

Abstract
Prompted by the increasing interest in networks in many fields, we present an attempt at unifying points of view and analyses of these objects coming from the social sciences, statistics, probability and physics communities. We apply our approach to the Newman–Girvan modularity, widely used for “community” detection, among others. Our analysis is asymptotic but we show by simulation and application to real examples that the theory is a reasonable guide to practice.
Keywords: modularity, profile likelihood, ergodic model, spectral clustering
The social sciences have investigated the structure of small networks since the 1970s, and have come up with elaborate modeling strategies, both deterministic, see Doreian et al. (1) for a view, and stochastic, see Airoldi et al. (2) for a view and recent work. During the same period, starting with the work of Erdös and Rényi (3), a rich literature has developed on the probabilistic properties of stochastic models for graphs. A major contribution to this work is Bollobás et al. (4). On the whole, the goals of the analyses of ref. 4, such as emergence of the giant component, are not aimed at the statistical goals of the social science literature we have cited.
Recently, there has been a surge of interest, particularly in the physics and computer science communities in the properties of networks of many kinds, including the Internet, mobile networks, the World Wide Web, citation networks, email networks, food webs, and social and biochemical networks. Identification of “community structure” has received particular attention: the vertices in networks are often found to cluster into small communities, where vertices within a community share the same densities of connecting with vertices in the their own community as well as different ones with other communities. The ability to detect such groups can be of significant practical importance. For instance, groups within the worldwide Web may correspond to sets of web pages on related topics; groups within mobile networks may correspond to sets of friends or colleagues; groups in computer networks may correspond to users that are sharing files with peer-to-peer traffic, or collections of compromised computers controlled by remote hackers, e.g. botnets (5). A recent algorithm proposed by Newman and Girvan (6), that maximizes a so-called “Newman–Girvan” modularity function, has received particular attention because of its success in many applications in social and biological networks (7).
Our first goal is, by starting with a model somewhat less general than that of ref. 4, to construct a nonparametric statistical framework, which we will then use in the analysis, both of modularities and parametric statistical models. Our analysis is asymptotic, letting the number of vertices go to ∞. We view, as usual, asymptotics as being appropriate insofar as they are a guide to what happens for finite n. Our models can, on the one hand, be viewed as special cases of those proposed by ref. 4, and on the other, as encompassing most of the parametric and semiparametric models discussed in Airoldi et al. (2) from a statistical point of view and in Chung and Lu (8) for a probabilistic one. An advantage of our framework is the possibility of analyzing the properties of the Newman–Girvan modularity, and the reasons for its success and occasional failures. Our approach suggests an alternative modularity which is, in principle, “fail-safe” for rich enough models. Moreover, our point of view has the virtue of enabling us to think in terms of “strength of relations” between individuals not necessarily clustering them into communities beforehand.
We begin, using results of Aldous and Hoover (9), by introducing what we view as the analogues of arbitrary infinite population models on infinite unlabeled graphs which are “ergodic” and from which a subgraph with n vertices can be viewed as a piece. This development of Aldous and Hoover can be viewed as a generalization of deFinetti's famous characterization of exchangeable sequences as mixtures of i.i.d. ones. Thus, our approach can also be viewed as a first step in the generalization of the classical construction of complex statistical models out of i.i.d. ones using covariates, information about labels and relationships.
It turns out that natural classes of parametric models which approximate the nonparametric models we introduce are the “blockmodels” introduced by Holland, Laskey and Leinhardt ref. 10; see also refs. 2 and 11, which are generalizations of the Erdös–Rényi model. These can be described as follows.
In a possibly (at least conceptually) infinite population (of vertices) there are K unknown subcommunities. Unlabeled individuals (vertices) relate to each other through edges which for this paper we assume are undirected. This situation leads to the following set of probability models for undirected graphs or equivalently the corresponding adjacency matrices {Aij : i,j ≥ 1}, where Aij = 1 or 0 according as there is or is not an edge between i and j.
Individuals independently belong to community j with probability πj, 1 ≤ j ≤ K, ∑j = 1K πj = 1.
