

Abstract
Procedures for estimating the parameters of the general class of semiparametric models for recurrent events proposed by Peña and Hollander (2004) are developed. This class of models incorporates an effective age function encoding the effect of changes after each event occurrence such as the impact of an intervention, it models the impact of accumulating event occurrences on the unit, it admits a link function in which the effect of possibly time-dependent covariates are incorporated, and it allows the incorporation of unobservable frailty components which induce dependencies among the inter-event times for each unit. The estimation procedures are semiparametric in that a baseline hazard function is nonparametrically specified. The sampling distribution properties of the estimators are examined through a simulation study, and the consequences of mis-specifying the model are analyzed. The results indicate that the flexibility of this general class of models provides a safeguard for analyzing recurrent event data, even data possibly arising from a frailtyless mechanism. The estimation procedures are applied to real data sets arising in the biomedical and public health settings, as well as from reliability and engineering situations. In particular, the procedures are applied to a data set pertaining to times to recurrence of bladder cancer and the results of the analysis are compared to those obtained using three methods of analyzing recurrent event data.
Keywords: Correlated inter-event times, counting process, effective age process, EM algorithm, frailty; intensity models, model mis-specification, sum-quota accrual scheme
1 Introduction
Recurrent events occur in many settings such as in biomedicine, public health, clinical trials, engineering and reliability studies, politics, economics, sociology, actuarial science, among others. Examples of recurrent events in the biomedical and public health settings are the re-occurrence of a tumor after surgical removal in cancer studies, epileptic seizures, drug or alcohol abuse of adolescents, outbreak of a disease such as encephalitis, recurring migraines, hospitalization, movement in the small bowel during fasting state, onset of depression, nauseous feeling when taking drugs for the dissolution of cholesterol gallstones, recurrence of caries, ulcers or inflammation in an oral health study, and angina pectoris for patients with coronary disease. Some other specific biomedical examples of recurrent events are described in Cook and Lawless (2002). In the engineering and reliability settings, recurrent events could be the breakdown or failure of a mechanical or electronic system, the discovery of a bug in an operating system software, the occurrence of a crack in concrete structures, the breakdown of a fiber in fibrous composites, among others. Non-life insurance claims, traffic accidents, terrorist attacks, the Dow Jones Industrial Average decreasing by more than 200 points on a trading day, change of employment, among many others, are but a few examples of recurrent phenomena in other settings.
There are several models and methods of analysis used for recurrent event data. See for example Hougaard (2000), Therneau and Hamilton (1997), and Therneau and Grambsch (2000) for some current approaches to analyzing recurrent event data. However, as pointed out in Peña and Hollander (2004), there is still a need for a general and flexible class of models that simultaneously incorporates the effects of covariates or concomitant variables, the impact on the unit of accumulating event occurrences, the effect of performed interventions after each event occurrence, as well as the effect of latent or unobserved variables which, for each unit, endow correlation among the inter-event times. In recognition of this need, Peña and Hollander (2004) proposed a general class of models for recurrent events which satisfies the above requirements. This class of models will be described in Section 2. The current paper deals with inference issues, specifically the estimation of parameters, for this new class of models. However, we limit the scope of this paper to examining the finite-sample properties through simulation studies of the resulting estimators and defer the analytical and asymptotic analysis of their properties to a forthcoming paper.
We consider an observational unit (e.g., a patient in a biomedical setting, an electronic system in a reliability setting) that is being monitored for the occurrence of a recurrent event over a study period , where may represent an administrative time, time of study termination, or some other right-censoring variable. The time could be a random time governed by an unknown probability distribution function . Let be the successive calendar times of event occurrences, and let be the times between successive event occurrences. Thus, for and . Over the observation period , the number of event occurrences is , which is a random variable whose distribution depends on the distributional properties of the inter-occurrence times and the distribution of . As such, is informative with regards to the distributional properties of event occurrences.
Assume for this unit a, possibly time-varying, -dimensional vector of covariates such as gender, age, race, disease status, white blood cell counts (WBC), prostate specific antigen (PSA) level, weight, blood pressure, treatment regimen, etc. We suppose that over the period , the realization of this covariate process is observable. We denote this covariate process by , with “ ” representing vector/matrix transpose. For this subject, the observable entities over the study period are therefore
| (1) |
Notice that since , specifying renders redundant; however, we still include to indicate that is the right-censoring variable for the inter-occurrence time . Furthermore, since is random, then the distributional properties of both and may be of a complicated form. When considering the data structure in this recurrent event situation, there is a need to recognize that is informative and that the censoring mechanism for is informative (cf., Wang and Chang, 1999; Lin et al., 1999; Peña et al., 2001). These aspects are borne out of the sum-quota data accrual scheme since the number of observed events is tied-in to the distributions governing the event occurrences themselves.
The observable entities may also be represented more succinctly and beneficially through the use of stochastic processes. Still considering one unit, with denoting indicator function, define for calendar time , , which is the process counting the number of events observed on or before calendar time during the study period . Furthermore, define for calendar time , the “at-risk” process which indicates whether the subject is still under observation at calendar time or not. The data in (1) could be represented by
| (2) |
where is an upper limit of observation time. Note that even though is not observed for this does not pose a problem since for , and so for such a subject, there will be no information obtainable beyond . If in the study there are subjects, the observables will be , where and for ,
| (3) |
Equivalently,
and are the calendar times of successive event occurrences for the th subject, and is the censoring time of the th subject.
We provide an outline of the contents of this paper. Section 2 will present a description of the class of models for recurrent events that is under investigation. Section 3 will examine the problem of estimating the parameters of the model when there are no frailty components. The results here are needed for the estimation procedure in the presence of frailties described in Section 4. Section 5 will summarize results of the simulation studies pertaining to the properties of the estimators. We demonstrate the estimation procedures discussed in Sections 3 and 4 on real data sets in Section 6. Section 7 will provide some concluding thoughts.
2 A General Class of Models
In this section we describe the general class of models for recurrent events in Peña and Hollander (2004). Let be a vector of independent and identically distributed (i.i.d.) positive-valued random variables from a parametric distribution where is a finite-dimensional parameter taking values in . These variables are unobservable random factors affecting the event occurrences for the subjects. Also, let be a filtration or history on some probability space such that the and are predictable and such that the are counting processes with respect to . The general class of models requires the specification, possibly done dynamically, of predictable observable processes , satisfying the following conditions: (I) , almost surely (a.s.), where , are nonnegative real numbers; (II) ; and (III) On is monotone and almost surely differentiable with a positive derivative . The class of models is obtained by postulating that, conditionally on , the -compensator of is with
| (4) |
| (5) |
This means that the process is a square-integrable -martingale. In (5), is an unknown baseline hazard rate function; is of known functional form with and with ; and is a nonnegative link function of known functional form with . The unknown model parameters are , where is non-prarametrically specified, and , and are finite-dimensional parameters. The main impetus in introducing this general class of models for recurrent events is that it incorporates simultaneously the effects of covariates through the link function , the associations among the event inter-occurrence times through the unobservable frailty variables the effects attributable to the accumulating event occurrences for a subject through the component , and the effects of performed interventions after each event occurrence through the effective age processes which act on the baseline hazard rate function , and which may even have nonlinear forms. There is a potential interplay between the effective age process and the function. This issue will be discussed in Section 5 dealing with the simulation studies and in the Section 6 dealing with the applications.
With no frailty, the generality of this class of models was discussed in Peña and Hollander (2004). With the added feature of frailty, this class of models subsumes many models in the literature, as described below. Indeed, one may view this class of models as a general synthesis of several recurrent event models in survival analysis and reliability, such as the modulated renewal process of Cox (1972b) and those by Self and Prentice (1982), Prentice and Self (1983), Kessing et al. (1999), and in the examples that follow where the model is described for only one unit, i.e., with .
