

Summary
Outcome-dependent sampling designs have been shown to be a cost effective way to enhance study efficiency. We show that the outcome-dependent sampling design with a continuous outcome can be viewed as an extension of the two-stage case-control designs to the continuous-outcome case. We further show that the two-stage outcome-dependent sampling has a natural link with the missing-data and biased-sampling framework. Through the use of semiparametric inference and missing-data techniques, we show that a certain semiparametric maximum likelihood estimator is computationally convenient and achieves the semiparametric efficient information bound. We demonstrate this both theoretically and through simulation.
Keywords: Biased sampling, Empirical process, Maximum likelihood estimation, Missing data, Outcome-dependent, Profile likelihood, Two-stage
1. INTRODUCTION
The case-control design, in which one over-samples the diseased individuals, is the most well known outcome-dependent sampling scheme for binary outcomes (Cornfield, 1951; Prentice & Pyke, 1979). The principal idea of an outcome-dependent sampling design is to concentrate resources on where there is the greatest amount of information. The two-stage case-control design is an extension of the simple case-control design that has been shown to improve statistical efficiency and reduce study costs in epidemiology studies (White, 1982). In the first stage of a typical two-stage design, information about the outcome Y is available for a study population or its random sample. Information about an exposure variable X is only available on a subset of the first-stage population; which is termed the second-stage. The second-stage sampling usually depends on the outcome. There is a large literature on analyzing data from two-stage designs; see Breslow & Cain (1988), Zhao & Lipsitz (1992), Weinberg & Wacholder (1993), Wacholder & Weinberg (1994), Lawless et al. (1999), Breslow et al. (2003) and Wang & Zhou (2006).
For outcome-dependent sampling with a continuous response, Zhou et al. (2002; 2007) considered an empirical likelihood approach for studies with only second-stage data. For the two-stage design, Chatterjee et al. (2003) proposed a pseudoscore estimator and Weaver & Zhou (2005) proposed a maximum estimated likelihood estimator. Both methods are computationally easy at the expense of efficiency. Lawless et al. (1999) recommended discretization of the continuous response to achieve an easily calculable maximum profile likelihood estimator. As discussed in Chatterjee et al. (2003), such a simplification entails a loss of information and a decrease in the external validity of the analyses, because the results may be sensitive to the choice of cutpoints. In summary, these existing methods are based on some approximations to the likelihood function. As far as we know, no one has developed fully efficient estimation for two-stage outcome-dependent sampling designs with a continuous response, because of the challenge in terms of both theory and computation. In this note, we develop a semiparametric maximum likelihood estimator that achieves full efficiency for this setting, and we point out that the two-stage outcome-dependent sampling estimate has a natural connection with the missing data and biased sampling literature. The connection occurs because the covariates can be viewed as missing by design, with the sampling probability of the covariates depending on the outcome.
2. TWO-STAGE OUTCOME-DEPENDENT SAMPLING WITH A CONTINUOUS OUTCOME
We consider the outcome-dependent sampling setting of Weaver & Zhou (2005) and recast it into a two-stage outcome-dependent sampling design. This design with a continuous outcome can be considered as a direct extension of White (1982) and Breslow & Cain (1988). The two-stage outcome-dependent sampling design for a continuous outcome (Weaver & Zhou, 2005) allows researchers to sample in the second-stage a simple random sample and some supplementary outcome-dependent samples from the first-stage population. In this setting, the response Y is observed for all in the first-stage, but the exposure variable X is only observed for those in the second-stage, i.e., the simple random sample and the supplementary outcome-dependent samples, in which the selection probability of the supplementary outcome-dependent sampling samples depends on Y. We assume that the joint density of (Y,X) is f(Y|X;θ)g(X) with respect to a dominating measure ν × μ on 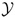 ×
× 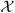 , where f(·|·) is known up to a d-dimensional parameter θ of interest and g(·) is an unknown probability density function.
, where f(·|·) is known up to a d-dimensional parameter θ of interest and g(·) is an unknown probability density function.