A symmetric K × K matrix {Pkl : 1 ≤ k,l ≤ K} of probabilities is given such that Pab is the probability that a specific individual i relates to individual j given that i ∈ a,j ∈ b. The membership relations between individuals are established independently. Thus 1 − ∑1≤a,b≤K πa πb Pab is the probability that there is no edge between i and j.
The Erdös–Rényi model corresponds to K = 1.
We proceed to define Newman–Girvan modularity and an alternative statistically motivated modularity. We give necessary and sufficient conditions for consistency based on the parameters of the block model, properties of the modularities, and average degree of the graph. By consistency we mean that the modularities can identify the members of the block model communities perfectly. We also give examples of inconsistency when the conditions fail. We then study the validity of the asymptotics in a limited simulation and apply our approach to a classical small example, the Karate Club and a large set of Private Branch Exchange (PBX) data. We conclude with a discussion and some open problems.
Random Graph Models
Consider any probability distribution ℙ on an infinite undirected graph, or equivalently a probability distribution on the set of all matrices ∥Aij : i,j ≥ 1∥ where Aij = 1 or 0, Aij = Aji for all i,j pairs, and Aii = 0 for all i, thus excluding self relation. If the graph is unlabeled, it is natural to restrict attention to ℙ such that ∥Aσi σj∥ ∼ ℙ for any permutation σ of {1,2,3,…}. Hoover (see ref. 9) has shown that all such probability distributions can be represented as,
where α, {ξi} and {λij} are i.i.d. U(0,1) variables and
for all u,v,w,z. The variables ξ correspond to latent variables, λ being completely individual specific, ξ generating relations between individuals and α a mixture variable which is unidentifiable even for an infinite graph. Note that g is unidentifiable and the ξ and λ could be put on another scale, e.g. Gaussian. We note that, this point of departure was also recently proposed by Hoff (12) but was followed to a different end.
It is clear that the distributions representable as,
where λij = λji, are the extreme points of this set and play the same role as sequences of i.i.d. variables play in de Finetti's theorem. Since given ξi and ξj, the λij are i.i.d., these distributions are naturally parametrized by the function
As Diaconis and Janson (13) point out h(.,.) does not uniquely determine ℙ but if h1 and h2 define the same ℙ, then there exists φ : [0,1] → [0.1] which is: measure preserving, i.e. such that φ(ξ1) has a U(0,1) distribution; and h1(u,v) = h2(φ(u),φ(v)).
Given any h corresponding to ℙ, let
It is well known (see section 10 of ref. 14) that there exists a measure preserving φg such that, g(φg(v)) is monotone non decreasing.
Define
We claim that
where F is the cdf of gCAN(ξi), and hCAN is unique up to sets of measure 0. To see this note that if h corresponds to ℙ and g(u) ≡ ∫01 h(u,v)dv is non decreasing, then since F is determined by ℙ only, g(u) = F−1(u). But g(φg(u)) = gCAN(u) and φg(u) = g−1gCAN(u) = u.
There is a reparametrization of hCAN (we drop the CAN subscript in the future) which enables us to think of our model in terms more familiar to statisticians.
Let
Then the conditional density of (ξi,ξj) given that there is an edge between i and j is w(u,v) = ρ−1h(u,v). This parametrization also permits us to decouple ρ ∝ E(Degree) of the graph from the inhomogeneity structure. It is natural finally to let ρ depend on n but w(·,·) to be fixed. If λn ≡ 𝔼(Degree) → ∞, we have what we may call the “dense graph” limit. If λn = Ω(1), we are in the case most studied in probability theory where, for instance, λn = 1 is the threshold at which the so called “giant component” appears. This is the situation Bollobas et al. focus on.
As we have noted, block models are of this type. Here we can think of the reparametrization as being ρ, π, ∥Sab∥ = ∥ρ−1Pab∥, or ∥Wab∥ ≡ ∥ρ−1Pabπaπb∥. The models studied by Chung and others (8) given by,
also fall under our description. The mixture model of Newman and Leicht (15) where, given communities 1,…,K,
is not of this type, since it is not invariant under permutations. It can be made invariant by summing over all permutations of {1,…,n}, but is then generally not ergodic. Such models can be developed from our framework by permitting covariates Zi depending on vertex identity or Zij depending on edge identity. Newman and Leicht's example where the communities are WEB pages falls under this observation. From a statistical point of view, these models bear the same relation to our models as regression models do to single population models.
