

Abstract
Matrix-assisted laser desorption/ionization Fourier transform ion cyclotron resonance mass spectrometry is a technique for high mass-resolution analysis of substances that is rapidly gaining popularity as an analytic tool. Extracting signal from the background noise, however, poses significant challenges. In this article, we model the noise part of a spectrum as an autoregressive, moving average (ARMA) time series with innovations given by a generalized gamma distribution with varying scale parameter but constant shape parameter and exponent. This enables us to classify peaks found in actual spectra as either noise or signal using a reasonable criterion that outperforms a standard threshold criterion.
Keywords: Fourier transform ion cyclotron resonance, Generalized gamma distribution, Matrix-assisted laser desorption/ionization
1 Introduction
Matrix-assisted laser desorption/ionization Fourier transform ion cyclotron resonance mass spectrometry (MALDI FT-ICR MS) is a technique for high mass-resolution analysis of substances that is rapidly gaining popularity as an analytic tool in proteomics. Typically in MALDI FT-ICR MS, a sample (the analyte) is mixed with a chemical that absorbs light at the wavelength of the laser (the matrix ) in a solution of organic solvent and water. The resulting solution is then spotted on a MALDI plate and the solvent is allowed to evaporate, leaving behind the matrix and the analyte. A laser is fired at the MALDI plate and is absorbed by the matrix. The matrix becomes ionized and transfers charge to the analyte, creating the ions of interest (with fewer fragments than would be created by direct ablation of the analyte with a laser). The ions are guided with a quadrupole ion guide into the ICR cell where the ions cyclotron in a magnetic field. While in the cell, the ions are excited and ion cyclotron frequencies are measured. The angular velocity, and therefore the frequency, of a charged particle is determined solely by its mass-to-charge ratio. Using Fourier analysis, the frequencies can be resolved into a sum of pure sinusoidal curves with given frequencies and amplitudes. The frequencies correspond to the mass-to-charge ratios and the amplitudes correspond to the concentrations of the compounds in the analyte. FT-ICR MS is known for high mass resolution, with separation thresholds on the order of 10−3 Daltons (Da) or better [1, 2].
The spectra analyzed in this article were recorded on an external source MALDI FT-ICR instrument (HiResMALDI, IonSpec Corporation, Irvine, CA) equipped with a 7.0 T superconducting magnet and a pulsed Nd:YAG laser 355 nm. In addition to hundreds of spectra generated as described above for a cancer study [3] using human blood serum as the analyte, we generated 56 spectra using neither analyte nor matrix. We will refer to the latter category of spectra as “noise spectra” and use them in Sections 2 and 3 to develop our model, then apply the model to a spectrum with known contents in Section 4.
We find that an autoregressive, moving average (ARMA) time series with innovations given by a generalized gamma distribution can closely model the properties of the noise spectra, and that this representation is useful for accurately identifying real substances in spectra produced using analyte. The modeling assumptions developed in this article are implemented in the R package FTICRMS, available either from the Comprehensive R Archive Network (http://www.r-project.org/) or from the first author.
2 Methods
2.1 Description of data
A typical noise spectrum is shown in Figure 1 with frequency in kilohertz (kHz) plotted on the horizontal axis. (In the mass spectrometry literature, it is more usual to see m/z—the mass-to-charge ratio—on the horizontal axis, but the actual process of measurement uses equally-spaced frequencies, and the m/z values are computed using one of several non-linear transformations on the frequencies [4]. Thus, the spectrum pictured in Figure 1 is how it appears after the Fast Fourier Transform is applied to the measured data.) The thick spike at a frequency of roughly 40 kHz is actually two peaks at frequencies 41.21 kHz and 42.21 kHz which extend upward to intensities of approximately 222.7 and 95.4, respectively, and are apparently instrumental noise—they appear in all 56 noise spectra at roughly the same spots and have no isotope peaks. In the analysis that follows, we set the values of the spectra at frequencies corresponding to these two peaks to be missing.
Figure 1.

