

Summary
Pathological behaviors such as problem gambling or shopping are characterized by compulsive choice despite alternative options and negative costs. Reinforcement learning algorithms allow a computation of prediction error, a comparison of actual and expected outcomes, which updates our predictions and influence our subsequent choices. Using a reinforcement learning model, we show data consistent with the idea that dopamine agonists in susceptible individuals with Parkinson's disease increase the rate of learning from gain outcomes. Dopamine agonists also increase striatal prediction error activity thus signifying a “better than expected” outcome. Thus, our findings are consistent with a model whereby a distorted estimation of the gain cue underpins a choice bias towards gains.
Introduction
Maladaptive behaviors such as pathological gambling or shopping are, by definition, problems of compulsive choice despite alternative options and negative costs. We used a model of reinforcement learning to deconstruct the decision making process underlying these compulsive behaviors. Reinforcement learning algorithms allow a computation of prediction error (δ) in classical and instrumental conditioning, which acts as a teaching signal to update our predictions and influence our subsequent choices (Sutton and Barto, 1998). Converging animal and human studies, the latter measuring the BOLD (Blood Oxygen Level Dependent) signal in fMRI studies suggest that phasic activity of midbrain dopamine encodes δ resulting in increased activity to unexpected rewards and decreased activity to unexpected reward omissions (Bayer and Glimcher, 2005; O'Doherty et al., 2003; Pessiglione et al., 2006; Schultz et al., 1997). Abnormalities in the expression of δ have been hypothesized to play a role in pathologies such as substance use disorders (Redish, 2004) but have not yet been demonstrated in human studies of behavioral pathology.
Here, we focused on compulsive disorders triggered in Parkinson's disease (PD) by dopamine agonists (DA) (Dagher and Robbins, 2009; Voon et al., 2007; Weintraub et al., 2006). A constellation of pathological behaviors, including gambling, shopping, binge eating and hypersexuality, is seen in 17% of those on DA (Voon et al., 2007). These behaviors are associated with factors predisposing to general substance use disorders such as higher novelty seeking, impulsivity, and alcohol abuse disorders thus emphasizing a common underlying susceptibility (Voon et al., 2007). The study of DA-induced compulsive behaviors provides a unique opportunity to unravel the core biology of “behavioral addiction” in susceptible individuals.
In normal volunteers, Levodopa improves learning from positive outcomes and is associated with enhanced ventral striatal BOLD signal modeling prediction error (δ) (Pessiglione et al., 2006). Levodopa, which is a precursor to dopamine, increases presynaptic and extrasynaptic dopamine levels and thus may enhance physiological phasic dopaminergic activity. In PD patients (without compulsive behaviors), the combination of Levodopa and DA can worsen learning from negative outcomes with effects of learning from positive outcomes being more variable (Frank et al., 2007b; Frank et al., 2004). DA, in contrast to Levodopa, tonically stimulates specific dopaminergic receptor subtypes. Frank et al. have suggested that the tonic stimulation of DA may block a phasic dopamine dip that serves as a crucial component of the learning signal (Frank et al., 2007b; Frank et al., 2004). DA may also interact with an underlying susceptibility. For instance, pathological gambling in the general population is associated with decision making impairments such as disadvantageous choices on gambling tasks and greater impulsive choice (Goudriaan et al., 2005; Petry, 2001). In PD patients with dopaminergic medication-related pathological gambling, a gambling task with both win and loss outcomes, has previously been shown to increase ventral striatal dopamine release (Steeves et al., 2009).
In this fMRI study, we aimed to describe brain mechanisms involved in DA modulation of learning from gain and loss outcomes in a population susceptible to compulsive behaviors. Consequently, we compared PD patients with dopamine dysregulation (DD patients) with matched PD controls on and off DA, and also with matched normal volunteers. We applied a reinforcement learning model to a probabilistic learning task and restricted our primary hypotheses to the ventral striatum. We hypothesized a group (DD patients compared to PD controls) by medication interaction effect during gain learning reflecting underlying susceptibility where DA would be associated with faster learning from gain outcomes along with greater ventral striatal positive δ activity in DD patients compared to PD controls. Given that different striatal regions, the amygdala, and orbitofrontal and anterior insular cortices are implicated in the coding of δ, we also examined these regions and relevant findings purely on a descriptive basis (O'Doherty et al., 2003; Pessiglione et al., 2006; Seymour et al., 2004).
Results
Patient and disease characteristics
Behavioral outcomes were obtained from 14 DD patients, 14 PD controls and 16 normal volunteers. Eleven DD patients, 11 PD controls and 16 normal volunteers were scanned. Ten of the DD patients had decreases in DA dose from the original presentation of pathological behaviors with concomitant increases in Levodopa doses. The other four patients were not able to tolerate changes in dose and/or their behaviors were controlled with external behavioral controls. There were no differences in demographic or disease characteristics (Table S1). The DD patients did not have problems with gambling or shopping behaviors prior to PD onset. DD patients had greater working memory impairments compared to PD controls as discussed more extensively elsewhere (Table S1) (Voon et al., 2009).
