

Abstract
The phenomenon identified as naming is a key stage of language function that is missing in many children with autism and other language delay diagnoses. We identified four children with autism, who, prior to the implementation of this experiment, did not have the naming repertoire (either speaker to listener or listener to speaker) and who had no tact responses for two- or three-dimensional stimuli. Tact training alone did not result in a naming repertoire or echoic-to-tact responses for these students. We then provided multiple exemplar instruction (MEI) across speaker and listener repertoires for a subset of stimuli (the teaching set) that resulted in untaught response components of naming and the capability to acquire naming after learning tacts for subsequent sets of stimuli. We used a delayed multiple-baseline probe design with stimuli counterbalanced across participants. The results showed that for all four students, mastery of tacts alone (the baseline or initial training condition) was not sufficient for the naming or echoic-to-tact repertoires to emerge. Following MEI the naming repertoire emerged for all four students for the initial set of stimuli. In addition, we tested for naming with novel stimuli that were probed prior to the MEI and naming also emerged following tact instruction alone for these sets. The results are discussed in terms of the role of naming in the incidental acquisition of verbal functions as part of the speaker-as-own-listener repertoire.
Keywords: naming, verbal behavior, multiple exemplar instruction, tact, learn unit, transformation of stimulus function
Research based on Skinner's (1957) theory has proliferated in recent years and has contributed to the identification of procedures for inducing verbal operants in children who are missing them. Much of this experimentation has focused on the dependence and interdependence of the classes of verbal repertoires (Becker, 1989; Greer, Nuzzolo-Gomez, Ross, & Rivera-Valdez, 2005; Lamarre & Holland, 1985; Lodhi & Greer, 1989; Michael, 1982; Twyman, 1996a, 1996b; Yoon, 1998), the variables that functionally control verbal operants (Chu, 1998; Karmali, Greer, Nuzzolo-Gomez, Ross, & Rivera-Valdes, 2005; Ross & Greer, 2003; Sundberg, Michael, Partington, & Sundberg, 1996; Tsiouri & Greer, 2003; Williams & Greer, 1993), and studies testing several theoretical explanations for, and the source of, productive verbal repertoires (Greer & Keohane, 2005; Greer & Ross, 2004; Greer, Stolfi, Chavez-Brown, & Rivera-Valdez, 2005; Greer, Yuan, & Gautreaux, 2005; Horne & Lowe, 1996; Ross & Greer, 2003). One source of verbal behavior that has been identified in the literature is naming.
Naming is a phenomenon first identified by Horne & Lowe (1996) that appears to be the source of much of children's verbal repertoire. Naming occurs when a child hears someone tact, or say the name, of an object that is present in the environment, and as a result, the child can respond to the item both as a listener and as a speaker. As a speaker, after this experience, the child can emit a pure or an impure tact for the object and the child can respond as a listener to the tact for the object. As a listener the child will orient to the object when the object is tacted by another, point to the object when asked to indicate where the object is located, or point on hearing the tact. For example, a parent might point to a bird and say, “Look, a robin!” Later, on seeing a robin, the parent might say. “Oh look, there's another robin,” and after hearing this, the child looks at or points to the robin. In addition, and at a different time, the child will say, “Robin,” on seeing a robin and the parent says, “Yes, that's a robin.” Thus, the child acquires a speaker and a listener response without direct instruction. Naming appears to be the incidental means whereby children acquire many, if not most, of their speaker and listener repertoires. If children do not have naming they can acquire speaker and listener responses only through direct instruction. When a child has naming, the child can select the stimulus as a listener and produce the name of the stimulus as a speaker when the item is present without direct instruction.
While much of the research on naming has concerned the question of its relation to stimulus equivalence or categorization, other recent research has concentrated on the acquisition of naming as a verbal developmental phenomenon in children who were found to be missing the capability (Greer, Stolfi, Chavez-Brown, & Rivera-Valdez, 2005). The naming repertoire or capability constitutes a critical means for acquiring new tacts, mands, and other verbal operants as well as listener responses without direct instruction and, as such, is a key part of inducing new verbal capabilities in children with verbal delays. Greer, Stolfi et al. (2005), found that this emergent behavior was attributable to certain exemplar experiences in children who were missing the naming capability.
Naming is one of three types of speaker-as-own-listener repertoires that have been identified in the research literature. They are: (a) correspondence between saying and doing (Paniagua & Baer, 1982), (b) acting as speaker and listener when talking to oneself aloud (Lodhi & Greer, 1989), and (c) naming (Horne & Lowe, 1996). Paniagua and Baer found that preschool children showed correspondence between saying and doing when they were reinforced for correspondence; thus, the children responded as listeners to their own speaker behavior. Lodhi and Greer (1989) found that typically developing 5-year-olds talked aloud to themselves in solitary play conditions in which anthropomorphic toys (i.e., toys that may be endowed with human characteristics such as dolls or animal figures) were available. When talking aloud to themselves the children alternated between speaker and listener functions, thus demonstrating what Skinner (1957) described as one example of speaker-as-own-listener behavior.
Some psychologists have argued that the presence of generative verbal behavior, such as naming, is not attributable to behavioral selection because the environment does not provide enough direct instruction (Pinker, 1999). Hayes, Barnes-Holmes, and Roche (2001) proposed that the source of “generative” (i.e., productive or emergent) verbal behavior was multiple exemplar instructional histories (MEI) and that MEI offered a “purely behavior analytic explanation” for generative verbal behavior. Several studies have subsequently found that certain types of multiple exemplar instruction (MEI) did result in the emergence of some generative or productive verbal functions in children with and without disabilities. Greer, Yuan, and Gautreux (2005) induced joint stimulus control across written and spoken spelling responses, Greer, Stolfi, Chavez-Brown, and Rivera-Valdez (2005) induced naming in 4- and 5-year-old children with mild or no language delays, Greer and Yuan (2005) induced irregular and regular verb usage, Nuzzolo-Gomez and Greer (2004), and Greer, Nirgudkar, and Park (2004) induced transformation of establishing operations across mand and tact functions, Speckman (2005) induced novel use of suffixes, and Marianno-Lapidus (2005) induced novel suffixes and joint control of suffixes across saying and writing.
Lowe, Horne, Harris, and Randle (2002) found that typically developing children demonstrated naming after being taught only the tacts suggesting that learning of tacts led to the emergence of naming. Horne, Lowe, and Randle (2004) also found that after teaching the listener component of naming, the tact component did not emerge, leading the authors to suggest that the listener component may be present even when the speaker component is missing. Greer, Stolfi, Chavez-Brown, and Rivera-Valdez (2005) found that the listener to speaker component of naming emerged following MEI instruction for a subset of stimuli in children with mild disabilities. Greer, Stolfi, et al. (2005) did not test for whether the naming response would emerge following tact instruction alone. The present experiment identified children with severe language delays who had no echoic-to-tact repertoire and who, when taught the tact repertoire, did not show naming. Next, we tested whether intensive multiple exemplar instruction with subsets of stimuli would lead to naming following tact instruction alone.