Example 2.1
Beginning with no frailty , taking , and , we obtain i.i.d. inter-occurrence times, one of the models examined in Gill (1981) and Peña et al. (2001). With frailty, one obtains associations among the inter-occurrence times, a model also considered in Peña et al. (2001) and Wang and Chang (1999). Still with no frailty but taking gives the extended Cox proportional hazards model considered by Prentice et al. (1981), Lawless (1987), and Aalen and Husebye (1991). Further changing to gives a model examined by Prentice et al. (1981), Brown and Proschan (1983), and Lawless (1987) referred to in the reliability literature as an imperfect repair model, since it arises by `restoring a system to the state just before it failed (minimally repaired)' whenever the system fails.
Example 2.2
Let be a sequence of i.i.d. Bernoulli random variables with success probability . Define the process via . Also let be defined according to , . By setting and , we obtain
| (6) |
This is the Brown and Proschan (1983) imperfect repair model, also studied by Whitaker and Samaniego (1989) who noted that the inter-failure times and the repair modes suffice for model identifiability. If the success probability depends on the time of event occurrence, the Block et al. (1985) model obtains (see Hollander et al., 1992; Presnell et al., 1994). Note in this example that the s represent event occurrences in which intervention causes the unit to acquire an effective age of zero. Furthermore, is the last time prior to that the subject had an effective age of zero. More generally, the class of models also subsumes the general repair model of Last and Szekli (1998), which includes as special cases models of Dorado et al. (1997), Kijima (1989), Baxter et al. (1996), and Stadje and Zuckerman (1991).
Example 2.3
Lindqvist et al. (2003) proposed the trend-renewal process (TRP) model and the heterogeneous TRP (HTRP) model for repairable systems, which are models built on the idea behind the inhomogeneous gamma process model of Berman (1981). The TRP has two parameters: a distribution function and a cumulative hazard function , and is such that if are the event times, then forms a renewal process from the distribution function . The TRP becomes a special case of the general class of models with effective age process where is the cumulative hazard function associated with and is function composition, and . However, for the inference setting we are considering in this paper, this is not covered because would not be observable since would not be known. Meanwhile, the HTRP model is simply the version with a frailty component.
Example 2.4
A special case obtains via , where is some positive real number, and is some nondecreasing function. One could interpret the parameter as an initial measure of the unit’s susceptibility to events, and specifies the rate at which this unit is becoming stronger as the event occurrences accumulate. If we take , the resulting model possesses the interesting property that the unit's defects contribute to the event occurrence intensity multiplicatively through the baseline hazard rate function . If and , where is some positive constant, then the Gail et al. (1980) tumor occurrence model and the Jelinski and Moranda (1972)) software reliability model are obtained.
Example 2.5
A popular load-sharing model is the equal load-share model considered in Kvam and Peña (2005). One context is a -component parallel system consisting of identical components, for which the event of interest is the occurrence of a component failure. Failed components are not replaced, and when a component fails, the load of the system is redistributed equally over the remaining functioning components. To model this, we let be an unknown vector of constants, and take the hazard rate of event occurrence at calendar time as , where is the hazard rate of each component at time zero and denotes the number of components that have failed up to time . This model is then a special case of the general model with , and one has the added flexibility of also incorporating a link function involving covariates if such are observed, as well as frailty components which could model unobserved operating environmental factors.
3 Estimation of Parameters: Model without Frailties
By virtue of the generality of the class of models, it is thus of importance to develop appropriate statistical inference methods. We address in this section the problem of estimating the model parameters , and for the model where it is assumed that , that is, the model without frailties. Thus, the model of interest has intensity process
| (7) |
The observables for the subjects, which now include the observable effective age processes, are , where and . The statistical identifiability of this class of models without frailties has been established in Theorem 1 of Peña and Hollander (2004). The two basic conditions to achieve identifiability, aside from the non-triviality of and sufficient variability of , are that for each value of the parameter set , the support of should contain , and that should satisfy the condition that for each implies . These two conditions are henceforth assumed to hold.
For this model, letting , then with respect to the filtration , the vector of processes
consists of orthogonal square-integrable martingales with predictable quadratic covariation processes . The usual martingale theory utilized by Aalen (1978), Gill (1980), Andersen and Gill (1982), and others (cf., Fleming and Harrington, 1991; Andersen et al., 1993) does not apply directly for the purpose of estimating . The reason is that the appearing in is time-transformed by the observable predictable process , while of interest is to estimate for a given . It is tempting and would seem natural to simply define new processes involving the gap times between the event occurrences. However, as pointed out in Peña et al. (2001), this approach does not work since the resulting processes no longer satisfy martingale properties owing to the effect of the sum-quota accrual scheme.
The technique utilized in Peña et al. (2001), extending an idea of Sellke (1988) and Gill (1981), is to define a doubly-indexed process . (Note that there is a notational, but tolerable, conflict with the frailty variables.) The index s represents calendar time, which is the natural time of data accrual; while the index represents gap times. This process indicates whether at calendar time , the effective age of the th subject is no more than . For , define also the doubly-indexed processes
Note that is the number of events for the th unit that occurred over with effective ages at most . For a given , by utilizing the martingale property of and the predictability of , the process is a square-integrable zero-mean martingale; however, for fixed , the process is not a martingale, but nevertheless, it also has mean zero.
A critical result is an equivalent expression for which involves directly, instead of its time-transformed version. To reveal this expression, define for the processes
| (8) |
Thus, is the restriction of on the th interval bounded by successive event occurrence times for the th subject. Note that on , the paths of are one-to-one, so its inverse exists; and furthermore, it is also differentiable. We now provide the alternative expression for in Proposition 1. The proof of the result is analogous to that in Peña et al. (2000). To achieve a more concise notation, with we define
| (9) |
Proposition 1 For each , where
The process is a generalized at-risk process and is an adjusted count of the number of events for the th unit which occurred over whose effective ages during their occurrences are at least . Using Proposition 1, we have the identity
So that , where
| (10) |
Because has mean zero, a method-of-moments ‘estimator’ of , given is
| (11) |
with and with the convention that . Notice that this ‘estimator’ is of the same flavor as the Nelson-Aalen estimator or the Aalen-Breslow estimator in single-event settings, although it should be pointed out that the derivation as well as the structure of the processes are quite different.
Next we develop the profile likelihood for from which the estimator of will be obtained. Following Jacod (1975) (see also Andersen et al., 1993), if the distribution of does not involve the model parameters, then the full likelihood process associated with the observables for the general model without frailties is
| (12) |
The argument of the exponential function could be re-expressed via
Since from (11), we have it therefore follows that which is independent of . Upon substituting the ‘estimator’ for in the argument of the exponential function in (12), the resulting term will not contribute to the profile likelihood for .
On the other hand, substituting for in the first term of (12), we obtain the relevant portion of the profile likelihood of to be
| (13) |
This process could also be viewed as the partial likelihood process for , which is a generalization of the partial likelihood for the Cox model (cf., Cox, 1972a, 1975; Andersen and Gill, 1982). The logarithm of the profile likelihood could be conveniently expressed in integral form via
| (14) |
From this profile likelihood, the estimators of and will be obtained. It is easy to see that the estimating equations for the profile maximum likelihood estimators are
| (15) |
| (16) |
Because is a step process with a finite number of jumps, then both of these estimating equations are finite sums with respect to the calendar times . Also, just like estimating equations in simpler models, such as for the Cox proportional hazards model, it is clear that numerical techniques will be needed to obtain the estimates and .