Medications
PD subjects were scanned either off DA or on DA in a pseudorandomized order. When scanned off DA, DA were held a mean of 21 (SD 4.5) hours and Levodopa held overnight before scanning. When scanned on DA, Levodopa was held overnight and DA administered 2 hours before scanning. The mean DA dose of the DD patients [2 hours before scanning: 67.35 (SD 11.31) Levodopa dose equivalents per day] was not significantly different from the PD controls [61.25 (SD 9.71) Levodopa dose equivalents per day] (t=1.35 df=21 p=0.19) (Hobson et al., 2002). The DA dose administered on the day of scanning ranged from 2 to 6 mg for ropinirole and 0.5 to 1 mg for pramipexole.
Reinforcement learning
Using a probabilistic gain and loss learning task (Figure 1A), we assessed actual learning behavior as “correct” response selected and the Q-learning reinforcement model-based parameters of learning rate (α), and temperature (β), an index of choice randomness.
Figure 1.

Learning task. (A) Subjects chose between probabilistic stimulus-pairs from three conditions: gain, loss and neutral. One stimulus-pair was associated with an 80:20 probability of either gaining, losing or “looking at” $10:$0 respectively with the opposite contingency in the other stimulus-pair. (B) Behavioral outcomes for model parameters. The learning rate (α) and temperature or choice randomness (β) are represented for gain and loss conditions. Higher α and β scores represent faster learning and greater temperature respectively. Parkinson disease (PD) patients with problem gambling or compulsive shopping (DD) and PD controls are represented on and off dopamine agonists. Error bars represent standard error of the mean. (*p<0.05 for mixed measures ANOVA group by medication interaction effects). (NV = Age- and gender-matched normal volunteers) (C) Learning curve. The learning curve plots indicate actual behavioral choices during gain and loss conditions. See also Tables S1, S2 and S3.
Behavioral outcomes
During gain learning, there were no main effects. We identified a susceptibility by medication interaction effect for the “correct” response selected and also for the model-based parameter of gain learning rate (α) (Figure 1B). Pair-wise analyses showed that DA were associated with a greater percentage of gain cues selected and faster learning rates (higher α) in DD patients. This effect of DA was not observed in PD controls. We have illustrated the “correct” response selected over the course of the trial (Figure 1C).
During loss learning, there were no main effects. We again observed a susceptibility by medication interaction effect for the behavioral measure of “correct” response selected (avoidance of the loss cue) and the model-based parameters of α and β (Figure 1B). Pair-wise analyses showed that DA were associated with a lower percentage of the “correct” response selected, lower α and lower β in PD controls. This effect of DA was not observed in DD patients. Statistics and other behavioral outcomes of gain and loss learning are reported in Table S1. Note that there was no correlation between α, β and actual choices for gain and loss learning (R2: α = 0.11; β = 0.09; % “correct” choices = 0.14; p>0.05). There were also no differences in group behavioral outcomes between PD patients with problem gambling or shopping [Gain/Loss learning rate in mean (SD): Gambling off DA 0.23 (0.08)/0.27 (0.04), Gambling on DA 0.51 (0.06)/0.15 (0.04), Shopping off DA 0.20 (0.05)/0.33 (0.10), Shopping on DA 0.46 (0.10)/0.20 (0.09), P=0.53/0.41].
Imaging
For the imaging analysis, we used a reinforcement learning model to extract trial-by-trial δ and predicted outcome which were then used as parametric modulators in the imaging analysis of outcome and stimuli phases respectively. We assessed activity corresponding to positive and negative δ separately for gain (i.e. gain and gain omissions) and loss learning (i.e. loss and loss omissions). We compared DD patients and PD controls on and off DA using a mixed measures ANOVA with DA status as a within-subject factor and susceptibility as a between-subject factor. Given our a priori hypothesis we also extracted the fitted event time course of bilateral ventral striatal ROIs and compared the area under the curves between groups using mixed measures ANOVA. The central coordinates for the ventral striatal ROIs were as follows (in mm: Gain: Left x=-10 - -12, y=9 – 14, z=-7 - -12; Right x=10 – 17, y=9 -11, z=-7 - -11) (Loss Left: x=-7 - -9, y=7 – 10, z=-10 - -16; Right x=7 – 15, y=9 – 10, z=-10 - -13).
In what follows we report the common activations for both positive δ and predicted outcome during gain learning (Table S5). We observed a group effect of greater left orbitofrontal cortex activity in DD patients compared to PD controls. There was also a susceptibility by medication interaction effect localized to the striatum with DA associated with greater bilateral ventral striatal δ [F(1,21)=5.51, p=0.01; ROI corrected] (Figure 2C) and greater left ventral striatal predicted outcome (P<0.05 FWE corrected) (Figure 2A) activity in DD patients with the opposite pattern in PD controls. Similarly, DA were associated with greater right posterior putamen δ (P<0.05 FWE corrected) (Figure 2A) activity in DD patients with the opposite pattern in PD controls. In the ventral striatal ROI analysis, there were no main effects (p>0.05).
Figure 2.