Method
Participants and Settings
Four children with diagnoses of Autistic Spectrum Disorder (ASD) who had significant delays in language acquisition were selected to participate in this experiment out of a set of ten potential candidates. The children were selected for participation when they did not demonstrate the basic naming repertoire for three-dimensional stimuli across the response components of naming. We selected three-dimensional stimuli because the children did not attend to representational stimuli in the form of pictures. We selected students who: (a) matched three-dimensional visual stimuli when presented with one of a set of target stimuli and one of a group of alternated non-target stimuli for a minimum of 50% of the 20 probe trials with familiar stimuli; (b) demonstrated the response topography of pointing to or touching everyday objects upon request (discrimination between stimuli was not part of the response expectation); (c) had vocal verbal repertoires that included echoic responses or partial vocal approximations to teacher vocal verbal antecedents for a minimum of 50% of the trials conducted; (d) did not have echoic-to-tact responses or a history of acquiring tacts via the echoic-to-tact training procedure (Ross & Greer, 2003; Tsiouri & Greer, 2003; Williams & Greer, 1993); and (e) did not have the naming repertoire as identified by screening probes and the baseline training procedure. All experimental phases were conducted in each child's respective home with a second independent observer present for a minimum of 35% of the sessions. Characteristics of the selected participants are shown in Table 1.
Table 1.
Participant characteristics at the onset of this experiment.
| Participant/Gender/Age | Verbal Repertoires |
| Student B point Male 2.4 yrs | Listener: non-verbal imitation, limited one-step commands, point response topography without discrimination Speaker: emerging, with partial vocal echoics and two independent mands (e.g., bubble and candy) Listener/Speaker, Conversational Units, Naming, Speaker as Own Listener, and Reader/Writer: none |
| Student X non-Male 2.4 yrs | Listener: point response topography without discrimination, nonverbal imitation, generalized match repertoire for identical stimuli Speaker: emerging, with vocal echoics for single syllables, two independent mands (e.g., Elmo and bus) Listener/Speaker, Conversational Units, Naming, Speaker as Own Listener, and Reader/Writer: none |
| Student L Male 2.0 yrs | Listener: non-verbal imitation with teacher prompts, inconsistent responding to name, point response topography without discrimination Speaker: minimally emerging, with partial vocal approximations Listener/Speaker, Conversational Units, Naming, Speaker as Own Listener, and Reader/Writer: none |
| Student N Male 2.4 yrs | Listener: point response topography without discrimination, non-verbal imitation of two actions, generalized matching for identical stimuli, responds to name Speaker: minimally emerging, with partial vocal approximations Listener/Speaker, Conversational Units, Naming, Speaker as Own Listener, and Reader/Writer: none |
Description of Stimuli
The stimuli included nonsense bi-syllabic labels (i.e., experimenter coined tacts) paired with unusual hardware items, such as clamps and bolts. Descriptions of the sets of stimuli (three per set) may be found in Table 2.
Table 2.
Description of stimuli.
| Phoneme | Item Description | |
| Set 1 | kabal | green electrical hook-up |
| woemup | black, wavy metal 3" object | |
| tingra | gray rubber ¾″ tube | |
| Set 2 | nipil | black clamp |
| keytoe | large 307A silver screw | |
| holub | large, round silver washer | |
| Set 3 | pakot | gold caps on green strip |
| dipoy | ¾″ silver object with cutout | |
| galoe | ½″ drill bit | |
| Set 4 | zimon | 1-½″ silver object with small screw |
| bikmo | ½″ bolt | |
| mooga | ¾″ silver pipe fitting with small hole |
The target stimuli were presented for each student in a counterbalanced manner and the positions of the target and non-target exemplar were rotated. The sequence of presentation and combination of stimuli varied to control for order effects (See Table 3). For each student, four sets of three stimuli (Sets 1, 2, 3, and 4) were selected. Set selection was counterbalanced to control for potential difficulty biases. Within each set the three stimuli were provided with a contrived nonsense monosyllabic or bi-syllabic vowel-consonant combination for each item.
Dependent Variables
The dependent variables consisted of the untaught listener response (i.e., point to target), and untaught impure tact responses (i.e., vocal verbal responses under the multiple antecedent control of a teacher-provided vocal antecedent [What is this?] plus a visual stimulus [the tact stimulus]) during pre-treatment and post-treatment probes. Responses in the probe trials were not consequated, that is students did not receive “feedback” for their responses to probe trials.
Independent Variables
The baseline or control condition consisted of teaching tacts to mastery using echoic to tact training learn units. The experimental condition, or independent variable, was the multiple exemplar instruction (MEI) with a training set (and in several cases, multiple training sets) of stimuli also taught to mastery using learn units. This procedure will be described later in detail.
Data Collection
Data were collected on the student responses during all phases using data collection forms and a pencil. A second observer was present for a minimum of 35% of the sessions. Prior to implementation of the experiment, the second observer was trained in the response definitions, and observers were calibrated to a criterion of 100%.
Design and Procedures
The design was a single-case, multiple-probe design across students. This procedure was selected as it provides a procedure to control for maturation and instructional history for non-reversible responses (Greer, Yuan, et al., 2005; Horner & Baer, 1978).
Experimental sequence. The experimental sequence is presented in abbreviated format first, followed by a detailed description of each step:
A pre-experimental screening test was conducted to determine whether or not students had the naming repertoire for familiar three-dimensional stimuli. Familiar three-dimensional stimuli were selected because the students did not have, at the time of this study, the ability to attend to two-dimensional representational stimuli.
We then probed the students to determine whether or not they could match the stimuli used in the experiment when asked to “match.” At this point we did not tact the term for the stimulus. This tested whether or not the child could match the visual characteristic of the stimuli alone.
Next we probed for the point responses when the experimenter asked the student to “Point to ____ (e.g., dipoy).”
Next we probed for the impure tact responses (i.e., “What is this?”).
We then taught the pure tact responses to mastery for the stimuli.
Subsequently we probed for the listener and the impure tact responses for the same stimuli mastered in Step 5.
When Step 6 showed that naming was not present as result of learning the tact response, a teaching set of stimuli was taught in a multiple exemplar instructional sequence by rotating the different responses to each stimulus until all of the responses were mastered for that particular set. That is they learned to respond to the listener and speaker responses with match responses while hearing the tact for the stimulus.
Following mastery of stimuli in Step 7, we again probed naming for the first set.
If naming was not present, a second or third set was introduced and all steps were repeated, beginning with Step 2.