Upon obtaining the estimators and from the estimating equations (15) and (16), the estimator of based on the realizations of the observables over is obtained by substituting ( ) for in the expression of given in (11). Thus,
| (17) |
Finally, for an estimator of the baseline survivor function associated with defined via by the product-integral representation and the substitution principle, we obtain
| (18) |
This estimator is of a product-limit type analogous to those arising in the estimation of the baseline survivor function in the Cox proportional hazards model or the multiplicative intensity model (see Cox, 1972a; Andersen and Gill, 1982).
For the i.i.d. interoccurrence times model in Example , which obtains when (no covariate effects), (no effects of accumulating event occurrences), and (upon each event occurrence, effective age is reset to zero, so this is just the backward recurrence time), the estimator of in (18) simplifies to that considered in Peña et al. (2001). Note, in particular, that for this special model, , and since , then the process simplifies to
which is the natural at-risk process for the gap times over the observation period .
4 Estimation of Parameters: Model with Frailties
We now consider the estimation of the parameters when the class of models includes frailties. It will be assumed that the frailties are i.i.d. from a distribution where . A common choice for this , which we adopt here, is the gamma distribution with unit mean and variance 1/ . Imposing the restriction that the gamma shape and scale parameters are identical, together with the identifiability conditions for the model without frailty stated in the beginning of Section 3, is needed to have model identifiability. We do not provide a rigorous proof of this identifiability result since it will lead us to excursions into product spaces and measures and ideas behind identifiability proofs for mixture models, but see, for example, Parner (1998) for such ideas. Recall at this stage that the are not observed. For the model at hand, the conditional intensity function is as given in (5), which for convenience is again displayed below:
To achieve brevity, we let . If the are observed, the complete likelihood process for the model parameters is given by
| (19) |
Since the are unobserved, integrating them out in (19) yields the full likelihood process, which is
| (20) |
The maximum likelihood estimators of the model parameters are the maximizers of this full likelihood process, with the proviso that the maximizing jumps only at observed values of . The expectation-maximization (EM) algorithm described in the sequel finds this set of maximizers.
In estimating the model parameters , and , we generalize and extend the approach implemented in Peña et al. (2001) which dealt with the frailty model without covariates, and without the term, and with . The computations of the estimates will be facilitated through the EM algorithm introduced by Dempster et al. (1977), and implemented in counting process frailty models by Nielsen et al. (1992). The main ingredients of this algorithm for the general class of recurrent event models are as follows. For the expectation-step, given and , the conditional expectations of and log are, respectively,
| (21) |
| (22) |
where is the di-gamma function, that is, For the maximization-step, with denoting the logarithm of the complete likelihood function and with denoting expectation with respect to when the parameter vector equals , define the function
where
In this maximization step, the function is maximized with respect to . This is achieved by separate maximization of the mappings given by
| (23) |
| (24) |
For the maximization of the mapping in (23), we basically adopt the procedures developed in the case without frailties. Examining the mapping, we note that the only difference with the case without frailties is that gets replaced by . Consequently, given , and the data , the ‘estimator’ of is given by
| (25) |
where with . Analogously to the estimating equations for and in the model without frailties in (15) and (16), given and , we may estimate and by solving the estimating equations
| (26) |
| (27) |
which we implemented through a Newton-Raphson procedure. For the maximization of mapping (24), we also implemented the Newton-Raphson procedure, though clearly there are other options for maximizing this mapping.
With these ingredients at hand, the EM recipe for obtaining the estimates of the model parameters in this general model with frailties is described by the following steps:
Step 0 (Initialization)
Specify initial estimates and of , and , respectively. By setting , obtain the initial estimate of via
which is just the ‘estimator’ in (11) under the model without frailties.
Step 1 (E-step)
Given and obtain and via formulas (21) and (22). Denote by By exploiting the property that the estimator is a step function, these quantities could be obtained according to the following expressions: For ,
| (28) |
| (29) |
where with being the distinct jump times of and is the jump of at , we have
| (30) |
Step 2 (M-step #1)
Applying formula (25), obtain
Step 3 (M-step #2)
After substituting for in the estimating equations (26) and (27), obtain the solutions of these equations and denote them by and .
Step 4 (M-step #3)
Obtain by maximizing the mapping in (24) in . Alternatively, for this step, we may obtain by maximizing the full likelihood in (20) with respect to given the current values Through our numerical investigations, and via a mathematical proof (see appendix), using this alternative step also leads to the maximizing values of the full likelihood. In the simulation studies, the code using this alternative implementation was utilized.
Step 5 (Convergence)
Compare the values with the values , according to some distance function, e.g., Euclidean distance. If the distance between the old and the new values satisfies a tolerance criterion, the algorithm terminates and the estimates are the final values in the iteration. If the distance criterion is not satisfied, then replace by , and proceed to Step 1 of the algorithm. Because of the possibility of very large, possibly infinite, estimates of , corresponding to the situation of approximate ‘uncorrelatedness,’ when comparing old and new iterates for , we compare instead the associated values for since this ratio takes values in .
Having obtained an estimator of the baseline hazard function given by , through the product integral representation, the semiparametric estimator of the baseline survivor function for this model with frailty is . A computational implementation of the procedures and algorithms described in Sections 3 and 4 have been implemented in an R package (Ihaka and Gentleman, 1996) called gcmrec in González et al. (2003).
5 Properties of Estimators
5.1 Simulation Design
We performed computer simulation studies to examine numerically the properties of the parameter estimators developed in Sections 3 and 4. The specific goals of these studies are: (i) to examine the effect of sample size on the distributional properties of the estimators; (ii) to examine the bias, variance, and root-mean-square error (rmse) of the estimators; (iii) to examine the performance of the semiparametric estimator of the baseline survivor function in terms of its bias function, variance function, and root-mean-squared error function at specified time points. The latter function is based on the loss function ; (iv) to examine the consequences when data that have been generated with frailty components are analyzed using the model without frailties, an under-specified model; and (v) to examine the consequences, such as the loss in efficiency, when data that were generated using the model without frailties are analyzed with methods developed under the model with frailties, an over-specified model. For the first three items, simulation runs were performed for both the frailty-less model and for the model with frailty. We describe the settings for the different simulation parameters.
Sample Size
To examine the impact of sample size, we choose two values of . Though we do not report results here, we also performed simulation runs with , which may not be realistic in biomedical and public health studies since they will usually have many subjects. However, small sample sizes may arise in the reliability and engineering settings, as in the hydraulic data set example. The simulation runs with did provide us some insights of the limitations of the numerical procedures for obtaining the estimates, such as non-convergence or convergence to a minimizing, instead of a maximizing, value of the likelihood.
Censoring Mechanism
The censoring variables , , are generated according to a uniform distribution over where is chosen in order that under perfect repair (i.e., ) and with , there are, on average, approximately 10 events per unit. Moreover, to place an upper limit to the number of events that could occur for a unit, when the number of events for a unit reaches 50 then we cease observing this unit and set . This has the potential consequence of introducing some bias because this amounts to doing a combination of Type II and random censoring. Nevertheless, because the value of 50 is large enough, we conjecture that the bias introduced is negligible.
ρ Function
The function which handles the impact of accumulating event occurrences is assumed to be of form with , which models the situations where an increasing number of event occurrences has a beneficial effect, has no effect, or has an adverse effect, respectively.
Effective Age Function
For the simulation studies we considered an effective age process corresponding to the general imperfect repair model (see Example 2.2) with perfect repair probability of . Recall that the upper bound for the uniform censoring was determined under the perfect repair model and with to have an average of approximately 10 events per unit. Because this did not take into consideration the exact form of and , the effective average number of events per unit in the simulations may either be smaller or larger than 10. This is a consequence of the interplay among the baseline hazard rate function (if it is increasing failure rate (IFR) or decreasing failure rate (DFR)), the minimal repairs performed, and the effect of increasing number of event occurrence quantified by .