Block models or models where
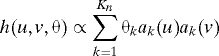 |
for known functions {ak} can be used to approximate general h. The latent eigenvalue model of Hoff (12) is of this type, but with ak which are extremely rough and unidentifiable since the aj(ξ) are independent, and for which no unique choice exists. We can think of the canonical version of the block model as corresponding to a labeling 1,…,K of the communities in the order W1 ≤… ≤ WK where Wj = ∑k Wjk, which is proportional to the expected degree of a member of community j. The function h(·,·) then takes value Pab on the (a,b) block of the product partition in which each axis is divided into consecutive intervals, of lengths π1,…,πK. Each corresponding vertical slice exhibits the relation pattern for that community with the diagonal block identifying the members of the community. The nonparametric h(·,·) gives the same intuitive picture on an arbitrarily fine scale. We note that, as in nonparametric statistics, to estimate h or w, regularization is needed. That is, we need to consider Kn → ∞ at rates which depend on n and λn to obtain good estimates of h or w by using estimates of θ above or of block model parameters. We will discuss this further later.
Newman–Girvan and Likelihood Modularities
The task of determining K communities corresponds to finding a good assignment for the vertices e ≡ {e1,…,en} where ej ∈{1,…,K}. There are Kn such assignments. Suppose that the distribution of A follows a K block model with parameters π = (π1,…,πK) and P = ∥Pab∥K×K. The observed A is a consequence of a realization c = (c1,…,cn) of n independent Multinomial(1,π) variables. Evidently we can measure the adequacy of an assignment through the matrix
where Rab = n−1 ∼i=1i I(ci = b, ei = a), the fraction of b members classified as a members if we use e. It is natural to ask for consistency of an assignment e, that is, e = c, i.e.
where fa(e) = n−1na(e) and na (e) = ∑i=1n I(ei = a). The Newman–Girvan modularity QNG(e,A) is defined as follows. Let {i : ei = k} denote e-community k, i.e. as estimated by e. Define
to be the block sum of A. Obviously, Okk is twice the number of edges among nodes in the k-th e-community and for k ≠ l, Okl is the number of edges between nodes in the k-th e-community and nodes in the l-th e-community. Let Dk(e,A) = ∑l=1K Okl(e,A). It is easy to verify that Dk is the sum of degrees for nodes in the k-th e-community. Let L = ∑k=1K Dk be twice the number of edges among all nodes. Then the Newman–Girvan modularity is defined by
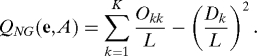 |
The Newman–Girvan algorithm then searches for the membership assignment vector e that maximizes QNG. Notice that if edges are randomly generated uniformly among all pairs of nodes with given node degrees, then the number of edges between the kth e-community and lth e-community is expected to be L−1DkDl. Therefore, the Newman–Girvan modularity measures the fraction of the edges on the graph that connect vertices of the same type (i.e. within-community edges) minus the expected value of the same quantity on a graph with the same community divisions but random connections between the vertices (6). Newman (16) contrasts and compares his modularity with spectral clustering, another common “community identification” method which we will also compare to the likelihood modularity below. We seek conditions under which the official N-G assignment
is consistent with probability tending to 1. Before doing so we consider alternative modularities.
For fixed e, the conditional, given {nk(e)}1K, log-likelihood of A is ∑1≤a,b≤K (Oab log(Pab) + (nab − Oab) :log(1 − Pab)), where nab = nanb if a ≠ b, naa = na(na − 1). If we maximize over P, we obtain by letting τ(x) = x logx + (1 − x)log(1 − x),
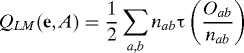 |
which we call the likelihood modularity. This is not a true likelihood but a profile likelihood where we treat e as an unknown parameter. We will argue below that the profile likelihood is optimal in the usual parametric sense if → ∞. But so are all other consistent modularities as defined below. However, we expect that if is bounded and certainly if λn = Ω(1), the most important case, this is false. We are deriving optimal and computationally implementable procedures for this case.