Instruction was terminated when the student achieved naming following tact-only instruction (Step 6) for that training set.
Pre-experimental screening. Step 1: One of the eligibility requirements for inclusion in this experiment was the absence of the naming repertoire for three-dimensional stimuli. Using three sets of everyday objects (other than stimuli used in the experiment and with which the students had prior contact) the experimenter presented targets and non-targets in an array of two on a child-sized work-table in front of each individual prospective participant. For all probe trial sets, there were four stimuli per set, and a total of 20 trials were conducted for each response repertoire (each stimulus was presented five times).
The experimenter said the name of the object, and a correct response consisted of the student pointing to the target item when the child had the target and a non-target stimulus on the table in front of them. The purpose of this segment of the screening was to determine whether the prospective participant had the requisite topographical response of pointing or touching a stimulus when named. Data were collected on all correct and incorrect responses. If the prospective participant responded with greater than 15% accuracy across all sets of stimuli, the student was determined to be ineligible for inclusion. An accuracy of less than 15% was arbitrarily identified since, in an array of two, a 50% chance probability for a correct response existed. Therefore, it was considered that if the student had less than 15% correct responding and also satisfied the criterion for speaker responses, then the participant did not have the naming repertoire. We did not provide reinforcement for correct responses or corrections for incorrect responses during this phase.
Match-to-sample trials without the tact said by the experimenter were conducted as part of the pre-experimental screening to ensure that the students could visually match the constructed novel stimuli included in this study, and also because the match instruction was to be integrated with the tact as a part of the antecedent presentation during MEI learn unit instruction to occasion the opportunity for naming to emerge. This probe was done to ensure that the children could match based on the visual properties of the stimuli alone. The protocol was as follows: An array of two stimuli (one positive exemplar and one negative exemplar with the order rotated between trials) was placed on the table in front of the student while the experimenter handed the sample to the student, and said, “Match.” The student matched without hearing the name of the object during these probe sessions. A correct response consisted of the student placing the sample on top of the correct target within three seconds of the antecedent.
All students were also assessed for speaker responses (i.e., pure tacts) for all stimuli across the three sets of stimuli used for the remainder of the experiment. The experimenter held up the object and waited for the student to tact the object. Data were collected on all correct and incorrect responses. If the prospective participant responded with greater than 15% accuracy across all sets of stimuli, the student was eliminated as a participant. We did not provide reinforcement for correct responses or corrections for incorrect responses during this phase. A total of ten students received the pre-experimental screening, and four were selected based on their performance.
Pre- and post-treatment probes. Steps 2, 3, 4 and 6: Probes for naming were conducted for each set of 3 stimuli for each of 4 sets (see Table 2). Data were collected in sets of 18 responses (6 exposures for each stimulus) for each dependent variable (i.e., 18 match trials when the experimenter said the tact for the stimulus, 18 point trials, and 18 impure tact trials). The probe trials were dispersed across the three responses (i.e., match, point, impure tact) and the stimulus for each response was rotated to avoid sequence effects. That is, a match response for one stimulus was followed by a tact response for a different stimulus, then a point response for the third stimulus in the set, and so on, in a counterbalanced rotation. This was done to avoid the child obtaining a correct response simply by repeating the response for the previous trial. During all probe trials, correct responses were not reinforced and no corrections were provided for incorrect responses. In the absence of reinforcement for correct responses and in order to control the setting events for instructional responses, the children were reinforced for appropriate behaviors previously mastered. That is, we interspersed opportunities for the children to respond to known items (i.e., pointing to body parts, following a simple command) and reinforced accurate responses to maintain motivation. These included but were not limited to sitting appropriately in the chair and making eye contact in response to experimenter requests.
For these pre-MEI probe trials, in order to control for the potential of an echoic response following trials, a minimum of three learn unit presentations separated stimuli. For example, the experimenter said, “Match” (i.e., dipoy), “What is this?” (i.e., bikmo), “Point to _____” (i.e., mooga), “What is this?” (i.e., dipoy), “Point to _____” (i.e., bikmo), and “Match” (i.e., mooga). Thus, presentations for the same stimuli were arranged such that the student could not echo a correct response as a function of proximate stimulus presentations. When the students demonstrated that naming did not emerge as a result of hearing the tact for the stimulus as a function of the matching trials, we began the tact training.
Pure tact instruction. Step 5: Following set assignments for each participant (see Table 3 for the counterbalanced scheme), the tact training condition was implemented. This consisted of using learn units to teach tact responses to the stimuli. Learn units are defined by the empirical literature and include at least two interlocking three-term contingencies for the experimenter and the potential operant for the student (Greer, 1992; Greer & McDonough, 1999; Greer, 2002). In the naming literature typically developing children have been shown to demonstrate full naming after learning the tact response alone (Lowe, Horne, Harris, & Randle, 2002).
Table 3.
Counterbalanced presentation of stimuli sets for each participant.
| Participant | 1st Set | 2nd Set | 3rd Set |
| B | 1 | 2 | 3 |
| X | 1 | 4 | 3 |
| N | 3 | 2 | none |
| L | 3 | 1 | 4 |
Learn units consisted of the experimenter first gaining student attention as the antecedent for the experimenter, the experimenter then presented the multiple antecedent to the student (i.e., “Match ___” as the visual stimulus was presented to the child), the student response, as the antecedent for the experimenter consequence (i.e., reinforcements for correct responses or corrections for incorrect responses), was followed by the experimenter consequence. The correction procedure required the student to say the correct response after hearing the experimenter say it (i.e., the correct response), and no reinforcements were provided for corrected responses. The experimenter evoked the corrected response while the student viewed the stimulus as part of the correction. If the student did not immediately echo the correct response, up to three echoic opportunities were conducted, consistent with the learn unit protocol. No reinforcement followed the corrected response consistent with the learn unit protocol.
Instruction was implemented as follows: After gaining student attention, as the antecedent for the experimenter, the experimenter then presented one of three stimuli within the visual field of the student. The reinforced response consisted of the student emitting the correct tact for the stimulus. Each student was provided with an echoic prompt when necessary until he/she met criterion for independent responses for all three stimuli in the particular set. The stimuli were presented in a counterbalanced order within an 18 learn unit session (3 stimuli presented 6 times in an 18 learn unit session). Depending upon the learning rate of the individual student, the echoic prompts were systematically faded until the student independently tacted all three stimuli within the set. In other words, the students had echoic-to-tact learn units that were reinforced. Following the echoic criterion, sessions followed in which only accurate independent tact responses to learn units were reinforced and incorrect responses resulted in the correction procedure previously identified. An example of this protocol follows:
The experimenter presented the first stimulus and provided the vocal tact, “Dipoy.” The student echoed the experimenter's vocal tact and that echoic response was reinforced. If the student emitted a vocal response other than the targeted one, or if no response was emitted, the experimenter provided the student with the correct model using the correction procedure.