Baseline Survivor Function
For the baseline hazard function we choose the flexible and commonly-used Weibull hazard function, with a unit scale parameter and shape parameter taking values in , the former leading to a DFR distribution, and the latter giving rise to an IFR distribution. Note that the estimation procedure proposed is semiparametric, hence the scale and shape parameters of this Weibull baseline distribution are not estimated.
Covariates
We consider a two-dimensional covariate vector with having a Bernoulli distribution with success probability of , having a standard normal distribution, and with and stochastically independent. The regression coefficient vector is set to be . The fact that the grouping induced by the first covariate is done using a symmetric Bernoulli mechanism leads sometimes to highly asymmetric allocations for some simulation replicates, which was the cause of some convergence problems in the iterative procedure when .
Frailty Component
The parameter of the gamma distribution governing the frailty variable was set to , with corresponding to the absence of frailties. With respect to the parametrization , these frailty values convert to having .
For each combination of these simulation parameters, replications were performed. In the analysis, we set . Also, to create the bias, variance, and root-mean-squared-error curves for the estimator of the baseline survivor function, we choose time values corresponding to the th percentiles of the true baseline distribution function.
5.2 Discussions of Simulation Results
In the discussion of the simulation results that follows, we will focus on the effects of changing , changing or , changing , and changing , on the distributional properties of the estimators of , and , as well as the estimator of the baseline survivor function . In addition, we address the consequences of analyzing data that follows the general model with frailties using procedures developed for the general model without frailties, an under-specification; and also consider the impact of over-specification, which is the situation where procedures developed under the model with frailties are utilized to analyze data from a model without frailties. Such analyses will provide information on which type of mis-specification is of a more serious type.
Results of the simulation studies are presented in Tables 1–3. Table 1 summarizes the mean values and standard deviations (i.e., standard errors of the estimates) of the sampling distributions of the estimators of , and for values of , and as varies in the set . We do not show the cases with to conserve space. Table 2 contains means and standard deviations summaries of the simulation runs pertaining to the under- and over-specified analysis. Table 3 contains plots of the bias and rmse curves for the estimator of under the case where for with the plots for different values of superimposed on each plot frame for a Weibull shape parameter of .
Table 1.
Summary of simulated means and standard deviations of the estimators of , and . The true value of is , and 1000 replications were run for each parameter combination. The other columns of this table are: denotes the Weibull shape parameter; is the sample size; NC is the number of replicates in which there was no convergence; is the observed mean number of events per unit in all the simulation replications.
| NC | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A2 | ||||||||||||||
| A3 | ||||||||||||||
| A5 | ||||||||||||||
| A6 | ||||||||||||||
| A8 | ||||||||||||||
| A9 | ||||||||||||||
| A11 | ||||||||||||||
| A12 | ||||||||||||||
| A14 | ||||||||||||||
| A15 | ||||||||||||||
| A17 | ||||||||||||||
| A18 | ||||||||||||||
| B2 | ||||||||||||||
| B3 | ||||||||||||||
| B5 | ||||||||||||||
| B6 | ||||||||||||||
| B8 | ||||||||||||||
| B9 | ||||||||||||||
| B11 | ||||||||||||||
| B12 | ||||||||||||||
| B14 | ||||||||||||||
| B15 | ||||||||||||||
| B17 | ||||||||||||||
| B18 | ||||||||||||||
| C2 | ||||||||||||||
| C3 | ||||||||||||||
| C5 | ||||||||||||||
| C6 | ||||||||||||||
| C8 | ||||||||||||||
| C9 | ||||||||||||||
| C11 | ||||||||||||||
| C12 | ||||||||||||||
| C14 | ||||||||||||||
| C15 | ||||||||||||||
| C17 | ||||||||||||||
| C18 |
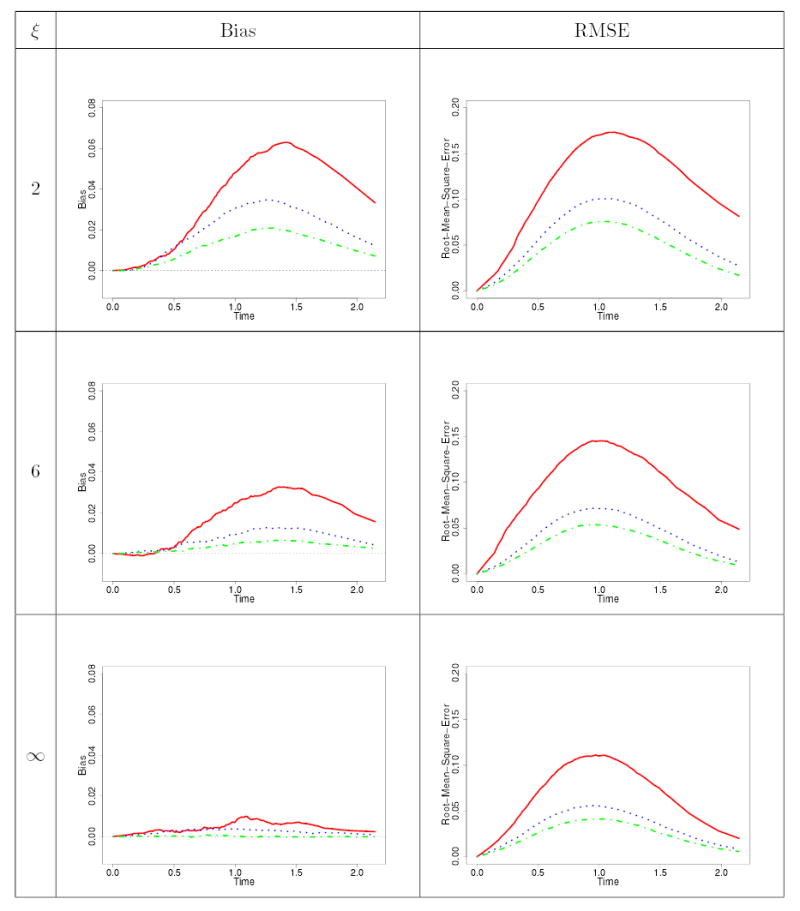
Table 3.
Bias and root mean squared error curves for the estimator of the baseline survivor function as the sample size varies [ is red; is blue; is green]. This is for the case where = and a Weibull shape parameter of = .
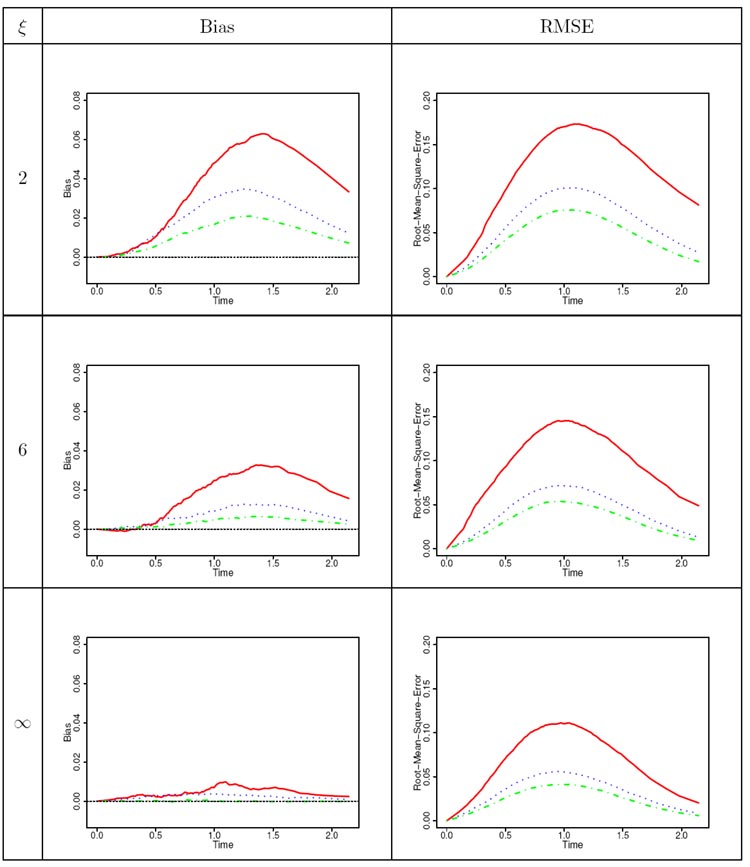
Table 2.