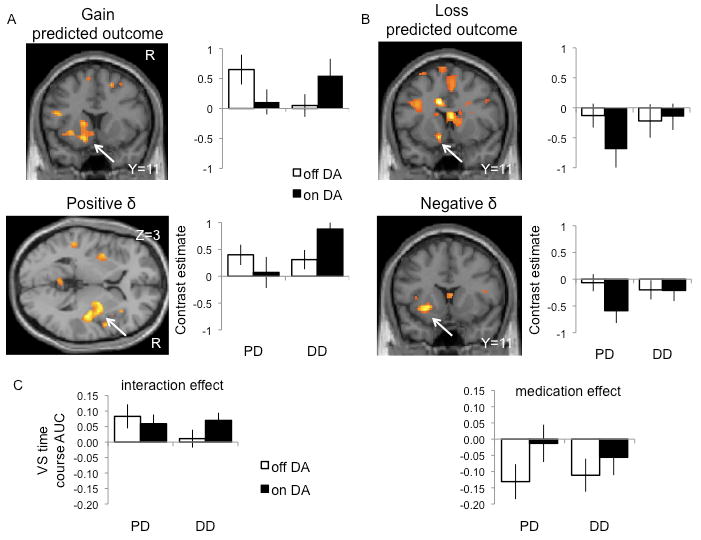
Striatal predicted outcome and prediction error activity. Gain learning is depicted on the left and loss learning on the right. The SPM images and contrast estimates show the significant striatal interaction effects (P<0.05 FWE corrected) comparing Parkinson's disease (PD) patients with problem gambling or shopping (DD) and PD controls on and off dopamine agonists (DA) (repeated measures ANOVA). (A) Gain predicted outcome (top) and positive prediction error (bottom). (B) Loss predicted outcome (top) and negative prediction error (bottom). (C) Ventral striatal prediction error activity. The bar graphs show the area under the curve (AUC) of the fitted event time course ROI analysis focusing on bilateral ventral striatal (VS) activity (repeated measures ANOVA). The left graph shows a significant group by medication interaction effect of bilateral ventral striatum for positive prediction error during gain learning. The right graph shows a significant medication effect of bilateral ventral striatum for negative prediction error during loss learning. The SPM images are shown at P<0.005 uncorrected. The error bars represent standard deviation. See also Tables S4, S5 and S6.
We also identified activation for both negative δ and predicted outcome during loss learning (Table S5). Here, we observed a group effect of greater left dorsolateral putamen and lesser bilateral orbitofrontal cortex activity in DD patients compared to PD controls. There was an interaction between susceptibility and medication: posthoc t-tests showed that DA were associated with greater (or less of a decrease in) striatal and bilateral anterior insular activity in PD controls with the opposite observed in DD patients. The interaction effect of the predicted outcome activity was localized to the left ventral striatum (Figure 2B) and the δ activity was localized to the left dorsolateral striatum (Figure 2B). There was also a medication effect with greater left ventral striatal negative δ activity on DA compared to off DA [P<0.05 FWE corrected; F(1,21) = 10.05, p<0.001; ROI corrected] (Figure 2C). In the ventral striatal ROI analysis, there were no group or interaction effects (p>0.05).
During gain learning, the activity to negative δ (i.e. gain omission or a relative loss) was consistent with that of negative δ during loss learning. Thus, there was a group effect of lower right orbitofrontal cortex activity in DD patients compared to PD controls. There was also a medication effect with greater right ventral striatal activity on DA compared to off DA (Table S2). During loss learning, activity to positive δ (i.e. loss omission or a relative gain) was consistent with that of positive δ during gain learning. There was an interaction between medication and susceptibility: DA were associated with greater right ventral striatal activity in DD patients with the opposite pattern seen in PD controls (Table S2).
Normal volunteers
We also compared behavioral (model-based learning rate) and neural δ activity with age- and gender-matched normal volunteers. To compare normal volunteers who were tested only once with the repeated measures of DD and PD controls on and off DA we used t-tests for both the behavioral and imaging analysis. For the behavioral measures, p<0.006 (Bonferroni correction for multiple comparisons) was considered significant. For the imaging analyses, p<0.05 FDR corrected was considered significant (Genovese et al., 2002) focusing only on the regions identified in the previous analyses (Table S3). During gain learning, DD patients off DA had slower learning rates compared to normal volunteers (t=3.43 df=28 p=0.002; other t-test outcomes: t<1.62, p>0.05). Relative to normal volunteers, DD patients on DA had greater right posterior putamen positive δ activity whereas PD patients on DA had the opposite with lower bilateral posterior putamen activity. During loss learning, PD controls off DA had slower learning rates relative to normal volunteers (t=3.65 df=28 p=0.001; other t-test outcomes t<1.60, p>0.05). Relative to normal volunteers, PD controls on DA had greater (or less of a decrease in) right lateral orbitofrontal cortex and bilateral anterior insular activity to negative δ (Figure 3).
Figure 3.