The experimenter presented the second stimulus and provided the vocal tact, “Bikmo.” The student echoed the experimenter's vocal tact and that echoic response was reinforced. If the student emitted a vocal response other than the targeted one, or if no response was emitted, the experimenter provided the student with the correct model using the correction procedure.
The experimenter presented the third stimulus and provided the vocal tact, “Mooga.” The student echoed the experimenter's vocal tact and that echoic response was reinforced. If the student emitted a vocal response other than the targeted one, or if no response was emitted, the experimenter provided the student with the correct model using the correction procedure.
This protocol continued until the student first met the criterion for echoic responses, and then the student was required to meet criterion for independent tacts. Correct responses were reinforced and incorrect responses were provided with a correction procedure consisting of the experimenter evoking the correct response from the student. The criterion-level was 17/18 or better across two consecutive sessions for learn unit instruction.
Post-tact instruction probes. Step 6: Once the student met criterion for the tacts for the stimulus set, he/she was probed for listener and impure tact responses. Criterion for the productive listener responses was set at 17/18 or 18/18 for probe trials as a measure of the presence or absence of naming. In the listener probes, the student was again presented with the target stimuli with negative exemplars and instructed to “Point to _____ (dipoy).” Each of the three stimuli was presented six times in the counterbalanced probe sessions consisting of 18 probe trials.
When the student demonstrated that he did not meet criterion for the naming responses (i.e., the untaught listener and speaker responses for target training set did not emerge), we introduced the MEI protocol using a training set (Greer, Stolfi, et al., 2005; Greer, Yuan, et al., 2005; Nuzzolo-Gomez & Greer, 2004). This phase demonstrated that the child did not have naming following mastery of the tact responses.
Multiple exemplar instruction. Step 7: Multiple exemplar instruction consisted of learn units alternated between match, point, and pure tact for a set of stimuli. For each set of three stimuli, learn unit presentations were rotated across these three responses for a total of 18 learn units per response category (i.e., 18 for match, 18 for point, and 18 for pure tact). However, while the stimuli were rotated across responses in the actual teaching sessions, the responses were blocked for mastery measures by response types (See Figure 2). For each student, counterbalanced sets of stimuli were selected to control for order and practice effects. An example of an instructional sequence was as follows: 1) teach the student to match dipoy; 2) teach the student to point to mooga; and 3) teach the student to tact golub. The student had rotated learn unit presentations for the match, the point, and the tact repertoires. Data for each function were recorded separately according to repertoire, and three columns were set up for data collection purposes prior to the session. Eighteen learn units for each repertoire constituted a teaching session, and the responses were blocked according to response types (i.e., match, point, and tact). Mastery criterion for each match, point and tact repertoire was set at 17/18 or better across two consecutive sessions, or 100% for one session. It is important to note that when a student met mastery criterion for a particular repertoire, presentations for the mastered repertoire continued to be rotated with non-mastered repertoires as part of the antecedent condition, consistent with the MEI protocol cited in Greer, Stolfi, et al. (2005). This was done in order to occasion the joint stimulus feature of the multiple exemplar instruction across the three repertoires.
Figure 2.
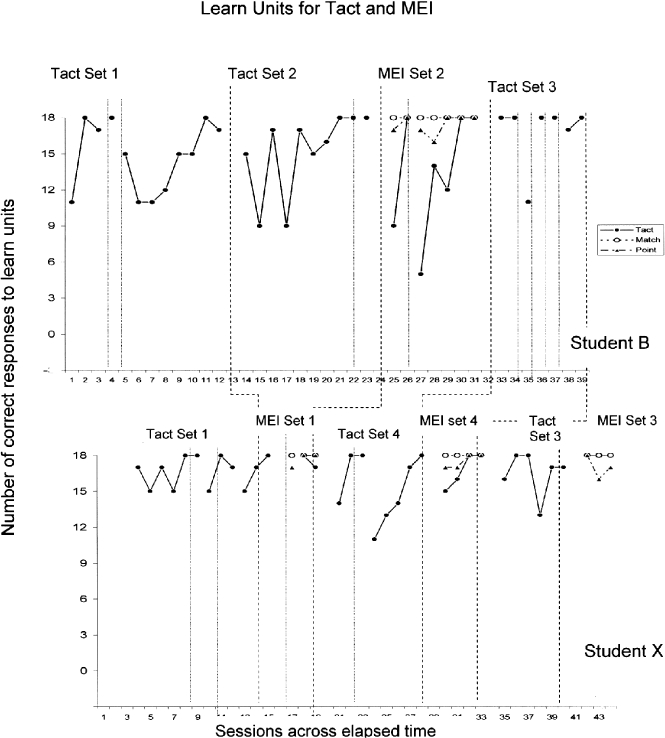
Delayed multiple baseline for learn unit instruction for Students B and X.
Post MEI probes. Step 8: Once the student met criterion for the tacts for the stimulus set, listener and impure tact responses were probed. Criterion for the listener and speaker responses was set at 17/18 or 18/18 for probe trials as a measure of the presence or absence of naming.
Step 9: When the student met the criterion for naming in Step 8, the student was taught to independently tact the three stimuli in a different set (repeat all steps from Step 2). When the student met mastery criterion for the pure tact for the alternate set, the student was then probed for the listener and impure tact responses.
Step 10: When the student met criterion for the untaught listener and impure tact responses following speaker (tact) only instruction, we decided that the student had demonstrated joint stimulus control across response categories and instruction was terminated.
Interobserver Agreement
Independent observers were present for between 35% and 55% of the probe and learn unit sessions. Indices of interobserver agreement (IOA) were taken on the numbers of correct responses emitted during probe and learn unit sessions. A second observer independently recorded the students' responses following a calibration training period. IOA was calculated for each session by dividing the total number of point-to-point agreements by the total number of agreements plus disagreements and multiplying by 100%. Interobserver agreement data were collected across all categories of responses (i.e., probes and learn units) for each student. The percentage of agreement was calculated in 55% of sessions for Student B, with a mean agreement of 99%; 35% of sessions for Student X, with a mean agreement of 99%; 46% of sessions for Student N, with a mean agreement of 98%; and 46% of sessions for Student L, with a mean agreement of 100%.
Results
During pre-experimental probes, three out of four students who participated in this experiment emitted match to sample responses (requiring visual to visual discrimination only, without the experimenter saying the tact for the stimulus) across generalized stimuli (an array of common environmental stimuli other than those in Table 2) with 100% accuracy, which satisfied the first component of the naming repertoire. Therefore, these three students could match common stimuli based on visual properties alone even with the lack of an instructional history with these specific target stimuli. One student (Student L) did not have the match response for common identical three-dimensional objects and was taught that repertoire prior to initiation of experimental conditions using stimuli other than those used for this study. It is essential to note that, since the stimuli were not tacted by the experimenter during pre-experimental match probe trials, there did not exist an incidental condition that could occasion the children to learn new words if, in fact, they did have the naming higher order operant.