We write general modularities in the form,
where μn = E(L) = n(n − 1)ρn and the matrix O(e,A) is defined by its elements Oab(e,A), f(e) = , and Fn : M × R+ × G → R where M is the set of all nonnegative K × K symmetric matrices and G is the K simplex. Note that both QNG and QLM can be written as such up to a proportionality constant. It is easy to see that if the K block model holds,
where, by definition, RT1 = f(c), R1 = f(e), 1 = (1,…,1)T, and Sab = ρn−1ℙ(A12 = 1∥c1 = a, c2 = b). Note that W ≡ D(π)SD(π), where D(v) ≡ diag(v) for v K × 1.
We define asymptotic consistency of a sequence of assignments ĉ by
as n → ∞.
We will assume that there exists a function F : M×ℝ+×G → ℝ such that Fn is approximated by F evaluated at the conditional expectation given c of the argument of Fn. Suppose first Fn ≡ F. It is intuitively clear from [3] that if ĉ → c, then R(c,ĉ) → D(π). Then, since f(c) → π, the following condition is natural.
I. F(RSRT,1,R1) is uniquely maximized over R = {R : R ≥ 0, RT 1 = π} by R = D(π), for all (π,S) in an open set Θ.
This means c with f(c) = π is the right assignment for the limiting problem. Note that since F is not concave in R, this is a strong condition.
For (π,S) to be identifiable uniquely, we clearly also need that:
II. S does not have two identical columns (Two communities cannot have identical probabilities of being related to other communities and within themselves) and π has all entries positive (Each community has some members).
We also need a few more technical conditions of a standard type.
III. a) F is Lipschitz in its arguments. b) The directional derivatives (M0+ɛ(M1−M0),r0+ɛ(r1−r0),t0+ɛ(t−t0))∥ɛ=0+are continuous in (M1,r1,t) for all (M0,r0,t0) in a neighborhood of (W,1,π). c) Let G(R,S) = F(RSRT,1,R1). Assume that on R,∥ɛ=0+ ≤ −C < 0 for all (π,S) ∈Θ.
Theorem 1. Suppose F,S and π satisfy I–III and ĉ is the maximizer of Q(e,A). Suppose → ∞. Then, for all (π,S) ∈Θ,
The proof is given in SI Appendix.
We note that Snijders and Nowicki (11) established a related result, exponential convergence to 0 of the mis-classification probability for λn = Ω (n) using node degree K-means clustering for K = 2.
Let F(c,e) ≡ F(R(c,e)SRT(c,e),fT(c)Sf(c),f(e)). In the general case it suffices to show,
for all δ > 0, some γ > 0, where
and ∥e − c∥ = ∑i=1n 1(ei ≠ ci). We show in SI Appendix that QNG and QLM satisfy I and III and Eq. 5 for selected (π,S) for QNG and all (π,S) for QLM.
An immediate consequence of the theorem is:
Corollary 1: If the conditions of Theorem 1 hold and,
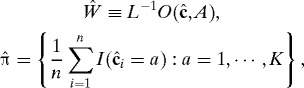 |
then,
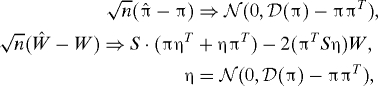 |
with A · B denoting point-wise product. The limiting variances are what we would get for maximum likelihood estimates if ĉ = c, i.e. we knew the assignment to begin with. So consistent modularities lead to efficient estimates of the parameters.
This follows since with probability tending to 1, ĉ = c.
To estimate w(·,·) in the nonparametric case we need K → ∞, and w(·,·) and π(·) smooth. We approximate by WK ∼ K−2∥w(aK−1,bK−1)∥, πK(a) ∼ K−1π(aK−1), where w(·,·), WK are canonical and the modularity defining FK, FK(·,·,·) is of order K−2. We have preliminary results in that direction but their formulation is complicated and we do not treat them further here.