Typical Noise Spectrum. A MALDI FT-ICR spectrum produced without matrix or analyte. The spike extending off the top of the picture is actually two peaks at frequencies of 41.21 kHz and 42.21 kHz which extend upward to intensities of approximately 222.7 and 95.4, respectively.
2.2 Properties of noise spectra
We start by considering two striking properties of the noise spectra. The first property is the special forms of the sample autocorrelation function (ACF) and sample partial autocorrelation function (PACF) of the noise spectra; Figure 2 displays the graphs of the sample ACF and sample PACF of the noise spectrum from Figure 1. Starting with lag 7, the sample ACF is nearly constant at roughly 0.0613. The sample PACF, on the other hand, oscillates between positive and negative values before decaying to a small positive value. As we show in Section 2.3, the sample ACF enables us to get information not only about the baseline but also about the coefficients to use in the ARMA representation of the spectrum. The sample PACF will be useful for evaluating the final ARMA model for accuracy.
Figure 2.
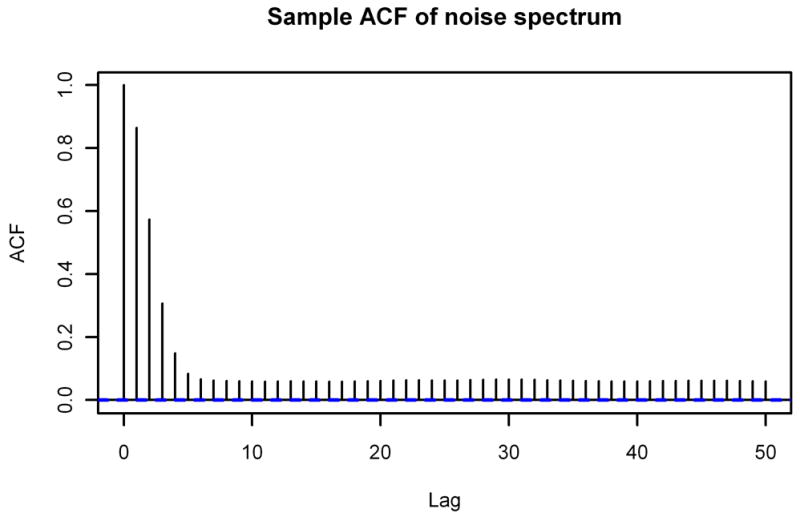

Sample ACF and Sample PACF of Typical Noise Spectrum. The sample autocorrelation function (top) and sample partial autocorrelation function (bottom) through lag 50 of the noise spectrum from Figure 1.
The second property comes from looking at the sample “homogenized” cumulants , … of the spectrum. (The sample homogenized cumulants of a set of data are related to the mean, variance, skewness, kurtosis, etc., of the data and will be defined precisely in Section 2.4, Equation (5).) Figure 3 displays scatterplots of the running sample homogenized cumulants (with bandwidth 4001 points—other bandwidths give similar plots) of the noise spectrum from Figure 1. It is clear that the first three sample homogenized cumulants have strong relationships. As we show in Section 2.4, this enables us to get information about the proper parameters to use in the generalized gamma distribution for the innovations in the ARMA representation of the spectrum.
Figure 3.

Sample Homogenized Cumulants of Typical Noise Spectrum. Running sample homogenized cumulants (bandwidth 4001 points) for the noise spectrum from Figure 1. See Section 2.4 for details.
2.3 Analysis of the ACF
The sample ACF r̂k at lag k of a realization of a time series is defined by
| (1) |
where ȳ is the sample mean. This is usually defined for stationary time series, in which (among other criteria) the means {μt} of the underlying random variables {Yt} are assumed to be constant. However, estimating the underlying means for a noise spectrum by some method (running means, running medians, etc.) clearly shows that they are not constant.