None of this group of participants could point to the target stimuli when requested during the first set of probes with more than 11% accuracy level (below the level of chance responding), nor could any of them tact the stimuli. When the student was requested to point to the stimuli in an array of two, the probability of chance responding at 50% correct responses existed. Results of post match probes are included in the graphs for purposes of establishing that none of the children had responses to the independent variables prior to implementation of experimental conditions.
Following the instruction that led to the mastery of the tact for one set of stimuli (counterbalanced across students to control for difficulty effects), none of the four participants acquired the naming repertoire at the preset criterion as a function of learning the tact response alone. Figure 1 shows that following tact learn unit instruction for two sets of three stimuli per set, neither Student B nor Student X subsequently acquired naming for either set. In reference to Figure 1, for Student B (see first row of data) post-tact instruction probes for the first set (Set 1) were 6/18 correct responses for the point response, and 16 out of 18 correct responses for the impure tact response. These results did not satisfy the preset criterion for the naming repertoire. Thus, while the child had the speaker response he did not have the listener response. We then introduced the MEI protocol, and the student met criterion for naming (i.e., he acquired the listener half of naming). Again, for Student B, post-tact instruction probes for the second set of stimuli (Set 2) were 12/18 correct responses for point, and 11/18 correct responses for the impure tact. These results did not satisfy the preset criterion for the naming repertoire. We then introduced MEI instruction, and the student met criteria for naming for both repertoires tested (i.e., point and impure tact). After learning to tact a third set of stimuli (Set 3), Student B did show mastery criterion for the untaught point and impure tact responses following tact only instruction. We decided that this satisfied the components for naming.
Figure 1.
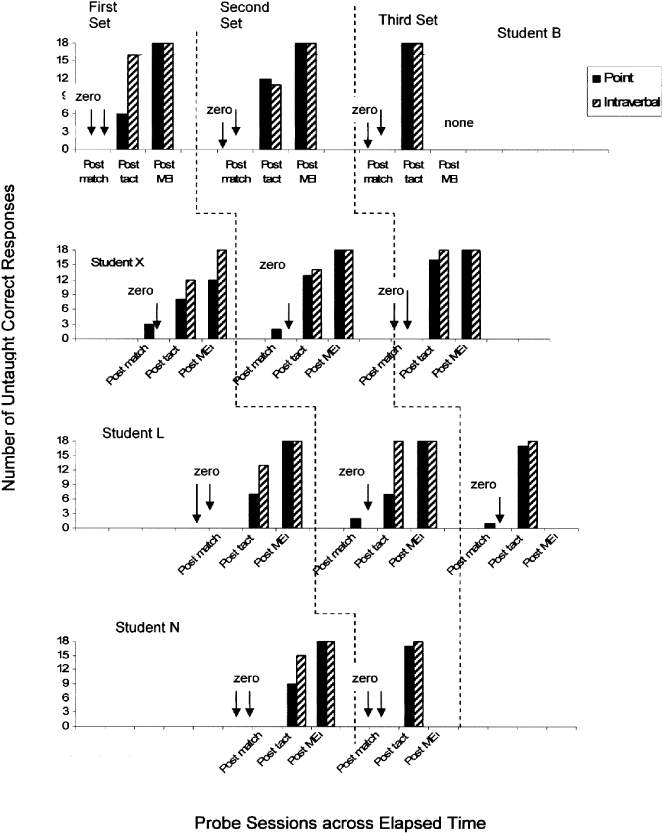
Delayed multiple baseline for naming probes for all students.
Again in reference to Figure 1, for Student X (see second row of data), post-tact instruction probes for the first set of stimuli (Set 1) were 8/18 correct responses for the point response, and 12/18 correct responses for the impure tact response. These results did not satisfy the preset criterion for the naming repertoire. We then introduced MEI, but the student did not meet criterion for naming for both repertoires tested (i.e., point and impure tact). We introduced a second set of stimuli (Set 4) and taught the tact response for all three stimuli in that set. Probes following tact instruction showed that Student X had 13/18 correct responses for the point response, and 14/18 correct responses for the impure tact response. These results did not satisfy the preset criterion for the naming repertoire. We then introduced another MEI set, and the student met criterion for naming. Student X was taught a third and novel set of stimuli (Set 3) for the tact response only. The post-tact instruction probes for this set were 16/18 correct responses for the point response, and 18/18 correct responses for the impure tact. These results were very close to criterion-level performance but did not absolutely satisfy the requirements. We went on to present MEI instruction for a third teaching set for this student and the student met criterion.
Figure 1 also shows that Student L (see third row of data) did not learn the naming repertoire for two sets of stimuli following the tact only instruction. Following tact instruction for the first set of stimuli (Set 3), Student L was probed and had 7/18 correct point responses and 13/18 correct impure tact responses. These results did not satisfy the preset criterion for the naming repertoire. We then taught another MEI set, and the student met criterion for naming for the first set. We introduced a second set (Set 1) and taught the tact to criterion for independent responses. We probed for the untaught point and impure tact responses, and the results showed 7/18 and 18/18, respectively. We then introduced MEI again for another teaching set, and the student met criterion for naming for this set. We went on to teach independent tact responses for a third set of stimuli (Set 4) and probed for the untaught point and impure tact responses. Results for Student L following post-tact probes showed that this student had 17/18 correct point and 18/18 correct impure tact responses. We decided that this student had the naming repertoire based on our preset criteria.
Following pre-experimental probes, it was determined that for Student N a monosyllabic phoneme would be chosen rather than a bi-syllabic phoneme because he was emitting only partial vocal approximations to teacher antecedent echoic stimuli. An alternate set of responses was identified for Set 3 (pakot, dipoy, and galoe), and the corresponding monosyllabic phonemes were ee, ay, and mm. In reference to Figure 1, Student N (see the fourth row of data) acquired the naming repertoire following one exposure to MEI. Following tact instruction for the first set of stimuli (Set 3), Student N was probed and had 9/18 correct point responses and 15/18 correct impure tact responses. These results did not satisfy the listener criterion for the naming repertoire. We then introduced MEI, and the student met criterion for naming for this first set. We introduced a second set (Set 2) and taught the tact to criterion for independent responses. We probed for the untaught point and impure tact responses, and the results showed 17/18 and 18/18, respectively. These results satisfied our preset criterion for the naming repertoire.
Student N was the only participant of the four who acquired the naming repertoire following only one exposure to MEI. It is important to note that he was required to emit only partial vocal approximations for all sets of stimuli. Two students required mastery of two sets with MEI, and one student required mastery of three sets with MEI in order to establish the joint stimulus control across speaker to listener and listener to speaker repertoires.
