

Abstract
Mesoamerica, defined as the broad linguistic and cultural area from middle southern Mexico to Costa Rica, might have played a pivotal role during the colonization of the American continent. The Mesoamerican isthmus has constituted an important geographic barrier that has severely restricted gene flow between North and South America in pre-historical times. Although the Native American component has been already described in admixed Mexican populations, few studies have been carried out in native Mexican populations. In this study, we present mitochondrial DNA (mtDNA) sequence data for the first hypervariable region (HVR-I) in 477 unrelated individuals belonging to 11 different native populations from Mexico. Almost all of the Native Mexican mtDNAs could be classified into the four pan-Amerindian haplogroups (A2, B2, C1, and D1); only two of them could be allocated to the rare Native American lineage D4h3. Their haplogroup phylogenies are clearly star-like, as expected from relatively young populations that have experienced diverse episodes of genetic drift (e.g., extensive isolation, genetic drift, and founder effects) and posterior population expansions. In agreement with this observation, Native Mexican populations show a high degree of heterogeneity in their patterns of haplogroup frequencies. Haplogroup X2a was absent in our samples, supporting previous observations where this clade was only detected in the American northernmost areas. The search for identical sequences in the American continent shows that, although Native Mexican populations seem to show a closer relationship to North American populations, they cannot be related to a single geographical region within the continent. Finally, we did not find significant population structure in the maternal lineages when considering the four main and distinct linguistic groups represented in our Mexican samples (Oto-Manguean, Uto-Aztecan, Tarascan, and Mayan), suggesting that genetic divergence predates linguistic diversification in Mexico.
Electronic supplementary material
The online version of this article (doi:10.1007/s00439-009-0693-y) contains supplementary material, which is available to authorized users.
Introduction
Although largely explored by many disciplines, the peopling of the Americas remains as an issue of intense debate. The tempo and mode in which modern humans colonized the New World through Beringia to the rest of the American continent remains unclear; with numerous hypotheses have been proposed in the last few decades (Campbell and Mithum 1979; Chakraborty and Weiss 1991; Greenberg et al. 1986; Laughlin 1988; Spencer et al. 1977; Szathmary et al. 1983; Wallace et al. 1985). However, a date of entry into the Americas roughly consistent with the archaeological record, has been placed around 15,000–17,000 years before present (ybp), followed by subsequent episodes of reduced population size, compatible with the current low genetic diversity observed in present day Native American populations (Mulligan et al. 2004).
Interest in the settlement of the New World has boosted genetic studies in Native American populations. These studies are based mainly on the analysis of the mitochondrial (mtDNA), a genome inherited exclusively throughout the maternal line. Most extant Native American mtDNAs, if not of recent admixture, descend from four main founding haplogroups, initially baptized as A, B, C, D (Torroni et al. 1993a) and further characterized as A2, B2, C1, and D1 (Achilli et al. 2008; Fagundes et al. 2008; Perego et al. 2009; Tamm et al. 2007); and five minor lineages, namely C4c, D2a, D3, D4h3, and X2a (Achilli et al. 2008; Bandelt et al. 2003; Brown et al. 1998; Fagundes et al. 2008; Schurr et al. 1990; Tamm et al. 2007; Torroni et al. 1992, 1993a). Based on mtDNA sequence data, Bonatto and Salzano (1997) proposed the hypothesis of a single and early migration that entered into the New World through Beringia where the population settled, expanded and diversified before the further colonization of the rest of the American continent. This “Out of Beringia” model, in contrast to the previous multiple migration scenarios for the Pleistocene peopling of the Americas, was compatible with recent studies supporting a single migration scenario. For instance, according to Tamm et al. (2007) and Fagundes et al. (2008), the ancestral population left from northeast Asia during the Last Glacial Maximum, defined as an interval centered on 21,000 ybp (Clark and Mix 2002), crossed through the Bering Strait bearing the five founder lineages and remained isolated long enough to generate the pan-American haplogroups A2, B2, C1, D1, and X2a (Achilli et al. 2008), which were distributed southward probably following a Pacific coastal route. This pattern of dispersion is indeed found in the actual distribution of Uto-Aztecan languages extending from the Western Plateau and Coast of California to Nicaragua in Central America (Miller 1983) and Oto-Manguean languages found from Middle America (Northeast Mexico) to Nicaragua and Honduras in Central America (Suaréz 1983). Recently, Perego et al. (2009) have reported the variation at two rare American mtDNA haplogroups D4h3 and X2a, based on complete genome sequencing of the mtDNA molecule, signaling for the first time the existence of two distinctive and almost concomitant Paleo-Indian migrations routes which would have occurred 15–17 kya from Beringia.
Specific geographic regions of the continent might have played a key role during the colonization of the Americas. One such region is the linguistic and cultural area called Mesoamerica (Campbell et al. 1986; Kirchhoff 1943; Pailes and Whitecotton 1995), which extends from middle southern Mexico to Guatemala, Belize, Honduras, El Salvador, Nicaragua, and Costa Rica, in which ancient native populations shared languages, traditions, customs, and history (López-Austin and Luján 2001). This evidence suggests that Mesoamerica represented a geographic bottleneck and possibly limited the gene flow between North and South America, and concentrated an invaluable source of diversity in that region. In fact, present day Mexican territories, which cover most of Mesoamerica, harbor one of the richest ethnic and linguistic diversities of the continent. Thus, Mexico has eleven linguistic families divided into 68 major linguistic groups which include 291 living languages and seven extinct ones (Inali 2007).
Despite the abundant genetic data on different Native American groups across the continent, the patterns of variability of Native Mexicans still remain unclear. Some prospective studies based on uniparental markers (Barrot et al. 2005; Buentello-Malo et al. 2003; Collins-Schramm et al. 2004; Rangel-Villalobos et al. 1999, 2000, 2001a, b) showed a relative genetic homogeneity of Mexican autochthonous populations. Other studies based on mixed urban samples (Mestizos) (Bonilla et al. 2005; Cerda-Flores et al. 2002a, b; Green et al. 2000) indicated that these groups are basically the result of admixture between Native Americans and Europeans but provided a poor idea about the genetic structure and diversity of autochthonous populations. Moreover, studies focused on ancient mtDNA (González-Oliver et al. 2001) have shown the presence of haplogroup A2, B2, and C1 (following the most recent nomenclature) mtDNA lineages in pre-Columbians; and analyses of extant mtDNA based on restriction enzymes have also shown the presence of the four major Amerindian haplogroups in Mexican samples (Penaloza-Espinosa et al. 2007). A deep genetic characterization of a larger number of Native Mexican populations might give insights, not only on the complex relationships between autochthonous groups inside Mexico, but also on the reconstruction of the human history of the Americas.
Here, we present mtDNA sequence data for 477 unrelated individuals belonging to eleven different native populations from Mexico, namely, Triqui, Tarahumara, Purépecha, Otomí, Mixtec, Nahua Xochimilco, Nahua Zitlala, Nahua Ixhuatlancillo, Nahua Necoxtla, Maya, and Pima. For the first time, an exhaustive analysis of maternal lineages in Native Mesoamerican populations is reported and the results are discussed within the context of continental genetic variation by constructing a mtDNA database with published reported sequences from populations from North, Central, and South America.