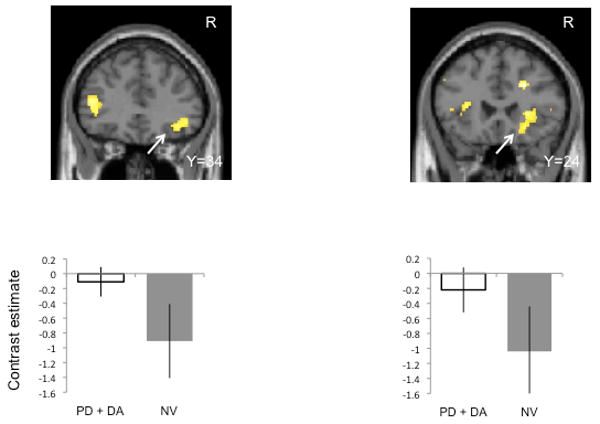
Negative prediction error activity during loss learning in Parkinson's disease controls and normal volunteers. The SPM images and bar graphs show the comparison of Parkinson's disease controls without gambling or shopping behaviors on dopamine agonists compared to normal volunteers (t-test, P<0.05 FDR corrected). The left shows the right orbitofrontal cortex and the right shows the right anterior insula. The SPM images are shown at P<0.005 uncorrected. Error bars represent standard deviation. See also Table S7.
Summary
We demonstrated several findings of note. First, the effects of DA on gain learning were observed only in the DD patients (susceptibility by medication interaction). Thus, DD patients on DA had faster gain learning rates, greater choice probability of the gain cue and greater ventral striatal activity to positive δ. Second, the behavioral effects of DA on loss learning were observed only in PD controls (susceptibility by medication interaction): PD controls on DA had slower loss learning rates, lower percentage of the “correct” cue selected and lower β. Similarly, we observed an interaction for striatal and bilateral insula activity to negative δ and loss predicted outcome corresponding with our behavioral findings. Different striatal regions corresponded with negative δ (left dorsolateral striatum) and with predicted outcome (left ventral striatum). Relative to normal volunteers, PD controls on DA were also slower at loss learning and had greater (or less of a decrease in) anterior insular and right orbitofrontal cortex activity. Overall, DA were also associated with greater left ventral striatal negative δ activity during loss learning compared to off DA. Third, consistent with the gain learning observations, the findings for positive δ during loss learning (i.e. loss omission or a relative gain) revealed a susceptibility by medication interaction: DD patients on DA had greater right ventral striatal activity to positive δ. Finally, DD patients overall had greater orbitofrontal cortex activity to gains and to loss omissions and lower activity to losses compared to PD controls suggesting overall better orbitofrontal cortex functioning in DD patients. Relative to normal volunteers during loss learning, PD controls on DA also had greater (i.e. less of a decrease in) right lateral orbitofrontal cortex negative δ activity.
Discussion
We used a reinforcement learning model to deconstruct decision making processes dysregulated by DA in a population susceptible to compulsive behaviors. We show a critical dissociation in the effects of gain learning. DA enhanced gain learning in a susceptible population of DD patients but not in PD controls. Chronic exposure to DA amplified a mismatch between expectation and outcome during gain learning in DD patients convergent with greater ventral striatal positive δ activity. Hence, DD patients had faster gain learning and greater choice bias for gain cues, a process possibly mediated via differences in δ activity. Our findings highlights a key decision making process dysregulated by DA in a population susceptible to compulsive behaviors and provides clues to mechanisms that underlie behavioral escalation in a disorder of behavioral addiction (Zernig et al., 2007).
The study results were limited by sample size due to the difficulties in recruiting DD patients on the same DA associated with their behaviors. Recruitment of patients whose DA were discontinued may implicate a different mechanism as a tolerable acute DA challenge may only demonstrate effect at a low dose. Chronic low doses of DA preferentially stimulate presynaptic D2 autoreceptors and furthermore, may not be associated with behavioral sensitization as compared to chronic higher doses of DA which stimulate postsynaptic DA receptors (Lomanowska et al., 2004). The duration of DA withdrawal was also limited at a mean of 21 hours due to difficulties in tolerance of motor symptoms. However, since the groups were matched for DA withdrawal, observed differences emphasized that the groups differed in sensitivity to DA. To ensure that working memory was not a confounder in the behavioral and imaging learning outcomes, we used the number of spatial working memory errors as a covariate in the behavioral and imaging analyses. Furthermore, as we were interested in pathophysiological similarities of decision making between the DA-related behavioral subgroups, we included subjects with either problem gambling or compulsive shopping behaviors. The behaviors can also occur concurrently suggesting overlapping mechanisms. We did not observe any behavioral differences between the two subgroups (Table S4).
Gain learning
The enhancement in gain learning in DD patients may reflect either presynaptic or postsynaptic mechanisms. Enhanced presynaptic ventral striatal dopamine release in response to a gambling task with both win and loss outcomes has been demonstrated in PD patients off medications with DA-induced pathological gambling (Steeves et al., 2009). Similarly, compulsive Levodopa use in PD, a behavior conceptually similar to substance abuse, is associated with greater presynaptic dopamine release to a Levodopa challenge, an effect hypothesized to be due to neuronal sensitization in a susceptible population (Evans et al., 2006). Our findings are compatible with enhanced presynaptic ventral striatal dopamine release in response to gain-specific outcomes possibly reflecting a premorbid susceptibility.
Alternatively, DD patients may have different genetic polymorphisms resulting in a different postsynaptic dopamine receptor profile which may enhance the detection of the phasic dopamine response. For instance, in healthy volunteers, genetic polymorphisms of the DDARP-32 gene, which modulate D1 receptor plasticity, affects learning from positive outcomes (Frank et al., 2007a). Chronic D3 receptor stimulation from DA is associated with enhanced post-synaptic maintenance of D1 receptors (Berthet et al., 2009). Thus, differences in the function or expression of postsynaptic D1 receptors, either as a premorbid susceptibility or as an adaptation to chronic D3 receptor stimulation may facilitate approach networks. Further genetic polymorphism studies are required to establish whether these observations are presynaptic or postsynaptic in nature.