Figures 2 and 3 show the progression of instruction using learn units for the tact and MEI responses for all four students across elapsed time. A comparison is shown (see Table 4) between the number of learn units required for criterion-level performance for tacts and multiple exemplar instruction, and the total, mean, and range for both conditions. The total number of learn units required for criterion-level performance for all students for learning the tact function was 1,926; in contrast, the total number of learn units for the MEI was 558. The mean for the tact function was 175.0 and for the MEI function was 79.7. The range for the tact function was 72–288 (4 to 16 training sessions), and the range for MEI was 36–126 (2 to 7 training sessions).
Figure 3.
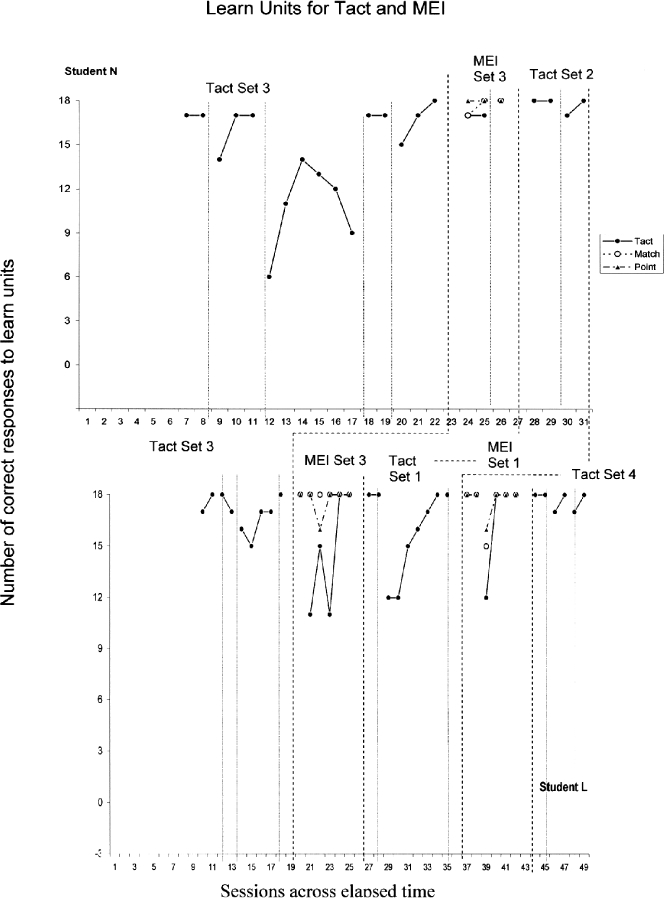
Delayed multiple baseline for learn unit instruction for Students L and N.
Table 4.
A comparison of the number of learn units required for tact and MEI.
| Participant/Sets | Tact | MEI |
| Student B | ||
| 1st Set | 216 | none |
| 2nd Set | 180 | 126 |
| 3rd Set | 216 | none |
| Student X | ||
| 1st Set | 216 | 54 |
| 2nd Set | 144 | 72 |
| 3rd Set | 108 | 36 |
| Student N | ||
| 1st Set | 288 | 54 |
| 2nd Set | 72 | none |
| Student L | ||
| 1st Set | 162 | 108 |
| 2nd Set | 162 | 108 |
| 3rd Set | 126 | none |
| Total Learn Units | 1926 | 558 |
| Mean | 175.0 | 79.7 |
| Range | 72–288 | 36–126 |
Prior to MEI none of the four students had the naming capability nor did they have an echoic-to-tact repertoire. All four students required more than one set of stimuli presented using the MEI protocol in order to learn the naming repertoire. For Student N, the joint stimulus control across repertoires occurred with less instruction than for the other three students. Thus, following mastery of one to three sets of training stimuli in MEI sessions, the students acquired naming from learning the tact function for the probe set, which they could not do prior to the MEI experiences. These students acquired the capability for naming from tact instruction as a direct result of exposure, in some cases multiple exposures, to MEI.
DISCUSSION
This experiment was conducted to test the conditions leading to transformation of stimulus function for the naming repertoire. In a previous study that tested the effects of multiple exemplar instruction on the transformation of stimulus function (Greer, Stolfi, et al., 2005), three students who did not have the listener to speaker component of the naming repertoire were taught to identify sets of pictures by teaching the match response first. Following exposure to MEI, all three students showed joint stimulus control from listener to speaker for untaught sets.
Four significant distinctions between the Greer, Stolfi, et al. (2005) study and this current study are that the children included in the first study had more extensive verbal repertoires than the children in the current study, none in the current study had any vocal tact repertoires or the echoic-to-tact capability. The Greer, Stolfi, et al. study used pictures of real objects that were unfamiliar to their participants whereas in the present study all the stimuli were contrived and the stimuli were three-dimensional. The students in the Greer, Stolfi, et al. study tested listener to speaker transformation of function (i.e., learning the listener component led to the speaker component) for 2-dimensional stimuli, whereas in this study speaker to listener was tested (i.e., learning the tact led to the listener component) for three-dimensional stimuli. Another point of distinction between these two studies is that in this study the participants were at least a year younger than the participants in the Greer, Stolfi, et al. (2005) study.
In a recent dissertation, Gilic (2005) tested for the presence of transformation of stimulus function across both listener to speaker and speaker to listener repertoires for typically developing 2-year-old children using three-dimensional stimuli. Maturation and instructional history were controlled for by using a combined multiple probe design within groups and an experimental control group design. The experimental group, following pre-treatment probes, was taught using MEI, while the control group was not initially exposed to MEI. The results showed that MEI functioned to establish the transformation of stimulus function across responses required for naming to emerge for the initial group, but this transformation did not emerge for the control group who did not receive MEI during this same time frame. Subsequently, the control group received MEI, and naming emerged for them also. These children were not, however, tested for whether or not naming would emerge after tact instruction alone.
Nuzzolo-Gomez and Greer (2004) showed transformation of establishing operations associated with the verbal operant functions of the mand and tact as a function of relevant MEI conditions. In the first condition, four students were taught either the mand or tact function for a set of forms and were then probed for the untaught function, which they did not show. They were then taught a training set of forms alternating between mand and tact establishing operation functions using MEI until the students mastered both functions. Subsequently they could emit untaught functions for the mands or tacts in the original set and then demonstrated transformation of establishing operation function for a novel set. The establishing operations came to control an untaught function for forms learned in the alternate function.
