is exact, (b) the distribution function FX(x) of unobserved X1, ···, Xn has continuous fourth derivative, and (c) for all j and C0 < ∞. Then, the estimator (7) is an asymptotically unbiased estimator of FX(x). The corresponding asymptotic variance is FX(x)(1 − FX(x))/n, which can be consistently estimated by F̂X,SIMEX(x)(1 − F̂X,SIMEX(x))/n.
Remark 2
Under realistic applications, the assumption (a) in proposition 1 will only be approximately true. See for instance Carroll et al. (1999); Staudenmayer and Ruppert (2004). As we show in the equation (8) in Appendix, the expectation of Ĝ*(x, λ) is a quadratic function of λ at a given x plus the approximation error term, . The success of the SIMEX method in practice depends on the fact that E[Ĝ*(x, λ)] can well-approximated by a quadratic function of λ.
From proposition 1, the estimated asymptotic pointwise confidence bands when data are contaminated with heteroscedastic Gaussian errors have the form
where c is chosen as the (1− α/2) quantile of the standard normal distribution.
Remark 3
Due to the heterogeneity of measurement errors, the variance estimation method in Stefanski and Bay (1996) can not be applied to our proposed estimator F̂X,SIMEX(x). However, the variance of F̂X,SIMEX(x) can be well approximated by the variance of Ĝ*(x, λ) as λ → −1. The latter can then be approximately consistently estimated. The naive confidence bands therefore can be constructed. The confidence bands based on the aforementioned variance estimation are simulated. It almost coincides the nonparametric bootstrap confidence band. This variance estimation of the distribution function can also be applied to the case of homoscedastic measurement errors.
Remark 4
In the SIMEX distribution estimation, it is possible that the estimated values are out of [0, 1] in tail regions. This situation is similar to many classes of kernel methods, such as wavelet density estimators, sinc kernel estimators, and spline estimators. The disadvantage will not affect the global performance of our estimation. A simple correction version of our SIMEX estimator in practice is
3. Numerical Study
3.1. Empirical choice of smoothing parameters
In the Fourier-type method, we consider a modified “plug-in” approach to select the bandwidth hn. Fan (1992) proposed a plug-in asymptotical bandwidth for the density estimation with homoscedastic errors. Delaigle and Gijbels (2004) suggested a “normal reference” approach and Hall and Lahiri (2008) discussed it for distribution estimation with homoscedastic errors. Here we adopt Hall and Lahiri’s (2008) “normal reference” bandwidth approach for the case of heteroscedastic errors. Specifically, we shall temporarily take fX be a normal density; and calculate an estimator of as the variance of the data Y minus , where .
The SIMEX estimator requires specification of λ1, ···, λl. They are not the smoothing parameters in the sense of the conventional kernel estimation. They act as “design points” of our estimator, which is similar to the knots in a spline (Kooperberg and Stone, 1992). So, the choice of λ1, ···, λl is not as sensitive as the bandwidth in density estimation is. Based on our extensive simulations, our experience suggests that the number of values, l, is not critical and neither is that of λl if λ1 is determined. Note that σjλ1/2 in (6) has some similarity to a bandwidth. Our proposed rule-of-thumb choice of λ1 can be obtained by solving the equation
where ĥrot,Y is the Silverman’s rule-of-thumb bandwidth (Silverman, 1986) based on the observed data Y and is a coefficient to adjust the effect of measurement errors. The sequence λ1, ···, λl is then taking equally-spaced values over the interval [λ1, 3 + λ1] with l = 50.
3.2. Finite-sample performance
We now investigate the finite sample performances of the Fourier-type estimator and the SIMEX estimator via a simulation study. Our study involves three types of target distributions: (1) X ~ N(0, 1), (2) X ~ 0.5 N(−3, 1) + 0.5 N(3, 1), and (3) X ~ Γ(2, 1). From each of these distributions, 500 samples of size n = 50, 100, and 500 are generated, each of which is then contaminated by heteroscedastic errors. The measurement errors are generated from , where σj (j = 1, ···, n) are generated from U(a, b) and (a, b) are chosen to be (0.4, 0.6), (0.8, 1), respectively.
To assess the quality of the smooth distribution function estimators, we use the integrated squared error (ISE) criterion:
We compare four estimators in the study: the Fourier-type estimator; the SIMEX estimator; the naive estimator, i.e. the smooth distribution estimator of Y where measurement errors are ignored; and the smooth distribution estimator from the uncontaminated sample X.