Loss learning
We show that DA were associated with slower loss learning along with greater (or less of a decrease in) expression of a striatal and insular negative δ activity in PD controls but not in DD patients. This medication by susceptibility interaction effect was localized to the left dorsolateral putamen for negative δ and to the left ventral striatum for predicted outcome. Our findings in PD controls confirm the effects of DA on loss learning outcomes observed by others (Frank et al., 2007b; Frank et al., 2004). Our observation that DA were associated with greater ventral striatal activity to negative δ during both gain and loss learning support the hypothesis that DA may impair the detection of the phasic dip in dopamine associated with avoidance learning. However, the behavioral effect is divergent in the two subject groups, which may reflect the interaction with other neural regions or the role of neurotransmitters other than dopamine.
Other neural regions implicated in our study include the anterior insula, orbitofrontal cortex and dorsolateral striatum. Our data show that during loss learning, DA were associated with greater (or less of a decrease in) bilateral anterior insular activity in PD controls but not in DD patients. Relative to normal volunteers, PD controls on DA had greater bilateral anterior insular activity. This finding highlights the role of the anterior insula, a key region implicated in learning from negative outcomes from both monetary loss (Pessiglione et al., 2006) and painful stimuli (Seymour et al., 2004). Consistent with a recent report (van Eimeren et al., 2009), we also confirmed that PD controls may have greater impairments in orbitofrontal cortex functioning, a region implicated in the updating and storage of value representation to enable flexible selection of actions (Dolan, 2007). Critically, these findings did not extend to DD patients. In our study, PD controls had lower activity during gain learning and greater activity (or less of a decrease) during loss learning relative to DD patients. Similarly, only PD controls on DA had greater orbitofrontal cortex activity during loss learning compared to normal volunteers. Finally, different striatal regions, such as the dorsolateral striatum, may also be implicated in coding for negative δ. This dovetails with an observation that different ventral striatal regions have been demonstrated code for positive and negative δ (Seymour et al., 2005). Greater disease-related impairment of the left dorsolateral striatum in DD patients may account for our findings. Taken together, our data suggests that the striatum, orbitofrontal cortex and anterior insula may act as a neural network in PD controls to influence the learning from negative outcomes. We also emphasize that while we have been focusing on the potential role of dopamine, serotonergic mechanisms may also be relevant and have been implicated in learning from negative outcomes possibly providing a wider range to code for negative δ outcomes in contrast to a mechanism based upon pauses in dopaminergic firing (Daw et al., 2002). For instance, relative differences in individual serotonergic function or dorsal raphe neurodegeneration related to PD may result in either direct serotonergic effects or interact with dopamine to influence loss learning. Such differences in the impact of premorbid function and degeneration of the ascending modulatory systems remains one potential source of the phenotypic variation manifest in the DD and PD groups. However, we note that the contribution of serotonergic function and that of other ascending neuromodulatory agents, to behavioural aberrations in this population remains unexplored.
Conclusion
Using a reinforcement learning computational model, the effect of DA on reinforcement learning was dissociated as a function of outcome valence in a group susceptible to compulsive behaviors. DA were associated with faster gain learning in DD patients. DA in DD patients increased striatal activity to δ resulting in a persistent “better than expected” outcome. The subsequent increase in valuation of the gain cue would appear to drive a selection bias towards the gain cues. This observation may underlie the anecdotal clinical descriptions of the onset or the escalation of pathological gambling behaviors following a ‘win’. In contrast, DA were associated with slower loss learning in PD controls, an effect that engages a neural network involved in the representation of negative δ. Thus, we reveal a crucial role for dopamine function in mediating selection biases.
Experimental Procedures
Inclusion and exclusion criteria
Patients with Parkinson disease (PD) and problem gambling or compulsive shopping (DD) and PD controls were recruited from the Parkinson Disease clinic at the National Institute of Neurological Disorders and Stroke, National Institutes of Health (NIH). Healthy volunteers were recruited from the NIH healthy volunteer database at NIH. Inclusion criteria for DD patients included (i) idiopathic PD defined by the Queen Square Brain Bank criteria; (ii) either problem gambling defined by the Research Definition Criteria of the Diagnostic and Statistical Manual of Mental Disorders, Version IV (DSM IV) (three positive criteria) (1994), or compulsive shopping defined by McElroy's criteria (McElroy et al., 1994); (iii) behavior onset after the initiation of DA; and (iv) on the same DA that resulted in their behavioral symptoms. Inclusion criteria for PD controls included idiopathic PD and no history of problem gambling, shopping, hypersexuality, punding or compulsive medication use (definitions reviewed in (Voon and Fox, 2007); and matched for gender, age (+/- 10 years), DA type, DA dose (+/- 1 mg pramipexole and +/- 4 mg ropinorole) and presence or absence of Levodopa. Exclusion criteria for both groups included the presence of dementia (DSM IV criteria), major depression or mania (DSM IV criteria) (1994) and contraindications for MRI including deep brain stimulation. Healthy controls were age- (+/- 5 years) and gender-matched. Subjects were assessed using the clinician-rated semi-structured interview, the Structured Clinical Interview for the Diagnosis of DSM IV psychiatric disorders, for the presence of affective, anxiety, and substance use disorders and also for the presence of visual hallucinations or illusions. The study was approved by the NIH Research Ethics Board and all subjects consented to the study.