It is important to distinguish between (a) stimulus generalization across stimulus classes and (b) the transfer of stimulus function to different response repertoires. The former term, stimulus generalization, identifies the spread of the effect of reinforcement for a single response emitted in the presence of a stimulus that maintains some property of the original stimulus presented under extinction conditions (Catania, 1998; Cuvo, 2003). Therefore, a target stimulus may be considered to have generalized stimulus control if the stimulus has properties of the original condition but differs from the original stimulus (Cuvo, 2003). The distinction is made in the case of the experiment presented herein in that the transformation of stimulus function does not refer to a particular stimulus or set of stimuli but rather to a repertoire of responses or response topographies that were present in the post-treatment probe condition but not present in the training condition. That is, the stimulus control was transformed from control over a single topography to multiple topographies. When the children mastered the tact repertoires, they still did not have the listener repertoire until they had experiences with a subset of stimuli that occasioned the joint control across speaker and listener responding with novel stimuli. The acquisition of this higher order operant, or possibly a relational frame (Hayes, Barnes-Holmes, & Roche, 2001), provides the students with the capability to learn incidental responses that they could not learn incidentally prior to the multiple exemplar experiences.
In order for the new repertoire to be identified as a relational frame, the new higher order operant would have to demonstrate the subcomponents of a frame or mutual entailment, combinatorial entailment, and derived relations (Hayes, et al., 2001). However, since no tests were made of the presence or absence of these components of a frame, it cannot be determined that the new higher order operant was a frame. Whether or not it is a relational frame, the new capability may still be categorized as a higher order operant (Catania, 1998) and the participants did acquire joint stimulus control across speaker and listener response when a single stimulus response relation was taught. Thus, the stimulus control was transformed from control of a single response (the taught speaker response) to the listener response (the untaught listener response).
Within the category of higher-order verbal operants it appears that there are several distinct types. Some of these include the transformation of stimulus function in which a single stimulus gains control over more than one response class as in the case of the present study and in the cases of the other studies (Greer, Stolfi, et al., 2005; Greer, Yuan, et al., 2005; Lamarre & Holland, 1985; Tsiouri & Greer, 2003; Twyman, 1996a & b). Nuzzolo-Gomez (2004) showed transformation of establishing operations associated with the verbal operant functions of the mand and tact following relevant MEI conditions. In the latter case, a single response came under the control of an untaught establishing operation condition.
In the present study, the tact training condition preceded the MEI condition and when the participants demonstrated they could not learn naming from tact instruction alone, they were exposed to the MEI intervention. After mastering two to three MEI training sets, the students demonstrated untaught listener response after tact instruction alone. In the Lowe, et al. (2002) study, the typically developing children emitted naming after learning the tact responses only. In the Horne, et al. (2004) study their participants acquired the listener component but did not demonstrate the speaker component. In the present study, the children could not demonstrate naming as a result of learning tacts alone until after they had received two or more MEI training sets for three of the four students. This suggests that the MEI experiences provided the means for the children to learn listener responses after learning speaker responses. In the Greer, Stolfi, et al. (2005) study, the children acquired the listener to speaker component after MEI training. These studies and the Gilic (2005) study suggest that either listener to speaker or speaker to listener components may be missing and that MEI can lead to both. We suspect that one may not speak but attain a listener component of naming as Horne, et al. (2004) have demonstrated. We are currently working on this with children who have no speaker responses.
While this and prior studies show that incidental learning of speaker and listener components of naming emerged for particular types of stimuli following intensive MEI, it does not necessarily follow that the students have naming for other types of stimuli. Future research needs to test for this. It is possible that MEI across different types of stimuli (i.e., two- and three-dimensional stimuli, abstractions, or print control) may be necessary to evoke broad based naming such that children can acquire a wide range of tacts or other verbal operants incidentally. This remains to be investigated. But these results to date are promising and it is apparent that without a fluent naming repertoire, children cannot acquire verbal operants incidentally. This repertoire is critical if children with language delays are to be incidental verbal learners (Greer & Ross, 2004).
Anecdotally, it was observed by an independent data collector (a parent) that Student B had generalized within the class of stimuli subsequent to experimental conditions. While watching his father work on the family automobile in the driveway, this student picked up a hardware item similar in color and shape but dissimilar in size to the stimulus used in this experiment, and the student shouted the correct contrived tact topography used in the experiment. This child had learned transformation of stimulus function across repertoires (i.e., speaker to listener and vice versa) and across classes of stimuli (generalization), neither of which was present before his participation in this study.
Prior to onset of experimental conditions, Student L required a mean of 400 instructional opportunities to meet one instructional objective across instruction in all of his curricula programs taught in home instruction. However, subsequent to experimental conditions, fewer numbers of instructional opportunities (a mean of 138) were required to meet one objective, with the greatest improvement in the area of listener repertoires. It is also important to note that, prior to his participation, this student did not reliably point to target stimuli on the table. Subsequent to termination of this study, he reliably pointed across all of his instructional programs. Student L showed an educationally significant improvement in acquisition rates across all programs within the listener repertoire. In addition, this student responded to teacher presented vocal echoic prompts during the first phase of tact instruction for the third set of stimuli with clear and consistent bi-syllabic phonemes, which he had been unable to do for the first two stimuli sets.
Two significant contributions of this study were the identification of a protocol for inducing the bidirectional listener to speaker and speaker to listener repertoires that constitute the higher-order operant of naming and the induction of naming as a function of instructional history. These findings replicate and extend those of the prior study on the induction of naming as a function of MEI history. In the present study, the students were younger and had significantly more deficits, suggesting that naming may be induced even with children significantly more impaired than those in the initial study. Also, in the present study, even though the students mastered the tact, mastery of the tact did not result in naming. Unlike the typically developing children in the Lowe, et al. (2002) study, acquiring the tact did not lead to naming until the MEI experiences. In this study, results showed that the independent speaker and listener repertoires came under joint stimulus control following MEI experiences with subsets of stimuli, and these students emitted naming responses to novel stimuli. MEI was an effective treatment for establishing the naming capability for students who, previous to experimental conditions, did not have this capability. Future related research should also be extended to test the effects of MEI on students who have no speaker repertoires to determine if the listener component of naming alone can be induced with relevant MEI experiences.
Footnotes
The research reported herein was completed as part of a Ph.D. dissertation by the first author under the sponsorship of the second author. Correspondence concerning this article should be addressed to the first author at carolfiorile@optonline.net.