Summary of simulated means and standard deviations for the estimators of , and for the situation of under-specification (label UVW) and over-specification (label XYZ). The true regression coefficients are and 1000 replications were run for each parameter combination.
| NC | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| U2. | |||||||||||
| U3 | |||||||||||
| U5 | |||||||||||
| U6 | |||||||||||
| U8 | |||||||||||
| U9 | |||||||||||
| U11 | |||||||||||
| U12 | |||||||||||
| V2 | |||||||||||
| V3 | |||||||||||
| V5 | |||||||||||
| V6 | |||||||||||
| V8 | |||||||||||
| V9 | |||||||||||
| V11 | |||||||||||
| V12 | |||||||||||
| W2 | |||||||||||
| W3 | |||||||||||
| W5 | |||||||||||
| W6 | |||||||||||
| W8 | |||||||||||
| W9 | |||||||||||
| W11 | |||||||||||
| W12 | |||||||||||
| X2 | |||||||||||
| X3 | |||||||||||
| X5 | |||||||||||
| X6 | |||||||||||
| Y2 | |||||||||||
| Y3 | |||||||||||
| Y5 | |||||||||||
| Y6 | |||||||||||
| Z2 | |||||||||||
| Z3 | |||||||||||
| Z5 | |||||||||||
| Z6 |
As is to be expected, for the simulation runs where there was no mis-specification, when the sample size increases, the performance of the estimators of the finite-dimensional parameters, as well as for the baseline survivor function, improved, with the biases decreasing and the standard errors also decreasing. This is also true for the over-specification runs. When the sample size is small, there is considerable over-estimation of , though this bias decreases with increasing sample size. When there is under-specification however, all the estimators are extremely biased (see UVW-runs in Table 2), demonstrating the undesirable consequences of committing this under-specification. Regarding the effect of the frailty parameter , for estimating the finite-dimensional parameters, the amount of bias for and are negligible. The impact of the is on the standard errors of the estimators, with larger values of translating into less correlation, leading to smaller standard errors for the same sample size. When considering on the other hand the estimator of the baseline survivor function, by examining the curves in Table 3, as well as other curves from the simulations that are not shown here, we observe that the bias and rmse curves of this estimator decrease as increases, and the same could also be said as increases. Generally, the bias function is positive, and as is to be expected there is more bias and rmse in the middle portion of the survivor function.
Some care, however, must be observed when considering the effects of changing and changing Weibull shape parameter in the context of the precision of the estimators because the interplay between these two parameters leads to differing observed number of events. To see this, examine the column in Table 1, which represents the mean number of events observed per unit. In this table, we notice that when and , the latter leading to a DFR Weibull baseline distribution, there tends to be a smaller number of observed events; whereas when and , the latter making the Weibull baseline IFR, then there tends to be more events observed. These differences in the observed number of events can be explained by taking into account the minimal repair model considered in the simulation. In the first situation for instance, an value less than unity makes the unit less likely to have events as calendar time increases since more event occurrences become beneficial to the unit and, in addition, when a minimal repair is performed, then the DFR nature (because ) of the baseline distribution diminishes the rate of event occurrences thereby lengthening the inter-event times. Because the upper bound for the uniformly distributed follow-up time was determined under and with a backward recurrence time effective age corresponding to a perfect repair mechanism, the impact of and is a smaller number of events compared to the target of approximately 10 events used in deriving . An analogous argument, but in the opposite direction, holds true when dealing with and . The impact of the minimal repair effective age and its interplay with a DFR or IFR baseline distribution can be further seen from Table 1 with , where we see that when the baseline distribution is DFR (IFR), the observed number of events per unit is less (more) than the target of approximately 10 events per unit used in deriving . A fascinating situation is when and , or when and , for the effects of and are in opposite directions in the context of event occurrences. Examining the bottom portion of the A-runs in Table 1 and the upper half of the C-runs in Table 1, and with reference to the B-runs in this same table, we observe that for the chosen and values in the simulation, there was a more pronounced effect of the values compared to the values since when and , the observed number of events is slightly below 10, whereas when and , the observed number of events is more than 10. The greater effect of than on the mean number of events is not surprising, because was partially accommodated in the determination of the upper bound for the censoring distribution. Apart from the impact on the precision of the estimates arising from the varying number of events due to the combination of values of and discussed above, the associate editor also perceptively pointed out that this interplay among whether is IFR or DFR, whether is increasing or decreasing, and the form of the effective age , will intrinsically impact the precision of the estimators. For instance, if and with in the simulation model, when both the and parameters are inducing a decrease in the number of events, the precision of their estimators will diminish since there is added uncertainty about their contributions to event occurrences. This decrease in the precision of estimators is a natural consequence of using a richer class of models which has the potential of better delineating the varied factors affecting event occurrences.
In the presence of model mis-specification, we find that under-specification leads to a non-negligible systematic bias that increases with and also with . In fact, for this type of mis-specification, we have observed that the mean of the process in does not converge to the zero function as increases, implying that with this mis-specification, the estimator may be inconsistent. In contrast, with over-specification, we find that there is no recognizable loss in efficiency compared to the correct analysis, though we observe some very slight increase in the standard errors of the finite-dimensional parameter estimators (see XYZ-runs in Table 2 and compare the standard deviations in the A9 row of Table 1 and the X3 row, B9 row of Table 1 with the Y3 row, and the C9 row of Table 1 and the Z3 row). This indicates that there is much to be gained in the context of robustness by simply fitting the frailty-based model since, if the data did come from the frailty model, then the analysis is correct, while if the data came from the frailty-less model, there is no significant efficiency loss incurred; whereas, if there is under-specification of the model, then the consequences are unacceptable if the data actually came from the model with frailty. This lends strong support that this new class of models provides a general and flexible class for fitting recurrent event data and provides an avenue for a robust method of analysis for real data sets.
In addition, we also examined the impact of mis-specifying the effective age process, which also has bearing in regards to the interplay between the and components of the class of models. We considered the same simulation model with a perfect repair probability of , and examined the impact of two types of effective age process mis-specification: that the interventions following event occurrences are all minimal repair, or that they are all perfect repair. The results (not shown) indicate an interesting interplay between the nature of the baseline survivor function (DFR/IFR) and the behavior of and . We observed that under the minimal repair mis-specification, when is DFR, exhibits negative bias and is positively biased. Additionally for this mis-specification, when is IFR, exhibits positive bias and is positively biased. Alternately, when the mis-specification is perfect repair, an underlying baseline DFR (IFR) is associated with positive (negative) bias in and negative (positive) bias in . We explain these findings as follows: When the model mistakenly assumes minimal repair at each event occurrence, it tends to overestimate the effective age of units. Hence, in the case of DFR, the model anticipates longer interevent times than are realized in the data, creating the negative bias, especially for larger interevent times, in the estimates of the baseline survivor function in this situation. In the case of IFR, the minimal repair mis-specification leads to longer interevent times in the data than are anticipated by the model, creating a positive bias in the estimated baseline survivor function. When a perfect repair is incorrectly assumed at each event occurrence, the model tends to underestimate the effective age of units. Hence, using reasoning analogous to that for the minimal repair mis-specification, there is positive (negative) bias in the estimated baseline survivor function in the case of DFR (IFR). Especially interesting is that this behavior induces biases also in the finite-dimensional parameter estimates, with , in particular, evidently compensating such that is positively biased when the baseline distribution is DFR, and negatively biased when this distribution is IFR. These results indicate the importance of monitoring the effective age process.