Thus, suppose that with known means and suppose that the correlation between Yt and Yt−k is given by ρ̃k (independent of t). Then, we have
| (2) |
where 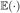 is the expected value operator. We subtract the right-hand side of Equation (2) from the left and add the result to the numerator in Equation (1). This gives us
is the expected value operator. We subtract the right-hand side of Equation (2) from the left and add the result to the numerator in Equation (1). This gives us
| (3) |
We can use Equation (3) to approximate r̂k when the underlying correlations ρ̃k are approximately zero. Write Yt = μt + εt, where 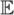 εt = 0; μt and εs are independent for all s, t; and k is large enough such that εtεt−k = 0 but is small compared to n. We then get
εt = 0; μt and εs are independent for all s, t; and k is large enough such that εtεt−k = 0 but is small compared to n. We then get
| (4) |
where ρμ(k) is the autocorrelation of the means at lag k, which for small k should be close to 1 if the mean is slowly changing. Similar calculations show that Equation (4) also holds if Yt = μt(1 + εt)—so the error is proportional to the mean—which will actually be the case for our spectra. In particular, for the noise spectrum pictured in Figure 1— using running means with bandwidth 4001 points to estimate {μt}—we get Var({μt}) ≈ 3.86, Var({yt}) ≈ 62.0, and ρμ(k) > 0.999 for all k ≤ 100. These values give an estimate of r̂k ≈ 0.0622, which closely matches the eventual value 0.0613 of the ACF in Figure 2.
Furthermore, we note that the sample ACF pictured in Figure 2 reaches the estimated value of 0.0622 for k ≥ 7 but is larger than that for k ≤ 6. That suggests that the underlying correlations ρ̃k are nonzero for k ≤ 6 and zero for k ≥ 7. This, along with the rapidly decaying sample PACF, indicates that an MA(6) process would be a reasonable model for the spectrum. However, as we show in the next section, a general ARMA process fits the spectrum much better.
2.4 Analysis of the cumulants
The cumulants κn(X) of a random variable X are related to the coefficients of the Taylor expansion of log(eitX) via
The most important property that cumulants have is that for independent random variables X and Y, we have κn(X + Y) = κn(X)+ κn(Y) for all n ≥ 1. (Contrast this with the central moments, where this property holds only for n = 1, 2, 3.) The first cumulant is equivariant under translation (i.e., κ1(X + c) = κ1(X)+ c for any constant c), and the higher-order cumulants are invariant under translation (i.e., κn(X + c) = κn(X) for n ≥ 2). In addition, the cumulants are homogeneous of degree n (i.e., κn(cX) = cn · κn(X) for all n). Finally, we have κ1(X) = X, κ2(X) = Var(X), and κ3(X) = {(X − X)3}, the mean and first two nonzero central moments of X. (This relationship does not hold for higher-order cumulants and central moments.)
For ease of presentation, we also introduce “homogenized cumulants” as
| (5) |
which are translation-equivariant for n = 1, translation-invariant for n ≥ 2, and homogeneous of degree 1 for all n. (It is these quantities, not the actual cumulants, that are plotted in Figure 3.)
For the remainder of this article, we will use capital letters to denote random variables and corresponding lower-case letters to denote realizations of those random variables. Thus, for example, the spectrum pictured in Figure 1 is {yt} for the time series {Yt}. The values of the sample cumulants and sample homogenized cumulants (estimated from data) will be denoted by κ̂n and , respectively.
As Figure 3 shows, , and are all nearly constant across the entire spectrum. Let {Ỹt} be the de-trended series obtained from {Yt} by dividing by the mean: Ỹt = Yt/μt. Then {Ỹt} should have a constant mean of 1 and constant variance, so it would be a stationary time series if, in addition, the auto-correlations did not depend on t. We checked this assumption by estimating μ̂t as a running mean with bandwidth 4001 points and considering the spectra given by . We divided each of these into 486 groups of 2000 points. For each spectrum we then calculated first six lags of the sample ACF for each of the 486 groups of points (denoted by ρ̂) and compared the resulting values to the first six lags of the sample ACF of the whole spectrum (denoted by ρ). From a standard result in time series analysis (see, e.g., Shumway and Stoffer [5, Theorem A.7]), we know that ρ̂ ~ AN(ρ, W/n), where n is the length of the time series and the covariance matrix W is computable from the full ACF of the actual time series {Yt}. Using the sample ACF of the entire spectrum {yt} to estimate ρ and W, for each set of 2000 points we computed (ρ̂ − ρ)′(W/2000)−1(ρ̂ − ρ), which under the null hypothesis of stationarity would be distributed as . At the 0.05 level of significance, we find that on average 28/486 ≈ 0.058 of the sets of points have a significantly different sample ACF than the entire spectrum—very close to the number expected under the null hypothesis.