Table 1 summarizes the results of the average of the 500 ISEs for different estimators under different simulation conditions. The simulation results show that both the Fourier-type estimator and the SIMEX estimator perform much better than the naive estimator in terms of the ISE criterion. The ISEs for the Fourier-type method and the ISEs for the SIMEX method become smaller and closer to the ISEs from the uncontaminated sample when sample sizes become larger. We also note that the ISEs are larger at the case of σU ~ U(0.8, 1) than those at the case of σU ~ U(0.4, 0.6) under the same simulation conditions. This is due to the level of difficulty of deconvolution. Comparing the Fourier method and the SIMEX method, we find that SIMEX estimator performs better than the Fourier method when the sample sizes are small and error variances are large. They become very close as sample size is sufficiently large. This is not surprising because the converge rate is slow for the Fourier method while the SIMEX method is fast when the polynomial extrapolant is accurate.
Table 1.
The average ISEs for the case of heteroscedastic Gaussian errors in the simulation study.
| ISE |
||||||
|---|---|---|---|---|---|---|
| Error | True dist* | Sample size | Fourier | SIMEX | Naive | F̂X(x) |
| σU ~ U(0.4, 0.6) | Normal | 50 | 0.0119 | 0.0127 | 0.0151 | 0.0095 |
| 100 | 0.0056 | 0.0058 | 0.0086 | 0.0045 | ||
| 500 | 0.0018 | 0.0016 | 0.0043 | 0.0010 | ||
| Mixture | 50 | 0.0124 | 0.0119 | 0.0215 | 0.0103 | |
| 100 | 0.0078 | 0.0074 | 0.0171 | 0.0061 | ||
| 500 | 0.0032 | 0.0031 | 0.0091 | 0.0014 | ||
| Gamma | 50 | 0.0184 | 0.0157 | 0.0282 | 0.0112 | |
| 100 | 0.0107 | 0.0090 | 0.0218 | 0.0057 | ||
| 500 | 0.0039 | 0.0041 | 0.0158 | 0.0016 | ||
| σU ~ U(0.8, 1) | Normal | 50 | 0.0241 | 0.0228 | 0.0291 | 0.0091 |
| 100 | 0.0165 | 0.0138 | 0.0257 | 0.0044 | ||
| 500 | 0.0073 | 0.0059 | 0.0166 | 0.0011 | ||
| Mixture | 50 | 0.0252 | 0.0218 | 0.0316 | 0.0102 | |
| 100 | 0.0171 | 0.0147 | 0.0286 | 0.0059 | ||
| 500 | 0.0089 | 0.0069 | 0.0197 | 0.0018 | ||
| Gamma | 50 | 0.0262 | 0.0230 | 0.0395 | 0.0109 | |
| 100 | 0.0193 | 0.0187 | 0.0303 | 0.0062 | ||
| 500 | 0.0097 | 0.0072 | 0.0211 | 0.0017 | ||
Normal = N(0, 1); Mixture = 0.5N(−3, 1)+0.5N(3, 1); Gamma = Γ(2, 1).
Figure 1 allows us to display and compare estimated curves visually. In the upper plot, the true distribution is standard normal, N(0, 1). The measurement errors are generated from and σj ~ U(0.4, 0.6), j = 1, ···, n with sample size n = 500. The solid line is the smooth distribution estimator from X; the dashed line is the SIMEX estimator; the dotted line is the Fourier estimator; and the dot-dashed line is the naive estimator. Both the Fourier estimator and the SIMEX estimator give very close results. They recover the true distribution accurately from the sample Y, while the naive estimator is far from the true distribution functions. In the lower plot, the true distribution is a normal mixture 0.5 N(−3, 1) + 0.5 N(3, 1). The measurement errors are generated from and θi ~ U(0.8, 1), j = 1, ···, n with sample size n = 500. Despite of the complexity of the true distribution and measurement errors, we see that both the Fourier method and the SIMEX method perform well in recovering the true distribution function.
Figure 1.

Distribution estimation for data contaminated with heteroscedastic errors: In the upper plot, the true distribution is standard normal, N(0, 1). The measurement errors are from and σj ~ U(0.4, 0.6), j = 1, ···, n with sample size n = 500. In the lower plot, the true distribution is a normal mixture 0.5N(−3, 1) + 0.5N(3, 1). The measurement errors are from and σj ~ U(0.8, 1), j = 1, ···, n with sample size n = 500. Solid line – the smooth distribution estimator from X; dashed line – the SIMEX estimator; dotted line – the Fourier estimator; dot-dashed line – the naive estimator.