Consistency of N-G, L-M
We show in SI Appendix using the appropriate FNG, FLM that the likelihood modularity is always consistent while the Newman–Girvan is not. This is perhaps not surprising since N-G focuses on the diagonal of O. In fact, we would hope that N-G is consistent under the submodel {(ρ, π W) : Waa > ∑b≠a Wab for all a}, which corresponds to Newman and Girvan's motivation. We have shown this for K = 2 but it surprisingly fails for K > 2. Here is a counterexample. Let K = 3, π = (1/3,1/3,1/3)T and
 |
As n → ∞, with true labeling, QNG approaches 0.033. However, the maximum QNG, about 0.038, is achieved by merging the first two communities. That is, two sparser communities are merged. This is consistent with an observation of Fortunato and Barthelemy (17).
If for the profile likelihood we maximize only over e such that Ŵaa (e) > ∑b≠a Ŵab (e) for all a, we obtain ĉ which is consistent under the submodel above, and in the Karate Club example performs like N-G.
Computational Issues
Computation of optimal assignments using modularities is, in principle, NP hard. However, although the surface is multimodal, in the examples we have considered and generally when the signal is strong, optimization from several starting points using a label switching algorithm (19) works well.
Simulation
We generate random matrices A and maximize QNG, QLM to obtain node labels respectively, where QLM is maximized using a label switching algorithm. To make a fair comparison, the initial labeling for QNG and QLM is to randomly choose 50% of the nodes with correct labels and the other 50% with random labels. For spectral clustering, we adopt the algorithm of (18) by using the first K eigenvectors of D(d)−1/2 AD(d)−1/2, where d = (d1,…,dn)T and di is the degree of the i-th node. We generate the P matrix randomly by forcing symmetry and then add a constant to diagonal entries such that I holds. The π is generated randomly from the simplex. To be precise, the values for Fig. 1 are π = (.203,.286,.511)T and
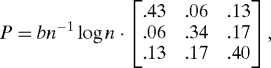 |
where n varies from 200 to 1,500 and b varies from 10 to 100. Obviously, Fig. 1 says that the likelihood method exhibits much less incorrect labeling than Newman–Girvan and spectral clustering. This is consistent with theoretical comparison.
Fig. 1.

Empirical comparison of Newman–Girvan, likelihood modularities and spectral clustering (18), where K = 3, the number of nodes n varies from 200 to 1500, and the percent of correct labeling is computed from 100 replicates of each simulation case. Here π, P are given in the text.
Data Examples
We compare the L-M and N-G modularity algorithms below with applications to two real data sets. To deal with the issue of non-convex optimization, we simply use many restarting points.
Zachary's “Karate Club” Network.
We first compare L-M and N-G with the famous “Karate Club” network of ref. 20, from the social science literature, which has become something of a standard test for community detection algorithms. The network shows the patterns of friendship between the members of a karate club at a US university in the 1970s. The example is of particular interest because shortly after the observation and construction of the network, the club in question split into two components separated by the dashed line as shown in Figs. 2 and 3 as a result of an internal dispute. Fig. 2 Left shows two communities identified by maximizing the likelihood modularity where the shapes of the vertices denote the membership of the corresponding individuals, and similarly the right panel shows communities identified by N-G. Obviously,the N-G communities match the two sub-divisions identified by the split save for one mis-classified individual. The L-M communities are quite different, and obviously one community consists of five individuals with central importance that connect with many other nodes while the other community consists of the remaining individuals. Although not reflecting the split this corresponds to other plausible distinguishing characteristics of the individuals. However, if we force the constraint that within-community density is no less than the density of relationship to all other communities, the submodel we discussed, then we obtain two L-M communities that match the split perfectly. The same partitions as ours with and without constraint have also been reported by Rosvall and Bergstrom using a data compression criterion (21), which is closely related to L-M. We note that, as is usual in clustering, there is no ground truth, only features which can be validated ex post fact. It is interesting to note that, if instead of K = 2, we put K = 4, as in Fig. 3, it is evident for both modularities that merging the communities on either side of the eigenvector split, gives the “correct” Karate Club split. This suggests that the standard policy mentioned by Newman (16) of increasing the number of communities by splitting is not necessarily ideal since in this case the “misclassified” individual of Fig. 2 would never be “correctly” classified.