Thus, there is good evidence that the de-trended series {Ỹt} is, in fact, stationary. If {Ỹt} arises as a causal ARMA process, then we can write
where . In particular, the innovations {Xt} will also have proportional cumulants.
Thus, we should look for a distribution for the innovations for which the second and third cumulants remain proportional to the mean as the mean varies. One such distribution is given by the generalized gamma distribution with exponent α, shape parameter β, and scale parameter ζt: . This distribution has probability density function given by
| (6) |
where is the standard gamma function. Easy calculations show that
In particular, note that , and are functions of α and β only and do not depend on ζt. By the homogeneity and additivity properties of cumulants, the homogenized cumulants for Yt will have the same property. Thus, we can use the ratios estimated from the data to solve for α and β, then use (the known values of) {μt} to find {ζt}.
In order to do this, we first need to find the causal representation of the ARMA process for the noise spectrum. We start by estimating the order of the process and the coefficients by looking at { }. Using the ARMA-fitting function arima in R (which does maximum-likelihood estimation), we tried all possible ARMA(p,q) models for p + q ≤ 7 and chose the one that maximized the modified Akaike’s information criterion (AICC) of [6]:
where L is the log-likelihood and n is the number of data points. The best model using this version of AIC was an ARMA(1,5) process:
| (7) |
For such a model, the causal representation
has coefficients given recursively by
Note that since θk = 0 for k ≥ 6, we have ψn+1 = φ1ψn for n ≥ 5. Thus, we can get a closed form for mn:
and we can use the recursion to write ψ0, …, ψ5 in terms of φ1, θ1, …, θ5.
It should be noted that the arima command in R assumes normal innovations, and therefore there might be some bias in our estimation of the ARMA coefficients. However, as Li and McLeod [7] observed, for large sample sizes the normal assumption introduces an extremely small amount of bias. We confirmed this by generating 50 spectra using the ARMA(1,5) model with generalized gamma innovations and mean derived from the running means with bandwidth 4001 points of the noise spectrum in Figure 1. We then compared the original ARMA coefficients to those obtained by dividing each simulated spectrum by its running means with bandwidth 4001 points and applying the arima command in R. The average absolute bias was less than 1% for each of the six coefficients, and each of the six 95% confidence intervals as well as the joint 95% confidence interval contained the original parameters. Thus, any bias in the estimation of the ARMA coefficients introduced by not assuming generalized gamma innovations is probably minimal.
We can then use the ARMA coefficients φ1, θ1, …, θ5 along with the running cumulants of the spectrum to estimate the parameters α and β. Let rjk be the least-squares estimate of . In Figure 3, it appears that r21 and r32 are the most consistent across the range of the spectrum, so we numerically solve the following system for α and β:
| (8) |
| (9) |
(Note that r21 is an estimate of the coefficient of variation of the innovations, and r32 is an estimate of the cube root of the skewness of the innovations.) The scale parameter ζt is then given by
3 Results
We applied the methods from Section 2 to each of the 56 noise spectra. The values of the ARMA coefficients φ1, θ1, …, θ5 estimated from {Ỹt}; the homogenized cumulant ratios r21, r31, and r32 estimated using bandwidths of 4001 points; and the exponent and shape parameters α and β estimated from Equations (8) and (9) are remarkably consistent across the 56 spectra, as shown in Table 1. (Note that the standard deviation of the estimate of r31 is 75% larger than either of the standard deviations of the estimates of r21 and r32, which serves as confirmation the latter two quantities are the better ones to use for estimating α and β.) Figure 4 shows (plotted on the same scale as Figure 1) a spectrum simulated (with arima.sim in the R software package) using the average ARMA coefficients, exponent, and shape parameter from Table 1 and {ζt} derived from {μt} calculated as the running means with bandwidth 4001 points of the spectrum in Figure 1. Note the remarkable similarity between the two graphs.