Materials and methods
Population sampling
A total of 477 unrelated Mexican individuals from 11 populations were sampled with their appropriate informed consent. All individuals were native speakers with two generation-local unrelated ancestors. The geographic location of collected samples is shown in Fig. 1 and comprised 107 Triquis, 15 Tarahumaras, 34 Purépechas, 68 Otomíes, 35 Nahuas from Xochimilco, 14 Nahuas from Zitlala, 10 Nahuas from Ixhuatlancillo, 25 Nahuas from Necoxtla, 19 Mixtecs, 98 Pimas, and 52 Mayas. An additional sample of 23 Quechua individuals from Peru was included and used for population comparisons as part of the Native American database. All sequences are available at Supplementary Table S1.
Fig. 1.

Map of Mexican populations sampled. Pima (PM), Tarahumara (R), Otomí (O), Purépecha (P), Nahua from Xochimilco (Nx), Nahua from Ixhuatlancillo (Ni), Nahua from Necoxtla (Na), Nahua from Zitlala (Nz), Mixtec (M), Triqui (T), and Maya (MY)
Mitochondrial DNA genotyping
DNA was extracted from blood samples using standard phenol chloroform method (Sambrook et al. 1982) and FTA® extraction according to the supplier’s protocol. DNA from Pimas, Mayas, and Quechuas was directly provided from the laboratory of Judith R. Kidd and Kenneth K. Kidd (Yale University, New Haven, CT, USA) where lymphoblastoid cell lines are maintained. The mtDNA control region was amplified using primers L15996 and H408 (Vigilant et al. 1989). PCR products were subsequently purified with GFX PCR DNA Kit (Amersham Biosciences, GE Healthcare Bio-Sciences AB, Uppsala, Sweden). Both strands of the hypervariable region I (HVRI) were sequenced with the Big Dye Terminator v3.1 Cycle Sequencing kit (Applied Biosystems, Carlsbad, CA, USA) using primers L15996 and H16401 (Vigilant et al. 1989). The sequence from positions 16024 to 16391 was determined (Anderson et al. 1981) for each individual. Length polymorphisms observed in the C-stretch from position 16184 to 16193 were not considered in those analyses involving population samples collected from the literature, due to lack of consistency when reporting variation at this region. In order to properly classify some sequences into haplogroups, additional markers in the mtDNA coding region were analyzed. The 9-bp tandem repeat (CCCCCTCTA) in the COII/tRNALys intergenic region, defining haplogroup B in Native Americans, was amplified using primers L8196 (5′-ACA GTT TCA TGC CCA TGG TC-3′) and H8297 (5′-ATG CTA AGT TAG CCT TAC AG-3′) and run into a 4% agarose gel (Comas et al. 2004). A diagnostic restriction enzyme (AluI for position 5176) was used to categorize haplogroup D, using the primers L5054 (5′-TAG GAT GAA TAA TAG CAG CTC TAC CG-3′), and H5189 (5′-GGG TGG ATG GAA TTA AGG GTG T-′3).
All the mtDNAs could be allocated to the Native American haplogroups A2, B2, C1, D1, and D4h3, with the exception of one Pima and one Quechua bearing West Eurasian haplogroups R1 and T, respectively. These two sequences were not considered for computational analysis. We follow Tamm et al. (2007), Fagundes et al. (2008), Achilli et al. (2008), and Perego et al. (2009) for the nomenclature of Native American clades. We are aware that HVRI alone is unable to distinguish Native American clades from their closest neighbors in northeast Asia; it is, however, commonly accepted that most of the variation belonging to haplogroups A, B, C, and D observed in Native Americans can be attributed to the American sub-lineages A2, B2, C1, and D1. This is particularly true for Mexico, where there is not known historical documentation supporting recent gene flow from Asian populations. We, therefore, use in what follows the latter nomenclature in the present study. Distinction of the minor Native American sub-clades, C4c, D2a, D3, D4h3, and X2a, as well as sub-lineages within A2, B2, C1, and D1, is also challenged by the limited resolution provided by the HVRI segment; some of these lineage, however, are characterized by diagnostic sites in this region (Achilli et al. 2008; Perego et al. 2009).
Data analysis
Intrapopulation genetic diversity parameters were computed using DnaSP software v4.0 (Rozas et al. 2003). The mean number of pairwise differences and the weighted intra-linage mean pairwise (WIMP) differences (Hurles et al. 2002) were calculated using the Arlequin program v3.1 (Excoffier et al. 2005).
A median joining network (Bandelt et al. 1995) was constructed using the Network 4.5.0.0 package (http://www.fluxus-engineering.com/) for each of the four main haplogroups (A2, B2, C1, and D1) found in Mexican populations. Positions 16024 to 16391 were considered and nucleotide position was given a weight as in Brandstätter et al. (2008) (Bandelt et al. 2006). The dating method employed (Saillard et al. 2000) is based on the average number of mutations accumulated from an ancestral sequence as a linear function of time and mutation rate. Values of ρ and σ were converted to age estimates using the most recent mutation rate available for the HVS-I segment of one transition per 18,845 years (in the sequence range 16090–16365) (Soares et al. 2009). This method was also performed with Network 4.5.0.0 program.
In order to compare the present Mexican results with other Native American populations, HVRI sequences from 52 Native American sample populations were collected from the literature (Supplementary Table S2). We removed from this database a total of 12 sequences belonging to non-Native American haplogroups (Achilli et al. 2008), considered to be the result of recent admixture with European and African individuals. For some analyses, population samples were grouped into major subcontinental areas: North (879 individuals from Alaska to southern Mexico), Central (234 individuals from Guatemala to Panama), and South America (1,633 individuals from Colombia southwards) (Table S2). For some analyses, Mexican samples were also considered as a separate category from North, Central, and South America. A spatial analysis of the molecular variance (SAMOVA) was also performed using the SAMOVA 1.0 program (Dupanloup et al. 2002) by presetting different numbers of population groups. This approach defines groups of populations that are geographically homogeneous and maximizes the proportion of total genetic variance due to differences between groups. Population genetic structure was tested through analysis of molecular variance (AMOVA) (Excoffier et al. 1992) using the Arlequin program v3.1 (Excoffier et al. 2005). Genetic relationships among Mexican and continental populations were analyzed by means of pairwise genetic differences and haplogroup absolute frequencies. The former were calculated using Arlequin program v3.1 (Excoffier et al. 2005) and represented in a Multidimensional Scaling plot (MDS) and the latter were used to construct a Correspondence Analysis (CA) plot using STATISTICA 7 package (http://www.statsoft.com).