6 Applications to Real Data
The first application is to the bladder cancer data used in Wei et al. (1989), which can be obtained from the survival package (Lumley and Therneau, 2003) in the R Library. These data provide the times to recurrence of bladder cancer for subjects. The covariates are , the treatment indicator ( placebo, thiotepa); , the size (in cm) of the largest initial tumor; and , the number of initial tumors. We first fitted the general model using the backward recurrence time as effective age. With , the maximum observation period, we fitted the general model without frailties, and obtained and . These are also the estimates obtained when the general model with frailty is fitted since in that case , a very large value indicating that there is no need for the frailty component when the effective age is the backward recurrence time. Thus, using the approximate inverse of the partial likelihood information matrix from fitting the model without frailties, the associated estimated standard errors are for and for . It remains to establish formally that these are indeed valid standard error estimates, an issue to be addressed in a future paper addressing asymptotic properties of model estimators. Since a formal theory for estimating standard errors under the general model with frailties is under development, we utilize jacknife estimates of the standard errors, which are the standard deviations of the estimates computed after deleting a unit. For the model without frailties for instance, the jacknife estimates of the standard errors for the bladder cancer data are for and for , which are close to the estimates obtained from the observed partial likelihood information matrix.
For lack of information about the effective age, we also fitted the general model with frailties assuming a ‘minimal repair’ after each event, . In this situation, the estimates are , , and , indicating the importance of the frailty component in this case. When the general model without frailties is fitted to this ‘always minimal repair’ data set, the resulting estimates are and . The estimates of the survivor functions for the two effective age specifications are presented in Figure 1. The lower curves (red), corresponding to the placebo group, are obtained by setting in the expression given by , while the upper curves (blue) are for the thiotepa group obtained by setting . The observed means were and . The solid curves are for the backward recurrence time effective age, while the dashed curves are for . These plots seem to indicate that the thiotepa group has a higher survival rate than the placebo group, although the statistical significance of this difference depends on which effective age process was used. A question that we will address in future work is the assessment of which effective age process leads to a better fit. This issue is related to model validation and goodness-of-fit aspects of the model.
Fig. 1.
This plot contains estimates of the survivor function for the baldder cancer data set when the model with frailties is fitted. The red curve (lower curve in each line type) is for the placebo group , while the blue curve is for the thiotepa group , both evaluated at the mean values of and . The solid curves are for effective age E † (perfect repair), while the dashed curves are when E (minimal repair).
It is of interest to compare the estimates of the regression coefficients from the general model with those obtained using the three existing methods of analysis described in Therneau and Hamilton (1997) and Therneau and Grambsch (2000). Table 4 summarizes the estimates from Andersen-Gill’s (AG) method, Wei, Lin and Weissfeld’s (WLW) marginal method, and Prentice, Williams and Peterson’s (PWP) conditional method as reported in Therneau and Grambsch (2000), together with the estimates obtained from the general model with frailty under these two specifications of the effective age process, and . From this table we note the crucial role that the effective age process and the component play in this analysis and how they provide some reconciliation of the varied estimates from these different methods. When the effective age process corresponds to perfect repair (in which case so that estimates arising from the frailty and no-frailty models coincide) or when the effective age corresponds to minimal repair and the model without frailties is fitted, then the -estimates from the general model are quite close to those obtained from PWP’s conditional method. On the other hand, when the effective age process corresponds to minimal repair and the model with frailties is fitted, the resulting estimates are close to those obtained from the WLW marginal method. The values from the AG method lie between these two cases. In the situation therefore where the model without frailties is fitted for both types of effective age specifications, it appears that the term in the general model induces a robustness property in the context of estimating the coefficients. Note that when we assume ‘always perfect repair' the estimate is less than unity; whereas when we assume ‘always minimal repair' the estimate is greater than unity (see the discussions in the preceding section pertaining to misspecified effective age process and the impact on the estimation of the baseline hazard and the parameter). Interestingly, when the general model with frailties is fitted to the ‘always minimal repair' data, the estimate now becomes less than unity, and the estimate of the frailty parameter is quite close to unity, indicating a strong association among the inter-event times for each subject. The ability of the general model to seemingly explain these varied estimates from these different methods indicates its flexibility and the crucial role of the effective age. Thus, there is a need to monitor this information since in its absence, different methods of analysis may produce varied estimates, which could lead to contradictory conclusions.
Table 4.
Summary of estimates for the bladder data set from the Andersen-Gill (AG), Wei, Lin and Weissfeld (WLW), and Prentice, Williams and Peterson (PWP) methods as reported in Therneau and Grambsch (2000), together with the estimates obtained from the general model using two effective ages corresponding to ‘perfect repairs’ and ‘minimal repairs.’
| General Model |
|||||||
|---|---|---|---|---|---|---|---|
| Perfect a | Minimal b | Minimal | |||||
| Term | Param | AG | WLW Marginal | PWP Cond*nal | Both c | Frailty d | No Frailty e |
| log | - | - | - | ||||
| Frailty | - | - | - | - | |||
| rx | |||||||
| Size | |||||||
| Number | |||||||
Effective Age is backward recurrence time .
Effective Age is calendar time .
Same results are obtained for either the model with or without frailties.
Reported standard errors are jacknifed estimates.
Reported standard errors are jacknifed estimates.
Another biomedical example pertains to the rehospitalization of patients diagnosed with colorectal cancer. The data, which can be obtained from the gcmrec package in the R Library, provide the calendar times (in days) of the successive hospitalizations after the date of surgery. The first readmission time was considered as the time between the date of the surgical procedure and the first rehospitalization after discharge related to colorectal cancer. Each subsequent readmission time was defined as the difference between the current hospitalization date and the previous discharge date. There were a total of 861 rehospitalization events recorded for the 403 patients included in the analysis. This data set was analyzed in Gonzalez et al. (2005) using a gamma frailty model, which corresponds to the general model with . Their goal being to determine whether there were differences regarding the time of the recurrent hospitalization due to social-demographic or clinical outcomes. We reanalyze this data set using the full general model where we consider the following variables: tumor stage (Dukes classification: A-B, C or D); whether the patient received chemotherapy; and the distance between the hospital and the patient's residence. We have coded these covariates using dummy variables such that the regression coefficients can be interpreted as follows: pertains to patients diagnosed with Dukes C stage, and for patients with Dukes D stage; for patients who did not receive chemotherapy, and for patients whose residence is more than 30 kilometers from the hospital. Since in this case we have no information about the effective age, we assumed the backward recurrence time, We fitted the general model without frailties, taking , the maximum follow-up time. The resulting estimates of the parameters, together with the information-based (se) and jacknife (jse) estimates of their standard errors, are , , , , and . Observe that the information-based and jacknife estimates of the standard errors are somewhat discrepant for this data set. We also fitted the general model with frailties. After 35 iterations the EM algorithm converged. The estimate of the frailty parameter was quite small so we conclude that the frailty component of the model is important for these data. The fitted frailty-based model provided the estimates: , , , , and , Based on these results, we conclude that among these covariates, only the advanced tumor stages (C or D) are associated with an elevated risk of rehospitalization. Furthermore, since the estimate of is larger than unity, there is an indication that each hospitalization increases the risk of further hospitalization.