To fix notation, we further assume that the base population consists of n individuals (Y,X), and the domain of Y is a union of K mutually exclusive intervals, Ck = (ck−1, ck] for k = 1,…,K, with ck, k = 0, 1,…,K, being prespecified constants satisfying c0 = −∞ < c1 < c2 < … < cK = ∞. Thus Y partitions the study population into K strata such that, for k = 1,…, K, the {Y ∈ Ck} stratum has Nk individuals, and we define Conditional on n, (N1, … ,NK) follows a multinomial distribution with size n and probabilities (π1, …, πK), where πk ≡ Pr(Y ∈ Ck) is the proportion of the population falling into the kth stratum, for k = 1, …, K. Among the n individuals, n0 are obtained from the simple random sample, and nk out of Nk individuals in stratum k, k = 1, …, K, are selected as the second-stage outcome-dependent supplemantary samples.
We consider two types of stage-two outcome-dependent sampling in this article: Bernoulli sampling and Negative Binomial sampling. With Bernoulli sampling, all subjects which are in the kth stratum, but not included in the simple random sample, are independently sampled with probability pk such that, conditional on Nk and n0k, Enk = (Nk − n0k)pk. In this sampling scheme, the sample size n is fixed and the second-stage outcome-dependent sample sizes {n1, …, nK} are random. With Negative Binomial sampling, all subjects which are in the kth stratum, but not included in the simple random sample, are sampled with the probability of success pk, until a total of nk subjects have been selected. In this sampling scheme, the sample size n is random and the values nk, k = 1, …, K, are prespecified.
Although assuming the existence of a simple random sample is not necessary for the theoretical aspect, in practice it ensures the availability of the exposure variable X for every stratum of the response Y. Moreover, it is a prevailing choice for epidemiologists to include a simple random sample in their studies. This will afford them the flexibility to study other endpoints and to validate their models.
Let be the total size of the second-stage sample for which we observe (Y,X), and let nV̄ = n − nV be the number of individuals in the first-stage population for whom only Y is observed. Define the sampling indicator for the ith individual, i = 1, …, n, as
Then V ≡ {i : Ri = 1} represents the index set of all complete observations, and V̄ ≡ {i : Ri = 0} represents the index set of all incomplete observations, such that nV = |V|, nV̄ = |V̄| and n = |V ∪ V̄|. Furthermore, we define Vk ≡ {i : Ri = 1, Yi ∈ Ck}, V̄k ≡ {i : Ri = 0, Yi ∈ Ck} and Nk ≡ |Vk ∪ V̄k|, k = 1,…, K. Thus, the data structure of two-stage outcome-dependent sampling with a continuous Y can be summarized as follows: in the first stage, we sample Yi, for i ∈ Vk + V̄k; in the second stage, we sample Xi, given Yi ∈ Ck, for i ∈ Vk.
In both sampling schemes, conditional on the sample size n and the first-stage sample, the individual (Xi, Yi) falling into kth stratum is selected for full observation, giving Ri = 1, with prespecified probability pk. Hence we have a ‘missing at random’ structure: Pr(Ri = 1|Yi ∈ Ck) = pk, k = 1, …, K. Thus we cast the two-stage outcome-dependent sampling design into a general missing-data framework.
With derivation based on integrating a multinomial law, as in Weaver & Zhou (2005), the likelihood function from the two-stage outcome-dependent sampling with Bernoulli sampling has the form
| (1) |
where g(·) and G(·) are the probability function and the cumulative distribution function for X respectively, and fY (·; θ,G) is the probability density function of Y. Taking steps similar to those in the Appendix B of Scott & Wild (2001), we can show that the likelihood function from the two-stage outcome-dependent sampling with Negative Binomial sampling takes the same form even though the second-stage outcome-dependent sample sizes {n1, …, nK} are chosen without replacement.