REFERENCES
- Becker B. J. 1989. The effect of mands and tacts on conversational units and other verbal operants. (Doctoral dissertation, 1989, Columbia University). Abstract from UMI Proquest Digital Dissertations [on-line]. DissertationsAbstracts Item:AAT 8913097. [Google Scholar]
- Catania C. A. Learning. Upper Saddle River, NJ: Prentice-Hall; 1998. [Google Scholar]
- Chu H. C. 1998. A comparison of verbal behavior and social skills approaches for development of social interaction skills and concurrent reduction of aberrant behaviors of children with developmental disabilities in the context of the matching theory. (Doctoral dissertation, 1998, Columbia University). Abstract from UMI Proquest Digital Dissertations [on-line]. Dissertations Abstracts Item: AAT 9838900. [Google Scholar]
- Cuvo A. J. On stimulus generalization and stimulus classes. Journal of Behavioral Education. 2003;12:77–83. [Google Scholar]
- Gilic L. The development of naming in two-year old children. 2005. Unpublished doctoral dissertation, Columbia University, NY. [Google Scholar]
- Greer R. D. Teaching Operations for Verbal Behavior. 1992. Unpublished manuscript. [Google Scholar]
- Greer R. D. Designing Teaching Strategies: An Applied Behavior Analysis Systems Approach. San Diego, CA: Academic Press; 2002. [Google Scholar]
- Greer R. D, Keohane D. D. The evolution of verbal development in young children. Behavior Development Bulletin. 2005;1:31–48. [Google Scholar]
- Greer R. D, McDonough S. H. Is the learn unit a functional measure of pedagogy. The Behavior Analyst. 1999;22:5–16. doi: 10.1007/BF03391973. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Greer R. D, Nirgudkar A, Park H. The effect of multiple exemplar instruction on the transformation of mand and tact functions. 2003. Paper presented at the International Conference of the Association for Behavior Analysis, San Francisco, CA. [Google Scholar]
- Greer R. D, Ross D. E. Research in the induction and expansion of complex verbal behavior. Journal of Early Intensive Behavioral Intervention. 2004;1(2):141–165. http://www.jeibi.com/JEIBI-I-2.pdf. [Google Scholar]
- Greer R. D, Stolfi L, Chavez-Brown M, Rivera-Valdez C. The emergence of the listener to speaker component of naming in children as a function of multiple exemplar instruction. The Analysis of Verbal Behavior. 2005;21:123–134. doi: 10.1007/BF03393014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Greer R. D, Yuan L, Gautreaux G. Novel dictation and intraverbal responses as a function of a multiple exemplar instructional histories. The Analysis of Verbal Behavior. 2005;21:99–116. doi: 10.1007/BF03393012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hayes S. C, Barnes-Holmes D, Roche B. Relational frame theory: A post-Skinnerian account of human language and cognition. New York: Kluwer/Academic Plenum; 2001. [DOI] [PubMed] [Google Scholar]
- Horne P. J, Lowe C. F. On the origins of naming and other symbolic behavior. Journal of the Experimental Analysis of Behavior. 1996;65:185–241. doi: 10.1901/jeab.1996.65-185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horne P. J, Lowe C. F, Randle V. R. L. Naming and categorization in young children: II. Listener behavior training. Journal of the Experimental Analysis of Behavior. 2004;81:267–288. doi: 10.1901/jeab.2004.81-267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horner R. D, Baer D. M. Multiple-probe technique: A variation on the multiple baseline. Journal of Applied Behavior Analysis. 1978;11:189–196. doi: 10.1901/jaba.1978.11-189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karmali I, Greer R. D, Nuzzolo-Gomez R, Ross D.E, Rivera-Valdes C. Reducing palilalia by presenting tact corrections to young children with autism. The Analysis of Verbal Behavior. 2005;21:145–154. doi: 10.1007/BF03393016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lamarre J, Holland J. G. The functional independence of mands and tacts. Journal of the Experimental Analysis of Behavior. 1985;43:5–19. doi: 10.1901/jeab.1985.43-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lodhi S, Greer R. D. The speaker as listener. Journal of the Experimental Analysis of Behavior. 1989;51:353–359. doi: 10.1901/jeab.1989.51-353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowe C. F, Horne P. J, Harris F. D. A, Randle V. R. L. Naming and categorization in young children: Vocal tact training. Journal of the Experimental Analysis of Behavior. 2002;78:527–549. doi: 10.1901/jeab.2002.78-527. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marianno-Lapidus S. 2005. (Doctoral dissertation, 2005, Columbia University). Abstract from: UMI Proquest Digital Dissertations [on-line]. Dissertations Abstracts Item. [Google Scholar]
- Michael J. Skinner's elementary verbal relations: Some new categories. The Analysis of Verbal Behavior. 1982;1:1–3. doi: 10.1007/BF03392791. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nuzzolo-Gomez R, Greer R. D. Emergence of untaught mand or tacts with novel adjective-object pairs as a function of instructional history. The Analysis of Verbal Behavior. 2004;24:30–47. doi: 10.1007/BF03392995. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Paniagua F. A, Baer D. M. The analysis of correspondence training as a chain reinforceable at any point. Child Development. 1982;53:786–798. [Google Scholar]
- Pinker S. Words and rules. New York: Perennial; 1999. [Google Scholar]
- Ross D. E, Greer R. D. Generalized imitation and the mand: Inducing first instances of speech in young children with autism. Research in Developmental Disabilities. 2003;24:58–74. doi: 10.1016/s0891-4222(02)00167-1. [DOI] [PubMed] [Google Scholar]
- Skinner B. F. Verbal Behavior. Acton, MA: Prentice-Hall; 1957. [Google Scholar]
- Speckman J. 2005. (Doctoral dissertation, 2005, Columbia University). Abstract from: UMI Proquest Digital Dissertations [online]. Dissertations Abstracts Item: AAT 3159757. [Google Scholar]
- Sundberg M. L, Michael J, Partington J. W, Sundberg C. A. The role of automatic reinforcement in early language acquisition. The Analysis of Verbal Behavior. 1996;13:21–37. doi: 10.1007/BF03392904. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsiouri I, Greer R. D. Inducing vocal verbal behavior through rapid motor imitation responding in children with severe language delays. Journal of Behavioral Education. 2003;12(3):185–206. [Google Scholar]
- Twyman J. S. An analysis of functional independence within and between secondary verbal operants. 1996a. (Doctoral dissertation, 1996, Columbia University). Abstract from: UMI Proquest Digital Dissertations [on-line]. Dissertations Abstracts Item: AAT9631793. [Google Scholar]
- Twyman J. S. The functional independence of impure mands and tacts of abstract stimulus properties. The Analysis of Verbal Behavior. 1996b;13:1–19. [Google Scholar]
- Williams G, Greer R. D. A comparison of verbal-behavior and linguistic-communication curricula for training developmentally delayed adolescents to acquire and maintain vocal speech. Behaviorology. 1993;1:31–46. [Google Scholar]
- Yoon S. Y. Effects of an adult's vocal sound paired with a reinforcing event on the subsequent acquisition of mand functions. 1998. (Doctoral dissertation, 1998, Columbia University). Abstract from: UMI Proquest Digital Dissertations [on-line]. Dissertations Abstracts Item: AAT9839031. [Google Scholar]