To investigate the performance of the estimated asymptotic confidence bands with the SIMEX method derived in the last section, we compare them with the nonparametric bootstrap confidence bands and the estimated confidence bands from the uncontaminated sample X. Figure 2 shows a simulated example of the SIMEX estimate and three different confidence bands of the distribution function F(x). The true distribution is a normal mixture 0.5N(−3, 1) + 0.5N(3, 1) and the measurement errors are generated from and σj ~ U(0.8, 0.9), j = 1, ···, n with sample size n = 500. The solid lines are the SIMEX estimate and its 95% associated asymptotic confidence bands from contaminated sample Y. The dashed lines are the nonparametric bootstrap confidence bands from Y. The number of bootstrap replicates is 1000. The dotted lines are the estimated confidence bands from the uncontaminated sample X. The estimated asymptotic confidence bands are nearly identical with the nonparametric bootstrap confidence bands and are very close to the the estimated confidence bands from uncontaminated sample except in the tail areas. The asymptotic estimates of confidence bands, hence, are recommended due to their simplicity and computational easiness.
Figure 2.

The SIMEX estimator and its associated 95% confidence bands of the distribution function: the true distribution is normal mixture 0.5N(−3, 1) + 0.5N(3, 1). The measurement errors are from and σj ~ U(0.8, 0.9), i = 1, ···, n with sample size n = 500. Solid line – the SIMEX estimator and its associated asymptotic confidence bands; dashed line – the nonparametric bootstrap confidence bands; dotted line – the estimated confidence bands from uncontaminated sample X.
4. A real data application
Spinal cord injury (SCI) is damage to the spinal cord often due to traumatic accident, resulting in upper and lower motor neuron lesions. It typically leads to paralysis and loss of sensation in parts of the body controlled through the spinal cord below the level where the injury occurred. All individuals with SCI, and particularly those with complete lesions, are considered to be at high risk of pressure ulcer development throughout their lifetime. Pressure ulcers are areas of damaged skin and tissue that develop when sustained pressure occurs. Traditionally, techniques to reduce pressure ulcer incidence have focused on reducing extrinsic risk factors. These techniques include providing cushions to improve pressure distribution. Another approach is educating individuals on the importance of regular pressure relief procedures. Neuro-muscular electrical stimulation (NMES) is the application of electrical stimuli to a group of muscles, which is a new clinic tool for pressure ulcers to produce beneficial changes at the user/support system interface by altering the intrinsic characteristics of the user’s paralyzed tissue itself (Bogie et al., 2006, 2008).
The primary goal of the NMES study at Cleveland FES center was to investigate the distribution of pressure intensities for each patient under different clinical conditions such as before and after NMES treatment. Pressure intensity data at the seating interface for each patient were recorded by using the Tekscan advanced clinseat pressure mapping system (Tekscan, Inc.). The seating interface was divided as a 48 × 42 matrix. The pressure intensity of each element was measured simultaneously. Figure 3 displays an example of pressure intensity data in the NMES study. Pressure intensities at the seating area for one subject correspond to color-scale rectangular segments in the image. The color bar indicates the mapping from data values to colors. However, the outcomes of pressure intensities are subject to measurement errors. Measurements were taken at several different times for a patient, resulting in replicate measurements of pressure intensity maps. It is reasonable to assume that the observable intensities are contaminated with heteroscedastic Gaussian errors at the seating area. From the replicate measurement data, we are able to estimate the heteroscedastic variances of measurement errors for each active location. Hence, the fundamental statistical question is how to estimate the unobserved distribution of pressure intensities from the data contaminated with errors. In this example, our pressure data contain total 1518 activated observations. The pressure intensities with measurement errors have mean 42.99 and standard deviation 16.73. The range of the observed intensities is from 11.0 to 120.0. The heteroscedastic standard deviations of measurement errors vary from 6.32 to 8.01.
Figure 3.