Task description
All subjects performed the probabilistic learning task. DD patients and PD controls performed the working memory and set shifting tasks.
Probabilistic learning task
In the learning task, subjects chose between stimuli-pairs with fixed probabilistic contingencies divided into three conditions: gain, loss and neutral (30 trials/condition/run; 3 runs). For example, in the gain condition, one stimulus-pair was associated with an 80:20 probability of winning $10:$0 and the opposing stimulus-pair with an 80:20 probability of winning $0:$10. Similarly, in the loss and neutral conditions, one stimulus-pair was associated with an 80:20 probability of losing $10:$0 or “looking” at $10:$0 respectively with the opposite contingencies in the other stimulus-pair. Subjects viewed the cues (4.5 seconds), selected their choice (1 second) and viewed the outcomes (3 seconds) followed by a fixation point (0.5 seconds) for a total of 90 trials lasting 13.5 minutes per run. The three conditions were randomly presented during each run. The stimuli positions were randomly presented on the left or right side of the screen. Subjects pressed either the left or right button of the Lumina response box with their right hand to indicate whether they chose the left or right choice. Subjects were instructed to maximize their earnings and were told they would receive a proportion of their earnings. The earnings ranged from $10 to $30. The task was coded using e-PRIME.
Subjects underwent 30 minutes (two sessions) of practice prior to the functional MRI (fMRI) study with one of the sessions occurring immediately before scanning using stimuli-pairs that differed from the scanning stimuli. Subjects who were unable to undergo fMRI testing similarly underwent 30 minutes of practice. The reported data represent behavioral outcomes of the scanning study and do not include the training data. Subjects were tested in a pseudorandomized order at least 3 days apart either 2 hours after DA administration or a mean of 21.3 hours (SD 4.4 hours) after withholding DA. Levodopa dose was held overnight where possible.
MRI scanning and preprocessing
MRI scanning was performed on a 1.5T General Electric scanner with an 8 channel head coil. Thirty-eight continuous axial slices (slice thickness=3mm, gap 1mm) were acquired using T2*-weighted echo planar images at a temporal resolution of 2.66 seconds, echo time 33 msec, flip angle 90, matrix 64 × 64 with interleaved acquisition. To minimize head movement, all subjects were stabilized with an elastic bandage wrapped around the forehead and tightly packed foam padding surrounding the head. Images were projected onto a screen at the foot of the subject. Subjects viewed the stimuli via a mirror placed above the top of the head coil reflecting images from the screen. The first four echo planar image volumes were discarded from analysis as dummy scans to allow for magnetization to reach steady state. The imaging data was preprocessed using SPM5 (www.fil.ion.ucl.ac.uk/spm). The data were adjusted for slice timing, realigned to the first image of the first run, normalized to the Montreal Neurological Institute atlas and smoothed using an 8 mm Gaussian kernel. Head motion parameters were used as regressors of no interest in the first level analysis.
Data and statistical analysis
Model-based outcome measures
The Q-learning algorithm was used to calculate the model-based parameters of learning rate (α), temperature (β) and predicted outcome of the cues (qA). These measures were obtained separately for the gain and loss learning conditions. The algorithm computed the predicted outcome of each stimulus-pair choice (qA or qB). For example, for choice A, the predicted outcome of cue A at t+1 was calculated as follows:
The predicted outcomes were initialized at zero. The actual outcome was set at +10 for gain and -10 for loss. The probability of choosing each option (pA) was calculated using a standard softmax function, a stochastic decision rule that calculates the probability of an option according to the associated value:
The algorithm iteratively samples α and β parameters from 0.01 to 1 to determine the optimal pair that best estimated the actual choices of each individual. The optimal pair of α and β parameters was determined using the maximum log likelihood. The log likelihood was determined for each combination of α and β parameters (between 0 and 1) and the pair corresponding the maximum log likelihood for each individual was used as the optimal parameter for that individual. The optimal fit α and β for each individual's behavioral choices were compared between groups. To ensure the model-based predicted outcome was not due to differences in individual α and β, the mean model-based predicted outcome for each individual was obtained using a single set of optimal α and β parameters across groups. The algorithm was processed using MATLAB Version 7.5.
Behavior-based outcome measures
The percentage of actual “correct” choices was calculated as “correct” choice / total choices where “correct” choices were defined as selection of the high probability gain cue and the low probability loss cue. The amount of money won and lost during the gain and loss conditions were calculated.
Statistical analysis
Patient characteristics were compared using Fisher's Exact Test for categorical variables or unpaired t-test or ANOVA for continuous variables. The behavioral outcomes were analyzed using a mixed measures ANOVA with medication status as a within subject comparison and patient group as a between subject comparison. Spatial working memory errors were used as a covariate. To parallel the imaging analysis, the behavioral analysis assessing normal volunteers was conducted using separate t-tests comparing normal volunteers with DD patients or PD controls on or off DA. P=0.006 Bonferroni corrected for multiple comparisons was considered significant. To assess if gain and loss learning were related, we conducted regression analyses between α, β and actual choices for gain and loss learning. All statistics were conducted using SPSS Version 16.0.