To obtain the maximum likelihood estimators of (θ,G), we will maximize the log-likelihood by replacing the term g(Xi) in equation (1) by its point-mass equivalent, G{Xi}, and similarly for dG(u). The loglikelihood in (1) can also be written in terms of missing-data notation: ℙn{Rlog fθ(Y|X; θ)+Rlog G{X}+(1 − R) log fY (Y; θ,G)}, where ℙn is the empirical measure of the observations; that is, for every measurable function f, .
When Y is discrete, van der Vaart & Wellner (2001) give some examples in which the maximum likelihood estimator of the full likelihood (θ̌n, Ǧn) of (θ, G) does not exist; this is because the strata are defined by continuous covariates. However, this is not the case in outcome-dependent sampling since the sampling probability here depends only on the outcome, not on the covariates. The existence of the maximum likelihood estimator can be shown in the same way as in Murphy & van der Vaart (2001). In general, however, the maximum likelihood estimator (θ̌n, Ǧn) is not unique (van der Vaart & Wellner, 1992), since Ǧn need not be concentrated on {Xi : Ri = 1}. Here we consider the restricted maximum likelihood estimator (θ̂n, Ĝn) of the empirical likelihood, where G is concentrated on {Xi : Ri = 1}. The asymptotic equivalence of these two types of estimator can be established in the same way as in van der Vaart & Wellner (2001) and Zhang & Rockette (2005).
3. STATISTICAL INFERENCE
To maximize the loglikelihood over {gi, i ∈ V}, the probability concentrated on i ∈ V, we consider the Lagrangian function
where λ is the Lagrange multiplier corresponding to the normalizing restriction on the {gi, i ∈ V}. We take the derivative of H with respect to gi and set it equal to 0:
| (2) |
Multiplying both sides of (2) by gi, summing over i, and taking the restrictions into account, we obtain
and thus λ = n. Substituting back into (2) and solving for gi yields the restricted maximum likelihood estimator
| (3) |
In the outcome-dependent sampling literature, Zhou et al. (2002) implement the empirical likelihood method of Qin (1993) to simplify the computation. In our setting, it is unlikely that this approach can be adapted, because of the nature of the continuous outcome: the number of constraints increases as the sample size increases, and hence the number of parameters is the same as the sample size. This poses a challenge for the computation of the proposed estimator. We recommend maximizing the restricted loglikelihood using the following mixed Newton's method.
Step 1. Start with an initial estimate θ0 and i ∈ V.
Step 2. Plug in θ0 and into the right-hand side of the score equations (3), solve the equations iteratively using the fixed-point algorithm until it converges, and call the solution
Step 3. Plug into the likelihood and maximize the parametric likelihood using Newton's method to update θc.
Step 4. Repeat steps 2 and 3 until convergence.
We found that the algorithm works well. The fixed-point algorithm is easy to solve and is particularly useful for cases with large sample sizes where the method avoids computing the inverse of a huge matrix, as required in the usual Newton method.
To obtain the variance estimator of θ̂n, we will use the profile likelihood approach proposed by Murphy & van der Vaart (2000) for a general semiparametric model. The smoothness conditions of Theorem 1 in Murphy & van der Vaart (2000) can be verified and the profile likelihood function pLn(θ) ≡ maxG∈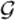 Ln(θ, G) can be shown to approximate a nondegenerate parabolic function around θ̂n. Moreover the inverse of the curvature of the profile loglikelihood function at θ̂n can be used to estimate consistently the asymptotic variance of θ̂n.
Ln(θ, G) can be shown to approximate a nondegenerate parabolic function around θ̂n. Moreover the inverse of the curvature of the profile loglikelihood function at θ̂n can be used to estimate consistently the asymptotic variance of θ̂n.
Using empirical process techniques and semiparametric inference, we establish the model identifiability, consistency and the weak convergence results. The identifiability of (θ,G) is summarized in the Appendix. Using a Wald-type argument, together with the identifiability result, we establish the following consistency result.