In order to compare Mexican mtDNA sequences within the American framework, sequence variation within the range 16090 to 16362 (Anderson et al. 1981) was used for inter-population comparisons. Each mitochondrial sequence found in Mexico was compared with the dataset (Supplementary Table S3). To estimate the most likely source ancestral population (North, Central, or South America) of each of the Mexican mtDNA observed in our study, we followed a Bayesian approach: the probability of each of the subcontinental regions was computed as 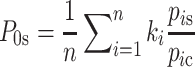 where n is the number of Mexican sequences matching at least one mtDNA in the whole continental database; k
i the number of times the sequence i is found in the Mexican sample; p
is the frequency of the sequence i in the subcontinental region database; and p
ic the frequency of the sequence i in the whole continental database. To provide confidence intervals for each of the estimations for the subcontinental regions, we also computed the standard deviations as
where n is the number of Mexican sequences matching at least one mtDNA in the whole continental database; k
i the number of times the sequence i is found in the Mexican sample; p
is the frequency of the sequence i in the subcontinental region database; and p
ic the frequency of the sequence i in the whole continental database. To provide confidence intervals for each of the estimations for the subcontinental regions, we also computed the standard deviations as 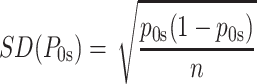 (Mendizabal et al. 2008).
(Mendizabal et al. 2008).
Results
Mitochondrial DNA diversity in Native Mexican populations
A total of 118 different sequences were found in the 477 Mexican individuals analyzed in the present study. The genetic diversity found in Mexican samples is summarized in Table 1. Three different estimates for the expected number of unique sequences in the different populations sampled are also provided (Egeland and Salas 2008) in Table 1, indicating that the samples sizes for the 12 ethnic groups analyzed in the present study cover reasonably well the expected variation at the HVRI segment. In addition, the sample coverage parameter (C; for definition see also Egeland and Salas 2008) also indicates that sample sizes represent in most of the cases more than 60% of the expected haplotypes in the populations; only the Quechua sample from Peru seems to represent only a very small proportion of the expected number of haplotypes in the population (~9%; data not shown). The results showed that Pimas (0.54 ± 0.05) and Triquis (0.55 ± 0.05) presented the lowest sequence diversity values despite their larger sample sizes. The average pairwise differences by population range from 1.69 to 7.42. Although most Mexican populations presented high sequence diversity and moderate mean pairwise differences, the WIMP differences value was low in all samples, suggesting that Mexican samples present a composition of distantly phylogenetic related haplogroups with low to moderate internal diversity.
Table 1.
Diversity parameters for the first mtDNA hypervariable region (HVRI) in eleven Mexican native populations
| Population | n | K | S | HD (SE) | H (SE) | Theta S | M | WIMP | N 1 | N 2 | N 3 | C (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Triqui | 107 | 15 | 28 | 0.550 (0.057) | 0.012 (0.001) | 5.33 | 4.54 | 1.06 | 19 | 31 | 47 | 78 |
| Tarahumara | 15 | 7 | 21 | 0.771 (0.100) | 0.012 (0.003) | 6.46 | 4.57 | 1.59 | 11 | 21 | 39 | 67 |
| Purépecha | 34 | 23 | 37 | 0.973 (0.014) | 0.017 (0.002) | 9.05 | 6.58 | 2.95 | 41 | 44 | 46 | 56 |
| Otomí | 68 | 32 | 40 | 0.969 (0.008) | 0.018 (0.001) | 8.35 | 6.96 | 2.45 | 42 | 50 | 56 | 76 |
| Mixtec | 19 | 10 | 19 | 0.825 (0.084) | 0.010 (0.002) | 5.44 | 3.69 | 1.53 | 16 | 36 | 74 | 63 |
| N.Xochimilco | 35 | 21 | 34 | 0.928 (0.034) | 0.013 (0.002) | 8.25 | 5.18 | 2.36 | 37 | 80 | 163 | 57 |
| N.Zitlala | 14 | 5 | 11 | 0.681 (0.132) | 0.004 (0.001) | 3.45 | 1.69 | 1.69 | 6 | 12 | 22 | 78 |
| N.Ixhuatlancillo | 10 | 8 | 23 | 0.956 (0.059) | 0.018 (0.002) | 8.13 | 7.42 | 2.6 | 20 | 20 | 20 | 40 |
| N.Necoxtla | 25 | 14 | 24 | 0.910 (0.043) | 0.015 (0.001) | 6.35 | 6.24 | 2.46 | 22 | 36 | 53 | 64 |
| Maya | 52 | 20 | 30 | 0.943 (0.016) | 0.016 (0.001) | 6.63 | 6.04 | 2.28 | 25 | 30 | 33 | 78 |
| Pimaa | 97 | 7 | 17 | 0.544 (0.056) | 0.008 (0.001) | 3.30 | 2.98 | 0.73 | 9 | 9 | 10 | 91 |
| Mexicans | – | – | – | – | – | – | – | – | 135 | 202 | 267 | 66 |
n number of individuals, K number of different sequences, S number of variable positions, HD haplotype diversity, SE standard errors, H nucleotide diversity, Theta S Watterson’s theta values, M mean number of pairwise differences, WIMP weighted intra-lineage mean pairwise differences, N 1 , N 2 , N 3 different estimates for the expected total number of unique sequences, C refers to sample coverage; see Egeland and Salas (2008) for definitions
aOne Pima sequence belonging to haplogroup R1 was excluded from the analyses
All Mexican sequences were classified into the five Amerindian haplogroups A2, B2, C1, D1, and D4h3, according to Achilli et al. (2008) and Perego et al. (2009), with the exception of one Pima individual who presented a sequence probably belonging to the Eurasian haplogroup R1 as suggested by the presence of exact matches (16278T 16311C) to other sample populations where coding region information was also available (Macaulay et al. 1999). This sequence was excluded from subsequent analyses (Table 1). The most frequent haplogroup in Native Mexican populations was haplogroup A2 (50.5%), followed by C1 (28.5%), B2 (17.6%), D1 (2.7%), and D4h3 (0.4%) (Table 2). With respect to the pan-American haplogroups, we noted that the composition of Native Mexicans contrasts with the pattern reported by Salzano (2002) based on restriction endonuclease analysis, in which Mexican and Central American samples have higher frequencies of haplogroups A2 and B2 when compared with C1 and D1. This is especially relevant in the Pima and Tarahumara samples were C1 is very frequent compared to other Mexican samples. We did not find the minor haplogroup X2a, which has been reported at low frequencies in North American samples and absent in South America (see Perego et al. 2009 for a recent analysis of this haplogroup based on complete genome sequences). The highest expected frequency (F) of the unobserved X2a haplogroup in the population can be estimated assuming that the pattern of variability follows a Poisson distribution and using a confidence interval of 95%; then 1 − e−Fn = 0.95, where n represents sample size. Therefore, the maximum frequency of the X2a haplogroup in native Mexican populations given our sample size would be 0.6% (see Egeland and Salas 2008 for some caveats concerning this approach).
Table 2.