Table 1.
Estimated Values of Parameters Averaged over the 56 Noise Spectra.
| Par. | μ | σ | Par. | μ | σ |
|---|---|---|---|---|---|
| φ1 | 0.21976 | 0.00900 | r21 | 1.11748 | 0.00211 |
| θ1 | 1.64359 | 0.00882 | r31 | 1.18650 | 0.00475 |
| θ2 | 1.40146 | 0.01641 | r32 | 1.06225 | 0.00273 |
| θ3 | 0.76632 | 0.01566 | α | 4.67444 | 0.13633 |
| θ4 | 0.25964 | 0.00927 | β | 0.07967 | 0.00263 |
| θ5 | 0.04348 | 0.00290 |
Figure 4.

Typical Simulated Spectrum. Compare to Figure 1.
In addition, we see that the sample ACF and sample PACF of the simulated spectrum match those of the actual noise spectrum quite well. The sample ACF of a spectrum simulated from an MA(6) model also closely matches the sample ACF of the noise spectrum, but the sample PACFs are noticeably different. Figure 5 shows the sample PACF of the simulated spectrum from Figure 4 along with the sample PACF of a spectrum simulated from an MA(6) model. It is clear that the sample PACF of the MA(6) model does not decay nearly as quickly as the sample PACF of the noise spectrum, but the sample PACF of the spectrum simulated from the ARMA(1,5) model matches very well.
Figure 5.

Sample PACFs of Simulated Spectra. The sample partial autocorrelation functions through lag 50 of spectra simulated using the ARMA(1,5) model (top) and an MA(6) model (bottom). Compare to the bottom part of Figure 2.
Another result of the ARMA representation of the noise is the explanation of an interesting phenomenon that had been previously observed in MALDI FT-ICR spectra. Barkauskas, et al. [3] used a criterion for peak location and quantification that involved taking a shifted logarithm of baseline-corrected data, then finding five consecutive points which, when fitted with a quadratic function, had a negative coefficient for the quadratic term and a correlation satisfying r2 ≥ 0.98 (see Figure 6). They observed that typical MALDI FT-ICR spectra have roughly 104,000 such non-overlapping peaks, which clearly indicates that they must be mostly noise and not actual compounds. With spectra simulated as in this article, we get an average of approximately 98,000 such peaks in each spectrum, so it turns out that the proliferation of peaks is probably largely due to the combination of the ARMA(1,5) model and the choice of distribution for the innovations. (Spectra simulated from the same ARMA(1,5) model using normal innovations had only 70,000 such peaks on average, illustrating the dependence on the distribution used for the innovations. Spectra simulated from an MA(6) model with generalized gamma innovations had only 90,000 such peaks on average, which serves as further confirmation that the ARMA(1,5) model is superior.)
Figure 6.

Parabolic Peak. A typical peak in a MALDI FT-ICR spectrum is approximately parabolic.
4 Application: beer spectrum
As an application of the techniques developed in the previous sections, we use them to detect peaks in a MALDI FT-ICR spectrum (shown in Figure 7) generated with beer as the analyte. (Beer was chosen because of its known composition with highly-structured mass patterns of glycans, the compounds of interest in the analysis in Barkauskas, et al. [3]). For a peak-detection criterion, we choose all “large” peaks, which we define as follows: we first take all local maxima in the spectrum which are k times the value of a baseline estimated using an improved version of a method of Xi and Rocke [8] (new version of algorithm submitted for publication), where k is a constant to be determined. We then use a logarithmic transformation on the data and for each maximum look for a set of five consecutive points containing that maximum which, when fitted with a quadratic function, has a negative coefficient for the quadratic term and a correlation satisfying r2 ≥ 0.98 as in Barkauskas, et al. [3]. (The taking of logarithms is justified because the data has constant coefficient of variation, so it follows from the δ-method (see, e.g., Bickel and Doksum [9, Theorem 5.3.3]) that taking the logarithm will approximately variance-stabilize the data, which will allow for the direct application of standard linear statistical models for analysis.)
Figure 7.

Spectrum with Analyte. A MALDI FT-ICR spectrum produced using beer as the analyte.