Theorem 1
Suppose that assumptions A2–A4 hold as given in the Appendix. Then |θ̂n − θ0| + suph∈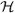 |(Ĝn − G0)h| → 0, almost surely, for every Glivenko-Cantelli class that is bounded in L1(G0), where L1(G0) refers to the class of integrable functions under G0.
|(Ĝn − G0)h| → 0, almost surely, for every Glivenko-Cantelli class that is bounded in L1(G0), where L1(G0) refers to the class of integrable functions under G0.
To derive the weak convergence result, let ψ ≡ (θ,G), and l̇(y; ψ) ≡ ḟ(y; ψ)/f(y; ψ). The score operator for ψ takes the form Un(ψ)(h) = ℙnU(ψ)(h), where U(ψ)(h) ≡ U1(ψ)(h1) + U2(ψ)(h2), and U1(ψ)(h1) ≡ l̇θ(r, z)h1 = {rl̇θ(y|x; θ) + (1 − r)l̇(y; ψ)}h1, U2(ψ)(h2) = rh2(x) + (1 − r)E{h2(X)|Y = y}, where h1 ∈ ℝd, h2 belongs to a class of square integrable functions, and ∫ h2dG0 = 0.
The adjoint operator of U2(ψ)(h) can be computed as
where qk = 1 − pk, and
We note that the score operator shares the same form as the score in the general ‘missing at random’ framework, whereas its adjoint operator has a special feature of the outcome-dependent sampling design. To obtain the information operator, we can differentiate the expectation of the score operator using the map t ↦ ψ + tψ1, where ψ, ψ1 ∈ Θ × . The information operator σψ(h) = Pσ̂ψ(h), where σ̂ψ(h) takes a 2 × 2 ‘matrix’ form, with . It can be shown that σψ0(h) is continuously invertible and onto.
The following theorem establishes the asymptotic distribution of ψ̂n.
Theorem 2
Under assumptions A1–A8 as given in the Appendix, √n(ψ̂n − ψ0) is asymptotically linear, with influence function h ∈ 1, converging weakly in the uniform norm to a tight, zero-mean Gaussian process ℤ with covariance E{l̃(g)l̃(h)}, for all g, h ∈ ℝd × 1, where , α > max(d/2, 1), is the class of α-smooth functions; see § 2·7·1 of van der Vaart & Wellner (1996).
Remark 1
Since √n(ψ̂n − ψ0) is asymptotically linear, with influence function contained in the closed linear span of the tangent space, ψ̂n is regular and hence efficient, by Theorems 5.2.3 and 5.2.1 of Bickel et al. (1998). The information bounds thus share the same form as that in Nan et al. (2004) after some algebra.
4. NUMERICAL RESULTS
We carried out simulations to evaluate the behaviour of the proposed estimators with that of Weaver & Zhou (2005) and Chatterjee et al. (2003). The data were generated from a linear regression model of the form Y = β0+β1X+β2Z+σϵ, where X ~ N(0, 1), Z ~ Ber(0·45) and ϵ ~ N0, 1); that is, given X and Z, Y ~ N(β0 + β1X + β2Z, σ2). We fix β0 = 1, β2 = −0·5 and σ2 = 1. We investigated the effect of strengthening the regression relationship between Y and X by allowing β1 to take successively the values 0, 0·5 and 1. Parameter and standard error estimates were obtained for each of 2000 independently generated datasets. All simulations were conducted using programs written in Matlab. The results are summarized in Table 1.
Table 1.
Simulation results with (a) n0 = 200, p1 = p3 = 0·185 and p2 = 0, and (b) n0 = 50, p1 = p3 = 1 and p2 = 0.