Absolute haplogroup frequencies of Native Mexican Populations (in parenthesis relative frequencies)
| Population | n | A2 | B2 | C1 | D1 | D4h3 | Other |
|---|---|---|---|---|---|---|---|
| Triqui | 107 | 77 (71.9) | 30 (28.0) | – | – | – | – |
| Tarahumara | 15 | 2 (13.3) | 1 (6.6) | 11 (73.3) | – | 1 (6.6) | – |
| Purépecha | 34 | 20 (58.8) | 3 (8.8) | 8 (23.5) | 3 (8.8) | – | – |
| Otomí | 68 | 27 (39.7) | 17 (25) | 20 (29.4) | 4 (5.8) | – | – |
| Mixtec | 19 | 15 (78.9) | 2 (10.5) | 1 (5.2) | 1 (5.2) | – | – |
| N.Xochimilco | 35 | 27 (77.1) | 5 (14.2) | 3 (8.5) | – | – | – |
| N.Zitlala | 14 | 14 (100) | – | – | – | – | – |
| N.Ixhuatlancillo | 10 | 4 (40) | 1 (10) | 3 (30) | 1 (10) | 1 (10) | – |
| N.Necoxtla | 25 | 12 (48) | 13 (52) | – | – | – | – |
| Maya | 52 | 32 (61.5) | 9 (17.3) | 8 (15.3) | 3 (5.7) | – | – |
| Pima | 98 | 11 (11.2) | 3 (3.06) | 82 (83.6) | 1 (1.0) | – | 1 (1.0) |
| Total Mexican sample | 477 | 241 (50.5) | 84 (17.6) | 136 (28.5) | 13 (2.7) | 2 (0.4) | 1 (0.2) |
n number of individuals
It is worth mentioning that the occurrences of two out of the three D4h3 mtDNAs observed in our samples were in one Mexican Tarahumara and one Peruvian Quechua, both living in the West side of the continent, as predicted by the results of (Perego et al. 2009), who postulated that this haplogroup spread into the Americas along the Pacific Coast. The third occurrence of D4h3 was in the Nahua from Ixhualtlancillo, a population living in the narrow region of southern Mexico, where it is also expected to find some members of this lineage (as it will probably occur in other studies on native populations living in other Mesoamerican countries).
The most common haplotypes are shared by almost all the populations. However, it is interesting to note that the pattern of haplotype frequencies varies significantly between populations (independently of their sample sizes). To give an example, haplotype 16111T 16223T 16290T 16319A 16362C makes up ~66% of the Triqui population, ~64% of the Nahuas from Zitlala, but it is ~10% of the Otomí sample and it is absent in Pima. The fact that these haplotypes are common in America and are phylogenetically related to each other (see below) indicates that genetic drift has played an important role in modulating their spatial distribution in Mexico.
In order to investigate the genetic relationship between the mtDNAs observed in our sample set, a median joining network was constructed for each of the most common mitochondrial haplogroups, namely A2, B2, C1, and D1. The four networks clearly have a star-like pattern and do not present any well-defined cluster (for an example of haplogroup A, see Supplementary Figure S1). The estimated ages for the four haplogroups were dated in a wide range of 18–31 kya. Given that recent studies by Tamm et al. (2007); Achilli et al. (2008) and Perego et al. (2009) based on complete genome analysis provided more recent ages for the four main Native American haplogroups; the ages obtained here probably represent an overestimate of the real haplogroup coalescent times likely due to the low resolution provided by the HVRI segment analyzed in the present study.
Genetic structure of Native Mexican populations
An AMOVA was performed in order to define the population structure of Mexican indigenous populations according to geographic and linguistic criteria (Table 3). When all Mexican populations were considered as a single group, 19.23% (p < 0.01) of the genetic variance was found between populations, showing a relevant genetic heterogeneity among Native Mexican populations. A significant proportion of the variance (19.17%; p < 0.01) was found between groups when populations were classified into northern (Tarahumara and Pima) and central-southern groups (Triqui, Purépecha, Otomí, Nahua, Mixtec, and Maya), meaning that significant mtDNA differences between the northern and central-southern Mexican populations exist, however no statistical differences were found between central (Purépecha, Otomí, and Nahua) and southern (Triqui, Mixtec, and Maya) groups (4.35%, p = 0.15). When the geographical location of the samples was taken into account in a SAMOVA analysis, the first grouping of populations was again Tarahumara and Pima versus the rest of populations, and subsequent partitions of the variance rendered only individual populations without a geographical structure (data not shown).
Table 3.
Results of the analysis of molecular variance (AMOVA) of Native Americans
| Among groups | Among populations within groups | Within populations | |
|---|---|---|---|
| Mexican populationsa | – | 19.23** | 80.77** |
| Linguistic classificationb | −0.45 ns | 19.59** | 80.86** |
| Mexican northern populationsc | 19.17** | 9.05** | 71.77** |
| American populationsd | – | 16.86** | 83.14** |
| Geographic classificatione | 0.65 ns | 16.44** | 82.91** |
| American populations and Mexicansf | 1.09* | 16.08** | 82.83** |
ns non-significant
* p < 0.05; ** p < 0.01
aThe eleven Mexican population samples analyzed
bMexican population samples were grouped according to their linguistic families
cNorthern samples (Tarahumara and Pima) were compared to Central-Southern samples
dAll Native American populations from the present database
eNative American population samples grouped according to their sub-continental regions (North, Central and South)
fFour groups: populations from North, Central, South America, and the Mexicans
Four major linguistic families found in Mexico were represented in our studied populations: Oto-Manguean (Mixtec, Triqui and Otomí), Uto-Aztecan (Nahua populations, Tarahumara and Pima), Tarascan (Purépecha) and Mayan (Maya). A non-significant −0.45% of the variance was explained by these linguistic groups, suggesting a lack of correlation between mtDNA genetic diversity and linguistic classification.
Mexican populations within the American genetic landscape
In order to compare the mtDNA diversity found in Mexico to the rest of the American continent, a Correspondence Analysis (CA) based on haplogroup frequencies was performed considering the whole set of populations included in our dataset (Fig. 2). The two-dimension plot accounts for 53.49% of the total variation whereas 28.31% is explained by the first dimension. Although the distribution along the second dimension (25.18%) slightly suggests a North-South pattern, no particular clustering of populations can be clearly detected. It is noteworthy that most Mexican populations are closely related to other North and Central American populations, with the clear exception of Pima and Tarahumara which appear considerably separated from the rest. A similar pattern is shown when a MDS analysis is performed at a continental scale; that is, no clear clusters, and a few outliers caused by low sequence diversity, such as Pima and Triqui (Mexico), Ayoreo (Bolivia and northern Paraguay) and Emerillon (French Guiana) were observed (data not shown).
Fig. 2.

Two-dimension Correspondence Analysis (CA) plot of Native American populations based on absolute haplogroup frequencies. Triangles stand for Northern, diamonds for Central, and circles for Southern populations. Mexican populations are shown in gray and haplogroups are underlined
An AMOVA considering all Native American populations showed a high degree of heterogeneity between populations (16.86% of the genetic variance; p < 0.01). It is noteworthy that this mtDNA heterogeneity is of a similar magnitude to that observed considering only Mexican populations. In order to ascertain whether this heterogeneity was caused by geographical factors, three continental groups (North, Central and South) were considered (Table S2). The AMOVA showed that a non-significant 0.65% (p = 0.15) of the genetic variance was due to differences between these three sub-continental groups, whereas the genetic variance within the three groups remained highly significant (16.44%, p < 0.01), pointing to an important genetic heterogeneity within the sub-continental areas and a lack of continental structure. When Mexican samples were considered as a separate category from northern, central and southern groups, a mere 1.09% (p = 0.046) of the genetic variance was attributed to differences among groups, whereas the genetic heterogeneity within groups remained highly significant (16.08%, p < 0.01).