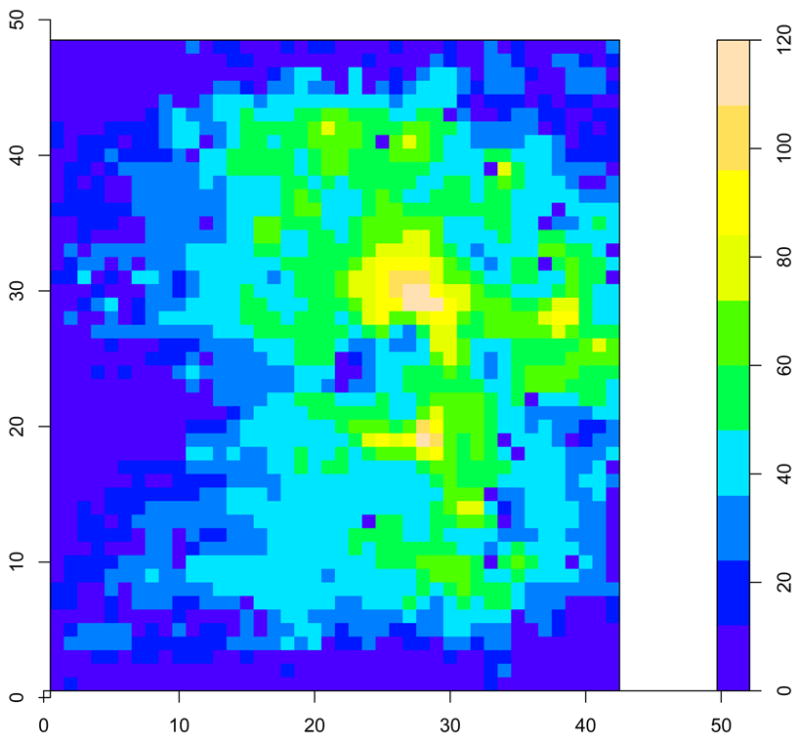
An example of pressure intensity data at the seating interface for one subject: each pressure intensity at the seating area corresponds to a color-scale rectangular segment in the image. The color bar indicates the mapping from intensity values to colors.
We conduct the analysis using both the Fourier-type and the SIMEX methods for the data from the NMES study. Figure 4 displays the smooth distribution estimation of pressure intensities in the single case study. The solid line is the estimated distribution function by the SIMEX method and the dotted line is the estimate by the Fourier-type method, while the dashed line is the estimated distribution function by the naive method where measurement errors are ignored. The recovered function shows asymmetric features. Both the Fourier-type estimator and the SIMEX estimator obtain coincident results and there is only a slight difference at the left tails. The curve for the naive estimator does not fall within the confidence region of the SIMEX estimator. The example demonstrates that correcting the measurement errors is critical in the statistical analysis. After recovering the distribution function, we will be able to make further statistical inferences, such as comparing two recovered distribution functions under different clinical treatments.
Figure 4.

Smooth distribution estimation of pressure intensities in the NMES study. Three estimators are considered here: the SIMEX estimator (solid line); the Fourier-type estimator (dotted line); the Naive estimator, i.e. ignoring the measurement errors (dashed line). The gray region is the 95% confidence region of the SIMEX estimator.
5. Discussion
We studied two bias-correction methods to estimate smooth distribution function for the data contaminated with heteroscedastic errors. The Fourier-type method was generalized from the conventional deconvolution kernel method (Hall and Lahiri, 2008), which can be applied to any arbitrary error distributions. The SIMEX method, extending the Stefanski and Bay’s (1996) work, was easy to be implemented and computationally fast due to the fact that the simulation step was bypassed. As shown in the simulation results, both methods allowed us to recover accurately the true distribution function from a contaminated sample when the sample size was large. However, the SIMEX method worked better than the Fourier-type method when sample size was small and the variances of measurement errors were large. The asymptotic variance of the SIMEX estimator was obtained and the simulation showed that the native estimate of the asymptotic confidence bands performed very well. Thus, applying the SIMEX method in real applications would be attractive.
We addressed in section 2 that the success of the SIMEX method depended on the fact that the expectation of Ĝ*(x, λ) was well-approximated by a quadratic function of λ for a small . How large should the error level be for the SIMEX method to be feasible? With a moderate sample size, our simulations suggested that max(σj) < 1 could work adequately well for the three special cases considered here. For other cases, more simulations and study would be needed in order to answer the above question.