The next data set, given in Blischke and Murthy (2000) and which was analyzed in Kumar and Klefsjo (1992), concerns hydraulic load-haul-dump (LHD) subsystems used in moving ore and rock in underground mines in Sweden. The data set provides the calendar times (in hours), excluding repair or down times, of the successive failures of such systems during the two-year development phase. Because the censoring times were not provided, we set . The first two machines are the oldest, the second two machines are of medium age, and the last two are relatively new machines. The covariate is the categorized age of the machines, coded as denoting old age, denoting medium age, and denoting young age. For our analysis, we assume that the effective age is the backward recurrence time The number of failure events for the six machines are . When the general model without frailty is fitted, the resulting parameter estimates are and . The corresponding standard errors, obtained from the estimate of the inverse of the partial likelihood information matrix, are and These estimates were obtained by setting to any value larger than hours. For the general model with gamma frailties, we find or , which indicates the absence of unobserved frailties which would have induced additional heterogeneity among the machines. As a consequence, the estimates of and ( ) were identical to those obtained when the model without frailties was fitted. A very large estimate of is also obtained if we analyze the data under the assumption of ‘always minimal repair,’ that is, . In this situation, ( and , so the main difference with the previous analysis is in the estimates of the parameter .
7 Concluding Remarks
In this paper procedures for estimating the parameters of a general and flexible class of models for recurrent events were developed and their properties examined through computer simulation studies. The class of models, which includes as special cases many well-known models in survival analysis and reliability, possesses the appealing properties that it takes into account the effect of interventions which are administered after each event occurrence through the notion of an effective age, the possible weakening (or strengthening) effect of accumulating event occurrences, the possible presence of unobserved frailties that could be inducing correlations among the inter-event times per unit, and the effect of observable covariates. Some data sets in the biomedical and reliability/engineering settings were reanalyzed using this new class of models. It was found in the simulation studies that an under-specification of the model, in the sense of analyzing a data set generated from the model with frailties using procedures developed from the model without frailties, could have unacceptable consequences in that the resulting estimators will have non-negligible systematic biases. On the other hand, it was found that over-specification of the model may provide a robust method of analysis with an acceptable loss in efficiency. The application of the procedures to the bladder cancer data set also provided a reconciliation of seemingly varied estimates obtained from currently available methods of analyzing recurrent event data, and highlights the importance of monitoring the effective age process.
There are still many interesting and important questions that need to be examined with regards to this general model. The first is the ascertainment of asymptotic properties of the estimators, such as their asymptotic normality or the weak convergence to a Gaussian process of a properly normed estimator of the baseline survivor function. This will be the topic of another paper, and the resolution of this asymptotic problem may require empirical process methods utilized in Murphy (1994, 1995) and Parner (1998); see also the recent paper of Kosorok et al. (2004). Some asymptotic results for specific models subsumed by the general class of models could be found in Peña et al. (2001) and Kvam and Peña (2005). Through such asymptotic analysis we will be able to obtain expressions for approximating analytically the standard errors of the estimators which will reflect the effects of an informative right-censoring mechanism as well as the impact of the sum-quota accrual scheme (see Peña et al. (2001) for the special case of a renewal model).
The problem of validating the class of models after it has been fitted to a specific data set is open, and calls for suitable goodness-of-fit and model validation procedures. For example, in the illustration using the LHD data set, the survivor curve estimate for the medium age group is a little higher than for the new age group, and when one examines the data, there is a long gap in the third machine which might have led to this ordering. A question of interest is whether this particular inter-event time is an outlier. We anticipate that model validation and diagnostics procedures to be developed for this class of models will answer this question. Another issue of interest is in the absence of effective age data, might it have been better to fit a minimal repair effective age function, instead of the perfect repair effective age for this LHD data? This question leads to the recognition that an existing limitation of this class of models is that currently available data sets do not possess information regarding the effective age process. Thus, in applying this model to currently available data sets, we are forced to assume simple forms of the effective age process, such as the imperfect repair or perfect repair models discussed here. This problem of not knowing the effective age was first highlighted in Whitaker and Samaniego (1989), where they pointed out that if the repair modes, hence the effective ages, are not known in the minimal repair model, then the model is nonidentifiable. For the purpose of demonstrating their inference methods using Proschan (1963)'s air-conditioning data, which did not include the mode-of-repairs, they therefore augmented the inter-failure times data with assumed mode-of-repair data to illustrate the estimation of the reliability function. As demonstrated by our simulation studies to assess the impact of mis-specifying the effective age process in relation to the bladder cancer data application, a mis-specification on this effective age could lead to systematic biases on the estimators. It is therefore our hope that researchers will make an effort in assessing the effective age during the data gathering stage of studies. Though it may be potentially difficult to achieve in biomedical settings, such information, if acquired, will prove useful and informative in the modeling and analysis. This somehow calls for a paradigm shift in the data gathering of recurrent event data.
Acknowledgments
E. Peña acknowledges the research support provided by NSF Grant DMS 0102870, NIH Grant GM056182, NIH COBRE Grant RR17698, and the USC/MUSC Collaborative Research Program. E. Slate acknowledges the research support provided by NIH Grant CA077789, NIH COBRE Grant RR17696, DAMD Grant 17-02-1-0138 and the USC/MUSC Collaborative Research Program. J. González acknowledges the research support provided by National Center of Genotyping-CEGEN funded by Genoma España. We also thank the two reviewers, the Associate Editor, and the Editor, for carefully reading the manuscript and for providing us with invaluable comments, criticisms, and suggestions which lead to improvements.
8 Appendix: Partial EM Algorithm
Consider the problem of finding the maximizing values of a full likelihood function where is the observed data. We assume that when given , maximizing in is practically feasible, but a joint maximization in is difficult. We suppose that, when given a value , we could implement the EM-step to get the next iterate and in such a way that in the M-step of the EM algorithm, and are obtained via maximization of two separate mappings, one depending only on and the other depending only on , such as in our case. In the partial EM algorithm we implemented, is replaced by which is , so the next iterate is obtained by setting , and proceeding as described above. That this algorithm will also lead to a maximizing value if the iteration converges follows by observing that the inequalities hold. The first inequality is true because the EM-step guarantees an improved value in the likelihood, whereas the second inequality is immediate from the definition of In our specific implementation, in the notation above, will be associated with , while above will be associated with the frailty parameter in our model.
References
- Aalen O. Nonparametric inference for a family of counting processes. Annals of Statistics. 1978;6:701–726. [Google Scholar]
- Aalen O, Husebye E. Statistical analysis of repeated events forming renewal processes. Statistics in Medicine. 1991;10:1227–1240. doi: 10.1002/sim.4780100806. [DOI] [PubMed] [Google Scholar]
- Andersen, P., O. Borgan, R. Gill, and N. Keiding (1993). Statistical Models Based on Counting Processes. New York: Springer-Verlag.
- Andersen P, Gill R. Cox’s regression model for counting processes: a large sample study. Annals of Statistics. 1982;10:1100–1120. [Google Scholar]
- Baxter L, Kijima M, Tortorella M. A point process model for the reliability of a maintained system subject to general repair. Stochastic Models. 1996;12:37–65. [Google Scholar]
- Berman M. Inhomogeneous and modulated gamma processes. Biometrika. 1981;68(1):143–152. [Google Scholar]
- Blischke, W. and P. Murthy (2000). Reliability: Modeling, Prediction, and Optimization. New York: Wiley-Interscience.
- Block H, Borges W, Savits T. Age-dependent minimal repair. J Appl Prob. 1985;22:51–57. [Google Scholar]
- Brown M, Proschan F. Imperfect repair. J Appl Prob. 1983;20:851–859. [Google Scholar]
- Cook R, Lawless J. Analysis of repeated events. Statistical Methods in Medical Research. 2002;11:141–166. doi: 10.1191/0962280202sm278ra. [DOI] [PubMed] [Google Scholar]
- Cox D. Regression models and life tables (with discussion) Journal of the Royal Statistical Society. 1972a;34:187–220. [Google Scholar]
- Cox D. Partial likelihood. Biometrika. 1975;62:269–276. [Google Scholar]
- Cox, D. R. (1972b). The statistical analysis of dependencies in point processes. In Stochastic point processes: statistical analysis, theory, and applications (Conf., IBM Res. Center, Yorktown Heights, N.Y., 1971), pp. 55–66. Wiley-Interscience, New York.