| Mean | Mean | 95% C.I. | Relative efficiencies | |||
|---|---|---|---|---|---|---|
| Model | θ̂n | SE(θ̂n) | ESE(θ̂n) | Coverage | MELE | PSE |
| (a) n0 = 200, p1 = p3 = 0·185 and p2 = 0 | ||||||
| β0 = 1 | 1·000 | 0·048 | 0·048 | 0·948 | 0·973 | 0·998 |
| β1 = 0 | −0·002 | 0·049 | 0·048 | 0·944 | 0·976 | 0·987 |
| β0 = 1 | 0·998 | 0·057 | 0·056 | 0·950 | 0·936 | 0·982 |
| β1 = 0·5 | 0·504 | 0·045 | 0·047 | 0·957 | 0·964 | 0·973 |
| β0 = 1 | 1·008 | 0·064 | 0·065 | 0·952 | 0·846 | 0·911 |
| β1 = 1 | 0·991 | 0·047 | 0·046 | 0·948 | 0·934 | 0·883 |
| (b) n0 = 50, p1 = p3 = 1 and p2 = 0 | ||||||
| β0 = 1 | 0·999 | 0·033 | 0·033 | 0·949 | 0·821 | 0·974 |
| β1 = 0 | 0·002 | 0·028 | 0·027 | 0·956 | 0·723 | 0·925 |
| β0 = 1 | 1·003 | 0·036 | 0·034 | 0·944 | 0·413 | 0·539 |
| β1 = 0·5 | 0·501 | 0·030 | 0·030 | 0·963 | 0·323 | 0·356 |
| β0 = 1 | 0·996 | 0·052 | 0·049 | 0·944 | 0·367 | 0·802 |
| β1 = 1 | 1·004 | 0·036 | 0·036 | 0·964 | 0·390 | 0·648 |
C.I., confidence interval; SE, standard error; ESE, estimated standard error; MELE, maximum estimated likelihood estimator; PSE, pseudoscore estimator.
The study population size was set to n = 2000. For Table 1(a), the outcome-dependent sampling design consisted of a simple random sample with n0 = 200, supplemented with additional samples from individuals with Y values in the tails of the marginal distribution, with cutpoints μY ± σY, where μY and σY represent respectively the mean and standard deviation of Y. We took the Bernoulli sampling for the second-stage outcome-dependent sampling. All 1800 subjects which were not included in the simple random sample were independently sampled with probability (0·185, 0, 0·185) from the three strata respectively. This yields the average second-stage outcome-dependent sample sizes to be n1 = n3 = 50, n2 = 0 and a validation sampling fraction ρV of about 0·15. In the second setting, presented in Table 1(b), we set the simple random sample n0 to be 50 and increased the second-stage outcome-dependent sampling probability of X in the two tails to be one; that is, we tried to include all samples in the tails while keeping very few samples in the middle, where the proportion is small. This sampling scheme yields the average second-stage outcome-dependent sample sizes to be n1 = n3 = 290, n2 = 0 and a validation sampling fraction ρV of about 0·32. Table 1 contains the results for β0 and β1 of three simulation settings corresponding to different values of β1 and includes the finite-sample properties of the restricted maximum likelihood estimator, as well as the finite-sample relative efficiencies, i.e., ratios of empirical variances of the estimators, for the pseudoscore estimator and the maximum estimated likelihood estimator, all calculated relative to the restricted maximum likelihood estimator.
All estimators exhibits negligible bias for all four model parameters, the means of the standard error estimates agree very well with the sample standard errors of the 2000 simulations, and the confidence intervals attain coverage close to the nominal 95% level; the corresponding results for the pseudoscore estimator and maximum estimated likelihood estimator are not shown. In both settings, the restricted maximum likelihood estimator is the most efficient of the three estimators, as expected; as the regression effect of X gets stronger, the efficiency gains of the restricted maximum likelihood estimator over the competing estimators becomes larger. When β1 = 0, the behaviour of these inefficient estimators is almost as good as that of the restricted maximum likelihood estimator. This is because the nonvalidation observations do not contain any information about X, although they still contain information about Z, and so we would not expect to see much gain in efficiency for the maximum likelihood estimator which can use more information contained in nonvalidation observations than can the other estimators.