Imaging analysis
We conducted separate imaging analyses for positive and negative δ and predicted outcomes for both gain and loss conditions (total of 6 analyses). The trial-by-trial δ and predicted outcome were extracted using the reinforcement learning model with individual optimal α and β parameters. δ was used as parametric modulator for the 3 second outcome phase and predicted outcome was used as a parametric modulator for the 3 second stimulus phase. The choice phase was also modeled. To compare δ and predicted outcome activity between DD patients and PD controls in the group analysis, we used a mixed measures ANOVA with DA status as a within-subject factor and susceptibility as a between-subjects factor with spatial working memory as a covariate. We focused on the striatum, amygdala, orbitofrontal cortex and insular cortices, regions previously implicated in δ activity with significance defined as P<0.05 whole brain FDR corrected. As we had a specific a priori hypothesis focusing on ventral striatal δ activity, we also used a ROI analysis. The coordinates of the ROIs were determined separately for gain and loss learning based on the peak local maximum ventral striatal activity for each group (DD patients and PD controls on and off DA) (Duvernoy 1999). In cases in which only a unilateral peak could be identified, the mirror coordinates in the opposite hemisphere were used to identify the opposite ROI. Thus, 8 different sets of bilateral ventral striatal ROIs were constructed with a 0.5 mm radius. We then extracted fitted event time course analyses using MarsBar (MARSeille Boite A Region d'Interet) of these ventral striatal ROIs and compared the area under the curve (Pessiglione et al., 2006). We compared the area under the curve between DD patients and PD controls on and off DA using a mixed measures ANOVA with DA status as a within-subject factor and susceptibility as a between-subject factor. To assess differences from normal volunteers, we used separate t-tests to assess normal volunteers versus DD patients or PD controls on or off DA using t-tests (since the data included both repeated measures and single measures) with SWM as a covariate. As we were interested in whether the previously identified imaging data differed from normal volunteers, we focused on the previously identified regions with FDR P<0.05 corrected considered as significant. We compared positive δ for gain learning and negative δ for loss learning.
Supplementary Material
Acknowledgments
This study was supported and conducted by the National Institute of Neurological Disorders and Stroke, National Institutes of Health. We would like to thank Dr. Grisel Lopez and the Parkinson Disease clinic at the National Institute of Neurological Disorders (NINDS), National Institutes of Health (NIH) for assistance in recruitment and assessment of patients. We would like to thank the patients for their involvement with this study. This study was funded and conducted at intramural NINDS/NIH. RJD is supported by a Wellcome Trust Programme Grant.
Footnotes
We demonstrate, within a reinforcement learning model, that dopamine agonists in susceptible individuals with Parkinson's Disease increase a bias towards gain cues a bias associated with increasing striatal prediction error activity.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Bayer HM, Glimcher PW. Midbrain dopamine neurons encode a quantitative reward prediction error signal. Neuron. 2005;47:129–141. doi: 10.1016/j.neuron.2005.05.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berthet A, Porras G, Doudnikoff E, Stark H, Cador M, Bezard E, Bloch B. Pharmacological analysis demonstrates dramatic alteration of D1 dopamine receptor neuronal distribution in the rat analog of L-DOPA-induced dyskinesia. J Neurosci. 2009;29:4829–4835. doi: 10.1523/JNEUROSCI.5884-08.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dagher A, Robbins TW. Personality, addiction, dopamine: insights from Parkinson's disease. Neuron. 2009;61:502–510. doi: 10.1016/j.neuron.2009.01.031. [DOI] [PubMed] [Google Scholar]
- Daw ND, Kakade S, Dayan P. Opponent interactions between serotonin and dopamine. Neural Netw. 2002;15:603–616. doi: 10.1016/s0893-6080(02)00052-7. [DOI] [PubMed] [Google Scholar]
- Dolan RJ. The human amygdala and orbital prefrontal cortex in behavioural regulation. Philos Trans R Soc Lond B Biol Sci. 2007;362:787–799. doi: 10.1098/rstb.2007.2088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Evans AH, Pavese N, Lawrence AD, Tai YF, Appel S, Doder M, Brooks DJ, Lees AJ, Piccini P. Compulsive drug use linked to sensitized ventral striatal dopamine transmission. Ann Neurol. 2006;59:852–858. doi: 10.1002/ana.20822. [DOI] [PubMed] [Google Scholar]