Fig. 2.

Zachary's karate club network. Communities were identified by maximizing the likelihood modularity (Left) and by maximizing the Newman–Girvan modularity with K = 2 (Right), where the shapes of vertices indicate the membership of the corresponding individuals. The dashed line cuts the nodes into two groups which are the “known” communities that the club was split into.
Fig. 3.

Zachary's karate club network. Communities were identified by maximizing the likelihood modularity (Left) and by maximizing the Newman–Girvan modularity with K = 4 (Right), where the shapes of vertices indicate the membership of the corresponding individuals. The dashed line cuts the nodes into two groups which are the known communities that the club was split into.
Private Branch Exchange.
Our second example is of a telephone communication network where connections are made among the internal telephones of a private business organization, a so called PBX. PBXs are differentiated from “key systems” in that users of key systems usually select their own outgoing lines, while PBXs select the outgoing line automatically. Our data contains 621 individuals. Fig. 4 Left shows the results of community detection by L-M, where the adjacency matrix is plotted but the nodes are sorted according to the membership of the corresponding individuals identified by maximizing the likelihood modularity. Similarly, the right panel of Fig. 4 shows the communities identified by N-G, where the maximum Newman–Girvan modularity is 0.4217. Note that the identified communities by L-M have sizes 323, 81, 78, 97, 41, and 1, respectively. The communities are ordered simply by their average node degrees, essentially the order for hCAN. Interestingly, the last L-M community has only one node that communicates with almost everyone else, nodes in the second community only communicate with internal nodes, nodes in the fourth community and the sixth community, but not with others; Similarly, the third community only communicates with the fifth and sixth communities, and so on. In other words, communication between communities is sparse. However, the communities identified by N-G are quite different with only the fifth community heavily overlapping with a community identified by L-M. This difference appears to be caused by the nodes in the 5th and 6th L-M communities which have many more between-community connections than within-community connections while N-G more or less maximizes within-community connections. We have verified that the group communicating with all others is a service group.
Fig. 4.

Private branch exchange data. (Left) The adjacency matrix where the nodes are sorted according to the membership of the corresponding individuals identified by maximizing L-M. (Right) Same as Left, but with individuals identified by maximizing N-G with K = 6. The colors on the within-community edges are used to differentiate the communities for both L-M and N-G.
Discussion
As we noted, under our conditions the usual statistical goal of estimating the parameters π and P is trivial, since, once we have assigned individuals to the K communities consistently, the natural estimates, Ŵ and π̂, are not just consistent but efficient. However, in the more realistic case where λn = Ω(1), or even just λn = Ω (logn), this is no longer true. Elsewhere, we shall show that, indeed, estimation of parameters by maximum likelihood and Bayes classification of individuals (no longer perfect) is optimal.
A difficulty faced by all these methods, modularities or likelihoods, is that if K is large, searching over the space of classifications becomes prohibitively expensive. In subsequent work we intend to show that this difficulty may be partly overcome by using the method of moments to first estimate π and P, and then study the likelihood in a neighborhood of the estimated values.
Open Problems
A fundamental difficulty not considered in the literature is the choice of K. From our nonparametric point of view, this can equally well be seen as, how to balance bias and variance in the estimation of w(·,·). We would like to argue that, as in nonparametric statistics, estimating w(·,·) without prior prejudices on its structure is as important an exploratory step in this context as, using histograms in ordinary statistics.
The linking of this framework to covariates depending on vertice or edge identity is crucial, permitting relationship strength to be assessed as a function of vector variables.
The links of our approach to spectral graph clustering and more generally clustering on the basis of similarities seem intriguing.
Acknowledgments.
We thank Tin K Ho for help in obtaining the PBX data and for helpful discussions. We also thank the referees, whose references and comments improved this article immeasurably.
Footnotes
The authors declare no conflict of interest.
This article is a PNAS Direct Submission.