The efficiency gains of the restricted maximum likelihood estimator are also associated with the validation sample proportion. For the same outcome-dependent sampling scheme, the efficiency gain of the restricted maximum likelihood estimator increases while the validation sample proportions of the two tails increase. In the extreme case of Table 1(b), the restricted maximum likelihood estimator has substantial efficiency gains when the regression effect of X is not zero. When the sampling proportion is not particularly ‘extreme’, such as with the sample validation proportion of the first setting (0·267, 0·1, 0·267), the restricted maximum likelihood estimator does not appear to lead to huge gains in efficiency over the maximum estimated likelihood estimator and the pseudoscore estimator. Nevertheless, the restricted maximum likelihood estimator never performs worse than either of the others.
ACKNOWLEDGEMENTS
This research is supported in part by grants from the U.S. National Institutes of Health. We thank an anonymous reviewer for very helpful comments.
APPENDIX
Technical details
First we present assumptions needed in section 3.
Assumption A1
The true parameters (θ0;G0) are identifiable in the model
where Θ is a compact metric space, and ≡ {G : G is a distribution on with density g with respect to μ}.
Assumption A2
The space X ∈ is a semimetric space that has a completion that is compact and contains as a Borel set.
Assumption A3
The maps (θ, x) ↦ f(y|x; θ) are uniformly continuous.
Assumption A4
We assume that P0[supθ∈Θ log{f(y|x; θ)/f(y|x; θ0)}] < ∞, and f(y|x; θ) > 0 for all y ∈ and x ∈ .
Assumption A5
The set is a bounded subset of ℝd with nonempty interior.
Assumption A6
We assume that , as θ → θ0, G → G0.
Assumption A7
The function x ↦ f(y|x; θ) is continuously differentiable for each y. For all x, x′ ∈ and constants D and α > 0,
and
Assumption A8
The map θ ↦ log f(y|x; θ) is three times differentiable with respect to θ, and the third-order derivatives are bounded by integrable functions of (Y;X) for θ ∈ Θ0, where Θ0 is a subset of Θ, and θ0 ∈ Θ0.
Identifiability result
Suppose that Assumption A1 holds. Then (θ;G) is identifiable in the model 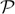 = {Pθ,G : dPθ,G/d(ν × μ) = p(·; θ,G), θ ∈ Θ, G ∈ }, where p(·; θ,G) is given by (1). This result can be proved by verifying the definition. Details can be found in a technical report available from the authors.
= {Pθ,G : dPθ,G/d(ν × μ) = p(·; θ,G), θ ∈ Θ, G ∈ }, where p(·; θ,G) is given by (1). This result can be proved by verifying the definition. Details can be found in a technical report available from the authors.
Proof of Theorem 1
If Ĝθ denotes the maximizer of G ↦ Ln(θ,G), the score function takes the form ℙn Rh = Ĝθ {sn (x; θ, Ĝθ)h}, where
With the asymptotic tightness of Ĝn not hard to verify, and with the Glivenko-Cantelli properties of the involved functions, shown in our technical report, we can establish the consistency by the Helly selection theorem.
Proof of Theorem 2
The proof mainly involves checking the conditions of Theorem 3.3.1 of van der Vaart & Wellner (1996). A critical step is to show that σ ψ0 is continuously invertible and onto, which can be established by using Lemma 25.93 of van der Vaart (1998).
Contributor Information
Rui Song, Email: rsong@bios.unc.edu.
Haibo Zhou, Email: zhou@bios.unc.edu.
Michael R. Kosorok, Email: kosorok@unc.edu.