To obtain rough estimates for the relationship of Mexican mtDNA lineages at a finer scale, we searched exact matching sequences in our dataset. This analysis assumes that the frequencies found nowadays are representatives of extinct populations. Although this assumption is somehow unrealistic due to the dramatic genetic drift events experienced by most of the Native American populations, this proxy is still useful to better describe the geographical distribution of haplotype Mexican sequences within the American continent. All the Mexican lineages were compared to our dataset of 2,746 published Native American sequences (Table S2) divided into the three main aforementioned geographical regions (North, Central, and South). Only 21 Native Mexican lineages, representing 59% of the individuals, were also found in the America dataset (Table S3). The average of the proportions of Mexican sequences found in each geographical region can be used as a proxy to infer the relationship of these populations within the continent. Thus, the distribution of the Native Mexican sequences could be described as follows: 46.29% (SD 2.98%) to North, 15.86% (SD 2.19%) to Central and 37.83% (SD 2.89%) to South America. As expected, the mtDNA variability observed in Mexicans cannot be allocated to a single geographical region within the continent (due to the lack of a clear geographical structure in the Americas as shown, e.g., in the AMOVA analysis). However, the Mexican mtDNA pool shows a closer relationship to northern American populations.
Discussion
Native American populations show a unique pattern of genetic diversity as a result of different demographic processes—population bottlenecks, founder effects, genetic drift—involved in the colonization of the New World and the posterior European contact and African slave trade (Mulligan et al. 2004; Salas et al. 2004). Presently Mexico is mainly inhabited by two distinct population groups: (1) the so-called ‘Mestizos’, a term used in the country and widely accepted by Mexicans to designate individuals of recent admixed ancestry (although the term is meaningless from a genetic point of view; see comments in Salas et al. (2004)), and (2) the native indigenous Mexican groups defined by their language, cultural traits, ethnicity, oral history and customs as part of their cultural complexity. Despite ‘Mestizos’ representing nearly 95% of the Mexican population (INEGI 2007), the Native American component is highly prevalent in their gene pool. Thus, for instance, the study by Cerda-Flores et al. (2002a) based on short tandem repeats showed the admixed percentage contribution of ‘Mestizo’ Mexicans from northeastern locations as deriving from Spanish (54.99 ± 3.44), Amerindian (39.99 ± 2.57) and African (5.02 ± 2.82). The analysis of the mtDNA in ‘Mestizos’ has shown that their maternal component is an admixture of Native American (89.1%), European (5.4%), and African (4.5%) lineages (Green et al. 2000).
Besides the intrinsic interest of exploring the variability of Native American groups, their analysis is also pivotal to understand the genetic composition of admixed populations in the Americas. Our results show that the majority of the mtDNAs of autochthonous Mexican individuals can be allocated to one of the four most common Native American haplogroups (A2, B2, C1, D1) (Achilli et al. 2008). We did not observe the mtDNA contribution of African and European ancestry, with the exception of one Pima individual who presented a Eurasian lineage that could be attributed to recent gene flow. The haplogroup distribution observed is similar to that found in an ancient Maya population in which haplogroup A2 accounted for most of the samples (84%) followed by C1 (8%) and B2 (4%), although haplogroup D1 was not found (González-Oliver et al. 2001).
It is noteworthy that no traces of haplogroup X2a were observed in our native Mexican populations. In contrast with haplogroups A2 to D1, which have an East Asian origin (Torroni et al. 1993b), haplogroup X has its origins in West Eurasia, and its entrance into the Americas is more controversial. Haplogroup X2a is not present in Central and South Native American populations (Perego et al. 2009) and represents a clade that lacks close relatives in the Old Word, including Siberia (Reidla et al. 2003). Our results point to a geographical limit in Mesoamerica beyond which haplogroup X2a is not found. Fagundes et al. (2008) suggested that this haplogroup was part of the gene pool of a single Native American founding population and its low frequency is probably due to a failed expansion as a result of its geographic location in the expansion wave and/or its low initial frequency. The most recent study of Perego et al. (2009) suggested however that X2a could have moved from Beringia directly into the North American regions located East of the Rocky Mountains; the X2a expansion could have occurred in the Great Plains region, where the terminal part of the glacial corridor ended, and is in complete agreement with both the extent of diversity and distribution of X2a observed in modern Native American populations. The absence of X2a in our samples supports the idea that Mesoamerica played an important role during the colonization of the continent, restricting this haplogroup to the northernmost lands and shaping the diversity of the other founder haplogroups on their way down to Central and South America.
We have shown a relevant genetic heterogeneity of indigenous groups within Mexico, probably due to processes such as extensive isolation, genetic drift, and founder effects. These demographic events have modulated the distinctive patterns of frequencies of the four main Native American haplogroups in the different Mexican populations. Some populations, in particular the northernmost Tarahumara and Pima, showed larger genetic distances from the rest of the Mexican populations and different haplogroup spectra. When our mtDNA sequences were analyzed together within the continental landscape, no particular structure was detected for the Mexican populations, and sub-continental division does not account for the genetic differences among Native American populations. These results point to a common origin of Native American populations, including the Mexican groups, with extensive isolation and genetic drift, which might have produced an extremely high heterogeneity in their haplogroup patterns.
The Americas are one of the most linguistically diverse regions in the world comprising about 150 linguistic stocks (Nichols 1992). In addition, languages in the Americas show a striking and unparalleled diversity in their grammatical structures. Divergence across populations is caused by genetic drift; however, the differences diminish by extensive contact between populations, i.e., by genetic exchange. The principles governing genetic and linguistic patterns are of different nature and, therefore, it is not uncommon to observe differences between them (Comas et al. 2008). In the Mexican samples analyzed, four major linguistic families are represented (Oto-Manguean, Uto-Aztecan, Tarascan, and Mayan). However, we did not find a correlation between linguistic affiliation and their mtDNA gene pool when populations were grouped according to their linguistic families. The genetic differences between linguistic groups were not significant, which concomitantly translates into a high genetic heterogeneity within linguistic groups. This heterogeneity and the lack of correlation between mtDNA diversity and linguistic affiliation could be explained by the extensive isolation between Mexican indigenous populations. Nonetheless, Tarahumara and Pima show a certain degree of genetic differentiation from the other nine groups, which could be explained by cultural isolation beyond language; note that these are the only two populations analyzed that lay out of the Mesoamerican area. This fact contrasts with the Nahua populations, which despite being affiliated with Uto-Aztecan, the same linguistic family as Tarahumara and Pima, do belong to the cultural-geographical Mesoamerican group. Overall, the data suggest that the Mesoamerican geographic barrier could explain population differences between Native American groups due to genetic drift.