- Dempster A, Laird N, Rubin D. Maximum likelihood estimation from incomplete data via the em algorithm (with discussion) J Roy Statist Soc B. 1977;39:1–38. [Google Scholar]
- Dorado C, Hollander M, Sethuraman J. Nonparametric estimation for a general repair model. Ann Statist. 1997;25:1140–1160. [Google Scholar]
- Fleming, T. and D. Harrington (1991). Counting Processes and Survival Analysis. New York: Wiley.
- Gail M, Santner T, Brown C. An analysis of comparative carcinogenesis experiments based on multiple times to tumor. Biometrics. 1980;36:255–266. [PubMed] [Google Scholar]
- Gill, R. (1980). Censoring and Stochastic Integrals. Amsterdam: Mathematisch Centrum.
- Gill RD. Testing with replacement and the product-limit estimator. The Annals of Statistics. 1981;9:853–860. [Google Scholar]
- González, J., E. Slate, and E. Peña (2003). The gcmrec Package. http://cran.r-project.org: The Comprehensive R Archive Network.
- Gonzalez JR, Fernandez E, Moreno V, Ribes J, Peris M, Navarro M, Cambray M, Borras JM. Sex differences in hospital readmission among colorectal cancer patients. J Epidemiol Community Health. 2005;59(6):506–11. doi: 10.1136/jech.2004.028902. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hollander M, Presnell B, Sethuraman J. Nonparametric methods for imperfect repair models. Ann Statist. 1992;20:879–896. [Google Scholar]
- Hougaard, P. (2000). Analysis of Multivariate Survival Data. New York: Springer.
- Ihaka R, Gentleman R. R: a language for data analysis and graphics. Journal of Computational and Graphical Statistics. 1996;5:299–314. [Google Scholar]
- Jacod J. Multivariate point processes: Predictable projection, Radon-Nikodym derivatives, representation of martingales. Z Wahrsch verw Geb. 1975;31:235–253. [Google Scholar]
- Jelinski, J. and P. Moranda (1972). Software reliability research, pp. 465–484. New York: Academic Press.
- Kessing L, Olsen E, Andersen P. Recurrence of affective disorders: analyses with frailty models. American Journal of Epidemiology. 1999;149:404–411. doi: 10.1093/oxfordjournals.aje.a009827. [DOI] [PubMed] [Google Scholar]
- Kijima M. Some results for repairable systems with general repair. J Appl Prob. 1989;26:89–102. [Google Scholar]
- Kosorok M, Lee B, Fine J. Robust inference for univariate proportional hazards frailty regression models. Annals of Statistics. 2004, August;32(4):1448–1491. [Google Scholar]
- Kumar D, Klefsjo B. Reliability analysis of hydraulic systems of lhd machines using the power law process model. Reliability Engineering and System Safety. 1992;35:217–224. [Google Scholar]
- Kvam P, Peña E. Journal of the American Statistical Association. 2005, March. Estimating load-sharing properties in a dynamic reliability system;100(469):262–272. doi: 10.1198/016214504000000863. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Last G, Szekli R. Asymptotic and monotonicity properties of some repairable systems. Adv in Appl Probab. 1998;30:1089–1110. [Google Scholar]
- Lawless J. Regression methods for poisson process data. J Amer Statist Assoc. 1987;82:808–815. [Google Scholar]
- Lin D, Sun W, Ying Z. Nonparametric estimation of the gap time distribution for serial events with censored data. Biometrika. 1999;86:59–70. [Google Scholar]
- Lindqvist BH, Elvebakk G, Heggland K. The trend-renewal process for statistical analysis of repairable systems. Technometrics. 2003;45(1):31–44. [Google Scholar]
- Lumley, T. and T. Therneau (2003). The survival Package. http://cran.r-project.org: The Comprehensive R Archive Network.
- Murphy S. Consistency in a proportional hazards model incorporating a random effect. The Annals of Statistics. 1994;22:712–731. [Google Scholar]
- Murphy S. Asymptotic theory for the frailty model. The Annals of Statistics. 1995;23(1):182–198. [Google Scholar]
- Nielsen G, Gill R, Andersen P, Sorensen T. A counting process approach to maximum likelihood estimation in frailty models. Scand J Statist. 1992;19:25–43. [Google Scholar]
- Parner E. Asymptotic theory for the correlated gamma frailty model. Annals of Statistics. 1998;26:183–214. [Google Scholar]
- Peña, E. and M. Hollander (2004). Mathematical Reliability: An Expository Perspective (eds., R. Soyer, T. Mazzuchi and N. Singpurwalla), Chapter 6. Models for Recurrent Events in Reliability and Survival Analysis, pp. 105–123. Kluwer Academic Publishers.
- Peña E, Strawderman R, Hollander M. Nonparametric estimation with recurrent event data. J Amer Statist Assoc. 2001, December;96(456):1299–1315. [Google Scholar]
- Peña, E. A., R. L. Strawderman, and M. Hollander (2000). A weak convergence result relevant in recurrent and renewal models. In Recent advances in reliability theory (Bordeaux, 2000), Stat. Ind. Technol., pp. 493–514. Boston, MA: BirkhÄauser Boston.
- Prentice R, Williams B, Peterson A. On the regression analysis of multivariate failure time data. Biometrika. 1981;68:373–379. [Google Scholar]
- Prentice RL, Self SG. Asymptotic distribution theory for Cox-type regression models with general relative risk form. Ann Statist. 1983;11(3):804–813. [Google Scholar]
- Presnell B, Hollander M, Sethuraman J. Testing the minimal repair assumption in an imperfect repair model. J Amer Statist Assoc. 1994;89:289–297. [Google Scholar]
- Proschan F. Theoretical explanation of observing decreasing failure rate. Techno-metrics. 1963;5:375–383. [Google Scholar]
- Self SG, Prentice RL. Commentary on: "Cox's regression model for counting processes: a large sample study" [Ann. Statist. 10 (1982), no. 4, 1100–1120; MR 84c:62054a] by P. K. Andersen and R. D. Gill. Ann Statist. 1982;10(4):1121–1124. [Google Scholar]
- Sellke, T. (1988). Weak convergence of the Aalen estimator for a censored renewal process. In Statistical Decision Theory and Related Topics IV (eds., S. Gupta and J. Berger) 2, 183–194.
- Stadje W, Zuckerman D. Optimal maintenance strategies for repairable systems with general degree of repair. J Appl Prob. 1991;28:384–396. [Google Scholar]
- Therneau, T. and P. Grambsch (2000). Modeling Survival Data: Extending the Cox Model.New York: Springer.
- Therneau T, Hamilton S. rhdnase as an example of recurrent event analysis. Statistics in Medicine. 1997;16:2029–2047. doi: 10.1002/(sici)1097-0258(19970930)16:18<2029::aid-sim637>3.0.co;2-h. [DOI] [PubMed] [Google Scholar]
- Wang MC, Chang SH. Nonparametric estimation of a recurrent survival function. Journal of the American Statistical Association. 1999;94:146–153. doi: 10.1080/01621459.1999.10473831. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei L, Lin D, Weissfeld L. Regression analysis of multivariate incomplete failure time data by modeling marginal distributions. J Amer Statist Assoc. 1989;84:1065– 1073. [Google Scholar]
- Whitaker L, Samaniego F. Estimating the reliability of systems subject to imperfect repair. J Amer Statist Assoc. 1989;84:301–309. [Google Scholar]