REFERENCES
- Bickel PJ, Klaassen CAJ, Ritov Y, Wellner JA. Efficient and Adaptive Estimation for Semiparametric Models. New York: Springer-Verlag; 1998. [Google Scholar]
- Breslow N, McNeney B, Wellner JA. Large sample theory for semiparametric regression models with two-phase, outcome dependent sampling. Ann. Statist. 2003;31:1110–1139. [Google Scholar]
- Breslow NE, Cain KC. Logistic regression for two-stage case-control data. Biometrika. 1988;75:11–20. [Google Scholar]
- Chatterjee N, Chen Y-H, Breslow NE. A pseudoscore estimator for regression problems with two-phase sampling. J. Am. Statist. Assoc. 2003;98:158–168. [Google Scholar]
- Cornfield J. A method of estimating comparatice rates from clinical data. J. Nat. Cancer Inst. 1951;11:1269–1275. [PubMed] [Google Scholar]
- Lawless JF, Kalbfleisch JD, Wild CJ. Semiparametric methods for response-selective and missing data problems in regression. J. R. Statist. Soc. 1999;B 61:413–438. [Google Scholar]
- Murphy SA, van der Vaart AW. On profile likelihood (with Discussion) J. Am. Statist. Assoc. 2000;95:449–485. [Google Scholar]
- Murphy SA, van der Vaart AW. Semiparametric mixtures in case-control studies. J. Mult. Anal. 2001;79:1–32. [Google Scholar]
- Nan B, Emond MJ, Wellner JA. Information bounds for Cox regression models with missing data. Ann. Statist. 2004;32:723–753. [Google Scholar]
- Prentice RL, Pyke R. Logistic disease incidence models and case-control studies. Biometrika. 1979;66:403–412. [Google Scholar]
- Qin J. Empirical likelihood in biased sample problems. Ann. Statist. 1993;21:1182–1196. [Google Scholar]
- Scott A, Wild C. Maximum likelihood for generalised case-control studies. J. Statist. Plan. Infer. 2001;96:3–27. [Google Scholar]
- van der Vaart A, Wellner JA. Existence and consistency of maximum likelihood in upgraded mixture models. J. Mult. Anal. 1992;43:133–146. [Google Scholar]
- van der Vaart A, Wellner JA. Consistency of semiparametric maximum likelihood estimators for two-phase sampling. Can. J. Statist. 2001;29:269–288. [Google Scholar]
- van der Vaart AW. Asymptotic Statistics. Cambridge: Cambridge University Press; 1998. [Google Scholar]
- van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. New York: Springer; 1996. [Google Scholar]
- Wacholder S, Weinberg CR. Flexible maximum likelihood methods for assessing joint effects in case-control studies with complex sampling. Biometrics. 1994;50:350–357. [PubMed] [Google Scholar]
- Wang X, Zhou H. A semiparametric empirical likelihood method for biased sampling schemes with auxiliary covariates. Biometrics. 2006;62:1149–1160. doi: 10.1111/j.1541-0420.2006.00612.x. [DOI] [PubMed] [Google Scholar]
- Weaver MA, Zhou H. An estimated likelihood method for continuous outcome regression models with outcome-dependent sampling. J. Am. Statist. Assoc. 2005;100:459–469. [Google Scholar]
- Weinberg CR, Wacholder S. Prospective analysis of case-control data under general multiplicative-intercept risk models. Biometrika. 1993;80:461–465. [Google Scholar]
- White JE. A two stage design for the study of the relationship between a rare exposure and a rare disease. Am. J. Epidem. 1982;115:119–128. doi: 10.1093/oxfordjournals.aje.a113266. [DOI] [PubMed] [Google Scholar]
- Zhang Z, Rockette H. On maximum likelihood estimation in parametric regression with missing covariates. J. Statist. Plan. Infer. 2005;134:206–223. [Google Scholar]
- Zhao LP, Lipsitz S. Designs and analysis of two-stage studies. Statist. Med. 1992;11:769–782. doi: 10.1002/sim.4780110608. [DOI] [PubMed] [Google Scholar]
- Zhou H, Chen J, Rissnen TH, Korrick SA, Hu H, Salonen JT, Longnecker MP. Outcome dependent sampling: An efficient sampling and inference procedure for studies with a continuous outcome. Epidemiology. 2007;18:461–468. doi: 10.1097/EDE.0b013e31806462d3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou H, Weaver MA, Qin J, Longnecker MP, Wang MC. A semiparametric empirical likelihood method for data from an outcome-dependent sampling scheme with a continuous outcome. Biometrics. 2002;58:413–421. doi: 10.1111/j.0006-341x.2002.00413.x. [DOI] [PubMed] [Google Scholar]