In summary, our findings suggest that the mtDNA diversity patterns in Native Mexicans have been mainly driven by genetic drift. Native Mexicans have preserved their native mtDNA background with almost no contribution from European and/or African populations. Although linguistic structure in Mexicans is highly stratified, we did not observe a correlation between linguistic and mtDNA patterns. Despite the fact that mtDNA represents just a small fraction of the human genome, it has been demonstrated once more to be useful to unravel demographic events in human populations. However, it would be worth exploring other genomic regions in Mexican DNA where natural selection could have played an important role in modulating their variation, providing the necessary adaptive skills in their way to the colonization of South America.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Haplogroup frequencies classified by population in the dataset used for comparison to the Mexican sequences analyzed in the present study (DOC 328 kb)
Mitochondrial DNA sequences found in Mexico with their haplogroup classification and number of (identical) matches in the database used for comparison. Only positions from 16090 to 16362 were taken into account in the comparison database (DOC 60 kb)
Acknowledgments
We would like to thank Andrés Moreno-Estrada, Isabel Mendizabal, Chiara Batini (Unitat de Biologia Evolutiva, UPF), Michelle Gardner (Department of Molecular Neuroscience, Institute of Neurology, University College London) for their comments and help; Mònica Vallés (Unitat de Biologia Evolutiva, UPF), Stéphanie Plaza and Roger Anglada (Servei Genòmica, UPF) for their technical support; and Kenneth Kidd and Judith Kidd (Yale University) for kindly providing Pima, Mayan and Quechua samples. This research was supported by the Agencia Española de Cooperación Internacional (AECI, Programa de Cooperación Interuniversitaria e Investigación Científica entre España e Iberoamérica) (A/7694/07) and Direcció General de Recerca, Generalitat de Catalunya (2005SGR/00608). Karla Sandoval received a fellowship from the Consejo Nacional de Ciencia y Tecnología (CONACyT), México.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
References
- Achilli A, Perego UA, Bravi CM, Coble MD, Kong QP, Woodward SR, Salas A, Torroni A, Bandelt HJ. The phylogeny of the four pan-American MtDNA haplogroups: implications for evolutionary and disease studies. PLoS ONE. 2008;3:e1764. doi: 10.1371/journal.pone.0001764. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, Bankier AT, Barrell BG, de Bruijn MH, Coulson AR, Drouin J, Eperon IC, Nierlich DP, Roe BA, Sanger F, Schreier PH, Smith AJ, Staden R, Young IG. Sequence and organization of the human mitochondrial genome. Nature. 1981;290:457–465. doi: 10.1038/290457a0. [DOI] [PubMed] [Google Scholar]
- Bandelt HJ, Forster P, Sykes BC, Richards MB. Mitochondrial portraits of human populations using median networks. Genetics. 1995;141:743–753. doi: 10.1093/genetics/141.2.743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bandelt HJ, Herrnstadt C, Yao YG, Kong QP, Kivisild T, Rengo C, Scozzari R, Richards M, Villems R, Macaulay V, Howell N, Torroni A, Zhang YP. Identification of Native American founder mtDNAs through the analysis of complete mtDNA sequences: some caveats. Ann Hum Genet. 2003;67:512–524. doi: 10.1046/j.1469-1809.2003.00049.x. [DOI] [PubMed] [Google Scholar]
- Bandelt HJ, Kong QP, Richards M, Macaulay V (2006) Estimation of mutation rates and coalescence times: some caveats. In: Bandelt HJ, Macaulay V, Richards M (eds) Human mitochondrial DNA and the evolution of Homo sapiens. Springer, Berlin, pp 47–90
- Barrot C, Sánchez C, Ortega M, Gonzalez-Martin A, Brand-Casadevall C, Gorostiza A, Huguet E, Corbella J, Gene M. Characterisation of three Amerindian populations from Hidalgo State (Mexico) by 15 STR-PCR polymorphisms. Int J Legal Med. 2005;119:111–115. doi: 10.1007/s00414-004-0488-6. [DOI] [PubMed] [Google Scholar]
- Bonatto SL, Salzano FM. A single and early migration for the peopling of the Americas supported by mitochondrial DNA sequence data. Proc Natl Acad Sci USA. 1997;94:1866–1871. doi: 10.1073/pnas.94.5.1866. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bonilla C, Gutierrez G, Parra EJ, Kline C, Shriver MD. Admixture analysis of a rural population of the state of Guerrero, Mexico. Am J Phys Anthropol. 2005;128:861–869. doi: 10.1002/ajpa.20227. [DOI] [PubMed] [Google Scholar]
- Brandstätter A, Zimmermann B, Wagner J, Gobel T, Rock AW, Salas A, Carracedo Á, Parson W. Timing and deciphering mitochondrial DNA macro-haplogroup R0 variability in Central Europe and Middle East. BMC Evol Biol. 2008;8:191. doi: 10.1186/1471-2148-8-191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown MD, Hosseini SH, Torroni A, Bandelt HJ, Allen JC, Schurr TG, Scozzari R, Cruciani F, Wallace DC. mtDNA haplogroup X: an ancient link between Europe/Western Asia and North America? Am J Hum Genet. 1998;63:1852–1861. doi: 10.1086/302155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buentello-Malo L, Penaloza-Espinosa RI, Loeza F, Salamanca-Gómez F, Cerda-Flores RM. Genetic structure of seven Mexican indigenous populations based on five polymarker loci. Am J Hum Biol. 2003;15:23–28. doi: 10.1002/ajhb.10116. [DOI] [PubMed] [Google Scholar]
- Campbell L, Mithum M. The languages of Native America. Austin: University of Texas Press; 1979. [Google Scholar]
- Campbell L, Kaufman T, Smith-Stark T (1986) Mesoamerica as a linguistic area. Language 62:530–570
- Cerda-Flores RM, Budowle B, Jin L, Barton SA, Deka R, Chakraborty R. Maximum likelihood estimates of admixture in Northeastern Mexico using 13 short tandem repeat loci. Am J Hum Biol. 2002;14:429–439. doi: 10.1002/ajhb.10058. [DOI] [PubMed] [Google Scholar]
- Cerda-Flores RM, Villalobos-Torres MC, Barrera-Saldana HA, Cortes-Prieto LM, Barajas LO, Rivas F, Carracedo A, Zhong Y, Barton SA, Chakraborty R. Genetic admixture in three Mexican Mestizo populations based on D1S80 and HLA-DQA1 loci. Am J Hum Biol. 2002;14:257–263. doi: 10.1002/ajhb.10020. [DOI] [PubMed] [Google Scholar]
- Chakraborty R, Weiss KM. Genetic variation of the mitochondrial DNA genome in American Indians is at mutation-drift equilibrium. Am J Phys Anthropol. 1991;86:497–506. doi: 10.1002/ajpa.1330860405. [DOI] [PubMed] [Google Scholar]