The SIMEX method we discussed only dealt with the case of the Gaussian errors, while the Fourier-type method could work with a large classes of errors including both super-smoothed errors and ordinary-smoothed errors as defined by Fan (1991). Indeed, the SIMEX method could also be applied to the case of exponential errors. Sometimes, measurement errors only could be positive in medical applications. An exponential distribution, as a non-zero mean, skewed distribution, was a common assumption in those studies (Ballico, 2001; Savin, 2000). We noticed that, however, the SIMEX estimator in the case of exponential errors was not asymptotically unbiased even if the polynomial extrapolant was exact. A natural idea was to apply an extra smoothing step (i.e. smoothing splines) on F̂X,SIMEX(x) to reduce the bias in the estimation. Our extended simulation study showed that the extra smoothing step made the SIMEX estimator for exponential errors surprisingly well to recover the true distribution.
As one of reviewers pointed out, it would be interesting to compare the performances of our estimators with (homoscedastic) estimators that heteroscedastic measurement error variances were replaced by a constant measurement error variance (the average of heteroscedastic variances). Our preliminary simulation showed that the degree of variation of heteroscedastic measurement error variances affected the estimators using the constant variance. A more comprehensive study of the model misspecification problem for both density and distribution estimation could be done in our future research.
The research of the confidence bands for the Fourier-type method remained as an open problem. Bissantz et al.’s (2007) nonparametric confidence intervals in deconvolution density estimation was relevant where they only focused on the homoscedastic and ordinary-smoothed errors.
Acknowledgments
We are grateful to the reviewers and the associate editor for their valuable comments. We thank Dr. Kath Bogie from the Cleveland FES center and Case Western Reserve University for making NMES clinical data available for this analysis. The research of Xiao-Feng Wang is supported in part by the NIH Clinical and Translational Science Awards. The research of Zhaozhi Fan is supported in part by the Natural Sciences and Engineering Research Council of Canada.
Appendix
Proof of Theorem 1
Under the regularity conditions (1) ~ (4), for x0 ∈ (−∞,∞) with specifically chosen sequence of numbers Mn → ∞ and bandwidth hn → 0, the bias of F̂n,Fourier(x0) is
The norm of the bias is then
It is uniformly bounded from above by
On the other hand, the variance of F̂n,Fourier(x0) is
which is uniformly bounded from above by
Thus, the conclusion follows.
Proof of Proposition 1
Under the conditions (a) ~ (c),
where Z is a standard normal random variable. By Lebesgue dominated convergence theorem, limλ→−1 E [Ĝ*(x, λ)]= F(x).
Using Taylor expansion, if, is small, the above expectation can be written as
| (8) |
Hence the expectation of Ĝ*(x, λ) is well-approximated by a quadratic function of λ at a given x with the approximation error . i.e. E[Ĝ*(x, λ)] ≈ β0 + β1λ + β2λ2.
Therefore,
By analogous argument as above, the variance of Ĝ*(x, λ) is
where V is a standard normal random variable,
which has standard normal distribution. W is a standard normal random variable, independent of V.
By Lebesgue dominated convergence theorem,
thus, it can then be estimated by F̂X,SIMEX(x)(1 − F̂X,SIMEX(x))/n. The proof is complete.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Azzalini A. A note on the estimation of a distribution function and quantiles by a kernel method. Biometrika. 1981;68:326–328. [Google Scholar]
- Ballico M. Calculation of key comparison reference values in the presence of non-zero-mean uncertainty distributions, using the maximum-likelihood technique. Metrologia. 2001;38:155–159. [Google Scholar]
- Bogie KM, Wang X, Fei B, Sun J. New technique for real-time interface pressure analysis: Getting more out of large image data sets. Journal of Rehabilitation Research and Development. 2008;45 (4):523–536. doi: 10.1682/JRRD.2007.03.0046. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bogie KM, Wang X, Triolo RJ. Long-term prevention of pressure ulcers in high-risk patients: a single case study of the use of gluteal neuromuscular electric stimulation. Arch Phys Med Rehabil. 2006;87 (4):585–591. doi: 10.1016/j.apmr.2005.11.020. [DOI] [PubMed] [Google Scholar]