For this article, we choose k to be such that the spectrum being larger than k times the estimated baseline is roughly equivalent to being n standard deviations above the mean for n ∈ {4, 4.25, 4.5, 4.75, 5} in an independent, identically-distributed normal situation (i.e., we want the Φ(n) quantile of the assumed distribution.) To estimate k, we ran 100 simulations of 107 observations of ARMA(1,5) data generated with coefficients from Table 1 and innovations given by a generalized gamma distribution with the exponent and shape parameter from Table 1 and scale parameter equal to 1, then scaled the observations so each sample mean was 1. For each simulation we calculated the observed Φ(n) quantile of the data (i.e., k) for each of the five choices for n. The estimated values of k and their standard deviations are displayed in Table 2. The choice of k then boils down to a sensitivity/specificity debate. If the primary goal is discovery, then a lower threshold for “large” peaks might be useful; if it is necessary to limit the number of false discoveries, then a higher threshold for “large” peaks would be better.
Table 2.
Estimated Quantiles of the ARMA(1,5) Distribution
|
σ-equivalent |
|||||
|---|---|---|---|---|---|
| Est. | 4 | 4.25 | 4.5 | 4.75 | 5 |
| k̄ | 3.5059 | 3.6546 | 3.7996 | 3.9377 | 4.0708 |
| s(k) | 0.0087 | 0.0138 | 0.0229 | 0.0364 | 0.0617 |
NOTE: “σ-equivalent” refers to the equivalence of the quantiles with the quantiles of the normal distribution that are 4, 4.25, 4.5, 4.75, and 5 standard deviations above the mean. k̄ is the mean and s(k) is the standard deviation of the 100 estimates of k.
For comparison, we also looked for “large” peaks using a simple threshold model with the threshold chosen using Tukey’s biweight with K = 9 to calculate robust measures of center c and scale s for the spectrum, then proceeding as above by starting with any local maximum which was at least c + 9s and looking for parabolic peaks.
We classified the peaks found by any of these methods as being either glycans, fragments of glycans, or unknown peaks. We then further subdivided the unknown peaks into those that had at least one isotope peak that was also detected by at least one method and those for which the main peak was the only peak ever detected. The presence of at least one detected isotope peak virtually guarantees that the peak is an actual compound, while a peak with no isotope peaks detected could be either (i) a real compound whose abundance is so low that its isotope peaks are lost in the noise, or (ii) some type of noise—for example, an electronic spike like those from the noise spectrum in Figure 1. The results of each of these procedures applied to the beer spectrum are summarized in Table 3, along with the same procedures applied to the noise spectrum from Figure 1.
Table 3.
Number of Peaks Found in Beer Spectrum and Noise Spectrum
|
σ-equivalent |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 4.25 | 4.5 | 4.75 | 5 | Threshold | |||||||
| Type of peak | PP | Iso | PP | Iso | PP | Iso | PP | Iso | PP | Iso | PP | Iso |
| Sugar | 27 | 55 | 27 | 55 | 27 | 54 | 27 | 54 | 27 | 54 | 27 | 55 |
| Fragment | 165 | 203 | 160 | 195 | 155 | 190 | 151 | 182 | 150 | 173 | 169 | 209 |
| Unknown, with isotope | 12 | 11 | 11 | 10 | 11 | 10 | 11 | 8 | 11 | 8 | 13 | 18 |
| Unknown, w/o isotope | 81 | — | 53 | — | 35 | — | 27 | — | 21 | — | 86 | — |
| Noise spectrum peaks | 30 | — | 12 | — | 5 | — | 3 | — | 2 | — | 34 | — |
NOTE: “PP” is the number of primary peaks detected; “Iso” is the number of isotopes of primary peaks detected (not counting the primary peaks).