- Clark P, Mix A. Ice sheets and sea level of the Last Glacial maximum. Quat Sci Rev. 2002;21:1–7. doi: 10.1016/S0277-3791(01)00118-4. [DOI] [Google Scholar]
- Collins-Schramm HE, Chima B, Morii T, Wah K, Figueroa Y, Criswell LA, Hanson RL, Knowler WC, Silva G, Belmont JW, Seldin MF. Mexican American ancestry-informative markers: examination of population structure and marker characteristics in European Americans, Mexican Americans, Amerindians and Asians. Hum Genet. 2004;114:263–271. doi: 10.1007/s00439-003-1058-6. [DOI] [PubMed] [Google Scholar]
- Comas D, Plaza S, Wells RS, Yuldaseva N, Lao O, Calafell F, Bertranpetit J. Admixture, migrations, and dispersals in Central Asia: evidence from maternal DNA lineages. Eur J Hum Genet. 2004;12:495–504. doi: 10.1038/sj.ejhg.5201160. [DOI] [PubMed] [Google Scholar]
- Comas D, Bosch E, Calafell F (2008) Human genetics and languages. In: Encyclopedia of life sciences. Wiley, Chichester. http://www.els.net/. doi:10.1002/9780470015902.a0020810
- Dupanloup I, Schneider S, Excoffier L. A simulated annealing approach to define the genetic structure of populations. Mol Ecol. 2002;11:2571–2581. doi: 10.1046/j.1365-294X.2002.01650.x. [DOI] [PubMed] [Google Scholar]
- Egeland T, Salas A. Estimating haplotype frequency and coverage of databases. PLoS ONE. 2008;3:e3988. doi: 10.1371/journal.pone.0003988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Excoffier L, Smouse PE, Quattro JM. Analysis of molecular variance inferred from metric distances among DNA haplotypes: application to human mitochondrial DNA restriction data. Genetics. 1992;131:479–491. doi: 10.1093/genetics/131.2.479. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Excoffier L, Laval G, Schneider S. Arlequin (version 3.0): an integrated software package for population genetics data analysis. Evol Bioinform Online. 2005;1:47–50. [PMC free article] [PubMed] [Google Scholar]
- Fagundes NJ, Kanitz R, Eckert R, Valls AC, Bogo MR, Salzano FM, Smith DG, Silva WA, Jr, Zago MA, Ribeiro-dos-Santos AK, Santos SE, Petzl-Erler ML, Bonatto SL. Mitochondrial population genomics supports a single pre-Clovis origin with a coastal route for the peopling of the Americas. Am J Hum Genet. 2008;82:583–592. doi: 10.1016/j.ajhg.2007.11.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- González-Oliver A, Márquez-Morfin L, Jimenez JC, Torre-Blanco A. Founding Amerindian mitochondrial DNA lineages in ancient Maya from Xcaret, Quintana Roo. Am J Phys Anthropol. 2001;116:230–235. doi: 10.1002/ajpa.1118. [DOI] [PubMed] [Google Scholar]
- Green LD, Derr JN, Knight A. mtDNA affinities of the peoples of North-Central Mexico. Am J Hum Genet. 2000;66:989–998. doi: 10.1086/302801. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Greenberg JH, Ii CGT, Zegura SL, Campbell L, Fox JA, Laughlin WS, EkJE Szathmary, Weiss KM, Woolford E. The settlement of the Americas: a comparison of the linguistic, dental, and genetic evidence (and Comments and Reply) Curr Anthropol. 1986;27:477–497. doi: 10.1086/203472. [DOI] [Google Scholar]
- Hurles ME, Nicholson J, Bosch E, Renfrew C, Sykes BC, Jobling MA. Y chromosomal evidence for the origins of oceanic-speaking peoples. Genetics. 2002;160:289–303. doi: 10.1093/genetics/160.1.289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Inali (2007) Catálogo de las lenguas indígenas nacionales: Variantes lingüísticas de México con sus autodenominaciones y referencias geoestadísticas, México
- INEGI (2007) XII Censo General de Población y Vivienda 2000. Instituto Nacional de Estadística y Geografía, México
- Kirchhoff P (1943) Mesoamérica: sus límites geográficos, composición étnica y caracteres culturales. Acta Americana 1:92–107 (Inter-American Society of Anthropology and Geography)
- Laughlin WS. From Ammassalik to Attu: 10, 000 years of divergent evolution. Objets et Mondes. 1988;25:141–148. [Google Scholar]
- López-Austin A, López-Luján L (2001) El pasado indígena. Fondo de Cultura Económica Editors, México
- Macaulay V, Richards M, Hickey E, Vega E, Cruciani F, Guida V, Scozzari R, Bonne-Tamir B, Sykes B, Torroni A. The emerging tree of West Eurasian mtDNAs: a synthesis of control-region sequences and RFLPs. Am J Hum Genet. 1999;64:232–249. doi: 10.1086/302204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mendizabal I, Sandoval K, Berniell-Lee G, Calafell F, Salas A, Martinez-Fuentes A, Comas D. Genetic origin, admixture, and asymmetry in maternal and paternal human lineages in Cuba. BMC Evol Biol. 2008;8:213. doi: 10.1186/1471-2148-8-213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller KW (1983) Uto-Aztecan languages. In Southwest. In: Alfonso Ortiz WCS (ed) Handbook of North American Indians, vol 10. Smithsonian Institution, Washington, pp 113–124
- Mulligan CJ, Hunley K, Cole S, Long JC. Population genetics, history, and health patterns in Native Americans. Annu Rev Genomics Hum Genet. 2004;5:295–315. doi: 10.1146/annurev.genom.5.061903.175920. [DOI] [PubMed] [Google Scholar]
- Nichols J. Linguistic diversity in space and time. Chicago: The University of Chicago Press; 1992. [Google Scholar]
- Pailes RA, Whitecotton JW. The frontiers of Mesoamerica: Northern and Southern. In: Reyman JE, editor. The Gran Chichimeca: essays of the archaeology and ethnohistory of Northern Mesoamerica. Avebury: Worldwide Archaeology series; 1995. [Google Scholar]
- Penaloza-Espinosa RI, Arenas-Aranda D, Cerda-Flores RM, Buentello-Malo L, Gonzalez-Valencia G, Torres J, Alvarez B, Mendoza I, Flores M, Sandoval L, Loeza F, Ramos I, Munoz L, Salamanca F. Characterization of mtDNA haplogroups in 14 Mexican indigenous populations. Hum Biol. 2007;79:313–320. doi: 10.1353/hub.2007.0042. [DOI] [PubMed] [Google Scholar]
- Perego UA, Achilli A, Angerhofer N, Accetturo M, Pala M, Olivieri A, Kashani BH, Ritchie KH, Scozzari R, Kong QP, Myres NM, Salas A, Semino O, Bandelt HJ, Woodward SR, Torroni A. Distinctive Paleo-Indian migration routes from Beringia marked by two rare mtDNA haplogroups. Curr Biol. 2009;19:1–8. doi: 10.1016/j.cub.2008.11.058. [DOI] [PubMed] [Google Scholar]