- Bowman A, Hall P, Prvan T. Bandwidth selection for the smoothing of distribution functions. Biometrika. 1998;85:799–808. [Google Scholar]
- Carroll RJ, Hall P. Optimal rates of convergence for deconvolving a density. Journal of the American Statistical Associations. 1989;83:1184–1186. [Google Scholar]
- Carroll RJ, Maca J, Ruppert D. Nonparametric regression in the presence of measurement error. Biometrika. 1999;86:541–554. [Google Scholar]
- Carroll RJ, Ruppert D, Stefanski LA, Crainiceanu C. Measurement Error in Nonlinear Models: A Modern Perspective. 2. Chapman Hall; New York: 2006. [Google Scholar]
- Cheng CL, Riu J. On estimating linear relationships when both variables are subject to heteroscedastic measurement errors. Technometrics. 2006;48:511–519. [Google Scholar]
- Cook JR, Stefanski LA. Simulation extrapolation estimation in parametric measurement error models. Journal of the American Statistical Association. 1994;89:1314–1328. [Google Scholar]
- Cordy C, Thomas D. Deconvolution of a distribution function. Journal of the American Statistical Association. 1996;92:1459–1465. [Google Scholar]
- Delaigle A, Gijbels I. Practical bandwidth selection in deconvolution kernel density estimation. Computational Statistics and Data Analysis. 2004;45:249–267. [Google Scholar]
- Delaigle A, Meister A. Density estimation with heteroscedastic error. Bernoulli. 2008;14:562–579. [Google Scholar]
- Fan J. On the optimal rates of convergence for nonparametric deconvolution problems. The Annals of Statistics. 1991;19:1257–1272. [Google Scholar]
- Fan J. Deconvolution with supersmooth distributions. The Canadian Journal of Statistics. 1992;20:155–169. [Google Scholar]
- Fuller WA. Measurement Error Models. John Wiley & Sons; New York: 1987. [Google Scholar]
- Hall P, Lahiri SN. Estimation of distributions, moments and quantiles in deconvolution problems. Annals of Statistics. 2008;36 (5):2110–2134. [Google Scholar]
- Kooperberg C, Stone C. Logspline density estimation for censored data. Journal of Computational and Graphical Statistics. 1992;1:301–328. [Google Scholar]
- Kulathinal SB, Kuulasmaa K, Gasbarra D. Estimation of an errors-in-variables regression model when the variances of the measurement errors vary between the observations. Statistics in Medicine. 2002;21:1089–1101. doi: 10.1002/sim.1062. [DOI] [PubMed] [Google Scholar]
- Nadaraya EA. Some new estimates for distribution functions. Theory of Probability and its Applications. 1964;9:497–500. [Google Scholar]
- Nusser SM, Carriquiry AL, Dodd KW, Fuller WA. A semi-parametric transformation approach to estimating usual daily intake distributions. Journal of the American Statistical Association. 1996;91 (436):1440–1449. [Google Scholar]
- Reiss RD. Nonparametric estimation of smooth distribution functions. Scandinavian Journal of Statistics. 1981;8:116–119. [Google Scholar]
- Sarda P. Smoothing parameter selection for smooth distribution functions. Journal of Statistical Planning and Inference. 1993;35:65–75. [Google Scholar]
- Savin SK. Reliability of parameter control with exponential error. Measurement Techniques. 2000;43:329–334. [Google Scholar]
- Silverman BW. Density Estimation. Chapman and Hall; London: 1986. [Google Scholar]
- Staudenmayer J, Ruppert D. Local polynomial regression and simulation-extrapolation. Journal of the Royal Statistical Society, Series B. 2004;66:17–30. [Google Scholar]
- Staudenmayer J, Ruppert D, Buonaccorsi J. Density estimation in the presence of heteroskedastic measurement error. Journal of the American Statistical Association. 2008;103:726–736. [Google Scholar]
- Stefanski LA, Bay JM. Simulation extrapolation deconvolution of finite population cumulative distribution function estimators. Biometrika. 1996;83:407–417. [Google Scholar]
- Stefanski LA, Carroll RJ. Deconvoluting kernel density estimators. Statistics. 1990;21:169–184. [Google Scholar]
- Stefanski LA, Cook JR. Simulation extrapolation: the measurement error jackknife. Journal of the American Statistical Association. 1995;90:1247–1256. [Google Scholar]
- Sun J, Morrison H, Harding P, Woodroofe M. Density and mixture estimation from data with measurement errors. 2002 Technical Report, http://sun.cwru.edu/~jiayang/india.ps.
- Zhang CH. Fourier methods for estimating mixing densities and distributions. The Annals of Statistics. 1990;18:806–830. [Google Scholar]