- Frank MJ, Moustafa AA, Haughey HM, Curran T, Hutchison KE. Genetic triple dissociation reveals multiple roles for dopamine in reinforcement learning. Proc Natl Acad Sci U S A. 2007a;104:16311–16316. doi: 10.1073/pnas.0706111104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frank MJ, Samanta J, Moustafa AA, Sherman SJ. Hold your horses: impulsivity, deep brain stimulation, and medication in parkinsonism. Science. 2007b;318:1309–1312. doi: 10.1126/science.1146157. [DOI] [PubMed] [Google Scholar]
- Frank MJ, Seeberger LC, O'Reilly RC. By carrot or by stick: cognitive reinforcement learning in parkinsonism. Science. 2004;306:1940–1943. doi: 10.1126/science.1102941. [DOI] [PubMed] [Google Scholar]
- Genovese CR, Lazar NA, Nichols T. Thresholding of statistical maps in functional neuroimaging using the false discovery rate. Neuroimage. 2002;15:870–878. doi: 10.1006/nimg.2001.1037. [DOI] [PubMed] [Google Scholar]
- Goudriaan AE, Oosterlaan J, de Beurs E, van den Brink W. Decision making in pathological gambling: a comparison between pathological gamblers, alcohol dependents, persons with Tourette syndrome, and normal controls. Brain Res Cogn Brain Res. 2005;23:137–151. doi: 10.1016/j.cogbrainres.2005.01.017. [DOI] [PubMed] [Google Scholar]
- Hobson DE, Lang AE, Martin WR, Razmy A, Rivest J, Fleming J. Excessive daytime sleepiness and sudden-onset sleep in Parkinson disease: a survey by the Canadian Movement Disorders Group. JAMA. 2002;287:455–463. doi: 10.1001/jama.287.4.455. [DOI] [PubMed] [Google Scholar]
- Lomanowska A, Gormley S, Szechtman H. Presynaptic stimulation and development of locomotor sensitization to the dopamine agonist quinpirole. Pharmacol Biochem Behav. 2004;77:617–622. doi: 10.1016/j.pbb.2003.12.018. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Dayan P, Friston K, Critchley H, Dolan RJ. Temporal difference models and reward-related learning in the human brain. Neuron. 2003;38:329–337. doi: 10.1016/s0896-6273(03)00169-7. [DOI] [PubMed] [Google Scholar]
- Pessiglione M, Seymour B, Flandin G, Dolan RJ, Frith CD. Dopamine-dependent prediction errors underpin reward-seeking behaviour in humans. Nature. 2006;442:1042–1045. doi: 10.1038/nature05051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Petry NM. Pathological gamblers, with and without substance use disorders, discount delayed rewards at high rates. J Abnorm Psychol. 2001;110:482–487. doi: 10.1037//0021-843x.110.3.482. [DOI] [PubMed] [Google Scholar]
- Redish AD. Addiction as a computational process gone awry. Science. 2004;306:1944–1947. doi: 10.1126/science.1102384. [DOI] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Seymour B, O'Doherty JP, Dayan P, Koltzenburg M, Jones AK, Dolan RJ, Friston KJ, Frackowiak RS. Temporal difference models describe higher-order learning in humans. Nature. 2004;429:664–667. doi: 10.1038/nature02581. [DOI] [PubMed] [Google Scholar]
- Seymour B, O'Doherty JP, Koltzenburg M, Wiech K, Frackowiak R, Friston K, Dolan R. Opponent appetitive-aversive neural processes underlie predictive learning of pain relief. Nat Neurosci. 2005;8:1234–1240. doi: 10.1038/nn1527. [DOI] [PubMed] [Google Scholar]
- Steeves TD, Miyasaki J, Zurowski M, Lang AE, Pellecchia G, Van Eimeren T, Rusjan P, Houle S, Strafella AP. Increased striatal dopamine release in Parkinsonian patients with pathological gambling: a [11C] raclopride PET study. Brain. 2009;132:1376–1385. doi: 10.1093/brain/awp054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sutton RS, Barto AG. Reinforcement learning: an introduction. Cambridge, MA: MIT Press; 1998. [Google Scholar]
- van Eimeren T, Ballanger B, Pellecchia G, Miyasaki JM, Lang AE, Strafella AP. Dopamine Agonists Diminish Value Sensitivity of the Orbitofrontal Cortex: A Trigger for Pathological Gambling in Parkinson's Disease. Neuropsychopharmacology. 2009 doi: 10.1038/sj.npp.npp2009124. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Voon V, Fernagut PO, Wickens J, Baunez C, Rodriguez M, Pavon N, Juncos JL, Obeso JA, Bezard E. Chronic dopaminergic stimulation in Parkinson's disease: from dyskinesias to impulse control disorders. Lancet Neurol. 2009;8:1140–1149. doi: 10.1016/S1474-4422(09)70287-X. [DOI] [PubMed] [Google Scholar]
- Voon V, Potenza MN, Thomsen T. Medication-related impulse control and repetitive behaviors in Parkinson's disease. Curr Opin Neurol. 2007;20:484–492. doi: 10.1097/WCO.0b013e32826fbc8f. [DOI] [PubMed] [Google Scholar]
- Weintraub D, Siderowf AD, Potenza MN, Goveas J, Morales KH, Duda JE, Moberg PJ, Stern MB. Association of dopamine agonist use with impulse control disorders in Parkinson disease. Arch Neurol. 2006;63:969–973. doi: 10.1001/archneur.63.7.969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zernig G, Ahmed SH, Cardinal RN, Morgan D, Acquas E, Foltin RW, Vezina P, Negus SS, Crespo JA, Stockl P, et al. Explaining the escalation of drug use in substance dependence: models and appropriate animal laboratory tests. Pharmacology. 2007;80:65–119. doi: 10.1159/000103923. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.