- Rangel-Villalobos H, Rivas F, Torres-Rodriguez M, Jaloma-Cruz AR, Gallegos-Arreola MP, López-Satow J, Cantu JM, Figuera LE. Allele frequency distributions of six Amp-FLPS (D1S80, APO-B, VWA, TH01, CSF1PO and HPRTB) in a Mexican population. Forensic Sci Int. 1999;105:125–129. doi: 10.1016/S0379-0738(99)00129-2. [DOI] [PubMed] [Google Scholar]
- Rangel-Villalobos H, Rivas F, Sandoval L, Ibarra B, Garcia-Carvajal ZY, Cantu JM, Figuera LE. Genetic variation among four Mexican populations (Huichol, Purepecha, Tarahumara, and Mestizo) revealed by two VNTRs and four STRs. Hum Biol. 2000;72:983–995. [PubMed] [Google Scholar]
- Rangel-Villalobos H, Jaloma-Cruz AR, Cerda-Aguilar L, Rios-Angulo CD, Mendoza-Carrera F, Patino-Garcia B, Sandoval-Ramirez L, Figuera-Villanueva LE. The genetic DNA trace in men: chromosome Y haplotypes in a Mexican population, analyzing 5 STRs. Rev Invest Clin. 2001;53:401–406. [PubMed] [Google Scholar]
- Rangel-Villalobos H, Jaloma-Cruz AR, Sandoval-Ramírez L, Velarde-Felix JS, Gallegos-Arreola MP, Figuera LE. Y-chromosome haplotypes for six short tandem repeats (STRs) in a Mexican population. Arch Med Res. 2001;32:232–237. doi: 10.1016/S0188-4409(01)00266-1. [DOI] [PubMed] [Google Scholar]
- Reidla M, Kivisild T, Metspalu E, Kaldma K, Tambets K, Tolk HV, Parik J, Loogvali EL, Derenko M, Malyarchuk B, Bermisheva M, Zhadanov S, Pennarun E, Gubina M, Golubenko M, Damba L, Fedorova S, Gusar V, Grechanina E, Mikerezi I, Moisan JP, Chaventre A, Khusnutdinova E, Osipova L, Stepanov V, Voevoda M, Achilli A, Rengo C, Rickards O, De Stefano GF, Papiha S, Beckman L, Janicijevic B, Rudan P, Anagnou N, Michalodimitrakis E, Koziel S, Usanga E, Geberhiwot T, Herrnstadt C, Howell N, Torroni A, Villems R. Origin and diffusion of mtDNA haplogroup X. Am J Hum Genet. 2003;73:1178–1190. doi: 10.1086/379380. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rozas J, Sanchez-DelBarrio JC, Messeguer X, Rozas R. DnaSP, DNA polymorphism analyses by the coalescent and other methods. Bioinformatics. 2003;19:2496–2497. doi: 10.1093/bioinformatics/btg359. [DOI] [PubMed] [Google Scholar]
- Saillard J, Magalhaes PJ, Schwartz M, Rosenberg T, Norby S. Mitochondrial DNA variant 11719G is a marker for the mtDNA haplogroup cluster HV. Hum Biol. 2000;72:1065–1068. [PubMed] [Google Scholar]
- Salas A, Richards M, Lareu MV, Scozzari R, Coppa A, Torroni A, Macaulay V, Carracedo A. The African diaspora: mitochondrial DNA and the Atlantic slave trade. Am J Hum Genet. 2004;74:454–465. doi: 10.1086/382194. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Salzano FM. Molecular variability in Amerindians: widespread but uneven information. An Acad Bras Cienc. 2002;74:223–263. doi: 10.1590/s0001-37652002000200005. [DOI] [PubMed] [Google Scholar]
- Sambrook J, Frisch EF, Maniatis TE. Molecular cloning. A laboratory manual. New York: Cold Spring Harbor Laboratory Press; 1982. [Google Scholar]
- Schurr TG, Ballinger SW, Gan YY, Hodge JA, Merriwether DA, Lawrence DN, Knowler WC, Weiss KM, Wallace DC. Amerindian mitochondrial DNAs have rare Asian mutations at high frequencies, suggesting they derived from four primary maternal lineages. Am J Hum Genet. 1990;46:613–623. [PMC free article] [PubMed] [Google Scholar]
- Soares P, Ermini L, Thomson N, Mormina M, Rito T, Röhl A, Salas A, Oppenheimer S, Macaulay V, Richards M (2009) Correcting for purifying selection: an improved human mitochondrial molecular clock. Am J Hum Genet (in press) [DOI] [PMC free article] [PubMed]
- Spencer RF, Jennings JD, Johnson E, King AR, Stern T, Stewart KM, Wallace WJ. The Native Americans: ethnology and backgrounds of the North American Indians. New York: Harper and Row Publishers; 1977. [Google Scholar]
- Suaréz JA. The Mesoamerican Indian languages (Cambridge Language Surveys) New York: Cambridge University Press; 1983. [Google Scholar]
- Szathmary EJ, Ferrell RE, Gershowitz H. Genetic differentiation in Dogrib Indians: serum protein and erythrocyte enzyme variation. Am J Phys Anthropol. 1983;62:249–254. doi: 10.1002/ajpa.1330620304. [DOI] [PubMed] [Google Scholar]
- Tamm E, Kivisild T, Reidla M, Metspalu M, Smith DG, Mulligan CJ, Bravi CM, Rickards O, Martinez-Labarga C, Khusnutdinova EK, Fedorova SA, Golubenko MV, Stepanov VA, Gubina MA, Zhadanov SI, Ossipova LP, Damba L, Voevoda MI, Dipierri JE, Villems R, Malhi RS. Beringian standstill and spread of Native American founders. PLoS ONE. 2007;2:e829. doi: 10.1371/journal.pone.0000829. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Torroni A, Schurr TG, Yang CC, Szathmary EJ, Williams RC, Schanfield MS, Troup GA, Knowler WC, Lawrence DN, Weiss KM, et al. Native American mitochondrial DNA analysis indicates that the Amerind and the Nadene populations were founded by two independent migrations. Genetics. 1992;130:153–162. doi: 10.1093/genetics/130.1.153. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Torroni A, Schurr TG, Cabell MF, Brown MD, Neel JV, Larsen M, Smith DG, Vullo CM, Wallace DC. Asian affinities and continental radiation of the four founding Native American mtDNAs. Am J Hum Genet. 1993;53:563–590. [PMC free article] [PubMed] [Google Scholar]
- Torroni A, Sukernik RI, Schurr TG, Starikorskaya YB, Cabell MF, Crawford MH, Comuzzie AG, Wallace DC. mtDNA variation of aboriginal Siberians reveals distinct genetic affinities with Native Americans. Am J Hum Genet. 1993;53:591–608. [PMC free article] [PubMed] [Google Scholar]
- Vigilant L, Pennington R, Harpending H, Kocher TD, Wilson AC. Mitochondrial DNA sequences in single hairs from a southern African population. Proc Natl Acad Sci USA. 1989;86:9350–9354. doi: 10.1073/pnas.86.23.9350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wallace DC, Garrison K, Knowler WC. Dramatic founder effects in Amerindian mitochondrial DNAs. Am J Phys Anthropol. 1985;68:149–155. doi: 10.1002/ajpa.1330680202. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Haplogroup frequencies classified by population in the dataset used for comparison to the Mexican sequences analyzed in the present study (DOC 328 kb)
Mitochondrial DNA sequences found in Mexico with their haplogroup classification and number of (identical) matches in the database used for comparison. Only positions from 16090 to 16362 were taken into account in the comparison database (DOC 60 kb)