This article contains supporting information online at www.pnas.org/cgi/content/full/0907096106/DCSupplemental.
References
- 1.Doreian P, Batagelj V, Ferligoj A. Generalized Blockmodeling. Cambridge, UK: Cambridge Univ Press; 2005. [Google Scholar]
- 2.Airoldi EM, Blei DM, Fienberg SE, Xing XP. Mixed-membership stochastic blockmodels. J Machine Learning Res. 2008;9:1981–2014. [PMC free article] [PubMed] [Google Scholar]
- 3.Erdös P, Rényi A. On the evolution of random graphs. Publ Math Inst Hungar Acad Sci. 1960;5:17–61. [Google Scholar]
- 4.Bollobas B, Janson S, Riordan O. The phase transition in inhomogeneous random graphs. Random Struct Algorithms. 2007;31:3–122. [Google Scholar]
- 5.Zhao Y, et al. Botgraph: Large scale spamming botnet detection. Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation; Berkeley, CA: USENIX; 2009. pp. 321–334. [Google Scholar]
- 6.Newman MEJ, Girvan M. Finding and evaluating community structure in networks. Phys Rev E. 2004;69:026113. doi: 10.1103/PhysRevE.69.026113. [DOI] [PubMed] [Google Scholar]
- 7.Guimera R, Amaral LAN. Functional cartography of complex metabolic networks. Nature. 2005;433:895–900. doi: 10.1038/nature03288. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Chung FRK, Lu L. CBMS Regional Conference Series in Mathematics. Providence, RI: Am Math Soc; 2006. Complex Graphs and Networks. [Google Scholar]
- 9.Kallenberg O. Probability and Its Application. New York: Springer; 2005. Probabilistic symmetries and invariance principles. [Google Scholar]
- 10.Holland PW, Laskey KB, Leinhardt S. Stochastic blockmodels: First steps. Soc Networks. 1983;5:109–137. [Google Scholar]
- 11.Snijders T, Nowicki K. Estimation and prediction for stochastic block-structures for graphs with latent block structure. J Classification. 1997;14:75–100. [Google Scholar]
- 12.Hoff PD. Modeling homophily and stochastic equivalence in symmetric relational data. In: Platt J, Koller D, Roweis S, editors. Advances in Neural Information Processing Systems. Vol. 20. Cambridge, MA: MIT Press; 2008. pp. 657–664. [Google Scholar]
- 13.Diaconis P, Janson S. Graph limits and exchangeable random graphs. Rendiconti di Matematica. 2008;28:33–61. [Google Scholar]
- 14.Hardy G, Littlewood J, Polya G. Inequalities. 2nd Ed. Cambridge, UK: Cambridge Univ Press; 1988. [Google Scholar]
- 15.Newman MEJ, Leicht EA. Mixture models and exploratory analysis in networks. Proc Natl Acad Sci USA. 2007;104:9564–9569. doi: 10.1073/pnas.0610537104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Newman MEJ. Finding community structure in networks using the eigenvectors of matrices. Phys Rev E. 2006;74:036104. doi: 10.1103/PhysRevE.74.036104. [DOI] [PubMed] [Google Scholar]
- 17.Fortunato S, Barthélemy M. Resolution limit in community detection. Proc Natl Acad Sci USA. 2007;104:36–41. doi: 10.1073/pnas.0605965104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Ng AY, Jordan MI, Weiss Y. Advances in Neural Information Processing Systems. Vol. 14. Cambridge, MA: MIT Press; 2001. On spectral clustering: Analysis and an algorithm; pp. 849–856. [Google Scholar]
- 19.Stephens M. Dealing with label-switching in mixture models. J R Stat Soc B. 2000;62:795–809. [Google Scholar]
- 20.Zachary W. An information flow model for conflict and fission in small groups. J Anthropol Res. 1977;33:452–473. [Google Scholar]
- 21.Rosvall M, Bergstrom C. An information-theoretic framework for resolving community structure in complex network. Proc Natl Acad Sci USA. 2007;104:7327–7331. doi: 10.1073/pnas.0611034104. [DOI] [PMC free article] [PubMed] [Google Scholar]