By examining the masses of the peaks detected by each method, it is clear that the threshold method is preferentially selecting peaks at higher masses (lower frequencies). This is due to the fact that the mean levels of MALDI FT-ICR spectra are basically increasing functions of mass, so naturally peaks at the higher masses will have a greater chance of being above the chosen threshold value. What might be surprising at first glance, however, is that the σ-equivalent methods are preferentially selecting peaks at lower masses (higher frequencies). If the model is correct, the detected peaks should consist of signal, which should be detected no matter which method is used; and noise, which should be approximately uniformly distributed throughout the spectrum. This apparent contradiction can be resolved by observing that because of the form of the transformation used to calculate mass from frequency, the vast majority of the data points are at low masses. When the masses are translated back to frequencies, we see that the peaks detected in the noise spectrum by the σ-equivalent methods are at frequencies that are roughly uniformly distributed throughout the spectrum (Figure 8), as expected. In addition, the σ-equivalent methods are clearly doing a better job of not detecting peaks in the noise spectrum. Thus, the σ-equivalent methods appear to be the correct ones to use for peak detection.
Figure 8.


Peak Detection Method Comparison. Peaks detected in noise spectrum by 4σ-equivalent method and threshold method, plotted by mass (top) and by frequency (bottom). Note that low masses correspond to high frequencies and vice versa.
5 Future directions
One obvious future direction is to implement a maximum-likelihood estimation algorithm following the methods of Li and McLeod [7] to find simultaneous estimates of the ARMA coefficients in Equation (7) and the parameters α and β from Equation (6) as well as standard errors for the estimates of α and β. Another is to explore models for the innovations other than the generalized gamma distribution.
Another possible direction is based on the observation that all of the spectra analyzed in this article were generated on the same machine; it would be interesting to see how much of this is machine-dependent by analyzing spectra from other MALDI FT-ICR MS machines. The ideal situation would be if one could calculate α, β, and (possibly even) {μt} once for each machine and then use these values for analysis going forward. In any case, the framework provided in this article should allow other researchers to determine appropriate parameters for their own MALDI FT-ICR mass spectrometry setups.
Acknowledgments
This work was supported by the National Human Genome Research Institute (R01-HG003352 to DAB, DMR); National Institute of Environmental Health Sciences Superfund (P42-ES04699 to DAB, DMR); National Institutes of Health (R01-GM49077 to CBL); National Institutes of Health Training Program in Biomolecular Technology (2-T32-GM08799 to DAB); and the Ovarian Cancer Research Fund.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Herbert CG, Johnstone RAW. Mass Spectrometry Basics. CRC Press; Boca Raton, FL: 2003. [Google Scholar]
- 2.Park Y, Lebrilla CB. Application of Fourier transform ion cyclotron resonance mass spectrometry to oligosaccharides. Mass Spec Rev. 2005;24(2):232–264. doi: 10.1002/mas.20010. [DOI] [PubMed] [Google Scholar]
- 3.Barkauskas DA, An HJ, Kronewitter SR, de Leoz ML, Chew HK, de Vere White RW, Leiserowitz GS, Miyamoto S, Lebrilla CB, Rocke DM. Detecting glycan cancer biomarkers in serum samples using MALDI FT-ICR mass spectrometry data. Bioinformatics. 2009;25(2):251–257. doi: 10.1093/bioinformatics/btn610. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Zhang LK, Rempel D, Pramanik BN, Gross ML. Accurate mass measurements by Fourier transform mass spectrometry. Mass Spec Rev. 2005;24(2):286–309. [Google Scholar]
- 5.Shumway RH, Stoffer DS. Time Series Analysis and Its Applications with R Examples. 2. Springer; New York, NY: 2006. [Google Scholar]
- 6.Hurvich CM, Tsai CL. Regression and time series model selection in small samples. Biometrika. 1989;76(2):297–307. [Google Scholar]
- 7.Li WK, McLeod AI. ARMA modelling with non-Gaussian innovations. J Time Series Analysis. 1988;9(2):155–168. [Google Scholar]
- 8.Xi Y, Rocke DM. Baseline correction for NMR spectroscopic metabolomics data analysis. BMC Bioinformatics. 2008 Jul;9 doi: 10.1186/1471-2105-9-324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Bickel PJ, Doksum KA. Mathematical Statistics. 2. Vol. 1. Prentice Hall; Upper Saddle River, NJ: 2001. [Google Scholar]